00:02 Introduction
01:43 Mécanisation
07:34 Au-delà du paradoxe
12:14 L’histoire jusqu’à présent
14:32 Les sous-modules d’aujourd’hui
16:24 Exigences (grand public 1/5)
20:12 Conception (grand public 2/5)
25:37 Construction (grand public 3/5)
30:29 Tests (grand public 4/5)
34:09 Maintenance (grand public 5/5)
41:12 Identité (trenches 1/8)
46:35 Résumé (trenches 2/8)
51:43 Pratiques (trenches 3/8)
56:47 Bastions (trenches 4/8)
01:02:00 Code writers (trenches 5/8)
01:06:23 Tolérance à la douleur (trenches 6/8)
01:14:55 Productivité (trenches 7/8)
01:21:37 L’Inconnu (trenches 8/8)
01:27:00 Conclusion
01:29:55 4.6 Ingénierie logicielle pour supply chain - Questions?
Description
Maîtriser la complexité et le chaos est la pierre angulaire de l’ingénierie logicielle. Étant donné que les supply chains sont à la fois complexes et chaotiques, il ne devrait pas être trop surprenant que la plupart des logiciels d’entreprise difficultés rencontrées par les supply chains se résument à une mauvaise ingénierie logicielle. Les recettes numériques utilisées pour optimiser supply chain sont des logiciels et, par conséquent, soumises exactement aux mêmes problèmes. Ces problèmes augmentent en intensité parallèlement à la sophistication des recettes numériques elles-mêmes. Une ingénierie logicielle appropriée représente pour les supply chains ce que l’asepsie représente pour les hôpitaux : en elle-même, elle ne fait rien – tout comme traiter des patients – mais sans elle, tout s’effondre.
Transcription complète

Bienvenue dans cette série de conférences sur supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter « Ingénierie logicielle pour supply chain ». Le logiciel constitue la base d’une pratique supply chain, pourtant la plupart des manuels sur supply chain sous-estiment largement le rôle du logiciel dans supply chain. Le logiciel pour supply chain n’est pas une simple exigence, comme l’accès aux moyens de transport ; c’est bien plus que cela. Du point de vue des professionnels de supply chain, la majorité du travail est dictée par le logiciel, par des bugs logiciels ou par des limitations du logiciel, et par des préoccupations liées au logiciel.
L’ingénierie logicielle est la discipline qui a pour ambition d’aider les gens à concevoir de meilleurs logiciels, à tirer davantage du logiciel, à le concevoir plus rapidement, et à dépenser moins pour obtenir plus. Le but de cette conférence est de comprendre ce qu’est l’ingénierie logicielle et d’appréhender sa grande pertinence pour supply chain. Le but de cette conférence est également de comprendre ce que, en tant que professionnel de supply chain, vous pouvez faire pour éviter de compromettre votre supply chain par des actions ou des inactions qui, malheureusement, ont eu pour effet de compromettre vos projets logiciels.

Le 20e siècle a été le siècle de la mécanisation de la main-d’œuvre. Les grandes entreprises et les grandes supply chains, telles que nous les connaissons, ont émergé au 20e siècle, et les progrès apportés par la mécanisation de la main-d’œuvre ont été incroyables. Au cours du siècle dernier, pour presque chaque tâche à forte intensité de main-d’œuvre pertinente pour supply chain, comme la production ou la distribution, la productivité a été multipliée par cent.
Au contraire, je crois que le 21e siècle est et sera le siècle de la mécanisation du travail intellectuel, et cette transition est très difficile à appréhender. Le type d’intuition qui s’applique lors de la mécanisation de la main-d’œuvre physique ne se traduit pas du tout dans l’intuition applicable à la mécanisation du travail intellectuel. Je ne dis pas que cette transition soit moins dramatique, mais la réalité est qu’à l’heure actuelle, la transition vers l’élimination de la main-d’œuvre qui s’occupait de tâches très intensives en main-d’œuvre est déjà derrière nous.
En 2020 en France, il y avait 27 millions de personnes occupant des emplois de cols blancs – essentiellement des employés de bureau – alors qu’il n’en restait moins d’un million qui étaient ouvriers d’usine. Le ratio est de 27 pour 1. Lorsque nous commençons à examiner ce que suppose la mécanisation du travail intellectuel, c’est très surprenant et étroitement lié à un paradoxe connu sous le nom de paradoxe de Moravec.
Hans Moravec, un informaticien, a remarqué en 1980 qu’en matière d’informatique, les tâches qui semblaient les plus difficiles pour l’esprit humain, comme devenir grand maître d’échecs, étaient en réalité les plus faciles à aborder avec les ordinateurs. Au contraire, si l’on considère des tâches qui paraissent extrêmement simples pour les humains, comme se tenir debout sur deux jambes, ces tâches s’avèrent être incroyablement difficiles pour les ordinateurs. Voilà l’essence du paradoxe de Moravec : notre intuition concernant ce qui est difficile à réaliser en termes de tâches intellectuelles avec des ordinateurs est très trompeuse.
Un élément qui complique encore davantage le problème est que, soudainement, lorsqu’il s’agit de l’automatisation des emplois de cols blancs, celle-ci est effectuée par les mêmes employés de cols blancs. Ce n’était pas le cas pour les ouvriers d’usine ; ils n’étaient pas ceux qui décidaient que l’usine serait davantage mécanisée et que leurs emplois seraient supprimés. Pourtant, c’est ce qui se produit avec les emplois de cols blancs. Ainsi, nous sommes confrontés à un défi où non seulement le processus de mécanisation est profondément contre-intuitif en raison du paradoxe de Moravec, mais la gestion des personnes chargées de mettre en œuvre cette mécanisation, à savoir les ingénieurs logiciels, est elle-même très contre-intuitive. C’est probablement l’un des plus grands défis pour supply chain : la gestion des personnes qui, d’une manière ou d’une autre, seront responsables de la gestion de cette mécanisation.
Je ne peux m’empêcher de constater que de nombreuses supply chains et entreprises associées restent encore fermement ancrées dans une mentalité du 20e siècle, où l’on aborde le monde de l’entreprise comme si des employés de cols blancs effectuaient le travail intellectuel, puis proposaient la solution ou le plan, qui était ensuite transmis aux ouvriers pour exécution. Cependant, avec un ratio de 27 pour 1 en France entre les emplois de bureau et les emplois d’usine, et probablement des statistiques similaires dans la plupart des pays développés, ce n’est plus ainsi que les choses se passent aujourd’hui. Il s’agit littéralement d’automatiser votre propre travail, ce qui signifie que, dans ce monde du 21e siècle, les meilleurs employés de cols blancs sont ceux qui parviennent constamment à s’automatiser eux-mêmes, à se rendre obsolètes, avant de passer à autre chose. Cela pose un défi majeur pour de nombreuses entreprises encore très enracinées dans la mentalité du 20e siècle.

Les opinions divergent largement quant à la notion même d’ingénierie logicielle. L’une des critiques les plus virulentes est venue d’Edsger Dijkstra, l’un des pères fondateurs de l’informatique. Selon lui, l’ingénierie logicielle n’est même pas envisageable en tant que discipline ou domaine de recherche, et il affirmait qu’elle se réduit, ou dégénère, en une sorte de recette du style « comment programmer si vous ne le pouvez pas ». La critique de Dijkstra, qui est très intéressante, est que l’ingénierie logicielle dégénère en une sorte de fiction d’auto-assistance qui ne peut réussir. En effet, si nous proposons que le but de l’ingénierie logicielle est de garantir le succès de la création de logiciels utiles et supérieurs, alors l’ingénierie logicielle est en grande partie vouée à l’échec. Réussir dans le domaine du logiciel est incroyablement difficile ; c’est aussi difficile que de réussir en science. Cela exige une étincelle de génie, pas mal de chance, et il n’existe aucune recette pour cela. De plus, chaque succès tend à consommer l’opportunité même qui a permis de l’atteindre, et par conséquent, l’ensemble devient non reproductible.
Cependant, je ne suis pas d’accord avec l’idée que l’ingénierie logicielle est vouée à l’échec. Je crois que le principal problème réside dans la définition de l’ambition de l’ingénierie logicielle. Si nous décidons que l’ambition de l’ingénierie logicielle consiste à réussir à créer des logiciels, alors, en effet, elle est condamnée. Cependant, si nous choisissons d’aborder l’ingénierie logicielle comme une branche étroite de la psychologie expérimentale, je pense que nous pouvons, sous cet angle, recueillir des idées très précieuses et exploitables, et c’est la perspective que j’adopterai aujourd’hui dans cette conférence. Ainsi, l’ingénierie logicielle concerne les ingénieurs logiciels eux-mêmes et leurs interactions. Se concentrer sur les ingénieurs logiciels est un bon point de départ car la nature humaine est stable dans le temps, contrairement à la technologie logicielle, qui est en constante évolution. La nature des personnes qui luttent contre cette technologie ne change pas ; la nature humaine est demeurée très stable depuis très longtemps.
Si nous regardons d’autres domaines, comme la science, nous pouvons constater qu’aborder un domaine en examinant ce que font ses praticiens peut s’avérer très fructueux. Par exemple, en science, il est désormais établi qu’un conflit d’intérêts conduit à une mauvaise science et à une corruption des connaissances. Ce point a été abordé précédemment dans la conférence intitulée “Adversarial Market Research for Enterprise Software.” Sous cet angle, nous voyons qu’il est possible de recueillir des idées d’une grande applicabilité et pertinence si nous nous concentrons sur les praticiens eux-mêmes. Ainsi, l’ingénierie logicielle concerne les personnes qui s’occupent de la technologie logicielle, leurs difficultés et leurs processus, et non pas tant la technologie elle-même.
Aujourd’hui est la sixième conférence des quatre chapitres. Ce chapitre est dédié aux sciences auxiliaires de supply chain. Ces sciences auxiliaires représentent des éléments que je considère comme fondamentaux pour une pratique moderne de supply chain, mais ils ne sont pas strictement parlant des éléments de supply chain. Ils sont plutôt des éléments de soutien pour votre pratique supply chain.
Jusqu’à présent, dans ce quatrième chapitre, nous avons commencé par la physique de l’informatique, en traitant des ordinateurs modernes, puis nous avons gravi les échelons d’un niveau d’abstraction supérieur. Nous sommes passés des ordinateurs aux algorithmes, qui représentent les plus infimes, les plus petits éléments d’intérêt dans le logiciel. Ensuite, nous avons abordé l’optimisation mathématique, qui intéresse supply chain mais également de nombreuses autres initiatives logicielles pertinentes, telles que le machine learning. Nous avons vu que l’optimisation mathématique revêt un intérêt direct pour supply chain, mais qu’elle intéresse également directement le machine learning, qui, à son tour, intéresse supply chain.
En ce qui concerne l’optimisation mathématique et le machine learning, la plupart des concepts et paradigmes intéressants de nos jours sont de nature programmatique. Il ne s’agit pas simplement d’algorithmes simples ; c’est quelque chose d’incroyablement expressif qui doit être abordé à travers le prisme des langages de programmation. C’est pourquoi la dernière conférence portait sur les langages et les compilateurs.
Aujourd’hui, nous continuons à gravir cette échelle d’abstraction, en nous concentrant sur les personnes plutôt que sur ce qu’elles font. Nous allons nous concentrer sur les ingénieurs logiciels eux-mêmes, et c’est là tout l’intérêt de cette analyse de l’ingénierie logicielle.

