一般化 (予測)
一般化とは、アルゴリズムがデータセットを活用して、これまで見たことのないデータに対しても優れた性能を発揮するモデルを生成する能力を指します。一般化はサプライチェーンにとって極めて重要であり、ほとんどの意思決定が将来の予測に基づいて行われるためです。予測の文脈において、データが見えない理由は、モデルが観察不可能な未来の出来事を予測するためです。1990年代以降、理論的にも実用的にも大きな進歩があったにもかかわらず、本当の意味での一般化は未だ捉えがたいものです。一般化問題の完全な解決は、人工汎用知能問題の解決と大差ないかもしれません。さらに、サプライチェーンは主流の一般化の課題に加えて、独自の厄介な問題を多く抱えています。

パラドックスの概要
手元にあるデータに対して完璧に機能するモデルを作成することは簡単です:必要なのは、データセットを完全に記憶し、そのデータセット自体を用いてデータセットに関するあらゆる問いに答えることです。コンピューターは大規模なデータセットの記録が得意なため、そのようなモデルを構築するのは容易です。しかし、これは通常、無意味です1。というのも、モデルを持つ本来の目的は、すでに観測されたものを超えた予測力にあるからです。
一見避けがたいパラドックスが現れます:良いモデルとは、現在利用できないデータに対してもうまく機能するモデルであるということですが、定義上、データが利用できない場合、評価を行うことはできません。従って、「一般化」という用語は、モデル構築時に存在する観測を超えて、その関連性と質を維持するモデルの捉えがたい能力を指します。
観測値を単に記憶することは不十分なモデリング戦略として却下されるかもしれませんが、モデルを作成するための他のいかなる戦略も同様の問題に直面する可能性があります。現在利用可能なデータに対してモデルが優れているように見えても、それが単なる偶然の産物であるか、さらにはモデリング戦略の欠陥によるものである可能性は常に否定できません。一見、周辺的な統計上のパラドックスに思える問題は、実際には極めて広範な問題なのです。
逸話的な証拠として、1979年に米国の資本市場を規制する機関であるSEC(証券取引委員会)は、有名な Rule 156 を導入しました。この規則は、ファンドマネージャーに対して、過去の実績が将来の結果を保証するものではない ことを投資家に知らせることを義務付けています。過去の実績は、SECがその「一般化」能力、すなわち将来について何かを語る力に対して信頼すべきでないと警告する「モデル」と暗黙のうちに見なされているのです。
科学そのものですら、狭い観測範囲の外に「真実」を外挿することの意味に苦戦しています。2000年代や2010年代に明るみに出た p-hacking 周辺の「悪い科学」スキャンダルは、研究分野全体が壊れており、信用できないことを示しています2。実験データが明らかに改ざんされた明白な詐欺事例もありますが、ほとんどの場合、問題の核心は観測されたものを 一般化 するために用いられた知的プロセス、つまり、モデルそのものにあります。
最も大局的な姿では、一般化の問題は科学そのものの問題と見分けがつかなくなるため、人間の創造力と可能性の広がりを再現するのと同じくらい難解です。しかし、一般化問題のより狭義の統計的側面ははるかに理解しやすく、以降のセクションではこの観点から議論を進めていきます。
新たな科学の出現
一般化は20世紀初頭に 予測精度3 の視点から、統計パラダイムとして登場しました。これは、時系列予測に密接に結びついた特殊なケースを表しています。1900年代初頭、米国で株式を保有する中産階級が台頭する中、人々が取引資産から金融リターンを確保するための方法に対して大きな関心が寄せられました。占い師や経済予測士は、熱心に支払う大衆のために未来の出来事を外挿することに挑みました。結果として富は生み出され、また失われましたが、これらの試みは問題に対する「適切な」アプローチ方法についてほとんど光を当てませんでした。
一般化は、20世紀の大部分において、ほとんどの人にとって理解し難い問題として残りました。それが、観測と実験に支配される自然科学の領域に属するのか、それとも論理と一貫性によって支配される哲学や数学の領域に属するのか、明確ではなかったのです。
