00:28 Introduction
00:43 Robert A. Heinlein
03:03 The story so far
06:52 A selection of paradigms
08:20 Static Analysis
18:26 Array programming
28:08 Hardware miscibility
35:38 Probabilistic programming
40:53 Differentiable programming
55:12 Versioning code+data
01:00:01 Secure programming
01:05:37 In conclusion, tooling matters in Supply Chain too
01:06:40 Upcoming lecture and audience questions
Description
Alors que la théorie de Supply Chain dominante peine à s’imposer dans les entreprises en général, un outil – à savoir Microsoft Excel – a rencontré un succès opérationnel considérable. La réimplémentation des recettes numériques de la théorie de Supply Chain dominante via des tableurs est triviale, pourtant, ce n’est pas ce qui s’est passé en pratique malgré la connaissance de la théorie. Nous démontrons que les tableurs ont triomphé en adoptant des paradigmes de programmation qui se sont révélés supérieurs pour fournir des résultats supply chain.
Transcription complète

Bonjour à tous, bienvenue dans cette série de conférences sur la Supply Chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter ma quatrième conférence : Paradigmes de programmation pour la Supply Chain.

Donc, quand on me demande, “Monsieur Vermorel, quelles sont selon vous les domaines les plus intéressants en matière de connaissances supply chain ?” l’une de mes réponses principales est généralement les paradigmes de programmation. Et puis, pas trop souvent, mais assez fréquemment, la réaction de mon interlocuteur est : “Les paradigmes de programmation, Monsieur Vermorel ? De quoi parlez-vous exactement ? En quoi cela est-il même vaguement pertinent par rapport à la tâche à accomplir ?” Et ces réactions, bien que rares, me rappellent invariablement cette citation absolument incroyable de Robert A. Heinlein, considéré comme le doyen des écrivains de science-fiction.
Heinlein possède une citation fantastique à propos de l’homme compétent, qui souligne l’importance de la compétence dans divers domaines, notamment en Supply Chain où nous sommes confrontés à des problèmes épineux. Ces problèmes sont presque aussi difficiles que la vie elle-même, et je crois qu’il vaut vraiment la peine de prendre le temps d’explorer l’idée des paradigmes de programmation, car cela pourrait apporter beaucoup de valeur à votre Supply Chain.
Jusqu’à présent, lors de la première conférence, nous avons vu que les problèmes de Supply Chain sont épineux. Quiconque évoque des solutions optimales se trompe d’approche ; il n’existe rien d’approchant l’optimalité. Lors de la deuxième conférence, j’ai présenté la Supply Chain Quantitative, une vision reposant sur cinq exigences clés pour atteindre l’excellence en gestion de la Supply Chain. Ces exigences ne suffisent pas à elles seules, mais elles sont incontournables si vous souhaitez atteindre l’excellence.
Dans la troisième conférence, j’ai traité de la livraison de produits logiciels dans le contexte de l’optimisation de Supply Chain. J’ai soutenu que l’optimisation de Supply Chain nécessite qu’un produit logiciel soit abordé de manière capitaliste, mais vous ne pouvez pas trouver un tel produit prêt à l’emploi. Il y a trop de diversité, et les défis rencontrés dépassent de loin les technologies dont nous disposons actuellement. Il s’agira donc, par nécessité, de quelque chose de complètement sur mesure. Ainsi, s’il s’agit d’un produit logiciel qui sera sur mesure pour l’entreprise ou la Supply Chain concernée, il faut se poser la question des outils appropriés pour livrer effectivement ce produit. Ce qui m’amène au sujet d’aujourd’hui : l’outil adéquat commence par les bons paradigmes de programmation, car nous allons devoir programmer ce produit d’une manière ou d’une autre.

Jusqu’à présent, nous avons besoin de capacités programmatiques pour gérer le volet optimisation du problème, sans confondre avec le volet gestion. Ce que nous avons vu, qui était le sujet de ma conférence précédente, c’est que Microsoft Excel est le grand gagnant jusqu’à présent. Des très petites aux très grandes entreprises, il est omniprésent, utilisé partout. Même dans les entreprises qui ont investi des millions de dollars dans des systèmes ultra-intelligents, Excel reste roi, et pourquoi ? Parce qu’il possède les bonnes propriétés de programmation. Il est très expressif, agile, accessible et maintenable. Cependant, Excel n’est pas la solution finale. Je suis fermement convaincu que nous pouvons faire bien plus, mais nous devons disposer des bons outils, de la bonne mentalité, de bonnes perspectives et des bons paradigmes de programmation.

Les paradigmes de programmation peuvent sembler trop obscurs pour le grand public, mais c’est en réalité un domaine d’étude qui a été intensivement exploré durant les cinq dernières décennies. Un travail immense a été réalisé dans ce domaine. Il n’est pas largement connu du grand public, mais il existe des bibliothèques entières regorgeant de travaux de haute qualité réalisés par de nombreuses personnes. Ainsi, aujourd’hui, je vais vous présenter une série de sept paradigmes qu’a adoptée Lokad. Nous n’avons inventé aucune de ces idées ; nous les avons reprises à ceux qui les avaient inventées avant nous. Tous ces paradigmes ont été implémentés dans le produit logiciel de Lokad, et après près d’une décennie de production chez Lokad, en tirant parti de ces paradigmes, je crois qu’ils ont été absolument essentiels à notre succès opérationnel jusqu’à présent.

Passons à cette liste avec l’analyse statique. Le problème ici est la complexité. Comment gérer la complexité en Supply Chain ? Vous allez être confronté à des systèmes d’entreprise comportant des centaines de tables, chacune avec des dizaines de champs. Si vous considérez un problème aussi simple que le réapprovisionnement de stocks dans un entrepôt, vous avez tellement de choses à prendre en compte. Vous pouvez avoir des MOQs, des remises sur les prix, des prévisions de la demande, des prévisions de délais d’approvisionnement, et toutes sortes de retours. Vous pouvez avoir des limitations d’espace de rayonnage, des limites de capacité de réception, et des dates d’expiration qui rendent certains de vos lots obsolètes. Ainsi, vous vous retrouvez avec une multitude de choses à considérer. En Supply Chain, l’idée de “bouger vite et casser des choses” n’est tout simplement pas la bonne mentalité. Si vous commandez par inadvertance pour un million de dollars de marchandises dont vous n’avez absolument pas besoin, c’est une erreur très coûteuse. Vous ne pouvez pas avoir un logiciel pilotant votre Supply Chain, prenant des décisions de routine, et lorsqu’un bug survient, cela coûte des millions. Nous devons disposer de quelque chose assurant un degré de correction très élevé dès la conception. Nous ne voulons pas découvrir les bugs en production. Cela diffère énormément de votre logiciel moyen où un crash n’est pas dramatique.
Lorsqu’il s’agit d’optimiser la Supply Chain, ce n’est pas un problème ordinaire. Si vous venez de passer une commande massive et incorrecte à un fournisseur, vous ne pouvez pas simplement l’appeler une semaine plus tard pour dire : “Oh, mon erreur, oubliez cela, nous n’avons jamais commandé cela.” Ces erreurs vont coûter très cher. L’analyse statique est ainsi appelée car elle consiste à analyser un programme sans l’exécuter. L’idée est que vous avez un programme écrit avec des instructions, des mots-clés, et tout, et sans même exécuter ce programme, pouvez-vous déjà dire si le programme présente des problèmes qui auraient presque certainement un impact négatif sur votre production, en particulier votre production de Supply Chain ? La réponse est oui. Ces techniques existent bel et bien, et elles sont mises en œuvre et extrêmement précieuses.
