00:17 Introduzione
03:35 Ordini di grandezza
06:55 Fasi dell’ottimizzazione della supply chain
12:17 Le curve a S dell’hardware
15:52 La storia finora
17:34 Scienze ausiliarie
20:25 Computer moderni
20:57 Latenza 1/2
27:15 Latenza 2/2
30:37 Calcolo, velocità di clock
36:36 Calcolo, pipelining, 1/3
39:11 Calcolo, pipelining, 2/3
40:27 Calcolo, pipelining, 3/3
46:36 Calcolo, superscalar 1/2
49:55 Calcolo, superscalar 2/2
56:45 Memoria 1/3
01:00:42 Memoria 2/3
01:06:43 Memoria 3/3
01:11:13 Archiviazione dati 1/2
01:14:06 Archiviazione dati 2/2
01:18:36 Larghezza di banda
01:23:20 Conclusione
01:27:33 Prossima lezione e domande dal pubblico
Descrizione
Le supply chain moderne richiedono risorse di calcolo per operare proprio come i nastri trasportatori motorizzati necessitano di elettricità. Eppure, i sistemi di supply chain lenti rimangono onnipresenti, mentre la potenza di calcolo dei computer è aumentata di un fattore superiore a 10.000 volte dal 1990. Una mancanza di comprensione delle caratteristiche fondamentali delle risorse di calcolo moderne - anche all’interno dei circoli IT o di scienza dei dati - spiega ampiamente questo stato di cose. Il design software alla base delle ricette numeriche non dovrebbe antagonizzare il substrato computazionale sottostante.
Trascrizione completa

Benvenuti a questa serie di lezioni sulla supply chain. Sono Joannes Vermorel, e oggi presenterò “Presentando Computer Moderni per Supply Chain.” Le supply chain occidentali sono state digitalizzate da molto tempo, a volte fino a tre decenni fa. Le decisioni basate su computer sono ovunque, e le ricette numeriche associate assumono nomi diversi, come punti di riordino, l’inventario min-max e le scorte di sicurezza, con vari gradi di supervisione umana.
Tuttavia, se osserviamo le grandi aziende di oggi che gestiscono supply chain altrettanto vaste, vediamo milioni di decisioni essenzialmente guidate dal computer, che determinano le prestazioni della supply chain. Di conseguenza, quando si tratta di migliorare le prestazioni della supply chain, tutto si riduce rapidamente al miglioramento delle ricette numeriche che ne guidano il funzionamento. Qui, invariabilmente, quando iniziamo a considerare ricette numeriche superiori di qualsiasi tipo, dove desideriamo modelli migliori e previsioni più accurate, quelle ricette superiori finiscono per richiedere molte più risorse di calcolo.
Le risorse di calcolo sono sempre state una sfida per la supply chain poiché costano molto, e c’è sempre la prossima fase di evoluzione per il modello successivo o il prossimo sistema di previsione che richiede dieci volte più risorse di calcolo rispetto al precedente. Sì, ciò potrebbe portare a una maggiore prestazione della supply chain, ma comporta anche costi di calcolo più elevati. Negli ultimi decenni, l’hardware di calcolo ha fatto enormi progressi, ma come vedremo oggi, questo progresso, sebbene ancora in atto, è spesso contrastato dal software enterprise. Di conseguenza, il software non diventa più veloce con hardware più moderno; al contrario, può molto frequentemente diventare più lento.
L’obiettivo di questa lezione è instillare nel pubblico una certa dose di simpatia meccanica, così da poter valutare se un pezzo di software enterprise, che dovrebbe implementare ricette numeriche volte a garantire prestazioni superiori della supply chain, sfrutta l’hardware di calcolo così come esiste attualmente e come esisterà tra un decennio, oppure lo antagonizza, impedendone essenzialmente il pieno utilizzo.

Uno degli aspetti più sconcertanti dei computer moderni è la gamma di ordini di grandezza coinvolti. Dal punto di vista della supply chain, solitamente abbiamo circa cinque ordini di grandezza, e questo è già un limite; di solito, non è nemmeno così. Cinque ordini di grandezza significa che possiamo passare da un’unità a 100.000 unità. Ricordate ciò di cui ho discusso nelle lezioni precedenti: la legge dei piccoli numeri in azione. Se si dispone di un gran numero di unità, non le elaborerete individualmente; le imballerete in scatole, e così rimarrà un numero molto minore di scatole. Analogamente, se avete molte scatole, le imballerete su pallet, ecc., in modo da avere un numero molto minore di pallet. Le economies of scale inducono previsioni di quantità, e dal punto di vista della supply chain, quando si tratta del flusso di merci fisiche, un’inefficienza del 10% tende già a essere piuttosto significativa.
Nel campo dei computer è molto diverso; stiamo parlando di 15 ordini di grandezza, il che è assolutamente gigantesco. Passare da un’unità a un milione di miliardi di unità è un numero così grande che è praticamente difficile da visualizzare. Passiamo da un byte, che è solo otto bit e può essere utilizzato per rappresentare una lettera o una cifra, a un petabyte, che corrisponde a un milione di gigabyte. Un petabyte è circa l’ordine di grandezza della quantità di dati che attualmente gestisce Lokad, e le grandi aziende che operano supply chain di grande dimensione gestiscono anche dataset dell’ordine di un petabyte.
Passiamo da un FLOP (operazione in virgola mobile al secondo) a un petaFLOP, cioè un milione di gigaFLOP. Questi ordini di grandezza sono assolutamente giganteschi e molto ingannevoli. Di conseguenza, nel dominio della supply chain, dove il 10% è considerato inefficiente, tipicamente in ambito informatico non si tratta di essere inefficiente del 10%, ma di essere inefficiente di un fattore 10, e a volte di diversi ordini di grandezza. Quindi, se commetti un errore in termini di prestazioni nel campo dei computer, la tua penalità non sarà del 10%; invece, il tuo sistema sarà 10 volte più lento di quanto dovrebbe esserlo, o 100 volte, e talvolta anche 1000 volte più lento di quanto avrebbe dovuto essere. Questo è davvero ciò in gioco: avere un vero allineamento, che richiede una sorta di simpatia meccanica tra il software enterprise e l’hardware di calcolo sottostante.
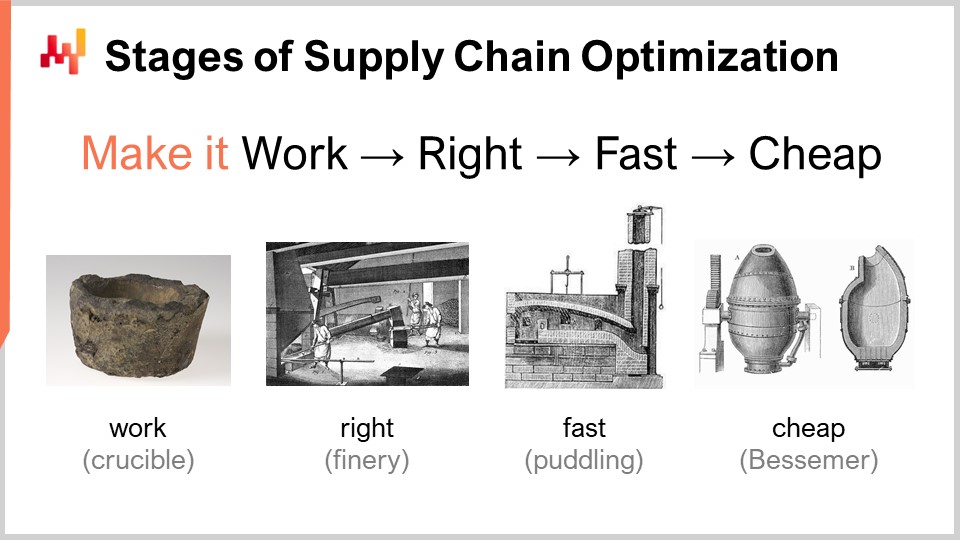
Quando si considera una ricetta numerica che dovrebbe garantire una sorta di prestazioni superiori della supply chain, esiste un insieme di fasi di maturità che sono concettualmente rilevanti. Ovviamente, i risultati possono variare nella pratica, ma tipicamente è quanto abbiamo identificato in Lokad. Queste fasi possono essere riassunte come: farla funzionare, farla giusta, farla veloce e farla economica.
“Farla funzionare” riguarda la valutazione se un prototipo di ricetta numerica stia realmente fornendo i risultati previsti, come livelli di servizio più elevati, meno stock morto, un migliore utilizzo degli asset, o qualsiasi altro obiettivo rilevante dal punto di vista della supply chain. L’obiettivo è innanzitutto assicurarsi che la nuova ricetta numerica funzioni effettivamente nella prima fase di maturità.
Poi, devi “farla giusta”. Dal punto di vista della supply chain, ciò significa trasformare quello che era sostanzialmente un prototipo unico in qualcosa di qualità industriale. Questo tipicamente comporta l’aggiunta, alla ricetta numerica, di un certo grado di correttezza per progetto. Le supply chain sono vaste, complesse e, soprattutto, molto caotiche. Se possiedi una ricetta numerica estremamente fragile, anche se il metodo numerico è valido, è molto facile commettere errori, e finirai per creare molti più problemi rispetto ai benefici che intendevi portare inizialmente. Questa non è una proposta vincente. Farla giusta significa garantire che tu abbia qualcosa che possa essere implementato su larga scala con una frizione minima. Successivamente, vuoi rendere questa ricetta numerica veloce, e quando dico veloce, intendo veloce in termini di tempo reale. Quando avvii il calcolo, dovresti ottenere i risultati nel giro di pochi minuti, oppure al massimo un’ora o due, ma non di più. Le supply chain sono caotiche, e ci sarà un momento nella storia della tua azienda in cui si verificheranno interruzioni, come navi portacontainer bloccate nel mezzo del Canale di Suez, una pandemia, o un magazzino allagato. Quando ciò accade, devi essere in grado di reagire rapidamente. Non sto dicendo di reagire nel giro di millisecondi, ma se hai ricette numeriche che impiegano giorni per completarsi, questo crea una frizione operativa massiccia. Hai bisogno di sistemi che possano operare in un lasso di tempo umano breve, quindi devono essere veloci.
Ricorda, il software enterprise moderno gira sui cloud, e puoi sempre pagare per ottenere più risorse di calcolo sulle piattaforme di cloud computing. Quindi, il tuo software può essere effettivamente veloce solo perché stai noleggiando molta potenza di elaborazione. Non è che il software debba essere progettato in modo adeguato per sfruttare tutta la potenza di elaborazione che un cloud può offrire, ma può essere veloce e molto inefficiente semplicemente perché stai noleggiando così tanta potenza di calcolo dal tuo fornitore di cloud computing.
La fase successiva è rendere il metodo economico, nel senso che non utilizzi troppe risorse di cloud computing. Se non raggiungi questa fase finale, significa che non potrai mai migliorare il tuo metodo. Se hai un metodo che funziona, è corretto e veloce ma consuma molte risorse, quando vorrai passare alla fase successiva della ricetta numerica, che inevitabilmente richiederà ancora più risorse di calcolo di quelle attualmente in uso, rimarrai bloccato. Devi rendere il metodo che hai estremamente snello, in modo da poter iniziare a sperimentare con ricette numeriche che siano meno efficienti di quelle attuali.
