00:54 Introduzione
02:25 Sulla natura del progresso
05:26 La storia finora
06:10 Alcuni principi quantitativi: principi osservazionali
07:27 Risolvere il problema del “ago in un pagliaio” tramite l’entropia
14:58 Le popolazioni SC sono distribuite secondo Zipf
22:41 Nei processi decisionali SC prevalgono numeri piccoli
29:44 I pattern sono ovunque in SC
36:11 Alcuni principi quantitativi: principi di ottimizzazione
37:20 Per risolvere qualsiasi problema in SC sono necessari da 5 a 10 cicli
44:44 Le SC invecchiate sono quasi ottimali in maniera unidirezionale
49:06 Le ottimizzazioni locali in SC spostano solo i problemi
52:56 Problemi migliori hanno la precedenza su soluzioni migliori
01:00:08 Conclusione
01:02:24 Prossima lezione e domande del pubblico
Descrizione
Mentre le supply chains non possono essere caratterizzate da leggi quantitative definitive - a differenza dell’elettromagnetismo - è comunque possibile osservare principi quantitativi generali. Con “generali” intendiamo applicabili a (quasi) tutte le supply chains. Scoprire tali principi è di primaria importanza poiché possono essere usati per facilitare l’ingegnerizzazione di ricette numeriche destinate all’ottimizzazione predittiva delle supply chains, ma possono anche rendere complessivamente quelle ricette numeriche più potenti. Esaminiamo due brevi elenchi di principi: alcuni principi osservazionali e alcuni principi di ottimizzazione.
Trascrizione completa

Ciao a tutti, benvenuti a questa serie di lezioni su supply chains. Sono Joannes Vermorel, e oggi presenterò alcuni “Quantitative Principles for Supply Chains.” Per chi sta guardando la lezione in diretta su YouTube, potete porre le vostre domande in qualsiasi momento tramite la chat di YouTube. Tuttavia, non leggerò le vostre domande durante la lezione. Tornerò alla chat alla fine della lezione e farò del mio meglio per rispondere almeno alla maggior parte delle domande.
I principi quantitativi sono di grande interesse perché, nelle supply chains, come abbiamo visto nelle prime lezioni, implicano la padronanza dell’opzionalità. La maggior parte di queste opzioni è di natura quantitativa. Devi decidere quanto acquistare, quanto produrre, quanto inventario spostare e, potenzialmente, il prezzo – se desideri aumentare o diminuire il prezzo. Quindi, un principio quantitativo che può guidare miglioramenti nelle ricette numeriche per le supply chains è di grande interesse.
Tuttavia, se chiedessi alla maggior parte degli esperti o delle autorità nel campo delle supply chains quali sono i loro principi quantitativi principali, sospetto che frequentemente otterrei una risposta sotto forma di una serie di tecniche per una migliore previsione delle serie temporali o qualcosa di equivalente. La mia reazione personale è che, sebbene ciò sia interessante e rilevante, manca il punto fondamentale. Credo che alla radice vi sia un fraintendimento nella natura stessa del progresso – cos’è il progresso e come si può implementare qualcosa come il progresso in ambito supply chain? Permettetemi di iniziare con un esempio illustrativo.

Seimila anni fa fu inventata la ruota, e seimila anni dopo fu inventata la valigia con ruote. L’invenzione è datata 1949, come illustrato da questo brevetto. Al momento in cui fu inventata la valigia con ruote, avevamo già sfruttato l’energia atomica e persino fatto esplodere le prime bombe atomiche.
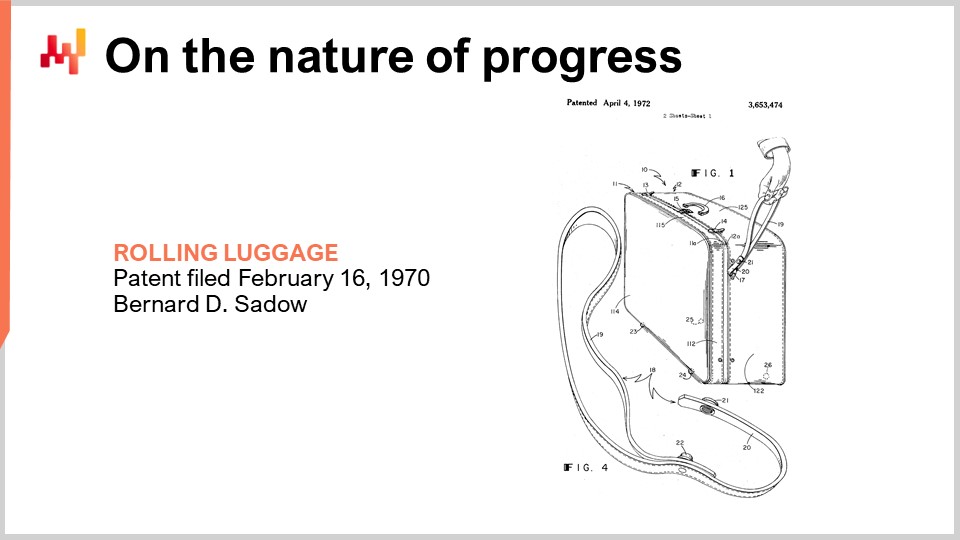
Avanti di 20 anni, nel 1969, l’umanità inviò le prime persone sulla luna. L’anno successivo, la valigia con ruote fu migliorata con un manico leggermente migliore, che assomiglia a un guinzaglio, come illustrato da questo brevetto. Non è ancora molto buona.

Poi, 20 anni dopo, a quel punto, avevamo già il sistema di posizionamento globale GPS che serviva i civili da quasi un decennio, e il manico adatto per la valigia con ruote fu finalmente inventato.
Ci sono almeno due lezioni interessanti qui. In primo luogo, non esiste una direzione del tempo ovvia per quanto riguarda il progresso. Il progresso avviene in modo altamente caotico e non lineare, ed è molto difficile valutare il progresso che dovrebbe verificarsi in un campo basandosi su ciò che accade in altri campi. Questo è un elemento che dobbiamo tenere a mente oggi.
La seconda cosa è che il progresso non va confuso con la sofisticazione. Puoi avere qualcosa di enormemente superiore ma anche estremamente più semplice. Se prendo l’esempio della valigia, una volta vista, il design appare completamente ovvio e scontato. Ma è stato un problema facile da risolvere? Direi decisamente di no. La semplice prova che la supply chain management era un problema difficile da risolvere è che una civiltà industriale avanzata impiegò un po’ più di quattro decenni per affrontare questa questione. Il progresso è ingannevole in quanto non rispetta la regola della sofisticazione. È molto difficile identificare com’era il mondo prima che il progresso accadesse, perché esso cambia letteralmente la tua visione del mondo nel suo manifestarsi.

Torniamo ora alla nostra discussione sulle supply chains. Questa è la sesta e ultima lezione di questo prologo. Esiste un piano completo che potete consultare online sul sito di Lokad riguardo all’intera serie di lezioni sulle supply chains. Due settimane fa, ho presentato le tendenze delle supply chains del XX secolo, adottando una prospettiva puramente qualitativa sul problema. Oggi, invece, sto adottando l’approccio opposto, abbracciando una prospettiva piuttosto quantitativa su questo insieme di problemi come punto di confronto.

