00:00:08 導入とRob Hyndmanの予測における経歴。
00:01:31 現実世界の予測技術とソフトウェアの持続可能性。
00:04:08 豊富なデータを持つさまざまな分野での予測技術の適用。
00:05:43 サプライチェーンにおけるさまざまな産業への対応の課題。
00:07:30 企業ソフトウェアとデータ収集の複雑さへの対処。
00:08:00 時系列予測と代替手法。
00:09:05 Lokadが予測分析で直面する課題。
00:11:29 学術ソフトウェア開発の長寿とモチベーション。
00:13:12 点予測から確率予測への移行。
00:15:00 学術的な手法の欠点と現実世界での実装。
00:16:01 シンプルなモデルの競技会でのパフォーマンス。
00:16:56 エレガントで簡潔な手法の重要性。
00:18:48 モデルの精度、複雑さ、コストのバランス。
00:19:25 予測のためのRパッケージの堅牢性と速度。
00:20:31 ビジネスにおける堅牢性、精度、実装コストのバランス。
00:21:35 予測における問題特化手法の重要性。
00:23:00 予測技術とライブラリの持続性の予測。
00:25:29 Robの予測ライブラリの維持に対する取り組み。
00:26:12 Fableの紹介と時系列予測への応用。
00:27:03 オープンソースの世界と予測ツールへの影響の評価。
概要
Lokadの創設者であるJoannes VermorelとMonash大学の統計学教授であるRob Hyndmanとのインタビューで、現実世界の予測技術の持続可能性について話し合われています。数百万人のユーザーによってダウンロードされたHyndmanのオープンソース予測ソフトウェアは、時間の試練に耐えることができ、企業の予測問題の約90%を解決することができます。ゲストは、供給チェーン業界において多様なニーズを持つ広範な観客に対応する課題と、効果的でアクセス可能なユーザーフレンドリーなソフトウェアの作成の重要性を強調しています。また、高品質な予測手法の開発におけるオープンソースソフトウェアと協力の重要性も強調しています。
詳細な概要
このインタビューでは、Kieran ChandlerがLokadの創設者であるJoannes VermorelとMonash大学の統計学教授であるRob Hyndmanと共に、現実世界の予測技術の持続可能性について話し合っています。Hyndmanのオープンソース予測ソフトウェアは、数百万人のユーザーによってダウンロードされ、他の多くのソフトウェアツールとは異なり、時間の試練に耐えることができます。
Vermorelは、Hyndmanの仕事を高く評価しており、一般的な学術ソフトウェアを超えて、包括的なライブラリの作成、自身の結果の多くを組み込み、人気のあるR言語に基づいた一貫したフレームワークを提供している点を特に称賛しています。Vermorelは、そのような耐久性と観客を持つ科学的なソフトウェアの例はほとんどないと考えています。
Hyndmanの学術研究は、サプライチェーンの予測に限定されているわけではありません。彼は大量のデータを持つあらゆる分野に予測技術を適用することに興味を持っています。彼の仕事には、電力消費量、死亡率、人口、観光客数、そして最近ではオーストラリア政府のCOVID-19の症例の予測も含まれています。予測に加えて、彼は異常検知と探索的なデータ分析にも取り組んでいます。
サプライチェーン業界の多様なニーズに対応する課題について話し合う中で、Vermorelは、企業ソフトウェア(ERP、MRP、WMS)によってデータがどのように認識され、記録されるかはしばしば偶発的であると説明しています。
彼らは、予測の目的で主に収集されていないデータを使用することから生じる複雑さや、エンタープライズリソースプランニング(ERP)システムから別のシステムへの移行についても取り上げています。また、異なるIT環境や企業ソフトウェアの展開における歴史的な偶発事象に適応できる予測技術の必要性についても議論しています。
