00:15 Introduction
02:28 Réfrigérateur intelligent
05:28 Biais de survie
07:28 L’histoire jusqu’à présent
08:46 Sur les tabous (récapitulatif)
12:06 Heuristiques de rejet (récapitulatif)
13:34 Connaissance positive de basse qualité
15:27 Antipatterns logiciels, 1/2
20:11 Antipatterns logiciels, 2/2
25:34 Antipatterns de supply chain
27:00 Prévisions à nu
32:36 Le taux de service de 100%
37:06 L’initiation Jedi
44:31 L’horreur non euclidienne
51:45 Avocat du diable
57:35 Récapitulatif, connaissance négative pour supply chain
01:01:04 Conclusion
01:02:45 Prochaine conférence et questions du public
Description
Les antipatterns sont les stéréotypes de solutions qui semblent efficaces mais qui ne fonctionnent pas en pratique. L’étude systématique des antipatterns a été initiée à la fin des années 1990 par le domaine de l’ingénierie logicielle. Lorsque cela est applicable, les antipatterns sont supérieurs aux résultats négatifs bruts, car ils sont plus faciles à mémoriser et à analyser. La perspective des antipatterns revêt une importance primordiale pour supply chain, et doit être considérée comme l’un des piliers de sa connaissance négative.
Transcription complète

Bonjour à tous, bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter la connaissance négative en supply chain. Pour ceux d’entre vous qui regardent la conférence en direct, vous pouvez poser des questions à tout moment via le chat YouTube. Je ne lirai pas le chat pendant la conférence ; cependant, je reviendrai sur le chat à la toute fin de la conférence pour la session de questions-réponses.
Aujourd’hui, le sujet d’intérêt est ce que gagne réellement une entreprise lorsqu’elle embauche un directeur de supply chain expérimenté, avec peut-être deux ou trois décennies d’expérience. Qu’est-ce que l’entreprise recherche exactement, et pourrions-nous, dans une mesure marginale, reproduire l’acquisition de cette expérience en beaucoup moins de temps ? C’est précisément de cela qu’il s’agit dans la connaissance négative.
Lorsque nous examinons une personne très expérimentée, quelqu’un qui travaille depuis deux décennies dans un domaine, cherchons-nous vraiment à ce que cette personne reproduise des solutions, des processus ou des technologies qu’elle a mis en œuvre il y a une ou deux décennies dans d’autres entreprises ? Probablement pas. Bien que cela puisse arriver de manière marginale, je suspecte que, généralement, c’est au mieux une raison très marginale.
Lorsque vous recherchez une personne très expérimentée, l’objectif n’est pas nécessairement de reproduire les méthodes du passé. La valeur clé que vous souhaitez acquérir est d’engager quelqu’un qui sait comment éviter toutes sortes d’erreurs et qui a l’expérience nécessaire pour s’assurer qu’un grand nombre d’idées naïves et mauvaises ne seront pas mises en œuvre dans votre entreprise. Il existe un adage selon lequel en théorie, la pratique et la théorie sont identiques, mais en pratique, ce n’est pas le cas. C’est précisément le cœur de la connaissance négative.
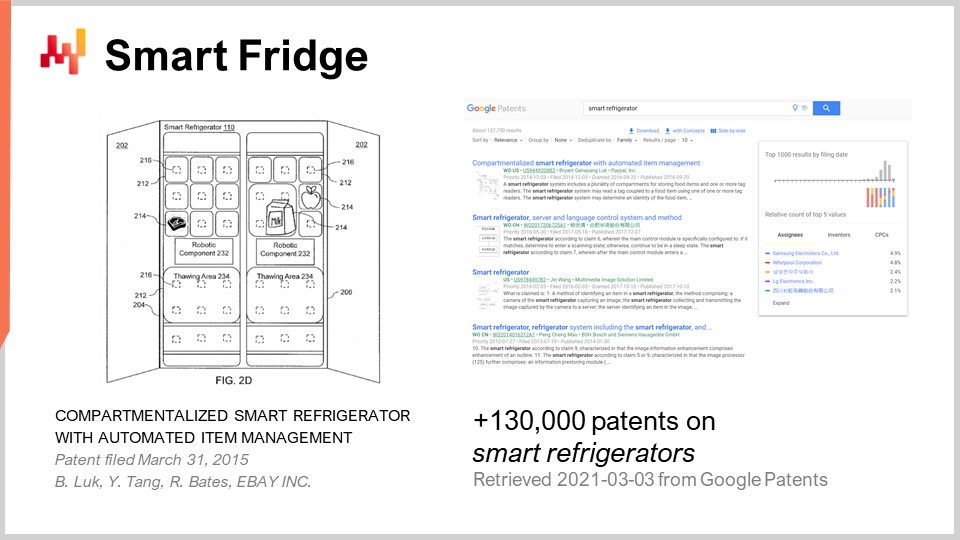
Ma proposition pour vous est que les mauvaises idées commerciales sont omniprésentes. Quand je dis mauvaises, je veux dire des idées qui, si elles étaient mises en œuvre, s’avéreraient complètement non rentables pour l’entreprise. Pour illustrer cela, j’ai simplement saisi la requête “smart refrigerators” dans le moteur de recherche Google Patents. Google Patents est un moteur de recherche spécialisé fourni par Google, et vous pouvez y rechercher dans une base de données de brevets. Et voilà, nous obtenons 130 000 résultats de brevets déposés sur des smart fridges.
Prenez ce chiffre avec précaution, car il y a probablement de nombreux doublons. Cependant, un examen rapide des résultats indique très clairement que nous avons plusieurs centaines, voire plusieurs milliers d’entreprises qui, au cours des dernières décennies, se sont donné la peine de faire de la recherche et développement pour déposer un brevet sur des réfrigérateurs intelligents. Lorsque vous regardez le type d’idées présentes dans ces brevets, vous constaterez qu’il s’agit toujours d’une combinaison consistant à prendre cet appareil très répandu, un frigo, et à y ajouter quelque chose, comme de l’électronique bon marché. Nous combinons les deux et, voilà, nous obtenons une solution d’une certaine sorte.
Mais pour quel type de problème, alors ? C’est très flou. Pour vous donner l’essentiel de la plupart des brevets, il s’agit d’une idée dans laquelle, si vous disposez d’un frigo équipé de capteurs, le frigo lui-même détectera si vous manquez de lait et passera automatiquement une commande de réapprovisionnement pour vous. Nous sommes en 2021, et à ma connaissance, les smart fridges n’existent pas. Ce n’est pas qu’ils ne soient pas techniquement réalisables – ils le sont tout à fait. C’est simplement qu’il n’existe littéralement aucun marché pour eux. Ainsi, nous avons une quantité massive de solutions sur le marché à la recherche d’un problème. Au cours des deux dernières décennies, je crois avoir été témoin, en moyenne deux fois par an, d’une startup promouvant un smart fridge d’une manière ou d’une autre. Fait intéressant, je n’ai jamais eu de retour de la part de ces startups. Je n’ai pas vraiment tenu compte, mais je suspecte fortement que chaque startup que j’ai vue promouvoir un smart fridge au cours des deux dernières décennies a échoué. Cependant, bien que l’idée soit très répandue et populaire, comme le démontrent ces milliers de brevets, les conséquences de ces idées, qui sont mauvaises car probablement la plupart de ces startups se sont tout simplement déclarées en faillite, ne se sont pas propagées.
Ici, nous voyons quelque chose de très intéressant : par l’expérience, vous pouvez accéder à une sorte de connaissance qui n’est pas facilement accessible aux observateurs du marché. Vous pouvez voir le côté obscur, c’est-à-dire les choses qui manquent, le genre de choses qui ont été promises et diffusées mais qui ne se sont pas révélées très réussies.

