00:12 Introducción
02:23 Falsabilidad
08:25 La historia hasta ahora
09:38 Enfoques de modelado : Optimización Matemática (MO)
11:25 Resumen de la Optimización Matemática
14:04 Teoría principal de supply chain (repaso)
19:56 Alcance de la perspectiva de Optimización Matemática
23:29 Heurísticas de rechazo
30:54 El día siguiente
32:43 ¿Cualidades redentoras?
36:13 Enfoques de modelado : Optimización Experimental (EO)
38:39 Resumen de la Optimización Experimental
42:54 Causas raíz de la insania
51:28 Identificar decisiones insanas
58:51 Mejorar la instrumentación
01:01:13 Mejorar y repetir
01:04:40 La práctica de EO
01:11:16 Resumen
01:14:14 Conclusión
01:16:39 Próxima conferencia y preguntas de la audiencia
Descripción
Lejos de la ingenua perspectiva cartesiana en la que la optimización se trataría simplemente de desplegar un optimizador para una función de puntuación dada, supply chain requiere un proceso mucho más iterativo. Cada iteración se utiliza para identificar decisiones “insanas” que deben ser investigadas. La causa raíz es, con frecuencia, el uso inadecuado de economic drivers, los cuales necesitan ser reevaluados en cuanto a sus consecuencias no intencionadas. Las iteraciones se detienen cuando las numerical recipes ya no producen resultados insanos.
Transcripción completa

Hola a todos, bienvenidos a esta serie de conferencias sobre supply chain. Soy Joannes Vermorel, y hoy presentaré “Experimental Optimization”, que debe entenderse como la optimización de supply chains mediante una serie de experimentos. Para aquellos que estén viendo la conferencia en vivo, pueden hacer preguntas en cualquier momento a través del chat de YouTube. Sin embargo, no estaré leyendo el chat durante la conferencia; me encargaré de responder las preguntas al final de la misma.
El objetivo para nosotros hoy es la mejora cuantitativa de supply chains, y queremos ser capaces de lograrlo de manera controlada, fiable y medible. Necesitamos algo parecido a un método científico, y una de las características clave de la ciencia moderna es que está profundamente arraigada en la realidad o, más precisamente, en el experimento. En una conferencia anterior, discutí brevemente la idea de los experimentos en supply chain y mencioné que, a primera vista, parecen largos y costosos. La duración y el costo podrían incluso derrotar el propósito de por qué se realizan dichos experimentos, hasta el punto en que tal vez ni siquiera valga la pena. Pero el desafío es que necesitamos una mejor forma de abordar la experimentación, y de eso se trata exactamente la optimización experimental.
La optimización experimental es, fundamentalmente, una práctica que surgió en Lokad hace aproximadamente una década. Proporciona una manera de realizar experimentos en supply chain que realmente funcionan, que se pueden llevar a cabo de forma conveniente y rentable, y que será el tema específico de la conferencia de hoy.

Pero primero, retrocedamos un segundo en esta noción misma de la naturaleza de la ciencia y su relación con la realidad.
Existe un libro, “The Logic of Scientific Discovery”, publicado en 1934 y cuyo autor es Karl Popper, que es considerado un hito absoluto en la historia de la ciencia. Propuso una idea completamente sorprendente, que es la falsabilidad. Para entender cómo surgió esta idea de la falsabilidad y de qué se trata, es muy interesante revisar el camino de Karl Popper en sí mismo.
Verán, en su juventud, Popper estuvo cerca de varios círculos de intelectuales. Entre esos círculos, había dos de interés clave: uno era un círculo de economistas sociales, típicamente defensores de la teoría marxista en ese momento, y el otro era un círculo de físicos, que incluía, sobre todo, a Albert Einstein. Popper observó que los economistas sociales tenían una teoría con la intención de contar con una teoría científica que pudiera explicar la evolución de la sociedad y su economía. Esta teoría marxista en realidad hacía predicciones sobre lo que sucedería. La teoría señalaba que habría una revolución, y que la revolución ocurriría en el país que estuviera más industrializado y donde se encontrara el mayor número de trabajadores de fábrica.
Resultó que la revolución sí ocurrió en 1917; sin embargo, ocurrió en Rusia, que era el país menos industrializado de Europa y, por lo tanto, fue completamente contrario a lo que la teoría predijo. Desde la perspectiva de Popper, había una teoría científica haciendo predicciones, y luego ocurrieron eventos que contradecían la teoría. Lo que él esperaba era que la teoría fuera refutada, y que la gente pasara a otra cosa. En cambio, lo que vio fue algo muy diferente. Los defensores de la teoría marxista modificaron la teoría para ajustarla a los eventos a medida que se desarrollaban. Al hacerlo, gradualmente hicieron que la teoría fuera inmune a la realidad. Lo que comenzó como una teoría científica fue modificada progresivamente hasta convertirse en algo completamente inmune, de modo que nada de lo que pudiera ocurrir en el mundo real contradeciría la teoría.
Esto contrastaba fuertemente con lo que sucedía en los círculos de físicos, donde Popper observó a personas como Albert Einstein creando teorías y luego haciendo grandes esfuerzos para idear experimentos que pudieran refutarlas. Los físicos no dedicaban toda su energía a probar las teorías, sino más bien a refutarlas. Popper consideró cuál enfoque era la mejor manera de hacer ciencia y desarrolló el concepto de falsabilidad.
Popper propuso que la falsabilidad es un criterio para establecer si una teoría puede considerarse científica. Dijo que una teoría es científica si satisface dos criterios. El primero es que la teoría debe estar en riesgo respecto a la realidad. La teoría necesita expresarse de tal manera que sea posible que la realidad contradiga lo que se está afirmando. Si una teoría no puede ser contradicha, no es que sea verdadera o falsa; está fuera de discusión, al menos desde una perspectiva científica. Por lo tanto, para que una teoría se considere científica, debe asumir cierto grado de riesgo en relación con la realidad.
El segundo criterio es que el nivel de credibilidad o confianza que podemos depositar en una teoría debería ser, en cierta medida (y aquí estoy simplificando), proporcional a la cantidad de trabajo que los propios científicos han invertido en tratar de refutarla. La característica científica de una teoría es que asume un gran riesgo, y muchas personas intentan explotar esas debilidades para refutarla. Si han fallado una y otra vez, entonces podemos otorgar cierta credibilidad a la teoría.
Esta perspectiva muestra que existe una asimetría profunda entre lo que es verdadero y lo que es falso. Las teorías científicas modernas nunca deben considerarse como verdaderas o probadas, sino simplemente como pendientes. El hecho de que muchas personas hayan intentado refutarlas sin éxito aumenta la credibilidad que podemos otorgarles. Esta perspectiva es de importancia crítica para el mundo de supply chain, y en particular, esta noción de falsabilidad ha impulsado muchos de los desarrollos más sorprendentes en la ciencia, especialmente en lo que respecta a la física moderna.
Hasta ahora, esta es la tercera conferencia del segundo capítulo de esta serie sobre supply chain. En el primer capítulo del prólogo, presenté mis puntos de vista sobre supply chain tanto como campo de estudio como de práctica. Una de las ideas clave fue que supply chain abarca un conjunto de problemas arduos, en contraste con problemas sencillos. Estos problemas no se prestan, por diseño, a una solución directa. Por lo tanto, debemos prestar mucha atención a la metodología que debemos utilizar tanto para estudiar como para practicar supply chain. Este segundo capítulo trata sobre esas metodologías.
En la primera conferencia del segundo capítulo, propuse un método cualitativo para aportar conocimiento y, posteriormente, mejora a supply chain mediante la noción de personas de supply chain. Aquí, en esta tercera conferencia, estoy proponiendo un método cuantitativo: optimización experimental.

Cuando se trata de lograr una mejora cuantitativa en supply chains, necesitamos un modelo cuantitativo, un modelo numérico. Hay al menos dos formas de abordar esto: la manera convencional, mathematical optimization, y otra perspectiva, la optimización experimental.
El enfoque convencional para lograr mejoras cuantitativas en supply chain es la optimización matemática. Este enfoque consiste esencialmente en construir un extenso catálogo de pares problema-solución. Sin embargo, creo que este método no es muy bueno, y necesitamos otra perspectiva, que es de lo que trata la optimización experimental. Debe entenderse como la optimización de supply chains mediante una serie de experimentos.
La optimización experimental no fue inventada por Lokad. Surgió en Lokad primero como una práctica y fue conceptualizada como tal años después. Lo que presento hoy no es la forma en que gradualmente emergió en Lokad. Fue un proceso mucho más gradual y confuso. Revisé esta práctica emergente años más tarde para consolidarla en forma de una teoría que puedo presentar bajo el título de optimización experimental.

