00:00:00 Introduction à la présentation sur le déversement sur disque
00:00:34 Traitement des données du détaillant et limitations de la mémoire
00:02:13 Solution de stockage persistant et comparaison des coûts
00:04:07 Comparaison de la vitesse entre le disque et la mémoire
00:05:10 Limitations des techniques de partitionnement et de streaming
00:06:16 Importance des données ordonnées et de la taille de lecture optimale
00:07:40 Scénario pire pour la lecture des données
00:08:57 Impact de la mémoire de la machine sur l’exécution du programme
00:10:49 Techniques de déversement sur disque et utilisation de la mémoire
00:12:59 Explication de la section de code et implémentation en .NET
00:15:06 Contrôle de l’allocation mémoire et conséquences
00:16:18 Pages mappées en mémoire et fichiers de mapping mémoire
00:18:24 Les mappings mémoire en lecture-écriture et les outils de performance du système
00:20:04 Utilisation de la mémoire virtuelle et des pages mappées en mémoire
00:22:08 Gestion de gros fichiers et de pointeurs 64 bits
00:24:00 Utilisation de span pour charger à partir de la mémoire mappée
00:26:03 Copie de données et utilisation d’une structure pour lire des entiers
00:28:06 Création d’un span à partir d’un pointeur et d’un Memory Manager
00:30:27 Création d’une instance de Memory Manager
00:31:05 Implémentation d’un programme de déversement sur disque et mapping mémoire
00:33:34 La version mappée en mémoire est préférable pour la performance
00:35:22 Stratégie de buffer de FileStream et limitations
00:37:03 Stratégie de mappage d’un gros fichier
00:39:30 Répartition de la mémoire sur plusieurs gros fichiers
00:40:21 Conclusion et invitation aux questions
Résumé
Pour traiter plus de données que ne peut contenir la mémoire, les programmes peuvent déverser une partie de ces données vers un stockage plus lent mais de plus grande capacité, tel que les disques NVMe. Grâce à une combinaison de deux fonctionnalités assez obscures de .NET (les fichiers mappés en mémoire et les gestionnaires de mémoire), cela peut être réalisé en C# avec peu ou pas de surcoût en performances. Cette présentation, donnée aux Warsaw IT Days 2023, plonge dans les détails approfondis de ce fonctionnement et explique comment le package NuGet open source Lokad.ScratchSpace masque la plupart de ces détails aux développeurs.
Résumé Étendu
Dans une conférence complète, Victor Nicolet, le CTO de Lokad, se penche sur les subtilités du déversement sur disque en .NET, une technique qui permet de traiter de larges ensembles de données dépassant la capacité de mémoire d’un ordinateur classique. Nicolet puise dans sa vaste expérience de gestion d’ensembles de données complexes dans le domaine de l’optimization quantitative de la supply chain chez Lokad, en fournissant un exemple pratique d’un détaillant avec cent mille produits répartis sur 100 emplacements. Cela aboutit à un ensemble de données de 10 milliards d’entrées lorsque l’on considère un point de données par jour sur trois ans, ce qui nécessiterait 37 gigaoctets de mémoire pour stocker une valeur flottante par entrée, dépassant de loin la capacité d’un ordinateur de bureau classique.
Nicolet suggère l’utilisation d’un stockage persistant, tel que les disques SSD NVMe, comme alternative économique à la mémoire. Il compare le coût de la mémoire et du stockage SSD, notant que pour le prix de 18 gigaoctets de mémoire, on peut acheter un téraoctet de stockage SSD. Il aborde également le compromis en termes de performances, soulignant que la lecture depuis le disque est six fois plus lente que la lecture depuis la mémoire.
Il présente le partitionnement et le streaming comme des techniques permettant d’utiliser l’espace disque en alternative à la mémoire. Le partitionnement permet de traiter des ensembles de données en plus petits morceaux qui tiennent en mémoire, mais n’autorise pas la communication entre les partitions. Le streaming, en revanche, permet de maintenir un certain état entre le traitement de différentes parties, mais il exige que les données sur disque soient ordonnées ou correctement alignées pour une performance optimale.
Nicolet présente ensuite les techniques de déversement sur disque comme solution aux limitations de l’approche consistant à tenir les données entièrement en mémoire. Ces techniques distribuent dynamiquement les données entre la mémoire et le stockage persistant, utilisant davantage de mémoire quand elle est disponible pour accélérer l’exécution, et ralentissant pour en utiliser moins lorsque la quantité disponible diminue. Il explique que ces techniques utilisent autant de mémoire que possible et ne commencent à déverser les données sur le disque qu’une fois la mémoire épuisée. Cela leur permet de mieux réagir à un surplus ou un déficit de mémoire par rapport aux prévisions initiales.
Il explique en outre que les techniques de déversement sur disque divisent l’ensemble des données en deux sections : la section chaude, qui reste toujours en mémoire, et la section froide, qui peut déverser des parties de son contenu vers le stockage persistant à tout moment. Le programme utilise des transferts chaud-froid, qui impliquent généralement de gros lots afin de maximiser l’utilisation de la bande passante NVMe. La section froide permet à ces algorithmes d’utiliser autant de mémoire que possible.
Nicolet aborde ensuite la mise en œuvre de cette technique en .NET. Pour la section chaude, on utilise des objets .NET normaux, tandis que pour la section froide, une classe de référence est utilisée. Cette classe conserve une référence à la valeur placée dans le stockage froid, et cette valeur peut être définie sur null lorsqu’elle n’est plus en mémoire. Un système central dans le programme suit l’ensemble des références froides, et chaque fois qu’une nouvelle référence froide est créée, il détermine si cela provoque un dépassement de la mémoire et invoque la fonction de déversement d’une ou plusieurs des références froides déjà présentes dans le système afin de rester dans le budget mémoire alloué au stockage froid.
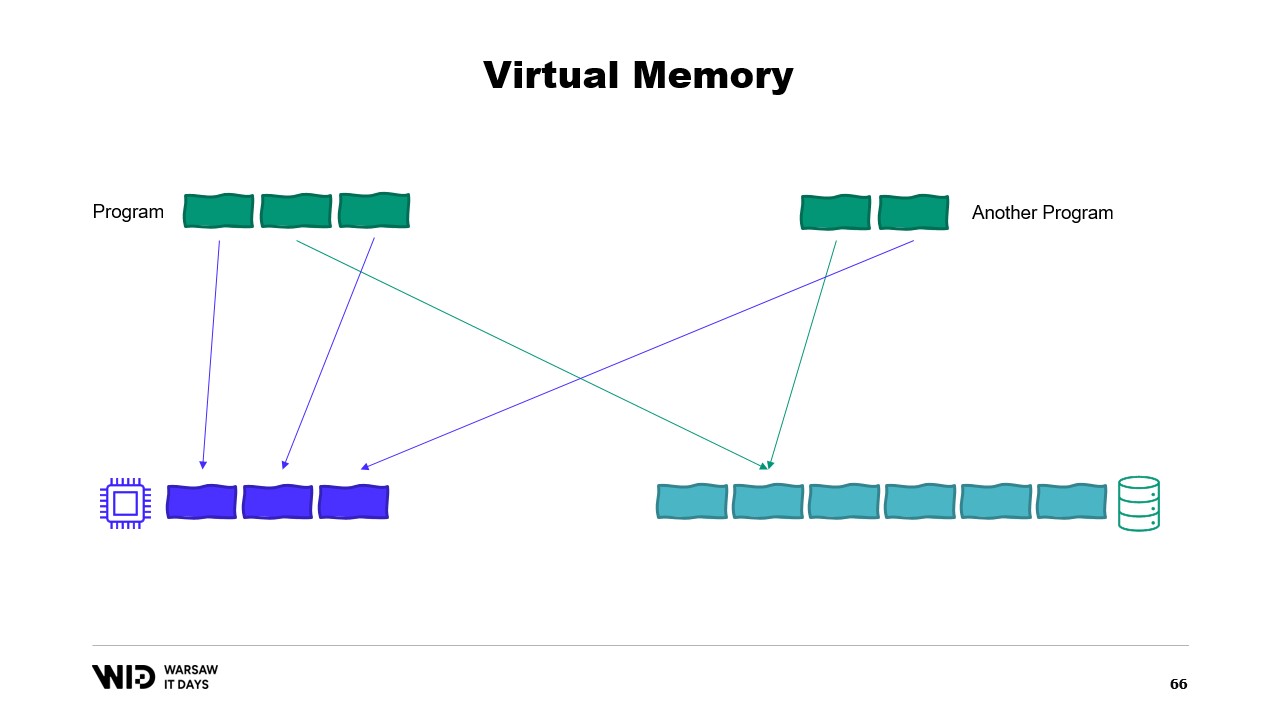
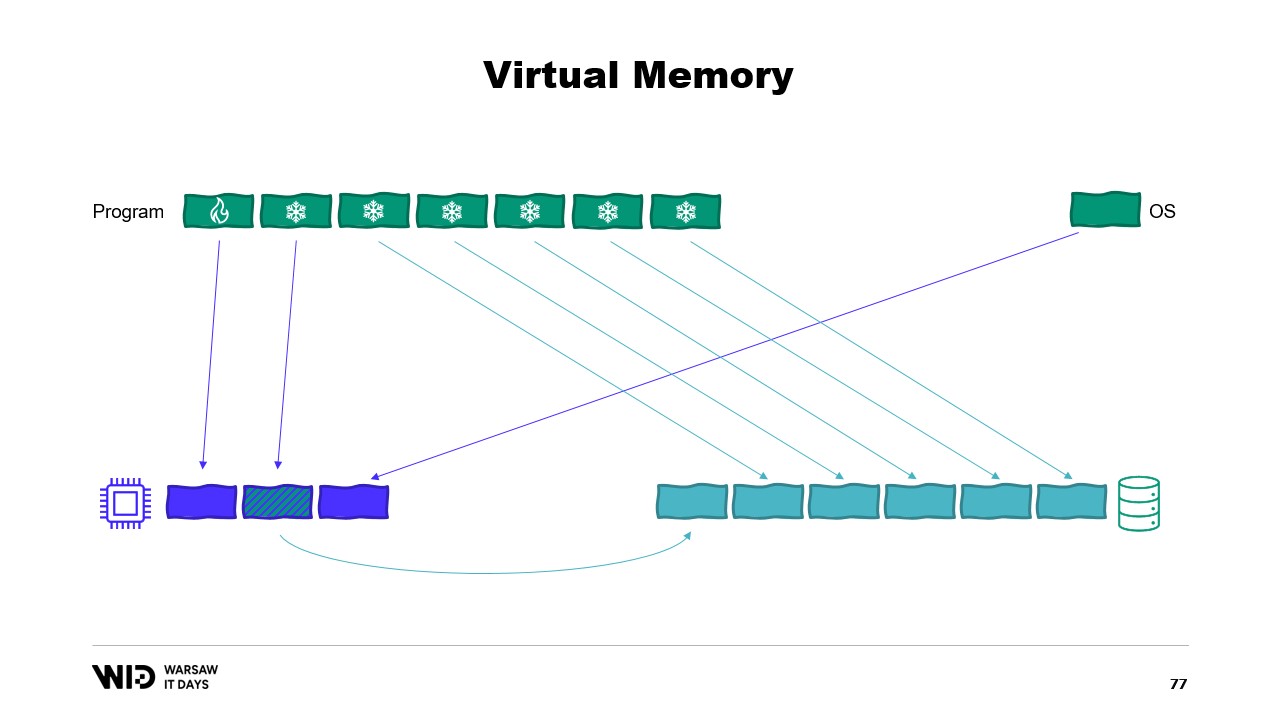
Il introduit ensuite le concept de mémoire virtuelle, où le programme n’a pas accès directement aux pages de mémoire physique, mais accède à des pages de mémoire virtuelle. Il est possible de créer une page mappée en mémoire, ce qui est une méthode courante pour implémenter la communication entre les programmes et les fichiers de mapping mémoire. Le but principal du mapping mémoire est d’éviter que chaque programme n’ait sa propre copie de la DLL en mémoire, puisque toutes ces copies sont identiques.
Nicolet évoque ensuite l’outil de performance système, qui affiche l’utilisation actuelle de la mémoire physique. En vert se trouve la mémoire qui a été directement attribuée à un processus, en bleu le cache de pages, et les pages modifiées au centre représentent celles qui devraient être une copie exacte du disque, mais présentent des modifications en mémoire.
Il aborde ensuite une seconde tentative en utilisant la mémoire virtuelle, où la section froide sera constituée entièrement de pages mappées en mémoire. Si le système d’exploitation a soudainement besoin de mémoire, il sait quelles pages sont mappées en mémoire et peut les supprimer en toute sécurité.
Nicolet explique ensuite les étapes de base pour créer un fichier mappé en mémoire dans .NET, à savoir d’abord créer un fichier mappé à partir d’un fichier sur disque, puis créer un view accessor. Ces deux éléments sont maintenus séparément car .NET doit gérer le cas d’un processus 32 bits. Dans le cas d’un processus 64 bits, il est possible de créer un view accessor qui charge l’intégralité du fichier.
Nicolet évoque ensuite l’introduction de types tels que memory et span il y a cinq ans, qui servent à représenter une plage de mémoire de manière plus sûre que de simples pointeurs. L’idée générale derrière span et memory est que, donné un pointeur et un nombre d’octets, un nouveau span représentant cette plage de mémoire peut être créé. Une fois le span créé, il peut être lu en toute sécurité n’importe où dans cette plage, sachant que si une tentative de lecture au-delà des limites est effectuée, le runtime le détectera et une exception sera levée au lieu de simplement laisser le processus se terminer.
Nicolet explique ensuite comment utiliser span pour charger depuis la mémoire mappée en mémoire gérée par .NET. Par exemple, s’il s’agit de lire une chaîne de caractères, de nombreuses API utilisant des spans peuvent être employées. Nicolet explique l’utilisation d’API centrées sur les spans, telles que MemoryMarshal.Read, qui peut lire un entier depuis le début du span. Il mentionne également la fonction Encoding.GetString, qui peut charger depuis un span d’octets vers une chaîne de caractères.
Il explique en outre que ces opérations sont effectuées sur des spans, qui représentent une section de données pouvant se trouver sur disque plutôt qu’en mémoire. Le système d’exploitation se charge de charger les données en mémoire lors de leur premier accès. Nicolet fournit un exemple d’une séquence de valeurs flottantes devant être chargées dans un tableau de float. Il explique l’utilisation de MemoryMarshal.Read pour lire la taille, l’allocation d’un tableau de valeurs flottantes de cette taille, et l’utilisation de MemoryMarshal.Cast pour transformer le span d’octets en un span de valeurs flottantes.
Il aborde également l’utilisation de la fonction CopyTo des spans, qui effectue une copie hautes performances des données depuis le fichier mappé en mémoire vers le tableau. Il note que ce processus peut être quelque peu inefficace car il implique la création d’une copie entièrement nouvelle. Nicolet suggère de créer une structure représentant l’en-tête contenant deux valeurs entières, pouvant être lue par MemoryMarshal. Il évoque aussi l’utilisation d’une bibliothèque de compression pour décompresser les données.
Nicolet aborde l’utilisation d’un type différent, Memory, pour représenter une plage de données à plus longue durée de vie. Il mentionne le manque de documentation sur la manière de créer un memory à partir d’un pointeur et recommande un gist sur GitHub comme la meilleure ressource disponible. Il explique la nécessité de créer un MemoryManager, qui est utilisé en interne par un Memory chaque fois qu’il doit effectuer une opération plus complexe que de simplement pointer vers une section d’un tableau.
Nicolet compare l’utilisation du mapping mémoire et de FileStream, notant que FileStream est le choix évident pour accéder aux données sur disque et que son utilisation est bien documentée. Il souligne que l’approche FileStream n’est pas thread-safe et nécessite un verrou autour de l’opération, empêchant la lecture depuis plusieurs emplacements en parallèle. Nicolet mentionne également que l’approche FileStream introduit un certain surcoût qui n’est pas présent avec la version mappée en mémoire.
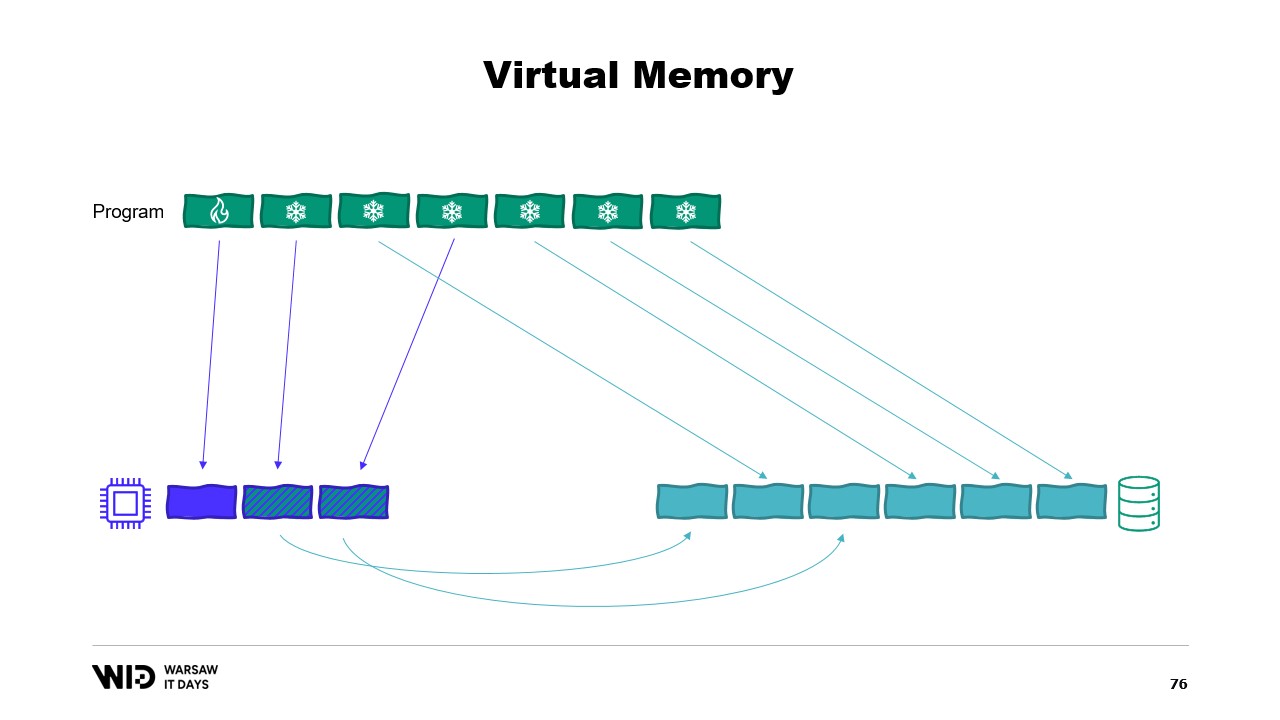
Il explique que la version mappée en mémoire doit être utilisée à la place, car elle est capable d’utiliser autant de mémoire que possible et, lorsque la mémoire vient à manquer, de déverser des parties des ensembles de données sur le disque. Nicolet soulève la question du nombre de fichiers à allouer, de leur taille et de la manière de faire tourner ces fichiers à mesure que la mémoire est allouée et désallouée.
Il suggère de répartir la mémoire sur plusieurs gros fichiers, de ne jamais écrire deux fois dans la même zone mémoire, et de supprimer les fichiers dès que possible. Nicolet conclut en partageant qu’en production chez Lokad, ils utilisent Lokad Scratch Space avec des paramètres spécifiques : chaque fichier a 16 gigaoctets, il y a 100 fichiers sur chaque disque, et chaque L32VM dispose de quatre disques, ce qui représente un peu plus de 6 téraoctets d’espace de déversement pour chaque VM.
Transcription Complète

