Technology

選択的経路自動微分:バックプロパゲーションドロップアウトにおける一様分布を超えて
選択的経路自動微分(SPAD)手法は、確率的勾配降下法(SGD)を部分データポイントの視点から強化します。この技術はコンパイラーレベルで実装され、勾配の質を犠牲にして勾配の量を補完することで、従来のSGD手法に比べてより精緻な視点を提供します。

ディープ・インベントリ・マネジメントの主観的レビュー
Amazonのチームが2022年後半にDeep Inventory Management (DIM)を発表しました。この論文は、強化学習と[深層学習](/ja/ディープ-ラーニング/)の両方を特徴とするDIM在庫最適化手法を提示しています。Lokadが過去に同様の道を歩んできたため、そのCEOで創業者のJoannes Vermorelは、提案手法について批判的な評価を下しています。
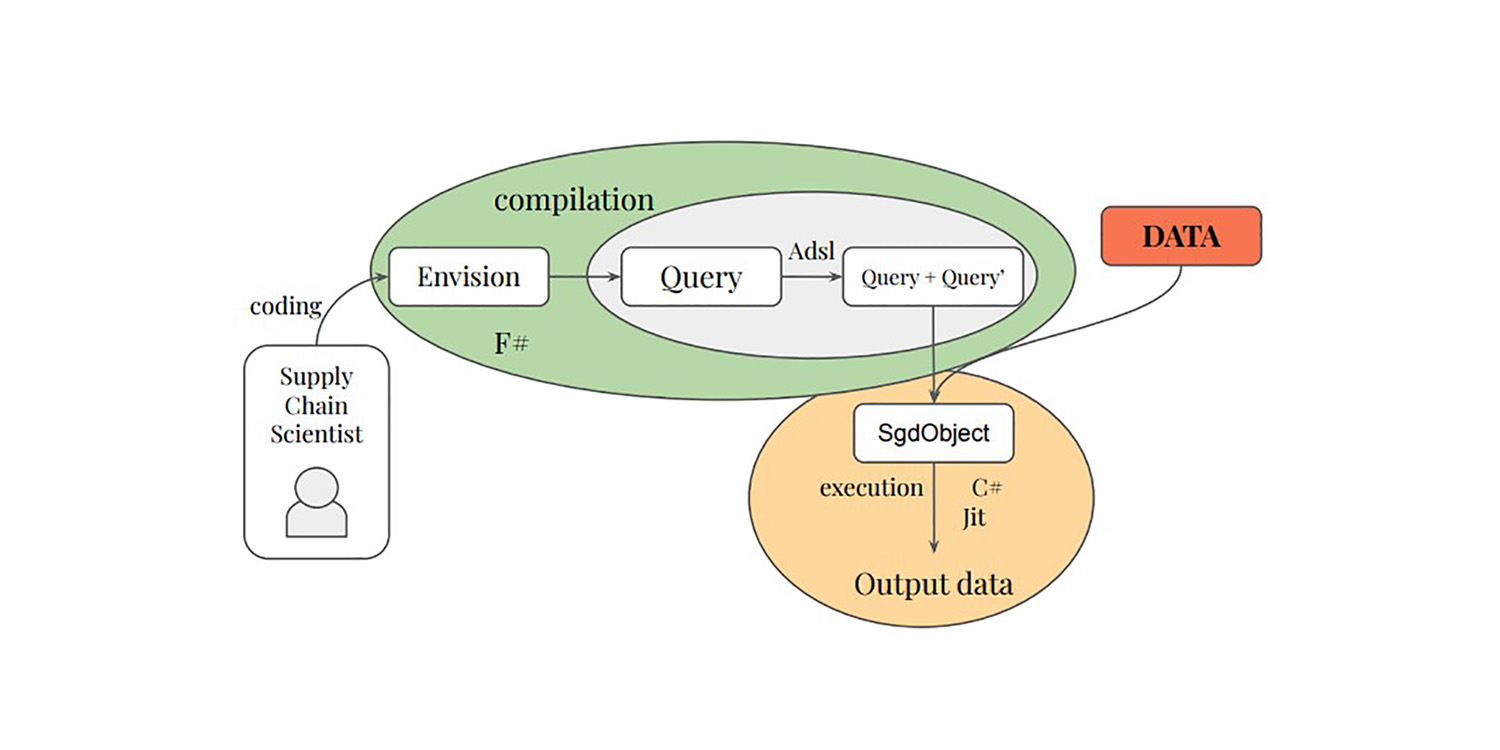
大規模リレーショナルデータの最適化のための微分可能プログラミング
Paul Peseux の博士研究は、リレーショナルクエリの微分化という、サプライチェーン分野であまり研究されていない領域に着目し、TOTAL JOIN オペレーター、Polystar、そしてリレーショナルクエリを微分するためのミニ言語 ADSL を提案しました。