Réapprovisionnement priorisé de stocks en Excel avec des prévisions probabilistes
La prévision comporte une incertitude irréductible. Pourtant, au XXe siècle, la prévision statistique est apparue dans l’espoir que, grâce à des modèles mathématiques adéquats, l’incertitude pourrait être éliminée. En conséquence, les premières théories de la supply chain ont minimisé ou rejeté l’incertitude, dans la mesure où l’on s’attendait à ce que des techniques de prévisions supérieures éliminent cette incertitude ou, à défaut, la rendent insignifiante. Bien que ces approches fussent bien intentionnées, elles étaient imparfaites, car après un siècle de modélisation statistique, l’incertitude demeure résolument irréductible. En 2012, Lokad a été le pionnier d’une perspective supply chain, qui embrasse et quantifie l’incertitude. Cette approche s’appuie sur des prévisions probabilistes au lieu des traditionnelles prévisions ponctuelles de séries temporelles. Dans ce guide, ainsi que dans la feuille de calcul Microsoft Excel associée, nous appliquons des prévisions probabilistes au problème de réapprovisionnement des stocks. Cette approche aboutit à une politique de réapprovisionnement priorisé de stocks, démontrée ici à travers Excel. Notre démarche est double : d’une part, populariser cette approche auprès d’un public qui pourrait ne pas être à l’aise avec des outils logiciels plus avancés ; d’autre part, démontrer que l’acceptation de l’incertitude relève plus d’un état d’esprit que de l’utilisation d’outils sophistiqués.
Télécharger: probabilistic-inventory-replenishment.xlsx
1. Le problème de réapprovisionnement des stocks
Le problème de réapprovisionnement des stocks consiste à identifier la meilleure liste d’achats – une liste qui prend en compte les contraintes financières essentielles et les objectifs de l’entreprise. La méthode pour produire une telle liste doit fonctionner de manière équivalente, quelle que soit la contrainte budgétaire, dans la mesure où elle tente de maximiser le retour sur investissement pour chaque dollar dépensé. Le problème est que tous les SKUs se font concurrence pour les mêmes dollars, ainsi le rendement financier de la mise en stock d’une unité donnée d’un SKU doit être quantifié et classé dans le contexte de toutes les unités supplémentaires de chaque SKU.
1.1 La solution de réapprovisionnement priorisé de stocks
Le processus de classement des stocks, tel que décrit ci-dessus, nécessite une perspective au niveau micro. Afin de comparer le rendement de l’ajout d’une unité donnée d’un SKU à une liste d’achats, plusieurs facteurs doivent être pris en compte. Notamment, la probabilité de sa vente, telle que fournie par une prévision de la demande probabiliste et les facteurs économiques — par exemple, la marge brute et le prix d’achat. Chaque quantité considérée doit, à son tour, être équilibrée par rapport aux contraintes internes et externes (telles que la capacité limitée de l’entrepôt, les multiplicateurs de lots et les MOQ/MOV, etc.). Des cas particuliers, tels que lorsque deux (ou plusieurs) unités présentent une rentabilité attendue égale, doivent être intégrés dans une politique de réapprovisionnement des stocks par l’évaluation de l’importance relative de chaque produit. Les SKUs ne doivent pas être considérés isolément, mais plutôt en paniers. Certains SKUs, malgré des marges bénéficiaires plus faibles (comme le lait), sont plus importants puisqu’ils favorisent la vente de produits à forte marge. Ainsi, la récompense financière pour le maintien des taux de service d’un produit à marge moindre — un produit facilitant d’autres ventes — représente un autre levier (“stockout cover”)1. Une approche de réapprovisionnement priorisé de stocks (PIR), utilisant la prévision probabiliste comme paramètre d’entrée, prend en compte tous les facteurs décrits ci-dessus.
En bref, la solution PIR peut être résumée en trois étapes :
1. Élaborer une prévision de demande probabiliste.
2. Lister toutes les quantités d’achat réalisables.
3. Classer toutes les quantités d’achat réalisables en fonction des facteurs économiques.
1.2 Réapprovisionnement priorisé de stocks en Excel
En utilisant les données financières d’un magasin fictif, incluant les facteurs économiques mentionnés dans la section précédente, cette feuille de calcul Excel modélise la politique de réapprovisionnement des stocks pour trois SKUs (stylos, claviers et bibliothèques)2. Les conséquences financières de chaque unité additionnelle d’un SKU (si commandée), ainsi que la probabilité de sa vente, sont illustrées dans la feuille Charts (voir Figure 1). Les diagrammes et graphiques se mettront à jour en fonction des entrées et des hypothèses du modèle (par exemple, les niveaux de stocks initiaux, les prix d’achat et de vente, etc.) dans la feuille Control Tower (Figure 2). Une liste détaillée des options décisionnelles réalisables est générée dans la feuille Micro purchasing decisions (Figure 3) à partir des entrées clés. Ces entrées proviennent des prévisions de demande probabilistes de la feuille Distribution generators (Figure 4) et des informations de la feuille Control Tower. Enfin, un tableau des décisions de réapprovisionnement priorisé de stocks est compilé et classé en fonction du retour sur investissement attendu (voir la feuille Ranked purchasing decisions dans la Figure 5).
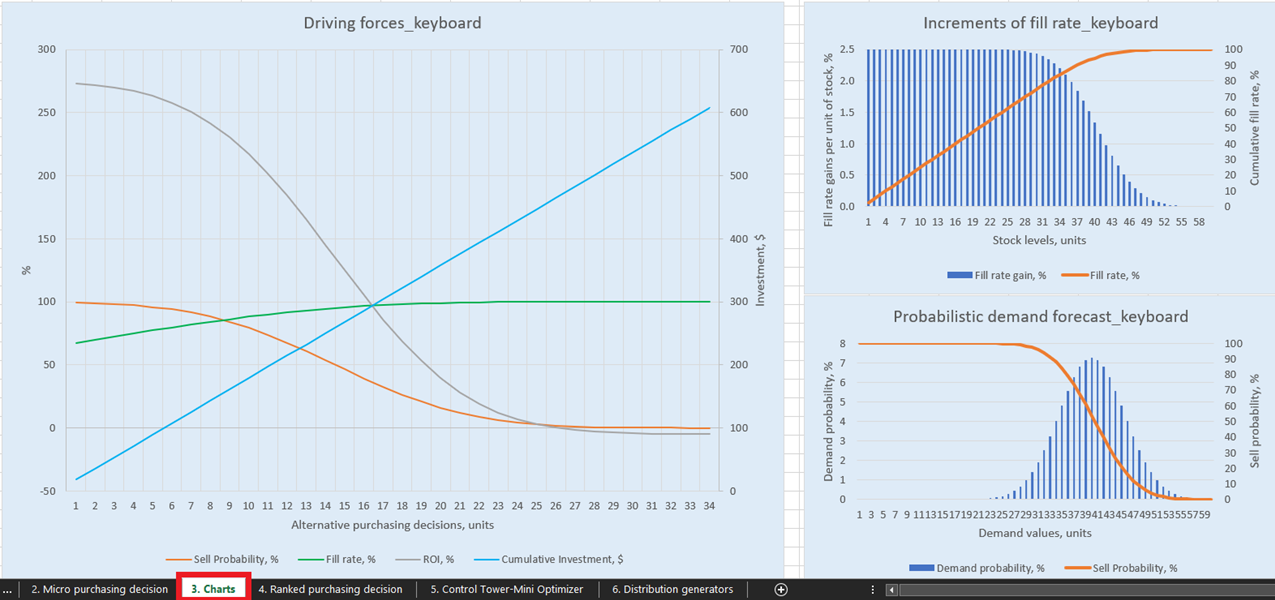
Figure 1. Vue du “Driving forces keyboard” dans Charts, emplacement surligné en rouge.