Il existe un exemple historique très notable tiré de la Seconde Guerre mondiale. L’armée américaine a mené une enquête sur les avions revenant à la base afin de collecter l’emplacement des impacts de balles sur les avions. Ce que vous voyez à l’écran était essentiellement la collection des emplacements des balles tels qu’observés sur les avions revenant des champs de bataille à la base. Au départ, les officiers de l’armée suivaient la logique selon laquelle ils devaient ajouter une armure dans les zones les plus touchées, les zones qui étaient manifestement sous le feu le plus intense pendant la bataille.
Puis, un autre monsieur, Abraham Wald, a rétorqué que non, c’est exactement le contraire. Le fait est que ce que vous voyez, ce sont des avions qui ont réussi à revenir à la base. Ce que vous ne voyez pas, c’est que, pour toutes les zones où vous ne voyez pas d’impacts de balles, il est fort probable que lorsqu’un impact de balle s’est produit dans cette zone, il s’est avéré létal soit pour l’avion, soit pour l’équipage, soit pour les deux. Ainsi, si vous devez ajouter de l’armure, il faut le faire précisément sur toutes les zones où vous ne voyez pas d’avions revenir à la base avec des impacts de balles. Ce sont ces zones qu’il faut protéger.
Ce qu’Abraham a souligné, c’est qu’il existait un phénomène connu sous le nom de biais de survie, où ce que vous observez, ce sont essentiellement les survivants, et non tous les avions qui n’ont pas réussi à revenir à la base. L’idée de la connaissance négative est exactement la même : vous prenez cette image photographique et son négatif, et c’est le reste qui doit réellement capter votre attention, car c’est là que se produisent les choses vraiment mauvaises. C’est, je dirais, l’essence de la connaissance négative.
Ceci est la quatrième conférence de ma série de conférences, et la première du deuxième chapitre. Dans le premier chapitre du prologue, j’ai présenté mes points de vue sur la supply chain, tant du point de vue de l’étude que de la pratique. Ce que nous avons vu, c’est que la supply chain est essentiellement un ensemble de problèmes épineux, par opposition aux problèmes bien définis. Les problèmes épineux sont très difficiles à aborder car ils ne se prêtent ni à des études faciles ni à une pratique aisée. Il y a fondamentalement quelque chose de défavorable en termes d’étude et de pratique avec ces problèmes épineux. C’est pourquoi le deuxième chapitre est dédié aux méthodologies.
Dans cette conférence, nous adoptons une approche qualitative, tout comme nous l’avons fait avec le persona de la supply chain, qui était la toute première conférence de ce chapitre. Nous approfondirons les types d’approches qualitatives que nous pouvons mettre en œuvre pour améliorer la supply chain de manière contrôlée, fiable et potentiellement mesurable à terme.

Récapitulatif : Bien que cette conférence soit dédiée à la connaissance négative, ce n’est pas la première fois dans cette série de conférences que j’aborde des éléments pouvant être qualifiés de bribes de connaissance négative. Lors de la première conférence de ce deuxième chapitre sur les personas de la supply chain, j’ai présenté mes points de vue sur les études de cas. J’ai dit que les études de cas positives, c’est-à-dire celles présentant des résultats positifs associés à une solution d’intérêt, sont associées à d’énormes conflits d’intérêts qui compromettent complètement toute confiance que nous pourrions avoir dans la validité des résultats. En revanche, j’ai affirmé que les études de cas négatives sont tout à fait acceptables, car ces conflits d’intérêts, bien qu’ils puissent être présents, sont beaucoup moins intenses.
Dans cette conférence sur les personas de la supply chain, j’ai présenté une fantastique étude de cas négative, “The Last Days of Target Canada” par Joe Castaldo, qui détaillait une défaillance épique de la supply chain ayant finalement conduit à la faillite de Target Canada. Il s’agit d’une forme de connaissance négative, où l’objet d’étude est littéralement ce qui n’a pas fonctionné, par opposition à ce que nous pouvons faire pour obtenir quelque chose qui fonctionne réellement.
Maintenant, pourrions-nous utiliser les études de cas négatives comme pratique fondatrice pour notre connaissance négative de la supply chain ? Je dirais principalement non, pour deux raisons bien distinctes. La première raison est tout simplement que les études de cas négatives sont extrêmement rares. J’estimerais, à titre de conjecture, qu’il existe en réalité plus de 100 fois plus de brevets sur des smart fridges, qui sont complètement inutiles, que d’études de cas négatives sur la supply chain. Nous avons donc un problème pratique : bien que ces études de cas négatives soient d’une importance primordiale et d’un très grand intérêt scientifique, elles se révèlent tout simplement extrêmement rares. Nous en disposons si peu qu’il est très difficile de fonder notre connaissance négative de la supply chain sur ce matériau.
Le second problème est celui de l’intelligibilité. Ces études de cas négatives, comme le fantastique article “The Last Days of Target Canada”, montrent qu’il y a des dizaines de problèmes qui se produisent simultanément, et que tous ces problèmes sont complètement imbriqués pour mener finalement à un échec épique. Le fait est que ces études de cas sont littéralement la vie réelle en action, et que ces événements sont très complexes. Il est difficile de communiquer et de raisonner sur ces études de cas parce que les détails comptent, et qu’ils sont très denses. Il y a un problème plus terre-à-terre : comment transmettre cela à un public plus large ?

