00:01 Introduction
01:56 Le défi d’incertitude du M5 - Données (1/3)
04:52 Le défi d’incertitude du M5 - Règles (2/3)
08:30 Le défi d’incertitude du M5 - Résultats (3/3)
11:59 L’histoire jusqu’ici
14:56 Ce qui est (probablement) sur le point de se produire
15:43 Perte de pinball – Fondation 1/3
20:45 Binomiale négative – Fondation 2/3
24:04 Modèle d’État de l’Espace d’Innovation (ISSM) – Fondation 3/3
31:36 Structure des ventes – Le modèle REMT 1/3
37:02 Assembler le tout – Le modèle REMT 2/3
39:10 Niveaux agrégés – Le modèle REMT 3/3
43:11 Apprentissage d’une seule étape – Discussion 1/4
45:37 Modèle complet – Discussion 2/4
49:05 Modèles manquants – Discussion 3/4
53:20 Limites du M5 – Discussion 4/4
56:46 Conclusion
59:27 Prochaine conférence et questions du public
Description
En 2020, une équipe de Lokad a atteint la 5e place sur 909 équipes concurrentes lors du M5, une compétition mondiale de prévision. Cependant, au niveau d’agrégation SKU, ces prévisions se sont hissées à la première place. La prévision de la demande est d’une importance primordiale pour supply chain. L’approche adoptée dans cette compétition s’est avérée atypique, et différente des autres méthodes utilisées par les 50 premiers concurrents. De multiples leçons peuvent être tirées de cette réussite en guise de prélude pour relever de nouveaux défis prédictifs pour supply chain.
Transcription complète

Bienvenue dans cette série de conférences sur supply chain. Je suis Joannes Vermorel, et aujourd’hui, je vais présenter « No1 au niveau SKU dans la compétition de prévision M5 ». Une prévision précise de la demande est considérée comme l’un des piliers de l’optimisation de la supply chain. En effet, chaque décision supply chain reflète une certaine anticipation de l’avenir. Si nous pouvons obtenir des insights supérieurs sur le futur, alors nous pourrons prendre des décisions quantitativement supérieures pour nos objectifs supply chain. Ainsi, identifier des modèles qui offrent une précision prédictive de pointe revêt une importance primordiale pour l’optimisation de la supply chain.
Aujourd’hui, je vais présenter un modèle simple de prévision des ventes qui, malgré sa simplicité, s’est classé numéro un au niveau SKU dans une compétition mondiale de prévision connue sous le nom de M5, basée sur un jeu de données fourni par Walmart. Cette conférence poursuivra deux objectifs. Le premier sera de comprendre ce qu’il faut pour obtenir une précision de prévision des ventes de pointe. Cette compréhension sera un élément fondamental pour les futurs travaux en modélisation prédictive. Le deuxième objectif sera d’adopter la bonne perspective en matière de modélisation prédictive pour supply chain. Cette perspective servira également à guider notre progression ultérieure dans ce domaine de modélisation prédictive pour supply chain.

Le M5 était une compétition de prévision qui a eu lieu en 2020. Cette compétition porte le nom de Spyros Makridakis, un chercheur de renom dans le domaine de la prévision. Il s’agissait de la cinquième édition de cette compétition. Ces compétitions ont lieu tous les deux ans environ et tendent à varier en fonction de l’objet du jeu de données utilisé. Le M5 était un défi lié à supply chain, puisque le jeu de données utilisé était celui des magasins de détail fourni par Walmart. Le défi M6, qui reste à venir, sera axé sur la prévision financière.
Le jeu de données utilisé pour le M5 était et reste un jeu de données public. Il s’agissait de données de magasins de détail Walmart agrégées au niveau quotidien. Ce jeu de données comprenait environ 30 000 SKU, ce qui, dans le secteur de la distribution, constitue un jeu de données relativement modeste. En effet, à titre indicatif, un supermarché détient généralement environ 20 000 SKU, et Walmart exploite plus de 10 000 magasins. Ainsi, dans l’ensemble, ce jeu de données – le jeu de données M5 – représentait moins de 0,1 % du jeu de données à l’échelle mondiale de Walmart qui serait pertinent d’un point de vue supply chain.
De plus, comme nous le verrons ci-après, certaines catégories de données étaient entièrement absentes du jeu de données M5. En conséquence, mon estimation approximative est que ce jeu de données se rapproche en réalité de 0,01 % de l’échelle requise à l’échelle de Walmart. Néanmoins, ce jeu de données est largement suffisant pour réaliser un benchmark très solide des modèles de prévision dans un contexte réel. Dans un contexte réel, nous devrions prêter une attention particulière aux questions de scalabilité. Cependant, du point de vue d’une compétition de prévision, il est légitime de rendre le jeu de données assez modeste pour que la plupart des méthodes, même celles notoirement inefficaces, puissent être utilisées lors de la compétition. De plus, cela garantit que les concurrents ne sont pas limités par la quantité de ressources de cloud computing qu’ils peuvent réellement mobiliser pour cette compétition de prévision.
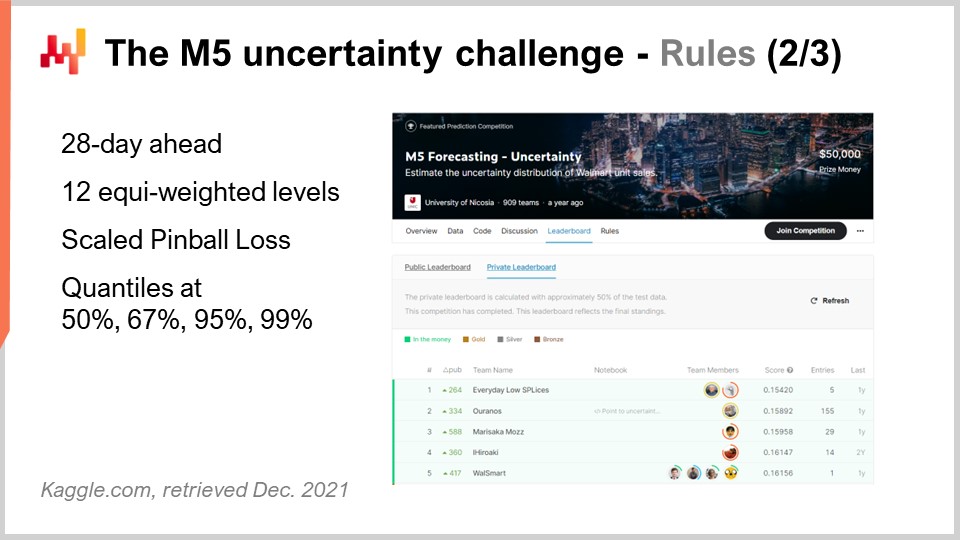
Le concours M5 comprenait deux défis distincts connus sous le nom de Accuracy et Uncertainty. Les règles étaient simples : il existait un jeu de données public accessible à tous les participants, et pour participer à l’un ou l’autre de ces défis, chaque participant devait produire son propre jeu de données, constitué de ses prévisions, et le soumettre sur la plateforme Kaggle. Le défi Accuracy consistait à fournir une prévision moyenne des séries temporelles, qui est la forme la plus classique de prévision formelle. Dans ce cas précis, il s’agissait de fournir une prévision quotidienne moyenne pour environ 40 000 séries temporelles. Le défi Uncertainty consistait à fournir des prévisions quantiles. Les quantiles sont des prévisions biaisées ; toutefois, ce biais est intentionnel. C’est tout l’intérêt d’avoir des quantiles. Cette conférence se concentre exclusivement sur le défi Uncertainty, et ce, parce que, dans supply chain, c’est la demande exceptionnellement élevée qui crée des ruptures de stock, et c’est la demande exceptionnellement faible qui engendre des radiations de stocks. Les coûts dans supply chain sont concentrés aux extrêmes. Ce n’est pas la moyenne qui nous intéresse.