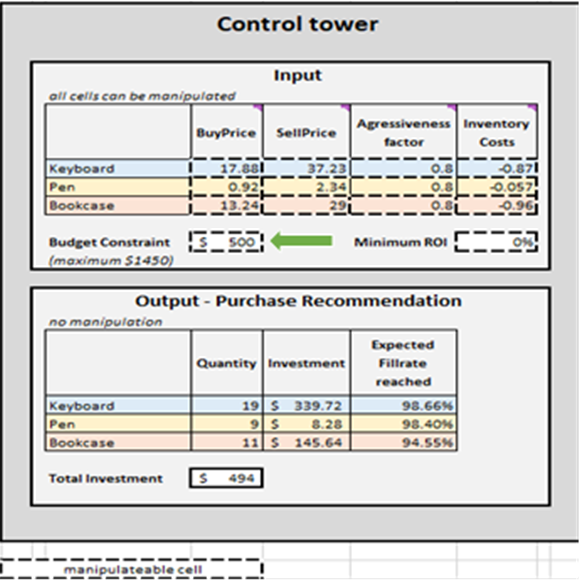
Figure 2. Vue de “Control Tower” située dans Control Tower – Mini Optimizer (feuille 5). On peut modifier la “Budget Constraint” à n'importe quelle valeur comprise entre $0 et $1450 (voir la flèche verte).
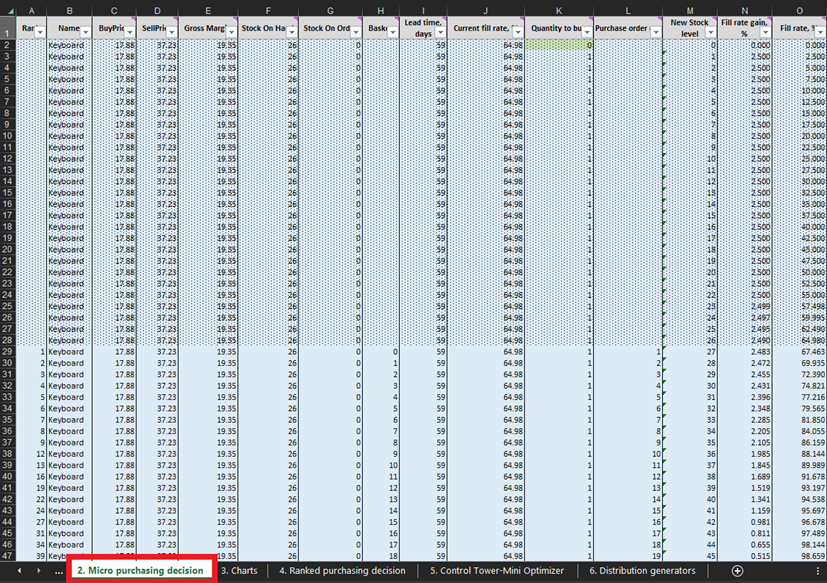
Figure 3. Emplacement des Micro purchasing decisions dans Excel, surligné en rouge. Les lignes recouvertes par un formatage conditionnel pointillé correspondent aux données passées (jusqu'à la ligne 28 incluse dans l'image ci-dessus). Ces informations représentent les décisions d'achat précédentes. Nous nous intéressons uniquement à tout ce qui se trouve en dessous de ce formatage conditionnel. Le même formatage pointillé s'applique aux données des stylos et des bibliothèques.
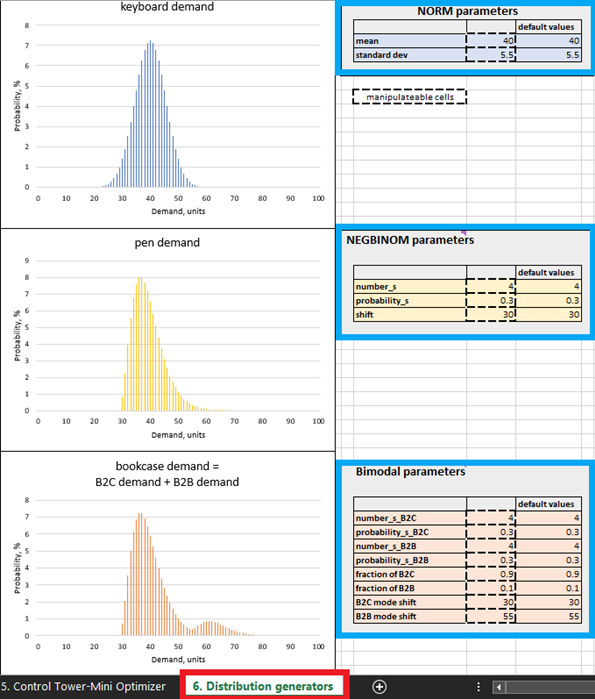
Figure 4. Emplacement des Distribution generators dans Excel, surligné en rouge. Les panneaux de contrôle du produit sont surlignés en bleu. Les cellules aux contours pointillés peuvent être modifiées.
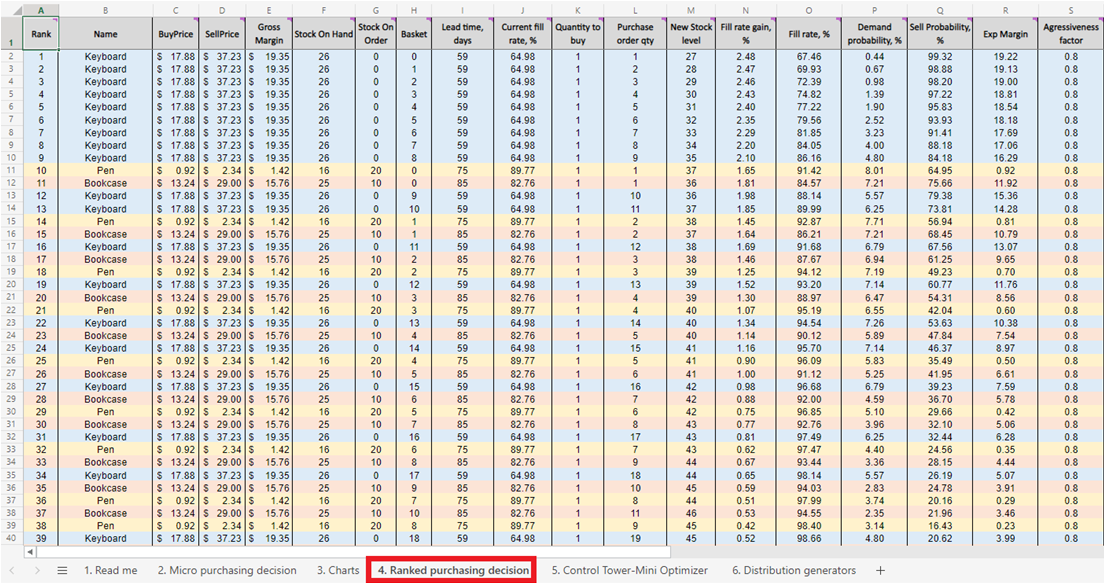
Figure 5. Une liste de réapprovisionnement priorisé de stocks des micro purchasing decisions, située dans la feuille 4.