Dans ma dernière conférence sur l’optimisation expérimentale, nous avons également vu un autre type de connaissance négative : les heuristiques de rejet. Il s’agissait essentiellement d’astuces simples pouvant être utilisées lorsqu’une proposition de solution quantitative est présentée comme candidat potentiel à l’amélioration de votre supply chain. Vous pouvez utiliser une série d’heuristiques ou de règles simples pour écarter des solutions qui, avec un très haut degré de certitude, ne fonctionneront tout simplement pas. Toutefois, ici nous rencontrons un problème d’évolutivité. Ces heuristiques ne fonctionnent que parce qu’elles sont obscures. Si elles devenaient bien connues dans les cercles de la supply chain, tant les articles scientifiques que les supply chain software s’adapteraient et modifieraient leur discours, rendant la situation plus confuse. Ces heuristiques sont très efficaces, mais si elles devenaient populaires, elles conserveraient leur validité tout en perdant leur efficacité en tant que filtres, simplement parce que les gens feraient attention à contourner ces heuristiques.
C’est pourquoi ces heuristiques, bien que très intéressantes, ne peuvent pas être utilisées comme fondement de la connaissance négative que nous souhaitons constituer pour la supply chain.

De plus, nous ne devons pas confondre la connaissance négative avec la connaissance positive de basse qualité. La différence tient vraiment à l’intention. Par exemple, l’intention des safety stocks est de donner aux entreprises un moyen contrôlé d’assurer la qualité de service qu’elles obtiendront. L’intention est positive ; il s’agit d’une solution destinée à fonctionner. Or, la réalité est que le modèle de safety stock repose sur des hypothèses complètement abusives : la future demand et les lead times sont supposés suivre une distribution normale, bien que ces hypothèses soient factuellement erronées. Je n’ai jamais observé de jeux de données supply chain où la demande ou les lead times étaient distribués normalement. Les distributions d’intérêt sont en réalité distribuées selon Zipf, comme je l’ai abordé dans mes conférences précédentes sur les principes quantitatifs de la supply chain. D’un point de vue juste, le safety stock est infirmé, mais néanmoins, il reste définitivement ancré dans le domaine de la connaissance positive, bien qu’on puisse dire qu’il s’agit d’une connaissance positive de très basse qualité.
Au cours de cette conférence, nous n’aurons pas le temps d’approfondir tous les éléments qui, de mon point de vue, pourraient être qualifiés de connaissance positive de très basse qualité, mais je serais ravi de répondre aux questions de ceux qui souhaiteraient m’interroger sur l’un de ces éléments lors de la session de questions-réponses.

Lorsqu’il s’agit de connaissances négatives d’intérêt pratique, il existe un livre intitulé “Anti-Patterns: Refactoring Software, Architectures, and Projects in Crisis” qui est une référence dans l’histoire de l’ingénierie logicielle. Publié en 1998, ce livre commence par une observation anodine selon laquelle, dans l’industrie du logiciel, lorsque de bonnes idées existent et que des projets en tirent parti, les éditeurs de logiciels voient ces bonnes idées être éclipsées par le succès du projet. Les auteurs se demandent si une bonne idée reste une bonne pratique une fois le produit mis en œuvre, et la réponse est essentiellement non. Il existe un avantage du premier arrivé, très spécifique à l’industrie du logiciel, et par conséquent, nous avons un problème. Presque toute série de règles que vous pourriez utiliser pour prédire le succès de quoi que ce soit dans l’industrie du logiciel se retourne contre vous, parce que les meilleures approches ont tendance à être absorbées par le succès qu’elles génèrent. Les auteurs d’“Anti-Patterns” ont constaté qu’il est presque impossible, de leur point de vue, de garantir le succès d’une initiative logicielle. Cependant, ils ont également remarqué que la situation est très asymétrique en ce qui concerne les échecs. Ils ont relevé qu’il est possible de prédire, avec un très haut degré de confiance (parfois frôlant la certitude), qu’un projet donné est sur le point d’échouer. C’est très intéressant car on ne peut pas garantir le succès, mais on peut disposer en quelque sorte d’une science qui garantit l’échec. Mieux encore, cette connaissance des éléments garantissant l’échec apparaît comme extrêmement stable dans le temps et très indépendante des aspects techniques de l’entreprise ou du secteur considéré.
Si nous revenons à l’idée initiale du frigo intelligent, nous pouvons constater que tous ces brevets relatifs au frigo intelligent offrent des solutions incroyablement diverses. Mais il s’avère que tous ces brevets mènent à des échecs commerciaux car ils relèvent tous du même concept : une solution à la recherche d’un problème. L’association d’un appareil électroménager omniprésent avec des composants électroniques bon marché crée une solution, mais est-ce réellement pertinent ? Dans ce cas, presque jamais.
Les auteurs d’“Anti-Patterns” ont entamé leur parcours en étudiant les causes profondes des échecs logiciels et ont identifié les sept péchés capitaux de l’ingénierie logicielle, à savoir la précipitation, l’apathie, l’étroitesse d’esprit, l’avidité, l’ignorance, la fierté et l’envie. Ces problèmes sont indépendants du contexte et des technologies impliquées car ils sont des invariants de la nature humaine elle-même. Lorsqu’on recherche un directeur de supply chain avec deux décennies d’expérience, il s’agira de quelqu’un qui a simplement vécu plus longtemps et qui a intériorisé la plupart des problèmes liés à la participation d’êtres humains, avec toutes leurs imperfections.
L’idée des auteurs est qu’il est utile de formaliser ces connaissances pour les rendre plus digestes et intelligibles, afin qu’il soit plus facile de communiquer et de raisonner sur ces problèmes. C’est l’essence même des anti-patterns – un format permettant de capter des bribes de connaissances négatives.

