00:00 Einführung
02:31 Ursachen des Scheiterns in der Praxis
07:20 Ergebnis: ein numerisches Rezept 1/2
09:31 Ergebnis: ein numerisches Rezept 2/2
13:01 Bisheriges Vorgehen
14:57 Heute zur Tat schreiten
15:59 Zeitplan der Initiative
21:48 Umfang: Applikationslandschaft 1/2
24:24 Umfang: Applikationslandschaft 2/2
27:12 Umfang: Systemeffekte 1/2
29:21 Umfang: Systemeffekte 2/2
32:12 Rollen: 1/2
37:31 Rollen: 2/2
41:50 Datenpipeline - Wie
44:13 Ein Wort zu transaktionalen Systemen
49:13 Ein Wort zum Data Lake
52:59 Ein Wort zu analytischen Systemen
57:56 Datenqualität: auf niedriger Ebene
01:02:23 Datenqualität: auf hoher Ebene
01:06:24 Datenprüfer
01:08:53 Fazit
01:10:32 Anstehende Vorlesung und Fragen des Publikums
Beschreibung
Die Durchführung einer erfolgreichen prädiktiven Optimierung einer supply chain ist eine Mischung aus weichen und harten Problemen. Leider ist es nicht möglich, diese Aspekte zu trennen. Die weichen und harten Facetten sind tief miteinander verwoben. Üblicherweise kollidiert diese Verflechtung frontal mit der Arbeitsteilung, wie sie im Organigramm des Unternehmens definiert ist. Wir beobachten, dass, wenn supply chain Initiativen scheitern, die Ursachen des Scheiterns meist Fehler in den frühesten Phasen des Projekts sind. Zudem prägen frühe Fehler die gesamte Initiative, sodass sie fast unmöglich im Nachhinein zu korrigieren sind. Wir präsentieren unsere wichtigsten Erkenntnisse, um diese Fehler zu vermeiden.
Vollständiges Transkript

Willkommen zu dieser Reihe von supply chain Vorlesungen. Ich bin Joannes Vermorel, und heute präsentiere ich “Einstieg in eine die Quantitative Supply Chain Initiative.” Die überwiegende Mehrheit der datenverarbeitenden supply chain Initiativen scheitert. Seit 1990 haben die meisten Unternehmen, die große supply chains betreiben, alle drei bis fünf Jahre größere prädiktive Optimierungsinitiativen gestartet, die kaum bis gar keine Ergebnisse lieferten. Heutzutage merken die meisten Teams in supply chains oder im data science, die eine weitere Runde prädiktiver Optimierung beginnen – typischerweise als ein Prognoseprojekt oder ein Bestandsoptimierungsprojekt ausgerichtet – nicht einmal, dass ihr Unternehmen diesen Weg bereits beschritten hat, es gemacht und möglicherweise ein halbes Dutzend Mal gescheitert ist.
Der erneute Versuch wird manchmal von dem Glauben getrieben, dass es diesmal anders wird, aber häufig sind sich die Teams der vielen vorangegangenen Fehlversuche gar nicht bewusst. Indizien hierfür liefern, dass Microsoft Excel nach wie vor das wichtigste Werkzeug zur Steuerung von supply chain decisions ist, während diese Initiativen eigentlich dazu gedacht waren, spreadsheets durch bessere Werkzeuge zu ersetzen. Dennoch gibt es heutzutage nur sehr wenige supply chains, die ohne spreadsheets operieren können.
Das Ziel dieser Vorlesung ist es, zu verstehen, wie man einer supply chain Initiative, die jegliche Form prädiktiver Optimierung liefern will, eine Erfolgschance geben kann. Wir werden eine Reihe kritischer Bestandteile durchgehen – diese Bestandteile sind einfach, erscheinen jedoch für die meisten Organisationen oft kontraintuitiv. Im Gegensatz dazu werden wir eine Reihe von Anti-Patterns betrachten, die das Scheitern einer solchen Initiative nahezu garantieren.
Heute liegt mein Fokus auf der taktischen Umsetzung des ganz Anfangs einer supply chain Initiative mit einer “Dinge erledigen”-Mentalität. Ich werde nicht die großen strategischen Implikationen für das Unternehmen erörtern. Strategie ist zwar sehr wichtig, aber dieses Thema werde ich in einer späteren Vorlesung behandeln.

Die meisten supply chain Initiativen scheitern, und das Problem wird kaum öffentlich erwähnt. Die Wissenschaft veröffentlicht jährlich Zehntausende von Arbeiten, die sich mit verschiedensten supply chain Innovationen rühmen, darunter Frameworks, Algorithmen und Modelle. Häufig behaupten die Arbeiten sogar, dass die Innovation bereits irgendwo in die Produktion übernommen wurde. Und dennoch zeigt meine eigene beiläufige Beobachtung in der supply chain Welt, dass diese Innovationen nirgends zu finden sind. Ebenso haben software vendors in den letzten drei Jahrzehnten überlegene Ersatzlösungen für spreadsheets versprochen, und wieder einmal weist meine beiläufige Beobachtung darauf hin, dass spreadsheets allgegenwärtig bleiben.
Wir greifen einen Punkt erneut auf, der bereits im zweiten Kapitel dieser supply chain Vorlesungsreihe berührt wurde. Kurz gesagt, Menschen haben keinerlei Anreiz, Misserfolge zu veröffentlichen, und daher tun sie es nicht. Zudem wird das Problem, da Unternehmen, die supply chains betreiben, in der Regel groß sind, typischerweise durch den natürlichen Verlust des institutionellen Gedächtnisses verstärkt, da Mitarbeiter ständig von einer Position zur nächsten wechseln. Deshalb erkennen weder die Wissenschaft noch die Anbieter diese eher düstere Situation an.
Ich schlage vor, mit einer kurzen Übersicht über die häufigsten Fehlerursachen aus der Perspektive der taktischen Umsetzung zu beginnen. Tatsächlich treten diese Fehlerursachen typischerweise in der frühesten Phase der Initiative auf.
Die erste Fehlerursache ist der Versuch, die falschen Probleme zu lösen – Probleme, die entweder nicht existieren, unerheblich sind oder ein Missverständnis über die supply chain widerspiegeln. Das Optimieren von Prozentzahlen der forecasting accuracy ist wahrscheinlich das Paradebeispiel für ein solches falsches Problem. Die Verringerung des Prognosefehlers in Prozent führt nicht direkt zu zusätzlichen Euro oder Dollar an Ertrag für das Unternehmen. Dasselbe geschieht, wenn ein Unternehmen spezielle service levels für seinen Bestand anstrebt. Es ist sehr selten, dass sich daraus ein deutlicher finanzieller Mehrwert ergeben würde.
Die zweite Fehlerursache ist der Einsatz unpassender Softwaretechnologien und Softwaredesigns. Zum Beispiel versuchen ERP Anbieter stets, eine transaktionale Datenbank zu verwenden, um datenlastige Initiativen zu unterstützen, weil auf dieser das ERP aufgebaut ist. Im Gegensatz dazu versuchen Data-Science-Teams, stets das neueste Open-Source-Machine-Learning-Toolkit zu verwenden, weil es gerade angesagt ist. Leider führen unpassende Technologiekomponenten typischerweise zu enormen Reibungsverlusten und viel unbeabsichtigter Komplexität.
Die dritte Fehlerursache ist eine falsche Arbeitsteilung und Organisation. In dem fehlgeleiteten Versuch, in jeder Phase des Prozesses Spezialisten einzusetzen, neigen Unternehmen dazu, die Initiative auf zu viele Personen zu fragmentieren. Zum Beispiel wird die data preparation sehr häufig von Personen durchgeführt, die nicht für die Prognose verantwortlich sind. Infolgedessen häufen sich Situationen, in denen schlechte Eingabedaten zu schlechten Ergebnissen führen (Garbage-in-Garbage-out). Die Verantwortung für die endgültigen supply chain Entscheidungen zu verwässern, ist ein Rezept für Misserfolg.
Ein Aspekt, den ich in dieser kurzen Liste der Fehlerursachen nicht aufgeführt habe, ist schlechte Datenqualität. Daten werden sehr häufig für das Scheitern von supply chain Initiativen verantwortlich gemacht, was allzu bequem ist, da Daten nicht wirklich auf diese Vorwürfe reagieren können. Allerdings sind in der Regel nicht die Daten schuld, zumindest nicht im Sinne von “schlechten Daten”. Die supply chain großer Unternehmen wurde bereits vor Jahrzehnten digitalisiert. Jeder Artikel, der gekauft, transportiert, transformiert, produziert oder verkauft wird, hat elektronische Aufzeichnungen. Diese Aufzeichnungen mögen nicht perfekt sein, aber sie sind in der Regel sehr genau. Wenn es den Menschen nicht gelingt, richtig mit den Daten umzugehen, kann man nicht wirklich die Transaktion dafür verantwortlich machen.

Damit eine quantitative Initiative erfolgreich ist, müssen wir den richtigen Kampf führen. Was ist es, das wir überhaupt zu liefern versuchen? Eines der wichtigsten Ergebnisse einer quantitative supply chain ist ein zentrales numerisches Rezept, das die abschließenden supply chain Entscheidungen berechnet. Dieser Aspekt wurde bereits in Vorlesung 1.3 im allerersten Kapitel “Produktorientierte Zustellung für supply chain” behandelt. Lassen Sie uns die beiden kritischsten Eigenschaften dieses Ergebnisses noch einmal betrachten.
Erstens muss das Ergebnis eine Entscheidung sein. Zum Beispiel ist es eine Entscheidung, zu bestimmen, wie viele Einheiten heute reorder für ein bestimmtes SKU nachbestellt werden sollen. Im Gegensatz dazu ist es ein numerisches Artefakt, wenn prognostiziert wird, wie viele Einheiten heute für ein bestimmtes SKU angefordert werden. Um eine Entscheidung als Endprodukt zu generieren, werden viele Zwischenergebnisse benötigt, also viele numerische Artefakte. Wir dürfen jedoch nicht das Mittel mit dem Zweck verwechseln.
Die zweite Eigenschaft dieses Ergebnisses ist, dass das Ergebnis, welches eine Entscheidung darstellt, vollständig automatisiert im Rahmen eines rein automatisierten Softwareprozesses ablaufen muss. Das numerische Rezept selbst, das Kernrezept, darf keine manuellen Eingriffe beinhalten. Natürlich hängt das Design des numerischen Rezepts wahrscheinlich stark von einem menschlichen Experten in der Wissenschaft ab. Die Ausführung sollte jedoch nicht von direkter menschlicher Intervention abhängig sein.
Ein numerisches Rezept als Ergebnis zu haben, ist essenziell, um die supply chain Initiative zu einem kapitalistischen Vorhaben zu machen. Das numerische Rezept wird zu einem produktiven Gut, das Renditen generiert. Das Rezept muss gepflegt werden, jedoch erfordert dies ein oder zwei Größenordnungen weniger Personal im Vergleich zu Ansätzen, die den Menschen auf der Mikroentscheidungs-Ebene einbinden.

