00:00 Introduction
02:52 Contexte et avertissement
07:39 Rationalisme naïf
13:14 L’histoire jusqu’ici
16:37 Scientifiques, nous avons besoin de vous !
18:25 Humain + Machine (le problème 1/4)
23:16 La mise en place (le problème 2/4)
26:44 La maintenance (le problème 3/4)
30:02 Le backlog IT (le problème 4/4)
32:56 La mission (le travail du scientifique 1/6)
35:58 Terminologie (le travail du scientifique 2/6)
37:54 Livrables (le travail du scientifique 3/6)
41:11 Le périmètre (le travail du scientifique 4/6)
44:59 Routine quotidienne (le travail du scientifique 5/6)
46:58 Responsabilité (le travail du scientifique 6/6)
49:25 Un poste en supply chain (RH 1/6)
51:13 Recruter un scientifique (RH 2/6)
53:58 Former le scientifique (RH 3/6)
55:43 Évaluer le scientifique (RH 4/6)
57:24 Fidéliser le scientifique (RH 5/6)
59:37 D’un scientifique à l’autre (RH 6/6)
01:01:17 À propos de l’informatique (dynamique d’entreprise 1/3)
01:03:50 À propos des finances (dynamique d’entreprise 2/3)
01:05:42 À propos du leadership (dynamique d’entreprise 3/3)
01:09:18 Planification à l’ancienne (modernisation 1/5)
01:11:56 Fin du S&OP (modernisation 2/5)
01:13:31 BI à l’ancienne (modernisation 3/5)
01:15:24 Abandon de la Data Science (modernisation 4/5)
01:17:28 Un nouvel accord pour l’informatique (modernisation 5/5)
01:19:28 Conclusion
01:22:05 7.3 Le Supply Chain Scientist - Questions ?
Description
Au cœur d’une initiative de la Supply Chain Quantitative, se trouve le Supply Chain Scientist (SCS) qui exécute la préparation des données, la modélisation économique et le reporting des KPI. L’automatisation intelligente des décisions de supply chain est le produit final du travail réalisé par le SCS. Le SCS prend en charge les décisions générées. Le SCS fournit une intelligence humaine amplifiée par la puissance de traitement machine.
Transcription complète

Bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter le Supply Chain Scientist du point de vue de la supply chain quantitative. Le Supply Chain Scientist est la personne, ou éventuellement le petit groupe de personnes, chargé de piloter l’initiative de supply chain. Cette personne supervise la création et, ultérieurement, la maintenance des recettes numériques qui générent les décisions d’intérêt. Elle est également responsable de fournir toutes les preuves nécessaires au reste de l’entreprise, démontrant que les décisions générées sont solides.
La devise de la supply chain quantitative est de tirer le meilleur parti de ce que le matériel moderne et le logiciel moderne peuvent offrir aux supply chains. Cependant, la saveur incarnée de cette perspective est naïve. L’intelligence humaine reste une pierre angulaire de l’ensemble du projet et, pour diverses raisons, ne peut pas encore être joliment emballée en ce qui concerne la supply chain. L’objectif de cette conférence est de comprendre pourquoi et comment le rôle du Supply Chain Scientist est devenu, au cours de la dernière décennie, une solution éprouvée pour tirer le meilleur parti des logiciels modernes à des fins supply chain.
Atteindre cet objectif commence par la compréhension des grands goulets d’étranglement auxquels les logiciels modernes sont encore confrontés lorsqu’ils tentent d’automatiser les décisions de supply chain. Forts de cette nouvelle compréhension, nous présenterons le rôle du Supply Chain Scientist, qui est, en tout point de vue, une réponse à ces goulets d’étranglement. Enfin, nous verrons comment ce rôle redéfinit, de manière modeste et significative, l’entreprise dans son ensemble. En effet, le Supply Chain Scientist ne peut opérer comme un silo au sein de l’entreprise. De même que le scientifique doit coopérer avec le reste de l’entreprise pour accomplir quoi que ce soit, le reste de l’entreprise doit également coopérer avec le scientifique pour que cela se produise.

Avant d’aller plus loin, je voudrais réitérer un avertissement que j’avais formulé dans la toute première conférence de cette série. La présente conférence est presque entièrement basée sur une expérience d’une dizaine d’années quelque peu unique réalisée chez Lokad, un éditeur de logiciels d’entreprise spécialisé dans l’optimisation de la supply chain. Toutes ces conférences ont été façonnées par le parcours de Lokad, mais en ce qui concerne le rôle du Supply Chain Scientist, le lien est encore plus fort. Dans une large mesure, le parcours de Lokad lui-même peut être interprété à travers le prisme de notre découverte progressive du rôle du Supply Chain Scientist.
Ce processus est toujours en cours. Par exemple, nous avons abandonné il y a environ cinq ans la perspective classique du data scientist avec l’introduction des paradigmes de programmation pour l’apprentissage et l’optimisation. Lokad emploie actuellement une trentaine de Supply Chain Scientists. Nos scientifiques les plus performants, grâce à leurs antécédents, se sont vus confier des décisions à grande échelle. Certains d’entre eux sont individuellement responsables de paramètres dont la valeur en stocks dépasse le demi-milliard de dollars. Cette confiance s’étend à une grande variété de décisions, telles que les bons de commande, les ordres de production, les ordres d’allocation de stocks, ou la tarification.
Comme vous pouvez le supposer, cette confiance a dû être méritée. En effet, très peu d’entreprises accorderaient même à leurs propres employés de tels pouvoirs, sans parler d’un fournisseur tiers comme Lokad. Obtenir ce degré de confiance est un processus qui prend généralement des années, indépendamment des moyens technologiques. Pourtant, une décennie plus tard, Lokad connaît une croissance plus rapide que jamais durant ses premières années, et une part importante de cette croissance provient de nos clients existants qui élargissent le périmètre des décisions confiées à Lokad.
Cela me ramène à mon point initial : cette conférence comporte presque certainement toutes sortes de biais. J’ai essayé d’élargir cette perspective grâce à des expériences similaires en dehors de Lokad ; cependant, il n’y a pas grand-chose à raconter à ce sujet. À ma connaissance, il existe quelques géants de la technologie, plus précisément quelques grandes entreprises de e-commerce, qui réalisent un degré d’automatisation des décisions comparable à celui que Lokad atteint.
Cependant, ces géants allouent généralement deux ordres de grandeur de ressources de plus que ce que les grandes entreprises classiques peuvent se permettre, avec des effectifs d’ingénieurs se chiffrant par centaines. La faisabilité de ces approches reste floue pour moi, car elles ne pourraient fonctionner que dans des entreprises extrêmement rentables. Sinon, les coûts de masse salariale exorbitants risquent fort de dépasser les bénéfices apportés par une meilleure exécution de la supply chain.
De plus, attirer des talents en ingénierie à une telle échelle devient un défi en soi. Recruter un ingénieur logiciel talentueux est déjà difficile ; en recruter 100 nécessite une marque employeur assez remarquable. Heureusement, la perspective présentée aujourd’hui est beaucoup plus sobre. De nombreuses initiatives de supply chain menées par Lokad sont réalisées avec un seul Supply Chain Scientist, avec un second agissant en tant que remplaçant. Au-delà des économies de masse salariale, notre expérience indique qu’il existe des bénéfices substantiels de supply chain associés à un effectif réduit.