Aujourd’hui, je vais présenter spécifiquement deux ensembles de points de vue sur l’ingénierie logicielle. D’abord, je présenterai le point de vue grand public, que je crois dominer le domaine. Malheureusement, ce point de vue grand public a suscité des critiques, comme mentionné précédemment, avec des approches d’auto-assistance que certains, moi y compris, ont des raisons de contester car elles ne présentent pas une ambition réaliste pour la discipline de l’ingénierie logicielle. Néanmoins, je vais passer en revue ce point de vue grand public, ne serait-ce que parce que certaines idées erronées restent incroyablement populaires. Se familiariser avec ces concepts erronés est d’une importance primordiale, ne serait-ce que pour enrayer les personnes incompétentes qui pourraient mettre en danger votre supply chain par leur incompétence.
Ensuite, j’aborderai un point de vue issu des tranchées, qui est un ensemble d’éléments ancré dans mon expérience personnelle en tant que PDG d’une entreprise de logiciels qui opère précisément dans le domaine des logiciels d’entreprise pour supply chain. Comme nous le verrons, les idées présentées concernent avant tout les personnes et non la technologie elle-même.

Le point de vue grand public de l’ingénierie logicielle postule qu’une initiative logicielle commence par la collecte des exigences pour le logiciel concerné. La plupart des initiatives logicielles dans les grandes entreprises adoptent cette perspective via un processus qui débute typiquement par une Request for Proposal (RFP), une Request for Quote (RFQ) ou une Request for Information (RFI). Cette approche est héritée des pratiques du 20e siècle qui ont rencontré un grand succès dans le génie mécanique et les travaux de construction. Cependant, je pense que, pour ce qui concerne le logiciel, ces méthodes de collecte des exigences sont profondément erronées.
Dans le logiciel, vous ne savez pas ce que vous voulez ; vous ne le savez tout simplement pas. Savoir ce que vous voulez est invariablement la partie la plus difficile du logiciel. Par exemple, si nous considérons un problème simple comme le réapprovisionnement de stocks, l’énoncé du problème est incroyablement simple : à tout moment, je veux connaître la quantité que je devrais réapprovisionner ou commander pour chaque SKU. Le problème lui-même est simple, pourtant définir ce qu’est une bonne quantité devient diaboliquement complexe et difficile. En règle générale, clarifier les exigences est bien plus difficile que d’écrire le logiciel lui-même.
Ce n’est qu’en confrontant votre intuition aux retours du monde réel que vous pouvez laisser progressivement émerger les exigences. Les exigences ne tombent pas du ciel ; elles ne peuvent être obtenues que par un processus assez expérimental, et vous devez avoir cette interaction avec le monde réel. Cependant, la seule façon d’avoir cette interaction est de disposer du produit logiciel, puisque recueillir les exigences est fondamentalement un processus très empirique et émergent. Le problème, c’est qu’au moment où vous avez terminé avec les exigences, le fait de les posséder devient caduque, car si vous avez les exigences, cela signifie que vous possédez déjà le produit correspondant qui les implémente. Ainsi, au moment où vous avez enfin accès aux exigences appropriées, vous avez déjà le produit en production, opérationnel, et le fait de posséder ces exigences est quelque peu sans importance.
Donc, le fait de démarrer le processus avec le prisme des exigences est, à mon avis, une folie. Les exigences devraient probablement venir en dernier en tant que documentation finale, où vous consignez toutes les raisons fondamentales qui vous ont conduit à implémenter le produit comme vous l’avez fait, et non l’inverse.
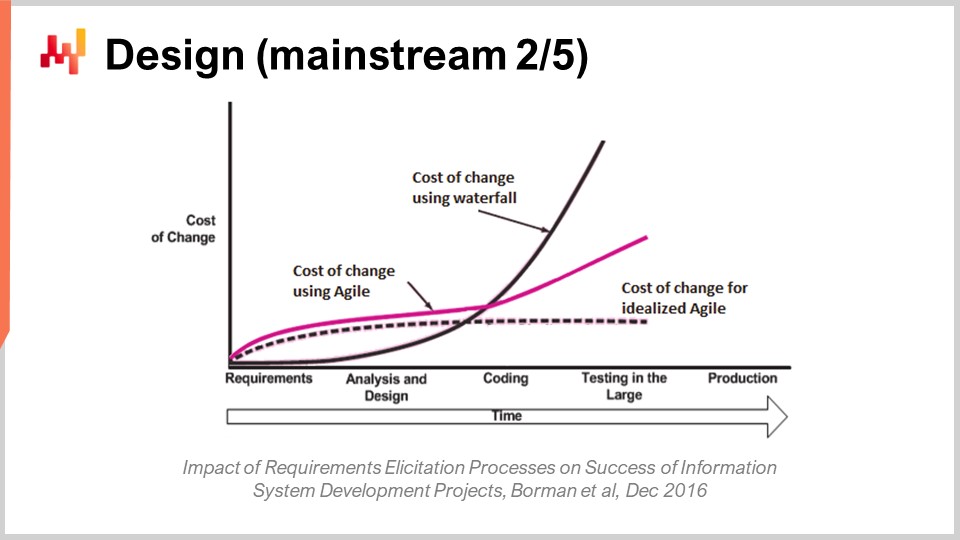
Une fois les exigences établies, l’approche classique affirme qu’il faut passer à la phase de conception. Je reconnais qu’à un certain moment, une conception peut avoir lieu. Cependant, le type de réflexion impliqué dans cette phase de conception est souvent mal orienté. Le problème se réduit à maîtriser le coût du changement. La perspective classique non logicielle du coût du changement est que celui-ci augmente de manière exponentielle avec le temps. Par exemple, si vous modifiez la conception d’une voiture très tôt, alors que vous n’avez qu’un plan, le coût du changement est minimal. En revanche, si vous attendez que des millions de ces voitures circulent, le coût du changement devient incroyablement élevé car cela implique un rappel, ce qui peut être extrêmement coûteux.
Cependant, contrairement au domaine physique, dans le domaine logiciel, le coût du changement n’augmente pas naturellement de manière exponentielle. L’augmentation du coût ne peut pas être entièrement atténuée ; toutefois, dans une large mesure, elle peut être gérée. En effet, le coût du changement augmente avec le temps, principalement parce que les bases de code tendent à croître. Je n’ai jamais vu une base de code d’un logiciel d’entreprise se réduire significativement d’une année à l’autre ; elles ont tendance à continuer de croître. Néanmoins, il est possible de contrôler le coût du changement dans une certaine mesure.
De nos jours, cet aspect est de plus en plus reconnu, même dans les cercles logiciels. D’ailleurs, c’est l’essence même de la méthodologie Agile. Vous avez peut-être entendu ces termes lorsqu’on dit, “Oh, nous avons cette méthodologie de software Agile.” L’un des principaux objectifs de la méthodologie Agile est de maîtriser le coût du changement. Je n’entrerai pas dans les détails aujourd’hui concernant la méthodologie Agile, mais il suffit de dire que je crois que cette approche est quelque peu erronée quant à la manière exacte de maîtriser ce coût du changement.
J’ai constaté que le coût du changement découle principalement des décisions prises concernant le logiciel et, plus précisément, du fait qu’il est très difficile de résister à l’envie de prendre des décisions. Imaginez que vous envisagez un futur produit logiciel potentiel, et qu’il y a de nombreuses décisions à prendre. La première tentative serait de prendre ces décisions simplement pour clarifier ce qui se présente devant vous. Au contraire, une très bonne phase de conception, plutôt qu’une bonne conception, réside dans la capacité à reporter toutes les décisions qui ne sont pas absolument indispensables, lorsque le produit n’exige pas que ces décisions soient prises immédiatement. En effet, tant que la décision n’est pas actée, et tant que vous n’avez pas établi que vous deviez adopter cette approche de conception ou cette approche technologique spécifique, elle reste en suspens, prête à être modifiée puisque rien n’a encore été décidé.
Un des aspects pour maîtriser le coût du changement est d’apprendre à reporter toutes les décisions autant que possible en pratique. Du point de vue de la supply chain, cela semble très étrange car cela signifie que toutes les personnes de l’équipe logicielle et tous ceux qui observent le produit et l’équipe semblent être tenus dans l’ignorance. C’est encore pire, car ils sont délibérément tenus à l’écart, ce qui est très déroutant. Pourtant, c’est précisément ce qui doit se produire, et cela doit être fait intentionnellement. C’est pourquoi c’est, pour le moins, déconcertant.