物事は進み、1982年、最初の公開予測コンペティション、通称 M コンペティション4という画期的な瞬間を迎えました。原則は単純でした:1000本の短縮時系列のデータセットを公開し、参加者に予測を提出させ、最後に残りのデータ(短縮された部分)と各参加者の達成した精度を公開するというものでした。このコンペティションを通じて、依然として 予測精度 の視点から見られていた一般化は、自然科学の領域に足を踏み入れました。以降、予測コンペティションはますます頻繁に開催されるようになりました。
数十年後、2010年に設立された Kaggle は、時系列に限らない一般的な予測問題に特化したプラットフォームを作ることで、こうしたコンペティションに新たな次元を加えました。2023年2月現在5、このプラットフォームは賞金付きで349回のコンペティションを開催しています。その原則は当初の M コンペティションと同じで、短縮データセットが提供され、参加者が与えられた予測タスクに対する回答を提出し、最後にランキングと隠されたデータの一部が明らかにされるというものです。これらのコンペティションは、モデルの一般化誤差を適切に評価するためのゴールドスタンダードと見なされています。
過学習と低学習
過学習(反意語である 低学習 と同様に)は、与えられたデータセットに基づいてモデルを作成する際によく発生する問題で、モデルの一般化能力を損ないます。歴史的には6、過学習は一般化に対する最初のよく理解された障害として浮上しました。
シンプルな時系列モデリングの問題を用いて 過学習 を視覚化することができます。この例のために、目的は一連の過去の観測値を反映するモデルを作成することだと仮定します。これらの観測値をモデル化する最も簡単なオプションの一つは、以下に示すような線形モデルです(図1参照)。
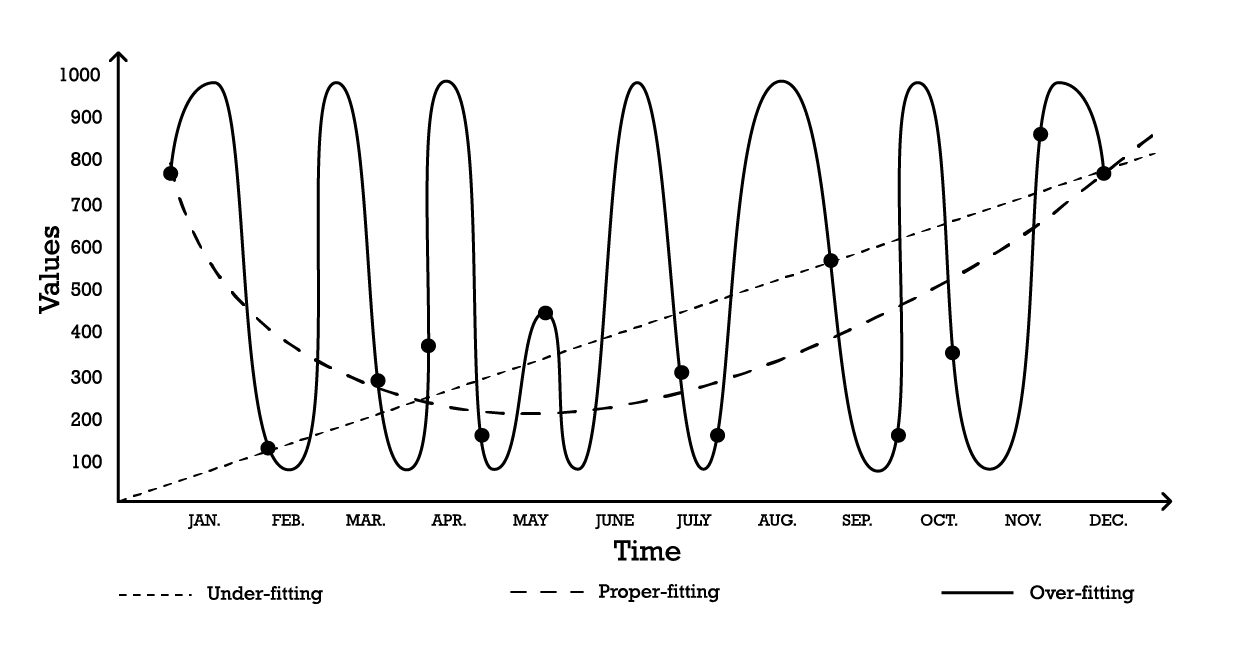
図1: 一連の観測値に対して「フィッティング」を試みた3つの異なる試みを示す合成グラフ
2つのパラメータを持つ「低学習」モデルは安定していますが、その名が示す通り、データの全体的な分布の形状を捉えきれていません。この線形アプローチはバイアスが高く、分散が低いのが特徴です。この文脈では、バイアス は観測値の詳細を捉えるためのモデリング戦略の固有の限界として理解されるべきであり、分散 は観測値の小さな変動、すなわちノイズに対する感受性として理解されるべきです。
「過学習」曲線(図1)に示されるように、かなり複雑なモデルを採用することも可能です。このモデルは多くのパラメータを含み、観測値に正確にフィットします。このアプローチはバイアスが低いものの、明らかに分散が高いです。あるいは、中程度の複雑さを持つモデル、いわゆる「適切なフィッティング」モデル(図1参照)を採用することもできます。このモデルは3つのパラメータを含み、バイアスも分散も中程度です。これら3つのオプションの中で、一般化に関しては常に 適切なフィッティング モデルが最も良い性能を発揮します。
これらのモデリングオプションは、バイアスと分散のトレードオフの本質を表しています7。8 バイアスは分散を増加させることで減少できると概説されており、一般化誤差はバイアスと分散の適切なバランスを見つけることによって最小化されます。
歴史的には、20世紀初頭から2010年代初頭にかけて、過学習モデルは9 データによって正当化される以上のパラメータを含むものとして定義されていました。実際、表面的には、モデルに自由度を加えすぎることは過学習問題の完璧なレシピのように見えます。しかし、ディープラーニングの登場はこの直感、そして過学習の定義を誤解を招くものとしていることを証明しました。この点はディープ・ダブル・ディセントのセクションで改めて論じられます。
クロスバリデーションとバックテスト
クロスバリデーションは、モデルがサポートデータセットを超えてどれだけ一般化できるかを評価するためのモデル検証手法です。これは、異なる部分のデータを用いて、交互にモデルのテストとトレーニングを行うサブサンプリング手法です。クロスバリデーションは現代の予測手法の基本であり、予測コンペティションのほぼ全ての勝者が広範に利用しています。