La perspective dominante de la supply chain adopte le point de vue des mathématiques appliquées. Les méthodes et algorithmes sont présentés de manière à éliminer complètement l’opérateur humain de l’équation. Par exemple, la formule du stock de sécurité et la formule de la quantité économique de commande sont exposées comme une simple application des mathématiques appliquées. L’identité de la personne utilisant ces formules, ses compétences ou son parcours, par exemple, n’a non seulement aucune importance, mais ne fait même pas partie de la présentation.
Plus généralement, ce point de vue est largement adopté dans les manuels de supply chain et, par conséquent, dans les logiciels de supply chain. Il semble certes plus objectif de supprimer la composante humaine de l’équation. Après tout, la validité d’un théorème ne dépend pas de la personne qui énonce la démonstration, et de même, la performance d’un algorithme ne dépend pas de la personne qui finit par appuyer sur la dernière touche de son implémentation. Cette approche vise à atteindre une forme supérieure de rationalité.
Cependant, je soutiens que ce point de vue est naïf et représente encore une autre manifestation du rationalisme naïf. Ma proposition est subtile mais importante : je n’affirme pas que le résultat d’une recette numérique dépend de la personne qui l’exécute finalement, ni que le caractère d’un mathématicien ait quoi que ce soit à voir avec la validité de ses théorèmes. Au contraire, ma proposition est que la posture intellectuelle associée à cette perspective est inappropriée pour aborder les supply chains.
Une recette de supply chain dans le monde réel est une œuvre artisanale complexe, et l’auteur de la recette n’est pas aussi neutre ou sans importance qu’il n’y paraît. Illustrons ce point en considérant deux recettes numériques identiques qui ne diffèrent que par le nommage de leurs variables. Sur le plan numérique, les deux recettes produisent des résultats identiques. Cependant, la première recette présente des noms de variables bien choisis et significatifs, tandis que la seconde a des noms cryptiques et incohérents. En production, la seconde recette (celle avec des noms de variables cryptiques et incohérents) est une catastrophe qui n’attend que de se produire. Chaque évolution ou correction de bogue appliquée à la seconde recette demandera des efforts d’un ordre de grandeur supérieur par rapport à la même tâche accomplie sur la première recette. En fait, les problèmes de nommage des variables sont si fréquents et sévères que de nombreux manuels d’ingénierie logicielle leur consacrent un chapitre entier.
Ni les mathématiques, ni l’algorithmique, ni les statistiques n’apportent quoi que ce soit concernant l’adéquation des noms de variables. L’adéquation de ces noms réside évidemment dans l’œil de celui qui les juge. Bien que nous ayons deux recettes numériquement identiques, l’une est jugée bien supérieure à l’autre pour des raisons apparemment subjectives. La proposition que je défends ici est qu’il existe une rationalité dans ces préoccupations subjectives également. Ces préoccupations ne doivent pas être écartées d’emblée du fait qu’elles dépendent d’un sujet ou d’une personne. Au contraire, l’expérience de Lokad indique que, avec les mêmes outils logiciels, instruments mathématiques et bibliothèque d’algorithmes, certains Supply Chain Scientists obtiennent des résultats supérieurs. En fait, l’identité du scientifique en charge est l’un des meilleurs indicateurs dont nous disposons pour le succès de l’initiative.
En supposant que le talent inné ne puisse pas expliquer entièrement les disparités dans le succès en supply chain, nous devrions adopter les éléments qui contribuent à des initiatives réussies, qu’ils soient objectifs ou subjectifs. C’est pourquoi, chez Lokad, nous avons consacré de nombreux efforts au cours des dernières décennies pour affiner notre approche du rôle du Supply Chain Scientist, qui est précisément le sujet de cette conférence. Les nuances associées au poste de Supply Chain Scientist ne doivent pas être sous-estimées. L’ampleur des améliorations apportées par ces éléments subjectifs est comparable à nos réalisations technologiques les plus notables.
Cette série de conférences est destinée à servir de matériel de formation pour les Supply Chain Scientists de Lokad. Cependant, j’espère également que ces conférences pourront intéresser un public plus large de professionnels de la supply chain, voire des étudiants en supply chain. Il est préférable de regarder ces conférences dans l’ordre pour bien comprendre à quoi sont confrontés les Supply Chain Scientists.
Dans le premier chapitre, nous avons vu pourquoi les supply chains doivent devenir programmatiques et pourquoi il est fortement souhaitable de pouvoir mettre en production une recette numérique. La complexité toujours croissante des supply chains rend l’automatisation plus urgente que jamais. De plus, il existe une nécessité financière de rendre les pratiques de supply chain capitalistiques.
Le deuxième chapitre est consacré aux méthodologies. Les supply chains sont des systèmes compétitifs, et cette combinaison rend caduques les méthodologies naïves. Le rôle des scientifiques peut être considéré comme un antidote à la méthodologie naïve des mathématiques appliquées.
Le troisième chapitre passe en revue les problèmes auxquels le personnel de la supply chain est confronté. Ce chapitre tente de caractériser les catégories de défis en matière de prise de décision qui doivent être relevées. Il montre que des perspectives simplistes, comme choisir la bonne quantité de stocks pour chaque SKU, ne correspondent pas aux situations du monde réel ; il y a invariablement une profondeur dans la prise de décision.
Le quatrième chapitre passe en revue les éléments nécessaires à la compréhension d’une pratique moderne de la supply chain, où les éléments logiciels sont omniprésents. Ces éléments sont fondamentaux pour comprendre le contexte global dans lequel la supply chain numérique opère.
Les chapitres 5 et 6 sont consacrés respectivement à la modélisation prédictive et à la prise de décision. Ces chapitres couvrent les aspects « smart » de la recette numérique, mettant en avant le machine learning et l’optimisation mathématique. Il est à noter que ces chapitres rassemblent des techniques qui se sont révélées performantes entre les mains des Supply Chain Scientists.
Enfin, le septième et présent chapitre est consacré à l’exécution d’une initiative de supply chain quantitative. Nous avons vu ce qu’il faut pour lancer une initiative tout en posant les fondations adéquates. Nous avons vu comment franchir la ligne d’arrivée et mettre la recette numérique en production.

Aujourd’hui, nous allons voir quel type de personne est nécessaire pour faire aboutir l’ensemble.
Le rôle du scientifique vise à résoudre des problèmes rencontrés dans la littérature académique. Nous examinerons le travail du Supply Chain Scientist, incluant leur mission, leur périmètre, leur routine quotidienne et les éléments d’intérêt. Cette description de poste reflète la pratique actuelle chez Lokad.
Un nouveau poste au sein de l’entreprise suscite une série de préoccupations, de sorte qu’il faut recruter, former, évaluer et fidéliser les scientifiques. Nous aborderons ces préoccupations sous l’angle des ressources humaines. Il est attendu que le scientifique collabore avec d’autres départements de l’entreprise, en dehors de leur département supply chain. Nous verrons quel type d’interactions est attendu entre les scientifiques et l’IT, la finance et même la direction de l’entreprise.
Le scientifique représente également une opportunité pour l’entreprise de moderniser son personnel et ses opérations. Cette modernisation est la partie la plus difficile du parcours, car il est bien plus difficile de supprimer un poste qui n’est plus pertinent que d’en introduire un nouveau.
Le défi que nous nous sommes fixé dans cette série de conférences est l’amélioration systématique des supply chains par des méthodes quantitatives. L’idée générale de cette approche est de tirer le meilleur parti de ce que le cloud computing moderne et les logiciels ont à offrir aux supply chains. Cependant, nous devons préciser ce qui relève encore de l’intelligence humaine et ce qui peut être automatisé avec succès.
La ligne de démarcation entre l’intelligence humaine et l’automatisation dépend encore fortement de la technologie. On s’attend à ce qu’une technologie supérieure mécanise un spectre plus large de décisions et produise de meilleurs résultats. Du point de vue de la supply chain, cela signifie prendre des décisions plus diverses, telles que des décisions de tarification en plus des décisions de réapprovisionnement de stocks, et produire de meilleures décisions qui améliorent encore la rentabilité de l’entreprise.
Le rôle du scientifique incarne cette frontière entre l’intelligence humaine et l’automatisation. Bien que des annonces routinières sur l’intelligence artificielle puissent donner l’impression que l’intelligence humaine est sur le point d’être automatisée, ma compréhension de l’état de l’art indique que l’intelligence artificielle générale reste lointaine. En effet, les insights humains sont encore très nécessaires lorsqu’il s’agit de concevoir des méthodes quantitatives pertinentes pour la supply chain. Établir une stratégie supply chain même basique demeure en grande partie hors du champ de ce que les logiciels peuvent offrir.
Plus généralement, nous ne disposons pas encore de technologies capables de s’attaquer à des problèmes mal cadrés ou non identifiés, qui sont monnaie courante dans la supply chain. Cependant, une fois qu’un problème étroit et bien défini a été isolé, il est concevable qu’un processus automatisé apprenne sa résolution et même l’automatise avec peu ou pas de supervision humaine.
Cette perspective n’est pas nouvelle. Par exemple, les filtres anti-spam sont devenus largement adoptés. Ces filtres accomplissent une tâche difficile : trier le pertinent de l’irrélevant. Cependant, la conception de la prochaine génération de filtres est encore largement laissée aux humains, même si des données plus récentes peuvent être utilisées pour mettre à jour ces filtres. En effet, les spammeurs qui souhaitent contourner les filtres anti-spam n’ont de cesse d’inventer de nouvelles méthodes qui contrecarrent de simples mises à jour basées sur les données.
Ainsi, bien que des insights humains soient encore nécessaires pour concevoir l’automatisation, il n’est pas clair pourquoi un éditeur de logiciels comme Lokad, par exemple, ne pourrait pas concevoir un grand moteur supply chain qui résoudrait tous ces défis. Certes, l’économie du logiciel est largement en faveur de la conception d’un tel grand moteur supply chain. Même si l’investissement initial est important, puisque le logiciel peut être reproduit à un coût négligeable, l’éditeur fera fortune grâce aux frais de licence en revendant ce grand moteur à un grand nombre d’entreprises.
Lokad, dès 2008, s’est lancé dans un tel parcours de création d’un grand moteur qui aurait pu être déployé sous forme de produit logiciel packagé. Plus précisément, à l’époque, Lokad se concentrait sur un grand moteur de prévision plutôt que sur un grand moteur supply chain. Pourtant, malgré ces ambitions comparativement plus modestes, puisque la prévision ne représente qu’une petite partie du défi global de la supply chain, Lokad n’a pas réussi à créer un tel grand moteur de prévision. La perspective de la Supply Chain Quantitative présentée dans cette série de conférences est née des cendres de cette ambition de grand moteur.
Du point de vue de la supply chain, il s’est avéré qu’il y a trois grands goulots d’étranglement à traiter. Nous verrons pourquoi ce grand moteur était voué à l’échec dès le premier jour et pourquoi nous sommes encore très probablement à des décennies d’une telle prouesse d’ingénierie.
Le paysage applicatif de la supply chain typique est une jungle qui s’est développée de manière désordonnée au cours des deux ou trois dernières décennies. Ce paysage n’est pas un jardin à la française avec des lignes géométriques nettes et des haies bien taillées ; c’est une jungle, à la fois vibrante mais aussi pleine d’épines et d’une faune hostile. Plus sérieusement, les supply chains sont le produit de leur histoire numérique. Il peut y avoir plusieurs ERP semi-redondants, des personnalisations maison à moitié finalisées, des intégrations par lots, notamment avec des systèmes provenant d’entreprises acquises, et des plateformes logicielles qui se chevauchent et qui se disputent les mêmes domaines fonctionnels.
Penser qu’un grand moteur quelconque pourrait être simplement branché est illusoire, compte tenu de l’état actuel des technologies logicielles. Réunir tous les systèmes qui font fonctionner la supply chain est une entreprise considérable entièrement dépendante des efforts d’ingénierie humaine.
L’analyse des dépenses collectives indique que le traitement des données représente au moins les trois quarts de l’effort technique global associé à une initiative supply chain. En revanche, l’élaboration des aspects intelligents de la recette numérique, tels que la prévision des séries temporelles et l’optimisation, ne représente pas plus de quelques pourcents de l’effort global. Ainsi, la disponibilité d’un grand moteur packagé est largement sans conséquence en termes de coût ou de délais. Il faudrait une intelligence de niveau humain intégrée pour que ce moteur s’intègre automatiquement dans le paysage informatique souvent désordonné que l’on trouve dans les supply chains.
De plus, tout grand moteur rend cette entreprise encore plus difficile en raison de son existence. Au lieu de devoir gérer un système complexe, le paysage applicatif, nous avons désormais deux systèmes complexes : le paysage applicatif et le grand moteur. La complexité d’intégrer ces deux systèmes n’est pas la somme de leurs complexités respectives, mais plutôt le produit de ces complexités.
L’impact de cette complexité sur le coût de l’ingénierie est extrêmement non linéaire, un point qui a déjà été évoqué dans le premier chapitre de cette série de conférences. Le premier grand goulot d’étranglement pour l’optimisation de la supply chain est la mise en place de la recette numérique, qui nécessite un effort d’ingénierie dédié. Ce goulot d’étranglement élimine en grande partie les avantages qui pourraient être éventuellement associés à un quelconque grand moteur packagé supply chain.

