CRUDビジネスアプリ
1980年代以降、ほとんどのビジネスアプリは内部設計としてCRUD(作成/読み取り/更新/削除)を採用しています。この設計は、ビジネスデータを永続化するためにリレーショナルデータベースを利用していることを反映しています。CRUD設計は、メインフレームに接続されたコンソール端末からクラウドプラットフォームに接続されたモバイルアプリに至るまで、数々の大きな技術的飛躍を経てもなお受け継がれています。サプライチェーンのような複雑な分野では、CRUDアプリで構成されるアプリケーション全体の上に成り立っているため、CRUD設計の理解は極めて重要です。この洞察は、ソフトウェアベンダーとの交渉から、これらすべてのアプリで収集されたデータエントリの活用に至るまで、適切にこのランドスケープをナビゲートするために不可欠です.

概要
1980年代初頭までに、リレーショナルデータベースはビジネスデータの保存およびアクセスのための支配的な手法として確立されました。1990年代末には、オープンソースのリレーショナルデータベースが登場し、この手法はさらに強固なものとなりました。今日では、CRUD設計はリレーショナルデータベース上にビジネスアプリを構築する最も普及したアプローチを反映しています.
リレーショナルな意味でのデータベースは、一連のテーブルを含みます。各テーブルには、列(フィールドとも呼ばれる)のリストがあり、各フィールドには数値、テキスト、日付などのデータ型が設定されています。テーブルはまた、行(レコードとも呼ばれる)のリストを含んでいます。一般的なルールとして、列の数は数百程度に留まる一方で、行の数は無制限であり、場合によっては数十億に達することもあります.
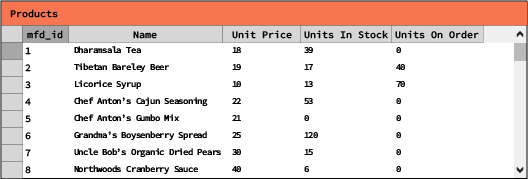
図1: 製品一覧とその在庫状況を示す単純なテーブル。リレーショナルデータベースで一般的に見られる構造の例です。
実際、リレーショナルアプローチでは、ビジネス上の関心事(例:購入注文)を反映するために、いくつかのテーブルを組み合わせる必要があります。これらのテーブルの「グループ」は_エンティティ_と呼ばれ、エンティティはビジネスの全体像を表現します.
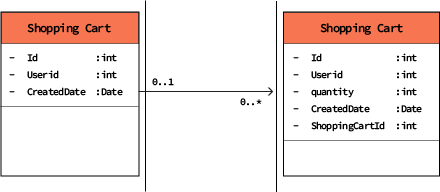
図2: 2つのテーブルから成る単純な「ショッピングカート」エンティティ。このエンティティは、ECサイト訪問者のショッピングカートの状態を表しています。
前述の通り、CRUDはリレーショナルデータベース内のテーブルに対して実行される4つの基本操作、すなわち作成(Create)、読み取り(Read)、更新(Update)、削除(Delete)を指します.
- 作成: テーブルに新しい行を追加する.
- 読み取り: テーブルから既存の行を取得する.
- 更新: テーブル内の既存の行を修正する.
- 削除: テーブルから既存の行を削除する.
これらの操作は、専用のデータベース言語、ほとんどの場合はSQL(Structured Query Language)の方言1によって実行されます.
CRUD設計は、エンティティとそれに対応するユーザーインターフェース(一般的に「画面」と呼ばれる)を導入することから成り立っています。画面(ウェブページなど)は、対象エンティティに対して通常、4つの操作を提供します.
シンプルなタイムトラッカーから非常に複雑なERPやCRMに至るまで、ほとんどの「トランザクショナル」なビジネスアプリは、4十年以上前に確立された同様のCRUD設計を採用しています。シンプルなアプリはエンティティが少数であるのに対し、複雑なアプリは数千のエンティティを持つことがあります。しかし、設計の本質においては、単純なものも複雑なものも基本的に同じアプローチです.
ビジネスアプリに見られるユーザーインターフェースの多様性は、一見するとアプリ同士に共通点がほとんどないように思われるかもしれません。しかし実際には、ほとんどのアプリはCRUDの視点に沿ったほぼ同一の内部設計を持っています.
