CRUD Business Apps
Since the 1980s, the vast majority of business apps have adopted a similar internal design, namely CRUD, which stands for Create / Read / Update / Delete. This design reflects the adoption of a relational database to persist the business data. The CRUD design has endured several great technological leaps, from console terminals connected to mainframes to mobile apps connected to cloud platforms. Understanding the CRUD design matters in complex fields - like supply chain - that typically operate on top of an entire applicative landscape made of CRUD apps. Such insight is instrumental in properly navigating this landscape, from negotiating with software vendors to the exploitation of the data entries collected through all these apps

Overview
By the early 1980s, relational databases had emerged as the dominant approach for storing and accessing business data. By the end of the 1990s, emergent open-source relational databases had further solidified this practice. These days, the CRUD design reflects the most widespread approach to engineering a business app on top of a relational database.
A database, in the relational sense, includes a list of tables. Each table includes a list of columns (also referred to as fields). Each field comes with a datatype: number, text, date, etc. A table contains a list of lines (also referred to as rows). As a rule of thumb, the number of columns is expected to remain limited, a few hundred at most, while the number of lines is unbounded, potentially reaching billions.
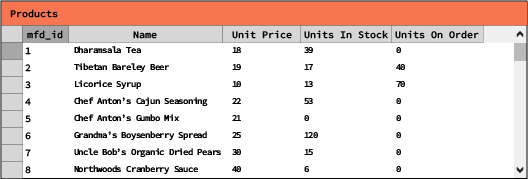
Figure 1: a simple table reflecting a list of products and their inventory situation, illustrative of what one typically finds in a relational database.
In practice, the relational approach requires several tables to reflect something of business interest (e.g., purchase orders). These “groupings” of tables are referred to as entities. An entity reflects the high-level understanding of the business.
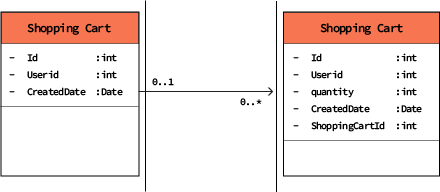
Figure 2: a simple “shopping cart” entity made of two tables. This entity reflects the state of the shopping cart for the visitor of an ecommerce website.
As mentioned above, CRUD refers to Create, Read, Update and Delete, the 4 fundamental operations to be performed on tables within a relational database.
- Create: add new lines to the table.
- Read: retrieve existing lines from the table.
- Update: modify existing lines in the table.
- Delete: delete existing lines from the table.
These operations are performed through a dedicated database language, almost always a SQL (Structured Query Language) dialect1 nowadays.
The CRUD design consists of introducing entities alongside their user interface counterparts, typically referred to as “screens”. A screen, which can be a web page, typically features the 4 operations for the entity of interest.
The vast majority of the “transactional” business apps, from a simple time tracker to a very complex ERP or CRM, adopt a similar CRUD design under the hood - a design pattern established more than 4 decades ago. Simple apps feature only a few entities while complex ones may feature thousands of them. However, from simple to complex, in terms of inherent design, it is just more of the same.
The diversity of user interfaces, as found among business apps, may be deceptive in the sense that it seems like the apps have very little in common. However, in practice, most apps have a near identical inner design aligned with the CRUD perspective.
CRUD apps in supply chain
Nearly all the apps (exposed to end-users) that are used to operate companies and their processes are CRUD. Generally speaking, if a piece of enterprise software benefits from a 3-letter initialism like ERP, MRP, CRM, SRM, PLM, PIM, WMS, OMS, EDI (etc.), then it is almost invariably implemented as CRUD. The most notable exception to this rule is document editors (e.g., spreadsheet software), which represent an entirely different type of software technology.
Internally, the IT department uses a wide array of technologies that are not CRUD: networking, virtualization, sysadmin tools, etc. However, these technologies tend to be largely invisible, or at the very least unobtrusive, to end-users.
Such CRUD apps contain almost all relevant historical transactional data that can be leveraged to quantitatively improve the supply chain (for example, optimizing stock levels). As a result, many CRUD apps attempt2, at some point, to branch into analytical capabilities (such as for planning or optimization purposes). Unfortunately, while CRUD presents numerous advantages, it also presents brutal shortcomings as far as analytical capabilities are concerned (see “The Limits of CRUD” below).
The Benefits of CRUD
CRUD has been the go-to approach for business apps for decades. From a technological perspective, this approach benefits from comprehensive open-source frameworks and tools in all the major software stacks. As a result, the technological path is exceptionally well-defined. Moreover, CRUD also benefits from high-quality development tools and, as a result, productivity tends to be high for software engineers involved in the development of a CRUD-based app.
