Différencier les requêtes relationnelles
Les données de supply chain se présentent presque exclusivement sous forme de données relationnelles : commandes, clients, fournisseurs, produits, etc. Ces données sont collectées via les systèmes d’information - l’ERP, le CRM, le WMS - utilisés pour faire fonctionner l’entreprise.
Cependant, la plupart des techniques d’apprentissage automatique les plus courantes ne sont pas adaptées pour traiter les données relationnelles. La gestion des données relationnelles est généralement une réflexion secondaire, impliquant typiquement quelques astuces ingénieuses reposant sur une conception résolument non alignée avec la perspective relationnelle.
Lokad a développé sa propre version de programmation différentiable en plaçant le cas d’utilisation relationnel au premier plan. En effet, nous souhaitons que nos outils d’apprentissage automatique intègrent nativement la nature relationnelle des données. Comparativement aux options alternatives, cette approche offre de nombreux avantages, ces modèles sont :
- plus simple à écrire
- plus facile à comprendre et à raisonner
- plus interprétable
- plus rapide à apprendre et à exécuter
- etc
La plateforme Lokad est programmatique et se concentre sur le traitement et la visualisation des données relationnelles depuis sa création. Cependant, en 2019, nous nous sommes lancés dans une nouvelle aventure, décidant de faire en sorte que l’ensemble de notre pile d’apprentissage automatique adopte également le paradigme relationnel.
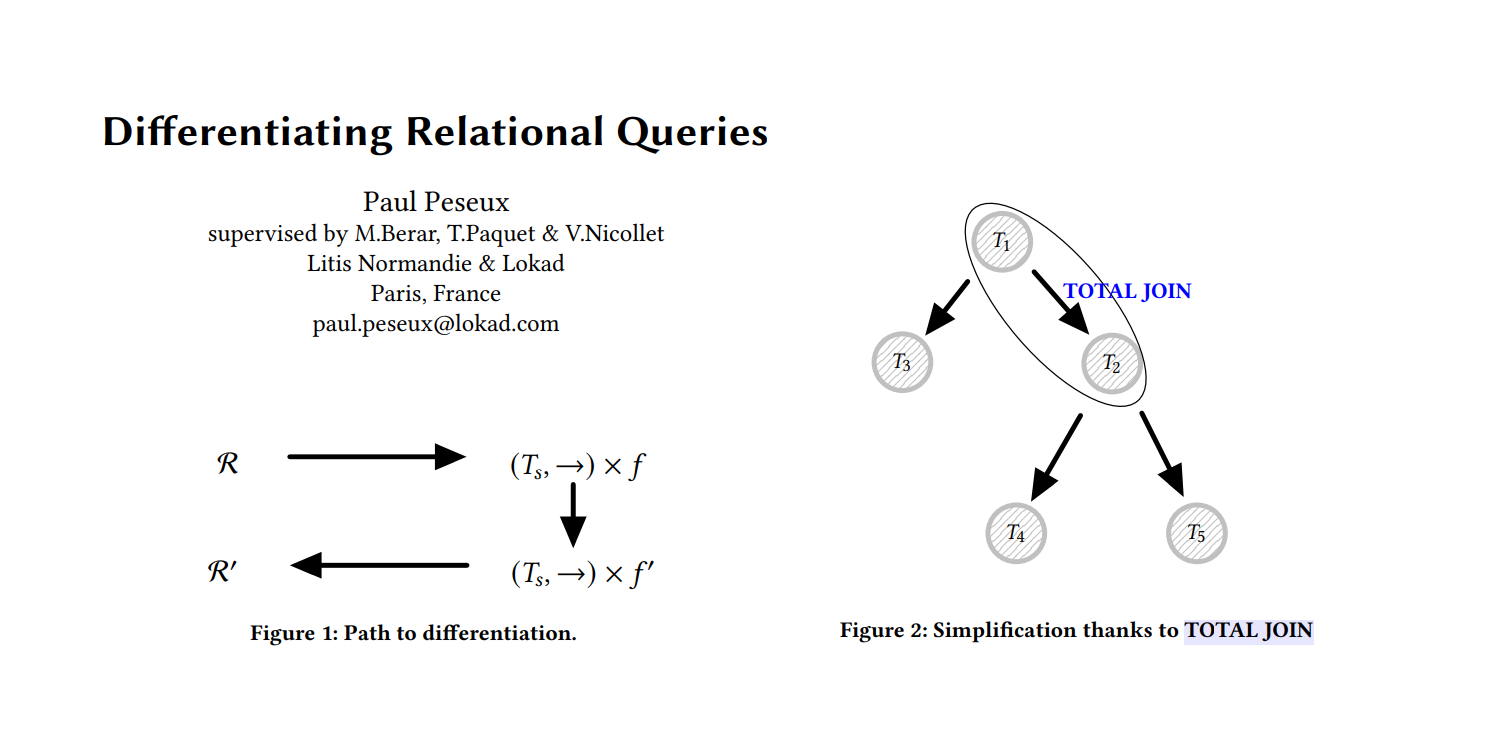
Différencier les requêtes relationnelles est un petit mais fondamental élément dans cette direction. C’est un moyen de propager des gradients à travers les requêtes relationnelles. Ces gradients sont utilisés, à leur tour, pour réaliser une descente de gradient stochastique qui représente généralement le cœur de la logique d’apprentissage/optimisation.
L’article ci-dessous présente une contribution de Paul Peseux (Lokad) sur ce sujet.
Title: Différencier les requêtes relationnelles
Author: Paul Peseux, Lokad
Extrait des Actes de l’atelier de thèse VLDB 2021, le 16 août 2021.
Abstract: Ce travail porte sur la différentiation automatique d’une requête dans le contexte des bases de données relationnelles et des requêtes. Cela est réalisé afin d’effectuer une optimisation par descente de gradient dans ces bases de données relationnelles. Ce travail décrit une forme de différentiation automatique pour un sous-ensemble de requêtes relationnelles