2. Prévision Probabiliste de la Demande
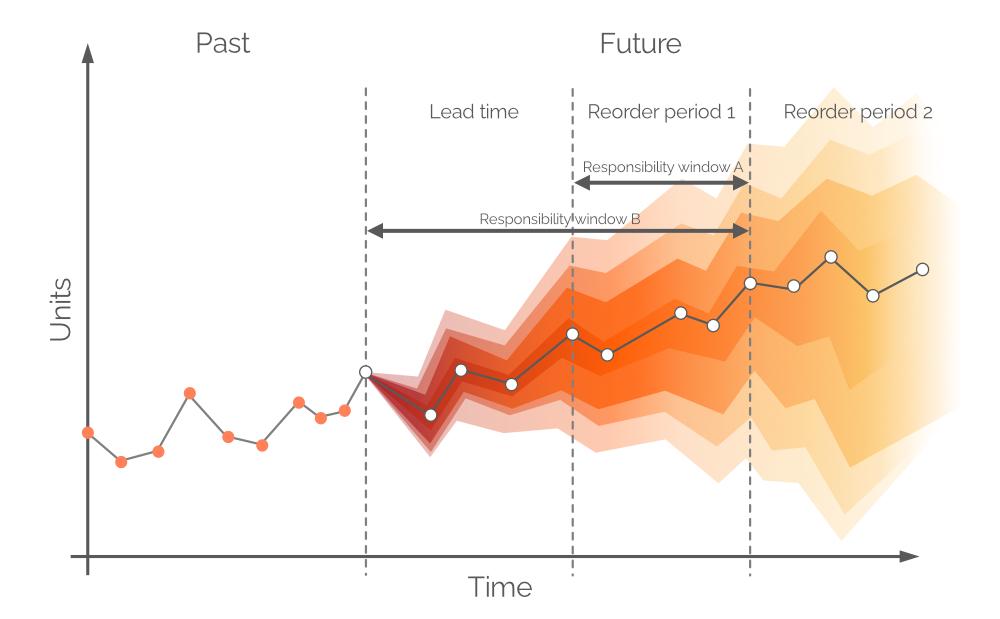
Dans ce contexte, une prévision probabiliste est un ensemble de toutes les valeurs de demande probables futures et de leurs probabilités respectives. Elle intègre l’incertitude inhérente à la demande future et peut être établie sur n’importe quelle période. Comme dans une prévision traditionnelle de séries temporelles, une valeur de demande unique, la plus probable, est identifiée (les points blancs dans la Figure 6) et une ligne de tendance (la ligne grise reliant les points blancs). Cependant, une prévision probabiliste intègre l’incertitude en additionnant toutes les valeurs possibles de demande (bien qu’elles ne soient pas toutes également probables). Cette approche est illustrée dans la Figure 6, où différents intervalles de confiance représentent des valeurs de demande ayant des probabilités différentes.
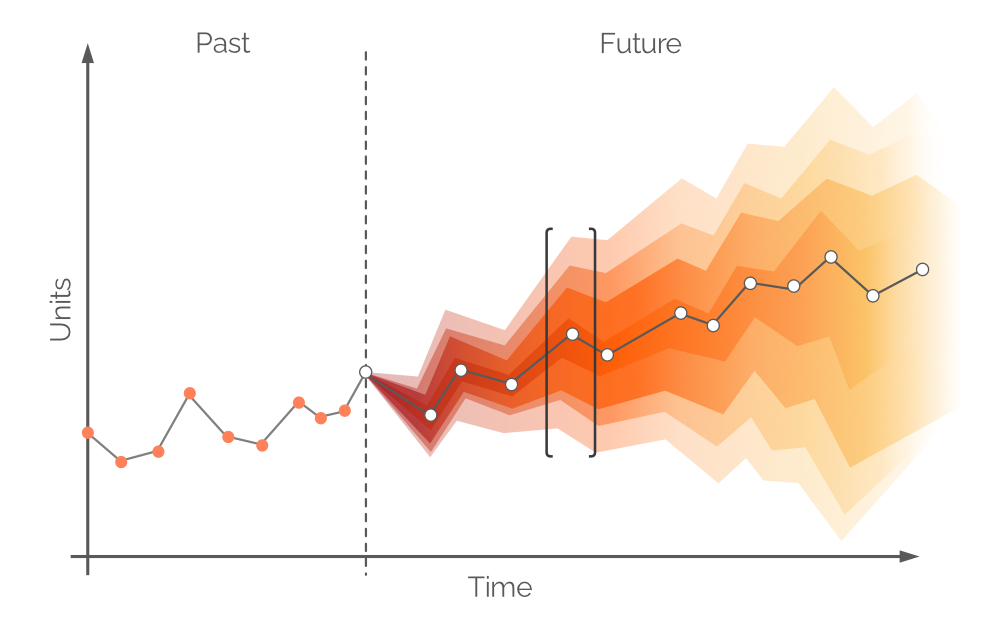
Figure 6. Une prévision probabiliste (demande sur l'axe des y ; temps sur l'axe des x). La ligne verticale grise en pointillés indique le moment présent (« now »). Le temps est mesuré en jours, bien que cela puisse être tout intervalle souhaité. La zone indiquée entre crochets noirs est abordée ultérieurement.
Les points blancs dans la Figure 6 représentent les valeurs de demande les plus probables à des intervalles futurs fixes. Une bande de couleur accompagne ces points et correspond à une plage de valeurs de demande alternatives – une distribution de probabilité en couleur. Cette couleur s’estompe le long de l’axe vertical au fur et à mesure que l’on s’éloigne du point blanc, traduisant une incertitude accrue et une probabilité moindre. Globalement, les bandes de couleur s’atténuent avec le temps (le long de l’axe horizontal), à mesure que l’incertitude s’intensifie. Cependant, quelle que soit l’incertitude, il existe toujours au moins une valeur qui est la plus probable, et cela est systématiquement représenté par les points blancs. Un exemple de distribution de probabilité pour un point dans le temps est illustré dans la Figure 7.
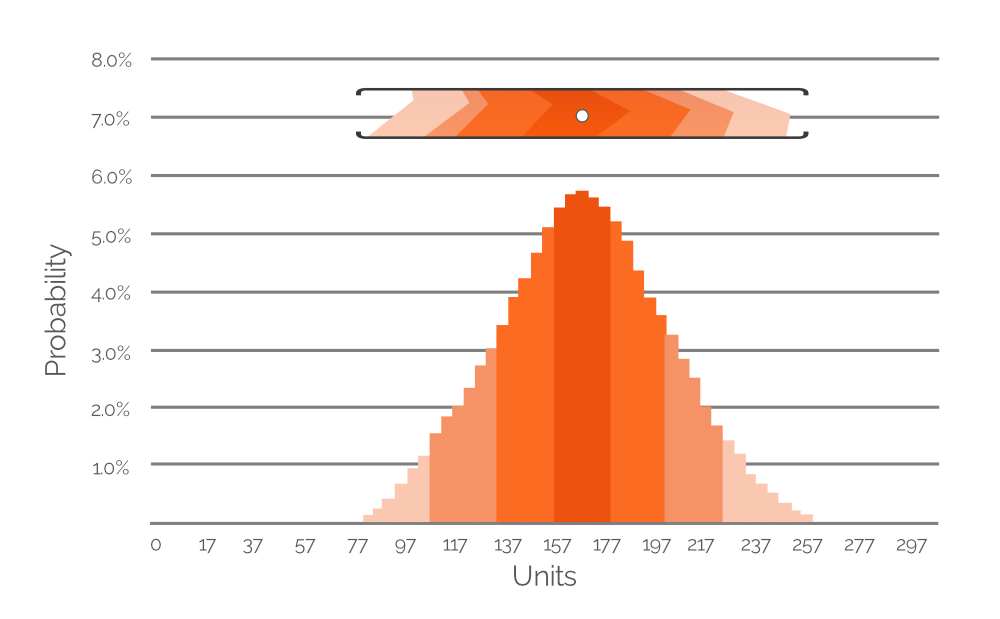
Figure 7. Un histogramme représentant la probabilité de plusieurs valeurs possibles de demande (par intervalles de 20 unités). L'axe des y indique la probabilité ; l'axe des x indique la demande en unités. L'histogramme est une représentation de la plage de valeurs mise en évidence dans la Figure 6 (incluse ici à titre de référence).
La Figure 7 exprime les données mises en évidence de la Figure 6 sous forme d’un histogramme de probabilité, avec des valeurs numériques explicites indiquant la probabilité de différentes valeurs de demande. Le code couleur est conservé pour faciliter la compréhension (rappelez-vous que des couleurs plus pâles indiquent une probabilité moindre ; des couleurs plus denses indiquent une probabilité supérieure). Dans cet exemple, la valeur de demande la plus probable est de 167 unités (approximativement), ce qui explique que le point blanc dans la plage de valeurs recadrée de la Figure 6 soit positionné directement au-dessus de la barre la plus haute de l’histogramme. Cependant, nous attribuons également des probabilités de demande à des valeurs extrêmement basses et élevées (autour de 80 et 260 unités, respectivement, toutes deux d’un orange très pâle). Cela démontre la richesse potentielle des données d’une prévision probabiliste et des histogrammes similaires sont inclus dans la feuille Excel – un pour chacun de nos SKUs (voir Figure 4). En utilisant ces histogrammes (comme dans la Figure 7 ci-dessus), il est possible d’identifier et de prendre en compte les valeurs de demande (en unités) dont la probabilité d’occurrence n’est pas nulle.