サプライチェーンにおけるCRUDアプリ
企業やそのプロセスの運営に使用されるほぼすべての(エンドユーザー向けの)アプリはCRUDです。一般的に、ERP、MRP、CRM、SRM、PLM、PIM、WMS、OMS、EDIなどの3文字の略語を冠するエンタープライズソフトウェアは、ほぼ間違いなくCRUDとして実装されています。このルールの最も際立った例外は、スプレッドシートなどのドキュメントエディターであり、これらは全く異なる種類のソフトウェア技術を表しています.
内部的には、IT部門は、ネットワーキング、仮想化、シスアドミンツールなど、CRUD以外のさまざまな技術を使用しています。しかし、これらの技術はエンドユーザーにとってほとんど見えないか、少なくとも目立たないものです.
このようなCRUDアプリは、サプライチェーンを定量的に改善するために活用できるほぼすべての関連する過去のトランザクションデータ(例えば、在庫水準の最適化)を含んでいます。その結果、多くのCRUDアプリは、ある時点で分析機能(計画や最適化などの目的で)に分岐しようと試みます2。残念ながら、CRUDは多くの利点を提供する一方で、分析機能に関しては深刻な欠点も抱えているのです(下記の「CRUDの限界」を参照)。
CRUDの利点
CRUDは何十年にもわたってビジネスアプリの主流の手法となってきました。技術的な観点からは、このアプローチは主要なソフトウェアスタックすべてにおける包括的なオープンソースフレームワークとツールの恩恵を受けており、そのため技術的な道筋は非常に明確です。さらに、CRUDは高品質の開発ツールの恩恵も受けているため、CRUDベースのアプリの開発に関わるソフトウェアエンジニアの生産性は高い傾向にあります.
人材の面では、CRUDに精通したソフトウェアエンジニアが多数存在します。さらに、CRUDはソフトウェアエンジニアリングの中でも最もアクセスしやすい分野の一つであり、主に高品質な開発ツールのおかげです。その結果、ジュニアレベルのエンジニア(あるいは才能の少ないシニアエンジニア)でさえも、CRUDは非常に扱いやすいものとなっています。基礎となるCRUD原則が何十年も安定しているため、新しい技術スタックへの移行も比較的容易に行えます—少なくとも、より技術に精通した他のアプローチと比べれば.
最後に、事業継続性の観点から、CRUDは基盤となるリレーショナルデータベースに付随するすべての利点を提供します。例えば、データベースがクライアント企業にアクセス可能である限り、データは引き続き利用可能であり、これは元のCRUDアプリのベンダーがもはや運用していない、またはクライアント企業との協力を停止した場合でも同様です。たとえ極端な状況でも、適度なリバースエンジニアリングによりデータアクセスは可能です.
CRUDの限界
CRUDアプリは、その内部でリレーショナルデータベースを活用する方法に起因する固有の制約に直面しています。これらの制約は、CRUDの利点自体を根本的に放棄しなければ回避できません。これらの制限は、大きく表現力とパフォーマンスの2つに分類されます.
表現力の制限は、4つの動作(または「動詞」)—作成、読み取り、更新、削除—が、より細分化された意図を適切に表現できないという事実を反映しています。例えば、SRM(Supplier Relationship Manager)内で誤って作成された複数のサプライヤーエントリの重複排除を従業員が試みる状況を考えてみてください。この操作に適した動詞は「統合」になるはずです。しかし、CRUD設計にはその動詞が存在しません。実際、このような機能は必ず2段階のプロセスとして実装されます。まず、削除される予定のサプライヤーエントリを参照していたすべての行を更新して、保持すべきエントリを指すように変更します。次に、余分なサプライヤーエントリを1つ以外すべて削除します。これにより、元々の意図であった統合は失われるだけでなく、データにとっては破壊的な変換となってしまいます。逸話的には、CRUDアプリがユーザーに対し、データに取り返しのつかない変更を加えようとしていると警告する場合、それはほぼ常にCRUDの制限3がユーザー体験に影響を及ぼしているためです.