Pour donner un exemple, vous pouvez voir une capture d’écran d’Envision à l’écran. Envision est un langage de programmation dédié qui a été conçu pendant près d’une décennie par Lokad et est dédié à l"optimisation prédictive de Supply Chain. Ce que vous voyez est une capture d’écran de l’éditeur de code d’Envision, une application web que vous pouvez utiliser en ligne pour éditer du code. La syntaxe est fortement influencée par Python. Dans cette minuscule capture, avec seulement quatre lignes, j’illustre l’idée que si vous rédigez une grande portion de logique pour le réapprovisionnement de stocks dans un entrepôt, et que vous introduisez quelques variables économiques, comme les remises sur les prix, via une analyse logique du programme, vous pouvez constater que ces remises sur les prix n’ont absolument aucune relation avec les résultats finaux renvoyés par le programme, à savoir les quantités à réapprovisionner. Ici, vous avez un problème évident. Vous avez introduit une variable importante, les remises sur les prix, et celles-ci n’ont logiquement aucune influence sur le résultat final. Ainsi, nous avons un problème qui peut être détecté grâce à l’analyse statique. C’est un problème flagrant, car si nous intégrons des variables dans le code qui n’ont aucun impact sur la sortie du programme, alors elles ne servent à rien. Dans ce cas, nous sommes face à deux possibilités : soit ces variables constituent du code mort et le programme ne devrait pas compiler (il faudrait simplement éliminer ce code mort afin de réduire la complexité et d’éviter d’accumuler une complexité accidentelle), soit il s’agit d’une erreur véritable et qu’une variable économique importante aurait dû être intégrée dans votre calcul, mais vous en êtes arrivé là par distraction ou pour une autre raison.
L’analyse statique est absolument fondamentale pour atteindre un degré de correction par conception. Il s’agit de corriger les choses au moment de la compilation, lorsque vous écrivez le code, avant même de manipuler les données. Si des problèmes se manifestent lors de l’exécution, il y a de fortes chances qu’ils apparaissent pendant la nuit, lorsque le traitement nocturne gère le réapprovisionnement de l’entrepôt. Le programme est susceptible de s’exécuter à des heures irrégulières, quand personne ne le surveille, et vous ne voulez pas qu’il plante en l’absence d’un observateur. Il devrait planter au moment où les développeurs écrivent le code.
L’analyse statique a de multiples objectifs. Par exemple, chez Lokad, nous utilisons l’analyse statique pour l’édition WYSIWYG des tableaux de bord. WYSIWYG signifie “what you see is what you get.” Imaginez que vous construisiez un tableau de bord pour le reporting, avec des graphiques linéaires, des graphiques à barres, des tableaux, des couleurs et divers effets de style. Vous souhaitez pouvoir le faire de manière visuelle, et non modifier le style de votre tableau de bord via le code, car c’est très fastidieux. Tous les paramètres que vous avez mis en place seront réinjectés dans le code lui-même, et cela se fait grâce à l’analyse statique.
Un autre aspect chez Lokad, qui peut ne pas revêtir une importance capitale pour la Supply Chain dans l’ensemble mais qui est certes critique pour mener à bien le projet, était la gestion d’un langage de programmation appelé Envision que nous sommes en train de développer. Nous savions, dès le premier jour, il y a presque une décennie, que des erreurs allaient être commises. Nous n’avions pas de boule de cristal pour avoir dès le départ la vision parfaite. La question était de savoir comment nous assurer de pouvoir corriger ces erreurs de conception dans le langage de programmation lui-même de la manière la plus aisée possible. Ici, Python a été pour moi une mise en garde.
Python, qui n’est pas un langage nouveau, a été publié pour la première fois en 1991, il y a presque 30 ans. La migration de Python 2 vers Python 3 a pris presque une décennie à toute la communauté, et ce fut un processus cauchemardesque, très douloureux pour les entreprises impliquées dans cette migration. J’ai eu l’impression que le langage lui-même ne disposait pas de suffisamment de constructions. Il n’a pas été conçu de manière à permettre la migration des programmes d’une version du langage à une autre. Il était en réalité extrêmement difficile de le faire de manière entièrement automatisée, et c’est parce que Python n’a pas été pensé en termes d’analyse statique. Lorsque vous disposez d’un langage de programmation pour la Supply Chain, vous souhaitez réellement en avoir un qui offre une excellente qualité en matière d’analyse statique, car vos programmes seront amenés à durer très longtemps. Les Supply Chains n’ont pas le luxe de dire : “Attendez trois mois, nous sommes en train de réécrire le code. Patientez, la cavalerie arrive. Cela ne va tout simplement pas fonctionner pendant quelques mois.” C’est littéralement comparable à réparer un train pendant qu’il roule à pleine vitesse sur les rails, et vous devez réparer le moteur pendant que le train fonctionne. Voilà à quoi ressemble la réparation de problèmes de Supply Chain qui sont effectivement en production. Vous n’avez pas le luxe de simplement mettre le système en pause ; il ne s’interrompt jamais.

Le second paradigme est la programmation par tableaux. Nous voulons maîtriser la complexité, car c’est un thème récurrent majeur en Supply Chain. Nous souhaitons instaurer une logique qui évite certaines catégories d’erreurs de programmation. Par exemple, chaque fois que vous rédigez explicitement des boucles ou des branches, vous vous exposez à des catégories entières de problèmes très difficiles. Cela devient extrêmement complexe lorsque l’on peut simplement écrire des boucles arbitraires pour garantir la durée du calcul. Bien que cela puisse sembler être un problème de niche, ce n’est pas tout à fait le cas dans l’optimization de la Supply Chain.
En pratique, disons que vous avez une chaîne de distribution. À minuit, ils auront complètement consolidé toutes les ventes de l’ensemble du réseau, et les données seront centralisées et transmises à un système quelconque pour l’optimisation. Ce système disposera exactement d’une fenêtre de 60 minutes pour effectuer les prévisions, l’optimisation de stocks, et les décisions de réaffectation pour chaque magasin du réseau. Une fois terminé, les résultats seront transmis au système de gestion d’entrepôt afin qu’ils puissent commencer à préparer toutes les expéditions. Les camions seront chargés, peut-être à 5h00, et à 9h00, les magasins ouvriront avec la marchandise déjà reçue et placée sur les étagères.
Cependant, vous avez un timing très strict, et si votre calcul dépasse cette fenêtre de 60 minutes, vous mettez en péril l’exécution de toute la supply chain. Vous ne voulez pas vous retrouver dans une situation où vous découvrez en production combien de temps les choses prennent. Si vous avez des boucles où les gens peuvent décider du nombre d’itérations qu’ils vont effectuer, il est très difficile d’apporter la moindre preuve de la durée de votre calcul. Gardez à l’esprit qu’il s’agit de l’optimization de la supply chain dont nous parlons. Vous n’avez pas le luxe de procéder à une revue par les pairs et de tout revérifier. Parfois, en raison de la pandémie, certains pays ferment tandis que d’autres rouvrent de façon assez erratique, généralement avec un préavis de 24 heures. Vous devez réagir rapidement.