Victor Nicolet: Bonjour et bienvenue à cette présentation sur le déversement sur disque en .NET.
Le déversement sur disque est une technique pour traiter des ensembles de données qui ne tiennent pas en mémoire en conservant, sur un stockage persistant, les parties de l’ensemble de données qui ne sont pas utilisées.
Cette présentation est basée sur mon expérience chez Lokad. Nous pratiquons l’optimization quantitative de la supply chain.
Le côté quantitatif signifie que nous travaillons avec de grands ensembles de données et la partie supply chain, eh bien, c’est le monde réel, donc ils sont désordonnés, surprenants et pleins de cas limites imbriqués.
Ainsi, nous effectuons de nombreux traitements assez complexes.
Examinons un exemple typique. Un détaillant disposerait d’environ cent mille produits.
Ces produits se trouvent dans jusqu’à 100 emplacements. Il peut s’agir de magasins, d’entrepôts, voire de sections d’entrepôts dédiées au le e-commerce.
Et si nous voulons effectuer une analyse réelle à ce sujet, nous devons examiner le comportement passé, ce qui arrive à ces produits et à ces emplacements.
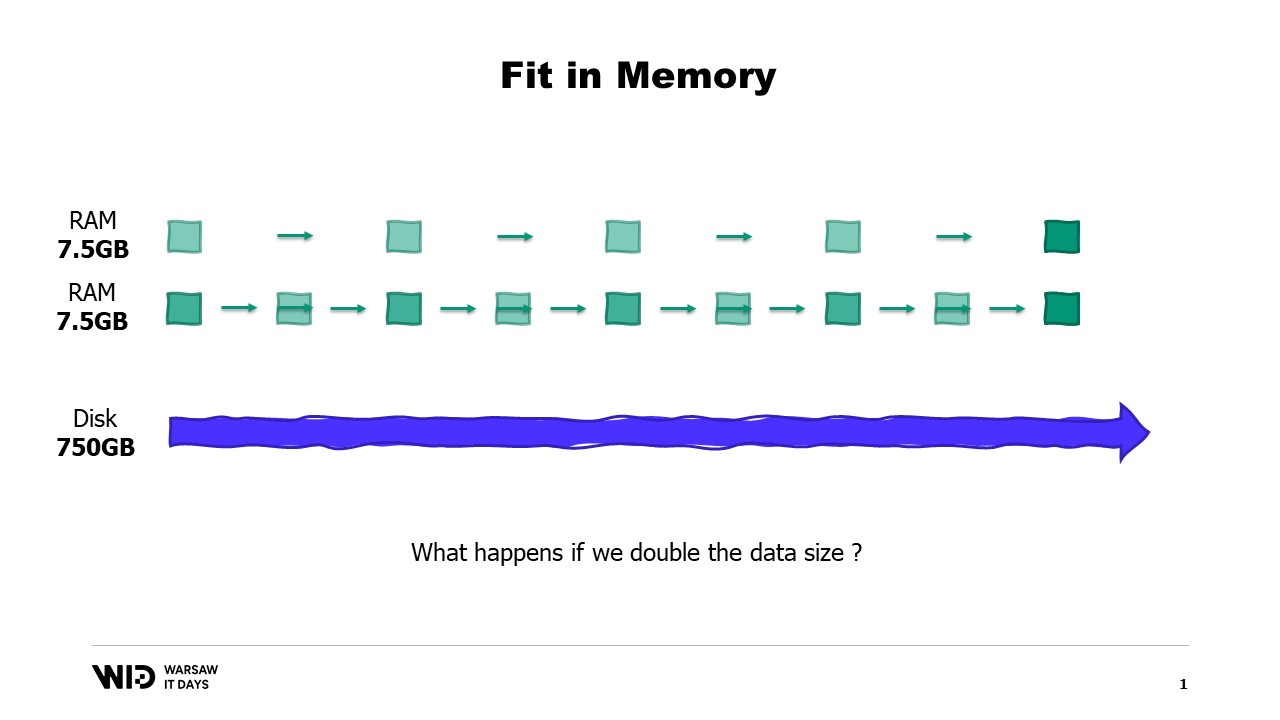
En supposant que nous conservions un seul point de données par jour et que nous ne regardions que trois ans dans le passé, cela représente environ 1000 jours. Multipliez le tout et notre ensemble de données comptera 10 milliards d’entrées.
Si nous conservons une seule valeur flottante par entrée, l’ensemble de données occupe déjà 37 gigaoctets de mémoire. Cela dépasse ce qu’un ordinateur de bureau typique posséderait.

Et une seule valeur flottante n’est absolument pas suffisante pour réaliser une quelconque analyse.
Un meilleur nombre serait 20 et même dans ce cas, nous déployons de grands efforts pour maintenir une empreinte mémoire réduite. Même ainsi, nous envisageons environ 745 gigaoctets d’utilisation de mémoire.
Cela tient dans des machines cloud si elles sont suffisamment grandes, pour environ sept mille dollars par mois. Ainsi, c’est relativement abordable, mais c’est aussi plutôt gaspilleur.

Comme vous l’avez peut-être deviné à partir du titre de cette présentation, la solution consiste à utiliser un stockage persistant à la place, qui est plus lent mais moins cher que la mémoire.
Aujourd’hui, vous pouvez acheter un stockage SSD NVMe pour environ 5 cents par gigaoctet. Un SSD NVMe est l’un des types de stockage persistant les plus rapides disponibles de nos jours.
En comparaison, un gigaoctet de RAM coûte 275 dollars. Cela représente environ 55 fois d’écart.

Une autre manière de voir les choses est que, pour le budget nécessaire à l’achat de 18 gigaoctets de mémoire, vous auriez assez pour payer un téraoctet de stockage SSD.

Qu’en est-il des offres Cloud ? Eh bien, en prenant l’exemple du cloud Microsoft, à gauche se trouve le L32s, faisant partie d’une série de machines virtuelles optimisées pour le stockage.
Pour environ deux mille dollars par mois, vous obtenez près de 8 téraoctets de stockage persistant.
À droite se trouve le M32ms, faisant partie d’une série optimisée pour la mémoire et pour un coût plus de deux fois et demie supérieur, vous n’obtenez que 875 gigaoctets de RAM.
Si mon programme s’exécute sur la machine de gauche et met deux fois plus de temps à se terminer, je reste gagnant en termes de coût.

Qu’en est-il de la performance ? Eh bien, la lecture depuis la mémoire s’effectue à environ 21 gigaoctets par seconde. La lecture depuis un NVMe SSD s’effectue à environ 3,5 gigaoctets par seconde.
Ce n’est pas un benchmark réel. J’ai simplement créé une machine virtuelle et exécuté ces deux commandes, et il existe de nombreuses façons d’augmenter ou de diminuer ces chiffres.
L’important ici est simplement l’ordre de grandeur de la différence entre les deux. La lecture depuis le disque est six fois plus lente que la lecture depuis la mémoire.
Ainsi, le disque est à la fois décevant par sa lenteur, vous ne voulez pas lire depuis le disque en permanence avec des schémas d’accès aléatoires. Mais d’autre part, il est également étonnamment rapide. Si votre traitement est principalement lié au processeur, vous pourriez même ne pas remarquer que vous lisez depuis le disque au lieu de la mémoire.

Une technique assez connue pour utiliser l’espace disque comme alternative à la mémoire est le partitionnement.
L’idée derrière le partitionnement est de sélectionner l’une des dimensions du jeu de données et de découper le jeu de données en morceaux plus petits. Chaque morceau doit être suffisamment petit pour tenir en mémoire.
Le traitement charge ensuite chaque morceau séparément, effectue son traitement, et sauvegarde ce morceau sur le disque avant de charger le morceau suivant.
Dans notre exemple, si nous devions découper les jeux de données selon les emplacements et traiter les emplacements un par un, alors chaque emplacement ne prendrait que 7,5 gigaoctets de mémoire. Cela est tout à fait dans la portée de ce qu’un ordinateur de bureau peut faire.

Cependant, avec le partitionnement, il n’y a pas de communication entre les partitions. Donc, si nous avons besoin de traiter des données sur plusieurs emplacements, nous ne pouvons plus utiliser cette technique.
Une autre technique est le streaming. Le streaming est assez similaire au partitionnement dans la mesure où nous ne chargeons en mémoire que de petits morceaux de données à un instant donné.
Contrairement au partitionnement, nous sommes autorisés à conserver un certain état entre le traitement de différentes parties. Ainsi, lors du traitement du premier emplacement, nous établirions l’état initial, puis, lors du traitement du second emplacement, nous pourrions utiliser ce qui était présent dans l’état à ce moment-là pour créer un nouvel état à la fin du traitement du second emplacement.
Contrairement au partitionnement, le streaming ne se prête pas à une exécution parallèle. Mais il résout le problème de calculer quelque chose sur l’ensemble des données du jeu de données au lieu d’être cloisonné dans chaque morceau séparément.
Toutefois, le streaming a sa propre limitation. Pour qu’il soit performant, les données sur disque doivent être ordonnées ou correctement alignées.
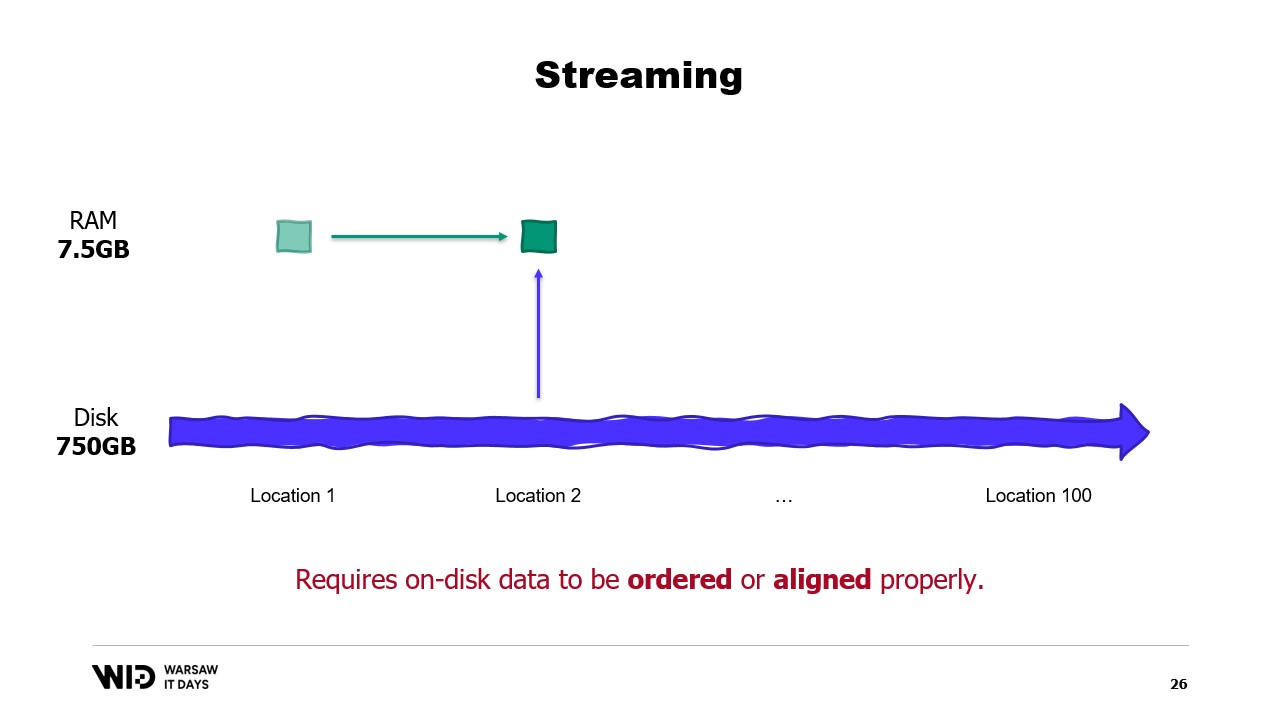
Pour comprendre ces exigences, vous devez savoir que NVMe lit et écrit des données en secteurs de 0,5 kilo-octet et que les valeurs de performance précédentes, comme 3,5 gigaoctets par seconde, supposent que les secteurs sont lus et utilisés dans leur intégralité.
Si nous n’utilisons qu’une portion du secteur mais que le secteur entier doit être lu, alors nous gaspillons de la bande passante et divisons notre performance par un facteur important.

Ainsi, il est optimal que les données que nous lisons soient un multiple de 0,5 kilo-octet et soient alignées sur les limites des secteurs.
Nous n’utilisons plus de disques rotatifs maintenant, donc sauter et ne pas lire le secteur se fait sans coût.

S’il n’est pas possible d’aligner les données sur les limites des secteurs, une autre solution consiste à les charger en ordre séquentiel.
En effet, une fois un secteur chargé en mémoire, lire la seconde partie du secteur ne nécessite pas un autre chargement depuis le disque. Au lieu de cela, le système d’exploitation sera simplement capable de vous fournir les octets restants qui n’ont pas encore été utilisés.
Ainsi, si les données sont chargées consécutivement, il n’y a pas de bande passante gaspillée et vous obtenez toujours la pleine performance.

Le pire des cas est lorsque vous ne lisez qu’un ou quelques octets de chaque secteur. Par exemple, si vous lisez une valeur à virgule flottante de chaque secteur, vous divisez votre performance par 128.

Pire encore, il existe une autre unité de regroupement des données au-dessus des secteurs, qui est la page du système d’exploitation, et le système d’exploitation charge généralement des pages entières d’environ 4 kilo-octets dans leur intégralité.
Ainsi, désormais, si vous lisez une valeur à virgule flottante de chaque page, vous avez divisé votre performance par 1024.
Pour cette raison, il est vraiment important de s’assurer que les lectures de données à partir du stockage persistant sont effectuées en grands lots consécutifs.