クロスバリデーションには多くのバリエーションがあります。最も一般的なバリエーションは k 分割検証で、元のサンプルをランダムに k 個のサブサンプルに分割します。各サブサンプルは一度だけ検証データとして使用され、残りのサブサンプルはすべて トレーニングデータ として使用されます。
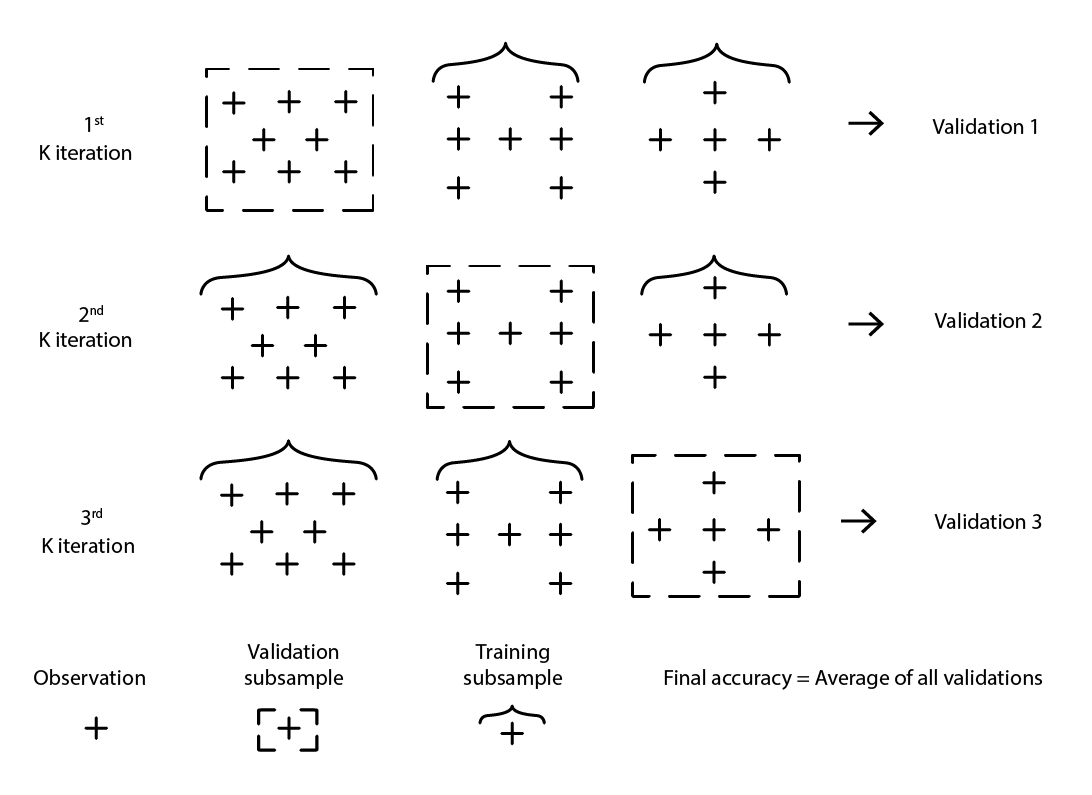
図2: 同一のデータセットからの観測値を用いたサンプルのK-分割検証。この手法により、検証とトレーニングのためのデータサブサンプルが構築されます。
k、つまりサブサンプルの数の選択は、統計的な利益と計算資源の要求との間のトレードオフです。実際、k 分割検証では計算資源は k に応じて線形に増加する一方、誤差削減という観点からの利益は著しく逓減します10。実務上、k の値を10または20に設定することが通常「十分良好」とされ、高い値による統計的利益は、計算資源の余分な消費による不便さに見合うものではありません。
クロスバリデーションは、データセットが一連の独立した観測値に分解できることを前提としています。しかし、サプライチェーンにおいては、データセットは通常、時系列依存性を伴う過去のデータを反映しているため、その前提は必ずしも成り立ちません。時間が存在する場合、トレーニング用のサブサンプルは検証用サブサンプルよりも厳密に「先行」している必要があります。言い換えれば、再サンプリングのカットオフに対して「未来」が検証用サブサンプルに流入してはいけないのです。
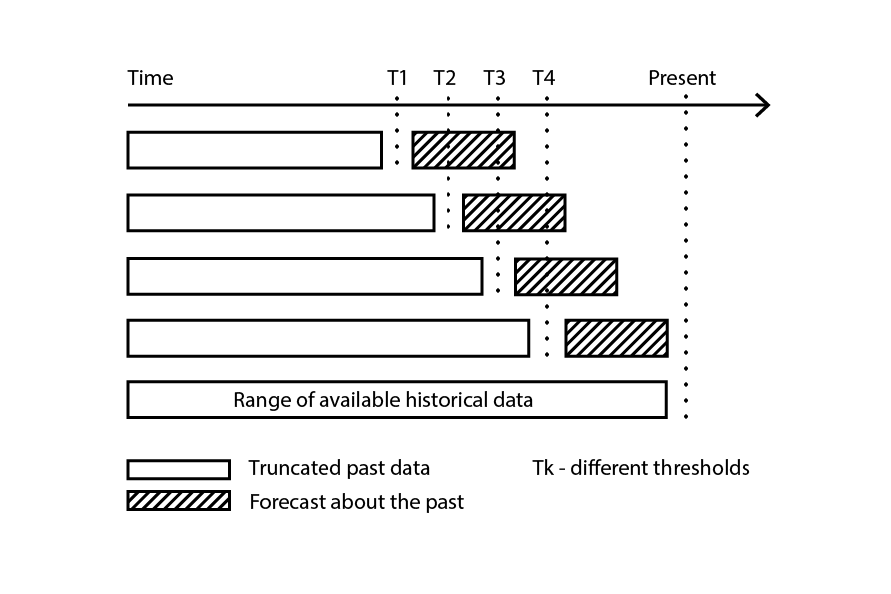
図3: データのサブサンプルを検証とトレーニングの目的で構築するバックテストのプロセスの例。
バックテスト は、時系列依存性に直接対応するクロスバリデーションの一形態です。ランダムなサブサンプルを考慮する代わりに、トレーニングデータと検証データはそれぞれカットオフによって取得され、カットオフより前の観測値はトレーニングデータに、カットオフ以降の観測値は検証データに属します。このプロセスは、異なるカットオフ値の一連を選択することで繰り返されます。
クロスバリデーションとバックテストの両方の核心にある再サンプリング手法は、モデリング努力をより高い一般化へと導く強力なメカニズムです。実際、この手法を中核とする(機械)学習アルゴリズムのクラスが存在するほど、その効率性は高いです。最も顕著なものは、ランダムフォレストや勾配ブースト木です。
次元の壁を打破する
当然ながら、データが多ければ多いほど、学ぶべき情報も増えます。したがって、他の条件が同じであれば、より多くのデータはより良いモデル、あるいは少なくともそれまでのモデルより悪くないモデルにつながるはずです。結局のところ、データが多くなることでモデルが悪化する場合は、最終手段としてデータを無視することも可能です。しかし、過学習の問題があるため、1990年代後半まではデータを削減することが より小さい悪 として残っていました。これが「次元の壁」問題の核心でした。この状況は困惑させると同時に、非常に不満をもたらすものでした。1990年代の突破口は、理論的にも実践的にも驚くべき洞察をもたらし、次元の壁を打破しました。その過程で、これらの突破口は大きな話題をさらい、この分野全体の進展を10年間遅らせ、主に次のセクションで議論されるディープラーニング手法の登場を遅らせました。
より多くのデータを持つことにかつてどのような問題があったのかをよりよく理解するために、以下のシナリオを考えてみましょう。ある架空のメーカーが、大型産業用機器の年間の計画外修理件数を予測したいとします。慎重に問題を検討した結果、エンジニアリングチームは、故障率に寄与しているように見える3つの独立した要因を特定しました。しかし、各要因が故障率全体にどの程度寄与しているかは不明です。
そこで、3つの入力変数を持つ単純な線形回帰モデルが導入されます。このモデルは Y = a1 * X1 + a2 * X2 + a3 * X3 と記述することができます。ここで
-
Y は線形モデルの出力(エンジニアが予測したい故障率)です。
-
X1, X2, および X3 は、故障に寄与する可能性のある3つの要因(稼働時間で表現される特定の作業負荷の種類)です。