2.1 La Construction d’une Prévision Probabiliste
Bien qu’il soit possible de construire une prévision probabiliste réelle à partir de données historiques dans Excel, cet outil est sans doute le moins adapté à ce type de calcul. Globalement, les spécificités de la construction d’une prévision probabiliste de niveau production dépassent le cadre de ce document, c’est pourquoi des prévisions probabilistes synthétiques ont été choisies par souci de simplicité. Les paramètres de ces prévisions synthétiques peuvent être modifiés dans Distribution generators (voir Figure 4). Il est toutefois recommandé d’étudier d’abord les paramètres par défaut avant d’apporter des modifications.
Dans les pratiques courantes de la supply chain, la demande est généralement considérée comme suivant une distribution normale, cependant cela est une exception. Dans les supply chains réelles, la plupart des SKUs s’écartent des modèles de distribution normale. Compte tenu de cette réalité, nous avons délibérément sélectionné trois modèles de distribution différents : normal (pour les claviers), binomial négatif (pour les stylos) et bimodal (pour les bibliothèques – un mélange de deux modèles binomiaux négatifs). Ce qui suit justifie cette hypothèse.
Par exemple, nous supposons que les bibliothèques sont achetées à la fois par des particuliers et par des entreprises (par exemple, des écoles), d’où l’utilisation d’une distribution bimodale. Dans le réglage par défaut pour les bibliothèques, il y a une demande fréquente de la part des particuliers, avec une ou deux unités achetées par client. Cela représente le premier mode de la distribution (voir Figure 4). Les entreprises, quant à elles, représentent des sources de demande moins fréquentes, mais passent des commandes plus importantes (plus importantes que celles des particuliers). Lorsque cela se produit, leur demande s’ajoute à celle générée par les achats des particuliers, et le deuxième mode de la distribution apparaît. Ce deuxième mode est décalé vers la droite (représentant des valeurs de demande élevées) et est nettement inférieur au premier mode, reflétant le fait que cela se produit moins fréquemment (Figure 4). Notre modèle suppose également que les stylos sont achetés par des particuliers avec une demande occasionnellement élevée (par exemple, des étudiants achetant avant des dates d’examens). Enfin, pour refléter le fait qu’une distribution normale se produit occasionnellement, les ventes de claviers suivent un modèle de distribution normale.
Dans Distribution generators (Figure 4), il est possible de modifier les distributions de demande en changeant les paramètres dans les cellules modifiables. Par exemple, augmenter la moyenne pour les claviers (voir les « paramètres NORM » dans la Figure 4) de 40 à 50 entraînera un décalage de la distribution de 10 unités vers la droite. En conséquence de cette augmentation de la demande moyenne, le ROI attendu pour toutes les unités de claviers augmentera. De même, il est possible d’apporter des modifications aux paramètres des distributions binomiales négatives (pour les stylos) et bimodales (pour les bibliothèques).
Comme Excel manque d’expressivité pour ce type de calcul, cette démonstration limite les modifications à 100 unités par produit. Par exemple, régler la moyenne pour les claviers à 99 entraînera qu’environ 50 % des unités de demande ne soient pas calculées dans la feuille Micro purchasing decisions.
2.2 Choisir un Horizon pour une Prévision Probabiliste de la Demande
Typiquement, les prévisions sont divisées en intervalles journaliers/hebdomadaires/mensuels, bien que ces périodes discrètes aient une utilité et une valeur limitées du point de vue du réapprovisionnement. La demande sur le prochain lead time ne peut être couverte par les décisions d’achat prises aujourd’hui, à moins que des backorders soient autorisées, car toute unité achetée arrivera après une période égale au lead time. Ainsi, la demande devrait être satisfaite avec les stocks disponibles en magasin et les stocks en commande (voir Figure 8), en supposant que les unités en commande arrivent avant la demande. Par conséquent, la prévision probabiliste concerne la demande entre les points de commande ou, en d’autres termes, la demande pendant la période de commande 1 (voir Figure 9). La demande plus lointaine sera couverte par des commandes futures (voir la période de commande 2, dans la Figure 9).

Figure 8. Les stocks disponibles (colonne F) et les stocks en commande (colonne G), surlignés en rouge, se trouvent dans Micro purchasing decisions. Le lead time, en colonne I, est surligné en bleu.
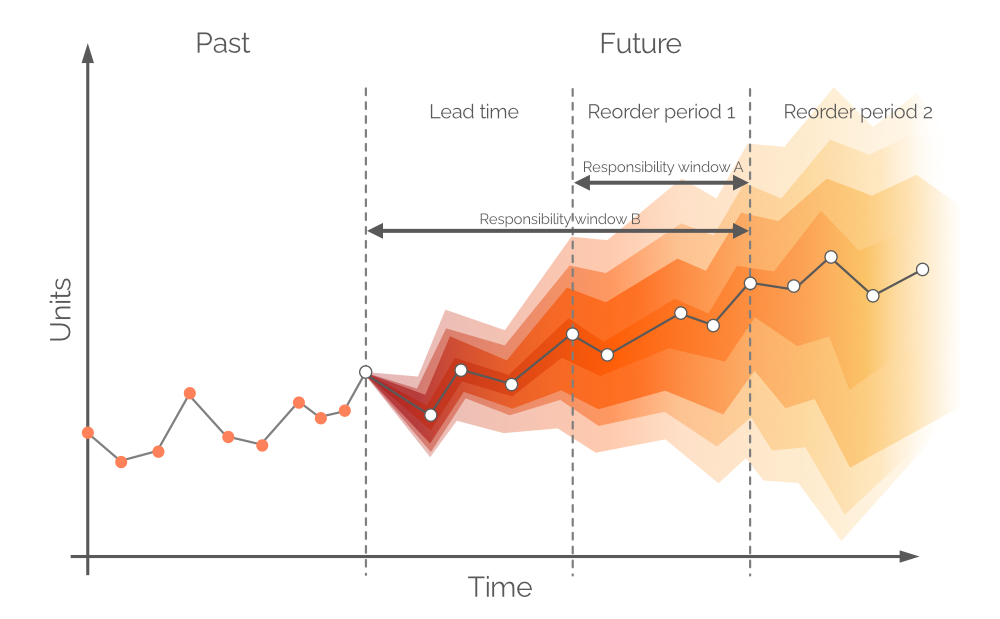
Figure 9. Une représentation visuelle des différentes fenêtres de responsabilité. La demande est en ordonnée, le temps en abscisse, avec la ligne verticale grise en pointillé à gauche indiquant le moment actuel (“now”, comme dans la Figure 6). La prévision probabiliste dans ce document concerne la demande sur l'horizon égal à la fenêtre de responsabilité B.
En théorie, la prévision probabiliste de la demande devrait être établie sur une période égale à la période de commande 1 – cette fenêtre temporelle est appelée fenêtre de responsabilité A (voir Figure 9). Pour ce faire, nous devrions établir des projections futures pour les stocks disponibles et les stocks en commande à la fin du lead time. Cependant, la demande sur le lead time – pour laquelle nous avons déjà pris des décisions lors de la période de commande précédente – est également probabiliste, ce qui entraînerait des niveaux de stocks qui sont eux-mêmes des distributions de probabilité3. En autorisant les backorders (une pratique courante dans certains secteurs), une prévision probabiliste peut être établie sur une période conjointe (le lead time plus la période de commande 1, selon la Figure 9, alias fenêtre de responsabilité B).
On peut supposer que les niveaux actuels de stocks disponibles et de stocks en commande couvriront la demande pendant le lead time. S’il y a un événement de rupture de stock, toute demande ultérieure sera couverte par des backorders. Ces backorders seront traités par les décisions d’achat micro prises dès aujourd’hui. Cela nous permet de considérer les stocks disponibles et les stocks en commande comme des valeurs discrètes (plutôt que comme des valeurs aléatoires)4.
