ПАРАДИГМЫ ПРОГРАММИРОВАНИЯ ДЛЯ ЦЕПОЧКИ ПОСТАВОК (РЕЗЮМЕ ЛЕКЦИИ 1.4)
Проблемы цепочки поставок являются очень сложными и попытка решить их без соответствующих инструментов программирования — в контексте крупной компании — оказывается неизменно дорогостоящим опытом обучения. Эффективная оптимизация цепочки поставок — разрозненной сети физических и абстрактных сложностей — требует набора современных, гибких и инновационных парадигм программирования. Эти парадигмы являются неотъемлемой частью успешного выявления, рассмотрения и решения огромного и разнообразного спектра проблем, присущих цепочке поставок.
Посмотреть лекцию

Статический анализ
Не обязательно быть программистом, чтобы мыслить как программист, и правильный анализ вопросов цепочки поставок лучше всего осуществляется с программным мышлением, а не просто с помощью программных инструментов. Традиционные программные решения (такие как ERP-системы) разработаны таким образом, что проблемы решаются во время выполнения, а не на этапе компиляции1.
Это разница между реактивным решением и проактивным. Это различие имеет решающее значение, поскольку реактивные решения, как правило, обходятся заметно дороже как с финансовой точки зрения, так и с точки зрения пропускной способности. Эти в значительной мере избегаемые затраты именно то, чего стремится избежать программное мышление, а статический анализ является воплощением этой концепции.
Статический анализ предполагает проверку программы (в данном случае оптимизации) без её запуска с целью выявления потенциальных проблем до того, как они смогут повлиять на производство. Lokad осуществляет статический анализ с помощью Envision, своего предметно-ориентированного языка (DSL). Это позволяет максимально быстро и удобно выявлять и исправлять ошибки на уровне проектирования (в языке программирования).
Представьте себе компанию, которая строит склад. Сначала не возводят склад, а затем не задумываются о его планировке. Напротив, стратегическое расположение проходов, стеллажей и погрузочных доков планируется заранее, чтобы выявить потенциальные узкие места до начала строительства. Это позволяет достичь оптимального проектирования — а значит, и эффективного потока — в будущем складе. Такая тщательная проработка плана аналогична тому статическому анализу, который Lokad осуществляет с помощью Envision.
Как описано выше, статический анализ моделирует основную программу оптимизации и выявляет любые потенциально вредоносные действия внутри алгоритма до его внедрения. Подобные вредоносные тенденции могут включать ошибку, приводящую к случайному заказу значительно большего количества запасов, чем требуется. В результате такие ошибки исключаются из кода до того, как они успевают нанести ущерб.
Массивное программирование
В оптимизации цепочки поставок крайне важна точность времени. Например, в розничной сети данные должны быть консолидированы, оптимизированы и переданы в систему управления складом в течение 60 минут. Если расчёты занимают слишком много времени, выполнение всей цепочки поставок может оказаться под угрозой. Массивное программирование решает эту проблему, устраняя некоторые классы ошибок программирования и гарантируя продолжительность расчётов, предоставляя специалистам по цепочке поставок предсказуемый временной горизонт для обработки данных.
Также известное как программирование с датафреймами, этот подход позволяет выполнять операции непосредственно над массивами данных, а не над отдельными элементами. Lokad реализует это с помощью Envision, своего DSL. Массивное программирование может упростить манипуляцию и анализ данных, например, выполняя операции над целыми столбцами данных вместо отдельных записей в каждой таблице. Это значительно повышает эффективность анализа и, в свою очередь, снижает вероятность появления ошибок в программе.
Представьте менеджера склада, у которого есть два списка: Список A содержит текущие уровни запасов, а Список B — поступающие поставки для продуктов из Списка A. Вместо того чтобы проходить по каждому продукту отдельно и вручную добавлять поставки (Список B) к текущим запасам (Список A), более эффективным методом будет обработка обоих списков одновременно, что позволит обновить уровни инвентаризации для всех продуктов разом. Это сэкономит и время, и усилия, и, по сути, является задачей, которую решает массивное программирование2.