Ainsi, la programmation sur tableaux est l’idée de pouvoir opérer directement sur des tableaux. Si l’on regarde ce fragment de code que nous avons ici, il s’agit de code Envision, le langage dédié de Lokad. Pour comprendre ce qui se passe, vous devez savoir que lorsque j’écris “orders.amounts”, ce qui en ressort est une variable et que “orders” est en réalité une table au sens d’une table relationnelle, comme dans votre base de données. Par exemple, ici, dans la première ligne, “amounts” serait une colonne de la table. Dans la première ligne, ce que je fais, c’est littéralement dire que pour chaque ligne de la table orders, je vais simplement prendre la “quantity”, qui est une colonne, la multiplier par “price”, et ainsi obtenir une troisième colonne générée dynamiquement, nommée “amount”.
Au fait, le terme moderne pour la programmation sur tableaux de nos jours est aussi appelé programmation sur data frames. Ce domaine d’étude est assez ancien ; il remonte à trois ou quatre décennies, voire même quatre ou cinq. Bien qu’il fût connu sous le nom de programmation sur tableaux, les gens sont aujourd’hui généralement plus familiers avec l’idée des data frames. À la deuxième ligne, ce que nous faisons, c’est appliquer un filtre, exactement comme en SQL. Nous filtrons les dates, et il se trouve que la table orders comporte une date. Elle va être filtrée, et je dis “date qui est supérieure à aujourd’hui moins 365”, c’est-à-dire en jours. Nous conservons les données de l’année dernière, puis nous écrivons “products.soldLastYear = SUM(orders.amount)”.
Maintenant, l’intérêt est que nous avons ce que nous appelons un natural join entre products et orders. Pourquoi ? Parce que chaque ligne de commande est associée à un seul produit, et un produit est associé à zéro ou plusieurs lignes de commande. Dans cette configuration, vous pouvez directement dire : “Je veux calculer quelque chose au niveau du produit qui soit simplement la somme de ce qui se passe au niveau des orders”, et c’est exactement ce qui est fait à la ligne neuf. Vous remarquerez que la syntaxe est très minimale ; il n’y a pas beaucoup d’accidentels ou de subtilités techniques. J’affirmerais que ce code est presque entièrement dépourvu d’accidentels en ce qui concerne la programmation sur data frames. Ensuite, aux lignes 10, 11 et 12, nous affichons simplement une table sur notre dashboard, ce qui peut être réalisé très commodément avec “LIST(PRODUCTS)” puis “TO(products)”.
Il y a de nombreux avantages à la programmation sur tableaux pour les supply chains. Tout d’abord, elle élimine des catégories entières de problèmes. Vous n’aurez pas de bugs d’indice (off-by-one) dans vos tableaux. Il sera bien plus facile de paralléliser, voire de distribuer les calculs. C’est très intéressant car cela signifie que vous pouvez écrire un programme et le faire exécuter non pas sur une machine locale, mais directement sur une flotte de machines qui résident dans le cloud, et d’ailleurs, c’est exactement ce qui se fait chez Lokad. Cette parallélisation automatique présente un intérêt extrêmement élevé.
Vous voyez, le procédé est le suivant : lorsque vous réalisez l’optimization de la supply chain, vos schémas de consommation typiques en termes de matériel informatique sont très intermittents. Si je reprends l’exemple que je donnais à propos de la fenêtre de 60 minutes pour les réseaux de distribution lors du réapprovisionnement des magasins, cela signifie qu’il y a une heure par jour où vous avez besoin de puissance de calcul pour effectuer tous vos calculs, mais que durant le reste du temps, les 23 autres heures, vous n’en avez pas besoin. Ce que vous voulez, c’est un programme qui, lorsqu’il est lancé, se répartisse sur de nombreuses machines et qui, une fois terminé, libère toutes ces machines afin que d’autres calculs puissent s’exécuter. L’alternative serait d’avoir de nombreuses machines que vous louez et payez toute la journée, mais que vous n’utilisez que 5 % du temps, ce qui est très inefficace.
Cette idée selon laquelle vous pouvez vous répartir rapidement et de manière prévisible sur de nombreuses machines, puis céder la puissance de traitement, nécessite le cloud dans une configuration multi-tenant et une série d’autres éléments que Lokad met en place. Mais avant tout, cela requiert la coopération du langage de programmation lui-même. C’est tout simplement impossible avec un langage de programmation générique comme Python, car le langage ne se prête pas à ce type d’approche à la fois intelligente et pertinente. Il ne s’agit pas simplement de subterfuges ; c’est littéralement une division de vos coûts matériels informatiques par 20, un accélération massive de l’exécution et l’élimination de catégories entières de bugs potentiels dans votre supply chain. Cela change la donne.
La programmation sur tableaux existe déjà sous de nombreuses formes, comme avec NumPy et pandas en Python, qui sont très populaires auprès du segment des data scientist. Mais la question que je vous pose est la suivante : si c’est si important et utile, pourquoi ces outils ne sont-ils pas considérés comme des citoyens de première classe du langage lui-même ? Si tout ce que vous faites est de passer par NumPy, alors NumPy devrait être un citoyen de première classe. Je dirais qu’on peut faire encore mieux que NumPy. NumPy ne concerne que la programmation sur tableaux sur une seule machine, mais pourquoi ne pas faire de la programmation sur tableaux sur une flotte de machines ? C’est beaucoup plus puissant et bien plus adéquat lorsqu’on dispose d’un cloud avec une capacité matérielle accessible.
Alors, quel sera le goulot d’étranglement dans l’optimization de la supply chain ? Il existe un adage de Goldratt qui affirme : “Toute amélioration apportée en dehors du goulot d’étranglement d’une supply chain est une illusion”, et je souscris pleinement à cette affirmation. En réalité, lorsque nous voulons réaliser l’optimization de la supply chain, le goulot d’étranglement sera les personnes, et plus précisément, les Supply Chain Scientist qui, malheureusement pour Lokad et mes clients, ne poussent pas sur les arbres.
Le goulot d’étranglement, ce sont les Supply Chain Scientist, les personnes capables de concevoir des recettes numériques intégrant toutes les stratégies de l’entreprise, les comportements antagonistes des concurrents, et qui transforment toute cette intelligence en quelque chose de mécanique pouvant être exécuté à grande échelle. La tragédie de la manière naïve de faire de la data science, lorsque j’ai commencé mon doctorat – que je n’ai d’ailleurs jamais terminé – était que je voyais tout le monde dans le laboratoire pratiquer littéralement la data science. La plupart des gens écrivaient du code pour une sorte de modèle de machine learning avancé, appuyaient sur entrée puis attendaient. Si vous disposez d’un grand ensemble de données, par exemple de 5 à 10 gigaoctets, ce ne sera pas en temps réel. Ainsi, le laboratoire était rempli de personnes qui écrivaient quelques lignes, appuyaient sur entrée, puis allaient prendre une tasse de café ou lire quelque chose en ligne. Par conséquent, la productivité était extrêmement faible.
Lorsque j’ai créé ma propre entreprise, j’avais en tête que je ne voulais pas finir par payer une armée de personnes super intelligentes qui passent la majeure partie de leur journée à siroter du café, attendant que leurs programmes se terminent pour obtenir des résultats et passer à autre chose. En théorie, ils pourraient paralléliser de nombreuses tâches à la fois et mener des expériences, mais en pratique, je n’ai jamais réellement constaté cela. Intellectuellement, lorsque vous vous employez à trouver une solution à un problème, vous souhaitez tester votre hypothèse, et vous avez besoin du résultat pour avancer. Il est très difficile de faire du multitâche sur des sujets hautement techniques et de poursuivre simultanément plusieurs pistes intellectuelles.