En utilisant ces techniques, il est possible de faire tenir le programme dans une quantité de mémoire plus réduite. Maintenant, ces techniques traiteront la mémoire et le disque comme deux espaces de stockage séparés, indépendants l’un de l’autre.
Ainsi, la répartition du jeu de données entre la mémoire et le disque est entièrement déterminée par l’algorithme et la structure du jeu de données.
Donc, si nous exécutons le programme sur une machine qui dispose exactement de la bonne quantité de mémoire, le programme tiendra parfaitement et sera capable de fonctionner.
Si nous fournissons une machine qui a moins que la quantité de mémoire requise, le programme ne pourra pas tenir en mémoire et ne pourra pas fonctionner.
Enfin, si nous fournissons une machine qui dispose de plus de mémoire que nécessaire, le programme fera ce que font habituellement les programmes, il n’utilisera pas la mémoire supplémentaire et fonctionnera toujours à la même vitesse.
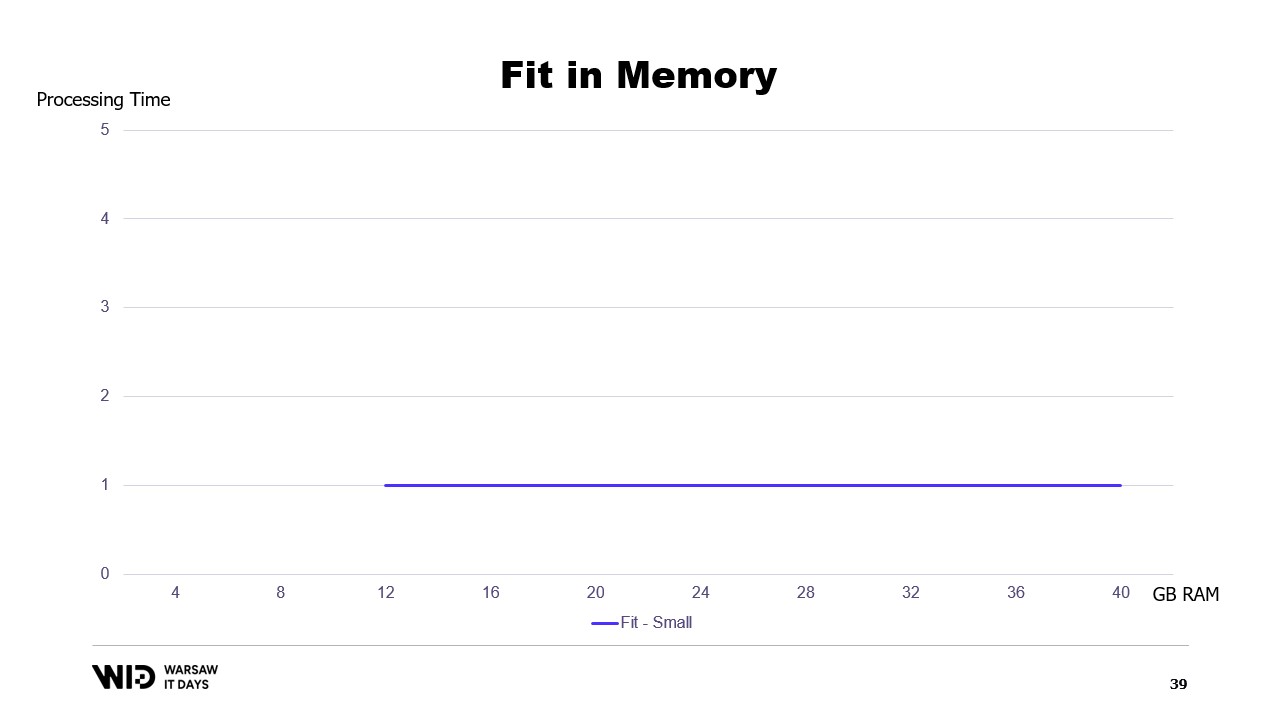
Si nous traçons un graphique du temps d’exécution en fonction de la mémoire disponible, il ressemblera à ceci. Au-dessous de l’empreinte mémoire, il n’y a pas d’exécution, donc il n’y a pas de temps de traitement. Au-dessus de l’empreinte, le temps de traitement est constant car le programme ne peut pas utiliser la mémoire supplémentaire pour fonctionner plus rapidement.
Et aussi, que se passe-t-il si le jeu de données grossit ? Eh bien, selon la dimension, si le jeu de données s’accroît de manière à augmenter le nombre de partitions, alors l’empreinte mémoire restera la même, il y aura simplement plus de partitions.
En revanche, si les partitions individuelles grossissent, alors l’empreinte mémoire augmentera également, ce qui accroîtra la quantité minimale de mémoire nécessaire pour que le programme puisse fonctionner.
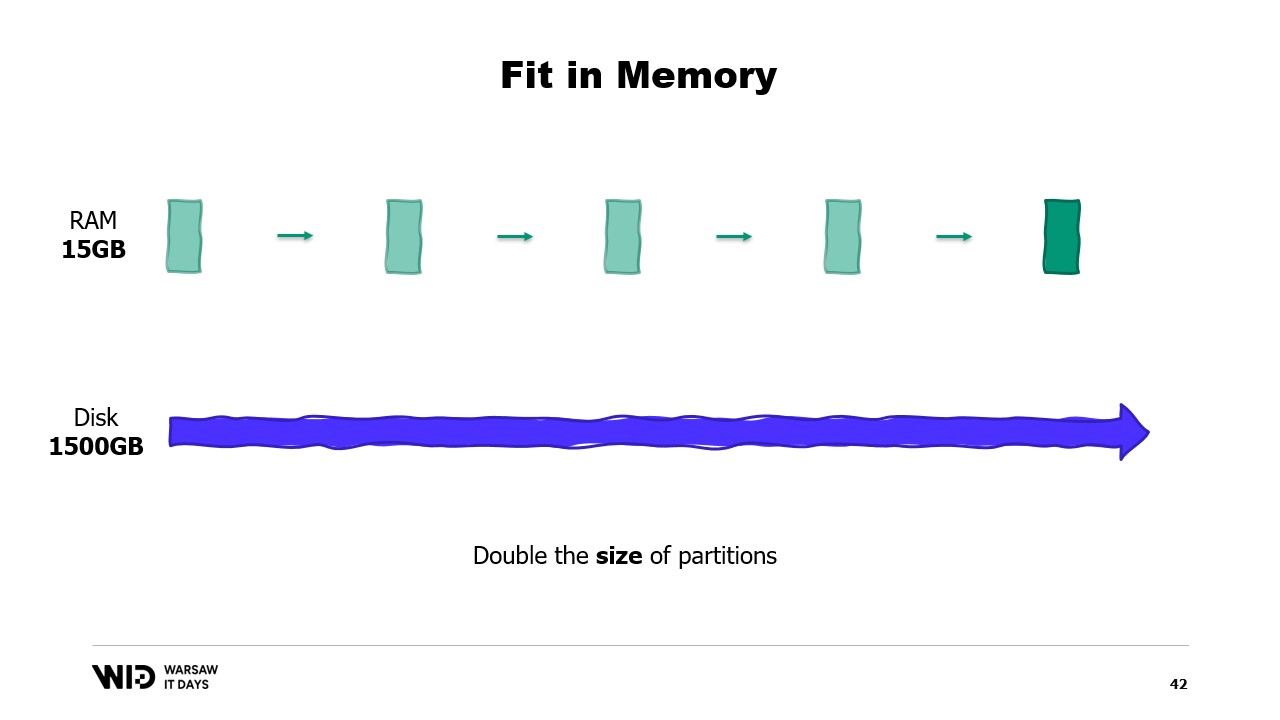
En d’autres termes, si j’ai un jeu de données plus volumineux à traiter, non seulement cela prendra plus de temps, mais cela aura également une empreinte plus grande.
Cela crée une situation délicate où il faudra ajouter plus de mémoire pour pouvoir faire tenir de grands jeux de données lorsqu’ils apparaissent, mais l’ajout de mémoire n’améliore rien aux jeux de données plus petits.
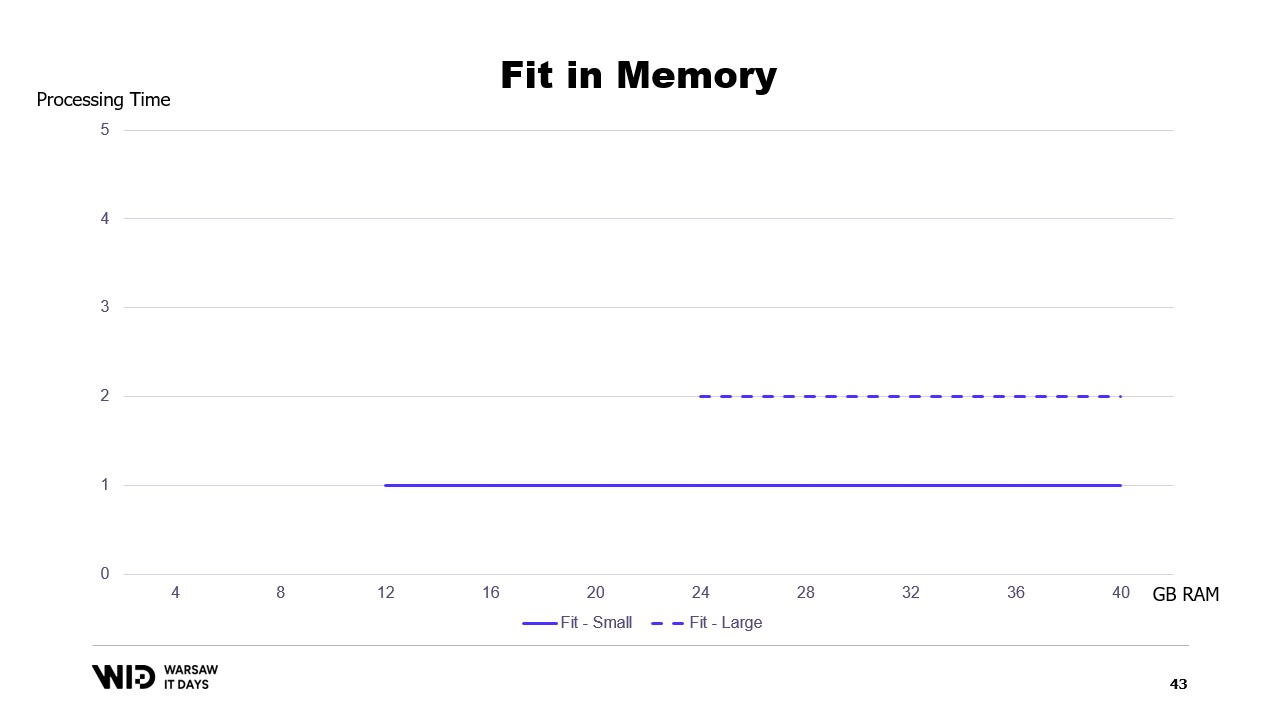
C’est une limitation de l’approche consistant à faire tenir en mémoire, où la répartition du jeu de données entre la mémoire et le stockage persistant est entièrement déterminée par la structure du jeu de données et l’algorithme lui-même.
Cela ne prend pas en compte la quantité réelle de mémoire disponible. Ce que font les techniques de spill to disk, c’est qu’elles effectuent cette répartition dynamiquement. Donc, s’il y a plus de mémoire disponible, elles utiliseront plus de mémoire pour fonctionner plus rapidement.
Et par contre, s’il y a moins de mémoire disponible, alors jusqu’à un certain point, elles pourront ralentir afin d’utiliser moins de mémoire. Les courbes sont bien meilleures dans ce cas. L’empreinte minimale est plus petite et identique pour les deux jeux de données.
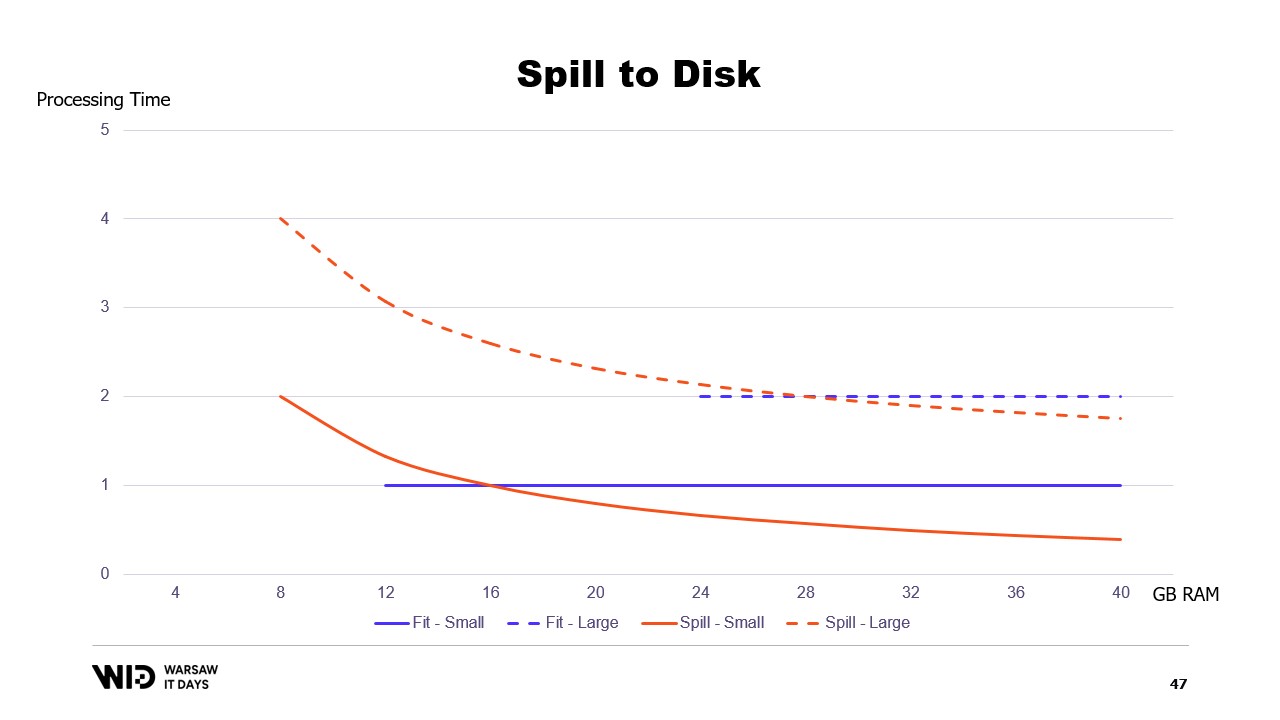
La performance augmente à mesure que l’on ajoute de la mémoire dans tous les cas. Les techniques de fit in memory déverseront de façon préventive certaines données sur le disque afin de réduire l’empreinte mémoire. En revanche, les techniques de spill to disk utiliseront autant de mémoire que possible et ce n’est que lorsqu’elles manqueront de mémoire qu’elles commenceront à déverser des données sur le disque pour libérer de l’espace.
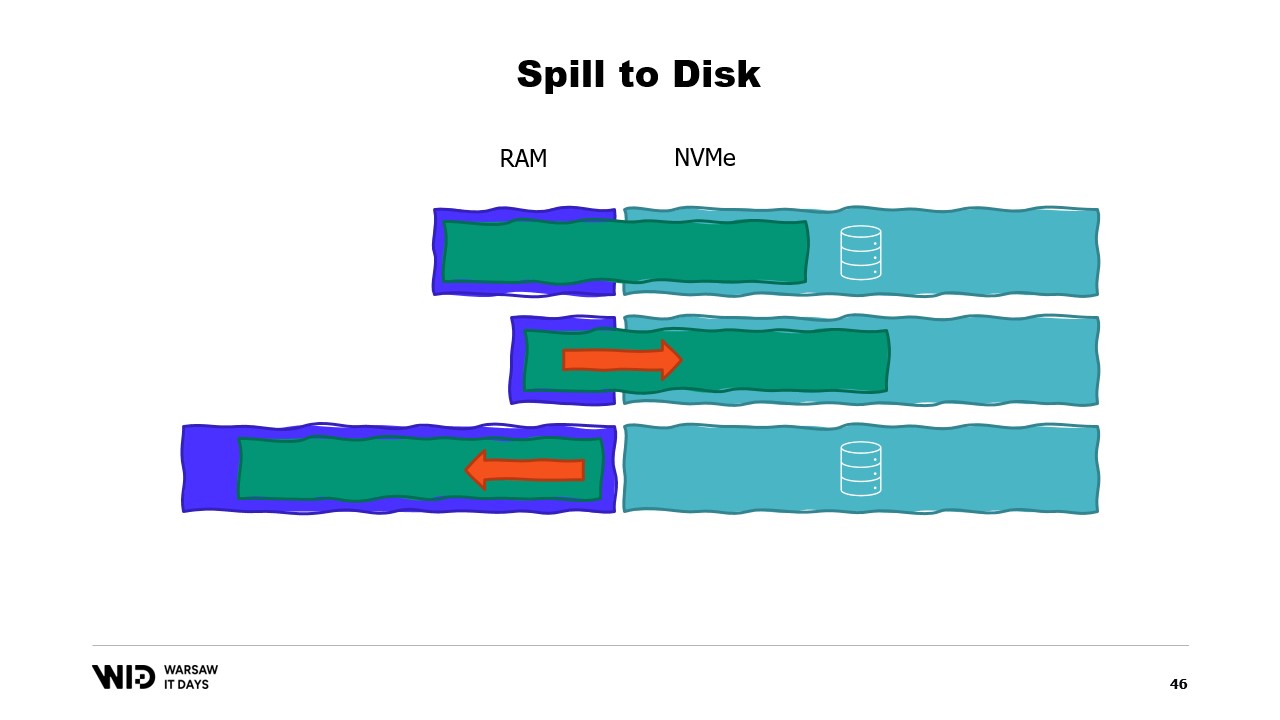
Cela les rend bien meilleurs pour réagir à un excès ou une pénurie de mémoire par rapport à ce qui était initialement prévu. Les techniques de spill to disk diviseront le jeu de données en deux sections. La section chaude est supposée toujours être en mémoire et il est donc toujours sûr, en termes de performance, d’y accéder avec des schémas d’accès aléatoires. Elle aura bien sûr un budget maximum, peut-être quelque chose comme 8 gigaoctets par CPU sur une machine Cloud typique.
D’un autre côté, la section froide est autorisée à déverser à tout moment des parties de son contenu vers le stockage persistant. Il n’y a pas de budget maximum, sauf la mémoire disponible. Et bien sûr, il n’est pas sécuritaire, en termes de performance, de lire depuis la section froide.
Ainsi, le programme utilisera des transferts chaud-froid. Ceux-ci impliqueront généralement de gros lots afin de maximiser l’utilisation de la bande passante NVMe. Et puisque les lots sont assez grands, ils seront également effectués à une fréquence relativement basse. Ainsi, c’est la section froide qui permet à ces algorithmes d’utiliser autant de mémoire que possible.