Dans leur livre, les auteurs présentent un modèle d’anti-pattern, qui commence par un nom accrocheur facile à retenir. Il faut caractériser l’ampleur, que ce soit au niveau du code source, de l’architecture logicielle, de l’entreprise ou de l’industrie. Il s’agit d’identifier les causes profondes réelles et les conséquences qui leur sont typiquement associées. Il convient également de caractériser les forces en présence, les symptômes et les conséquences inattendues que l’on ne prévoit pas, lesquelles vont complètement compromettre les bénéfices escomptés de la solution initiale.
Les auteurs soutiennent qu’il est nécessaire de présenter des preuves anecdotiques, et c’est pourquoi ils utilisent des entreprises fictives dans leurs anti-patterns. Cela permet d’éviter les tabous liés à la discussion de véritables entreprises et de vraies personnes, ce qui pourrait empêcher l’établissement d’une communication honnête. Le modèle d’anti-pattern doit se conclure par une solution refaite, c’est-à-dire un chemin permettant de transformer ce qui est essentiellement une solution mal orientée en une variante qui fonctionne réellement dans le monde réel, où les conséquences inattendues sont atténuées et, idéalement, éliminées.
Cette conférence ne porte pas sur les anti-patterns de supply chain, mais simplement pour donner deux exemples d’anti-patterns logiciels dont vous avez peut-être entendu parler, le premier étant le Golden Hammer. Le Golden Hammer repose sur l’idée que si vous avez un marteau doré en main, tout le reste ressemble à un clou. Cet anti-pattern affirme essentiellement que si vous demandez à un programmeur Java comment il aborderait un nouveau problème, il vous proposera sans doute d’écrire un programme en Java pour le résoudre. Si vous présentez un autre problème à cette même personne, celle-ci dira que cet autre problème pourrait également être résolu avec un programme en Java. Si vous présentez 20 problèmes différents, à chaque fois la réponse sera : “Je pense qu’un programme en Java ferait l’affaire.” Il s’agit d’un biais énorme où les personnes expérimentées dans une technologie donnée ont tendance à recycler leurs connaissances techniques pour résoudre de nouveaux problèmes, au lieu de prendre le temps d’évaluer si leurs connaissances sont vraiment pertinentes pour aborder le nouveau problème. Il est bien plus simple intellectuellement de se rabattre sur ce que l’on connaît déjà.
Un autre est la Paralysie de l’Analyse. Dans le monde des logiciels, il existe de nombreuses situations où les possibilités sont infinies, et il est tentant de dire : “Au lieu de tester 20 approches différentes vouées à l’échec, réfléchissons intensément à la conception et, une fois absolument convaincus d’avoir la bonne solution en tête, nous procéderons à la mise en œuvre.” Malheureusement, cela est très difficile à exécuter et conduit généralement à une paralysie de l’analyse, où l’on consacre plus de temps et d’efforts à examiner une multitude d’options potentielles plutôt que d’essayer simplement une solution pour voir si elle fonctionne.

De toute évidence, nous avons expliqué que ce livre portait sur les anti-patterns logiciels, et je pense que l’ingénierie logicielle présente de nombreuses similitudes avec les problèmes rencontrés en supply chain, en particulier l’optimization de la supply chain. Les deux domaines sont essentiellement des ensembles de problèmes épineux, et la supply chain moderne consiste en grande partie à livrer un produit logiciel. Il existe donc un certain recoupement entre les problèmes de supply chain et ceux de l’ingénierie logicielle, mais ces deux domaines ne sont pas complètement à des années-lumière l’un de l’autre.
Ici, je vais présenter cinq anti-patterns de supply chain, que l’on peut retrouver par écrit sur le site de Lokad, avec une présentation plus détaillée disponible pour les personnes intéressées.

Le premier est Naked Forecast. Inspiré de la nouvelle “Les habits neufs de l’empereur” de Hans Christian Andersen, le contexte est celui d’une entreprise engagée dans une initiative continue pour améliorer la précision des prévisions. Parmi les symptômes, on note des prévisions historiques dont tout le monde se plaint — production, marketing, ventes, achats, et même la supply chain, la division des prévisions faisant généralement partie de la supply chain. Des tentatives ont été faites pour améliorer la précision des prévisions au cours des une ou deux dernières décennies, mais il semble que, peu importe l’effort consenti, une série interminable d’excuses est avancée par les responsables des prévisions pour justifier leur faible précision.
Le fait est qu’il existe ensuite une nouvelle initiative dont l’objectif est de redresser la précision des prévisions, de résoudre définitivement ce problème de prévisions inexactes. Voilà ce qu’on appelle l’anti-pattern Naked Forecast. Les conséquences inattendues sont, d’une part, qu’il ne fournira pas des prévisions significativement plus précises. D’autre part, se lancer dans une nouvelle initiative va simplement créer une organisation encore plus byzantine, où ce qui avait commencé comme une pratique modeste de production des prévisions se complique de plus en plus, avec davantage de personnes impliquées dans leur élaboration. Finalement, on se retrouve avec quelque chose qui demeure aussi inexact qu’auparavant, mais qui est passé d’une situation modeste et imprécise à une grande bureaucratie toujours aussi imprécise.
Je pense que la cause fondamentale ici est ce que j’appelle le rationalisme naïf ou l’illusion de la science. Lorsque cette initiative démarre, le problème se présente comme s’il était parfaitement objectif : “Nous allons produire des prévisions plus précises selon une métrique, disons l’erreur absolue moyenne.” Le tout paraît très simple, avec un problème bien défini. Cependant, le problème, c’est que tout cela est très naïf, car il n’existe aucune corrélation directe entre la précision des prévisions et la rentabilité de l’entreprise. Ce que vous devriez rechercher, ce sont des moyens d’améliorer la rentabilité de l’entreprise, c’est-à-dire penser en termes de dollars ou d’euros d’erreur, et non en pourcentages d’erreur.
Fondamentalement, la cause essentielle est que ces prévisions sont isolées et ne bénéficient d’aucun retour d’information de la réalité de l’entreprise. La précision des prévisions n’est qu’un artefact numérique ; ce n’est pas un véritable retour sur investissement tangible pour l’entreprise. À titre d’anecdote, si je recevais un chèque supplémentaire de mille dollars à chaque fois que j’avais une conversation téléphonique avec un directeur de supply chain qui me disait qu’il lançait une nouvelle initiative pour améliorer la précision des prévisions, je serais un homme encore plus riche.
La conclusion est que, en termes de solution refaite, tant que les prévisions restent nues, cela ne fonctionnera pas. Il faut les vêtir, et ces vêtements sont les décisions. Comme nous l’avons exploré dans la conférence précédente sur l’optimization expérimentale, si les prévisions ne sont pas directement liées à des décisions concrètes et tangibles — comme la quantité à acheter, la quantité à produire, ou la décision de modifier les prix — vous n’obtiendrez jamais le retour d’information réel qui compte. Ce retour réel ne se trouve pas dans l’indicateur KPI du back-test sur la mesure ; ce qui importe, ce sont ces décisions. Ainsi, en termes de solution refaite pour remédier à l’anti-pattern Naked Forecast, il s’agit essentiellement de décider que les mêmes personnes qui génèrent la prévision doivent vivre avec les conséquences de ces prévisions lorsqu’il s’agit des véritables décisions supply chain mises en œuvre.