Questa ultima fase è quella in cui devi veramente sfruttare l’hardware sottostante disponibile nei computer moderni. Puoi cavartela con le prime tre fasi senza troppa affinità, ma l’ultima è fondamentale. Ricorda, se non raggiungi la fase “renderlo economico”, non sarai in grado di iterare, e così rimarrai bloccato. Ecco perché, anche se rappresenta la fase finale, questo è un gioco iterativo e diventa essenziale attraversare tutte le fasi se vuoi iterare ripetutamente.
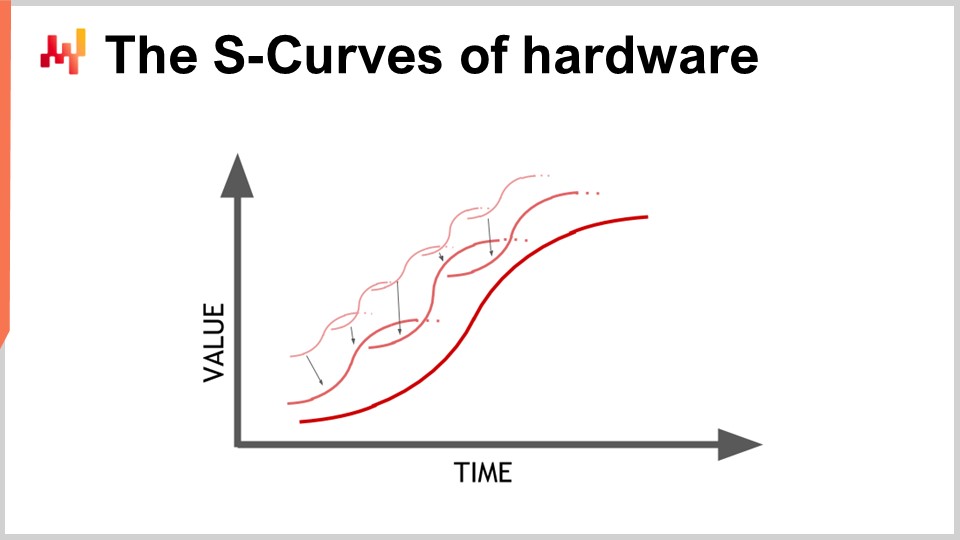
L’hardware sta progredendo, e sembra seguire una progressione esponenziale, ma la realtà è che questa progressione esponenziale dell’hardware di calcolo è in realtà composta da migliaia di curve a S. Una curva a S è una curva in cui si introduce un nuovo design, processo, materiale o architettura e, inizialmente, non è davvero migliore di ciò che si aveva in precedenza. Poi, entra in gioco l’effetto dell’innovazione prevista, dando luogo a un aumento rapido, seguito da un plateau una volta esauriti tutti i benefici dell’innovazione. Le curve a S che raggiungono il plateau sono caratteristiche del progresso dell’hardware dei computer, che è costituito da migliaia di queste curve. Dal punto di vista del profano, questo appare come una crescita esponenziale. Tuttavia, gli esperti vedono le singole curve a S raggiungere il plateau, il che può portare a una visione pessimistica. Anche gli esperti non vedono sempre l’emergere di nuove curve a S che sorprendono tutti e continuano la crescita esponenziale del progresso.
Sebbene l’hardware di calcolo continui a progredire, il tasso di progresso non è affatto paragonabile a quello sperimentato negli anni ‘80 o ‘90. Il ritmo ora è molto più lento e abbastanza prevedibile, in gran parte a causa degli enormi investimenti richiesti per costruire nuove fabbriche per la produzione dell’hardware di calcolo. Questi investimenti ammontano spesso a centinaia di milioni di dollari, offrendo una visione chiara per i prossimi cinque-dieci anni. Sebbene il progresso si sia rallentato, abbiamo ancora una visione abbastanza accurata di ciò che accadrà in termini di progresso dell’hardware di calcolo per il prossimo decennio.
La lezione per il software enterprise che implementa ricette numeriche è che non puoi passivamente aspettarti che l’hardware futuro migliori tutto per te. L’hardware continua a progredire, ma catturare questo progresso richiede sforzi dal lato del software. Potrai fare di più con l’hardware che esisterà fra un decennio, ma solo se l’architettura alla base del tuo software enterprise sfrutta appieno l’hardware di calcolo sottostante. Altrimenti, potresti fare peggio di quanto stai facendo oggi, una proposizione che non è affatto irragionevole.
Questa lezione è la prima del quarto capitolo di questa serie di lezioni sulla supply chain. Non ho ancora completato il terzo capitolo sulle personae della supply chain. Nelle lezioni successive, probabilmente alterno tra il capitolo attuale, in cui tratterò le scienze ausiliarie della supply chain, e il terzo capitolo sulle personae della supply chain.
Nel primissimo capitolo del prologo, ho presentato le mie opinioni sulla supply chain sia come campo di studio che come pratica. Abbiamo visto che la supply chain è essenzialmente un insieme di problemi complessi, a differenza dei problemi semplici, afflitti da comportamenti antagonisti e giochi competitivi. Pertanto, è necessario prestare molta attenzione alla metodologia perché le metodologie dirette e ingenue rendono scarsamente in questo settore. Ecco perché il secondo capitolo è stato dedicato alla metodologia necessaria per studiare le supply chain e stabilire pratiche per migliorarle nel tempo.
Il terzo capitolo, Supply Chain Personae, si è concentrato sulla caratterizzazione dei problemi della supply chain stessi, con il motto “innamorati del problema, non della soluzione.” Il quarto capitolo che apriamo oggi parla delle scienze ausiliarie della supply chain.

Le scienze ausiliarie sono discipline che supportano lo studio di un’altra disciplina. Non c’è un giudizio di valore; non si tratta di una disciplina superiore a un’altra. Ad esempio, la medicina non è superiore alla biologia, ma la biologia è una scienza ausiliaria per la medicina. La prospettiva delle scienze ausiliarie è ben consolidata e diffusa in molti campi di ricerca, come le scienze mediche e la storia.
Nelle scienze mediche, le scienze ausiliarie includono biologia, chimica, fisica e sociologia, tra le altre. Un medico moderno non sarebbe considerato competente se non avesse conoscenze di fisica. Ad esempio, comprendere le basi della fisica è necessario per interpretare un’immagine a raggi X. Lo stesso vale per la storia, che vanta una lunga serie di scienze ausiliarie.
Quando si tratta di supply chain, una delle mie critiche più grandi ai materiali, corsi, libri e articoli tipici sulla supply chain è che trattano l’argomento senza approfondire le scienze ausiliarie. Trattano la supply chain come se fosse un pezzo di conoscenza isolato e autonomo. Tuttavia, credo che la pratica moderna della supply chain possa essere raggiunta solo sfruttando appieno le scienze ausiliarie della supply chain. Una di queste scienze ausiliarie, e il fulcro della lezione di oggi, è l’hardware informatico.
Questa lezione non è strettamente una lezione di supply chain, ma riguarda l’hardware informatico con applicazioni alla supply chain in mente. Credo che sia fondamentale praticare la supply chain in modo moderno, a differenza di come veniva fatta un secolo fa.

Diamo un’occhiata ai computer moderni. In questa lezione, esamineremo cosa possono fare per la supply chain, concentrandoci in particolare sugli aspetti che hanno un impatto enorme sulle prestazioni del software aziendale. Esamineremo latenza, calcolo, memoria, archiviazione dei dati e larghezza di banda.

La velocità della luce è di circa 30 centimetri per nanosecondo, il che è relativamente lento. Se consideri la distanza caratteristica di interesse per una CPU moderna che opera a 5 gigahertz (5 miliardi di operazioni al secondo), la distanza di andata e ritorno che la luce può percorrere in 0,2 nanosecondi è di soli 3 centimetri. Ciò significa che, a causa della limitazione della velocità della luce, le interazioni non possono avvenire oltre i 3 centimetri. Questa è una limitazione rigida imposta dalle leggi della fisica, ed è incerto se riusciremo mai a superarla.
La latenza è un vincolo estremamente rigido. Dal punto di vista della supply chain, sono coinvolte almeno due distribuzioni di hardware informatico. Quando parlo di hardware informatico distribuito, intendo hardware che coinvolge molti dispositivi che non possono occupare lo stesso spazio fisico. Ovviamente, è necessario tenerli separati poiché hanno dimensioni proprie. Tuttavia, il primo motivo per cui abbiamo bisogno di computing distribuito è la natura delle supply chain, che sono distribuite geograficamente. Per progettazione, le supply chain sono sparse attraverso le geografie e, di conseguenza, anche l’hardware informatico sarà distribuito in quelle stesse aree. Dal punto di vista della velocità della luce, anche se hai dispositivi distanti solo tre metri, è già molto lento perché ci vogliono 100 cicli di clock per completare il giro. Tre metri rappresentano una distanza considerevole dal punto di vista della velocità della luce e della frequenza di clock delle CPU moderne.
Un altro tipo di distribuzione è lo scaling orizzontale. Il modo moderno di avere più potenza di elaborazione a disposizione non consiste nell’avere un dispositivo informatico 10 volte o un milione di volte più potente; non è così che viene ingegnerizzato. Se desideri più risorse di elaborazione, hai bisogno di dispositivi informatici aggiuntivi, di più processori, più chip di memoria e più hard disk. È impilando l’hardware che puoi avere a disposizione maggiori risorse computazionali. Tuttavia, tutti questi dispositivi occupano spazio, e quindi, finisci per distribuire il tuo hardware informatico semplicemente perché non puoi centralizzarlo in un computer largo un centimetro.
Quando si parla di latenze, osservando quelle che si ottengono su internet professionale (quelle che puoi avere in un data center, non con il Wi-Fi di casa), siamo già entro il 30% della velocità della luce. Ad esempio, la latenza tra un data center vicino a Parigi, Francia, e New York, Stati Uniti, è solo entro il 30% della velocità della luce. Questo è un risultato incredibile per l’umanità; l’informazione scorre attraverso internet quasi alla velocità della luce. Sì, c’è ancora margine di miglioramento, ma siamo già vicini ai limiti rigidi imposti dalla fisica.
Di conseguenza, ci sono persino aziende che ora vogliono posare un cavo attraverso il fondo marino artico per collegare Londra a Tokyo con un cavo che passerebbe sotto il Polo Nord, solo per ridurre di pochi millisecondi la latenza nelle transazioni finanziarie. Fondamentalmente, la latenza e la velocità della luce sono preoccupazioni molto reali, e internet che abbiamo è sostanzialmente il meglio che potremo avere, a meno che non ci siano rivoluzioni nella fisica. Tuttavia, non abbiamo nulla del genere in vista per il prossimo decennio.
