00:01 Introducción
01:56 El desafío Uncertainty de la M5 - Datos (1/3)
04:52 El desafío Uncertainty de la M5 - Reglas (2/3)
08:30 El desafío Uncertainty de la M5 - Resultados (3/3)
11:59 La historia hasta ahora
14:56 Lo que (probablemente) está a punto de suceder
15:43 Pinball loss - Fundamento 1/3
20:45 Binomial negativa - Fundamento 2/3
24:04 Innovation Space State Model (ISSM) - Fundamento 3/3
31:36 Estructura de ventas - El modelo REMT 1/3
37:02 Uniéndolo todo - El modelo REMT 2/3
39:10 Niveles agregados - El modelo REMT 3/3
43:11 Aprendizaje de una sola etapa - Discusión 1/4
45:37 Patrón completo - Discusión 2/4
49:05 Patrones faltantes - Discusión 3/4
53:20 Límites del M5 - Discusión 4/4
56:46 Conclusión
59:27 Próxima lección y preguntas de la audiencia
Descripción
En 2020, un equipo en Lokad logró el No5 entre 909 equipos competidores en la M5, una competencia mundial de forecast. Sin embargo, a nivel de agregación de SKU, esos forecast lograron el No1. La forecast de demanda es de importancia primordial para supply chain. El enfoque adoptado en esta competencia resultó ser atípico, y a diferencia de los otros métodos adoptados por los otros 50 principales competidores. Hay múltiples lecciones que aprender de este logro como preludio para abordar futuros desafíos predictivos para supply chain.
Transcripción completa

Bienvenidos a esta serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy presentaré “Number One at the SKU Level in the M5 Forecasting Competition.” Una forecast de demanda precisa se considera uno de los pilares de supply chain optimization. De hecho, cada supply chain decision refleja una cierta anticipación del futuro. Si podemos reunir insights superiores sobre el futuro, entonces podremos derivar decisiones que sean cuantitativamente superiores para nuestros propósitos en supply chain. Así, identificar modelos que entreguen accuracy predictiva de última generación es de importancia e interés primordial para fines de optimización en supply chain.
Hoy presentaré un modelo simple de forecast de ventas que, a pesar de su simplicidad, se ubicó en el primer puesto a nivel de SKU en una competencia mundial de forecast conocida como la M5, basado en un dataset proporcionado por Walmart. Habrá dos objetivos para esta conferencia. El primer objetivo será comprender lo que se requiere para lograr una accuracy de forecast de ventas de última generación. Esta comprensión será de interés fundamental para futuros esfuerzos en predictive modeling. El segundo objetivo será establecer la perspectiva correcta cuando se trate de predictive modeling para fines de supply chain. Esta perspectiva también se empleará para guiar nuestro avance posterior en esta área de predictive modeling para supply chain.

La M5 fue una competencia de forecast que tuvo lugar en 2020. Esta competencia lleva el nombre de Spyros Makridakis, un investigador notable en el campo del forecast. Esta fue la quinta edición de la competencia. Estas competencias se realizan cada dos años y tienden a variar en términos de enfoque dependiendo del tipo de dataset que se utilice. La M5 fue un desafío relacionado con supply chain, ya que el dataset utilizado era de datos de tiendas minoristas proporcionados por Walmart. El desafío M6, que aún está por suceder, se enfocará en el forecast financiero.
El dataset utilizado para la M5 fue y sigue siendo un dataset público. Era datos de tiendas minoristas de Walmart agregados a nivel diario. Este dataset incluía alrededor de 30,000 SKUs, lo cual, en términos de retail, es un dataset bastante pequeño. De hecho, como regla general, un supermercado típico posee alrededor de 20,000 SKUs, y Walmart opera en más de 10,000 tiendas. Así, en conjunto, este dataset – el dataset M5 – representaba menos del 0.1% del dataset a escala mundial de Walmart que sería relevante desde la perspectiva de supply chain.
Además, como veremos a continuación, había clases enteras de datos que faltaban en el dataset M5. Como resultado, mi estimación aproximada es que este dataset se acerca en realidad a un 0.01% de la escala de lo que se necesitaría a escala de Walmart. No obstante, este dataset es lo suficientemente amplio para realizar un benchmark muy sólido de modelos de forecast en un entorno real. En un entorno real, tendríamos que prestar mucha atención a las preocupaciones de escalabilidad. Sin embargo, desde la perspectiva de una competencia de forecast, es razonable hacer el dataset lo suficientemente pequeño para que la mayoría de los métodos, incluso los métodos ampliamente ineficientes, puedan ser utilizados en la competencia de forecast. Además, asegura que los contendientes no se vean limitados por la cantidad de recursos de computación que realmente pueden destinar a esta competencia de forecast.
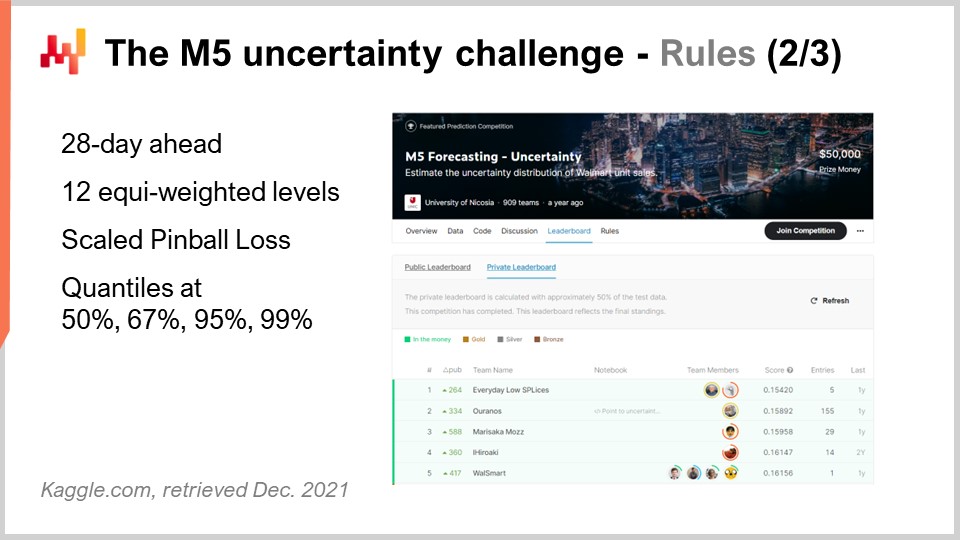
La competencia M5 incluyó dos desafíos distintos conocidos como Accuracy y Uncertainty. Las reglas eran simples: existía un dataset público al que cada participante podía acceder, y para participar en uno o ambos de estos desafíos, cada participante tenía que producir su propio dataset, que era su dataset de forecast, y enviarlo a la plataforma Kaggle. El desafío Accuracy consistía en entregar un forecast promedio de time series, que es el tipo más clásico de forecast formal. En esta situación específica, se trataba de entregar un forecast diario promedio para alrededor de 40,000 series de tiempo. El desafío Uncertainty consistía en entregar quantile forecasts. Los cuantiles son forecast con un sesgo; sin embargo, el sesgo es intencional. Este es el punto de tener cuantiles. Esta conferencia se centra exclusivamente en el desafío Uncertainty, y la razón es que en supply chain, es la demanda inesperadamente alta la que crea faltante de stock, y es la demanda inesperadamente baja la que crea bajas de inventario. Los costos en supply chain se concentran en los extremos. Este no es el promedio que nos interesa.