En effet, si l’on considère ce que représente la moyenne dans le cas de Walmart, il s’avère que pour la plupart des produits, dans la plupart des magasins, pour la plupart des jours, les ventes moyennes observées sont nulles. Ainsi, la plupart des produits bénéficient d’une prévision moyenne fractionnaire. De telles prévisions moyennes sont très peu significatives du point de vue de supply chain. Si vos options se réduisent à stocker zéro unité ou à réapprovisionner une unité, les prévisions moyennes sont de peu d’utilité. Le secteur de la distribution n’est pas dans une position unique ici ; c’est pratiquement la même situation que l’on aborde en FMCG, aviation, en industrie manufacturière ou dans le luxe – pratiquement tous les autres secteurs.
Pour revenir au défi Uncertainty du M5, il fallait produire quatre quantiles, respectivement à 50 %, 67 %, 95 % et 99 %. Vous pouvez considérer ces cibles quantiles comme des objectifs de taux de service. La précision de ces prévisions quantiles a été évaluée selon une métrique connue sous le nom de pinball loss function. Je reviendrai sur cette métrique d’erreur plus tard dans cette conférence.

909 équipes concouraient à l’échelle mondiale dans ce défi Uncertainty. Une équipe de Lokad s’est classée cinquième au classement général, mais première au niveau SKU. En effet, bien que les SKU représentaient environ les trois-quarts des séries temporelles dans ce défi, il existait divers niveaux d’agrégation allant de l’État (comme aux États-Unis – Texas, Californie, etc.) jusqu’au SKU, et tous ces niveaux d’agrégation avaient le même poids dans le score final de cette compétition. Ainsi, même si les SKU représentaient environ les trois-quarts des séries temporelles, ils ne constituaient qu’environ 8 % du poids total dans le score final de la compétition.
La méthode utilisée par cette équipe de Lokad a été publiée dans un article intitulé “A White Box ISSM Approach to Estimate Uncertainty Distribution of Walmart’s Sales.” Je mettrai un lien vers cet article dans la description de cette vidéo une fois cette conférence terminée. Vous y trouverez tous les éléments en détail. Pour plus de clarté et de concision, je désignerai le modèle présenté dans cet article sous le nom de modèle BRAMPT, simplement d’après les initiales des quatre coauteurs.
À l’écran, j’ai listé les cinq premiers résultats du M5, obtenus à partir d’un article qui offre un aperçu général des résultats de cette compétition de prévision. Le détail du classement dépendait assez fortement de la métrique choisie. Cela n’est pas particulièrement surprenant. Le défi Uncertainty utilisait une variante échelonnée de la fonction de perte pinball. Nous reviendrons sur cette métrique d’erreur dans une minute. Bien que le défi Uncertainty du M5 ait démontré que nous ne disposons pas des moyens pour éliminer l’incertitude avec les méthodes de prévision dont nous disposons, et pas du tout, ce résultat n’est pas étonnant. Étant donné que les ventes en magasin de détail tendent à être erratiques et intermittentes, cela souligne l’importance d’embrasser l’incertitude plutôt que de la rejeter entièrement. Toutefois, il est remarquable de constater que les vendeurs de logiciels supply chain étaient tous absents du top 50 de cette compétition de prévision, ce qui est d’autant plus intrigant que ces vendeurs vantent une technologie de prévision de pointe soi-disant supérieure.
Maintenant, cette conférence fait partie d’une série de conférences sur supply chain. La présente conférence est la première de ce qui sera mon cinquième chapitre dans cette série. Ce cinquième chapitre sera dédié à la modélisation prédictive. En effet, recueillir des insights quantitatifs est nécessaire pour optimiser une supply chain. Chaque décision supply chain – qu’il s’agisse de décider d’acheter des matériaux, de produire un certain produit, de déplacer des stocks d’un endroit à un autre, ou d’augmenter ou de diminuer le prix de quelque chose que vous vendez – s’accompagne d’une anticipation de la demande future. En fin de compte, chaque décision supply chain comporte une attente implicite quant à l’avenir. Cette attente peut être implicite et cachée. Cependant, si nous voulons améliorer la qualité de notre prévision de l’avenir, nous devons la concrétiser, ce qui se fait généralement par une prévision, bien qu’elle ne doive pas forcément être une prévision de séries temporelles.
Le cinquième et actuel chapitre est intitulé “Modélisation prédictive” plutôt que “Prévision” pour deux raisons. Premièrement, la prévision est presque invariablement associée à la prévision de séries temporelles. Toutefois, comme nous le verrons dans ce chapitre, il existe de nombreuses situations supply chain qui ne se prêtent pas vraiment à la perspective de la prévision de séries temporelles. À cet égard, la modélisation prédictive est donc un terme plus neutre. Deuxièmement, c’est la modélisation qui renferme le véritable insight, et non les modèles eux-mêmes. Nous recherchons des techniques de modélisation, et c’est grâce à ces techniques que nous pouvons espérer faire face à la diversité des situations rencontrées dans les supply chain du monde réel.
La conférence actuelle sert de prologue à notre chapitre sur la modélisation prédictive afin d’établir que la modélisation prédictive n’est pas une simple utopie en matière de prévision, mais qu’elle constitue une technique de prévision de pointe. Ceci s’ajoute à tous les autres avantages qui deviendront progressivement clairs au fil de ce chapitre.
Le reste de cette conférence sera organisé en trois parties. Premièrement, nous passerons en revue une série d’ingrédients mathématiques, qui constituent essentiellement les éléments de base du modèle BRAMPT. Deuxièmement, nous assemblerons ces ingrédients afin de construire le modèle BRAMPT, exactement comme cela a été fait lors de la compétition M5. Troisièmement, nous discuterons de ce qui pourrait être fait pour améliorer le modèle BRAMPT et également de ce qui pourrait être envisagé pour améliorer le défi de prévision lui-même, tel qu’il a été présenté dans la compétition M5.

Le défi Uncertainty du M5 vise à calculer des estimations quantiles des ventes futures. Un quantile est un point dans une distribution unidimensionnelle, et par définition, un quantile à 90 % est le point où il y a 90 % de chances d’être en dessous de cette valeur et 10 % de chances d’être au-dessus. La médiane est, par définition, le quantile à 50 %.
La fonction de perte pinball est une fonction profondément liée aux quantiles. Essentiellement, pour toute valeur de tau comprise entre zéro et un, tau peut être interprété, du point de vue supply chain, comme un objectif de taux de service. Pour toute valeur de tau, le quantile associé correspond à la valeur au sein de la distribution de probabilité qui minimise la fonction de perte pinball. À l’écran, nous voyons une implémentation simple de cette fonction de perte pinball, écrite en Envision, le langage de programmation spécifique à Lokad dédié à l’optimisation supply chain. La syntaxe est assez proche de Python et devrait être relativement transparente pour l’audience.
Si nous essayons d’analyser ce code, nous avons y, qui est la valeur réelle, y-chapeau, qui est notre estimation, et tau, qui est notre objectif quantile. Encore une fois, l’objectif quantile est fondamentalement l’objectif de taux de service en termes supply chain. Nous constatons que le déficit de prévision est pondéré par tau, tandis que le surplus de prévision est pondéré par un moins tau. La fonction de perte pinball est une généralisation de l’erreur absolue. Si nous revenons à tau égal à 0,5, nous pouvons constater que la fonction de perte pinball n’est autre que l’erreur absolue. Si nous obtenons une estimation qui minimise l’erreur absolue, nous obtenons une estimation de la médiane.
À l’écran, vous pouvez voir un graphique de la fonction de perte pinball. Cette fonction de perte est asymétrique, et grâce à une fonction de perte asymétrique, nous pouvons obtenir non pas la prévision moyenne ou médiane, mais une prévision avec un biais contrôlé, ce qui est exactement ce que nous recherchons pour une estimation de quantile. La beauté de la fonction de perte pinball réside dans sa simplicité. Si vous disposez d’une estimation qui minimise la fonction de perte pinball, alors vous obtenez par construction une prévision de quantile. Ainsi, si vous avez un modèle avec des paramètres et que vous orientez l’optimisation de ces paramètres au prisme de la fonction de perte pinball, ce que vous obtiendrez de votre modèle est essentiellement un modèle de prévision par quantile.
