Generalización (previsión)
La generalización es la capacidad de un algoritmo de generar un modelo - aprovechando un conjunto de datos - que funcione bien con datos nunca antes vistos. La generalización es de vital importancia para supply chain, ya que la mayoría de las decisiones reflejan una anticipación del futuro. En el contexto de la previsión, los datos son desconocidos porque el modelo predice eventos futuros, los cuales son inobservables. Aunque se ha logrado un progreso sustancial, tanto teórico como práctico, en el frente de la generalización desde la década de 1990, la verdadera generalización sigue siendo esquiva. La resolución completa del problema de la generalización puede no ser muy diferente de la del problema de la inteligencia artificial general. Además, supply chain añade su propio lote de problemas espinosos sobre los desafíos generales de la generalización.

Visión general de una paradoja
Crear un modelo que funcione a la perfección con los datos disponibles es sencillo: basta con memorizar por completo el conjunto de datos y luego utilizar ese mismo conjunto para responder a cualquier consulta sobre él. Dado que las computadoras son buenas para almacenar grandes conjuntos de datos, diseñar tal modelo es fácil. Sin embargo, generalmente resulta inútil1, ya que el objetivo principal de tener un modelo reside en su poder predictivo más allá de lo ya observado.
Se presenta una paradoja aparentemente ineludible: un buen modelo es aquel que funciona bien con datos que actualmente no están disponibles, pero, por definición, si los datos no están disponibles, el observador no puede realizar la evaluación. Por lo tanto, el término “generalización” se refiere a la escurridiza capacidad de ciertos modelos de conservar su relevancia y calidad más allá de las observaciones disponibles en el momento en que se construye el modelo.
Aunque memorizar las observaciones puede descartarse como una estrategia de modelado inadecuada, cualquier estrategia alternativa para crear un modelo está potencialmente sujeta al mismo problema. Por mucho que el modelo parezca funcionar bien con los datos actualmente disponibles, siempre es concebible que se trate simplemente de una cuestión de azar o, peor aún, de un defecto en la estrategia de modelado. Lo que al principio puede parecer una paradoja estadística marginal es, de hecho, un asunto de gran alcance.
A modo de evidencia anecdótica, en 1979 la SEC (Securities and Exchange Commission), la agencia de Estados Unidos encargada de regular los mercados de capital, introdujo su famosa Regla 156. Esta regla exige a los gestores de fondos informar a los inversores que el rendimiento pasado no es indicativo de resultados futuros. El rendimiento pasado es, implícitamente, el “modelo” que la SEC advierte no confiar por su poder de “generalización”; es decir, su capacidad de decir algo sobre el futuro.
Incluso la propia ciencia se enfrenta a lo que significa extrapolar la “verdad” fuera de un conjunto limitado de observaciones. Los escándalos de “ciencia mala”, que se desarrollaron en los años 2000 y 2010 alrededor del p-hacking, indican que campos enteros de la investigación están quebrados y no pueden confiarse2. Aunque existen casos de fraude descarado en los que los datos experimentales han sido manipulados claramente, la mayor parte de las veces, el meollo del problema radica en los modelos; es decir, en el proceso intelectual utilizado para generalizar lo observado.
Bajo su manifestación más amplia, el problema de la generalización es indistinguible del de la propia ciencia, por lo que es tan difícil como replicar la amplitud de la creatividad y el potencial humano. Sin embargo, el matiz estadístico más restringido del problema de la generalización es mucho más abordable, y es esta la perspectiva que se adoptará en las siguientes secciones.
Surgimiento de una nueva ciencia
La generalización emergió como un paradigma estadístico a comienzos del siglo XX, principalmente desde la perspectiva de la precisión de la previsión3, que representa un caso especial estrechamente vinculado a las previsiones de series temporales. A principios de 1900, el surgimiento de una clase media propietaria de acciones en Estados Unidos generó un enorme interés en métodos que ayudaran a las personas a asegurar rendimientos financieros en sus activos comercializados. Tanto los adivinos como las previsiones económicas se dignaron a extrapolar eventos futuros para un público ansioso por pagar. Se hicieron y perdieron fortunas, pero esos esfuerzos arrojaron muy poca luz sobre la forma “correcta” de abordar el problema.
En general, la generalización siguió siendo un problema desconcertante durante la mayor parte del siglo XX. Ni siquiera estaba claro si pertenecía al ámbito de las ciencias naturales, regido por observaciones y experimentos, o al ámbito de la filosofía y las matemáticas, regido por la lógica y la autoconsistencia.
El panorama avanzó hasta un momento trascendental en 1982, el año de la primera competencia pública de previsión - coloquialmente conocida como la competencia M4. El principio era sencillo: publicar un conjunto de datos de 1000 series de tiempo truncadas, dejar que los concursantes enviaran sus previsiones, y finalmente publicar el resto del conjunto de datos (las colas truncadas) junto con las precisiones respectivas logradas por los participantes. Con esta competencia, la generalización, aún vista desde la perspectiva de precisión de la previsión, había entrado en el ámbito de las ciencias naturales. En adelante, las competencias de previsión se volvieron cada vez más frecuentes.
Unos pocos décadas después, Kaggle, fundada en 2010, añadió una nueva dimensión a dichas competencias al crear una plataforma dedicada a problemas de predicción general (no solo de series de tiempo). A febrero de 20235, la plataforma ha organizado 349 competencias con premios en efectivo. El principio sigue siendo el mismo que en la competencia M original: se pone a disposición un conjunto de datos truncado, los concursantes envían sus respuestas a las tareas de predicción planteadas y, por último, se revelan los rankings junto con la parte oculta del conjunto de datos. Las competencias siguen siendo consideradas el estándar de oro para la evaluación adecuada del error de generalización de los modelos.
