PARADIGMAS DE PROGRAMACIÓN PARA SUPPLY CHAIN (RESUMEN DE CONFERENCIA 1.4)
Los problemas de supply chain son perversos y tratar de abordarlos sin las herramientas apropiadas de programación – en el contexto de una empresa de gran escala – resulta ser una experiencia de aprendizaje invariablemente costosa. Optimizar eficazmente el supply chain – una red dispersa de complejidades físicas y abstractas – requiere un conjunto de paradigmas de programación modernos, ágiles e innovadores. Estos paradigmas son fundamentales para la identificación, consideración y resolución exitosa del vasto y variado conjunto de problemas inherentes al supply chain.
Mira la conferencia

Análisis estático
No es necesario ser programador para pensar como uno, y el análisis adecuado de los problemas de supply chain se aborda mejor con una mentalidad de programación, no solo con herramientas de programación. Las soluciones de software tradicionales (como los ERPs) están diseñadas de tal manera que los problemas se resuelven en tiempo de ejecución en lugar de en tiempo de compilación1.
Esta es la diferencia entre una solución reactiva y una proactiva. Esta distinción es crucial porque las soluciones reactivas tienden a ser mucho más costosas que las proactivas, tanto en términos financieros como de capacidad. Estos costos, en gran medida evitables, son precisamente lo que una mentalidad de programación busca evitar, y el análisis estático es la expresión de este marco.
El análisis estático implica inspeccionar un programa (en este caso, la optimización) sin ejecutarlo, como medio para identificar posibles problemas antes de que puedan impactar en la producción. Lokad aborda el análisis estático a través de Envision, su lenguaje específico de dominio (DSL). Esto permite identificar y corregir errores a nivel de diseño (en el lenguaje de programación) de manera tan rápida y conveniente como sea posible.
Considera una empresa en proceso de construir un almacén. No se levanta el almacén y luego se contempla su distribución. Más bien, la disposición estratégica de pasillos, estanterías y muelles de carga se considera anticipadamente, para identificar posibles cuellos de botella antes de la construcción. Esto permite un diseño óptimo – y, por ende, un flujo óptimo – dentro del futuro almacén. Este cuidadoso diseño es análogo al tipo de análisis estático que Lokad realiza mediante Envision.
El análisis estático, tal como se describe aquí, modelaría la programación subyacente de la optimización e identificaría cualquier comportamiento potencialmente adverso dentro de la receta antes de su implementación. Estas tendencias adversas podrían incluir un error que resulte en la ordenación accidental de mucho más stock del necesario. Como resultado, tales errores serían eliminados del código antes de tener la oportunidad de causar estragos.
Programación en arreglos
En la optimización de supply chain, el tiempo estricto es esencial. Por ejemplo, en una cadena minorista, los datos deben ser consolidados, optimizados y transmitidos al sistema de gestión de almacenes en un plazo de 60 minutos. Si los cálculos tardan demasiado, la ejecución de todo el supply chain puede ponerse en peligro. La programación en arreglos aborda este problema eliminando ciertas clases de errores de programación y garantizando la duración de los cálculos, proporcionando así a los profesionales de supply chain un horizonte temporal predecible para el procesamiento de datos.
También conocida como programación con data frames, este enfoque permite realizar operaciones directamente sobre arreglos de datos, en lugar de sobre datos aislados. Lokad lo consigue aprovechando Envision, su DSL. La programación en arreglos puede simplificar la manipulación y el análisis de datos, por ejemplo, permitiendo operar sobre columnas enteras de datos en lugar de sobre entradas individuales dentro de cada tabla. Esto aumenta drásticamente la eficiencia del análisis y, a su vez, reduce las posibilidades de errores en la programación.
Considera a un gerente de almacén que tiene dos listas: la Lista A corresponde a los niveles de stock actuales, y la Lista B a los envíos entrantes para los productos de la Lista A. En lugar de revisar cada producto uno por uno y sumar manualmente los envíos entrantes (Lista B) a los niveles de stock actuales (Lista A), un método más eficiente sería procesar ambas listas simultáneamente, permitiendo así actualizar los niveles de inventario de todos los productos de un solo golpe. Esto ahorraría tanto tiempo como esfuerzo, y es esencialmente lo que busca lograr la programación en arreglos2.