Parce que la section froide remplira autant de RAM que disponible, puis déversera le reste vers le stockage persistant. Alors, comment pouvons-nous faire fonctionner cela en .NET ? Puisque j’appelle cela la première tentative, vous pouvez deviner que cela ne fonctionnera pas. Essayez donc de découvrir à l’avance quel sera le problème.
Pour la section chaude, j’utiliserai des objets .NET normaux et le problème que nous examinerons est un programme .NET normal. Pour la section froide, j’utiliserai ce qu’on appelle une classe de référence. Cette classe garde une référence à la valeur qui est placée dans le stockage froid et cette valeur peut être mise à null lorsqu’elle n’est plus en mémoire. Elle dispose d’une fonction de spill qui prend la valeur depuis la mémoire et l’écrit dans le stockage, puis met la référence à null, ce qui permettra au ramasse-miettes .NET de récupérer cette mémoire lorsqu’il ressentira une certaine pression.
Et enfin, elle possède une propriété value. Cette propriété, lorsqu’elle est accédée, renverra la valeur depuis la mémoire si elle est présente et sinon, nous la rechargerons depuis le disque en mémoire avant de la retourner. Maintenant, si je mets en place un système central dans mon programme qui suit toutes les références froides, alors chaque fois qu’une nouvelle référence froide est créée, je peux déterminer si elle cause un débordement de mémoire et invoquer la fonction de spill d’une ou plusieurs des références froides déjà présentes dans le système, simplement pour rester dans le budget mémoire disponible pour le stockage froid.

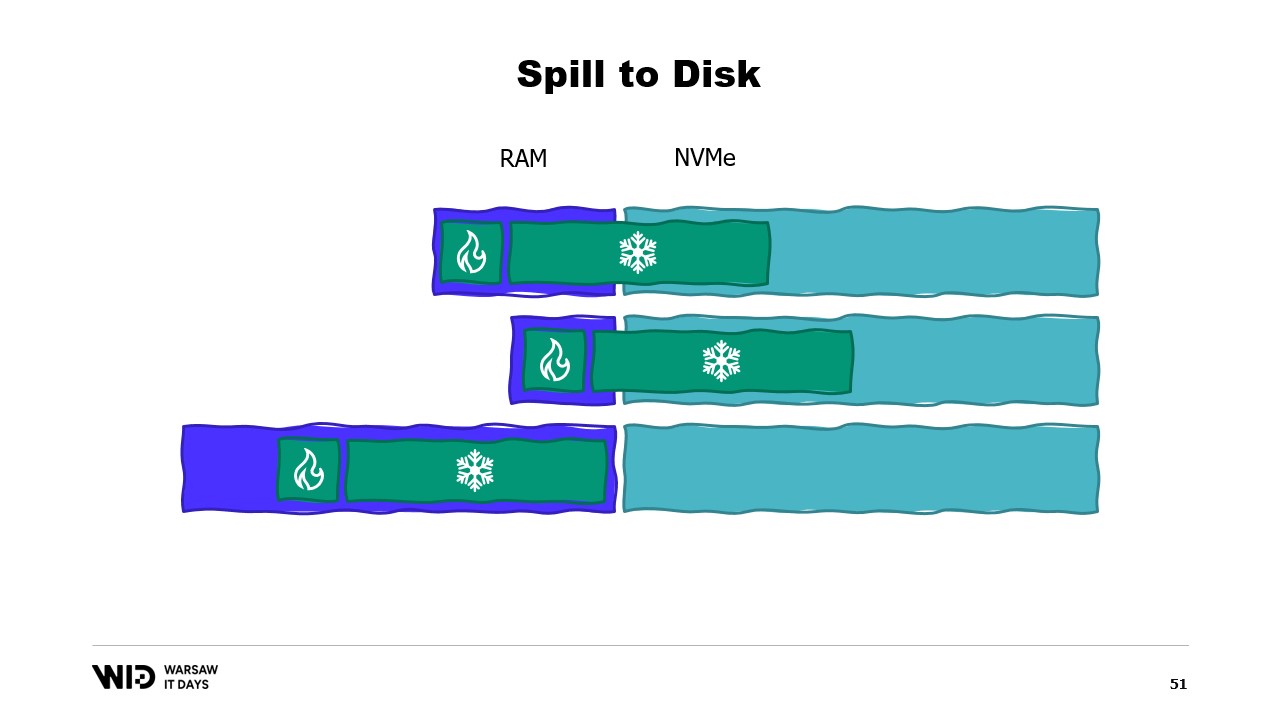
Alors, quel sera le problème ? Eh bien, si je regarde le contenu de la mémoire d’une machine qui exécute notre programme, dans le cas idéal, cela ressemblera à ceci. Tout d’abord, à gauche se trouve la mémoire du système d’exploitation qu’il utilise pour ses propres besoins. Ensuite, il y a la mémoire interne utilisée par .NET pour des choses comme les assemblages chargés ou la surcharge du ramasse-miettes, etc. Puis vient la mémoire de la section chaude et enfin, occupant tout le reste, la mémoire allouée à la section froide.
Avec quelques efforts, nous sommes capables de contrôler tout ce qui se trouve à droite car c’est ce que nous allouons et choisissons de libérer pour que le ramasse-miettes collecte. Cependant, ce qui est à gauche est hors de notre contrôle. Et que se passe-t-il si soudainement le système d’exploitation a besoin de mémoire supplémentaire et constate que tout est occupé par ce que le processus .NET a créé ?
Eh bien, la réaction typique du noyau Linux dans ce cas sera de tuer le programme qui utilise le plus de mémoire et il n’existe aucun moyen de réagir assez rapidement pour libérer de la mémoire auprès du noyau afin qu’il ne nous tue pas. Alors, quelle est la solution ?

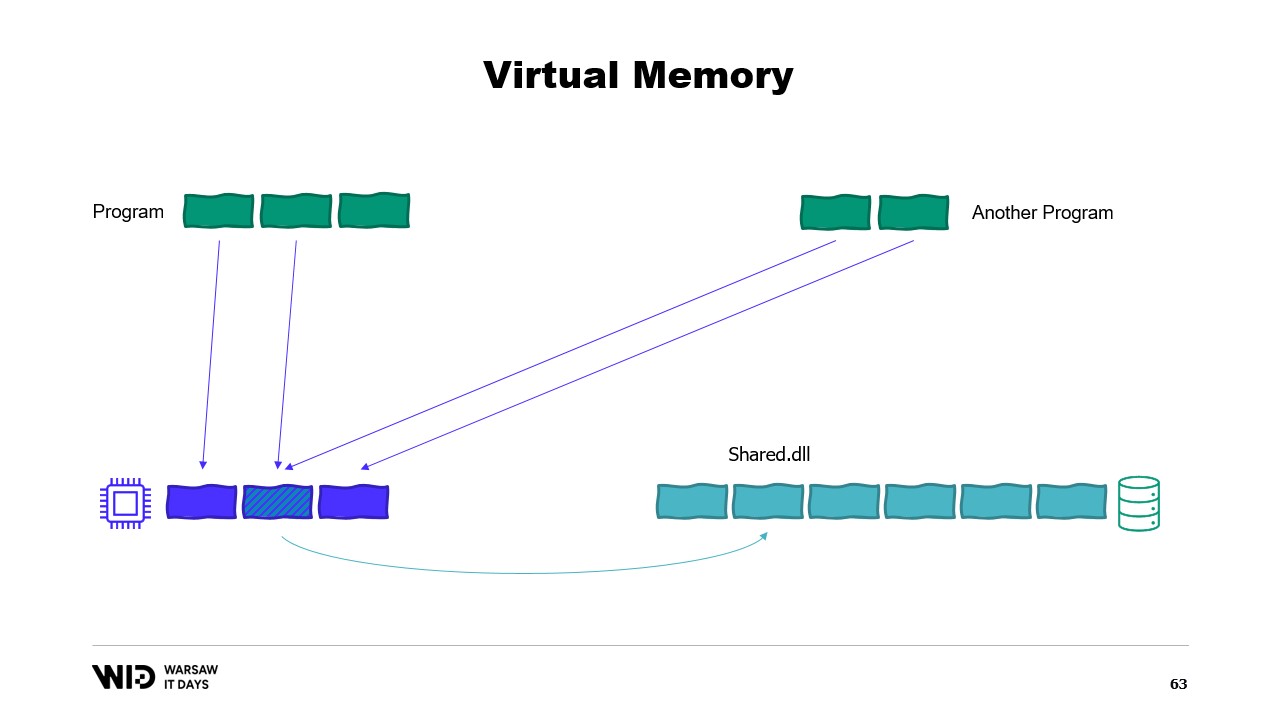
Les systèmes d’exploitation modernes ont le concept de mémoire virtuelle. Le programme n’a pas accès directement aux pages de mémoire physique. À la place, il a accès aux pages de mémoire virtuelle et il existe une correspondance entre ces pages et les pages réelles de la mémoire physique. Si un autre programme s’exécute sur le même ordinateur, il ne pourra pas accéder par lui-même aux pages du premier programme. Il existe toutefois des moyens de partager.
Il est possible de créer une page mappée en mémoire. Dans ce cas, tout ce que le premier programme écrit dans la page partagée sera immédiatement visible par l’autre partie. C’est une façon courante d’implémenter la communication entre programmes, mais son objectif principal est le mapping de fichiers. Ici, le système d’exploitation saura que cette page est une copie exacte d’une page sur le stockage persistant, généralement des parties d’un fichier de bibliothèque partagée.
L’objectif principal ici est d’empêcher chaque programme d’avoir sa propre copie du DLL en mémoire, car toutes ces copies sont identiques et il n’y a donc aucune raison de gaspiller de la mémoire en stockant ces copies. Ici, par exemple, nous avons deux programmes totalisant quatre pages de mémoire alors que la mémoire physique n’a de place que pour trois. Maintenant, que se passe-t-il si nous voulons allouer une page supplémentaire dans le premier programme ? Il n’y a pas de place disponible, mais le système d’exploitation du noyau sait que la page mappée en mémoire peut être supprimée temporairement et, si nécessaire, elle pourra être rechargée de façon identique depuis le stockage persistant.
Ainsi, il en sera ainsi. Les deux pages partagées pointeront désormais vers le disque au lieu de la mémoire. La mémoire est effacée, mise à zéro par le système d’exploitation, puis attribuée au premier programme pour être utilisée pour sa troisième page logique. Maintenant, la mémoire est complètement remplie et si l’un ou l’autre programme tente d’accéder à la page partagée, il n’y aura pas de place pour qu’elle soit rechargée en mémoire, car les pages attribuées aux programmes ne peuvent pas être récupérées par le système d’exploitation.
Ainsi, ce qui se passera ici sera une erreur de manque de mémoire. L’un des programmes mourra, la mémoire sera libérée, puis réaffectée pour recharger le fichier mappé en mémoire. De plus, bien que la plupart des mappings en mémoire soient en lecture seule, il est également possible d’en créer certains en lecture-écriture.
Un programme effectue une modification de la mémoire dans la page mappée, puis le système d’exploitation sauvegardera, à un moment donné dans le futur, le contenu de cette page sur le disque. Et bien sûr, il est possible de demander que cela se produise à un moment précis en utilisant des fonctions comme flush sur Windows. L’outil Performance système dispose de cette belle fenêtre qui affiche l’utilisation actuelle de la mémoire physique.
En vert se trouve la mémoire qui a été assignée directement à un processus. Elle ne peut être récupérée sans tuer le processus. En bleu se trouve le cache de pages. Ce sont des pages qui sont connues pour être des copies identiques d’une page sur le disque et donc, chaque fois qu’un processus a besoin de lire du disque une page déjà présente dans le cache, aucune lecture du disque n’aura lieu et la valeur sera renvoyée directement depuis la mémoire.
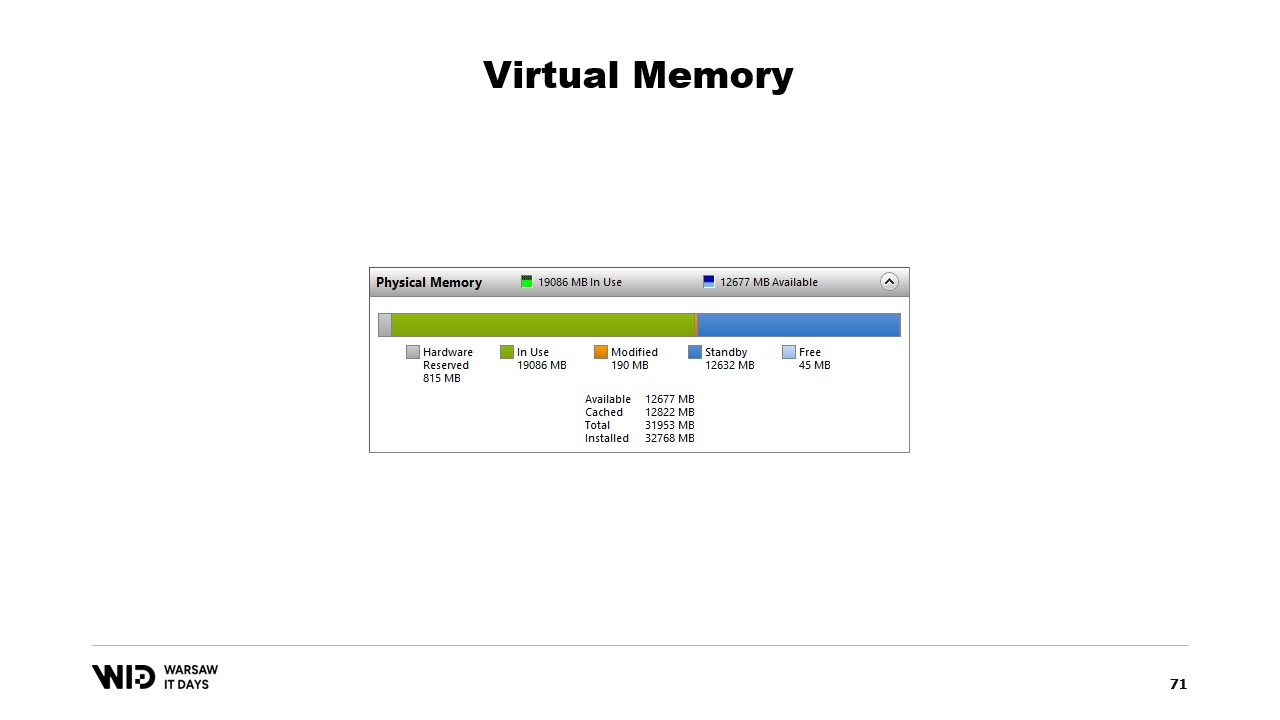
Enfin, les pages modifiées au milieu sont celles qui devraient être une copie exacte du disque mais qui contiennent des modifications en mémoire. Ces modifications n’ont pas encore été répercutées sur le disque, mais elles le seront dans un délai relativement court. Sous Linux, l’outil h-stop affiche un graphique similaire. À gauche se trouvent les pages qui ont été assignées directement aux processus et qui ne peuvent être récupérées sans les tuer, et à droite, en jaune, se trouve le cache de pages.