Bien que la mise en place nécessite un effort d’ingénierie substantiel, il pourrait s’agir d’un investissement unique, semblable à l’achat d’un ticket d’entrée. Malheureusement, les supply chains sont des entités vivantes en constante évolution. Le jour où une supply chain cesse de changer est le jour où l’entreprise fait faillite. Les changements sont à la fois internes et externes.
En interne, le paysage applicatif change constamment. Les entreprises ne peuvent pas figer leur paysage applicatif même si elles le voulaient, car de nombreuses mises à jour sont imposées par les éditeurs de logiciels d’entreprise. Ignorer ces obligations déchargerait les éditeurs de leurs engagements contractuels, ce qui n’est pas un résultat acceptable. Au-delà des mises à jour purement techniques, toute supply chain de taille significative est destinée à intégrer et éliminer des composants logiciels au fur et à mesure que l’entreprise évolue.
À l’extérieur, les marchés évoluent également de manière continue. De nouveaux concurrents, canaux de vente et fournisseurs potentiels émergent constamment, tandis que d’autres disparaissent. Les réglementations changent sans cesse. Bien que les algorithmes puissent automatiquement capter certains changements simples, comme la croissance de la demande pour une catégorie de produits, nous ne disposons pas encore d’algorithmes capables de faire face aux changements qualitatifs du marché, et non simplement quantitatifs. Les problèmes mêmes que l’optimisation de la supply chain cherche à résoudre sont en perpétuelle évolution.
Si le logiciel responsable de l’optimisation de la supply chain ne parvient pas à gérer ces changements, les employés se rabattent sur des spreadsheets. Les spreadsheets peuvent être rudimentaires, mais au moins, les employés peuvent les adapter à la tâche à accomplir. De manière anecdotique, la grande majorité des supply chains fonctionnent encore sous forme de spreadsheets au niveau décisionnel, et non transactionnel. C’est la preuve vivante de l’échec de la maintenance logicielle.
Depuis les années 1980, les éditeurs de logiciels d’entreprise livrent des produits logiciels pour automatiser les décisions de la supply chain. La plupart des entreprises qui gèrent de grandes supply chains ont déjà déployé plusieurs de ces solutions au cours des dernières décennies. Pourtant, les employés reviennent invariablement à leurs spreadsheets, prouvant que même si la mise en place avait été initialement considérée comme un succès, quelque chose a mal tourné dans la maintenance.
La maintenance est le deuxième grand goulot d’étranglement de l’optimisation de la supply chain. La recette nécessite une maintenance active, même si son exécution peut en grande partie être laissée sans surveillance.

À ce stade, nous avons montré que l’optimisation de la supply chain nécessite non seulement des ressources initiales en ingénierie logicielle mais aussi des ressources continues en ingénierie logicielle. Comme cela a été souligné précédemment dans cette série de conférences, rien de moins que des capacités programmatiques ne peut réellement approcher la diversité des problèmes rencontrés par les supply chains du monde réel. Les spreadsheets comptent comme des outils programmables, et leur expressivité, contrairement aux boutons et aux menus, est ce qui les rend si attractifs pour les praticiens de la supply chain.
Comme les ressources en ingénierie logicielle doivent être sécurisées dans la plupart des entreprises, il semble naturel de faire appel au département IT. Malheureusement, la supply chain n’est pas le seul département avec cette logique. Chaque département, y compris les ventes, le marketing et la finance, finit par se rendre compte que l’automatisation de leurs processus décisionnels respectifs nécessite des ressources en ingénierie logicielle. De plus, ils doivent également s’occuper de la couche transactionnelle et de toute son infrastructure sous-jacente.
En conséquence, la plupart des entreprises qui exploitent de grandes supply chains ont de nos jours leurs départements IT submergés par des années d’arriéré. Ainsi, s’attendre à ce que le département IT alloue davantage de ressources continues à la supply chain ne fait qu’aggraver l’arriéré. L’option d’allouer plus de ressources au département IT a déjà été explorée, et elle n’est généralement plus viable. Ces entreprises font déjà face à de sévères déséconomies d’échelle en ce qui concerne le département IT. L’arriéré IT représente le troisième grand goulot d’étranglement pour l’optimisation de la supply chain.
Des ressources continues en ingénierie sont nécessaires, mais la majeure partie de ces ressources ne peut pas provenir du département IT. Un certain soutien de l’IT peut être envisagé, mais cela doit rester discret.
Ces trois grands goulots d’étranglement définissent pourquoi un rôle spécifique est nécessaire : le Supply Chain Scientist est le nom que nous donnons à ces ressources continues en ingénierie logicielle nécessaires pour automatiser les décisions routinières et les processus décisionnels exigeants de la supply chain.

