Technology

Selective Path Automatic Differentiation: Beyond Uniform Distribution on Backpropagation Dropout
The Selective Path Automatic Differentiation (SPAD) approach enhances Stochastic Gradient Descent (SGD) by adopting a sub-data-point perspective. This technique, implemented at the compiler level, trades gradient quality for gradient quantity, supplementing traditional SGD methods with a more nuanced view.

An opinionated review of Deep Inventory Management
A team at Amazon has published Deep Inventory Management (DIM) late 2022. This paper presents an DIM inventory optimization technique that features both reinforcement learning and deep learning. As Lokad went through similar path in the past, its CEO and founder Joannes Vermorel provides his critical assessment of the suggested technique.
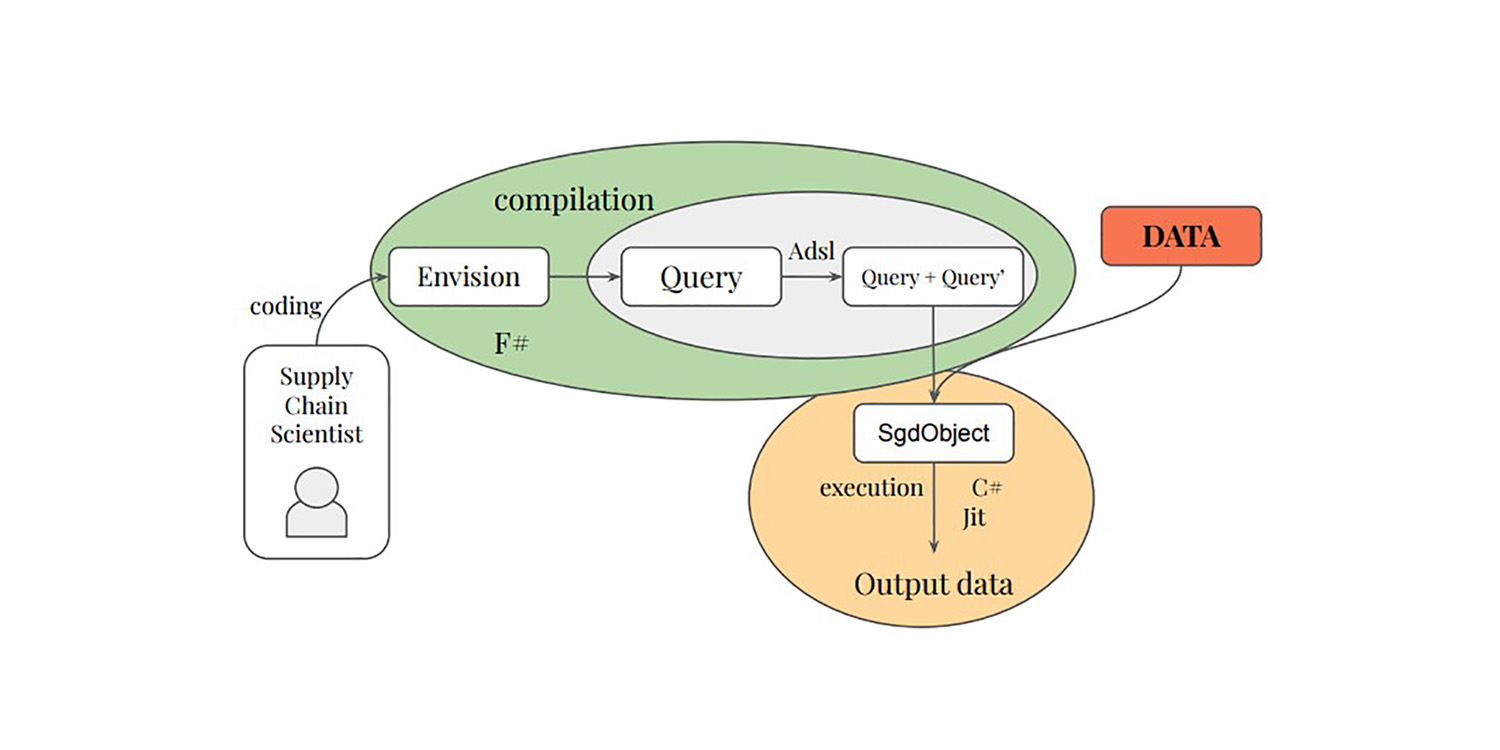
Differentiable programming to optimize over large scale relational data
Paul Peseux's PhD research on differentiating relational queries - another under-researched area of supply chain - introduced TOTAL JOIN operator, Polystar and a mini-language