En realidad, la programación en arreglos facilita la paralelización y distribución del cómputo de las vastas cantidades de datos involucrados en la optimización de supply chain. Al distribuir el procesamiento entre múltiples máquinas, se pueden reducir los costos y acortar los tiempos de ejecución.
Miscibilidad de hardware
Uno de los principales cuellos de botella en la optimización de supply chain es el número limitado de Supply Chain Scientist. Estos científicos son responsables de crear recetas numéricas que tienen en cuenta las estrategias de los clientes, así como las maquinaciones antagónicas de los competidores, para producir insights accionables.
No solo es difícil hallar a estos expertos, sino que una vez encontrados, a menudo deben superar varios obstáculos de hardware que se interponen entre ellos y la ejecución rápida de sus tareas. La miscibilidad de hardware – la capacidad de que varios componentes dentro de un sistema se integren y trabajen conjuntamente – es crucial para eliminar estos obstáculos. Aquí se consideran tres recursos informáticos fundamentales:
- Compute: La capacidad de procesamiento de una computadora, proporcionada ya sea por la CPU o la GPU.
- Memory: La capacidad de almacenamiento de datos de una computadora, proporcionada a través de la RAM o la ROM.
- Bandwidth: La tasa máxima a la que la información (datos) puede transferirse entre las diferentes partes de una computadora, o a través de una red de computadoras.
Procesar grandes conjuntos de datos es generalmente un proceso que consume mucho tiempo, lo que resulta en una menor productividad mientras los ingenieros esperan la ejecución de los trabajos. En una optimización de supply chain, se podrían almacenar fragmentos de código (que representan pasos intermedios de cálculo rutinario) en discos de estado sólido (SSDs). Este sencillo paso permite a los Supply Chain Scientist ejecutar scripts similares con solo cambios menores de manera mucho más rápida, incrementando así notablemente la productividad.
En el ejemplo anterior, se ha aprovechado un truco de memoria económico para reducir la sobrecarga de cómputo: el sistema nota que el script que se está procesando es casi idéntico a los anteriores, por lo que el cómputo se puede realizar en segundos en lugar de en decenas de minutos.
Este tipo de miscibilidad de hardware permite a las empresas extraer el mayor valor de cada dólar invertido.
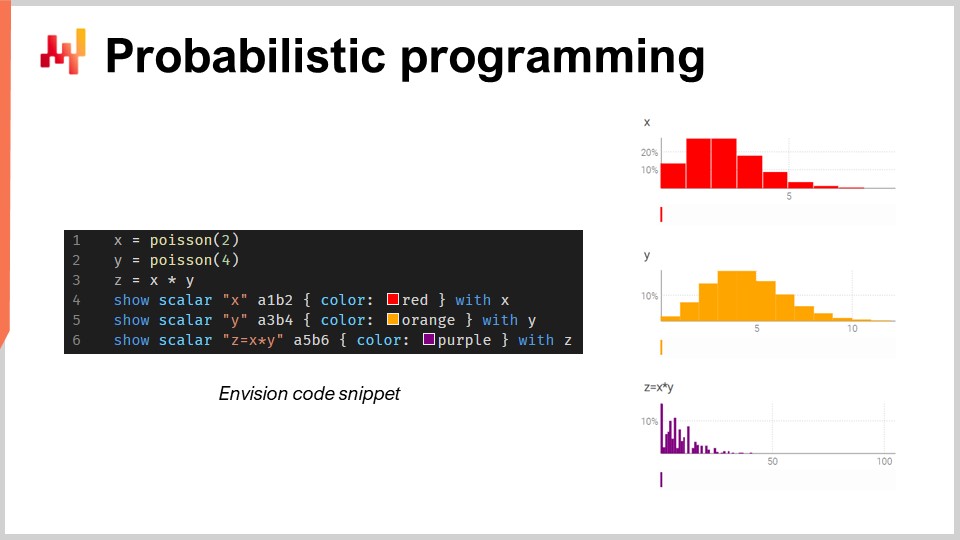
Programación probabilística
Existe un número infinito de posibles resultados futuros, pero no todos son igual de probables. Dada esta incertidumbre irreducible, la(s) herramienta(s) de programación deben adoptar un paradigma de forecast probabilístico. Aunque Excel ha sido históricamente la base de muchas supply chain, no puede ser desplegado a gran escala utilizando forecast probabilísticos, ya que este tipo de forecasting requiere la capacidad de procesar el álgebra de variables aleatorias3.