-
a1、a2、およびa3 は、特定すべき3つのモデルパラメータです。
3つのパラメータについて「十分に良い」推定値を得るために必要な観測数は、観測に含まれるノイズの水準と、「十分に良い」と見なす基準に大きく依存します。しかし直感的には、最も好条件な状況であっても、3つのパラメータを当てはめるには最低でも数十件の観測が必要です。そこでエンジニアたちは100件の観測を収集し、3つのパラメータの回帰に成功します。得られたモデルは実務上の関心に値する程度には「十分に良い」ように見えます。このモデルは100件の観測の多くの側面を捉え損ねており、かなり粗い近似にすぎませんが、思考実験を通じて他の状況に当てはめてみると、直感と経験の両方から、このモデルはそれなりに妥当な振る舞いを示すように思われます。
最初の成功を受けて、エンジニアたちはさらに深く調べることにします。今度は機械に埋め込まれた電子センサーを全面的に活用し、それらのセンサーが生み出す電子記録を通じて、入力要因の数を1万まで増やすことに成功します。当初のデータセットは100件の観測から成り、各観測は3つの数値で特徴づけられていました。今やデータセットは拡張され、観測件数は同じ100件のままですが、各観測につき1万個の数値が存在するようになります。
しかし、この大幅に豊かになったデータセットに同じ手法を適用しようとすると、線形モデルはもはや機能しません。次元が1万あるため、線形モデルには1万個のパラメータが必要になります。そして、100件の観測では、それほど多くのパラメータを回帰するにはまったく足りません。問題は、適合するパラメータ値を見つけるのが不可能だということではなく、正反対です。観測値に完全に適合するパラメータの組を、いくらでも容易に見つけられるようになってしまうのです。ところが、そのような「適合した」モデルはどれも実務上の役に立ちません。これらの「大きな」モデルは100件の観測には完全に一致するものの、その外側では無意味な振る舞いを示します。
エンジニアたちはここで次元の壁に直面します。見かけ上、パラメータ数は観測数に比べて小さく保たれなければならず、そうでなければモデリングの試み自体が崩壊してしまうのです。この問題が厄介なのは、3次元ではなく1万次元を持つ「より大きな」データセットの方が、明らかにより多くの情報を含んでいるからです。したがって、まともな統計モデルであれば、この追加情報を捉えるべきであって、それに直面した途端に機能不全に陥るべきではありません。
1990年代半ばには、理論面と実験面の双方における二重の突破口11がコミュニティを席巻しました。理論上の突破口は Vapnik–Chervonenkis(VC)理論12です。VC理論は、特定の種類のモデルに関して、_真の誤差_が、おおまかに言えば経験誤差と構造リスクの和によって上から抑えられることを示しました。ここで「真の誤差」とは手元に_ない_データ上で生じる誤差であり、「経験誤差」とは手元に_ある_データ上で生じる誤差です。経験誤差と構造リスクの和を最小化することで、_真の誤差_もまた最小化できると考えられました。真の誤差が「箱の中に収まった」からです。これは驚異的な結果であると同時に、過学習問題そのものが認識されて以来、一般化に向けた最大の前進だったとも言えます。
実験面では、後に Support Vector Machines(SVM)として知られるモデルが、VC理論が学習について明らかにした内容の教科書的な導出例のような形で導入されました。これらのSVMは、次元数が観測数を上回るデータセットを十分に活用できる、最初の広く成功したモデルとなりました。
真の誤差を箱に収めたこの理論的成果により、VC理論はほぼ1世紀にわたって悩まされてきた次元の壁を打ち破りました。また、高次元データを活用できるモデルへの道も開きました。とはいえ、ほどなくしてSVM自体も別のモデルに置き換えられていきます。主としてアンサンブル法、すなわちランダムフォレスト13や勾配ブースティングです。これらは2000年代初頭に、一般化と計算要件の両面でより優れた代替案14であることを示しました。SVMと同様、アンサンブル法も過学習を避ける能力に関して理論的保証を持っています。これらの手法に共通していたのは、いずれもノンパラメトリック手法であったことです。次元の壁は、各次元ごとに1つ以上のパラメータを導入する必要のないモデルが登場したことで打破されたのであり、既知の過学習ルートを回避できたのです。