ADSL to differentiate relational queries, all of which Lokad integrated into its DSL Envision as part of autodiff for optimizing daily inventory decision-making.
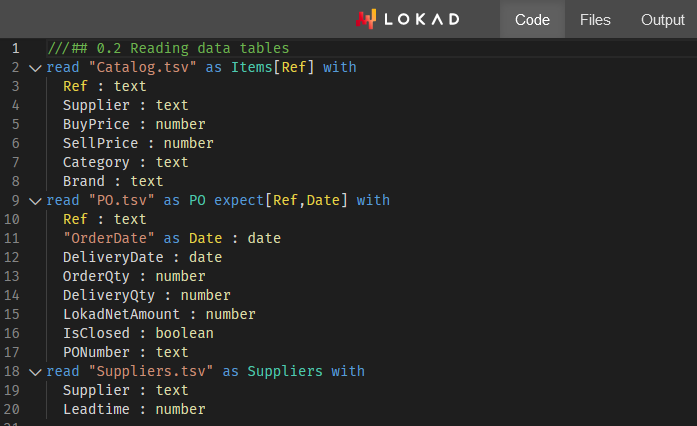
Supplier Analysis through Envision - Workshop #1
Lokad launches its first Envision Workshop, teaching students (and supply chain specialists) how to analyze retail suppliers using Lokad's probabilistic, risk management perspective.
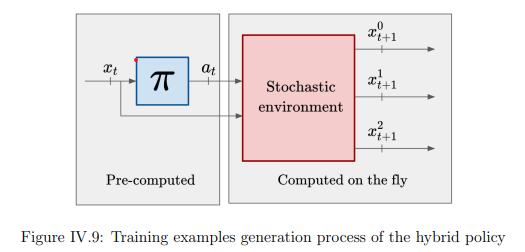
Inventory management under the constraint of multi-reference minimal order quantities
Gaetan Delétoille's PhD research on MOQs - a surprisingly under-researched area of supply chain - introduced the w-policy, something Lokad integrated into its solution for daily inventory decision-making.
Classification algorithms distributed on the cloud
Matthieu Durut, second employee at Lokad, defended his PhD back in 2012 for his research work done at Lokad. This PhD paved the way for the transition of Lokad toward cloud-native distributed computing architectures, nowadays critical to deal with large-scale supply chains.

