テクノロジー
Back to the blog ›
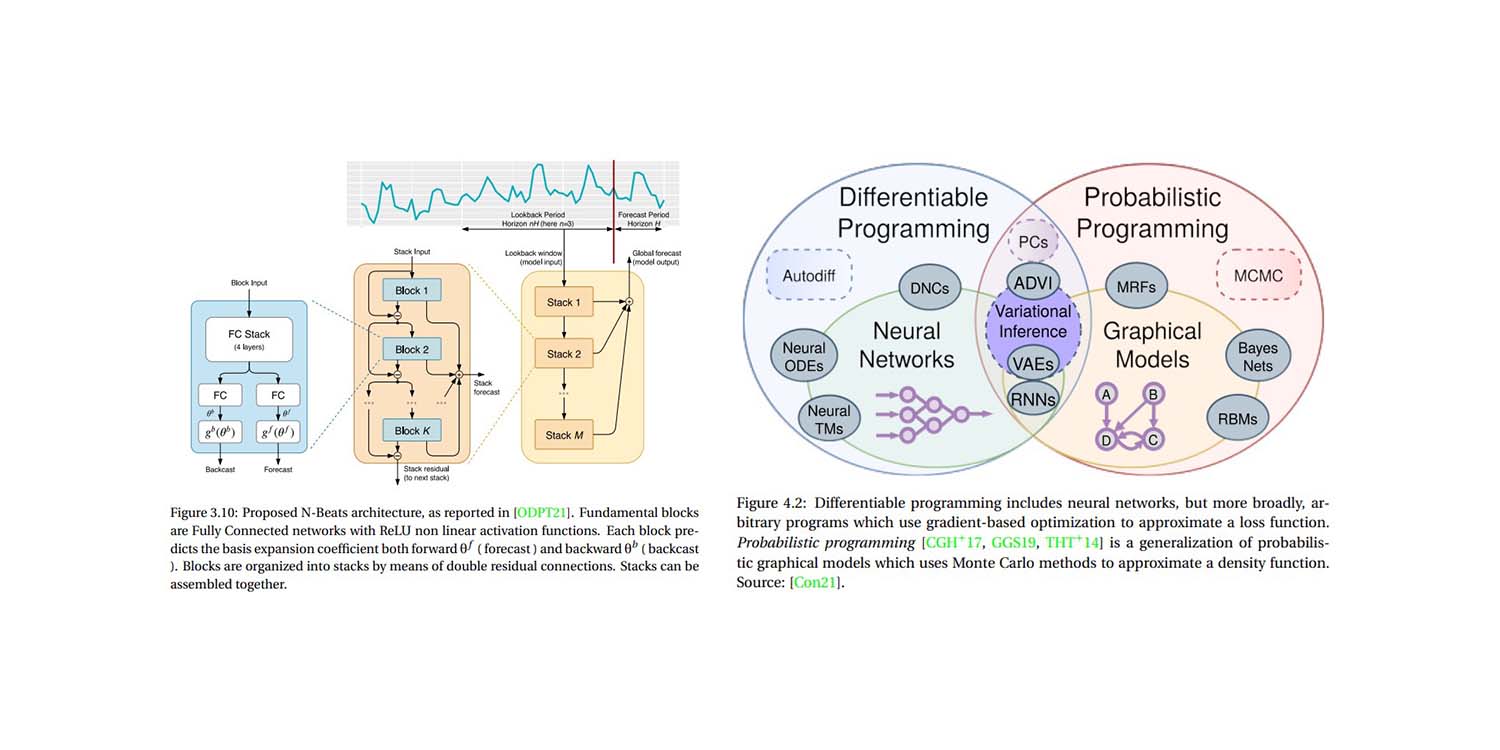
サプライチェーン領域における説明可能AIのための確率的指数平滑法
アントニオ・チフォネッリの博士研究『サプライチェーン領域における説明可能AIのための確率的指数平滑法』をお読みください。基本的な指数平滑法というモデルが、巧妙な工夫の数々によって最先端の深層学習モデルを凌駕するレーシングカーへと変貌するという、また一つの素晴らしい研究事例です。
エンビジョンを通じた販売分析 - ワークショップ #2
この第2回エンビジョンワークショップは、学生とサプライチェーン専門家に、Lokadの確率論的リスク管理の視点から小売顧客を分析するための指導付きトレーニングを提供します.