Primero, necesitamos aclarar el término optimización matemática. Tenemos que diferenciar dos cosas: la optimización matemática como un campo de investigación independiente y la optimización matemática como una perspectiva para la mejora cuantitativa de supply chain, que es el tema de interés hoy. Dejemos de lado la segunda perspectiva por un momento y aclaremos de qué se trata la optimización matemática como campo independiente de investigación.
Es un campo de investigación interesado en la clase de problemas matemáticos que se presentan como se describe en la pantalla. Esencialmente, se parte de una función que va de un conjunto arbitrario (A mayúscula) a un número real. Esta función, frecuentemente referida como la loss function, se denota por f. Buscamos la solución óptima, que será un punto x que pertenece al conjunto A y no puede mejorarse. Obviamente, este es un campo de investigación muy amplio con una gran cantidad de tecnicismos involucrados. Algunas funciones pueden no tener ningún mínimo, mientras que otras podrían tener muchos mínimos distintos. Como campo de investigación, la optimización matemática ha sido prolífica y exitosa. Existen numerosas técnicas que se han ideado y conceptos que se han introducido, los cuales han sido utilizados con gran éxito en muchos otros campos. Sin embargo, no discutiré todo eso hoy, ya que no es el objetivo de esta conferencia.
El punto que me gustaría destacar es que la optimización matemática, como ciencia auxiliar en lo que respecta a supply chain, ha gozado de un grado considerable de éxito por sí misma. A su vez, esto ha moldeado profundamente el estudio cuantitativo de supply chains, que es de lo que trata la perspectiva de optimización matemática de supply chain perspective.

Regresemos a dos libros que introduje en mi primera conferencia de supply chain. Estos dos libros representan, creo, la teoría cuantitativa dominante de supply chain, abarcando las últimas cinco décadas de publicaciones científicas y producción de software. No se trata solo de los artículos publicados, sino también del software que se ha lanzado al mercado. En lo que respecta a la optimización cuantitativa de supply chains, todo se hace y se ha hecho desde hace mucho tiempo mediante instrumentos de software.
Si observas estos libros, cada capítulo puede verse como una aplicación de la perspectiva de optimización matemática. Siempre se reduce a una formulación del problema con varios conjuntos de supuestos, seguida de la presentación de una solución. La corrección y, a veces, la optimalidad de la solución se demuestran en relación con la formulación del problema. Estos libros son, esencialmente, catálogos de pares problema-solución, presentándose como problemas de optimización matemática.
Por ejemplo, forecast se puede ver como un problema en el que se tiene una loss function, que será tu error de forecast, y un modelo con parámetros que deseas ajustar. Luego, se quiere aprender el proceso de optimización, numéricamente hablando, que te proporcione los parámetros óptimos. El mismo enfoque se aplica a una política de inventario, donde puedes formular hipótesis sobre la demanda y luego demostrar que tienes una solución que resulta ser óptima en relación con los supuestos que acabas de hacer.
Como ya comenté en la primera conferencia, tengo grandes reservas acerca de esta teoría dominante de supply chain. Los libros que mencioné no son selecciones al azar; creo que reflejan con precisión las últimas décadas de investigación en supply chain. Ahora, al observar las ideas sobre la falsabilidad tal como las introdujo Karl Popper, podemos ver más claramente cuál es el problema: ninguno de estos libros es realmente ciencia, ya que la realidad no puede refutar lo que se presenta. Esos libros son, esencialmente, completamente inmunes a las supply chains del mundo real. Cuando tienes un libro que es, esencialmente, una colección de pares problema-solución, no hay nada que refutar. Esto es una construcción puramente matemática. El hecho de que una supply chain esté haciendo esto o aquello no tiene relevancia para probar o refutar nada de lo que se presenta en esos libros. Esa es, probablemente, mi mayor preocupación con estas teorías.
Esto no es solo una cuestión de investigación que se discute aquí. Si observas lo que existe en términos de enterprise software para atender supply chains, el software que hoy existe en el mercado es, de manera dominante, un reflejo de estas publicaciones científicas. Este software no fue inventado por separado de esas publicaciones científicas; usualmente, van de la mano. La mayoría de las piezas de enterprise software que se encuentran en el mercado para abordar problemas de optimización supply chain son reflejos de cierta serie de artículos o libros, a veces escritos por las mismas personas que produjeron el software y los libros.
El hecho de que la realidad no tenga en cuenta las teorías presentadas aquí es, creo, una explicación muy plausible de por qué tan pocas de las teorías presentadas en estos libros son realmente útiles en los supply chains del mundo real. Esta es una afirmación bastante subjetiva que estoy haciendo, pero en mi carrera he tenido la oportunidad de dialogar con varios cientos de directores de supply chain. Ellos están al tanto de estas teorías, y si no son muy conocedores de ellas, tienen personas en su equipo que lo son. Muy frecuentemente, el software que utiliza la empresa ya implementa una serie de soluciones tal como se presentan en estos libros, y sin embargo, no se utilizan. La gente recurre por diversas razones a sus propias hojas de cálculo.
Así que, esto no es ignorancia. Tenemos este problema muy real, y creo que la causa raíz es literalmente que no es ciencia. No se puede falsificar ninguna de las cosas que se presentan. No es que estas teorías sean incorrectas –son matemáticamente correctas–, pero no son científicas en el sentido de que ni siquiera califican para ser ciencia.

Ahora, la pregunta sería: ¿cuál es el alcance del problema? Porque en realidad escogí dos libros, pero ¿cuál es el alcance real de esta perspectiva de optimización matemática en supply chain? Diría que el alcance de esta perspectiva es absolutamente masivo. Como evidencia anecdótica para demostrarlo, recientemente utilicé Google Scholar, un motor de búsqueda especializado proporcionado por Google que solo ofrece resultados de publicaciones científicas. Si buscas “optimal inventory” solo para el año 2020, obtendrás más de 30,000 resultados.
Este número debe tomarse con cierta cautela. Obviamente, probablemente haya numerosos duplicados en esta lista, y es muy probable que existan falsos positivos –artículos en los que tanto las palabras “inventory” como “optimal” aparecen en el título y el resumen, pero el artículo no trata sobre supply chain en absoluto. Es simplemente accidental. No obstante, una inspección superficial de los resultados sugiere de manera contundente que hablamos de varios miles de artículos publicados al año en esta área. Como línea de base, este número es muy grande, incluso comparado con campos que son absolutamente masivos, como deep learning. Deep learning es probablemente una de las teorías de la informática que disfruta del mayor grado de éxito durante las últimas dos o tres décadas. Así que, el hecho de que solo la consulta “optimal inventory” devuelva algo del orden de una quinta parte de lo que obtienes para deep learning es realmente impresionante. Optimal inventory es, obviamente, solo una fracción de lo que tratan los estudios de Supply Chain Quantitativa.
Esta consulta simple muestra que la perspectiva de optimización matemática es realmente masiva, y sostendría, aunque quizá de manera algo subjetiva, que en lo que respecta a los estudios cuantitativos de supply chain, realmente domina. Si tenemos varios miles de artículos que proporcionan políticas optimal inventory y modelos óptimos de inventory management para dirigir empresas, producidos anualmente, seguramente la mayoría de las grandes compañías deberían operar basándose en estos métodos. No estamos hablando de solo unos pocos artículos; estamos hablando de una cantidad absolutamente masiva de publicaciones.
En mi experiencia, con unos pocos cientos de datos sobre supply chain que conozco, realmente no es así. Estos métodos prácticamente no se ven por ningún lado. Existe una desconexión absolutamente sorprendente entre el estado del campo en lo que respecta a los artículos que se publican –y, por cierto, el software, ya que, nuevamente, el software es prácticamente un reflejo de lo que se publica en forma de artículos científicos– y la manera en que los supply chains operan en la realidad.

