00:21 Introducción
01:53 De forecast a aprendizaje
05:32 Machine learning 101
09:51 La historia hasta ahora
11:49 Mis predicciones para hoy
13:54 Precisos sobre datos que no tenemos 1/4
16:30 Precisos sobre datos que no tenemos 2/4
20:03 Precisos sobre datos que no tenemos 3/4
25:11 Precisos sobre datos que no tenemos 4/4
31:49 Gloria al template matcher
35:36 Una profundidad en el aprendizaje 1/4
39:11 Una profundidad en el aprendizaje 2/4
44:27 Una profundidad en el aprendizaje 3/4
47:29 Una profundidad en el aprendizaje 4/4
51:59 A lo grande o vete a casa
56:45 Más allá de la pérdida 1/2
01:00:17 Más allá de la pérdida 2/2
01:04:22 Más allá de la etiqueta
01:10:24 Más allá de la observación
01:14:43 Conclusión
01:16:36 Próxima conferencia y preguntas de la audiencia
Descripción
Los forecasts son irreducibles en supply chain ya que cada decisión (compra, producción, almacenamiento, etc.) refleja una anticipación de eventos futuros. El aprendizaje estadístico y machine learning han reemplazado en gran medida el campo clásico del ‘forecasting’, tanto desde una perspectiva teórica como práctica. Intentaremos entender qué significa una anticipación basada en datos del futuro desde una perspectiva moderna de aprendizaje.
Transcripción completa

Bienvenidos a la serie de conferencias de supply chain. Soy Joannes Vermorel, y hoy estaré presentando “Machine Learning for Supply Chain.” No podemos imprimir en 3D bienes en tiempo real, ni podemos teletransportarlos a donde deben ser entregados. De hecho, casi todas las supply chain decisions deben tomarse con una mirada hacia el futuro, anticipando future demand o movimientos de precios, reflejando de manera implícita o explícita algunas condiciones de mercado futuras anticipadas, ya sea del lado de la demanda o del suministro. Como resultado, el forecast es una parte integral e irreducible de supply chain. Nunca sabemos el futuro con certeza; solo podemos conjeturar sobre el futuro con distintos grados de seguridad. El objetivo de esta conferencia es entender lo que machine learning aporta en cuanto a captar el futuro se refiere.

Veremos en esta conferencia que entregar accurate forecasts más precisos es, en el gran esquema de las cosas, una preocupación relativamente secundaria. De hecho, en supply chain hoy en día, forecasting significa el forecasting de time series. Históricamente, los forecasts de series de tiempo se popularizaron a comienzos del siglo XX en EE.UU. De hecho, EE.UU. fue el primer país en tener millones de empleados de clase media que también poseían acciones. A medida que la gente quería ser inversores astutos, buscaban obtener insights sobre sus inversiones, y resultó que las series de tiempo y los forecasts de series de tiempo eran una manera intuitiva y efectiva de transmitir esos insights. Podías obtener forecasts de series de tiempo sobre precios de mercado futuros, dividendos futuros y cuotas de mercado futuras.
En los años 80 y 90, cuando supply chain se digitalizó esencialmente, el enterprise software de supply chain también comenzó a beneficiarse de los forecasts de series de tiempo. De hecho, los forecasts de series de tiempo se volvieron ubicuos en ese tipo de software empresarial. Sin embargo, si miras esta imagen, puedes darte cuenta de que los forecasts de series de tiempo son, en realidad, una forma muy simplista y ingenua de ver el futuro.
Verás, si simplemente miro esta imagen, ya puedo decir lo que sucederá a continuación: muy probablemente llegará un equipo, limpiarán este desorden, y es muy probable que luego inspeccionen las carretillas elevadoras por razones de seguridad. Incluso podrían realizar algunas reparaciones ligeras, y con un alto grado de confianza, puedo decir que muy probablemente esta carretilla elevadora pronto volverá a estar en funcionamiento. Solo con mirar esta imagen, también podemos predecir qué tipo de condiciones llevaron a esta situación. Nada de esto encaja en la perspectiva de un forecast de series de tiempo, y sin embargo, todas estas predicciones son muy relevantes.
Estas predicciones no se refieren al futuro per se, ya que esta imagen fue tomada hace un tiempo, e incluso los eventos que siguieron a que se tomara esta imagen son ahora parte de nuestro pasado. Pero, sin embargo, son predicciones en el sentido de que estamos haciendo afirmaciones sobre cosas que no sabemos con certeza. No tenemos una medición directa. Así que lo primordial es, ¿cómo soy siquiera capaz de producir estas predicciones y formular estas afirmaciones?
Resulta que, como ser humano, he vivido, he presenciado eventos, y he aprendido de ellos. Así es como realmente puedo producir estas afirmaciones. Y resulta que machine learning es justamente eso: la ambición de ser capaz de replicar esta capacidad de aprendizaje en las máquinas, siendo las computadoras, por mucho, el tipo de máquina preferido hoy en día. En este punto, podrías preguntarte cómo es que machine learning es incluso diferente de otros términos como inteligencia artificial, tecnologías cognitivas o aprendizaje estadístico. Pues bien, resulta que estos términos dicen mucho más sobre las personas que los utilizan que sobre el problema en sí. En cuanto al problema, los límites entre todos esos campos son muy difusos.

Ahora, vamos a adentrarnos con una revisión del arquetipo de los marcos de machine learning, abarcando una breve serie de conceptos centrales de machine learning. La mayoría de los artículos científicos y el software producido en este campo de machine learning aprovechan este marco en gran medida. La feature representa una parte de datos que se pone a disposición para realizar la tarea de predicción. La idea es que tienes una tarea de predicción que quieres realizar, y una feature (o varias features) representa lo que se pone a disposición para llevar a cabo esa tarea. En el contexto de los forecasts de series de tiempo, la feature representaría la sección pasada de la serie de tiempo, y tendrías un vector de features que representa todos los puntos de datos pasados.
La etiqueta representa la respuesta a la tarea de predicción. En el caso de un forecast de series de tiempo, típicamente representa la porción de la serie de tiempo que no conoces, donde reside el futuro. Si tienes un conjunto de features más una etiqueta, se le denomina una observación. La configuración típica de machine learning asume que tienes un conjunto de datos que contiene tanto features como etiquetas, lo que representa tu training data set.
El objetivo es crear un programa llamado el modelo que tome las features como entrada y calcule la etiqueta predicha deseada. Este modelo se crea típicamente mediante un proceso de aprendizaje que recorre todo el conjunto de training data y construye el modelo. El aprendizaje en machine learning es la parte en la que realmente construyes el programa que hace las predicciones.
Finalmente, está la loss. La loss es esencialmente la diferencia entre la etiqueta real y la predicha. El objetivo es que el proceso de aprendizaje genere un modelo que haga predicciones lo más cercanas posible a las etiquetas verdaderas. Quieres un modelo que mantenga las etiquetas predichas lo más cerca posible de las etiquetas verdaderas.
Machine learning puede verse como una amplia generalización del forecasting de series de tiempo. Desde la perspectiva de machine learning, las features pueden ser cualquier cosa, no solo un segmento pasado de una serie de tiempo. Las etiquetas también pueden ser cualquier cosa, no solo el segmento futuro de una serie de tiempo. El modelo puede ser cualquier cosa, e incluso la loss puede ser prácticamente cualquier cosa. Así que, tenemos un marco que es muchísimo más expresivo que los forecasts de series de tiempo. Sin embargo, como veremos, la mayoría de los principales logros de machine learning como campo de estudio y práctica se derivan de los descubrimientos de elementos que nos obligan a revisar y desafiar la lista de conceptos que acabo de introducir brevemente.
Esta conferencia es la cuarta en la serie de conferencias de supply chain. Las ciencias auxiliares representan elementos que no son supply chain per se, pero que son de importancia fundamental para supply chain. En el primer capítulo, presenté mis puntos de vista sobre supply chain tanto como estudio físico como práctica. En el segundo capítulo, revisamos una serie de metodologías requeridas para abordar un dominio como supply chain que presenta muchos comportamientos adversariales y no puede ser fácilmente aislado. El tercer capítulo está completamente dedicado a las personas de supply chain, que es una forma de centrarse en los problemas que estamos tratando de resolver.
En este cuarto capítulo, he ido ascendiendo gradualmente por la escalera de abstracción, comenzando con las computadoras, luego algoritmos, y la conferencia anterior sobre optimización matemática, que puede verse como la capa base del machine learning moderno. Hoy, nos aventuramos en machine learning, que es esencial para captar el futuro que prevalece en todas las decisiones de supply chain que debemos tomar cada día.

Entonces, ¿cuál es el plan para esta conferencia? Machine learning es un campo de investigación enorme, y esta conferencia se guiará por una breve serie de preguntas que se relacionan con los conceptos e ideas que he introducido anteriormente. Veremos cómo las respuestas a estas preguntas nos obligan a reconsiderar la misma noción de aprendizaje y la forma en que abordamos los datos. Uno de los logros más espectaculares de machine learning es que nos ha obligado a darnos cuenta de que hay mucho más en juego en comparación con las grandiosas ambiciones iniciales de los investigadores que pensaban que seríamos capaces de replicar la inteligencia humana en una década.
En particular, echaremos un vistazo a deep learning, que es probablemente el mejor candidato que tenemos para emular un mayor grado de inteligencia en este momento. Aunque deep learning ha surgido como una práctica increíblemente empírica, el progreso y los logros conseguidos a través de deep learning arrojan nueva luz sobre la perspectiva fundamental del aprendizaje a partir de fenómenos observados.