Avançons vers une définition plus précise basée sur la pratique de Lokad. La mission du scientifique de la supply chain est de concevoir des recettes numériques qui génèrent les décisions routinières nécessaires au fonctionnement quotidien de la supply chain. Le travail du scientifique commence par les extractions de bases de données collectées dans tout le paysage applicatif. Le scientifique est censé coder la recette qui traite ces extractions de bases de données et mettre ces recettes en production. Le scientifique assume l’entière responsabilité de la qualité des décisions générées par la recette. Les décisions ne sont pas générées par un système ambiant quelconque ; elles sont l’expression directe des insights du scientifique transmis à travers une recette.
Cet aspect unique constitue un départ critique par rapport à ce que l’on entend habituellement par le rôle d’un data scientist. Cependant, la mission ne s’arrête pas là. Le Supply Chain Scientist doit être capable de présenter des preuves à l’appui de chaque décision générée par la recette. Il ne s’agit pas d’un système opaque responsable des décisions ; c’est la personne, le scientifique. Le scientifique devrait être en mesure de rencontrer le responsable de la supply chain, voire le CEO, et de fournir une explication convaincante pour toute décision générée par la recette.
Si le scientifique n’est pas en position de potentiellement causer beaucoup de dégâts à l’entreprise, alors quelque chose ne va pas. Je ne préconise pas d’accorder à quiconque, et certainement pas au scientifique, de larges pouvoirs sans supervision ni responsabilité. Je fais simplement remarquer l’évidence : si vous n’avez pas le pouvoir d’impacter négativement votre entreprise, quelle que soit la médiocrité de vos performances, vous n’avez pas le pouvoir d’impacter positivement votre entreprise, quelle que soit l’excellence de vos performances.
Les grandes entreprises sont malheureusement averses au risque par nature. Ainsi, il est très tentant de remplacer le scientifique par un analyste. Contrairement au scientifique chargé des décisions elles-mêmes, l’analyste est seulement responsable d’apporter un éclairage ici et là. L’analyste est relativement inoffensif et ne peut guère faire plus que gaspiller son propre temps et quelques ressources informatiques. Cependant, ne pas être dangereux n’est pas l’essence du rôle du Supply Chain Scientist.

Discutons un instant du terme “supply chain scientist”. Cette terminologie est malheureusement imparfaite. J’ai à l’origine inventé cette expression comme une variante de “data scientist” il y a environ une décennie, dans l’idée de positionner ce rôle comme une variante du data scientist mais avec une forte spécialisation en supply chain. L’idée de spécialisation était correcte, mais celle relative à la data science ne l’était pas. Je reviendrai sur ce point à la fin de la conférence.
Un “supply chain engineer” aurait peut-être constitué une meilleure formulation, car cela souligne le désir de maîtriser et de contrôler le domaine, par opposition à une simple compréhension. Cependant, les ingénieurs, tels qu’ils sont communément entendus, ne sont pas censés être en première ligne de l’action. Le terme approprié aurait probablement dû être supply chain quant, comme pour désigner les praticiens de la Supply Chain Quantitative.
En finance, un quant ou trader quantitatif est un spécialiste qui exploite des algorithmes et des méthodes quantitatives pour prendre des décisions de trading. Les quants peuvent rendre une banque extrêmement rentable ou, au contraire, extrêmement non rentable. L’intelligence humaine est amplifiée par les machines, pour le meilleur comme pour le pire.
Dans tous les cas, il reviendra à la communauté dans son ensemble de décider de la terminologie appropriée : analyste, scientist, ingénieur, opérateur ou quant. Pour des raisons de cohérence, je continuerai à utiliser le terme scientist dans le reste de cette conférence.

Le livrable principal pour le scientist est un logiciel, plus précisément, la recette numérique responsable de la génération quotidienne des décisions de supply chain d’intérêt. Cette recette est un ensemble de tous les scripts impliqués, depuis les premières étapes de préparation des données jusqu’aux dernières phases de validation corporative des décisions elles-mêmes. Cette recette doit être de niveau production, c’est-à-dire qu’elle peut fonctionner sans surveillance et que les décisions qu’elle génère sont de confiance par défaut. Naturellement, cette confiance a d’abord dû être acquise, et une supervision continue doit garantir que ce niveau de confiance reste justifié au fil du temps.
Fournir une recette de niveau production est fondamental pour transformer la pratique de la supply chain en un atout productif. Cet angle a déjà été abordé dans la conférence précédente sur la livraison orientée produit.
Au-delà de cette recette, il existe de nombreux livrables secondaires. Certains d’entre eux sont également des logiciels, même s’ils ne contribuent pas directement à la génération des décisions. Cela inclut, par exemple, toute l’instrumentation que le scientist doit mettre en place pour concevoir puis maintenir ultérieurement la recette elle-même. D’autres éléments sont destinés aux collègues de l’entreprise, incluant toute la documentation relative à l’initiative et à la recette.
Le code source de la recette répond au « comment » – comment est-ce fait ? Cependant, le code source ne répond pas au « pourquoi » – pourquoi est-ce fait ? Le « pourquoi » doit être documenté. Souvent, la justesse de la recette repose sur une compréhension subtile de l’intention. La documentation livrée doit faciliter autant que possible la transition harmonieuse d’un scientist à l’autre, même si l’ancien scientist n’est pas disponible pour accompagner le processus.
Chez Lokad, notre procédure standard consiste à produire et à maintenir un grand livre de l’initiative, appelé le Joint Procedure Manual (JPM). Ce manuel n’est pas seulement un guide opérationnel complet de la recette, mais aussi une collection de toutes les idées stratégiques qui sous-tendent les choix de modélisation effectués par les scientists.
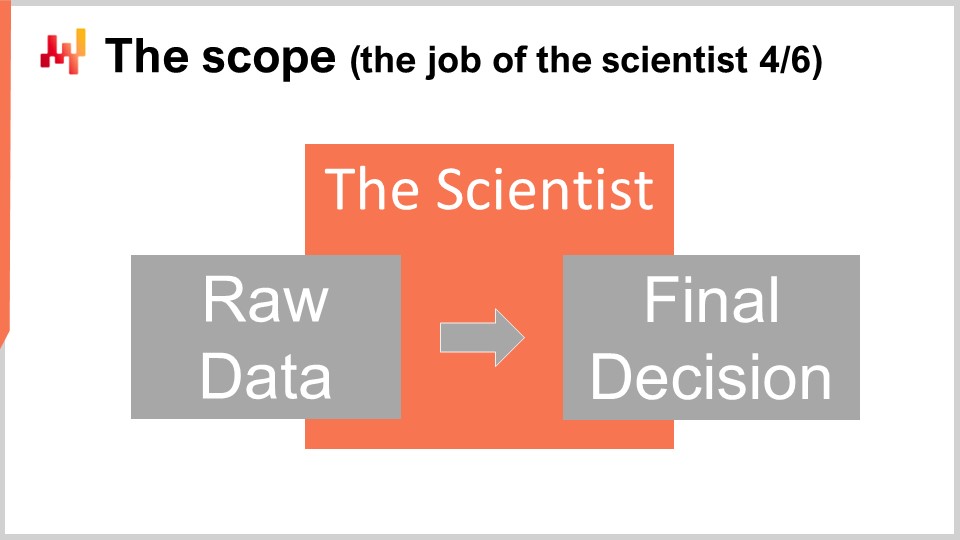
Sur le plan technique, le travail du scientist commence dès l’extraction des données brutes et se termine par la génération des décisions de supply chain finalisées. Le scientist doit travailler à partir des données brutes telles qu’extraites des systèmes d’information existants. Comme chaque système d’information dispose de sa propre pile technologique, l’extraction elle-même est généralement mieux confiée aux spécialistes IT. Il n’est pas raisonnable d’attendre du scientist qu’il se perfectionne dans une demi-douzaine de dialectes SQL ou dans une demi-douzaine de technologies API simplement pour accéder aux données commerciales. En revanche, rien ne devrait être attendu des spécialistes IT, si ce n’est des extractions de données brutes, et non une transformation ou une préparation des données. Les données extraites mises à la disposition du scientist doivent être aussi fidèles que possible aux données telles qu’elles se présentent dans les systèmes d’information.
À l’autre extrémité du pipeline, la recette élaborée par le scientist doit générer les décisions finalisées. Les éléments associés au déploiement des décisions ne relèvent pas de la compétence du scientist. Ils sont importants, mais également largement indépendants de la décision elle-même. Par exemple, lorsqu’il s’agit de bons de commande, établir les quantités finales relève du champ d’action du scientist, mais générer le fichier PDF – le document de commande attendu par le fournisseur – ne l’est pas. Malgré ces limites, le périmètre reste assez vaste. Par conséquent, il est tentant mais erroné de fragmenter ce périmètre en une série de sous-périmètres. Dans les grandes entreprises, cette tentation devient très forte et doit être combattue. Fragmenter le périmètre est la manière la plus sûre de créer de nombreux problèmes.
En amont, si quelqu’un tente d’aider les scientists en manipulant les données d’entrée, cette tentative se solde invariablement par des problèmes de « garbage in, garbage out ». Les systèmes d’information sont suffisamment complexes ; transformer les données en amont ne fait qu’ajouter une couche accidentelle supplémentaire de complexité. Au milieu de la chaîne, si quelqu’un tente d’aider les scientists en prenant en charge un segment difficile de la recette, tel que la prévision, alors les scientists se retrouvent face à une boîte noire au cœur de leur propre recette. Une telle boîte noire compromet les efforts de transparence des scientists. Et en aval, si quelqu’un tente d’aider le scientist en ré-optimisant davantage les décisions, cette tentative crée inévitablement de la confusion, et les logiques d’optimisation à deux niveaux peuvent même être contradictoires.
Cela n’implique pas que le scientist doive travailler seul. Une équipe de scientists peut être constituée, mais le périmètre reste le même. Si une équipe est formée, il doit y avoir une propriété collective de la recette. Cela signifie, par exemple, que si un défaut dans la recette est identifié, n’importe quel membre de l’équipe devrait pouvoir intervenir pour le corriger.