Vermorelは、ファッションなどの時系列分析に適さない文脈での予測の重要性を強調しています。需要のエンジニアリングや新製品の導入が予測問題に影響を与える場合、予測モデルはフィードバックループや予測に基づいて行われるアクション、製品のアソートメントやプロモーション戦略など、さまざまな要素を制御する必要があります。Lokadが直面する複雑な予測分析の課題に対応するためには、この多面的なアプローチが重要です。
Hyndmanは、彼の時系列ソフトウェアが企業の予測問題の約90%を解決できると説明していますが、残りの10%は異なるアプローチが必要です。また、短命な学術ソフトウェアの問題にも言及し、それを論文の発表に焦点を当て、ソフトウェアの長期的な維持に対する報酬がないことに帰因しています。これにより、実践者との協力や方法の適切な文書化と持続性に焦点を当てることができなくなります。
このインタビューでは、適応性のある技術の必要性、時系列以外の文脈を考慮する重要性、フィードバックループや意思決定が予測モデルに与える影響など、サプライチェーンの最適化と予測の課題と複雑さが強調されています。さらに、予測の分野における学術研究と実践の応用との間の乖離も示されています。
両ゲストは、効果的でアクセスしやすいユーザーフレンドリーなソフトウェアの重要性を強調しており、それが世界に変革をもたらすために必要です。
Hyndmanは、過去15年間の学術文献におけるポイント予測から確率的予測への移行に言及しています。Lokadは、この変化をソフトウェアに取り入れた最初のサプライチェーン予測会社の1つでした。Hyndmanの初期のソフトウェアはポイント予測に焦点を当てていましたが、彼の新しいパッケージでは確率的予測が優先されています。
Vermorelは、多くの学術論文における隠れた欠陥(数値の不安定性、計算時間の過剰、複雑な実装など)を指摘しています。彼はまた、精度とシンプルさのバランスの重要性も強調しており、過度に複雑なモデルは実用的でないか必要ない場合があります。Vermorelは、Lokadが比較的シンプルなモデルを使用して高い精度を達成したM5コンペティションの例を挙げています。
Hyndmanは、ソフトウェアの製造コスト、計算、精度のバランスを取ることの重要性に同意しています。両ゲストは、Hyndmanのライブラリなど、広範な適用性を持つ簡潔でエレガントな予測手法を高く評価しています。
この会話は、予測モデルの精度と複雑さのトレードオフについての疑問を提起しています。Vermorelは、深層学習モデルのような非常に高い複雑さによるわずかな精度向上の追求の賢明さに疑問を投げかけています。VermorelとHyndmanの両者は、追加の複雑さを正当化しない微小な改善に迷い込むことなく、良い予測の本質に焦点を当てることの重要性を強調しています。
Hyndmanは、予測手法の開発時に精度と計算コストの両方を考慮することの重要性を強調しています。彼は、自身の予測パッケージの堅牢性を、コンサルティングプロジェクトでの起源に帰することができると述べています。それらのパッケージは、高速で信頼性があり、さまざまな状況に適用可能である必要がありました。
Vermorelは、予測手法が問題にもたらす付加価値を考慮することの重要性を強調しています。彼は、単純なパラメトリックモデルと勾配ブースティングツリーなどのより複雑な手法を対比し、一部の場合にはよりシンプルなモデルでも十分であることを指摘しています。Vermorelは、ファッションや自動車アフターマーケットなどの産業における予測の固有の課題についても議論しており、代替と互換性の要素が重要な役割を果たすことを指摘しています。
インタビュー対象者は、洗練さに気を取られることの重要性を強調しており、それが必ずしもより良い科学的または正確な結果に結び付くわけではないと述べています。Vermorelは、基本的な時系列予測技術が20年後も重要であると予測しており、現在のハードウェアに依存する複雑な手法は時代遅れになる可能性があると述べています。
Rob Hyndmanは、予測に関する自身の業績について話し、特に数千の時系列を同時に予測するための予測プロセスを簡素化するオープンソースソフトウェアパッケージ「Fable」の開発について説明しています。彼は、少なくとも10年間パッケージを維持することへの取り組みを強調し、コラボレーションやアクセシビリティなど、オープンソースソフトウェアの利点についても言及しています。