De hecho, si observamos lo que incluso significa el promedio en la situación de Walmart, resulta que para la mayoría de los productos, en la mayoría de las tiendas, para la mayoría de los días, las ventas promedio que se van a observar son cero. Así, la mayoría de los productos tienen un forecast promedio fraccionado. Dichos forecast promedio son muy poco impresionantes en lo que respecta a supply chain. Si tus opciones son almacenar cero o reponer una unidad, los forecast promedio tienen muy poca relevancia. El retail no se encuentra en una posición única aquí; es prácticamente la misma situación ya sea que estemos hablando de FMCG, aviation, manufactura o lujo – prácticamente todos los demás sectores.
Volviendo al desafío Uncertainty de la M5, había que producir cuatro cuantiles, respectivamente al 50%, 67%, 95% y 99%. Puedes pensar en esos objetivos de cuantil como objetivos de nivel de servicio. La precisión de esos quantile forecasts se evaluó mediante una métrica conocida como pinball loss function. Volveré a esta métrica de error más adelante en esta conferencia.

Hubo 909 equipos compitiendo mundialmente en este desafío Uncertainty. Un equipo de Lokad se ubicó en el número cinco a nivel general, pero en el número uno a nivel de SKU. De hecho, aunque los SKU representaban alrededor de tres cuartas partes de las series de tiempo en este desafío, existían varios niveles de agregación que iban desde el estado (como en Estados Unidos – Texas, California, etc.) hasta el SKU, y todos los niveles de agregación tenían el mismo peso en la puntuación final de esta competencia. Así, incluso si los SKU representaban alrededor de tres cuartas partes de las series de tiempo, solo constituían aproximadamente el 8% del peso total en la puntuación final de la competencia.
El método utilizado por este equipo de Lokad fue publicado en un artículo titulado “A White Box ISSM Approach to Estimate Uncertainty Distribution of Walmart’s Sales.” Incluiré un enlace a este artículo en la descripción de este video después de que esta conferencia se complete. Encontrarás todos los elementos con mayor detalle. Por cuestiones de claridad y concisión, me referiré al modelo presentado en este artículo como el modelo BRAMPT, simplemente nombrado así por las iniciales de los cuatro coautores.
En la pantalla, he listado los cinco mejores resultados para la M5, obtenidos de un artículo que ofrece insights generales sobre el resultado de esta competencia de forecast. Los detalles del ranking dependen bastante de la métrica elegida. Esto no es nada sorprendente. El desafío Uncertainty utilizó una versión escalada de la pinball loss function. Volveremos a esta métrica de error en un momento. Aunque el desafío Uncertainty de la M5 demostró que no disponemos de los medios para eliminar la incertidumbre con los forecasting methods que tenemos, ni mucho menos, no es en absoluto un resultado sorprendente. Considerando que las ventas en tiendas minoristas tienden a ser erráticas e intermitentes, resalta la importancia de abrazar la incertidumbre en lugar de simplemente descartarla por completo. Sin embargo, es notable observar que los software vendors de supply chain estuvieron completamente ausentes de los 50 primeros puestos de esta competencia de forecast, lo cual es aún más intrigante dado que esos proveedores presumen de contar con una tecnología de forecast de última generación supuestamente superior.
Ahora, esta conferencia es parte de una serie de conferencias de supply chain. La presente conferencia es la primera de lo que será mi quinto capítulo en esta serie. Este quinto capítulo se dedicará al predictive modeling. De hecho, reunir insights cuantitativos es necesario para optimizar un supply chain. Cada vez que se toma una supply chain decision – ya sea decidir comprar materiales, producir cierto producto, mover stock de un lugar a otro, o aumentar o disminuir el precio de algo que vendes – dicha decisión viene con una cierta anticipación de la demanda futura. Marginalmente, cada supply chain decision viene con una expectativa incorporada sobre el futuro. Esta expectativa puede ser implícita y oculta. Sin embargo, si queremos mejorar la calidad de nuestra expectativa sobre el futuro, necesitamos reificar esta expectativa, lo cual normalmente se hace a través de un forecast, aunque no necesariamente tiene que ser un forecast de series de tiempo.
El quinto y presente capítulo se llama “Predictive Modeling” en lugar de “Forecasting” por dos razones. Primero, forecasting se asocia casi invariablemente con el forecast de series de tiempo. Sin embargo, como veremos en este capítulo, hay muchas situaciones en supply chain que realmente no se prestan a la perspectiva del forecast de series de tiempo. Así, en este sentido, predictive modeling es un término más neutral. Segundo, es el modeling lo que aporta la verdadera insight, no los modelos. Buscamos técnicas de modeling, y es a través de estas técnicas que podemos esperar ser capaces de afrontar la gran diversidad de situaciones que se encuentran en los supply chains del mundo real.
La presente conferencia sirve como prólogo para nuestro capítulo de predictive modeling para establecer que predictive modeling no es una especie de pensamiento ilusorio sobre forecast, sino que califica como una técnica de forecast de última generación. Esto se suma a todos los otros beneficios que se irán haciendo evidentes a medida que avance en este capítulo.
El resto de esta conferencia se organizará en tres partes. Primero, revisaremos una serie de ingredientes matemáticos, que son esencialmente los bloques de construcción del modelo BRAMPT. Segundo, ensamblaremos esos ingredientes para construir el modelo BRAMPT, tal como se hizo durante la competencia M5. Tercero, discutiremos lo que se puede hacer para mejorar el modelo BRAMPT y también para ver qué se podría hacer para mejorar el desafío de forecast en sí, tal como fue presentado en la competencia M5.

El desafío Uncertainty de la M5 busca calcular estimaciones de cuantiles de las ventas futuras. Un cuantil es un punto en una distribución unidimensional, y por definición, un cuantil del 90 por ciento es el punto en el que hay un 90 por ciento de probabilidad de estar por debajo de este valor y un 10 por ciento de probabilidad de estar por encima. La mediana es, por definición, el cuantil del 50 por ciento.
La función pinball loss es una función con una afinidad profunda por los cuantiles. Esencialmente, para cualquier valor de tau dado entre cero y uno, tau puede interpretarse, desde una perspectiva de supply chain, como un objetivo de service level. Para cualquier valor de tau, el cuantil asociado a tau resulta ser el valor dentro de la distribución de probabilidad que minimiza la función pinball loss. En la pantalla, vemos una implementación sencilla de la función pinball loss, escrita en Envision, el lenguaje de programación específico del dominio de Lokad dedicado a fines de optimización de supply chain. La sintaxis es bastante similar a Python y debería ser relativamente transparente para la audiencia.
Si intentamos desglosar este código, tenemos y, que es el valor real, y-hat, que es nuestra estimación, y tau, que es nuestro objetivo de cuantil. Nuevamente, el objetivo de cuantil es fundamentalmente el objetivo de service level en términos de supply chain. Observamos que el under forecast viene con un peso igual a tau, mientras que el over forecast viene con un peso igual a uno menos tau. La función pinball loss es una generalización del error absoluto. Si volvemos a tau igual a 0.5, podemos ver que la función pinball loss es simplemente el error absoluto. Si tenemos una estimación que minimiza el error absoluto, lo que obtenemos es una estimación de la mediana.
En la pantalla, puedes ver un gráfico de la función de pérdida pinball. Esta función de pérdida es asimétrica, y mediante una función de pérdida asimétrica, podemos obtener no el forecast promedio o mediano, sino un forecast con un sesgo controlado, que es exactamente lo que queremos tener para una estimación de cuantil. La belleza de la función de pérdida pinball es su simplicidad. Si tienes una estimación que minimiza la función de pérdida pinball, entonces tienes un forecast de cuantil por construcción. Así, si tienes un modelo que cuenta con parámetros y diriges la optimización de los mismos a través del lente de la función de pérdida pinball, lo que obtendrás de tu modelo es esencialmente un modelo de forecast de cuantil.