先ほどの計画外修理の問題に戻ると、線形回帰のような古典的統計モデルは次元の壁の前で崩れてしまうのに対し、アンサンブル法は観測数が100件しかなくても、その大規模データセットと1万次元を活用することに成功します。しかもアンサンブル法は、ほぼそのまま、いわばout of the boxで優れた性能を発揮します。実務上、これは非常に大きな進展でした。入力次元の正しい組み合わせを慎重に選び取ってモデルを手作りする必要がなくなったからです。
学界の内外を問わず、この影響は非常に大きなものでした。2000年代初頭の研究努力の大半は、こうしたノンパラメトリックな「理論に裏打ちされた」アプローチを探究することに費やされました。ところが、その成功は年を追うごとに比較的早く色あせていきます。実際、20年余りを経た現在でも、統計的学習の視点から最良と見なされるモデルはほぼ同じであり、変わったのは主として実装性能の向上だけです15。
ディープ・ダブル・ディセント
2010年頃までの通説では、過学習を避けるためにはパラメータ数を観測数よりはるかに小さく保たなければならないとされていました。各パラメータは暗黙のうちに自由度を1つ表しているため、観測数と同じだけのパラメータを持てば過学習を確実に招く、という考えです16。アンサンブル法は、そもそもノンパラメトリックであることでこの問題を回避していました。しかし、この重要な洞察は、しかも劇的な形で、誤りであることが明らかになりました。
後にディープラーニングと呼ばれるようになったアプローチは、過剰な数のパラメータを持つモデルによってコミュニティのほぼ全体を驚かせました。これらのモデルは、観測数をはるかに上回る数のパラメータを含んでいるにもかかわらず、過学習しないのです。
ディープラーニングの起源は複雑であり、脳の働きをモデル化しようとした初期の試み、すなわちニューラルネットワークにまでさかのぼります。この起源を詳しくたどることは本稿の範囲を超えますが、2010年代初頭のディープラーニング革命が、ちょうどこの分野がニューラルネットワークという比喩から離れ、機械的親和性を重視し始めた時期に起きたことは注目に値します。ディープラーニングの実装は、以前のモデルをずっと単純な変種へと置き換えました。これらの新しいモデルは、別種の計算ハードウェア、特にGPU(graphics processing units)を活用しました。GPUは、やや偶然にも、ディープラーニングモデルを特徴づける線形代数演算に非常に適していたのです17。
ディープラーニングが広く突破口として認識されるまでには、さらに5年近くを要しました。この躊躇のかなりの部分は、統計的学習陣営、つまり20年前に次元の壁を打ち破った当のコミュニティから生じていました。この慎重姿勢の理由にはさまざまな説明がありますが、従来の過学習に関する常識とディープラーニングの主張とのあいだに見える矛盾が、この新しいモデル群に対する初期の懐疑をかなり強めたことは間違いありません。
この矛盾は、2019年に_ディープ・ダブル・ディセント_と呼ばれる現象が特定されるまで、ほぼ未解決のままでした18。これは特定の種類のモデルの振る舞いを特徴づける現象です。この種のモデルでは、パラメータ数を増やすと、まず過学習によってテスト誤差が悪化します。しかし、パラメータ数が十分に大きくなると、その傾向が反転し、再びテスト誤差が改善し始めます。この「第2の下降」は、バイアス・トレードオフの観点からは予測されていなかった挙動です。
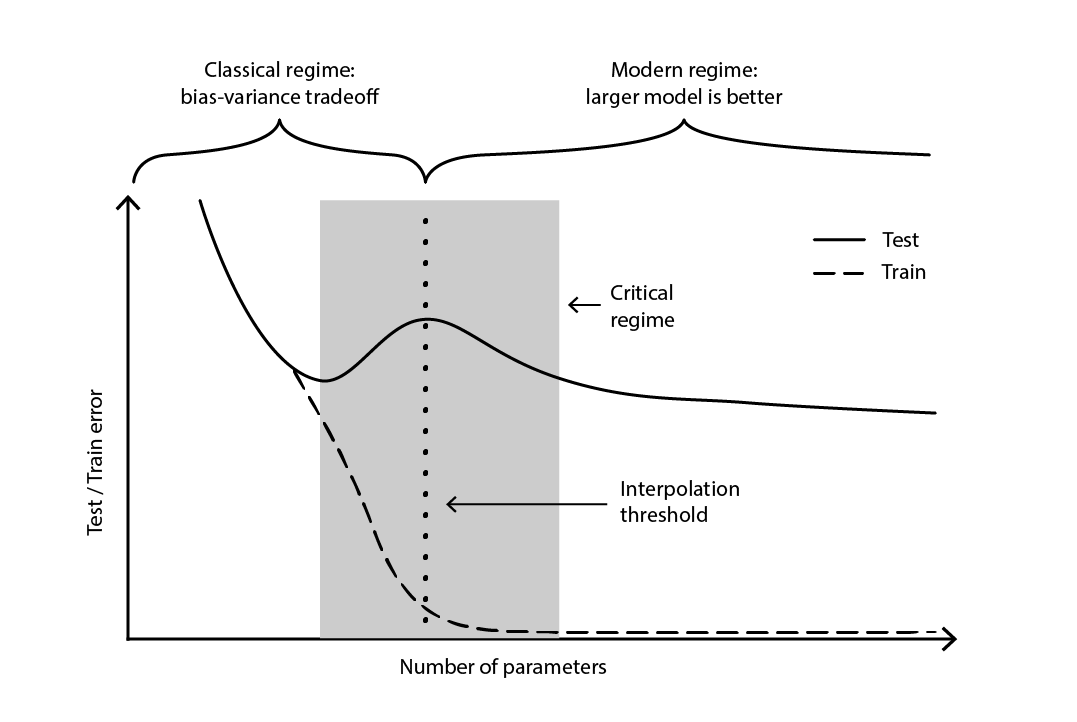
図4. ディープ・ダブルディセント.
図4は、上で述べた2つの連続した局面を示しています。第1の局面は、見かけ上「最適」なパラメータ数を持つ古典的なバイアス・分散トレードオフです。しかし、この最小値は局所最小にすぎません。パラメータ数をさらに増やし続けると観測される第2の局面が存在し、そこではモデルの真の最適テスト誤差へ向かって漸近的に収束していきます。