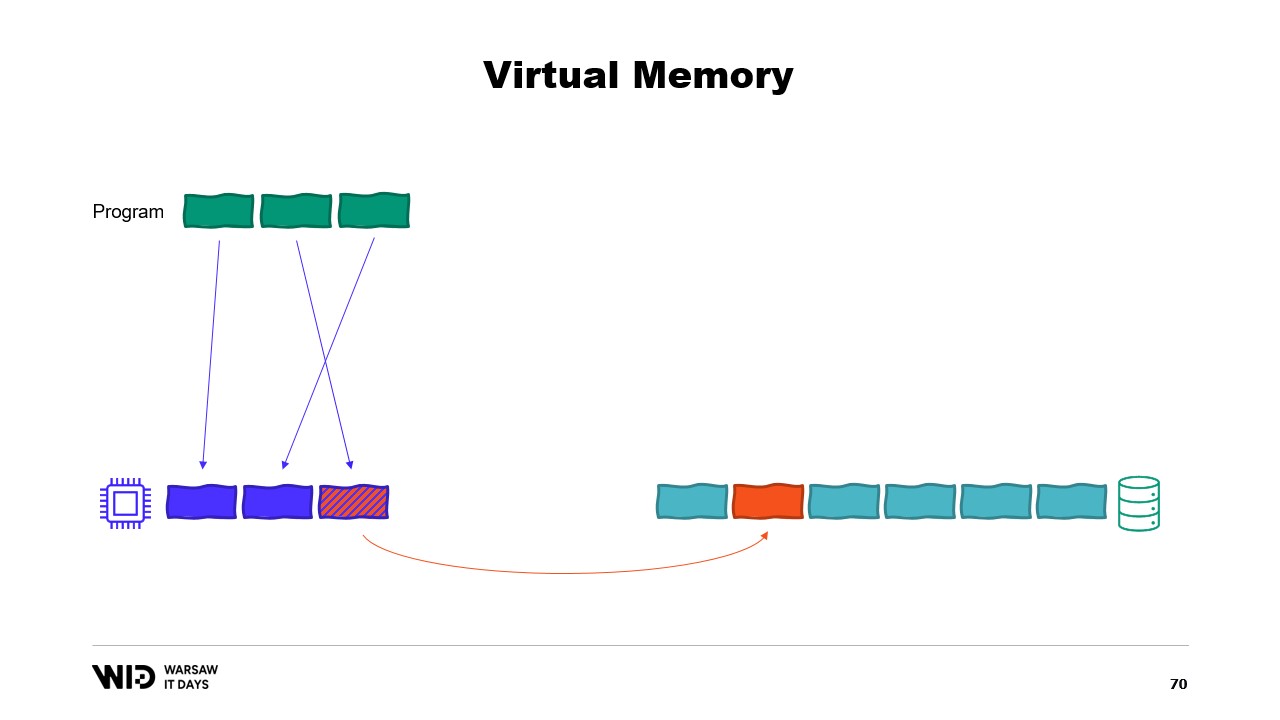
Si cela vous intéresse, il existe une excellente ressource de Vyacheslav Biryukov expliquant le fonctionnement du cache de pages de Linux. En utilisant la mémoire virtuelle, tentons notre deuxième essai. Cela fonctionnera-t-il cette fois-ci ? Désormais, nous décidons que la section froide sera composée exclusivement de pages mappées en mémoire. Ainsi, on s’attend à ce que toutes soient d’abord présentes sur le disque.
Le programme n’a plus aucun contrôle sur les pages qui seront en mémoire et celles qui ne seront présentes que sur le disque. Le système d’exploitation fait cela de manière transparente. Ainsi, si le programme tente d’accéder, disons, à la troisième page de la section froide, le système d’exploitation détectera qu’elle n’est pas présente en mémoire, déchargera l’une des pages existantes, par exemple la deuxième, puis chargera la troisième page en mémoire.
Du point de vue du processus lui-même, cela était complètement transparent. L’attente pour la lecture depuis la mémoire était juste un peu plus longue que d’habitude. Et que se passe-t-il si le système d’exploitation a soudainement besoin de mémoire pour ses propres opérations ? Eh bien, il sait quelles pages sont mappées en mémoire et peuvent être jetées en toute sécurité. Il se contentera donc d’abandonner l’une des pages, de l’utiliser pour ses propres besoins, puis de la libérer une fois terminé.
Toutes ces techniques s’appliquent à .NET et sont présentes dans le projet open source Lokad Scratch Space. Et la majeure partie du code qui suit est basée sur la manière dont ce package NuGet fonctionne.

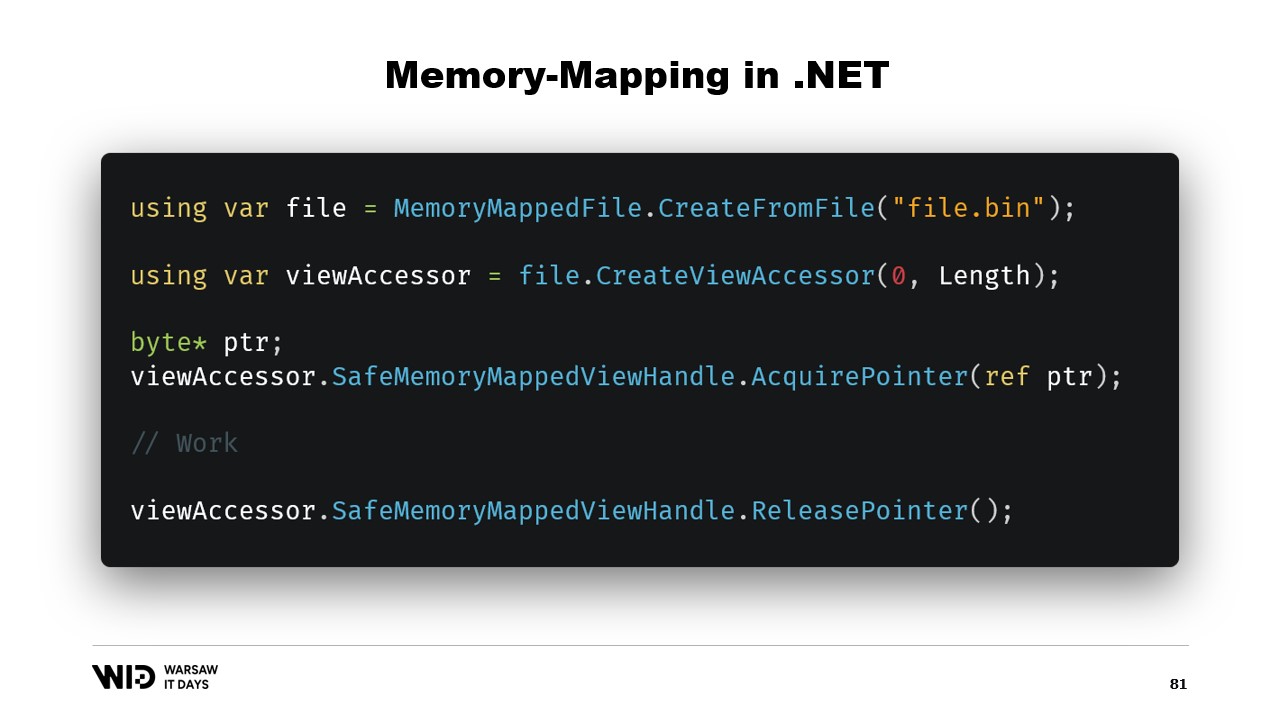
Tout d’abord, comment créer un fichier mappé en mémoire dans .NET ? Le mappage mémoire existe depuis .NET Framework 4, il y a environ 13 ans. Il est assez bien documenté sur Internet et le code source est entièrement disponible sur GitHub.

Les étapes de base consistent d’abord à créer un fichier mappé en mémoire à partir d’un fichier sur le disque, puis à créer un accesseur de vue. Ces deux types sont maintenus séparés car ils ont des significations différentes. Le fichier mappé en mémoire indique simplement au système d’exploitation que certaines sections de ce fichier seront mappées dans la mémoire du processus. L’accesseur de vue représente lui-même ces mappages.
Ils sont maintenus séparés car .NET doit traiter le cas d’un processus 32 bits. Un fichier très volumineux, supérieur à quatre gigaoctets, ne peut pas être mappé dans l’espace mémoire d’un processus 32 bits. Il est trop grand. Le pointeur n’est pas assez large pour le représenter. On peut donc mapper uniquement de petites sections du fichier, une à la fois, de manière à ce qu’elles tiennent.
Dans notre cas, nous travaillerons avec des pointeurs 64 bits. Ainsi, nous pouvons simplement créer un accesseur de vue qui charge l’ensemble du fichier. Et maintenant, j’utilise AcquirePointer pour obtenir le pointeur vers les premiers octets de cette plage de mémoire mappée. Une fois que j’ai fini d’utiliser le pointeur, je peux simplement le libérer. Travailler avec des pointeurs dans .NET est dangereux. Cela nécessite d’ajouter le mot-clé unsafe partout, et cela peut provoquer des plantages si vous tentez d’accéder à une mémoire au-delà des limites autorisées.
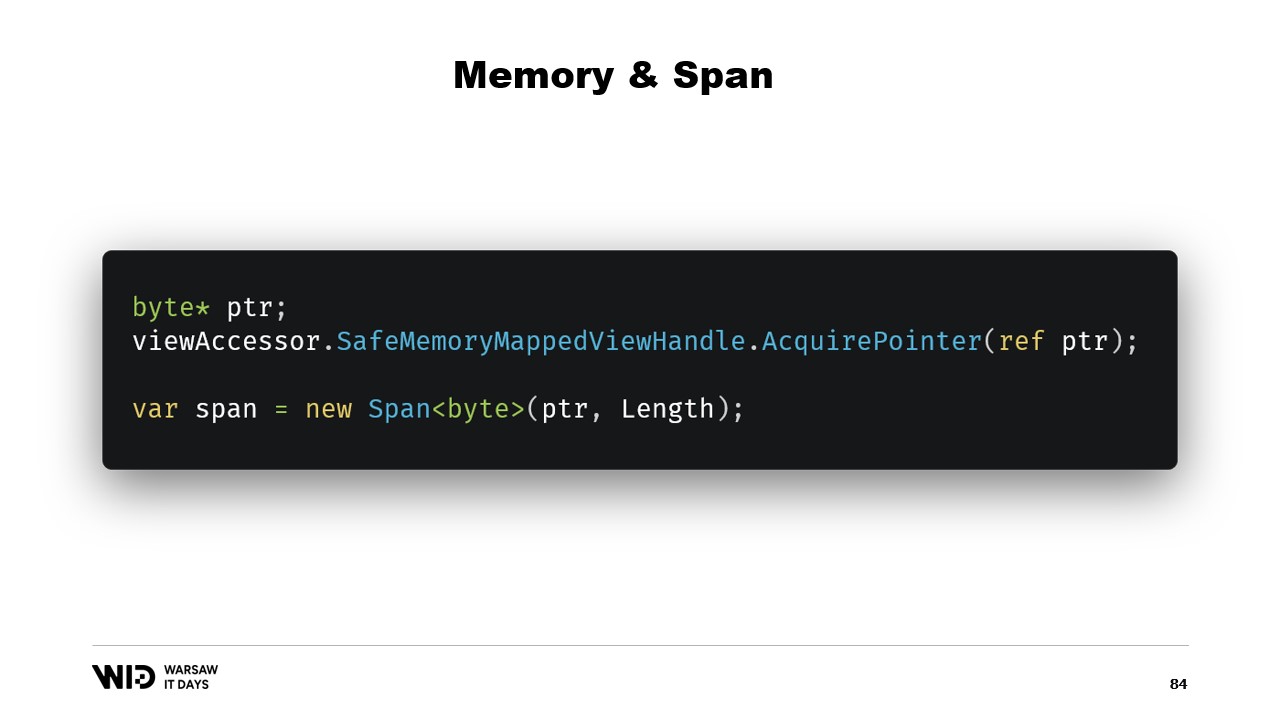
Heureusement, il existe une solution pour contourner ce problème. Il y a cinq ans, .NET a introduit Memory et Span. Ce sont des types utilisés pour représenter une plage de mémoire de manière plus sûre que les simples pointeurs. Ils sont assez bien documentés et la majeure partie du code peut être trouvée à cet emplacement sur GitHub.