Sobreajuste y subajuste
Sobreajuste, al igual que su antónimo subajuste, es un problema que surge frecuentemente al producir un modelo basado en un conjunto de datos dado, y socava el poder de generalización del modelo. Históricamente6, el sobreajuste surgió como el primer obstáculo bien entendido para la generalización.
Visualizar el sobreajuste se puede hacer utilizando un problema simple de modelado de series de tiempo. Para los propósitos de este ejemplo, suponga que el objetivo es crear un modelo que refleje una serie de observaciones históricas. Una de las opciones más simples para modelar estas observaciones es un modelo lineal como se ilustra a continuación (véase la Figura 1).
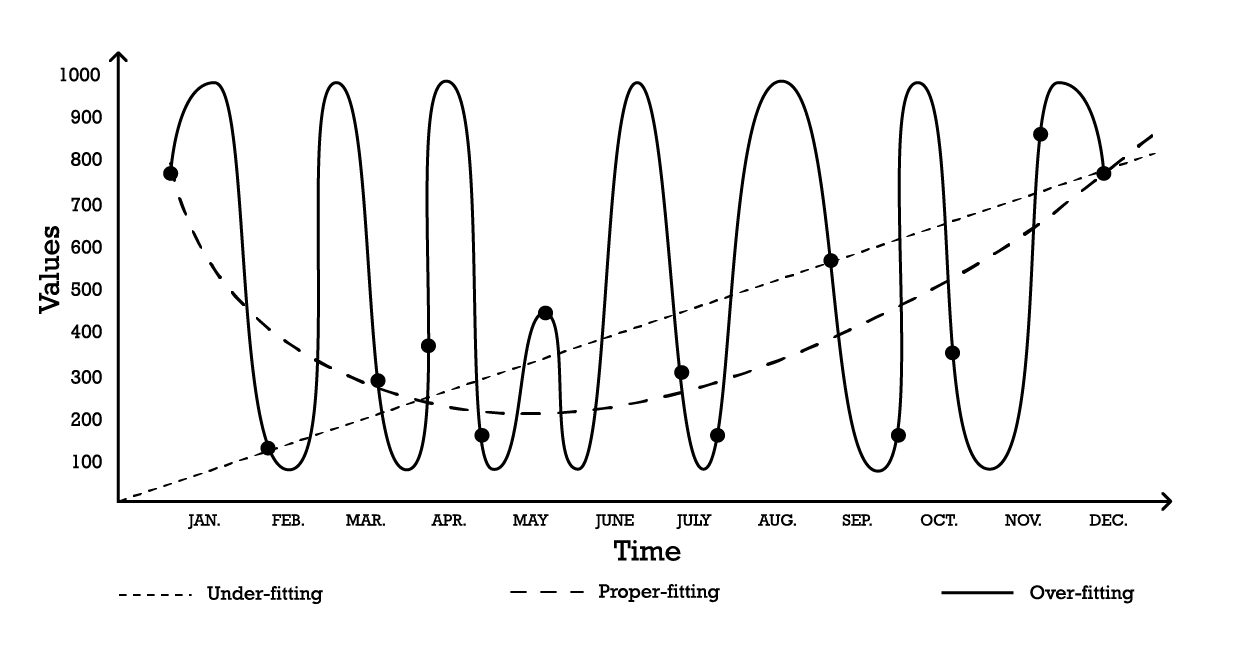
Figure 1: A composite graph depicting three different attempts at “fitting” a series of observations.
Con dos parámetros, el modelo de “subajuste” es robusto, pero, como su nombre indica, subajusta los datos, ya que claramente no es capaz de capturar la forma general de la distribución de las observaciones. Este enfoque lineal tiene un alto sesgo pero una baja varianza. En este contexto, el sesgo debe entenderse como la limitación inherente de la estrategia de modelado para captar los detalles de las observaciones, mientras que la varianza debe interpretarse como la sensibilidad a pequeñas fluctuaciones – posiblemente ruido – de las observaciones.
Se podría adoptar un modelo bastante complejo, según la curva de “sobreajuste” (Figura 1). Este modelo incluye muchos parámetros y se ajusta exactamente a las observaciones. Este enfoque tiene un sesgo bajo pero una varianza demostrablemente alta. Alternativamente, se podría optar por un modelo de complejidad intermedia, como se observa en la curva de “ajuste correcto” (Figura 1). Este modelo incluye tres parámetros, tiene un sesgo medio y una varianza media. De estas tres opciones, el modelo de ajuste correcto es invariablemente el que mejor funciona en términos de generalización.
Estas opciones de modelado representan la esencia del compromiso entre sesgo y varianza.7 8 El compromiso entre sesgo y varianza es un principio general que establece que el sesgo se puede reducir aumentando la varianza. El error de generalización se minimiza al encontrar el equilibrio adecuado entre la cantidad de sesgo y varianza.
Históricamente, desde principios del siglo XX hasta comienzos de la década de 2010, un modelo sobreajustado se definía9 como aquel que contiene más parámetros de los que puede justificar la información. De hecho, a primera vista, añadir demasiados grados de libertad a un modelo parece ser la receta perfecta para problemas de sobreajuste. Sin embargo, la aparición de deep learning demostró que esta intuición, y la definición misma de sobreajuste, eran engañosas. Este punto se retomará en la sección sobre el deep double-descent.