Viele supply chain Initiativen scheitern jedoch, weil sie supply chain Entscheidungen nicht als das eigentlich zu liefernde Ergebnis richtig einordnen. Stattdessen konzentrieren sich diese Initiativen darauf, numerische Artefakte bereitzustellen. Numerische Artefakte sind als Zutaten gedacht, um zur endgültigen Lösung des Problems zu gelangen, typischerweise zur Unterstützung der Entscheidungen selbst. Die am häufigsten in supply chain anzutreffenden Artefakte sind Prognosen, safety stocks, EOQs, KPIs. Auch wenn diese Zahlen von Interesse sein können, sind sie nicht real. Diese Zahlen haben keinen unmittelbaren, greifbaren physischen Gegenpart in der supply chain und spiegeln willkürliche Modellierungsperspektiven auf die supply chain wider.
Die Konzentration auf die numerischen Artefakte führt zum Scheitern der Initiative, da diesen Zahlen eine entscheidende Zutat fehlt: direktes Feedback aus der realen Welt. Wenn die Entscheidung falsch ist, können die negativen Konsequenzen eindeutig auf die Entscheidung zurückgeführt werden. Bei numerischen Artefakten hingegen ist die Situation wesentlich ambulanter. Tatsächlich ist die Verantwortung überall verteilt, da viele Artefakte zu jeder einzelnen Entscheidung beitragen. Das Problem verschärft sich noch, wenn menschliche Eingriffe dazwischen stattfinden.
Dieser Mangel an Feedback erweist sich als tödlich für numerische Artefakte. Moderne supply chains sind komplex. Wählen Sie irgendeine willkürliche Formel zur Berechnung eines safety stock, einer optimalen Bestellmenge oder eines KPI; die Wahrscheinlichkeit ist überwältigend, dass diese Formel in mancherlei Hinsicht fehlerhaft ist. Das Problem der Korrektheit der Formel ist kein mathematisches, sondern ein geschäftliches Problem. Es geht darum, die Frage zu beantworten: “Spiegelt diese Berechnung wirklich die strategische Ausrichtung meines Unternehmens wider?” Die Antwort variiert von Unternehmen zu Unternehmen und sogar von Jahr zu Jahr, wenn sich Unternehmen weiterentwickeln.
Da numerische Artefakte direktes Feedback aus der realen Welt fehlen, fehlt ihnen der Mechanismus, mit dem es möglich ist, von einer naiven, simplen und höchstwahrscheinlich weitgehend fehlerhaften Erstimplementierung zu einer annähernd korrekten Version der Formel zu iterieren, die als produktionsreif gelten könnte. Dennoch sind numerische Artefakte sehr verlockend, weil sie die Illusion erwecken, der Lösung näherzukommen. Sie vermitteln den Eindruck, rational, wissenschaftlich und sogar unternehmerisch zu handeln. Wir haben Zahlen, Formeln, Algorithmen, Modelle. Es ist sogar möglich, Benchmarks durchzuführen und diese Zahlen mit ebenso erfundenen Zahlen zu vergleichen. Die Verbesserung gegenüber einem erfundenen Benchmark vermittelt ebenfalls den Eindruck von Fortschritt und ist sehr beruhigend. Aber letztlich bleibt es eine Illusion, eine Frage der Modellierungsperspektive.
Unternehmen erwirtschaften keine Gewinne, indem sie Menschen dafür bezahlen, KPIs zu betrachten oder Benchmarks durchzuführen. Sie erzielen Gewinne, indem sie eine Entscheidung nach der anderen treffen und hoffentlich jedes Mal besser darin werden, die nächste Entscheidung zu treffen.
Diese Vorlesung ist Teil einer Reihe von supply chain Vorlesungen. Ich versuche, diese Vorlesungen einigermaßen unabhängig zu gestalten, aber wir haben einen Punkt erreicht, an dem es mehr Sinn macht, diese Vorlesungen in einer bestimmten Reihenfolge anzusehen. Diese Vorlesung ist die allererste Vorlesung des siebten Kapitels, das der Umsetzung von supply chain Initiativen gewidmet ist. Mit supply chain Initiativen meine ich quantitative supply chain Initiativen – Initiativen, die darauf abzielen, etwas in Richtung prädiktiver Optimierung für das Unternehmen zu liefern.
Das allererste Kapitel war meinen Ansichten über supply chain gewidmet, sowohl als Studienfeld als auch in der Praxis. Im zweiten Kapitel stellte ich eine Reihe von für supply chain wesentlichen Methodologien vor, da naive Methodologien aufgrund der gegnerischen Natur vieler supply chain Situationen scheitern. Im dritten Kapitel präsentierte ich eine Reihe von supply chain personae mit einem reinen Fokus auf die Probleme; mit anderen Worten, worum es überhaupt geht.
Im vierten Kapitel habe ich eine Reihe von Feldern vorgestellt, die, obwohl sie nicht supply chain an sich sind, meiner Ansicht nach für eine moderne Praxis der supply chain wesentlich sind. In den Kapiteln fünf und sechs habe ich die cleveren Elemente eines numerischen Rezepts präsentiert, das darauf abzielt, supply chain-Entscheidungen voranzutreiben, nämlich prädiktive Optimierung (die verallgemeinerte Perspektive der Prognose) und Entscheidungsfindung (im Wesentlichen mathematische Optimierung, angewendet auf supply chain-Probleme). In diesem siebten Kapitel diskutieren wir, wie man diese Elemente in einer tatsächlichen supply chain-Initiative zusammenführt, die beabsichtigt, diese Methoden und Technologien in die Produktion zu bringen.

Heute werden wir überprüfen, was als die korrekte Vorgehensweise für die Durchführung einer supply chain-Initiative gilt. Dies umfasst die Einrahmung der Initiative mit dem richtigen Ergebnis, das wir gerade besprochen haben, aber auch den richtigen Zeitrahmen, den richtigen Umfang und die richtigen Rollen. Diese Elemente stellen den ersten Teil der heutigen Vorlesung dar.
Der zweite Teil der Vorlesung wird der Data Pipeline gewidmet sein, einem kritischen Bestandteil für den Erfolg einer derartigen datengetriebenen oder von Daten abhängigen Initiative. Obwohl die Data Pipeline ein ziemlich technisches Thema ist, erfordert sie eine angemessene Arbeitsteilung und Organisation zwischen IT und supply chain. Insbesondere werden wir sehen, dass Qualitätskontrollen weitgehend in den Händen von supply chain liegen sollten, einschließlich der Erstellung von Daten-Gesundheitsberichten und Dateninspektoren.
Das Onboarding ist die erste Phase der Initiative, in der das zentrale numerische Rezept, das zusammen mit nur unterstützenden Elementen die Entscheidung generiert, entwickelt wird. Das Onboarding endet mit einem schrittweisen Rollout in die Produktion, und während dieses Rollouts werden die bisherigen Prozesse nach und nach durch das numerische Rezept selbst automatisiert.
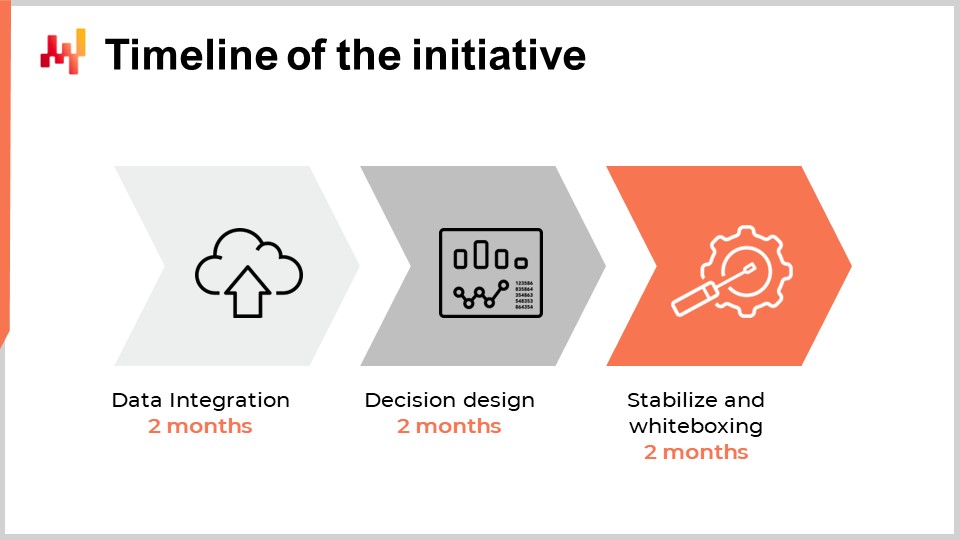
Bei der Festlegung des angemessenen Zeitrahmens für die erste die Quantitative Supply Chain Initiative in einem Unternehmen könnte man denken, dass er von der Größe, Komplexität, der Art der supply chain-Entscheidungen und dem Gesamtkontext des Unternehmens abhängt. Zwar stimmt dies in begrenztem Maße, doch die Erfahrungen, die Lokad über ein Jahrzehnt und Dutzende solcher Initiativen gesammelt hat, deuten darauf hin, dass sechs Monate nahezu ausnahmslos der geeignete Zeitrahmen sind. Überraschenderweise hat dieser Sechsmonats-Zeitrahmen wenig mit der Technologie oder sogar den Besonderheiten der supply chain zu tun; er hängt vielmehr mit den Menschen und den Organisationen selbst sowie der Zeit zusammen, die sie benötigen, um sich mit dem üblicherweise als ganz anders empfundenen Vorgehen in der supply chain anzufreunden.
Die ersten zwei Monate sind der Einrichtung der Data Pipeline gewidmet. Wir werden diesen Punkt in wenigen Minuten noch einmal aufgreifen, aber diese Verzögerung von zwei Monaten wird durch zwei Faktoren verursacht. Erstens müssen wir die Data Pipeline zuverlässig machen und seltene Probleme beseitigen, die möglicherweise Wochen brauchen, um sich zu zeigen. Der zweite Faktor ist, dass wir die Semantik der Daten herausfinden müssen, also verstehen, was die Daten aus supply chain Perspektive bedeuten.
Die Monate drei und vier sind der schnellen Iteration des numerischen Rezepts selbst gewidmet, das die supply chain-Entscheidungen vorantreiben wird. Diese Iterationen sind notwendig, da die Generierung tatsächlicher Endentscheidungen in der Regel der einzige Weg ist, um zu beurteilen, ob mit dem zugrunde liegenden Rezept oder allen in das Rezept eingebetteten Annahmen etwas nicht stimmt. Diese zwei Monate sind auch typischerweise die Zeit, die supply chain-Praktiker benötigen, um sich an die sehr quantitative, finanzielle Perspektive zu gewöhnen, die diese softwaregestützten Entscheidungen antreibt.
Schließlich sind die letzten zwei Monate der Stabilisierung des numerischen Rezepts gewidmet, nach einer in der Regel relativ intensiven Phase schneller Iterationen. Dieser Zeitraum bietet auch die Gelegenheit, das Rezept in einer produktionsähnlichen Umgebung auszuführen, ohne jedoch die Produktion zu steuern. Diese Phase ist wichtig, damit die supply chain-Teams Vertrauen in diese entstehende Lösung gewinnen.
Auch wenn es wünschenswert wäre, diesen Zeitrahmen weiter zu verkürzen, stellt sich heraus, dass dies in der Regel sehr schwierig ist. Die Einrichtung der Data Pipeline kann bis zu einem gewissen Grad beschleunigt werden, wenn die entsprechende IT-Infrastruktur bereits vorhanden ist, aber sich mit den Daten vertraut zu machen, erfordert Zeit, um zu verstehen, was die Daten aus supply chain Perspektive bedeuten. In der zweiten Phase, wenn die Iteration über das numerische Rezept sehr schnell konvergiert, werden die supply chain-Teams vermutlich beginnen, die Nuancen des numerischen Rezepts zu erkunden, was die Verzögerung ebenfalls verlängern wird. Schließlich sind die letzten zwei Monate in der Regel erforderlich, um die Saisonalität sich entfalten zu sehen und Vertrauen in die Software zu gewinnen, die wichtige supply chain-Entscheidungen in der Produktion steuert.
Insgesamt dauert es etwa sechs Monate, und obwohl es wünschenswert wäre, diesen Zeitraum weiter zu verkürzen, ist dies eine Herausforderung. Sechs Monate stellen jedoch bereits einen beträchtlichen Zeitraum dar. Wenn von Tag eins an damit gerechnet wird, dass die Onboarding-Phase, in der das numerische Rezept noch nicht die supply chain-Entscheidungen steuert, mehr als sechs Monate dauert, dann ist die Initiative bereits gefährdet. Wenn die zusätzliche Verzögerung mit der Datenextraktion und der Einrichtung der Data Pipeline zusammenhängt, liegt ein IT-Problem vor. Wenn die zusätzliche Verzögerung mit dem Design oder der Konfiguration der Lösung verbunden ist, möglicherweise durch einen Drittanbieter, dann liegt ein Problem mit der Technologie selbst vor. Schließlich, wenn nach zwei Monaten eines stabilisierten produktionsähnlichen Betriebs der Produktionsrollout nicht erfolgt, dann gibt es typischerweise ein Problem mit dem Management der Initiative.