En resumen, Excel está diseñado principalmente para datos deterministas (es decir, valores fijos, como números enteros estáticos). Aunque se puede modificar para realizar algunas funciones de probabilidad, carece de la funcionalidad avanzada – y de la flexibilidad y expresividad general – necesarias para afrontar la compleja manipulación de variables aleatorias que se encuentra en el forecast probabilístico de la demanda. Más bien, un lenguaje de programación probabilística – como Envision – es más adecuado para representar y procesar las incertidumbres que se presentan en supply chain.
Considera una tienda del mercado de repuestos automotriz que vende pastillas de freno. En este escenario hipotético, los clientes deben comprar pastillas de freno en lotes de 2 o 4 a la vez, y la tienda debe tener en cuenta esta incertidumbre al realizar forecast de la demanda.
Si la tienda dispone de un lenguaje de programación probabilística (en lugar de un mar de hojas de cálculo), puede estimar con mucha mayor precisión el consumo total utilizando el álgebra de variables aleatorias, típicamente ausente en los lenguajes de programación generales.
Programación diferenciable
En el contexto de la optimización de supply chain, la programación diferenciable permite que la receta numérica aprenda y se adapte en función de los datos que se le proporcionan. La programación diferenciable, una vez combinada con un descenso de gradiente estocástico, permite a un Supply Chain Scientist descubrir patrones y relaciones complejas dentro del supply chain. Los parámetros se aprenden con cada nueva iteración de programación, y este proceso se repite miles de veces. Esto se hace para minimizar la discrepancia entre el modelo de forecast actual y los datos históricos4.
La canibalización y la sustitución – dentro de un mismo catálogo – son dos problemas de modelo que vale la pena desglosar en este contexto. En ambos escenarios, múltiples productos compiten por los mismos clientes, lo que presenta una capa desconcertante de complejidad en el forecast. Los efectos secundarios de estas fuerzas generalmente no son capturados por el forecast de series de tiempo, que considera principalmente la tendencia, la estacionalidad y el ruido para un único producto, sin tener en cuenta la posibilidad de interacciones.
La programación diferenciable y el descenso de gradiente estocástico se pueden aprovechar para abordar estos problemas, por ejemplo, analizando los datos históricos de las transacciones que vinculan a los clientes y productos. Envision es capaz de realizar tal investigación – llamada análisis de afinidad – entre clientes y compras mediante la lectura de archivos planos simples que contengan una profundidad histórica suficiente: es decir, transacciones, fechas, productos, clientes y cantidades compradas5.
Utilizando apenas un puñado de código único, Envision puede determinar la afinidad entre un cliente y un producto, lo que permite al Supply Chain Scientist optimizar aún más la receta numérica que ofrece la recomendación de interés6.
Versionado de código y datos
Un elemento pasado por alto en la viabilidad de la optimización a largo plazo es asegurar que la receta numérica – incluyendo cada fragmento de código y mínimo dato – pueda ser obtenido, rastreado y reproducido7. Sin esta capacidad de versionado, la capacidad para revertir la ingeniería de la receta se ve enormemente reducida cuando surgen excepciones desconcertantes (los heisenbugs en el ámbito informático).
Los heisenbugs son excepciones molestas que causan problemas en los cálculos de optimización, pero desaparecen cuando se vuelve a ejecutar el proceso. Esto puede hacer que sean extraordinariamente difíciles de solucionar, lo que resulta en el fracaso de algunas iniciativas y en que el supply chain vuelva a depender de hojas de cálculo de Excel. Para evitar los heisenbugs, es necesario que la lógica y los datos de la optimización sean completamente replicables. Esto requiere versionar todo el código y los datos utilizados en el proceso, asegurando que el entorno pueda ser reproducido en las mismas condiciones exactas de cualquier punto anterior en el tiempo.