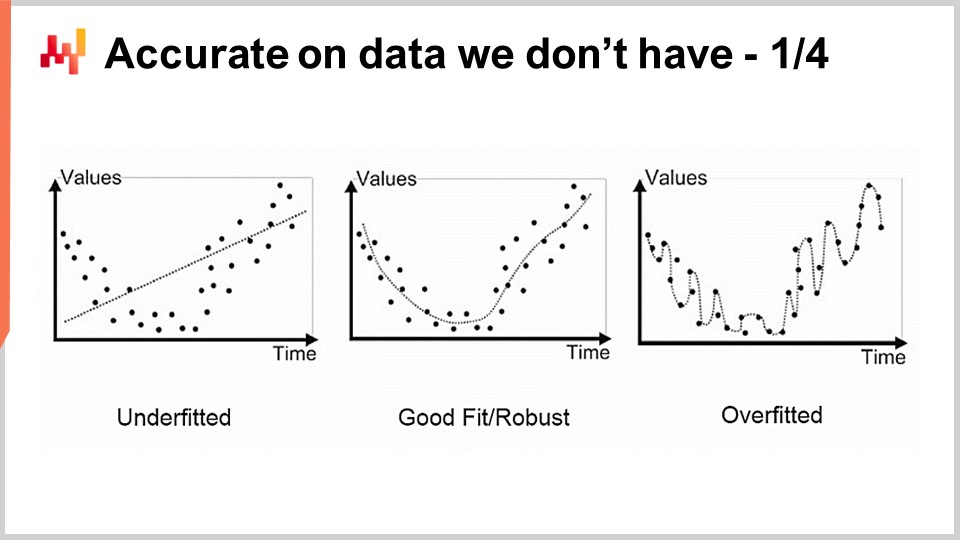
El primer problema que tenemos con el modelado, estadístico o de otra índole, es la precisión de los datos que no tenemos. Desde una supply chain perspective, esto es esencial porque nuestro interés radica en ser capaces de captar el futuro. Por definición, el futuro representa un conjunto de datos que aún no tenemos. Existen técnicas, como el backtesting o la validación cruzada, que pueden darnos algunas medidas empíricas sobre lo que deberíamos esperar de la precisión de los datos que no tenemos. Sin embargo, por qué estos métodos funcionan en absoluto es un problema relativamente intrigante y difícil. El problema no es tener un modelo que se ajuste a los datos que tenemos; es fácil construir un modelo que se ajuste a los datos usando un polinomio con un grado suficiente. Sin embargo, este modelo no es muy satisfactorio porque no está capturando lo que nos gustaría capturar.
El enfoque clásico para este problema se conoce como el tradeoff bias-variance. A la derecha, tenemos un modelo con muy pocos parámetros que underfitea el problema, al que decimos que tiene mucho bias. A la izquierda, tenemos un modelo con demasiados parámetros que overfitea y tiene demasiada variance. En el medio, tenemos un modelo que logra un buen equilibrio entre bias y variance, al que llamamos un buen fit. Hasta el final del siglo XX, era bastante poco claro cómo abordar este problema más allá del tradeoff bias-variance.

La primera verdadera percepción sobre la precisión de los datos que no tenemos provino de las teorías de learnability publicadas por Valiant en 1984. Valiant introdujo la teoría PAC - Probably Approximately Correct. En esta teoría PAC, la parte “probably” se refiere a un modelo con una probabilidad dada de dar respuestas lo suficientemente buenas. La parte “approximately” significa que la respuesta no está demasiado lejos de lo que se considera bueno o válido.
Valiant demostró que en muchas situaciones, simplemente no es posible aprender nada o, más precisamente, que para aprender, necesitaríamos una cantidad de muestras tan extraordinariamente grande que no sería práctica. Este ya fue un resultado muy interesante. La fórmula mostrada proviene de la teoría PAC, y es una desigualdad que te indica que si deseas producir un modelo que sea probably approximately correct, necesitas tener un número de observaciones, n, mayor que cierta cantidad. Esta cantidad depende de dos factores: epsilon, la tasa de error (la parte approximately correct), y eta, la probabilidad de fallo (uno menos eta es la probabilidad de no fallar).
Lo que vemos es que si queremos tener una probabilidad menor de fallo o un epsilon menor (un rango lo suficientemente bueno), necesitamos más muestras. Esta fórmula también depende de la cardinalidad del espacio de hipótesis. La idea es que, cuanto más numerosas sean las hipótesis competitivas, más observaciones necesitamos para diferenciarlas. Esto es muy interesante porque, esencialmente, aunque la teoría PAC nos ofrece resultados mayormente negativos, nos dice lo que no podemos hacer, que es construir un modelo provadamente Probably Approximately Correct con menos muestras. La teoría realmente no nos dice cómo hacer nada; no es muy prescriptiva en la forma de mejorar en la resolución de cualquier tipo de tarea de predicción. No obstante, fue un hito porque cristalizó la idea de que era posible abordar este problema de la precisión y los datos que no teníamos de maneras mucho más robustas que simplemente realizando algunas mediciones muy empíricas con, digamos, validación cruzada o backtesting.
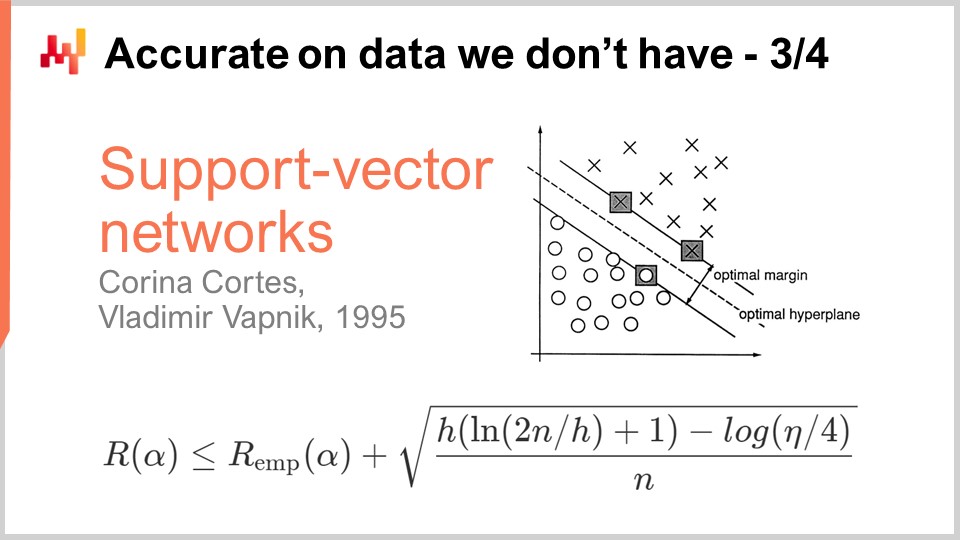
Una década después, el primer avance operativo llegó cuando Vapnik y algunos otros establecieron lo que hoy se conoce como la teoría Vapnik-Chervonenkis (VC). Esta teoría demuestra que es posible capturar la pérdida real, referida como el riesgo, que es la pérdida que observarás en los datos que no tienes. Fue posible demostrar matemáticamente que tenías la capacidad de conocer algo del error real, el cual, por definición, nunca se puede medir. Este es un resultado muy desconcertante.
Básicamente, esta fórmula, directamente extraída de la teoría VC, nos dice que el riesgo real está acotado superiormente por el riesgo empírico, que es el riesgo que podemos medir en los datos que sí tenemos, más otro término frecuentemente referido como el riesgo estructural. Tenemos el número de observaciones, n, y eta, que es la probabilidad de fallo, tal como en la teoría PAC. También tenemos h, que es una medida de la dimensión VC del modelo. La dimensión VC refleja la capacidad del modelo para aprender; cuanto mayor es la capacidad del modelo para aprender, mayor es la dimensión VC.
Con estos resultados, vemos que para los modelos que tienen la capacidad de aprender cualquier cosa, no podemos decir nada sobre ellos. Esto es muy desconcertante. Si tu modelo puede aprender cualquier cosa, entonces, al menos matemáticamente, no puedes decir nada sobre él.
El avance en 1995 surgió de una implementación realizada por Cortes y Vapnik de lo que más tarde se conocería como Support Vector Machines (SVM). Estos SVM son literalmente la implementación directa de esta teoría matemática. La idea es que, dado que tenemos una teoría que nos proporciona esta desigualdad, podemos implementar un modelo que equilibre la cantidad de error que cometemos en los datos (el riesgo empírico) y la dimensión VC. Podemos construir directamente un modelo matemático que equilibre exactamente estos dos factores para hacer que la igualdad sea lo más ajustada y baja posible. Eso es exactamente de lo que tratan las Support Vector Machines (SVM). Estos resultados fueron tan impresionantes, operativamente, que obtuvieron resultados muy buenos y tuvieron un impacto significativo en la comunidad de machine learning. Por primera vez, la precisión en los datos que no tenemos no fue una ocurrencia posterior; se obtuvo directamente por el diseño matemático del método en sí. Esto fue tan impresionante y poderoso que mantuvo a toda la comunidad de machine learning distraída durante una década persiguiendo este camino. Como veremos, este camino resultó ser en su mayoría un callejón sin salida, pero había buenas razones para ello: fue un resultado absolutamente asombroso.
Operativamente, debido a que los SVM surgieron principalmente de una teoría matemática, tenían muy poca simpatía mecánica. No eran un buen ajuste para el hardware de computación que tenemos. Más específicamente, la implementación ingenua de los SVM tiene un costo cuadrático en términos de huella de memoria respecto al número de observaciones. Esto es mucho, y como consecuencia, hace que los SVM sean muy lentos. Ha habido mejoras posteriores con algunas variantes online de SVM que han reducido enormemente los requisitos de memoria, pero, aun así, los SVM nunca fueron considerados realmente un enfoque verdaderamente escalable para realizar machine learning.