Considerando che la latenza è un problema estremamente difficile, le implicazioni per il software aziendale sono significative. I round trip, in termini di flusso di informazioni, sono critici, e le prestazioni del tuo software aziendale dipenderanno in larga misura dal numero di round trip tra i vari sottosistemi presenti nel tuo software. Il numero di round trip caratterizzerà la latenza inconcompressibile che subisci. Minimizzare i round trip e migliorare le latenze è, per la maggior parte dei software aziendali, compresi quelli dedicati all’ottimizzazione predittiva delle supply chain, il problema numero uno. Mitigare le latenze spesso equivale a fornire migliori prestazioni.

Un trucco interessante, anche se non è qualcosa che tutti in questo pubblico implementeranno in produzione, è affrontare le complicazioni introdotte dalla latenza. Il tempo stesso diventa sfuggente e confuso quando entri nel regno dei calcoli al nanosecondo. Ottenere orologi precisi è difficile nel computing distribuito, e la loro assenza introduce complicazioni all’interno del software aziendale distribuito. Sono necessari numerosi round trip per sincronizzare le varie parti del sistema. A causa della mancanza di un orologio preciso, si finisce per ricorrere ad alternative algoritmiche come vector clocks o timestamp multipart, che sono strutture dati che riflettono un ordinamento parziale degli orologi dei dispositivi nel tuo sistema. Questi round trip extra possono compromettere le prestazioni.
Un design intelligente adottato da Google oltre un decennio fa consisteva nell’utilizzare orologi atomici a scala chip. La risoluzione di questi orologi atomici è notevolmente migliore rispetto a quella degli orologi a quarzo presenti negli orologi elettronici o nei computer. Il NIST ha dimostrato una nuova configurazione di orologio atomico a scala chip con una deriva giornaliera ancora più precisa. Google ha utilizzato orologi atomici interni per sincronizzare le varie parti del loro database SQL distribuito a livello globale, Google Spanner, per risparmiare round trip e migliorare le prestazioni su scala globale. Questo è un modo per aggirare la latenza attraverso misurazioni del tempo molto precise.
Guardando a un decennio di distanza, è probabile che Google non sarà l’ultima azienda a utilizzare questo tipo di trucco intelligente, e questi orologi sono relativamente economici, con costi di circa 1.500 dollari ciascuno.

Ora, diamo un’occhiata al compute, che riguarda l’esecuzione dei calcoli con un computer. La velocità di clock era l’ingrediente magico per il miglioramento durante gli anni ‘80 e ‘90. Infatti, se potessi raddoppiare la velocità di clock del tuo computer in modo uniforme, raddoppieresti effettivamente le prestazioni del tuo computer, indipendentemente dal tipo di software coinvolto. Tutti i software sarebbero linearmente più veloci in base alla velocità di clock. È estremamente interessante aumentare la velocità di clock, e continua a migliorare, anche se il progresso si è appiattito col tempo. Quasi 20 anni fa, la velocità di clock era di circa 2 GHz, mentre oggi è di 5 GHz.
La ragione chiave di questo appiattimento del miglioramento è il power wall. Il problema è che quando aumenti la velocità di clock su un chip, tendi a raddoppiare approssimativamente il consumo energetico, e poi devi dissipare questa energia. Il problema è la dissipazione termica, perché se non riesci a dissipare l’energia, il tuo dispositivo accumula calore fino al punto di danneggiarlo. Oggi, l’industria dei semiconduttori si è spostata dal puntare a più operazioni al secondo a più operazioni per watt.
Questa regola secondo cui un aumento del 30% raddoppia il consumo energetico è a doppio taglio. Se sei disposto a rinunciare a un quarto della tua potenza di elaborazione per unità di tempo sulla CPU, puoi effettivamente dimezzare il consumo energetico. Questo è particolarmente interessante per gli smartphone, dove il risparmio energetico è cruciale, e anche per il cloud computing, dove uno dei principali fattori di costo è l’energia stessa. Per avere potenza di elaborazione per il cloud computing a costi contenuti, non si tratta di avere CPU superveloci, ma piuttosto di avere CPU sottoclockate che possono operare fino a 1 GHz, fornendo più operazioni al secondo per il tuo investimento energetico.
Il power wall è un problema tale che le architetture moderne della CPU utilizzano ogni sorta di trucco intelligente per mitigarne gli effetti. Ad esempio, le CPU moderne possono regolare la loro velocità di clock, potenziandola temporaneamente per un secondo o giù di lì prima di ridurla per dissipare il calore. Possono anche sfruttare ciò che viene chiamato dark silicon. L’idea è che, se la CPU può alternare le aree calde sul chip, diventa più facile dissipare l’energia rispetto ad avere sempre la stessa area attiva ciclo dopo ciclo. Questo è un ingrediente fondamentale del design moderno. Dal punto di vista del software aziendale, significa che vuoi davvero essere in grado di scalare orizzontalmente. Vuoi poter fare di più con molte volte più CPU, ma individualmente, quei processori saranno più deboli rispetto a quelli precedenti che avevi. Non si tratta di ottenere processori migliori nel senso che tutto è migliore in assoluto; si tratta di avere processori che ti offrono più operazioni per watt, e questa tendenza continuerà.
Forse tra un decennio, con difficoltà, raggiungeremo i sette o forse gli otto gigahertz, ma non sono nemmeno sicuro che ci riusciremo. Quando guardo la velocità di clock nel 2021 nella maggior parte dei provider di cloud computing, è tipicamente allineata a circa 2 GHz, quindi siamo tornati alla velocità di clock che avevamo 20 anni fa, e quella è la soluzione più economica.
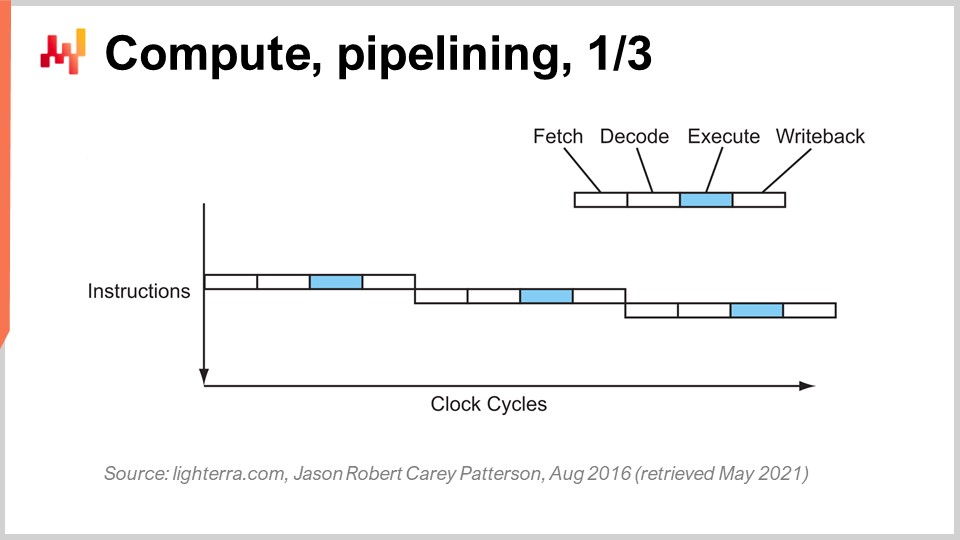
Raggiungere le attuali prestazioni delle CPU ha richiesto una serie di innovazioni fondamentali. Ne presenterò alcune, in particolare quelle che hanno il maggiore impatto sul design del software aziendale. Su questo schermo, quello che vedi è il flusso di istruzioni di un processore sequenziale, come venivano realizzati essenzialmente fino ai primi anni ‘80. Hai una serie di istruzioni che vengono eseguite dall’alto verso il basso del grafico, rappresentando il tempo. Ogni istruzione passa attraverso una serie di fasi: fetch, decode, execute e write back.
Durante la fase di fetch, si preleva l’istruzione, si registra, si afferra la prossima istruzione, si incrementa il contatore delle istruzioni e si prepara la CPU. Durante la fase di decode, si decodifica l’istruzione ed si emette il microcodice interno, che è ciò che la CPU esegue internamente. La fase di execution prevede di prelevare gli input rilevanti dai registri ed eseguire il calcolo effettivo, mentre la fase di write back consiste nel prendere il risultato appena calcolato e posizionarlo in uno dei registri. In questo processore sequenziale, ogni singola fase richiede un ciclo di clock, quindi sono necessari quattro cicli di clock per eseguire un’istruzione. Come abbiamo visto, è molto difficile aumentare la frequenza dei cicli di clock stessi a causa di molte complicazioni.
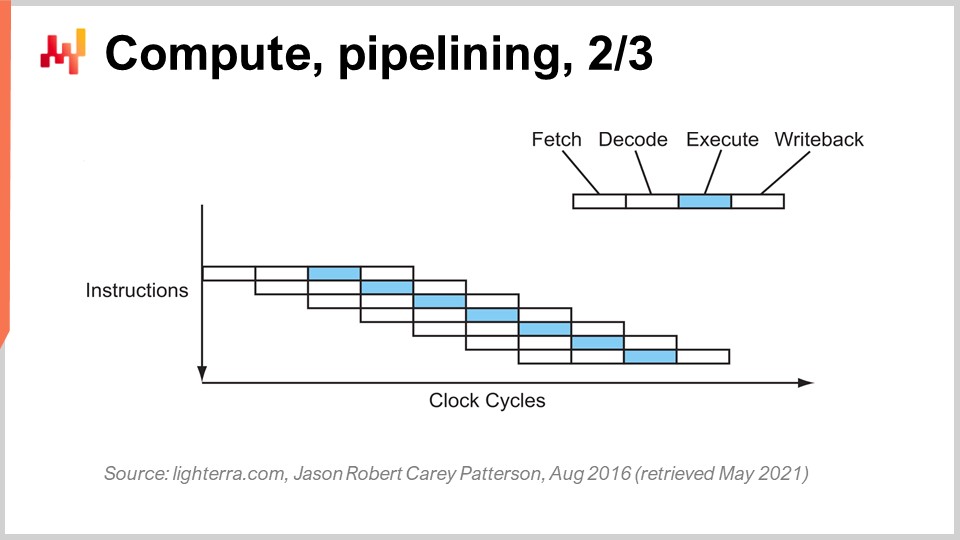
Il trucco fondamentale in uso dagli inizi degli anni ‘80 in poi è noto come pipelining. Il pipelining può accelerare enormemente il calcolo della tua CPU. L’idea è che, dato che ogni istruzione passa attraverso una serie di fasi, sovrapporremo le fasi, e così la CPU avrà un’intera pipeline di istruzioni. In questo diagramma, puoi vedere una CPU con una pipeline di profondità quattro, dove ci sono sempre quattro istruzioni che vengono eseguite contemporaneamente. Tuttavia, non sono nella stessa fase: una istruzione è in fase di fetch, una in fase di decode, una in fase di execute e una in fase di write-back. Con questo semplice trucco, rappresentato qui come un processore a pipeline, abbiamo moltiplicato per quattro le prestazioni effettive della CPU, semplicemente effettuando il pipelining delle operazioni. Tutte le CPU moderne utilizzano il pipelining.