Cependant, il y avait une lueur d’espoir. Les data scientists, et désormais les Supply Chain Scientist chez Lokad, ne finissent pas par écrire mille lignes de code pour ensuite dire “please run.” Ils ajoutent généralement deux lignes à un script de mille lignes, puis demandent son exécution. Ce script s’exécute sur exactement les mêmes données qu’ils ont utilisées quelques minutes auparavant. La logique est presque identique, à l’exception de ces deux lignes. Alors, comment pouvez-vous traiter des téraoctets de données en quelques secondes au lieu de plusieurs minutes ? La réponse est que, lors de l’exécution précédente du script, si vous avez enregistré toutes les étapes intermédiaires du calcul et les avez stockées (typiquement sur des disques SSD), qui sont très bon marché, rapides et pratiques.
La prochaine fois que vous exécuterez votre programme, le système remarquera que le script est presque identique. Il effectuera une comparaison (diff) et constatera qu’en termes de graphe de calcul, il est pratiquement identique, à l’exception de quelques éléments. En termes de données, il est généralement 100 % identique. Parfois, il y a quelques modifications, mais presque rien. Le système diagnostiquera automatiquement que vous n’avez que quelques éléments à recalculer, ce qui vous permettra d’obtenir les résultats en quelques secondes. Cela peut augmenter de manière spectaculaire la productivité de votre Supply Chain Scientist. Vous pouvez passer de personnes qui appuient sur entrée et attendent 20 minutes pour obtenir le résultat à des personnes qui, après avoir appuyé sur entrée, obtiennent le résultat en 5 ou 10 secondes et peuvent poursuivre leur travail.
Je parle de quelque chose qui peut sembler très obscur, mais en pratique, il s’agit d’un élément ayant un impact multiplié par 10 sur la productivité. C’est énorme. Ce que nous faisons ici, c’est utiliser une astuce ingénieuse que Lokad n’a pas inventée. Nous substituons une ressource de calcul brute, qui est le compute, par une autre, qui est la mémoire et le stockage. Nous disposons des ressources informatiques fondamentales : le compute, la mémoire (qu’elle soit volatile ou persistante) et la bande passante. Ce sont les ressources de base pour lesquelles vous payez lorsque vous achetez des ressources sur une plateforme de cloud computing. Vous pouvez en fait substituer une ressource par une autre, l’objectif étant d’obtenir le meilleur rapport qualité-prix.
Quand on dit que vous devriez utiliser le in-memory computing, je dirais que c’est absurde. Employer le in-memory computing signifie que l’on met l’accent sur une ressource au détriment des autres. Mais non, il y a des compromis, et l’intérêt, c’est que vous pouvez disposer d’un langage de programmation et d’un environnement qui facilite la mise en place de ces compromis et perspectives. Dans un langage de programmation généraliste, il est possible de faire cela, mais il faut le faire manuellement. Cela signifie que la personne qui s’en charge doit être un ingénieur logiciel professionnel. Un Supply Chain Scientist n’est pas censé réaliser ces opérations de bas niveau avec les ressources informatiques fondamentales de votre plateforme. Cela doit être intégré au niveau même du langage de programmation.
Parlons maintenant de programmation probabiliste. Dans la deuxième conférence où j’ai présenté la vision de la supply chain quantitative, ma première exigence était que nous devions examiner tous les futurs possibles. La réponse technique à cette exigence est la prévision probabiliste. Vous voulez traiter des futurs où les probabilités interviennent. Tous les futurs sont possibles, mais ils ne le sont pas tous avec la même probabilité. Il vous faut une algèbre qui vous permette d’effectuer des calculs dans l’incertitude. L’une de mes grandes critiques concernant Excel est qu’il est extrêmement difficile de représenter l’incertitude dans un tableur, que ce soit avec Excel ou toute autre version moderne basée sur le cloud. Dans un tableur, il est très délicat de représenter l’incertitude car il vous faut quelque chose de mieux que de simples chiffres.
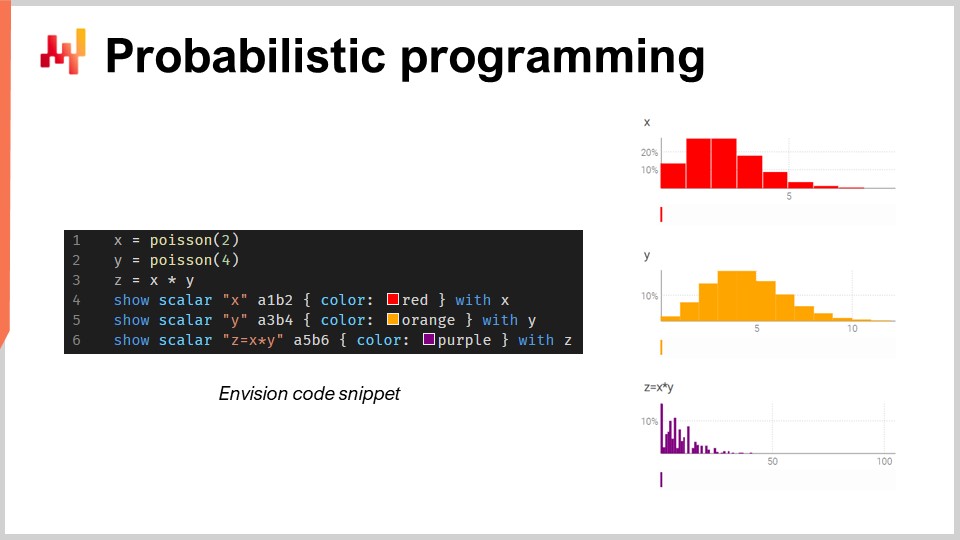
Dans ce petit extrait, j’illustre l’algèbre des variables aléatoires, qui est une fonctionnalité native d’Envision. À la première ligne, je génère une distribution de Poisson discrète, avec une moyenne de 2, et je l’affecte à la variable X. Ensuite, je fais de même pour une autre distribution de Poisson, Y. Puis, je calcule Z en multipliant X par Y. Cette opération, la multiplication de variables aléatoires, peut sembler très bizarre. Pourquoi auriez-vous besoin de ce genre de chose d’un point de vue supply chain ? Laissez-moi vous donner un exemple.
Supposons que vous évoluiez dans le secteur de l’après-vente automobile et que vous vendiez des plaquettes de frein. Les clients n’achètent pas les plaquettes de frein à l’unité ; ils en achètent soit deux, soit quatre. La question est donc la suivante : si vous souhaitez faire une prévision, vous voudrez peut-être estimer les probabilités que des clients se présentent réellement pour acheter un certain type de plaquettes de frein. Ce sera votre première variable aléatoire, qui vous donnera la probabilité d’observer zéro unité de demande, une unité, deux, trois, quatre, etc. pour les plaquettes de frein. Ensuite, vous aurez une autre distribution de probabilité qui représentera si les clients vont acheter deux ou quatre plaquettes. Peut-être sera-ce 50-50, ou peut-être 10 % pour l’achat de deux et 90 % pour l’achat de quatre. Le fait est que vous avez ces deux angles, et si vous souhaitez connaître la consommation totale réelle des plaquettes de frein, vous devez multiplier la probabilité qu’un client se présente pour ces plaquettes par la distribution de probabilité d’achat (deux ou quatre). Ainsi, il vous faut effectuer cette multiplication entre deux quantités incertaines.
Ici, je suppose que les deux variables aléatoires sont indépendantes. D’ailleurs, cette multiplication de variables aléatoires est connue en mathématiques sous le nom de convolution discrète. Vous pouvez voir sur la capture d’écran le dashboard généré par Envision. Dans les trois premières lignes, j’effectue ce calcul d’algèbre aléatoire, puis, aux lignes quatre, cinq et six, j’affiche ces éléments sur la page web, dans le dashboard généré par le script. Je trace A1, B2, par exemple, comme dans une grille Excel. Les dashboards de Lokad sont organisés de manière similaire aux grilles Excel, avec des positions correspondant aux colonnes B, C, etc., et aux lignes 1, 2, 3, 4, 5.