Validación cruzada y backtesting
La validación cruzada es una técnica de validación de modelos utilizada para evaluar qué tan bien un modelo generalizará más allá del conjunto de datos que lo respalda. Es un método de submuestreo que emplea diferentes porciones de los datos para probar y entrenar un modelo en diversas iteraciones. La validación cruzada es el pan de cada día de las prácticas modernas de predicción, y casi todos los participantes ganadores en competencias de predicción hacen un uso extensivo de la validación cruzada.
Existen numerosas variantes de validación cruzada. La variante más popular es la validación k-fold, en la cual la muestra original se divide aleatoriamente en k subconjuntos. Cada subconjunto se utiliza una vez como datos de validación, mientras que el resto – todos los demás subconjuntos – se emplean como datos de entrenamiento.
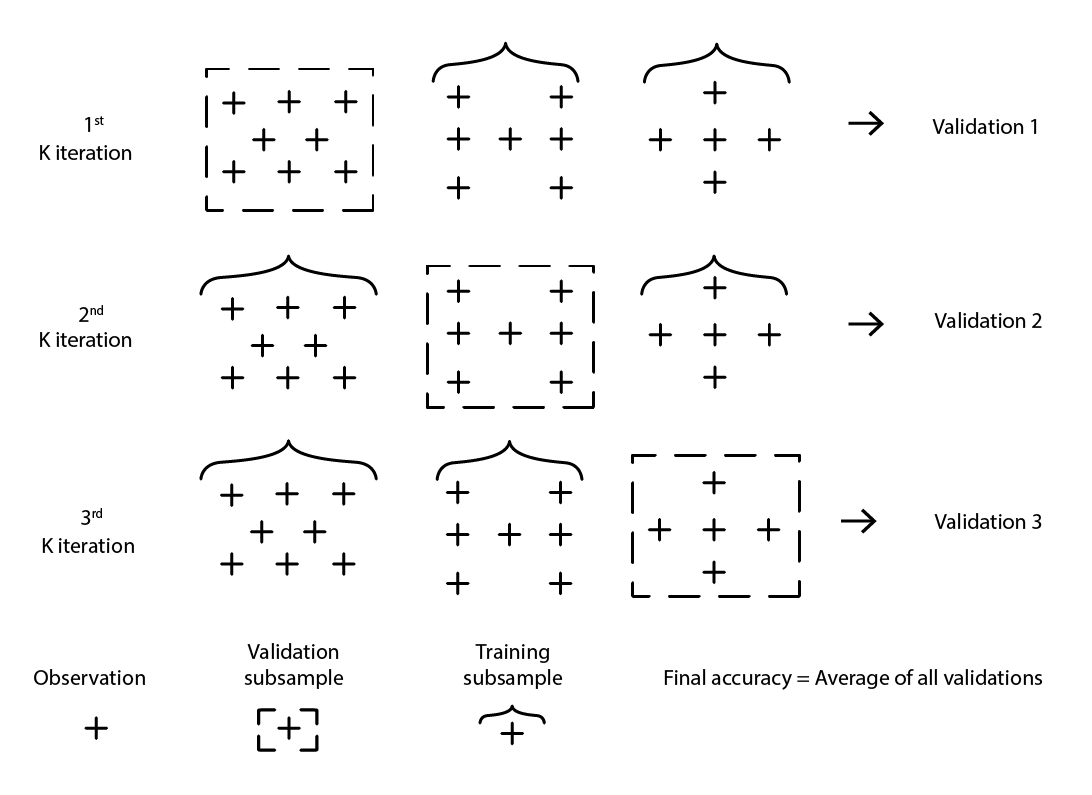
Figure 2: A sample K-fold validation. The observations above are all from the same dataset. The technique thus constructs data subsamples for validation and training purposes.
La elección del valor k, el número de subconjuntos, es un compromiso entre ganancias estadísticas marginales y los requerimientos en términos de recursos de computación. De hecho, con el método k-fold, los recursos de computación crecen de manera lineal con el valor k, mientras que los beneficios, en términos de reducción de error, experimentan rendimientos decrecientes extremos10. En la práctica, seleccionar un valor de 10 o 20 para k suele ser “suficientemente bueno”, ya que las ganancias estadísticas asociadas con valores más altos no justifican la incomodidad adicional asociada con el mayor gasto de recursos de computación.
La validación cruzada asume que el conjunto de datos puede descomponerse en una serie de observaciones independientes. Sin embargo, en supply chain, esto con frecuencia no es así, ya que el conjunto de datos suele reflejar algún tipo de información histórica en la que está presente una dependencia temporal. En presencia del tiempo, se debe asegurar que el subconjunto de entrenamiento preceda estrictamente al de validación. En otras palabras, el “futuro”, relativo al corte de re-muestreo, no debe filtrarse en el subconjunto de validación.