VermorelとHyndmanの両者は、高品質な予測手法の開発におけるオープンソースソフトウェアの重要性とコラボレーションの可能性を強調しています。Hyndmanは、2005年以来存在している公共のライブラリの維持にも取り組んでおり、データ分析を一般の人々にアクセス可能にする役割も果たしています。
全体的に、このインタビューは、複雑で急速に変化する世界での予測の課題と、効果的な解決策の開発におけるソフトウェアとコラボレーションの重要性を強調しています。オープンソースソフトウェアと公共のアクセスへの焦点は、データ分析と予測をより広い観客に提供する価値を強調しています。
両インタビュイーは、自身の仕事のオープンソース性を高く評価しており、高品質な予測手法の開発における広範なアクセスとコラボレーションを可能にしています。
フルトランスクリプト
Kieran Chandler: 予測は古代の実践であり、絶えず進化しているため、多くのソフトウェアは時代の試練に耐えられません。今日のゲストであるRob Hyndmanは、何百万人ものユーザーによってダウンロードされたオープンソースソフトウェアを実装した人物です。そのため、今日は彼と一緒に実世界の予測手法の持続可能性について話し合います。では、オーストラリアからの生中継で参加してくれたRob、ありがとうございます。あなたについて少し知りたいので、まずは自己紹介からお願いできますか。
Rob Hyndman: ありがとう、Kieran。参加できてうれしいです。こちらはオーストラリアで午後8時ですので、そんなに遅くはありません。私はモナッシュ大学の統計学教授であり、計量経済学とビジネス統計学の学科長を務めています。私は26年間そこに在籍しています。そのほとんどの期間、私は国際予測学会の編集長および国際予測研究所の理事も務めていました(2005年から2018年まで)。私は学者であり、たくさんの論文を書いており、予測に関する3冊の本も書いています。それ以外の時間は、通常テニスをしています。
Kieran Chandler: いいですね、私も夏の間はテニスを楽しんでいます。いつか一緒に試合をすることができるかもしれませんね。ジョアネス、今日のトピックは現実世界の予測技術の持続可能性と、ソフトウェアの一部が持続可能で長期間続くというアイデアです。その背後にあるアイデアは何ですか?
Joannes Vermorel: 多くのソフトウェアはさまざまな理由で時間の経過とともに劣化していく傾向があります。科学ソフトウェアに関しては、このソフトウェアがどのように作成されるかを考える必要があります。通常、論文の発表をサポートするために作成されるため、基本的には使い捨てのソフトウェアです。私がProfessor Hyndmanの仕事で非常に注目すべきと思ったのは、彼が学術界で通常行われていることを超えていったことです。つまり、使い捨てのソフトウェアを作成し、論文を発表し、終わり、次の論文に移るということではありませんでした。彼は実際には非常に広範なライブラリを構築しました。それは彼自身の結果や彼の同僚の結果を多く組み込んでおり、非常に人気のある言語であるRをベースに非常に一貫性のあるフレームワークを提供しています。これは数十年にわたってその価値を証明しており、それは非常に素晴らしい成果です。私たちが今日見るほとんどのソフトウェアは古く、Unixから派生したものやより高度なものがほとんどです。データサイエンスの観点からは、線形代数や類似の分野の基本的なビルディングブロック以外に、時間の試練に耐えるものはあまりありません。
Kieran Chandler: …分析ですが、よく考えてみると、そのような観客と耐久性を持つソフトウェアの例を十数個挙げることができるかもしれません。しかし、実際にはあまりありません。私はここには学術研究で通常行われることを超えた非常に注目すべきものがあると信じています。Rob、それではもう少し学術研究について話しましょう。あなたは明らかに私たちがこちらで取り組んでいるサプライチェーンの世界に焦点を当てているわけではありません。では、予測技術をどのような他の分野に応用することに興味がありますか?