これらはすべて、日々の在庫意思決定の最適化のための自動微分の一環として、Lokad の DSL Envision に統合されています。
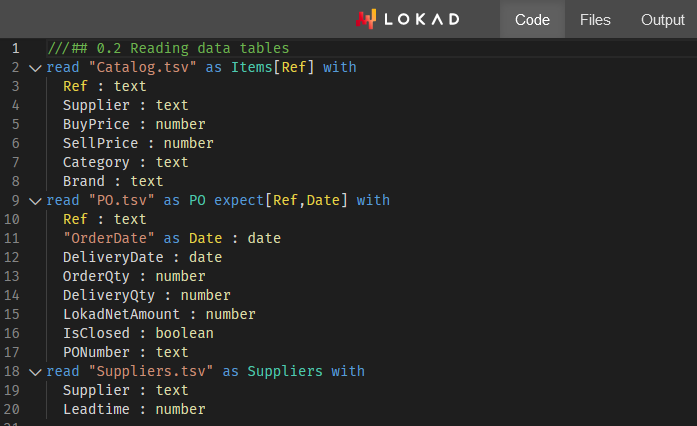
エンビジョンを通じたサプライヤー分析 - ワークショップ #1
Lokadは初のエンビジョンワークショップを開始し、学生(およびサプライチェーンの専門家)に、Lokad独自の確率的リスク管理の視点を用いて小売サプライヤーを分析する方法を教えます。
複数参照の最小発注量制約下における在庫管理
Gaetan Delétoille の MOQ に関する博士研究は、サプライチェーンという驚くほど研究が不足している分野に焦点を当て、w-policy を導入しました。これはLokadが日々の在庫意思決定ソリューションに統合している手法です。
クラウド上に分散された分類アルゴリズム
Lokadの第2従業員であるMatthieu Durutは、2012年にLokadでの研究成果をもとに博士号を取得しました。この博士論文は、今日の大規模サプライチェーンに対応するために不可欠な、クラウドネイティブな分散コンピューティングアーキテクチャへのLokadの移行の道を開きました。