Large scale learning: a contribution to distributed asynchronous clustering algorithms
Benoit Patra, first employee at Lokad, defended his PhD back in 2012 for his research done at Lokad. This PhD brought radically novel elements to the supply chain theory, and set the stage for the future development of Lokad's probabilistic forecasting approach.

Stochastic gradient descent with gradient estimator for categorical features
The broad field of machine learning (ML) provides a wide array of techniques and methods that cover numerous situations. Supply chain, however, comes with its own specific set of data challenges, and sometimes aspects that might be deemed basic by supply chain practitioners do not benefit from satisfying ML instruments – at least according to our standards.
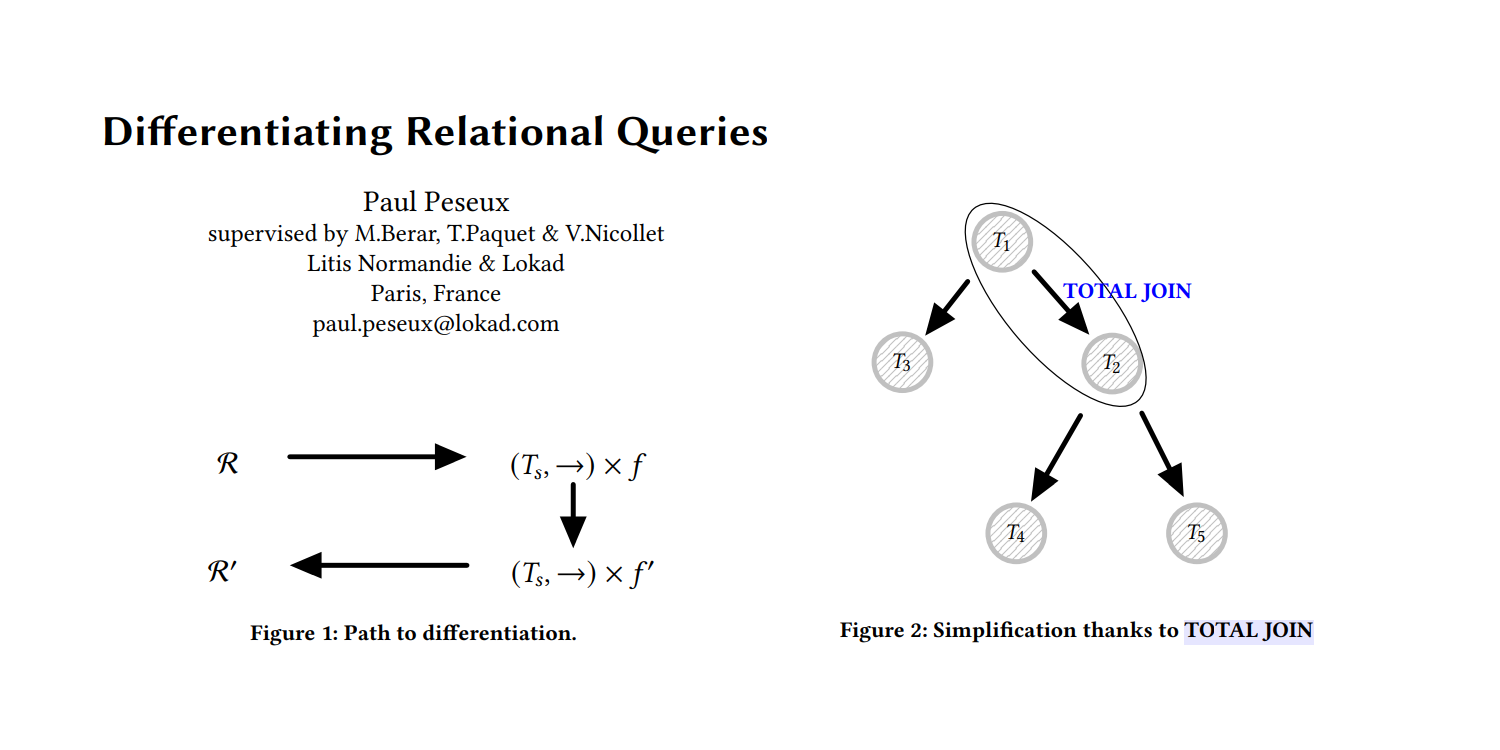
Differentiating Relational Queries
Supply chain data present themselves almost exclusively as relational data such as orders, clients, suppliers, products, etc. Those data are collected through the business systems - the ERP, the CRM, the WMS - that are used to operate the company.

Reproducible Parallel Stochastic Gradient Descent
The stochastic gradient descent (SGD) is one of the most successful techniques ever devised for both machine learning and mathematical optimization. Lokad has been extensively exploiting the SGD for years for supply chain purposes, mostly through differentiable programming. Most of our clients have a least one SGD somewhere in their data pipeline.

Envision VM (part 4), Distributed Execution
The previous articles mostly examined how individual workers executed Envision scripts. However, both for resilience and for performance, Envision is actually executed across a cluster of machines.

