Tecnologia

Differenziazione Automatica del Percorso Selettivo: Oltre la Distribuzione Uniforme sul Backpropagation Dropout
L'approccio Selective Path Automatic Differentiation (SPAD) potenzia il Stochastic Gradient Descent (SGD) adottando una prospettiva a sotto-punto dati. Questa tecnica, implementata a livello di compilatore, scambia la qualità del gradiente per la quantità di gradiente, integrando i metodi tradizionali di SGD con una visione più sfumata.

Una recensione schietta di Deep Inventory Management
Un team di Amazon ha pubblicato Deep Inventory Management (DIM) alla fine del 2022. Questo articolo presenta una tecnica di ottimizzazione dell'inventario DIM che presenta sia il reinforcement learning che il deep learning. Poiché Lokad ha percorso in passato un cammino simile, il suo CEO e fondatore Joannes Vermorel fornisce la sua valutazione critica della tecnica proposta.
Programmazione differenziabile per ottimizzare dati relazionali su larga scala
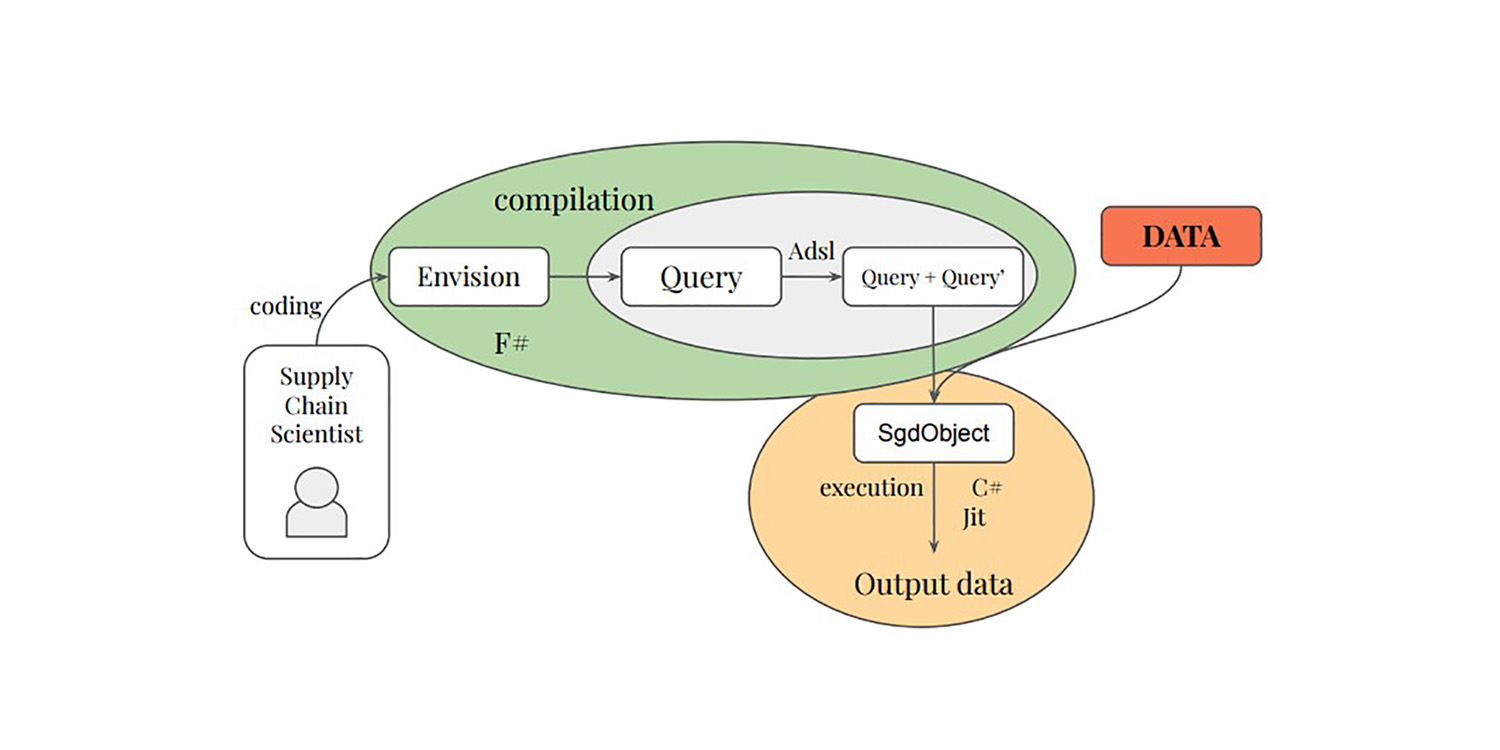
La ricerca di dottorato di Paul Peseux sulla differenziazione delle query relazionali - un altro ambito poco studiato della supply chain - ha introdotto l'operatore TOTAL JOIN, Polystar e un