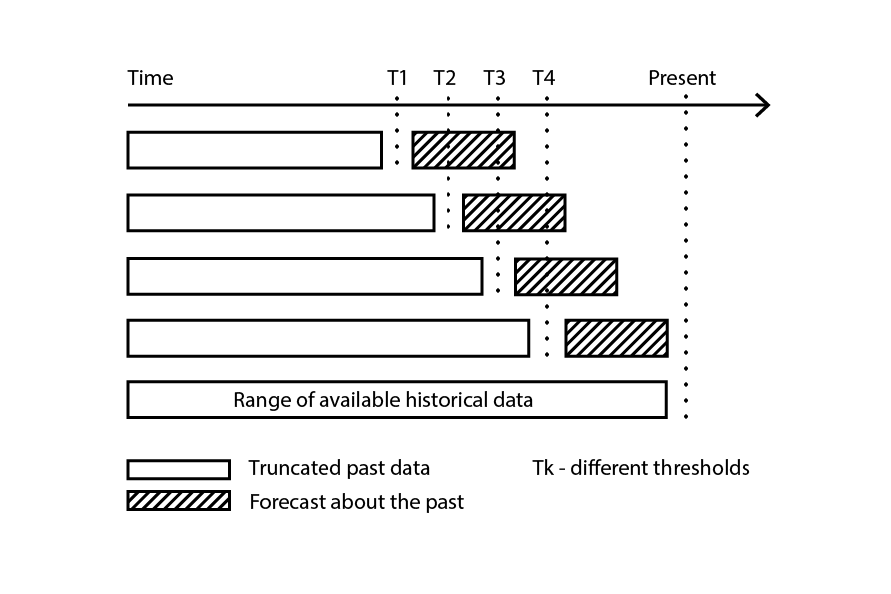
Figure 3: A sample backtesting process constructs data subsamples for validation and training purposes.
Backtesting representa la variante de validación cruzada que aborda directamente la dependencia temporal. En lugar de considerar subconjuntos aleatorios, los datos de entrenamiento y validación se obtienen respectivamente mediante un corte: las observaciones anteriores al corte pertenecen a los datos de entrenamiento, mientras que las observaciones posteriores al corte pertenecen a los datos de validación. El proceso se repite seleccionando una serie de valores de corte distintos.
El método de re-muestreo que se encuentra en el núcleo tanto de la validación cruzada como del backtesting es un mecanismo poderoso que orienta el esfuerzo de modelado hacia un camino de mayor generalización. De hecho, es tan eficiente que existe toda una clase de algoritmos de (machine) learning que incorporan este mismo mecanismo en su esencia. Los más notables son los random forests y los gradient boosted trees.
Rompiendo la barrera dimensional
Naturalmente, cuanto más datos se tienen, mayor es la información de la cual aprender. Por lo tanto, todo lo demás igual, más datos deberían conducir a mejores modelos, o al menos, a modelos que no sean peores que los anteriores. Después de todo, si más datos empeoran el modelo, siempre es posible ignorarlos como último recurso. Sin embargo, debido a los problemas de sobreajuste, descartar datos se mantuvo como la solución del mal menor hasta finales de la década de 1990. Este fue el meollo del problema de la “barrera dimensional”. Esta situación resultó tanto desconcertante como profundamente insatisfactoria. Los avances revolucionarios de los años 90 rompieron las barreras dimensionales con sorprendentes aportaciones, tanto teóricas como prácticas. En el proceso, esos avances lograron descarrilar – a fuerza de distracción – todo el campo de estudio durante una década, retrasando la llegada de sus sucesores, principalmente los métodos de deep learning, que se discutirán en la siguiente sección.
Para comprender mejor lo que solía estar mal con tener más datos, considere el siguiente escenario: un fabricante ficticio quiere predecir el número de reparaciones no programadas por año en grandes equipos industriales. Tras una cuidadosa consideración del problema, el equipo de ingeniería ha identificado tres factores independientes que parecen contribuir a las tasas de fallo. Sin embargo, la contribución respectiva de cada factor en la tasa de fallo general no está clara.
Así, se introduce un modelo de regresión lineal simple con 3 variables de entrada. El modelo puede escribirse como Y = a1 * X1 + a2 * X2 + a3 * X3, donde
- Y es la salida del modelo lineal (la tasa de fallo que los ingenieros quieren predecir)
- X1, X2 y X3 son los tres factores (tipos específicos de cargas de trabajo expresadas en horas de operación) que pueden contribuir a los fallos
- a1, a2 y a3 son los tres parámetros del modelo que se deben identificar.
El número de observaciones necesarias para obtener estimaciones “suficientemente buenas” para los tres parámetros depende en gran medida del nivel de ruido presente en la observación, y de lo que se considere “suficientemente bueno”. Sin embargo, intuitivamente, para ajustar tres parámetros se requerirían al menos dos docenas de observaciones, incluso en las situaciones más favorables. A medida que los ingenieros logran recolectar 100 observaciones, ajustan con éxito 3 parámetros, y el modelo resultante parece “suficientemente bueno” como para ser de interés práctico. El modelo no logra capturar muchos aspectos de las 100 observaciones, convirtiéndose en una aproximación muy burda, pero cuando este modelo es confrontado con otras situaciones mediante experimentos mentales, la intuición y la experiencia indican a los ingenieros que el modelo parece comportarse de manera razonable.
Basándose en su primer éxito, los ingenieros deciden investigar más a fondo. Esta vez, aprovechan toda la gama de sensores electrónicos integrados en la maquinaria, y a través de los registros electrónicos producidos por esos sensores, logran aumentar el conjunto de factores de entrada a 10,000. Inicialmente, el conjunto de datos estaba compuesto por 100 observaciones, con cada observación caracterizada por 3 números. Ahora, el conjunto de datos se ha ampliado; siguen siendo las mismas 100 observaciones, pero hay 10,000 números por observación.