Wenn man versucht, eine Neuheit, einen neuen Prozess oder eine neue Technologie in eine Organisation einzuführen, besagt die allgemeine Weisheit, klein anzufangen, sicherzustellen, dass es funktioniert, und auf frühem Erfolg aufzubauen, um schrittweise zu expandieren. Leider ist supply chain nicht gnädig gegenüber der allgemeinen Weisheit, und diese Perspektive kommt mit einer speziellen Wendung in Bezug auf den Umfang der supply chain. Was den Umfang betrifft, gibt es zwei Haupttriebkräfte, die weitgehend definieren, was als ein zulässiger Umfang einer supply chain-Initiative gilt und was nicht.
Die anwendungsspezifische Landschaft ist die erste Kraft, die den Umfang beeinflusst. Eine supply chain als Ganzes kann nicht direkt beobachtet werden; sie kann nur indirekt durch die Brille von Unternehmenssoftware betrachtet werden. Die Daten werden durch diese Softwarestücke gewonnen. Die Komplexität der Initiative hängt stark von der Anzahl und Vielfalt dieser Softwarestücke ab. Jede App ist eine eigene Datenquelle, und die Extraktion und Analyse der Daten aus einer beliebigen Business-App erweist sich in der Regel als ein erhebliches Unterfangen. Mit mehr Apps umzugehen bedeutet meistens, dass man sich mit mehreren Datenbanktechnologien, uneinheitlichen Terminologien, inkonsistenten Konzepten und einer erheblich verkomplizierten Situation auseinandersetzen muss.
Daher müssen wir bei der Festlegung des Umfangs anerkennen, dass die zulässigen Grenzen oder Rahmen üblicherweise von den Business-Apps selbst und ihrer Datenbankstruktur definiert werden. In diesem Kontext muss „klein anfangen“ dahingehend verstanden werden, dass der anfängliche Fußabdruck der Datenintegration so klein wie möglich gehalten wird, während die Integrität der supply chain-Initiative als Ganzes gewahrt bleibt. Es ist besser, in der App-Integration in die Tiefe zu gehen, als breit zu streuen. Sobald das IT-System eingerichtet ist, um einige Datensätze aus einer Tabelle in einer bestimmten App zu erhalten, ist es in der Regel unkompliziert, alle Datensätze aus dieser Tabelle und alle Datensätze aus einer anderen Tabelle in derselben App zu erhalten.

Ein häufiger Fehler bei der Festlegung des Umfangs besteht im Sampling. Sampling wird in der Regel dadurch erreicht, dass eine kurze Liste von Produktkategorien, Standorten oder Lieferanten ausgewählt wird. Sampling ist gut gemeint, folgt aber nicht den Grenzen, wie sie durch die anwendungsspezifische Landschaft definiert sind. Um Sampling umzusetzen, müssen Filter während der Datenextraktion angewendet werden, und dieser Prozess erzeugt eine Reihe von Problemen, die die supply chain-Initiative gefährden können.
Erstens erfordert eine gefilterte Datenextraktion aus einem Stück Unternehmenssoftware mehr Aufwand vom IT-Team im Vergleich zu einer ungefilterten Extraktion. Filter müssen zunächst entwickelt werden, und der Filterprozess selbst ist fehleranfällig. Das Debuggen fehlerhafter Filter ist in der Regel mühsam, da es zahlreiche Rücksprachen mit den IT-Teams erfordert, was die Initiative verlangsamt und somit gefährdet.
Zweitens ist es ein Rezept für massive Software-Leistungsprobleme, wenn die Initiative ihr Onboarding an einem Datensample durchführt, während sie sich später auf den vollen Umfang ausweitet. Eine schlechte Skalierbarkeit oder die Unfähigkeit, eine große Datenmenge zu verarbeiten, während die Rechenkosten unter Kontrolle gehalten werden, ist ein sehr häufiger Mangel in der Software. Indem man die Initiative über ein Sample operieren lässt, werden Skalierbarkeitsprobleme verschleiert, die aber zu einem späteren Zeitpunkt mit Macht zurückkommen werden.
Die Arbeit mit einem Datensample erschwert die Statistik, anstatt sie zu erleichtern. Tatsächlich ist der Zugang zu mehr Daten wahrscheinlich der einfachste Weg, um die Genauigkeit und Stabilität fast aller Machine-Learning-Algorithmen zu verbessern. Das Sampling der Daten widerspricht dieser Erkenntnis. Daher kann es bei der Verwendung eines kleinen Datensamples dazu kommen, dass die Initiative aufgrund unregelmäßiger numerischer Verhaltensweisen, die im Sample beobachtet werden, scheitert. Diese Verhaltensweisen wären weitgehend gemildert worden, wenn stattdessen der gesamte Datensatz verwendet worden wäre.
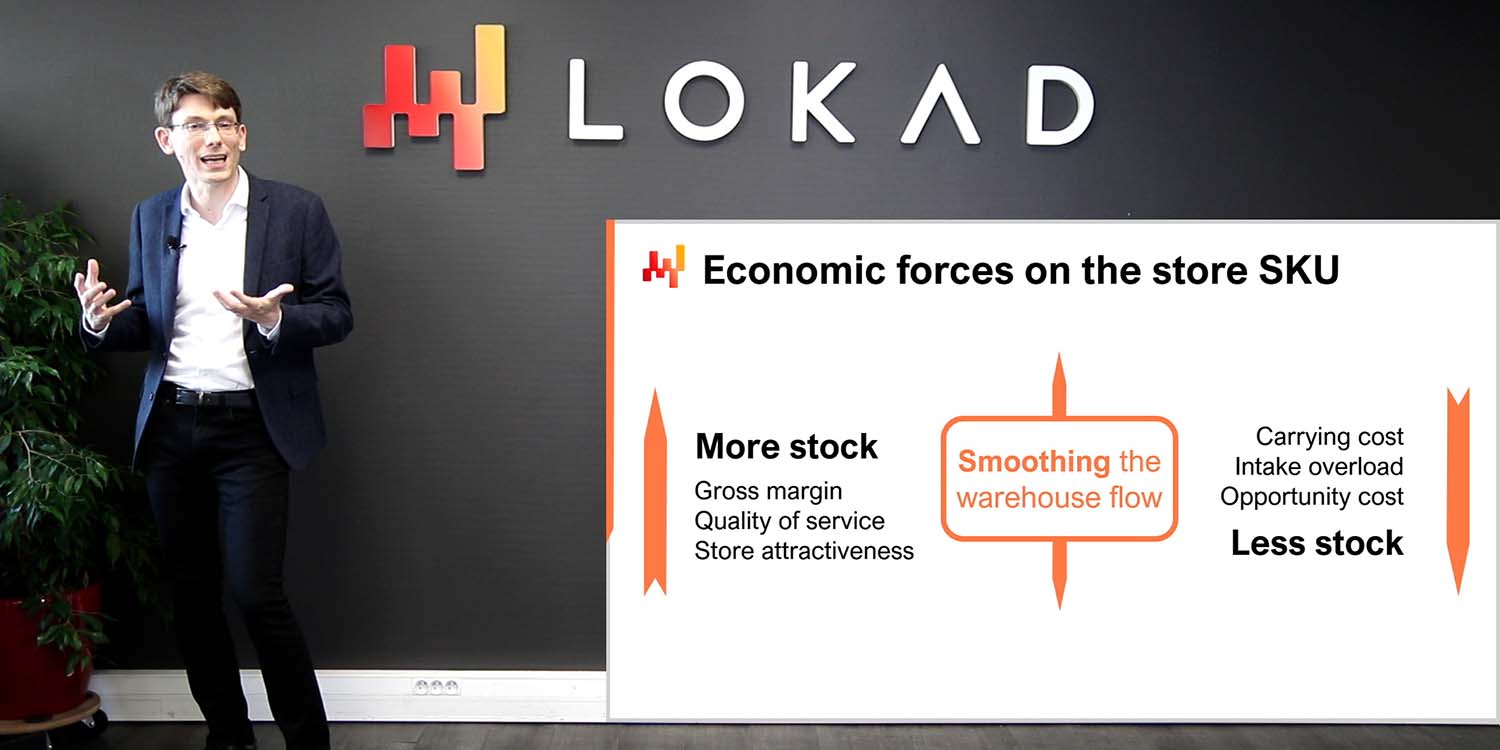
Systemeffekte sind die zweite Kraft, die den Umfang beeinflusst. Eine supply chain ist ein System, und alle ihre Teile sind bis zu einem gewissen Grad miteinander verbunden. Die Herausforderung bei Systemen, jedem System, besteht darin, dass Versuche, ein einzelnes Teil des Systems zu verbessern, dazu neigen, Probleme zu verlagern anstatt sie zu beheben. Zum Beispiel betrachten wir ein Bestandskontrolle-Problem für ein Einzelhandelsnetzwerk mit einem Distributionszentrum und vielen Filialen. Wenn wir eine einzelne Filiale als anfänglichen Umfang für unser Bestandskontrolle-Problem auswählen, ist es trivial sicherzustellen, dass diese Filiale einen sehr hohen Servicegrad vom Distributionszentrum erhält, indem im Voraus Inventar für sie reserviert wird. Dadurch können wir sicherstellen, dass das Distributionszentrum nie Fehlbestand läuft, während es diese Filiale versorgt. Allerdings würde diese Inventarreservierung auf Kosten der Servicequalität für die anderen Filialen im Netzwerk gehen.
Daher müssen wir bei der Festlegung eines Umfangs für eine supply chain-Initiative die Systemeffekte berücksichtigen. Der Umfang sollte so gestaltet sein, dass eine lokale Optimierung auf Kosten der Elemente außerhalb des Umfangs weitgehend verhindert wird. Dieser Teil der Umfangsbestimmung ist schwierig, da alle Umfänge bis zu einem gewissen Grad durchlässig sind. Zum Beispiel konkurrieren schließlich alle Teile der supply chain letztlich um die auf Unternehmensebene verfügbaren Mittel. Jeder irgendwo zugewiesene Dollar ist ein Dollar, der für andere Zwecke nicht zur Verfügung steht. Dennoch sind bestimmte Umfänge viel leichter zu manipulieren als andere. Es ist wichtig, einen Umfang zu wählen, der dazu tendiert, die Systemeffekte zu mildern, anstatt sie zu verstärken.