La pregunta que me surgió es: ¿con miles de artículos, hay algo bueno que encontrar? Tuve el placer de revisar cientos de artículos de Supply Chain Quantitativa, y puedo ofrecerte una serie de heurísticas que te darán casi la certeza de que el artículo no presenta ningún valor añadido en el mundo real. Estas heurísticas no son absolutamente ciertas, pero son muy precisas, con una exactitud de más del 99%. No es perfectamente exacto, pero es casi perfectamente exacto.
Entonces, ¿cómo detectamos los artículos que aportan un valor real, o, por el contrario, cómo rechazamos los artículos que no aportan ningún valor? He listado una breve serie de heurísticas. La primera es que, si el artículo hace alguna afirmación sobre cualquier tipo de optimalidad, puedes estar seguro de que el artículo no aporta ningún valor a los supply chains del mundo real. Primero, porque refleja el hecho de que los autores ni siquiera entienden, o tienen el más mínimo entendimiento, de que los supply chains son, esencialmente, un problema wicked. El hecho de decir que tienes una solución óptima de supply chain es muy similar a decir que existe un límite estricto a la ingenuidad humana. No lo creo ni por un momento. Creo que es una proposición completamente irracional. Vemos que hay un problema muy grande en la forma en que se aborda el supply chain.
Otro problema es que, cada vez que se hace una afirmación de optimalidad, lo que sigue es que invariablemente se tiene una solución que depende fuertemente de ciertas suposiciones. Puede que tengas una solución que se ha probado ser óptima según un determinado conjunto de suposiciones, pero ¿qué pasa si se violan esas suposiciones? ¿La solución seguirá siendo buena? Por el contrario, creo que si tienes una solución cuya optimalidad puedes demostrar, esa solución depende increíblemente de que las suposiciones realizadas sean, aunque sea remotamente, correctas. Si violas las suposiciones, es muy probable que la solución resultante sea absolutamente terrible, porque nunca fue diseñada para ser robusta ante nada. Las afirmaciones de optimalidad se pueden descartar prácticamente de inmediato.
La segunda cuestión son las distribuciones normales. Cada vez que ves un artículo o una pieza de software que afirma utilizar distribuciones normales, puedes estar seguro de que lo que se propone no funciona en los supply chains del mundo real. En una conferencia anterior, donde presenté principios cuantitativos para supply chain, demostraba que todas las poblaciones de interés en supply chains tienen una distribución Zipf y no están distribuidas normalmente. Las distribuciones normales no se encuentran en supply chains, y estoy absolutamente convencido de que este resultado se conoce desde hace décadas. Si encuentras artículos o piezas de software que se basan en esta suposición, es casi seguro que tienes una solución diseñada por conveniencia, para que sea más fácil escribir la demostración matemática o el software, y no porque exista algún deseo de obtener un rendimiento real. La presencia de distribuciones normales es simplemente pura pereza o, en el mejor de los casos, una señal de una profunda incomprensión de lo que tratan los supply chains. Esto puede utilizarse para rechazar esos artículos.
Luego, la estacionariedad – no existe tal cosa. Es una suposición que parece estar bien: las cosas son estacionarias, una y otra vez. Pero no lo son; es una suposición muy fuerte. Básicamente, dice que tienes algún tipo de proceso que comenzó al inicio de los tiempos y continuará hasta el final de los tiempos. Esta es una perspectiva muy irracional para los supply chains del mundo real. En los supply chains, cualquier producto fue introducido en un punto en el tiempo y cualquier producto será retirado del mercado en un punto en el tiempo. Incluso si observas productos con una vida razonablemente larga, como los que se encuentran, por ejemplo, en la industria automotriz, estos procesos no son estacionarios. Durarán quizá una década, en el mejor de los casos. La vida de interés, el lapso de tiempo de interés, es finito, por lo que la perspectiva estacionaria es simplemente incorrecta.
Otro elemento para identificar un estudio cuantitativo que no funcionará es si la propia noción de sustitución está ausente. En los supply chains del mundo real, las sustituciones están por todas partes. Si volvemos al ejemplo de supply chain que introduje hace dos semanas en una conferencia anterior, podrías observar al menos media docena de situaciones en las que las sustituciones estaban presentes –en el lado de la oferta, en el de la transformación y en el de la demanda. Si tienes un modelo en el que, conceptualmente, la sustitución ni siquiera existe, entonces tienes algo que está realmente en desacuerdo con los supply chains del mundo real.
De manera similar, la falta de globalidad o la carencia de una perspectiva holística sobre supply chain es también un indicio revelador de que algo no está bien. Si vuelvo a la conferencia anterior en la que introduje los principios cuantitativos para supply chain, afirmé que si tienes algo que se asemeja a un proceso de optimización local, no optimizarás nada; simplemente desplazarás los problemas dentro de tu supply chain. El supply chain es un sistema, una red, y por lo tanto no puedes aplicar algún tipo de optimización local esperando que realmente beneficie al supply chain en su conjunto. Esto simplemente no es el caso.
Con estas heurísticas, creo que puedes eliminar casi la mayor parte de la literatura de Supply Chain Quantitativa, lo cual es, en sí mismo, algo asombroso.

El caso es que, si lograra convencer a cada junta editorial de cada conferencia y revista de supply chain de que deberían utilizar estas heurísticas para filtrar las contribuciones de baja calidad, no funcionaría. Los autores simplemente se adaptarían y evadirían el proceso, incluso si estuviéramos añadiendo esas directrices para la publicación en revistas de supply chain. Si los analistas de mercado incluyeran esos puntos en su lista de verificación, lo que ocurriría es que los autores, tanto de artículos como de software, simplemente se adaptarían. Ofuscarían el problema, haciendo suposiciones más complicadas en las que ya no se nota que se reduce a una distribución normal o a una suposición de estacionariedad. Es solo que está redactado de manera muy opaca.
Estas heurísticas son útiles para identificar contribuciones de baja calidad, tanto en artículos como en software, pero no podemos usarlas simplemente para filtrar lo que es bueno. Necesitamos un cambio más profundo; debemos revisar todo el paradigma. En este punto, aún nos falta falsabilidad. La realidad no tiene forma de responder y, de alguna manera, refutar lo que se está presentando.

Como último elemento para cerrar esta parte de la conferencia sobre la perspectiva de optimización matemática, ¿existe alguna cualidad redentora en esta enorme producción de artículos y software? Mi respuesta, muy subjetiva, a esta pregunta es absolutamente no. Estos artículos, y he leído muchísimos artículos de Supply Chain Quantitativa, no son interesantes. Al contrario, son sumamente aburridos, incluso los mejores de ellos. Cuando observamos las ciencias auxiliares, no se encuentran pepitas de cosas realmente interesantes. Puedes mirar todos esos artículos, y he listado miles de ellos. Desde una perspectiva matemática, es muy aburrido. No se están presentando grandes ideas matemáticas. Desde una perspectiva algorítmica, es simplemente una aplicación directa de lo que se conoce desde hace mucho tiempo en el campo de los algoritmos. Lo mismo se puede decir del modelado estadístico y la metodología, que es sumamente pobre. En términos metodológicos, todo se reduce a la perspectiva de optimización matemática, donde presentas un modelo, optimizas algo, proporcionas la solución y demuestras que esta solución tiene ciertas características matemáticas respecto a la declaración del problema.
Realmente necesitamos cambiar más que superficialmente. No estoy criticando el enfoque. Existen precedentes históricos para esto. Puede sonar completamente asombroso que afirme que tenemos decenas de miles de artículos que son completamente estériles, pero eso ocurrió históricamente. Si observas la vida de Isaac Newton, uno de los padres de la física moderna, verás que pasó aproximadamente la mitad de su tiempo trabajando en física, dejando un legado masivo, y la otra mitad en alquimia. Fue un físico brillante y un alquimista muy pobre. Los registros históricos tienden a mostrar que Isaac Newton fue tan brillante, dedicado y serio en su trabajo en alquimia como lo fue en su trabajo en física. Debido a que la perspectiva alquímica estaba simplemente mal enmarcada, todo el trabajo e inteligencia que Newton aportó en esta área resultó completamente estéril, sin ningún legado del que se pueda hablar. Mi crítica no es que tengamos a miles de personas publicando cosas idiotas. La mayoría de esos autores son muy inteligentes. El problema es que el marco en sí es estéril. Ese es el punto que quiero destacar.

Ahora, pasemos al segundo enfoque de modelado que quiero presentar hoy. En los primeros años, la metodología de Lokad estaba profundamente arraigada en la perspectiva de optimización matemática. Éramos muy convencionales en este sentido, y estaba funcionando muy mal para nosotros. Una cosa que fue muy específica de Lokad, y que fue casi accidental, es que en un momento decidí que Lokad no vendería enterprise software, sino que vendería directamente decisiones de supply chain de fin de juego. Realmente me refiero a las cantidades exactas que una determinada empresa necesita comprar, las cantidades que necesita producir y cuántas unidades deben trasladarse del lugar A al lugar B –ya sea que algún precio en particular deba bajar–. Lokad estaba en el negocio de vender decisiones de supply chain de fin de juego. Debido a esta decisión semi-accidental mía, nos vimos brutalmente confrontados con nuestras propias insuficiencias. Fuimos puestos a prueba, y hubo un enfrentamiento con la realidad que fue muy brutal. Si estábamos produciendo decisiones de supply chain que resultaban ser malas, los clientes se volcarían de inmediato contra mí, gritando a todo pulmón porque Lokad no estaba entregando algo satisfactorio.
De alguna manera, la optimización experimental emergió en Lokad. No fue inventada en Lokad; fue una práctica emergente que surgió como respuesta al hecho de que estábamos bajo una inmensa presión por parte de nuestra base de clientes para hacer algo respecto a esos defectos que abundaban al principio. Tuvimos que idear algún tipo de mecanismo de supervivencia, y probamos muchas cosas, a veces casi al azar. Lo que emergió fue lo que se conoce como optimización experimental.