Maintenant, si les décisions de conception prématurées sont enracinées dans le besoin parfois mal orienté de contrôle, les problèmes associés à ce besoin de contrôle ne s’arrêtent pas là. Une fois la phase de conception terminée, la vision dominante en ingénierie logicielle affirme que nous devrions passer à la construction du logiciel, souvent appelée phase d’implémentation. La manière dont cela est généralement fait consiste à présenter une sorte de projection en cascade, également appelée diagrammes de Gantt. Voilà ce que vous pouvez voir à l’écran. Je crois que cette approche, avec les diagrammes de Gantt et les cascades, est incroyablement toxique, et la toxicité de cette approche ne doit pas être sous-estimée en ce qui concerne les logiciels. Aborder le problème de cette manière, c’est littéralement préparer l’échec de votre supply chain, du moins en ce qui concerne ses initiatives logicielles.
Une bien meilleure façon de comprendre le problème et d’aborder la construction du logiciel est de la considérer comme un processus d’apprentissage. La construction du logiciel consiste à apprendre tout ce qu’il faut pour obtenir un bon produit. C’est un processus d’apprentissage, et toutes les connaissances acquises résultent de l’interaction du monde avec le logiciel qui émerge du processus de construction. Le principal problème d’une prévision en cascade, c’est que vous projetez ce que vous êtes sur le point de découvrir. Cela est par définition impossible. Ce que vous allez découvrir demeurait inconnu jusqu’à ce que vous en preniez connaissance. Vous ne pouvez pas projeter vos découvertes. Vous pouvez les anticiper, mais vous ne pouvez pas planifier les détails de ce que vous êtes sur le point de découvrir. Vous pouvez avoir des intuitions, mais c’est le mieux que vous puissiez obtenir. L’idée de transformer ces intuitions vagues en une prévision en cascade précise est, encore une fois, une pure folie.
Au fait, ce petit paradoxe apparent concernant la construction du logiciel en tant que processus d’apprentissage explique également pourquoi la réplication d’un logiciel peut parfois être incroyablement facile ou incroyablement difficile. Si une équipe tente de répliquer un produit logiciel déjà sur le marché, et que cette équipe a accès à la compréhension ou aux enseignements qui ont conduit à la production du logiciel qu’elle essaie de copier, alors, en général, réimplémenter ou recoder le produit peut être réalisé avec seulement une infime fraction du temps et du budget nécessaires à sa création initiale. En revanche, si l’équipe n’a pas accès à ces éclairages de haut niveau, et par exemple, si tout ce dont elle dispose est le code source, l’équipe se retrouvera très souvent avec un produit de très basse qualité, car essentiellement, toutes les connaissances acquises ou les bribes de savoir auront été perdues. Vous avez simplement répliqué l’apparence superficielle du produit.
Du point de vue de la supply chain, le plus grand défi ici est d’accepter volontairement de renoncer et de maîtriser votre besoin de contrôle. Le processus en cascade est l’expression d’une entreprise qui souhaite contrôler le processus. Par exemple, si je dis “mettons ce projet sous contrôle”, cela serait perçu comme quelque chose de très raisonnable. Pourquoi feriez-vous le contraire ? Pourquoi déclarer, par exemple, “laissons ce projet complètement hors de contrôle ?” Mais la réalité est que ce degré de contrôle est une illusion totale quand il s’agit de logiciels, et cela nuit complètement à votre capacité de livrer un produit de haute qualité au final. Maîtriser votre désir de contrôle est, du point de vue de la supply chain, probablement le plus grand défi en ce qui concerne la construction de logiciels.

Depuis l’apparition des programmes informatiques, ils ont été truffés de bugs et de défauts. Pour remédier à ces problèmes évidents, la vision dominante est que des tests doivent avoir lieu. Les tests se présentent sous plusieurs formes. Concernant la nécessité des tests, je suis d’accord, bien que cela soit très vague à ce stade. Certains outils insistent sur le fait que les tests doivent être effectués après la construction, d’autres sur le fait qu’ils doivent être réalisés pendant la construction, et d’autres précisent encore qu’ils doivent être effectués avant la construction. Certaines approches affirment que les tests doivent être effectués avant, pendant et après la construction du logiciel.
Ma vision générale du problème est que vous devez faire tout ce qui est nécessaire pour que le cycle de rétroaction soit le plus court possible. Nous avons abordé ce point dans la conférence précédente : maintenir un cycle de rétroaction aussi court que possible est d’une importance cruciale pour obtenir réellement quelque chose qui fonctionne dans le monde réel. Ainsi, je recommanderais généralement de prêter attention à savoir si ce que vous faites en termes de tests permet réellement de resserrer ce cycle ou non. Par exemple, dans la plupart des cas, je ne recommanderais pas naturellement le développement piloté par les tests (une méthodologie qui veut que les tests viennent en premier), simplement parce que, dans la plupart des situations, effectuer les tests d’abord ne ferait que retarder le temps nécessaire pour obtenir des retours sur votre logiciel par le monde extérieur.
Cependant, ma plus grande préoccupation concernant les tests est une limitation souvent passée sous silence, quelque chose qui semble généralement être écarté. Les tests ne peuvent en fin de compte qu’évaluer la conformité par rapport aux règles mêmes que vous avez établies vous-même. Le problème est que, dans les logiciels, il n’existe pas de contraintes rigides. Il n’y a pas de méthode infaillible pour aborder l’adéquation de votre produit par rapport au problème que vous tentez de résoudre. Cela diffère grandement du domaine physique. Par exemple, en ingénierie mécanique, il existe un critère canonique : la tolérance dimensionnelle d’une pièce. Quoi que vous conceviez en ingénierie mécanique, la tolérance dimensionnelle sera d’une importance primordiale. C’est une candidate évidente et naturelle. Cependant, il n’existe pas de telles candidates évidentes et naturelles en matière de logiciels.
Le problème ici devient une question d’adéquation. Si nous voulons prendre un exemple supply chain, tel que les stocks de sécurité, il est tout à fait simple de concevoir une suite de tests automatisés pour valider les calculs des stocks de sécurité. Il est très facile de mettre en œuvre ce type de logique de test. Cependant, cela ne peut pas vous dire que les stocks de sécurité sont une mauvaise idée dès le départ. Vous ne faites que tester ce que vous savez.
Lorsque nous traitons avec une machine physique, nous nous attendons à l’usure, et donc à une forme de maintenance pour maintenir la machine en état de fonctionnement. Cependant, pourquoi le logiciel aurait-il besoin d’une quelconque maintenance pour continuer à fonctionner ? Certes, nous devons remplacer les ordinateurs qui tombent en panne de temps en temps. Cependant, cet aspect est très marginal, et dans les logiciels d’entreprise, les pannes physiques des machines ne représentent même pas 10 % des coûts réels de maintenance. Cela existe, mais l’impact de ce type de maintenance est incroyablement mince.
Pourtant, la maintenance dans les logiciels d’entreprise est d’une importance primordiale. Les coûts de maintenance sont énormes. Pour de nombreux fournisseurs de logiciels d’entreprise, la maintenance représente littéralement 80 % ou plus du coût d’ingénierie. Il s’avère que les facteurs qui engendrent ce besoin de maintenance ont très peu à voir avec la physique. Le premier facteur est la volonté de payer des clients eux-mêmes. Si un fournisseur peut se contenter d’une redevance annuelle de maintenance de 20 % par rapport à ce qui a été payé pour la mise en place du logiciel durant la première année, alors il facturera cela. Essentiellement, d’un point de vue coût, le coût de maintenance est déterminé par la volonté de payer des clients d’entreprise.
Le deuxième facteur est le type de maintenance nécessaire simplement pour que le logiciel continue de fonctionner. En effet, chaque jour qui passe, l’environnement entourant le produit d’intérêt s’écarte de celui-ci. Le système d’exploitation continue d’évoluer, le système de base de données continue d’évoluer, et il en va de même pour toutes les bibliothèques tierces utilisées par le logiciel. Aucun produit logiciel n’est une île. Chaque produit logiciel dépend d’une myriade d’autres produits, et ces autres produits évoluent par eux-mêmes. Les personnes qui développent ces produits continuent de travailler dessus et, au fur et à mesure qu’elles les modifient, elles les changent. Ainsi, il arrive un moment où le produit cesse de fonctionner en raison d’une incompatibilité. Vous n’avez rien fait d’autre qu’une incapacité à suivre le reste du marché. Le deuxième facteur englobe toute la maintenance nécessaire simplement pour garder le logiciel en état de marche et compatible avec le reste du marché.
Le troisième facteur est la quantité de travail nécessaire pour maintenir l’utilité du produit. En effet, le logiciel a été conçu et développé à un moment donné, et chaque jour qui passe, le monde s’écarte de ce qui avait été envisagé lors de l’ingénierie initiale du produit. Ainsi, même si rien ne se détériore véritablement en termes de compatibilité matérielle, il s’avère qu’au fur et à mesure que le monde change, l’utilité du produit diminue inévitablement parce que le monde s’éloigne des attentes intégrées au produit. Si vous souhaitez que le logiciel reste utile, vous devez le maintenir en permanence.
Du point de vue de la supply chain, la maintenance est un grand défi, et nous avons abordé cet aspect dans la conférence précédente, qui portait sur la livraison orientée produit pour la supply chain. Le coût de maintenance a un impact significatif sur les bénéfices capitalistes que vous pouvez tirer de votre investissement logiciel. Idéalement, vous souhaitez que votre entreprise logicielle génère un très haut retour sur investissement, mais pour cela, vous devez vous assurer de ne pas vous retrouver avec des coûts de maintenance massifs. Ces coûts annuleraient complètement le profit capitaliste et le rendement que vous pouvez obtenir de votre investissement logiciel.
La plus grande difficulté ici, de nouveau d’un point de vue de la supply chain, est que la manière la plus simple de minimiser le coût de maintenance est de se concentrer sur ce qui ne change pas. Comme je l’ai mentionné plus tôt, la plupart des coûts sont liés aux éléments qui se trouvent en train de changer, que ce soit dans l’écosystème logiciel ou dans le monde en général. Cependant, si vous vous concentrez sur ce qui ne change pas, vous obtenez essentiellement l’essentiel de votre logiciel qui ne se dégradera que lentement car, précisément, la majeure partie de ce que votre logiciel aborde est ce qui ne change pas.
Le problème est que se concentrer sur ce qui ne change pas est plus facile à dire qu’à faire, car il existe une force très humaine qui s’oppose à cette intention : la peur de manquer quelque chose. Lorsque vous regardez la presse, les médias, vos collègues, etc., un flux constant de nouveautés et de buzzwords se dégage, et chacun de ces buzzwords ressent, en raison de la peur de manquer quelque chose, le besoin de simplement faire l’affaire sans être laissé pour compte. Par exemple, tous ces buzzwords seraient AI, blockchain, IoT, et toutes ces choses très présentes. Je crois que, dans la supply chain, ces buzzwords constituent réellement une distraction et contribuent de manière significative aux problèmes de maintenance car ils détournent l’attention de ce qui ne change pas. Au contraire, lorsque vous commencez à prêter attention à ces buzzwords, vous surfez sur une vague, et vous surfez exactement sur ce type de phénomènes qui sont très susceptibles de changer au fil du temps, augmentant ainsi votre coût de maintenance avec le temps.