Le challenge d’incertitude M5 a présenté une série de quatre cibles de quantiles à 50, 67, 95 et 99. Je fais généralement référence à une telle série de cibles de quantiles comme à une grille de quantiles. Une grille de quantiles, ou des prévisions de grille quantisée, ne sont pas tout à fait des prévisions probabilistes ; c’est proche, mais pas tout à fait là. Avec une grille de quantiles, nous choisissons encore arbitrairement nos cibles. Par exemple, si nous disons que nous voulons produire une prévision de quantile pour 95 pour cent, la question se pose : pourquoi 95, et non 94 ou 96 ? Cette question reste sans réponse. Nous y jetterons un coup d’œil plus tard dans ce chapitre, mais pas dans cette conférence. Disons simplement que le principal avantage des prévisions probabilistes est d’éliminer complètement cet aspect de sélection arbitraire des grilles de quantiles.
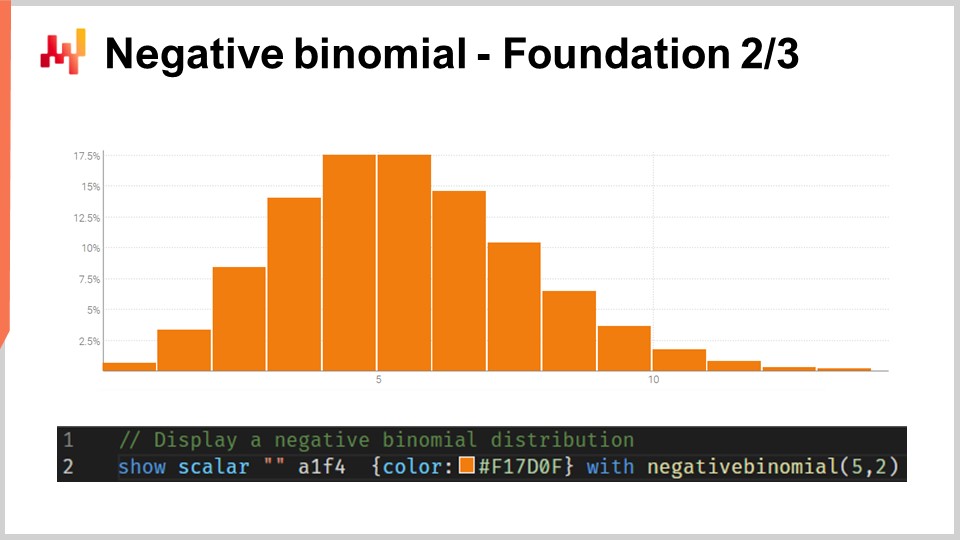
La plupart du public est probablement familier avec la distribution normale, la courbe en cloche gaussienne qui apparaît très fréquemment dans les phénomènes naturels. Une distribution de comptes est une répartition de probabilités sur chaque entier. Contrairement aux distributions réelles continues comme la distribution normale qui vous attribue une probabilité pour chaque entier réel, les distributions de comptes ne concernent que les entiers non négatifs. Il existe de nombreuses classes de distributions de comptes ; toutefois, aujourd’hui, notre intérêt se porte sur la distribution binomiale négative, qui est utilisée par le modèle REM.
La distribution binomiale négative comporte deux paramètres, tout comme la distribution normale, qui contrôlent en effet la moyenne et la variance de la distribution. Si nous choisissons la moyenne et la variance d’une distribution binomiale négative de sorte que l’essentiel de la masse de la distribution de probabilité soit éloigné de zéro, nous obtenons un comportement qui converge asymptotiquement vers celui d’une distribution normale si nous rassemblons toutes les valeurs de probabilité vers les entiers les plus proches. Cependant, si nous examinons des distributions où la moyenne est faible, en particulier par rapport à la variance, nous verrons que la distribution binomiale négative commence à diverger de manière significative par rapport à une distribution normale. En particulier, si nous observons des distributions binomiales négatives à faible moyenne, nous constatons que ces distributions deviennent très asymétriques, contrairement à la distribution normale, qui reste entièrement symétrique quelle que soit la moyenne et la variance choisies.
À l’écran, une distribution binomiale négative est tracée via Envision. La ligne de code utilisée pour produire ce graphique est affichée ci-dessous. La fonction prend deux arguments, ce qui est attendu puisque cette distribution comporte deux paramètres, et le résultat est simplement une variable aléatoire affichée sous forme d’histogramme. Je ne vais pas m’attarder sur les subtilités de la distribution binomiale négative dans cette conférence. Il s’agit d’une théorie des probabilités élémentaire. Nous disposons de formules analytiques explicites en forme fermée pour le mode, la médiane, la fonction de répartition cumulée, l’asymétrie, la curtose, etc. La page Wikipedia offre un résumé assez complet de toutes ces formules, donc j’invite le public à la consulter s’il souhaite en savoir plus sur ce type spécifique de distribution de comptes.
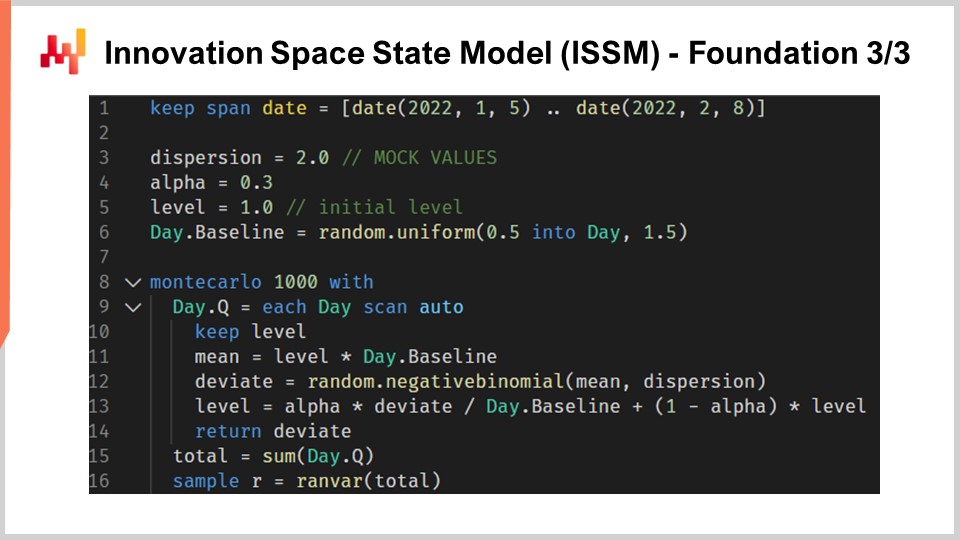
Passons au Innovation Space State Model, ou ISSM. Le “innovation space state model” est un nom long et impressionnant pour réaliser quelque chose de très simple. En effet, l’ISSM est un modèle qui transforme une série temporelle en random walk. Avec l’ISSM, vous pouvez transformer une prévision de séries temporelles classique – et par classique, j’entends une prévision où, pour chaque période, vous disposez d’une valeur fixée à la moyenne – en une prévision probabiliste, et pas seulement en une prévision de quantile, mais directement en une prévision probabiliste. À l’écran, vous pouvez voir une implémentation complète de l’ISSM écrite une fois de plus en Envision. On constate qu’il ne s’agit que d’une dizaine de lignes de code, et en réalité, la plupart de ces lignes ne font même pas grand-chose. L’ISSM est littéralement très simple, et il serait aisé de réimplémenter ce morceau de code dans un autre langage, tel que Python.
