Applications métier CRUD
Depuis les années 1980, la grande majorité des applications métier ont adopté une conception interne similaire, à savoir CRUD, qui signifie Create / Read / Update / Delete. Cette conception reflète l’adoption d’une base de données relationnelle pour conserver les données métier. La conception CRUD a traversé plusieurs grandes avancées technologiques, passant des terminaux de console connectés aux mainframes aux applications mobiles connectées aux plateformes cloud. Comprendre la conception CRUD importe dans des domaines complexes – comme la supply chain – qui fonctionnent typiquement au sein d’un paysage applicatif entièrement composé d’applications CRUD. Une telle connaissance est essentielle pour naviguer correctement dans ce paysage, depuis la négociation avec vendeurs de logiciels jusqu’à l’exploitation des entrées de données collectées par toutes ces applications.

Aperçu
Au début des années 1980, les bases de données relationnelles s’étaient imposées comme l’approche dominante pour stocker et accéder aux données métier. À la fin des années 1990, l’émergence de bases de données relationnelles open source avait encore renforcé cette pratique. De nos jours, la conception CRUD reflète l’approche la plus répandue pour concevoir une application métier reposant sur une base de données relationnelle.
Une base de données, dans le sens relationnel, comprend une liste de tables. Chaque table contient une liste de colonnes (également appelées champs). Chaque champ possède un type de données : nombre, texte, date, etc. Une table renferme une liste de lignes (également appelées enregistrements). En règle générale, le nombre de colonnes doit rester limité, à quelques centaines tout au plus, tandis que le nombre de lignes est illimité, pouvant potentiellement atteindre des milliards.
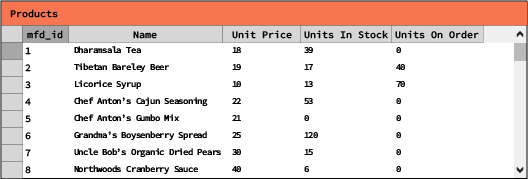
Figure 1 : une table simple illustrant une liste de produits et leur situation des stocks, typique de ce que l'on trouve dans une base de données relationnelle.
En pratique, l’approche relationnelle requiert plusieurs tables pour refléter un aspect d’intérêt métier (par exemple, des bons de commande). Ces regroupements de tables sont appelés entités. Une entité reflète la vision globale de l’entreprise.
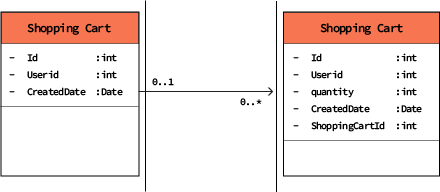
Figure 2 : une entité « panier d'achat » simple composée de deux tables. Cette entité reflète l'état du panier d'un visiteur d'un site e-commerce.
Comme mentionné ci-dessus, CRUD fait référence à Create, Read, Update et Delete, les 4 opérations fondamentales à effectuer sur les tables d’une base de données relationnelle.
- Create : ajouter de nouvelles lignes à la table.
- Read : récupérer les lignes existantes de la table.
- Update : modifier les lignes existantes dans la table.
- Delete : supprimer les lignes existantes de la table.
Ces opérations sont effectuées à l’aide d’un langage de base de données dédié, presque toujours un dialecte SQL (Structured Query Language) de nos jours.1
La conception CRUD consiste à introduire des entités ainsi que leurs homologues en interface utilisateur, généralement appelés « écrans ». Un écran, qui peut être une page web, comporte typiquement les 4 opérations pour l’entité concernée.
La grande majorité des applications métier « transactionnelles », allant d’un simple outil de suivi du temps à un ERP ou CRM très complexe, adoptent en coulisses une conception CRUD similaire – un modèle établi il y a plus de 4 décennies. Les applications simples comprennent seulement quelques entités tandis que les complexes en comptent des milliers. Cependant, qu’elles soient simples ou complexes, la conception reste fondamentalement la même.
La diversité des interfaces utilisateur, telle qu’on la trouve dans les applications métier, peut être trompeuse dans la mesure où l’on pourrait penser que ces applications n’ont que peu de points communs. Cependant, en pratique, la plupart des applications possèdent une conception interne presque identique, alignée sur la perspective CRUD.
Applications CRUD dans la supply chain
Pratiquement toutes les applications (exposées aux utilisateurs finaux) utilisées pour gérer les entreprises et leurs processus sont CRUD. De manière générale, si un logiciel d’entreprise bénéficie d’un sigle de 3 lettres tel que ERP, MRP, CRM, SRM, PLM, PIM, WMS, OMS, EDI (etc.), il est alors presque invariablement implémenté en tant que CRUD. La plus notable exception à cette règle concerne les éditeurs de documents (par exemple, les logiciels de tableur), qui représentent un tout autre type de technologie logicielle.