Maintenant que nous avons terminé avec la vision grand public de l’ingénierie logicielle, penchons-nous sur une série d’astuces personnelles qui, espérons-le, se révéleront utiles pour mener des initiatives logicielles tout en gardant en tête la supply chain. L’un des problèmes les plus fréquents lorsque l’on traite avec des professionnels du logiciel est une idée erronée concernant leur propre identité, et je me permets d’emprunter cette idée à un entrepreneur nommé Paul Graham. Un ingénieur dira, par exemple, “I am a Python engineer.” Bien que cela ne soit peut-être pas aussi extrême, il est très fréquent que les ingénieurs logiciels perçoivent leur identité à travers la courte série de technologies qu’ils ont maîtrisées, lesquelles constituent leur ensemble de compétences. Cette confusion entre leur identité et leur ensemble de compétences actuel tend à être renforcée par les pratiques de recrutement qui prévalent dans le monde de l’IT et du logiciel en général. Du point de vue du recrutement, de nombreuses entreprises indiquent dans leurs offres d’emploi, “I need a Python programmer.” Ainsi, d’une part, quelqu’un pense “I am a Python programmer” et, d’autre part, une entreprise va publier un poste où il est essentiellement indiqué “I need a Python programmer.” Par conséquent, avoir soudainement la bonne identité n’est pas seulement une question de perception ; des récompenses financières sont attachées au fait de posséder la bonne identité, le bon libellé, ou la bonne étiquette à s’attribuer, ce qui vous rend plus attractif sur le marché.
Cependant, cette perception axée sur l’identité, où les technologies se rattachent à soi en tant qu’ingénieur logiciel, conduit à de nombreux problèmes qui impactent pratiquement chaque projet logiciel, en particulier les projets logiciels de supply chain. Lorsqu’on interagit avec une personne, typiquement un ingénieur logiciel, dont l’identité est fortement liée à la technologie en place dans votre entreprise, le problème devient que chaque critique de cette technologie tend à être perçue sur un plan personnel. Si vous dites “I am a Python programmer” et que vous critiquez mon logiciel, je le prends personnellement. Le problème est que dès que les gens interprètent la critique de la technologie comme une attaque personnelle, il devient très difficile de raisonner sur ces problèmes. Malheureusement, ces ingénieurs logiciels auront tendance à écarter tous les retours, simplement parce qu’ils les perçoivent en partie comme des critiques personnelles.
Inversement, si l’entreprise utilise une technologie qui n’est pas celle perçue comme l’identité fondamentale par l’ingénieur logiciel, par exemple, si votre entreprise a certains systèmes implémentés en Java et qu’un ingénieur logiciel déclare “I am a Python programmer,” alors tous les problèmes seront perçus à travers le prisme d’une technologie jugée médiocre. Encore une fois, c’est un autre problème où la critique et les retours seront rejetés avec l’attitude “pas mon problème ; c’est simplement à cause de cette technologie très médiocre qui a été utilisée ici et maintenant dans cette entreprise.” Dans les deux situations, que l’ingénieur logiciel ait une identité liée à la technologie que vous utilisez ou à une technologie que vous n’utilisez pas, cela engendre toute une série de problèmes, et les retours sont écartés au lieu d’être exploités pour améliorer la technologie.
Maintenant, d’un point de vue supply chain, nous devons garder à l’esprit que l’environnement de la supply chain est incroyablement chaotique, et par conséquent les problèmes surviendront constamment. Précisément à cause de ce chaos ambiant, il est très important de disposer d’équipes d’ingénieurs logiciels capables de regarder ces problèmes droit dans les yeux et d’agir, plutôt que de simplement éluder les retours lorsqu’ils se produisent. Il est crucial de constituer des équipes qui ne favorisent pas le drame en plus du chaos supply chain en raison de leur perception de leur identité.

Cette idée s’étend aux ingénieurs logiciels, qui choisissent souvent des technologies correspondant à leur identité ou à l’identité qu’ils souhaitent acquérir. Ils sélectionnent une technologie pour acquérir des compétences, afin d’ajouter un autre mot-clé à leur CV. Cependant, cette approche conduit à choisir des technologies pour des raisons sans rapport avec la résolution des problèmes auxquels l’entreprise est confrontée. C’est la mauvaise perspective pour décider si une technologie est pertinente ou adéquate pour répondre aux problèmes spécifiques de l’organisation.
Construire un CV peut être un puissant moteur pour les ingénieurs logiciels, car il existe de véritables avantages financiers associés à la présence d’une liste de mots-clés. Les meilleures entreprises de logiciels méprisent souvent les CV comportant une longue liste de mots-clés. En tant que CEO de Lokad, si je vois un CV contenant une demi-page de mots-clés, il est directement écarté. Cependant, de nombreuses entreprises, en particulier les entreprises médiocres, recherchent activement des personnes possédant de nombreux mots-clés, pensant que ces individus seront incroyablement polyvalents et agiles au sein de l’organisation. D’après mon expérience, c’est souvent le contraire.
Poursuivant sur le thème de l’identité et de la constitution de CV, il est vital de considérer que les architectes logiciels ne devraient pas être trop attachés à une technologie particulière. Il est déjà difficile de recruter des ingénieurs logiciels, de sorte que des compromis doivent parfois être faits. Cependant, lorsqu’il s’agit d’architectes logiciels, choisir des individus ayant un attachement émotionnel à une certaine technologie peut s’avérer désastreux. Ces individus auront un impact à grande échelle sur votre entreprise.
Ce problème de biais lié à la construction de CV ne se limite pas aux ingénieurs logiciels ou aux professionnels du logiciel. Il se produit également parmi le personnel IT. Par exemple, j’ai rencontré plusieurs directeurs IT dans de grandes entreprises qui souhaitaient passer à SAP alors que leur ancien ERP était parfaitement fonctionnel. Les coûts massifs associés à la transition vers SAP ne seraient jamais compensés par les avantages attendus d’un ERP plus moderne. Dans ces cas, un comportement irrationnel était en jeu, où l’intérêt personnel du directeur IT à intégrer SAP dans son CV primait sur l’intérêt de l’entreprise elle-même.
D’un point de vue supply chain, il est essentiel de prêter attention à ces conflits d’intérêts. Il ne faut pas beaucoup de compétences en logiciel ou d’expertise pour détecter ces conflits. Dans d’autres domaines, comme la médecine, même des médecins peuvent prescrire les mauvais médicaments à cause de conflits d’intérêts, même lorsque des vies sont en jeu. Cela démontre que les conflits d’intérêts sont incroyablement toxiques. Imaginez simplement comment ces problèmes se manifestent dans la gestion de la supply chain, où aucune vie n’est en jeu et où la principale préoccupation est l’argent. Il y a encore moins de réticence à laisser les conflits d’intérêts se déployer dans ce contexte.