El desafío M5 de Uncertainty presentó una serie de cuatro objetivos de cuantil en 50, 67, 95 y 99. Normalmente me refiero a tal serie de objetivos de cuantil como una cuadrícula de cuantiles. Una cuadrícula de cuantiles, o forecasts de cuadrícula cuantizada, no son exactamente forecasts probabilísticos; se acerca, pero aún no lo es. Con una cuadrícula de cuantiles, todavía estamos seleccionando a dedo nuestros objetivos. Por ejemplo, si decimos que queremos producir un forecast de cuantil para el 95 por ciento, la pregunta se vuelve, ¿por qué 95 y no 94 o 96? Esta pregunta queda sin respuesta. Más adelante en este capítulo lo veremos con más detalle, pero no en esta conferencia. Basta con decir que la principal ventaja que tenemos con los forecasts probabilísticos es eliminar por completo ese aspecto de selección a dedo de las cuadrículas de cuantiles.
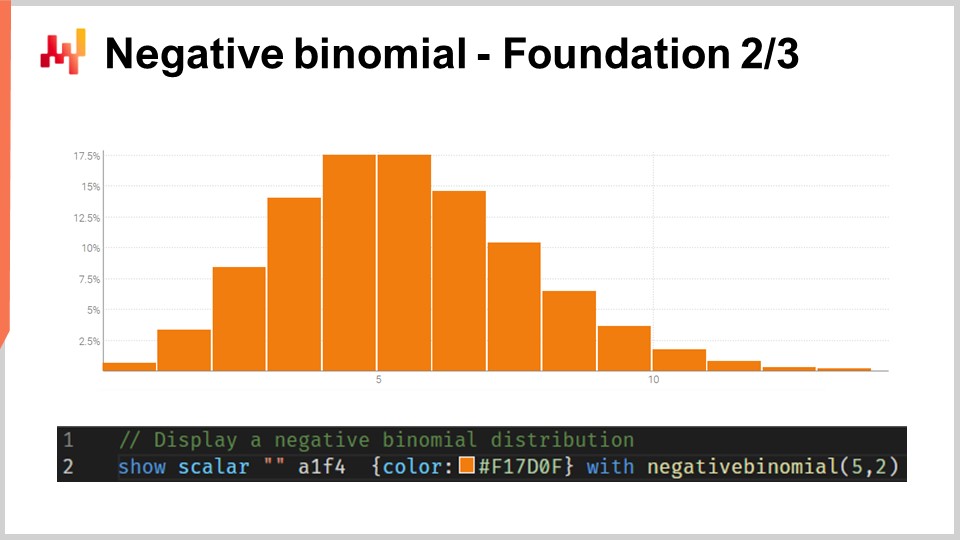
La mayoría de la audiencia probablemente esté familiarizada con la distribución normal, la curva en forma de campana gaussiana que ocurre muy frecuentemente en fenómenos naturales. Una distribución de conteo es una distribución de probabilidades sobre cada entero. A diferencia de las distribuciones reales continuas, como la distribución normal que te da una probabilidad para cada entero, las distribuciones de conteo solo se interesan en los enteros no negativos. Existen muchas clases de distribuciones de conteo; sin embargo, hoy nuestro interés se centra en la distribución binomial negativa, que es utilizada por el modelo REM.
La distribución binomial negativa viene con dos parámetros, al igual que la distribución normal, que también controlan efectivamente la media y la varianza de la distribución. Si elegimos la media y la varianza para una distribución binomial negativa de modo que la mayor parte de la masa de la distribución de probabilidad se encuentre lejos de cero, tenemos un comportamiento para la distribución binomial negativa que asintóticamente converge a un comportamiento de distribución normal si colapsáramos todos los valores de probabilidad hacia los enteros más cercanos. Sin embargo, si observamos distribuciones donde la media es pequeña, especialmente en comparación con la varianza, veremos que la distribución binomial negativa comienza a divergir significativamente en cuanto a comportamiento en comparación con una distribución normal. En particular, si observamos distribuciones binomiales negativas de media pequeña, veremos que estas distribuciones se vuelven altamente asimétricas, a diferencia de la distribución normal, que permanece completamente simétrica sin importar qué media y varianza se elijan.
En la pantalla, se muestra una distribución binomial negativa a través de Envision. La línea de código que se utilizó para producir este gráfico se muestra a continuación. La función toma dos argumentos, lo cual es esperado ya que esta distribución tiene dos parámetros, y el resultado es simplemente una variable aleatoria que se muestra como un histograma. No voy a profundizar en los detalles de la distribución binomial negativa aquí en esta conferencia. Esto es teoría de probabilidad básica. Tenemos fórmulas analíticas explícitas en forma cerrada para la moda, la mediana, la función de distribución acumulada, asimetría, curtosis, etc. La página de Wikipedia ofrece un resumen bastante decente de todas esas fórmulas, por lo que invito a la audiencia a echar un vistazo si desea saber más sobre este tipo específico de distribución de conteo.
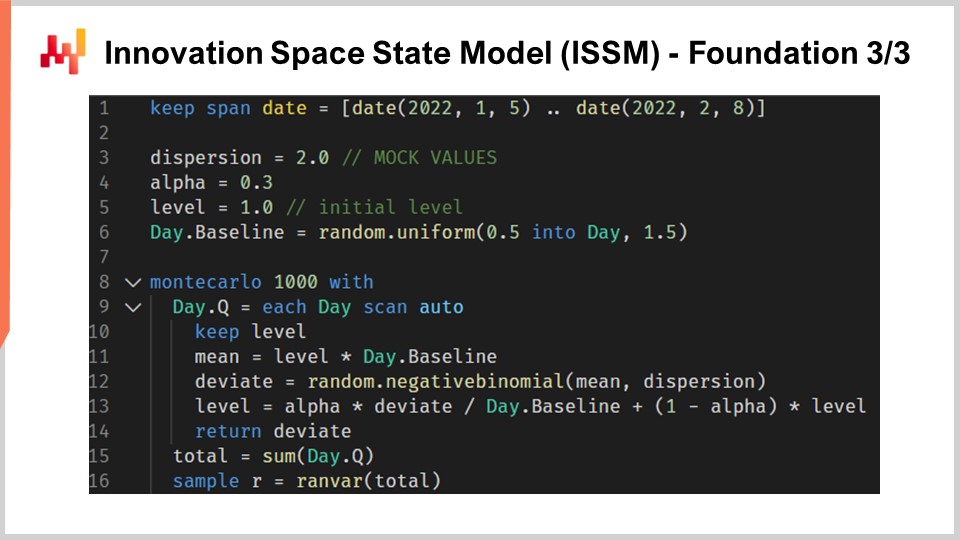
Pasemos al Modelo de Estado del Espacio de Innovación, o ISSM. El modelo de estado del espacio de innovación es un nombre largo y que suena impresionante para hacer algo que es bastante simple. De hecho, el ISSM es un modelo que transforma una serie temporal en una caminata aleatoria. Con el ISSM, puedes convertir simplemente un forecast de serie temporal básico, y cuando digo básico, me refiero a un forecast en el que para cada período tendrás un valor fijado en el promedio, en un forecast probabilístico, y no solo un forecast de cuantil sino directamente un forecast probabilístico. En la pantalla, puedes ver una implementación completa del ISSM escrita una vez más en Envision. Podemos notar que es solo una docena de líneas de código, y en realidad, la mayoría de esas líneas ni siquiera hacen mucho. El ISSM es literalmente muy sencillo, y sería muy fácil reimplementar este fragmento de código en cualquier otro lenguaje, como Python.
