Programmation différentiable pour optimiser des données relationnelles à grande échelle
Dans le monde complexe de supply chain management les données relationnelles règnent en maître. ERPs, WMS, PMS et d’autres outils logiciels omniprésents dans la supply chain fonctionnent sur des bases de données relationnelles qui suivent tout, des niveaux de stocks aux relations avec les fournisseurs. Les données relationnelles consistent en une série de tables interconnectées, chacune riche en colonnes d’information. Cependant, lorsqu’il s’agit de machine learning et d’optimisation mathématique, les données relationnelles sont souvent éclipsées par des formes plus simples comme les vecteurs, les séquences et les graphes.
Les données relationnelles – grâce à leur richesse complexe – offrent une vision plus profonde et nuancée des opérations que leurs homologues plus simples (les vecteurs, séquences et graphes susmentionnés). Pourtant, la plupart des enterprise software peinent à utiliser efficacement les données sous leur forme relationnelle. Le résultat ? Une tentative forcée de faire rentrer des chevilles carrées dans des trous ronds, cherchant désespérément à comprimer les données relationnelles dans des outils conçus pour des modèles plus simples. Ce décalage handicape les entreprises, semblable à l’utilisation d’un bâton de hockey au golf – théoriquement faisable, mais loin de l’alliance optimale entre outil et objectif.
Déterminé à étudier ce point aveugle, il y a quelques années, Paul Peseux a commencé un doctorat chez Lokad dans l’intention de transformer les données relationnelles en citoyennes de première classe, tant pour l’apprentissage que pour l’optimisation. Ses travaux de recherche ont conduit à une série d’améliorations remarquables de notre support de differentiable programming au sein de Envision – le DSL (langage de programmation spécifique au domaine) de Lokad dédié à l’optimisation de la supply chain. Les résultats impressionnants de Paul sont désormais en production, généralement enfouis dans les capacités autodiff du DSL.
Auteur: Paul Peseux
Date: September 2023
Résumé:
Cette thèse de doctorat présente trois contributions au domaine de la programmation différentiable en mettant l’accent sur les données relationnelles. Les données relationnelles sont prépondérantes dans des secteurs tels que la santé et la supply chain, où l’information est souvent organisée dans des tableaux structurés ou des bases de données. Les approches traditionnelles de machine learning peinent à traiter les données relationnelles, tandis que les modèles de machine learning en boîte blanche conviennent mieux, bien qu’ils soient difficiles à développer.