Examinons de plus près les détails de ces lignes de code. À la ligne un, je spécifie l’intervalle des périodes pendant lesquelles le random walk aura lieu. Du point de vue du M5, nous voulons un random walk sur une période de 28 jours, donc nous avons 28 points, un par jour. Aux lignes trois, quatre et cinq, nous introduisons une série de paramètres qui vont contrôler le random walk lui-même. Le premier paramètre est la dispersion, qui sera utilisée en argument pour contrôler la forme des binomiales négatives qui interviennent dans le processus ISSM. Ensuite, nous avons alpha, qui est essentiellement le facteur contrôlant le processus de lissage exponentiel qui s’effectue également au sein de l’ISSM. À la ligne cinq, nous avons le niveau, qui représente simplement l’état initial du random walk. Enfin, à la ligne six, nous disposons d’une série de facteurs qui sont typiquement destinés à capturer tous les effets calendaires que nous souhaitons intégrer dans notre modèle de prévision.
Maintenant, les valeurs des lignes trois à six ne sont qu’une initialisation fictive. Pour des raisons de concision, je vais expliquer dans une minute comment ces valeurs sont réellement optimisées, mais ici, toutes les initialisations que vous voyez ne sont que des valeurs fictives. Je me contente de tirer des valeurs aléatoires pour la baseline. Nous verrons ensuite comment, en réalité, si vous souhaitez utiliser ce modèle, vous devrez initialiser correctement ces valeurs, ce que nous ferons plus tard dans cette conférence.
Passons maintenant au cœur du processus ISSM. Celui-ci commence à la ligne huit par une boucle de 1000 itérations. Je viens de dire que le processus ISSM est un moyen de générer des random walks, donc ici nous effectuons 1000 itérations, autrement dit, nous allons générer 1000 random walks. Nous pourrions en effectuer davantage, ou moins ; il s’agit d’un processus Monte Carlo simple. Ensuite, à la ligne neuf, nous effectuons une seconde boucle. C’est la boucle qui itère un jour à la fois pour la période d’intérêt. Ainsi, nous avons la boucle externe, qui correspond essentiellement à une itération par random walk, puis la boucle interne, qui correspond à une itération, en passant d’un jour à l’autre au sein du random walk lui-même.
À la ligne 10, nous avons une commande pour maintenir le niveau. Maintenir le niveau signifie simplement que ce paramètre sera modifié dans la boucle interne, et non dans la boucle externe. Cela signifie donc que le niveau varie d’un jour à l’autre, mais lorsqu’on passe d’un random walk à l’autre via la boucle Monte Carlo, ce niveau est réinitialisé à sa valeur initiale déclarée ci-dessus. À la ligne 11, nous calculons la moyenne. La moyenne est le second paramètre utilisé pour contrôler la distribution binomiale négative. Nous avons donc la moyenne, la dispersion et la distribution binomiale négative. À la ligne 12, nous effectuons un tirage aléatoire selon la distribution binomiale normale. Tirer un écart signifie simplement que nous prenons un échantillon aléatoire extrait de cette distribution de comptes. Puis, à la ligne 13, nous mettons à jour ce niveau en fonction de l’écart observé, et le processus de mise à jour est simplement un lissage exponentiel très simple, guidé par le paramètre alpha. Si nous prenons alpha très élevé, égal à un, cela signifie que nous accordons tout le poids à la dernière observation. Au contraire, si nous fixons alpha à zéro, cela signifierait que nous aurions une dérive nulle ; nous resterions fidèles à la série temporelle originale telle que définie dans la baseline.
Soit dit en passant, dans Envision, lorsqu’il est écrit “.baseline”, cela signifie qu’il existe une table, disons NDM5, qui comporte 28 valeurs, et baseline est simplement un vecteur appartenant à cette table. À la ligne 15, nous collectons tous les écarts et les additionnons via “someday.q”. Nous les stockons dans une variable nommée “total”, ce qui signifie que, dans un random walk, nous obtenons le total des écarts collectés pour chaque jour. Ainsi, nous obtenons le total des ventes sur 28 jours. Enfin, à la ligne 16, nous rassemblons essentiellement ces échantillons dans un “render”. Un render est un objet spécifique dans Envision, qui est essentiellement une distribution de probabilité d’entiers relatifs, positifs et négatifs.
En résumé, ce que nous avons, c’est l’ISSM en tant que générateur aléatoire de random walks unidimensionnels. Dans le contexte de la prévision des ventes, vous pouvez considérer ces random walks comme des observations futures possibles pour les ventes elles-mêmes. Il est intéressant de noter que nous ne concevons pas la prévision comme la moyenne ou la médiane ; nous envisageons littéralement notre prévision comme une instance possible d’un futur.

À ce stade, nous avons rassemblé tout ce dont nous avons besoin pour commencer à assembler le modèle REMT, ce que nous allons faire maintenant.
Le modèle REMT adopte une structure multiplicative, qui rappelle le modèle de prévision Holt-Winters. Chaque jour se voit attribuer une baseline, qui est une valeur unique résultant du produit de cinq effets calendaires. Nous avons, à savoir, l’effet du mois de l’année, le jour de la semaine, le jour du mois, ainsi que les effets de Noël et d’Halloween. Cette logique est implémentée sous forme d’un script Envision concis.
Envision propose une algèbre relationnelle qui offre des relations de diffusion entre les tables, ce qui est très pratique dans ce contexte. Les cinq tables que nous avons construites, une table par motif calendaire, sont établies comme des tables de regroupement. Ainsi, nous avons la table des dates, et cette table possède une clé primaire nommée “date”. Lorsque nous déclarons une nouvelle table avec une agrégation “by” suivie de la date, ce que nous construisons est une table ayant une relation de diffusion directe avec la table des dates.
Si nous regardons spécifiquement la table du jour de la semaine à la ligne quatre, ce que nous construisons est une table qui comportera exactement sept lignes. Chaque ligne de la table sera associée à une et une seule ligne du jour de la semaine. Ainsi, si nous plaçons des valeurs dans cette table du jour de la semaine, nous pouvons diffuser ces valeurs de manière tout à fait naturelle, car chaque ligne du côté récepteur, dans la table des dates, trouvera une ligne correspondante dans cette table du jour de la semaine.
À la ligne neuf, avec le vecteur “de.dot.baseline”, celui-ci est calculé comme la multiplication simple des cinq facteurs situés à droite de l’affectation. Tous ces facteurs sont d’abord diffusés dans la table des dates, puis nous procédons à une multiplication simple, ligne par ligne, pour chaque ligne de la table des dates.
Nous avons maintenant un modèle qui comporte quelques dizaines de paramètres. Nous pouvons les dénombrer : nous disposons de 12 paramètres pour le mois de l’année, de 1 à 12 ; nous avons sept paramètres pour le jour de la semaine ; et nous avons 31 paramètres pour le jour du mois. Cependant, dans le cas du NDM5, nous n’allons pas apprendre une valeur de paramètre pour chacune de ces valeurs pour chaque SKU, car nous nous retrouverions avec un nombre massivement élevé de paramètres qui suradapteraient très probablement le jeu de données de Walmart. Au lieu de cela, dans le NDM5, ce qui a été fait fut d’exploiter une astuce connue sous le nom de partage de paramètres.
Le partage de paramètres signifie qu’au lieu d’apprendre des paramètres distincts pour chaque SKU, nous allons établir des sous-groupes et apprendre ces paramètres au niveau du sous-groupe. Ensuite, nous utilisons les mêmes valeurs au sein de ces groupes pour ces paramètres. Le partage de paramètres est une technique très classique qui est largement utilisée en deep learning, bien qu’elle précède même l’ère du deep learning. Lors du M5, le mois de l’année et le jour de la semaine ont été appris au niveau de l’agrégation des départements des magasins. Je reviendrai sur les différents niveaux d’agrégation du M5 dans un instant. La valeur du jour du mois était en réalité constituée de facteurs codés en dur, définis au niveau de l’État, et par État, j’entends les États-Unis, tels que la Californie, le Texas, etc. Lors du M5, tous ces paramètres calendaires ont été simplement appris comme des moyennes directes sur leurs périmètres respectifs. C’est une manière très directe de déterminer ces paramètres : il suffit de prendre tous les SKU appartenant au même périmètre, d’en faire la moyenne, de normaliser, et voilà votre paramètre.