Sin embargo, al intentar los ingenieros aplicar el mismo enfoque a su conjunto de datos enormemente enriquecido, el modelo lineal ya no funciona. Dado que hay 10,000 dimensiones, el modelo lineal cuenta con 10,000 parámetros; y las 100 observaciones están muy lejos de ser suficientes para soportar la regresión de tantos parámetros. El problema no es que sea imposible encontrar valores de parámetros que se ajusten, sino todo lo contrario: se ha vuelto trivial encontrar conjuntos interminables de parámetros que encajan perfectamente con las observaciones. Sin embargo, ninguno de estos modelos “ajustados” es de utilidad práctica. Estos modelos “grandes” se ajustan perfectamente a las 100 observaciones; sin embargo, fuera de ellas, los modelos se vuelven sin sentido.
Los ingenieros se enfrentan a la barrera dimensional: aparentemente, el número de parámetros debe permanecer pequeño en comparación con las observaciones, de lo contrario el esfuerzo de modelado se desmorona. Este problema es desconcertante, ya que el conjunto de datos “más grande”, con 10,000 dimensiones en lugar de 3, es obviamente más informativo que el más pequeño. Por lo tanto, un modelo estadístico adecuado debería ser capaz de capturar esta información adicional en lugar de volverse disfuncional ante ella.
A mediados de la década de 1990, un doble avance11, tanto teórico como experimental, sorprendió a la comunidad. El avance teórico fue la teoría Vapnik–Chervonenkis (VC)12. La teoría VC demostró que, considerando tipos específicos de modelos, el error real podía ser acotado superiormente por lo que, en términos generales, equivalía a la suma del error empírico más el riesgo estructural, una propiedad intrínseca del modelo mismo. En este contexto, “error real” es el error experimentado en los datos que uno no tiene, mientras que “error empírico” es el error experimentado en los datos que uno sí tiene. Al minimizar la suma del error empírico y el riesgo estructural, se podía minimizar el error real, ya que quedaba “encerrado”. Esto representó un resultado sorprendente y, posiblemente, el mayor paso hacia la generalización desde la identificación del problema del sobreajuste.
En el frente experimental, modelos que más tarde se conocerían como Máquinas de Vectores de Soporte (SVMs) fueron introducidos casi como una derivación de libro de texto de lo que la teoría VC había identificado sobre el aprendizaje. Estas SVMs se convirtieron en los primeros modelos de éxito general, capaces de hacer un uso satisfactorio de conjuntos de datos donde el número de dimensiones excedía al número de observaciones.
Al encerrar el error real, un resultado teórico verdaderamente sorprendente, la teoría VC había roto la barrera dimensional, algo que había resultado desconcertante durante casi un siglo. También abrió el camino para modelos capaces de aprovechar datos de alta dimensión. Sin embargo, pronto las SVMs fueron desplazadas por modelos alternativos, principalmente métodos de ensamblaje (random forests13 y gradient boosting), que resultaron ser alternativas superiores14 a principios de la década de 2000, prevaleciendo tanto en generalización como en requerimientos computacionales. Al igual que las SVMs que reemplazaron, los métodos de ensamblaje también se benefician de garantías teóricas en cuanto a su capacidad para evitar el sobreajuste. Todos estos métodos compartían la propiedad de ser no paramétricos. La barrera dimensional se rompió al introducir modelos que no necesitaban incorporar uno o más parámetros por cada dimensión; evitando así un camino conocido hacia los problemas de sobreajuste.
Volviendo al problema de las reparaciones no programadas mencionado anteriormente, a diferencia de los modelos estadísticos clásicos –como la regresión lineal, que se desmorona ante la barrera dimensional–, los métodos de ensamblaje lograrían aprovechar el gran conjunto de datos y sus 10,000 dimensiones, aunque solo existan 100 observaciones. Además, los métodos de ensamblaje sobresaldrían, más o menos, tal como vienen. Operativamente, esto fue un desarrollo bastante notable, ya que eliminó la necesidad de elaborar meticulosamente modelos seleccionando el conjunto preciso de dimensiones de entrada.
El impacto en la comunidad en general, tanto dentro como fuera del ámbito académico, fue masivo. La mayoría de los esfuerzos de investigación a principios de la década de 2000 se dedicaron a explorar estos enfoques no paramétricos “respaldados por la teoría”. Sin embargo, los éxitos se desvanecieron bastante rápido a medida que pasaban los años. De hecho, unos veinte años después, los mejores modelos de lo que llegó a conocerse como la perspectiva de aprendizaje estadístico siguen siendo los mismos, beneficiándose simplemente de implementaciones más eficientes15.
El deep double-descent
Hasta 2010, la sabiduría convencional dictaba que, para evitar problemas de sobreajuste, el número de parámetros debía permanecer mucho más pequeño que el número de observaciones. De hecho, dado que cada parámetro representaba implícitamente un grado de libertad, tener tantos parámetros como observaciones era una receta para asegurar el sobreajuste16. Los métodos de ensamblaje evitaban por completo este problema al ser no paramétricos desde el principio. Sin embargo, esta percepción crítica resultó estar equivocada, y de manera espectacular.
Lo que más tarde se conocería como el enfoque de deep learning sorprendió a casi toda la comunidad mediante modelos hiperparamétricos. Se trata de modelos que no sufren sobreajuste y, sin embargo, contienen muchas veces más parámetros que observaciones.