Rob Hyndman: 大量のデータを取得できる場所なら何でも興味があります。例えば、電力消費量の予測を行っており、数十年にわたる非常に良いデータがあります。死亡率、人口、最近では観光客数の予測も行っていますが、パンデミックの最中にはかなり困難な予測です。オーストラリア政府がその仕組みを考えるのを手伝っています。オーストラリア政府のためにCOVID-19のケースを予測する仕事もしています。これは私が流行病学の世界で何かをする最初の試みであり、流行病学的アプローチのモデリングにかなりの知識を身につけ、それをいくつかの予測アンサンブルに組み込んできました。それは興味深い経験でした。基本的には、データが豊富な場合には、それをモデル化しようとする興味があります。また、大量のデータがある場合には、異常検知や探索的データ分析などの作業も行っています。多くの企業や政府機関と協力しており、彼らが大量のデータを含む問題を持って私のもとに来た場合、現在行われている予測よりもより良い予測を考えることに興味があります。
Kieran Chandler: 素晴らしいですね、観光業は現在非常に興味深いものです。予測の観点からは本当に異例ですね。ヨハネス、私たちの焦点は明らかにサプライチェーン業界にありますが、その中のただ1つの業界に焦点を当てているわけではありません。非常に幅広い視聴者を対象にしているので、さまざまなニーズを持つさまざまな人々に対応しようとする際にどのような課題が生じるか、どのような課題が生じるか教えていただけますか?
Joannes Vermorel: まず、私たちが世界を認識する方法です。私たちには、死亡率やその他のものに対して確立された統計のようなものはありません。エンタープライズソフトウェア(ERP、MRP、WMSなど)は、ほぼ偶発的な方法でデータを生成または記録します。データの収集は、これらのソフトウェアが導入された理由ではありませんでしたので、記録はありますが、時間の経過にわたって予測できるように設計されたツールとしては設計されていません。これはほぼ偶発的な副産物であり、それによって多くの複雑さが生じます。その中の1つの課題は、予測技術と重点的な研究によって、ERPから次のERPに移行しても生き残ることができるかどうかです。非常に混乱して偶発的なシステムを変更する場合、予測プロセスにどのような影響を与えるかを考慮する必要があります。
Kieran Chandler: では、次に議論したいのは、異なるITの景観とさまざまなエンタープライズソフトウェアツールの展開における歴史的な偶発性です。メソッドを完全に変更する必要がある場合、明らかに知識や技術のセットを構築していません。その中の1つの課題は、この領域で何かできるかどうかですか?そして、Lokadの視点からは、私たちにとって最も興味深い予測は、通常、時系列として自然に現れないものです。時系列として便利にフレーム化できない問題がある場合、どうすれば予測に類似したものが必要になるのでしょうか?ロブ、時系列予測以外の代替手法の使用についてどう思いますか?
Rob Hyndman: まあ、それはデータに非常に依存します。Joannesが言ったように、その特定の問題に対してどのようなモデルが必要になるかを判断するためです。私の時系列ソフトウェアは多くの問題を扱いますが、すべての問題を扱うわけではありません。一部の企業は、データセットがそのような方法で設定されているか、記録されているかによって、それを修正したり別の解決策を見つける必要があります。私が書いたソフトウェアの中で最も人気のあるものは、企業の予測問題の90%を解決します。残りの10%については、異なるアプローチが必要です。
Kieran Chandler: Joannes、あなたの経験では、そのような10%の問題がどれくらい頻繁に発生すると言えますか?