La optimización experimental es un método muy simple. El objetivo es producir decisiones de supply chain mediante la redacción de una receta, impulsada por software, que genere decisiones de supply chain. El método comienza de la siguiente manera: paso cero, simplemente escribes recetas que generan decisiones. Existe una gran cantidad de know-how, tecnologías y herramientas que son de interés aquí. Este no es el tema de esta conferencia; se cubrirá en gran detalle en conferencias posteriores. Entonces, paso uno, simplemente redactas una receta, y lo más probable es que no sea muy buena.
Luego entras en una práctica de iteración indefinida, donde primero vas a ejecutar la receta. Con “ejecutar” me refiero a que la receta debe ser capaz de ejecutarse en un entorno de producción. No se trata solo de tener un algoritmo en el data science lab que puedas correr. Se trata de tener una receta que posea todas las cualidades, de modo que, si decides que esas decisiones son lo suficientemente buenas para ser puestas en producción, puedas hacerlo con un solo clic. Todo el entorno debe ser de nivel producción; de eso se trata ejecutar la receta.
Lo siguiente es que necesitas identificar las decisiones insanas, lo cual se ha cubierto en una de mis conferencias anteriores sobre entrega orientada al producto para supply chain. Para aquellos de ustedes que no asistieron a esta conferencia, en resumen, queremos que las inversiones en supply chain sean capitalistas, acrecentadoras, y para lograr eso, tenemos que asegurarnos de que las personas que trabajan en esta división de supply chain no estén apagando incendios. La situación por defecto en la gran mayoría de las empresas en la actualidad es que las decisiones de supply chain son generadas por software – la mayoría de las empresas modernas ya usan extensivamente piezas de software empresarial para operar su supply chain, y todas las decisiones ya se generan mediante software. Sin embargo, una gran parte de esas decisiones son completamente insanas. Lo que hacen la mayoría de los equipos de supply chain es revisar manualmente todas esas decisiones insanas y comprometerse en esfuerzos continuos de lucha contra incendios para eliminarlas. Así, todos los esfuerzos terminan siendo consumidos por la operación de la empresa. Un día limpias todas tus excepciones, y al día siguiente regresas con un conjunto completamente nuevo de excepciones que atender, y el ciclo se repite. No puedes capitalizar; simplemente consumes el tiempo de tus expertos en supply chain. Así que la idea de Lokad es que necesitamos tratar esas decisiones insanas como defectos de software y eliminarlas por completo, para que podamos tener un proceso y una práctica capitalista de la propia supply chain.
Una vez que tenemos eso, necesitamos mejorar la instrumentación y, a su vez, mejorar la receta numérica en sí. Todo este trabajo es llevado a cabo por el Supply Chain Scientist, una noción que introduje en mi segunda conferencia del primer capítulo, “La perspectiva Supply Chain Quantitativa,” según lo visto por Lokad. La instrumentación es de suma importancia porque es a través de una mejor instrumentación que puedes entender mejor lo que está sucediendo en tu supply chain, lo que está pasando en tu receta, y cómo puedes mejorarla aún más para abordar esas decisiones insanas que siguen apareciendo.

Profundicemos por un momento en las causas fundamentales de la insania que explican esas decisiones insanas. Con frecuencia, cuando pregunto a los directores de supply chain por qué creen que sus sistemas de software empresarial que gobiernan sus operaciones de supply chain siguen produciendo esas decisiones insanas, una respuesta muy común pero equivocada que recibo es: “Oh, es solo porque tenemos malos forecast.” Creo que esta respuesta es equivocada en al menos dos aspectos. Primero, si pasas de la precisión que se puede obtener de un modelo de promedio móvil muy simplista a un modelo de machine learning de última generación, hay quizá un 20% de precisión que ganar. Así que sí, es significativo, pero no puede marcar la diferencia entre una decisión que es muy buena y una decisión que es completamente insana. Segundo, el mayor problema con los forecast es que no consideran todas las alternativas; no son probabilísticos. Pero me desvío; este sería un tema para otra conferencia.
Si volvemos a la causa raíz de la insania, creo que, aunque los errores de forecast son una preocupación, absolutamente no son la principal. Con una década de experiencia en Lokad, puedo decir que esto es, en el mejor de los casos, una preocupación secundaria. La preocupación principal, el mayor problema que genera decisiones insanas, es la semántica de datos. Recuerda que no puedes observar un supply chain directamente; no es posible. Solo puedes observar un supply chain como una reflexión a través de los registros electrónicos que recopilas mediante piezas de software empresarial. La observación que haces sobre tu supply chain es un proceso muy indirecto a través del prisma del software.
Aquí, estamos hablando de cientos de tablas relacionales y miles de campos, y la semántica de cada uno de esos campos realmente importa. Pero, ¿cómo sabes que tienes la comprensión y mentalidad correctas? La única manera de saber con certeza que realmente entiendes lo que significa una columna específica es ponerla a prueba mediante un experimento. En la optimización experimental, la prueba experimental es la generación de decisiones. Asumes que esta columna significa algo; esa es, de alguna manera, tu teoría científica. Luego generas una decisión basada en ese entendimiento, y si la decisión es buena, entonces tu comprensión es correcta. Fundamentalmente, lo único que puedes observar es si tu entendimiento conduce a decisiones insanas o no. Aquí es donde la realidad contraataca.
Esto no es un problema menor; es uno muy grande. El software empresarial es complejo, por decir lo menos, y existen bugs. El problema con la perspectiva de optimización matemática es que aborda el problema como si fuera una serie simple de suposiciones, y luego puedes implementar una solución relativamente simple y matemáticamente elegante. Pero la realidad es que tenemos capas de software empresarial sobre capas, y los problemas pueden ocurrir en todas partes. Algunos de estos problemas son muy mundanos, como copias incorrectas, enlazado incorrecto entre variables, o sistemas que deberían estar sincronizados y se desincronizan. Puede haber actualizaciones de versión para el software que crean bugs, y así sucesivamente. Estos bugs están por todas partes, y la única manera de saber si tienes bugs o no es, nuevamente, observar las decisiones. Si las decisiones resultan correctas, entonces o no hay bugs o los bugs presentes son inconsecuentes y no nos importan.
En cuanto a los impulsores económicos, surge con frecuencia otro enfoque incorrecto al hablar con los directores de supply chain. A menudo me piden que pruebe que habrá algún tipo de retorno económico para su empresa. Mi respuesta a eso es que ni siquiera conocemos aún los impulsores económicos. Mi experiencia en Lokad me ha enseñado que la única manera de saber con certeza cuáles son los impulsores económicos – y estos impulsores se utilizan para construir la función de pérdida que, a su vez, se usa para realizar la optimización real en la receta numérica – es realmente ponerlos a prueba, nuevamente, a través de la experiencia de generar decisiones y observar si esas decisiones son insanas o no. Estos impulsores económicos deben ser descubiertos y validados según la experiencia. En el mejor de los casos, solo puedes tener una intuición de lo que es correcto, pero solo la experiencia y los experimentos pueden decirte si tu entendimiento es realmente correcto.
Luego, también están todas las impracticidades. Tienes una receta numérica que genera decisiones, y esas decisiones parecen cumplir con todas las reglas que has establecido. Por ejemplo, si existen cantidades mínimas de pedido (MOQs), generas órdenes de compra que cumplen con tus MOQs. Pero ¿qué pasa si un proveedor regresa y te dice que el MOQ es algo distinto? A través de este proceso, podrías descubrir muchas impracticidades y decisiones que aparentemente son factibles pero que, cuando intentas ponerlas a prueba en el mundo real, resultan inviables. Descubres todo tipo de casos extremos y limitaciones, a veces incluso casos en los que ni habías pensado, donde el mundo contraataca y necesitas arreglarlo también.
Luego está incluso tu estrategia. Puede que pienses que tienes una estrategia general y de alto nivel para tu supply chain, ¿pero es correcta? Solo para darte una idea, tomemos a Amazon como ejemplo. Puedes decir que quieres ser customer-first. Por ejemplo, si los clientes compran algo en línea y no les gusta, deberían poder devolverlo muy fácilmente. Quieres ser muy generoso en lo que respecta a las devoluciones. Pero entonces, ¿qué pasa si tienes adversarios o malos clientes que se aprovechan del sistema? Pueden ordenar en línea un costoso smartphone de $500, recibirlo, reemplazar el smartphone genuino por uno falso que vale solo $50, y luego devolverlo. Amazon termina con falsificaciones en su inventario sin siquiera darse cuenta. Este es un problema muy real que se ha discutido en línea muchas veces.
Podrías tener una estrategia que diga que quieres ser customer-first, pero tal vez tu estrategia debería ser ser customer-first solo para clientes honestos. Así que, no se trata de todos los clientes; es una subsección de ellos. Incluso si tu estrategia es aproximadamente correcta, el diablo está en los detalles. Nuevamente, la única manera de ver si lo implicitado en tu estrategia es correcto es a través de la experimentación, donde puedes observar los detalles.