Examinemos con más detalle los pormenores de esas líneas de código. En la línea uno, estoy especificando el rango de los períodos en los que ocurrirá la caminata aleatoria. Desde la perspectiva del M5, queremos una caminata aleatoria para un período de 28 días, por lo que tenemos 28 puntos, uno por día. En las líneas tres, cuatro y cinco, introducimos una serie de parámetros que controlarán la propia caminata aleatoria. El primer parámetro es la dispersión, que se usará como argumento para controlar la forma de las binomiales negativas que ocurren dentro del proceso ISSM. Luego tenemos alfa, que es esencialmente el factor que controla el proceso de suavizamiento exponencial que también ocurre dentro del ISSM. En la línea cinco, tenemos el nivel, que es simplemente el estado inicial de la caminata aleatoria. Finalmente, en la línea seis, tenemos una serie de factores que están destinados, típicamente, a capturar todos los patrones de calendario que queremos incorporar en nuestro modelo de forecast.
Ahora bien, los valores de las líneas tres a seis vienen simplemente con una inicialización simulada. Por cuestión de concisión, en un momento explicaré cómo se optimizan realmente esos valores, pero aquí toda la inicialización que ves son solo valores simulados. Incluso estoy generando valores aleatorios para la línea base. Más adelante veremos cómo, en realidad, si deseas utilizar este modelo, deberás inicializar adecuadamente esos valores, lo cual haremos más adelante en esta conferencia.
Ahora miremos el núcleo del proceso ISSM. El núcleo comienza en la línea ocho y empieza con un bucle de 1000 iteraciones. Acabo de decir que el proceso ISSM es un proceso para generar caminatas aleatorias, por lo que aquí estamos realizando 1000 iteraciones, o vamos a hacer 1000 caminatas aleatorias. Podríamos tener más, podríamos tener menos; es un proceso Monte Carlo sencillo. Luego, en la línea nueve, realizamos un segundo bucle. Este es el bucle que itera un día a la vez para el período de interés. Así, tenemos el bucle exterior, que es esencialmente una iteración por cada caminata aleatoria, y luego tenemos el bucle interior, que es una iteración, pasando de un día al siguiente dentro de la propia caminata aleatoria.
En la línea 10, tenemos un keep level. Para mantener el nivel, basta decir que este parámetro se va a mutar dentro del bucle interno, no dentro del bucle externo. Esto significa que el nivel es algo que varía cuando pasamos de un día a otro, pero cuando pasamos de una caminata aleatoria a otra a través del bucle Monte Carlo, este nivel se reiniciará a su valor inicial declarado anteriormente. En la línea 11, calculamos la media. La media es el segundo parámetro que usamos para controlar la distribución binomial negativa. Así que tenemos la media, la dispersión y una distribución binomial negativa. En la línea 12, extraemos un deviante de acuerdo con la distribución binomial normal. Extraer un deviante significa simplemente tomar una muestra aleatoria extraída de esta distribución de conteo. Luego, en la línea 13, actualizamos este nivel basándonos en el deviante que hemos observado, y el proceso de actualización es simplemente un proceso muy sencillo de suavizamiento exponencial, guiado por el parámetro alfa. Si tomamos alfa muy grande, igual a uno, eso significa que ponemos todo el peso en la última observación. Por el contrario, si estableciéramos alfa igual a cero, significaría que no habría deriva; nos mantendríamos fieles a la serie temporal original, tal como se define en la línea base.
Por cierto, en Envision, cuando se escribe “.baseline”, lo que vemos aquí es que existe una tabla; es decir, una tabla que tiene, digamos, NDM5, que contendría 28 valores, y baseline es simplemente un vector que pertenece a esta tabla. En la línea 15, recopilamos todos los deviantes y los sumamos a través de “someday.q”. Los enviamos a una variable llamada “total”, de manera que, dentro de una caminata aleatoria, tenemos el total de los deviantes que se recopilaron para cada día. Así, tenemos el total de las ventas durante 28 días. Finalmente, en la línea 16, estamos esencialmente recolectando y agrupando esas muestras en un “render”. Un render es un objeto específico en Envision, que es esencialmente una distribución de probabilidad de enteros relativos, tanto positivos como negativos.
En resumen, lo que tenemos es el ISSM como un generador aleatorio de caminatas aleatorias unidimensionales. En el contexto del forecast de ventas, puedes pensar en esas caminatas aleatorias como posibles observaciones futuras de las propias ventas. Es interesante porque no concebimos el forecast como el promedio o la mediana; literalmente pensamos en nuestro forecast como una posible instancia de un futuro.

En este punto, hemos reunido todo lo que necesitamos para comenzar a ensamblar el modelo REMT, lo cual haremos ahora.
El modelo REMT adopta una estructura multiplicativa, que recuerda al modelo de forecast Holt-Winters. Cada día obtiene una línea base, que es un valor único que resulta ser el producto de cinco efectos de calendario. Tenemos, a saber, el mes del año, el día de la semana, el día del mes, y los efectos de Navidad y Halloween. Esta lógica se implementa como un script conciso de Envision.
Envision tiene un álgebra relacional que ofrece relaciones de difusión entre tablas, lo cual es muy práctico para esta situación. Las cinco tablas que hemos construido, una tabla por patrón de calendario, se construyen como tablas de agrupación. Así, tenemos la tabla de fechas, y la tabla de fechas tiene una clave primaria llamada “date”. Cuando declaramos una nueva tabla con una agregación “by” y luego incluimos la fecha, lo que estamos construyendo es una tabla que tiene una relación de difusión directa con la tabla de fechas.
Si observamos específicamente la tabla del día de la semana en la línea cuatro, lo que estamos construyendo es una tabla que tendrá exactamente siete líneas. Cada línea de la tabla estará asociada con una y solo una línea del día de la semana. Así, si colocamos valores en esta tabla del día de la semana, podemos difundir esos valores de manera muy natural, ya que cada línea en el lado receptor, en la tabla de fechas, tendrá una línea que coincida en esta tabla del día de la semana.
En la línea nueve, con el vector “de.dot.baseline”, se calcula como la multiplicación simple de los cinco factores que están a la derecha de la asignación. Todos esos factores se difunden primero a la tabla de fechas, y luego procedemos con una multiplicación línea por línea para cada línea de la tabla de fechas.
Ahora, tenemos un modelo que cuenta con unas pocas docenas de parámetros. Podemos contarlos: tenemos 12 parámetros para el mes del año, de 1 a 12; tenemos siete parámetros para el día de la semana; y tenemos 31 parámetros para el día del mes. Sin embargo, en el caso de NDM5, no vamos a aprender un valor de parámetro distinto para cada SKU, ya que terminaríamos con un número masivamente grande de parámetros que probablemente sobreajustarían enormemente el conjunto de datos de Walmart. En cambio, en NDM5, lo que se hizo fue aprovechar un truco conocido como parameter sharing.