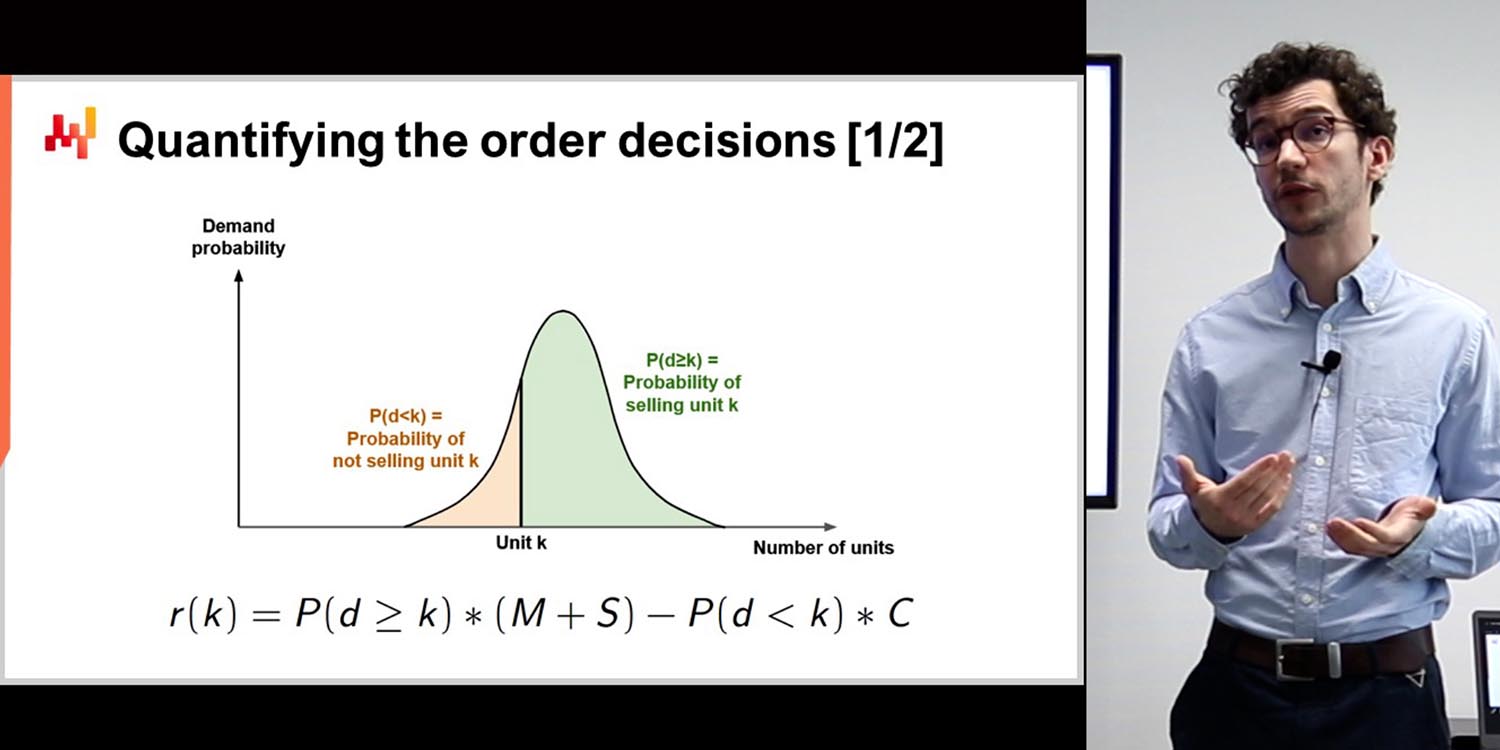
Joannes Vermorel: それは非常に微妙な問題です。Lokadでの予測の世界を通じて、その深さに気づいたのです。まず、私たちは点予測から確率的な予測に移行しました。これにより、問題の見方が変わりました。しかし、それ以上に深いです。例えば、ファッションを見てみましょう。需要を予測して何を生産するかを知りたいのですが、生産するものを決める際には、より多くまたはより少ない製品を導入する柔軟性があります。したがって、予測可能な問題に時系列があるという考え自体は、あなたの意思決定に依存します。例えば、ファッションでは、アソートメントに1つの製品を追加することが予測の問題の一部です。需要を予測するだけでなく、需要を設計することも望んでいます。私たちの旅の中で、私たちは古典的な点予測の視点とは全く異なる完全に直交する角度を持つ、削減できない不確実性があることに気づきました。しかし、すべてのフィードバックループにも対処しなければなりません。
Kieran Chandler: では、Joannes、予測モデルがサプライチェーンの最適化にどのような影響を与えるか教えていただけますか?