На практике массивное программирование упрощает параллельную обработку и распределение вычислений огромных объёмов данных, вовлечённых в оптимизацию цепочки поставок. Распределяя вычисления между несколькими машинами, можно снизить затраты и сократить время выполнения.
Совместимость аппаратного обеспечения
Ограниченное число специалистов по цепочке поставок является одной из основных проблем в оптимизации цепочки поставок. Эти специалисты отвечают за создание числовых рецептов, которые учитывают стратегии клиентов, а также враждебные махинации конкурентов для получения практических инсайтов.
Этих экспертов не только сложно найти, но как только они найдены, им часто приходится преодолевать несколько аппаратных препятствий, стоящих между ними и быстрой реализацией их задач. Совместимость аппаратного обеспечения — способность различных компонентов системы сливаться и работать вместе — играет решающую роль в устранении этих барьеров. Здесь рассматриваются три основных вычислительных ресурса:
- Вычислительная мощность: Производительность компьютера, предоставляемая либо CPU, либо GPU.
- Память: Вместимость хранения данных компьютера, осуществляемая с помощью RAM или ROM.
- Пропускная способность: Максимальная скорость, с которой информация (данные) может передаваться между различными частями компьютера или через сеть компьютеров.
Обработка больших наборов данных, как правило, занимает много времени, что приводит к снижению производительности, пока инженеры ждут выполнения задач. В оптимизации цепочки поставок можно хранить фрагменты кода (отражающие рутинные промежуточные вычислительные шаги) на твёрдотельных накопителях (SSD). Этот простой шаг позволяет специалистам по цепочке поставок запускать похожие скрипты с лишь незначительными изменениями гораздо быстрее, что существенно повышает производительность.
В приведённом примере используется дешевая оптимизация памяти для снижения вычислительной нагрузки: система замечает, что обрабатываемый скрипт почти идентичен предыдущим, поэтому вычисления могут быть выполнены за секунды, а не за десятки минут.
Такой уровень совместимости аппаратного обеспечения позволяет компаниям извлекать наибольшую пользу из вложенных средств.
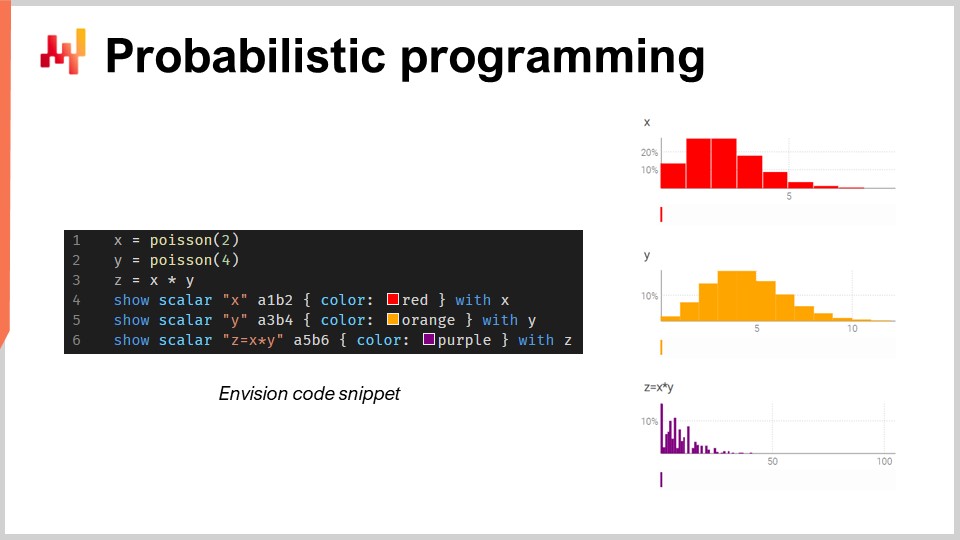
Вероятностное программирование
Существует бесконечное число возможных будущих исходов, но они не все равновероятны. Учитывая эту неизбежную неопределённость, инструменты программирования должны использовать парадигму вероятностного прогнозирования. Хотя Excel исторически был основой многих цепочек поставок, он не может быть развернут в масштабах с использованием вероятностных прогнозов, поскольку такой тип прогнозирования требует возможности обработки алгебры случайных величин3.