L’expérience de Lokad indique qu’un équilibre sain pour un Supply Chain Scientist implique de consacrer 40 % de son temps à coder, 30 % à dialoguer avec le reste de l’entreprise, et 30 % à rédiger des documents, des supports de formation et à échanger avec d’autres praticiens de la supply chain ou d’autres Supply Chain Scientists.
Le codage est évidemment nécessaire pour implémenter la recette elle-même. Cependant, une fois la recette en production, la majeure partie des efforts de codage ne vise pas la recette directement, mais plutôt son instrumentation. Pour améliorer la recette, le scientist a besoin d’éclairages supplémentaires, lesquels nécessitent, à leur tour, la mise en place d’une instrumentation dédiée.
Dialoguer avec le reste de l’entreprise est fondamental. Contrairement au S&OP, l’objectif de ces discussions n’est pas d’orienter la prévision à la hausse ou à la baisse. Il s’agit de s’assurer que les choix de modélisation intégrés dans la recette reflètent toujours fidèlement à la fois la stratégie de l’entreprise et l’ensemble de ses contraintes opérationnelles.
Enfin, nourrir le savoir institutionnel que possède l’entreprise sur l’optimisation de la supply chain, que ce soit par la formation directe des scientists ou par la production de documents destinés aux collègues, est essentiel. La performance de la recette reflète, en grande partie, la compétence du scientist. Avoir accès à des pairs et solliciter des retours est, sans surprise, l’un des moyens les plus efficaces pour améliorer la compétence des scientists.

La plus grande différence entre un Supply Chain Scientist, tel qu’envisagé par Lokad, et un data scientist grand public réside dans l’engagement personnel envers des résultats concrets. Cela peut sembler être une chose minime et sans conséquence, mais l’expérience prouve le contraire. Il y a dix ans, Lokad a appris à ses dépens que l’engagement en faveur de la livraison d’une recette de niveau production n’était pas acquis d’avance. Au contraire, l’attitude par défaut des personnes formées en tant que data scientists semble être de traiter la production comme une préoccupation secondaire. Le data scientist grand public s’attend à gérer les parties intelligentes, comme le machine learning et l’optimisation mathématique, tandis que s’occuper de toutes ces trivialités aléatoires inhérentes à la supply chain réelle est trop souvent perçu comme étant en deçà de leurs aspirations.
Cependant, l’engagement envers une recette de niveau production implique de gérer les situations les plus aléatoires. Par exemple, en juillet 2021, de nombreux pays européens ont subi des inondations catastrophiques. Un client de Lokad basé en Allemagne a vu la moitié de ses warehouses être inondée. Le Supply Chain Scientist en charge de ce compte a dû reconcevoir la recette presque du jour au lendemain pour tirer le meilleur parti de cette situation fortement dégradée. La solution n’était pas une sorte d’algorithme de machine learning grandiose, mais plutôt un ensemble d’heuristiques décodées. À l’inverse, si le Supply Chain Scientist ne maîtrise pas la décision, cette personne ne pourra pas concevoir une recette de niveau production. C’est une question de psychologie. Fournir une recette de niveau production requiert un immense effort intellectuel, et les enjeux doivent être réels pour obtenir le niveau de concentration nécessaire chez un employé.
Après avoir clarifié le rôle d’un Supply Chain Scientist, discutons de son fonctionnement d’un point de vue des ressources humaines. Tout d’abord, parmi les préoccupations de l’entreprise, le scientist doit relever du responsable de la supply chain ou, au moins, de quelqu’un qui occupe une position de haute direction supply chain. Peu importe que le scientist soit interne ou externe, comme c’est souvent le cas chez Lokad. L’essentiel reste que le scientist doit être sous la supervision directe de quelqu’un disposant du pouvoir d’un cadre de la supply chain.
Une erreur courante consiste à faire relever le scientist du responsable IT ou du responsable de l’analytics de données. Comme la conception d’une recette relève d’un exercice de codage, la direction supply chain pourrait ne pas se sentir entièrement à l’aise pour superviser une telle entreprise. Toutefois, cela est incorrect. Le scientist a besoin de la supervision de quelqu’un qui puisse approuver si les décisions générées sont acceptables ou non, ou qui puisse, à tout le moins, faire en sorte que cette approbation ait lieu. Placer le scientist n’importe où ailleurs qu’en dessous de la supervision directe de la direction supply chain est une recette pour fonctionner indéfiniment avec des prototypes qui ne voient jamais le jour en production. Dans cette situation, le rôle revient inévitablement à celui d’un analyste, et les ambitions initiales de l’initiative Supply Chain Quantitative sont abandonnées.

Les meilleurs Supply Chain Scientists génèrent des retours sur investissement exceptionnels comparativement aux profils moyens. C’est l’expérience de Lokad et cela reflète le schéma identifié il y a des décennies dans l’industrie du logiciel. Les entreprises de logiciels observent depuis longtemps que les meilleurs ingénieurs logiciels ont au moins dix fois la productivité des ingénieurs moyens, et que des ingénieurs médiocres peuvent même afficher une productivité négative, détériorant ainsi le logiciel pour chaque heure passée sur la base de code.
Dans le cas des Supply Chain Scientists, une compétence supérieure améliore non seulement la productivité, mais, plus important encore, elle améliore la performance de la supply chain. Étant donné les mêmes outils logiciels et instruments mathématiques, deux scientists n’obtiennent pas le même résultat. Ainsi, recruter quelqu’un ayant le potentiel de devenir l’un des meilleurs scientists revêt une importance primordiale.
L’expérience de Lokad, basée sur le recrutement de plus de 50 scientists, indique que les profils d’ingénierie non spécialisés sont généralement assez bons. Contrairement à ce que l’on pourrait penser, les personnes ayant une formation formelle en data science, en statistiques ou en informatique ne sont généralement pas les mieux adaptées aux postes de Supply Chain Scientist. Ces individus compliquent trop souvent la recette et n’accordent pas assez d’attention aux aspects banals mais critiques de la supply chain. La capacité à prêter attention à une multitude de détails et à persévérer sans relâche en poursuivant des artefacts numériques marginaux semble être la qualité principale des meilleurs scientists.
Anecdotiquement, chez Lokad, les jeunes ingénieurs ayant passé quelques années en tant qu’auditeurs ont démontré d’excellents résultats. En plus de leur familiarité avec la finance d’entreprise, il semble que les auditeurs talentueux développent une capacité à naviguer à travers un océan de documents corporatifs, ce qui correspond à la réalité quotidienne d’un Supply Chain Scientist.

Si le recrutement garantit que les nouveaux arrivants ont le potentiel adéquat, l’étape suivante consiste à s’assurer qu’ils soient correctement formés. La position par défaut de Lokad est de ne pas attendre des gens qu’ils connaissent la supply chain au préalable. Avoir des connaissances en supply chain est un atout, mais le milieu académique reste quelque peu déficient à cet égard. La plupart des diplômes en supply chain se concentrent sur la gestion et le leadership, mais pour les jeunes diplômés, il est essentiel de disposer d’une base solide dans des sujets tels que ceux abordés dans les deuxième, troisième ou quatrième chapitres de cette série de conférences. Malheureusement, ce n’est souvent pas le cas, et les volets quantitatifs de ces diplômes peuvent être décevants. Par conséquent, les Supply Chain Scientists doivent être formés par leurs employeurs. Cette série de conférences reflète le type de supports de formation utilisés chez Lokad.