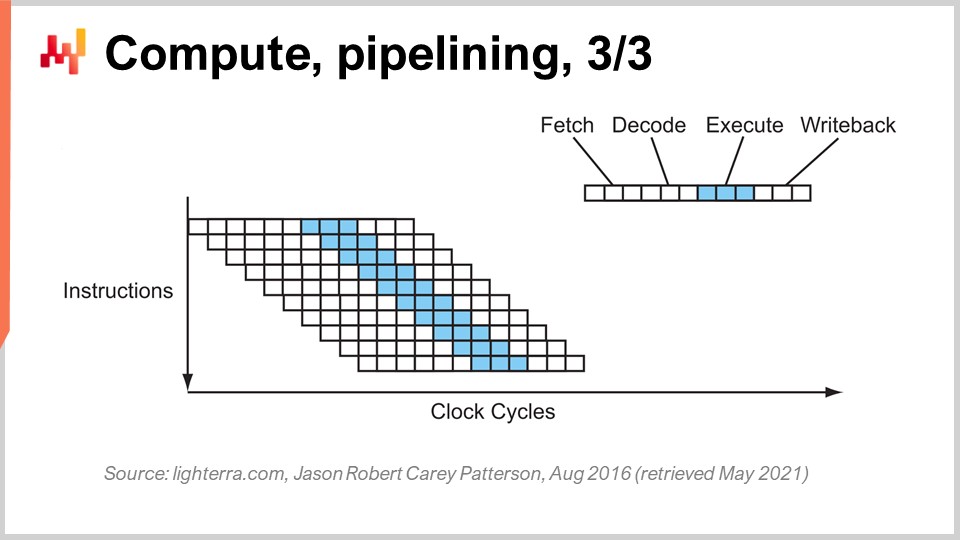
La fase successiva di questo miglioramento è chiamata super pipelining. Le CPU moderne vanno ben oltre il semplice pipelining. In realtà, il numero di fasi coinvolte in una CPU moderna è di circa 30 fasi. Nel grafico, puoi vedere una CPU con 12 fasi come esempio, ma in realtà sarebbe più simile a 30 fasi. Con questa pipeline più profonda, 12 operazioni possono essere eseguite contemporaneamente, il che è molto positivo per le prestazioni pur continuando a utilizzare lo stesso ciclo di clock.
Tuttavia, sorge un nuovo problema: la prossima istruzione inizia prima che la precedente sia terminata. Ciò significa che se hai operazioni dipendenti, hai un problema perché il calcolo degli input per la prossima istruzione non è ancora pronto, e devi aspettare. Vogliamo utilizzare l’intera pipeline a nostra disposizione per massimizzare la potenza di elaborazione. Perciò, le CPU moderne prelevano non una sola istruzione alla volta, ma circa 500 istruzioni alla volta. Esse guardano lontano nella lista delle istruzioni in arrivo e le riorganizzano per mitigare le dipendenze, intercalando i flussi di esecuzione per sfruttare appieno la profondità della pipeline.
Esistono molte cose che complicano questa operazione, in particolare i branch. Un branch è semplicemente una condizione in programmazione, come quando scrivi un’istruzione “if”. Il risultato della condizione può essere vero o falso e, a seconda del risultato, il tuo programma eseguirà una logica o un’altra. Questo complica la gestione delle dipendenze perché la CPU deve indovinare la direzione che prenderanno i branch in arrivo. Le CPU moderne utilizzano la branch prediction, che impiega euristiche semplici e ha una precisione di previsione molto elevata. Possono prevedere la direzione dei branch con una precisione superiore al 99%, cosa migliore di quanto possa fare la maggior parte di noi in un contesto reale di supply chain. Questa precisione è necessaria per sfruttare pipeline estremamente profonde.
Per darti un’idea delle euristiche utilizzate per la branch prediction, una euristica molto semplice consiste nel dire che il branch seguirà la stessa direzione di quella presa l’ultima volta. Questa semplice euristica ti offre una precisione intorno al 90%, che è abbastanza buona. Se aggiungi una variazione a questa euristica, ovvero che il branch seguirà la stessa direzione dell’ultima volta, ma considerando l’origine, cioè trattandosi dello stesso branch proveniente dalla stessa origine, otterrai una precisione intorno al 95%. Le CPU moderne utilizzano in realtà perceptron abbastanza complessi, una tecnica di machine learning, per prevedere la direzione dei branch.
Sotto le giuste condizioni, puoi prevedere i branch con una buona precisione e sfruttare così l’intera pipeline per ottenere il massimo da una CPU moderna. Tuttavia, da un punto di vista dell’ingegneria del software, devi collaborare con il tuo processore, specialmente per quanto riguarda la branch prediction. Se non collabori, il predittore di branch si sbaglia e, quando ciò accade, la CPU prevede la direzione del branch, organizza la pipeline e inizia a eseguire calcoli in anticipo. Quando il branch viene effettivamente incontrato e il calcolo viene completato, la CPU si rende conto che la previsione era errata. Una previsione di branch inesatta non produce un risultato sbagliato; comporta una perdita di prestazioni. La CPU non avrà altra scelta che svuotare l’intera pipeline, o una sua larga parte, attendere che vengano eseguiti altri calcoli e poi riavviare il processo. L’impatto sulle prestazioni può essere molto significativo, e puoi facilmente perdere uno o due ordini di grandezza in performance a causa della logica del software enterprise che non si integra bene con la logica della branch prediction della tua CPU.
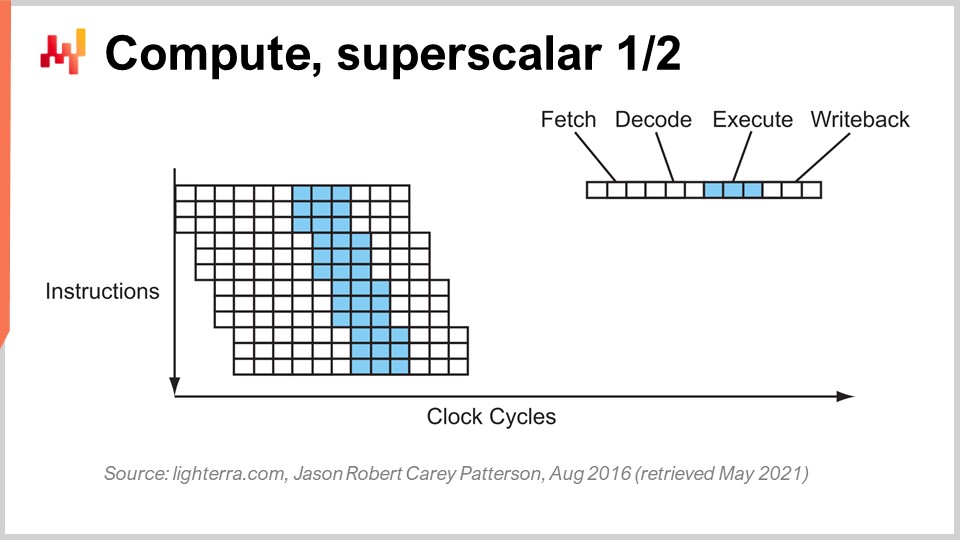
Un altro trucco notevole oltre al pipelining è l’istruzione superscalar. Le CPU tipicamente elaborano scalari, o coppie di scalari, alla volta – per esempio, due numeri con precisione floating-point a 32 bit. Eseguono operazioni scalari, elaborando essenzialmente un numero alla volta. Tuttavia, le CPU moderne dell’ultimo decennio hanno praticamente tutte adottato le istruzioni superscalar, che possono effettivamente elaborare diversi vettori di numeri ed eseguire operazioni vettoriali direttamente. Ciò significa che una CPU può prendere un vettore di, diciamo, otto numeri in virgola mobile e un secondo vettore di otto numeri in virgola mobile, eseguire un’addizione e ottenere un vettore di numeri in virgola mobile che rappresentano il risultato di questa somma. Tutto ciò viene eseguito in un solo ciclo.
Ad esempio, set di istruzioni specializzati come AVX2 ti consentono di eseguire operazioni considerando 32 bit di precisione con blocchi di otto numeri, mentre AVX512 ti permette di farlo con blocchi di 16 numeri. Se sei in grado di sfruttare queste istruzioni, significa che puoi letteralmente guadagnare un ordine di grandezza in termini di velocità di elaborazione, perché una singola istruzione, un ciclo di clock, esegue molti più calcoli rispetto all’elaborazione dei numeri uno per uno. Questo processo è noto come SIMD (Single Instruction, Multiple Data) ed è molto potente. Ha guidato gran parte dei progressi nell’ultimo decennio in termini di potenza di calcolo, e i processori moderni sono sempre più basati sui vettori e sono superscalar. Tuttavia, dal punto di vista del software enterprise, è relativamente complicato. Con il pipelining, il tuo software deve collaborare, e magari lo fa accidentalmente con la branch prediction. Tuttavia, quando si tratta di istruzioni superscalar, non c’è nulla di accidentale. Il tuo software deve fare esplicitamente alcune cose, per lo più, per sfruttare questa potenza di calcolo extra. Non te la viene data gratuitamente; devi abbracciare questo approccio e, tipicamente, devi organizzare i dati in modo che ci sia parallelismo dei dati, organizzandoli in una maniera adatta alle istruzioni SIMD. Non è scienza missilistica, ma non accade per caso, e ti offre un enorme incremento in termini di potenza di elaborazione.

Ora, le CPU moderne possono avere molti core, e un core della CPU può fornire un flusso distinto di istruzioni. Con le CPU molto moderne che dispongono di molti core, tipicamente le CPU attuali possono arrivare fino a 64 core, cioè 64 flussi indipendenti di esecuzione concorrente. Puoi praticamente raggiungere circa un teraflop, che è il limite superiore del throughput di elaborazione che puoi ottenere da un processore molto moderno. Tuttavia, se vuoi andare oltre, puoi considerare le GPU (Graphical Processing Units). Nonostante quello che potresti pensare, questi dispositivi possono essere utilizzati per compiti che non hanno nulla a che fare con la grafica.
Una GPU, come quella di NVIDIA, è un processore superscalar. Invece di avere fino a 64 core come le CPU di fascia alta, le GPU possono avere più di 10.000 core. Questi core sono molto più semplici e non potenti o veloci come i core delle CPU tradizionali, ma ce ne sono molte volte di più. Portano le istruzioni SIMD a un nuovo livello, dove puoi elaborare non solo blocchi di 8 o 16 numeri alla volta, ma letteralmente migliaia di numeri contemporaneamente per eseguire istruzioni vettoriali. Con le GPU, puoi raggiungere oltre 30 teraflops su un singolo dispositivo, il che è enorme. Le migliori CPU sul mercato possono offrire un teraflop, mentre le migliori GPU ne offrono oltre 30. Si tratta di una differenza di oltre un ordine di grandezza, che è molto significativa.