Vous pouvez voir que la convolution discrète, Z, présente un motif très bizarre, extrêmement pointu, qui est en réalité très courant dans les supply chains lorsque les clients peuvent acheter des packs, des lots ou des quantités multiples. Dans ce genre de situation, il est généralement préférable de décomposer les sources des événements multiplicatifs associés au lot ou au pack. Il vous faut un langage de programmation offrant ces capacités directement à portée de main, en tant que citoyens de première classe. C’est exactement de cela qu’il s’agit en programmation probabiliste, et c’est ainsi que nous l’avons implémenté dans Envision.

Maintenant, parlons de la programmation différentiable. Je dois apporter une mise en garde ici : je ne m’attends pas à ce que le public comprenne réellement ce qui se passe, et je m’en excuse. Ce n’est pas que votre intelligence fasse défaut ; c’est simplement que ce sujet mérite toute une série de conférences. En fait, si vous regardez le plan des prochaines conférences, il y a toute une série dédiée à la programmation différentiable. Je vais y aller très rapidement, et cela va être assez cryptique, donc je m’excuse d’avance.
Continuons avec le problème de supply chain qui nous intéresse ici, à savoir la cannibalisation et la substitution. Ces problèmes sont très intéressants, et c’est probablement dans ce contexte que la prévision des séries temporelles — omniprésente — échoue de la manière la plus brutale. Pourquoi ? Parce que, fréquemment, des clients ou prospects viennent me voir et me demandent si nous pouvons effectuer, par exemple, des prévisions sur 13 semaines pour certains articles comme des sacs à dos. Je répondrais que oui, nous pouvons le faire, mais évidemment, si nous prenons un sac à dos et que nous voulons prévoir la demande pour ce produit, cela dépend massivement de ce que vous faites avec vos autres sacs à dos. Si vous n’avez qu’un seul sac à dos, alors peut-être allez-vous concentrer toute la demande de sacs à dos sur ce produit. Si vous introduisez 10 variantes différentes, il y aura évidemment une tonne de cannibalisation. Vous n’allez pas multiplier le montant total des ventes par un facteur de 10 simplement parce que vous avez multiplié le nombre de références par 10. Il y a donc clairement de la cannibalisation et de la substitution qui se produisent. Ces phénomènes sont répandus dans les supply chains.
Comment analyser la cannibalisation ou la substitution ? La méthode que nous utilisons chez Lokad, et je ne prétends pas que ce soit la seule manière, mais c’est certainement une méthode qui fonctionne, consiste généralement à examiner le graphe qui relie les clients et les produits. Pourquoi cela ? Parce que la cannibalisation se produit lorsque des produits se font concurrence eux-mêmes pour les mêmes clients. La cannibalisation représente littéralement le fait qu’un client a un besoin, mais qu’il a des préférences et va choisir un produit parmi l’ensemble des produits correspondant à son affinité, et n’en sélectionner qu’un seul. C’est l’essence même de la cannibalisation.
Si vous souhaitez analyser cela, vous devez examiner non pas les séries temporelles des ventes, car vous ne capturez pas cette information en premier lieu, mais le graphe qui relie les transactions historiques entre clients et produits. Il s’avère que dans la plupart des entreprises, ces données sont facilement disponibles. Pour le e-commerce, c’est acquis. Pour chaque unité que vous vendez, vous connaissez le client. En B2B, c’est la même chose. Même en B2C dans le commerce de détail, la plupart du temps, les chaînes de distribution actuelles disposent de programmes de loyalty dans lesquels ils connaissent un pourcentage à deux chiffres des clients qui se présentent avec leurs cartes, ainsi vous savez qui achète quoi. Pas pour 100 % du trafic, mais cela suffit pour ce genre d’analyse.
Dans cet extrait relativement court, je vais détailler une analyse d’affinité entre les clients et les produits. C’est littéralement l’étape fondamentale à réaliser pour toute analyse de cannibalisation. Examinons ce qui se passe dans ce code.
De la ligne 1 à 5, c’est très banal ; je lis simplement un fichier plat qui contient un historique de transactions. Je lis simplement un fichier CSV qui comporte quatre colonnes : date, produit, client et quantité. Quelque chose de très basique. Je n’utilise même pas toutes ces colonnes, mais c’est juste pour rendre l’exemple un peu plus concret. Dans l’historique des transactions, je suppose que les clients sont connus pour toutes ces transactions. Donc, c’est très banal ; je lis simplement des données à partir d’une table.
Ensuite, aux lignes 7 et 8, je me contente de créer la table pour les produits et la table pour les clients. Dans une configuration de production réelle, je ne créerais généralement pas ces tables ; je les lirais à partir d’autres fichiers plats situés ailleurs. Je voulais garder l’exemple super simple, donc j’extrais simplement une table des produits à partir des produits observés dans l’historique des transactions, et je fais de même pour les clients. Vous voyez, c’est simplement un truc pour maintenir la simplicité.
Maintenant, les lignes 10, 11 et 12 concernent des espaces latins, et cela va devenir un peu plus obscur. D’abord, à la ligne 10, je crée une table de 64 lignes. La table ne contient rien ; elle est définie uniquement par le fait qu’elle comporte 64 lignes, et c’est tout. C’est donc comme un espace réservé, une table triviale avec de nombreuses lignes et aucune colonne. Ce n’est pas très utile en soi. Ensuite, “P” est essentiellement un produit cartésien, une opération mathématique englobant toutes les paires. C’est une table où vous avez une ligne pour chaque ligne dans les produits et chaque ligne dans la table “L”. Ainsi, cette table “P” possède 64 lignes de plus que la table des produits, et je fais la même chose pour les clients. J’inflate simplement ces tables par cette dimension supplémentaire, qui est cette table “L”.
Ceci sera mon support pour mes espaces latins, ce que je vais précisément apprendre. Ce que je souhaite apprendre, c’est que, pour chaque produit, un espace latin qui sera un vecteur de 64 valeurs, et pour chaque client, un espace latin de 64 valeurs également. Si je veux connaître l’affinité entre un client et un produit, je souhaite simplement pouvoir effectuer le produit scalaire entre les deux. Le produit scalaire est simplement la multiplication terme à terme de tous les éléments de ces deux vecteurs, suivi d’une somme. Cela peut sembler très technique, mais c’est juste une multiplication terme à terme plus une somme – c’est le produit scalaire.
Ces espaces latins ne sont qu’un jargon sophistiqué pour créer un espace avec des paramètres un peu inventés, que je souhaite simplement apprendre. Toute la magie de la programmation différentiable se réalise en seulement cinq lignes, de la ligne 14 à 18. J’utilise un mot-clé, “autodiff”, et “transactions”, qui indique qu’il s’agit d’une table d’intérêt, une table d’observations. Je vais traiter cette table ligne par ligne pour effectuer mon processus d’apprentissage. Dans ce bloc, je déclare un ensemble de paramètres. Les paramètres sont les éléments que vous souhaitez apprendre, comme des nombres, mais dont vous ignorez encore les valeurs. Ces éléments vont simplement être initialisés de manière aléatoire, avec des nombres aléatoires.