Les évaluations de performance pour les Supply Chain Scientists sont importantes pour diverses raisons, telles que s’assurer que l’argent de l’entreprise est bien investi et déterminer les promotions. Les critères habituels s’appliquent : attitude, diligence, compétence, etc. Toutefois, un aspect contre-intuitif subsiste : les meilleurs scientists obtiennent des résultats qui font paraître les défis de la supply chain presque invisibles, avec un minimum de dramatique.

Former un scientist afin de maintenir les recettes existantes tout en conservant le niveau antérieur de performance de la supply chain prend environ six mois, tandis que former un scientist pour implémenter une recette de niveau prévision à partir de zéro prend environ deux ans. La rétention des talents est cruciale, d’autant plus que le recrutement de Supply Chain Scientists expérimentés n’est pas encore envisageable.
Dans de nombreux pays, la durée moyenne d’emploi pour les ingénieurs de moins de 30 ans dans le domaine des logiciels et secteurs connexes est assez faible. Lokad parvient à obtenir une durée moyenne d’emploi plus longue en se concentrant sur le bien-être des employés. Les entreprises ne peuvent pas apporter le bonheur à leurs employés, mais elles peuvent éviter de les rendre misérables grâce à des processus ineptes. Le bon sens contribue grandement à la rétention des employés.

Un Supply Chain Scientist compétent et expérimenté ne peut être censé reprendre rapidement une recette existante, car celle-ci reflète la stratégie unique de l’entreprise et les particularités de la supply chain. Passer d’une supply chain à une autre peut prendre environ un mois dans les meilleures conditions. Il n’est pas raisonnable qu’une entreprise de taille importante dépende d’un seul scientifique ; Lokad veille à ce que deux scientifiques maîtrisent toute recette utilisée en production à tout moment donné. La continuité est essentielle, et l’une des manières d’y parvenir est de recourir à un manuel élaboré conjointement avec les clients, ce qui peut faciliter les transitions imprévues entre scientifiques.

Le rôle du Supply Chain Scientist requiert un niveau de coopération inhabituel avec de multiples départements, notamment l’IT. La bonne exécution de la recette dépend du pipeline d’extraction de données, qui relève de la responsabilité de l’IT.
Il existe une phase relativement intense d’interaction entre l’IT et le Supply Chain Scientist au début de la première initiative de la Supply Chain Quantitative, qui dure environ deux à trois mois. Par la suite, une fois le pipeline d’extraction de données en place, l’interaction devient moins fréquente. Ce dialogue permet au Supply Chain Scientist de rester informé de la feuille de route IT et de toute mise à niveau ou modification logicielle susceptible d’impacter la supply chain.
Lors de la phase initiale d’une initiative de la Supply Chain Quantitative, il existe une interaction relativement intense entre l’IT et les Supply Chain Scientists. Pendant les deux à trois premiers mois, le Supply Chain Scientist doit interagir avec l’IT plusieurs fois par semaine. Par la suite, une fois le pipeline d’extraction de données installé, l’interaction devient beaucoup moins fréquente, environ une fois par mois, voire moins. En plus de résoudre de temps à autre un problème dans le pipeline, ce dialogue permet au Supply Chain Scientist de rester informé de la feuille de route IT. Toute mise à niveau ou remplacement logiciel peut nécessiter quelques jours, voire quelques semaines de travail pour le Supply Chain Scientist. Pour éviter toute interruption, la recette doit être modifiée afin de s’adapter aux changements du paysage applicatif.

La recette, telle qu’implémentée par le Supply Chain Scientist, optimise des rendements en dollars ou en euros. Nous avons abordé cet aspect dès les toutes premières conférences de cette série. Cependant, il ne faut pas s’attendre à ce que le Supply Chain Scientist décide de la manière de modéliser les coûts et les profits. Bien qu’il doive proposer des modèles pour refléter les moteurs économiques, il revient en définitive au département financier de déterminer si ces moteurs sont jugés corrects ou non. De nombreuses pratiques de supply chain contournent le problème en se concentrant sur des pourcentages, tels que les taux de service et les précisions des prévisions. Toutefois, ces pourcentages présentent presque aucune corrélation avec la santé financière de l’entreprise. Ainsi, le Supply Chain Scientist doit régulièrement collaborer avec le département financier et le pousser à remettre en question les choix de modélisation et les hypothèses formulées dans la recette numérique.
Les choix de modélisation financière sont transitoires, car ils reflètent l’évolution de la stratégie de l’entreprise. Le Supply Chain Scientist est également censé élaborer une instrumentation associée à la recette pour le département financier, notamment le montant maximal projeté de fonds de roulement associé aux stocks pour l’année à venir. Pour une entreprise de taille moyenne ou grande, il est raisonnable qu’un cadre financier examine trimestriellement le travail réalisé par le Supply Chain Scientist.

L’une des plus grandes menaces pesant sur la validité de la recette est de trahir accidentellement l’intention stratégique de l’entreprise. Trop de pratiques de supply chain contournent la stratégie en se cachant derrière des pourcentages utilisés comme indicateurs. Gonfler ou dégonfler les prévisions par le biais du Sales and Operations Planning (S&OP) ne peut se substituer à la clarification de l’intention stratégique. Le Supply Chain Scientist n’est pas responsable de la stratégie de l’entreprise, mais la recette sera erronée s’il ne la comprend pas. L’alignement de la recette avec la stratégie doit être soigneusement conçu.
La manière la plus directe d’évaluer si le Supply Chain Scientist comprend la stratégie est de lui demander de la réexpliquer aux dirigeants. Cela permet de détecter plus aisément les malentendus. En théorie, cette compréhension est déjà consignée par le Supply Chain Scientist dans le manuel de l’initiative. Cependant, l’expérience montre que les dirigeants disposent rarement du temps nécessaire pour examiner en détail la documentation opérationnelle. Une simple conversation accélère le processus pour les deux parties.
Cette réunion n’a pas pour vocation que le Supply Chain Scientist explique en détail tout ce qui concerne les modèles de supply chain ou les résultats financiers. Son unique objectif est de s’assurer que la personne tenant le stylo numérique comprend bien. Même dans une grande entreprise, il est raisonnable que le Supply Chain Scientist rencontre au moins une fois par an le PDG ou le cadre concerné. Les bénéfices d’une recette davantage en phase avec l’intention du leadership sont immenses et souvent sous-estimés.

Les améliorations de supply chain font partie de la modernisation digitale en cours. Cela nécessite une certaine réorganisation de l’entreprise elle-même. Bien que les changements ne soient pas drastiques, éliminer les pratiques obsolètes demeure un combat ardu. Lorsqu’il est exécuté correctement, la productivité du Supply Chain Scientist est nettement supérieure à celle d’un planificateur traditionnel. Il n’est pas rare qu’un seul Supply Chain Scientist soit responsable de stocks d’une valeur de plus d’un demi-milliard de dollars ou d’euros.
Une réduction drastique des effectifs de la supply chain est envisageable. Certaines entreprises clientes de Lokad, historiquement soumises à une pression concurrentielle immense, ont opté pour cette approche et ont survécu en partie grâce à ces économies. La plupart de nos clients, cependant, préfèrent une réduction plus progressive des effectifs, les planificateurs se dirigeant naturellement vers d’autres postes.
Les planificateurs restants réorientent leurs efforts vers les clients et les fournisseurs. Les retours qu’ils recueillent s’avèrent très utiles aux Supply Chain Scientists. En effet, le travail du Supply Chain Scientist est, par nature, tourné vers l’interne. Il opère sur les données de l’entreprise, et il est difficile de discerner ce qui manque simplement.
De nombreuses voix du monde des affaires militent depuis longtemps pour forger des liens plus étroits avec les clients et les fournisseurs. Cependant, c’est plus facile à dire qu’à faire, surtout si les efforts sont régulièrement neutralisés par des interventions de gestion de crise, la nécessité de rassurer les clients et la pression exercée sur les fournisseurs. Les Supply Chain Scientists peuvent apporter un soulagement tant nécessaire sur ces deux fronts.