Über die Festlegung des Umfangs einer supply chain-Initiative unter dem Gesichtspunkt der Systemeffekte nachzudenken, mag für viele supply chain-Praktiker ungewöhnlich erscheinen. Wenn es um die Umfangsbestimmung geht, neigen die meisten Unternehmen dazu, ihre interne Organisation auf diese Übung zu projizieren. Somit tendieren die für den Umfang gewählten Grenzen zwangsläufig dazu, die Grenzen der bestehenden Arbeitsteilung im Unternehmen nachzuahmen. Dieses Muster ist als Conway’s Law bekannt. Von Melvin Conway vor einem halben Jahrhundert für Kommunikationssysteme vorgeschlagen, hat sich das Gesetz seither als weitaus breiter anwendbar erwiesen, einschließlich einer herausragenden Relevanz für das supply chain Management.
Die Grenzen und Silos, die gegenwärtige supply chains dominieren, werden durch Arbeitsteilungen bestimmt, die die Folge von ziemlich manuellen Prozessen sind, die zur Steuerung von supply chain-Entscheidungen eingesetzt werden. Wenn beispielsweise ein Unternehmen feststellt, dass ein supply and demand planner nicht mehr als 1.000 SKUs verwalten kann, und das Unternehmen insgesamt 50.000 SKUs zu managen hat, wird das Unternehmen 50 supply and demand planner benötigen, um dies zu bewältigen. Dennoch führt die Aufteilung der Optimierung der supply chain auf 50 Teams zweifellos zu vielen Ineffizienzen auf Unternehmensebene.
Im Gegenteil, eine Initiative, die diese Entscheidungen automatisiert, muss sich nicht an jene Grenzen halten, die lediglich eine veraltete oder bald veraltete Arbeitsteilung widerspiegeln. Ein numerisches Rezept kann diese 50.000 SKUs auf einmal optimieren und die Ineffizienzen beseitigen, die sich daraus ergeben, dass Dutzende von Silos gegeneinander arbeiten. Daher ist es nur natürlich, dass eine Initiative, die beabsichtigt, diese Entscheidungen in erheblichem Maße zu automatisieren, mit vielen vorbestehenden Grenzen im Unternehmen überschneidet. Das Unternehmen – oder genauer gesagt, das Management des Unternehmens – muss dem Drang widerstehen, die bestehenden organisatorischen Grenzen zu imitieren, insbesondere auf der Ebene der Umfangsbestimmung, da dies den Ton für das Folgende vorgibt.

Supply chains sind in Bezug auf Hardware, Software und Menschen komplex. Auch wenn es bedauerlich ist, erhöht der Start einer die Quantitative Supply Chain Initiative zunächst die Komplexität der supply chain zusätzlich. Langfristig kann sie die Komplexität der supply chain jedoch erheblich verringern, aber darauf werden wir wahrscheinlich in einer späteren Vorlesung eingehen. Außerdem gilt: Je mehr Personen in die Initiative involviert sind, desto größer ist auch die Komplexität der Initiative selbst. Wenn diese zusätzliche Komplexität nicht sofort unter Kontrolle gebracht wird, ist die Wahrscheinlichkeit groß, dass die Initiative unter ihrer eigenen Komplexität zusammenbricht.
Daher müssen wir bei der Überlegung der Rollen in der Initiative, also wer was übernimmt, an die kleinstmögliche Anzahl von Rollen denken, die die Initiative tragfähig macht. Durch die Minimierung der Anzahl der Rollen reduzieren wir die Komplexität der Initiative, was wiederum die Erfolgsaussichten erheblich verbessert. Diese Perspektive erscheint großen Unternehmen, die auf eine extrem feingliedrige Arbeitsteilung setzen, oft kontraintuitiv. Große Unternehmen neigen dazu, extreme Spezialisten zu bevorzugen, die nur eine Sache tun. Allerdings ist supply chain ein System, und wie bei allen Systemen zählt die End-to-End-Perspektive.
Basierend auf den bei Lokad gesammelten Erfahrungen bei der Durchführung dieser Arten von Initiativen haben wir vier Rollen identifiziert, die in der Regel die minimal tragfähige Arbeitsteilung zur Durchführung der Initiative darstellen: ein supply chain Executive, ein Data Officer, ein Supply Chain Scientist und ein supply chain Practitioner.
Die Rolle des supply chain Executives besteht darin, die Initiative zu unterstützen, damit sie überhaupt stattfinden kann. Eine gut gestaltete numerische Rezeptur, die die supply chain Entscheidungen in der Produktion vorantreibt, stellt einen enormen Gewinn sowohl in Bezug auf Rentabilität als auch auf Produktivität dar. Es ist jedoch auch viel Veränderung zu verarbeiten. Es erfordert viel Energie und Unterstützung des Top-Managements, damit eine solche Veränderung in einer großen Organisation stattfinden kann.
Die Rolle des Data Officer besteht darin, die Datenpipeline einzurichten und zu warten. Der Großteil ihrer Beiträge wird innerhalb der ersten zwei Monate der Initiative erwartet. Wenn die Datenpipeline korrekt konzipiert wurde, ist danach nur ein sehr geringer laufender Aufwand für den Data Officer nötig. Der Data Officer ist typischerweise in den späteren Phasen der Initiative nicht stark eingebunden.
Die Rolle des Supply Chain Scientist besteht darin, die zentrale numerische Rezeptur zu erstellen. Diese Rolle beginnt mit den rohen Transaktionsdaten, die vom Data Officer bereitgestellt werden. Vom Data Officer wird keine Datenaufbereitung erwartet, nur die Datenextraktion. Die Rolle des Supply Chain Scientist endet mit der Übernahme der Verantwortung für die generierte supply chain Entscheidung. Es ist nicht ein Softwarestück, das für die Entscheidung verantwortlich ist; es ist der Supply Chain Scientist. Für jede generierte Entscheidung muss der Scientist selbst in der Lage sein zu begründen, warum diese Entscheidung angemessen ist.
Schließlich besteht die Rolle des supply chain Practitioner darin, die durch die numerische Rezeptur generierten Entscheidungen zu hinterfragen und dem Supply Chain Scientist Feedback zu geben. Der Practitioner hat keine Aussicht darauf, die Entscheidung selbst zu treffen. Diese Person war bisher typischerweise für diese Entscheidungen verantwortlich, zumindest in einem Teilbereich, und zwar meist mit Hilfe von Tabellenkalkulationen und bestehenden Systemen. In einem kleinen Unternehmen ist es möglich, dass eine Person sowohl die Rolle des supply chain Executives als auch des supply chain Practitioners übernimmt. Es ist auch möglich, auf einen Data Officer zu verzichten, wenn die Daten leicht zugänglich sind. Dies könnte in Unternehmen der Fall sein, die in Bezug auf ihre Dateninfrastruktur sehr ausgereift sind. Umgekehrt, wenn das Unternehmen sehr groß ist, ist es möglich, dass nur wenige, und zwar nur sehr wenige, Personen jede Rolle ausfüllen.
Der erfolgreiche Rollout der zentralen numerischen Rezeptur in der Produktion hat einen erheblichen Einfluss auf die Welt des supply chain Practitioner. Tatsächlich ist es in hohem Maße das Ziel der Initiative, den bisherigen Job des supply chain Practitioners zu automatisieren. Dies bedeutet jedoch nicht, dass die beste Vorgehensweise darin besteht, diese Practitioners zu entlassen, sobald die numerische Rezeptur in Produktion ist. Wir werden diesen spezifischen Aspekt in der nächsten Vorlesung noch einmal aufgreifen.