En interne, le département informatique utilise un large éventail de technologies qui ne sont pas CRUD : réseaux, virtualisation, outils d’administration système, etc. Cependant, ces technologies restent en grande partie invisibles, ou du moins peu intrusives, pour les utilisateurs finaux.
Ces applications CRUD contiennent presque toutes les données transactionnelles historiques pertinentes qui peuvent être exploitées pour améliorer quantitativement la supply chain (par exemple, pour optimiser les niveaux de stocks). En conséquence, de nombreuses applications CRUD tentent2, à un moment donné, de se diversifier en proposant des capacités analytiques (comme pour la planification ou l’optimisation). Malheureusement, bien que le CRUD présente de nombreux avantages, il comporte également d’importantes lacunes en matière de capacités analytiques (voir « Les limites du CRUD » ci-dessous).
Les avantages du CRUD
Le CRUD est l’approche de référence pour les applications métier depuis des décennies. D’un point de vue technologique, cette approche bénéficie de cadres et d’outils open source complets dans toutes les grandes piles logicielles. En conséquence, le parcours technologique est exceptionnellement bien défini. De plus, le CRUD bénéficie également d’outils de développement de haute qualité, ce qui se traduit par une grande productivité pour les ingénieurs logiciels impliqués dans le développement d’une application basée sur le CRUD.
D’un point de vue en matière de recrutement, il existe un vaste marché d’ingénieurs logiciels expérimentés avec le CRUD. De plus, le CRUD figure parmi les aspects les plus accessibles de l’ingénierie logicielle – en grande partie grâce à ses outils de développement de haute qualité. En conséquence, le CRUD est extrêmement accessible, même pour les ingénieurs logiciels juniors (et les seniors moins talentueux). Étant donné que les principes fondamentaux du CRUD sont stables depuis des décennies, la transition vers une pile technologique plus récente peut également être réalisée avec une relative facilité – du moins par rapport à d’autres approches plus pointues sur le plan technologique.
Enfin, d’un point de vue de continuité d’activité, le CRUD offre tous les avantages associés à sa base de données relationnelle sous-jacente. Par exemple, tant que la base de données reste accessible pour l’entreprise cliente, les données resteront accessibles ; cela demeure vrai même si le fournisseur initial de l’application CRUD n’est plus opérationnel ou coopératif avec l’entreprise cliente. Même dans ce cas extrême, l’accessibilité aux données est réalisable grâce à de modestes efforts de rétro-ingénierie.
Les limites du CRUD
Les applications CRUD font face à des limitations inhérentes liées à la manière dont elles exploitent la base de données relationnelle en leur cœur. Ces limitations ne peuvent être contournées sans renoncer fondamentalement aux avantages même associés au CRUD. Ces limitations se répartissent en deux grandes catégories : expressivité et performance.
La limitation d’expressivité reflète le fait que les quatre actions (ou « verbes ») – create, read, update et delete – ne peuvent pas capturer correctement une gamme plus granulaire d’intentions. Par exemple, considérez une situation où un employé cherche à dédupliquer plusieurs entrées de fournisseurs qui ont été créées par erreur dans le SRM (Supplier Relationship Manager). Le verbe approprié pour cette opération serait fusionner. Cependant, la conception CRUD ne prévoit pas ce verbe. En réalité, une telle capacité est invariablement mise en œuvre en deux étapes. D’abord, mettre à jour toutes les lignes qui pointaient vers les entrées de fournisseurs destinées à être supprimées, afin qu’elles pointent désormais vers celle à conserver. Ensuite, supprimer toutes les entrées excédentaires sauf une. Non seulement l’intention originale (la fusion) est perdue, mais la transformation est destructrice en termes de données. De manière anecdotique, lorsque les applications CRUD avertissent leurs utilisateurs qu’ils sont sur le point d’apporter une modification irréversible aux données, c’est presque toujours une limitation du CRUD3 qui intervient dans l’expérience utilisateur.
La limitation de performance reflète le fait que toute opération de longue durée – c’est-à-dire toute opération qui lit plus qu’une infime fraction de la base de données – expose l’application CRUD au risque de devenir non réactive. En effet, pour une application CRUD, les utilisateurs finaux s’attendent à ce que la latence soit à peine perceptible pour presque toutes les opérations banales. Par exemple, la mise à jour d’un niveau de stocks dans le WMS (Warehouse Management System) devrait s’effectuer en quelques millisecondes (afin de maintenir la fluidité des opérations). Comme toutes les opérations confiées à l’application CRUD consomment des ressources informatiques provenant de la même base de données relationnelle sous-jacente, presque toute opération non triviale compromet ce noyau en risquant un manque de ressources informatiques. De manière anecdotique, dans les grandes entreprises, les applications CRUD deviennent fréquemment non réactives pendant quelques secondes (voire minutes) à la fois. Ces situations sont presque toujours causées par quelques opérations « lourdes » qui finissent par monopoliser les ressources informatiques pendant une courte durée, retardant ainsi toutes les autres opérations – y compris les opérations « légères ». Ce problème explique pourquoi les opérations non triviales sont généralement isolées sous forme de travaux par lots exécutés la nuit. Il explique également pourquoi les applications CRUD sont généralement mauvaises en analytique, étant donné qu’il est impraticable d’exécuter des charges analytiques uniquement en dehors des heures de bureau.