3. Identification des options de décision de réapprovisionnement réalisables
Dans un scénario réel de réapprovisionnement de stocks, il faudrait définir toutes les options de décision réalisables, car il n’existe pas de méthode simple pour passer d’une prévision probabiliste à la meilleure décision unique (quantité d’achat, dans ce cas) pour chaque produit. Au lieu d’un choix parfait unique, une approche probabiliste présente une gamme de décisions possibles que l’on doit considérer en termes de faisabilité.
Faisabilité ici a le sens ordinaire selon lequel une décision est immédiatement applicable; elle peut être exécutée “telle quelle” sans calculs ou vérifications supplémentaires. Par exemple, une décision est “faisable” si elle est rentable et satisfait toutes nos contraintes (par exemple, les MOQs, les EOQs, les tailles de lots, les expéditions complètes par container shipments, et toute autre contrainte pouvant exister dans notre supply chain)5.
À chaque ligne de la feuille Micro purchasing decisions (Figures 3 et 10), nous devons envisager d’ajouter une unité supplémentaire de stock à notre bon de commande pour un produit particulier6. Notre “présent” (ou Jour 1 de cette expérience) commence à la ligne 29, qui affiche le niveau de stock actuel. Celui-ci est calculé comme la somme des stocks disponibles et des stocks en commande. Si nous décidons d’ajouter une unité au bon de commande, alors la quantité d’achat globale sera calculée dans la colonne L comme la somme de toutes les unités envisagées jusqu’à présent pour l’achat (voir les notes dans la Figure 10).
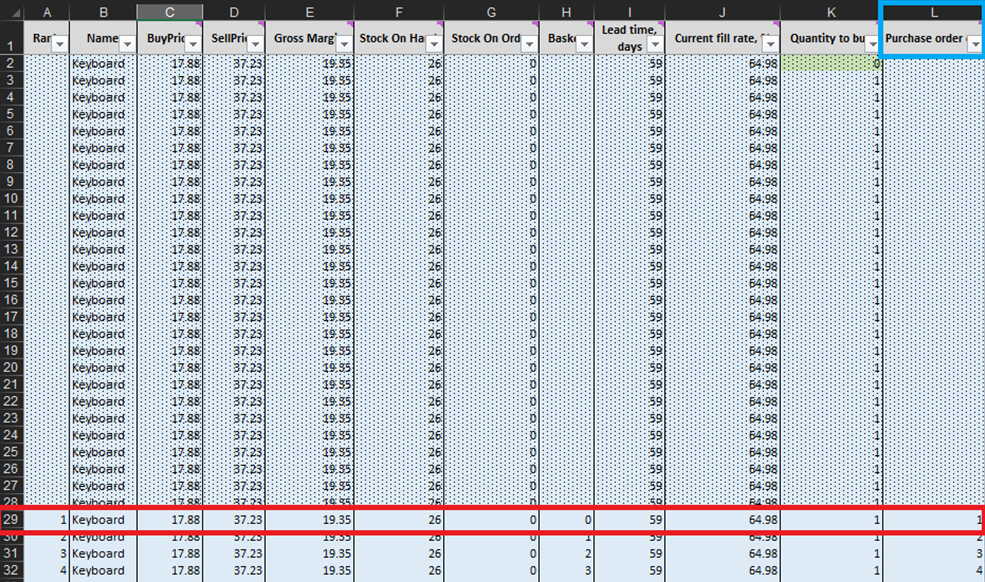
Figure 10. Vue de l'intérieur de la feuille Micro purchasing decisions. La ligne 29, surlignée en rouge, marque le début de notre expérience (pour les claviers). La colonne du bon de commande est surlignée en bleu. Le même principe s'applique aux lignes 140 (pour les commandes de stylos) et 240 (pour les commandes de bibliothèques).
Une fois ces décisions d’achat de stocks réalisables identifiées, nous calculerons et classerons la récompense économique de chaque achat possible. Notez que nous n’évaluons pas la récompense d’achat pour les unités qui sont actuellement soit en stocks disponibles soit en stocks en commande (colonnes F et G dans la Figure 10). Étant donné que nous avons déjà acheté ces unités, la récompense économique théorique avait été déterminée (et classée) à une date antérieure. Par exemple, si nous regardons les données relatives aux claviers dans la Figure 10, il y a actuellement 26 unités en stock. Ainsi, nous commencerons les calculs à la ligne 29 et envisagerons s’il faut commander notre première unité de stock supplémentaire (ce qui porterait le niveau de stock de 26 à 27 unités).
3.1 Évaluation des décisions d’achat réalisables
Pour choisir la meilleure quantité d’achat pour chaque produit, il est nécessaire de calculer le rendement monétaire attendu au niveau unitaire pour chaque quantité réalisable pour chaque produit (en tenant compte de l’avenir incertain représenté par la prévision probabiliste). Il s’agit d’un concept de valeur attendue adapté au niveau le plus granulaire de la prise de décision en matière de stocks.
En réalité, tout type de moteur économique doit être pris en compte lorsqu’on tente de calculer le rendement attendu pour chaque décision réalisable7. Pour les besoins de cette démonstration, voici les facteurs que nous considérerons :
- Prix de vente : Combien nous facturons aux clients pour le produit.
- Coût de portage/de stockage : Combien il nous en coûte de conserver le produit.
- Prix d’achat : Combien il nous en coûte d’acheter le produit auprès de notre fournisseur/grossiste.
- Stockout cover : Décrit en détail ci-dessous car il s’agit d’un levier moins connu mais néanmoins important8.
Figure 11. Note explicative pour Prix d'achat, visible en survolant l'en-tête de la colonne. Une définition est fournie pour chaque colonne dans chaque feuille du document Excel.
Stockout cover représente une incitation financière à conserver une unité d’un produit en stock, mais sans l’objectif explicite de la vendre. Ce levier économique est utilisé pour modéliser l’importance relative d’un produit par rapport à d’autres. Il incite à éviter un événement de rupture de stock pour des produits qui pourraient être perçus comme moins importants en raison de leurs contributions directes à la marge, ces produits pouvant contribuer de manière indirecte aux marges bénéficiaires. En ce sens, il s’apparente davantage à un levier de récompense9. Bien que ce levier soit flou, il est essentiel d’identifier tous les produits critiques (même ceux qui ne sont pas des moteurs de marge directs).
3.2 Calcul du score de chaque décision réalisable
La conséquence économique totale (ou récompense d’achat) d’une décision de réapprovisionnement de stocks est la somme de tous les leviers économiques, y compris la marge attendue, le coût de stocks, et le stockout cover (défini en détail ci-dessous). Le coût de stockage est inclus dans ces calculs en tant que levier négatif, agissant comme une contre-force pour équilibrer nos décisions de réapprovisionnement de stocks.
Voici une analyse des implications économiques des formules dans chaque colonne, en utilisant la ligne 29 de la feuille Micro purchasing decisions comme exemple (voir Figure 12)

Figure 12. Répartition des leviers par colonnes clés, en utilisant la ligne 29 de Micro purchasing decisions (feuille Excel 2). Certaines colonnes ont été masquées pour faciliter la lecture de la figure.
Pour calculer la récompense attendue pour chaque décision, nous avons besoin des leviers suivants :
Marge brute (colonne E) = Prix de vente – Prix d’achat.
Probabilité de vente (colonne Q) = voir la formule dans la feuille10.
Probabilité de non-vente (aucune colonne) = 100% - Probabilité de vente
Marge attendue (colonne R) = Marge brute * Probabilité de vente/100.
Facteur d’agressivité (colonne S) = Varie de 0 à 1. 0,8 sélectionné pour cet outil.
Stockout cover (colonne T) = Prix de vente * Facteur d’agressivité * Probabilité de vente
Coût de stockage (colonne U)
Coût attendu des stocks (colonne V) = Coût de stockage * Probabilité de non-vente11.
