Tecnología
Volver al blog ›
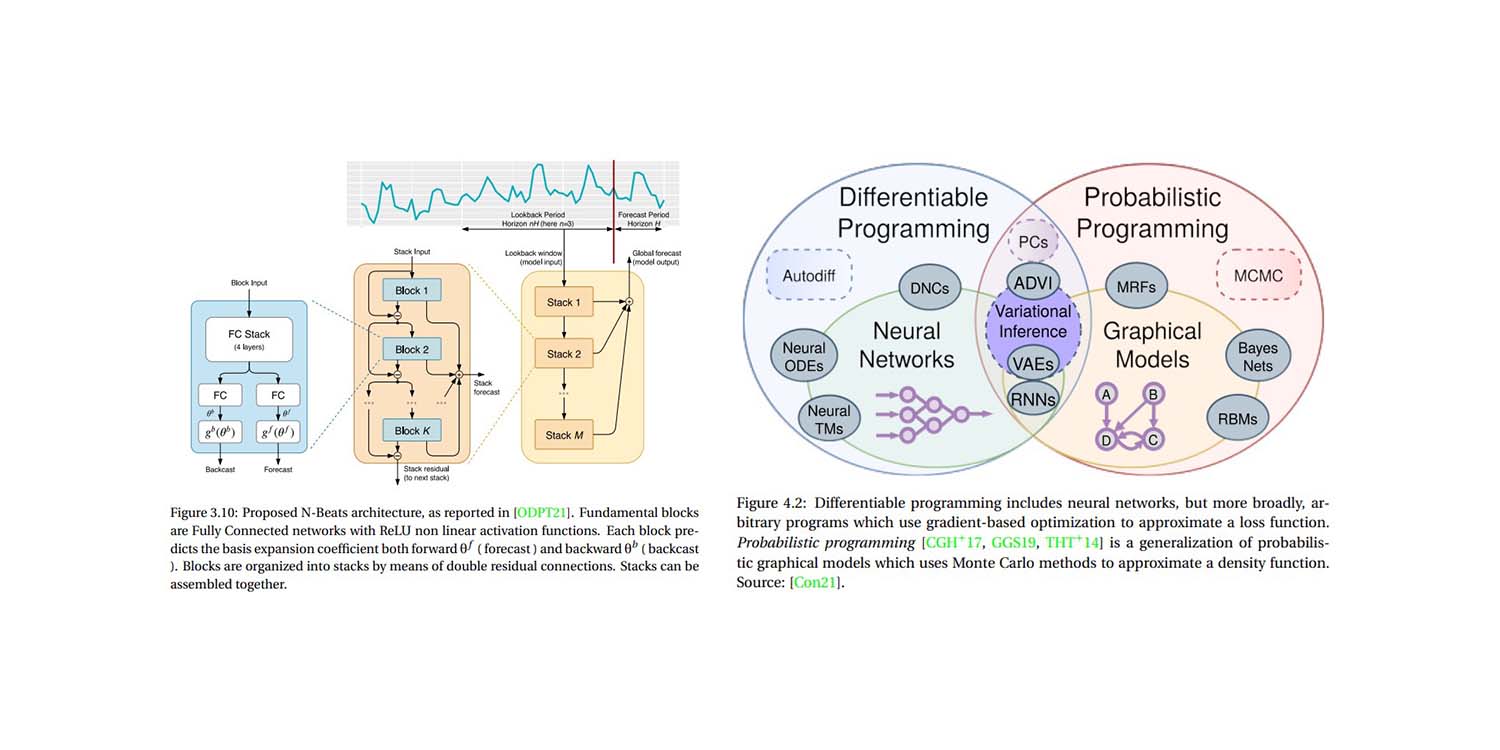
Suavizado Exponencial Probabilístico para IA Explicable en el ámbito de la supply chain
Lee la investigación doctoral de Antonio Cifonelli sobre Suavizado Exponencial Probabilístico para IA Explicable en el ámbito de la supply chain—otro gran estudio que demuestra que media docena de trucos ingeniosos pueden transformar un modelo tan básico como el suavizado exponencial en un coche de carreras que supera a los modelos deep learning de última generación.