Le deuxième anti-pattern serait le mythique Taux de Service à 100%. La situation débute typiquement ainsi : le conseil d’administration se réunit et, quelque part dans la presse ou sur les réseaux sociaux, certaines personnes se plaignent bruyamment de la qualité du service. La situation n’est pas favorable pour l’entreprise, puisqu’il semble que celle-ci ne tienne pas les promesses qu’elle avait formulées. Le conseil exerce une pression énorme sur le PDG pour qu’il fasse quelque chose face à ce problème de qualité de service, qui impacte négativement la marque, l’image et potentiellement la croissance de l’entreprise. Le PDG déclare alors : “Nous devons vraiment mettre fin à cette série interminable de problèmes de qualité de service.” Ainsi, le PDG se tourne vers le VP of Supply Chain et lui demande de mettre fin à ces problèmes. Le VP of Supply Chain, à son tour, sollicite le Supply Chain Director pour qu’il en fasse autant, et ce dernier demande au Supply Chain Manager de prendre en charge le problème. Le Supply Chain Manager règle alors le taux de service à un niveau très élevé, proche de 100%.
Et voilà, même si à court terme vous obtenez des taux de service marginalement plus élevés, très vite les problèmes de qualité de service refont surface. Ces taux de service élevés ne sont pas durables, et vous vous retrouvez avec des fluctuations de stocks, des stocks gaspillés et, bien que l’intention ait été d’augmenter le taux de service, il arrive fréquemment que celui-ci baisse six ou douze mois plus tard.
La cause profonde ici n’est pas seulement l’ignorance, mais aussi le souhait irréaliste. Mathématiquement parlant, si vous visez un taux de service à 100%, cela implique une quantité infinie de stocks, ce qui est techniquement impossible. On se berce d’illusions en pensant pouvoir résoudre pleinement ce problème, alors que cela est impossible. Dans le meilleur des cas, vous pouvez atténuer les problèmes de qualité de service, mais vous ne pourrez jamais les éliminer complètement.
À titre d’anecdote, j’ai constaté que de nombreuses entreprises rencontrent de grandes difficultés parce qu’elles adoptent cette mentalité de l’objectif mythique du taux de service à 100%. Si votre entreprise n’est pas prête à accepter que, pour certains produits (pas pour tous ni pour les plus importants), les taux de service soient volontairement abaissés, alors vous vous dirigez droit vers de gros ennuis. La seule manière d’améliorer réellement la qualité de service est d’accepter d’abord que se focaliser sur tout équivaut à ne se focaliser sur rien. Tant que vous n’accepterez pas que, pour certains SKUs, il faille avoir délibérément un taux de service inférieur comme résultat acceptable, vous ne pourrez pas améliorer votre qualité de service globale.
En termes de solutions refaites, la solution repose sur les leviers économiques. C’est un point que j’ai présenté dans la deuxième conférence du tout premier chapitre, la vision pour la Supply Chain Quantitative. Les leviers économiques montrent que vous avez le coût des rupture de stock et le coût de possession des stocks, et qu’il faut trouver un équilibre. Vous ne pouvez pas simplement viser un taux de service à 100% car c’est complètement déséquilibré d’un point de vue économique ; ce n’est pas durable. Tenter de pousser dans cette direction est très malavisé, car cela ne fera que nuire à l’entreprise. La solution consiste à injecter une dose saine de leviers économiques dans votre pratique de supply chain.

Maintenant, le troisième anti-pattern, l’Initiation Jedi, peut être observé lorsque la haute direction de nombreuses grandes entreprises subit une pression constante de la part des médias en raison du flux continu de mots à la mode. Ces mots incluent l’intelligence artificielle, la blockchain, cloud computing, le big data, l’IoT, etc. Les influenceurs leur affirment que si leur entreprise ne s’adapte pas à ces tendances, elle deviendra obsolète. Il y a une peur constante de passer à côté, qui agit comme une force puissante exerçant une pression constante sur la haute direction de la plupart des grandes entreprises qui opèrent de grandes supply chains.
Les symptômes de l’initiation Jedi peuvent être observés si votre entreprise dispose d’une division composée de jeunes ingénieurs enthousiastes arborant des mots à la mode dans leurs intitulés de poste, tels que chercheurs en intelligence artificielle, ingénieurs blockchain, ou data scientists. La devise est “maîtriser la force”, la force étant le mot à la mode du moment. La direction sélectionne, de manière discutable, des personnes jeunes ou inexpérimentées et leur demande de réaliser quelque chose de grand pour l’entreprise, tout en n’étant pas impliquée ou familière avec les aspects techniques de ces concepts.
Ce qui se passe, c’est que ces équipes créent des prototypes intéressants qui, au final, ne parviennent pas à apporter de la valeur réelle à l’entreprise. En conséquence, bien qu’elle ait commencé avec l’idée que l’entreprise serait révolutionnée selon le mot à la mode du moment, les pratiques et technologies héritées demeurent prépondérantes, inchangées par ce mot-clé ou l’équipe supplémentaire bâtie autour de lui.
En termes de preuves anecdotiques, de nos jours, en 2021, la grande majorité des entreprises disposant d’une équipe de data science n’obtiennent absolument aucun retour sur investissement. L’équipe de data science crée des prototypes Python sophistiqués en utilisant des bibliothèques open-source vraiment intéressantes, mais en termes de retour sur investissement pratique pour la grande majorité du marché, c’est exactement zéro. C’est précisément le genre d’initiation Jedi dont la direction se laisse séduire : ils lisent dans la presse que la data science est la nouvelle tendance, alors ils recrutent une équipe de data science. Pour ne citer qu’un élément anecdotique, je constate que ces équipes ne sont pas seulement assez jeunes et inexpérimentées, mais elles le restent aussi avec le temps. Cela s’explique par un taux de rotation très élevé. Vous pouvez avoir une entreprise très solide et robuste, où la durée moyenne en poste est généralement de cinq à dix ans, sauf pour l’équipe de data science, où les collaborateurs restent en moyenne 18 mois. L’une des raisons pour lesquelles rien de valeur ne sort de ces équipes est que les gens arrivent, réalisent quelques prototypes, puis s’en vont. Pour l’entreprise, il n’y a pas de capitalisation, et elle ne parvient jamais vraiment à se transformer.
En ce qui concerne la refonte de cette solution, d’abord, il n’existe pas d’autre alternative que de montrer l’exemple. Si vous voulez réellement faire de la data science, alors la haute direction doit avoir une connaissance approfondie de la data science. Par exemple, Jeff Bezos a démontré sa familiarité avec les techniques d’apprentissage automatique à la pointe de la technologie de son époque. Amazon peut connaître un grand succès grâce au machine learning, mais cela s’explique par le fait que la direction est très au fait des détails. Montrer l’exemple est essentiel.
Deuxièmement, vous devez vous assurer que lorsque vous recrutez ces ingénieurs jeunes, enthousiastes et potentiellement talentueux, vous les confrontez à des problèmes réels, et non à des méta-problèmes. Ils doivent être ancrés dans la réalité. Cela nous ramène à ma conférence précédente sur l’optimisation empirique et expérimentale. Si vous engagez un data scientist pour effectuer de la segmentation client ou une meilleure analyse ABC pour votre entreprise, il ne s’agit pas de problèmes réels. Ce ne sont que des chiffres fictifs. Si vous engagez ces personnes et les mettez en charge du réapprovisionnement effectif, en les tenant responsables des quantités exactes à réapprovisionner auprès d’une série de fournisseurs, là, c’est du très concret. C’est pour cette raison qu’il y a une décennie, Lokad est passé en interne des data scientists aux Supply Chain Scientists.

