Paradigmi di programmazione per la supply chain (Riassunto Lezione 1.4)
Problemi della supply chain sono ardui e cercare di affrontarli senza gli opportuni strumenti di programmazione - nel contesto di una grande azienda - si rivela un’esperienza di apprendimento inevitabilmente costosa. Ottimizzare efficacemente la supply chain - una rete dispersa di complessità fisiche e astratte - richiede una suite di paradigmi di programmazione. Questi paradigmi sono parte integrante dell’identificazione, della considerazione e della risoluzione dell’enorme e variegata gamma di problemi intrinseci alla supply chain.
Guarda la Lezione

Analisi Statica
Non è necessario essere un programmatore per pensare come tale, e una corretta analisi delle problematiche della supply chain è meglio affrontata con una mentalità da programmatore, non solo con strumenti di programmazione. Le soluzioni software tradizionali (come gli ERP) sono progettate in modo tale che i problemi vengano affrontati in fase di esecuzione piuttosto che in fase di compilazione1.
Questa è la differenza tra una soluzione reattiva e una proattiva. Tale distinzione è cruciale perché le soluzioni reattive tendono ad essere molto più costose di quelle proattive, sia in termini finanziari che di banda. Questi costi, per lo più evitabili, sono esattamente ciò che una mentalità da programmatore mira ad evitare, e l’analisi statica ne è l’espressione.
L’analisi statica comporta l’ispezione di un programma (in questo caso, l’ottimizzazione) senza eseguirlo, al fine di identificare potenziali problemi prima che possano influire sulla produzione. Lokad affronta l’analisi statica tramite Envision, il suo linguaggio specifico di dominio (DSL). Ciò consente di identificare e correggere gli errori a livello di progettazione (nel linguaggio di programmazione) nel modo più rapido e conveniente possibile.
Considera un’azienda che sta costruendo un magazzino. Non si erige il magazzino per poi contemplarne la disposizione. Piuttosto, la disposizione strategica delle corsie, degli scaffali e dei punti di carico viene pianificata in anticipo, al fine di identificare possibili strozzature prima della costruzione. Ciò consente un design ottimale - e di conseguenza un flusso ottimale - all’interno del futuro magazzino. Questa accurata pianificazione è analoga al tipo di analisi statica che Lokad realizza tramite Envision.
L’analisi statica, come descritta qui, modella la programmazione sottostante l’ottimizzazione e identifica eventuali comportamenti potenzialmente avversi all’interno della ricetta prima della sua implementazione. Tali tendenze potrebbero includere un bug che porta all’ordinazione accidentale di molto più stock del necessario. Di conseguenza, tali bug verrebbero eliminati dal codice prima che abbiano la possibilità di causare danni.
Programmazione Array
Nell’ottimizzazione della supply chain, il rispetto dei tempi è essenziale. Ad esempio, in una catena retail, i dati devono essere consolidati, ottimizzati e trasferiti al sistema di gestione del magazzino entro una finestra di 60 minuti. Se i calcoli richiedono troppo tempo, l’esecuzione dell’intera supply chain può essere compromessa. La programmazione array affronta questo problema eliminando alcune classi di errori di programmazione e garantendo la durata dei calcoli, fornendo così ai professionisti della supply chain un orizzonte temporale prevedibile per il trattamento dei dati.
Conosciuta anche come programmazione di data frame, questo approccio consente di eseguire operazioni direttamente sugli array di dati, anziché su singoli elementi. Lokad lo realizza sfruttando Envision, il suo DSL. La programmazione array può semplificare la manipolazione e l’analisi dei dati, ad esempio operando su intere colonne anziché sui singoli elementi di ciascuna tabella. Ciò aumenta notevolmente l’efficienza dell’analisi e, di conseguenza, riduce le possibilità di errori di programmazione.
Considera un responsabile di magazzino che dispone di due liste: la Lista A rappresenta gli attuali livelli di stock, e la Lista B rappresenta le spedizioni in arrivo per i prodotti presenti nella Lista A. Invece di analizzare ogni prodotto singolarmente e aggiungere manualmente le spedizioni in arrivo (Lista B) agli attuali livelli di stock (Lista A), un metodo più efficiente sarebbe elaborare entrambe le liste simultaneamente, permettendo così di aggiornare i livelli di inventario per tutti i prodotti in un solo colpo. Ciò permetterebbe di risparmiare tempo e fatica, ed è essenzialmente ciò che la programmazione array intende fare2.