Se vai ancora oltre, per tipi specializzati di calcoli come l’algebra lineare (a proposito, cose come il machine learning e deep learning sono fondamentalmente algebra lineare basata su matrici dappertutto), puoi avere processori come le TPU (Tensor Processing Units). Google ha deciso di chiamarle Tensors a causa di TensorFlow, ma in realtà le TPU sarebbero meglio denominate Matrix Multiplication Processing Units. La cosa interessante della moltiplicazione di matrici è che non solo c’è un’enorme quantità di parallelismo dei dati, ma vi è anche una ripetizione immensa, poiché le operazioni sono altamente ripetitive. Organizzando una TPU come una matrice sistolica, che è essenzialmente una griglia bidimensionale con unità di calcolo, puoi superare la barriera del petaflop, raggiungendo oltre 1000 teraflops su un singolo dispositivo. Tuttavia, c’è un avvertimento: Google lo sta facendo con numeri in virgola mobile a 16 bit anziché i consueti 32 bit. Dal punto di vista della supply chain, 16 bit di precisione non sono male; significa che hai circa lo 0,1% di accuratezza nelle operazioni, e per molte operazioni di machine learning o statistiche, lo 0,1% di accuratezza è più che sufficiente se eseguito correttamente e senza accumulare bias.
Quello che vediamo è che la traiettoria del progresso in termini di hardware di calcolo, considerando solo l’elaborazione, è stata quella di optare per dispositivi più specializzati e più rigidi. Grazie a questa specializzazione, è possibile ottenere enormi incrementi in potenza di calcolo. Se passi all’istruzione superscalar, guadagni un ordine di grandezza; se scegli una scheda grafica, guadagni uno o due ordini di grandezza; e se opti per la pura algebra lineare, guadagni essenzialmente due ordini di grandezza. Questo è molto significativo.
A proposito, tutti questi design hardware sono bidimensionali. I chip moderni e le strutture di elaborazione sono molto piatti. Una CPU moderna non prevede più di 20 strati e, poiché questi strati sono spessi solo pochi micron, CPU, GPU o TPU sono essenzialmente strutture piatte. Potresti pensare: “E la terza dimensione?” Beh, si scopre che, a causa del power wall – il problema della dissipazione dell’energia – non possiamo veramente passare alla terza dimensione perché non sappiamo come evacuare tutta l’energia immessa nel dispositivo.
Quello che possiamo prevedere per il prossimo decennio è che questi dispositivi rimarranno essenzialmente bidimensionali. Dal punto di vista del software enterprise, la lezione più importante è che devi progettare il parallelismo dei dati fin dal cuore del tuo software. Se non lo fai, non riuscirai a sfruttare tutti i progressi relativi alla pura potenza di calcolo. Tuttavia, non può essere un ripensamento successivo. Deve accadere al nucleo stesso dell’architettura, a livello di organizzazione di tutti i dati che devono essere elaborati nei tuoi sistemi. Se non lo fai, rimarrai bloccato con il tipo di processori che avevamo due decenni fa.
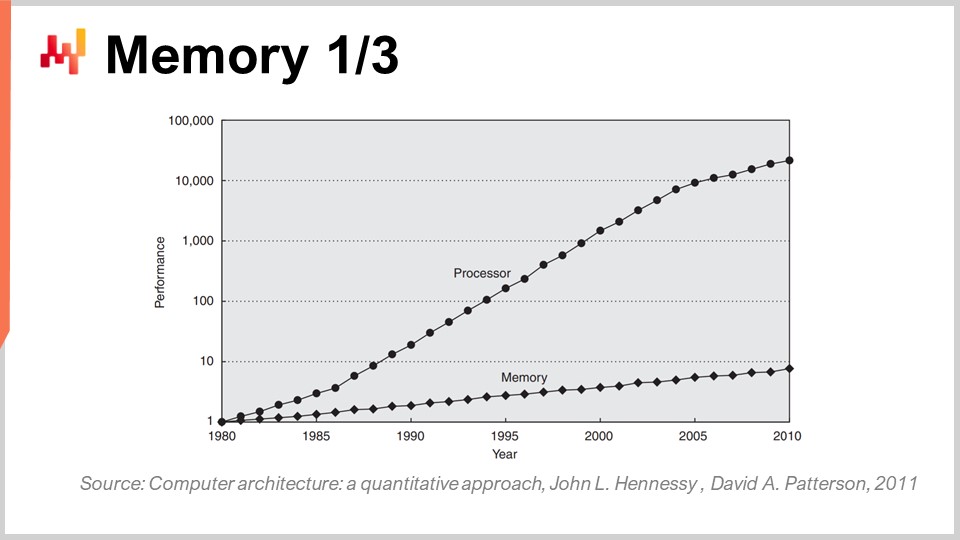
Ora, la memoria nei primi anni ‘80 era veloce quanto i processori, il che significava che un ciclo di clock valeva sia per la memoria che per la CPU. Tuttavia, non è più così. Col passare del tempo, dagli anni ‘80, il rapporto tra la velocità della memoria e le latenze per accedere ai dati già presenti nei registri della CPU è aumentato costantemente. Si è partiti da un rapporto di uno, e ora tipicamente il rapporto supera il mille. Questo problema è noto come memory wall, e si è aggravato negli ultimi quattro decenni. Continua ad aumentare anche oggi, sebbene molto lentamente, soprattutto perché la velocità di clock dei processori aumenta molto lentamente. Poiché i processori non stanno facendo grandi progressi in termini di velocità di clock, questo problema del memory wall non sta ulteriormente peggiorando. Tuttavia, l’attuale situazione è incredibilmente sbilanciata, dove l’accesso alla memoria è essenzialmente tre ordini di grandezza più lento rispetto all’accesso ai dati già comodamente presenti nella CPU.
Questa prospettiva sminuisce completamente tutta l’algoritmica classica, così come viene ancora insegnata oggi nella maggior parte delle università. L’approccio algoritmico classico presume che tu abbia un tempo uniforme per accedere alla memoria, ovvero che accedere a qualsiasi bit di memoria richieda lo stesso tempo. Ma nei sistemi moderni non è affatto così. Il tempo necessario per accedere a una certa porzione di memoria dipende fortemente da dove i dati si trovano fisicamente nel tuo sistema informatico.
Dal punto di vista del software enterprise, si scopre che, sfortunatamente, la maggior parte dei design software stabiliti negli anni ‘80 e ‘90 ignorava completamente il problema perché era molto trascurabile nel primo decennio. Il problema è esploso solo negli ultimi due decenni e, di conseguenza, la maggior parte dei pattern presenti nel software enterprise odierno si oppone completamente a questo design, in quanto presumono di avere un accesso in tempo costante a tutta la memoria.
A proposito, se inizi a pensare a linguaggi di programmazione come Python (pubblicato per la prima volta nel 1989) o Java (nel 1995) che adottano la programmazione orientata agli oggetti, questo va ben contro il funzionamento della memoria nei computer moderni. Ogni volta che hai degli oggetti, e la situazione peggiora con i late binding come in Python, significa che per fare qualsiasi cosa dovrai seguire puntatori ed eseguire salti casuali in memoria. Se uno di questi salti risulta sfortunato perché si tratta di una porzione non già presente nel processore, può essere mille volte più lento. Questo è un problema molto serio.

Per comprendere meglio l’entità del memory wall, è interessante osservare le latenze tipiche in un computer moderno. Se ridimensioniamo queste latenze in termini umani, supponiamo che un processore operasse a un ciclo di clock per secondo. Con tale ipotesi, la latenza tipica della CPU sarebbe di un secondo. Tuttavia, se vogliamo accedere ai dati in memoria, potrebbero volerci fino a sei minuti. Quindi, mentre puoi eseguire un’operazione al secondo, se devi accedere a qualcosa in memoria, devi attendere sei minuti. E se vuoi accedere a qualcosa su disco, può volerci fino a un mese o addirittura un anno intero. Questo è incredibilmente lungo, ed è esattamente di questo che parlano gli ordini di grandezza delle prestazioni menzionati all’inizio di questa lezione. Quando hai a che fare con 15 ordini di grandezza, la situazione è molto ingannevole; non ti rendi necessariamente conto dell’enorme impatto sulle prestazioni, tanto che, letteralmente, potresti finire per dover aspettare l’equivalente umano di mesi se non posizioni le informazioni nel posto giusto. Questo è assolutamente gigantesco.
A proposito, gli ingegneri del software enterprise non sono gli unici a lottare con questa evoluzione dell’hardware di calcolo moderno. Se esaminiamo le latenze ottenute con SSD ultraveloci, come la serie Intel Optane, possiamo osservare che metà della latenza per accedere alla memoria su questo dispositivo è effettivamente causata dall’overhead del kernel stesso, in questo caso il kernel Linux. È il sistema operativo stesso a generare metà della latenza. Cosa significa questo? Beh, significa che anche chi sta sviluppando Linux ha ancora del lavoro da fare per recuperare il ritardo rispetto all’hardware moderno. Comunque, è una grande sfida per tutti.
Tuttavia, ciò penalizza fortemente il software enterprise, specialmente quando si pensa all’ottimizzazione della supply chain, a causa del fatto che abbiamo tonnellate di dati da elaborare. È già un’impresa piuttosto complessa fin dall’inizio. Dal punto di vista del software enterprise, devi davvero adottare un design che si integri bene con la cache, poiché questa contiene copie locali che sono più veloci da accedere e più vicine alla CPU.
Il funzionamento è il seguente: quando accedi a un byte nella memoria principale, non puoi accedere a un singolo byte nel software moderno. Quando desideri accedere anche a un solo byte nella RAM, l’hardware copierà in realtà 4 kilobyte, ovvero l’intera pagina di 4 kilobyte. L’ipotesi di base è che, una volta iniziato a leggere un byte, il byte successivo che richiederai sarà quello seguente. Questo è il principio della località, il che significa che se rispetti la regola e imposti un accesso che ne preservi la località, la memoria funzionerà quasi alla stessa velocità della CPU.
Tuttavia, ciò richiede un allineamento tra gli accessi alla memoria e la località dei dati. In particolare, esistono molti linguaggi di programmazione, come Python, che non offrono nativamente questo tipo di funzionalità. Al contrario, essi presentano una sfida enorme per garantire anche solo un minimo grado di località. Questa è una lotta immensa e, in definitiva, è una battaglia in cui ci si trova di fronte a un linguaggio di programmazione progettato attorno a schemi che antagonizzano completamente l’hardware a nostra disposizione. Questo problema non cambierà nel prossimo decennio; peggiorerà soltanto.
Pertanto, da una prospettiva di software enterprise, devi imporre la località dei dati ma anche la minificazione. Se riesci a rendere i tuoi big data piccoli, saranno più veloci. È qualcosa che non è molto intuitivo, ma se riesci a ridurre la dimensione dei dati, tipicamente eliminando parte della ridondanza, potrai rendere il tuo programma più veloce perché sarai molto più compatibile con la cache. Inserirai più dati rilevanti nei livelli inferiori della cache, che hanno latenze molto inferiori, come mostrato in questo display.