Organisiert zu sein bedeutet nicht, effizient oder effektiv zu sein. Es gibt Rollen, die, obwohl gut gemeint, Friktionen in supply chain Initiativen verursachen, häufig bis zu dem Punkt, dass sie ganz scheitern. Heutzutage ist es meist die Rolle des Data Scientist, die am stärksten dazu beiträgt, dass solche Initiativen scheitern, und noch mehr, wenn ein ganzes Data Science Team involviert ist. Übrigens hat Lokad dies vor etwa einem Jahrzehnt auf die harte Tour gelernt.
Trotz der Namensähnlichkeit zwischen Data Scientists und Supply Chain Scientists sind die beiden Rollen tatsächlich sehr unterschiedlich. Der Supply Chain Scientist kümmert sich in erster Linie darum, praxisnahe, produktionsreife Entscheidungen zu liefern. Wenn dies mit einer halbwegs trivialen numerischen Rezeptur erreicht werden kann, umso besser; die Wartung wird ein Kinderspiel. Der Supply Chain Scientist übernimmt die volle Verantwortung für die kleinsten Details der supply chain. Zuverlässigkeit und Resilienz gegenüber allgegenwärtigem Chaos sind wichtiger als Raffinesse.
Im Gegensatz dazu konzentriert sich der Data Scientist auf die smarten Teile der numerischen Rezeptur, also die Modelle und Algorithmen. Der Data Scientist sieht sich im Allgemeinen als Experte für Machine Learning und mathematische Optimierung. Technologisch ist ein Data Scientist bereit, das neueste, topaktuelle Open-Source-numerische Toolkit zu erlernen, aber diese Person ist typischerweise nicht gewillt, sich mit dem drei Jahrzehnte alten ERP auseinanderzusetzen, das das Unternehmen betreibt. Außerdem ist der Data Scientist kein supply chain Experte und in der Regel auch nicht bereit, einer zu werden. Der Data Scientist versucht, die besten Ergebnisse gemäß vereinbarten Metriken zu liefern. Der Scientist hat nicht den Ehrgeiz, sich mit den sehr banalen Details der supply chain zu beschäftigen; diese Aspekte werden von anderen Personen übernommen.
Die Einbeziehung von Data Scientists bedeutet das Untergehen dieser Initiativen, denn sobald Data Scientists involviert sind, steht die supply chain nicht mehr im Mittelpunkt – Algorithmen und Modelle tun es. Unterschätzt niemals die Ablenkungskraft, die das neueste Modell oder der neueste Algorithmus für eine intelligente, technikbegeisterte Person darstellt.
Die zweite Rolle, die typischerweise Reibungsverluste in einer supply chain Initiative verursacht, ist das Business Intelligence (BI) Team. Wenn das BI-Team Teil der Initiative ist, erweisen sie sich eher als Hindernis denn als Hilfe, wenn auch in einem wesentlich geringeren Ausmaß als das Data Science Team. Das Problem mit BI ist vorwiegend kulturell. BI liefert Berichte, keine Entscheidungen. Das BI-Team ist typischerweise bereit, endlose Metrik-Wände zu produzieren, wie es jede einzelne Abteilung des Unternehmens verlangt. Dies ist nicht die richtige Einstellung für eine Initiative, in der die Quantitative Supply Chain eingesetzt wird.
Zudem ist Business Intelligence als Software eine sehr spezifische Klasse der Datenanalyse, die sich auf Cubes oder OLAP-Cubes konzentriert, welche es ermöglichen, die meisten In-Memory-Systeme in Unternehmenssystemen zu segmentieren. Dieses Design eignet sich in der Regel überhaupt nicht dazu, supply chain Entscheidungen zu steuern.

Nachdem wir die Initiative umrissen haben, werfen wir einen Blick auf die hochrangige IT-Architektur, die die Initiative erfordert.
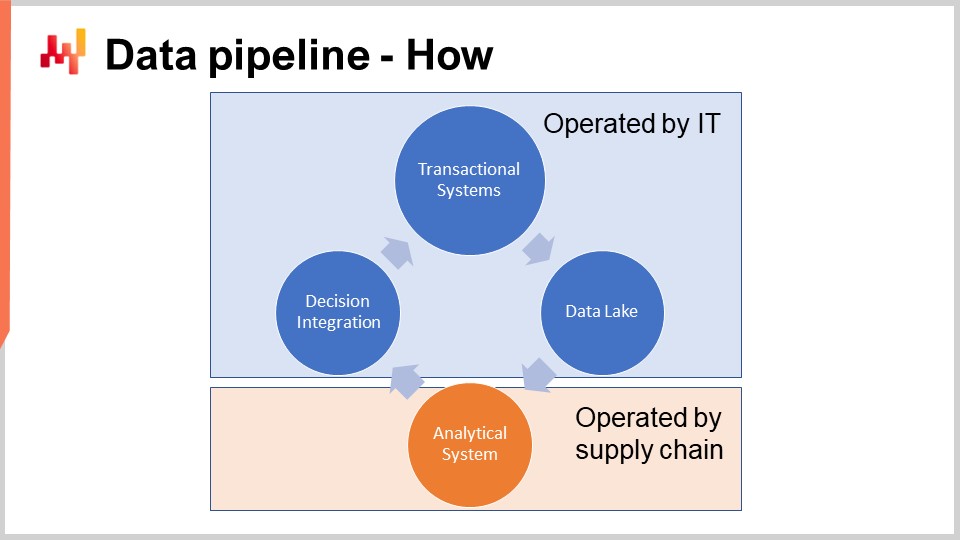
Das Schema auf dem Bildschirm veranschaulicht eine typische Datenpipeline-Konfiguration für eine Initiative der Quantitative Supply Chain. In dieser Vorlesung bespreche ich eine Datenpipeline, die keine Anforderungen an geringe Latenzzeiten unterstützt. Wir möchten in der Lage sein, einen vollständigen Zyklus in etwa einer Stunde abzuschließen, nicht in einer Sekunde. Die meisten supply chain Entscheidungen, wie Bestellungen, erfordern keine geringen Latenzzeiten. Die Erreichung einer durchgängigen geringen Latenz erfordert eine andere Art von Architektur, die den Rahmen der heutigen Vorlesung sprengt.