Los SVM allanaron el camino para otra clase de modelos, mejor, que probablemente tampoco sobreajustaban. Sobreajustar es, básicamente, ser muy inexacto en los datos que no tienes. Los ejemplos más notables son probablemente Random Forests y Gradient Boosted Trees, que resultan ser sus casi inmediatos descendientes. En el núcleo está el boosting, un meta-algoritmo que transforma modelos débiles en modelos más fuertes. El boosting surgió de preguntas planteadas a finales de los 80 entre Kearns y Valiant, a quienes mencionamos anteriormente en esta conferencia.
Para entender cómo funciona un Random Forest, es relativamente sencillo: toma tu conjunto de datos de entrenamiento y luego extrae una muestra de él. Sobre esta muestra, construye un árbol de decisión. Repite el proceso, creando otra muestra del conjunto de datos de entrenamiento inicial y construyendo otro árbol de decisión. Itera este proceso, y al final, tendrás muchos árboles de decisión. Los árboles de decisión son relativamente débiles en términos de modelos de machine learning, ya que no pueden capturar patrones muy complejos. Sin embargo, si juntas todos estos árboles y promedias los resultados, lo que obtienes es un bosque, denominado Random Forest, porque cada árbol se ha construido sobre una submuestra aleatoria del conjunto de datos de entrenamiento inicial. Lo que obtienes con un Random Forest es un modelo de machine learning mucho más fuerte y mejor.
Los Gradient Boosted Trees son solo una variación menor de esta idea. La principal variación es que, en lugar de muestrear tu conjunto de datos de entrenamiento y construir un árbol al azar, con todos los árboles construidos de forma independiente, los Gradient Boosted Trees primero construyen el bosque, y luego el siguiente árbol se construye observando los residuos del bosque que ya tienes. La idea es que has comenzado a construir un modelo compuesto de muchos árboles, y haces predicciones que se desvían de la realidad. Tienes estos deltas, que son las diferencias entre los valores reales y los predichos, llamados residuos. La idea es que vas a entrenar el siguiente árbol no contra el conjunto de datos original, sino contra una muestra de residuos. Los Gradient Boosted Trees funcionan incluso mejor que los Random Forests. En la práctica, los Random Forests sí sobreajustan, pero solo un poco. Existen algunas pruebas que muestran que, bajo ciertas condiciones, los Random Forests no deberían sobreajustar.
Curiosamente, los Gradient Boosted Trees han estado dominando las puntuaciones más altas de casi todas las competencias de machine learning durante una década y media. Cuando observas alrededor del 80-90% de las competencias en Kaggle, verás que esencialmente es un Gradient Boosted Tree el que se ubica en primer lugar. Sin embargo, a pesar de este increíble dominio en las competencias de machine learning, ha habido muy pocos avances en la aplicación de Gradient Boosted Trees a problemas de supply chain en el mundo real. La razón principal es que los Gradient Boosted Trees tienen muy poca simpatía mecánica; su diseño no es nada amigable con el hardware de computación que tenemos.
Es fácil entender por qué: construyes un modelo con una serie de árboles, y el modelo termina siendo tan grande como una fracción de tu conjunto de datos. En muchas situaciones, terminas con un modelo que es, en términos de datos, mayor que el conjunto de datos con el que comenzaste. Entonces, si tu conjunto de datos ya es muy grande, tu modelo es gigantesco, y ese es un asunto muy problemático.
En cuanto a la historia de los Gradient Boosted Trees, ha habido una serie de implementaciones, comenzando con GBM (Gradient Boosted Machines) en 2007, que realmente popularizó este enfoque en un paquete de R. Desde el principio, hubo problemas con la escalabilidad. La gente rápidamente comenzó a paralelizar la ejecución con PGBRT (Parallel Gradient Boosted Regression Trees), pero seguía siendo muy lento. XGBoost fue un hito porque consiguió un orden de magnitud en escalabilidad. La idea clave en XGBoost fue adoptar un diseño columnar en los datos para hacer la construcción de árboles más rápida. Más tarde, LightGBM recicló todas las ideas de XGBoost pero cambió la estrategia sobre cómo construir los árboles. XGBoost hacía crecer el árbol por niveles, mientras que LightGBM decidió hacerlo por hojas. El resultado neto es que LightGBM ahora es varias órdenes de magnitud más rápido, considerando el mismo hardware de computación, que GBM jamás lo fue. Sin embargo, desde una perspectiva práctica de supply chain, usar Gradient Boosted Trees generalmente es imprácticamente lento. No es imposible usarlos; es solo que es un obstáculo tal que usualmente no vale la pena.

Lo desconcertante es que los Gradient Boosted Trees son lo suficientemente poderosos como para ganar casi todas las competencias de machine learning y, sin embargo, en mi humilde opinión, estos modelos son un callejón sin salida tecnológico. Las Support Vector Machines, los Random Forests y los Gradient Boosted Trees tienen en común que no son más que comparadores de plantillas. Son comparadores de plantillas muy buenos, ten en cuenta, pero realmente nada más. Lo que hacen excepcionalmente bien es, esencialmente, la selección de variables, y son muy buenos en eso, pero no hay mucho más en ello. En particular, no existe expresividad en su capacidad para transformar la entrada en algo que no sea una simple selección o filtrado directo de la misma.
Si volvemos a la imagen de la carretilla elevadora que presenté al comienzo de esta conferencia, no hay ninguna esperanza de que alguno de esos modelos pueda hacer el mismo tipo de afirmaciones que acabo de hacer, sin importar lo grande que sea el conjunto de datos de imágenes. Literalmente, podrías alimentar a todos esos modelos con millones de imágenes tomadas de warehouses en todo el mundo, y aún así no serían capaces de hacer afirmaciones como, “Oh, he visto una carretilla elevadora en esta situación; un equipo se presentará y realizará reparaciones.” Realmente no.
En la práctica, lo que hemos visto es que el hecho de que estos modelos estén ganando competencias de machine learning es engañoso, porque hay factores que juegan a su favor en tales situaciones. Primero, los conjuntos de datos del mundo real son muy complejos, lo cual es diferente a las competencias de machine learning donde, en el mejor de los casos, tienes conjuntos de datos de juguete que representan solo una fracción de las complejidades que se enfrentan en entornos reales. Segundo, para ganar una competencia de machine learning usando modelos como los Gradient Boosted Trees, tienes que hacer una extensa ingeniería de características. Debido a que estos modelos son glorificados comparadores de plantillas, necesitas tener las características adecuadas para que tan solo la selección de variables haga que el modelo funcione de maravilla. Debes inyectar una alta dosis de inteligencia humana en la preparación de los datos para que funcione. Este es un gran problema porque, en el mundo real, al tratar de resolver un problema para supply chain, el número de horas de ingeniería que puedes dedicar al problema es limitado. No puedes dedicar seis meses a un pequeño problema puntual y de tiempo limitado de tu supply chain.
El tercer problema es que, en las supply chains, los conjuntos de datos están cambiando constantemente. No es solo que los datos cambian, sino que el problema también cambia gradualmente. Esto complica aún más los problemas que tienes con la ingeniería de características. Fundamentalmente, nos quedamos con modelos que ganan competencias de machine learning y forecasting competitions, pero si miramos una década hacia el futuro, vemos que estos modelos no son el futuro del machine learning; son el pasado.

El deep learning fue la respuesta a estos comparadores de plantillas superficiales. El deep learning a menudo se presenta como el descendiente de las redes neuronales artificiales, pero la realidad es que el deep learning solo despegó el día en que los investigadores decidieron abandonar las metáforas biológicas y centrarse, en cambio, en la simpatía mecánica. De nuevo, la simpatía mecánica, que significa llevarse bien con las computadoras que tenemos, es esencial. El problema que teníamos con las redes neuronales artificiales era que estábamos tratando de imitar la biología, pero las computadoras que tenemos son completamente diferentes de los sustratos biológicos que soportan nuestros cerebros. Esta situación recuerda los inicios de la aviación, donde numerosos inventores intentaron construir máquinas voladoras imitando a los pájaros. Hoy en día, tenemos máquinas voladoras que vuelan muchas veces más rápido que los pájaros más veloces, pero la forma en que estas máquinas vuelan tiene casi nada en común con la manera en que vuelan los pájaros.
La primera idea acerca del deep learning fue la necesidad de algo profundo y expresivo que pudiera aplicar cualquier tipo de transformación a los datos de entrada, permitiendo que surgiera un comportamiento predictivo inteligente a partir del modelo. Sin embargo, también necesitaba llevarse bien con el hardware de computación que teníamos. La idea era que, si contábamos con modelos complejos que se adaptaban muy bien al hardware de computación, lo más probable es que pudiéramos aprender funciones que son varias órdenes de magnitud más complejas, todo considerado igual, en comparación con cualquier método que no tuviera el mismo grado de simpatía mecánica.
Differentiable programming, que se presentó en la conferencia anterior, puede considerarse como la capa base del deep learning. No voy a volver a entrar en differentiable programming en esta conferencia, pero invito a la audiencia a ver la conferencia anterior si no la han visto. Deberían ser capaces de entender lo que sigue, incluso si no han visto la conferencia anterior. La conferencia anterior debería aclarar algunos de los detalles minuciosos del proceso de aprendizaje en sí. En resumen, differentiable programming es solo una manera de, si elegimos una forma específica de modelo, identificar los mejores valores para los parámetros que existen dentro de dicho modelo.