パフォーマンスの制限は、長時間実行される操作、つまりデータベースのごく一部以上を読み込む操作が、CRUDアプリを反応不能に陥らせるリスクを孕んでいるという事実を反映しています。実際、CRUDアプリの場合、エンドユーザーはほとんどすべての日常的な操作でレイテンシーがほとんど感じられないことを期待しています。例えば、WMS(Warehouse Management System)における在庫水準の更新は、スムーズな運用を維持するためにミリ秒単位で行われるべきです。CRUDアプリに与えられるすべての操作が同一のリレーショナルデータベースの計算資源を消費するため、ほぼどんな非自明な操作も、このコアが資源不足に陥るリスクを伴います。逸話的には、大企業ではCRUDアプリが数秒(場合によっては数分)にわたって反応不能になることがよくあります。これらの状況は、短期間で計算資源を独占してしまういくつかの「重い」操作によって引き起こされ、結果として「軽い」操作を含む他のすべての操作の遅延を招いています。この問題は、通常、非自明な操作が夜間に実行されるバッチジョブとして分離される理由を説明しています。また、分析ワークロードが営業時間外のみで実行されるのが非現実的であるため、CRUDアプリが分析に不向きである理由もここにあります.
現代のCRUDの形態
過去数十年にわたり、エンタープライズソフトウェアは大きな進化を遂げてきました。1990年代には、多くのアプリがコンソール端末からデスクトップユーザーインターフェースへと移行し、2000年代には、デスクトップユーザーインターフェースからウェブユーザーインターフェースへと進化しました。ここ十数年では、多くのアプリがSaaS(サービスとしてのソフトウェア)へと舵を切り、クラウドコンピューティングへと移行しました。しかし、CRUD設計はこれらの進化にほとんど影響を受けていません.
シングルテナンシーからマルチテナンシーへの移行4は、ソフトウェアベンダーに対して、エンティティへのデータアクセスをAPI(アプリケーションプログラミングインターフェース)の背後に制限することを強いる結果となりました。実際、たとえ読み取り専用であったとしてもデータベースに直接アクセスすると、少数の重いリクエストによりトランザクショナルコアの計算資源が枯渇する可能性があります。APIはこうした問題を軽減します。さらに、APIの背後でアプリデータへのアクセスを制限することで、少なくともクライアント企業にとってはCRUDのいくつかの利点が相殺されることになります。APIから大量のデータを確実に抽出するには、通常、同等のSQLクエリ群を作成するよりも多くの労力が必要です。さらに、APIは不完全である場合があり、アプリ内に存在するデータを十分に公開しないこともあります—本来、直接のデータベースは設計上完全なアクセスを許すはずであったとしても.
CRUDの主な進化はツールに見られます。2010年代には、CRUDアプリの開発を支援するために、さまざまな高品質なオープンソースエコシステムが登場しました。これらのエコシステムは、CRUDアプリの開発を広く商品化し、その結果、開発に必要なスキルを大幅に低減させ、開発プロセスの摩擦を軽減しました.
ベンダーの動向
CRUDアプリの開発コストは主にエンティティの数によって左右されます。エンティティの数が増えれば増えるほど、開発、文書化、保守すべき画面も増加します。したがって、CRUDアプリを提供するソフトウェアベンダーにとっては、限られた数のエンティティから始め、時間の経過とともに追加していくのが自然な流れです.
エンティティの追加は、新たな機能を解放し、ベンダーに対して、クライアント企業に創出する付加価値を反映して価格を引き上げる機会を与えます。また、ビジネス関連のエンティティの集まりであるモジュール5は、ソフトウェア製品の使用状況に応じて、より高い料金を請求するための価格設定メカニズムとして頻繁に導入されます.
その結果、CRUDアプリは時間とともに複雑化する一方で、個々のクライアント企業にとっての関連性は低下していきます。実際、全クライアントの利益に資するために新たなエンティティが追加されると、多くの場合、新たに導入されたエンティティの大半は、個々のクライアント企業にとっては意味をなさなくなります。これらの「不要な」エンティティは、クライアント企業の視点から見ると、CRUDを汚染する増大する偶発的な複雑さを表しています.
SaaSとして販売されるCRUDアプリは、その機能や知名度が向上するにつれて高額になりがちです。しかし、参入障壁が非常に低いため6、低価格帯のユースケースに焦点を当てた新たなベンダーが頻繁に登場し、そのサイクルは無限に繰り返されます.
Lokadの見解
多くの大企業は、CRUDアプリのコモディティ化の程度を十分に評価していません。これらのアプリを販売するほとんどのエンタープライズソフトウェアベンダーにとって、開発コストは会社全体の支出のごく一部に過ぎず、アプリ自体のマーケティングや販売にかかるコストに比べれば非常に小さいのです。特に、CRUDアプリを開発するベンダーは、CRUDアプローチ(その全体的なアクセスのしやすさのおかげで)が、それほど優秀でなく、かつ低コストなエンジニア人材でも十分に対応可能であるため、エンジニアリングチームを低コスト国に分散することがよくあります.