L’horreur non-euclidienne. Dans ce contexte, vous avez une entreprise qui gère une large supply chain, et le paysage IT est très complexe. Il existe plusieurs logiciels d’entreprise, tels que ERP, WMS, et EDI, qui sont complexes par eux-mêmes. Ensuite, on retrouve toute la colle qui relie ces éléments entre eux, et l’ensemble est d’une complexité stupéfiante. Alors, comment savoir que vous êtes en réalité dans une entreprise confrontée à une solution non acclimatée ? Quels en sont les symptômes ? Les symptômes résident dans le fait que chacun dans l’entreprise ressent une incompétence généralisée au sein de la division IT. Les personnes du service IT semblent dépassées et donnent l’impression de ne pas comprendre ce qui se passe dans le système qu’elles sont censées gérer et faire fonctionner. Un autre symptôme est que vous observez quotidiennement des problèmes IT ayant un impact sur la production. Ce sont là les symptômes clés de la solution non acclimatée.
La conséquence d’un paysage IT non acclimaté est que les changements à apporter à l’entreprise s’accompagnent généralement également de modifications aux systèmes IT. Les supply chains modernes reposent en grande partie sur leurs composants logiciels. Tous ces changements se produisent très lentement, et c’est toujours un processus fastidieux où même les ajustements minimes prennent une éternité. À chaque changement, il y a généralement une multitude de régressions. Comme on dit, vous avancez de deux pas et reculez de trois, puis avancez de deux pas à nouveau et reculez d’un pas. Le changement n’est pas seulement lent, il s’accompagne aussi d’un flux constant de régressions. La situation ne s’améliore pas vraiment avec le temps ; au mieux, elle stagne.
En ce qui concerne les causes profondes, la direction ne se soucie pas vraiment des détails, et la direction non-IT ne se préoccupe guère de tous ces systèmes IT. Cela conduit à une approche que j’appelle l’incrémentalisme, où, quel que soit le changement à opérer dans le système IT de l’entreprise, ces modifications seront demandées par la supply chain, par exemple. Chaque fois qu’un changement doit être effectué, la direction dira toujours : “Veuillez prendre le chemin le plus facile, celui nécessitant le moins d’efforts et de temps afin que nous puissions le mettre en œuvre le plus rapidement possible.” Voilà ce qu’est l’incrémentalisme.
Je pense que l’incrémentalisme est une cause profonde très dangereuse. Le problème avec l’incrémentalisme, c’est qu’il revient littéralement à une mort par mille coupures. Chaque modification apportée au système le rend un peu plus complexe, un peu plus ingérable et un peu plus difficile à tester. Bien que chaque changement pris individuellement soit insignifiant, lorsqu’on cumule une décennie de dizaines de modifications quotidiennes aux systèmes IT, on se retrouve avec un océan de complexité. Chaque modification a rendu le système plus complexe et l’ensemble de la vision est complètement perdue. Au bout d’une décennie, le système devient massif et convoluté, et semble tout simplement insensé.
À titre d’exemple anecdotique, vous pouvez constater qu’il existe encore de très grandes entreprises de le e-commerce où, en tant que consommateur, vous pouvez régulièrement observer des périodes d’indisponibilité. Ce genre de situation ne devrait jamais se produire. En tant qu’entreprise de le e-commerce en 2021, votre taux de disponibilité devrait se limiter à environ 10 minutes d’indisponibilité par an. Chaque seconde d’indisponibilité représente une opportunité perdue. Concevoir un logiciel de panier d’achat en 2021 n’est plus de la science-fusée ; c’est en réalité un logiciel très basique du point de vue des logiciels d’entreprise. Il n’y a aucune raison de ne pas avoir quelque chose qui soit toujours opérationnel. Cependant, la réalité est que lorsque vous constatez une panne du e-commerce, ce n’est généralement pas le panier d’achat qui échoue ; c’est une solution non acclimatée située juste derrière le e-commerce. Le fait que le e-commerce soit en panne n’est qu’un reflet d’un problème survenu quelque part dans le paysage IT.
Si nous voulons refondre la solution non acclimatée, nous devons cesser de chercher la solution la plus facile pour opérer le changement. Il faut penser non pas à une solution facile, mais à une solution simple. Une solution simple diffère de la solution facile d’une manière cruciale : elle rend l’ensemble du paysage un peu plus ordonné et plus raisonnable, facilitant ainsi l’intégration de changements ultérieurs. Vous pourriez dire, “Mais ce n’est qu’une question purement technique, donc c’est le travail de l’IT.” Je répondrais, non, absolument pas. C’est avant tout un problème de supply chain. Adopter une solution simple n’est pas qu’une question de disposer d’une solution simple du point de vue IT ; c’est d’avoir une solution simple du point de vue de la supply chain.
La simplicité de la solution, ainsi que sa conséquence escomptée de faciliter la mise en œuvre de changements ultérieurs, dépend de votre feuille de route. Quels types de changements futurs souhaitez-vous apporter à votre paysage IT ? L’IT, en tant que division, n’a pas le temps d’être expert en supply chain ni de savoir exactement où vous voulez orienter l’entreprise dans dix ans en matière d’exécution de la supply chain. C’est la gestion de la supply chain qui doit avoir cette vision et qui doit orienter le développement, potentiellement avec le soutien de l’IT, dans une direction où les changements deviennent de plus en plus faciles à implémenter au fil du temps.