Mientras differentiable programming se centra en identificar los mejores parámetros, el machine learning se centra en identificar las formas superiores de modelos que tienen la mayor capacidad para aprender de los datos.

Entonces, ¿cómo creamos una plantilla para una función arbitrariamente compleja que pueda reflejar cualquier transformación arbitrariamente compleja en los datos de entrada? Empecemos con un circuito de valores en punto flotante. ¿Por qué valores en punto flotante? Bueno, es porque es el tipo de cosa en la que podemos aplicar descenso por gradiente, que, como vimos en la conferencia anterior, es muy escalable. Así que, son números en punto flotante. Vamos a tener una secuencia de números en punto flotante, lo que significa puntos flotantes como entradas y puntos flotantes como salidas.
Ahora, ¿qué hacemos en el medio? Hagamos álgebra lineal, y más específicamente, hagamos multiplicación de matrices. ¿Por qué es eso? La respuesta a por qué la multiplicación de matrices se dio en la primera conferencia de este cuarto capítulo. Se relaciona con la manera en que se diseñan las computadoras modernas; esencialmente, es posible lograr una aceleración relativamente dramática en términos de velocidad de procesamiento si simplemente te atienes al álgebra lineal. Así que, álgebra lineal es. Ahora, si tomo mis entradas y aplico una transformación lineal, que es simplemente una multiplicación matricial con una matriz llamada W (esta matriz contiene los parámetros que queremos aprender más adelante), ¿cómo podemos hacerla más compleja? Podemos agregar una segunda multiplicación de matrices. Sin embargo, si recuerdas tus cursos de álgebra lineal, cuando multiplicas una función lineal por otra función lineal, lo que obtienes es una función lineal. Así que, si simplemente componemos la multiplicación de matrices, seguiremos teniendo una multiplicación de matrices, y ésta continuará siendo completamente lineal.
Lo que vamos a hacer es intercalar no linealidades entre las operaciones lineales. Esto es exactamente lo que he hecho en esta pantalla. He intercalado una función típicamente conocida en la deep learning literature como una Unidad Lineal Rectificada (ReLU). Este nombre, que es fantásticamente complicado comparado con lo que hace, es simplemente una función muy simple que dice que si tomo un número y si este número es positivo, entonces devuelvo el mismo número (es decir, es una función identidad), pero si el número es negativo, devuelvo 0. También se puede escribir como el máximo entre tu valor y cero. Esta es una no linealidad muy trivial.
Podríamos usar funciones no lineales mucho más sofisticadas. Históricamente, cuando la gente trabajaba con redes neuronales, querían usar funciones sigmoides sofisticadas porque se suponía que así funcionaban nuestras neuronas. Pero la realidad es: ¿por qué querríamos desperdiciar potencia de procesamiento para calcular cosas que son irrelevantes? La clave está en introducir algo que sea no lineal, y realmente no importa qué función no lineal usemos. Lo único que importa es que sea muy rápida. Queremos mantener todo lo más rápido posible.
Lo que estoy construyendo aquí se llama capas densas. Una capa densa es esencialmente una multiplicación matricial con una no linealidad (la Unidad Lineal Rectificada). Podemos apilarlas. En la pantalla, puedes ver una red, que típicamente se llama perceptrón multicapa, y tenemos tres capas. Podríamos seguir apilándolas, y podríamos tener 20 o 2,000 de ellas; realmente no importa. La realidad es que, por simple que parezca, si tomas una red así con sólo un par de capas y la introduces en tu framework de differentiable programming, el differentiable programming como capa base podrá entrenar los parámetros, que inicialmente se seleccionan de forma aleatoria. Si quieres inicializarla, simplemente inicializa todos los parámetros de manera aleatoria. Obtendrás resultados bastante decentes para una gran variedad de problemas.
Eso es muy interesante porque, en este punto, tienes prácticamente todos los ingredientes fundamentales del deep learning. Así que, para la audiencia, ¡felicitaciones! Probablemente ya puedas empezar a agregar “deep learning specialist” a tu currículum, porque esto es casi todo lo que hay. Bueno, no es realmente así, pero digamos que es un buen punto de partida.

La realidad es que el deep learning involucra muy poca teoría además del álgebra tensorial, que es esencialmente álgebra lineal computarizada. Sin embargo, el deep learning involucra un montón de trucos. Por ejemplo, tenemos que normalizar las entradas y estabilizar los gradientes. Si empezamos a apilar muchas operaciones de ese tipo, los gradientes pueden crecer exponencialmente a medida que retrocedemos en la red, y en algún momento eso sobrepasará la capacidad de representar esos números. Contamos con computadoras del mundo real, y no son capaces de representar números arbitrariamente grandes. En algún momento, simplemente sobrecargas tu capacidad para representar el número con un valor de punto flotante de 32 bits o 16 bits. Existen un montón de trucos para la estabilización de gradientes. Por ejemplo, el truco suele ser la normalización por lotes, pero hay otros trucos para ello.
Si tienes entradas que tienen una estructura geométrica, por ejemplo, unidimensional como una serie temporal (ventas históricas, como vemos en supply chain), que pueden ser bidimensionales (piensa en ello como una imagen), tridimensionales (eso podría ser una película) o cuatridimensionales, etc., si las entradas tienen una estructura geométrica, entonces existen capas especiales que pueden capturar esta estructura geométrica. Las más famosas probablemente se llamen capas convolucionales.
Luego, también tienes técnicas y trucos para tratar con entradas categóricas. En el deep learning, todas tus entradas son valores de punto flotante, así que, ¿cómo tratas con variables categóricas? La respuesta son los embeddings. Tienes pérdidas sustitutas, que son pérdidas alternativas que exhiben gradientes muy pronunciados y facilitan el proceso de convergencia, amplificando en última instancia lo que se puede aprender de los datos. Hay un montón de trucos, y todos esos trucos normalmente se pueden incorporar al programa que estás componiendo porque operamos con differentiable programming como nuestra capa base.
El deep learning se trata realmente de cómo componemos un programa que, una vez que se ejecuta a través del proceso de entrenamiento ofrecido por differentiable programming, tiene una capacidad muy alta para aprender. La mayoría de los elementos que acabo de enumerar en la pantalla también tienen una naturaleza programática, lo cual es muy conveniente considerando que tenemos differentiable programming, un paradigma de programación, para respaldar todo eso.
En este punto, debería quedar más claro por qué el deep learning es diferente al machine learning clásico. El deep learning no se trata de modelos. De hecho, la mayoría de las bibliotecas open source de deep learning ni siquiera incluyen modelos. Con el deep learning, lo que realmente importa son las arquitecturas de los modelos, que puedes considerar como plantillas que deben ser altamente personalizadas cuando quieres adaptarte a una situación específica. Sin embargo, si adoptas una arquitectura adecuada, puedes anticipar que tu personalización aún preservará la esencia de la capacidad de tu modelo para aprender. Con el deep learning, desplazamos el interés desde el modelo final, que se vuelve algo no muy interesante, hacia la arquitectura, que se convierte en el verdadero asunto de la investigación.
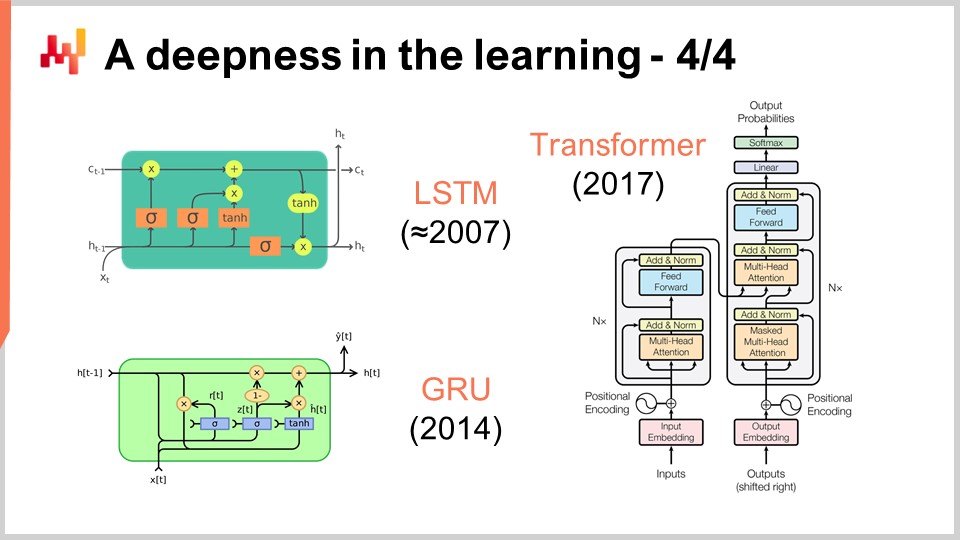
En la pantalla, puedes ver una serie de ejemplos notables de arquitecturas. Primero, LSTM, que significa Long Short-Term Memory, empezó a funcionar alrededor de 2007. La historia de publicaciones del LSTM es un poco más complicada, pero esencialmente comenzó a trabajar al estilo deep learning en 2007. Fue sustituido por las Gated Recurrent Units (GRU), que son esencialmente lo mismo que el LSTM pero simplemente más simples y agradables. Básicamente, mucha de la complejidad del LSTM proviene de las metáforas biológicas. Resulta que puedes descartar las metáforas biológicas, y lo que obtienes es algo más simple que funciona prácticamente igual. Esas son las Gated Recurrent Units (GRU). Más adelante, aparecieron los transformers, que básicamente hicieron obsoletos tanto el LSTM como el GRU. Los transformers fueron un avance, ya que eran mucho más rápidos, consumían menos recursos de computación y poseían una capacidad de aprendizaje aún mayor.