選択的経路自動微分:バックプロパゲーションドロップアウトにおける一様分布を超えて
選択的経路自動微分(SPAD)手法は、確率的勾配降下法(SGD)を部分データポイントの視点から強化します。この技術はコンパイラーレベルで実装され、勾配の質を犠牲にして勾配の量を補完することで、従来のSGD手法に比べてより精緻な視点を提供します。

ディープ・インベントリ・マネジメントの主観的レビュー
Amazonのチームが2022年後半にDeep Inventory Management (DIM)を発表しました。この論文は、強化学習と[深層学習](/ja/ディープ-ラーニング/)の両方を特徴とするDIM在庫最適化手法を提示しています。Lokadが過去に同様の道を歩んできたため、そのCEOで創業者のJoannes Vermorelは、提案手法について批判的な評価を下しています。
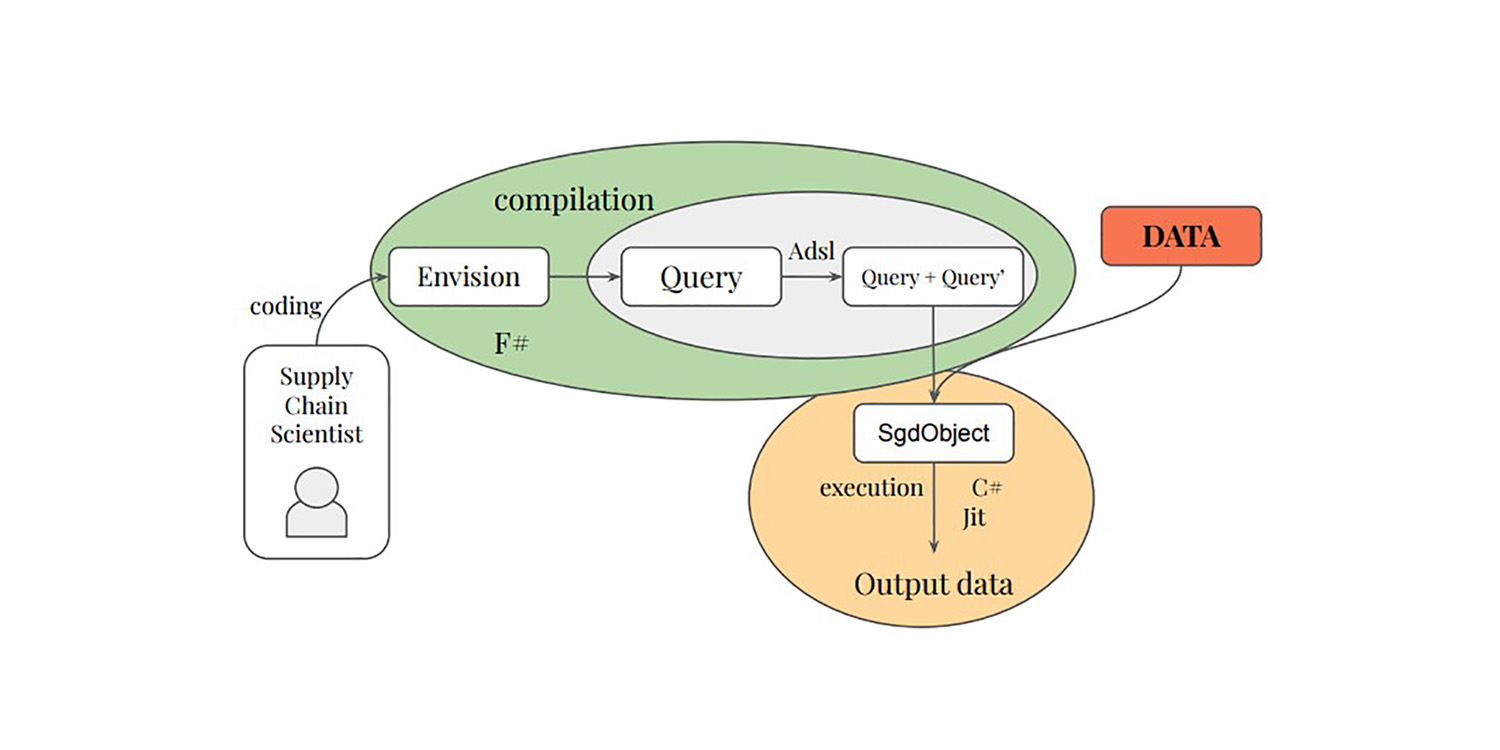
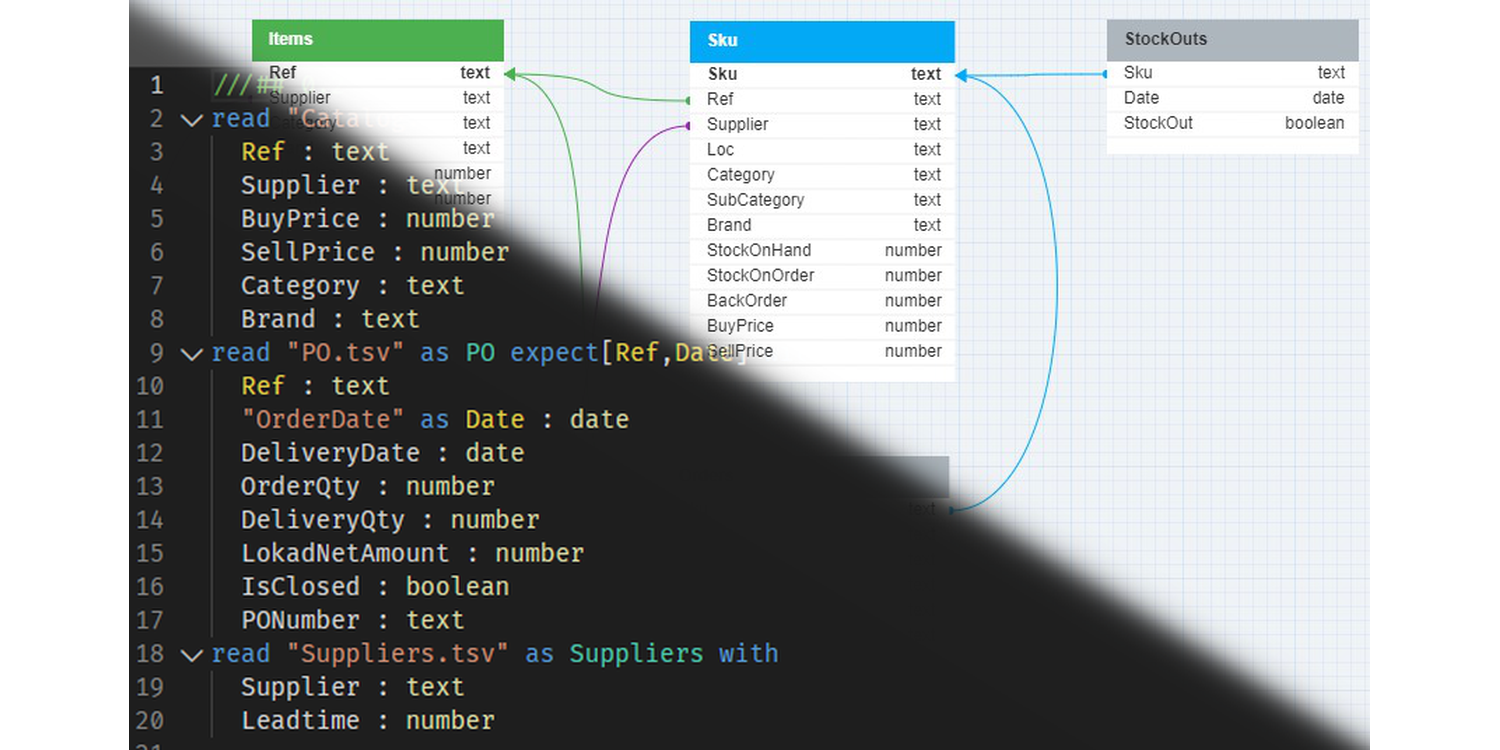
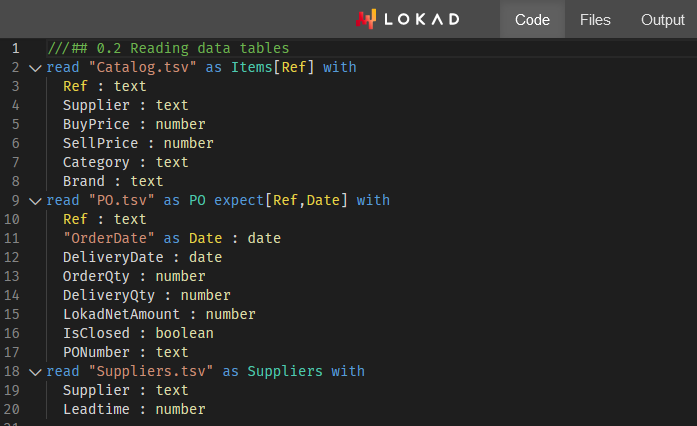
大規模リレーショナルデータの最適化のための差分可能プログラミング
Paul Peseux の博士研究は、リレーショナルクエリの微分化という、供給チェーン分野であまり研究されていない領域に着目し、TOTAL JOIN オペレーター、Polystar、そしてリレーショナルクエリを微分するためのミニ言語 ADSL を提案しました。これらはすべて、日々の在庫意思決定の最適化のための自動微分の一環として、Lokad の DSL Envision に統合されています。
エンビジョンを通じたサプライヤー分析 - ワークショップ #1