Joannes Vermorel: 予測を行うと、より情報を得た行動をとることができます。それは私たちが予測モデルを構築する方法に深い影響を与えます。その後、製品の度合い、価格帯、メッセージ、さらには製品のプロモーションなど、より多くの変数を追加することができます。ファッションの例を続けると、必要な数量を予測し、その後、店舗では一部の製品を他の製品よりも永続的に配置することになります。それは、観察するものに深い影響を与えます。Lokadが予測分析に直面した課題は、純粋な時系列の視点を複雑にするさまざまな角度を見ることができるようにすることでした。
Kieran Chandler: では、Rob、学術的な観点から話を進めましょう。多くの人々がソフトウェアを純粋に論文のために作成し、それからほとんど捨てられるということがあります。なぜ人々が作成しているソフトウェアにはあまり長期的な持続性がないと思いますか?
Rob Hyndman: まず、ほとんどの学者の動機について考える必要があります。彼らは論文を書くこととクラスを教えることに対して給与をもらっています。論文が書かれた後、それを実装するためのソフトウェアを提供するように促されることもあるかもしれません。しかし、ほとんどの学者にとって、それをすることには実際的な報酬はありませんし、長期間にわたってそのソフトウェアを維持することについては確かに報酬はありません。それを行う人は、それに関心があるか、それが愛の勤務であるからです。それは彼らの本業ではありません。実際、学術界にはその問題があります。新しい手法を出すこととそれを公表することに重点が置かれすぎており、実践者コミュニティとの連携や、手法が適切に文書化され、ユーザーフレンドリーなソフトウェアが長期間利用可能であることに十分な焦点が当てられていません。これは学術界の動機づけの問題です。私の動機づけは、新しい手法を開発したときに、人々にそれを使ってもらいたいということです。私は単に論文を公表して、数人または多くても100人に読まれるだけではなく、私の手法が実際に世界で使われることを望んでいます。私がやるべきこととは別に、私の手法が実際に実践で使用されることを見ることで多くの満足感を得るからです。
Joannes Vermorel: 予測モデルはより複雑になり、堅牢にすることは簡単ではありません。Lokadでは、モデルを実行し続けるために多くの古いコードを維持する必要があります。課題は、派手なモデルを考え出してそれで終わることはできないということです。モデルが何をしているのか、なぜそれをしているのかを説明する方法が必要です。モデルが適切に文書化され、人々が実践できるようにする必要があります。それは簡単なことではありませんが、モデルが採用される場合に重要です。
Rob Hyndman: また、時間の経過とともに事柄が変化するにつれて、新しい手法が開発され、予測に関する新しいソフトウェアやツールを提供する必要があります。Joannesが言及したのは、最後の15年ほどの学術文献でのポイント予測から確率予測への移行です。そして、Lokadは確率予測を取り入れて最初のサプライチェーン予測会社の1つだったと思います。私の初期のソフトウェアは確率予測を生成することができましたが、重点は常にポイント予測にありました。
Kieran Chandler: 過去数年間の開発では、重点は逆になっています。まず確率予測を取得し、次にポイント予測を行います。
Joannes Vermorel: 私自身が学術論文について多くの批判を持っている1つは、通常、方法にはたくさんの隠れた欠陥があるということです。ベンチマークで優れたパフォーマンスを発揮することがわかっている方法がある一方で、実際の実装にそれを入れようとすると、例えば数値的に非常に不安定であるか、計算時間が非常に長くなるなどの問題が発生することがあります。おもちゃのデータセットを使用する場合でも、計算に数日かかることがあります。実際のデータセットを使用する場合は、数年の計算が必要になるでしょう。