In realtà, la programmazione array facilita la parallelizzazione e la distribuzione del calcolo dei vasti quantitativi di dati coinvolti nell’ottimizzazione della supply chain. Distribuendo il calcolo su più macchine, i costi possono essere ridotti e i tempi di esecuzione abbreviati.
Miscibilità hardware
Uno dei principali colli di bottiglia nell’ottimizzazione della supply chain è il numero limitato di Supply Chain Scientist. Questi esperti sono responsabili della creazione di ricette numeriche che tengono conto delle strategie dei clienti, nonché delle macchinazioni antagonistiche dei concorrenti, per produrre intuizioni attuabili.
Non solo questi esperti sono difficili da reperire, ma, una volta trovati, devono spesso superare diverse barriere hardware che li separano dall’esecuzione rapida dei loro compiti. La miscibilità hardware - la capacità dei vari componenti di un sistema di integrarsi e lavorare insieme - è cruciale per eliminare questi ostacoli. Qui vengono considerate tre risorse informatiche fondamentali:
- Compute: La potenza di elaborazione di un computer, fornita dalla CPU o dalla GPU.
- Memory: La capacità di memorizzazione dei dati di un computer, ospitata tramite RAM o ROM.
- Bandwidth: La velocità massima con cui le informazioni (dati) possono essere trasferite tra diverse parti di un computer o attraverso una rete di computer.
Elaborare grandi set di dati è generalmente un processo che richiede tempo, con conseguente minore produttività mentre gli ingegneri attendono l’esecuzione dei compiti. In un’ottimizzazione della supply chain, si potrebbero memorizzare piccoli frammenti di codice (che rappresentano passaggi intermedi di calcolo di routine) su dischi a stato solido (SSD). Questo semplice accorgimento permette ai Supply Chain Scientist di eseguire script simili, con solo lievi modifiche, molto più rapidamente, aumentando così significativamente la produttività.
Nell’esempio sopra, si è sfruttato un trucco economico per la memoria per ridurre il carico computazionale: il sistema rileva che lo script in esecuzione è quasi identico a quello precedente, permettendo di eseguire il calcolo in pochi secondi anziché in decine di minuti.
Questo tipo di miscibilità hardware consente alle aziende di estrarre il massimo valore dai loro investimenti.
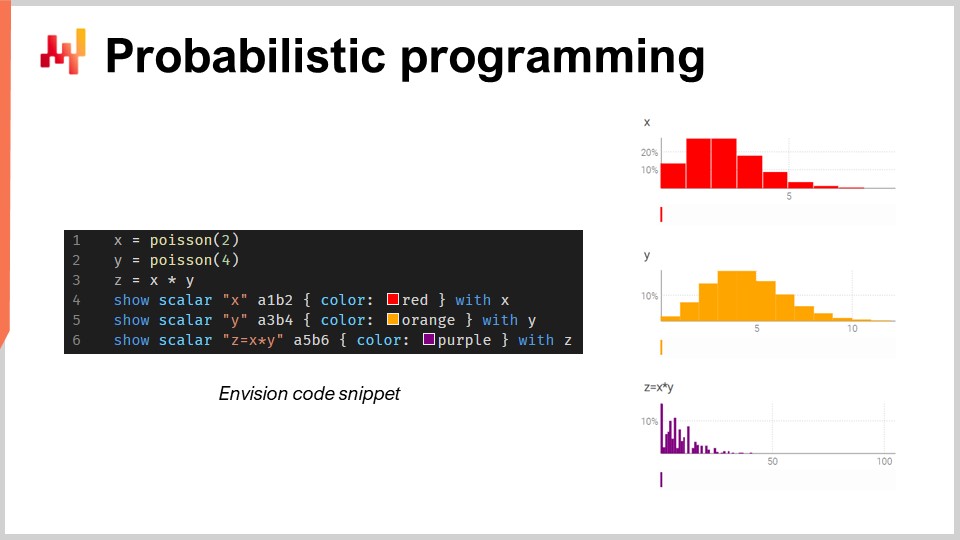
Programmazione probabilistica
Esistono un numero infinito di possibili esiti futuri, ma non sono tutti ugualmente probabili. Data questa incertezza irreducibile, lo strumento (o gli strumenti) di programmazione devono adottare un paradigma di previsione probabilistica. Sebbene Excel sia storicamente stato la base di molte supply chain, non può essere utilizzato su larga scala con previsioni probabilistiche, poiché questo tipo di previsione richiede la capacità di elaborare l’algebra delle variabili casuali3.