ディープ・ダブル・ディセントは、統計的学習とディープラーニングの視点を和解させただけでなく、一般化がなお十分には理解されていないことも示しました。2010年代後半まで広く受け入れられていた理論が、一般化について歪んだ見方を与えていたことを証明したのです。しかし、ディープ・ダブル・ディセント自体は、モデルの構造に基づいて一般化能力の有無を予測できるような枠組み、あるいはそれに相当するものを、まだ提供していません。現時点では、このアプローチは徹底して経験的なままです。
サプライチェーン特有の難題
ここまで詳しく見てきた通り、一般化はきわめて難しい問題であり、サプライチェーンはさらに独自の癖を持ち込むことで、その難しさをいっそう増幅させます。第一に、サプライチェーン担当者が求めるデータは、部分的に見えないだけでなく、完全に観測不可能なままであり続けるかもしれません。第二に、予測という行為そのものが未来を変え、その予測の妥当性までも変えてしまう可能性があります。なぜなら、意思決定はまさにその予測の上に築かれるからです。したがって、サプライチェーンの文脈で一般化に取り組む際には、二本立てのアプローチが必要です。一方の柱はモデルの統計的健全性であり、もう一方はそれを支える高次の推論です。
さらに、利用可能なデータが、必ずしも望ましいデータであるとは限りません。たとえば、製造業者が生産数量を決めるために需要予測を行いたいとします。しかし、「過去の需要データ」なるものは存在しません。代わりに、過去の販売データが、歴史的需要を反映するために利用可能な最良の代理変数となります。ところが、過去の販売は、過去のストックアウトによって歪められています。ストックアウトによるゼロ販売は、ゼロ需要と混同してはなりません。この販売履歴を何らかの需要履歴に補正するモデルを作ることはできますが、そのモデルの一般化誤差は設計上つかみどころがありません。過去にも未来にも、その「真の需要」データが存在しないからです。要するに、「需要」とは必要不可欠ではあるものの、目に見えない構築物なのです。
機械学習の用語で言えば、需要モデリングは教師なし学習の問題です。というのも、モデルの出力が直接観測されることはないからです。この教師なしという性質は、大半の学習アルゴリズムを無力化し、多くのモデル検証手法もまた、少なくともその「素朴な」形では役に立たなくします。さらにこれは、予測コンペティションという発想そのものも揺るがします。ここで言う予測コンペティションとは、元のデータセットを公開された学習用部分集合と非公開の検証用部分集合に分ける単純な二段階プロセスのことです。しかしこの場合、検証そのものが必然的に一つのモデリング作業になってしまいます。
簡単に言えば、製造業者が作った予測は、何らかの形で、その製造業者が経験する未来そのものを形作ります。高い需要予測が出れば、製造業者は生産を増やします。事業運営がうまくいっていれば、製造工程では規模の経済が働き、生産コストが下がるでしょう。すると製造業者は、その新たに得られた経済性を利用して価格を下げ、競合に対する優位を獲得する可能性が高まります。市場は最も安い選択肢を求めるため、この製造業者を最も競争力の高い選択肢として素早く受け入れ、結果として当初の予測を大きく上回る需要急増を引き起こすかもしれません。
この現象は_自己成就的予言_として知られています。つまり、予測そのものに対する参加者の信念が影響力を持つことで、その予測が真実になりやすくなるのです。型破りではあるものの、決して不合理ではない見方をすれば、サプライチェーンとは巨大な自己成就型のルーブ・ゴールドバーグ装置だと言えるかもしれません。方法論の水準では、この観測者と観測対象のもつれ合いが状況をさらに複雑にします。なぜなら一般化は、サプライチェーンの展開の背後にある戦略的意図を捉えることとも結びついてくるからです。
この段階まで来ると、サプライチェーンにおける一般化の課題は克服不能に見えるかもしれません。サプライチェーンの世界で依然としてスプレッドシートが遍在していることは、多くの企業が暗黙のうちにその立場を取っていることを示唆しています。しかしスプレッドシートとは、第一に、体系的方法を適用するための道具ではなく、その問題の解決を場当たり的な人間の判断へ先送りするための道具なのです。