Ahora, hablemos de cómo identificamos las decisiones insanas. ¿Cómo diferenciamos entre decisiones sensatas e insanas? Con “decisión insana” me refiero a una decisión que no es sensata para tu empresa. Este es un tipo de problema que realmente requiere inteligencia humana general. No hay esperanza alguna de que puedas resolver este problema mediante un algoritmo. Puede parecer una paradoja, pero este es el tipo de problema que requiere inteligencia a nivel humano, pero no necesariamente un humano muy inteligente.
Existen muchos otros problemas similares en el mundo real. Por ejemplo, una analogía son los errores en las películas. Si le pidieras a los estudios de Hollywood un algoritmo que pueda identificar todos los errores en cualquier película, probablemente dirían que no tienen idea de cómo concebir tal algoritmo, ya que parece ser una tarea que requiere inteligencia humana. Sin embargo, si transformas el problema en uno donde solo quieres contar con personas que puedan ser entrenadas para ser muy buenas identificando errores en las películas, la tarea se vuelve mucho más sencilla. Es muy fácil concebir que puedes consolidar un manual con todos los trucos para identificar errores en las películas. No necesitas tener personas excepcionalmente inteligentes para hacer este trabajo; solo necesitas personas que sean razonablemente inteligentes y dedicadas. De eso se trata exactamente.
Entonces, ¿cómo se ve la situación desde la perspectiva de supply chain? Si queremos examinar el problema de manera concreta, fundamentalmente, vamos a buscar valores atípicos. Solo necesitamos comenzar con un ángulo. Digamos, por ejemplo, que volvemos a la persona de París que presenté hace dos semanas. Esta es una empresa de moda que opera una gran red minorista de tiendas de moda. Digamos, por ejemplo, que nos preocupa la calidad del servicio.
Comencemos con faltantes de stock. Si simplemente realizamos una consulta sobre todos los productos y todas las tiendas, veremos que tenemos miles de faltantes de stock en toda la red. Así que, realmente, eso no ayuda; tenemos miles de ellos, y la respuesta es “¿y qué?”. Tal vez no se trate solo de los faltantes de stock; lo que realmente interesa son los faltantes de stock en las tiendas principales, las tiendas que venden mucho. Ahí es donde importa, y no los faltantes de stock de cualquier producto, sino de los más vendidos. Limitemos nuestra búsqueda a los faltantes de stock que ocurren en las tiendas principales para los productos más vendidos.
Luego, podemos examinar un SKU donde el stock resulta ser cero. Pero en una inspección más detallada, veremos que tal vez al comienzo del día, el stock era en realidad de tres unidades, y la última unidad se vendió solo 30 minutos antes del cierre de la tienda. Si prestamos más atención, veremos que tres unidades serán reabastecidas al día siguiente. Así que aquí, tenemos una situación en la que vemos que hay un faltante de stock, pero ¿es realmente importante? Pues, resulta que no, porque la última unidad se vendió justo antes de cerrar la tienda en la tarde, y la cantidad se reabastecerá. Además, si observamos más a fondo, veremos que quizás no hay suficiente espacio en la tienda para colocar más de tres unidades, por lo que estamos limitados aquí.
Así que, esto no es exactamente una preocupación significativa. Tal vez deberíamos limitar la búsqueda a los faltantes de stock donde tuvimos la oportunidad de reabastecer – tienda principal, producto principal – pero no lo hicimos. Encontramos un ejemplo de dicho SKU, y luego vemos que no queda stock en el centro de distribución. Entonces, en este caso, ¿es realmente un problema? Podríamos decir que no, pero espera un minuto. No tenemos stock en el centro de distribución, pero para el mismo producto, echemos un vistazo a la red en general. ¿Aún tenemos stock en alguna parte?
Supongamos que, para este producto – producto principal, tienda principal – tenemos muchas tiendas débiles que todavía tienen mucho inventario del mismo producto, pero simplemente no lo rotan. Aquí, vemos que efectivamente tenemos un problema. La cuestión no fue que no se asignara suficiente stock a la tienda principal; el problema es que se asignó demasiado stock, probablemente durante la asignación inicial a las tiendas para la nueva colección, a tiendas muy débiles. Así, vamos paso a paso para identificar la causa raíz del problema. Podemos rastrearlo hasta un problema de calidad del servicio causado no por enviar poco stock, sino, por el contrario, por enviar demasiado, lo que termina teniendo un impacto a nivel sistémico en la calidad del servicio de esas tiendas principales.
Lo que he hecho aquí es muy diferente a la estadística, y eso es algo importante cuando buscamos decisiones “insanas”. No se desea agregar los datos; por el contrario, se quiere trabajar con datos completamente desagregados para que todos los problemas se manifiesten. Tan pronto como comienzas a agregar los datos, usualmente, esos comportamientos sutiles desaparecen. El truco suele ser empezar en el nivel más desagregado y recorrer la red para averiguar exactamente qué está pasando, no a un nivel estadístico, sino a un nivel muy básico y elemental en el que puedas comprender.
Este método también se presta muy bien a la perspectiva que introduje en la Supply Chain Quantitativa, donde digo que necesitas tener impulsores económicos. Es todo futuros posibles, todas las decisiones posibles, y luego evalúas todas las decisiones de acuerdo con los impulsores económicos. Resulta que esos impulsores económicos son muy útiles a la hora de ordenar todas esas SKUs, decisiones y eventos que ocurren en la supply chain. Puedes ordenarlos por dólares de impacto decreciente, y ese es un mecanismo muy poderoso, incluso si los impulsores económicos son parcialmente incorrectos o incompletos. Resulta ser un método muy efectivo para investigar y diagnosticar con alta productividad lo que está pasando en una determinada supply chain.
A medida que investigas decisiones “insanas” a lo largo de las iniciativas en las que implementas este método experimental de optimización, se produce un cambio gradual de decisiones verdaderamente insanas y disfuncionales a simplemente decisiones que son simplemente malas. No van a hacer estallar tu empresa, pero simplemente no son muy buenas.

Aquí es donde tenemos una divergencia profunda respecto a la perspectiva de optimización matemática para la supply chain.
Con la optimización experimental, la función de pérdida en sí misma, debido a que la optimización experimental utiliza internamente herramientas de optimización matemática, usualmente en el núcleo de las recetas numéricas que generan la decisión, tiene un componente de optimización matemática. Pero es solo un medio, no un fin, que respalda tu proceso. En lugar de pasar por la perspectiva de optimización matemática en la que planteas tu problema y luego optimizas, aquí estás desafiando repetidamente lo que incluso entiendes sobre el problema y modificando la función de pérdida en sí misma.
Para lograr un mejor entendimiento, necesitas instrumentar prácticamente todo. Necesitas instrumentar tu proceso de optimización en sí, tu receta numérica, y todo tipo de características que tienes sobre los datos con los que trabajas. Es muy interesante porque, desde una perspectiva histórica, cuando observas muchos de los mayores desarrollos científicos en los que había descubrimientos significativos por hacer, usualmente, unas pocas décadas antes de que se hicieran esos descubrimientos, se produjo un avance en términos de instrumentación. Cuando se trata de descubrir conocimiento, usualmente primero descubres una nueva forma de observar el universo, logras un avance a nivel de instrumentación, y luego realmente puedes lograr tu avance en lo que es de interés en el mundo. Esto es realmente lo que está pasando aquí. Por cierto, Galileo hizo la mayoría de sus descubrimientos porque fue la primera persona en disponer de un telescopio casero, y así descubrió las lunas de Júpiter, por ejemplo. Todas esas métricas son los instrumentos que realmente impulsan tu camino hacia adelante.

Ahora, el desafío es que, como dije, la optimización experimental es un proceso iterativo. La pregunta que es muy importante aquí es si estamos cambiando una burocracia por otra. Una de mis mayores críticas al supply chain management convencional es que terminamos con una burocracia de personas que simplemente están apagando incendios, lidiando a diario con todas esas excepciones, y su trabajo no es capitalista. Presenté la perspectiva contrastante del Supply Chain Scientist, donde se supone que su trabajo es capitalísticamente acrecentativo. Sin embargo, en realidad se reduce a qué tan productivos pueden ser los Supply Chain Scientists, y estas personas necesitan ser muy productivas.
Aquí, te ofrezco una lista corta de KPIs sobre lo que implica esta productividad. Primero, realmente quieres ser capaz de recorrer los pipelines de datos en menos de una hora, de principio a fin. Como dije, una de las causas fundamentales de la locura es la semántica de los datos. Cuando te das cuenta de que tienes un problema a nivel semántico, quieres ponerlo a prueba y necesitas volver a ejecutar todo el pipeline de datos. Tu equipo de supply chain o tu Supply Chain Scientist necesita ser capaz de hacerlo múltiples veces al día.
Cuando se trata de la receta numérica que realiza la optimización en sí, en este punto, los datos ya están preparados y consolidados, por lo que es un subconjunto de todo el pipeline de datos. Necesitarás un número muy grande de iteraciones, así que querrás ser capaz de realizar docenas de iteraciones cada día. En tiempo real sería fantástico, pero la realidad es que la optimización local en la supply chain solo desplaza los problemas. Necesitas tener una perspectiva holística, y el problema con los modelos ingenuos o triviales sobre tu supply chain es que no serán muy buenos en términos de su capacidad para abarcar todas las complejidades que se encuentran en las supply chains. Tienes una disyuntiva entre la expresividad y capacidad de la receta numérica y el tiempo que lleva actualizarla. Normalmente, el equilibrio es bueno siempre y cuando mantengas el cálculo dentro de unos pocos minutos.
Por último, y este punto también se abordó en la conferencia sobre entrega de software orientado al producto para supply chain, realmente necesitas ser capaz de poner una nueva receta en producción cada día. No es exactamente que yo recomiende hacer eso, sino que, más bien, necesitas poder hacerlo porque sucederán eventos inesperados. Puede ser una pandemia, o a veces no es tan extravagante como eso. Siempre existe la posibilidad de que un warehouse se inunde, que puedas tener un incidente de producción, o que puedas tener una gran sorpresa promotion de un competidor. Todo tipo de cosas pueden suceder y alterar tu operación, por lo que necesitas poder aplicar medidas correctivas de manera muy rápida. Eso significa que necesitas tener un entorno en el que sea posible poner en producción una nueva iteración de tu receta de supply chain cada día.