La programmation différentiable offre une solution potentielle en traitant les requêtes sur les bases de données relationnelles comme des programmes différentiables, permettant ainsi le développement de modèles de machine learning en boîte blanche capables de raisonner directement sur les données relationnelles. L’objectif principal de cette recherche est d’explorer l’application du machine learning aux données relationnelles en utilisant des techniques de programmation différentiable.
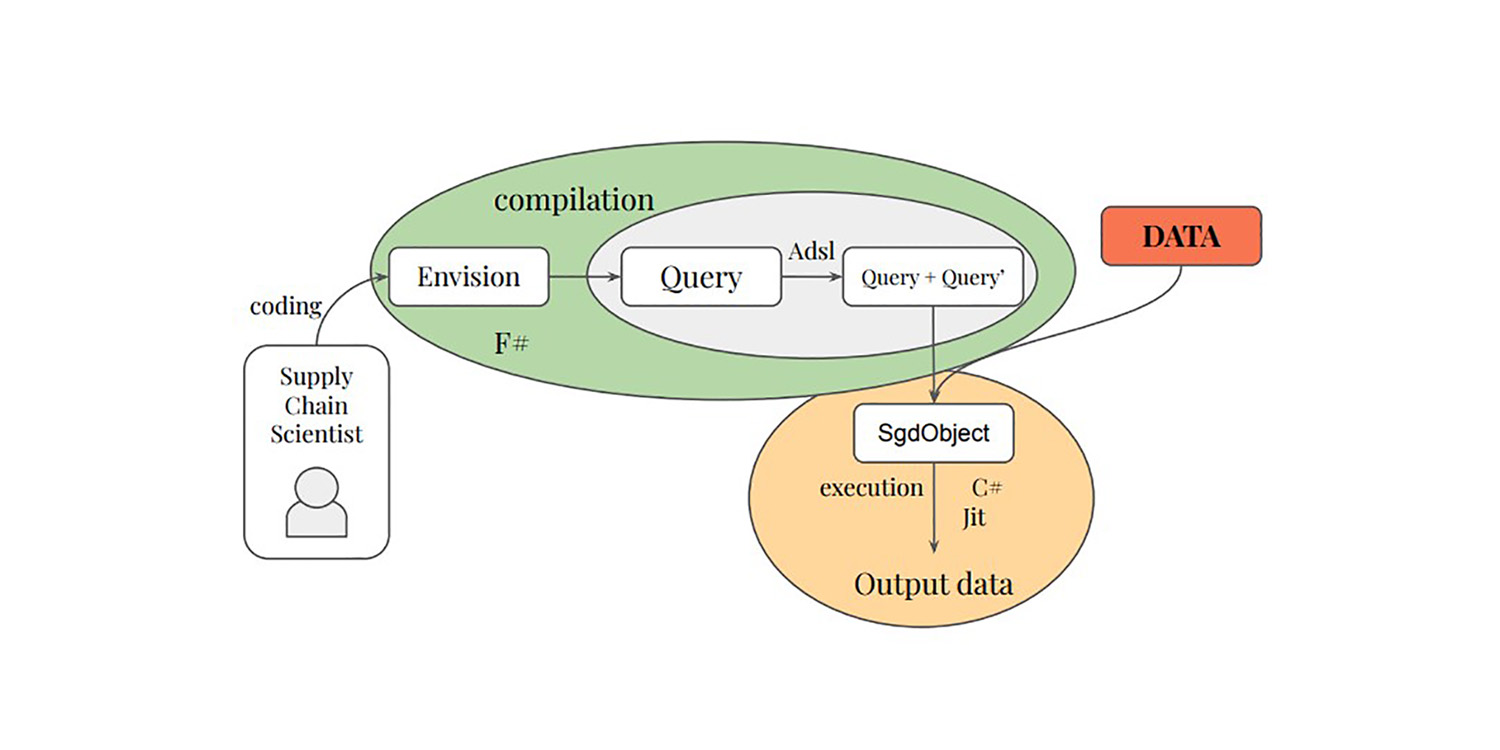
La première contribution de la thèse introduit une couche différentiable dans les langages de programmation relationnels, tant sur le plan théorique que pratique. Le langage de programmation Adsl a été créé pour effectuer la différentiation et transcrire les opérations relationnelles d’une requête. Le langage spécifique au domaine Envision a été enrichi de fonctionnalités de programmation différentiable, permettant le développement de modèles qui exploitent les données relationnelles dans un environnement de langage de programmation relationnel natif.
La deuxième contribution développe un nouvel estimateur de gradient appelé GCE, conçu pour les variables catégorielles représentées dans les données relationnelles. Il est démontré que le GCE est utile sur divers ensembles de données et modèles catégoriels et a été implémenté pour des modèles deep learning. Le GCE est également intégré en tant qu’estimateur de gradient natif dans la couche de programmation différentiable d’Envision, facilité par la première contribution de cette thèse.
La troisième contribution développe un estimateur de gradient généralisé appelé Stochastic Path Automatic Differentiation (SPAD), qui tire sa stochastique de la décomposition du code. SPAD introduit l’idée de rétropropager une fraction du gradient afin de réduire la consommation de mémoire lors des mises à jour des paramètres. La mise en œuvre de cette approche d’estimation de gradient est rendue possible par les choix de conception effectués lors de la différentiation d’Adsl.
Cette recherche a des implications significatives pour les industries reposant sur les données relationnelles, permettant de découvrir de nouvelles perspectives et d’améliorer la prise de décision en appliquant des modèles de machine learning en boîte blanche aux données relationnelles grâce aux techniques de programmation différentiable.
Jury:
La soutenance a eu lieu devant un jury composé de :
- Thierry Paquet, Professeur d’université (Université de Rouen Normandie), directeur de thèse.
- Maxime Berar, Maître de conférences (Université de Rouen Normandie), co-encadrant de la thèse.
- Romain Raveaux, Maître de conférences (Université de Tours), rapporteur.
- Thierry Artières, Professeur d’université (ECM / LIS – AMU – CNRS), rapporteur.
- Cécilia Zanni-Merk, Professeure d’université (INSA Rouen Normandie), examinatrice.
- Laurent Wendling, Professeur d’université (Université Paris Cité), examinateur.
- Victor Nicolet, CTO de Lokad, conseiller.