El parameter sharing significa que, en lugar de aprender parámetros distintos para cada SKU, vamos a establecer subgrupos y luego aprender esos parámetros a nivel de subgrupo. Luego, usamos los mismos valores dentro de esos grupos para dichos parámetros. El parameter sharing es una técnica muy clásica que se utiliza extensamente en deep learning, aunque es anterior al propio deep learning. Durante el M5, el mes del año y el día de la semana se aprendieron a nivel de agregación del departamento de tienda. Volveré a los diversos niveles de agregación del M5 en un segundo. El valor del día del mes fue en realidad un factor codificado de forma fija que se estableció a nivel estatal, y cuando digo el estado, me refiero a los Estados Unidos, como California, Texas, etc. Durante el M5, todos esos parámetros de calendario se aprendieron simplemente como promedios directos sobre sus respectivos ámbitos. Es una forma muy directa de establecer esos parámetros: simplemente tomas todos los SKUs que pertenecen al mismo ámbito, promedias todo, normalizas, y ahí tienes tu parámetro.

Ahora, en este punto, hemos reunido todo para ensamblar el modelo REMT. Hemos visto cómo construir la línea base diaria, que incorpora todos los patrones de calendario. Los patrones de calendario se han aprendido a través de promedios directos de un cierto ámbito, que es un mecanismo de aprendizaje crudo pero efectivo. También hemos visto que el ISSM transforma una serie temporal en una caminata aleatoria. Solo nos queda establecer los valores adecuados para los parámetros del ISSM, a saber, alfa, el parámetro utilizado para el proceso de suavizamiento exponencial que ocurrió dentro del SSM; la dispersión, que es un parámetro utilizado para controlar la distribución binomial negativa; y el valor inicial para el nivel, que se usa para inicializar nuestra caminata aleatoria.
Durante la competencia M5, el equipo de Lokad aprovechó una optimización simple mediante grid search para aprender esos tres parámetros restantes. Grid search esencialmente significa que iteras sobre todas las combinaciones posibles de esos valores, avanzando en pequeños incrementos a la vez. El grid search se dirigió utilizando la función de pérdida pinball, que describí anteriormente, para orientar la optimización de esos tres parámetros. Para cada SKU, el grid search es probablemente una de las formas más ineficientes de optimización matemática. Sin embargo, considerando que solo tenemos tres parámetros y que solo necesitamos realizar una optimización por serie temporal, y que el conjunto de datos M5 en sí es bastante pequeño, fue adecuado para la competencia M5.
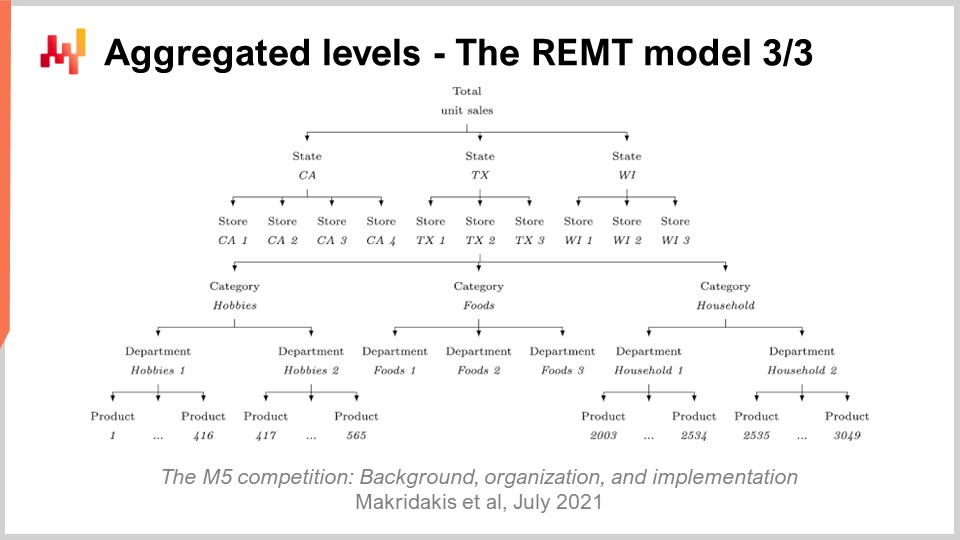
Hasta ahora, hemos presentado cómo opera el modelo REMT a nivel de SKU. Sin embargo, en el M5, había 12 niveles distintos de agregación. El nivel SKU, siendo el más desagregado, era el más importante. Un SKU, o unidad de mantenimiento de stock, es literalmente un producto en una ubicación. Si tienes el mismo producto en 10 ubicaciones, entonces tienes 10 SKUs. Aunque el SKU es, probablemente, el nivel de agregación más relevante para una supply chain, casi todas las decisiones relacionadas con el inventario, como reabastecimiento y surtido, se toman a nivel de SKU. El M5 fue principalmente una competencia de forecast, y por lo tanto se hizo mucho énfasis en los otros niveles de agregación.
En la pantalla, estos niveles resumen los niveles de agregación que estaban presentes en el conjunto de datos M5. Puedes ver que tenemos los estados, como California y Texas. Para abordar los niveles de agregación más altos, el equipo de Lokad utilizó dos técnicas: o sumando las caminatas aleatorias, es decir, se realizan las caminatas aleatorias a un nivel de agregación inferior, se suman y luego se obtienen caminatas aleatorias a un nivel de agregación superior; o reiniciando completamente el proceso de aprendizaje, saltando directamente al nivel de agregación superior. En el desafío de incertidumbre del M5, el modelo REMT fue el mejor a nivel de SKU, pero no fue el mejor en los otros niveles de agregación, aunque en general tuvo un buen desempeño en todos ellos.
Mi propia hipótesis de trabajo sobre por qué el modelo REMT no fue el mejor en todos los niveles es la siguiente (por favor, ten en cuenta que se trata de una hipótesis y en realidad no la probamos): la distribución binomial negativa ofrece dos grados de libertad a través de sus dos parámetros. Al observar datos bastante escasos, como los que se encuentran a nivel de SKU, dos grados de libertad representan el equilibrio adecuado entre subajuste y sobreajuste. Sin embargo, a medida que avanzamos hacia niveles de agregación superiores, los datos se vuelven más densos y ricos, por lo que el trade-off probablemente se desplace hacia algo mejor adaptado para capturar con mayor precisión la forma de la distribución. Necesitaríamos unos pocos grados de libertad adicionales – probablemente solo uno o dos parámetros adicionales – para lograr esto.
Sospecho que aumentar el grado de parametrización de la distribución de conteos utilizada en el núcleo del modelo REMT habría contribuido en gran medida a lograr algo muy cercano, si no directamente de última generación, para los niveles de agregación superiores. Sin embargo, no tuvimos tiempo de hacer eso, y es posible que volvamos a revisar este caso en el futuro. Esto concluye lo realizado por el equipo de Lokad durante la competencia M5.

Discutamos lo que podría haberse hecho de manera diferente o mejor. Aunque el modelo REMT es un modelo paramétrico de baja dimensión con una estructura multiplicativa simple, el proceso utilizado para obtener los valores de los parámetros durante el M5 fue, de manera algo accidental, complicado. Era un proceso de múltiples etapas, en el que cada patrón calenario tenía su propio tratamiento especial ad hoc, finalizando con una búsqueda en cuadrícula hecha a la medida para completar el modelo REMT. Todo el proceso consumió bastante tiempo para los científicos de datos, y sospecho que sería bastante poco fiable en entornos de producción debido a la gran cantidad de código ad hoc involucrado.