À ce stade, nous avons rassemblé tous les éléments pour assembler le modèle REMT. Nous avons vu comment construire la baseline quotidienne, qui intègre tous les motifs calendaires. Les motifs calendaires ont été appris à partir de moyennes directes sur un certain périmètre, ce qui constitue un mécanisme d’apprentissage crud mais efficace. Nous avons également vu que l’ISSM transforme une série temporelle en random walk. Il ne nous reste plus qu’à établir les valeurs appropriées pour les paramètres de l’ISSM, à savoir alpha, le paramètre utilisé pour le processus de lissage exponentiel qui s’effectue au sein du SSM ; la dispersion, paramètre utilisé pour contrôler la distribution binomiale négative ; et la valeur initiale du niveau, qui sert à initialiser notre random walk.
Lors de la compétition M5, l’équipe de Lokad a utilisé une optimisation par recherche sur grille simple pour apprendre ces trois paramètres restants. La recherche sur grille signifie essentiellement que vous itérez sur toutes les combinaisons possibles de ces valeurs, en procédant par petits incréments à la fois. Elle a été dirigée à l’aide de la fonction de perte pinball, que j’ai décrite précédemment, afin d’orienter l’optimisation de ces trois paramètres. Pour chaque SKU, la recherche sur grille est probablement l’une des formes d’optimisation mathématique les moins efficaces. Cependant, étant donné que nous n’avons que trois paramètres et que nous n’avons besoin d’effectuer qu’une optimisation par série temporelle, et que le jeu de données M5 est lui-même assez réduit, cette approche était adaptée pour la compétition M5.
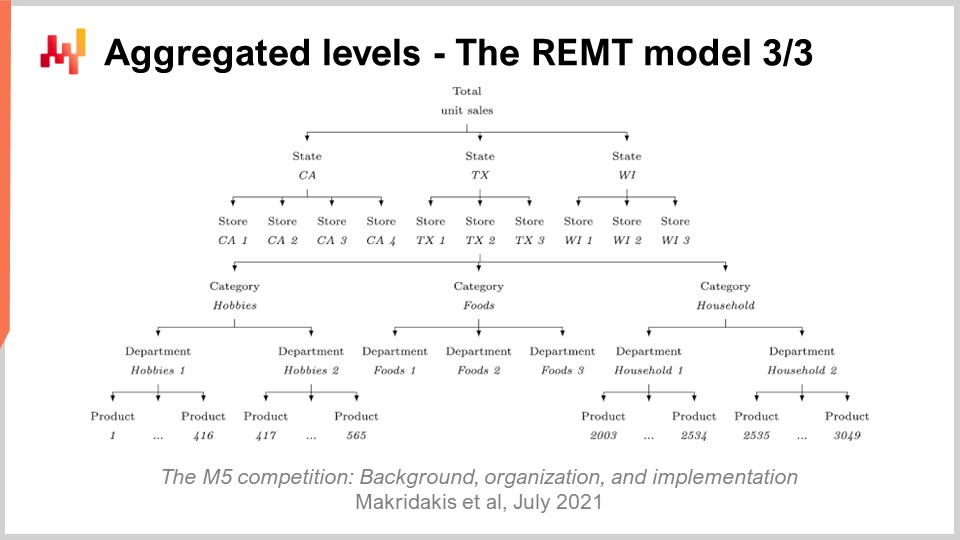
Jusqu’à présent, nous avons présenté comment le modèle REMT fonctionne au niveau SKU. Cependant, dans le M5, il existait 12 niveaux d’agrégation distincts. Le niveau SKU, étant le plus désagrégé, était le plus important. Un SKU, ou unité de gestion de stock, représente littéralement un produit à un emplacement donné. Si vous avez le même produit dans 10 emplacements, vous avez alors 10 SKU. Bien que le SKU soit sans doute le niveau d’agrégation le plus pertinent pour une supply chain, presque toutes les décisions liées aux stocks, telles que réapprovisionnement et assortiment, se prennent au niveau SKU. Le M5 était principalement un concours de prévision, et ainsi, l’accent était mis sur les autres niveaux d’agrégation.
À l’écran, ces niveaux résument les niveaux d’agrégation présents dans le jeu de données M5. Vous pouvez voir que nous avons les états, tels que la Californie et le Texas. Pour aborder les niveaux d’agrégation supérieurs, l’équipe de Lokad a utilisé deux techniques : soit en additionnant les marches aléatoires, c’est-à-dire en effectuant les marches aléatoires à un niveau d’agrégation inférieur, en les additionnant pour obtenir des marches aléatoires à un niveau d’agrégation supérieur ; soit en redémarrant entièrement le processus d’apprentissage pour passer directement au niveau d’agrégation supérieur. Dans le défi d’incertitude M5, le modèle REMT était le meilleur au niveau SKU, mais il ne l’était pas aux autres niveaux d’agrégation, bien qu’il ait globalement très bien performé.
Mon hypothèse de travail sur la raison pour laquelle le modèle REMT n’était pas le meilleur à tous les niveaux est la suivante (veuillez noter qu’il s’agit d’une hypothèse que nous n’avons pas réellement testée) : la distribution binomiale négative offre deux degrés de liberté grâce à ses deux paramètres. Lorsqu’on examine des données relativement rares, comme on en trouve au niveau SKU, ces deux degrés de liberté représentent le juste équilibre entre sous-ajustement et sur-ajustement. Cependant, à mesure que nous passons à des niveaux d’agrégation supérieurs, les données deviennent plus denses et plus riches, de sorte que le compromis se déplace probablement vers quelque chose de mieux adapté pour capturer plus précisément la forme de la distribution. Nous aurions besoin de quelques degrés de liberté supplémentaires – probablement un ou deux paramètres de plus – pour y parvenir.
Je soupçonne qu’augmenter le degré de paramétrisation de la distribution de comptage utilisée au cœur du modèle REMT aurait permis d’atteindre quelque chose de très proche, sinon directement à la pointe de l’état-de-l’art, pour les niveaux d’agrégation supérieurs. Néanmoins, nous n’avons pas eu le temps de le faire, et nous pourrions revenir sur ce cas à un moment donné dans le futur. Cela conclut ce qui a été réalisé par l’équipe de Lokad lors du concours M5.

Examinons ce qui aurait pu être fait différemment ou mieux. Même si le modèle REMT est un modèle paramétrique de faible dimension avec une structure multiplicative simple, le processus utilisé pour obtenir les valeurs des paramètres lors du M5 était quelque peu compliqué de manière fortuite. C’était un processus en plusieurs étapes, chaque motif de calendrier bénéficiant d’un traitement ad hoc spécifique, se terminant par une recherche sur grille personnalisée pour compléter le modèle REMT. L’ensemble du processus était assez chronophage pour les data scientists, et je soupçonne qu’il serait assez peu fiable en production en raison de la quantité énorme de code ad hoc impliqué.
Plus précisément, selon moi, nous pouvons et devons unifier le processus d’apprentissage de tous les paramètres en un processus unique ou, à tout le moins, unifier le processus d’apprentissage afin que la même méthode soit utilisée de manière répétée. Aujourd’hui, Lokad utilise la differentiable programming pour faire exactement cela. La differentiable programming supprime le besoin d’agrégations ad hoc en ce qui concerne les motifs de calendrier. Elle élimine également le problème de l’ordre précis d’extraction des motifs de calendrier en les extrayant tous d’un coup. Enfin, comme la differentiable programming est un processus d’optimisation à part entière, elle remplace la recherche sur grille par une logique d’optimisation beaucoup plus efficace. Nous reviendrons en détail sur la manière dont la differentiable programming peut être utilisée pour la modélisation prédictive dans le contexte des besoins de supply chain dans les prochaines conférences de ce chapitre.
