Business Intelligence (BI)
BI (Business Intelligence) refers to a class of enterprise software dedicated to the production of analytical reports primarily based on the transactional data collected through the various business systems that the company uses to operate. BI is intended to offer self-servicing reporting capabilities to users who are not IT specialists. These self-servicing capabilities can range from adjusting parameters on existing reports to the creation of wholly new ones. Most large companies have at least one BI system in operation on top of their transactional ones, which frequently includes an ERP.
Origin and motivation
The modern analytical report emerged with the first economic forecasters1 2, predominantly in the USA, at the beginning of the 20th century. This early iteration proved exceedingly popular, receiving mainstream press attention and wide circulation. This popularity demonstrated there was a pronounced interest in high-information-density quantitative reports. During the 1980s, many large companies started preserving their business transactions as electronic records, stored in transactional databases, typically leveraging some early ERP solutions. These ERP solutions were primarily intended to streamline existing processes, improving productivity and reliability. However, many understood the enormous untapped potential of these records and, in 1983, SAP introduced the ABAP 3 programming language, dedicated to the generation of reports based on the data collected within the ERP itself.
However, the relational database systems, as typically sold in the 1980s, presented two major limitations as far as the production of analytical reports was concerned. First, the design of the reports had to be done by highly trained IT specialists. This made the process slow and expensive, severely limiting the diversity of reports that could be introduced. Second, the generation of the reports was very taxing for the computing hardware. Reports could, usually, only be produced during the night (and in batch), when company operations had ceased. To some extent, this reflected the limitations of the computing hardware of the time, but it also reflected software limitations.
In the early 1990s, computing hardware progress allowed a different class of software solutions to emerge 4, Business Intelligence solutions. The cost of RAM (random-access memory) had been steadily decreasing, while its storage capacity had been steadily increasing. As a result, storing a specialized, more compact version of business data in memory (in RAM) for immediate access became a viable solution, from both technological and economic viewpoints. These developments addressed the two principal limitations of reporting systems as implemented a decade earlier: the newer software front-ends were much more accessible to non-specialists; and the newer software back-ends – featuring OLAP technologies (discussed below) – eliminated some of the biggest IT constraints. Thanks to these advancements, by the close of the decade, BI solutions had become mainstream among large companies.
As computer hardware continued to progress, a new generation of BI tools emerged 5 in the late 2000s. The relational database systems of the 1980s that were incapable of conveniently producing reports became, in the 2000s, increasingly capable of holding a business’ entire transactional history in RAM. As a result, complex analytical queries could be completed within seconds without a dedicated OLAP back-end. Thus, the focus of BI solutions shifted to the front-end, delivering even more accessible web user interfaces - predominantly SaaS (software-as-a-service) - while featuring increasingly interactive dashboards that leveraged the versatility of the relational back-end.
OLAP and multi-dimensional cubes
OLAP stands for online analytical processing. OLAP is associated with the design of the back-end of a BI solution. The term, coined in 1993 by Edgar Codd, federates a series of software design ideas 6, most of them predating the 1990s, with some stretching back to the 1960s. These design ideas were instrumental in the emergence of BI as a distinct class of software products in the 1990s. OLAP addressed the challenge of being able to produce fresh analytical reports in a timely manner, even when the amount of data involved in the production of the report was too large to be processed swiftly.
The most straightforward technique for producing a fresh analytical report involves reading the data at least once. However, if the dataset is so large 7 that reading it in its entirety takes hours (if not days), then producing a fresh report will also require hours or days. Thus, in order to produce an updated report in seconds, the technique cannot entail re-reading the complete dataset whenever a report refresh is requested.
OLAP proposes to leverage smaller, more compact, data structures - reflecting the reports of interest. These specific data structures are intended to be incrementally updated as newer data become available. As a result, when a fresh report is requested, the BI system does not have to re-read the entire historical dataset, rather only the compact data structure that contains all the information needed to generate the report. Moreover, if the data structure is small enough, then it can be kept in memory (in RAM), and thus be accessed faster than the persistent storage used for transactional data.
Consider the following example: imagine a retail network operating 100 hypermarkets. The CFO wants a report with the total sales in euros per store per day over the last 3 years. The raw historical sales data over the last 3 years represent more than 1 billion lines of data (every barcode scanned in every store for this period), and more than 50GB in their raw tabular format. However, a table with 100 columns (1 per hypermarket) 1095 lines (3 years * 365 days) totals less than 0.5MB (at a rate of 4 bytes per number). Moreover, every time a transaction happens, the corresponding cells in the table can be updated accordingly. Creating and maintaining such a table illustrates what an OLAP system looks like under the hood.