J’introduis “X”, “X*” et “Y”. Je ne vais pas entrer dans le détail de ce que fait exactement “X*” ; peut-être lors des questions. Je renvoie une expression qui est ma fonction de perte, et qui correspond à la somme. L’idée du filtrage collaboratif ou de la décomposition matricielle est simplement que vous souhaitez apprendre des espaces latins qui s’adaptent à toutes vos arêtes dans votre graphe bipartite. Je sais que c’est un peu technique, mais ce que nous faisons est littéralement très simple, du point de vue de la supply chain. Nous apprenons l’affinité entre les produits et les clients.
Je sais que cela semble probablement très opaque, mais restez avec moi, et il y aura d’autres conférences où je vous offrirai une introduction plus approfondie à ce sujet. Le tout se fait en cinq lignes, ce qui est tout à fait remarquable. Quand je dis cinq lignes, je ne cherche pas à tromper en disant : “Regardez, ce sont seulement cinq lignes”, alors qu’en réalité j’appelle une bibliothèque tierce d’une complexité gigantesque où toute l’intelligence est dissimulée. Non, non, non. Ici, dans cet exemple, il n’y a littéralement aucune magie de machine learning à part les deux mots-clés “autodiff” et “params”. “Autodiff” est utilisé pour définir un bloc où la programmation différentiable aura lieu, et, d’ailleurs, c’est un bloc où je peux programmer n’importe quoi, donc littéralement, je peux injecter notre programme. Ensuite, j’utilise “params” pour déclarer mes problèmes, et c’est tout. Vous voyez, il n’y a aucune magie opaque en action ; il n’existe pas une bibliothèque d’un million de lignes en arrière-plan effectuant tout le travail pour vous. Tout ce que vous devez savoir est littéralement sur cet écran, et c’est la différence entre un paradigme de programmation et une bibliothèque. Le paradigme de programmation vous donne accès à des capacités apparemment incroyablement sophistiquées, telles que réaliser une analyse de cannibalisation avec seulement quelques lignes de code, sans recourir à d’immenses bibliothèques tierces qui masquent la complexité. Cela transcende le problème, le rendant beaucoup plus simple, afin que vous puissiez résoudre quelque chose qui semble super compliqué en seulement quelques lignes.
Maintenant, quelques mots sur le fonctionnement de la programmation différentiable. Il y a deux points clés. L’un est la différentiation automatique. Pour ceux d’entre vous qui ont bénéficié d’une formation en ingénierie, vous avez vu deux façons de calculer des dérivées. Il existe une dérivée symbolique, par exemple, si vous avez x au carré, vous dérivez par rapport à x, ce qui donne 2x. C’est une dérivée symbolique. Ensuite, il y a la dérivée numérique, donc si vous avez une fonction f(x) que vous souhaitez différencier, ce sera f’(x) ≈ (f(x + ε) - f(x))/ε. C’est la dérivation numérique. Les deux ne conviennent pas à ce que nous essayons d’accomplir ici. La dérivation symbolique pose des problèmes de complexité, car votre dérivée pourrait être un programme beaucoup plus complexe que le programme original. La dérivation numérique est numériquement instable, vous rencontrerez donc de nombreux problèmes de stabilité numérique.
La différentiation automatique est une idée fantastique datant des années 70 et redécouverte par le grand public la dernière décennie. C’est l’idée que vous pouvez calculer la dérivée d’un programme informatique quelconque, ce qui est époustouflant. Encore plus incroyable, le programme qui est la dérivée a la même complexité computationnelle que le programme original, ce qui est stupéfiant. La programmation différentiable n’est rien d’autre qu’une combinaison de différentiation automatique et de paramètres que vous souhaitez apprendre.
Alors, comment apprenez-vous ? Lorsque vous disposez de la dérivation, cela signifie que vous pouvez faire remonter les gradients, et avec la descente de gradient stochastique, vous pouvez ajuster légèrement les valeurs des paramètres. En modifiant ces paramètres, vous convergerez progressivement, au fil de nombreuses itérations de descente de gradient stochastique, vers des paramètres qui ont du sens et qui permettent d’atteindre ce que vous souhaitez apprendre ou optimiser.
La programmation différentiable peut être utilisée pour des problèmes d’apprentissage, comme celui que j’illustre, où je souhaite apprendre l’affinité entre mes clients et mes produits. Elle peut également être employée pour des problèmes d’optimisation numérique, tels que l’optimisation de paramètres sous contraintes, et c’est un paradigme très scalable. Comme vous pouvez le constater, cet aspect a été élevé au rang de citoyen de première classe dans Envision. D’ailleurs, il reste encore quelques éléments en cours de développement en termes de syntaxe Envision, donc n’attendez pas exactement ces fonctionnalités pour l’instant ; nous affinons encore certains aspects. Mais l’essence est là. Je ne vais pas discuter des détails de ces quelques éléments qui sont encore en évolution.

Passons maintenant à un autre problème pertinent pour la préparation opérationnelle de votre installation. Typiquement, dans l’optimisation de la supply chain, vous faites face à des Heisenbugs. Qu’est-ce qu’un Heisenbug ? C’est un type de bug frustrant où une optimisation s’effectue et produit des résultats absurdes. Par exemple, vous aviez un calcul par lots pour le réapprovisionnement des stocks pendant la nuit, et le matin, vous découvrez que certains de ces résultats étaient insensés, entraînant des erreurs coûteuses. Vous ne voulez pas que le problème se reproduise, alors vous relancez votre processus. Cependant, lorsque vous relancez le processus, le problème disparaît. Vous ne pouvez pas reproduire l’incident, et le Heisenbug ne se manifeste pas.
Cela peut sembler être un cas limite étrange, mais pendant les premières années de Lokad, nous avons rencontré ces problèmes à plusieurs reprises. J’ai vu de nombreuses initiatives de supply chain, notamment de type data science, échouer en raison de Heisenbugs non résolus. Ces projets comportaient des bugs en production, les problèmes étaient reproduits en local sans succès, et par conséquent, ils n’ont jamais été corrigés. Après quelques mois de panique, le projet entier était généralement abandonné discrètement, et les gens revenaient à l’utilisation de feuilles de calcul Excel.
Si vous souhaitez obtenir une reproductibilité complète de votre logique, vous devez versionner le code ainsi que les données. La plupart des personnes dans l’audience, qu’elles soient ingénieurs logiciels ou data scientists, connaissent probablement l’idée de versionner le code. Cependant, vous devez également versionner toutes les données afin que, lorsque votre programme s’exécute, vous sachiez exactement quelle version du code et des données est utilisée. Vous pourriez ne pas être en mesure de reproduire le problème le lendemain, car les données ont changé en raison de nouvelles transactions ou d’autres facteurs, de sorte que les conditions à l’origine du bug ne sont plus présentes.
Vous devez vous assurer que votre environnement de programmation peut reproduire exactement la logique et les données telles qu’elles étaient en production à un moment précis. Cela nécessite une version complète de tout. Encore une fois, le langage de programmation et la stack de programmation doivent coopérer pour que cela soit possible. C’est réalisable sans que le paradigme de programmation ne soit un citoyen de première classe de votre stack, mais dans ce cas, le Supply Chain Scientist doit être extrêmement prudent quant à tout ce qu’il fait et à la manière dont il programme. Sinon, il ne pourra pas reproduire ses résultats. Cela met une pression immense sur les épaules des Supply Chain Scientists, qui sont déjà soumis à une pression considérable de la part de la supply chain elle-même. Vous ne voulez pas que ces professionnels soient accablés par une complexité accidentelle, comme l’incapacité de reproduire leurs propres résultats. Chez Lokad, nous appelons cela une “time machine” où vous pouvez répliquer tout à n’importe quel moment du passé.