From a staffing perspective, there is a large market of software engineers experienced with CRUD. Furthermore, CRUD is among the most accessible parts of software engineering – largely due to its high-quality development tools. As a result, CRUD is extremely accessible even to junior software engineers (and less talented senior ones). As the underlying CRUD principles have been stable for decades, transitioning towards a newer technological stack can also be done with relative ease – at least compared to other, more tech-savvy approaches.
Finally, from a business continuity perspective, CRUD offers all the benefits associated with its underlying relational database. For example, as long as the database is accessible to the client company, the data will remain accessible; this holds true even if the original vendor of the CRUD app is no longer operational/cooperative with the client company. Even in this extreme case, data-accessibility is achievable through modest reverse engineering efforts.
The Limits of CRUD
CRUD apps face inherent limitations associated with the way they internally leverage the relational database at their core. These limitations cannot be bypassed without fundamentally surrendering the very benefits associated with CRUD. These limitations fall into two broad categories: expressiveness and performance.
The expressiveness limitation reflects the fact that the four actions (or “verbs”) – create, read, update and delete – cannot properly capture a more granular array of intents. For example, consider a situation where an employee seeks to deduplicate several supplier entries that have been created by mistake within the SRM (Supplier Relationship Manager). The appropriate verb for this operation would be merge. However, the CRUD design does not have this verb. In fact, such capability is invariably implemented as a two-stage process. First, update all lines that used to point toward the soon-to-be-deleted supplier entries, so that they now point to the one to be preserved. Second, delete all but one of the extra supplier entries. Not only is the original intent (the merge) lost, but the transformation is destructive in terms of data. Anecdotally, when CRUD apps warn their users that they are about to bring some irreversible change to the data, it is almost always a CRUD limitation3 that is intruding into the user experience.
The performance limitation reflects the fact that any long-running operation – that is, any operation that reads more than a tiny fraction of the database – puts the CRUD app at risk of becoming unresponsive. Indeed, for a CRUD app, end-users expect the latency to be barely noticeable for nearly all mundane operations. For example, updating a stock level in the WMS (Warehouse Management System) should happen in milliseconds (in order to keep operations smooth). As all operations given to the CRUD app consume computing resources from the same underlying relational database, almost any non-trivial operation puts this core at risk of being starved of computing resources. Anecdotally, in large companies, CRUD apps commonly become unresponsive for seconds (even minutes) at a time. These situations are almost invariably caused by a few “heavy” operations that end up monopolizing computing resources for a short duration, thus delaying all other operations - including the “light” ones. This issue explains why non-trivial operations are usually segregated into batch jobs that run at night. It also explains why CRUD apps are typically bad at analytics, given that analytical workloads are impractical to run only outside office hours.
Modern CRUD flavors
During the last few decades, enterprise software has undergone substantial evolutions. During the 1990s, most apps upgraded from console terminals to desktop user interfaces. During the 2000s, most apps upgraded from desktop user interfaces to web user interfaces. In the last decade or so, most apps pivoted to SaaS (software as a service) and migrated toward cloud computing in the process. However, the CRUD design remained largely untouched by these evolutions.
The transition from single tenancy to multi-tenancy4 forced software vendors to gate data accesses to entities behind APIs (Application Programming Interfaces). Indeed, direct access to the database, even if read-only, creates the possibility of starving the computing resources of the transactional core through just a small number of heavy requests. The API mitigates these types of problems. Gating access to the app data behind an API also negates some of the CRUD benefits, at least as far as the client company is concerned. Reliably extracting a lot of data from an API typically requires more effort than composing a comparable series of SQL queries. Moreover, the API may be incomplete – not exposing data that exist in the app – even though the direct database should have granted complete access to the data by design.
The main evolution of CRUD is to be found in the tooling. During the 2010s, a wide variety of high-quality open-source ecosystems emerged to support the development of CRUD apps. These ecosystems have extensively commoditized the development of CRUD apps, in turn vastly lowering the skills needed to develop them, and reducing the frictions associated with the development process.
Vendor dynamics
The development cost of a CRUD app is largely driven by the number of entities. The greater the number of entities, the more screens have to be developed, documented, and maintained. Thus, the natural path for a software vendor promoting a CRUD app consists of starting with a limited number of entities, and over time adding more.