Infine, discutiamo nello specifico il caso della DRAM. La DRAM è letteralmente il componente fisico che compone la RAM che utilizzi per la tua workstation desktop o per il tuo server nel cloud. La DRAM è anche chiamata memoria principale, ed è costruita con chip DRAM. Negli ultimi dieci anni, in termini di prezzo, la DRAM è diminuita di poco. Siamo passati da 5 dollari per gigabyte a 3 dollari per gigabyte un decennio dopo. Il prezzo della RAM sta ancora scendendo, sebbene non molto rapidamente. Si prevede che rimarrà stagnante per i prossimi anni, e dato che ci sono solo tre grandi attori in questo mercato con la capacità di produrre DRAM su larga scala, c’è pochissima speranza che accada qualcosa di inaspettato in questo mercato nel decennio a venire.
Ma questo non è nemmeno il problema più grave. C’è anche il consumo energetico per gigabyte. Se osservi il consumo energetico, risulta che la RAM moderna consuma un po’ più di energia per gigabyte rispetto a un decennio fa. La ragione essenziale è che la RAM che abbiamo oggi è più veloce, e la stessa regola del power wall si applica: se aumenti la frequenza di clock, aumenti in modo significativo il consumo energetico. A proposito, la RAM consuma parecchia energia perché la DRAM è fondamentalmente un componente attivo. Devi rinfrescare la RAM continuamente a causa delle perdite elettriche, quindi se spegni la RAM, perdi tutti i dati. È necessario rinfrescare costantemente le celle.
Pertanto, la conclusione per il software enterprise è che la DRAM è l’unico componente che non sta più progredendo. Ci sono moltissime cose che continuano ad avanzare molto rapidamente, come la potenza di elaborazione; tuttavia, questo non vale per la DRAM – è fortemente stagnante. Se consideriamo anche il consumo energetico, che rappresenta una parte considerevole dei costi del cloud computing, la RAM sta facendo ben poco progresso. Quindi, se adotti un design che enfatizza eccessivamente la memoria principale – ed è tipicamente ciò che otterrai quando un fornitore dice, “Oh, abbiamo un design in-memory per il software” – ricorda queste parole chiave.
Ogni volta che senti un fornitore affermare di avere un design in-memory, quello che intende dire – e non è una proposta particolarmente convincente – è che il loro design si basa interamente sull’evoluzione futura della DRAM, della cui natura sappiamo già che i costi non diminuirebbero. Quindi, se consideriamo il fatto che tra 10 anni la tua supply chain probabilmente dovrà elaborare circa 10 volte più dati, semplicemente perché le aziende stanno diventando sempre più brave a raccogliere più dati nelle loro supply chain e a collaborare per raccogliere ulteriori dati dai loro clienti e fornitori, non è irragionevole aspettarsi che un decennio da ora, qualsiasi grande azienda che gestisce una grande supply chain raccoglierà 10 volte più dati di quanti ne abbia attualmente. Tuttavia, il prezzo per gigabyte di RAM rimarrà lo stesso. Quindi, se fai i conti, potresti ritrovarti con costi di cloud computing o IT essenzialmente quasi di un ordine di grandezza più elevati, solo per fare sostanzialmente la stessa cosa, semplicemente perché devi far fronte a una massa di dati in continua crescita che non si adatta facilmente alla memoria. La chiave è che devi davvero evitare ogni tipo di design in-memory. Questi design sono ormai obsoleti, e vedremo in seguito quale alternativa abbiamo.

Adesso, diamo un’occhiata all’archiviazione dei dati, che riguarda lo storage persistente. Fondamentalmente, esistono due classi di archiviazione dei dati diffuse. La prima è rappresentata dagli hard disk drive (HDD) o dischi rotativi. La seconda sono gli solid-state drive (SSD). La cosa interessante è che la latenza dei dischi rotativi è terribile, e quando guardi questa immagine, puoi facilmente capire il motivo. Questi dischi ruotano letteralmente, e quando vuoi accedere a un punto qualsiasi dei dati sul disco, in media, devi aspettare mezza rotazione. Considerando che i dischi di fascia alta ruotano a circa 10.000 giri al minuto, significa che c’è una latenza intrinseca di tre millisecondi che non può essere ridotta. È letteralmente il tempo necessario affinché il disco ruoti e possa leggere il punto preciso di interesse. È un meccanismo meccanico che non migliorerà ulteriormente.
Gli HDD sono terribili in termini di latenza, ma presentano anche un altro problema, ovvero il consumo energetico. In linea di massima, sia un HDD che un SSD consumano circa tre watt per ora per dispositivo. Questo è lo status quo attuale. Tuttavia, quando l’hard disk è in funzione, anche se non stai leggendo attivamente nulla da esso, consumerai tre watt semplicemente perché è necessario mantenere il disco in rotazione. Raggiungere 10.000 giri al minuto richiede molto tempo, quindi devi tenere il disco in movimento costante, anche se lo usi molto di rado.
D’altra parte, per quanto riguarda gli solid-state drive, consumano tre watt quando vi accedi, ma quando non accedi ai dati, praticamente non consumano energia. Hanno un consumo residuo, ma è estremamente ridotto, dell’ordine dei milliwatt. Questo è molto interessante perché puoi avere un’infinità di SSD; se non li usi, non paghi per l’energia che consumano. L’intera industria si è gradualmente spostata dagli HDD agli SSD nell’ultimo decennio.
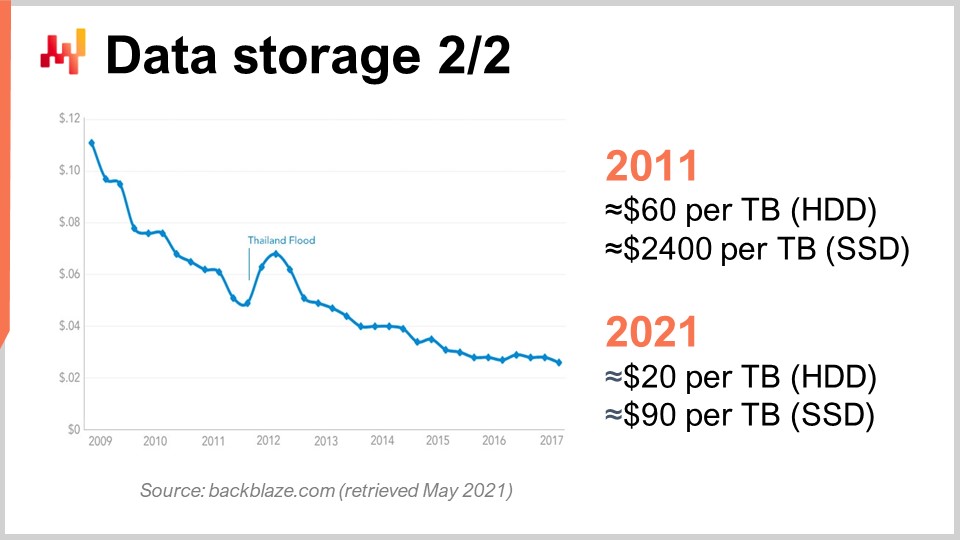
Per capirlo, possiamo osservare questa curva. Quello che vediamo è che il prezzo per gigabyte sia degli HDD che degli SSD è diminuito negli ultimi anni. Tuttavia, il prezzo ora sta raggiungendo un plateau. I dati sono leggermente datati, ma non sono variati molto negli ultimi anni. Negli ultimi 10 anni, un decennio fa, gli SSD erano estremamente costosi a 2.400 dollari per terabyte, mentre gli hard disk costavano solo 60 dollari per terabyte. Tuttavia, oggi il prezzo degli hard disk è stato ridotto di un terzo, essenzialmente a 20 dollari per terabyte. Il prezzo degli SSD è diminuito di oltre 25 volte, e la tendenza al ribasso dei prezzi degli SSD non si ferma. Gli SSD sono attualmente, ed è probabile che lo siano per il decennio a venire, il componente che più progredisce, ed è davvero molto interessante.
A proposito, ti ho detto che il design dei dispositivi di calcolo moderni (CPU, GPU, TPU) era essenzialmente bidimensionale, con al massimo 20 strati. Tuttavia, per quanto riguarda gli SSD, il design è sempre più tridimensionale. Gli SSD più recenti hanno attorno a 176 strati. Stiamo raggiungendo, in termini di ordine di grandezza, i 200 strati. Dato che questi strati sono incredibilmente sottili, non è irragionevole aspettarsi che in futuro avremo dispositivi con migliaia di strati e potenzialmente capacità di archiviazione di ordini di grandezza superiori. Ovviamente, il trucco sarà che non potrai accedere a tutti questi dati continuamente, ancora una volta a causa del dark silicon e della dissipazione di potenza.
Risulta che, se giochi bene le tue carte, molti dati vengono accessati molto raramente. Gli SSD implicano un design hardware molto specifico che comporta una miriade di peculiarità, come il fatto che puoi solo trasformare i bit da 0 a 1, ma non da 1 a 0. In sostanza, immagina di avere inizialmente tutti zeri; puoi trasformare uno zero in uno, tuttavia, non puoi trasformare questo uno in zero localmente. Se vuoi farlo, devi resettare l’intero blocco, che può essere grande fino a otto megabyte, il che significa che quando scrivi puoi trasformare i bit da zero a uno, ma non da uno a zero. Per trasformare i bit da uno a zero, devi cancellare l’intero blocco e riscriverlo, il che porta a vari problemi noti come amplificazione della scrittura.
Negli ultimi dieci anni, i drive SSD includono internamente uno strato chiamato flash translation layer che può mitigare tutti questi problemi. Questi flash translation layer stanno migliorando sempre di più col tempo. Tuttavia, ci sono grandi opportunità di ulteriore miglioramento e, in termini di software enterprise, significa che devi davvero ottimizzare il tuo design per sfruttare al meglio gli SSD. Gli SSD sono già un affare molto migliore rispetto alla DRAM per lo storage dei dati, e se giochi in modo intelligente, puoi aspettarti che, un decennio da ora, si verifichino guadagni di ordini di grandezza grazie al progresso dell’industria hardware, cosa che non vale per la DRAM.
Infine, parliamo della larghezza di banda. La larghezza di banda è probabilmente il problema più risolto in termini di tecnologia. Tuttavia, anche se la larghezza di banda può essere raggiunta, possiamo ottenere livelli di banda assolutamente incredibili ai giorni nostri. Commercialmente, l’industria delle telecomunicazioni è molto complessa e ci sono innumerevoli problemi, per cui i consumatori finali in realtà non vedono tutti i benefici del progresso compiuto nelle comunicazioni ottiche.