もっとも、人間の判断へ委ねることは、それ自体としてほぼ常に誤った対応であり、しかも問題への満足できる答えにもなっていません。ストックアウトが存在するからといって、需要について何でもありになるわけではありません。たとえば、製造業者が過去3年間に平均90%以上のサービスレベルを維持していたのであれば、観測された需要が販売の10倍であった可能性はきわめて低いでしょう。したがって、そのような歪みに対処できる体系的方法を設計できると期待するのは合理的です。同様に、自己成就的予言もまたモデル化できます。特に制御理論で理解されるところの_policy_の概念を通じてです。
したがって、現実のサプライチェーンを考えるとき、一般化には二本立てのアプローチが必要です。第一に、モデルは広義の「学習」科学が許す範囲で、統計的に健全でなければなりません。これには、古典統計学や統計的学習のような理論的視点だけでなく、機械学習や予測コンペティションのような経験的な取り組みも含まれます。21世紀のサプライチェーン実務において、19世紀の統計学へ立ち戻ることは合理的な提案ではありません。
第二に、モデルは高度な推論によって支えられていなければならない。つまり、モデルのすべての構成要素とモデリングプロセスの各ステップには、サプライチェーンの視点から意味のある正当性が求められる。この要素が欠ければ、通常はサプライチェーン自体の進化、運用エコシステム、またはその下にあるアプリケーション環境のいずれかによって引き起こされる運用上の混乱19がほぼ確実に発生する。実際、高度な推論の本質は、一度だけモデルを機能させることではなく、絶えず変化する環境下で_数年にわたって_持続的に機能させることにある。この推論こそが、モデルの設計が現実および/またはビジネス目標と一致しなくなったと判断した際に、モデルを見直す時期であることを決定する、決して秘密ではない要素である。
遠くから見ると、この提案は以前にスプレッドシートに対して行われた批判―困難な作業を捉えどころのない「人間の判断」に委ねるという批判―に対して脆弱に見えるかもしれない。たとえこの提案が依然としてモデルの評価を人間の判断に委ねるとしても、実行は完全自動化を意図している。したがって、日々の運用は完全に自動化されることを目指しており、たとえ数値レシピのさらなる改善のための継続的なエンジニアリング努力がそうでなくとも。
ノート
-
「メモ化」と呼ばれる重要なアルゴリズム技法があり、これは再計算可能な結果をあらかじめ計算された結果で置き換えることで、計算処理を軽減する代わりにメモリを多く使用する。しかし、この技法は本議論には関係がない。 ↩︎
-
Why Most Published Research Findings Are False, John P. A. Ioannidis, 2005年8月 ↩︎
-
時系列予測の観点から、一般化という概念は「精度」という概念を通じて捉えられる。精度は、時系列を考慮する際の「一般化」の特別なケースと見なすことができる。 ↩︎
-
Makridakis, S.; Andersen, A.; Carbone, R.; Fildes, R.; Hibon, M.; Lewandowski, R.; Newton, J.; Parzen, E.; Winkler, R. (1982年4月). “The accuracy of extrapolation (時系列) methods: Results of a forecasting competition”. Journal of Forecasting. 1 (2): 111–153. doi:10.1002/for.3980010202. ↩︎
-
Kaggle in Numbers, Carl McBride Ellis, 2023年2月8日取得, ↩︎
-
1935年の抜粋 “Perhaps we are old fashioned but to us a six-variate analysis based on thirteen observations seems rather like overfitting”(おそらく我々は古風かもしれないが、私たちにとっては13の観測値に基づく6変量解析は過剰適合に思える)は、“The Quarterly Review of Biology” (1935年9月、Volume 10, Number 3, pp. 341–377)に掲載されており、当時すでに統計学における過剰適合の概念が確立されていたことを示唆している。 ↩︎