Les variantes modernes du CRUD
Au cours des dernières décennies, les logiciels d’entreprise ont connu des évolutions substantielles. Dans les années 1990, la plupart des applications sont passées des terminaux de console aux interfaces utilisateur de bureau. Dans les années 2000, la plupart des applications sont passées des interfaces de bureau aux interfaces web. Au cours de la dernière décennie environ, la plupart des applications se sont orientées vers le SaaS (software as a service) et ont migré vers le cloud computing dans le processus. Cependant, la conception CRUD est restée largement inchangée par ces évolutions.
La transition de la location unique à la multi-location4 a contraint les fournisseurs de logiciels à restreindre l’accès aux données des entités via des API (Application Programming Interfaces). En effet, l’accès direct à la base de données, même en lecture seule, crée la possibilité d’épuiser les ressources informatiques du cœur transactionnel par seulement quelques requêtes lourdes. L’API atténue ce type de problème. Restreindre l’accès aux données de l’application derrière une API annule également certains des avantages du CRUD, du moins du point de vue de l’entreprise cliente. Extraire de manière fiable une grande quantité de données à partir d’une API nécessite généralement plus d’efforts que de composer une série comparable de requêtes SQL. De plus, l’API peut être incomplète – ne pas exposer des données existant dans l’application – même si l’accès direct à la base de données aurait dû permettre un accès complet aux données par conception.
La principale évolution du CRUD se trouve au niveau des outils. Dans les années 2010, une grande variété d’écosystèmes open source de haute qualité a émergé pour soutenir le développement des applications CRUD. Ces écosystèmes ont largement standardisé le développement des applications CRUD, réduisant ainsi considérablement les compétences requises pour les développer et diminuant les frictions associées au processus de développement.
Dynamique des fournisseurs
Le coût de développement d’une application CRUD est largement déterminé par le nombre d’entités. Plus il y a d’entités, plus le nombre d’écrans à développer, documenter et maintenir est important. Ainsi, la voie naturelle pour un fournisseur de logiciels proposant une application CRUD consiste à démarrer avec un nombre limité d’entités, puis à en ajouter au fil du temps.
L’ajout d’entités débloque de nouvelles fonctionnalités et offre au fournisseur l’opportunité d’augmenter ses prix, reflétant ainsi la valeur ajoutée pour l’entreprise cliente. De plus, les modules5, c’est-à-dire des regroupements d’entités liées au métier, sont fréquemment introduits comme mécanisme de tarification pour facturer davantage (en fonction de l’étendue de l’utilisation du produit logiciel).
En conséquence, les applications CRUD tendent à devenir de plus en plus complexes avec le temps, mais aussi moins pertinentes. En effet, à mesure que de nouvelles entités sont ajoutées pour servir l’intérêt de l’ensemble de la clientèle, bon nombre (voire la majorité) des entités nouvellement introduites ne sont pas pertinentes pour une entreprise cliente individuelle. Ces entités « mortes » – du point de vue de l’entreprise cliente – représentent une complexité accidentelle croissante qui pollue le CRUD.
Les applications CRUD vendues en tant que SaaS tendent à devenir plus coûteuses à mesure qu’elles gagnent en fonctionnalités et en notoriété. Cependant, comme les barrières à l’entrée sont très faibles6, de nouveaux fournisseurs émergent fréquemment, chacun se concentrant sur des cas d’utilisation à des niveaux de prix bien inférieurs – et le cycle se répète à l’infini.
L’avis de Lokad
Beaucoup, voire la majorité, des grandes entreprises sous-estiment l’ampleur de la standardisation des applications CRUD. Pour la plupart des fournisseurs de logiciels d’entreprise qui les vendent, le coût de développement n’est qu’une infime fraction des dépenses totales de l’entreprise, bien en deçà des coûts liés au marketing et à la vente des applications elles-mêmes. En particulier, les fournisseurs développant des applications CRUD délocalisent fréquemment leurs équipes d’ingénierie dans des pays à bas coûts, car l’approche CRUD (étant donné son accessibilité globale) peut tolérer une main-d’œuvre en ingénierie moins talentueuse – et moins coûteuse.