Attention, il ne s’agit pas seulement de reproduire ce qui s’est passé la nuit dernière. Parfois, vous découvrez une erreur bien après les faits. Par exemple, si vous passez une commande d’achat auprès d’un fournisseur ayant un délai de trois mois, vous pourriez découvrir, trois mois plus tard, que la commande était aberrante. Vous devez remonter trois mois dans le temps jusqu’au moment où vous avez généré cette commande d’achat bidon pour comprendre quel a été le problème. Il ne s’agit pas de versionner seulement les dernières heures de travail ; il s’agit littéralement de disposer d’un historique complet de l’exécution de la dernière année.

Un autre point à considérer est la montée en puissance des ransomwares et des cyberattaques sur les supply chains. Ces attaques sont extrêmement perturbatrices et peuvent coûter très cher. Lors de la mise en place de solutions pilotées par logiciel, vous devez vous demander si vous ne rendez pas votre entreprise et votre supply chain plus vulnérables aux cyberattaques et aux risques. Dans cette optique, Excel et Python ne sont pas idéaux. Ces composants sont programmables, ce qui signifie qu’ils peuvent comporter de nombreuses vulnérabilités en matière de sécurité.
Si vous avez une équipe de data scientists ou de Supply Chain Scientist qui traitent des problèmes de supply chain, ils ne peuvent pas se permettre le processus de revue par des pairs itératif et minutieux du code que l’on trouve couramment dans l’industrie logicielle. Si un tarif change du jour au lendemain ou si un entrepôt est inondé, vous avez besoin d’une réponse rapide. Vous ne pouvez pas passer des semaines à produire des spécifications de code, des revues, etc. Le problème est que vous donnez des capacités de programmation à des personnes qui, par défaut, ont le potentiel de causer des dommages accidentels à l’entreprise. Cela peut être encore pire s’il y a un employé renégat intentionnel, mais même en mettant cela de côté, vous avez toujours le problème de quelqu’un qui expose accidentellement une partie interne des systèmes informatiques. N’oubliez pas que les systèmes d’optimisation de la supply chain, par définition, ont accès à une grande quantité de données dans l’ensemble de l’entreprise. Ces données ne sont pas seulement un actif, mais aussi un passif.
Ce que vous souhaitez, c’est un paradigme de programmation qui favorise la programmation sécurisée. Vous voulez un langage de programmation dans lequel il y a des classes entières de choses que vous ne pouvez pas faire. Par exemple, pourquoi devriez-vous avoir un langage de programmation capable de faire des appels systèmes à des fins d’optimisation de la supply chain ? Python peut faire des appels systèmes, et Excel peut le faire également. Mais pourquoi voudriez-vous un système programmable avec de telles capacités en premier lieu ? C’est comme acheter une arme pour se tirer une balle dans le pied.
Vous voulez quelque chose où des classes entières ou des fonctionnalités sont absentes parce que vous n’en avez pas besoin pour l’optimisation de la supply chain. Si ces fonctionnalités sont présentes, elles deviennent un passif énorme. Si vous introduisez des capacités programmables sans les outils qui imposent une programmation sécurisée par conception, vous augmentez le risque de cyberattaques et de rançongiciels, aggravant ainsi la situation.
Bien sûr, il est toujours possible de compenser en doublant la taille de l’équipe de cybersécurité, mais cela coûte très cher et n’est pas idéal face à des situations urgentes de supply chain. Vous devez agir rapidement et de manière sécurisée, sans avoir le temps pour les processus, revues et approbations habituels. Vous voulez également une programmation sécurisée qui élimine les problèmes banals tels que les exceptions de référence nulles, les erreurs de mémoire insuffisante, les boucles off-by-one et les effets de bord.

En conclusion, les outils comptent. Il y a un adage : “N’emmenez pas une épée à une fusillade.” Vous avez besoin des outils et des paradigmes de programmation appropriés, pas seulement de ceux que vous avez appris à l’université. Vous avez besoin de quelque chose de professionnel et de qualité production pour répondre aux besoins de votre supply chain. Bien que vous puissiez obtenir quelques résultats avec des outils médiocres, ce ne sera pas excellent. Un musicien fantastique peut créer de la musique avec une simple cuillère, mais avec un instrument approprié, il peut faire bien mieux.

Maintenant, passons aux questions. Veuillez noter qu’il y a un délai d’environ 20 secondes, donc il y a une certaine latence dans le flux entre la vidéo que vous voyez et moi lisant vos questions.
Question: Que dire de la programmation dynamique en matière de recherche opérationnelle ?
La programmation dynamique, malgré son nom, n’est pas un paradigme de programmation. C’est plutôt une technique algorithmique. L’idée est que si vous voulez réaliser une tâche algorithmique ou résoudre un problème particulier, vous répéterez très fréquemment la même sous-opération. La programmation dynamique est un cas spécifique du compromis entre espace et temps que j’ai mentionné précédemment, où vous investissez un peu plus en mémoire pour économiser du temps de calcul. C’était l’une des premières techniques algorithmiques, remontant aux années 60 et 70. C’est une bonne technique, mais le nom est un peu malheureux parce qu’il n’y a rien de vraiment dynamique, et ce n’est pas vraiment de la programmation. Il s’agit plus de la conception d’algorithmes. Donc, pour moi, malgré le nom, cela ne qualifie pas comme un paradigme de programmation ; c’est plutôt une technique algorithmique spécifique.
Question: Johannes, pourriez-vous avoir l’amabilité de fournir quelques livres de référence que tout bon ingénieur supply chain devrait avoir ? Malheureusement, je suis nouveau dans le domaine, et mon focus actuel est la data science et l’ingénierie des systèmes.
J’ai une opinion très mitigée sur la littérature existante. Dans ma première conférence, j’ai présenté deux livres que je considère comme le summum des études universitaires concernant la supply chain. Si vous voulez lire deux livres, vous pouvez lire ces livres. Cependant, j’ai un problème constant avec les livres que j’ai lus jusqu’à présent. Fondamentalement, il y a des personnes qui présentent des collections de recettes numériques pour des supply chains idéalisées, et je pense que ces livres n’abordent pas la supply chain sous le bon angle, et ils passent complètement à côté du fait que c’est un problème épineux. Il existe un corpus étendu de littérature qui est très technique, avec des équations, des algorithmes, des théorèmes et des preuves, mais je pense que cela passe complètement à côté de l’essentiel.
Ensuite, il y a un autre style de livres sur la gestion de la supply chain, qui sont de style consultant. Vous pouvez facilement reconnaître ces livres car ils utilisent des analogies sportives toutes les deux pages. Ces livres comportent toutes sortes de schémas simplistes, comme des variantes 2x2 des diagrammes SWOT (Forces, Faiblesses, Opportunités, Menaces), que je considère comme des façons de raisonnage de faible qualité. Le problème avec ces livres est qu’ils tendent à mieux comprendre que la supply chain est une entreprise épineuse. Ils saisissent mieux qu’il s’agit d’un jeu joué par des personnes, où toutes sortes de choses bizarres peuvent se produire, et vous pouvez être intelligent quant aux méthodes. Je leur donne crédit pour cela. Le problème avec ces livres, typiquement écrits par des consultants ou des professeurs d’écoles de management, c’est qu’ils ne sont pas très exploitables. Le message se réduit à “soyez un meilleur leader”, “soyez plus malin”, “ayez plus d’énergie”, et pour moi, cela n’est pas exploitable. Cela ne vous donne pas des éléments que vous pouvez transformer en quelque chose de très précieux, comme le fait le logiciel.