Enfin, en tant que dernier anti-pattern du jour, celui de l’avocat du diable. Le contexte est généralement une grande entreprise qui a rencontré d’importants problèmes de supply chain et a décidé de choisir un grand fournisseur, en misant beaucoup d’argent. L’initiative démarre, et quelques mois plus tard, typiquement environ six mois, le fournisseur a très peu de résultats à montrer. Une grosse somme d’argent a été investie dans le fournisseur, et il y a très peu de résultats en retour. D’ailleurs, en 2021, six mois représentent beaucoup de temps. Si vous avez une initiative logicielle qui ne fournit pas de résultats tangibles et de niveau production en six mois, vous devriez être très inquiet, car d’après mon expérience, si vous ne pouvez pas livrer des résultats tangibles en six mois, il y a de fortes chances que l’initiative soit vouée à l’échec, et vous n’obtiendrez jamais de retour sur investissement positif pour l’entreprise.
Ce qui se passe, c’est que la direction constate que le projet prend du retard et qu’il y a très peu de résultats à présenter. La haute direction, au lieu de devenir de plus en plus agressive envers le fournisseur technologique et de le tenir responsable, change soudainement de camp et se montre très défensive à son égard. Cela est très déconcertant. Vous lancez une grande initiative, investissez beaucoup d’argent dans une autre entreprise, et l’initiative progresse, mais de manière médiocre et avec peu de résultats. Au lieu de reconnaître que l’initiative est en réalité en échec, la direction s’enfonce davantage et commence à défendre le fournisseur, ce qui est très étrange. C’est comme s’il se produisait une sorte de syndrome de Stockholm, où quelqu’un vous nuit, mais lorsqu’il cause suffisamment de tort, à un moment donné vous finissez par apprécier cette personne.
La direction et l’initiative elle-même deviennent trop importantes pour échouer et, par conséquent, il y a énormément d’argent gaspillé et une quantité massive d’opportunités perdues, surtout en termes de temps. Au fur et à mesure que l’initiative progresse, de l’argent est perdu, mais plus important encore, du temps est perdu – six mois, un an, deux ans. Le véritable coût, c’est le temps. Pour ne citer qu’une preuve anecdotique, on peut lire très régulièrement dans la presse des échecs épiques de mise en œuvre d’ERP pour des projets qui durent presque une décennie, voire cinq à dix ans. Vous vous demandez comment un projet peut durer cinq ans ? La réponse est que les gens continuent d’investir dans ce projet, et il faut littéralement des années pour enfin admettre que c’était un échec complet et que cela ne fonctionnera jamais.
Une autre preuve anecdotique est que, après avoir été témoin de l’intérieur de ces mises en œuvre d’ERP à l’échelle épique et sur plusieurs années, il arrive fréquemment que le projet cesse non pas parce que les gens conviennent que le fournisseur a échoué, mais parce qu’à un moment donné, la haute direction impliquée dans la décision d’engager le fournisseur passe simplement à d’autres entreprises. Lorsque presque toutes les personnes qui faisaient initialement partie de la décision de faire appel à ce grand fournisseur ont quitté l’entreprise, celles qui se sentent moins attachées à ce fournisseur conviennent collectivement de l’abandonner et de clore le projet.
En ce qui concerne une solution refondue, je pense que les entreprises doivent être plus tolérantes face à l’échec. Il faut être dur avec les problèmes mais indulgent envers les personnes. Si vous cultivez une culture où vous dites des choses comme “Nous devons faire les choses bien du premier coup”, cela est très néfaste, car cela signifie que vous n’obtiendrez pas moins d’échecs. C’est une méprise sur le fonctionnement de l’esprit humain et sur la nature humaine de penser que si vous adoptez une culture tolérant l’échec, vous aurez en réalité plus d’échecs. Certes, vous constaterez légèrement plus de petits échecs, mais ce qui se produit, c’est que les gens seront enclins à reconnaître leurs erreurs et à aller de l’avant. En revanche, si vous avez une culture du “bien faire du premier coup”, alors pratiquement personne ne peut perdre la face. Ainsi, même lorsqu’il y a quelque chose de complètement dysfonctionnel, l’instinct de survie des personnes impliquées consiste à persister dans ce qui ne fonctionne pas, simplement pour sauver leur image et, éventuellement, passer à une autre entreprise afin de ne pas affronter les conséquences de leurs erreurs.

Pour résumer, nous avons la connaissance positive face à la connaissance négative. La connaissance positive consiste essentiellement à résoudre des problèmes ; c’est une sorte d’intelligence de niveau doctorat, une intelligence de résolution de problèmes, où l’on déchiffre des énigmes et peut progresser d’une solution à une solution meilleure. Il est possible de constater qu’une solution est meilleure qu’une autre, et le summum de cette réflexion est d’atteindre une solution optimale. Cependant, ce que les gens pensent rechercher – des solutions optimales, parfaitement valides et immortelles – ce qu’ils obtiennent, ce sont des solutions très éphémères.
À titre d’exemple, tout au long de la vie de Lokad, mon entreprise, nous avons traversé six générations de moteurs de prévision. La connaissance positive est éphémère dans le sens où cette connaissance, cette solution, est menacée dès qu’une meilleure approche se présente, et vous finirez par vous en débarrasser. Chez Lokad, nous avons dû nous livrer à l’exercice fastidieux de réécrire notre propre technologie de prévision de zéro à six reprises depuis tout début en 2008. C’est pourquoi je dis que la connaissance positive est très éphémère, car elle devient rapidement obsolète dès qu’apparaissent des solutions nouvelles et meilleures.
À l’inverse, si l’on se penche sur la connaissance négative, c’est une perspective complètement différente. On pense en termes de bourdes monumentales, et l’intelligence que l’on cherche à saisir est celle de la débrouillardise, celle qui vous aide à survivre dans une rue dangereuse la nuit. L’accent n’est pas tant mis sur des énigmes ou sur des notions très complexes à comprendre et à transmettre, mais plutôt sur ce que vous ne savez pas ou sur les tabous. Il ne s’agit pas tant de ce que vous ignorez, mais de ce que les gens ne veulent pas vous dire, ou de ces choses pour lesquelles certains iront jusqu’à vous mentir simplement pour sauver la face. La connaissance négative consiste à combattre tous ces tabous qui vous empêchent de voir la réalité telle qu’elle est.
Avec la connaissance négative, l’état d’esprit n’est pas celui du progrès ; c’est un état d’esprit de survie. On veut simplement survivre pour pouvoir se battre un autre jour. C’est une perspective très différente, et c’est exactement le genre de chose que les entreprises recherchent instinctivement lorsqu’elles optent pour un supply chain director très expérimenté. Elles veulent s’assurer qu’à travers cette personne, l’entreprise survivra un jour de plus. Ce qui peut surprendre, c’est que la connaissance négative tend à être beaucoup plus durable. Ce sont en grande partie les défauts de la nature humaine en jeu, et ils ne changent pas avec le temps simplement parce qu’il existe une nouvelle technologie, approche ou méthode. Ces choses sont là pour rester.

En conclusion, je dirais que la connaissance négative revêt une importance primordiale pour tous les problèmes épineux, le supply chain n’étant que le domaine d’intérêt de cette conférence, mais ce n’est pas le seul domaine où la connaissance négative peut être appliquée.
Les supply chain anti-patterns ne sont que quelques exemples, mais je suis convaincu que des dizaines d’autres pourraient être identifiées pour saisir les problèmes qui se répètent dans les supply chains réelles. Nous ne pouvons pas espérer tout capturer à travers des anti-patterns, mais je crois que nous pouvons en couvrir une portion décente. Après avoir lu un livre sur les anti-patterns logiciels, mon opinion subjective était que j’avais acquis l’équivalent de cinq ans d’expérience en ingénierie logicielle en seulement 200 pages. Mon espoir est que, pour une collection de supply chain anti-patterns, nous puissions également reproduire cet effet, où quelqu’un pourrait acquérir l’équivalent de cinq années d’expérience en beaucoup moins de temps, peut-être en seulement quelques semaines.

