Technology

Différentiation Automatique par Chemins Sélectifs: Au-delà de la Distribution Uniforme sur le Dropout en Rétropropagation
L'approche de Différentiation Automatique par Chemins Sélectifs (SPAD) améliore la Stochastic Gradient Descent (SGD) en adoptant une perspective inférieure au niveau du point de données. Cette technique, implémentée au niveau du compilateur, échange la qualité du gradient contre sa quantité, complétant les méthodes traditionnelles de SGD avec une vision plus nuancée.

Une critique opiniâtre de Deep gestion des stocks
Une équipe d'Amazon a publié vers la fin de l'année 2022 Deep gestion des stocks (DIM). Cet article présente une technique d'optimisation de stocks DIM qui combine à la fois le reinforcement learning et le deep learning. Alors que Lokad a suivi un chemin similaire par le passé, son PDG et fondateur Joannes Vermorel livre ici son évaluation critique de la technique suggérée.
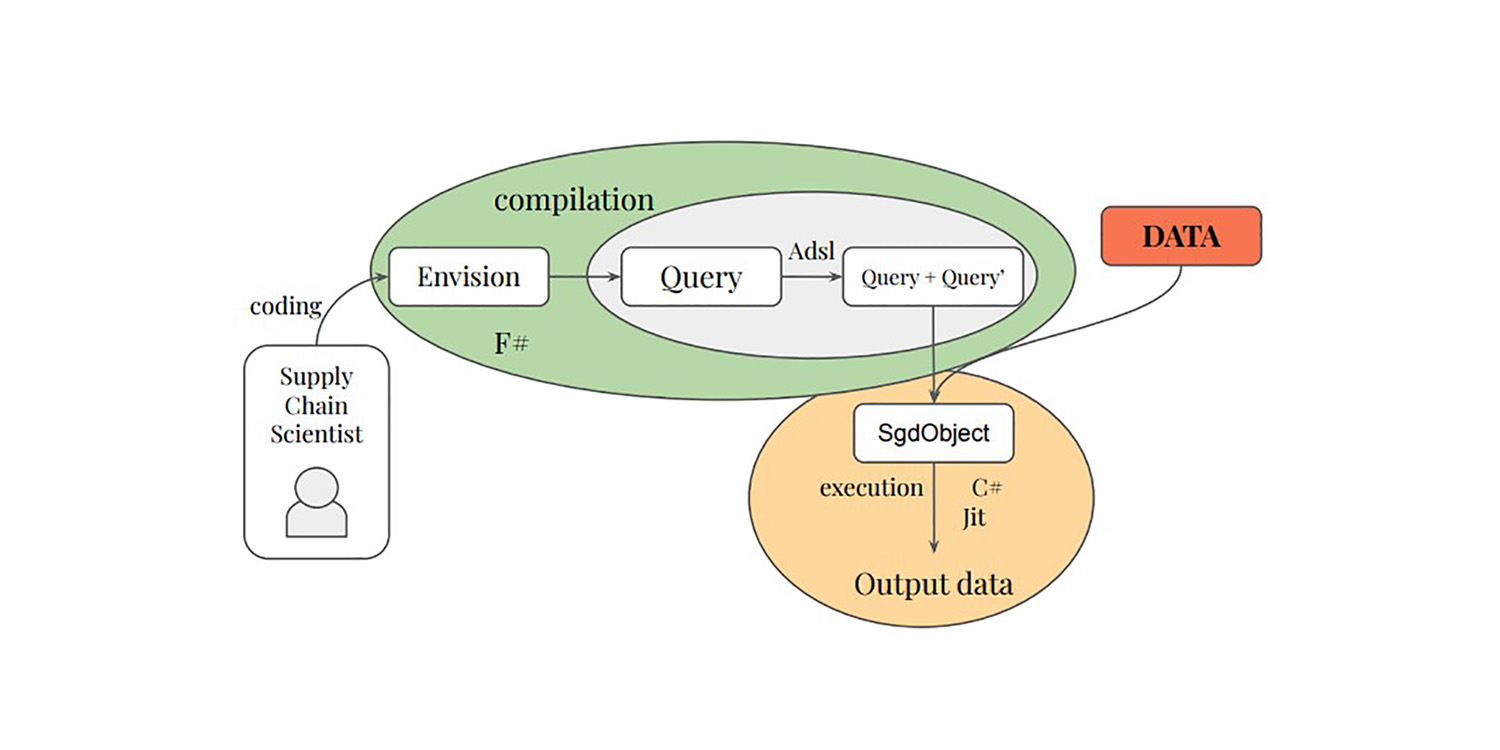
Programmation différentiable pour optimiser des données relationnelles à grande échelle