La mayoría de estas arquitecturas vienen con metáforas. El LSTM tiene una metáfora cognitiva, long short-term memory, mientras que los transformers vienen con una metáfora de recuperación de información. Sin embargo, estas metáforas tienen muy poco poder predictivo, y en realidad podrían ser más una fuente de confusión y distracción de lo que realmente hace que estas arquitecturas funcionen, lo cual no se entiende del todo en este momento.
Los transformers son de gran interés para supply chain porque son una de las arquitecturas más versátiles. Se utilizan para prácticamente todo en la actualidad, desde la conducción autónoma hasta la traducción automatizada y muchos otros problemas difíciles. Esto es una prueba del poder de elegir la arquitectura correcta, que luego puede usarse para adaptarse a una enorme diversidad de problemas. En lo que respecta a supply chain, una de las principales dificultades de hacer cualquier cosa con machine learning es que tenemos una diversidad increíble de problemas que abordar. No podemos permitirnos tener un equipo que dedique cinco años a esfuerzos de investigación para cada subproblema que enfrentamos. Necesitamos algo en lo que podamos movernos rápido y no tener que reinventar la mitad del machine learning cada vez que queremos resolver el siguiente problema.
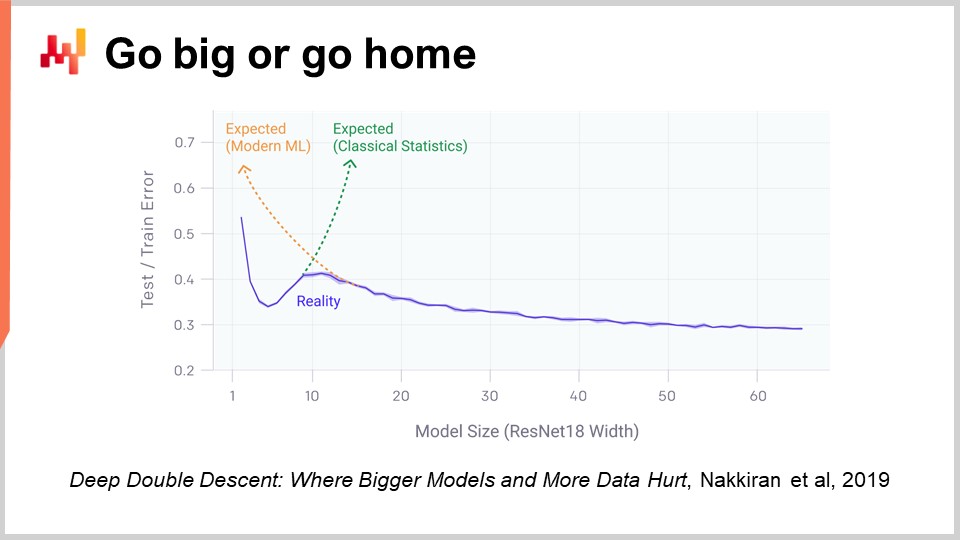
Un aspecto del deep learning que es realmente impactante cuando comienzas a pensarlo es la cantidad masiva de parámetros. En el perceptrón multicapa que introduje hace unos minutos, con capas densas que implican multiplicación matricial, podemos tener muchos parámetros en esas matrices. De hecho, no es muy difícil tener tantos parámetros como puntos de datos u observaciones en nuestros conjuntos de datos de entrenamiento. Como hemos visto al inicio de nuestra conferencia, si tenemos un modelo con tantos parámetros, debería sufrir dramáticamente de sobreajuste.
La realidad con el deep learning es aún más desconcertante. Hay muchas situaciones en las que tenemos muchos más parámetros de los que tenemos observaciones, y sin embargo no experimentamos problemas dramáticos de sobreajuste. Aún más desconcertante, los modelos de deep learning tienden a ajustarse completamente al conjunto de datos de entrenamiento, de modo que terminas con un error casi nulo en tu conjunto de entrenamiento, y aún así conservan su poder predictivo para datos que no tenemos.
Hace dos años, el artículo Deep Double Descent publicado por OpenAI arrojó una luz muy interesante sobre esta situación. El equipo demostró que tenemos esencialmente un valle inquietante en el ámbito del machine learning. La idea es que si tomas un modelo y tiene sólo unos pocos parámetros, tendrás mucho sesgo, y la calidad de tus resultados en datos no vistos no es tan buena. Esto se ajusta tanto a la visión clásica del machine learning como a la visión estadística clásica. Si aumentas el número de parámetros, vas a mejorar la calidad de tu modelo, pero en algún momento comenzarás a sobreajustar. Esto es exactamente lo que hemos visto con la discusión anterior sobre bajoajuste y sobreajuste. Hay que encontrar un equilibrio.
Sin embargo, lo que han demostrado es que si sigues incrementando el número de parámetros, sucederá algo muy extraño: vas a sobreajustar cada vez menos, lo cual es exactamente lo opuesto a lo que predice la teoría clásica del aprendizaje estadístico. Este comportamiento no es accidental. Los autores demostraron que este comportamiento es muy robusto y extendido. Ocurre prácticamente todo el tiempo en una gran variedad de situaciones. Aún no se entiende muy bien por qué, pero lo que se entiende muy bien en este momento es que el deep double descent es muy real y generalizado.
Esto también ayuda a entender por qué el deep learning llegó relativamente tarde a la fiesta del machine learning. Para que el deep learning tuviera éxito, primero tuvimos que lograr construir modelos que pudieran procesar decenas de miles o incluso cientos de miles de parámetros para superar este valle inquietante. En los 80 y 90 no habría sido posible lograr ningún avance en deep learning, simplemente porque los recursos de hardware de computación no podían saltar ese valle inquietante.
Afortunadamente, con el hardware de computación actual es posible entrenar modelos sin mucho esfuerzo que tengan millones o incluso miles de millones de parámetros. Como señalamos en las conferencias anteriores, ahora hay empresas como Facebook que están entrenando modelos que tienen más de un billón de parámetros. Así que podemos llegar muy lejos.

Hasta ahora, hemos asumido que la función de pérdida era conocida. Sin embargo, ¿por qué debería ser así? De hecho, consideremos la situación de una tienda de moda desde una perspectiva de supply chain. Una tienda de moda tiene niveles de stock para cada SKU, y queremos proyectar la demanda futura. Queremos proyectar un escenario posible que sea creíble para la demanda futura de esta tienda en particular. Lo que sucederá es que, a medida que ciertos SKUs se queden sin stock, deberíamos observar canibalización y sustitución. Cuando un SKU dado alcanza un faltante de stock, normalmente la demanda, en parte, debería rebotar hacia productos similares.
Pero si intentamos abordar este tipo de enfoque con métricas clásicas de forecast como el Mean Absolute Percentage Error (MAPE), el Mean Absolute Error (MAE), el Mean Square Error (MSE) u otras métricas que operan SKU por SKU, día a día o semana a semana, no capturaremos ninguno de estos comportamientos. Lo que realmente queremos es una métrica que capte si somos muy buenos capturando todos esos efectos de canibalización y sustitución. Pero, ¿cómo debería ser esta función de pérdida? Es muy poco claro, y parece requerir un comportamiento bastante sofisticado. Uno de los avances clave del deep learning fue, esencialmente, llegar a la idea de que la función de pérdida debía ser aprendida. Así es exactamente como se produjo la imagen en la pantalla. Esta es una imagen completamente generada por máquina; ninguna de esas personas es real. Han sido generadas, y el problema era: ¿cómo construyes una función de pérdida o una métrica que te diga si una imagen es un buen retrato fotorrealista de un humano o no?
La realidad es que si empiezas a pensar en términos del Mean Absolute Percentage Error (MAPE) píxel a píxel, terminas con una métrica que opera píxel por píxel. El problema es que una métrica que opera píxel por píxel no te dice nada sobre si la imagen en su conjunto parece un rostro humano. Tenemos el mismo problema en la tienda de moda con los SKUs y la proyección de la demanda. Es muy fácil tener una métrica a nivel de SKU, pero eso no nos dice nada sobre el panorama general de la tienda en su conjunto. Sin embargo, desde una perspectiva de supply chain, no nos interesa la precisión a nivel de SKU; nos interesa la precisión a nivel de tienda. Queremos saber si los niveles de stock son buenos en su totalidad para la tienda, y no si son buenos para un SKU y luego para otro SKU. Entonces, ¿cómo abordó este problema la comunidad de deep learning?
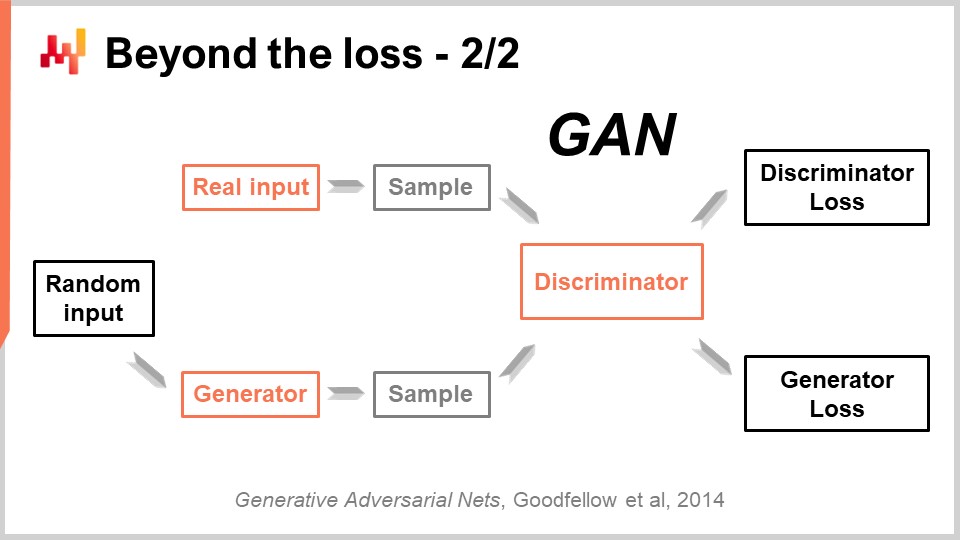
Este logro tan impresionante se ha obtenido con una técnica bellamente simple llamada Generative Adversarial Networks (GANs). En la prensa, es posible que hayas oído hablar de estas técnicas como deepfakes. Los deepfakes son imágenes que han sido producidas con esta técnica de GAN. ¿Cómo funciona?