mini-linguaggio ADSL per differenziare le query relazionali, il tutto integrato da Lokad nel suo DSL Envision nell'ambito dell'autodiff per ottimizzare il decision-making quotidiano nella gestione delle scorte.
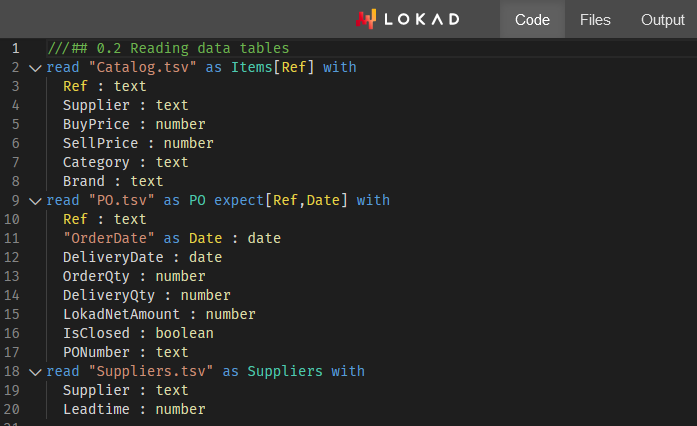
Analisi dei Fornitori attraverso Envision - Workshop #1
Lokad lancia il suo primo Envision Workshop, insegnando agli studenti (e supply chain specialists) come analizzare i fornitori al dettaglio usando la prospettiva probabilistica e di gestione del rischio di Lokad.
Gestione dell’inventario sotto il vincolo di quantitativi minimi d’ordine multi-referenza
La ricerca del dottorato di Gaetan Delétoille sui MOQs - un'area sorprendentemente poco studiata della supply chain - ha introdotto la w-policy, che Lokad ha integrato nella sua soluzione per il decision-making quotidiano dell'inventario.
Algoritmi di classificazione distribuiti sul cloud
Matthieu Durut, secondo dipendente di Lokad, ha difeso il suo dottorato nel 2012 per il lavoro di ricerca svolto presso Lokad. Questo dottorato ha aperto la strada alla transizione di Lokad verso architetture di calcolo distribuito cloud-native, oggi fondamentali per gestire supply chains su larga scala.