C’est tout pour cette conférence. La prochaine conférence portera sur l’évaluation des fournisseurs, ce qui est un problème très intéressant. Les supply chains modernes vivent ou meurent selon les produits logiciels qui les soutiennent, et la question est de savoir comment nous raisonnons à propos de ces produits logiciels et comment nous choisissons les bons ainsi que les bons fournisseurs. Malgré mes nombreux conflits d’intérêts, c’est un problème intéressant, et la question est de savoir comment nous pouvons mettre en place une méthodologie permettant, même si toutes les personnes ont des biais, d’obtenir des résultats non biaisés grâce à la méthode.
Maintenant, je vais répondre aux questions.
Question: Qu’est-ce qui constitue une bonne prévision dans un cadre d’optimisation probabiliste, et comment mesurer la qualité ? Y a-t-il un rôle pour des enrichissements manuels ?
Une bonne prévision probabiliste comporte des métriques de précision probabiliste, mais ce n’est probablement pas ce à quoi vous vous attendez. Dans le cadre d’une initiative d’optimisation expérimentale, vous voudrez optimiser. Des métriques telles que l’entropie croisée ou la vraisemblance s’appliquent aux prévisions probabilistes. Plus important encore, il y aura des éléments que vous découvrirez progressivement en identifiant des décisions insensées. La prévision n’est qu’un moyen d’atteindre une fin, à savoir la décision. Vous devez faire attention aux décisions. Nous avons brièvement abordé ce point dans la conférence précédente sur l’optimisation expérimentale. Le processus est le même pour les prévisions classiques ou probabilistes. Si vous souhaitez avoir des exemples concrets de prévisions probabilistes, cela sera traité en détail dans les conférences suivantes. Je suis désolé de m’être quelque peu égaré en répondant à cette question.
Question: Que pensez-vous d’utiliser l’AI (Appreciative Inquiry) pour soutenir votre AI (Artificial Intelligence) ? Quelles techniques utiliserez-vous pour analyser logiquement de grands ensembles de données, et pourquoi les taux de conversion diminuent-ils malgré une bonne performance globale ? Que faut-il aborder pour remédier aux causes de cette activité ?
L’AI, en tant qu’ensemble d’algorithmes, repose actuellement principalement sur le deep learning. Le deep learning est un ensemble de techniques très performantes pour traiter des données hautement non structurées. La vraie question à se poser est comment relier cela à la réalité. Dans le supply chain, les données ont tendance à être très rares. La plupart des produits dans un magasin donné se vendent à moins d’une unité par jour. Les grands ensembles de données ne sont grands en agrégé que lorsque l’on observe une très grande entreprise avec des tonnes de transactions. Si on examine les granularités qui comptent vraiment, on ne dispose pas de tant de données.
L’Appreciative Inquiry, en termes de méthodologies, concerne en réalité l’optimisation expérimentale abordée dans la conférence précédente.
Question: Beaucoup de managers ne comprennent pas le pouvoir de la data science, et proposer des problèmes fictifs pour eux est une voie sûre. S’ils ne veulent pas se plonger dans l’apprentissage de la data science, quelle alternative existe-t-il pour leur faire croire en la data science et dans les approches orientées décision ? Comment commencer petit et déployer à grande échelle ?
Tout d’abord, si vous avez des personnes qui ne croient pas en une technologie, c’est tout à fait acceptable. Prenez Warren Buffett, par exemple. C’est un investisseur très riche qui a passé sa vie à investir dans des entreprises qu’il comprend. Il investit dans des entreprises dont les modèles commerciaux sont simplistes, comme les compagnies de transport ferroviaire ou les sociétés de location de meubles. Warren Buffett a déclaré : “Je ne suis pas intéressé par la compréhension de toutes ces technologies.” Par exemple, lorsque l’on lui demandait pourquoi il n’investissait pas dans Google, Buffett répondait : “Je ne comprends rien à ce que fait Google, donc même si cela peut être un bon investissement, je ne suis pas assez intelligent pour cela. Je vais simplement investir dans des entreprises que je comprends.”
Mon point de vue est que, pour la direction, il est complètement illusoire de se lancer dans des domaines que l’on ne comprend pas. À un certain moment, si vous n’êtes pas prêt à faire l’effort, cela ne fonctionnera tout simplement pas. C’est le Jedi anti-pattern en action – la direction n’étant pas disposée à faire le moindre effort, et pensant qu’embaucher des ingénieurs jeunes, intelligents et avisés suffira. Si tel avait été le cas, Amazon n’aurait pas connu le succès qu’il a connu. S’il était possible pour une entreprise traditionnelle retail chain d’embaucher simplement quelques ingénieurs pour lancer un site web de le e-commerce et concurrencer Amazon, elles l’auraient toutes fait. Jusqu’environ 2005, ces entreprises disposaient de capacités et de ressources en ingénierie nettement supérieures à celles d’Amazon lui-même.
Le problème est que c’est illusoire, et c’est de cela qu’il s’agit avec la connaissance négative – mettre en lumière le genre de problèmes qui se retrouvent partout. C’est pourquoi il vous faut un titre accrocheur pour communiquer le problème aux managers. Vous ne devriez pas non plus avoir peur d’apprendre de nouvelles choses. Lorsque vous retenez vraiment le bon côté des nouvelles technologies, ce n’est généralement pas si compliqué. Tout n’est pas ultra technique ; de nombreuses choses pourraient être expliquées. Par exemple, même quelque chose comme les blockchains – la moitié de ces technologies blockchain soi-disant ultra avancées pourrait être expliquée à des enfants de 10 ans. Beaucoup des idées derrière ces technologies sont en réalité assez simples. Il existe une multitude de subtilités mathématiques accidentelles, qui sont très complexes, mais ce n’est pas l’essence du problème.
Donc, ma réponse serait la suivante : si la direction souhaite croire aux contes de fées, il y a peu de choses à faire dans cette situation. Si la direction est prête à investir dans la data science, elle devrait également être disposée à investir un minimum de temps pour comprendre ce qu’est la data science. Sinon, c’est tout simplement illusoire.
C’est tout pour aujourd’hui. Merci beaucoup, et la prochaine conférence aura lieu le même jour, mercredi, dans deux semaines, à la même heure. À bientôt.
Références
- ‘‘AntiPatterns: Refactoring Software, Architectures, and Projects in Crisis’’. par William J. Brown, Raphael C. Malveau, Hays W. “Skip” McCormick, Thomas J. Mowbray, 1998