Bueno, la forma en que funciona es que primero empiezas con un generador. El generador toma algo de ruido como entrada, que son simplemente valores aleatorios, y va a producir una imagen en el caso presente. Si volvemos al caso de supply chain, produciría trayectorias para todos los puntos de demanda observados para cada SKU, digamos, para los próximos tres meses en esta tienda de moda. Este generador es en sí mismo una red de deep learning.
Ahora, vamos a tener un discriminador. Un discriminador es también una red de deep learning, y el objetivo del discriminador es aprender a predecir si lo que acaba de generarse es real o sintético. El discriminador es un clasificador binario que solo necesita decir si es real o no real. Si el discriminador es capaz de predecir correctamente que una muestra es falsa, es decir, sintética, vamos a retroceder los gradientes al generador y dejar que el generador aprenda a partir de ello.
Lo que sucede en este planteamiento es que el generador empieza a aprender cómo generar muestras que efectivamente engañan y confunden al discriminador. Al mismo tiempo, el discriminador aprende a mejorar discriminando entre las muestras reales y las sintéticas. Si tomas este proceso, con suerte converge a un estado en el que terminas teniendo tanto un generador de muy alta calidad que genera muestras increíblemente realistas, como un discriminador muy bueno que puede decirte si es real o no. Esto es exactamente lo que se está haciendo con las GANs para generar esas imágenes fotorrealistas. Si volvemos a la supply chain, encontrarás expertos en círculos de supply chain que dicen que, para una situación particular, la mejor métrica es MAPE, o MAPE ponderado, o lo que sea. Ellos propondrán recetas diciéndote que, en ciertas situaciones, necesitas usar esta métrica o aquella. La realidad es que el deep learning muestra que una métrica de forecast es un concepto anticuado. Si quieres alcanzar una precisión de alta dimensión, no solo precisión puntual, necesitas aprender la métrica. Aunque por el momento, sospecho que hay casi cero supply chains que están aprovechando estas técnicas, en algún momento en el futuro, lo estarán. Se convertirá en la norma aprender la métrica de forecast usando redes generativas antagónicas o los descendientes de estas técnicas, porque es una manera de capturar el comportamiento sutil y de alta dimensión que realmente es de interés, en lugar de tener solamente precisión puntual.

Ahora, hasta ahora, cada observación venía con una etiqueta, y la etiqueta era la salida que queríamos predecir. Sin embargo, hay situaciones que no pueden enmarcarse como problemas de entrada-salida. Las etiquetas simplemente no están disponibles. Si queremos tomar un ejemplo de supply chain, sería un hipermercado. En los hipermercados, los niveles de stock no son perfectamente precisos. Las mercancías pueden dañarse, ser robadas o caducar, y hay muchas razones por las cuales los registros electrónicos en tu sistema no reflejan verdaderamente lo que está disponible en el estante tal como lo perciben los clientes. Hacer inventario es demasiado costoso para ser una fuente de datos en tiempo real de inventario preciso. Puedes hacer inventario, pero no puedes recorrer todo el hipermercado cada día. Lo que terminas teniendo es una gran cantidad de stock ligeramente inexacto. Tienes toneladas de él, pero realmente no puedes decir cuáles son precisos o no.
Esta es esencialmente la clase de situación donde el aprendizaje no supervisado realmente tiene sentido. Queremos aprender algo; tenemos datos, pero no tenemos las respuestas correctas disponibles. No tenemos esas etiquetas. Lo que tenemos es simplemente toneladas de datos. La comunidad de machine learning ha considerado el aprendizaje no supervisado como un santo grial por décadas. Durante mucho tiempo, fue el futuro, pero un futuro lejano. Sin embargo, recientemente ha habido algunos avances increíbles en esta área. Uno de los avances fue, por ejemplo, logrado por un equipo de Facebook con un artículo titulado “Unsupervised Machine Translation Using Monolingual Corpora Only.”
Lo que el equipo de Facebook hizo en este artículo fue construir un sistema de traducción que solo utilizaba un corpus de texto en inglés y un corpus de texto en francés. Estos dos corpus no tienen nada en común; ni siquiera es el mismo texto. Es simplemente texto en inglés y texto en francés. Luego, sin darle ninguna traducción real al sistema, aprendieron un sistema que traduce de inglés a francés. Esto es un resultado absolutamente impresionante. Por cierto, la forma en que se logra es utilizando una técnica que recuerda increíblemente a las redes generativas antagónicas que acabo de presentar anteriormente. De manera similar, un equipo en Google publicó BERT (Bidirectional Encoder Representations from Transformers) hace dos años. BERT es un modelo que se entrena de una manera que es en gran parte no supervisada. Estamos hablando nuevamente de texto. La forma en que se hace con BERT es tomando enormes bases de datos de texto y enmascarando palabras al azar. Luego, entrenas el modelo para predecir esas palabras y repites el proceso para todo el corpus. Algunas personas se refieren a esta técnica como auto-supervisada, pero lo que es muy interesante con BERT y donde se vuelve relevante para supply chain es que, de repente, la forma de abordar tus datos es construir una máquina donde puedes ocultar partes de los datos, y la máquina aún es capaz de completarlos de nuevo.
La razón por la que esto es de suma relevancia para supply chain es que, fundamentalmente, lo que se está haciendo con BERT en el contexto del procesamiento de lenguaje natural puede extenderse a muchos otros dominios. Es la máquina definitiva de respuestas de “what-if”. Por ejemplo, ¿qué pasaría si tuviera una tienda más? Este “what-if” puede ser respondido porque simplemente puedes modificar tus datos, agregar la tienda y consultar el modelo de machine learning que acabas de construir. ¿Qué pasaría si tuviera un producto extra? ¿Qué pasaría si tuviera un cliente extra? ¿Qué pasaría si tuviera un punto de precio diferente para este producto? Y así sucesivamente. El aprendizaje no supervisado es de interés primordial porque comienzas a tratar tus datos en su totalidad, no solo como una lista de pares. Terminas con un mecanismo que es completamente general y puede hacer predicciones sobre cualquier aspecto que resulte estar algo presente en los datos. Esto es muy poderoso.
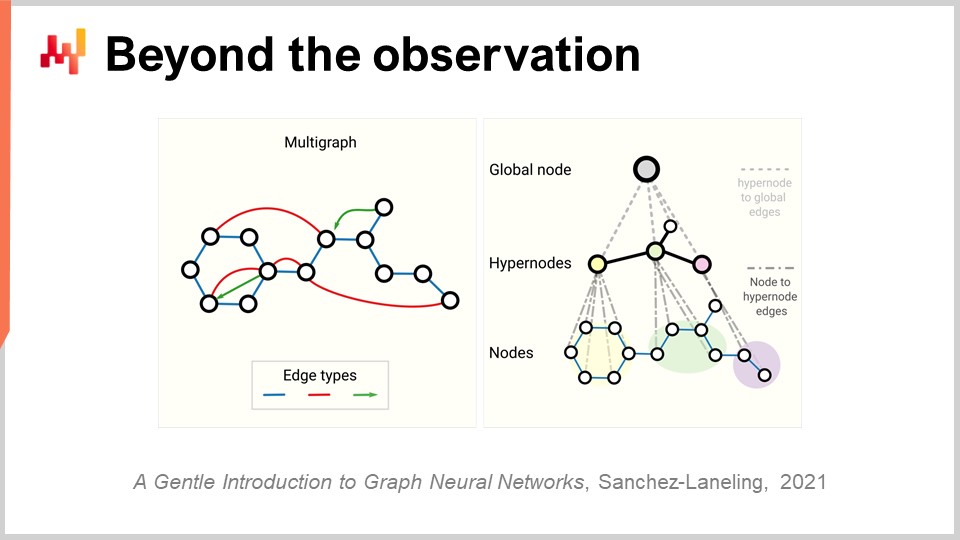
Ahora, finalmente, tenemos que revisar todo el concepto de observación. Inicialmente, dijimos que una observación era un par de características más una etiqueta. Hemos visto cómo podemos remover la etiqueta, pero ¿qué hay de las propias características y de la observación? El problema con supply chain es que realmente no tenemos observaciones. Ni siquiera está claro que podamos descomponer una supply chain en una lista de observaciones independientes u homogéneas. Como se discutió en una conferencia anterior, lo que tenemos para observar en una supply chain no es ninguna observación científica directa de la supply chain en sí. Lo que tenemos es una serie de piezas de software empresarial, y la única forma en que podemos observar una supply chain es de manera indirecta a través de los registros recopilados en esas piezas de software empresarial. Eso puede ser el ERP, el WMS, el punto de venta, etc. Pero la conclusión es que lo único que tenemos es esencialmente registros electrónicos que son transaccionales por naturaleza, ya que todos esos sistemas se implementan típicamente sobre bases de datos transaccionales. Así, las observaciones no son independientes. Los registros que tenemos son relacionales, literalmente, porque viven en una base de datos relacional. Cuando digo que tienen relaciones, me refiero a que, si miras a un cliente con una tarjeta de loyalty, por ejemplo, están conectados a todos los productos que compró. Cada producto está conectado a todas las tiendas donde el producto forma parte del surtido. Cada tienda está conectada a todos los almacenes que tienen la capacidad de servir a la tienda de interés. Por lo tanto, no tenemos observaciones independientes; tenemos datos con toneladas de estructura relacional superpuesta, y ninguno de esos elementos es verdaderamente independiente de los demás.