Contrairement au domaine physique, le domaine logiciel offre très peu de contraintes quant à la manière de mener des initiatives logicielles et d’aborder le travail. La nature humaine n’aime pas le vide, et les gens peuvent être déstabilisés par un manque de structure. En conséquence, de nombreuses pratiques sont apparues au fil des ans et continuent d’émerger. À chaque pratique correspond une notion d’orthodoxie. Quelques exemples de ces pratiques incluent extreme programming, domain-driven design, test-driven design, microservices, Scrum et agile programming. Il existe de nombreuses pratiques, et de nouvelles émergent chaque année.
À chaque pratique correspond une notion d’orthodoxie. Dès que les gens commencent à suivre une pratique, ils peuvent se demander s’ils respectent bien les principes fondamentaux. Les ingénieurs logiciels ne sont que des personnes, et les gens aiment les rituels et les tribus. Une pratique procure un sentiment d’appartenance à une tribu aux croyances communes. C’est pourquoi vous trouverez également des meetups associés à ces pratiques, répondant ainsi à un besoin très humain.
Il peut être difficile, voire déprimant, de fixer son regard sur un problème, dans l’incertitude totale, et de n’avoir pratiquement personne à qui se confier lorsqu’il s’agit d’y faire face. Ce qui est intéressant, c’est qu’une pratique, bien qu’elle puisse être discutable ou légèrement irrationnelle, peut apporter de réels bénéfices. Promouvoir une pratique à l’intérieur comme à l’extérieur de votre entreprise peut booster le moral et aider à recruter des candidats potentiels.
Lors d’un entretien d’embauche, lorsque l’on vous demande comment vous travaillez, il n’est pas vraiment convaincant de dire que vous improvisez et que vous n’avez aucune règle. Il est plus efficace d’inspirer confiance en présentant une pratique comme si elle résolvait les problèmes au sein de l’entreprise. Le point essentiel est que, à court terme, ces pratiques ne sont pas toutes mauvaises, même si elles sont majoritairement irrationnelles. Générer un sentiment d’appartenance peut être bénéfique. Cependant, cela devient toxique si les pratiques sont prises trop au sérieux ou pour trop longtemps. Une pratique peut être intéressante simplement parce qu’elle vous oblige à examiner le problème sous un angle différent. Mais une fois que vous avez envisagé le problème sous un angle, vous devriez essayer d’en trouver un autre. Vous ne devez pas vous en tenir à un seul angle pendant trop longtemps. D’un point de vue supply chain, cela illustre l’étrangeté radicale du domaine logiciel.
Dans l’atelier, l’excellence signifie toujours faire exactement la même chose. Dans le monde du logiciel, c’est tout le contraire. Si vous faites toujours la même chose, c’est une recette de stagnation et d’échec sur le long terme.

Le logiciel est complexe, et les logiciels d’entreprise le sont encore plus. Fréquemment, plusieurs ingénieurs finissent par travailler sur une initiative donnée, ce qui conduit à une tendance naturelle à la spécialisation. Lorsqu’un ingénieur travaille sur une certaine partie de la base de code, il y a une inclination naturelle à confier cette même personne lorsque de nouvelles tâches nécessitent d’intervenir sur cette partie du code. Les avantages sont réels, car cette personne connaît déjà le code et peut être plus productive.
Le principal problème de la spécialisation est qu’elle peut conduire à un sentiment de propriété sur certaines parties de la base de code, créant divers problèmes. Il existe deux catégories de problèmes associés à cette appropriation : le “truck factor” et les jeux de pouvoir. Le truck factor fait référence au risque de perdre un employé possédant des connaissances ou compétences uniques. Cela peut être dû au départ de cet employé pour une autre entreprise ou à son incapacité à travailler pour toute autre raison. Les jeux de pouvoir peuvent survenir si un employé se rend compte que sa contribution est vitale pour l’entreprise et utilise cet avantage pour exiger un salaire plus élevé ou d’autres bénéfices.
D’après mon expérience, les ingénieurs logiciels n’ont généralement pas une forte propension à jouer aux jeux de pouvoir, mais ces problèmes peuvent devenir de plus en plus fréquents dans les grandes entreprises. Il existe de nombreuses pratiques en ingénierie logicielle qui tentent de s’attaquer directement à ce problème, comme le pair programming. Cependant, l’idée clé est que trop de bien peut devenir toxique pour l’entreprise. Le mieux est d’être conscient de ce type de problème, plutôt que de s’en tenir à une pratique particulière censée y remédier. Cela s’explique par le fait que de telles pratiques peuvent engendrer d’autres problèmes, vous distraire ou restreindre votre capacité à prêter attention à d’autres éléments que vous n’avez pas encore identifiés. D’un point de vue logiciel, la leçon essentielle ici est que la culture est l’antidote à cette catégorie de problèmes, et non le processus.
Nous sommes confrontés à une situation où il existe un compromis très subtil entre les gains de productivité obtenus en ayant des personnes spécialisées sur certaines parties du code et les risques liés au fait que ces personnes se sentent propriétaires de ces portions de code. Ce que vous souhaitez, c’est instaurer une situation où subsiste toujours un certain degré de redondance en termes de connaissances sur la base de code au sein de l’équipe, afin que chaque ingénieur bénéficie d’un certain chevauchement de compétences. Il s’agit d’un compromis très subtil à réaliser si vous voulez maintenir un niveau de productivité quelconque. La seule manière d’y parvenir concrètement dans le monde réel est à travers une culture de l’ingénierie logicielle bien comprise. Aucun processus ne peut garantir que les gens seront curieux du travail de leurs collègues. Vous ne pouvez pas instaurer un processus pour la curiosité ; cela doit faire partie intégrante de la culture.

Évaluer les compétences et le savoir-faire des ingénieurs logiciels est difficile, et cette question est primordiale car, même si le logiciel est clairement un effort collectif et que l’équipe est plus que la somme de ses membres, le niveau de base des membres a un impact considérable sur la performance globale de l’équipe.
Un aspect que j’ai constaté être largement sous-estimé par les personnes extérieures à l’industrie du logiciel, et parfois même par celles qui y travaillent, est l’importance des compétences rédactionnelles. Si vous créez un logiciel, vous vous adressez à deux publics distincts. D’une part, il y a le public de la machine — votre compilateur. Vous écrivez du code, et votre compilateur l’accepte ou le rejette. C’est la partie facile. Votre compilateur est votre compagnon infatigable qui vous dira si votre code est correct ou non. Le compilateur est entièrement prévisible et possède une patience infinie.
De l’autre côté, vous avez le public de vos collègues, qui inclura probablement vous-même dans six mois. Vous écrivez du code et finirez par l’oublier. Six mois plus tard, vous regarderez le code que vous avez écrit, en pensant qu’il a été rédigé par quelqu’un d’autre parce qu’il vous semble tellement étranger. Lorsque vous écrivez du code pour vos collègues, l’avantage est que, contrairement aux compilateurs, vos collègues essaieront de comprendre ce que vous tentez d’accomplir. Le compilateur n’essaie pas de comprendre vos intentions; il applique mécaniquement un ensemble de règles.
Vos collègues essaieront de comprendre, mais malheureusement, ils ne sont pas comme des compilateurs. Ils n’ont pas une patience infinie, et ils peuvent être facilement confus et induits en erreur par votre code. C’est pourquoi, par exemple, choisir des noms mémorables, perspicaces et appropriés est d’une importance primordiale. Un bon programme ne se contente pas d’être correct; même le choix des noms des variables, fonctions et modules est d’une importance cruciale si vous souhaitez que votre code s’accorde bien avec vos collègues, et encore, vos collègues incluent vous-même dans six mois. D’un point de vue supply chain, l’idée principale est que les compétences rédactionnelles sont d’une importance primordiale, et j’irais jusqu’à dire que ces compétences sont fréquemment plus importantes que les compétences techniques brutes. De bonnes compétences rédactionnelles sont la compétence numéro un dont vous aurez besoin pour maîtriser la complexité présente dans votre supply chain. Maîtriser la complexité de votre paysage applicatif n’est pas un grand défi technique; c’est un défi d’organisation des idées et des éléments, et de maintien d’une cohérence dans l’ensemble. Ce sont avant tout des compétences rédactionnelles, et nous avons abordé cet aspect dans une conférence précédente intitulée “Writing for Supply Chain.”