Oggi esamineremo un insieme di principi. Per principio, intendo qualcosa che può essere utilizzato per migliorare il design delle ricette numeriche in generale per tutte le supply chains. Abbiamo qui l’ambizione della generalizzazione, ed è proprio in questo ambito che è piuttosto difficile trovare elementi di primaria rilevanza per tutte le supply chains e per tutti i metodi numerici per migliorarle. Esamineremo due brevi elenchi di principi: principi osservazionali e principi di ottimizzazione.
I principi osservazionali si applicano al modo in cui è possibile acquisire conoscenze e informazioni in maniera quantitativa riguardo le supply chains. I principi di ottimizzazione riguardano il modo in cui agisci una volta acquisita una conoscenza qualitativa della tua supply chain, in particolare, come utilizzare questi principi per migliorare i tuoi processi di ottimizzazione.
Iniziamo osservando una supply chain. Mi sorprende quando le persone parlano delle supply chains come se potessero osservarle direttamente con i propri occhi. Per me, questa è una percezione molto distorta della realtà delle supply chains. Le supply chains non possono essere osservate direttamente da un punto di vista umano, almeno non da una prospettiva quantitativa. Questo perché le supply chains, per loro natura, sono distribuite geograficamente, coinvolgendo potenzialmente migliaia di SKU e decine di migliaia di unità. Con i tuoi occhi umani, puoi osservare la supply chain solo com’è oggi e non come era in passato. Non puoi ricordare più di pochi numeri o una piccolissima frazione dei numeri associati alla tua supply chain.
Ogni volta che vuoi osservare una supply chain, effettuerai tali osservazioni indirettamente tramite software aziendale. Questo è un modo molto specifico di guardare le supply chains. Tutte le osservazioni che possono essere fatte in maniera quantitativa sulle supply chains avvengono attraverso questo mezzo specifico: il software aziendale.
Caratterizziamo un tipico pezzo di software aziendale. Conterrà un database, come la stragrande maggioranza di tale software è progettata. Il software probabilmente avrà circa 500 tabelle e 10.000 campi (un campo è essenzialmente una colonna in una tabella). Come punto di ingresso, abbiamo un sistema che contiene potenzialmente una quantità enorme di informazioni. Tuttavia, nella maggior parte dei casi, solo una piccola frazione di questa complessità del software è effettivamente rilevante per la supply chain di interesse.
I fornitori di software progettano il software aziendale tenendo conto di situazioni molto diverse. Quando si guarda a un cliente specifico, è probabile che solo una piccola frazione delle capacità del software venga effettivamente utilizzata. Ciò significa che, mentre in teoria potrebbero esserci 10.000 campi da esplorare, in realtà le aziende utilizzano solo una piccola frazione di tali campi.
La sfida è come distinguere le informazioni rilevanti dai dati inesistenti o irrilevanti. Possiamo osservare le supply chains solo attraverso il software aziendale, e potrebbe esserci coinvolto più di un applicativo. In alcuni casi, un campo non è mai stato utilizzato, e i dati sono costanti, contenenti solo zeri o nulli. In questa situazione, è facile eliminare il campo perché non contiene alcuna informazione. Tuttavia, in pratica, il numero di campi che possono essere eliminati utilizzando questo metodo potrebbe essere solo intorno al 10%, poiché molte funzionalità del software sono state utilizzate nel corso degli anni, anche se solo accidentalmente.
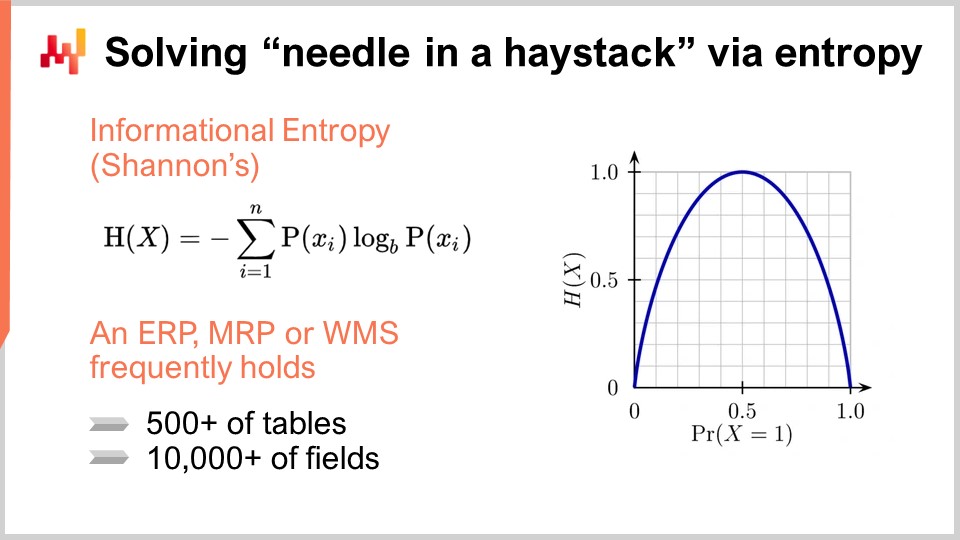
Per identificare i campi che non sono mai stati messi ad un uso significativo, possiamo ricorrere a uno strumento chiamato entropia informativa. Per chi non familiarizza con la teoria dell’informazione di Shannon, il termine può sembrare intimidatorio, ma in realtà è più semplice di quanto sembri. L’entropia informativa riguarda la quantificazione della quantità di informazione in un segnale, definito come una sequenza di simboli. Ad esempio, se abbiamo un campo che contiene solo due tipi di valori, vero o falso, e la colonna oscilla casualmente tra questi valori, essa contiene molti dati. Al contrario, se c’è solo una riga su un milione in cui il valore è vero e tutte le altre righe sono false, il campo nel database contiene quasi nessuna informazione.
L’entropia informativa è molto interessante perché ti permette di quantificare, in bit, la quantità di informazione presente in ogni campo del tuo database. Conducendo un’analisi, puoi classificare questi campi dal più ricco al più povero in termini di informazioni ed eliminare quelli che contengono a malapena informazioni rilevanti per scopi di ottimizzazione delle supply chains. L’entropia informativa può sembrare complicata all’inizio, ma non è difficile da capire.