El origen del deep learning es complejo y se remonta a los primeros intentos de modelar los procesos del cerebro, es decir, las redes neuronales. Desentrañar este origen está fuera del alcance de la presente discusión; sin embargo, es importante señalar que la revolución del deep learning a principios de la década de 2010 comenzó justo cuando el campo abandonó la metáfora de las redes neuronales en favor de la simpatía mecánica. Las implementaciones de deep learning reemplazaron a los modelos anteriores por variantes mucho más simples. Estos modelos más recientes aprovecharon hardware de computación, en particular las GPUs (unidades de procesamiento gráfico), que resultaron ser, de manera algo accidental, muy adecuadas para las operaciones de álgebra lineal que caracterizan a los modelos de deep learning17.
Tomó casi cinco años más para que el deep learning fuera ampliamente reconocido como un avance. Una parte considerable de la reticencia provino del ámbito del aprendizaje estadístico –casualmente, la sección de la comunidad que había logrado romper la barrera dimensional dos décadas antes. Aunque las explicaciones varían para esta reticencia, la aparente contradicción entre la sabiduría convencional sobre el sobreajuste y las afirmaciones del deep learning ciertamente contribuyó a un notable nivel de escepticismo inicial respecto a esta nueva clase de modelos.
La contradicción permaneció en gran medida sin resolver hasta 2019, cuando se identificó el deep double descent18, un fenómeno que caracteriza el comportamiento de ciertas clases de modelos. Para tales modelos, aumentar el número de parámetros primero degrada el error en el test (a través del sobreajuste), hasta que el número de parámetros se vuelve lo suficientemente grande como para revertir la tendencia y mejorar nuevamente el error en el test. La “segunda disminución” (del error en el test) no era un comportamiento predicho por la perspectiva de la compensación de sesgos.
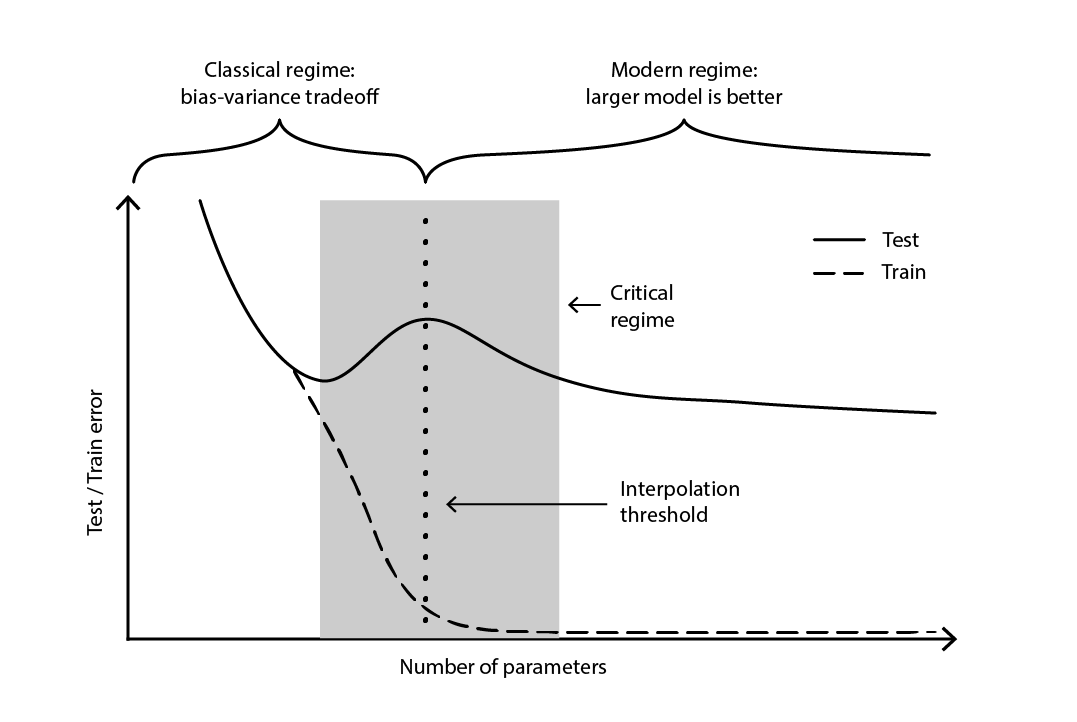
Figure 4. A deep double descent.
La Figura 4 ilustra los dos regímenes sucesivos descritos anteriormente. El primer régimen es la clásica compensación entre sesgo y varianza que aparentemente viene con un número “óptimo” de parámetros. Sin embargo, este mínimo resulta ser un mínimo local. Existe un segundo régimen, observable si se continúa aumentando el número de parámetros, que exhibe una convergencia asintótica hacia un error en el test realmente óptimo para el modelo.
El deep double descent no solo reconcilió las perspectivas estadística y de deep learning, sino que también demostró que la generalización sigue siendo relativamente poco comprendida. Se comprobó que las teorías ampliamente sostenidas –comunes hasta finales de la década de 2010– presentaban una perspectiva distorsionada sobre la generalización. Sin embargo, el deep double descent aún no proporciona un marco –o algo equivalente– que prediga las capacidades de generalización (o la falta de ellas) de los modelos en función de su estructura. Hasta la fecha, el enfoque sigue siendo decididamente empírico.
Las espinas de la supply chain
Como se ha tratado en profundidad, la generalización es extremadamente desafiante, y las supply chains logran añadir a su situación una serie de peculiaridades, intensificándola aún más. Primero, los datos que buscan los profesionales de la supply chain pueden permanecer para siempre inaccesibles; no parcialmente invisibles, sino totalmente inobservables. Segundo, el mismo acto de predecir puede alterar el futuro, al igual que la validez de la predicción, dado que las decisiones se basan en esas mismas predicciones. Por lo tanto, al abordar la generalización en un contexto de supply chain, se debe utilizar un enfoque de dos vertientes: una que asegure la solidez estadística del modelo y otra que aporte el razonamiento de alto nivel que lo respalde.
