Les espèces de prévisions : classification vs. régression
Le terme prévision couvre un très large spectre de processus, de technologies et même de marchés. Par le passé, nous avions présenté les mondes des logiciels de prévision, en faisant la distinction entre:
- Logiciel de simulation déterministe
- Logiciel d’agrégation d’experts
- Logiciel de prévision statistique
Lokad appartient à la dernière catégorie puisque notre technologie est purement statistique. Cependant, Lokad ne couvre pas l’ensemble du spectre statistique à lui seul. Deux grandes catégories de prévisions existent en prévision statistique (*):
- Prévisions de classification
- Prévisions de régression
(*) Nous simplifions ici pour plus de clarté, car les subtilités de l’apprentissage statistique dépassent de loin le cadre de ce modeste billet de blog.
La classification consiste à séparer (ou classer) des objets selon leurs propriétés. L’illustration ci-dessous, provenant du blog de Tomasz Malisiewicz, illustre une tâche de classification visant à séparer les images représentant une chaise de celles représentant une table.
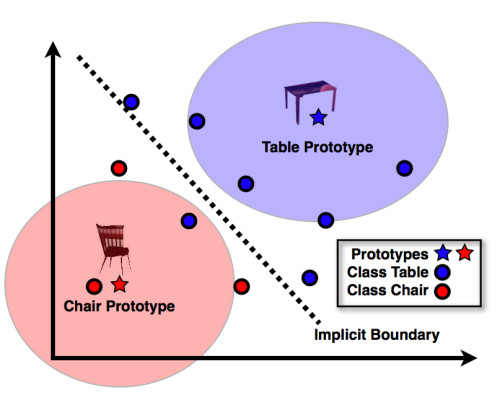
Illustration tirée du blog de tombone
La sortie d’une classification est binaire (ou plutôt discrète) : les objets se voient attribuer des classes avec plus ou moins de confiance, c’est-à-dire avec des probabilités plus ou moins élevées.
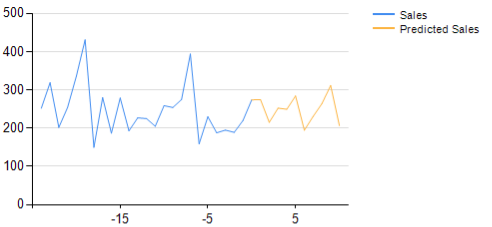
D’autre part, les régressions produisent généralement des courbes. L’illustration ci-dessous concerne une séries temporelles représentant les ventes historiques, et affiche la prévision correspondante.
La prévision par régression est une courbe plutôt qu’une configuration binaire (ou une combinaison de configurations binaires). Les entrées se prolongent dans le futur.
En quoi cette distinction impacte-t-elle le business ?
Eh bien, il s’avère que Lokad - tel qu’il est début 2010 - ne fournit que des prévisions par régression. Ainsi, il existe de nombreux problèmes intéressants auxquels Lokad ne peut pas répondre, car il s’agit de problèmes de classification:
- Segmentation de la clientèle : pour chaque client, nous aimerions évaluer la probabilité de réaliser une vente additionnelle réussie par une action de marketing direct. Dans le même ordre d’idées, nous pourrions également essayer de prédire le churn.
- Détection de fraude : pour chaque transaction, nous aimerions évaluer - à partir du profil de la transaction - la probabilité que l’opération soit une tentative de fraude.
- Priorisation des opportunités : en se basant sur les caractéristiques du prospect (disponibilité du budget, secteur d’activité, rang du contact dans l’entreprise, niveau d’intérêt exprimé, …), nous aimerions évaluer la probabilité d’obtenir une affaire profitable pour chaque prospect afin de prioriser les efforts de l’équipe commerciale.
On nous demande fréquemment si Lokad pourrait également fournir des prévisions de classification. Malheureusement, la réponse est négative pour le moment. Bien qu’elles reposent sur la même théorie mathématique, la classification et la régression impliquent des technologies très différentes ; et Lokad concentre tous ses efforts sur les problèmes de régression.
Cependant, nous ne sommes pas dédaigneux à l’égard des problèmes de classification, ils méritent véritablement attention et efforts. Pour 2010, nous restons fidèles à notre feuille de route, mais à l’avenir, la classification pourrait constituer une extension naturelle de nos services de prévision.