Apprendimento su larga scala: un contributo agli algoritmi di clustering asincroni distribuiti
Benoit Patra, primo impiegato di Lokad, ha difeso il suo PhD nel 2012 per la ricerca condotta presso Lokad. Questo PhD ha introdotto elementi radicalmente innovativi nella teoria del supply chain, e ha preparato il terreno per lo sviluppo futuro dell'approccio di previsione probabilistica di Lokad.

Discesa del gradiente stocastico con stimatore di gradiente per variabili categoriche
Il vasto campo del machine learning (ML) offre un'ampia varietà di tecniche e metodi che coprono numerose situazioni. Supply chain, tuttavia, presenta una propria serie di sfide relative ai dati, e talvolta aspetti che potrebbero essere considerati di base dai professionisti della supply chain non beneficiano di strumenti ML soddisfacenti – almeno secondo i nostri standard.
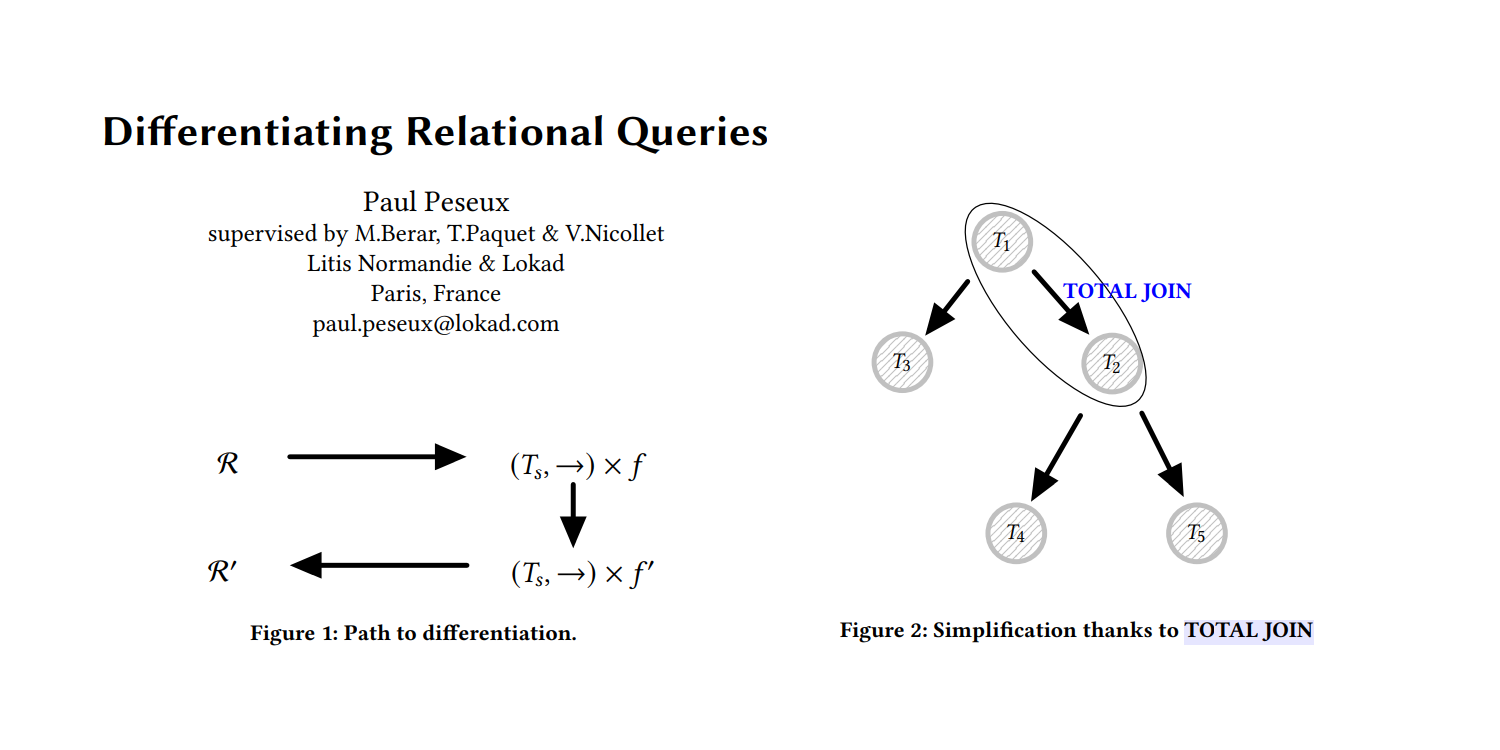
Differenziare query relazionali
I dati di supply chain si presentano quasi esclusivamente come dati relazionali, quali ordini, clienti, fornitori, prodotti, ecc. Questi dati vengono raccolti attraverso i sistemi aziendali - l'ERP, il CRM, il WMS - che vengono utilizzati per gestire l'azienda.

Discesa del gradiente stocastico parallelo riproducibile
La discesa del gradiente stocastico (SGD) è una delle tecniche di maggior successo mai ideate sia per l'apprendimento automatico che per l'ottimizzazione matematica. Lokad ha sfruttato ampiamente lo SGD per anni per scopi di supply chain, principalmente attraverso la programmazione differenziabile. La maggior parte dei nostri clienti possiede almeno uno SGD da qualche parte nella loro pipeline di estrazione dati.

Envision VM (parte 4), Esecuzione Distribuita
I precedenti articoli hanno esaminato principalmente come i worker eseguivano gli script di Envision. Tuttavia, sia per la resilience che per le prestazioni, Envision viene effettivamente eseguito su un cluster di macchine.