En particular, mi opinión es que podemos y debemos unificar el proceso de aprendizaje de todos los parámetros en un proceso de una sola etapa o, al menos, unificar el proceso de aprendizaje de manera que se utilice el mismo método de forma repetida. En la actualidad, Lokad utiliza programación diferenciable para hacer exactamente eso. La programación diferenciable elimina la necesidad de agregaciones ad hoc en lo que respecta a los patrones calenarios. También elimina el problema de ordenar precisamente la extracción de los patrones calenarios al extraerlos todos de una vez. Finalmente, dado que la programación diferenciable es un proceso de optimización en sí mismo, reemplaza la búsqueda en cuadrícula con una lógica de optimización mucho más eficiente. Revisaremos en detalle cómo se puede utilizar la programación diferenciable para el modelado predictivo en el contexto de propósitos de supply chain en posteriores conferencias de este capítulo.
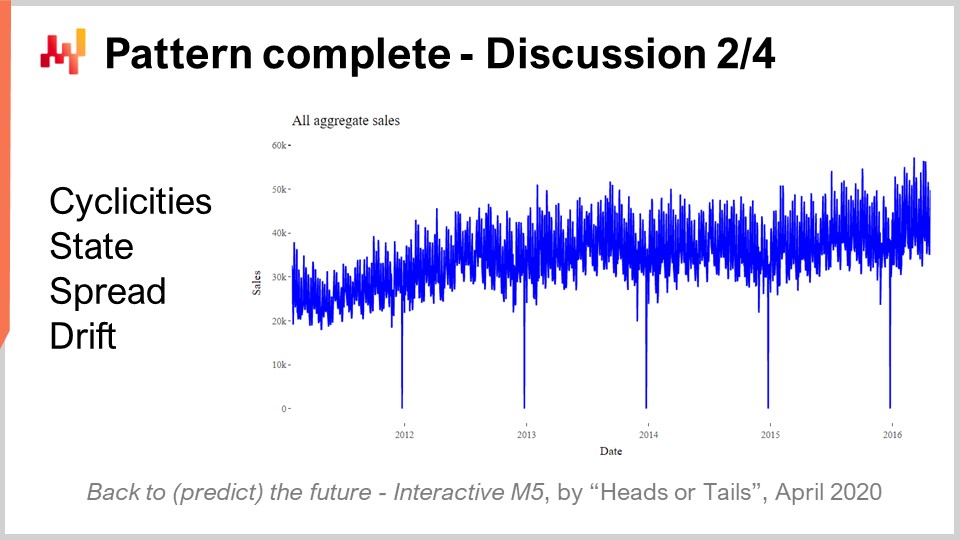
Ahora, uno de los resultados más sorprendentes de la competencia M5 fue que ningún patrón estadístico quedó sin nombre. Literalmente, teníamos cuatro patrones: simplicities, state, spread y drift, que fueron todo lo necesario para lograr una precisión de forecast de última generación en la competencia M5.
Simplicities se basan en el calendario y ninguno de ellos es siquiera remotamente sorprendente. El state puede representarse como un único número que indica el nivel alcanzado por el SKU en un momento específico. El spread puede representarse con un único número que es la dispersión utilizada para parametrizar la binomial negativa, y el drift puede representarse con un único número asociado al proceso de suavizado exponencial que se llevó a cabo dentro del SSM. Ni siquiera tuvimos que incluir la tendencia, que era demasiado débil para un horizonte de 28 días.
Mientras observamos los cinco años totales de ventas agregadas para el M5, tal como se muestra en la pantalla, la agregación muestra claramente una modesta tendencia ascendente. Sin embargo, el modelo REMT opera sin ella y no tuvo ninguna consecuencia en términos de precisión. El desempeño del modelo REMT plantea la pregunta: ¿existe algún otro patrón por capturar, y nos hemos perdido algún patrón?
Por lo menos, el desempeño del modelo REMT demuestra que ninguno de los modelos más sofisticados involucrados en esta competencia, tales como gradient boosting trees o deep learning methods, capturó algo más allá de esos cuatro patrones. De hecho, si alguno de esos modelos hubiera logrado capturar sustancialmente algo, habrían superado con creces al modelo REMT a nivel de SKU, cosa que no ocurrió. Lo mismo se puede decir de todos los métodos estadísticos más sofisticados como ARIMA. Esos modelos tampoco lograron capturar nada más allá de lo que este modelo paramétrico multiplicativo muy simple ha capturado.
El principio de la navaja de Occam nos dice que, a menos que podamos encontrar una muy buena razón para pensar que un patrón se nos escapa o una muy buena razón debido a alguna propiedad muy interesante que supere la simplicidad de este modelo, no tenemos ninguna razón para utilizar algo que no sea un modelo al menos tan simple como el modelo REMT.

Sin embargo, una serie de patrones estuvieron ausentes en la competencia M5 debido al propio diseño del conjunto de datos M5. Esos patrones son importantes, y en la práctica, cualquier modelo que los ignore funcionará mal en un entorno de retail real. Estoy basando esta afirmación en mi propia experiencia.
Primero, tenemos los lanzamientos de productos. La competencia M5 solo incluyó productos que tenían al menos cinco años de historial de ventas. Esta es una suposición irrazonable en lo que respecta a la supply chain. De hecho, los productos FMCG típicamente tienen una vida útil de solo un par de años, y por lo tanto, en una tienda real, siempre hay una porción significativa del surtido que tiene menos de un año de historial de ventas. Además, al observar productos con largos lead times, se deben tomar numerosas decisiones de supply chain incluso antes de que el producto tenga la oportunidad de venderse una sola vez en cualquier tienda. Por lo tanto, necesitamos modelos de forecast que puedan incluso operar sin historial de ventas para un determinado producto.
El segundo patrón de importancia crítica son los faltantes de stock. Los faltantes de stock ocurren en el retail, y el conjunto de datos de la competencia M5 los ignoró por completo. Sin embargo, los faltantes de stock limitan las ventas. Si un producto se agota en la tienda, no se venderá ese día, y por lo tanto, los faltantes de stock introducen un sesgo significativo en las ventas que observamos. El problema, en el caso de Walmart y las tiendas de mercancías generales, es aún más complicado porque los registros electrónicos que capturan los valores de stock disponible no pueden ser plenamente confiables. Existen numerosas inexactitudes en el inventario, y esto debe tenerse en cuenta también.
Tercero, tenemos las promociones. La competencia M5 incluyó precios históricos; sin embargo, no se proporcionaron los datos de precios para el período de forecast. Como resultado, parece que ningún competidor en esta competencia logró aprovechar la información de precios para mejorar la precisión del forecast. El modelo REMT no utiliza información de precios en absoluto. Más allá del hecho de que nos faltó la información de precios para el período del forecast, las promociones no se tratan solo de precios. Un producto puede promocionarse al estar exhibido de manera prominente en una tienda, lo cual puede aumentar significativamente la demanda, independientemente de si se ha bajado el precio. Además, con las promociones, debemos considerar efectos de canibalización y sustitución.
En general, el conjunto de datos M5, desde una perspectiva de supply chain, puede considerarse un conjunto de juguete. Aunque probablemente sigue siendo el mejor conjunto de datos público existente para llevar a cabo benchmarks de supply chain, aún está lejos de ser verdaderamente equivalente a una configuración de producción real en una cadena de retail de tamaño modesto.

Sin embargo, las limitaciones de la competencia M5 no se deben únicamente al conjunto de datos. Desde una perspectiva de supply chain, existen problemas fundamentales con las reglas utilizadas para llevar a cabo la competencia M5.
El primer problema fundamental es no confundir las ventas con la demanda. Ya hemos abordado este tema con los faltantes de stock. Desde una perspectiva de supply chain, el verdadero interés radica en anticipar la demanda, no las ventas. Sin embargo, el problema es más profundo. La estimación adecuada de la demanda es, fundamentalmente, un problema de aprendizaje no supervisado. No es que, debido a que se han tomado decisiones arbitrarias sobre el surtido aplicable en una tienda, la demanda de un producto no deba estimarse. Debemos estimar la demanda de los productos, independientemente de si forman parte del surtido en una tienda determinada.