Die Transaktionssysteme stellen die primäre Datenquelle und den Ausgangspunkt der Datenpipeline dar. Diese Systeme umfassen ERP, WMS und EDI. Sie befassen sich mit dem Warenfluss wie Einkauf, Transport, Produktion und Verkauf. Diese Systeme enthalten nahezu alle Daten, die die zentrale numerische Rezeptur benötigt. In praktisch jedem größeren Unternehmen sind diese Systeme oder deren Vorgänger seit mindestens zwei Jahrzehnten im Einsatz.
Da diese Systeme nahezu alle benötigten Daten enthalten, wäre es verlockend, die numerische Rezeptur direkt in diese Systeme zu implementieren. Tatsächlich, warum nicht? Indem wir die numerische Rezeptur direkt in das ERP einbetten, würden wir den Aufwand für den Aufbau dieser gesamten Datenpipeline überflüssig machen. Leider funktioniert dies nicht aufgrund des grundlegenden Designs dieser Transaktionssysteme.
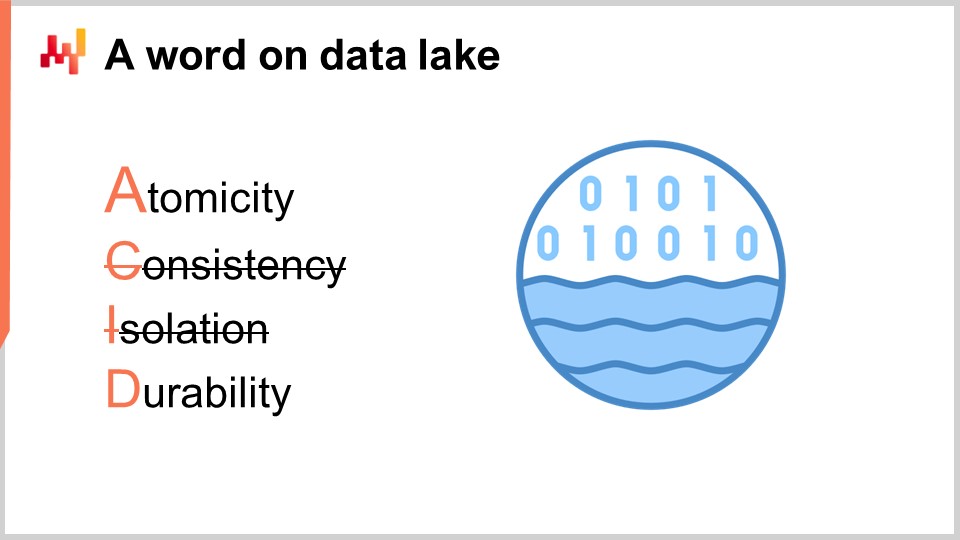
Diese Transaktionssysteme basieren stets auf einer transaktionalen Datenbank. Dieser Ansatz für das Design von Unternehmenssoftware ist in den letzten vier Jahrzehnten außerordentlich stabil geblieben. Wählt man irgendein zufälliges Unternehmen, ist die Wahrscheinlichkeit groß, dass jede einzelne Business-App in der Produktion auf einer transaktionalen Datenbank implementiert wurde. Transaktionale Datenbanken bieten vier Schlüsseleigenschaften, die unter dem Akronym ACID bekannt sind, was für Atomarität, Konsistenz, Isolation und Dauerhaftigkeit steht. Ich werde nicht auf die Details dieser Eigenschaften eingehen, aber es genügt zu sagen, dass diese Eigenschaften die Datenbank sehr gut dafür geeignet machen, viele kleine Lese- und Schreiboperationen sicher und gleichzeitig durchzuführen. Die jeweiligen Mengen an Lese- und Schreiboperationen sollen auch ziemlich ausgewogen sein.
Allerdings hat der Preis für diese sehr nützlichen ACID-Eigenschaften auf der feinsten Ebene, dass die transaktionale Datenbank auch sehr ineffizient ist, wenn es darum geht, große Leseoperationen zu bedienen. Eine Leseoperation, die einen beträchtlichen Teil der gesamten Datenbank umfasst, führt in der Regel – wenn die Daten über eine Datenbank bereitgestellt werden, die sich auf die sehr detaillierte Bereitstellung dieser ACID-Eigenschaften konzentriert – zu einem um den Faktor 100 höheren Aufwand für die Rechenressourcen im Vergleich zu Architekturen, die nicht so stark auf diese ACID-Eigenschaften auf so granularer Ebene setzen. ACID ist schön, aber es hat seinen hohen Preis.
Zudem, wenn jemand versucht, einen beträchtlichen Teil der gesamten Datenbank zu lesen, wird die Datenbank wahrscheinlich für eine Weile nicht mehr reagieren, da sie den Großteil ihrer Ressourcen auf diese eine große Anfrage konzentriert. Viele Unternehmen klagen darüber, dass ihre gesamten Geschäftssysteme träge sind und dass diese Systeme häufig für eine Sekunde oder länger einfrieren. Meist lässt sich diese mangelhafte Servicequalität auf schwere SQL-Abfragen zurückführen, die versuchen, zu viele Zeilen auf einmal zu lesen.
Deshalb darf die zentrale numerische Rezeptur nicht in derselben Umgebung betrieben werden wie die Transaktionssysteme, die die Produktion unterstützen. Tatsächlich müssen numerische Rezepturen bei jedem Lauf auf die meisten Daten zugreifen. Daher muss die numerische Rezeptur strikt in einem eigenen Subsystem isoliert werden, wenn auch nur, um eine weitere Verschlechterung der Leistung dieser Transaktionssysteme zu vermeiden.
Übrigens, obwohl seit Jahrzehnten bekannt ist, dass es eine furchtbare Idee ist, einen datenintensiven Prozess innerhalb eines transaktionalen Systems laufen zu lassen, hindert dies die meisten Anbieter von Transaktionssystemen (ERP, MRP, WMS) nicht daran, integrierte analytische Module, zum Beispiel Module zur Bestandsoptimierung, zu verkaufen. Dass diese Module integriert sind, führt zwangsläufig zu Problemen bei der Servicequalität, während sie enttäuschende Fähigkeiten bieten. All diese Probleme lassen sich auf dieses einzige Designproblem zurückführen: Das Transaktionssystem und das analytische System müssen strikt voneinander isoliert bleiben.
Der Data Lake ist einfach. Er ist ein Spiegelbild der Transaktionsdaten, ausgerichtet auf sehr große Leseoperationen. Tatsächlich haben wir gesehen, dass Transaktionssysteme für viele kleine Leseoperationen optimiert sind, nicht für sehr große. Um also die Servicequalität des Transaktionssystems zu erhalten, besteht das korrekte Design darin, die Transaktionsdaten sorgfältig in ein anderes System zu replizieren, nämlich in den Data Lake. Diese Replikation muss mit Bedacht implementiert werden, um die Servicequalität des Transaktionssystems zu wahren, was in der Regel bedeutet, die Daten sehr inkrementell zu lesen und Druckspitzen auf das Transaktionssystem zu vermeiden.
Sobald die relevanten Transaktionsdaten in den Data Lake gespiegelt wurden, bedient der Data Lake selbst alle Datenanfragen. Ein zusätzlicher Vorteil des Data Lake ist seine Fähigkeit, mehrere analytische Systeme zu unterstützen. Während hier über supply chain gesprochen wird, benötigt das Marketing, wenn es eigene Analysen wünscht, dieselben Transaktionsdaten, und dasselbe gilt für Finanzen, Vertrieb usw. Daher ist es sinnvoll, statt jeder Abteilung im Unternehmen, die ihren eigenen Datenextraktionsmechanismus implementiert, all diese Extraktionen in einem einzigen Data Lake, demselben System, zusammenzufassen.
Auf technischer Ebene kann ein Data Lake mit einer relationalen Datenbank umgesetzt werden, die typischerweise auf Big-Data-Extraktion abgestimmt ist und eine spaltenbasierte Datenspeicherung verwendet. Data Lakes können auch als Repository von Flachdateien implementiert werden, die über ein verteiltes Dateisystem bereitgestellt werden. Im Vergleich zu einem transaktionalen System verzichtet ein Data Lake auf die feingranularen transaktionalen Eigenschaften. Das Ziel ist es, eine große Menge an Daten so kostengünstig und zuverlässig wie möglich bereitzustellen – nicht mehr und nicht weniger.
Der Data Lake muss die ursprünglichen Transaktionsdaten spiegeln, was bedeutet, dass sie kopiert werden, ohne etwas zu verändern. Es ist wichtig, die Daten im Data Lake nicht aufzubereiten. Leider ist das IT-Team, das für die Einrichtung des Data Lake verantwortlich ist, oft versucht, die Dinge für andere Teams zu vereinfachen und die Daten daher ein wenig aufzubereiten. Doch jede Datenänderung führt unweigerlich zu Komplikationen, die die Analysen in einer späteren Phase beeinträchtigen. Außerdem verringert die strikte Spiegelungs-Policy erheblich den Aufwand, den das IT-Team für die Einrichtung und spätere Wartung des Data Lake benötigt.
In Unternehmen, in denen bereits ein BI-Team vorhanden ist, kann es verlockend sein, die BI-Systeme als Data Lake zu verwenden. Ich rate jedoch dringend davon ab und empfehle niemals, ein BI-Setup als Data Lake zu nutzen. Tatsächlich sind die Daten in BI-Systemen (Business Intelligence Systems) in der Regel bereits stark transformiert. Die Nutzung der BI-Daten, um automatisierte supply chain Entscheidungen zu treffen, ist ein Rezept für das Garbage-in-Garbage-out-Problem. Der Data Lake darf nur mit primären Datenquellen wie ERP gespeist werden, nicht mit sekundären Datenquellen wie dem BI-System.
Das analytische System ist dasjenige, das die zentrale numerische Rezeptur enthält. Es ist auch das System, das alle Berichte liefert, die zur Implementierung der Entscheidungen selbst benötigt werden. Auf technischer Ebene enthält das analytische System die „smarten Komponenten“, wie die Machine-Learning-Algorithmen und mathematischen Optimierungsalgorithmen. In der Praxis dominieren diese smarten Komponenten jedoch nicht den Codebestand der analytischen Systeme. Üblicherweise umfasst die Datenaufbereitung und Dateninstrumentierung mindestens das Zehnfache der Codezeilen der Teile, die sich mit Lernen und Optimierung befassen.
Das analytische System muss vom Data Lake entkoppelt werden, da diese beiden Systeme technologisch völlig unterschiedliche Ansätze verfolgen. Als Software wird vom Data Lake erwartet, dass er sehr einfach, sehr stabil und extrem zuverlässig ist. Im Gegensatz dazu soll das analytische System hochentwickelt, ständig im Wandel und in Bezug auf die supply chain performance äußerst leistungsfähig sein. Anders als der Data Lake, der nahezu perfekte Betriebszeit liefern muss, muss das analytische System nicht die meiste Zeit in Betrieb sein. Zum Beispiel, wenn wir tägliche Entscheidungen zur Bestandsauffüllung betrachten, muss das analytische System nur einmal pro Tag laufen und verfügbar sein.
Als Faustregel gilt, dass es besser ist, wenn das analytische System keine Entscheidungen produziert, als falsche Entscheidungen zu generieren und sie in die Produktion fließen zu lassen. Das Verzögern von supply chain Entscheidungen um ein paar Stunden, wie z. B. Bestellungen, ist in der Regel viel weniger dramatisch, als falsche Entscheidungen zu treffen. Da das Design des analytischen Systems tendenziell stark von den intelligenten Komponenten beeinflusst wird, die es enthält, gibt es nicht unbedingt viel Allgemeingültiges über das Design des analytischen Systems zu sagen. Es gibt jedoch mindestens ein zentrales Entwurfsprinzip, das im gesamten Ökosystem eingehalten werden muss: Dieses System muss zustandslos sein.
Das analytische System muss soweit wie möglich darauf verzichten, einen internen Zustand zu haben. Mit anderen Worten, das gesamte Ökosystem muss mit den Daten beginnen, wie sie vom Data Lake präsentiert werden, und mit den generierten, beabsichtigten supply chain Entscheidungen enden – zusammen mit unterstützenden Berichten. Was oft geschieht, ist, dass, wann immer es eine Komponente im analytischen System gibt, die zu langsam ist, wie ein Machine-Learning-Algorithmus, es verlockend wird, einen Zustand einzuführen, also einige Informationen aus der vorherigen Ausführung zu persistieren, um die nächste Ausführung zu beschleunigen. Allerdings ist es gefährlich, sich dabei auf zuvor berechnete Ergebnisse zu verlassen, anstatt jedes Mal alles von Grund auf neu zu berechnen.
Tatsächlich setzt ein Zustand im analytischen System die Entscheidung einem Risiko aus. Auch wenn Datenprobleme unvermeidlich auftreten und auf Ebene des Data Lake behoben werden, kann das analytische System dennoch Entscheidungen zurückgeben, die ein bereits behobenes Problem widerspiegeln. Zum Beispiel, wenn ein Demand-Forecasting-Modell auf einem fehlerhaften Verkaufsdatensatz trainiert wird, bleibt das Forecasting-Modell fehlerhaft, bis es mit einer frischen, korrigierten Version des Datensatzes neu trainiert wird. Der einzige Weg, um zu vermeiden, dass das analytische System von Echos bereits behobener Datenprobleme des Data Lake betroffen ist, besteht darin, jedes Mal alles zu erneuern. Das ist das Wesen des Zustandslosseins.
Als Faustregel gilt: Wenn sich ein Teil des analytischen Systems als zu langsam erweist, um ihn täglich zu ersetzen, muss dieser Teil als von einem Leistungsproblem betroffen betrachtet werden. Supply chains sind chaotisch, und es wird der Tag kommen, an dem etwas passiert – ein Brand, ein Lockdown, ein Cyberangriff –, das sofortiges Eingreifen erfordert. Das Unternehmen muss in der Lage sein, alle seine supply chain Entscheidungen innerhalb einer Stunde zu aktualisieren. Das Unternehmen darf nicht zehn Stunden warten, während die langsame Machine-Learning-Trainingsphase stattfindet.

Damit das analytische System zuverlässig arbeiten kann, muss es ordnungsgemäß instrumentiert sein. Genau darum geht es beim Data Health Report und bei den Data Inspectors. Übrigens liegt all dies in der Verantwortung der supply chain; es ist nicht die Verantwortung der IT. Die Überwachung der Data Health stellt die allererste Phase der Datenverarbeitung dar – noch vor der eigentlichen Datenaufbereitung – und findet innerhalb des analytischen Systems statt. Data Health ist ein Teil der Instrumentierung des numerischen Rezepts. Der Data Health Report gibt an, ob es akzeptabel ist, das numerische Rezept überhaupt auszuführen. Dieser Bericht weist zudem, falls vorhanden, auf den Ursprung des Datenproblems hin, um die Behebung des Problems zu beschleunigen.
Die Überwachung der Data Health ist bei Lokad eine etablierte Praxis. In den letzten zehn Jahren hat sich diese Praxis als unschätzbar wertvoll erwiesen, um Garbage-In-Garbage-Out-Situationen zu vermeiden, die in der Welt der Unternehmenssoftware allgegenwärtig zu sein scheinen. Wenn eine datenintensive Initiative scheitert, werden häufig schlechte Daten als Ursache herangezogen. Es ist jedoch wichtig anzumerken, dass in der Regel kaum technische Maßnahmen ergriffen werden, um die Datenqualität von vornherein sicherzustellen. Datenqualität fällt nicht vom Himmel; sie erfordert technischen Einsatz.
Die bisher vorgestellte Datenpipeline ist ziemlich minimalistisch. Das Data Mirroring ist so einfach wie möglich gestaltet, was sich positiv auf die Softwarequalität auswirkt. Dennoch gibt es, trotz dieses Minimalismus, zahlreiche bewegliche Teile: viele Tabellen, viele Systeme, viele Personen. Daher gibt es überall Fehler. Dies ist Unternehmenssoftware, und das Gegenteil wäre durchaus überraschend. Die Überwachung der Data Health ist eingerichtet, um dem analytischen System zu helfen, das allgegenwärtige Chaos zu überstehen.
Data Health darf nicht mit Datenbereinigung verwechselt werden. Data Health bedeutet lediglich sicherzustellen, dass die dem analytischen System zur Verfügung gestellten Daten eine getreue Darstellung der Transaktionsdaten sind, die in den Transaktionssystemen existieren. Es wird nicht versucht, die Daten zu korrigieren; die Daten werden so analysiert, wie sie sind.
Bei Lokad unterscheiden wir typischerweise zwischen Low-Level Data Health und High-Level Data Health. Low-Level Data Health ist ein Dashboard, das alle strukturellen und volumetrischen Unregelmäßigkeiten der Daten konsolidiert – wie offensichtliche Probleme, etwa Einträge, die nicht einmal als sinnvolle Daten oder Zahlen durchgehen, oder verwaiste Identifikatoren, denen ihre erwarteten Gegenstücke fehlen. All diese Probleme können erkannt werden und sind tatsächlich die einfachen. Das schwierige Problem beginnt bei denjenigen Themen, die nicht sichtbar sind, weil die Daten zunächst fehlen. Wenn beispielsweise bei einer Datenauslesung etwas schiefläuft und die gestern extrahierten Verkaufsdaten nur die Hälfte der erwarteten Zeilen enthalten, kann dies die Produktion ernsthaft gefährden. Unvollständige Daten sind besonders heimtückisch, weil sie in der Regel nicht verhindern, dass das numerische Rezept Entscheidungen generiert – nur dass diese Entscheidungen Müll sind, da die Eingabedaten unvollständig sind.
Technisch gesehen versuchen wir bei Lokad, die Überwachung der Data Health auf einem einzigen Dashboard zusammenzufassen. Dieses Dashboard ist typischerweise für das IT-Team bestimmt, da die meisten Probleme, die durch die Low-Level Data Health erfasst werden, mit der Datenpipeline selbst zusammenhängen. Idealerweise sollte das IT-Team auf einen Blick feststellen können, ob alles in Ordnung ist oder ob weiterer Eingriff erforderlich ist.