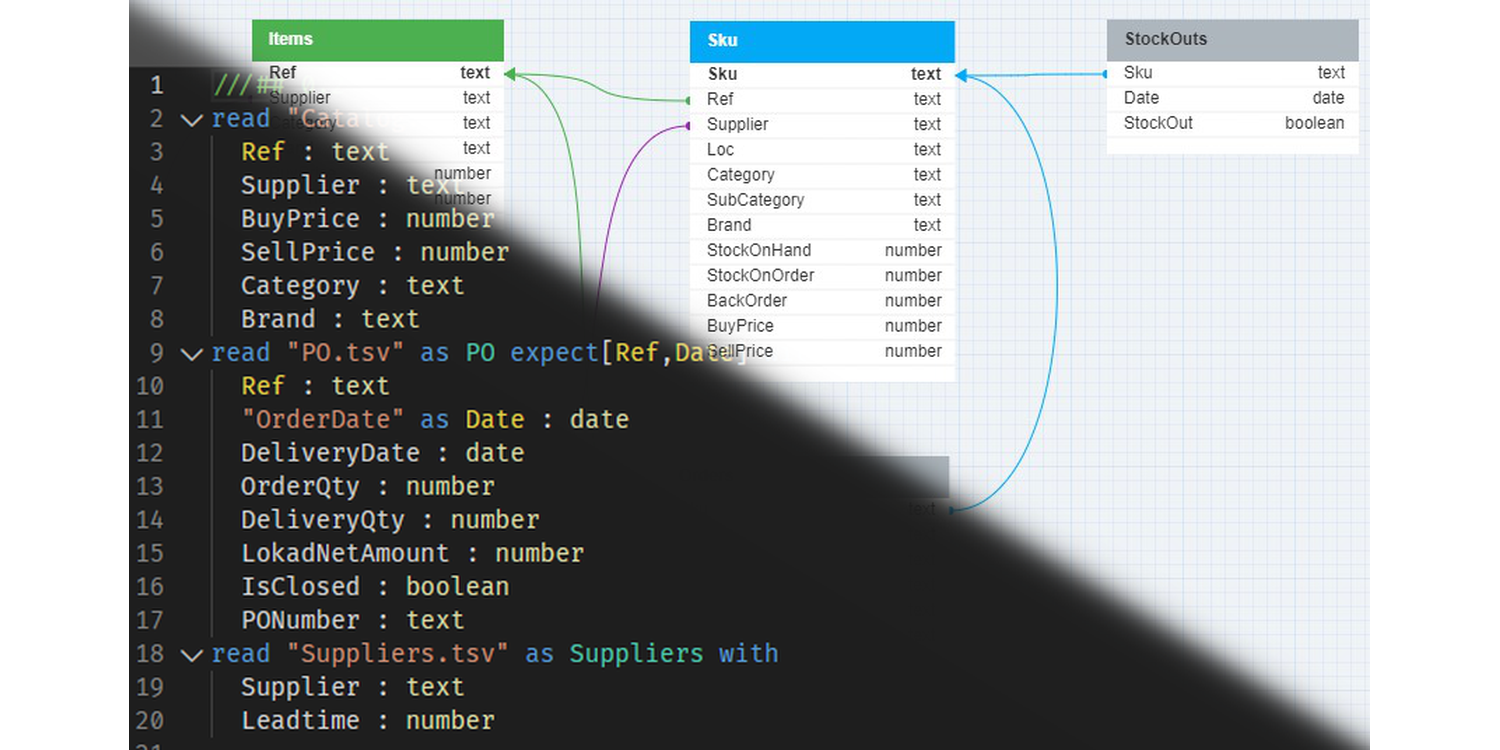
Análisis de ventas a través de Envision - Workshop #2
Este segundo Envision Workshop ofrece a estudiantes y supply chain specialists una formación guiada sobre el análisis de clientes minoristas desde la perspectiva probabilística y de gestión de riesgo de Lokad.