Ad esempio, immaginando un linguaggio di programmazione specifico per il dominio, abbiamo implementato l’entropia informativa come aggregatore. Prendendo una tabella, come dati provenienti da un file flat chiamato data.csv con tre colonne, possiamo tracciare un riepilogo di quanta entropia è presente in ogni colonna. Questo processo ti permette di determinare facilmente quali campi contengono la minore quantità di informazione ed eliminarli. Usando l’entropia come guida, puoi avviare rapidamente un progetto invece di impiegare anni.
Passando alla fase successiva, facciamo le nostre prime osservazioni sulle supply chains e consideriamo cosa aspettarci. Nelle scienze naturali, l’aspettativa predefinita sono le distribuzioni normali, note anche come curve a campana o gaussiane. Ad esempio, l’altezza di un maschio umano di 20 anni o il suo peso seguiranno una distribuzione normale. Nel regno degli esseri viventi, molte misurazioni seguono questo schema. Tuttavia, per quanto riguarda la supply chain, non è così. Praticamente nulla di interessante nelle supply chains segue una distribuzione normale.
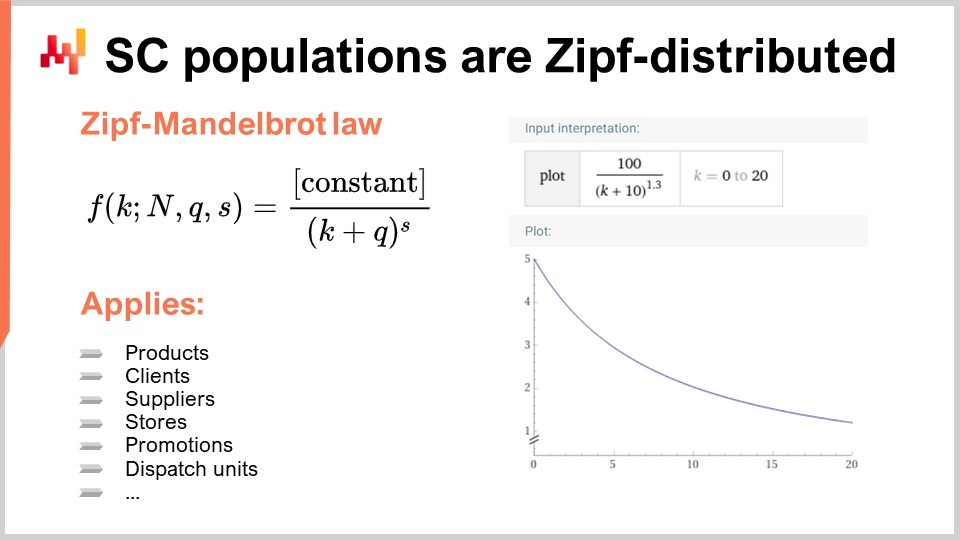
Invece, quasi tutte le distribuzioni di interesse nelle supply chains sono distribuite secondo Zipf. La distribuzione Zipf è illustrata nella formula fornita. Per comprendere questo concetto, considera una popolazione di prodotti, dove la misura di interesse è il volume delle vendite per ciascun prodotto. Classificheresti i prodotti dalla vendita più alta a quella più bassa in un determinato periodo di tempo, ad esempio un anno. La domanda diventa quindi se esista un modello che predice la forma della curva e, dato il rango, fornisca il volume di vendite atteso. Questo è esattamente ciò di cui tratta la distribuzione Zipf. Qui, f rappresenta la forma di una legge di Zipf-Mandelbrot, e k si riferisce al k-esimo elemento più grande. Ci sono due parametri, q e s, che sono essenzialmente appresi, proprio come mu (la media) e sigma (la varianza) per una distribuzione normale. Questi parametri possono essere utilizzati per adattare la distribuzione a una popolazione di interesse. La legge di Zipf-Mandelbrot comprende questi parametri.
È importante notare che praticamente ogni singola popolazione di interesse nella supply chain segue una distribuzione Zipf. Questo è vero per prodotti, clienti, fornitori, promozioni, e persino unità di spedizione. La distribuzione Zipf è fondamentalmente un discendente del principio di Pareto, ma è più gestibile e, a mio parere, più interessante, in quanto fornisce un modello esplicito di ciò che ci si può aspettare per qualsiasi popolazione di interesse nella supply chain. Se ti imbatti in una popolazione che non è distribuita secondo Zipf, è più probabile che vi sia un problema con i dati, piuttosto che una vera deviazione dal principio.

Per sfruttare il concetto di distribuzione Zipf nel mondo reale, puoi usare Envision. Se osserviamo questo frammento di codice, vedrai che bastano solo poche righe di codice per applicare questo modello a un dataset reale. Qui, presumo che ci sia una popolazione di interesse in un file piatto chiamato “data.csv” con una colonna che rappresenta la quantità. Normalmente, avresti un identificatore di prodotto e la quantità. Alla linea 4, sto calcolando i ranghi usando l’aggregatore di ranghi e ordinando in base alla quantità. Poi, tra le linee 6 e 11, entro in un blocco di programmazione differenziabile reso esplicito da Autodev, dove dichiaro tre parametri scalari: c, q e s, proprio come nella formula a sinistra dello schermo. Successivamente calcolo le previsioni del modello Zipf e utilizzo l’errore quadratico medio tra la quantità osservata e la previsione del modello. Puoi letteralmente effettuare una regressione della distribuzione Zipf con solo poche righe di codice. Anche se sembra sofisticato, è abbastanza semplice con gli strumenti appropriati.