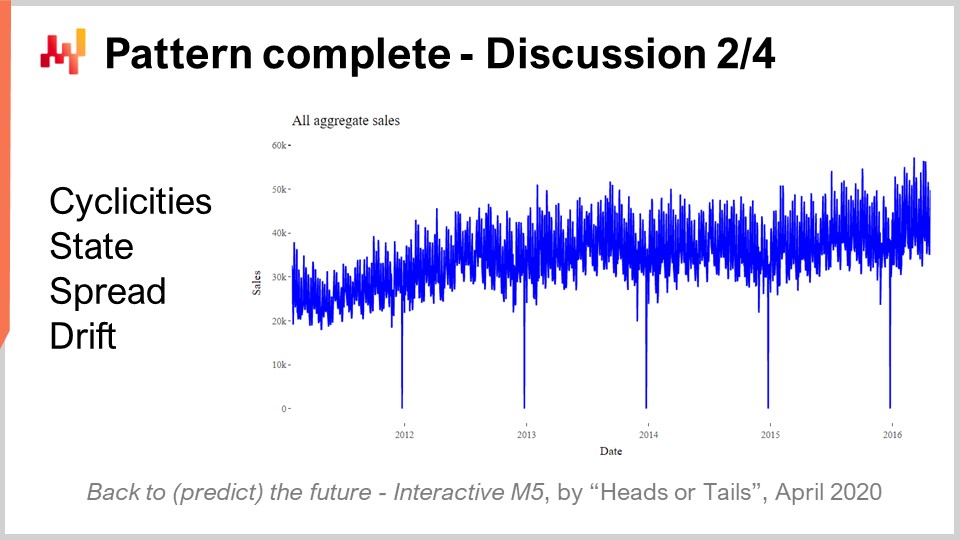
Maintenant, l’un des résultats les plus surprenants du concours M5 était qu’aucun motif statistique ne restait sans nom. Nous avions littéralement quatre motifs : simplicities, state, spread et drift, qui suffisaient à eux seuls pour atteindre une précision de prévision à la pointe de l’état-de-l’art lors du concours M5.
Les simplicities sont toutes basées sur le calendrier et aucune d’entre elles n’est le moins du monde surprenante. Le state peut être représenté par un seul nombre qui indique le niveau atteint par le SKU à un moment précis. Le spread peut être représenté par un nombre unique qui correspond à la dispersion utilisée pour paramétrer la binomiale négative, et le drift peut être représenté par un nombre associé au processus de lissage exponentiel qui s’est déroulé au sein du SSM. Nous n’avons même pas eu besoin d’inclure la tendance, qui était trop faible pour un horizon de 28 jours.
Alors que nous examinons les cinq années de ventes agrégées du M5 affichées à l’écran, l’agrégation montre clairement une légère tendance à la hausse. Néanmoins, le modèle REMT fonctionne sans elle et cela n’a eu aucune conséquence sur la précision. La performance du modèle REMT pose la question : existe-t-il un autre motif à capturer, ou en avons-nous omis un ?
Au minimum, la performance du modèle REMT montre qu’aucun des modèles plus sophistiqués impliqués dans ce concours, tels que les arbres de gradient boosting ou les méthodes de deep learning, n’a capturé quoi que ce soit au-delà de ces quatre motifs. En effet, si l’un de ces modèles avait réussi à capturer quelque chose de substantiel, il aurait largement surpassé le modèle REMT au niveau SKU, ce qui n’a pas été le cas. Il en va de même pour toutes les méthodes statistiques plus sophistiquées comme ARIMA. Ces modèles n’ont pas non plus réussi à capturer quoi que ce soit au-delà de ce que ce modèle paramétrique multiplicatif très simple a capturé.
Le principe du rasoir d’Occam nous enseigne que, à moins de trouver une très bonne raison de penser qu’un motif nous échappe ou une raison convaincante de privilégier une propriété très intéressante au détriment de la simplicité de ce modèle, nous n’avons aucune raison d’utiliser autre chose qu’un modèle au moins aussi simple que le modèle REMT.

Cependant, une série de motifs était absente du concours M5 en raison de la conception même du jeu de données M5. Ces motifs sont importants, et en pratique, tout modèle qui les ignore fonctionnera mal dans un environnement de vente au détail réel. Je base cette affirmation sur ma propre expérience.
Premièrement, il y a les lancements de produits. Le concours M5 n’incluait que les produits disposant d’au moins cinq ans d’historique de ventes. C’est une hypothèse déraisonnable en ce qui concerne la supply chain. En effet, les produits FMCG ont généralement une durée de vie de seulement quelques années, et ainsi, dans un magasin réel, une portion significative de l’assortiment possède moins d’un an d’historique de ventes. De plus, lorsque l’on considère des produits avec de longs délais d’approvisionnement, de nombreuses décisions de supply chain doivent être prises avant même que le produit ait la chance d’être vendu une fois dans un magasin.
Le deuxième motif d’importance cruciale est celui des ruptures de stocks. Les ruptures de stocks se produisent dans le commerce de détail, et le jeu de données du concours M5 les ignorait complètement. Cependant, les ruptures de stocks limitent les ventes. Si un produit est en rupture dans le magasin, il ne sera pas vendu ce jour-là, et ainsi, les ruptures de stocks introduisent un biais significatif dans les ventes observées. Le problème, dans le cas de Walmart et des magasins de grande distribution, est encore plus compliqué puisque les enregistrements électroniques qui capturent les valeurs de stocks disponibles ne peuvent pas être entièrement fiables. Il existe de nombreuses inexactitudes de stocks, et cela doit également être pris en compte.
Troisièmement, il y a les promotions. Le concours M5 incluait des données historiques de tarification ; cependant, les données de prix n’étaient pas fournies pour la période à prévoir. En conséquence, il semble qu’aucun concurrent de ce concours n’ait réussi à exploiter l’information sur les prix pour améliorer la précision de la prévision. Le modèle REMT n’utilise pas du tout l’information de tarification. Au-delà du fait que l’information sur le prix manquait pour la période de prévision, les promotions ne se résument pas uniquement à la tarification. Un produit peut être promu en étant mis en avant dans un magasin, ce qui peut stimuler significativement la demande, indépendamment d’une éventuelle baisse de prix. De plus, avec les promotions, nous devons prendre en compte les effets de cannibalisation et de substitution.
Dans l’ensemble, le jeu de données M5, d’un point de vue supply chain, peut être considéré comme un jeu de données jouet. Bien qu’il reste probablement le meilleur jeu de données public existant pour réaliser des benchmarks supply chain, il n’est en rien comparable à une configuration de production réelle, même pour une chaîne de distribution de taille modeste.

Cependant, les limites du concours M5 ne sont pas uniquement dues au jeu de données. D’un point de vue supply chain, il existe des problèmes fondamentaux liés aux règles utilisées pour organiser le concours M5.
Le premier problème fondamental est de ne pas confondre les ventes avec la demande. Nous avons déjà abordé ce point avec les ruptures de stocks. En supply chain, le véritable enjeu est d’anticiper la demande, et non les ventes. Toutefois, le problème est plus profond. La bonne estimation de la demande relève fondamentalement d’un problème d’apprentissage non supervisé. Ce n’est pas parce que des choix arbitraires ont été faits concernant l’assortiment applicable dans un magasin que la demande pour un produit ne doit pas être estimée. Nous devons estimer la demande pour les produits, qu’ils fassent ou non partie de l’assortiment d’un magasin donné.