Diferenciación Automática de Rutas Selectiva: Más Allá de la Distribución Uniforme en el Dropout de Retropropagación
El enfoque Selective Path Automatic Differentiation (SPAD) mejora el Stochastic Gradient Descent (SGD) al adoptar una perspectiva sub-punto de datos. Esta técnica, implementada a nivel de compilador, intercambia la calidad del gradiente por la cantidad del mismo, complementando los métodos tradicionales de SGD con una visión más matizada.

Una reseña con opinión sobre Deep Inventory Management
Un equipo en Amazon publicó Deep Inventory Management (DIM) a finales de 2022. Este artículo presenta una técnica de optimización de inventario DIM que cuenta tanto con reinforcement learning como con deep learning. Como Lokad siguió un camino similar en el pasado, su CEO y fundador Joannes Vermorel ofrece su evaluación crítica de la técnica sugerida.
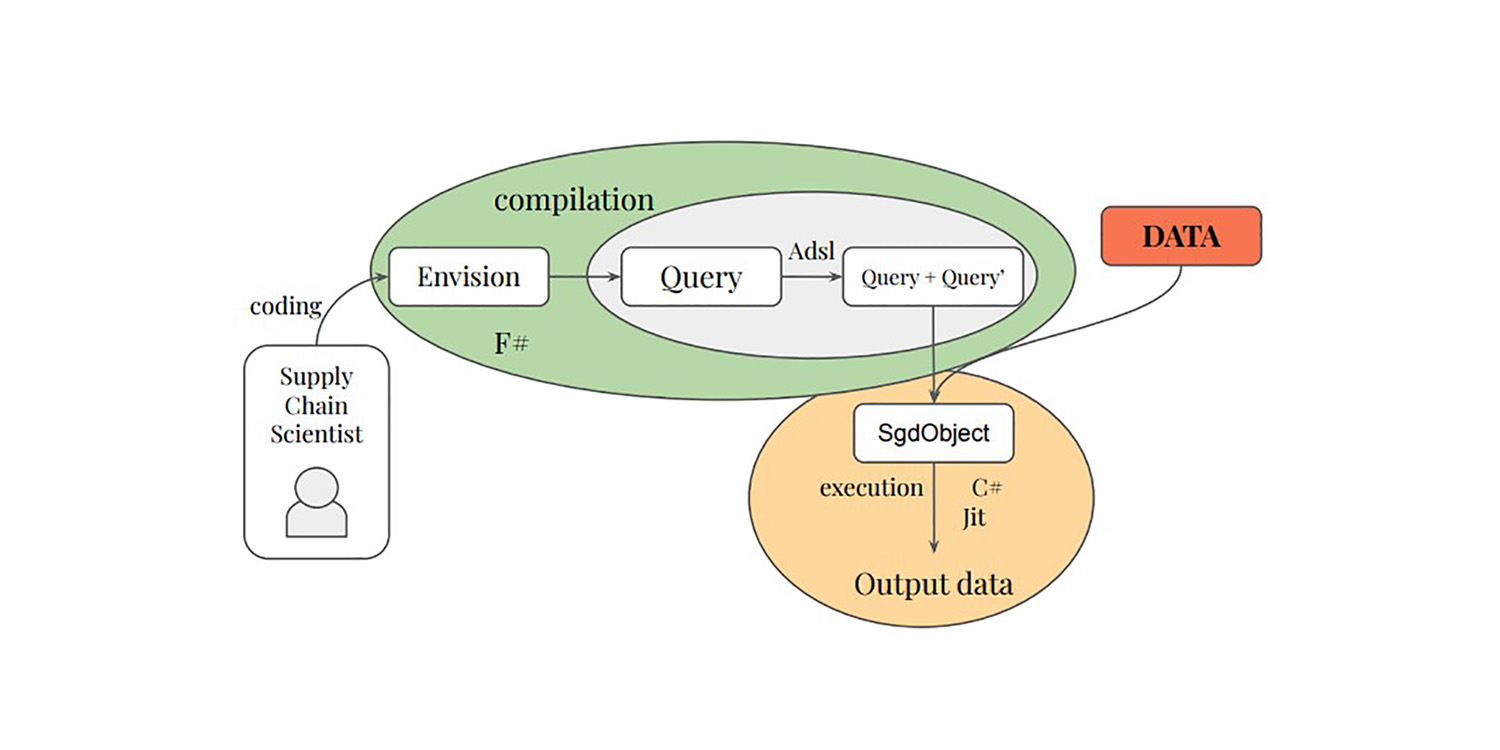
Programación diferenciable para optimizar sobre datos relacionales a gran escala
La investigación doctoral de Paul Peseux sobre la diferenciación de consultas relacionales -otra área poco investigada de supply chain- introdujo el operador TOTAL JOIN, Polystar y un mini-language ADSL para diferenciar consultas relacionales, todo lo cual Lokad integró en su DSL Envision como parte del autodiff para optimizar la toma de decisiones diarias de inventario.