Die Überwachung der High-Level Data Health betrachtet alle unternehmensbezogenen Unregelmäßigkeiten – Elemente, die aus geschäftlicher Sicht falsch erscheinen. High-Level Data Health umfasst Aspekte wie negative Lagerbestände oder abnorm hohe Mindestbestellmengen. Sie erfasst auch Preise, die keinen Sinn ergeben, weil das Unternehmen mit Verlusten oder mit lächerlich hohen Margen arbeiten würde. High-Level Data Health versucht, all jene Elemente abzudecken, bei denen ein Supply Chain Practitioner die Daten betrachtet und sagt: “Das kann unmöglich stimmen, hier liegt ein Problem vor.”
Im Gegensatz zum Low-Level Data Health Report ist der High-Level Data Health Report in erster Linie für das supply chain Team gedacht. Probleme wie anomale Mindestbestellmengen werden nur von einem Practitioner wahrgenommen, der zumindest etwas mit der Geschäftsumgebung vertraut ist. Ziel dieses Berichts ist es, auf einen Blick festzustellen, dass alles in Ordnung ist und dass kein weiterer Eingriff notwendig ist.
Zuvor sagte ich, dass das analytische System zustandslos sein sollte. Nun, es stellt sich heraus, dass Data Health die Ausnahme ist, die die Regel bestätigt. Tatsächlich können viele Probleme identifiziert werden, indem man die aktuellen Indikatoren mit denselben Indikatoren der vergangenen Tage vergleicht. Daher speichert die Überwachung der Data Health typischerweise eine Art Zustand, nämlich Schlüsselindikatoren, wie sie in den vorangegangenen Tagen beobachtet wurden, um so Ausreißer im aktuellen Zustand der Daten zu identifizieren. Da Data Health jedoch rein ein Überwachungsprozess ist, ist das Schlimmste, was passieren kann, wenn ein auf dem Data Lake behobenes Problem weiterhin als Echo in der gespeicherten Data Health erscheint, dass die Berichte eine Reihe von Fehlalarmen auslösen. Die Logik, die die supply chain Entscheidungen generiert, bleibt dabei vollständig zustandslos; der Zustand betrifft nur einen kleinen Teil der Instrumentierung.
Die Überwachung der Data Health, sowohl auf Low-Level als auch auf High-Level, ist eine Abwägung zwischen dem Risiko, falsche Entscheidungen zu liefern, und dem Risiko, Entscheidungen nicht rechtzeitig zu liefern. Betrachtet man große supply chains, ist es nicht realistisch zu erwarten, dass 100 Prozent der Daten korrekt sind – fehlerhafte transaktionale Einträge können vorkommen, wenn auch selten. Daher muss ein Problemvolumen toleriert werden, das als ausreichend gering erachtet wird, damit das numerische Rezept funktioniert. Die Abwägung zwischen diesen beiden Risiken – entweder zu empfindlich auf Datenstörungen zu reagieren oder zu tolerant gegenüber Datenproblemen zu sein – hängt stark von der wirtschaftlichen Struktur der supply chain ab.
Bei Lokad erstellen und optimieren wir diese Berichte individuell für jeden Kunden. Anstatt jedem denkbaren Fall von Datenkorruption hinterherzujagen, versucht der Supply Chain Scientist, der für die Implementierung der Low-Level und High-Level Data Health sowie der Data Inspectors verantwortlich ist, die Überwachung der Data Health so abzustimmen, dass sie empfindlich für jene Probleme ist, die tatsächlich schädlich sind und in der betreffenden supply chain auch wirklich auftreten.
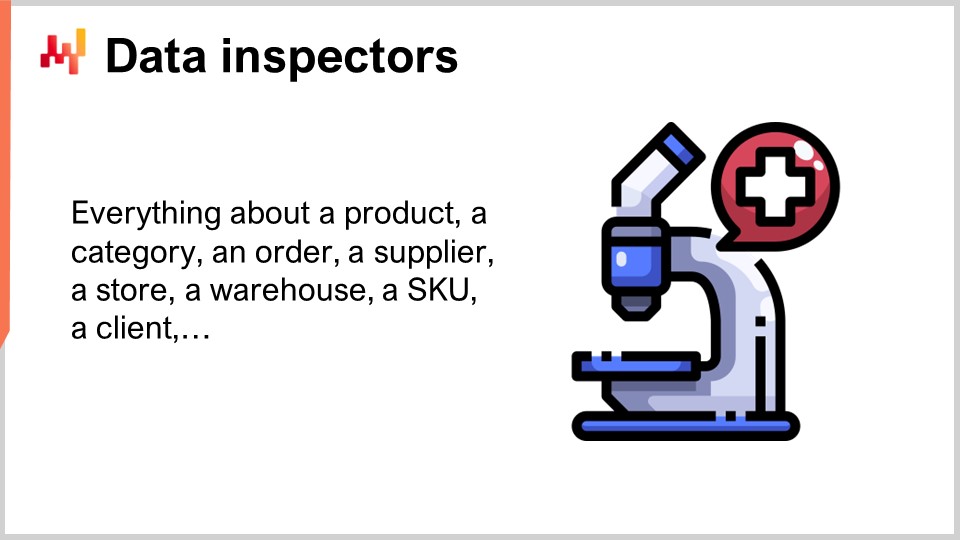
Im Lokad-Jargon ist ein Data Inspector, oder einfach ein Inspector, ein Bericht, der alle relevanten Daten bezüglich eines interessierenden Objekts konsolidiert. Das interessierende Objekt wird aus der Perspektive der supply chain als erstklassiger Bürger erwartet – sei es ein Produkt, ein Lieferant, ein Kunde oder ein Warehouse. Wenn wir beispielsweise einen Data Inspector für Produkte betrachten, sollte es möglich sein, für jedes vom Unternehmen verkaufte Produkt auf einem einzigen Bildschirm alle an dieses Produkt angehängten Daten einzusehen. Im Data Inspector für Produkte gibt es so viele Ansichten, wie es Produkte gibt, denn wenn ich sage, wir sehen alle Daten, meine ich alle Daten, die einem Barcode oder einer Teilenummer zugeordnet sind – nicht alle Produkte im Allgemeinen.
Im Gegensatz zu den Low-Level und High-Level Data Health Reports, die als zwei Dashboards konzipiert sind, die auf einen Blick inspizierbar sein sollen, werden Inspectors dazu implementiert, Fragen und Bedenken zu adressieren, die unweigerlich während der Gestaltung und dem Betrieb des kern-numerischen Rezepts auftreten. Tatsächlich ist es bei der Entscheidungsfindung in der supply chain nicht ungewöhnlich, Daten aus einem Dutzend Tabellen zusammenzuführen, die möglicherweise aus mehreren Transaktionssystemen stammen. Da die Daten überall verteilt sind, ist es üblicherweise schwierig, den Ursprung eines Problems festzustellen, wenn eine Entscheidung verdächtig erscheint. Es kann eine Diskrepanz zwischen den Daten, wie sie vom analytischen System erfasst werden, und den Daten, die in den Transaktionssystemen existieren, geben. Es kann ein fehlerhafter Algorithmus vorliegen, der es versäumt, ein statistisches Muster in den Daten zu erfassen. Oder es kann eine falsche Wahrnehmung vorliegen, sodass die als verdächtig angesehene Entscheidung in Wirklichkeit korrekt ist. In jedem Fall soll der Inspector die Möglichkeit bieten, in das interessierende Objekt hineinzuzoomen.
Um nützlich zu sein, müssen Inspectors die Besonderheiten sowohl der supply chain als auch der Anwendungslandschaft widerspiegeln. Daher ist die Erstellung von Inspectors fast immer eine maßgeschneiderte Angelegenheit. Sobald diese Arbeit jedoch abgeschlossen ist, stellt der Inspector einen der Pfeiler der Instrumentierung des analytischen Systems dar.
Zusammenfassend lässt sich sagen, dass die meisten Initiativen der die Quantitative Supply Chain sogar schon vor ihrem Start zum Scheitern verurteilt sind – es muss aber nicht so sein. Eine sorgfältige Auswahl von Ergebnissen, Zeitplänen, Umfang und Regeln ist notwendig, um Probleme zu vermeiden, die diese Initiativen unweigerlich zum Scheitern bringen. Leider sind diese Entscheidungen häufig etwas kontraintuitiv, wie Lokad in 14 Jahren Betrieb auf die harte Tour gelernt hat.
Der allererste Schritt der Initiative muss der Einrichtung einer Datenpipeline gewidmet sein. Eine unzuverlässige Datenpipeline ist eine der sichersten Methoden, um sicherzustellen, dass jede datengesteuerte Initiative scheitert. Die meisten Unternehmen, selbst die meisten IT departments, unterschätzen die Bedeutung einer hochzuverlässigen Datenpipeline, die keine dauerhafte Fehlerbehebung erfordert. Während der Großteil der Einrichtung der Datenpipeline in den Händen der IT-Abteilung liegt, muss die supply chain selbst für die Instrumentierung des von ihr betriebenen analytischen Systems verantwortlich sein. Erwarte nicht, dass die IT dies für dich übernimmt; das liegt in der Verantwortung des supply chain Teams. Wir haben zwei verschiedene Arten der Instrumentierung kennengelernt, nämlich die Data Health Reports, die eine unternehmensweite Perspektive einnehmen, und die Data Inspectors, die tiefgehende Diagnosen unterstützen.