Además, los datos disponibles no siempre son los datos deseados. Considera un fabricante que quiere prever la demanda para decidir las cantidades a producir. No existe algo como datos históricos de “demand”. En su lugar, los datos históricos de ventas representan el mejor proxy disponible para que el fabricante refleje la demanda histórica. Sin embargo, las ventas históricas están distorsionadas por pasados faltante de stock. Las ventas nulas, causadas por faltantes de stock, no deben confundirse con una demanda nula. Si bien se puede elaborar un modelo para rectificar este historial de ventas convirtiéndolo en una especie de historial de demanda, el error de generalización de este modelo es esquivo por diseño, ya que ni el pasado ni el futuro disponen de esos datos. En resumen, la “demand” es un constructo necesario pero intangible.
En la jerga del machine learning, modelar la demanda es un problema de unsupervised learning en el que la salida del modelo nunca se observa directamente. Este aspecto no supervisado derrota a la mayoría de los algoritmos de aprendizaje y a la mayoría de las técnicas de validación de modelos –al menos, en su forma “ingenua”. Además, también derrota la misma idea de prediction competition, que aquí significa un proceso simple de dos etapas en el que un conjunto de datos original se divide en un subconjunto público (de entrenamiento) y uno privado (de validación). La validación en sí se convierte, por necesidad, en un ejercicio de modelado.
En términos simples, la predicción creada por el fabricante moldeará, de una manera u otra, el futuro que éste experimente. Una alta demanda proyectada significa que el fabricante incrementará la producción. Si la empresa está bien gestionada, es probable que se logren economías de escala en el proceso de manufactura, lo que reducirá los costos de producción. A su vez, es probable que el fabricante aproveche estas nuevas economías para bajar los precios, obteniendo así una ventaja competitiva sobre sus rivales. El mercado, en busca de la opción de menor precio, puede adoptar rápidamente a este fabricante como su opción más competitiva, desencadenando un aumento de la demanda muy superior a la proyección inicial.
Este fenómeno se conoce como una profecía autocumplida, una predicción que tiende a hacerse realidad en virtud de la creencia influyente que los participantes tienen en ella. Una perspectiva poco ortodoxa, pero no del todo irrazonable, caracterizaría a las supply chains como gigantescas maquinarias de Rube Goldberg autocumplidas. A nivel metodológico, este enredo entre el observador y lo observado complica aún más la situación, ya que la generalización se asocia con la captura de la intención estratégica que subyace en los desarrollos de la supply chain.
En este punto, el desafío de la generalización, tal como se presenta en la supply chain, podría parecer insuperable. Las hojas de cálculo, que siguen siendo ubicuas en las supply chains, insinúan ciertamente que esta es la posición predeterminada, aunque implícita, de la mayoría de las empresas. Sin embargo, una hoja de cálculo es, ante todo, una herramienta para posponer la resolución del problema a un juicio humano ad hoc, en lugar de la aplicación de un método sistemático.
Aunque deferir al juicio humano es invariablemente la respuesta incorrecta (por sí misma), tampoco es una respuesta satisfactoria al problema. La presencia de faltantes de stock no significa que se pueda poner todo vale en lo que respecta a la demand. Ciertamente, si el fabricante ha mantenido niveles medios de niveles de servicio por encima del 90% durante los últimos tres años, sería altamente improbable que la demanda (observada) hubiera sido 10 veces mayor que las ventas. Por lo tanto, es razonable esperar que se pueda desarrollar un método sistemático para hacer frente a tales distorsiones. De manera similar, la profecía autocumplida también puede ser modelada, sobre todo mediante la noción de policy tal como se entiende en la teoría de control.
Así, al considerar una supply chain del mundo real, la generalización requiere un enfoque de dos vertientes. Primero, el modelo debe ser estadísticamente sólido, en la medida que lo permitan las amplias ciencias del “learning”. Esto abarca no solo perspectivas teóricas como la estadística clásica y el aprendizaje estadístico, sino también esfuerzos empíricos como el machine learning y las prediction competitions. Revertir a la estadística del siglo XIX no es una proposición razonable para una supply chain practice del siglo XXI.
Segundo, el modelo debe estar respaldado por un razonamiento a alto nivel. En otras palabras, para cada componente del modelo y cada paso del proceso de modelado, debe haber una justificación que tenga sentido desde una perspectiva de supply chain. Sin este ingrediente, el caos operativo19 está casi garantizado, usualmente provocado por alguna evolución de la propia supply chain, su ecosistema operativo o su paisaje aplicativo subyacente. De hecho, el objetivo del razonamiento a alto nivel no es hacer que un modelo funcione una vez, sino lograr que funcione de manera sostenible a lo largo de varios años en un entorno en constante cambio. Este razonamiento es el ingrediente no tan secreto que ayuda a decidir que es hora de revisar el modelo cuando su diseño, sea lo que sea, ya no se alinea con la realidad y/o los objetivos del negocio.
Desde lejos, esta proposición podría parecer vulnerable a la crítica anterior dirigida a las hojas de cálculo – aquella que se opone a delegar el trabajo duro a un escurridizo “juicio humano”. Aunque esta proposición sigue delegando la evaluación del modelo al juicio humano, la ejecución del modelo está pensada para ser completamente automatizada. Así, se pretende que las operaciones diarias estén completamente automatizadas, incluso si los esfuerzos de ingeniería en curso para mejorar aún más las recetas numéricas no lo están.