Ahora, la práctica de la optimización experimental es interesante. El enfoque de Lokad fue una práctica emergente, y se ha ido incorporando gradualmente a la práctica diaria durante una década. Durante los primeros años, tuvimos algo así como un proceso proto-optimización experimental en marcha. La principal diferencia fue que aún estábamos iterando, pero estábamos utilizando modelos matemáticos de supply chain obtenidos de la literatura de supply chain. Resultó que esos modelos son usualmente monolíticos y no se prestan al proceso iterativo que estoy describiendo con la optimización experimental. Como resultado, estábamos iterando, pero estábamos lejos de ser capaces de poner una nueva receta en producción cada día. Era más bien como si tomara varios meses desarrollar una nueva receta. Si miras el sitio web de Lokad sobre el camino que tomamos, las iteraciones sucesivas que tuvimos en nuestro forecast engine reflejaban este enfoque. Básicamente, tomaba 18 meses pasar de un forecast engine a la siguiente generación de forecast engines, con una breve serie de quizás una gran iteración por trimestre o algo así.
Eso fue lo que vino antes, y donde realmente el juego cambió fue con la introducción de paradigmas de programación. Hay una conferencia previa en mi prólogo donde introduje paradigmas de programación para supply chain. Ahora, con esta conferencia, debería quedar más claro por qué nos importan tanto esos paradigmas de programación. Son los que impulsan este método de optimización experimental. Son los paradigmas que necesitas para construir una receta numérica, donde puedas iterar de manera eficiente cada día para deshacerte de todas esas decisiones insanas y encaminarte hacia algo que realmente cree mucho valor para la supply chain.
Ahora, la optimización experimental en la práctica, bueno, mi convicción es que es algo que emergió. No fue realmente inventada en Lokad; es más bien que emergió allí, simplemente porque nos enfrentamos una y otra vez a nuestras propias insuficiencias cuando se trataba de decisiones reales de supply chain. Sospecho firmemente que otras empresas, sujetas a las mismas fuerzas, idearon sus propios procesos de optimización experimental que son solo alguna variante de lo que les he presentado hoy.
Aquí, si observas a gigantes tecnológicos como GAFA, tengo contactos allí que, sin revelar secretos comerciales, parecen insinuar que este tipo de práctica se conoce por diferentes nombres pero ya está muy presente en esos gigantes tecnológicos. Incluso se puede notar, como observador externo, por el hecho de que muchas de las herramientas open-source que publican son herramientas que realmente tienen sentido cuando comienzas a pensar en el tipo de herramientas que te gustaría tener si fueras a llevar a cabo iniciativas siguiendo este método de optimización experimental. Por ejemplo, PyTorch no es un modelo; es una meta-solución, un paradigma de programación para hacer machine learning, así que encaja dentro de este marco.
Entonces, te podrías preguntar por qué, si es tan exitoso, no se reconoce más como tal. Cuando se trata de reconocer la optimización experimental en la práctica, es complicado. Si tomas una instantánea de una empresa en un momento dado, se ve exactamente como la perspectiva de optimización matemática. Por ejemplo, si Lokad toma una instantánea de cualquiera de las empresas a las que servimos, tenemos una declaración del problema en ese momento y una solución que presentamos. Así, en ese momento, la situación se ve exactamente como la perspectiva de optimización matemática. Sin embargo, esto es solo la perspectiva estática. En cuanto comienzas a observar la dimensión temporal y las dinámicas, es radicalmente diferente.
Además, es importante notar que, aunque es un proceso iterativo, no es convergente. Esto puede ser un poco inquietante. La idea de que puedes tener un proceso iterativo que converge en algo óptimo es como decir que existe un límite fijo a la ingeniosidad humana. Creo que esta es una propuesta extravagante. Los problemas de supply chain son complejos, por lo que no hay convergencia simplemente porque siempre hay cosas que pueden cambiar radicalmente el juego. No es un problema definido de manera estrecha en el que puedas tener alguna esperanza de encontrar la solución óptima. Además, otro factor por el cual no hay convergencia en la práctica es que el mundo sigue cambiando. Tu supply chain no opera en un vacío; tus proveedores, clientes y el entorno están cambiando. Cualquier receta numérica que tuvieras en un momento dado puede empezar a producir decisiones insanas simplemente porque las condiciones del mercado han cambiado, y lo que era razonable en el pasado ya no lo es. Necesitas reajustarte para adaptarte a la situación presente. Solo mira lo que sucedió en 2020 con la pandemia; obviamente, hubo tantos cambios que algo sensato antes de la pandemia no pudo mantenerse sensato durante ella. Lo mismo volverá a suceder.
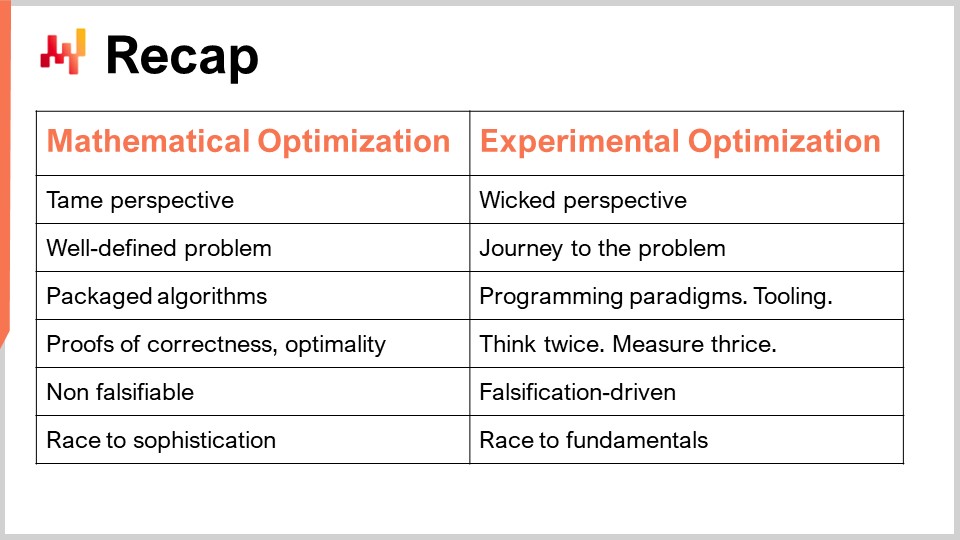
Para recapitular, tenemos dos perspectivas diferentes: la perspectiva de optimización matemática, donde tratamos con problemas bien definidos, y la perspectiva de optimización experimental, donde el problema es complejo. Ni siquiera puedes definir el problema; solo puedes avanzar hacia el problema. Como consecuencia de tener un problema bien definido dentro de la perspectiva de optimización matemática, puedes tener un algoritmo claro como solución que ofreces, y puedes empaquetarlo en un software, demostrando su corrección y optimalidad. En el mundo de la optimización experimental, sin embargo, no puedes empaquetarlo todo ya que es demasiado complejo. Lo que puedes tener son paradigmas de programación, herramientas, infraestructura, y luego se trata, todo el tiempo, de la inteligencia humana. Se trata de pensar dos veces, medir tres veces y dar un paso adelante. No hay nada que se pueda automatizar al respecto; todo se reduce a la inteligencia humana del Supply Chain Scientist.
En términos de falsabilidad, mi propuesta principal es que la perspectiva de optimización matemática no es ciencia porque no se puede falsificar nada de lo que produce. Así, al final, se termina en una carrera hacia la sofisticación: quieres modelos que sean siempre más complejos, pero no es porque sean más sofisticados que sean más científicos o creen más valor para la empresa. En marcado contraste, la optimización experimental se basa en la falsificación. Todas las iteraciones se impulsan por el hecho de que sometes tus recetas numéricas a la prueba del mundo real, generando decisiones e identificando las decisiones correctas. Esta prueba experimental se puede hacer múltiples veces al día para desafiar tu teoría y demostrar que está equivocada una y otra vez, iterando a partir de ahí, y con suerte entregando mucho valor en el proceso.
Es interesante porque, en términos del resultado final, la optimización experimental no es una carrera hacia la sofisticación; es una carrera hacia los fundamentos. Se trata de entender qué hace funcionar tu supply chain, los elementos fundamentales que rigen la supply chain, y exactamente cómo debes entender lo que está pasando dentro de tus recetas numéricas para que no sigan produciendo esas decisiones insanas que perjudican a tu supply chain. En última instancia, quieres producir algo muy bueno para tu supply chain.