L’idée générale derrière Span et Memory est qu’étant donné un pointeur et un nombre d’octets, vous pouvez créer un nouveau Span qui représente cette plage de mémoire.
Une fois que vous avez ce Span, vous pouvez lire en toute sécurité n’importe où dans la plage, sachant que si vous tentez de lire au-delà des limites, le runtime le détectera et vous obtiendrez une exception au lieu d’un simple arrêt du processus.
Voyons comment nous pouvons utiliser Span pour charger depuis la mémoire mappée en mémoire la mémoire gérée par .NET. Rappelez-vous, nous ne voulons pas accéder directement à la section froide pour des raisons de performance. À la place, nous souhaitons effectuer des transferts de la section froide vers la section chaude, qui chargent beaucoup de données en même temps.
Par exemple, disons que nous avons une chaîne de caractères que nous voulons lire. Elle sera disposée dans le fichier mappé en mémoire sous la forme d’une taille suivie d’une charge utile d’octets encodée en UTF-8, et nous voulons charger une chaîne .NET à partir de cela.
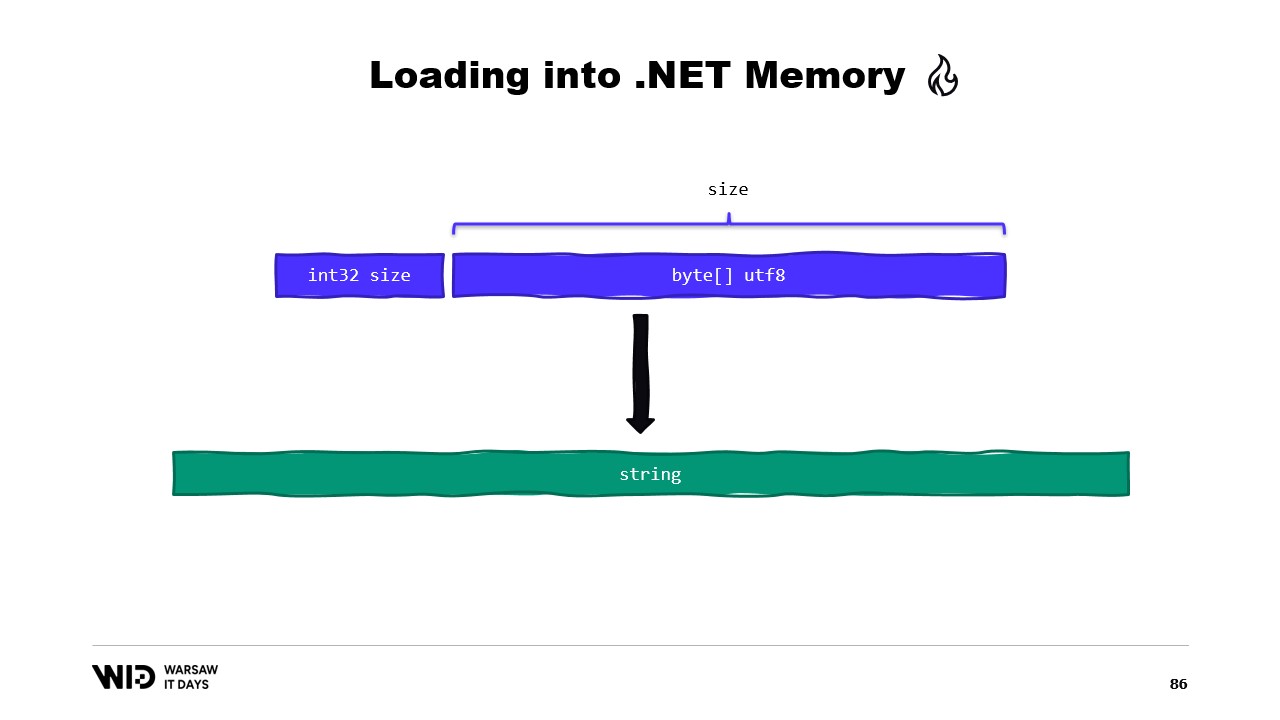
Eh bien, il existe de nombreuses API axées sur Span que nous pouvons utiliser. Par exemple, MemoryMarshal.Read peut lire un entier depuis le début du Span. Ensuite, en utilisant cette taille, je peux demander à la fonction Encoding.GetString de charger à partir d’un Span d’octets dans une chaîne de caractères.
Toutes ces opérations se font sur des Span et, même si le Span représente une section de données qui est éventuellement présente sur le disque plutôt qu’en mémoire, le système d’exploitation se charge de charger les données en mémoire de manière transparente dès leur premier accès.
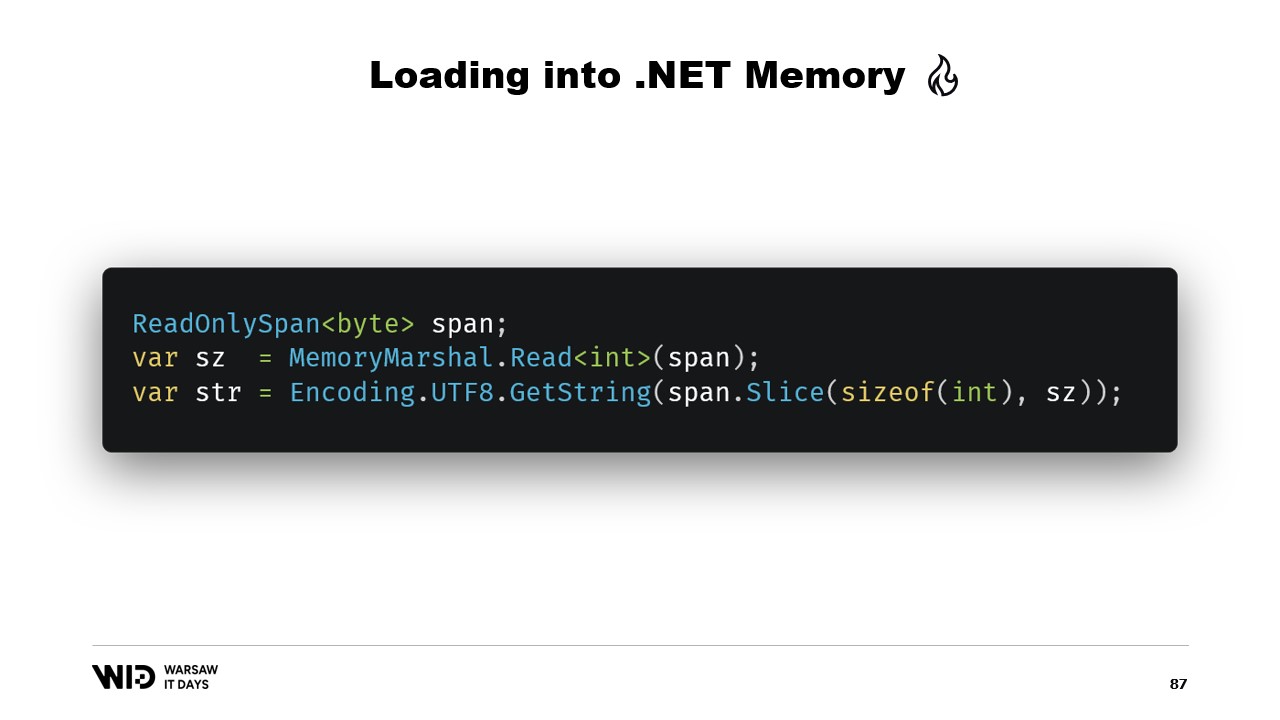
Un autre exemple serait une séquence de valeurs à virgule flottante que nous voulons charger dans un tableau de floats.
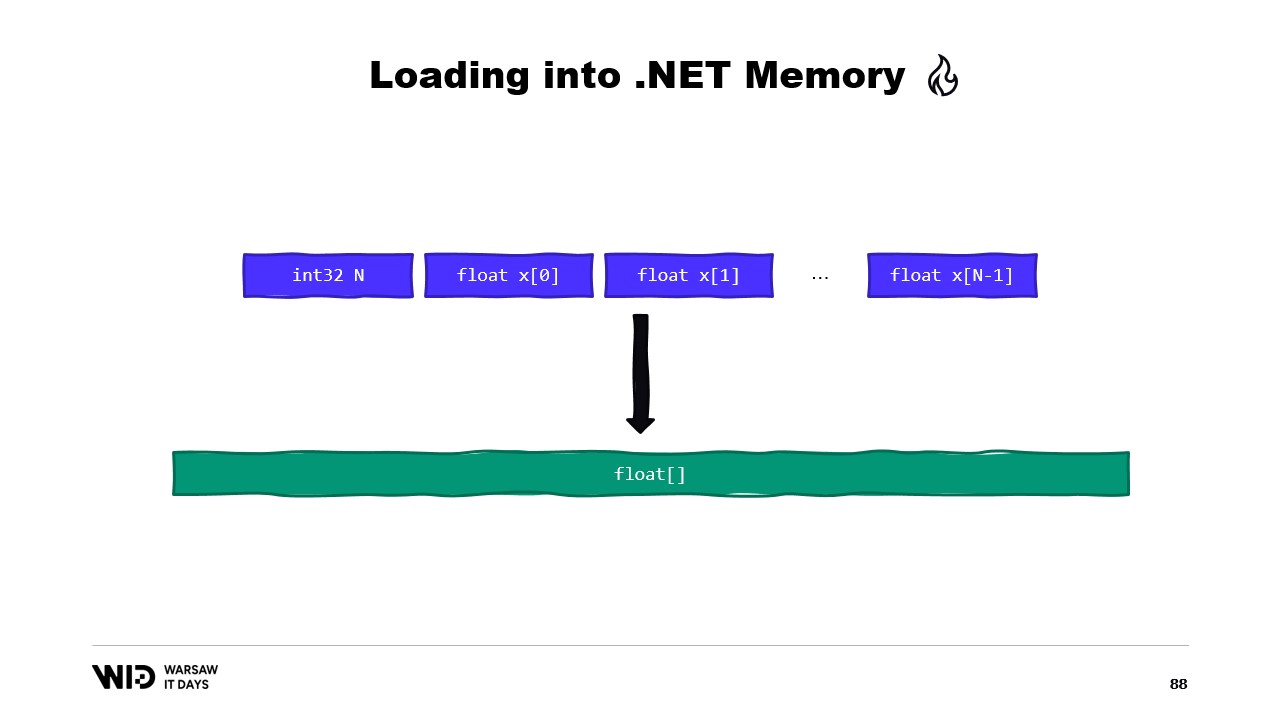
Encore une fois, nous utilisons MemoryMarshal.Read pour lire la taille. Nous allouons un tableau de valeurs à virgule flottante de cette taille, puis nous utilisons MemoryMarshal.Cast pour convertir le Span d’octets en un Span de valeurs à virgule flottante. Cela se contente de réinterpréter les données présentes dans le Span comme des valeurs à virgule flottante au lieu de simples octets.
Enfin, nous utilisons la fonction CopyTo des Span qui effectue une copie haute performance des données du fichier mappé en mémoire vers le tableau lui-même. D’une certaine manière, c’est un peu gaspilleur, car nous réalisons une copie entièrement nouvelle.
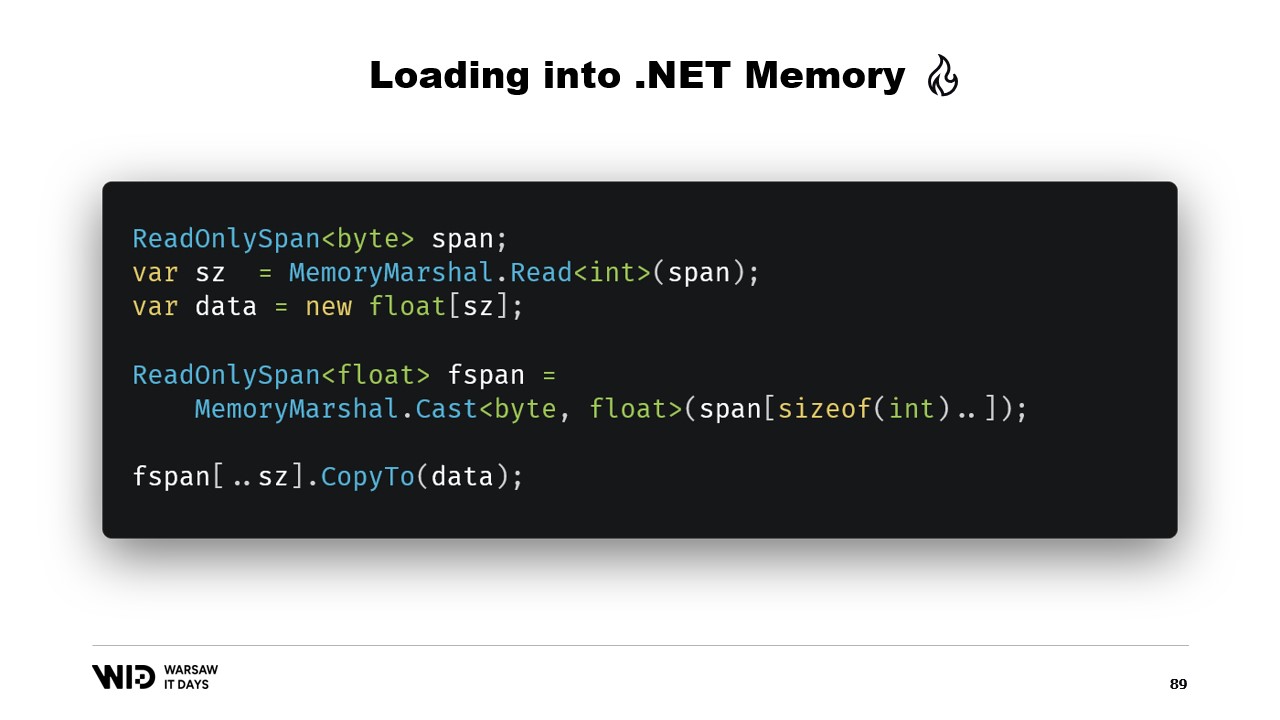
Peut-être pourrions-nous éviter cela. Eh bien, habituellement, ce que nous stockerons sur le disque ne sera pas les valeurs à virgule flottante brutes. À la place, nous sauvegarderons une version compressée d’entre elles. Ici, nous stockons la taille compressée, qui nous indique combien d’octets nous devons lire. Nous stockons la taille de destination ou la taille décompressée. Cela nous indique combien de valeurs à virgule flottante nous devons allouer en mémoire gérée. Et enfin, nous stockons la charge utile compressée elle-même.
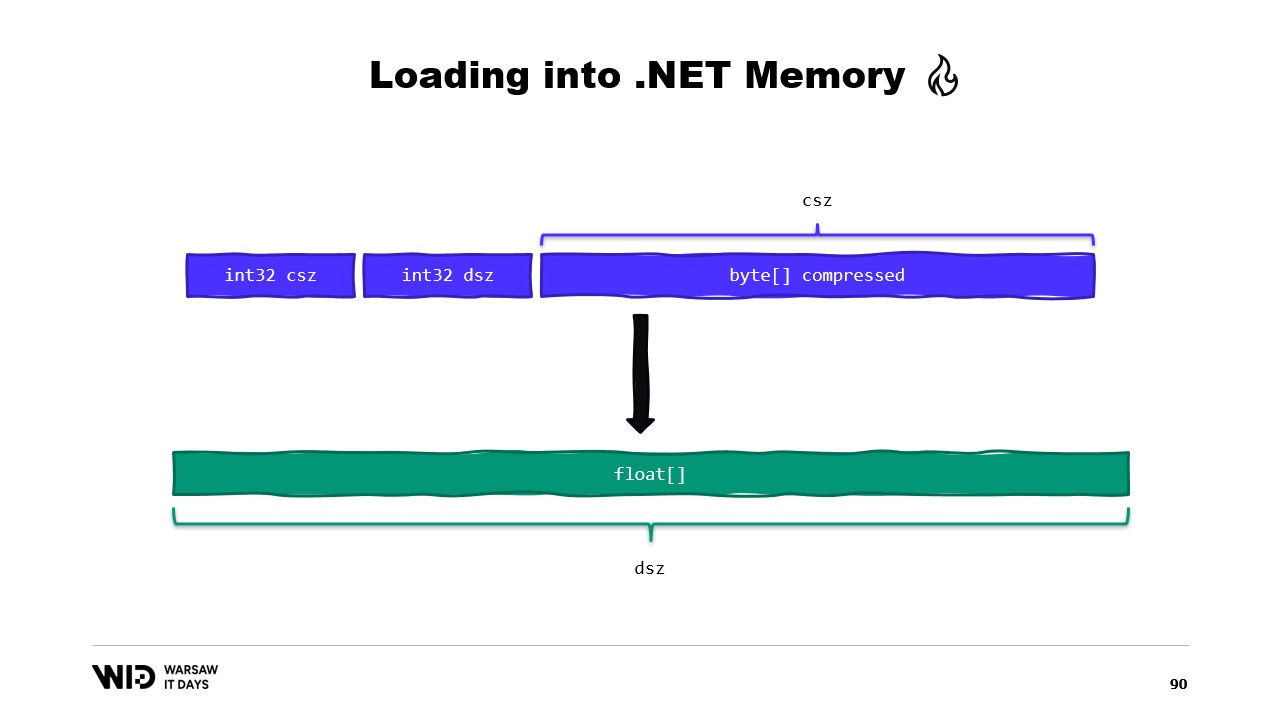
Pour charger cela, il vaudra mieux, plutôt que de lire deux entiers, de créer une structure qui représente cet en-tête avec deux valeurs entières à l’intérieur.

MemoryMarshal sera capable de lire une instance de cette structure, en chargeant les deux champs simultanément. Nous allouons un tableau de valeurs à virgule flottante, puis notre bibliothèque de compression dispose presque certainement d’une variante d’une fonction de décompression qui prend en entrée un Span d’octets en lecture seule et renvoie un Span d’octets en sortie. Nous pouvons réutiliser MemoryMarshal.Cast, cette fois en convertissant le tableau de valeurs à virgule flottante en un Span d’octets à utiliser comme destination.
Désormais, aucune copie n’est impliquée. Au lieu de cela, l’algorithme de compression lit directement depuis le disque, généralement via le cache de pages, dans le tableau de floats destination.

Span présente une limitation majeure, à savoir qu’il ne peut pas être utilisé en tant que membre de classe et, par extension, il ne peut pas non plus être utilisé comme variable locale dans une méthode async.
Heureusement, il existe un type différent, Memory, qui doit être utilisé pour représenter une plage de données de plus longue durée.
Malheureusement, il existe très peu de documentation sur la manière de procéder. Créer un Span à partir d’un pointeur est facile, mais créer une Memory à partir d’un pointeur n’est pas documenté au point que la meilleure documentation disponible est un gist sur GitHub, que je vous recommande vivement de lire.
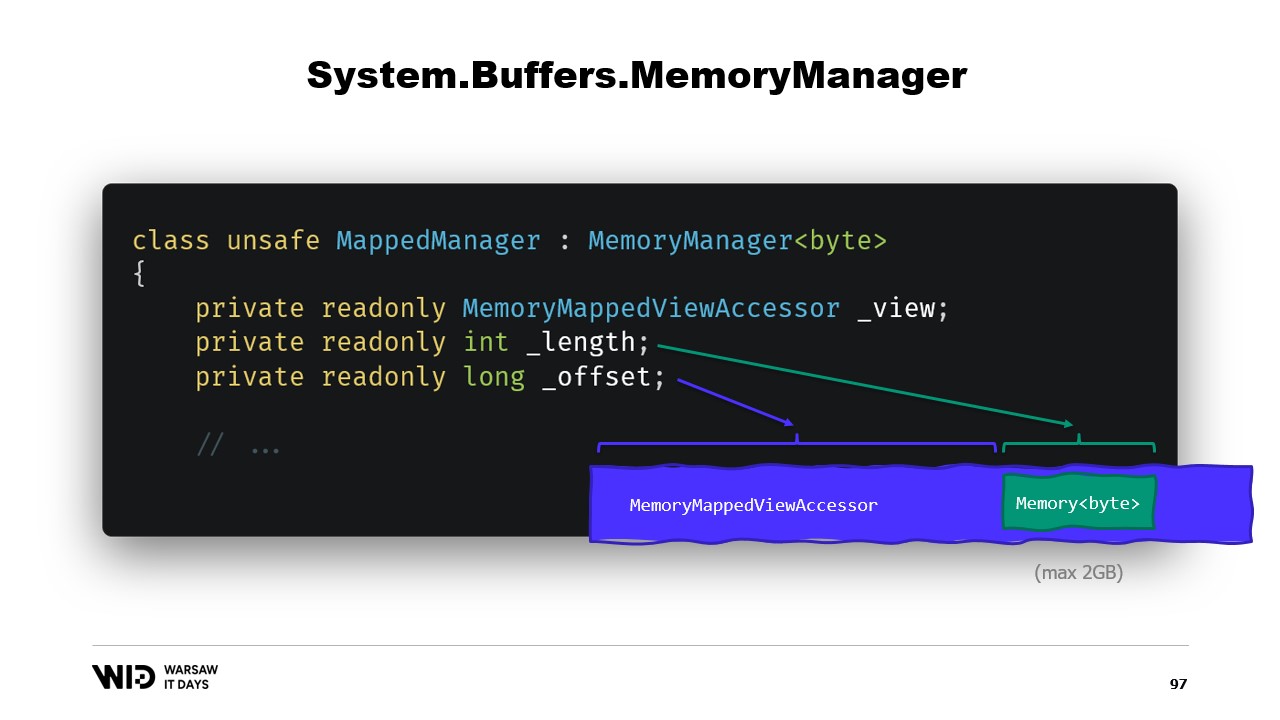
En bref, ce que nous devons faire est de créer un MemoryManager. Le MemoryManager est utilisé en interne par une Memory chaque fois qu’elle a besoin de faire quelque chose de plus complexe que de simplement pointer vers une section d’un tableau.
Dans notre cas, nous devons référencer l’accesseur de vue mappé en mémoire dans lequel nous regardons. Nous devons connaître la longueur que nous sommes autorisés à consulter et, enfin, nous aurons besoin d’un offset. Cela est dû au fait qu’une Memory d’octets ne peut représenter, par conception, pas plus de deux gigaoctets, et le fichier lui-même sera probablement plus long que deux gigaoctets. Ainsi, l’offset nous donne l’endroit où la mémoire commence dans l’accesseur de vue plus large.
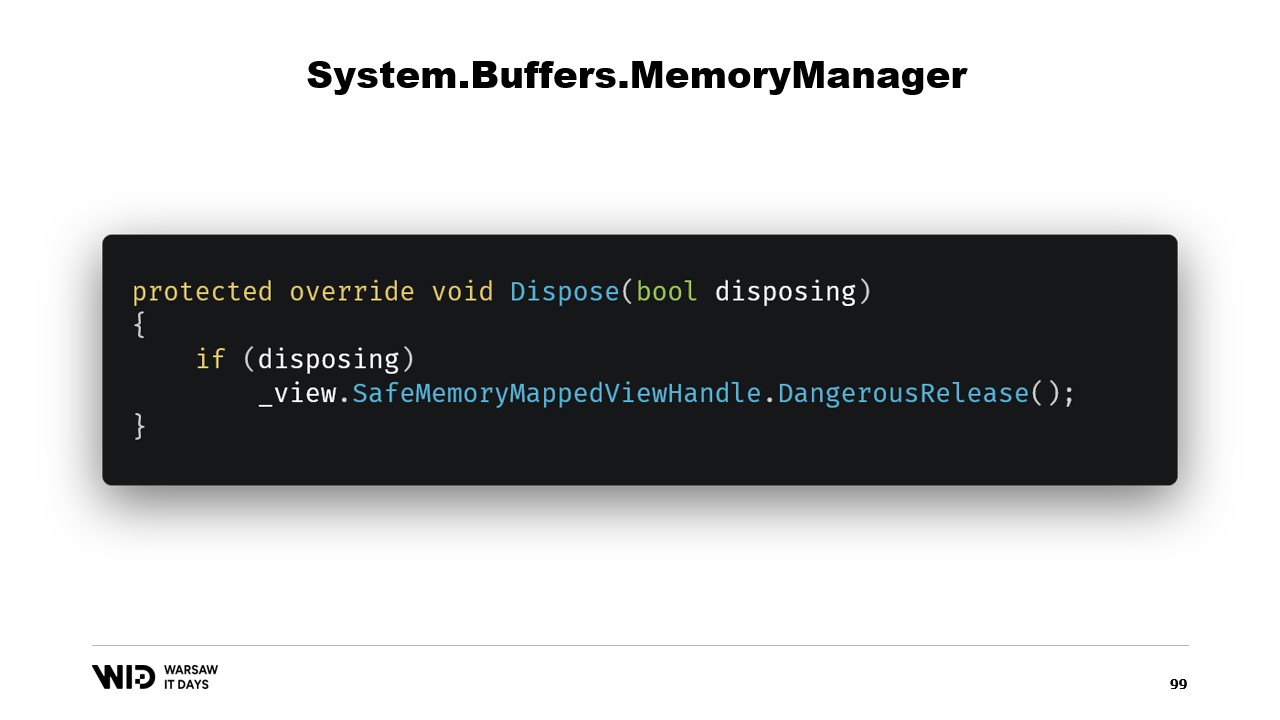
Le constructeur de la classe est assez simple.