Le second aspect est que les prévisions quantiles sont moins utiles que les prévisions probabilistes. Choisir certains taux de service laisse des lacunes dans l’image globale, et les prévisions quantiles sont relativement faibles en termes d’usage pour la supply chain. Une prévision probabiliste offre une vision bien plus complète car elle fournit l’intégralité de la distribution de probabilité, éliminant ainsi cette classe de problèmes. Le seul inconvénient majeur des prévisions probabilistes est qu’elles nécessitent plus d’outils, notamment lorsqu’il s’agit d’exploiter réellement la prévision une fois celle-ci produite. D’ailleurs, le modèle REMT délivre en réalité quelque chose qui se qualifie de prévision probabiliste car, grâce au procédé Monte Carlo, vous pouvez générer une distribution de probabilité complète. Il suffit de régler le nombre d’itérations Monte Carlo.
Dans le commerce de détail, les clients ne se préoccupent pas véritablement de la perspective SKU ou du taux de service qui peut être atteint sur un SKU donné. La perception des clients dans un magasin de grande distribution comme Walmart est guidée par le panier. Habituellement, les clients entrent dans un magasin Walmart avec une liste de courses complète en tête, et non un unique produit. De plus, il existe de nombreux substituts disponibles dans le magasin. Le problème d’utiliser un seul indicateur SKU pour évaluer la qualité de service est qu’il ne prend pas du tout en compte ce que les clients perçoivent comme qualité de service dans le magasin.
En conclusion, en tant que référence en prévision des séries temporelles, le concours M5 est solide en termes de jeux de données et de méthodologie. Cependant, la perspective des séries temporelles elle-même fait défaut lorsqu’il s’agit de supply chain. Les séries temporelles ne reflètent pas les données telles qu’elles existent dans les supply chains, ni les problèmes tels qu’ils se présentent dans les supply chains. Lors du concours M5, de nombreuses méthodes bien plus sophistiquées figuraient parmi les meilleures. Toutefois, à mon avis, ces modèles s’avèrent être de véritables impasses. Ils sont déjà trop compliqués pour une utilisation en production, et ils adoptent la perspective des séries temporelles à tel point qu’ils n’offrent aucune marge opérationnelle pour évoluer vers la perspective novatrice nécessaire pour adapter ces modèles à nos propres besoins en supply chain.
Au contraire, comme point de départ, le modèle REMT est le meilleur qui soit. C’est une combinaison très simple d’ingrédients qui, pris individuellement, sont très simples. De plus, il ne faut pas beaucoup d’imagination pour constater qu’il existe de nombreuses manières d’utiliser et de combiner ces éléments au-delà de la combinaison spécifique élaborée pour le concours M5. Le classement obtenu par le modèle REMT dans le concours M5 démontre que, jusqu’à preuve du contraire, nous devrions nous en tenir à un modèle très simple, car nous n’avons aucune raison impérieuse d’opter pour des modèles très compliqués qui sont presque assurément plus difficiles à déboguer, plus difficiles à mettre en production et qui consomment énormément plus de ressources informatiques.
Dans les conférences à venir dans ce cinquième chapitre, nous verrons comment nous pouvons utiliser les ingrédients qui composaient le modèle REMT, ainsi que bien d’autres ingrédients, pour relever la grande variété de défis prédictifs tels qu’ils se présentent dans les supply chains. L’essentiel à retenir est que le modèle est sans importance ; c’est la modélisation qui compte.

Question: Pourquoi les binomiales négatives ? Quelle a été la raison lorsque vous les avez sélectionnées ?
C’est une très bonne question. Eh bien, il s’avère que s’il existe un bestiaire mondial des distributions de comptage, il y en a probablement une vingtaine de très connues. Chez Lokad, nous en avons testé une douzaine pour nos besoins internes. Il s’avère que la distribution de Poisson, qui est une distribution de comptage très simpliste avec un seul paramètre, fonctionne assez bien lorsque les données sont très rares. La distribution de Poisson est donc assez bonne, mais en réalité, le jeu de données M5 était un peu plus riche. Dans le cas du jeu de données Walmart, nous avons essayé des distributions de comptage comportant quelques paramètres supplémentaires, et cela semblait fonctionner. Nous n’avons pas la preuve qu’il s’agisse réellement de la meilleure option ; il existe probablement de meilleures alternatives. La binomiale négative possède quelques avantages clés : son implémentation est très simple et c’est une distribution de comptage largement étudiée. Ainsi, vous disposez d’un algorithme très connu, non seulement pour calculer les probabilités, mais aussi pour générer un échantillon, obtenir la moyenne ou la distribution cumulée. Tous les outils que l’on peut attendre en termes de distribution de comptage sont disponibles, ce qui n’est pas le cas pour toutes les distributions.
Il y a un certain pragmatisme qui a guidé ce choix, mais aussi un brin de logique. Avec Poisson, vous avez un degré de liberté ; la binomiale négative en a deux. Ensuite, vous pouvez utiliser des astuces comme la binomiale négative à excès de zéros, qui vous donne en quelque sorte deux degrés et demi de liberté, etc. Je ne dirais pas qu’il existe une valeur spécifique et définitive pour cette distribution de comptage.
Question: Il y avait d’autres fournisseurs de logiciels d’optimization de la Supply Chain dans le M5, mais personne n’utilisait de modèles en production capables de bien monter en échelle. Qu’est-ce que la majorité utilise, des modèles de machine learning lourds ?
Tout d’abord, je dirais qu’il faut distinguer et clarifier que le M5 s’est déroulé sur Kaggle, une plateforme de data science. Sur Kaggle, vous avez un incitatif énorme à utiliser la machinerie la plus compliquée possible. L’ensemble de données est petit, vous disposez de beaucoup de temps, et pour atteindre le sommet du classement, il suffit d’être précis de 0,1 % de plus que l’autre. C’est tout ce qui compte. Ainsi, dans pratiquement chaque compétition sur Kaggle, vous verrez que les premières places sont occupées par des personnes ayant réalisé des choses très complexes juste pour obtenir une précision supplémentaire de 0,1 %. En somme, la nature même d’une compétition de prévision vous incite fortement à tout essayer, y compris les modèles de machine learning les plus lourds que vous puissiez trouver.
Si l’on se demande si les gens utilisent réellement ces modèles de machine learning lourds en production, mon observation informelle est absolument négative. C’est en réalité extrêmement rare. En tant que PDG de Lokad, un fournisseur de logiciels d’optimization de la Supply Chain, j’ai parlé à des centaines de directeurs supply chain. Littéralement, plus de 90 % des grandes Supply Chains sont gérées via Excel. Je n’ai jamais vu de grande Supply Chain fonctionner avec des arbres boostés par gradient ou des réseaux de deep learning. Mis à part Amazon, qui est probablement unique en son genre, il n’existe peut-être qu’une demi-douzaine d’entreprises, comme Amazon, Alibaba, JD.com et quelques autres – les très grands supergiants du e-commerce – qui utilisent réellement ce genre de technologie. Mais ils sont exceptionnels à cet égard. Vos grandes entreprises FMCG grand public ou vos grandes enseignes de vente au détail en boutique n’utilisent pas ce type de solution en production.
Question: Il est étrange que vous mentionniez de nombreux termes mathématiques et statistiques, mais que vous ignoriez la nature des ventes au détail ainsi que les principaux facteurs d’influence.
Je dirais, oui, c’est plutôt un commentaire, mais ma question pour vous serait : Qu’est-ce que vous apportez ? C’est ce que je disais lorsque les fournisseurs de logiciels d’optimization de la Supply Chain vantant une technologie de prévision supérieure étaient tous absents. Pourquoi, si vous disposez d’une technologie de prévision absolument supérieure, seriez-vous absent dès qu’il y a un benchmark public ? L’autre explication est que les gens bluffent.