In breve, Excel è progettato principalmente per dati deterministici (cioè, valori fissi, come numeri interi statici). Sebbene possa essere modificato per eseguire alcune funzioni di probabilità, gli manca la funzionalità avanzata - oltre alla flessibilità ed espressività complessive - necessaria per gestire la complessa manipolazione delle variabili casuali che si incontrano nelle previsioni della domanda probabilistica. Piuttosto, un linguaggio di programmazione probabilistica - come Envision - è più adatto a rappresentare ed elaborare le incertezze presenti nella supply chain.
Considera un negozio di ricambi per auto che vende pastiglie dei freni. In questo scenario ipotetico, i clienti devono acquistare le pastiglie in lotti di 2 o 4 alla volta, e il negozio deve tener conto di questa incertezza quando prevede la domanda.
Se il negozio ha accesso a un linguaggio di programmazione probabilistica (invece di una marea di fogli di calcolo), può stimare il consumo totale in modo più accurato utilizzando l’algebra delle variabili casuali - tipicamente assente nei linguaggi di programmazione generali.
Programmazione differenziabile
Nel contesto dell’ottimizzazione della supply chain, la programmazione differenziabile consente alla ricetta numerica di apprendere e adattarsi in base ai dati disponibili. Combinata con la discesa del gradiente stocastico, essa permette a un Supply Chain Scientist di scoprire schemi e relazioni complesse all’interno della supply chain. I parametri vengono appresi ad ogni nuova iterazione, e questo processo viene ripetuto migliaia di volte, al fine di minimizzare la discrepanza tra il modello di previsione attuale e i dati storici4.
La cannibalizzazione e la sostituzione - all’interno di un singolo catalogo - sono due problematiche del modello che valgono la pena di essere analizzate in questo contesto. In entrambi gli scenari, più prodotti competono per gli stessi clienti, introducendo un livello intricatamente complesso di difficoltà nella previsione. Gli effetti a valle di tali dinamiche generalmente non vengono catturati dalle tradizionali previsioni tramite serie temporali, che considerano principalmente la tendenza, la stagionalità e il rumore per un singolo prodotto, senza tenere conto della possibilità di interazioni.
La programmazione differenziabile e la discesa del gradiente stocastico possono essere sfruttate per affrontare questi problemi, ad esempio analizzando i dati storici delle transazioni che collegano clienti e prodotti. Envision è in grado di eseguire tale analisi - detta analisi di affinità - tra clienti e acquisti leggendo file flat semplici che contengono una sufficiente profondità storica: cioè transazioni, date, prodotti, clienti e quantità acquistate5.
Con un numero davvero limitato di righe di codice uniche, Envision può determinare l’affinità tra un cliente e un prodotto, permettendo così al Supply Chain Scientist di ottimizzare ulteriormente la ricetta numerica che fornisce la raccomandazione di interesse6.
Versionamento di codice e dati
Un elemento trascurato per la sostenibilità a lungo termine dell’ottimizzazione è garantire che la ricetta numerica - includendo ogni singolo frammento di codice e ogni minima traccia di dato - possa essere reperita, tracciata e riprodotta7. Senza questa capacità di versionamento, la possibilità di decodificare la ricetta risulta notevolmente compromessa quando insorgono eccezioni esasperanti (heisenbugs nei circoli informatici).
Gli heisenbugs sono eccezioni fastidiose che causano problemi nei calcoli di ottimizzazione, ma scompaiono quando il processo viene eseguito nuovamente. Questo li rende estremamente difficili da correggere, con il risultato che alcune iniziative falliscono e la supply chain torna a fare affidamento su fogli di calcolo Excel. Per evitare gli heisenbugs è necessaria una replicabilità completa della logica e dei dati dell’ottimizzazione. Ciò richiede il versionamento di tutto il codice e dei dati utilizzati nel processo, garantendo che l’ambiente possa essere replicato alle stesse condizioni di qualsiasi punto nel tempo.