Кратко говоря, Excel в первую очередь предназначен для работы с детерминированными данными (то есть с фиксированными значениями, такими как статичные целые числа). Хотя его можно модифицировать для выполнения некоторых функций, связанных с вероятностями, ему не хватает продвинутой функциональности, общей гибкости и выразительности, необходимых для работы со сложными операциями над случайными величинами, встречающимися при вероятностном прогнозировании спроса. Вместо этого язык вероятностного программирования, такой как Envision, гораздо лучше подходит для представления и обработки неопределённостей, присутствующих в цепочке поставок.
Представьте магазин автозапчастей, торгующий тормозными колодками. В этом гипотетическом сценарии покупатели должны приобретать тормозные колодки партиями по 2 или 4 штуки, и магазин должен учитывать эту неопределённость при прогнозировании спроса.
Если у магазина есть доступ к языку вероятностного программирования (в отличие от множества таблиц), он может гораздо точнее оценить общее потребление с использованием алгебры случайных величин, которая обычно отсутствует в общих языках программирования.
Дифференцируемое программирование
В контексте оптимизации цепочки поставок дифференцируемое программирование позволяет числовому рецепту учиться и адаптироваться на основе предоставленных данных. Дифференцируемое программирование, в сочетании со стохастическим градиентным спуском, позволяет специалисту по цепочке поставок обнаруживать сложные закономерности и взаимосвязи внутри цепочки поставок. Параметры корректируются с каждой новой итерацией, и этот процесс повторяется тысячи раз. Это делается для минимизации расхождения между текущей моделью прогнозирования и историческими данными4.
Каннибализация и замещение — в рамках одного каталога — являются двумя вопросами модели, которые следует подробно рассмотреть в этом контексте. В обоих случаях несколько продуктов конкурируют за одних и тех же клиентов, что создаёт запутанный уровень сложности в прогнозировании. Последствия этих процессов обычно не учитываются традиционными методами прогнозирования временных рядов, которые в первую очередь рассматривают тренд, сезонность и шум для одного продукта, не принимая во внимание возможность взаимодействия.
Дифференцируемое программирование и стохастический градиентный спуск могут быть использованы для решения этих проблем, например, путём анализа исторических данных транзакций, связывающих клиентов и продукты. Envision способен выполнять такое исследование — называемое анализом аффинности — между клиентами и покупками, считывая простые плоские файлы, содержащие достаточную историческую глубину: а именно транзакции, даты, продукты, клиентов и объёмы покупок5.
Используя всего лишь небольшое количество уникального кода, Envision может определить степень аффинности между клиентом и продуктом, что позволяет специалисту по цепочке поставок дополнительно оптимизировать числовой рецепт, обеспечивающий требуемую рекомендацию6.
Версионирование кода и данных
Часто упускаемый из виду элемент долгосрочной жизнеспособности оптимизации — это гарантия того, что числовой рецепт, включая каждый составляющий фрагмент кода и каждую крупицу данных, может быть найден, отслежен и воспроизведён7. Без этой возможности версионирования способность воссоздать рецепт существенно снижается, когда неизбежно возникают непредсказуемые исключения (хейзенбаги в компьютерных кругах).
Хейзенбаги — это надоедливые исключения, которые вызывают проблемы в расчетах оптимизации, но исчезают при повторном запуске процесса. Это может сделать их чрезвычайно сложными для устранения, что приводит к провалу некоторых инициатив, и цепочка поставок возвращается к Excel-таблицам. Чтобы избежать хейзенбагов, необходима полная воспроизводимость логики и данных оптимизации. Это требует версионирования всего кода и данных, используемых в процессе, чтобы гарантировать возможность воссоздания среды в точных условиях любого предыдущего момента.