El avance relevante en deep learning para abordar este tipo de datos interconectados se conoce como graph learning. Graph learning es exactamente lo que necesitas para abordar comportamientos como la sustitución y la cannibalización en la moda. La mejor forma de ver la cannibalización es pensar que todos los productos compiten por los mismos clientes, y al analizar los datos que conectan clientes y productos, puedes analizar la cannibalización. Cuidado, graph learning no tiene nada que ver con las bases de datos gráficas, que son algo completamente diferente. Las bases de datos gráficas son esencialmente solo bases de datos utilizadas para consultar gráficos, sin aprendizaje involucrado. Graph learning se trata de aprender algunas propiedades extra de los propios gráficos. Se trata de aprender relaciones que pueden o no ser observadas, o que no pueden observarse completamente, o de decorar el tipo de relación que tenemos con una superposición de conocimiento accionable.
Mi opinión es que, debido a que por diseño, supply chain es un sistema en el que todas las partes están interconectadas – esa es la maldición de supply chain, donde no puedes simplemente optimizar localmente nada sin desplazar problemas – graph learning se volverá cada vez más prevalente como un enfoque para abordar esos problemas en supply chain y machine learning. Esencialmente, las redes neuronales gráficas son técnicas de deep learning diseñadas para tratar con gráficos.
En conclusión, pensar que el machine learning se trata de entregar forecasts más precisos es, por decirlo suavemente, bastante ingenuo. Es como decir que el objetivo principal de un automóvil es tener acceso a un caballo más rápido. Sí, es cierto que, muy probablemente, a través del machine learning, podemos lograr forecasts más precisos. Sin embargo, esto es una pequeña parte de un panorama muy amplio, y un panorama que sigue ampliándose a medida que se logran avances en la comunidad de machine learning. Empezamos con marcos de machine learning que incluían una serie de conceptos: característica, etiqueta, observación, modelo y pérdida. Este pequeño y elemental marco ya era vastamente más general que la perspectiva de forecast de series temporales. Con el reciente desarrollo del machine learning, vemos que incluso esos conceptos poco a poco están quedando en irrelevancia debido a que estamos descubriendo maneras de trascenderlos. Para supply chain, este cambio de paradigma es de importancia crítica porque significa que tenemos que aplicar este mismo tipo de cambio de paradigma cuando se trata de forecast. El machine learning nos obliga a repensar completamente cómo abordar los datos y qué podemos hacer con ellos. El machine learning abre puertas que estaban muy firmemente cerradas hasta hace muy poco.

Ahora, veamos algunas preguntas.
Pregunta: ¿No usan los random forests el bagging?
Mi punto es que, sí, son una extensión de eso, y tienen más que solo bagging. Bagging es una técnica interesante, pero cada vez que ves una técnica de machine learning, tienes que preguntarte: ¿esta técnica me va a hacer progresar hacia mi capacidad de aprender los problemas realmente difíciles como la cannibalización o la sustitución? Y, ¿esta técnica va a funcionar bien con el hardware computacional que tienes? Esta es una de las ideas clave que debes llevarte de esta conferencia.
Pregunta: Con el impulso de que las empresas tengan todo automatizado con robótica, ¿cuál es el futuro de los trabajadores de almacén logísticos?
Esta pregunta no está exactamente relacionada con el machine learning, pero es una muy buena pregunta. Las fábricas han experimentado una transformación masiva hacia una robotization, que puede o no utilizar robots. La productividad de las fábricas ha aumentado, y aun ahora en China, las fábricas están en gran parte automatizadas. Los almacenes llegaron tarde a la fiesta. Sin embargo, lo que veo hoy en día es el desarrollo de almacenes que son cada vez más mecánicos y automatizados. No diría que necesariamente son robots; hay muchas tecnologías competitivas para construir un almacén que logre un mayor grado de automatización. Lo esencial es que la tendencia está clara. Los almacenes y centros logísticos, en general, van a experimentar la misma clase de mejora masiva en productividad que ya hemos presenciado en la producción.
Para responder a tu pregunta, no estoy diciendo que las personas serán reemplazadas por robots; serán reemplazadas por automatización. La automatización a veces tomará la forma de algo como un robot, pero también puede tomar muchas otras formas. Algunas de esas formas son simplemente configuraciones ingeniosas que mejoran enormemente la productividad sin involucrar la tecnología que intuitivamente asociamos con los robots. Sin embargo, creo que la parte logística de supply chain en general va a disminuir. Lo único que mantiene esto en ascenso actualmente es el hecho de que, con el auge del e-commerce, tenemos que ocuparnos de la última milla. La última milla ocupa cada vez más la mayor parte de la fuerza laboral que tiene que tratar con logística. Incluso la última milla será automatizada en un futuro no tan lejano. Los vehículos autónomos están a la vuelta de la esquina; se prometieron para esta década, y aunque puedan estar llegando un poco tarde, están en camino.
Pregunta: ¿Crees que vale la pena invertir tiempo en aprender machine learning para trabajar en supply chain?
Absolutamente. En mi opinión, el machine learning es una ciencia auxiliar de supply chain. Considera la relación que tiene un médico con la química. Si eres un médico de la actualidad, nadie espera que seas un químico. Sin embargo, si le dices a tu paciente que no sabes absolutamente nada sobre química, la gente pensaría que no tienes lo que se necesita para ser un médico moderno. El machine learning debe abordarse de la misma manera que las personas que estudian medicina abordan la química. No es un fin, sino un medio. Si quieres hacer un trabajo serio en supply chain, necesitas tener fundamentos sólidos en machine learning.
Pregunta: ¿Podrías dar ejemplos donde aplicaste machine learning? ¿Se volvió operativo la herramienta?
Hablando por mí, como Joannes Vermorel, el entrepreneur y CEO de Lokad, tenemos más de 100 empresas en producción en este momento, todas utilizando machine learning para tareas diversas. Estas tareas incluyen forecast de lead times, producción de forecasts probabilísticos de demanda, predicción de devoluciones, predicción de problemas de calidad, revisión de estimados del tiempo medio entre reparaciones no programadas y detección de si los precios competitivos son correctos o no. Hay muchas aplicaciones, como revalorar matrices de compatibilidad entre automóviles y partes en el mercado de posventa automotriz. Con machine learning, se puede arreglar una gran parte de los errores de bases de datos automáticamente. En Lokad, no solo tenemos esas 100 empresas en producción, sino que así ha sido durante casi una década. El futuro ya está aquí; solo que no está distribuido de manera equitativa.
Pregunta: ¿Cuál es la mejor forma de aprender machine learning por tu cuenta? ¿Recomendarías sitios como Udemy, Coursera u otro?
Mi sugerencia sería una combinación de Wikipedia y la lectura de artículos. Como has visto en esta conferencia, es importante entender los fundamentos y mantenerse al día con los últimos desarrollos en el campo. Como has visto en estas conferencias, estoy citando artículos de investigación reales. No confíes en información de segunda mano; ve directamente a lo que fue publicado. Todas estas cosas están disponibles directamente en línea. Existen artículos en machine learning que están mal escritos e indescifrables, pero también hay artículos que están brillantemente escritos y ofrecen ideas cristalinas sobre lo que está sucediendo. Mi sugerencia es recurrir a Wikipedia para obtener una visión general de alto nivel de un campo, de modo que puedas captar el panorama general, y luego comenzar a leer artículos. Al principio, puede parecer oscuro, pero después de un tiempo te acostumbrarás. Puedes tomar cursos en Udemy o Coursera, pero personalmente, yo nunca hice eso. Mi objetivo al impartir estas conferencias es darte algunos destellos de intuición para que comprendas el panorama general. Si quieres adentrarte en los detalles minuciosos, simplemente sumérgete en el artículo real que fue publicado hace años o décadas. Recurre a la información de primera mano y confía en tu propia inteligencia.
Deep learning es un campo de investigación muy empírico. La mayor parte de lo que se hace no es extremadamente complejo, matemáticamente hablando. Normalmente, no va más allá de lo que se aprende al final de la escuela secundaria, por lo que es bastante accesible.
Pregunta: ¿Con el auge de herramientas sin código como CodeX y Co-Pilot de OpenAI, ves a los profesionales de supply chain escribiendo modelos en inglés simple en algún momento?
La respuesta corta es: no, para nada. La idea de que se podría eludir la programación existe desde hace mucho tiempo. Por ejemplo, Visual Basic de Microsoft estaba destinado a ser una herramienta visual para que las personas no tuvieran que programar más; simplemente podían componer cosas de forma visual como piezas de Lego. Pero hoy en día, este enfoque ha demostrado ser ineficaz, y la próxima tendencia es expresar las cosas de forma verbal.