Si la compétence rédactionnelle est d’une importance primordiale pour être un bon ingénieur logiciel, il existe une autre compétence essentielle pour être ingénieur logiciel en général : la tolérance à la douleur. Je crois que c’est la compétence numéro un en ce qui concerne ce qu’il faut réellement pour être ingénieur logiciel, pas forcément un grand ingénieur, simplement pour l’être. Plus précisément, quand je parle de douleur, j’entends la résistance à l’ennui et à la frustration qui accompagne le processus d’ingénierie logicielle face à des systèmes incroyablement fragiles, mal conçus et truffés de pièges de toutes sortes, parfois posés par des personnes qui ne sont même plus là. Lorsque vous traitez avec des logiciels, vous avez sous vos pieds quatre décennies de problèmes accumulés, et vous luttez contre cela en permanence. Cela peut parfois s’avérer être un exercice incroyablement frustrant.
Pour vous donner une illustration, en tant qu’ingénieur logiciel, vous devrez avoir la patience de passer quatre heures à fouiller dans des conversations aléatoires, semi-déchets, sur un forum web mentionnant un code d’erreur similaire à celui auquel vous êtes confronté. Vous devrez consacrer des heures à ce genre d’absurdités pour en venir à bout, et il arrive parfois qu’il faille des semaines pour résoudre un bug apparemment trivial. Ainsi, la conséquence est que nous assistons à un processus d’adverse sélection particulièrement intense dans l’ensemble de l’industrie du logiciel, qui sélectionne des personnes dotées d’une grande tolérance à la douleur. Ce processus de sélection a deux conséquences majeures.
Premièrement, les personnes qui restent ingénieurs logiciels tendent à afficher une tolérance à la douleur incroyablement élevée. Quand je dis « tolérance à la douleur », j’entends la résistance à la frustration causée par les problèmes logiciels constants. Comme on sélectionne des personnes dotées d’une tolérance exceptionnelle, elles ne se rendent peut-être même pas compte que leurs actions aggravent la situation. Elles peuvent ajouter des bizarreries supplémentaires aux produits logiciels, augmentant ainsi la douleur rencontrée par tous lors de l’interaction avec le logiciel, elles-mêmes y compris. Toutefois, si elles se montrent incroyablement tolérantes, elles ne font pas attention. Ce processus d’adverse sélection écarte les personnes ordinaires qui prêteraient attention mais qui ne sont pas devenues ingénieurs logiciels parce qu’elles ne supportaient pas la douleur. Ce problème est particulièrement aigu pour les logiciels de supply chain, car de nombreuses parties ne sont pas très enthousiasmantes. Certains aspects peuvent être nécessaires mais banals, ce qui signifie que les personnes ayant une haute tolérance à la douleur dans ce domaine peuvent aggraver la situation en raison de l’abondance de tâches potentiellement rébarbatives.
Le second aspect de ce processus d’adverse sélection est que, lorsque les gens peuvent se permettre le luxe d’accepter un salaire inférieur pour éviter des problèmes générant une douleur intense, ils le font. Si quelqu’un est déjà bien rémunéré, il peut décider d’opter pour un emploi moins bien payé mais comportant l’avantage d’une douleur moins intense. La plupart des gens feraient probablement ce choix, et en pratique, beaucoup le font. Cela signifie que les personnes qui restent dans cette industrie, où l’intensité de la douleur ambiante est très élevée, sont souvent celles qui ne peuvent pas se permettre de renoncer à l’opportunité d’un salaire plus élevé. Cela explique en grande partie pourquoi un nombre significatif d’ingénieurs logiciels provient de l’Inde et d’Afrique du Nord. Ces pays disposent de systèmes éducatifs assez performants qui produisent des individus bien formés, mais ces pays restent néanmoins relativement pauvres. Les personnes dans ces situations n’ont pas le luxe de renoncer à des emplois d’ingénierie logicielle mieux rémunérés en raison de la forte demande et des salaires plus élevés par rapport à leurs salaires de base. Elles n’ont pas le luxe de viser autre chose, et se retrouvent donc fortement représentées dans l’industrie.
Il n’y a rien de mal avec ces pays; c’est simplement une application mécanique des forces du marché. Ce n’est pas un jugement, simplement une observation. Le fait est que la tolérance à la douleur n’est pas tout ce qu’il faut pour être un grand ingénieur logiciel. C’est seulement une condition, mais si vous ne la possédez pas, alors vous n’êtes pas ingénieur logiciel du tout. Pourtant, si la tolérance à la douleur est la seule compétence dont vous disposez, cela fera de vous un ingénieur logiciel plutôt médiocre. Du point de vue supply chain, la leçon ici est de prêter une attention particulière aux types d’équipes que votre entreprise rassemble, que ce soit en interne ou via des fournisseurs de logiciels. Assurez-vous que les ingénieurs recrutés n’ont pas la tolérance à la douleur comme unique compétence, car cela signifie que vous obtiendrez un résultat très médiocre en termes de qualité logicielle et de valeur ajoutée apportée par le logiciel. Encore une fois, la tolérance à la douleur est nécessaire, mais elle ne suffit tout simplement pas.

En 1975, Frederick Brooks soulignait déjà que les mois-homme n’étaient pas représentatifs de la valeur créée par le logiciel ni de la valeur générée par les ingénieurs logiciels en général. Près de cinq décennies plus tard, les entreprises IT figurent parmi les plus grands employeurs du monde. En 2020, aux États-Unis, il y avait 3 millions d’employés dans l’industrie IT, contre moins d'1 million pour l’ensemble de l’industrie automobile. L’industrie IT compte désormais au moins trois fois plus de personnes que l’industrie automobile. La plupart de ces entreprises IT, certaines étant absolument gigantesques avec plusieurs centaines voire des milliers d’employés, ne facturent plus à la manière des mois-homme. C’était dans les années 70. Désormais, nous facturons au kilo-jours, c’est-à-dire essentiellement mille jours de travail. La situation est sans doute devenue bien pire que le problème que Frederick Brooks exposait il y a presque cinq décennies, principalement en raison de l’augmentation incroyable en termes d’échelle et d’ampleur. Cependant, la plupart des premières leçons restent valables. “The Mythical Man-Month” demeure un livre très intéressant sur l’ingénierie logicielle.
Dans le domaine du logiciel, la productivité varie énormément. À une extrémité du spectre, il n’y a pas de personnes ayant une faible productivité; il y a des personnes dont la productivité est négative. Cela signifie que lorsqu’elles commencent à travailler sur un produit logiciel, elles ne font qu’empirer la situation. Il n’est même plus possible d’établir un ratio entre la productivité des individus. C’est bien pire: certaines personnes vont activement dégrader votre produit. C’est un problème colossal. À l’autre extrémité du spectre, il y a les soi-disant ingénieurs 10x, des personnes dont la productivité est dix fois supérieure à celle de votre ingénieur moyen, qui espérons-le affiche une productivité positive. Ces ingénieurs 10x existent, mais cette productivité massive dépend énormément du contexte. Vous ne pouvez pas simplement transférer un ingénieur logiciel 10x d’une entreprise à une autre, ou d’un poste à un autre, et vous attendre à ce qu’il conserve son incroyable productivité. Habituellement, c’est une combinaison de compétences uniques et d’une situation spécifique qui génère cette productivité. Néanmoins, il est important de garder à l’esprit qu’un très petit nombre de personnes peut générer l’essentiel de la valeur d’un produit logiciel. Parfois, tout se résume à une seule personne qui crée la majeure partie de tous les éléments astucieux du logiciel et la véritable valeur ajoutée, tandis que le reste ne s’occupe que de choses dont la valeur ajoutée est, tout au mieux, discutable. La leçon clé ici, identifiée il y a cinq décennies, est que lorsqu’on est contre la montre en supply chain, la seule option raisonnable à votre disposition est de réduire la portée de l’initiative logicielle. Toutes les autres options sont pires.
Ajouter de la main-d’œuvre empire les choses, comme on dit souvent qu’ajouter de la main-d’œuvre à un projet logiciel en retard ne fait que le retarder davantage. Cette affirmation de Brooks était valable il y a cinq décennies et l’est toujours aujourd’hui. Les autres options ne fonctionnent pas non plus. Si vous commencez à faire faire des heures supplémentaires aux gens, cela se retournera contre vous car ils seront fatigués et introduiront plus de bugs, retardant encore le produit. Si vous essayez de baisser la qualité, vous finirez par obtenir quelque chose qui ne fonctionne plus. Ces choses vont rapidement dérailler et exploser entre vos mains, vous ne pouvez donc pas compromettre la qualité.
D’un point de vue supply chain, la leçon ici est que si vous entreprenez une initiative qui semble nécessiter plus de dix ingénieurs logiciels à temps plein, agissez avec la plus grande prudence. Généralement, c’est le signe d’un problème très mal cadré. Il faut un travail d’équipe extraordinaire pour que dix personnes travaillent simultanément sur le même produit tout en maintenant leur productivité. En supply chain, j’observe que les gens sont souvent trop ambitieux en termes d’échelle et de nombre de personnes impliquées. J’ai vu des projets de migration ERP avec 50, 100 ou 200 personnes travaillant simultanément dessus. Cela est tout simplement absurde. Pour parvenir à un quelconque niveau de coopération, il faut des coéquipiers incroyablement compétents afin d’éviter de tout perdre à cause des frictions. Si vous rencontrez des difficultés, gardez votre initiative logicielle ciblée, courte et étroite.

Ma dernière observation porte sur une incompréhension fréquente concernant les grandes entreprises. La plupart des gens diraient que les grandes entreprises sont averses au risque, mais ce n’est pas de mon expérience. Mon expérience est que les grandes entreprises sont averse à l’incertitude, et non au risque, bien qu’à première vue, les deux puissent être confondus. De loin, l’explication rationnelle donnée est que les grandes entreprises sont averse au risque, mais en réalité, j’ai observé à maintes reprises que, lorsqu’elles sont confrontées au choix entre un échec certain et un succès incertain, elles privilégient invariablement la certitude de l’échec plutôt que l’incertitude du succès.
Les grandes entreprises privilégient invariablement la certitude de l’échec plutôt que l’incertitude du succès, encore et encore. Cela peut paraître déconcertant et irrationnel en surface, mais ce n’est pas le cas. Les grandes entreprises ne forment pas une entité unique; ce sont des bêtes politiques composées de nombreuses personnes. La politique et l’apparence priment, surtout dans des structures très vaste.
Considérez la perspective de celui ou celle qui est en charge d’une initiative logicielle. D’une part, vous avez une initiative dont l’issue est certaine – elle échouera. Cependant, vous jouez selon les règles, en suivant le livre, et tout le monde sait qu’elle va échouer. Personne ne vous reprochera d’avoir joué la sécurité et d’avoir échoué, car c’est ce à quoi ils s’attendent. Au contraire, un succès incertain paraît bizarre. Emprunter cette voie signifie faire des choses inhabituelles et potentiellement dommageables pour la carrière, bien plus que de simplement suivre le livre.
Du point de vue supply chain, la leçon ici est que dans le monde du logiciel, il est crucial de ne pas se préparer à l’échec simplement pour suivre les règles, surtout lorsque celles-ci sont complètement bidon. Par exemple, j’ai vu des entreprises échouer pendant des décennies en utilisant des méthodes telles que l’analyse ABC et les safety stocks, des méthodes qui peuvent être démontrées comme incorrectes et qui garantissent l’échec des initiatives correspondantes. Ces méthodes sont erronées pour des raisons mathématiques et statistiques fondamentales, il ne devrait donc pas être surprenant qu’elles n’apportent pas de valeur ajoutée en supply chain. Cependant, elles étaient jugées préférables car elles n’apparaissaient pas comme extravagantes, puisqu’il s’agissait de cours théoriques.
Méfiez-vous du confort que peut procurer le fait de se préparer à l’échec simplement pour éliminer l’incertitude. Éliminer l’incertitude n’est pas le but; le but est de maximiser les chances de succès, pas de réduire l’incertitude.