Concernant la nature des ventes au détail et les nombreux facteurs d’influence, j’ai énuméré les motifs qui ont été utilisés, et en appliquant ces quatre motifs, le modèle REMT s’est classé numéro un au niveau SKU en termes de précision. Si vous avancez l’hypothèse qu’il existe des motifs bien plus importants, la charge de la preuve vous incombe. Mon propre soupçon est que, si parmi plus de 900 équipes ces motifs n’ont pas été observés, c’est qu’ils n’étaient probablement pas là, ou bien qu’extraire ces motifs dépasse largement ce que la technologie dont nous disposons permet, de sorte qu’en pratique, ces motifs n’existent pas.
Question: Certains concurrents du M5 ont-ils appliqué des idées qui, sans toutefois battre Lokad, auraient été précieuses à intégrer, notamment pour des applications génériques ? Mention honorable ?
J’ai porté une grande attention à mes concurrents, et je suis à peu près sûr qu’ils s’intéressent quelque peu à Lokad. Je n’ai pas constaté le contraire. Le modèle REMT était vraiment unique en son genre, complètement différent de ce qui a été réalisé par pratiquement tous les 50 premiers candidats pour chaque tâche. Les autres participants utilisaient des techniques bien plus classiques dans les cercles du machine learning.
Pendant la compétition, plusieurs astuces très ingénieuses en data science ont été démontrées. Par exemple, certaines personnes ont utilisé des astuces sophistiquées pour réaliser une augmentation de données sur l’ensemble Walmart, afin de le rendre bien plus volumineux et gagner ainsi un pourcentage supplémentaire de précision. Cela a été réalisé par le candidat classé numéro un dans le challenge d’incertitude. Le terme approprié est augmentation de données, et non inflation de données. L’augmentation de données est couramment utilisée dans les techniques de deep learning, mais ici, elle était appliquée avec des arbres boostés par gradient de manière assez inhabituelle. Des astuces de data science sophistiquées ont été démontrées lors de cette compétition. Je ne suis pas très sûr de l’applicabilité de ces astuces à la Supply Chain, mais j’en mentionnerai probablement quelques-unes au reste de ce chapitre si l’occasion se présente.
Question: Avez-vous estimé les niveaux supérieurs en agrégeant vos niveaux SKU ou en recalculant fraîchement une approche middle-out pour les niveaux supérieurs ? Si les deux, comment se sont-ils comparés ?
Le problème avec les grilles de quantiles est que l’on a tendance à optimiser les modèles séparément pour chaque niveau cible. Ce qui peut arriver, c’est d’obtenir des croisements de quantiles, ce qui signifie que, simplement à cause d’instabilités numériques, votre 99e quantile se retrouve inférieur à votre 97e quantile. Cela est sans conséquence ; en général, il suffit de réordonner les valeurs. Fondamentalement, c’est le genre de problème auquel je faisais référence lorsque j’indiquais que les grilles de quantiles ne donnaient pas tout à fait des prévisions probabilistes. Vous avez une foule de détails minutieux à résoudre, mais en réalité, ils sont insignifiants dans l’ensemble. Lorsque vous passez aux prévisions probabilistes, ces problèmes n’existent même plus.
Question: Si vous conceviez une autre compétition pour les fournisseurs de logiciels, à quoi ressemblerait-elle ?
Honnêtement, je ne sais pas, et c’est une question très difficile. Je crois que, malgré toutes mes critiques virulentes, en ce qui concerne les benchmarks de prévision, le M5 est le meilleur que nous ayons. Maintenant, en termes de benchmarks supply chain, le problème est que je ne suis même pas complètement convaincu que ce soit possible. Lorsque j’ai laissé entendre que certains problèmes nécessitent en réalité l’apprentissage non supervisé, cela devient complexe. Une fois dans le domaine de l’apprentissage non supervisé, il faut renoncer à disposer de métriques, et l’ensemble du domaine du machine learning avancé peine encore, en tant que communauté, à comprendre ce que signifie réellement faire fonctionner des outils d’apprentissage automatisés supérieurs dans un contexte non supervisé. Comment peut-on même établir des benchmarks pour ce type de choses ?
Pour le public qui n’était pas présent à ma conférence sur le machine learning, dans un cadre supervisé, vous essayez essentiellement d’accomplir une tâche où vous disposez d’entrées, de sorties et d’une métrique pour évaluer la qualité de vos résultats. En mode non supervisé, cela signifie que vous n’avez pas de labels, rien avec quoi comparer, et les choses deviennent bien plus difficiles. De plus, je tiens à souligner que, dans la Supply Chain, il existe de nombreux cas où l’on ne peut même pas effectuer de back-testing. Au-delà de l’aspect non supervisé, la perspective du back-testing n’est pas totalement satisfaisante. Par exemple, prévoir la demande engendrera certains types de décisions, telles que des décisions de tarification. Si vous décidez d’ajuster le prix à la hausse ou à la baisse, c’est une décision que vous avez prise, et elle influencera l’avenir de manière irréversible. Vous ne pouvez donc pas remonter le temps pour dire : “D’accord, je vais faire une prévision de demande différente, puis prendre une décision de tarification différente, et laisser l’histoire se répéter, sauf que cette fois j’ai un prix différent.” Il existe de nombreux aspects pour lesquels l’idée même de back-testing ne fonctionne pas. C’est pourquoi je crois qu’une compétition est un concept très intéressant d’un point de vue prévisionnel. Elle est utile comme point de départ pour des applications supply chain, mais nous devons faire mieux et autrement si nous voulons aboutir à quelque chose de véritablement satisfaisant pour la Supply Chain. Dans ce chapitre sur la modélisation prédictive, je vais montrer pourquoi la modélisation mérite une telle attention.
Question: Cette méthodologie peut-elle être utilisée dans des situations où vous disposez de peu de données ?
Je dirais absolument. Ce type de modélisation structurée, tel que démontré ici avec le modèle REMT, brille particulièrement dans les situations où les données sont très rares. La raison est simple : vous pouvez intégrer une grande quantité de connaissances humaines dans la structure même du modèle. La structure du modèle n’est pas quelque chose sorti de nulle part ; c’est littéralement la conséquence de la compréhension du problème par l’équipe Lokad. Par exemple, lorsque nous examinons des motifs calendaires tels que le jour de la semaine, le mois de l’année, etc., nous n’avons pas cherché à les découvrir ; l’équipe Lokad savait dès le départ que ces motifs étaient déjà présents. La seule incertitude concernait la prévalence du motif du jour du mois, qui tend à être faible dans de nombreuses situations. Dans le cas de l’implémentation chez Walmart, c’était simplement dû au fait qu’il existe un programme de timbres aux États-Unis faisant que ce motif du jour du mois est aussi fort qu’il l’est.
Si vous avez peu de données, ce type d’approche fonctionne extrêmement bien car, quel que soit le mécanisme d’apprentissage que vous tentez d’utiliser, il va largement exploiter la structure que vous avez imposée. Alors oui, cela soulève la question : que se passe-t-il si la structure est erronée ? Mais c’est précisément pourquoi la réflexion et la compréhension de la Supply Chain sont essentielles afin de prendre les bonnes décisions. En fin de compte, vous disposez de moyens pour évaluer si vos décisions arbitraires étaient bonnes ou mauvaises, mais fondamentalement, cela intervient très tard dans le processus. Plus loin dans ce chapitre sur la modélisation prédictive, nous montrerons comment la modélisation structurée peut être utilisée efficacement sur des ensembles de données incroyablement rares, tels que ceux de l’aviation, du hard luxury et des émeraudes de toutes sortes. Dans ces situations, les modèles structurés brillent véritablement.
La prochaine conférence aura lieu le 2 février, qui est un mercredi, à la même heure, 15 h, heure de Paris. À bientôt !
Références
- Une approche ISSM en boîte blanche pour estimer les distributions d’incertitude des ventes chez Walmart, Rafael de Rezende, Katharina Egert, Ignacio Marin, Guilherme Thompson, décembre 2021 (link)
- La compétition M5 Uncertainty : Résultats, constats et conclusions, Spyros Makridakis, Evangelos Spiliotis, Vassilis Assimakopoulos, Zhi Chen, novembre 2020 (link)