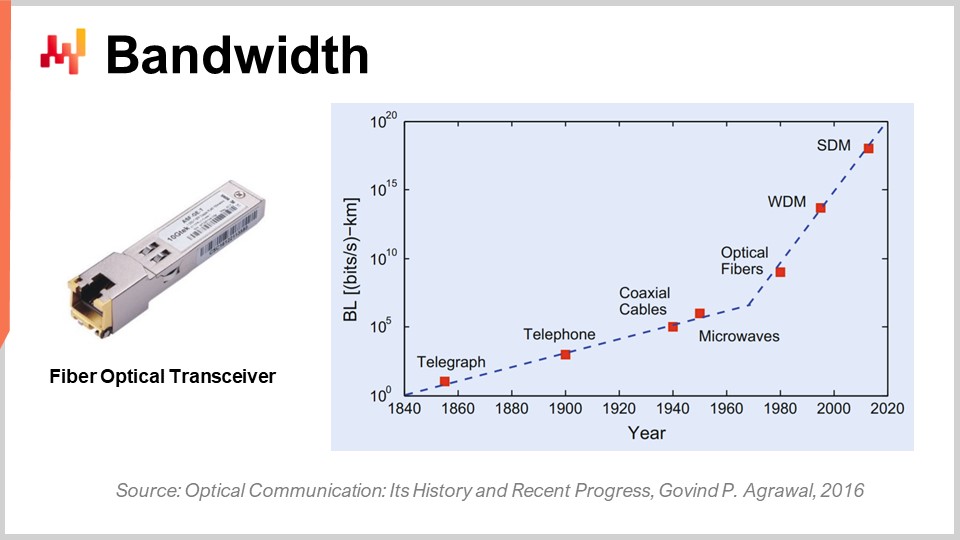
In termini di comunicazione ottica con transceiver in fibra ottica, il progresso è assolutamente incredibile. Probabilmente è una di quelle cose che stanno progredendo come le CPU negli anni ‘80 o ‘90. Solo per farti un’idea, con il multiplexing a divisione di lunghezza d’onda (WDM) o il multiplexing a divisione spaziale (SDM), ora possiamo ottenere letteralmente un decimo di terabyte di dati trasferiti al secondo su un singolo cavo in fibra ottica. Questo è assolutamente enorme. Stiamo raggiungendo il punto in cui un singolo cavo può trasportare abbastanza dati da alimentare essenzialmente un intero data center. Ciò che è ancor più impressionante è che l’industria delle telecomunicazioni è riuscita a sviluppare nuovi transceiver che possono fornire queste prestazioni folli basandosi su vecchi cavi. Non è nemmeno necessario installare nuove fibre nelle strade o fisicamente; puoi letteralmente prendere la fibra installata un decennio fa, montare il nuovo transceiver e ottenere diversi ordini di grandezza in più di larghezza di banda sullo stesso cavo.
La cosa interessante è che esiste una legge generale nelle comunicazioni ottiche: ogni decennio, la distanza a partire dalla quale diventa conveniente sostituire la comunicazione elettrica con quella ottica si riduce. Se andiamo indietro di qualche decennio, due decenni fa, servivano circa 100 metri affinché la comunicazione ottica superasse quella elettrica. Quindi, se avevi distanze inferiori a 100 metri, avresti optato per il rame; se avevi più di 100 metri, per la fibra. Tuttavia, al giorno d’oggi, con l’ultima generazione, possiamo ottenere prestazioni ottiche anche a distanze di soli tre metri. Se guardiamo a un decennio di distanza, non mi sorprenderebbe vedere situazioni in cui le comunicazioni ottiche vincono anche a distanze di soli mezzo metro. Ciò significa che, a un certo punto, non mi stupirà se i computer stessi avranno percorsi ottici interni, semplicemente perché sono più performanti dei percorsi elettrici.
Dal punto di vista del software enterprise, questo è anche molto interessante perché significa che, guardando al futuro, il costo della larghezza di banda diminuirà drasticamente. Questo è sostanzialmente sovvenzionato da aziende come Netflix, che hanno un consumo di banda drammatico. Significa che, per “battere” la latenza, potresti fare cose come prelevare in anticipo una quantità enorme di dati per l’utente e poi permettere all’utente di interagire con dati che sono stati avvicinati a lui con una latenza molto minore. Anche se porti dati non necessari, ciò che penalizza è la latenza, non la banda. È meglio dire: “Ho dei dubbi su quale tipo di dati sarà necessario; posso prendere mille volte più dati di quelli di cui ho realmente bisogno, portarli più vicino all’utente finale, lasciare che l’utente o il programma interagiscano con questi dati e così minimizzare il round trip, ottenendo un miglioramento in termini di prestazioni.” Ciò influisce profondamente sulle decisioni architettoniche prese oggi, perché determineranno se potrai trarre vantaggio dal progresso di questa classe di hardware un decennio da ora.

In conclusione, la latenza è la grande battaglia del nostro tempo in termini di ingegneria del software. Essa condiziona davvero tutte le tipologie di prestazioni che abbiamo e che avremo. Le prestazioni sono assolutamente fondamentali, perché non solo influenzeranno i costi IT, ma determineranno anche la produttività delle persone che operano nella tua supply chain. In definitiva, ciò influenzerà anche le prestazioni della supply chain stessa, perché senza queste prestazioni non puoi nemmeno implementare una sorta di ricetta numerica che sia veramente intelligente e che garantisca eventi di ottimizzazione avanzata e predittiva, ciò che cerchiamo. Tuttavia, a tutto tondo, questa battaglia per prestazioni migliori non sta andando in nostro favore, almeno non nel campo del software enterprise. I nuovi sistemi possono essere, e spesso lo sono, più lenti di quelli vecchi. Questo è un problema acuto. Prestazioni software più lente generano costi sbalorditivi per le aziende che ne risentono.
Solo per farti un esempio, non si dovrebbe dare per scontato che un hardware di calcolo migliore offra prestazioni migliori. Alcune persone su internet hanno deciso di misurare la latenza di input, o input lag, che è il tempo che intercorre dopo la pressione di un tasto affinché la lettera corrispondente venga visualizzata sullo schermo. Con un Apple II nel 1983, che montava un processore da 1 MHz, il tempo impiegato era di 30 millisecondi. Nel 2016, con un Lenovo X1, dotato di un processore da 2.6 GHz, un notebook molto bello, la latenza si è rivelata essere di 110 millisecondi. Quindi, abbiamo un hardware di calcolo migliore di diverse migliaia di volte, eppure finiamo per avere una latenza che è quasi quattro volte più lenta. Questo è caratteristico di ciò che succede quando non si ha simpatia meccanica e non si presta attenzione all’hardware di calcolo a disposizione. Se antagonizzi l’hardware di calcolo, questo ti restituisce prestazioni scarse.
Il problema è molto reale. Il mio suggerimento è: quando inizi a considerare qualsiasi software aziendale per la tua impresa, sia che si tratti di open-source o meno, ricorda gli elementi della mechanical sympathy che hai appreso oggi. Osserva il software e rifletti attentamente se esso abbraccia le tendenze profonde dell’hardware di calcolo oppure se le ignora del tutto. Se le ignora, ciò significa che non solo le prestazioni non miglioreranno col tempo, ma molto probabilmente peggioreranno. La maggior parte dei miglioramenti oggigiorno si ottiene tramite la specializzazione piuttosto che tramite l’aumento della frequenza di clock. Se perdi questa superstrada, intraprendi un percorso che diventerà via via più lento. Evita queste soluzioni perché solitamente sono il risultato di decisioni chiave prese all’inizio del design che non possono essere annullate. Rimarrai bloccato con esse per sempre, e peggiorerà di anno in anno. Pensa a un decennio avanti quando inizi ad analizzare questi aspetti.

Adesso diamo un’occhiata alle domande. È stata una lezione piuttosto lunga, ma è un argomento impegnativo.
Domanda: Qual è la tua opinione sui computer quantistici e sulla loro utilità nell’affrontare complessi problemi di ottimizzazione della supply chain?
Una domanda molto interessante. Mi sono iscritto alla beta del computer quantistico di IBM 18 mesi fa, quando hanno aperto l’accesso al loro computer quantistico nel cloud. La mia sensazione è che sia emozionante, poiché gli esperti osservano tutte le curve a S appiattirsi, senza vedere nuove curve emergere dal nulla. Il quantum computing è una di queste situazioni. Tuttavia, credo che i computer quantistici presentino sfide assai difficili per quanto riguarda le supply chain. In primo luogo, come ho detto, la battaglia del nostro tempo nel software aziendale è la latenza, e i computer quantistici non fanno nulla a riguardo. I computer quantistici offrono, potenzialmente, un’accelerazione fino a 10 ordini di grandezza per problemi di calcolo con requisiti estremamente stringenti. Quindi, i computer quantistici rappresenterebbero la fase successiva rispetto ai TPU, dove è possibile eseguire operazioni estremamente stringenti a una velocità incredibile.
Questo è molto interessante, ma ad essere sincero, al momento, a mia conoscenza ci sono pochissime aziende che riescono persino a sfruttare le istruzioni superscalari all’interno del loro software aziendale. Ciò significa che l’intero mercato sta lasciando sul tavolo un potenziamento da 10 a 28 volte offerto dalle GPU superscalari. Ci sono pochissime realtà nel mondo della supply chain che lo fanno; forse Lokad, forse no. Per quanto riguarda i TPU, credo che letteralmente nessuno li utilizzi. Google li usa in maniera estesa, ma non sono a conoscenza di nessuno che abbia mai impiegato i TPU per qualcosa di correlato alla supply chain. I processori quantistici rappresenterebbero la fase successiva rispetto ai TPU.
Sono decisamente molto attento a quanto sta accadendo con i computer quantistici, ma credo che questo non sia il collo di bottiglia che affrontiamo. È emozionante perché rivisitiamo il design von Neumann stabilito circa 70 anni fa, ma questo non sarà il problema a cui noi o la supply chain saremo sottoposti nei prossimi dieci anni. Oltre a questo, il futuro è incerto. Sì, potrebbe potenzialmente cambiare tutto, oppure no.
Domanda: Le offerte di cloud e SaaS stanno permettendo alle organizzazioni di sfruttare e convertire i costi fissi. Le aziende che offrono tali servizi stanno anche lavorando per ridurre i loro costi fissi e il rischio associato?
Beh, dipende. Se sono una piattaforma di cloud computing e ti vendo potenza di calcolo, è davvero nel mio interesse rendere il tuo software aziendale il più efficiente possibile? Non proprio. Ti sto vendendo macchine virtuali, gigabyte di banda e spazio di archiviazione, quindi in realtà è esattamente il contrario. Il mio interesse è assicurarmi che tu abbia un software il più inefficiente possibile, così da consumare e pagare a consumo per una quantità incredibile di risorse.