Безопасное программирование
Помимо непредсказуемых хейзенбагов, возрастающая цифровизация цепочки поставок сопровождается соответствующей уязвимостью к цифровым угрозам, таким как кибератаки и программы-вымогатели. Здесь существует два основных — и обычно непреднамеренных — вектора хаоса: программируемые системы, которые используются, и люди, которым разрешено ими пользоваться. Что касается последних, очень трудно предусмотреть случайную некомпетентность (не говоря уже о случаях преднамеренной злонамеренности); а в отношении первых осознанный выбор на уровне проектирования имеет первостепенное значение для обхода этих мин.
Вместо того чтобы инвестировать драгоценные ресурсы в расширение команды кибербезопасности (в ожидании реактивных мер, таких как тушение пожаров), разумные решения на этапе проектирования системы программирования могут исключить целые классы последующих проблем. Устраняя избыточные функции — как, например, SQL-базу данных в случае Lokad — можно предотвратить предсказуемые катастрофы, такие как SQL-инъекция. Аналогично, выбор слоёв хранения с поддержкой только добавления данных (как это делает Lokad) означает, что удаление данных (как другом, так и врагом) становится гораздо сложнее8.
Хотя у Excel и Python есть свои преимущества, им не хватает необходимой безопасности программирования для защиты всего кода и данных, требуемых для оптимизации цепочки поставок в масштабах, обсуждаемых в этих лекциях.
Примечания
-
Этап компиляции означает стадию, когда код программы преобразуется в формат, понятный машине, до его выполнения. Этап выполнения означает стадию, когда программа фактически выполняется компьютером. ↩︎
-
Это очень грубая аппроксимация процесса. Реальность куда сложнее, но это и возложение ответственности на компьютерных специалистов. Пока что главное в том, что массивное программирование приводит к гораздо более оптимизированному (и экономичному) процессу вычислений, преимущества которого многочисленны в контексте цепочки поставок. ↩︎
-
Говоря простыми словами, это относится к манипуляции и комбинации случайных значений, таких как вычисление результата броска кубика (или нескольких сотен тысяч бросков кубика в контексте большой сети цепочки поставок). Это включает всё: от базового сложения, вычитания и умножения до куда более сложных функций, таких как нахождение дисперсий, ковариаций и ожидаемых значений. ↩︎
-
Попробуйте усовершенствовать настоящий рецепт. Возможно, у вас есть базовая схема, на которую можно опереться, но достижение идеального баланса ингредиентов — и приготовления — оказывается неуловимым. На самом деле, рецепт включает не только вкусовые, но и тактильные и визуальные аспекты. Чтобы найти идеальную версию рецепта, вносятся мельчайшие корректировки и фиксируются результаты. Вместо того чтобы экспериментировать с каждым возможным приправой и кухонным инструментом, вносятся обоснованные изменения на основе обратной связи, наблюдаемой с каждой итерацией (например, добавить чуточку соли больше или меньше). С каждой итерацией узнается больше об оптимальных пропорциях, и рецепт эволюционирует. По сути, именно это делают дифференцируемое программирование и стохастический градиентный спуск с числовым рецептом в оптимизации цепочки поставок. Пожалуйста, ознакомьтесь с лекцией для подробного математического описания. ↩︎
-
Когда обнаруживается сильная взаимосвязь между двумя продуктами, уже присутствующими в каталоге, это может указывать на то, что они взаимодополняющие, то есть часто покупаются вместе. Если замечается, что клиенты переключаются между двумя продуктами с высокой степенью сходства, это может говорить о замещении. Однако если новый продукт демонстрирует сильную взаимосвязь с существующим и приводит к снижению продаж последнего, это может указывать на каннибализацию. ↩︎
-
Само собой разумеется, что это упрощенные описания математических операций, участвующих в процессе. Тем не менее, как объясняется в лекции, математические операции вовсе не столь сложны для понимания. ↩︎
-
Популярные системы контроля версий включают Git и SVN. Они позволяют нескольким людям одновременно работать над одним и тем же кодом (или любым другим содержимым) и объединять (или отклонять) изменения. ↩︎
-
Слой хранения данных с режимом “только добавление” относится к стратегии, при которой новая информация вносится в базу данных без изменения или удаления уже существующих данных. Дизайн безопасности компании Lokad, основанный на данной стратегии, подробно изложен в их обширном FAQ по безопасности. ↩︎