Adding entities unlocks new capabilities and gives the vendor the opportunity to raise its prices, reflecting the extra value created for the client company. Also, modules5, i.e., groupings of business-related entities, are frequently introduced as a pricing mechanism to charge more (depending on the extent of the usage of the software product).
As a result, CRUD apps tend to grow more complex over time, but less relevant as well. Indeed, as new entities get added to serve the interest of the entire client base, many (if not most) of the newly introduced entities are not relevant for any individual client company. These “dead” entities – from the perspective of the client company – represent a growing accidental complexity that pollutes the CRUD.
CRUD apps sold as SaaS tend to become more expensive as they grow in capability and notoriety. However, as there are very few barriers to entry6, new vendors frequently emerge, each focusing on use cases at much lower price points - and the cycle repeats ad infinitum.
Lokad’s take
Many, if not most, large companies under-appreciate the extent of the commoditization of CRUD apps. For most enterprise software vendors who sell them, the development cost is but a tiny fraction of the total company expenditure, far behind the costs involved in marketing and selling the apps themselves. In particular, vendors developing CRUD apps frequently delocalize their engineering teams in low-cost countries, as the CRUD approach (given its overall accessibility) can tolerate a less talented - and less expensive - engineering workforce.
There is very little reason nowadays to pay hefty amounts for CRUD apps. As a rule of thumb, any CRUD app that costs over 250k USD per year is a serious candidate for in-house software replacement. Any CRUD app that costs over 2.5M USD per year should, almost without fail, be replaced by in-house software (possibly starting from a pre-existing, open-source baseline and customizing from there).
Enterprise software vendors who sell CRUD apps are keenly aware of this issue (and have been for a long time). Thus, it is tempting for the vendor to add non-CRUD functionality/apps/elements7 into the solution and try to convince clients (a) that these pieces matter and (b) that these pieces represent some kind of “secret sauce” that the client will not be able to replicate. However, this approach almost never succeeds, mostly because the vendor does not have the right engineering DNA8. By way of anecdotal evidence, almost all notable and established ERPs have extensive forecasting and planning capabilities, almost all of which go largely unused given how poorly they actually perform these tasks.
Lokad is an enterprise software vendor that specializes in the predictive optimization of supply chain. Our technology has been designed to leverage historical transactional data – the kind that can be extracted from the CRUD apps that support the daily operations of a company. However, Lokad itself is not a CRUD app. Our production environment does not even include a relational database. While CRUD is a valid technological answer for the management of a company’s transactional workflows, it has no relevance whatsoever for either the predictive modeling or mathematical optimization of a supply chain.
Notes
-
Each database vendor tends to have its own SQL dialect. The fine print of the syntax varies from one vendor to another, but such languages are very similar. Tools exist to automatically translate between dialects. ↩︎
-
The ERP initialism stands for Enterprise Resource Planning. Yet, this is a misnomer. This class of enterprise software should be named Enterprise Resource Management. Indeed, “planning” was introduced in the 1990s as a marketing gimmick by certain software vendors in order to differentiate themselves through the introduction of analytical capabilities. However, three decades later, ERPs are still not a good fit for analytical workloads, precisely due to their CRUD design. ↩︎
-
With enough effort, it is possible to make all operations reversible with CRUD. However, this usually defeats the point of adopting CRUD in the first place; namely, its simplicity and productivity for the software engineering team. ↩︎
-
An app is said to be single tenant if one instance of the application serves a single client, typically a client company in the case of a business app. An app is said to be multi-tenant if a single instance serves many clients (possibly all the clients of the software vendor). ↩︎
-
The terminology varies. SaaS vendors tend to use the term plans or editions rather than modules to refer to the pricing mechanism that grants access to extra entities, and thus extra capabilities. ↩︎
-
Typically, a CRUD app can be almost entirely reverse-engineered through the careful inspection of the various “screens” it offers its end-users. ↩︎
-
The non-CRUD piece tends to be themed with the buzzword of the day. In the early 2000s, apps were fitted with “data mining” capabilities. In the early 2010s, apps with “big data” capabilities were in vogue. Since the early 2020s, apps have been gaining “AI” capabilities. Unfortunately, the CRUD approach does not mix well with more sophisticated alternatives. For CRUD app vendors, such capabilities are invariably nothing but marketing gimmicks. ↩︎
-
Few talented software engineers are willing to work for a vendor that sells CRUD apps; the salaries are too low, and an engineer’s talent is largely irrelevant due to the adopted technological path. The talent gap between CRUD and non-CRUD software engineers is about as large as that between wedding photographers and luxury brand photographers. ↩︎