Questo mi porta a un altro aspetto osservazionale delle supply chain: i numeri che ti aspetteresti a qualsiasi livello della supply chain sono piccoli, solitamente inferiori a 20. Non solo avrai poche osservazioni, ma i numeri che osservi saranno anche piccoli. Ovviamente, questo principio dipende dalle unità di misura utilizzate, ma quando dico “numeri” intendo quelli che hanno senso canonico da una prospettiva supply chain, cioè quelli che stai cercando di osservare e ottimizzare.
La ragione per cui abbiamo solo numeri piccoli è dovuta alle economie di scala. Prendiamo ad esempio le t-shirt in un negozio. Il negozio potrebbe avere migliaia di t-shirt in magazzino, il che sembra un numero elevato, ma in realtà dispone di centinaia di tipi diversi di t-shirt con variazioni di taglia, colore e design. Quando inizi a considerare le t-shirt con la granularità rilevante per una supply chain, cioè la SKU, il negozio non avrà migliaia di unità per una data SKU; invece, ne avrà solo un pugno.
Se hai un numero maggiore di t-shirt, non avranno migliaia di t-shirt sparse in giro, poiché sarebbe un incubo in termini di elaborazione e movimentazione. Invece, confezionerai quelle t-shirt in scatole comode, che è esattamente ciò che accade in pratica. Se disponi di un centro di distribuzione che gestisce molte t-shirt, perché le spedisci ai negozi, è probabile che quelle t-shirt siano effettivamente confezionate in scatole. Potresti persino avere una scatola contenente un assortimento completo di t-shirt con taglie e colori diversi, rendendo più agevole il processo lungo la catena. Se hai molte scatole sparse, non avrai migliaia di scatole identiche; invece, se hai decine di scatole, le organizzerai ordinatamente su pallet. Un pallet può contenere diverse decine di scatole. Se hai molti pallet, non li organizzerai come singoli pallet; molto probabilmente, li organizzerai come container. E se hai molti container, utilizzerai una nave cargo o qualcosa di simile.
Il mio punto è che, quando si tratta di numeri nella supply chain, il numero veramente rilevante è sempre un numero piccolo. Questa situazione non può essere superata semplicemente passando a un livello aggregato superiore perché, man mano che si sale di livello, entra in gioco una sorta di economie di scala e si desidera introdurre un meccanismo di raggruppamento per ridurre i costi operativi. Questo accade più volte, quindi non importa quale scala si osservi, che si tratti del prodotto finale venduto all’unità in un negozio o di un articolo di produzione di massa, è sempre un gioco di numeri piccoli.
Anche se hai una fabbrica che produce milioni di t-shirt, è probabile che tu gestisca lotti giganteschi, e i numeri di interesse non sono il numero di t-shirt, ma il numero di lotti, che risulta essere molto inferiore.
A che punto voglio arrivare con questo principio? In primo luogo, devi osservare come si presentano la maggior parte dei metodi nel calcolo scientifico o nella statistica. Si scopre che nella maggior parte degli altri campi, che non riguardano la supply chain, è prevalente l’opposto: enormi quantità di osservazioni e numeri elevati nei quali la precisione conta. Nella supply chain, invece, i numeri sono piccoli e discreti.
La mia proposta è che abbiamo bisogno di strumenti basati su questo principio che accolgano e abbracciano profondamente il fatto che dovremo lavorare con numeri piccoli anziché con numeri grandi. Se utilizzi strumenti progettati esclusivamente pensando alla legge dei grandi numeri, sia a causa del gran numero di osservazioni sia per i numeri elevati, avrai un completo disallineamento quando si tratta di supply chain.
A proposito, questo ha profonde implicazioni software. Se disponi di numeri piccoli, esistono molti modi per far sì che gli strati software sfruttino questa osservazione. Ad esempio, se osservi il dataset delle linee transazionali per un ipermercato, noterai che, basandomi sulla mia esperienza e osservazione, l'80% delle righe presenta una quantità venduta a un cliente finale in un ipermercato pari esattamente a uno. Quindi, hai davvero bisogno di 64 bit di informazione per rappresentare questo dato? No, sarebbe uno spreco completo di spazio e tempo di elaborazione. Abbracciare questo concetto può portare a un guadagno operativo di uno o due ordini di grandezza. Non si tratta solo di un pensiero utopistico; ci sono reali guadagni operativi. Potresti pensare che i computer oggi siano molto potenti, e lo sono, ma se hai a disposizione maggiore potenza di elaborazione, puoi implementare algoritmi più avanzati che facciano cose ancora migliori per la tua supply chain. È inutile sprecare questa potenza di calcolo semplicemente perché si adotta un paradigma che si aspetta numeri grandi, quando invece prevalgono numeri piccoli.
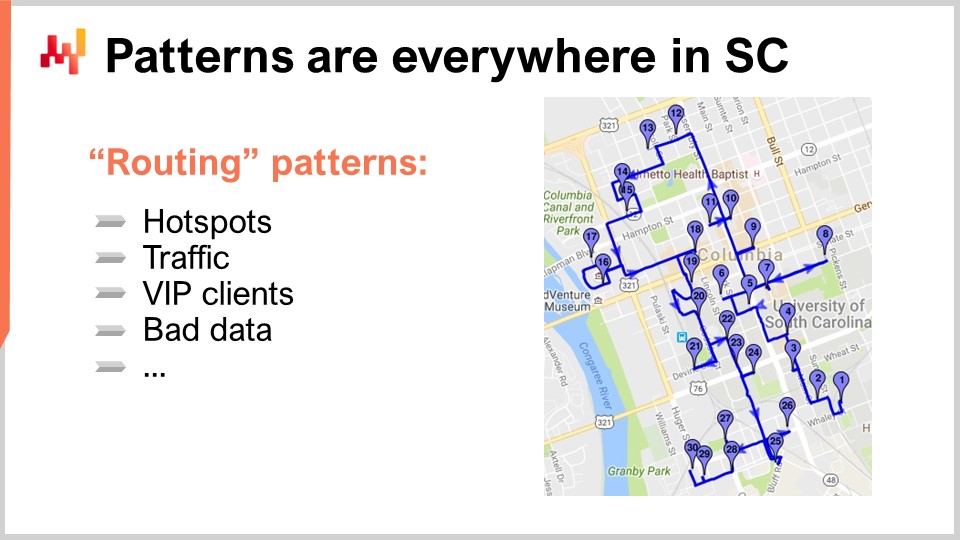
Questo mi porta al mio ultimo principio osservazionale per oggi: i modelli sono ovunque nella supply chain. Per comprenderlo, diamo un’occhiata a un classico problema della supply chain in cui solitamente si ritiene l’assenza di modelli: l’ottimizzazione del percorso. Il classico problema dell’ottimizzazione del percorso riguarda una lista di consegne da effettuare. Puoi posizionare le consegne su una mappa e desideri trovare il percorso che minimizza il tempo di trasporto. Vuoi stabilire un percorso che attraversi ogni singolo punto di consegna, minimizzando il tempo totale di trasporto. A prima vista, questo problema appare come un problema puramente geometrico, senza che vi sia alcun coinvolgimento di modelli nella sua risoluzione.
Tuttavia, propongo che questa prospettiva sia del tutto errata. Avvicinandosi al problema da questo punto di vista, stai considerando il problema matematico, non quello della supply chain. Le supply chain sono giochi iterativi in cui i problemi si manifestano ripetutamente. Se sei nel business dell’organizzazione delle consegne, è probabile che tu effettui consegne quotidianamente. Non si tratta di un’unica rotta; è letteralmente una rotta al giorno, almeno.
Inoltre, se operi nel settore delle consegne, probabilmente disponi di un’intera flotta di veicoli e autisti. Il problema non consiste semplicemente nell’ottimizzare una rotta, ma nell’ottimizzare un’intera flotta, e questo ciclo si ripete ogni singolo giorno. È in questo contesto che emergono tutti i modelli.
Innanzitutto, i punti non sono distribuiti casualmente sulla mappa. Esistono hotspot, ovvero aree geografiche con un’elevata densità di consegne. Potresti avere indirizzi che ricevono consegne quasi ogni giorno, come la sede centrale di una grande azienda in una grande città. Se sei una grande azienda di e-commerce, probabilmente effettui consegne a questo indirizzo ogni giorno lavorativo. Questi hotspot non sono immutabili; hanno la loro stagionalità. Alcuni quartieri potrebbero essere molto tranquilli durante l’estate o l’inverno. Esistono dei modelli, e se vuoi essere davvero bravo nel gioco dell’ottimizzazione dei percorsi, devi tenere conto non solo di dove si verificheranno questi hotspot, ma anche di come si sposteranno nel corso dell’anno. Inoltre, occorre considerare il traffico. Non dovresti pensare soltanto alla distanza geometrica, poiché il traffico è dipendente dal tempo. Se un autista parte in un certo momento della giornata, man mano che procede lungo il percorso, il traffico varierà. Per ottimizzare efficacemente questo gioco, è necessario considerare i modelli del traffico, che variano e possono essere previsti con affidabilità in anticipo. Ad esempio, a Parigi, alle 9:00 e alle 18:00, tutta la città è completamente congestionata, e non occorre essere esperti di previsioni per saperlo.
Ci sono anche eventi che si verificano sul momento, come incidenti che disturbano i modelli abituali del traffico. Se osserviamo le consegne da una prospettiva matematica, si assume che tutti i punti di consegna siano identici, ma non lo sono. Potresti avere clienti VIP o indirizzi specifici dove devi consegnare metà della tua spedizione. Questi punti chiave nel percorso devono essere considerati per un’ottimizzazione efficace.
Devi anche essere consapevole del contesto, ed è comune disporre di dati imperfetti sul mondo reale. Ad esempio, se un ponte è chiuso e il software non ne viene informato, il problema non è tanto il fatto di non sapere che il ponte fosse chiuso in un primo momento, ma che il software non impara mai dall’evento e propone sempre un percorso che, pur essendo teoricamente ottimale, risulta insensato. Le persone poi si oppongono al sistema, e ciò non rappresenta una buona soluzione pratica di ottimizzazione dei percorsi dal punto di vista della supply chain.
Il punto è che, osservando le situazioni nella supply chain, emergono innumerevoli modelli. Dobbiamo stare attenti a non farci distrarre da eleganti strutture matematiche e ricordare che queste considerazioni valgono anche per le previsioni delle serie temporali. Ho scelto il problema dell’ottimizzazione dei percorsi come esempio perché in questo caso i modelli diventano particolarmente evidenti.
In conclusione, dobbiamo osservare la supply chain da tutte le dimensioni osservabili, non solo da quelle ovvie o in cui la soluzione si presenta in modo elegante.