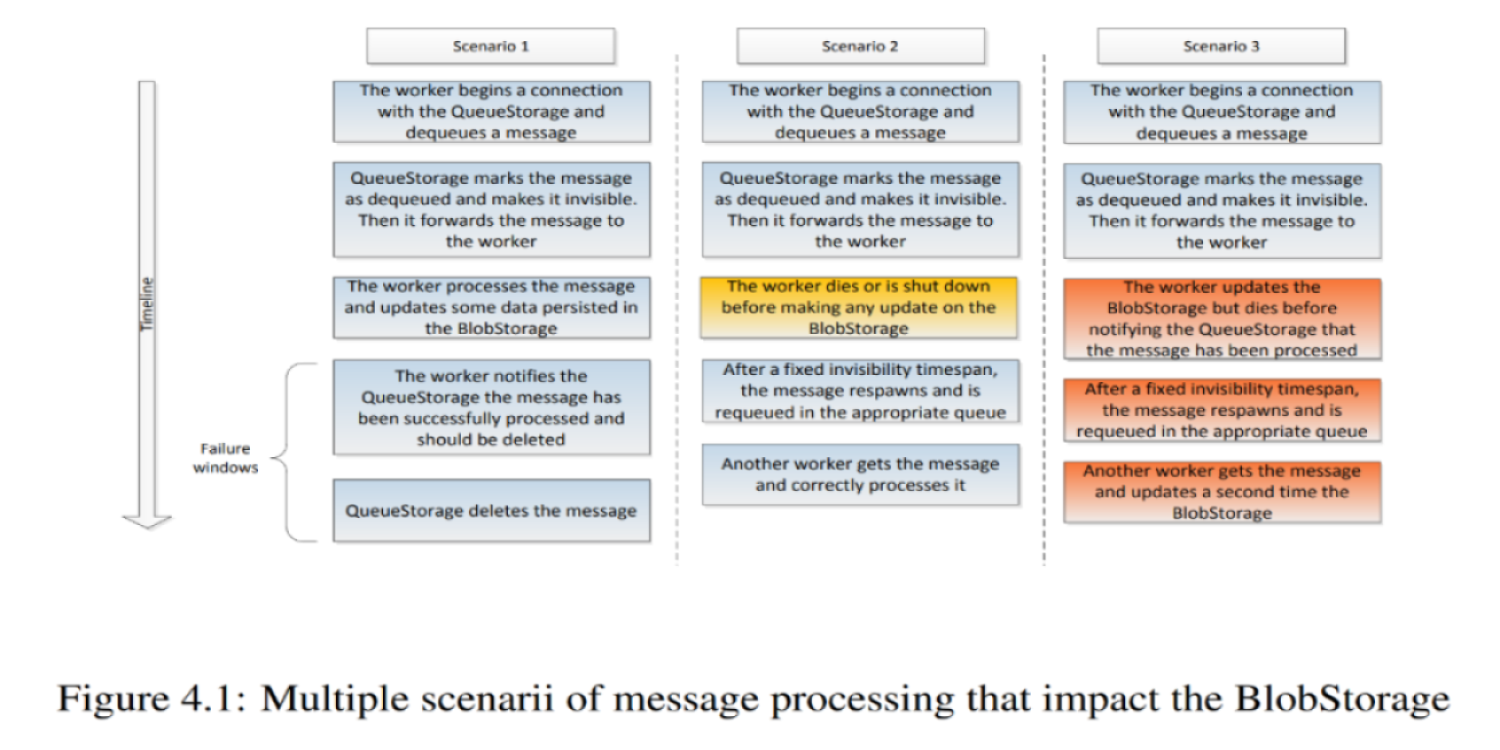
Envision VM (parte 3), Atomi e Archiviazione dei Dati
Durante l'esecuzione, i thunk leggono i dati di input e scrivono i dati di output, spesso in grandi quantità. Come preservare questi dati dal momento in cui vengono creati fino al loro utilizzo (parte della risposta è data dall'utilizzo di NVMe drives distribuiti su diverse macchine), e come minimizzare la quantità di dati che transitano attraverso canali più lenti della RAM (rete e archiviazione persistente).