En utilisant les données ci-dessus, la récompense d’achat pour chaque décision d’achat au niveau micro (chaque unité de chaque produit) est calculée comme suit :
Récompense d’achat (colonne W) = Marge attendue + Stockout cover + Coût attendu des stocks.
Une fois l’estimation de la récompense d’achat obtenue, nous pouvons calculer le score final que nous utiliserons ensuite pour classer toutes les décisions envisagées.
Score (colonne Y) = Récompense d’achat / Investissement (colonne X)12.
Étant donné que le stockout cover est un levier flou qui intègre à la fois des rendements directs et indirects, la récompense d’achat n’est pas une réflexion stricte du rendement attendu d’une décision d’achat de stocks à elle seule. Si l’on souhaite calculer ce type de rendement, il faudrait exclure le stockout cover de cette formule13.
4. Classement des décisions de réapprovisionnement de stocks réalisables
Une fois que nous avons le score pour chaque décision d’achat de stocks réalisable (pour chaque produit), une liste est générée et triée par ordre décroissant (du plus élevé au plus bas) dans Ranked purchasing decisions (voir Figure 13). Chaque décision d’achat réalisable est classée en termes de pourcentage de ROI positif. Un classement ordinal (1er, 2e, 3e, etc.) est également attribué à chaque décision (voir la colonne A de la même figure).
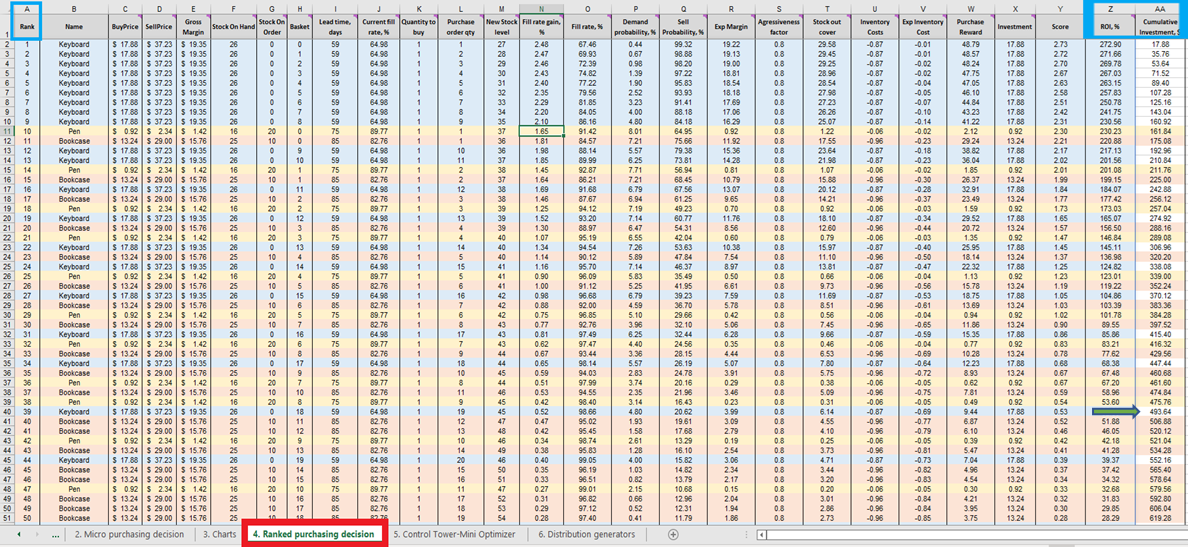
Figure 13. Emplacement de *Ranked purchasing decisions* surligné en rouge. Les colonnes A, Z et AA sont surlignées en bleu. La cellule 40 (le seuil pour un budget de 500 $ – la valeur par défaut du tableur) est indiquée par la flèche verte.
Ranked purchasing decisions présente des lignes codées par couleur pour chaque produit (claviers, stylos et bibliothèques), utilisés ici pour démontrer comment le choix d’ajouter une seule unité supplémentaire de n’importe quel produit interagit avec toutes les autres unités supplémentaires de chaque produit. Chacune de ces décisions d’achat de stocks influence collectivement le ROI. Enfin, une valeur d’investissement cumulatif est calculée (colonne AA, Figure 13). Cela peut être utilisé pour indiquer où il convient de terminer les décisions d’achat compte tenu des contraintes budgétaires - bien que ce ne soit qu’un des indicateurs de terminaison possibles14.
5. Détermination des critères de terminaison
En ce qui concerne le choix d’un point de terminaison (tant dans Ranked purchasing decisions qu’en réalité), les critères varieront en fonction d’un ensemble de variables. Par exemple, on peut avoir un budget modeste et ainsi maximiser le ROI devient problématique compte tenu de marges particulièrement serrées. Alternativement, il est possible que l’on dispose d’un objectif global pour le taux de service et doive alors équilibrer cette priorité avec une volonté de maximiser les marges bénéficiaires.
Pour être encore plus précis, les critères de terminaison pourraient inclure une volonté de maximiser le ROI avec des objectifs de taux de service variables pour chaque produit ou catégorie. Les critères de terminaison constituent ainsi un choix stratégique qui doit être effectué après une réflexion sincère sur les objectifs commerciaux globaux d’une entreprise. Le réapprovisionnement priorisé est remarquablement flexible à cet égard ; les critères de terminaison pour chaque cycle d’achat peuvent être ajustés en utilisant la même procédure de classement globale.
Pour des visualisations explicites de nos décisions de réapprovisionnement de stocks possibles, il existe trois graphiques pour chaque produit dans le Charts dashboard (feuille 3, voir Figure 14). De particulier intérêt est « Driving forces_product name » (l’exemple du Keyboard est utilisé dans la Figure 14), qui montre l’évolution du ROI en fonction de différentes quantités d’achat au niveau unitaire.
Comme le montre clairement le graphique, il arrive un moment où l’augmentation des quantités d’achat conduit à un ROI négatif. Cela s’explique par le fait qu’à un certain niveau, acheter davantage d’unités n’a plus de sens car nos marges attendues seront considérablement réduites par l’augmentation des coûts attendus des stocks.
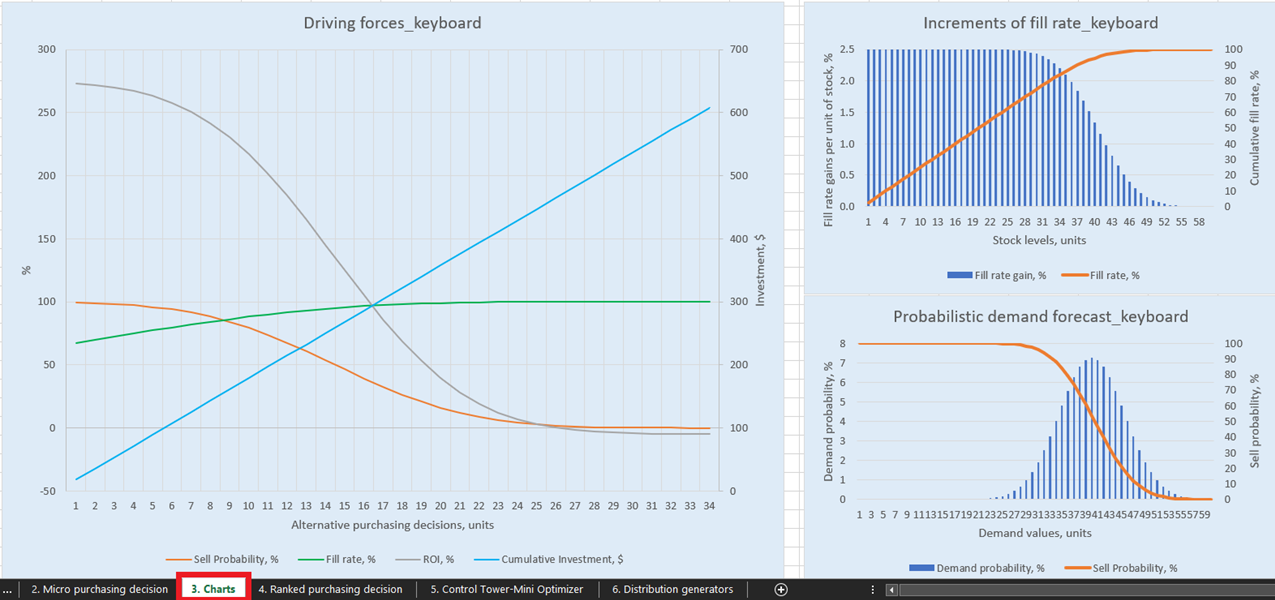
Figure 14. Vue de « Driving forces_keyboard » dans Charts, emplacement surligné en rouge.