Notas
-
Existe una importante técnica algorítmica llamada “memoization” que precisamente reemplaza un resultado que podría ser recomputado por su resultado precomputado, intercambiando así más memoria por menos cómputo. Sin embargo, esta técnica no es relevante para la presente discusión. ↩︎
-
Por qué la mayoría de los hallazgos de investigación publicados son falsos, John P. A. Ioannidis, agosto 2005 ↩︎
-
Desde la perspectiva de la previsión de series temporales, la noción de generalización se aborda a través del concepto de “exactitud”. La exactitud puede considerarse como un caso especial de “generalización” al analizar series temporales. ↩︎
-
Makridakis, S.; Andersen, A.; Carbone, R.; Fildes, R.; Hibon, M.; Lewandowski, R.; Newton, J.; Parzen, E.; Winkler, R. (abril 1982). “La exactitud de los métodos de extrapolación (series temporales): Resultados de una competencia de previsión”. Revista de Previsión. 1 (2): 111–153. doi:10.1002/for.3980010202. ↩︎
-
Kaggle in Numbers, Carl McBride Ellis, consultado el 8 de febrero de 2023, ↩︎
-
El extracto de 1935 “Quizás seamos anticuados, pero para nosotros un análisis de seis variables basado en trece observaciones parece más bien un sobreajuste”, de “The Quarterly Review of Biology” (sep., 1935 Volumen 10, Número 3, pp. 341 – 377), parece indicar que el concepto estadístico de sobreajuste ya estaba establecido en esa época. ↩︎
-
Grenander, Ulf. Sobre el análisis espectral empírico de procesos estocásticos. Ark. Mat., 1(6):503–531, 08 1952. ↩︎
-
Whittle, P. Pruebas de ajuste en series temporales, Vol. 39, No. 3/4 (dic., 1952), pp. 309-318 (10 páginas), Oxford University Press ↩︎
-
Everitt B.S., Skrondal A. (2010), Diccionario de Estadísticas de Cambridge, Cambridge University Press. ↩︎
-
Los beneficios asintóticos de usar valores mayores de k para el k-fold pueden inferirse del teorema del límite central. Esta conclusión sugiere que, al incrementar k, podemos acercarnos aproximadamente a 1 / sqrt(k) de agotar todo el potencial de mejora que aporta el k-fold en primer lugar. ↩︎
-
Redes de soporte vectorial, Corinna Cortes, Vladimir Vapnik, Machine Learning, volumen 20, páginas 273–297 (1995) ↩︎
-
La teoría Vapnik-Chervonenkis (VC) no fue la única candidata para formalizar lo que significa el “aprendizaje”. El marco PAC (probablemente aproximadamente correcto) de Valiant en 1984 allanó el camino para enfoques formales de aprendizaje. Sin embargo, el marco PAC careció del enorme impacto y de los éxitos operativos que la teoría VC disfrutó alrededor del cambio de milenio. ↩︎
-
Random Forests, Leo Breiman, Machine Learning, volumen 45, páginas 5–32 (2001) ↩︎
-
Una de las consecuencias desafortunadas de que las máquinas de vectores de soporte (SVMs) estén fuertemente inspiradas en una teoría matemática es que esos modelos tienen poca “simpatía mecánica” por el hardware de computación moderno. La inadecuación relativa de las SVM para procesar grandes conjuntos de datos – incluyendo millones de observaciones o más – en comparación con alternativas marcó la caída de esos métodos. ↩︎
-
XGBoost y LightGBM son dos implementaciones de código abierto de los métodos de conjunto que siguen siendo muy populares en los círculos de machine learning. ↩︎
-
Para efectos de concisión, aquí se está haciendo una simplificación excesiva. Existe un campo de investigación entero dedicado a la “regularización” de modelos estadísticos. En presencia de restricciones de regularización, el número de parámetros, incluso en un modelo clásico como la regresión lineal, puede exceder con seguridad el número de observaciones. En presencia de regularización, ningún valor de parámetro representa por completo un grado de libertad, sino una fracción de este. Por lo tanto, sería más correcto referirse al número de grados de libertad, en lugar de referirse al número de parámetros. Dado que estas consideraciones tangenciales no alteran fundamentalmente las ideas presentadas aquí, la versión simplificada será suficiente. ↩︎
-
De hecho, la causalidad es inversa. Los pioneros del deep learning lograron reingeniar sus modelos originales - redes neuronales - en modelos más simples que dependían casi exclusivamente del álgebra lineal. El objetivo de esta reingeniería fue precisamente hacer posible ejecutar estos modelos más nuevos en hardware de computación que intercambiaba versatilidad por potencia bruta, es decir, GPUs. ↩︎
-
Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, diciembre 2019 ↩︎
-
La gran mayoría de las iniciativas de data science en supply chain fracasan. Mis observaciones casuales indican que la ignorancia del data scientist sobre lo que hace funcionar a la supply chain es la causa raíz de la mayoría de estos fracasos. Aunque resulta increíblemente tentador – para un data scientist recién formado – aprovechar el paquete de machine learning de código abierto más reciente y reluciente, no todas las técnicas de modelado son igualmente adecuadas para respaldar un razonamiento a alto nivel. De hecho, la mayoría de las técnicas “mainstream” son francamente terribles a la hora del proceso de whiteboxing. ↩︎