Programación segura
Más allá de los heisenbugs incontrolados, la creciente digitalización del supply chain conlleva una vulnerabilidad consecuente a las amenazas digitales, tales como ciberataques y ransomware. Existen dos vectores principales –y generalmente involuntarios– de caos en este sentido: el(los) sistema(s) programable(s) que se utilizan, y las personas a las que se les permite usarlos. En cuanto a estas últimas, es muy difícil prever la incompetencia accidental (sin mencionar los incidentes de malicia intencional); respecto a lo primero, las decisiones intencionales a nivel de diseño que se toman son fundamentales para eludir estas minas terrestres.
En lugar de invertir recursos valiosos en aumentar el equipo de ciberseguridad (en anticipación a comportamientos reactivos, como apagar fuegos), las decisiones prudentes en la fase de diseño del sistema de programación pueden eliminar categorías enteras de problemas posteriores. Al eliminar funciones redundantes – como una base de datos SQL en el caso de Lokad – se pueden prevenir catástrofes predecibles, como un ataque de inyección SQL. De manera similar, optar por capas de persistencia de solo anexado (como hace Lokad) significa que eliminar datos (ya sea por un amigo o un enemigo) resulta mucho más difícil8.
Aunque Excel y Python tienen sus ventajas, carecen de la seguridad de programación necesaria para la protección de todo el código y datos requeridos para el tipo de optimización de supply chain escalable discutido en estas conferencias.
Notas
-
El tiempo de compilación se refiere a la etapa en la que el código de un programa se está convirtiendo en un formato legible por la máquina antes de ser ejecutado. El tiempo de ejecución se refiere a la etapa en la que el programa se está ejecutando efectivamente en la computadora. ↩︎
-
Esta es una aproximación muy burda del proceso. La realidad es mucho más compleja, pero ese es el ámbito de los expertos informáticos. Por ahora, la idea es que la programación en arreglos resulta en un proceso de cálculo mucho más optimizado (y eficiente en costos), cuyos beneficios son abundantes en el contexto de supply chain. ↩︎
-
En términos simples, esto se refiere a la manipulación y combinación de valores aleatorios, como calcular el resultado de una tirada de dados (o de varios cientos de miles de tiradas, en el contexto de una gran red de supply chain). Engloba desde sumas, restas y multiplicaciones básicas hasta funciones mucho más complejas como encontrar varianzas, covarianzas y valores esperados. ↩︎
-
Considere intentar perfeccionar una receta real. Puede haber un esquema base del que extraer, pero lograr el equilibrio perfecto de ingredientes - y de la preparación - resulta difícil de alcanzar. De hecho, una receta no solo involucra consideraciones de sabor, sino también de textura y apariencia. Para encontrar la iteración perfecta de la receta, se realizan ajustes minuciosos y se anotan los resultados. En lugar de experimentar con cada condimento y utensilio de cocina concebible, se hacen ajustes fundamentados en función del feedback que se observa con cada iteración (p.ej., añadiendo una pizca más o menos de sal). Con cada iteración se aprende más sobre las proporciones óptimas, y la receta evoluciona. En esencia, esto es lo que la programación diferenciable y el descenso del gradiente estocástico hacen con la receta numérica en una optimización de supply chain. Por favor, revisa la conferencia para los detalles matemáticos. ↩︎
-
Cuando se identifica una fuerte afinidad entre dos productos que ya se encuentran en el catálogo, puede indicar que son complementarios, es decir, que a menudo se compran juntos. Si se observa que los clientes intercambian uno por otro dos productos con un alto grado de similitud, podría sugerir sustitución. Sin embargo, si un nuevo producto muestra una fuerte afinidad con un producto existente y provoca una disminución en las ventas de este último, podría indicar canibalización. ↩︎
-
Se sobreentiende que estas son descripciones simplificadas de las operaciones matemáticas involucradas. Dicho esto, las operaciones matemáticas no resultan demasiado complicadas, como se explica en la conferencia. ↩︎
-
Los sistemas de versionado populares incluyen Git y SVN. Permiten que múltiples personas trabajen en el mismo código (o en cualquier contenido) de forma simultánea y fusionen (o rechacen) los cambios. ↩︎
-
La capa de persistencia de solo anexado se refiere a una estrategia de almacenamiento de datos en la que la nueva información se añade a la base de datos sin modificar o eliminar los datos existentes. El diseño de seguridad de solo anexado de Lokad se explica en su extensa sección de preguntas frecuentes sobre seguridad. ↩︎