Une fois les critères de terminaison déterminés, les décisions de réapprovisionnement de stocks priorisées sont agrégées par SKU, ce qui met à jour les Quantité, Investissement et Taux de service attendu atteints dans la recommandation d’achat en sortie pour chaque SKU (voir Figure 15). On peut modifier les contraintes budgétaires (0 $ à 1450 $), ce qui, à son tour, mettra à jour la liste d’achats recommandée. Pour plus de commodité, la control tower comporte deux blocs supplémentaires : Base Case – hard copy et Changes to base scenario. Le premier est statique et affiche les paramètres par défaut de la démonstration tels que conçus par Lokad ; le second affiche la différence entre toute modification apportée et le paramètre par défaut de Lokad.
La liste de recommandations d’achat dans Control tower représente l’objectif de cette démonstration (voir Figure 15).
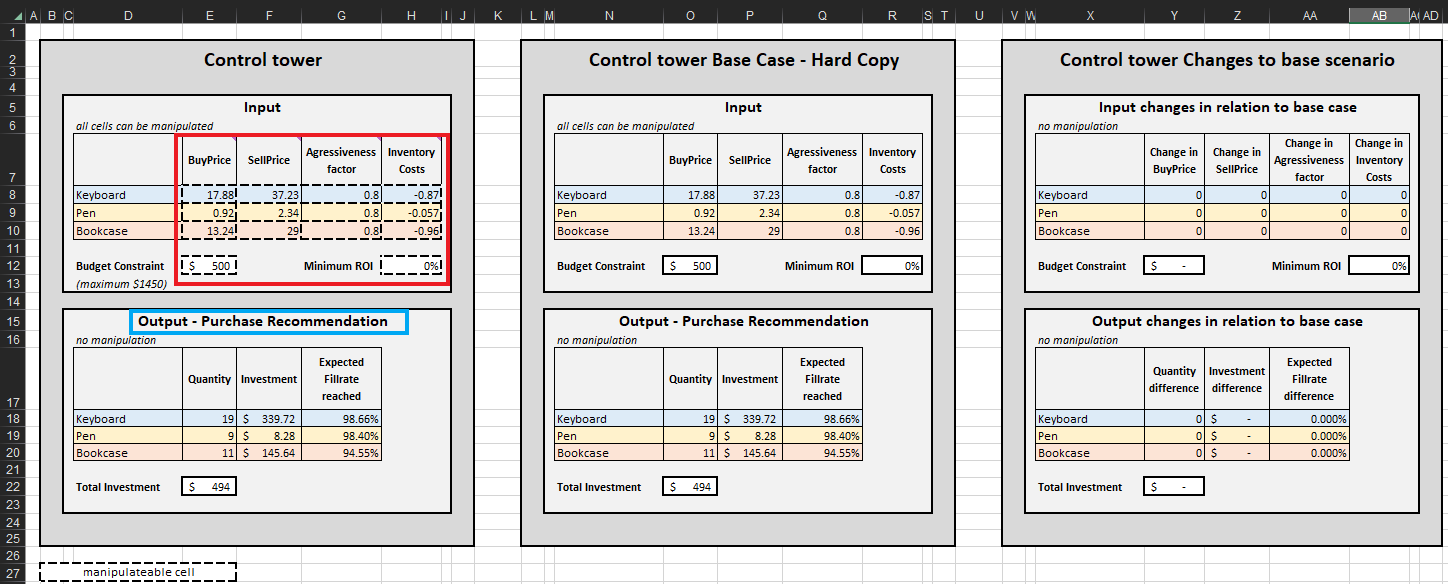
Figure 15. Vue de Control Tower-Mini Optimizer (feuille 5). Les cellules modifiables sont surlignées en rouge. « Purchase recommendation » est surligné en bleu et représente l'objectif d'une approche de réapprovisionnement priorisé.
6. Conclusion
Les prévisions traditionnelles des séries temporelles sont tout simplement incapables de capturer le niveau de granularité nécessaire pour prendre des décisions de réapprovisionnement de stocks qui reflètent l’incertitude future et l’ampleur totale des contraintes et des facteurs déterminants. Cela s’explique par l’absence d’une dimension explicite d’incertitude, représentée par des valeurs de probabilité pour les résultats futurs attendus. Comme une série temporelle traditionnelle est effectivement aveugle à ce type de données, un moyen conventionnel tel que le stock de sécurité revient à de la conjecture ; insuffisant, et l’on perd des ventes rentables avec un ROI attendu positif ; excessif, et l’on réduit son ROI en stockant des unités qui (comme démontré dans le tableur) présentent un ROI attendu négatif.
Le réapprovisionnement priorisé de stocks, utilisant des prévisions probabilistes, est notre solution à ce problème. Une telle approche considère les choix de réapprovisionnement de stocks en combinaison, plutôt que de manière isolée. Ce faisant, la récompense financière attendue de nos choix de réapprovisionnement peut être entièrement quantifiée et révélée. Le fondement d’une telle approche réside dans l’acceptation de l’incertitude et dans l’exploitation des données issues des prévisions probabilistes. En conséquence, on peut également mieux comprendre quels taux de service (par SKU) procurent des récompenses financières significatives, au lieu de fixer des cibles arbitraires.
L’approche PIR démontrée dans ce document a été construite en utilisant des données synthétiques et des paramètres restreints. Ces choix ont été faits pour adapter un outil commun (Excel) à un objectif inhabituel (PIR). Parmi d’autres concessions nécessaires, les SKU et les unités ont été limités (à 3 et 100, respectivement) afin de réduire le temps de traitement, car l’ensemble des données d’un catalogue (sans parler des données de plusieurs magasins) aurait été trop laborieux à traiter. De plus, aucune contrainte de supply chain n’a été ajoutée. Il est crucial de noter qu’Excel n’est pas conçu pour traiter des variables aléatoires – une étape clé dans la génération des prévisions probabilistes et l’élaboration de la politique PIR. Ces limitations ne s’appliquent pas à une solution PIR de niveau production.
Les professionnels de la supply chain dont les entreprises ont dépassé Excel sont invités à envoyer un e-mail à contact@lokad.com pour organiser une démonstration d’une solution PIR de niveau production.
7. Aperçu du tableur
7.1 Lisez-moi
Cette feuille sert de page d’accueil pour l’utilisateur. Il y a un lien vers un tutoriel en ligne (celui que vous lisez actuellement).
7.2 Décisions d’achat micro
Ceci est la deuxième feuille et est dédiée à une analyse financière fine et granulée de toutes les options de décisions de réapprovisionnement faisables. Veuillez noter qu’aucune manipulation manuelle des données n’est effectuée ici. Cette feuille affiche uniquement les résultats des calculs basés sur les données provenant des feuilles Control Tower et Distribution generators.
Caractéristiques clés :
- Les lignes avec une mise en forme conditionnelle représentent des « décisions passées » et ne peuvent être modifiées. Nous recommandons d’utiliser une application de bureau, car la version navigateur d’Excel est parfois peu fiable en matière de mise en forme.
- En survolant chaque en-tête de colonne, une définition/une note utile apparaît.
7.3 Graphiques
Ceci est la troisième feuille et est dédiée à la visualisation des principaux moteurs qui interviennent dans les décisions de réapprovisionnement de stocks. Veuillez noter qu’aucune manipulation manuelle des données n’est effectuée ici. Cette feuille a été conçue pour aider le praticien à visualiser (et ainsi mieux comprendre) le fonctionnement interne du processus PIR.
Caractéristiques clés :
- Trois graphiques par SKU (clavier, stylo et bibliothèque).