大規模学習: 分散非同期クラスタリングアルゴリズムへの貢献
Benoit Patra は、Lokad の最初の従業員として、2012年にLokadで行われた研究により博士号を取得しました。この博士論文はサプライチェーン理論に根本的に新しい要素をもたらし、Lokadの確率的予測アプローチの将来の発展の基礎を築きました。

確率的勾配降下法とカテゴリカル特徴のための勾配推定器
機械学習(ML)の広範な分野は、さまざまな状況に対応するための多彩な技法と手法を提供します。しかし、サプライチェーンには独自のデータ上の課題があり、しばしばサプライチェーン実務者によって「基本的」とみなされる側面は、私たちの基準では満足のいくML手法の恩恵を受けられないことがあります。
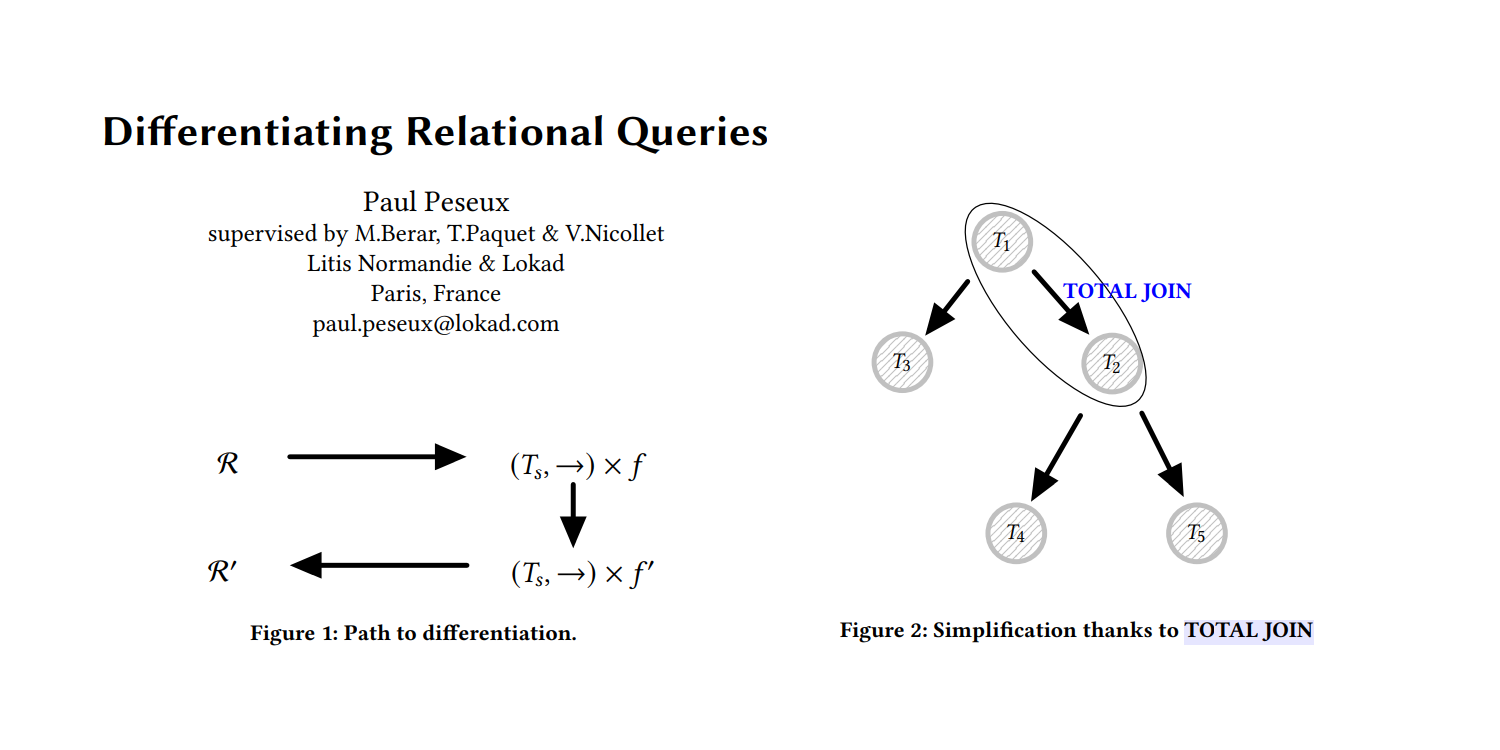
リレーショナルクエリの微分
サプライチェーンデータは、注文、顧客、サプライヤー、製品などのリレーショナルデータとしてほぼ独占的に現れます。これらのデータは、会社の運営に用いられるビジネスシステム―ERP、CRM、WMS―を通じて収集されます。

再現可能な並列確率的勾配降下法
確率的勾配降下法 (SGD) は、機械学習と数学的最適化の両方において、これまでに考案された中でも最も成功した手法の一つです。Lokadは供給連鎖の目的で、主に微分可能プログラミングを通じて、長年にわたりSGDを積極的に活用してきました。私たちの顧客のほとんどは、どこかに少なくとも一つのSGDをデータパイプラインに持っています。