そして、実装が非常に複雑であるため、理論的には正しくできるかもしれませんが、実際には何かを達成することができない愚かなバグが常に発生します。また、メタパラメータの長いシリーズに非常に微妙な依存関係がある場合もあります。そのため、メソッドを動作させるためには、20の不明瞭なパラメータを調整する必要がありますが、これらの方法の作成者の頭の中にしか文書化されていない方法で調整する必要があります。
Rob Hyndman: それは非常に興味深いです。私が時間の試練に耐える方法を見るとき、Hyndmanが作成した非常にクラシックな方法の多くは、非常に洗練された方法に対して驚くほど良い結果を示しています。昨年のM5コンペティションでは、Lokadは909チームの中で予測の正確さにおいて6位にランクインしました。しかし、私たちは非常にシンプルなモデルでそれを行いました。ほとんど教科書のパラメトリック予測モデルであり、その上にETSモデリングの小さなトリックを使用して、ショットガン効果と確率分布を得ました。
しかし、全体として、それはおそらく私たちが季節性、週の日、月の週、年の週のいくつかの係数で1ページで要約できるモデルでした。つまり、私たちは勾配ブースティングツリーを使用して最も正確なモデルから1パーセント離れたと言えますが、コードの複雑さ、モデルの複雑さ、および全体的な不透明性に関しては、おそらく3桁以上複雑です。
Joannes Vermorel: それは私があなたのライブラリの成功を信じるものです。私が方法について本当に好きなのは、ほとんどの方法がエレガントな実装を持ち、簡潔であるということです。したがって、適用性の観点では、最小限の努力と騒ぎで正確性を得ることができるという点で、それについては真実であり、有効です。一方で、ディープラーニングキャンプの反対側、つまり、非常に困難な問題に取り組む場合には、ディープラーニングには何の問題もありませんが…
Kieran Chandler: エピソードへようこそ。今日は、Lokadの創設者であるJoannes Vermorelと、Monash大学の統計学教授であり、計量経済学およびビジネス統計学の学科長であるRob Hyndmanが登場します。機械翻訳とモデルの正確性について話しましょう。
Joannes Vermorel: 私は、1パーセント正確性が高くなるが、数百万のパラメータが必要であり、非常に複雑で不透明なモデルを持つことについての考え方に疑問を投げかけます。科学的な観点からは本当に優れているのでしょうか?おそらく、1000倍も複雑なものをわずか1パーセントの正確性のために追求することによって、完全に迷子になる危険性があります。予測においては、わずかな追加の正確性をもたらすが、多くの混乱をもたらすような気を散らす要素を置いておくべきではないということがあります。
Rob Hyndman: 2つのコスト、ソフトウェアの作成コストと実際の計算コスト、正確性のコストをバランスする必要があります。学術界では、通常、計算やコードの開発のコストを考慮せずに正確性に焦点を当てています。私はあなたと同意します、Joannes、両方を考慮に入れる必要があります。時には、計算やコードのメンテナンスに時間がかかりすぎる場合、最も正確な方法を必ずしも必要としないこともあります。私の予測パッケージは、コンサルティングプロジェクトを通じて開発されたため、堅牢です。これらの関数はさまざまなコンテキストで適用されたため、比較的堅牢でなければなりませんでした。企業が壊れているとか、データセットで機能しないと言って戻ってくることは望んでいませんでした。多くのコンサルティングを行ったことは、それらの関数が一般の人々に公開される前に多くのデータを見てきたことを意味します。また、ほとんどの企業は、ファンシーなベイジアンモデルでのMCMC計算に数日待ちたくないので、比較的高速である必要もあります。
Kieran Chandler: ビジネスの観点から、堅牢性、精度、およびモデルの実装コストのバランスをどのように取っていますか、ジョアネス?