Nous avons simplement besoin d’ajouter une référence au safe handle qui représente la région mémoire, et cette référence sera libérée dans la fonction dispose.
Ensuite, nous avons une propriété address qui n’est pas un autre bonus, c’est simplement quelque chose d’utile à avoir. Nous utilisons DangerousGetHandle pour obtenir un pointeur et nous ajoutons l’offset afin que l’adresse pointe vers les premiers octets de la région que nous voulons que notre Memory représente.
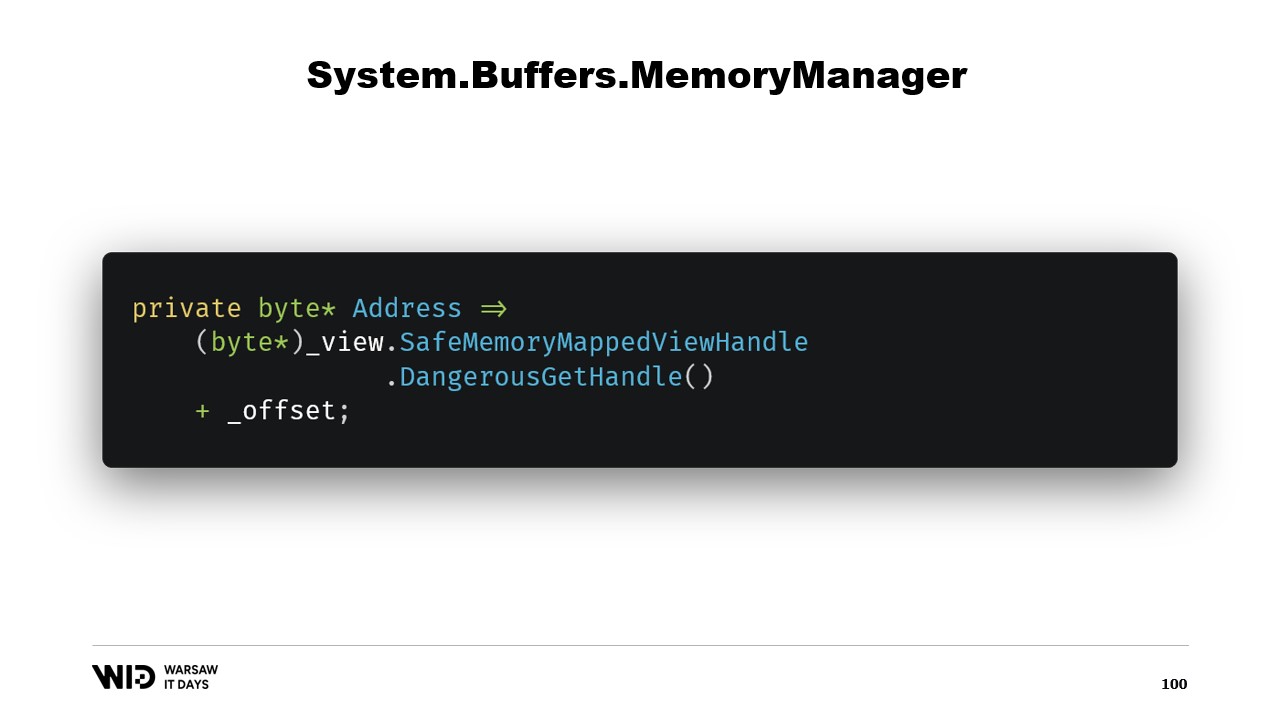
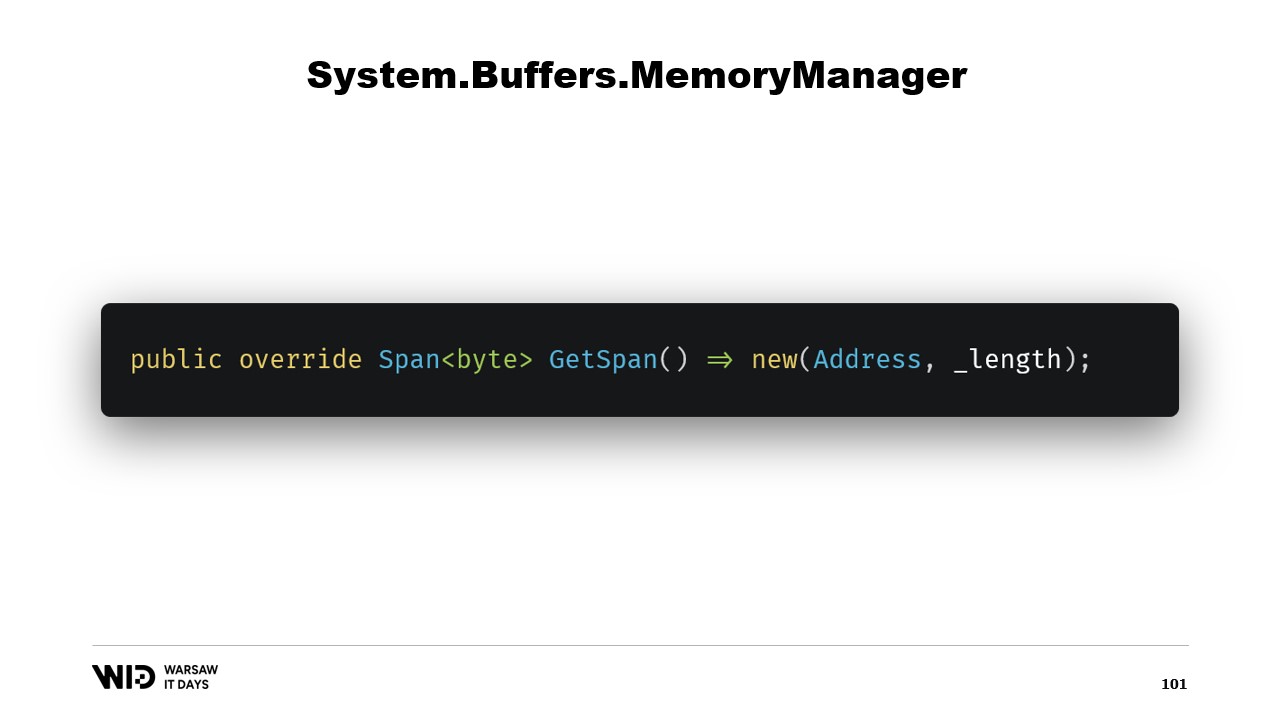
Nous redéfinissons la fonction GetSpan qui fait toute la magie. Elle se contente de créer un Span en utilisant l’adresse et la longueur.
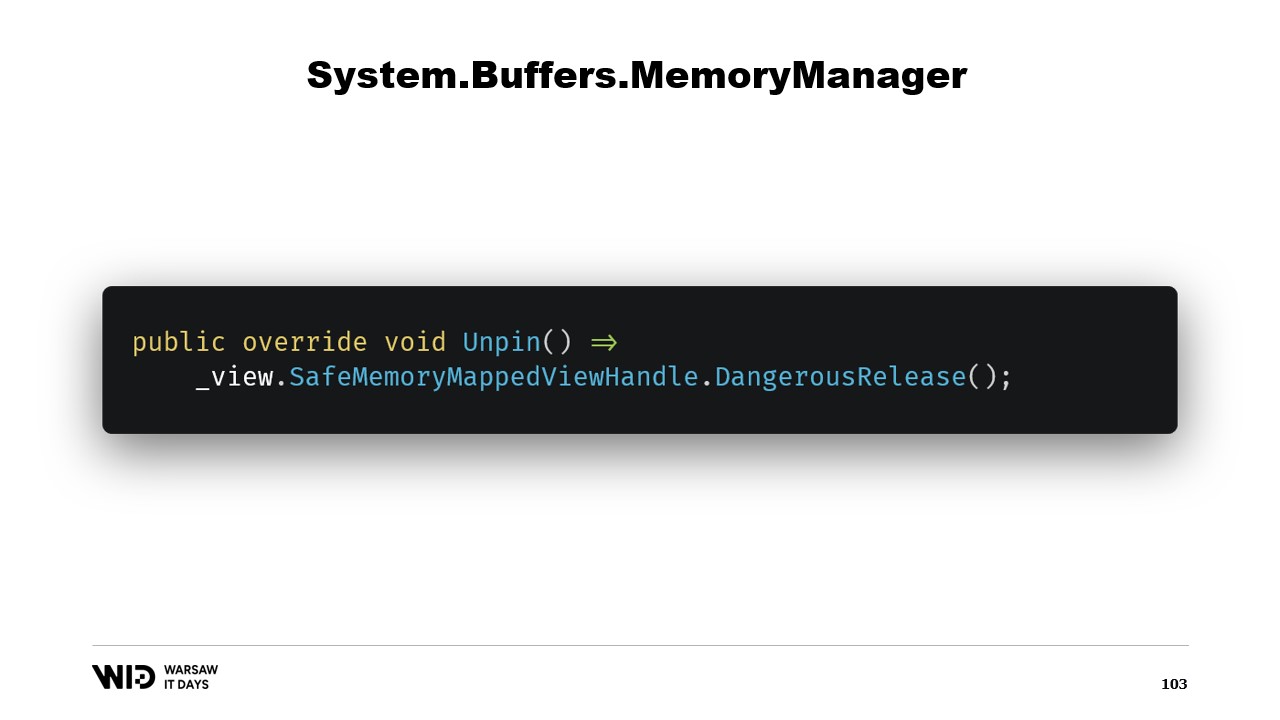
Il y a deux autres méthodes qui doivent être implémentées dans le MemoryManager. L’une d’elles est Pin. Elle est utilisée par le runtime dans un cas où la mémoire doit être maintenue à la même position pendant une courte durée. Nous ajoutons une référence et nous renvoyons un MemoryHandle qui pointe vers l’emplacement correct et qui référence également l’objet actuel en tant que pinnable.