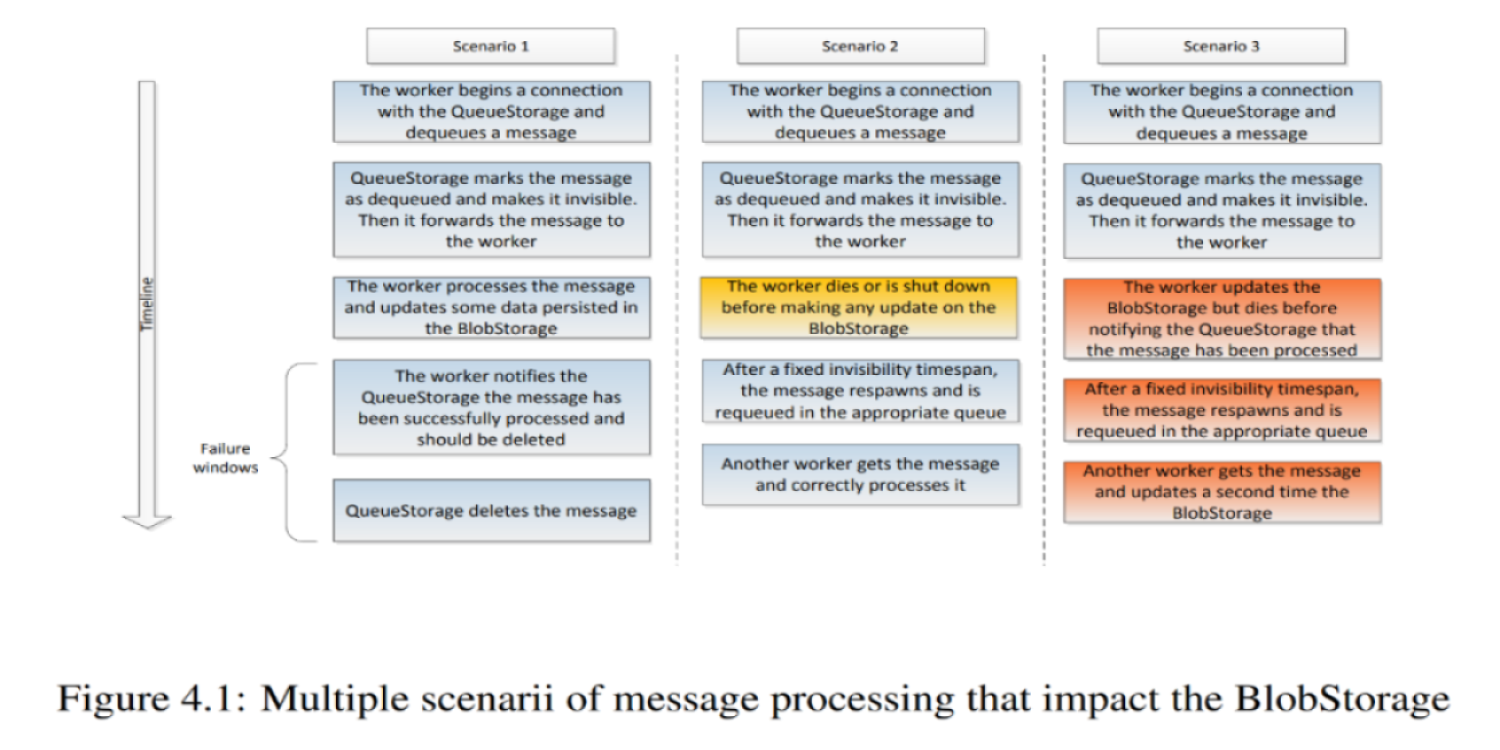
Envision VM (パート4), 分散実行
前回の記事では、主に各ワーカーが Envision スクリプトをどのように実行したかが検証されました。しかし、レジリエンスとパフォーマンスの両面から、Envision は実際にはクラスター内の複数のマシンで実行されます。

Envision VM(パート3)、アトムとデータストレージ
実行中、thunk は入力データを読み取り、出力データを書き込みます。これらはしばしば大量に発生します。データが生成された瞬間から使用されるまでどのように保持するか(その一部の答えは複数のマシンに分散した NVMe ドライブ上にあります)、そして RAM(ネットワークおよび永続的ストレージなどRAMより遅いチャネル)を通過するデータ量を最小限に抑える方法について説明します。