La thèse de Paul Peseux sur la différentiation des requêtes relationnelles - un autre domaine sous-étudié de la supply chain - a introduit l'opérateur TOTAL JOIN, Polystar et un mini-langage ADSL pour différencier les requêtes relationnelles, le tout intégré par Lokad dans son langage dédié Envision dans le cadre de l'autodiff pour optimiser la prise de décision quotidienne sur les stocks.
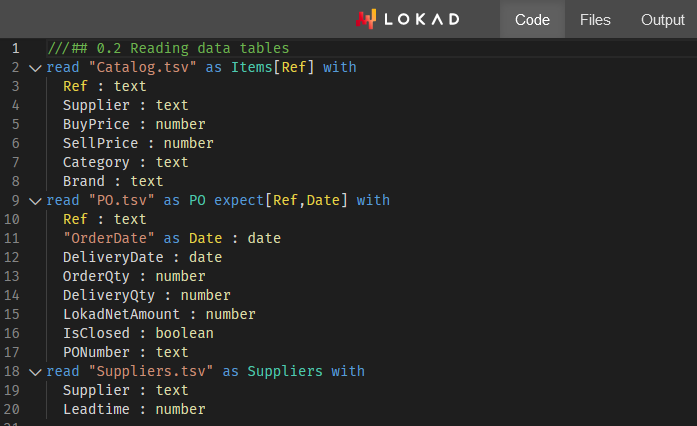
L’analyse des fournisseurs via Envision - Atelier #1
Lokad lance son premier Envision Workshop, enseignant aux étudiants (et aux spécialistes de la supply chain) comment analyser les fournisseurs de la distribution en utilisant la perspective probabiliste de gestion des risques de Lokad.
Gestion des stocks sous la contrainte de quantités minimales de commande multi-référence
La recherche de doctorat de Gaetan Delétoille sur les MOQs - un domaine étonnamment sous-étudié de la supply chain - a introduit la w-policy, quelque chose que Lokad a intégré dans sa solution pour la prise de décision quotidienne concernant les stocks.
Algorithmes de classification distribués sur le cloud
Matthieu Durut, deuxième employé chez Lokad, a soutenu son doctorat en 2012 pour ses travaux de recherche réalisés chez Lokad. Ce doctorat a ouvert la voie à la transition de Lokad vers des architectures de calcul distribué cloud-native, aujourd'hui essentielles pour faire face à de vastes supply chains.