Esta ha sido una conferencia larga, pero la conclusión debería ser que la optimización matemática es una ilusión. Es una ilusión seductora, sofisticada y atractiva, pero una ilusión de todos modos. La optimización experimental, en lo que a mí respecta, es el mundo real. La hemos estado utilizando durante casi una década para respaldar el proceso en empresas reales. Lokad es solo un dato, pero desde mi punto de vista, es un dato muy convincente. Realmente se trata de probar el mundo real. Por cierto, este enfoque es brutalmente duro contigo porque cuando sales al mundo real, la realidad contraataca. Tenías tus bonitas teorías acerca de qué tipo de receta numérica debía funcionar para gobernar y optimizar el supply chain, y luego la realidad contraataca. A veces puede ser increíblemente frustrante porque la realidad siempre encuentra la manera de deshacer todas las cosas ingeniosas que se te ocurran. Este proceso es mucho más frustrante, pero creo que esta es la dosis de realidad que necesitamos realmente para generar retornos reales y rentables para tus supply chains. Mi opinión es que, en el futuro, llegará un momento en el que la optimización experimental, o quizás un descendiente de este método, reemplace por completo la perspectiva de optimización matemática cuando se trate de estudios y prácticas de supply chain.

En las próximas conferencias, estaremos repasando los métodos reales, métodos numéricos y herramientas numéricas que podemos usar para respaldar esta práctica. La conferencia de hoy solo trató el método; más adelante, nos ocuparemos del know-how y las tácticas necesarias para hacerlo funcionar. La próxima conferencia será dentro de dos semanas, el mismo día y hora, y tratará sobre el conocimiento negativo en supply chain.
Ahora, permítanme echar un vistazo a las preguntas.
Pregunta: Si los artículos de supply chain no tienen ninguna posibilidad de estar conectados a la realidad, ni remotamente, y cualquier caso real estaría bajo NDA, ¿qué sugerirías a aquellos dispuestos a realizar estudios de supply chain y publicar sus hallazgos?
Mi sugerencia es que necesitas desafiar el método. Los métodos que tenemos no son adecuados para estudiar supply chain. He presentado dos vías en esta serie de conferencias: el personal de supply chain y la optimización experimental. Hay mucho por hacer basado en esas metodologías. Esas son solo dos metodologías; estoy bastante seguro de que hay muchas más que aún están por descubrirse o inventarse. Mi sugerencia sería cuestionar en el fondo lo que hace de una disciplina una ciencia de verdad.
Pregunta: Si la optimización matemática no es la mejor representación de cómo debería operar el supply chain en el mundo real, ¿por qué el método de deep learning sería mejor? ¿Acaso deep learning no toma decisiones basadas en decisiones óptimas previas?
En esta conferencia, hice una distinción clara entre la optimización matemática como un campo independiente de investigación y deep learning como un campo independiente de investigación, y la optimización matemática como una perspectiva aplicada a supply chain. No estoy criticando que la optimización matemática como campo de investigación sea inválida; todo lo contrario. En este método de optimización experimental que estoy discutiendo, en el núcleo de la receta numérica, usualmente tendrás algún tipo de algoritmo de optimización matemática. El punto es la optimización matemática como una perspectiva; esto es lo que estoy cuestionando aquí. Sé que es sutil, pero esta es una diferencia crítica que estoy señalando. Deep learning es una ciencia auxiliar. Deep learning es un campo de investigación separado, al igual que la optimización matemática es un campo de investigación separado. Ambos son grandes campos de investigación, pero son completamente independientes y distintos de los estudios de supply chain. Lo que realmente nos preocupa hoy es la mejora cuantitativa de los supply chains. De eso se trata: de métodos para lograr mejoras cuantitativas en el supply chain de manera controlada, confiable y medible. Eso es lo que está en juego aquí.
Pregunta: ¿Puede el reinforcement learning ser el enfoque correcto para la gestión de supply chain?
Primero, diría que es probablemente el enfoque correcto para la optimización de supply chain. Es una distinción que hice en una de mis conferencias anteriores: desde una perspectiva de software, tienes el lado de la gestión con Enterprise Resource Management, y luego tienes el lado de la optimización. Reinforcement learning es otro campo de investigación que también puede aprovechar elementos de deep learning y de la optimización matemática. Es el tipo de ingrediente que puedes usar en este método de optimización experimental. La parte crítica será si cuentas con los paradigmas de programación que puedan importar estas técnicas de reinforcement learning de maneras en las que puedas operar de forma muy fluida e iterativa. Ese es un gran desafío. Quieres poder iterar, y si tienes algo que sea un modelo complejo y monolítico de reinforcement learning, entonces tendrás dificultades, tal como lo hizo Lokad en los primeros años cuando tratábamos de usar este tipo de modelos monolíticos en los que nuestras iteraciones eran muy lentas. Se requirió una serie de avances técnicos para hacer de la iteración un proceso mucho más fluido.
Pregunta: ¿Es la optimización matemática un elemento integral del reinforcement learning?
Sí, reinforcement learning es un subdominio del machine learning, y el machine learning puede verse, de cierta manera, como un subdominio de la optimización matemática. Sin embargo, lo sucedido es que cuando haces eso, todo está contenido en todo, y lo que realmente diferencia a todos esos campos es que no adoptan la misma perspectiva sobre el problema. Todos esos campos están conectados, pero usualmente, lo que realmente los diferencia es la intención que tienes.
Pregunta: ¿Cómo defines una decisión insana en el contexto de los métodos de deep learning que a menudo anticipan muchas decisiones?
Una decisión insana depende de decisiones futuras. Exactamente eso demostré en el ejemplo cuando dije, “¿Es tener un faltante de stock un problema?” Bueno, no es un problema si ves que la siguiente decisión que se está a punto de tomar es un reabastecimiento. Así que, si calificaba esta situación como insana o no, en realidad dependía de una decisión que estaba a punto de tomarse. Esto complica la investigación, pero de eso se trata cuando digo que necesitas tener una instrumentación muy buena. Por ejemplo, significa que cuando investigues una situación de falta de stock, necesitas ser capaz de proyectar las decisiones futuras que estás a punto de tomar, para que puedas ver no solo los datos que tienes, sino también las decisiones que proyectas que se tomarán de acuerdo con tu receta numérica actual. Ya ves, se trata de tener una instrumentación adecuada, y de nuevo, no es una tarea fácil. Requiere de inteligencia a nivel humano; no puedes simplemente automatizarlo.
Pregunta: ¿Cómo funcionan en la práctica la optimización experimental, la identificación de lo insano y la búsqueda de soluciones? No puedo esperar a que ocurra la insania en la realidad, ¿correcto?
Absolutamente correcto. Si vuelvo al inicio de esta conferencia, mencioné a dos grupos de personas: físicos modernos y marxistas. El grupo de físicos, cuando dije que estaban haciendo ciencia de verdad, no eran pasivos, esperando a que sus teorías fueran falsificadas. Se esforzaban por diseñar experimentos increíblemente ingeniosos que tuvieran la posibilidad de refutar sus teorías. Era un mecanismo muy proactivo.
Si observas lo que Albert Einstein hizo durante la mayor parte de su vida, fue encontrar formas ingeniosas de poner a prueba las teorías de la física que había inventado, al menos en parte, mediante experimentos. Así que sí, no esperas a que ocurra la decisión insana. Por eso necesitas ser capaz de ejecutar tu receta una y otra vez e invertir tiempo en buscar la decisión insana. Obviamente, hay algunas decisiones, como aquellas con impracticidades, donde no hay esperanza: tienes que hacerlo en producción, y entonces el mundo contraatacará. Pero para la gran mayoría, las decisiones insanas pueden identificarse simplemente realizando experimentos día tras día. Pero necesitas datos, y necesitas tener el proceso real que genere las decisiones reales que podrían ponerse en producción.
Pregunta: Si una receta pudiera romperse debido a un método y/o perspectiva matemática, y si no conoces esta otra perspectiva, ¿cómo puedes descubrir que tienes un problema de perspectiva, y no de método, e impulsarte a descubrir otra perspectiva que se ajuste mejor al problema?