Programmazione sicura
Oltre agli heisenbugs imprevedibili, la crescente digitalizzazione della supply chain comporta una conseguente vulnerabilità alle minacce digitali, quali attacchi informatici e ransomware. Esistono due vettori principali - e solitamente inconsapevoli - del caos in tal senso: i sistemi programmabili che si utilizzano e le persone a cui si concede l’accesso. Per questo secondo aspetto è molto difficile prevedere l’incompetenza accidentale (per non parlare di casi di malizia intenzionale); per il primo, le scelte progettuali deliberate sono fondamentali per evitare queste insidie.
Invece di investire risorse preziose nell’espansione del team di cyber security (in previsione di comportamenti reattivi, come lo spegnimento degli incendi), decisioni prudenti nella fase di progettazione del sistema di programmazione possono eliminare intere classi di problemi successivi. Rimuovendo funzionalità ridondanti - come nel caso di un database SQL utilizzato da Lokad - si possono prevenire catastrofi prevedibili, come un attacco di SQL injection. Allo stesso modo, optare per livelli di persistenza in append-only (come fa Lokad) significa che l’eliminazione dei dati (sia da parte di alleati che di avversari) diventa molto più difficile8.
Sebbene Excel e Python abbiano i loro vantaggi, essi non dispongono della sicurezza di programmazione necessaria per proteggere tutto il codice e i dati richiesti per il tipo di ottimizzazione della supply chain scalabile discusso in queste lezioni.
Note
-
Il compile-time si riferisce alla fase in cui il codice di un programma viene convertito in un formato leggibile dalla macchina prima della sua esecuzione. Il run-time si riferisce alla fase in cui il programma viene effettivamente eseguito dal computer. ↩︎
-
Questa è un’approssimazione molto grossolana del processo. La realtà è molto più complessa, ma questo è il compito degli esperti informatici. Per ora, l’essenza è che la programmazione array porta a un processo di calcolo molto più snello (e economicamente vantaggioso), i cui benefici sono numerosi nel contesto della supply chain. ↩︎
-
In termini semplici, questo si riferisce alla manipolazione e combinazione di valori casuali, come calcolare l’esito di un lancio di dado (o di centinaia di migliaia di lanci, nel contesto di una vasta rete di supply chain). Comprende tutto, dalla somma, sottrazione e moltiplicazione di base fino a funzioni molto più complesse come il calcolo di varianze, covarianze e valori attesi. ↩︎
-
Considera di provare a perfezionare una ricetta reale. Potrebbe esserci uno schema di base su cui basarsi, ma ottenere il perfetto equilibrio di ingredienti - e preparazione - risulta sfuggente. In realtà, in una ricetta non ci sono solo considerazioni sul gusto, ma anche sulla consistenza e sull’aspetto. Per trovare l’iterazione perfetta della ricetta, si apportano piccole modifiche e si annotano i risultati. Piuttosto che sperimentare con ogni condimento e utensile da cucina concepibile, si effettuano modifiche ponderate basate sul feedback osservato a ogni iterazione (es., aggiungere un pizzico in più o in meno di sale). Ad ogni iterazione, si apprende di più sulle proporzioni ottimali, e la ricetta evolve. Alla base, questo è ciò che la programmazione differenziabile e la discesa del gradiente stocastica fanno con la ricetta numerica in un’ottimizzazione supply chain. Per favore, consulta la lezione per le note matematiche. ↩︎
-
Quando viene identificata una forte affinità tra due prodotti già presenti nel catalogo, ciò può indicare che sono complementari, nel senso che vengono spesso acquistati insieme. Se si osserva che i clienti passano da un prodotto all’altro con un alto grado di similarità, ciò può suggerire una sostituzione. Tuttavia, se un nuovo prodotto mostra una forte affinità con un prodotto esistente e provoca una diminuzione delle vendite del prodotto esistente, ciò può indicare una cannibalizzazione. ↩︎
-
È superfluo dire che queste sono descrizioni semplificate delle operazioni matematiche coinvolte. Detto ciò, le operazioni matematiche non sono affatto complicate, come spiegato nella lezione. ↩︎
-
I sistemi di versionamento più popolari includono Git e SVN. Permettono a più persone di lavorare contemporaneamente sullo stesso codice (o su qualsiasi contenuto) e di unire (o rifiutare) le modifiche. ↩︎
-
Il livello di persistenza in sola aggiunta si riferisce a una strategia di memorizzazione dei dati in cui le nuove informazioni vengono aggiunte al database senza modificare o eliminare i dati esistenti. Il design di sicurezza in sola aggiunta di Lokad è trattato nella sua estesa FAQ di sicurezza. ↩︎