Joannes Vermorel: それは本当に、あなたがテーブルに追加しているものによるところが大きいです。たとえば、M5コンペティションで使用したような非常に単純なパラメトリックモデルで、非常に洗練された勾配ブースターツリーメソッドの精度の1%に到達した場合、追加の複雑さの価値はあるでしょうか?勝者である勾配ブースターツリーを使用した方法は、非常に洗練されたデータ拡張スキームを使用しており、基本的にはデータセットを大幅に拡大する方法でした。
Kieran Chandler: それはかなり大きいですし、結果としてデータセットが20倍になります。そして、それに重い複雑なモデルを適用します。ですから、問題は、あなたが何か根本的に新しくて深遠なものを持ち込んでいるのか、そしてそれをどのようにバランスさせるのか、ということです。
Joannes Vermorel: 私がそれをバランスさせる方法は、本当に考えることです。私が本当に考慮すべき大きな問題が見落とされていないかどうかを考えるのです。たとえば、ファッションについて話す場合、明らかにカニバリゼーションと代替は非常に強力です。人々はファッションストアに入ってきて、この正確なバーコードが欲しいと思っているわけではありません。それは問題を考える正しい方法です。カニバリゼーションと代替はどこにでもあり、それを受け入れる必要があります。たとえば、自動車について考えてみましょう。自動車のアフターマーケットを見ると、問題は人々が車の部品を好きで買っているわけではなく、自分の車に問題があって修理したいから買っているということです。そして、車と部品の間には非常に複雑な互換性行列が存在します。ヨーロッパでは、100万以上の異なる車の部品と10万以上の異なる車があります。そして通常、あなたが持つ問題に対しては、数十の互換性のある異なる車の部品が存在するので、代替がありますが、ファッションとは異なり、それは完全に決定論的な方法で現れます。代替はほぼ完全に知られており、完全に構造化されています。そして、それについてはゼロの不確実性があるという事実を活かす方法を持っていたいのです。
ですから、問題ごとに、私がそれをバランスさせる方法は、追加の洗練さを支払いたい場合、それが本当に価値があるかどうかを確認することです。たとえば、教授ヒンドマンのライブラリとTensorFlowを比較してみましょう。ほとんどのモデルについて、私たちはおそらくキロバイトのコードを話しています。TensorFlowを見てみると、1つのライブラリをコンパイルするだけで800メガバイトもあり、TensorFlowバージョン1を含めると、数十億行のコードが含まれることになります。
時には、私たちはただグレーのニュアンスの問題で議論していると思われるかもしれませんが、それはただ好みの問題であり、正しい答えがないということです。少しシンプルにするか、少し複雑にするか、ということです。しかし、私が観察した現実は、通常、単なるグレーのニュアンスではないということです。私たちは、数桁もの複雑さを持つ方法について話しています。ですから、私が自分自身の予測をする場合、例えば、教授ヒンドマンのライブラリが20年後もまだ存在している確率はどれくらいであり、TensorFlowバージョン1が20年後もまだ存在している確率はどれくらいでしょうか?私は、基本的な時系列の方法は依然として関連性があるという考えにかなりのお金を賭けるでしょう。
Kieran Chandler: 予測技術は20年後も存在すると思いますか?
Joannes Vermorel: 過去5年間に製造されたグラフィックカードの特異性についての数十億行の偶発的な複雑さを組み込んだものはなくなるでしょう。私は深層学習において驚くべきブレークスルーがあったことを否定していません。私が言っているのは、私たちは本当に付加価値を理解する必要があるということです。それは、私たちが見ている問題によってかなり異なります。洗練されているからといって、それが科学的、正確、または妥当であるというわけではありません。それは印象的でTEDトークのようかもしれませんが、それについては非常に注意が必要です。
Kieran Chandler: Rob、最後の質問はあなたにお任せします。Joannesが話したことについて、10年から20年後もまだ存在していると思えますか?あなたは今日何に取り組んでいて、将来役立つと思いますか?
Rob Hyndman: 私の最初の公開ライブラリは2005年ごろで、それまで15年間続いています。私はすべてのライブラリの維持に取り組んでいますし、他のライブラリに取って代わられたと考えているものでも維持するつもりです。それにはそれほど多くの努力は必要ありません。私が取り組んでいる新しいパッケージは、Fableというパッケージで、同じ技術のほとんどを実装していますが、ユーザーが同時に数千の時系列を予測しやすくするために異なる方法で行っています。Fableとその関連パッケージは数年前から存在しており、私の最新のテキストブックでも使用しています。私は少なくとも10年間広く使用されることを期待しており、私が能力を持っている限り、それらを維持し、存在することを確認します。私は非常に優れたアシスタントを持っており、パッケージのメンテナンスを手伝ってもらっています。彼もオープンソースの世界とオープンソース開発における高品質なソフトウェアの提供に取り組んでいます。
Kieran Chandler: それは素晴らしいことですし、オープンソースの世界では誰もがアクセスできるようになっています。お時間いただき、ありがとうございました。ここで終わりにし、ご視聴いただきありがとうございました。次のエピソードでお会いしましょう。