Questo mi porta alla seconda serie di principi relativi a come dovremmo osservare la nostra supply chain. Finora, abbiamo esaminato quattro principi: osservazione indiretta, software aziendale, il filtraggio del caos per determinare ciò che è rilevante e ciò che non lo è, ed entropia. Abbiamo osservato che le distribuzioni spesso seguono la legge di Zipf, e che, nonostante i numeri piccoli, si possono ancora osservare dei modelli. La domanda ora è: come agiamo? Matematicamente parlando, quando vogliamo decidere la migliore linea d’azione, effettuiamo una sorta di ottimizzazione, che rappresenta la prospettiva quantitativa.

La prima cosa da notare è che non appena metti in produzione una logica di ottimizzazione per le supply chain, sorgono problemi, come bug. Il software aziendale è una bestia molto complessa e spesso è pieno di bug. Mentre sviluppi la tua logica di ottimizzazione per la supply chain, incontrerai numerosi problemi. Tuttavia, se una logica è sufficientemente valida da essere messa in produzione, eventuali problemi riscontrati ora saranno probabilmente casi limite. Se non fossero casi limite e il software o la logica fallisse ogni singola volta, non sarebbe mai arrivato in produzione.
L’idea di questo principio è che ci vogliono da cinque a dieci cicli per risolvere un problema. Quando dico da cinque a dieci cicli, intendo che affronterai un problema, lo analizzerai per comprenderne la causa radice, e poi cercherai di applicare una soluzione. Ma nella maggior parte dei casi, la soluzione non risolve il problema. Scoprirai che c’era un problema nascosto all’interno del problema, o che quello che credevi di aver risolto non era la vera causa, oppure che la situazione ha rivelato una classe più ampia di problemi. Potresti aver risolto un piccolo caso di una classe più ampia di problemi, ma altri problemi continueranno a verificarsi come varianti di quello che pensavi di aver sistemato.
Le supply chain sono entità complesse e in continuo mutamento che operano nel mondo reale, rendendo difficile progettare una soluzione perfettamente adatta ad ogni situazione. Nella maggior parte dei casi, si cerca di risolvere il problema con il massimo impegno, ma poi è necessario mettere alla prova la logica rivista con l’esperienza reale per verificare se funziona o meno. Occorrerà iterare per correggere il problema. Con il principio che ci vogliono da cinque a dieci iterazioni per risolvere un problema, emergono conseguenze profonde sulla velocità di adattamento e sulla frequenza con cui rinnovi o ricalcoli la logica di ottimizzazione della tua supply chain. Ad esempio, se hai una logica che produce una previsione trimestrale per i due anni successivi e la esegui solo una volta per trimestre, ci vorranno da uno a due anni per risolvere eventuali problemi riscontrati in quella logica di previsione, il che è un lasso di tempo incredibilmente lungo.
Anche se disponi di una logica che viene eseguita ogni mese, come nel caso di un processo di S&OP (Sales and Operations Planning), potrebbe comunque richiedere fino a un anno per risolvere un problema. Questo è il motivo per cui è importante aumentare la frequenza con cui fai girare la logica di ottimizzazione della tua supply chain. Ad esempio, a Lokad, ogni pezzo di logica viene eseguito quotidianamente, anche per previsioni che si estendono a cinque anni. Queste previsioni vengono aggiornate ogni giorno, anche se non subiscono grandi variazioni da un giorno all’altro. L’obiettivo non è ottenere una maggiore accuratezza statistica, ma garantire che la logica venga eseguita con sufficiente frequenza da poter risolvere eventuali problemi o bug in tempi ragionevoli.
Questa osservazione non è unica alla gestione della supply chain. I team di ingegneria intelligenti in aziende come Netflix hanno reso popolare l’idea del chaos engineering. Hanno compreso che i casi limite sono rari e che l’unico modo per risolvere tali problemi è ripetere l’esperienza con maggiore frequenza. Di conseguenza, hanno creato un software chiamato Chaos Monkey, che introduce caos nella loro infrastruttura software creando interruzioni di rete e crash casuali. Lo scopo del Chaos Monkey è far emergere i casi limite più rapidamente, consentendo al team di ingegneria di risolverli in tempi più brevi.
Anche se può sembrare controintuitivo introdurre un ulteriore livello di caos nelle tue operazioni, questo approccio si è dimostrato efficace per Netflix, nota per l’eccellente affidabilità. Essi comprendono che, davanti a un problema software, sono necessarie numerose iterazioni per risolverlo, e l’unico modo per arrivare al nocciolo del problema è iterare rapidamente. Il Chaos Monkey è solo uno dei modi per aumentare la velocità delle iterazioni.
Da una prospettiva supply chain, il Chaos Monkey potrebbe non essere direttamente applicabile, ma il concetto di aumentare la frequenza di esecuzione della tua logica di ottimizzazione della supply chain è ancora molto rilevante. Qualsiasi logica tu abbia per ottimizzare la supply chain, essa deve funzionare ad alta velocità e con alta frequenza; altrimenti, non risolverai mai nessuno dei problemi che incontri.