- Le graphique des « forces motrices » visualise les principaux moteurs de chaque décision au niveau unitaire (pour chaque SKU). C’est pourquoi l’axe des x ne contient que les unités d’un SKU qui doivent encore être commandées.
- Deux autres graphiques (« incréments de taux de remplissage » et « prévision probabiliste de la demande » contiennent toutes les unités de stock – le stock disponible et les unités pouvant être commandées.
7.4 Décisions d’achat classées
Il s’agit de la quatrième feuille, dédiée à la liste de toutes les décisions de réapprovisionnement faisables, triées par ROI/score par ordre décroissant. Cette liste est automatiquement établie à partir des données de la feuille 2 (Décisions d’achat micro). Les décisions faisables sont affichées les unes par rapport aux autres (voir les « Caractéristiques clés » ci-dessous). Veuillez noter qu’aucune manipulation manuelle des données n’est effectuée ici. Selon les modifications apportées aux entrées des feuilles 5 et 6, cette liste évoluera.
Caractéristiques clés :
- Les décisions de réapprovisionnement de stocks faisables sont classées par ordre décroissant (de la plus élevée à la plus faible) selon le ROI/score.
- L’investissement cumulé est calculé pour les décisions triées (voir la colonne AA de la feuille 4).
- En survolant chaque en-tête de colonne, une définition/une note utile apparaît.
7.5 Control tower - mini optimiseur
Il s’agit de la cinquième feuille et elle résume les hypothèses du modèle (entrées) ainsi que les décisions recommandées (sorties). Les données dans les cellules modifiables peuvent être changées pour modifier les hypothèses du modèle et, par conséquent, le résultat du modèle.
Caractéristiques clés :
- Trois blocs pour aider à la démonstration : « Control tower » pour la manipulation manuelle des entrées ; « Base Case – Hard copy » pour afficher les paramètres par défaut ; et « Changes to base scenario » pour montrer la différence entre les paramètres mis à jour et ceux par défaut (voir la feuille 5).
- Un quatrième bloc (« Model Assumptions »), situé sous « Control tower », est dédié à la manipulation des hypothèses initiales de stocks (voir la feuille 5).
- Seules les données dans les cellules modifiables peuvent être modifiées.
7.6 Générateurs de distribution
Il s’agit de la sixième feuille et elle est dédiée à la génération de prévisions probabilistes de la demande. Les paramètres dans les cellules modifiables peuvent être modifiés, ce qui entraînera la mise à jour des distributions et l’affichage de nouvelles valeurs de demande probabiliste.
Caractéristiques clés :
- Un graphique de distribution par SKU.
- Chaque SKU possède un schéma de distribution différent (le raisonnement est expliqué dans la section 2.1).
- Il y a un tableau à gauche de la série de graphiques de distribution, dédié à la manipulation des paramètres des distributions.
- Seuls les paramètres dans les cellules modifiables peuvent être modifiés.
- En survolant les en-têtes de colonne pertinents (dans le tableau), une définition/une note utile apparaît.
Notes
-
Considérez le lait et le chocolat. Le premier est un produit à faible marge, pourtant il est considéré comme un produit de base, tandis que le second est discrétionnaire avec des marges bénéficiaires plus élevées. Les gens ont tendance à acheter des produits de base et des produits discrétionnaires ensemble, mais la pénalité de l’absence de lait est différente de celle du chocolat. Un client peut échanger un produit discrétionnaire (biscuits) contre un autre (chocolat) en cas de rupture de stock, mais s’il ne peut pas acheter un produit de base (lait), il peut quitter complètement le magasin. C’est pourquoi la couverture de rupture de stock serait plus importante pour le lait que pour le chocolat, indépendamment de la marge brute. De notre point de vue, la couverture de rupture de stock est une récompense plutôt qu’une pénalité, car elle est conçue pour permettre des ventes plus importantes. ↩︎
-
Trois produits suffisent à illustrer le concept tout en gardant le document concis et digeste. ↩︎
-
Les niveaux de stocks deviennent probabilistes lorsque nous soustrayons une demande probabiliste de valeurs discrètes de stocks (une valeur discrète moins une distribution de probabilité donne lieu à une autre distribution de probabilité). Tout cela rendrait les explications via Excel trop complexes, car il n’est pas adapté pour effectuer des calculs avec des variables aléatoires (pensez aux « distributions de probabilité de la demande »). ↩︎
-
Ces concessions sont nécessaires pour démontrer le principe général d’une approche probabiliste. En réalité, les commandes en souffrance ne sont pas toujours utilisées et les délais de livraison sont probabilistes et susceptibles d’évoluer. ↩︎
-
Pour plus de simplicité, nous n’avons appliqué aucune contrainte de supply chain. ↩︎
-
Comme mentionné précédemment, il n’est pas nécessaire de modifier les données dans les Décisions d’achat micro. Toute manipulation des données s’effectue via les feuilles 5 et 6. ↩︎
-
Dans cette feuille Excel, les moteurs économiques sont exprimés en dollars, bien que la devise soit sans importance. ↩︎
-
La liste des moteurs économiques ci-dessus n’est pas exhaustive et les scénarios réels de réapprovisionnement de stocks (et de supply chain) comporteront presque certainement davantage de moteurs. Cela est particulièrement vrai lorsqu’il s’agit de la production de marchandises et des contraintes de péremption. ↩︎
-
Ce moteur est moins précis dans un contexte B2C que dans un contexte B2B. Dans ce dernier, il existe souvent des pénalités explicites associées aux événements de rupture de stock, comme les pénalités contractuelles ; dans le premier, il est difficile de quantifier financièrement l’impact négatif d’un événement de rupture de stock. En général, il sera élevé pour les produits qui portent un coût disproportionné à l’attractivité d’une entreprise (indépendamment de la contribution directe à la marge du SKU). Le lait, comme mentionné précédemment, n’est pas un moteur de marge pour les supermarchés, mais son emplacement stratégique (généralement à l’arrière du supermarché) incite les clients à parcourir allée après allée d’autres produits (dont presque tous ont des marges plus élevées). Si un supermarché connaît un événement de rupture de stock avec ce produit de base (celui que les clients achètent très régulièrement et en panier), cela peut pousser les clients à quitter le supermarché, à acheter ailleurs et possiblement à ne pas revenir (si ces événements de rupture de stock sont récurrents). ↩︎
-
La probabilité de vente est dérivée des distributions de probabilité générées dans Générateurs de distribution (feuille 6). ↩︎
-
Le coût continu lié à l’incapacité de vendre et donc au stockage d’une unité invendue d’un SKU. ↩︎
-
L’investissement est, dans ce scénario, identique au prix d’achat, mais uniquement parce que nos décisions d’achat ne sont pas contraintes par les quantités minimales de commande (MOQ) ou les multiplicateurs de lots. ↩︎
-
La manière la plus simple de procéder consiste à fixer le facteur d’agressivité (colonne S dans la Figure 12) à zéro, ce qu’une entreprise pourrait faire si elle décidait qu’un événement de rupture de stock n’a aucun impact négatif. Un petit conseil gratuit : ce n’est définitivement pas le cas. ↩︎
-
Par exemple, notre budget par défaut est de 500 $, nous mettrions donc fin à nos décisions d’achat à la cellule 40 (voir la Figure 13), puisque la cellule 41 affiche une valeur de 506,88 $ et dépasse notre budget. Nous regrouperions ensuite les chiffres par produit, ce qui constituerait notre liste d’achat (voir « Output – Purchase recommendation in Control Tower », comme indiqué dans la Figure 2). Comme mentionné précédemment, il est possible de modifier le budget prédéfini de 500 $ (voir les indications dans la Figure 2) pour toute valeur comprise entre 0 $ et 1450 $. Cela démontrera comment la liste d’achat évolue en fonction des différentes contraintes budgétaires. Indépendamment des limitations financières, les décisions d’achat classées identifieront la meilleure combinaison de décisions de stocks, d’un point de vue ROI, pour toutes les lignes comprises entre le rang 1 et le point de terminaison. ↩︎