Heute haben wir besprochen, wie man eine Initiative startet, aber beim nächsten Mal werden wir sehen, wie man sie beendet oder besser gesagt, hoffentlich zum Erfolg führt. In der nächsten Vorlesung, die am Mittwoch, den 14. September stattfinden wird, setzen wir unsere Reise fort und sehen, welche Art von Umsetzung nötig ist, um ein kern-numerisches Rezept zu entwickeln und anschließend die von ihm generierten Entscheidungen schrittweise in Produktion zu überführen. Wir werden auch einen genaueren Blick darauf werfen, was diese neue Art, die supply chain zu betreiben, für den täglichen Betrieb der Supply Chain Practitioner bedeutet.
Schauen wir uns nun die Fragen an.
Frage: Warum ist es genau sechs Monate als Zeitlimit, nach denen eine Implementierung nicht korrekt durchgeführt wird?
Ich würde sagen, das Problem liegt nicht primär darin, dass das Zeitlimit sechs Monate beträgt. Vielmehr ist es so, dass Initiativen von Anfang an zum Scheitern verurteilt sind. Das ist das Problem. Wenn deine Initiative zur prädiktiven Optimierung mit der Erwartung startet, dass Ergebnisse in zwei Jahren geliefert werden, ist es nahezu garantiert, dass die Initiative irgendwann aufgelöst wird und nichts in die Produktion kommt. Wenn es nach meiner Vorstellung gelänge, würde ich es bevorzugen, dass die Initiative in drei Monaten erfolgreich ist. Sechs Monate stellen jedoch nach meiner Erfahrung den minimalen Zeitrahmen dar, um eine solche Initiative in Produktion zu bringen. Jede zusätzliche Verzögerung erhöht das Risiko des Scheiterns. Es ist sehr schwierig, diesen Zeitrahmen weiter zu verkürzen, denn sobald alle technischen Probleme gelöst sind, spiegeln die verbleibenden Verzögerungen die Zeit wider, die benötigt wird, um in den Rhythmus der Initiative zu finden.
Frage: Supply chain practitioners könnten frustriert sein über eine Initiative, die den Großteil ihrer Arbeitslast ersetzt – wie beispielsweise die Einkaufsabteilung – und damit in Konflikt mit der Entscheidungsautomatisierung steht. Wie würden Sie empfehlen, damit umzugehen?
Das ist eine sehr wichtige Frage, die hoffentlich in der nächsten Vorlesung behandelt wird. Für heute kann ich nur sagen, dass ich glaube, dass der Großteil dessen, was supply chain practitioners in den heutigen supply chains tun, wenig lohnend ist. In den meisten Unternehmen erhalten die Mitarbeiter eine Reihe von SKUs oder Teilenummern und durchlaufen sie anschließend endlos, während sie alle notwendigen Entscheidungen treffen. Das bedeutet, dass ihre Aufgabe im Wesentlichen darin besteht, eine Tabelle anzusehen und sie einmal pro Woche oder möglicherweise einmal pro Tag zu durchlaufen. Das ist kein erfüllender Beruf.
Die kurze Antwort ist, dass der Lokad-Ansatz das Problem dadurch angeht, dass er alle monotonen Aspekte der Arbeit automatisiert, sodass die Personen mit echter Expertise in der supply chain anfangen können, die Grundlagen der supply chain in Frage zu stellen. Dadurch können sie mehr mit Kunden und Lieferanten diskutieren, um alles effizienter zu gestalten. Es geht darum, Erkenntnisse zu sammeln, damit wir das numerische Rezept verbessern können. Das Ausführen des numerischen Rezepts ist mühsam, und es wird nur sehr wenige Menschen geben, die die alten Zeiten bedauern, in denen sie täglich Tabellen durchgehen mussten.
Frage: Ist von supply chain practitioners zu erwarten, dass sie mit Daten-Gesundheitsberichten arbeiten, um die von Supply Chain Scientists generierten Entscheidungen in Frage zu stellen?
Von supply chain practitioners wird erwartet, dass sie mit Dateninspektoren arbeiten, nicht mit Daten-Gesundheitsberichten. Daten-Gesundheitsberichte sind wie eine unternehmensweite Bewertung, die die Frage beantwortet, ob die Daten am Eingang des analytischen Systems gut genug sind, damit ein numerisches Rezept auf dem Datensatz ausgeführt werden kann. Das Ergebnis des Daten-Gesundheitsberichts ist eine binäre Entscheidung: Entweder wird die Ausführung des numerischen Rezepts freigegeben oder es wird widersprochen, weil ein Problem besteht, das behoben werden muss. Dateninspektoren, die in der nächsten Vorlesung ausführlicher besprochen werden, sind der Einstiegspunkt für supply chain practitioners, um Einblicke in eine vorgeschlagene supply chain Entscheidung zu gewinnen.
Frage: Ist es machbar, ein analytisches Modell zu aktualisieren, zum Beispiel indem man eine inventory policy täglich festlegt? Das supply chain system kann doch nicht auf tägliche Richtlinienänderungen reagieren – wird es nicht einfach das System mit Rauschen versorgen?
Um den ersten Teil der Frage zu beantworten, ist es durchaus machbar, ein analytisches Modell täglich zu aktualisieren. Zum Beispiel, als Lokad im Jahr 2020 während der Lockdowns in Europa tätig war, schlossen und öffneten sich Länder mit nur 24 Stunden Vorwarnzeit. Dies schuf eine äußerst chaotische Situation, die ständige, unmittelbare tägliche Anpassungen erforderte. Unter diesem extremen Druck managte Lokad Lockdowns, die fast 14 Monate lang täglich in ganz Europa begannen oder endeten.
Also, ein tägliches Aktualisieren eines analytischen Modells ist machbar, aber nicht unbedingt wünschenswert. Es ist wahr, dass supply chain systems viel Trägheit besitzen, und das Erste, was ein angemessenes numerisches Rezept berücksichtigen muss, ist der Ratschen-Effekt der meisten Entscheidungen. Sobald die Produktion in Gang gesetzt und Rohmaterialien verbraucht wurden, kann die Produktion nicht rückgängig gemacht werden. Man muss berücksichtigen, dass viele Entscheidungen bereits getroffen wurden, wenn man neue fasst. Wenn man jedoch erkennt, dass die supply chain einen drastischen Kurswechsel benötigt, macht es keinen Sinn, diese Korrektur nur um ihrer selbst willen zu verzögern. Der beste Zeitpunkt, die Änderung umzusetzen, ist genau jetzt.
Bezüglich des Aspekts des Rauschens in der Frage kommt es auf das korrekte Design der numerischen Rezepte an. Es gibt viele fehlerhafte Designs, die instabil sind, bei denen kleine Änderungen in den Daten große Veränderungen in den Entscheidungen hervorrufen, welche das Ergebnis des numerischen Rezepts darstellen. Ein numerisches Rezept sollte nicht sprunghaft reagieren, wenn es zu einer kleinen Schwankung in der supply chain kommt. Aus diesem Grund hat Lokad eine probabilistische Perspektive beim Forecasting übernommen. Durch die Verwendung einer probabilistischen Perspektive können Modelle so konzipiert werden, dass sie wesentlich stabiler sind als Modelle, die versuchen, den Mittelwert zu erfassen und bei dem das Auftreten eines Ausreißers in der supply chain zu sprunghaften Veränderungen führt.
Frage: Eines der Probleme, mit denen wir in der supply chain bei sehr großen Unternehmen konfrontiert sind, ist ihre Abhängigkeit von verschiedenen Quellsystemen. Ist es nicht extrem schwierig, alle Daten aus diesen Quellsystemen in ein einheitliches System zu überführen?
Ich stimme vollkommen zu, dass das Beschaffen aller Daten für viele Unternehmen eine große Herausforderung darstellt. Wir müssen uns jedoch fragen, warum es überhaupt eine Herausforderung ist. Wie bereits erwähnt, basieren heutzutage 99 % der Geschäftsanwendungen großer Unternehmen auf Mainstream, gut entwickelten transaktionalen Datenbanken. Es mag noch einige veraltete COBOL-Implementierungen geben, die auf arkane Binärspeicher zurückgreifen, aber das ist selten. Die überwiegende Mehrzahl der Geschäftsanwendungen, selbst diejenigen, die in den 1990er Jahren eingeführt wurden, arbeitet mit einer sauberen, produktionsfertigen transaktionalen Datenbank im Backend.
Sobald man ein transaktionales Backend hat, warum sollte es schwierig sein, diese Daten in einen Data Lake zu kopieren? Meistens besteht das Problem darin, dass Unternehmen nicht nur versuchen, die Daten zu kopieren – sie versuchen, noch viel mehr zu tun. Sie versuchen, die Daten vorzubereiten und zu transformieren, was den Prozess oft unnötig verkompliziert. Die meisten modernen Datenbank-Setups verfügen über eingebaute Daten-Spiegelungsfunktionen, die es ermöglichen, alle Änderungen von einer transaktionalen Datenbank in eine sekundäre Datenbank zu replizieren. Dies ist eine eingebaute Eigenschaft der vermutlich 20 meistgenutzten transaktionalen Systeme auf dem Markt.
Unternehmen haben oft Schwierigkeiten, die Daten zu konsolidieren, weil sie zu viel auf einmal zu tun versuchen, und ihre Initiativen unter ihrer eigenen Komplexität zusammenbrechen. Sobald die Daten konsolidiert sind, begehen Unternehmen oft den Fehler zu denken, dass das Verbinden der Daten von IT-, BI- oder Data Science-Teams erledigt werden sollte. Der Punkt, den ich hier machen möchte, ist, dass die supply chain für ihre eigenen numerischen Rezepte verantwortlich sein muss, genauso wie Marketing, Vertrieb und Finanzen es sein sollten. Es sollte keine abteilungsübergreifende Support-Division sein, die versucht, dies für das Unternehmen zu übernehmen. Das Verbinden von Daten aus verschiedenen Systemen erfordert typischerweise eine Menge Geschäftseinblicke. Große Unternehmen scheitern oft, weil sie versuchen, einen Experten aus IT-, BI- oder Data Science-Teams für diese Aufgabe heranzuziehen, obwohl dies innerhalb der betreffenden Abteilung erledigt werden sollte.
Vielen Dank für Ihre Zeit heute, Ihr Interesse und Ihre Fragen. Bis zum nächsten Mal nach dem Sommer, im September.