Le S&OP (Sales and Operations Planning) est une pratique répandue visant à favoriser l’alignement de l’ensemble de l’entreprise grâce à une prévision commune de la demande. Cependant, quelles que fussent les ambitions initiales, les processus de S&OP que j’ai pu observer se résument à une série interminable de réunions peu productives. À l’exception des implémentations d’ERP et des questions de conformité, je ne connais aucune pratique d’entreprise aussi épuisante pour l’âme que le S&OP. L’Union soviétique a peut-être disparu, mais l’esprit du Gosplan survit à travers le S&OP.
Une critique approfondie du S&OP mériterait une conférence à part entière. Cependant, par souci de brièveté, je dirai simplement qu’un Supply Chain Scientist est, dans toutes les dimensions importantes, une alternative supérieure au S&OP. Contrairement au S&OP, le Supply Chain Scientist est ancré dans des décisions concrètes. La seule chose qui empêche un scientifique de devenir un agent de plus d’une bureaucratie d’entreprise surdimensionnée n’est ni son caractère ni sa compétence, mais bien le fait d’avoir « la peau dans le jeu » grâce à ces décisions réelles.
Les planificateurs, gestionnaires de stocks et responsables de production sont fréquemment de grands consommateurs de toutes sortes de rapports d’affaires. Ces rapports sont généralement produits par des logiciels d’entreprise, souvent désignés sous le terme d’outils de business intelligence. La pratique typique en supply chain consiste à exporter une série de rapports sous forme de tableurs, puis à utiliser une collection de formules pour fusionner ces informations afin de générer, de manière semi-manuelle, les décisions pertinentes. Pourtant, comme nous l’avons constaté, la recette du Supply Chain Scientist remplace cette combinaison de business intelligence et de tableurs.
De plus, ni la business intelligence ni les tableurs ne conviennent pour soutenir la mise en œuvre d’une recette. La business intelligence manque d’expressivité, puisque les calculs pertinents ne peuvent être exprimés avec ce type d’outils. Les tableurs souffrent d’un manque de maintenabilité et parfois d’évolutivité, mais surtout de maintenabilité. La conception des tableurs est largement incompatible avec toute approche de rigueur par conception, ce qui est indispensable pour la supply chain.
En pratique, l’instrumentation d’une recette telle qu’implémentée par le Supply Chain Scientist inclut de nombreux rapports d’affaires. Ces rapports remplacent ceux qui étaient produits jusqu’à présent via la business intelligence. Cette évolution n’implique pas nécessairement la fin de la business intelligence, car d’autres départements peuvent encore bénéficier de ce type d’outils. Cependant, en ce qui concerne la supply chain, l’introduction du Supply Chain Scientist annonce la fin de l’ère de la business intelligence.

Si l’on met de côté quelques géants de la tech qui peuvent se permettre de consacrer des centaines, voire des milliers, d’ingénieurs à chaque problème logiciel, le résultat typique des équipes de data science dans les entreprises classiques est désastreux. En général, ces équipes n’accomplissent jamais rien de substantiel. Cependant, la data science, en tant que pratique d’entreprise, n’est que la dernière itération d’une série de modes passagères.
Dans les années 1970, la recherche opérationnelle était en vogue. Dans les années 1980, les moteurs de règles et les experts en connaissances étaient populaires. Au tournant du siècle, le data mining et les data miners étaient recherchés. Depuis les années 2010, la data science et les data scientists sont considérés comme la prochaine grande nouveauté. Toutes ces tendances d’entreprise suivent le même schéma : une véritable innovation logicielle apparaît, l’enthousiasme des gens explose, puis ils décident d’intégrer de force cette innovation dans l’entreprise en créant un nouveau département dédié. Cela s’explique par le fait qu’il est toujours beaucoup plus facile d’ajouter des divisions à une organisation que de modifier ou de supprimer celles existantes.
Cependant, la data science en tant que pratique d’entreprise échoue parce qu’elle n’est pas solidement ancrée dans l’action. Cela fait toute la différence entre un Supply Chain Scientist, engagé dès le premier jour à générer des décisions concrètes, et le département IT.

Si l’on peut mettre de côté les ego et les querelles de territoire, le Supply Chain Scientist représente une bien meilleure option que l’ancien statu quo. Le département IT typique est submergé par des années d’arriérés, et obtenir davantage de ressources n’est pas une proposition raisonnable, car cela finit par augmenter les attentes des autres départements et par aggraver l’arriéré.
Au contraire, le Supply Chain Scientist ouvre la voie à une diminution des attentes. Le scientifique n’attend que la mise à disposition d’extractions de données brutes, et c’est à lui de mener la charge pour les traiter. Il n’attend rien du département IT à cet égard. Le Supply Chain Scientist ne doit pas être perçu comme une version approuvée par l’entreprise du shadow IT. Il s’agit de rendre le département supply chain responsable et redevable de sa compétence principale. Le département IT gère l’infrastructure de bas niveau et la couche transactionnelle, tandis que la couche décisionnelle de la supply chain devrait relever entièrement du département supply chain.
Le département IT doit être un facilitateur, et non un décideur, sauf pour les volets véritablement IT-centrés de l’entreprise. De nombreux départements IT sont conscients de leur arriéré et adoptent ce nouvel arrangement. Cependant, si l’instinct de protéger ce qui est perçu comme leur territoire est trop fort, ils peuvent refuser de lâcher prise sur la couche décisionnelle de la supply chain. Ces situations sont pénibles et ne peuvent être résolues qu’avec l’intervention directe du PDG.

De loin, notre conclusion pourrait être que le rôle du Supply Chain Scientist peut être considéré comme une variante plus spécialisée du data scientist. Historiquement, c’est ainsi que Lokad a tenté de résoudre les problèmes liés à la pratique d’entreprise de la data science. Cependant, il y a une dizaine d’années, nous avons réalisé que cela était insuffisant. Il nous a fallu des années pour découvrir progressivement tous les éléments qui ont été présentés aujourd’hui.
Le Supply Chain Scientist n’est pas un supplément à la supply chain de l’entreprise ; il clarifie la répartition des responsabilités en matière de décisions quotidiennes banales de la supply chain. Pour tirer le meilleur parti de cette approche, la supply chain, ou du moins sa composante planification, doit être remodelée. Des départements adjacents comme la finance et les opérations doivent également s’accommoder de quelques changements, bien que dans une moindre mesure.
Former une équipe de Supply Chain Scientists représente un engagement considérable pour une entreprise, mais lorsqu’il est bien mené, la productivité est élevée. En pratique, chaque Supply Chain Scientist finit par remplacer de 10 à 100 planificateurs, prévisionnistes ou gestionnaires de stocks, engendrant d’énormes économies sur la masse salariale, même si les scientifiques perçoivent des salaires plus élevés. Le Supply Chain Scientist illustre un nouvel accord avec l’IT, repositionnant ce dernier en tant que facilitateur plutôt que fournisseur de solutions, et éliminant nombre, voire la plupart, des goulets d’étranglement liés à l’IT.
Plus généralement, cette approche peut être reproduite dans tous les autres départements non-IT de l’entreprise, tels que le marketing, les ventes et la finance. Chaque département doit prendre en charge ses propres décisions quotidiennes banales, et bénéficierait grandement du même type d’automatisation. Cependant, tout comme un Supply Chain Scientist est avant tout un expert en supply chain
Cependant, tout comme un Supply Chain Scientist est avant tout un expert en supply chain, un marketing scientist ou un marketing quant devrait être un expert en marketing. La perspective du scientifique ouvre la voie pour tirer le meilleur parti de la combinaison de l’intelligence machine et humaine en ce début de XXIe siècle.
La prochaine conférence aura lieu le 10 mai, un mercredi, à la même heure de la journée, 15 h, heure de Paris. Today’s lecture was non-technical, but the next one will be largely technical. I will be presenting techniques for pricing optimization. Mainstream supply chain textbooks typically do not feature pricing as an element of supply chain; however, pricing does substantially contribute to the balance of supply and demand. Also, pricing tends to be highly domain-specific, as it is all too easy to incorrectly approach the challenge altogether when thinking in abstract terms. Thus, we will narrow our investigations to the automotive aftermarket. This will be the occasion to revisit the elements brought forward with Stuttgart, one of the supply chain personas I introduced in the third chapter of this series of lectures.