Il y a de très bonnes raisons de ne pas payer des montants exorbitants pour des applications CRUD de nos jours. En règle générale, toute application CRUD coûtant plus de 250k USD par an est un sérieux candidat à être remplacée par un logiciel interne. Toute application CRUD coûtant plus de 2.5M USD par an devrait, presque sans exception, être remplacée par un logiciel interne (éventuellement en partant d’une base open source préexistante et en la personnalisant par la suite).
Les fournisseurs de logiciels d’entreprise qui vendent des applications CRUD sont bien conscients de ce problème (et cela depuis longtemps). Ainsi, il est tentant pour le fournisseur d’ajouter à la solution des fonctionnalités/applications/éléments non-CRUD7 et d’essayer de convaincre les clients (a) que ces éléments sont importants et (b) qu’ils représentent une sorte de « secret sauce » que le client ne pourra pas reproduire. Cependant, cette approche réussit presque jamais, principalement parce que le fournisseur ne possède pas l’ADN d’ingénierie adéquat8. À titre d’exemple anecdotiques, presque tous les ERP notables et établis disposent de vastes capacités de prévision et de planification, dont la quasi-totalité restent largement inutilisées compte tenu de leur faible performance dans ces tâches.
Lokad est un éditeur de logiciels d’entreprise spécialisé dans l’optimisation prédictive de la supply chain. Notre technologie a été conçue pour tirer parti des données transactionnelles historiques – le type de données pouvant être extrait des applications CRUD qui soutiennent les opérations quotidiennes d’une entreprise. Cependant, Lokad lui-même n’est pas une application CRUD. Notre environnement de production n’inclut même pas de base de données relationnelle. Bien que CRUD soit une réponse technologique valide pour la gestion des flux transactionnels d’une entreprise, elle n’a aucune pertinence, que ce soit pour la modélisation prédictive ou pour l’optimisation mathématique d’une supply chain.
Notes
-
Chaque fournisseur de bases de données a tendance à avoir son propre dialecte SQL. Les subtilités de la syntaxe varient d’un fournisseur à l’autre, mais ces langages sont très similaires. Des outils existent pour traduire automatiquement entre les dialectes. ↩︎
-
L’acronyme ERP signifie Enterprise Resource Planning. Pourtant, c’est un abus de langage. Cette catégorie de logiciels d’entreprise devrait être appelée Enterprise Resource Management. En effet, le terme “planning” a été introduit dans les années 1990 comme un effet de mode marketing par certains éditeurs de logiciels afin de se différencier grâce à l’introduction de capacités analytiques. Cependant, trois décennies plus tard, les ERP ne conviennent toujours pas aux charges analytiques, précisément en raison de leur conception CRUD. ↩︎
-
Avec suffisamment d’efforts, il est possible de rendre toutes les opérations réversibles avec CRUD. Cependant, cela va généralement à l’encontre de l’objectif même d’adopter CRUD dès le départ ; à savoir, sa simplicité et sa productivité pour l’équipe d’ingénierie logicielle. ↩︎
-
Une application est dite mono-locataire si une instance de l’application dessert un seul client, généralement une entreprise cliente dans le cas d’une application métier. Une application est dite multi-locataire si une seule instance dessert de nombreux clients (éventuellement tous les clients de l’éditeur de logiciels). ↩︎
-
La terminologie varie. Les éditeurs de SaaS ont tendance à utiliser le terme plans ou éditions plutôt que modules pour désigner le mécanisme de tarification qui donne accès à des entités supplémentaires, et donc à des capacités supplémentaires. ↩︎
-
En général, une application CRUD peut être presque entièrement rétro-conçue grâce à l’inspection minutieuse des différents “écrans” qu’elle propose à ses utilisateurs finaux. ↩︎
-
La partie non-CRUD a tendance à être thématisée avec le mot à la mode du moment. Au début des années 2000, les applications étaient dotées de capacités de “data mining”. Au début des années 2010, les applications avec des capacités de “big data” étaient à la mode. Depuis le début des années 2020, les applications intègrent des capacités “AI”. Malheureusement, l’approche CRUD ne se marie pas bien avec des alternatives plus sophistiquées. Pour les éditeurs d’applications CRUD, ces capacités ne sont invariablement que de simples effets de mode marketing. ↩︎
-
Peu d’ingénieurs logiciels talentueux sont prêts à travailler pour un éditeur qui vend des applications CRUD ; les salaires sont trop bas, et le talent d’un ingénieur est largement inutile en raison de la voie technologique adoptée. L’écart de talent entre les ingénieurs logiciels CRUD et non-CRUD est à peu près aussi grand que celui entre les photographes de mariage et les photographes de marques de luxe. ↩︎