En conclusion, l’ingénierie logicielle est trop importante pour être laissée uniquement entre les mains des ingénieurs logiciels. Les logiciels sont omniprésents dans la supply chain et conduisent à la mécanisation du travail intellectuel. Nous en sommes encore aux débuts du processus, mais on peut déjà affirmer, sans aucun doute, que les entreprises qui ne resteront pas extrêmement compétitives sur ce front seront éliminées du marché par les forces du marché classiques. Pour la supply chain, le plus grand défi est d’ordre culturel. Ce n’est pas un problème technique, mais un problème de culture. L’ingénierie logicielle remet en question notre manière de voir et d’aborder les problèmes. La plupart des solutions intuitives tendent à se révéler fausses, de façon spectaculaire.
D’une certaine manière, l’ingénierie logicielle en supply chain consiste à maîtriser le chaos, à dompter toute la complexité et l’incertitude qui règnent dans la supply chain. Pour dompter ce chaos, qui sera la tâche des ingénieurs logiciels, si le processus lui-même est trop poli ou ordonné, si le processus ne possède pas un élément de chaos à son cœur, alors il n’y a plus de place pour le changement, le hasard ou la créativité. Ce qui est perçu comme excellence se transforme rapidement en stagnation, puis en échec. Pour les entreprises plus traditionnelles, le plus grand défi de cette approche culturelle, outre le choc culturel, est de renoncer à l’illusion de contrôle. Votre plan de migration ERP sur cinq ans est une illusion; vous n’avez aucun contrôle sur un projet aussi massif. De même, votre business case qui expose les profits attendus de votre initiative actuelle est également une illusion.
Lorsqu’on s’attaque à la mécanisation du travail intellectuel, le plus grand danger est de faire des choses que l’on ne peut pas pleinement rationaliser. Le plus grand danger est de faire des choses complètement irrationnelles sous couvert de rationalité.