Apprentissage à grande échelle : une contribution aux algorithmes de clustering asynchrones distribués
Benoit Patra, premier employé chez Lokad, a soutenu son doctorat en 2012 pour ses recherches menées chez Lokad. Ce doctorat a apporté des éléments radicalement nouveaux à la théorie de la supply chain, et a préparé le terrain pour le développement futur de l'approche de prévision probabiliste de Lokad.

Descente de gradient stochastique avec estimateur de gradient pour variables catégoriques
Le vaste domaine du machine learning (ML) offre un large éventail de techniques et de méthodes couvrant de nombreuses situations. La supply chain, cependant, présente son propre ensemble de défis en matière de données, et parfois, des aspects jugés « basiques » par les praticiens de la supply chain ne bénéficient pas d'instruments ML satisfaisants – du moins selon nos critères.
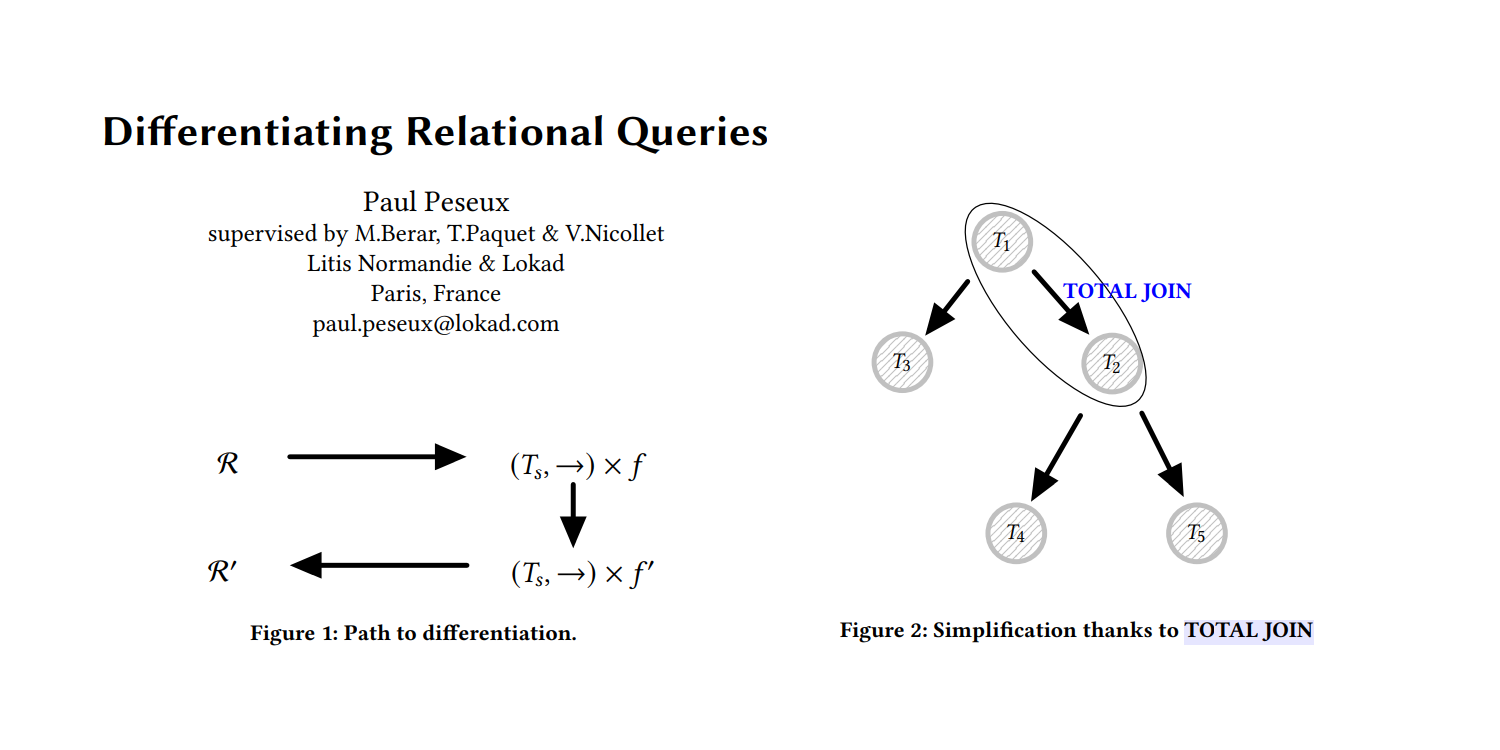
Différencier les requêtes relationnelles
Les données de supply chain se présentent presque exclusivement sous forme de données relationnelles telles que commandes, clients, fournisseurs, produits, etc. Ces données sont collectées via les systèmes d'information - l'ERP, le CRM, le WMS - utilisés pour faire fonctionner l'entreprise.

Gradient descendant stochastique parallèle reproductible
La descente de gradient stochastique (SGD) est l'une des techniques les plus performantes jamais conçues pour l'apprentissage automatique et l'optimisation mathématique. Lokad exploite le SGD depuis des années pour des applications supply chain, principalement par la programmation différentiable. La plupart de nos clients possèdent au moins un SGD quelque part dans leur pipeline de données.

Envision VM (partie 4), Exécution distribuée
Les articles précédents examinaient principalement comment les travailleurs individuels exécutaient les scripts Envision. Cependant, tant pour la résilience que pour la performance, Envision est en réalité exécuté sur un cluster de machines.