El segundo aspecto es que los forecast cuantiles son menos útiles que los forecast probabilísticos. Seleccionar a dedo niveles de servicio deja huecos en la imagen, y los forecast cuantiles son relativamente débiles en términos de uso en supply chain. Un forecast probabilístico ofrece una visión mucho más completa porque proporciona la distribución de probabilidad completa, eliminando esta clase de problemas. La única desventaja clave de los forecast probabilísticos es que requieren más herramientas, especialmente cuando se trata de hacer algo efectivo con el forecast en etapas posteriores, después de que el forecast se haya producido. Por cierto, el modelo REMT en realidad entrega algo que califica como un forecast probabilístico, porque, mediante el proceso Monte Carlo, se puede generar una distribución de probabilidad completa. Solo es necesario ajustar el número de iteraciones de Monte Carlo.
En el retail, a los clientes realmente no les interesa la perspectiva de SKU ni el nivel de servicio que se puede alcanzar en un SKU determinado. La percepción de los clientes en una tienda de mercancías generales como Walmart está impulsada por la cesta de la compra. Típicamente, los clientes entran a una tienda Walmart con toda una lista de compras en mente, no solo un producto. Además, hay toneladas de sustitutos disponibles en la tienda. El problema de utilizar una métrica única de SKU para evaluar la calidad del servicio es que se pierde por completo lo que los clientes perciben como calidad del servicio en la tienda.
En conclusión, como benchmark de forecast de series temporales, la competencia M5 es sólida en términos de conjuntos de datos y metodología. Sin embargo, la perspectiva de series temporales en sí misma es insuficiente en lo que respecta a supply chain. Las series temporales no reflejan los datos tal como se encuentran en las supply chains, ni reflejan los problemas tal como se presentan en las supply chains. Durante la competencia M5, hubo muchos métodos mucho más sofisticados entre los primeros puestos. Sin embargo, en mi opinión, esos modelos son, en efecto, callejones sin salida. Ya son demasiado complicados para su uso en producción, y abrazan tanto la perspectiva de series temporales que no tienen margen operativo para evolucionar hacia la clase de perspectiva fresca necesaria para ajustar esos modelos a nuestras propias necesidades de supply chain.
Al contrario, como punto de partida, el modelo REMT es lo mejor que se puede obtener. Es una combinación muy simple de ingredientes que, por sí solos, son muy simples. Además, no se requiere mucha imaginación para ver que existen muchas maneras de utilizar y combinar estos elementos más allá de la combinación específica reunida para la competencia M5. El puesto alcanzado por el modelo REMT en la competencia M5 demuestra que, hasta que se demuestre lo contrario, deberíamos ceñirnos a un modelo muy simple, ya que no tenemos ninguna razón convincente para optar por modelos muy complicados que casi con seguridad serán más difíciles de depurar, más difíciles de operar en producción y consumirán muchos más recursos informáticos.
En las próximas conferencias de este quinto capítulo, veremos cómo podemos utilizar los ingredientes que formaban parte del modelo REMT, así como varios otros ingredientes, para abordar la extensa variedad de desafíos predictivos tal como se presentan en las supply chains. Lo clave a recordar es que el modelo es irrelevante; lo que importa es el modelado.

Pregunta: ¿Por qué las binomiales negativas? ¿Cuál fue el razonamiento al seleccionarlas?
Esa es una muy buena pregunta. Bueno, resulta que, si existe un bestiario mundial de distribuciones de conteo, probablemente haya unas 20-something distribuciones de conteo muy conocidas. En Lokad, probamos una docena para nuestras propias necesidades internas. Resulta que Poisson, que es una distribución de conteo muy simplista con solo un parámetro, funciona bastante bien cuando los datos son muy escasos. Así que Poisson es bastante bueno, pero en realidad, el conjunto de datos M5 era un poco más rico. En el caso del conjunto de datos de Walmart, probamos distribuciones de conteo que tenían unos cuantos parámetros más, y parecía funcionar. No tenemos prueba de que sea realmente la mejor; probablemente existan opciones mejores. La binomial negativa tiene algunas ventajas clave: la implementación es muy sencilla, y es una distribución de conteo ampliamente estudiada. Por lo tanto, se cuenta con un algoritmo muy conocido, no solo para calcular las probabilidades, sino también para generar una muestra, obtener la media o la distribución acumulativa.
Hay un grado de pragmatismo involucrado en esta elección, pero también un poco de lógica. Con Poisson, tienes un grado de libertad; la binomial negativa tiene dos. Luego puedes usar trucos como la binomial negativa con exceso de ceros, que te da como dos grados y medio de libertad, etc. No diría que existe un valor específico y definitivo para esta distribución de conteo.
Pregunta: Había otros proveedores de software de optimización de supply chain en el M5, pero nadie usaba modelos en vivo que escalaran bien en producción. ¿Qué es lo que utiliza la mayoría, modelos pesados de machine learning?
Primero, diría que debemos distinguir y aclarar que el M5 se llevó a cabo en Kaggle, una plataforma para la ciencia de datos. En Kaggle, tienes un incentivo enorme para usar la maquinaria más complicada posible. El conjunto de datos es pequeño, tienes mucho tiempo, y para estar en el primer puesto, solo tienes que ser 0.1% más preciso que el otro. Eso es lo único que importa. Así, en prácticamente cada competencia de Kaggle, verías que los puestos superiores están llenos de personas que hicieron cosas muy complicadas solo para obtener un 0.1% extra de precisión. Entonces, la propia naturaleza de ser una competencia de forecast te da un fuerte incentivo para probar de todo, incluidos los modelos de machine learning más pesados que puedas encontrar.
Si nos preguntamos si la gente está utilizando realmente estos modelos de machine learning pesados en producción, mi observación casual es que absolutamente no. Es, de hecho, extremadamente raro. Como CEO de Lokad, un proveedor de software de supply chain, he hablado con cientos de directores de supply chain. Literalmente, más del 90% de las grandes supply chain se operan a través de Excel. Nunca he visto ninguna supply chain a gran escala operada con árboles potenciados por gradiente o redes de deep learning. Si dejamos de lado a Amazon, Amazon es probablemente única en su tipo. Quizás haya media docena de empresas, como Amazon, Alibaba, JD.com y algunas otras –los supergigantes del ecommerce– que están usando este tipo de tecnología. Pero son excepcionales en este sentido. Las grandes empresas convencionales de FMCG o las grandes compañías minoristas físicas no están utilizando este tipo de cosas en producción.
Pregunta: Es extraño que menciones muchos términos matemáticos y estadísticos, pero ignores la naturaleza de las ventas minoristas y los principales factores influyentes.
Diría que sí, esto es más bien un comentario, pero mi pregunta para ti sería: ¿Qué aportas tú? Eso es a lo que me refería cuando los proveedores de supply chain que se jactaban de tener una tecnología de forecast superior estaban completamente ausentes. ¿Por qué es que, si tienes una tecnología de forecast absolutamente superior, resultas ausente cada vez que hay algo como un benchmark público? La otra explicación es que la gente está haciendo farol.