Lokadは初のエンビジョンワークショップを開始し、学生(およびサプライチェーンの専門家)に、Lokad独自の確率的リスク管理の視点を用いて小売サプライヤーを分析する方法を教えます。
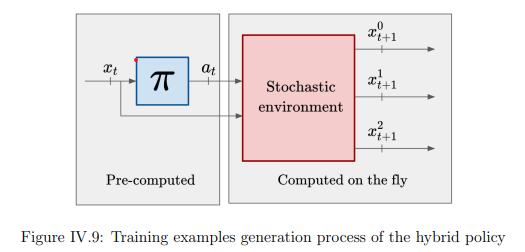
複数参照の最小発注量制約下における在庫管理
Gaetan Delétoille の MOQ に関する博士研究は、サプライチェーンという驚くほど研究が不足している分野に焦点を当て、w-policy を導入しました。これは Lokad が日々の在庫意思決定ソリューションに統合しているものです。
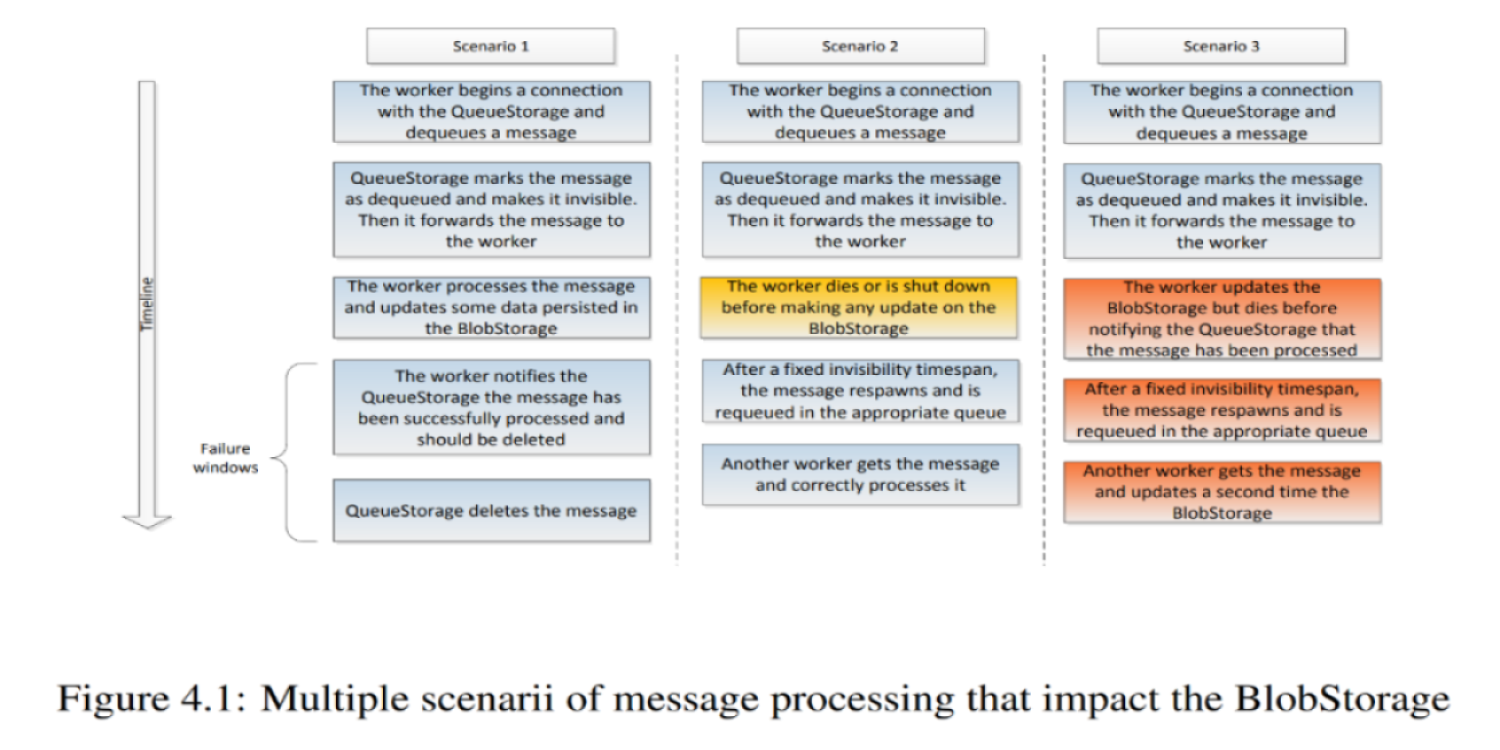
クラウド上に分散された分類アルゴリズム
Lokadの第2従業員であるMatthieu Durutは、2012年にLokadでの研究成果をもとに博士号を取得しました。この博士論文は、今日の大規模サプライチェーンに対応するために不可欠な、クラウドネイティブな分散コンピューティングアーキテクチャへのLokadの移行の道を開きました。

大規模学習: 分散非同期クラスタリングアルゴリズムへの貢献
Benoit Patra は、Lokad の最初の従業員として、2012年にLokadで行われた研究により博士号を取得しました。この博士論文はサプライチェーン理論に根本的に新しい要素をもたらし、Lokadの確率的予測アプローチの将来の発展の基礎を築きました。

確率的勾配降下法とカテゴリカル特徴のための勾配推定器
機械学習(ML)の広範な分野は、さまざまな状況に対応するための多彩な技法と手法を提供します。しかし、サプライチェーンには独自のデータ上の課題があり、しばしばサプライチェーン実務者によって「基本的」とみなされる側面は、私たちの基準では満足のいくML手法の恩恵を受けられないことがあります。