Cela informera le runtime que lorsque la mémoire sera dé-pinnée, il appellera la méthode Unpin de cet objet, ce qui entraînera à nouveau la libération du safe handle.
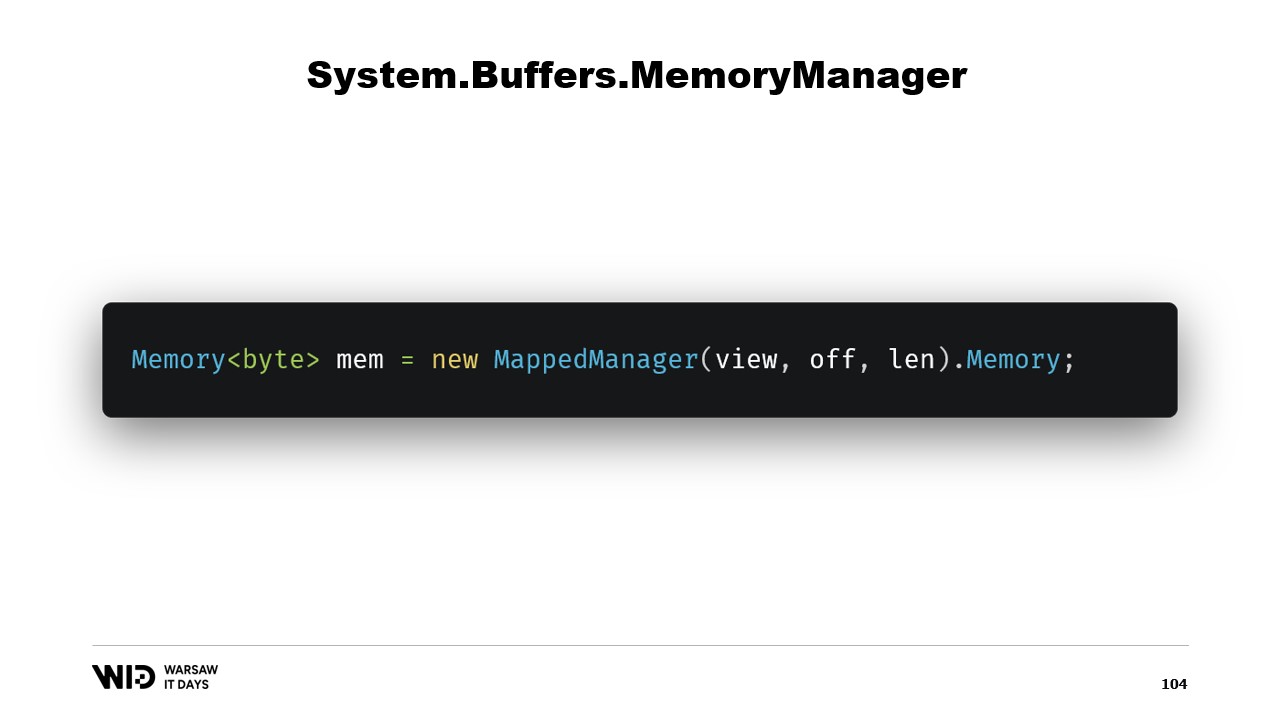
Une fois cette classe créée, il suffit d’en créer une instance et d’accéder à sa propriété Memory qui renverra une Memory d’octets référencée en interne par le MemoryManager que nous venons de créer. Et voilà, vous disposez désormais d’un morceau de mémoire. Lorsque vous y écrivez, elle sera automatiquement déchargée sur le disque lorsque l’espace sera nécessaire et, lorsqu’elle sera accédée, elle sera chargée de manière transparente depuis le disque dès que vous en aurez besoin.
Voilà, cela suffit à implémenter notre programme de déversement sur disque. Une autre question se pose : pourquoi utiliser le mappage mémoire alors que nous pourrions utiliser FileStream à la place ? Après tout, FileStream est le choix évident pour accéder aux données présentes sur le disque et son utilisation est assez bien documentée. Pour lire un tableau de valeurs à virgule flottante, par exemple, vous avez besoin d’un FileStream et d’un BinaryReader enveloppé autour du FileStream. Vous positionnez le FileStream à l’offset où se trouvent les données dans le fichier, vous lisez un Int32 pour obtenir la taille, allouez le tableau de valeurs à virgule flottante, puis utilisez MemoryMarshal.Cast pour le convertir en un Span d’octets.
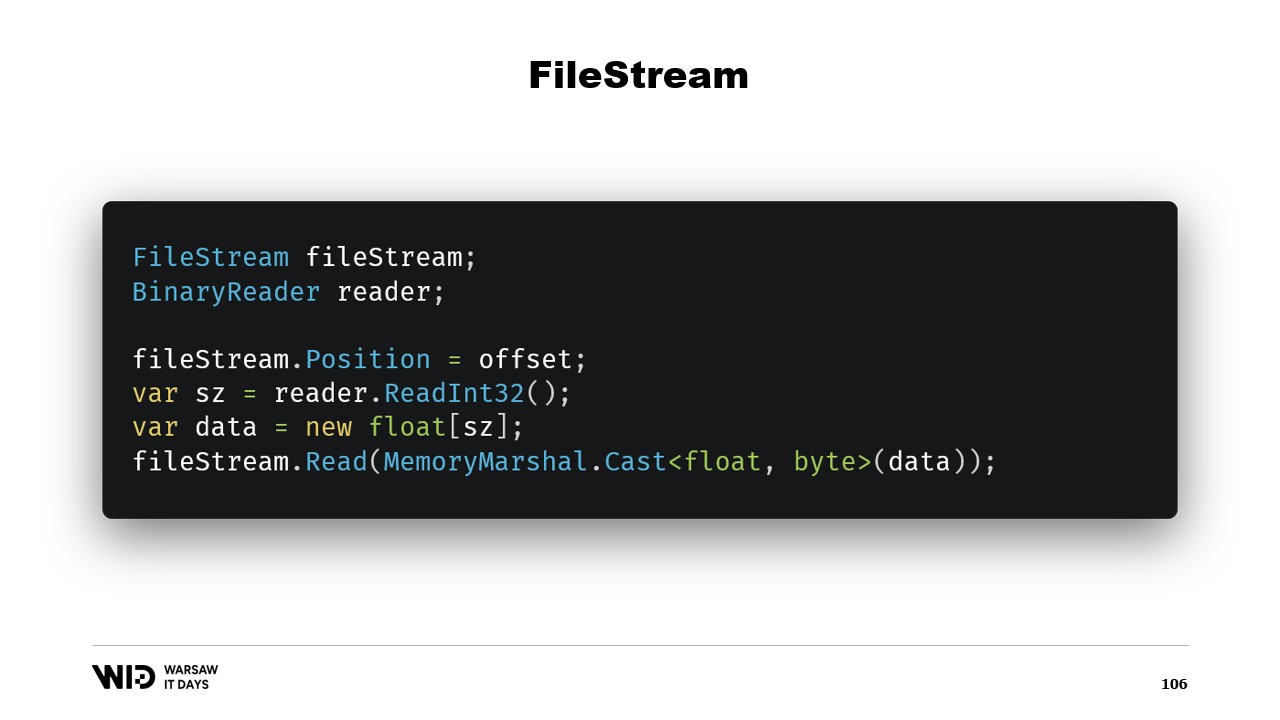
FileStream.Read dispose désormais d’une surcharge qui prend un Span d’octets comme destination. Cela utilise en fait également le cache de pages. Au lieu de mapper ces pages dans l’espace d’adressage de votre processus, le système d’exploitation les conserve et, pour lire les valeurs, il se contente de charger depuis le disque en mémoire, puis de copier depuis cette page vers le Span de destination que vous avez fourni. Ainsi, cela est équivalent en termes de performance et de comportement à ce qui se passe dans la version mappée en mémoire.
Cependant, il existe deux différences majeures. Premièrement, ce n’est pas thread-safe. Vous positionnez le pointeur sur une ligne, puis dans une autre instruction, vous comptez sur le fait que cette position est toujours la même. Cela signifie que vous avez besoin d’un verrou autour de cette opération et que vous ne pouvez donc pas lire depuis plusieurs emplacements en parallèle, même si cela est possible avec des fichiers mappés en mémoire.
Un autre problème est que, selon la stratégie utilisée par le FileStream, vous effectuez deux lectures, une pour l’Int32 et une pour la lecture vers le Span. Il se peut que chacune d’elles effectue un appel système. Le système d’exploitation sera appelé et copiera des données de sa propre mémoire vers la mémoire du processus. Cela entraîne une certaine surcharge. L’autre possibilité est que le stream soit mis en tampon. Dans ce cas, lire quatre octets initialement créera probablement une copie d’une page. Et cette copie intervient en plus de la copie réelle effectuée par la fonction de lecture par la suite. Ainsi, cela introduit une surcharge qui n’existe pas dans la version mappée en mémoire.
Pour cette raison, l’utilisation de la version mappée en mémoire est préférable en termes de performances. Après tout, FileStream est le choix évident pour accéder aux données présentes sur le disque et son utilisation est très bien documentée. Par exemple, pour lire un tableau de valeurs à virgule flottante, vous avez besoin d’un FileStream et d’un BinaryReader. Vous positionnez le FileStream à l’offset où se trouvent les données dans le fichier, vous lisez un Int32 pour obtenir la taille, allouez le tableau de valeurs à virgule flottante, le convertissez en un Span d’octets à l’aide de MemoryMarshal.Cast et le passez à la surcharge de FileStream.Read qui attend un Span d’octets comme destination pour la lecture. Et cela utilise également le cache de pages. Au lieu que les pages soient associées au processus, elles sont conservées par le système d’exploitation lui-même qui se contente de les charger du disque dans le cache de pages et de copier depuis le cache de pages dans la mémoire du processus, exactement comme nous l’avons fait avec la version mappée en mémoire.
L’approche FileStream, cependant, présente deux inconvénients majeurs. Le premier est que ce code n’est pas sûr pour une utilisation multi-thread. Après tout, la position est réglée sur une instruction puis utilisée dans les instructions suivantes. Nous avons donc besoin d’un verrou autour de ces opérations de lecture. La version à mémoire mappée n’a pas besoin de verrous et, en fait, est capable de charger à partir de plusieurs emplacements du disque en parallèle. Pour les SSD, cela augmente la profondeur de la file d’attente, ce qui améliore les performances et est donc généralement souhaitable. L’autre problème est que le FileStream doit effectuer deux lectures.
Selon la stratégie utilisée en interne par le flux, cela peut entraîner deux appels système qui nécessitent de réveiller le système d’exploitation. Il copiera certaines données de sa propre mémoire dans la mémoire du processus, puis il devra tout effacer et rendre le contrôle au processus. Cela engendre une certaine surcharge. L’autre stratégie possible est que le FileStream soit mis en mémoire tampon. Dans ce cas, un seul appel système serait effectué, mais cela impliquerait une copie de la mémoire du système d’exploitation vers le tampon interne du FileStream, puis l’instruction de lecture devra copier à nouveau depuis le tampon interne du FileStream dans le tableau de nombres à virgule flottante. Cela crée donc une copie inutile qui n’est pas présente avec la version à mémoire mappée.
Le flux de fichier, bien que légèrement plus facile à utiliser, présente certaines limitations. La version à mémoire mappée devrait donc être utilisée à la place. Nous nous retrouvons ainsi avec un système capable d’utiliser autant de mémoire que possible et, en cas d’épuisement de la mémoire, de déverser des parties des ensembles de données sur le disque. Ce processus est entièrement transparent et coopère avec le système d’exploitation. Il fonctionne à des performances maximales car les morceaux de l’ensemble de données qui sont fréquemment accédés sont toujours maintenus en mémoire.
Cependant, il reste une dernière question à laquelle nous devons répondre. Après tout, lorsque vous faites du memory mapping, vous ne mettez pas en mémoire le disque, vous mettez en mémoire les fichiers présents sur le disque. La question est donc : combien de fichiers allons-nous allouer ? Quelle sera leur taille ? Et comment allons-nous faire tourner ces fichiers lors de l’allocation et de la désallocation de la mémoire ?
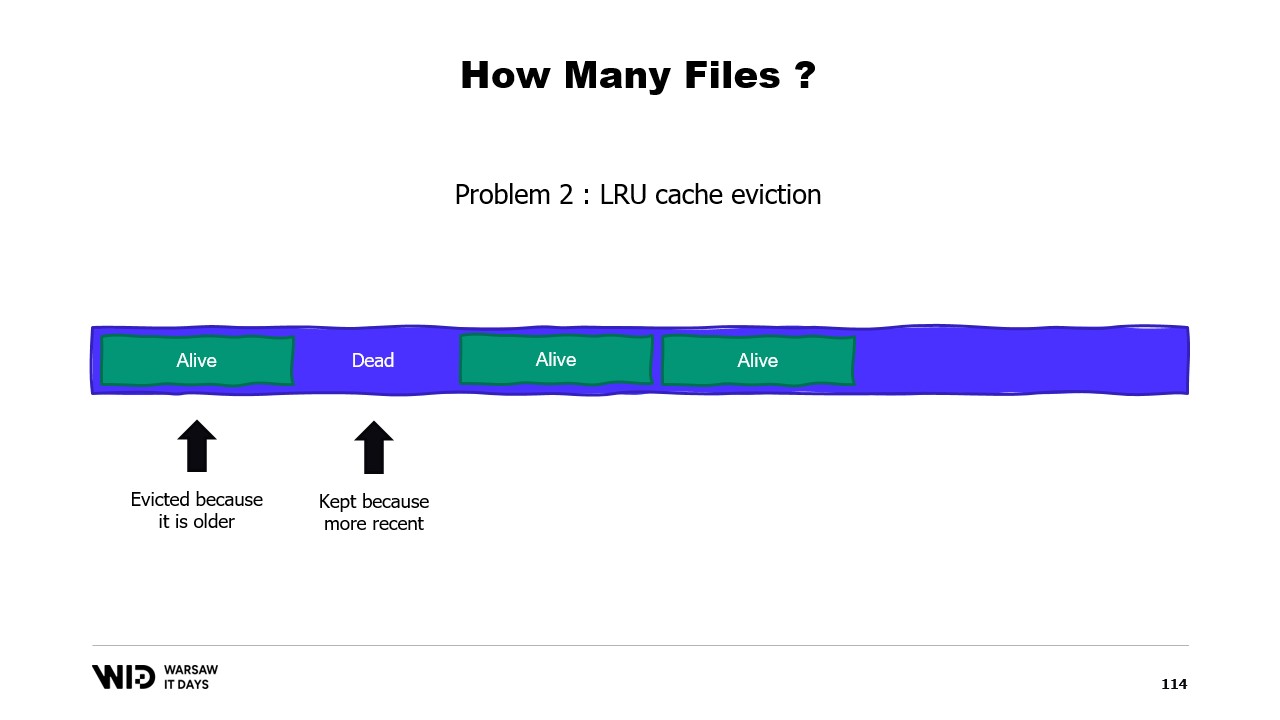
Le choix évident consiste simplement à mapper un grand fichier, le faire dès le démarrage du programme, et continuer à le parcourir. Lorsque qu’une partie n’est plus utilisée, il suffit de l’écraser. Cela semble évident et c’est pourquoi c’est faux.

Le premier problème avec cette approche est que l’écriture sur une page de mémoire nécessite un algorithme distinct.
L’algorithme est le suivant : d’abord, vous chargez immédiatement la page en mémoire. Ensuite, vous modifiez le contenu de la page en mémoire. Le système d’exploitation n’a aucun moyen de savoir qu’à l’étape deux, vous allez effacer tout et le remplacer, il doit donc toujours charger la page afin que les parties que vous ne changez pas restent inchangées. Enfin, vous programmez l’écriture de la page sur le disque à un moment futur.
Maintenant, la première fois que vous écrivez sur une page donnée dans un fichier tout neuf, il n’y a aucune donnée à charger. Le système d’exploitation sait que toutes les pages sont nulles, ainsi le chargement est gratuit. Il se contente de prendre une page nulle et de l’utiliser. Mais lorsque la page a déjà été modifiée et n’est plus en mémoire, le système d’exploitation doit la recharger depuis le disque.

Un deuxième problème est que les pages du cache de pages sont évincées selon l’algorithme du moins récemment utilisé, et le système d’exploitation n’est pas informé qu’une section morte de votre mémoire, qui ne sera plus jamais utilisée, doit être supprimée. Ainsi, il pourrait se retrouver à conserver en mémoire certaines portions de l’ensemble de données qui ne sont pas nécessaires et à évincer des portions qui le sont. Il n’existe aucun moyen d’indiquer au système d’exploitation qu’il doit tout simplement ignorer les sections mortes.
Un troisième problème est également lié au fait que l’écriture des données sur le disque accuse toujours un retard par rapport à l’écriture des données en mémoire. Et si vous savez qu’une page n’est plus nécessaire et qu’elle n’a pas encore été écrite sur le disque, eh bien, le système d’exploitation ne le sait pas. Il consacre donc toujours du temps à écrire ces octets qui ne seront plus jamais utilisés sur le disque, ralentissant ainsi l’ensemble.
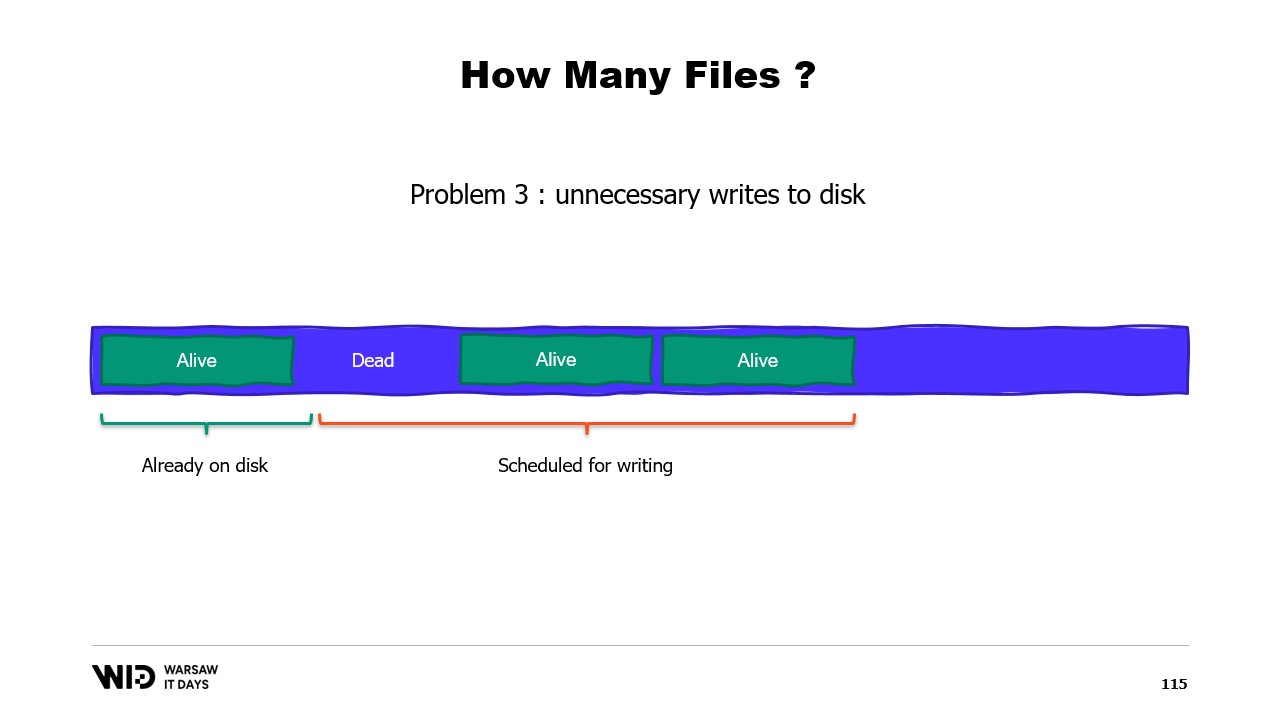
Au lieu de cela, nous devrions répartir la mémoire sur plusieurs gros fichiers. Nous n’écrivons jamais deux fois sur la même mémoire. Cela garantit que chaque écriture touche une page que le système d’exploitation sait être entièrement nulle et ne nécessite pas de chargement depuis le disque. Et nous supprimons les fichiers dès que possible. Cela indique au système d’exploitation que ce fichier n’est plus nécessaire, qu’il peut être supprimé du cache de pages et qu’il ne doit pas être écrit sur le disque s’il ne l’a pas déjà été.

En production chez Lokad, sur une VM de production typique, nous utilisons un espace de travail Lokad avec les paramètres suivants : chaque fichier a 16 gigaoctets, il y a 100 fichiers sur chaque disque, et chaque L32VM possède quatre disques. Au total, cela représente un peu plus de 6 téraoctets d’espace de débordement pour chaque VM.

C’est tout pour aujourd’hui. N’hésitez pas à nous contacter si vous avez des questions ou des commentaires, et merci de votre attention.