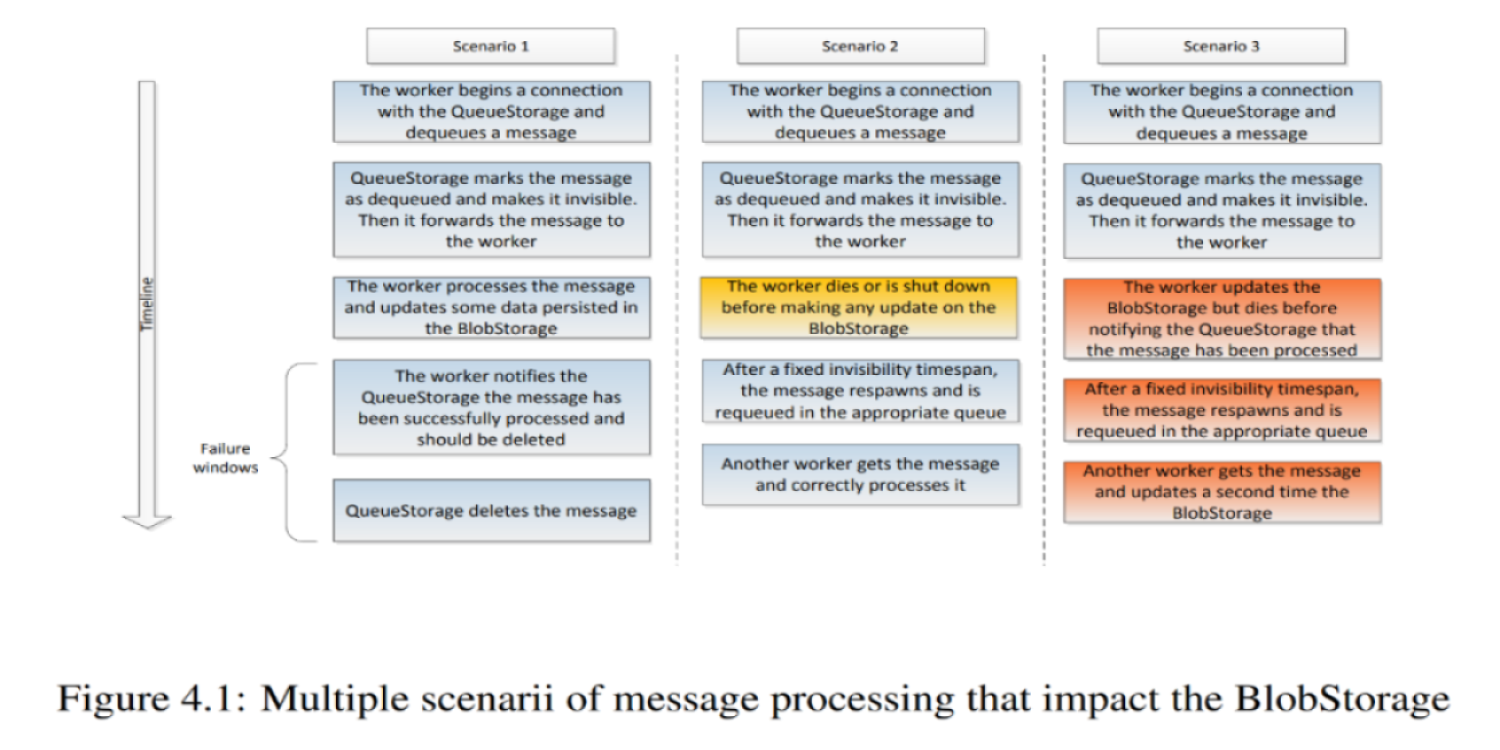
Envision VM (part 3), Atomes et Stockage de données
Pendant l'exécution, les thunks lisent des données d'entrée et écrivent des données de sortie, souvent en grandes quantités. Comment préserver ces données dès leur création et jusqu’à leur utilisation (une partie de la réponse réside dans l’utilisation de disques NVMe répartis sur plusieurs machines), et comment minimiser la quantité de données transitant par des canaux plus lents que la RAM (réseau et stockage persistant).