Et maintenant, je vais passer aux questions.
Question : Il a fallu presque une décennie au milieu académique pour comprendre que le domaine de la data science avait émergé et qu’il fallait l’enseigner au lycée. Voyez-vous déjà la même chose se produire dans les cercles académiques de la supply chain en adoptant la perspective des sciences de la supply chain ?
Tout d’abord, je ne suis pas au courant que la data science soit enseignée dans les lycées en France. Ils n’enseignent guère quoi que ce soit en lien avec l’informatique au lycée, et encore moins la data science. Je ne suis pas vraiment sûr de savoir où ils trouveraient même des professeurs ou enseignants pour cela. Mais je comprends que vous souhaitiez que les lycéens acquièrent une certaine aisance numérique. Je pense que se familiariser avec la programmation est une très bonne chose, et vous pouvez commencer dès le plus jeune âge – d’après ma propre expérience, à partir de sept ou huit ans, selon la maturité de l’enfant. On peut le faire même à l’école primaire, tout en ne couvrant que les concepts de base de la programmation : variables, listes d’instructions et ce genre de choses. Je crois que la data science dépasse largement ce qui devrait être enseigné au lycée, à moins de disposer de prodiges ou de cas particuliers. Pour moi, c’est clairement quelque chose destiné aux personnes au niveau universitaire, que ce soit en licence ou en master.
En effet, il a fallu une décennie au milieu académique pour mettre la data science en avant, mais faisons une pause un instant. J’ai décrit la data science comme une pratique d’entreprise, ce qui est en quelque sorte le reflet de ce que fait le milieu académique en enseignant la data science. Nous devons donc réfléchir au problème, et ici, je pense que l’un des soucis réside dans le fait qu’il est incroyablement difficile d’enseigner quelque chose que l’on ne pratique pas. Du moins au niveau universitaire, si ce n’est même en dessous. Ce que je constate, c’est que nous avons déjà un problème avec la data science, car ceux qui l’enseignent ne sont pas les mêmes que ceux qui la pratiquent dans des entreprises importantes, comme Microsoft, Google, Facebook, OpenAI, etc.
Pour la supply chain, nous rencontrons un problème similaire, et avoir accès à des personnes possédant la bonne expérience est tout simplement incroyablement difficile. J’espère – et voici une autopromotion sans complexe de ma part – que Lokad commencera, dans les semaines à venir, à proposer des supports destinés aux diplômes en supply chain. Nous commencerons à diffuser des matériaux présentés de manière à ce qu’ils soient appropriés pour les professeurs du milieu académique, afin qu’ils puissent transmettre ces connaissances. Évidemment, ils devront user de leur propre jugement pour évaluer si ces supports proposés par Lokad méritent réellement d’être enseignés aux étudiants.
Question : Le langage spécifique au domaine de Lokad n’est-il pas utilisé ailleurs ? Au-delà de Lokad, comment motiver les nouveaux employés potentiels à apprendre quelque chose qu’ils n’utiliseront probablement plus jamais dans leur prochain emploi ?
C’est exactement ce que je disais à propos du problème que j’avais avec les data scientists. Les gens postulaient littéralement en disant : “Je veux faire du TensorFlow, je suis un gars TensorFlow” ou “Je suis un gars PyTorch.” Ce n’est pas la bonne attitude. Si vous confondez votre identité avec un ensemble d’outils techniques, vous passez à côté de l’essentiel. Le défi consiste à comprendre les problèmes de supply chain et à les aborder de manière quantitative afin de générer des décisions de niveau production.
Dans cette conférence, j’ai mentionné qu’il fallait six mois à un Supply Chain Scientist pour acquérir la maîtrise nécessaire afin de maintenir une recette et deux ans pour en concevoir une de zéro. Combien de temps faut-il pour maîtriser complètement Envision, notre langage de programmation propriétaire ? D’après notre expérience, trois semaines suffisent. Envision est un petit détail comparé au défi global, mais c’est un élément important. Si vos outils sont médiocres, vous ferez face à d’immenses problèmes accidentels. Cependant, soyons réalistes : ce n’est qu’une petite partie de l’ensemble du puzzle.
Les personnes qui passent du temps chez Lokad apprennent énormément sur les problèmes de supply chain. Le langage de programmation pourrait être réécrit dans d’autres langages, mais cela impliquerait probablement plus de lignes de code. Ce que les gens, en particulier les jeunes ingénieurs, ne réalisent souvent pas, c’est à quel point de nombreuses technologies sont éphémères. Elles ne durent généralement que quelques années avant d’être remplacées par autre chose.
Nous avons vu une série interminable de technologies aller et venir. Si un candidat dit “je me soucie vraiment des détails techniques”, il n’est probablement pas un bon candidat. C’était mon souci avec les data scientists – ils voulaient le dernier cri, le plus innovant. Les supply chains sont des systèmes d’une complexité immense, et lorsqu’une erreur est commise, cela peut coûter des millions. Vous avez besoin d’outils de niveau production, et non du dernier package non testé.
Les meilleurs candidats ont un véritable intérêt à devenir des professionnels de la supply chain. L’essentiel, c’est la supply chain, pas les détails du langage de programmation.
Question : Je poursuis une licence en supply chain, transport et gestion logistique. Comment puis-je devenir un Supply Chain Scientist ?
Tout d’abord, je vous encourage à postuler chez Lokad. Nous avons des postes ouverts en permanence. Mais plus sérieusement, la clé pour devenir un Supply Chain Scientist est d’avoir une opportunité dans une entreprise prête à automatiser ses décisions de supply chain. L’aspect le plus important est la responsabilité des décisions. Si vous trouvez une entreprise prête à tenter l’expérience, cela vous aidera grandement à devenir un scientifique.
Lorsque vous serez confronté aux défis de la prise de décisions de niveau production, vous réaliserez l’importance des sujets dont je discute dans cette série de conférences. Lorsque vous gérerez des prévisions qui piloteront des stocks, des commandes et des mouvements de stocks d’une valeur de millions de dollars, vous comprendrez l’énorme responsabilité et la nécessité d’une exactitude par conception. Je suis presque sûr que d’autres entreprises se développeront et obtiendront bien d’autres opportunités. Mais même dans mes rêves les plus fous, je ne pense pas pouvoir espérer que chaque entreprise sur Terre adopte Lokad. Il y aura de nombreuses entreprises qui décideront toujours de faire les choses à leur manière, et elles s’en sortiront très bien.
Question : Puisque 40 % de la routine quotidienne d’un Supply Chain Scientist consiste à coder, quel langage de programmation suggéreriez-vous aux étudiants de premier cycle, en particulier ceux qui étudient la gestion ?
Je dirais tout simplement ce qui est facilement accessible. Python est un bon début. Mon conseil est d’essayer plusieurs langages de programmation. Ce que vous attendez d’un ingénieur de supply chain est à peu près le contraire de ce que vous attendez des ingénieurs logiciels. Pour ces derniers, mon conseil par défaut est de choisir un langage et de plonger extrêmement en profondeur, en en maîtrisant toutes les subtilités. Mais pour des personnes qui sont au final généralistes, je dirais de faire l’inverse. Essayez un peu de SQL, un peu de Python, un peu de R. Faites attention à la syntaxe d’Excel, et jetez un œil à des langages comme Rust, juste pour voir à quoi ils ressemblent. Donc, optez pour ce qui est accessible. Au fait, Lokad prévoit de rendre Envision facilement accessible aux étudiants gratuitement, alors restez à l’écoute.
Question : Voyez-vous les bases de données graphe avoir un impact significatif sur les prévisions de supply chain ?
Absolument pas. Les bases de données graphe existent depuis plus de deux décennies et, bien qu’elles soient intéressantes, elles ne sont pas aussi puissantes que les bases de données relationnelles comme PostgreSQL et MariaDB. Pour les prévisions de supply chain, disposer d’opérateurs similaires à ceux des graphes ne suffit pas. Dans les compétitions de prévision, aucun des 100 meilleurs participants n’a utilisé de base de données graphe. Cependant, il est possible de faire des choses avec le deep learning appliqué aux graphes, ce que j’illustrerai dans ma prochaine conférence sur le pricing.
En ce qui concerne la question de savoir si les Supply Chain Scientists devraient être impliqués dans la définition des objectifs au sein des projets de data science orientés client, je pense qu’il y a un problème dans l’hypothèse de se concentrer sur la data science avant de comprendre le problème que nous cherchons à résoudre. Cependant, pour reformuler la question, les Supply Chain Scientists devraient-ils être impliqués dans la définition des objectifs de l’optimisation de la supply chain ? Oui, absolument. Il est difficile pour le scientifique de déterminer ce que nous voulons réellement, et cela nécessite une collaboration étroite avec les parties prenantes pour s’assurer que les bons objectifs sont poursuivis. Alors, les scientifiques doivent-ils être impliqués ? Absolument, c’est essentiel.
Cependant, clarifions que ce n’est pas une initiative de data science ; c’est une initiative de supply chain qui se permet d’utiliser les données comme ingrédient adéquat. Nous devons vraiment partir des problèmes et des ambitions de la supply chain, et ensuite, puisque nous voulons tirer le meilleur parti des logiciels modernes, nous avons besoin de ces scientifiques. Ils vous aideront à affiner encore votre compréhension du problème, car la ligne de démarcation entre ce qui est réalisable avec un logiciel et ce qui relève strictement du domaine de l’intelligence humaine est assez floue. Vous avez besoin des scientifiques pour naviguer sur cette ligne de démarcation.
J’espère vous voir dans deux mois, le 10 mai, pour la prochaine conférence, où nous parlerons du pricing. À bientôt.