The compact data structures described above usually take the form an OLAP cube, also called a multidimensional cube. Cells exist in the cube at the intersection of the discrete dimensions that define the cube’s overall structure. Each cell holds a measure (or value) extracted from the original transactional data, frequently referred to as the facts table. This data structure is similar to multidimensional arrays that are found in most mainstream programming languages. The OLAP cube lends itself to efficient projection or aggregation operations along the dimensions (like summing and averaging), given the cube remains small enough to fit in the memory of the computer.
Interactive reporting and data visualization
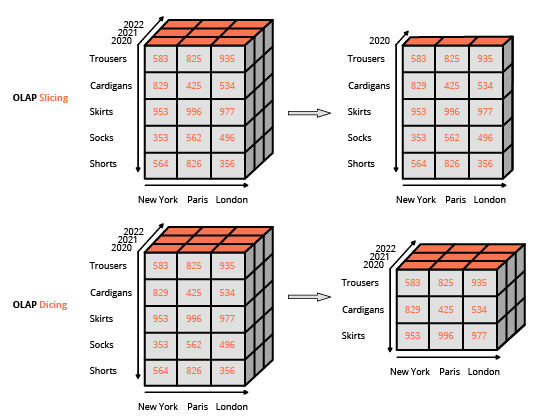
Making reporting capabilities accessible to end-users who were not IT specialists was a key driver in the adoption of BI tools. As such, the tech adopted a WYSIWYG (what-you-see-is-what-you-get) design, relying on rich user interfaces. This approach differs from the usual approach for interacting with a relational database, which consists of composing queries using a specialized language (like SQL). The usual interface to manipulate an OLAP cube is a matrix interface, like pivot tables in a spreadsheet program, that allows users to apply filters (referred to as slice and dice in the BI terminology) and perform aggregations (average, min, max, sum, etc.).
Except for processing especially large datasets, the need for OLAP cubes regressed in the late 2000s in parallel with the vast strides made in computing hardware. Newer “thin” BI tools were introduced with an exclusive focus on the front-end. The thin BI tools were primarily designed to interact with relational databases, unlike their “thick” predecessors that were leveraging integrated back-ends featuring OLAP cubes. This evolution was possible because the performance of relational databases, at that time, usually allowed complex queries to be executed over the whole dataset in seconds – again, as long as the dataset remained below a certain size. Thin BI tools can be seen as unified WYSIWYG editors for the various SQL dialects that they supported. (In fact, under the hood, these BI tools generate SQL queries.) The main technical challenge was the optimization of the generated queries, in order to minimize the response time of the underlying relational database.
The data visualization capabilities of BI tools were largely a matter of data presentation on the client-side, either through a desktop or web app. Presentation capabilities progressed steadily until the 2000s when the end-user’s hardware (e.g., workstations and notebooks) started to vastly exceed (computationally speaking) what was needed for data visualization purposes. Nowadays, even the most elaborate data visualizations are untaxing processes, dwarfed in scale by the consumption of computing resources associated with the extraction and transformation of the underlying data being visualized.
The organizational impact of BI
While ease of access has been a decisive factor for the adoption of most BI tools, navigating the data landscape of large companies is difficult, if only due to the sheer diversity of data available. Moreover, even if the BI tool is fairly accessible, the reporting logic that companies implement through BI tools tend to reflect the complexity of the business, and as a result, the logic itself can be much less accessible than the tool supporting its execution.
As a result, the adoption of BI tools lead – for most large companies – to the creation of dedicated analytics teams, which usually operate as a support function alongside the IT department. As predicted by Parkinson’s Law, work expands so as to fill the time available for its completion; these teams tend to expand over time alongside the number of generated reports, independent of the benefits gained (perceived or actual) by the company from access to said reports.
Technical limits of BI
As is so often the case, there is a trade-off between virtues when it comes to BI tools, which is to say that greater ease of access comes at the cost of expressiveness; in this case, the transformations applied to data are limited to a relatively narrow class of filters and aggregations. This is the first major limitation, as many – if not most – business questions cannot be addressed with those operators (for example, what is a client’s churn risk?). Of course, introducing advanced operators to the BI user interface is possible, however such “advanced” features defeat 8 the initial purpose of making the tool readily accessible to non-technical users. As such, designing advanced data queries is no different to building software, a task that proves inherently difficult. By way of anecdotal evidence, most BI tools offer the possibility to write “raw” queries (typically in SQL or an SQL-like dialect), falling back to the technical path that the tool was supposed to eliminate.
The second major limitation is performance. This limitation presents itself in two distinct flavors for thin and thick BI tools, respectively. Thin BI tools typically include sophisticated logic to optimize the database queries that they generate. However, these tools are ultimately limited by the performance that can be offered by the database serving as the back-end. A seemingly simple query can prove to be inefficient to execute, leading to long response times. A database engineer can certainly modify and improve the database to address this concern. However, once more, this solution defeats the initial goal of keeping the BI tool accessible to non-technical users.