Sin embargo, la razón por la que utilizo fórmulas matemáticas en estas conferencias es que existen muchas situaciones en las que usar una fórmula matemática es la única forma de transmitir claramente lo que se quiere decir. El problema con el idioma inglés, o cualquier idioma natural, es que a menudo es impreciso y propenso a interpretaciones erróneas. En contraste, las fórmulas matemáticas son precisas y claras. El inconveniente del lenguaje llano es que es increíblemente vago, y aunque tiene su utilidad, la razón por la que empleamos fórmulas es para proporcionar un significado inequívoco a lo que se expresa. Intento usar fórmulas de forma limitada, pero cuando incluyo una, es porque siento que es la única manera de transmitir la idea de forma clara, con un nivel de claridad que supera lo que puedo expresar verbalmente.
En cuanto a las plataformas de low-code, soy muy escéptico, ya que este enfoque se ha intentado muchas veces en el pasado sin mucho éxito. Mi opinión personal es que deberíamos hacer que la programación sea más adecuada para la gestión de supply chain, identificando por qué la programación es difícil y eliminando la complejidad accidental. Lo que queda es la programación hecha correctamente para supply chain, que es lo que Lokad aspira a hacer.
Pregunta: ¿Hace machine learning que el forecast de la demanda sea más preciso para datos históricos de ventas estacionales o regulares?
Como mencioné en esta presentación, machine learning hace que el concepto de precisión resulte obsoleto. Si observas la última competencia a gran escala de forecast de series temporales, la competencia M5, los 10 mejores modelos eran, en cierta medida, modelos de machine learning. Entonces, ¿hace machine learning que los forecasts sean más precisos? Fácticamente, basándonos en la competencia de forecast, sí. Pero es solo marginalmente más preciso en comparación con otras técnicas, y no es una precisión extra revolucionaria.
Además, no deberías concebir el forecast de forma unidimensional. Cuando preguntas sobre la precisión para seasonality, estás considerando un producto a la vez, pero ese no es el enfoque correcto. La verdadera precisión consiste en evaluar cómo el lanzamiento de un new product afecta a todos los demás productos, ya que existirá cierto grado de canibalización. La clave es evaluar si la forma en que reflejas esta canibalización en tu modelo es precisa o no. De repente, esto se convierte en un problema multidimensional. Como presenté en la conferencia con redes generativas, la métrica de lo que realmente significa la precisión debe ser aprendida; no se puede proporcionar. Las fórmulas matemáticas, como el error absoluto medio, el error porcentual absoluto medio y el error cuadrático medio, son solo criterios matemáticos. No son el tipo de métricas que realmente necesitamos; son simplemente métricas muy ingenuas.
Pregunta: ¿Será que el trabajo mundano de los forecasters será reemplazado por el forecast en modo automático?
Yo diría que el futuro ya está aquí, pero no está distribuido de manera uniforme. En Lokad, ya hacemos forecast de decenas de millones de SKUs diarios, y no tengo a nadie ajustando forecasts en nómina. Así que sí, ya se está haciendo, pero esto es solo una pequeña parte del panorama. Si necesitas que personas ajusten forecasts o calibren modelos de forecast, eso indica un enfoque disfuncional. Deberías considerar la necesidad de ajustar forecasts como un error y solucionarlo automatizando esa parte del proceso.
De nuevo, según la experiencia de Lokad, estas cosas se eliminarán por completo porque ya lo hemos hecho. No somos los únicos que lo hacemos de esta manera, así que para nosotros es casi historia antigua, habiendo sido así durante casi una década.
Pregunta: ¿Hasta qué punto se está utilizando activamente machine learning en la toma de decisiones de supply chain?
Depende de la empresa. En Lokad, se utiliza en todas partes, y obviamente, cuando digo “en Lokad” me refiero a las empresas atendidas por Lokad. Sin embargo, la gran mayoría del mercado sigue utilizando esencialmente Excel, sin machine learning alguno. Lokad gestiona activamente inventarios por valor de miles de millones de euros o dólares, por lo que eso ya es una realidad y lo ha sido durante bastante tiempo. Pero Lokad ni siquiera representa el 0.1% del mercado, por lo que seguimos siendo una anomalía. Estamos creciendo rápidamente, al igual que bastos competidores. Mi sospecha es que sigue siendo una configuración marginal en todo el mercado de supply chain, pero con un crecimiento de dos dígitos. Nunca subestimes el poder del crecimiento exponencial durante un largo período. En última instancia, se hará muy grande, con suerte con Lokad, pero esa es otra historia.
Pregunta: Con tantas incertidumbres en supply chain, ¿cuál es una estrategia que pueda hacer que se asuman los inputs para un modelo?
La idea es que, sí, hay toneladas de incertidumbres, pero los inputs de tu modelo realmente no se eligen. Todo se reduce a lo que posees en tus sistemas empresariales, como el tipo de datos que existen en tu ERP. Si tu ERP cuenta con niveles históricos de stock, entonces puedes usarlos como parte de tu modelo de machine learning. Si tu ERP solo registra los niveles actuales de stock, entonces esos datos no están disponibles. Puedes comenzar a hacer instantáneas de tus niveles de stock si deseas utilizarlos como inputs adicionales, pero el mensaje central es que hay muy poca elección en lo que se puede usar como inputs; literalmente es lo que existe en tus sistemas.
Mi enfoque típico es que, si tienes que crear nuevas fuentes de datos, será un proceso lento y doloroso, y probablemente no sea tu punto de partida para utilizar machine learning en supply chain. Las empresas más grandes se han digitalizado durante décadas, por lo que lo que tienes en tus sistemas transaccionales, como tu ERP y WMS, ya es un excelente punto de partida. Si más adelante te das cuenta de que quieres tener más, como inteligencia competitiva, niveles de stock autorizados o ETAs proporcionados por tus proveedores, esos serán añadidos valiosos para usar como inputs en tus modelos. Generalmente, lo que usas como inputs es algo que, por intuición, se correlaciona bien con lo que intentas predecir en primer lugar, y esa intuición de alto nivel suele ser suficiente. El sentido común, que es difícil de definir, es ampliamente suficiente. Este no es el cuello de botella en términos de ingeniería.
Pregunta: ¿Cuál es el impacto de las decisiones de precios en la estimación de la demanda futura, incluso desde una perspectiva probabilística, y cómo se aborda desde la perspectiva de machine learning?
Esta es una muy buena pregunta. Hubo un episodio en LokadTV que abordó exactamente este problema. La idea es que lo que aprendes se convierte en lo que se conoce típicamente como una política, un objeto que controla la forma en que reaccionas ante varios eventos. La manera de forecast consiste en producir una especie de paisaje, al estilo Monte Carlo. Vas a generar una trayectoria, pero tu forecast no serán puntos de datos estáticos. Será un proceso mucho más generativo, en el que, en cada etapa del proceso de forecast, tendrás que generar el tipo de demanda que puedes observar, generar las decisiones que tomas y regenerar el tipo de respuesta del mercado a lo que acabas de hacer.
Se vuelve muy complicado evaluar la precisión de tu proceso generador de demand response, y por ello necesitas aprender verdaderamente tus métricas de forecast. Eso es muy complejo, pero justamente por eso no puedes concebir tus métricas de forecast, tus métricas de precisión, como un problema unidimensional. En resumen, el forecast de la demanda se convierte en un generador, por lo que es fundamentalmente dinámico, no estático. Es algo generativo. Este generador reacciona a un agente, un agente que se implementará como una política. Tanto el generador como el sistema de formulación de políticas deben ser aprendidos. También debes aprender la función de pérdida. Hay mucho por aprender, pero afortunadamente, deep learning es un enfoque muy modular y programático que se presta bien a la composición de todas estas técnicas.
Pregunta: ¿Es difícil recopilar datos, especialmente de las PYMEs?
Sí, es muy difícil. La razón es que, si tratas con una empresa que tiene menos de 10 millones en facturación, no existe algo como un IT department. Puede que exista un ERP pequeño, pero incluso si las herramientas son buenas, decentes y modernas, no cuentas con un equipo de IT. Cuando solicitas los datos, no hay nadie en la empresa cliente que tenga la competencia para ejecutar una consulta SQL y extraerlos.
No estoy seguro de entender tu pregunta correctamente, pero el problema no es exactamente recopilar los datos. La recopilación se realiza de forma natural a través del software contable o el ERP que se tenga, y hoy en día, los ERPs son accesibles incluso para empresas bastante pequeñas. El problema radica en la extracción de datos de esos programas de software empresarial. Si trabajas en una empresa que tiene menos de 20 millones de dólares en facturación y no es una compañía de ecommerce, es probable que el departamento de IT sea inexistente. Incluso cuando existe un pequeño departamento de IT, normalmente es solo una persona encargada de configurar máquinas y escritorios de Windows para todos. No es alguien familiarizado con bases de datos y tareas administrativas más avanzadas en cuanto a configuraciones de IT.
Bien, supongo que eso es todo. La próxima sesión será dentro de un par de semanas. Será el miércoles 13 de octubre. ¡Hasta la próxima!
Referencias
- A theory of the learnable, L. G. Valiant, noviembre 1984
- Support-vector networks, Corinna Cortes, Vladimir Vapnik, septiembre 1995
- Random Forests, Leo Breiman, octubre 2001
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree, Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu, 2017
- Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, última revisión diciembre 2017
- Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, diciembre 2019
- Analyzing and Improving the Image Quality of StyleGAN, Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila, última revisión marzo 2020
- Generative Adversarial Networks, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, junio 2014
- Unsupervised Machine Translation Using Monolingual Corpora Only, Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, última revisión abril 2018
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, última revisión mayo 2019
- A Gentle Introduction to Graph Neural Networks, Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko, septiembre 2021