Adesso, le supply chain invecchiate sono quasi ottimali, e quando dico invecchiate intendo supply chain operative da due decenni o più. Un altro modo per esprimere questo principio è che i tuoi predecessori della supply chain non erano tutti incompetenti. Quando osservi le iniziative di ottimizzazione della supply chain, troppo spesso trovi grandi ambizioni come dimezzare i livelli di stock, aumentare i livelli di servizio dal 95% al 99%, eliminare gli rotture di stock o dividere per due i tempi di consegna. Questi sono grandi movimenti unidirezionali in cui ti concentri su un KPI cercando di migliorarlo massicciamente. Tuttavia, ho osservato che queste iniziative falliscono quasi sempre per una ragione molto semplice: quando prendi una supply chain operativa da decenni, di solito vi è una saggezza latente nel modo in cui sono state svolte le cose.
Ad esempio, se i livelli di servizio sono al 95%, è probabile che se provi ad aumentarli al 99%, aumenterai notevolmente i livelli di stock e creerai una quantità massiccia di stock inattivo nel processo. Allo stesso modo, se disponi di una certa quantità di stock e lanci un’iniziativa massiccia per ridurlo della metà, probabilmente creerai problemi significativi di qualità del servizio che non sono sostenibili.
Quello che ho osservato è che molti operatori della supply chain che non comprendono il principio per cui le supply chain invecchiate sono quasi ottimali in un’unica direzione tendono ad avere oscillazioni attorno all’optimum locale. Ricorda che non sto dicendo che le supply chain invecchiate siano ottimali, ma sono quasi ottimali in un’unica direzione. Se osservi l’analogia del Grand Canyon, il fiume scolpisce il percorso ottimale grazie alla forza unidirezionale della gravità. Se applicassi una forza dieci volte maggiore, il fiume subirebbe comunque molte convoluzioni.
Il punto è che, con le supply chain invecchiate, se vuoi ottenere miglioramenti significativi, devi modificare molte variabili contemporaneamente. Concentrarti su una sola variabile non produrrà i risultati desiderati, soprattutto se la tua azienda opera da decenni con lo status quo. I tuoi predecessori probabilmente hanno fatto alcune cose giuste a loro tempo, per cui le probabilità di imbatterti in una supply chain enormemente disfunzionale alla quale nessuno abbia mai prestato attenzione sono minime. Le supply chain sono problemi complessi, e sebbene sia possibile progettare situazioni completamente disfunzionali su larga scala, ciò avviene al massimo molto raramente.

Un altro aspetto da considerare è che l’ottimizzazione locale sposta solo i problemi invece di risolverli. Per comprendere questo, devi riconoscere che le supply chain sono sistemi, e quando si pensa in termini di supply chain performance, è solamente la performance a livello di sistema ad essere rilevante. La performance locale è importante, ma rappresenta solo una parte del quadro complessivo.
Un modo di pensare comune è che si possa applicare la strategia del divide et impera per affrontare i problemi in generale, non solo quelli della supply chain. Ad esempio, in una rete retail con molti negozi, potresti voler ottimizzare i livelli di stock in ciascun punto vendita. Tuttavia, il problema è che se hai una rete di negozi e centri di distribuzione, ognuno dei quali serve molti negozi, è del tutto banale micro-ottimizzare un negozio ottenendo un’eccellente qualità del servizio per quel negozio a scapito di tutti gli altri.
La prospettiva corretta è pensare che, quando hai un’unità disponibile nel centro di distribuzione, la domanda che dovresti porti è: dove è più necessaria questa unità? Qual è la mossa più redditizia per me? Il problema di ottimizzare la distribuzione dell’inventario, o il problema di inventory allocation, ha senso solo a livello di sistema, non a livello di singolo negozio. Se ottimizzi ciò che accade in un negozio, probabilmente creerai problemi in un altro.
Quando dico “locale”, questo principio non va inteso solo in senso geografico; può anche essere una questione puramente logica all’interno della supply chain. Ad esempio, se sei un’azienda di e-commerce con molte categorie di prodotti, potresti voler allocare budget differenti per le varie categorie. Questo è un altro tipo di strategia divide et impera. Tuttavia, se parti il tuo budget e allochi un importo fisso all’inizio dell’anno per ciascuna categoria, cosa succede se la domanda per i prodotti in una categoria raddoppia mentre in un’altra si dimezza? In questo caso, ti ritrovi con un problema di allocazione errata dei fondi tra le due categorie. La sfida qui è che non puoi applicare alcun tipo di logica divide et impera. Se utilizzi tecniche di ottimizzazione locale, potresti finire per creare problemi nel tentativo di realizzare una soluzione che supponi essere ottimizzata.

Questo mi porta all’ultimo principio, che è probabilmente il più complicato tra tutti quelli che ho presentato oggi: problemi migliori superano soluzioni migliori. Questo può risultare estremamente confuso, specialmente in alcuni circoli accademici. Il modo tipico in cui le cose vengono presentate attraverso un’educazione classica è che ti viene proposto un problema ben definito, e poi inizi a cercare soluzioni per quel problema. In un problema matematico, ad esempio, uno studente può proporre una soluzione più concisa e più elegante, e quella viene considerata la migliore.
Tuttavia, nella realtà le cose non accadono così nel management della supply chain. Per illustrare questo, torniamo indietro di 60 anni e osserviamo il problema della cucina, un’attività che richiede molto tempo. In passato, si immaginava che in futuro i robot potessero essere utilizzati per svolgere compiti culinari, aumentando così in maniera significativa la produttività per chi era responsabile della cucina. Questo tipo di pensiero era diffuso negli anni ‘50 e ‘60.
Avanzando fino ad oggi, è ovvio che non è così che le cose si sono evolute. Per ridurre gli sforzi in cucina, le persone ora acquistano pasti precucinati. Questo è un altro esempio di spostamento del problema. Fornire ai supermercati pasti precucinati è più impegnativo da una prospettiva supply chain che fornire loro prodotti grezzi, a causa del maggior numero di referenze e delle date di scadenza più brevi. Il problema è stato risolto attraverso una soluzione supply chain superiore, e non offrendo una soluzione migliore per la cucina. Il problema della cucina è stato completamente eliminato e ridefinito come il fornire un pasto accettabile con il minimo sforzo.
Per quanto riguarda le supply chain, la prospettiva accademica spesso si concentra nel trovare soluzioni migliori ai problemi esistenti. Un buon esempio sono le competizioni su Kaggle, dove hai un set di dati, un problema e potenzialmente centinaia o migliaia di team che competono per ottenere la migliore previsione su tali set di dati. Hai un problema ben definito e migliaia di soluzioni che competono tra loro. Il problema con questo approccio è che ti dà l’impressione che, se vuoi apportare miglioramenti alla tua supply chain, ciò di cui hai bisogno sia una soluzione migliore.
L’essenza del principio è che una soluzione migliore potrebbe aiutare in maniera marginale, ma solo marginalmente. Di solito, ciò che veramente aiuta è ridefinire il problema, e questo risulta sorprendentemente difficile. Questo vale anche per i problemi quantitativi. Devi ripensare la tua effettiva strategia supply chain e il problema chiave che dovresti ottimizzare.
In molti circoli, le persone considerano i problemi come se fossero statici e immutabili, cercando soluzioni migliori. Non nego che avere un algoritmo migliore per la previsione delle serie temporali possa essere d’aiuto, ma la previsione delle serie temporali appartiene al campo della statistical forecasting, e non alla padronanza del management della supply chain. Se torniamo al mio esempio iniziale della valigia da viaggio, il miglioramento chiave per una valigia con ruote non riguardava le ruote, ma la maniglia. A prima vista, sembrava qualcosa di non correlato alle ruote, ed è per questo che ci sono voluti 40 anni per arrivare a una soluzione: bisogna pensare fuori dagli schemi per far emergere il problema migliore.
Questo principio quantitativo riguarda il mettere in discussione i problemi che affronti. Forse non stai riflettendo abbastanza sul problema, e c’è la tendenza a innamorarsi della soluzione invece di concentrarsi sul problema e su ciò che non capisci a riguardo. Appena hai un problema ben definito, avere una buona soluzione diventa solitamente solo una questione banale di esecuzione, che non è così difficile.