今日、CRUDアプリに高額な費用を支払う理由はほとんどありません。経験則として、年間25万USDを超えるCRUDアプリは、社内ソフトウェアへの置き換えの有力候補となります。年間250万USDを超えるCRUDアプリは、ほぼ確実に社内ソフトウェアに置き換えるべきです(既存のオープンソースのベースラインから開始し、そこからカスタマイズする形で).
CRUDアプリを販売するエンタープライズソフトウェアベンダーは、この問題を長い間鋭敏に認識してきました。そのため、ベンダーはソリューションに非CRUDの機能、アプリ、もしくは要素7を追加し、クライアントに対して (a) それらの要素が重要であること、(b) それらがクライアントには模倣できない一種の「秘密のタレ」であることを説得しようとする誘惑に駆られます。しかし、このアプローチはほとんど成功せず、その主な理由は、ベンダーが適切なエンジニアリングDNA8を有していないためです。逸話的な例として、ほとんどすべての著名かつ確立されたERPは、広範な予測および計画機能を備えていますが、実際にはそれらの機能がほとんど活用されないほど低いパフォーマンスで運用されています.
Lokad はサプライチェーンの予測最適化に特化したエンタープライズ向けソフトウェアベンダーです。我々の技術は、企業の日常業務を支える CRUD アプリから抽出可能な歴史的トランザクションデータを活用するために設計されました。しかしながら、Lokad 自体は CRUD アプリではありません。我々の本番環境にはリレーショナルデータベースすら含まれていません。CRUD は企業のトランザクションワークフローの管理に対して有効な技術的解答である一方、サプライチェーンの予測モデリングや数学的最適化には全く関係がありません。
注釈
-
各データベースベンダーは独自の SQL 方言を持つ傾向があります。構文の細かい点はベンダーごとに異なりますが、これらの言語は非常に似通っています。方言間を自動的に翻訳するツールも存在します。 ↩︎
-
ERP の頭字語は Enterprise Resource Planning を意味します。しかし、これは誤称です。この種のエンタープライズソフトウェアは Enterprise Resource Management と呼ぶべきです。実際、「計画」は 1990 年代に特定のソフトウェアベンダーが分析機能を導入することで差別化を図るためのマーケティング戦略として導入されました。しかし三十年後も、ERP はその CRUD 設計のために分析的なワークロードに適していません。 ↩︎
-
十分な工夫があれば、CRUD を用いてすべての操作を可逆にすることは可能です。しかしながら、これはそもそも CRUD を採用する理由である、ソフトウェアエンジニアリングチームにとっての単純さと生産性を損なうことになります。 ↩︎
-
アプリがシングルテナントと呼ばれるのは、アプリの1つのインスタンスが1つのクライアント(通常、ビジネスアプリの場合はクライアント企業)にサービスを提供する場合です。一方、1つのインスタンスが多くのクライアント(場合によってはソフトウェアベンダーの全クライアント)にサービスを提供する場合は、マルチテナントと呼ばれます。 ↩︎
-
用語は様々です。SaaS ベンダーは、追加のエンティティおよびそれに伴う追加機能へのアクセスを提供する価格設定の仕組みを示す際、モジュールというよりもプランやエディションという用語を用いる傾向があります。 ↩︎
-
通常、CRUD アプリはエンドユーザーに提供される様々な「画面」を注意深く調査することで、ほぼ完全にリバースエンジニアリングすることが可能です。 ↩︎
-
CRUD 以外の部分は、その時々の流行語でテーマ付けされる傾向があります。2000年代初頭にはアプリに「データマイニング」機能が搭載され、2010年代初頭には「ビッグデータ」機能が流行し、2020年代初頭からは「AI」機能が注目されるようになりました。残念ながら、CRUD アプローチはより高度な代替手段とうまく組み合わせることができません。CRUD アプリのベンダーにとって、これらの機能は常に単なるマーケティング戦略にすぎません。 ↩︎
-
有能なソフトウェアエンジニアが CRUD アプリを販売するベンダーで働くことを望むケースはほとんどありません。給料が低すぎる上、採用された技術的手法のためにエンジニアの才能はほとんど評価されないからです。CRUD エンジニアと非 CRUD エンジニアの才能の差は、結婚式のカメラマンと高級ブランドのカメラマンとの差に匹敵するといえます。 ↩︎