Ese es un problema muy grande. ¿Cómo puedes ver algo que no está ahí? Si vuelvo al ejemplo del personal de supply chain de París, una empresa de moda que opera tiendas minoristas, imaginemos por un segundo que olvidaste pensar en el efecto a largo plazo que tenías en los hábitos de tus clientes al regalar descuentos de fin de temporada. No te das cuenta de que estás creando un hábito en tu base de clientes. ¿Cómo podrías darte cuenta de ello? Este es un problema de inteligencia general. No hay una solución mágica.
Necesitas hacer una lluvia de ideas, y por cierto, la respuesta muy concreta de Lokad es que la empresa tiene su sede en París. Servimos a clientes en unos 20 países distantes, incluyendo Australia, Rusia, Estados Unidos y Canadá. ¿Por qué reuní a todos mis equipos de Supply Chain Scientist en París, aunque con la pandemia es un poco más complicado y hay mucho trabajo remoto? Pero, ¿por qué puse a todos esos Supply Chain Scientist en un solo lugar en lugar de subcontratarlos por doquier? La respuesta fue porque necesitaba que esas personas estuvieran en un mismo lugar para que pudieran hablar, hacer lluvia de ideas y generar nuevas ideas. De nuevo, esta es una solución de muy baja tecnología, pero realmente no puedo prometer algo mejor. Cuando hay algo que no puedes ver, como, por ejemplo, la necesidad de pensar en las implicaciones a largo plazo, y simplemente lo olvidaste o nunca lo consideraste, este problema puede ser muy obvio y ausente. En una de mis conferencias anteriores, di el ejemplo de la maleta. Tardaron 5,000 años en llegar a la invención de que sería una buena idea poner ruedas a las maletas. Las ruedas se inventaron hace miles de años, y la versión mejorada de la maleta se inventó décadas después de enviar gente a la luna. Ese es el tipo de cosa en el que podría haber algo obvio que no ves. No hay receta para eso; es simplemente inteligencia humana. Simplemente haces lo que tienes.
Pregunta: Las condiciones que cambian constantemente harán que la solución óptima para tu supply chain quede constantemente obsoleta, ¿verdad?
Sí y no. Desde la perspectiva de la optimización experimental, no existe algo como una solución óptima. Tienes soluciones optimizadas, pero la diferencia hace toda la diferencia. Las soluciones optimizadas están lejos de ser óptimas. Óptimo es como decir, y me repito, que hay un límite fijo a la creatividad humana. Así que, no hay nada óptimo; solo hay optimizado. Y sí, a medida que pasa cada día, el mercado se desvía de todos los experimentos que has realizado hasta ahora. La simple evolución del mundo degrada la optimización que has producido. Así es el mundo. Hay algunos días, por ejemplo, cuando ocurre una pandemia, y la desviación se acelera enormemente. De nuevo, así es el mundo. El mundo está cambiando, y por lo tanto, tu receta numérica necesita cambiar junto con él. Esto es una fuerza externa, así que sí, no hay escapatoria; la solución tendrá que ser revisada todo el tiempo.
Esa es una de las razones por las cuales Lokad está vendiendo una suscripción, y les decimos a nuestros clientes: “No, no podemos venderte un Supply Chain Scientist solo para la fase de implementación. Esto es un sinsentido. El mundo seguirá cambiando; este Supply Chain Scientist que ideó la receta numérica tendrá que estar presente hasta el fin de los tiempos o hasta que te hartes de nosotros.” Así que, esta persona podrá adaptar la receta numérica. No hay escapatoria; este es simplemente el mundo externo que sigue cambiando.
Pregunta: El camino hacia el problema, aunque correcto, vuelve locos a los altos directivos. Simplemente no pueden entender esto; piensan, “¿Cómo puedes revisar el problema múltiples veces a lo largo de la vida del proyecto?” ¿Qué analogías conocidas de la vida sugerirías para entablar esas conversaciones y demostrar que es un problema ampliamente existente?
Primero, eso es exactamente lo que dije en la última diapositiva donde puse la captura de pantalla de The Matrix. En algún momento, tienes que decidir si quieres vivir en una fantasía o en el mundo real. La dirección, espero, si la alta dirección de tu empresa es simplemente un grupo de idiotas, mi única sugerencia es que mejor vayas a otra compañía porque no estoy seguro de que esta empresa vaya a durar mucho. Pero la realidad es que, creo, los directivos no son tontos. No quieren lidiar con problemas inventados. Si eres un directivo en una gran empresa, tienes gente que se te acerca diez veces al día con un “gran problema”, que no es un problema real. La respuesta de la dirección, que es una reacción correcta, es “No hay ningún problema, simplemente sigue haciendo lo que has hecho. Lo siento, no tengo tiempo para reconstruir el mundo contigo. Esta no es la manera adecuada de abordar el problema.” Tienen razón en hacerlo porque, a través de décadas de experiencia, pueden resolverlo. Tienen mejores heurísticas que aquellos en niveles inferiores de la jerarquía.
Pero a veces existe una preocupación muy real. Por ejemplo, tu pregunta es, ¿cómo convences a la alta dirección hace dos décadas de que el ecommerce va a ser una fuerza dominante a tener en cuenta dentro de dos décadas? En algún momento, simplemente tienes que elegir tus batallas sabiamente. Si tu alta dirección no es tonta y llegas preparado a una reunión, diciendo, “Jefe, tengo este problema. No es una broma. Es una preocupación clave con millones de dólares en juego. No estoy bromeando. Son toneladas de dinero lo que estamos dejando sobre la mesa. Peor aún, sospecho que la mayoría de nuestros competidores se van a comer nuestro almuerzo si no hacemos nada. Esto no es un asunto menor; es un problema muy real. Necesito que me dediques 20 minutos de tu atención.” De nuevo, es raro en las grandes empresas que la alta dirección sea un grupo de completos idiotas. Pueden estar ocupados, pero no son idiotas.
Pregunta: ¿Cuál sería el panorama adecuado de herramientas para las empresas manufactureras: optimización experimental como la de Lokad, más ERP, más visualización? ¿Qué hay del papel de los sistemas de planificación concurrente en línea?
La gran mayoría de nuestros competidores se alinea con la perspectiva de optimización matemática en supply chain. Han definido el problema e implementado software para resolverlo. Lo que estoy diciendo es que cuando ponen el software a prueba y éste termina invariablemente produciendo toneladas de decisiones insanas, dicen, “Oh, es porque no configuraste el software correctamente.” Esto hace que el producto de software sea inmune a la prueba de la realidad. Encuentran formas de desviar la crítica en lugar de abordarla.
En Lokad, este método surgió únicamente porque éramos muy diferentes de nuestros competidores. No teníamos el lujo de tener una excusa. Como dice el refrán, “O tienes excusas o resultados, pero no puedes tener ambos.” En Lokad, no teníamos la opción de poner excusas. Estábamos entregando decisiones, y no había nada que configurar o ajustar por parte del cliente. Lokad enfrentaba frontalmente sus propias deficiencias. Hasta donde yo sé, todos nuestros competidores están firmemente anclados en la perspectiva de optimización matemática, y sufren de estar algo inmunes a la realidad. Para ser honesto, no son completamente inmunes a la realidad, pero terminan teniendo un ritmo de iteración muy lento, como el que describí para Lokad durante los primeros años. No son completamente inmunes a la realidad, pero su proceso de mejora es glacialmente lento, y el mundo sigue cambiando.
Lo que invariablemente sucede es que el software empresarial no cambia lo suficientemente rápido para mantenerse al día con el mundo en general, por lo que terminas con un software que simplemente envejece. No está realmente mejorando porque, cada año que pasa, el software mejora, pero el mundo se vuelve más extraño y diferente. El software empresarial se retrasa cada vez más en un mundo que está cada vez más desconectado de donde se originó.
Pregunta: ¿Cuál sería el panorama adecuado de herramientas para las empresas manufactureras?
El panorama adecuado es contar con herramientas de gestión de recursos empresariales que puedan manejar todos los aspectos transaccionales. Además de eso, lo realmente importante es tener una solución que esté muy integrada cuando se trata de tu receta numérica. No quieres tener una pila tecnológica para visualización, otra para optimización, otra para investigación y otra para preparación de datos. Si terminas con media docena de pilas tecnológicas para todas esas cosas, necesitarás un ejército de ingenieros de software para conectarlas todas, y acabarás con algo que es lo opuesto a ágil.
Se requiere tanta competencia en ingeniería de software que no queda espacio para la verdadera competencia en supply chain. Recuerda, ese fue el punto de mi tercera conferencia sobre la entrega de software orientada al producto. Necesitas algo que pueda operar un Supply Chain Scientist, no un ingeniero de software.
Eso es todo. Nos vemos dentro de dos semanas, el mismo día y a la misma hora, para “Conocimiento Negativo en Supply Chain.”
Referencias
- La Lógica de la Investigación Científica, Karl Popper, 1934