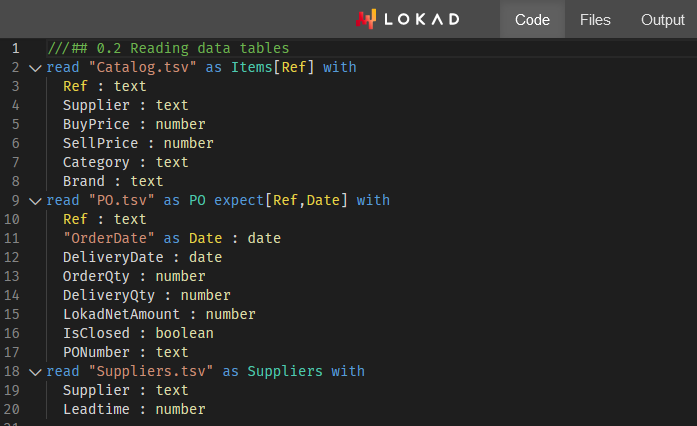
Análisis de Proveedores a través de Envision - Workshop #1
Lokad lanza su primer Envision Workshop, enseñando a estudiantes (y a especialistas de supply chain) cómo analizar proveedores de retail utilizando la perspectiva probabilística y de gestión de riesgos de Lokad.
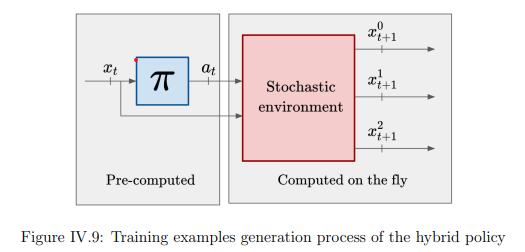
Gestión de inventario bajo la restricción de cantidades mínimas de pedido multi-referencia
La investigación doctoral de Gaetan Delétoille sobre MOQs - una área sorprendentemente poco estudiada de supply chain - introdujo la w-policy, algo que Lokad integró en su solución para la toma de decisiones diarias de inventario.