-
Grenander, Ulf. 『確率過程の経験的スペクトル解析について』. Ark. Mat., 1(6):503–531, 1952年8月. ↩︎
-
Whittle, P. 『時系列におけるフィットテスト』, Vol. 39, No. 3/4 (1952年12月), pp. 309-318 (10ページ), Oxford University Press ↩︎
-
Everitt B.S., Skrondal A. (2010), 『ケンブリッジ統計学辞典』, Cambridge University Press. ↩︎
-
k-分割交差検証においてより大きなkの値を用いることの非漸近的な利点は、中心極限定理から推測できる。この洞察は、kを増加させることで、そもそもk分割法がもたらす改善可能性の全体に対して、約1 / sqrt(k)に近づけることができることを示唆している。 ↩︎
-
サポートベクターネットワーク, Corinna Cortes, Vladimir Vapnik, 機械学習, 巻20, pp. 273–297 (1995) ↩︎
-
Vapnik–Chervonenkis (VC) 理論は、「学習」とは何かを形式化するための唯一の候補ではなかった。Valiantの1984年のPAC(Probably Approximately Correct)フレームワークは、形式的な学習アプローチへの道を切り開いた。しかし、PACフレームワークは、ミレニアム期にVC理論が享受した大きな支持と運用上の成功を欠いていた。 ↩︎
-
ランダムフォレスト, Leo Breiman, 機械学習, 巻45, pp. 5–32 (2001) ↩︎
-
数学理論に大きく触発されたサポートベクターマシン(SVM)の不運な結果の一つは、これらのモデルが現代のコンピュータハードウェアに対してほとんど「機械的親和性」を持たないことである。何百万もの観測値を含む大規模データセットの処理において、代替手段と比較してSVMが相対的に不十分であったことが、これらの手法の衰退を招いた。 ↩︎
-
XGBoostとLightGBMは、機械学習界で広く人気のあるアンサンブル手法の2つのオープンソース実装である。 ↩︎
-
簡潔さのために、ここではやや単純化している。統計モデルの「正則化」に専念する研究分野が存在する。正則化制約下では、古典的なモデルである線形回帰でさえも、パラメータの数が観測値の数を安全に超える場合がある。正則化が存在すると、各パラメータ値はもはや完全な自由度を表すのではなく、その一部に過ぎない。したがって、パラメータの数ではなく、自由度の数を参照する方が適切である。これらの周辺的な考察がここで提示する見解の本質を根本的に変えるものではないため、単純化したバージョンで十分である。 ↩︎
-
実際、因果関係は逆である。ディープラーニングの先駆者たちは、元々のモデル―ニューラルネットワーク―をほぼ線形代数学に依存するより単純なモデルへと再設計することに成功した。この再設計の目的は、汎用性よりも生の計算能力、すなわちGPUに重きを置くコンピュータハードウェア上でこれらの新しいモデルを動作させることを可能にするためであった。 ↩︎
-
Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, 2019年12月 ↩︎
-
サプライチェーンにおけるデータサイエンスの取り組みの大部分は失敗に終わる。私のざっくりとした観察では、サプライチェーンの仕組みを理解していないデータサイエンティストの無知が、これらの失敗の根本原因であることが多いと示唆している。新たに訓練されたデータサイエンティストにとって、最新かつ最も輝かしいオープンソースの機械学習パッケージを活用するのは非常に魅力的であるが、すべてのモデリング技術が高度な推論を支えるのに同等に適しているわけではない。実際、「主流」の技術の多くは、ホワイトボックス化プロセスにおいては実にひどいものである。 ↩︎