En lo que respecta a la naturaleza de las ventas minoristas y a muchos factores influyentes, enumeré los patrones que se utilizaron y, al usar esos cuatro patrones, el modelo REMT terminó siendo el número uno a nivel de SKU en términos de precisión. Si tomas la proposición de que existen muchos patrones más importantes, la carga de la prueba es tuya. Mi propia sospecha es que, si entre más de 900 equipos esos patrones no se observaron, probablemente no estaban allí, o captar esos patrones está tan fuera del alcance de lo que podemos hacer con la tecnología que tenemos, que, por ahora, es como si esos patrones no existieran desde una perspectiva práctica.
Pregunta: ¿Algún competidor en el M5 aplicó ideas que, aunque no superaran a Lokad, serían valiosas para incorporar, especialmente para aplicaciones genéricas? ¿Mención honorífica?
He estado prestando mucha atención a mis competidores, y estoy bastante seguro de que ellos están prestando algo de atención a Lokad. Yo no vi eso. El modelo REMT fue realmente único, completamente diferente a lo que hicieron prácticamente casi los otros 50 principales contendientes para cualquiera de las tareas. Los otros participantes estaban usando cosas mucho más clásicas en los círculos de machine learning.
Se demostraron algunos trucos muy inteligentes de data science durante la competencia. Por ejemplo, algunas personas usaron trucos muy astutos y sofisticados para realizar data augmentation en el conjunto de datos de Walmart, para hacerlo mucho más grande de lo que era y ganar algunos puntos porcentuales extra de precisión. Esto lo hizo el contendiente que quedó en el número uno en el desafío de incertidumbre. Data augmentation, y no data inflation, es el término adecuado. Data augmentation se usa comúnmente en técnicas de deep learning, pero aquí se utilizó con árboles potenciados por gradiente de maneras bastante inusuales. Se demostraron trucos de data science muy sofisticados e inteligentes durante esta competencia. No estoy muy seguro de si esos trucos se generalizan bien a supply chain, pero probablemente mencionaré un par de ellos durante el resto de este capítulo si se presenta la oportunidad.
Pregunta: ¿Estimaste niveles superiores agregando tus niveles SKU o calculando de nuevo middle-out para niveles superiores? Si ambos, ¿cómo se compararon?
El problema con las rejillas de quantiles es que tiendes a optimizar los modelos por separado para cada nivel objetivo. Lo que puede suceder con las rejillas de quantiles es que puede haber cruce de quantiles, lo que significa que, simplemente por inestabilidades numéricas, tu quantile del 99% termina siendo inferior que el quantile del 97%. Esto es inconsecuente; típicamente, solo reordenas los valores. Fundamentalmente, ese es el tipo de problema al que me refería en términos de que las rejillas de quantiles no son del todo forecast probabilístico. Tienes toneladas de detalles minuciosos por resolver, pero la realidad es que son inconsecuentes en el gran esquema de las cosas. Cuando pasas a forecast probabilístico, esos problemas ya ni siquiera existen.
Pregunta: Si estuvieras diseñando otra competencia para proveedores de software, ¿cómo sería?
Francamente, no lo sé, y esta es una pregunta muy difícil. Creo que, a pesar de todas mis fuertes críticas, en lo que respecta a benchmark de forecast, el M5 es el mejor que tenemos. Ahora, en términos de benchmark de supply chain, el problema es que ni siquiera estoy completamente convencido de que sea posible. Cuando insinué que algunos de los problemas en realidad requieren aprendizaje no supervisado, esto se complica. Cuando entras en el ámbito del aprendizaje no supervisado, tienes que renunciar a tener métricas, y todo el ámbito del machine learning avanzado aún lucha como comunidad para llegar a un acuerdo sobre lo que realmente significa operar herramientas automatizadas de aprendizaje superiores en un entorno no supervisado. ¿Cómo se benchmarkean siquiera ese tipo de cosas?
Para la audiencia que no estuvo presente en mi conferencia sobre machine learning, en entornos supervisados, esencialmente estás tratando de lograr una tarea en la que tienes entradas y salidas y una métrica para evaluar la calidad de tus resultados. Cuando estás en un entorno no supervisado, significa que no tienes etiquetas, no tienes nada con lo que comparar, y las cosas se vuelven mucho más difíciles. Además, señalaría que en supply chain hay muchas cosas en las que ni siquiera se puede hacer back-testing. Más allá del aspecto no supervisado, incluso la perspectiva del back-testing no es completamente satisfactoria. Por ejemplo, forecast de la demanda generará ciertos tipos de decisiones, como decisiones de precios. Si decides ajustar el precio hacia arriba o hacia abajo, esa es una decisión que tomaste y que influirá para siempre en el futuro. Entonces, no puedes retroceder en el tiempo para decir: “Vale, voy a hacer un forecast de demanda diferente y luego tomar una decisión de precios distinta, y luego dejar que la historia se repita, excepto que esta vez tengo un precio diferente.” Hay muchos aspectos en los que incluso la idea del back-testing no funciona. Por eso, creo que una competencia es algo muy interesante desde la perspectiva del forecast. Es útil como punto de partida para fines de supply chain, pero necesitamos hacer algo mejor y diferente si queremos terminar con algo que sea verdaderamente satisfactorio para fines de supply chain. En este capítulo sobre modelado predictivo, voy a mostrar por qué el modelado merece tal enfoque.
Pregunta: ¿Se puede utilizar esta metodología en situaciones donde tienes pocos datos?
Yo diría que absolutamente. Este tipo de modelado estructurado, como se demuestra aquí con el modelo REMT, brilla intensamente en situaciones donde tienes datos muy escasos. La razón es simple: puedes incorporar mucho conocimiento humano en la propia estructura del modelo. La estructura del modelo no es algo que se sacó de la nada; es literalmente la consecuencia de que el equipo de Lokad entendiera el problema. Por ejemplo, cuando observamos patrones de calendario como el día de la semana, el mes del año, etc., no intentamos descubrir esos patrones; el equipo de Lokad sabía desde el principio que esos patrones ya estaban allí. La única incertidumbre era la prevalencia respectiva del patrón del día del mes, que tiende a ser débil en muchas situaciones. En el caso de la configuración de Walmart, fue simplemente debido a que existe un programa de sellos en EE.UU. por el cual este patrón del día del mes es tan fuerte como lo es.
Si tienes pocos datos, este tipo de enfoque funciona extraordinariamente bien porque, sea cual sea el mecanismo de aprendizaje que estés tratando de usar, aprovechará extensamente la estructura que has impuesto. Así que sí, surge la pregunta: ¿qué pasa si la estructura es incorrecta? Pero por eso es tan importante el pensamiento y la comprensión de supply chain, para que puedas tomar las decisiones correctas. Al final, tienes formas de evaluar si tus decisiones arbitrarias fueron buenas o malas, pero fundamentalmente, esto sucede muy tarde en el proceso. Más adelante en este capítulo sobre modelado predictivo, ilustraremos cómo el modelado estructurado puede utilizarse eficazmente en conjuntos de datos increíblemente escasos, como aquellos en aviación, hard luxury y todo tipo de esmeraldas. En estas situaciones, los modelos estructurados realmente brillan.
La próxima clase se llevará a cabo el 2 de febrero, que es miércoles, a la misma hora del día, a las 3 p.m. hora de París. ¡Nos vemos entonces!
Referencias
- Un enfoque ISSM de caja blanca para estimar distribuciones de incertidumbre de las ventas de Walmart, Rafael de Rezende, Katharina Egert, Ignacio Marin, Guilherme Thompson, diciembre 2021 (link)
- La competencia de incertidumbre M5: Resultados, hallazgos y conclusiones, Spyros Makridakis, Evangelos Spiliotis, Vassilis Assimakopoulos, Zhi Chen, noviembre 2020 (link)