Donc, je reviens à la première conférence : lisez les deux livres si vous le souhaitez, mais je ne suis pas sûr que ce soit du temps bien investi. Il est bon de savoir ce que les gens ont écrit. Du côté des consultants dans la littérature, mon préféré est probablement le travail de Katana, que je n’avais pas listé dans la première conférence. Tout n’est pas mauvais ; certaines personnes ont plus de talent, même si elles sont plus orientées consultant. Vous pouvez consulter le travail de Katana ; il a un livre sur la supply chain dynamique. Je vais lister le livre dans les références.
Question: Comment utilisez-vous la parallélisation lorsqu’il s’agit de décisions de cannibalisation ou d’assortiment, où le problème n’est pas facilement parallélisable ?
Pourquoi n’est-ce pas facilement parallélisable ? La descente de gradient stochastique est assez triviale à paralléliser. Vous avez des étapes de gradient stochastique qui peuvent être effectuées dans des ordres aléatoires, et vous pouvez avoir plusieurs étapes en même temps. Donc, je crois que tout ce qui est piloté par la descente de gradient stochastique est assez facile à paralléliser.
Lorsqu’il s’agit de cannibalisation, ce qui est plus difficile, c’est de gérer une autre sorte de parallélisation, celle de ce qui vient en premier. Si je mets ce produit en premier, puis que je fais une prévision, mais ensuite je prends un autre produit, cela modifie le paysage. La réponse est que vous souhaitez avoir une manière d’aborder le paysage dans son ensemble de façon frontale. Vous ne dites pas : “D’abord, j’introduis ce produit et je fais la prévision ; j’introduis un autre produit puis je refais la prévision, modifiant la première.” Vous le faites de façon frontale, toutes ces choses en même temps, simultanément. Vous avez besoin de plus de paradigmes de programmation. Les paradigmes de programmation que j’ai présentés aujourd’hui peuvent y contribuer grandement.
En ce qui concerne les décisions d’assortiment, ce type de problème ne présente aucune difficulté majeure pour la parallélisation. Il en va de même si vous avez un réseau de vente au détail mondial, et que vous souhaitez optimiser l’assortiment pour tous vos magasins. Vous pouvez effectuer des calculs pour tous les magasins en parallèle. Vous ne voulez pas le faire en séquence, où vous optimisez l’assortiment pour un magasin puis passez au suivant. C’est la mauvaise manière de procéder, mais vous pouvez optimiser le réseau en parallèle, propager toutes les informations, puis réitérer. Il existe toutes sortes de techniques, et les outils peuvent grandement vous aider à le faire de manière beaucoup plus simple.
Question: Utilisez-vous une approche par base de données graphe ?
Non, pas dans le sens technique canonique. Il existe de nombreuses bases de données graphe sur le marché qui suscitent un grand intérêt. Ce que nous utilisons en interne chez Lokad, c’est une intégration verticale complète à travers une pile de compilateurs monolithique unifiée pour éliminer complètement tous les éléments traditionnels que l’on trouverait dans une pile classique. C’est ainsi que nous obtenons de très bonnes performances, en termes de performance de calcul, très proches du métal. Ce n’est pas parce que nous sommes des codeurs fantastiquement intelligents, mais simplement parce que nous avons éliminé à peu près toutes les couches qui existent traditionnellement. Lokad n’utilise littéralement aucune base de données. Nous avons un compilateur qui s’occupe de tout, jusqu’à l’organisation des structures de données pour la persistance. C’est un peu bizarre, mais c’est beaucoup plus efficace de le faire de cette manière, et ainsi, vous jouez beaucoup mieux avec le fait que vous compilez un script vers une flotte de machines sur le cloud computing. Votre plateforme cible, en termes de matériel, n’est pas une seule machine ; c’est une flotte de machines.
Question: Quelle est votre opinion sur Power BI, qui exécute également des codes Python et des algorithmes associés tels que la descente de gradient, greedy, etc. ?
Le problème que j’ai avec tout ce qui est lié à la business intelligence, Power BI en étant un exemple, c’est qu’il possède un paradigme que je trouve inadapté pour la supply chain. Vous voyez tous les problèmes comme un hypercube, où vous avez des dimensions que vous ne faites que découper et trancher. Au cœur, vous avez un problème d’expressivité, qui est très limitatif. Lorsque vous finissez par utiliser Power BI avec Python au milieu, vous avez besoin de Python car l’expressivité liée à l’hypercube est très faible. Pour retrouver de l’expressivité, vous ajoutez Python au milieu. Cependant, rappelez-vous ce que j’ai dit dans la question précédente à propos de ces couches : la malédiction des logiciels d’entreprise modernes est que vous avez trop de couches. Chaque couche ajoutée va introduire des inefficacités et des bugs. Si vous utilisez Power BI plus Python, vous allez avoir beaucoup trop de couches. Ainsi, vous avez Power BI qui se trouve au-dessus d’autres systèmes, ce qui signifie que vous avez déjà plusieurs systèmes avant Power BI. Puis vous avez Power BI par-dessus, et au-dessus de Power BI, il y a Python. Mais est-ce que Python agit seul ? Non, il y a de fortes chances que vous utilisiez des bibliothèques Python, comme Pandas ou NumPy. Vous vous retrouvez donc avec des couches en Python qui vont s’empiler, et vous finissez avec des dizaines de couches. Vous pouvez avoir des bugs dans n’importe laquelle de ces couches, de sorte que la situation va devenir véritablement cauchemardesque.
Je ne suis pas partisan de ces solutions où l’on finit par accumuler un nombre massif de stacks. Il y a cette blague selon laquelle, en C++, vous pouvez toujours résoudre n’importe quel problème en ajoutant une couche d’indirection supplémentaire, y compris le problème d’avoir trop de couches d’indirection. Évidemment, c’est un peu absurde comme affirmation, mais je suis profondément en désaccord avec l’approche selon laquelle les gens proposent un produit avec un design central inadéquat, et au lieu d’aborder le problème de front, ils finissent par empiler des éléments alors que les fondations sont fragiles. Ce n’est pas la bonne manière de faire, et vous allez avoir une productivité médiocre, des batailles incessantes avec des bugs que vous ne résoudrez jamais, et en termes de maintenabilité, c’est tout simplement une recette pour un cauchemar.
Question: Comment les résultats d’une analyse de filtrage collaboratif peuvent-ils être intégrés dans l’algorithme de prévision de la demande pour chaque produit, comme par exemple les sacs à dos ?
Je suis désolé, mais j’aborderai ce sujet dans la prochaine conférence. La réponse courte est que vous ne voulez pas l’intégrer dans un algorithme de prévision existant. Vous voulez avoir quelque chose de beaucoup plus intégré nativement. Vous ne faites pas cela et puis vous revenez à vos anciennes méthodes de prévision ; au lieu de cela, vous jetez l’ancienne méthode de prévision et vous faites quelque chose de radicalement différent qui en tire parti. Mais j’en discuterai dans une conférence ultérieure. Ce serait trop pour aujourd’hui.
Je suppose que c’est tout pour cette conférence. Merci beaucoup à tous pour votre présence. La prochaine conférence aura lieu le mercredi 6 janvier, à la même heure et le même jour de la semaine. Je prendrai quelques vacances de Noël, donc je souhaite à chacun un joyeux Noël et une bonne année. Nous poursuivrons notre série de conférences l’année prochaine. Merci beaucoup.