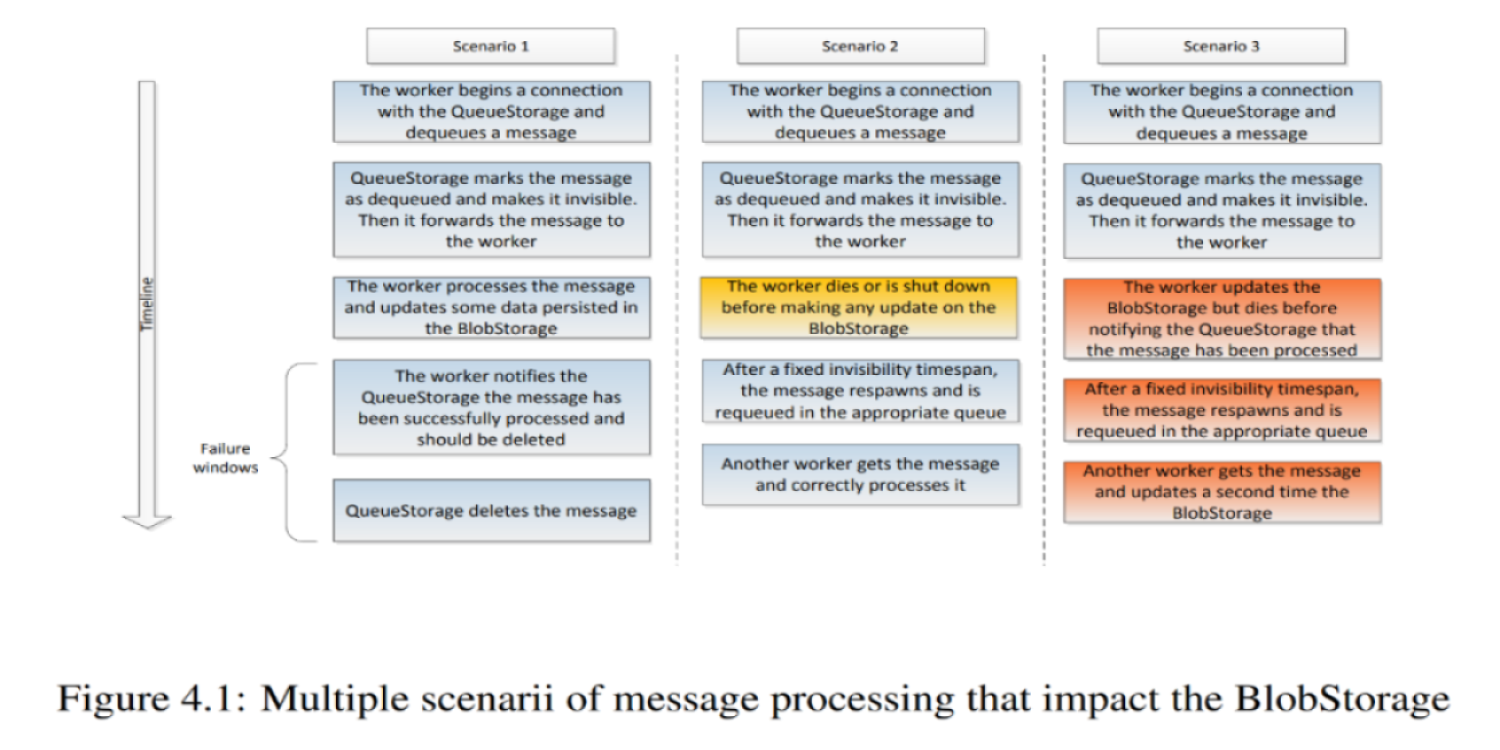
Algoritmos de clasificación distribuidos en la computación en la nube
Matthieu Durut, segundo empleado en Lokad, defendió su doctorado en 2012 por su trabajo de investigación realizado en Lokad. Este doctorado sentó las bases para la transición de Lokad hacia arquitecturas de computación distribuida nativas de la nube, actualmente críticas para gestionar a gran escala supply chain.

Aprendizaje a gran escala: una contribución a algoritmos de clustering distribuidos asincrónicos
Benoit Patra, el primer empleado de Lokad, defendió su doctorado en 2012 por su investigación realizada en Lokad. Este doctorado aportó elementos radicalmente novedosos a la teoría de supply chain, y sentó las bases para el futuro desarrollo del enfoque probabilistic forecasting de Lokad.

Descenso por gradiente estocástico con estimador de gradiente para variables categóricas
El amplio campo del aprendizaje automático (ML) proporciona una amplia gama de técnicas y métodos que cubren numerosas situaciones. Supply chain, sin embargo, cuenta con su propio conjunto específico de desafíos de datos, y a veces aspectos que podrían considerarse 'básicos' por los profesionales de supply chain, no se benefician de instrumentos de ML satisfactorios – al menos según nuestros estándares.