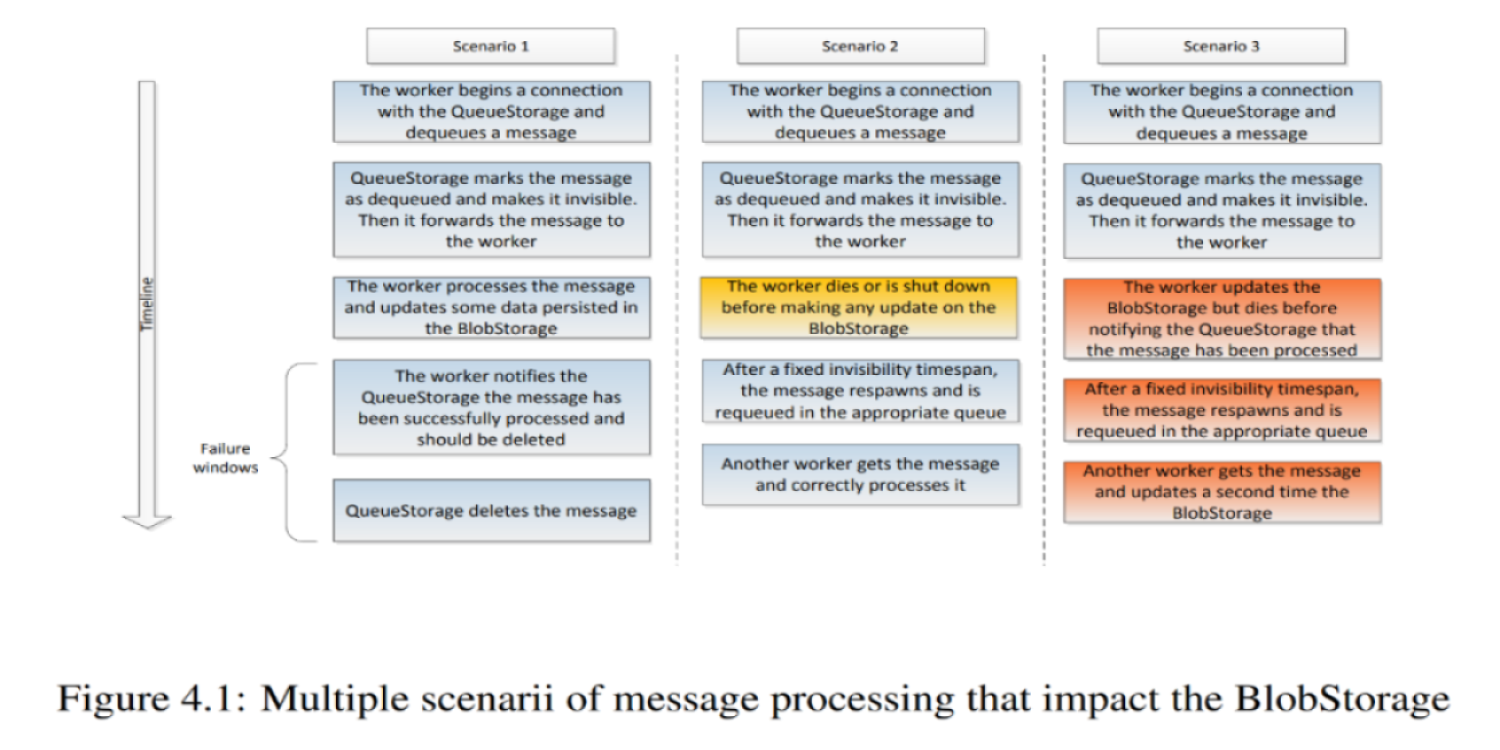
Envision VM (part 3), Atoms and Data Storage
During execution, thunks read input data and write output data, often in large quantities. How to preserve this data from the moment it is created and until it is used (part of the answer is on NVMe drives spread over several machines), and how to minimize the amount of data that goes through channels slower than RAM (network and persistent storage).