Thick BI tools have their performance limited by the design of the OLAP cubes themselves. First, the amount of RAM required to keep a multidimensional cube in memory rapidly escalates as the cube’s dimensions increase. Even a moderate number of dimensions (e.g., 10) can lead to severe problems associated with the memory footprint of the cube. More generally, in-memory designs (OLAP cubes being the most frequent), usually suffer from memory-related problems.
Furthermore, the cube is a lossy representation of the original transactional data: no analytics performed with the cube can recover information that has been lost in the first place. Recall the example of the hypermarket. In such a scenario, baskets cannot be represented in a cube. Thus, the “purchased together” information is lost. The OLAP’s overall “cube” design severely limits what data can even be represented; however, this limitation is precisely what makes the “online” property possible in the first place.
Business limits of BI
The introduction of BI tools in a company is less transformative than it may appear. Simply put, producing numbers, in and of themselves, is of no value for the company if no action is attached to those numbers. The very design of BI tools emphasizes a “limitless” production of reports, but the design does not support any actual course of action. In fact, in most situations, the scant expressiveness of the BI tools prove too limiting when it comes to automating anything based on the BI reports.
Also, the BI tool tends to exacerbate the bureaucratic tendencies of large companies. Anecdotal evidence, rough numbers, and sound judgement are often sufficient to establish priorities for a company. However, the existence of a self-serving analytical tool – like BI – provides ample opportunity to procrastinate and muddy the waters with a ceaseless stream of questionable and non-actionable metrics.
BI tools are vulnerable to design by committee woes where everybody’s ideas get included in the project. The self-servicing nature of the tool emphasizes an extensively inclusive approach when it comes to the introduction of new reports. As a result, the complexity of the reporting landscape tends to grow over time, independent of the business complexity that those reports are supposed to reflect. The term vanity metrics has become widely used to reflect metrics – usually implemented through a BI tool - like these that do not contribute to a company’s bottom line.
Lokad’s take
Considering the capabilities of modern computing hardware, using a reporting system to produce 1 million numbers per day is easy; producing 10 numbers per day worth reading is hard. While a BI tool used in small doses is a good thing for most companies, in higher doses it becomes a poison.
In practice, there are only so many insights that can be gained from BI. Introducing more and more reports results in quickly diminishing returns in terms of new (or improved) insights gained through each extra report. Remember, the depth of data analytics accessible from a BI tool is limited by design as queries must remain easily accessible to non-specialists through the user interface.
Also, even when a new insight is acquired through the data, it does not imply that the company can turn it into anything actionable. BI is, at its core, a reporting technology: it does not emphasize any call to action for the company. The BI paradigm is not geared towards automating business decisions (not even the mundane ones).
The Lokad platform features extensive bespoke reporting capabilities, like BI. However, unlike BI, Lokad is aimed at the optimization of business decisions, more specifically of those concerning supply chain. In practice, we recommend having a supply chain scientist in charge of the design, and later maintenance, of the numerical recipe that generates – through Lokad – the supply chain decisions of interest.
Notes
-
Fortune Tellers: The Story of America’s First Economic Forecasters, by Walter Friedman (2013). ↩︎
-
A Selection of Early Forecasting & Business Charts, By Walter Friedman (2014) (PDF) ↩︎
-
ABAP is a programming language released by SAP in 1983 that stands for Allgemeiner Berichts-Aufbereitungs-Prozessor, German for “general report preparation processor”. This language was introduced as a precursor to the BI systems to supplement the ERP (also named SAP) with reporting capabilities. The intent of ABAP was to alleviate the engineering overhead associated with the implementation of custom reports. In the 1990’s, ABAP was re-purposed as a configuration and extension language for the ERP itself. The language was also renamed in English to Advanced Business Application Programming to reflect this change of focus. ↩︎
-
BusinessObjects founded in 1990 and acquired by SAP in 2008 is the archetype of the BI solutions that emerged in the 1990s. ↩︎
-
Tableau founded in 2003 and acquired by Salesforce in 2019 is the archetype of the BI solutions that emerged in the 2000s. ↩︎
-
The origins of today’s OLAP products, Nigel Pendse, last updated August 2007, ↩︎
-
Computing hardware has been progressing steadily since the 1950s. However, every time it became cheaper to process more data, it also became cheaper to store more data. As a result, since the 1970s, the amount of business data has been growing almost as fast the capabilities of the computing hardware. Thus, the notion of “too much data” is largely a moving target. ↩︎
-
In the late 1990s and early 2000s, many software companies tried – and failed – to replace programming languages with visual tools. See also, Lego Programming by Joel Spolsky, December 2006 ↩︎