In conclusione, la supply chain come campo di studio offre molte prospettive impressionanti e autorevoli. Queste possono essere sofisticate, ma la domanda che vorrei porre a questo pubblico è: potrebbe essere che tutto ciò sia gravemente fuorviante? Siamo davvero convinti che elementi come la previsione delle serie temporali e la ricerca operativa siano le prospettive adeguate sul problema? Indipendentemente dall’ammontare di sofisticazione e dai decenni di ingegneria e sforzi investiti nel perseguire quelle direzioni, siamo veramente sulla strada giusta?
Oggi presento una serie di principi che ritengo di fondamentale importanza per il management della supply chain. Tuttavia, potrebbero sembrarvi strani a molti. Abbiamo due mondi qui – quello collaudato e quello bizzarro – e la domanda è cosa accadrà tra qualche decennio.

Il progresso tende a svilupparsi in modo caotico e non lineare. L’idea alla base di questi principi è quella di farti abbracciare un mondo estremamente caotico, in cui c’è spazio per l’inaspettato. Questi principi possono aiutarti a sviluppare soluzioni più rapide, più affidabili e più efficienti che apporteranno miglioramenti alle tue supply chain da una prospettiva quantitativa.

Ora passiamo ad alcune domande.
Domanda: Come si confrontano le distribuzioni di Zipf con la legge di Pareto?
La legge di Pareto è la regola empirica dell'80-20, ma da una prospettiva quantitativa la distribuzione di Zipf è un modello predittivo esplicito. Possiede capacità predittive che possono essere verificate sui set di dati in maniera molto diretta.
Domanda: Non sarebbe meglio considerare la distribuzione di Zipf-Mandelbrot come una curva logaritmica per osservare le fluttuazioni della supply chain, come fanno gli epidemiologi con i casi e i decessi segnalati?
Assolutamente. A livello filosofico, la questione è se vivi nel Mondo della Mediocrità o in quello degli Estremi. Le supply chain e la maggior parte degli affari umani esistono nel mondo degli estremi. Le curve logaritmiche sono infatti utili se vuoi visualizzare l’ampiezza delle promozioni. Ad esempio, se desideri osservare le ampiezze di tutte le promozioni passate delle grandi reti retail negli ultimi 10 anni, l’uso di una scala regolare potrebbe far diventare invisibili le altre, semplicemente perché la promozione più grande è stata molto superiore alle altre. Quindi, utilizzare una scala logaritmica può aiutarti a vedere le variazioni in modo più chiaro. Con la distribuzione di Zipf-Mandelbrot ti fornisco un modello che puoi letteralmente implementare con poche righe di codice, che va oltre una semplice rappresentazione logaritmica dei dati. Tuttavia, concordo sul fatto che l’intuizione di base sia la stessa. Per una prospettiva filosofica di alto livello, consiglio di leggere il lavoro di Nassim Taleb su Mediocristan contro Extremistan nel suo libro “Antifragile.”
Domanda: Sul tema dell’ottimizzazione locale della supply chain, ti riferisci ai dati sottostanti che supportano la collaborazione nella rete supply chain e l’SNLP?
Il mio problema con l’ottimizzazione locale è che le grandi aziende che gestiscono supply chain rilevanti solitamente adottano organizzazioni a matrice. Questa struttura organizzativa, con la sua mentalità divide et impera, porta all’ottimizzazione locale per progettazione. Ad esempio, considera due team differenti: uno responsabile della previsione della domanda e l’altro delle decisioni d’acquisto. Questi due problemi – la previsione della domanda e l’ottimizzazione degli acquisti – sono completamente interconnessi. Non puoi eseguire un’ottimizzazione locale concentrandoti solo sulla percentuale di errore nella previsione della domanda e poi ottimizzare separatamente gli acquisti in base all’efficienza del processo. Ci sono effetti sistemici che devi considerare nel loro insieme.
La sfida più grande per la maggior parte delle grandi aziende affermate che gestiscono supply chain significative oggi è che, puntando all’ottimizzazione quantitativa, devi pensare a livello di sistema e aziendale. Questo va contro decenni di sedimentazione dell’organizzazione a matrice all’interno dell’azienda, dove le persone si sono concentrate esclusivamente sui loro confini ben definiti, dimenticando il quadro complessivo.
Un altro esempio di questo problema è l’inventario dei negozi. Lo stock ha due scopi: da un lato soddisfa la domanda dei clienti, e dall’altro funge da merce. Per avere la giusta quantità di stock, devi affrontare sia il problema della qualità del servizio che quello dell’appeal del negozio. L’appeal del negozio riguarda il rendere il punto vendita attraente e interessante per i clienti, il che è più un problema di marketing. In un’azienda, hai una divisione marketing e una divisione supply chain, e non collaborano naturalmente quando si tratta di ottimizzazione della supply chain. Il mio punto è che, se non unisci tutti questi aspetti, l’ottimizzazione non funzionerà.
Per quanto riguarda la tua preoccupazione sull’SNLP, il problema è che le persone si incontrano solo per fare riunioni, il che non è molto efficiente. Abbiamo pubblicato un episodio di Lokad TV sull’SNLP qualche mese fa, quindi puoi farvi riferimento se desideri approfondire l’argomento.
Domanda: Come dovremmo distribuire il tempo e l’energia tra la strategia supply chain e l’esecuzione quantitativa?
È una domanda eccellente. La risposta, come ho menzionato nella mia seconda lezione, è che hai bisogno di una completa robotizzazione delle attività banali. Questo ti permette di dedicare tutto il tuo tempo e la tua energia al continuo miglioramento strategico delle tue ricette numeriche. Se trascorri più del 10% del tuo tempo a gestire aspetti banali dell’esecuzione della supply chain, hai un problema con la tua metodologia. Gli esperti della supply chain sono troppo preziosi per sprecare il loro tempo e la loro energia su problemi di esecuzione banali che andrebbero automatizzati sin dall’inizio.
Devi seguire una metodologia che ti consenta di dedicare quasi tutta la tua energia al pensiero strategico, che poi viene immediatamente implementato come ricette numeriche superiori che guidano l’esecuzione quotidiana della supply chain.
Domanda: È possibile ipotizzare una sorta di analisi di ceiling, il miglior miglioramento possibile per i problemi della supply chain data la loro formulazione sistemica?
Direi di no, assolutamente no. Pensare che esista una sorta di ottimo o di tetto equivale a dire che esiste un limite all’ingegno umano. Anche se non ho alcuna prova che non vi sia un limite all’ingegno umano, è una delle mie convinzioni fondamentali. Le supply chain sono wicked problems. Puoi trasformare il problema, e persino convertire ciò che appare come un grande problema in una grande soluzione e in un potenziale di crescita per l’azienda. Per esempio, guarda Amazon. Jeff Bezos, all’inizio degli anni 2000, capì che per essere un rivenditore di successo avrebbe avuto bisogno di un’infrastruttura software massiccia e solida come una roccia. Ma questa infrastruttura, di grado industriale e per la produzione su scala, necessaria per gestire l’e-commerce di Amazon, era incredibilmente costosa, costando all’azienda miliardi. Così, i team di Amazon decisero di trasformare questa infrastruttura di cloud computing, che rappresentava un enorme investimento, in un prodotto commerciale. Oggi, questa infrastruttura di calcolo su larga scala è effettivamente una delle principali fonti di profitto per Amazon.