Internamente, le grandi aziende tecnologiche come Microsoft, Amazon e Google sono incredibilmente aggressive quando si tratta di ottimizzare le loro risorse di calcolo. Ma sono anche altrettanto decise quando devono farsi carico del conto, addebitando a un cliente l’affitto di una macchina virtuale. Se il cliente affitta una macchina virtuale che è 10 volte più grande di quanto effettivamente necessario, semplicemente perché il software aziendale che utilizza è estremamente inefficiente, non conviene loro interrompere l’errore del cliente. Per loro va bene così; è un buon affare. Quando consideri che gli integratori di sistema e le piattaforme di cloud computing tendono a lavorare mano nella mano come partner, ti rendi conto che queste categorie di persone non hanno necessariamente a cuore i tuoi migliori interessi. Ora, per quanto riguarda il SaaS, è un po’ diverso. Infatti, se finisci per pagare un fornitore SaaS per utente, allora è nell’interesse dell’azienda, come nel caso di Lokad, per esempio. Noi non addebitiamo in base alle risorse di calcolo che consumiamo; di solito addebitiamo ai nostri clienti una tariffa mensile fissa. Pertanto, i fornitori SaaS tendono ad essere molto aggressivi per quanto riguarda il loro consumo di risorse di calcolo.
Tuttavia, attenzione, c’è un bias: se sei un’azienda SaaS, potresti essere piuttosto riluttante a fare qualcosa che sarebbe molto migliore per i tuoi clienti ma molto più costoso in termini di hardware per te. Non è tutto rose e fiori. Esiste una sorta di conflitto di interessi che impatta tutti i fornitori SaaS operanti nel settore della supply chain. Ad esempio, potrebbero investire nel reingegnerizzare tutti i loro sistemi per offrire una latenza migliore e pagine web più veloci, ma il fatto è che ciò richiede risorse, e i loro clienti non pagheranno naturalmente di più se lo fanno.
Il problema tende ad amplificarsi quando si tratta di software aziendale. Perché? Perché la persona che acquista il software generalmente non è quella che lo utilizza. Ecco perché gran parte del sistema aziendale è incredibilmente lento. Chi acquista il software non ne soffre quanto, ad esempio, un povero demand planner o un responsabile di magazzino che deve fare i conti ogni singolo giorno dell’anno con un sistema super lento. Quindi esiste un altro aspetto specifico dell’ambito del software aziendale. È necessario analizzare davvero la situazione, esaminare tutti gli incentivi in gioco, e quando si tratta di software aziendale di solito ci sono molti incentivi in conflitto.
Domanda: Quante volte Lokad ha dovuto rivedere il suo approccio, dato il progresso osservato nell’hardware? Puoi menzionare un esempio, se possibile, per contestualizzare questo contenuto in termini di problemi reali risolti?
Credo che Lokad abbia ristrutturato profondamente il nostro technology stack circa mezza dozzina di volte. Tuttavia, Lokad è stata fondata nel 2008, e abbiamo avuto circa sei riscritture maggiori dell’intera architettura. Non è che il software fosse progredito tantissimo; il software ha progredito, sì, ma ciò che ha guidato la maggior parte delle nostre riscritture non è stato il fatto che l’hardware fosse migliorato così tanto. È stato piuttosto il fatto che abbiamo acquisito una maggiore comprensione dell’hardware. Tutto ciò che ho presentato oggi era sostanzialmente noto a chi già prestava attenzione un decennio fa. Quindi, vedi, l’hardware evolve, ma in maniera molto lenta, e la maggior parte delle tendenze sono prevedibili anche con un decennio di anticipo. Si tratta di un gioco a lungo termine.
Lokad ha dovuto subire riscritture massicce, ma ciò rifletteva piuttosto il fatto che stavamo gradualmente diventando meno incompetenti. Stavamo acquisendo competenze, ed è per questo che abbiamo imparato a sfruttare l’hardware, piuttosto che semplicemente adattarci al fatto che l’hardware stesse cambiando il compito. Non è sempre stato così; ci sono stati elementi specifici che hanno veramente fatto la differenza per noi. Il più notevole è stato rappresentato dagli SSD. Siamo passati dagli HDD agli SSD, e questo ha rivoluzionato completamente le nostre prestazioni, con impatti massicci sulla nostra architettura. In termini di esempi molto concreti, l’intero design di Envision, il linguaggio di programmazione domain-specific che Lokad offre, si basa sulle intuizioni raccolte a livello hardware. Non si tratta di un singolo traguardo; è una questione di fare tutto ciò che puoi immaginare in modo semplicemente più veloce.
Vuoi processare una tabella con un miliardo di righe e 100 colonne, e vuoi farlo 100 volte più velocemente con le stesse risorse di calcolo? Sì, puoi farlo. Vuoi essere in grado di eseguire join tra tabelle molto grandi con risorse di calcolo minime? Sì, ancora. Puoi avere dashboard super complesse dashboards con letteralmente una centinaia di tabelle visualizzate all’utente finale in meno di 500 millisecondi? Sì, l’abbiamo fatto. Questi sono risultati ordinari, ma è grazie al fatto che siamo riusciti a ottenere tutto ciò che ci permette di mettere in produzione ricette predittive di ottimizzazione abbastanza sofisticate. Dobbiamo assicurarci che tutti i passaggi che ci hanno condotto fin lì vengano eseguiti con altissima produttività.
La sfida più grande, quando vuoi fare qualcosa di molto elaborato per la supply chain in termini di ricette numeriche, non è la fase del “far funzionare”. Puoi prendere studenti universitari e ottenere una serie di prototipi che forniscono qualche tipo di miglioramento delle prestazioni della supply chain in poche settimane. Basta prendere Python e qualunque libreria open-source di machine learning del momento, e quegli studenti, se sono intelligenti e motivati, produrranno un prototipo funzionante in poche settimane. Tuttavia, non riuscirai mai a portarlo in produzione su larga scala. Questo è il problema. Si tratta di come superare tutte quelle fasi di maturità del “farlo bene”, “farlo veloce” e “farlo a basso costo”. È qui che l’affinità con l’hardware brilla davvero e che si manifesta la tua capacità di iterare.
Non esiste un singolo risultato. Tuttavia, tutto ciò che facciamo, per esempio quando diciamo che Lokad si occupa di previsione probabilistica, non richiede una potenza di calcolo smisurata. Quello che richiede veramente potenza di calcolo è sfruttare distribuzioni di probabilità estremamente ampie e analizzare tutti quei possibili futuri, combinandoli con tutte le possibili decisioni che puoi prendere. In questo modo puoi scegliere le migliori soluzioni tramite un’ottimizzazione finanziaria, che diventa molto costosa. Se non possiedi qualcosa di fortemente ottimizzato, sei bloccato. Il semplice fatto che Lokad riesca a utilizzare la previsione probabilistica in produzione è una testimonianza dell’ottimizzazione a livello hardware che abbiamo implementato lungo tutti i processi per tutti i nostri clienti. Al giorno d’oggi serviamo circa 100 aziende.
Domanda: È meglio avere un server interno per il software aziendale (ERP, WMS) piuttosto che utilizzare servizi cloud per evitare la latenza?
Direi che oggi non importa, perché la maggior parte della latenza che sperimenti avviene all’interno del sistema. Questo non è il problema della latenza tra il tuo utente e l’ERP. Sì, se hai una latenza davvero elevata, potresti aggiungere circa 50 millisecondi di ritardo. Ovviamente, se hai un ERP, non vuoi che esso sia situato a Melbourne mentre operi, per esempio, a Parigi. Vuoi mantenere il data center vicino a dove operi. Tuttavia, le moderne piattaforme di cloud computing dispongono di decine di data center, per cui non c’è molta differenza in termini di latenza tra l’hosting interno e i servizi cloud.
In genere, l’hosting interno non significa posizionare l’ERP a terra, nel mezzo della fabbrica o del magazzino. Invece, significa collocare il tuo ERP in un data center dove stai noleggiando hardware di calcolo. Credo che, dal punto di vista delle moderne piattaforme di cloud computing con data center in tutto il mondo, non ci sia alcuna differenza pratica tra l’hosting interno e le piattaforme cloud.
Ciò che davvero fa la differenza è se possiedi un ERP che minimizza internamente tutti i round trip. Ad esempio, ciò che tipicamente rovina le prestazioni di un ERP è l’interazione tra la logica di business e il database relazionale. Se hai centinaia di interazioni avanti e indietro per visualizzare una pagina web, il tuo ERP sarà terribilmente lento. Quindi, devi considerare progetti di software aziendale che non comportino un numero massiccio di round trip. Questa è una caratteristica intrinseca del software aziendale che stai analizzando, e non dipende molto da dove esso viene collocato.
Domanda: Pensi che abbiamo bisogno di nuovi linguaggi di programmazione che abbraccino il nuovo design hardware a livello di core, sfruttando a pieno le caratteristiche dell’architettura hardware?
Sì, e sì. Ma per essere completamente trasparente, ho un conflitto di interessi qui. Questo è esattamente ciò che Lokad ha fatto con Envision. Envision è nato dall’osservazione che è difficile sfruttare tutta la potenza di calcolo disponibile nei computer moderni, ma non dovrebbe esserlo se si progetta il linguaggio di programmazione stesso mettendo la performance al centro. Puoi renderlo quasi surreale, ed è per questo che, nella lezione 1.4 sui paradigmi di programmazione per la supply chain, ho affermato che se scegli i paradigmi di programmazione giusti, come l’array programming o il data frame programming, e costruisci un linguaggio di programmazione che abbraccia tali concetti, ottieni performance quasi gratuitamente.
Il prezzo da pagare è che non sarai espressivo come un linguaggio di programmazione tipo Python o C++, ma se sei disposto ad accettare una minore espressività e a coprire tutti i casi d’uso rilevanti per la supply chain, allora sì, potrai ottenere miglioramenti di performance massicci. Questa è la mia convinzione, ed è per questo che ho anche affermato che, per esempio, la programmazione orientata agli oggetti, dal punto di vista dell’ottimizzazione della supply chain, non apporta nulla di utile.
Al contrario, si tratta di un paradigma che antagonizza soltanto l’hardware sottostante. Non sto dicendo che la programmazione orientata agli oggetti sia tutta negativa; non è questo il mio punto di vista. Sto dicendo che ci sono ambiti nell’ingegneria del software in cui ha perfettamente senso, ma che non funziona per l’ottimizzazione predittiva della supply chain. Quindi sì, decisamente sì, abbiamo bisogno di linguaggi di programmazione che abbraccino veramente questo concetto.
So che tendo a ripetermi, ma Python è stato essenzialmente progettato alla fine degli anni ‘80, e in qualche modo hanno trascurato tutto ciò che c’era da vedere sui computer moderni. Hanno qualcosa in cui, per design, non possono sfruttare il multi-threading. Hanno questo global lock, quindi non possono sfruttare più core. Non possono sfruttare la località. Hanno il late binding che complica davvero gli accessi alla memoria. Sono molto variabili, quindi consumano molta memoria, il che significa che andrà contro la cache, ecc.
Questi sono il genere di problemi in cui, se usi Python, significa che affronterai battaglie ripide per i prossimi decenni, e la battaglia peggiorerà soltanto col passare del tempo. Non miglioreranno affatto.
La prossima lezione si terrà tra tre settimane, nello stesso giorno della settimana, alla stessa ora. Sarà alle 15:00 ora di Parigi, il 9 giugno. Discuteremo degli algoritmi moderni per supply chain, che sono una sorta di controparte dei computer moderni per supply chain. A presto.