Regardons la question. La prochaine conférence aura lieu le mercredi 15 décembre, à la même heure, 15 h, heure de Paris, et portera sur la cybersécurité. Maintenant, je vais examiner la question.
Question: Comment mesurez-vous le retour capitaliste sur vos investissements logiciels ?
La plupart du temps, ce n’est pas le cas. La mesure est le sous-produit de l’entreprise elle-même. C’est quelque chose d’étonnant si l’on veut mesurer le retour sur investissement. Cela suppose que l’on peut concevoir une mesure au préalable, ce qui est généralement implicite avec ce genre de question. Cela suppose que l’on peut imaginer cette mesure avant de construire son business case avec des scénarios, puis prendre une décision pour continuer ou non avec son investissement logiciel. Ce que je dis, c’est que cela ne fonctionne pas ainsi avec les logiciels. C’est littéralement d’abord, vous faites la chose, puis vous apprenez ce qu’il faut apprendre, et ensuite, en cours de route, vous découvrirez même quels types d’avantages existent. Pour guider votre action, vous avez besoin d’une compréhension de haut niveau. La leçon n’est pas de faire les choses au hasard, mais de ne pas faire des choses profondément irrationnelles sous couvert de rationalité. L’intuition de haut niveau, si vous êtes absolument convaincu de quelque chose et que votre instinct vous dit que c’est la bonne voie, peut constituer un argument beaucoup plus rationnel comparé à des calculs sophistiqués qui n’ont que la prétention de rationalité mais reposent sur des chiffres sans valeur. La réalité est qu’au fur et à mesure de l’avancée de votre projet logiciel, les mesures deviendront plus claires parce que vous commencerez à comprendre ce que vous essayez d’accomplir, puis vous apprendrez comment mesurer la pertinence de ce que vous faites par rapport à ce que vous devriez faire. La mesure viendra comme un sous-produit si vous faites bien les choses. Cependant, en conséquence, cela signifie qu’en ce qui concerne les logiciels, il est bien meilleur d’essayer des choses et d’échouer rapidement. Vous ne souhaitez pas vous engager dans un engagement massif ; il vaut mieux procéder de manière incroyablement incrémentale, avec moins de personnes et une forte productivité. Vous apprenez au fur et à mesure comment procéder.
Mais vient ensuite un autre problème : dès que vous commencez à faire cela, la direction dans les entreprises doit être capable de jongler avec de nombreuses initiatives en même temps. C’est très déconcertant, en particulier pour les entreprises plus traditionnelles, car la direction ne s’attend pas à avoir autant d’initiatives allant dans des directions différentes. Pourtant, c’est exactement ce qui se passe depuis des décennies dans les grandes entreprises de logiciels, et c’est l’une des essences des enseignements de l’ingénierie logicielle d’un point de vue humain.
Question: N’est-il pas contradictoire de dire que ceux qui ont beaucoup de mots-clés ne s’associent pas à une technologie particulière ?
Eh bien, je ne dis pas qu’avoir beaucoup de mots-clés vous protège de vous associer à une technologie particulière. Il y a deux problèmes différents. L’un est le problème d’avoir une personne qui a une forte association entre son identité personnelle, son identité perçue et son ensemble de compétences. C’est le problème numéro un. Le problème numéro deux est que la construction de votre CV s’accompagne d’un conflit d’intérêts latent très fort. Mon message est, d’une part, méfiez-vous de ces politiques identitaires ; elles sont incroyablement toxiques. Mon second message est : méfiez-vous des conflits d’intérêts sous toutes leurs formes ; ils sont également incroyablement toxiques.
Maintenant, si vous insistez vraiment sur une technologie en particulier, vous pouvez retirer certains mots-clés pour des technologies que vous désapprouvez sur votre CV. Cependant, généralement, les deux problèmes sont distincts, et vous pouvez même avoir quelqu’un qui dit, “Mon identité, c’est que je suis programmeur Python,” comme je l’ai montré dans une diapositive, et puis sur votre CV, insérer plus de 20 mots-clés. Les deux choses ne sont pas exclusives ; elles peuvent même se produire simultanément. De plus, ne sous-estimez pas le fait que parfois l’identité peut être associée à quelque chose d’aspirationnel, quelque chose que vous voulez acquérir. Vous pouvez dire, “Jusqu’à présent, j’ai programmé en Python, mais je veux devenir programmeur Rust, alors je vais me considérer comme programmeur Rust, même si jusqu’à présent j’ai surtout fait du Python.” Toutes sortes de comportements sont possibles.
Question: L’ingénierie logicielle est considérée comme une science auxiliaire pour la supply chain. Quelles seraient les sciences auxiliaires pour l’ingénierie logicielle ?
Probablement que la psychologie, la sociologie et l’ethnologie sont toutes des disciplines pertinentes en ce qui concerne l’ingénierie logicielle. Si vous commencez à l’aborder comme essentiellement l’interaction entre les personnes, alors ces sciences auxiliaires sont cruciales. Pour faire un travail sérieux en ingénierie logicielle, il ne s’agit pas uniquement de la technologie logicielle, bien que vous deviez comprendre le contexte logiciel afin que les interactions entre les personnes aient du sens. Vous n’avez pas nécessairement besoin de comprendre ce qui se passe dans le code, mais vous devez comprendre des concepts comme une base de code ou les outils qui existent et les problèmes qu’ils cherchent à résoudre. Cependant, pour les besoins de cette série de conférences sur la supply chain, je dois tracer une ligne, décider de ce que j’inclus et ce que je n’inclus pas, car, évidemment, je ne peux pas couvrir chaque domaine de recherche.
Question: Demandez à dix personnes intelligentes une solution, et elles proposeront plus de dix façons. Se mettre d’accord sur l’une des cinq meilleures et l’utiliser de manière cohérente est mieux. Comment équilibrez-vous ces deux approches et bénéfices conflictuels ?
C’est une question très vaste, mais si j’essaie de la cadrer dans le cas spécifique de l’ingénierie logicielle, vous pouvez avoir de nombreuses propositions, mais toutes ne doivent pas être considérées avec le même poids. Il existe une compétence qui consiste à avoir une vision à long terme du logiciel. Quand je dis que vous devez vous concentrer sur ce qui ne change pas, il s’avère que certaines personnes excellent dans ce domaine, et d’autres non. L’expérience joue un rôle lorsqu’il s’agit de voir qui possède les compétences pour cette vision à long terme et ce qui demeure constant. D’après ma modeste expérience, il faut généralement qu’une personne ait au moins 35 ans pour commencer à devenir vraiment bonne dans ce domaine, et les meilleures personnes ont plus de 60 ans. Il faut des années d’expérience pour percevoir les mouvements et les schémas.
Quand vous dites que vous disposez d’autant de personnes, une illusion est que toutes ces solutions semblent bonnes, mais ce n’est qu’une apparence. Vous ne savez pas combien d’efforts il faudra pour tester le terrain. Pouvez-vous simplement prototyper ou tester ? Parmi ces dix personnes, y en a-t-il qui possèdent des compétences uniques pour identifier des solutions qui seront toxiques à long terme ? Rappelez-vous que vos coûts de maintenance sont essentiellement déterminés par les décisions que vous avez prises. Y a-t-il une décision importante qui pourrait vous nuire à long terme ?
C’est un aspect délicat, et d’ailleurs, quelqu’un qui a une vision à long terme peut expliquer pourquoi une certaine option, à long terme, engendrera toutes sortes de problèmes. Ce n’est pas juste un pressentiment ou une intuition. Il vous dira, “Ce genre de situation, déjà vécu, déjà accompli. J’ai vu cela dans d’autres produits.” Il y a un adage : l’homme intelligent apprend de ses propres erreurs, mais l’homme sage apprend des erreurs des autres. Cela est très applicable dans ce cas.
Question: Comment les entreprises mesurent-elles l’augmentation de l’efficacité opérationnelle par dollar investi dans la mise en œuvre de logiciels pour la supply chain ?
C’est une question incroyablement difficile. Le problème réside littéralement dans l’incommensurabilité des paradigmes. Cela provient de l’épistémologie ; l’idée est que lorsque vous passez d’une façon d’opérer à une autre, et que ces paradigmes sont radicalement différents, la plupart des mesures deviennent tout simplement inutiles. Prenons l’exemple du télémarketing par téléphone versus le e-commerce, par exemple. Les entreprises de vente par correspondance existent depuis le milieu du XIXe siècle. Si vous commencez à considérer le e-commerce comme une amélioration par rapport aux entreprises de vente par correspondance, vous pourriez essayer de mesurer l’amélioration, mais la réalité est que pratiquement toutes les entreprises de vente par correspondance ont fait faillite. Les entreprises de e-commerce qui dominent de nos jours sont de plusieurs ordres de grandeur supérieures à la plus grande entreprise historique de vente par correspondance, et la comparaison est très floue.
La mécanisation du travail intellectuel est tellement troublante et déroutante parce que ce n’est pas comme dans le domaine physique. Avec la production matérielle, vous pouvez mesurer l’efficacité par des moyens canoniques. Cependant, lorsque vous commencez à mécaniser votre travail intellectuel, que signifie même l’efficacité ? Pour une entreprise comme Amazon, toute sa supply chain est entièrement pilotée par des logiciels. Si les gens restaient simplement chez eux sans rien faire, je soupçonne que toute la supply chain fonctionnerait parfaitement, même si tous ces ingénieurs ne faisaient rien pendant un jour ou deux. Alors, pourquoi Amazon garde-t-il encore ces ingénieurs ? Eh bien, parce qu’ils investissent dans leurs améliorations.
Au fait, une chose intéressante à propos de Jeff Bezos est son processus de gestion appelé “disagree but commit.” Il dit qu’il y a des projets pour lesquels son intuition de PDG lui indique que c’est erroné, et il est en désaccord avec le projet. Cependant, il s’engage à soutenir le budget du projet parce qu’il a embauché et fait confiance aux personnes qui y travaillent. C’est une approche un peu schizophrénique – en tant que PDG, il est censé être l’autorité suprême dans l’entreprise, mais il renonce à cette autorité et dit, “Je suis en désaccord, mais vous pouvez avoir le budget et poursuivre.”
La raison de cette approche est que les projets logiciels sont généralement assez bon marché. Si quelqu’un propose une idée apparemment folle, qui n’est pas très coûteuse et qui ne mettra pas l’entreprise en faillite, pourquoi ne pas essayer ? Si cela fonctionne, cela pourrait être une idée brillante. Cela représente un choc culturel lors de la transition depuis les entreprises traditionnelles de supply chain, où la direction est censée avoir la vision et conduire les équipes. Dans le domaine des logiciels, le leadership consiste principalement à résoudre les problèmes qui surgissent parmi les ingénieurs logiciels.
Chez Lokad, lors de l’investissement dans des logiciels, la préoccupation principale n’est pas le retour en dollars. Au lieu de cela, l’accent est mis sur le fait que l’investissement répond à un aspect fondamental de la gestion de la supply chain. Si c’est au cœur d’une grande variété de situations de supply chain, alors cela vaut la peine d’être poursuivi.
Par exemple, dans le marché de l’après-vente automobile, s’attaquer au problème de la compatibilité mécanique est d’une importance primordiale. Vous ne vendez pas des pièces automobiles pour servir les gens ; vous vendez des pièces pour servir les voitures. Une seule pièce peut être compatible avec plusieurs véhicules, et certaines pièces peuvent présenter un chevauchement mécanique. Ce problème doit être résolu ; il est au cœur de l’activité. Si vous ne vous en occupez pas, quelqu’un d’autre le fera, et vous finirez par être évincé du marché.
En ce qui concerne les investissements logiciels, il est important de prendre des risques et d’embrasser l’innovation, tant qu’ils ne menacent pas la stabilité financière de l’entreprise.
Question: Il est trompeur de dire que les grandes équipes de projets sont absurdes. Dans les systèmes ERP, une équipe de 10 personnes peut être suffisante pour le développement, mais les projets de plus grande envergure nécessitent plus de monde. Une tour nécessite plus de personnes pour être construite qu’une maison. Pourriez-vous clarifier vos commentaires ?
Je vais prendre une position qui risque d’antagoniser beaucoup de gens. Les moyens de subsistance de millions de personnes dépendent d’entreprises informatiques incroyablement grandes. Aux États-Unis en 2020, les entreprises informatiques représentaient trois millions d’employés américains. Ainsi, lorsque je dis qu’il n’y a absolument aucune raison d’avoir un ERP qui nécessite autant de personnes, évidemment, toutes les personnes qui gagnent leur vie soit en vendant de grandes équipes, soit en faisant partie d’une telle équipe, seront farouchement en désaccord avec moi.
Mon contre-argument est le suivant : est-ce que votre désaccord vient de raisons scientifiques fondamentales expliquant pourquoi le travail ne peut pas être effectué avec moins de personnes, ou est-ce dans votre propre intérêt financier de maintenir le statu quo et d’avoir une armée de personnes pour accomplir le travail ? Si l’on observe toutes les innovations qui ont eu lieu – la destruction créatrice décrite par l’économiste Schumpeter – chaque fois qu’il y a eu une innovation économique majeure, il y a généralement eu une amélioration massive de la productivité. Mais ceux qui étaient en retard se sont battus avec acharnement pour empêcher ces innovations de se produire.
Les ERP ne sont pas une nouveauté ; ils existent essentiellement depuis quatre décennies. La plupart des ERP que je vois de nos jours n’ajoutent pas beaucoup de valeur par rapport à ceux que les entreprises avaient il y a une ou deux décennies. J’ai vu de nombreux ERP plus anciens qui fonctionnent très bien, et les nouveaux ERP ne sont souvent pas sensiblement meilleurs, surtout en tenant compte des millions investis dans les projets de migration ERP. Dans ces projets gigantesques, je constate une productivité lamentable de la part des entreprises informatiques.
Mon contre-argument est d’examiner des entreprises comme JD.com, Amazon ou Rakuten. Combien de personnes ces entreprises nécessitent-elles pour accomplir des tâches similaires ? Habituellement, on se retrouve avec des ratios insensés. Par exemple, Zalando, une grande entreprise européenne de e-commerce basée à Berlin, en Allemagne, a construit son propre ERP avec une équipe plus petite que la plupart des équipes que j’ai vues pour des entreprises de taille similaire qui doivent simplement migrer leur ERP. Vous voyez donc, d’un côté, vous avez une entreprise comme Zalando, capable d’ingénierie sur son propre ERP, entièrement adapté à ses besoins. Il fait un très bon travail en tant qu’ERP adapté pour eux, et le coût ainsi que le nombre de personnes impliquées ne représentent qu’une fraction de ce dont d’autres entreprises de taille similaire auraient besoin simplement pour effectuer une mise à jour de version. Le coût est à nouveau seulement une fraction. Je conteste la nécessité d’avoir autant de personnes impliquées, et c’est là le problème du travail de col blanc au XXIe siècle. Pour être un très bon employé, il faut avoir le courage de s’automatiser soi-même, de se rendre obsolète.
C’est quelque chose de très particulier. Lorsque les travailleurs manuels ont été rendus obsolètes, cela a été fait par d’autres. Mais de nos jours, il ne reste presque plus de travailleurs manuels. Cela demande un état d’esprit différent, et c’est pourquoi il y a une lutte pour s’adapter à ce nouveau paradigme, venant principalement de l’industrie du logiciel. Il est acceptable de se rendre obsolète parce que vous ne vous rendez pas réellement obsolète ; il n’y a pas de limite à l’ingéniosité humaine. Vous automatisez simplement certaines tâches, vous vous libérant ainsi pour relever le prochain défi, qui est encore plus intéressant que le précédent. Des entreprises comme Amazon ne licencient pas leurs ingénieurs logiciels dès qu’ils résolvent un problème. Ils les récompensent et les promeuvent pour relever le défi suivant, plus difficile.
En réponse à une question concernant des praticiens de supply chain bloqués dans une pensée analytique d’après-Seconde Guerre mondiale, je conviens que, pour de nombreuses entreprises – pas toutes – l’ingénierie logicielle a évolué. Elle se définit comme un processus centré sur les personnes, ou un processus interprétatif. Je suis d’accord. L’industrie du logiciel ne se résume pas uniquement à des technologies essentielles. Bien que certains postes requièrent d’incroyables compétences techniques quantitatives, l’essentiel de l’industrie du logiciel se perçoit comme adoptant une approche axée sur l’humain, une culture partagée.
Dans une large mesure, je pense que la domination exercée par les États-Unis et la Silicon Valley dans le secteur du logiciel à travers le monde repose sur la difficulté de reproduire leur culture. La culture tend à être très intangible et difficile à documenter. Lorsque vous la documentez, vous apprivoisez l’ingrédient chaotique nécessaire à l’innovation. Si vous documentez, organisez et structurez la culture, vous perdez soudainement cet aspect de l’émergence brute et chaotique des idées et innovations.
Il existe des endroits, comme la Silicon Valley, où cette culture prédomine, et ils sont en avance sur leur temps à cet égard. Pour conclure sur ce sujet, j’aimerais citer William Gibson, qui a dit, “L’avenir est déjà là ; il n’est simplement pas réparti de manière homogène.” Je constate que cette culture est désormais reproduite à une échelle beaucoup plus réduite dans de nombreux autres endroits, et ce processus continuera et se développera au fil du temps.
C’est tout pour aujourd’hui. À la prochaine. Lors de notre prochaine session, nous aborderons un sujet qui peut être assez déprimant mais qui est très important : la cybersécurité. À bientôt!