Quando inizi a considerare i wicked problems, puoi sempre ridefinire il problema in modo superiore. È per questo che penso sia fuorviante credere che esista una sorta di soluzione ottimale. Quando pensi in termini di analisi di ceiling, stai considerando un problema fisso e, da tale prospettiva, potresti avere una soluzione probabilmente quasi ottimale. Per esempio, se osservi le ruote delle valigie moderne, esse sono probabilmente quasi ottimali. Ma esiste qualcosa di completamente ovvio che ci sfugge? Forse esiste un modo per rendere le ruote molto migliori, un’invenzione che non è ancora stata concepita. Non appena succederà, sembrerà del tutto evidente.
È per questo che dobbiamo ritenere che non esista un tetto per questi problemi, poiché i problemi stessi sono arbitrari. Puoi ridefinire il problema e decidere che il gioco debba essere giocato secondo regole completamente diverse. Questo è sconcertante, perché alla gente piace pensare di avere un problema ben definito e di poter trovare soluzioni. Il moderno sistema educativo occidentale enfatizza una mentalità orientata alla ricerca di soluzioni, in cui ti viene assegnato un problema e si valuta la qualità della tua risposta. Tuttavia, una questione molto più interessante riguarda la qualità del problema stesso.
Domanda: Le migliori soluzioni risolveranno i problemi, ma a volte trovare la soluzione migliore può costare sia tempo che denaro. Esistono delle alternative?
Assolutamente. Inoltre, se hai una soluzione teoricamente corretta ma che richiede un’eternità per essere implementata, non è affatto una buona soluzione. Questo tipo di pensiero tende a prevalere in certi ambienti accademici, dove ci si concentra sulla ricerca della soluzione perfetta secondo criteri matematici ristretti che non hanno nulla a che fare con il mondo reale. È proprio a questo che mi riferivo quando parlavo del giusto problema di ottimizzazione.
Ogni trimestre, più o meno, c’è un professore che viene da me e chiede se posso rivedere il suo algoritmo online per risolvere il problema di ottimizzazione del percorso. La maggior parte degli articoli che esamino oggigiorno sono incentrati sulle varianti online. La mia risposta è sempre la stessa: non state risolvendo il problema giusto. Non mi interessa la vostra soluzione, perché non state nemmeno affrontando correttamente il problema stesso.
Il progresso non deve essere confuso con la sofisticazione. È un’idea errata quella secondo cui il progresso si sposti da qualcosa di semplice a qualcosa di sofisticato. In realtà, il progresso si ottiene spesso partendo da qualcosa di incredibilmente complicato e, grazie a un pensiero superiore e alla tecnologia, raggiungendo la semplicità. Per esempio, se guardi la mia ultima lezione sulle tendenze della supply chain per il 21° secolo, vedrai la Macchina di Marly, che portava l’acqua al Palazzo di Versailles. Era un sistema incredibilmente complicato, mentre le pompe elettriche moderne sono molto più semplici ed efficienti.
Il progresso non si trova necessariamente in una sofisticazione extra. A volte è necessario, ma non è un ingrediente essenziale del progresso.
Domanda: Le grandi reti di vendita al dettaglio gestiscono i loro livelli di stock, ma devono evadere gli ordini quasi immediatamente. A volte decidono di fare una promozione per conto proprio che non è stata avviata dal fornitore. Quale sarebbe l’approccio per prevedere e prepararsi di conseguenza a livello di fornitore?
Prima di tutto, dobbiamo guardare il problema da una prospettiva diversa. Supponi di adottare una prospettiva di previsione, in cui il tuo cliente, un grande retailer, sta facendo una grande promozione che arriva all’improvviso. Innanzitutto, è davvero una cosa così negativa? Se promuovono i tuoi prodotti senza informarti, è semplicemente un dato di fatto. Se osservi il tuo passato, di solito lo fanno regolarmente, e ci sono persino dei modelli.
Se torno ai miei principi, i modelli sono ovunque. Innanzitutto, devi adottare la prospettiva secondo la quale non puoi prevedere il futuro; invece, hai bisogno di previsioni probabilistiche. Anche se non puoi anticipare perfettamente le fluttuazioni, esse potrebbero non essere del tutto inaspettate. Forse devi cambiare le regole del gioco invece di lasciarti completamente sorprendere dal fornitore. Forse devi negoziare impegni che vincolino il retailer, la rete di vendita al dettaglio e il fornitore. Se la rete di vendita al dettaglio inizia a fare una grande spinta senza avvisare il fornitore, quest’ultimo non può realisticamente essere ritenuto responsabile per il mancato mantenimento della qualità del servizio.
Forse la soluzione è qualcosa di più collaborativo. Forse il fornitore dovrebbe avere una migliore valutazione del rischio. Se i materiali venduti dal fornitore non sono deperibili, potrebbe essere più redditizio avere un paio di mesi di scorte. La gente spesso pensa a zero ritardo, zero scorte, e zero tutto, ma è davvero questo che i tuoi clienti si aspettano da te? Forse ciò che i tuoi clienti si aspettano è un valore aggiunto sotto forma di scorte abbondanti. Ancora una volta, la risposta dipende da vari fattori.
Devi considerare il problema da molti punti di vista, e non esiste una soluzione banale. Devi riflettere molto sul problema e considerare tutte le opzioni disponibili. Forse il problema non è avere più scorte, ma una maggiore capacità produttiva. Se c’è un grande aumento della domanda e non è troppo costoso gestire un picco massiccio, e se i fornitori dei fornitori possono fornire i materiali abbastanza rapidamente, forse tutto ciò di cui hai bisogno è una capacità produttiva più versatile. Questo ti permetterebbe di reindirizzare la tua capacità produttiva verso ciò che sta crescendo ora.
A proposito, questo esiste in certi settori. Ad esempio, l’industria del packaging ha capacità massicce. La maggior parte delle macchine nell’industria del packaging sono stampanti industriali, che sono relativamente economiche. Chi opera nel settore del packaging solitamente dispone di molte stampanti che non vengono utilizzate per la maggior parte del tempo. Tuttavia, quando c’è un grande evento o un grande marchio vuole fare una spinta massiccia, hanno la capacità di stampare tonnellate di nuovi imballaggi che si adattano alla nuova spinta di marketing del marchio.
Quindi, dipende davvero da vari fattori, e mi scuso per non avere una risposta definitiva. Ma ciò che posso dire con certezza è che devi riflettere profondamente sul problema che stai affrontando.
Questo conclude la lezione di oggi, la sesta e ultima del prologo. Tra due settimane, lo stesso giorno e alla stessa ora, presenterò le personalità della supply chain. A presto.


