00:00 Introduction
02:53 Décisions vs Artéfacts
10:07 Optimisation expérimentale
13:51 L’histoire jusqu’ici
17:01 Les décisions d’aujourd’hui
19:36 Le manifeste de la Supply Chain Quantitative
21:01 Le problème d’allocation de stocks de détail
24:49 Forces économiques sur le SKU du magasin
29:35 Concrétiser les futurs
32:41 Concrétisation des options - 1/3
38:25 Concrétisation des options - 2/3
43:02 Concrétisation des options - 3/3
44:44 Fonction de récompense de stocks - 1/2
51:41 Fonction de récompense de stocks - 2/2
56:19 Allocations de stocks prioritaires - 1/4
59:59 Allocations de stocks prioritaires - 2/4
01:03:39 Allocations de stocks prioritaires - 3/4
01:06:34 Allocations de stocks prioritaires - 4/4
01:12:58 Lissage du flux d’entrepôt - 1/2
01:16:48 Lissage du flux d’entrepôt - 2/2
01:22:12 Fonction de récompense d’action
01:25:02 Le monde réel est désordonné
01:27:38 Conclusion
01:30:00 Prochaine conférence et questions du public
Description
Les décisions supply chain nécessitent des évaluations économiques ajustées au risque. Convertir des prévisions probabilistes en évaluations économiques n’est pas trivial et requiert des outils dédiés. Cependant, la priorisation économique qui en résulte, illustrée par les allocations de stocks, s’avère plus puissante que les techniques traditionnelles. Nous commençons par le défi de l’allocation de stocks de détail. Dans un réseau à 2 échelons comprenant à la fois un centre de distribution (DC) et plusieurs magasins, nous devons décider comment répartir les stocks du DC entre les magasins, sachant que tous les magasins sont en concurrence pour le même stock.
Transcription complète

Bienvenue dans cette série de conférences supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter “Allocation de stocks de détail avec des prévisions probabilistes.” L’allocation de stocks de détail est un défi à la fois simple et fondamental : quand et quelle quantité de stock décidez-vous de déplacer entre les centres de distribution et les magasins que vous exploitez ? La décision de déplacer le stock dépend de la demande future, d’où le besoin d’une prévision de la demande.
Cependant, la demande de détail au niveau des magasins est incertaine, et l’incertitude de la demande future est irréductible. Il nous faut une prévision qui reflète correctement cette incertitude irréductible du futur, d’où la nécessité d’une prévision probabiliste. Pourtant, tirer pleinement parti des prévisions probabilistes afin d’optimiser supply chain est une tâche non triviale. Il serait tentant de recycler une technique de gestion des stocks existante qui a été initialement conçue pour une prévision déterministe classique. Toutefois, cela irait à l’encontre même de la raison pour laquelle nous avons introduit les prévisions probabilistes dès le départ.
Le but de cette conférence est d’apprendre à tirer le meilleur parti des prévisions probabilistes dans leur forme native pour optimiser les décisions supply chain. À titre d’exemple, nous examinerons le problème d’allocation de stocks de détail et, à travers l’étude de ce problème, nous verrons comment nous pouvons réellement optimiser le niveau de stocks au niveau des magasins. De plus, grâce à l’examen des prévisions probabilistes, nous pouvons même aborder de nouvelles catégories de problèmes supply chain, tels que le lissage du flux de stocks des centres de distribution vers les magasins, afin d’optimiser et de réduire le coût opérationnel du réseau.
Cette conférence ouvre le sixième chapitre de cette série, qui est dédié aux techniques et processus de prise de décision dans un contexte supply chain. Nous verrons que les décisions doivent être optimisées en tenant compte de l’ensemble du réseau supply chain, en tant que système intégré, plutôt que de réaliser une série d’optimisations locales isolées. Par exemple, adopter une perspective étroite du SKU (unité de gestion des stocks).
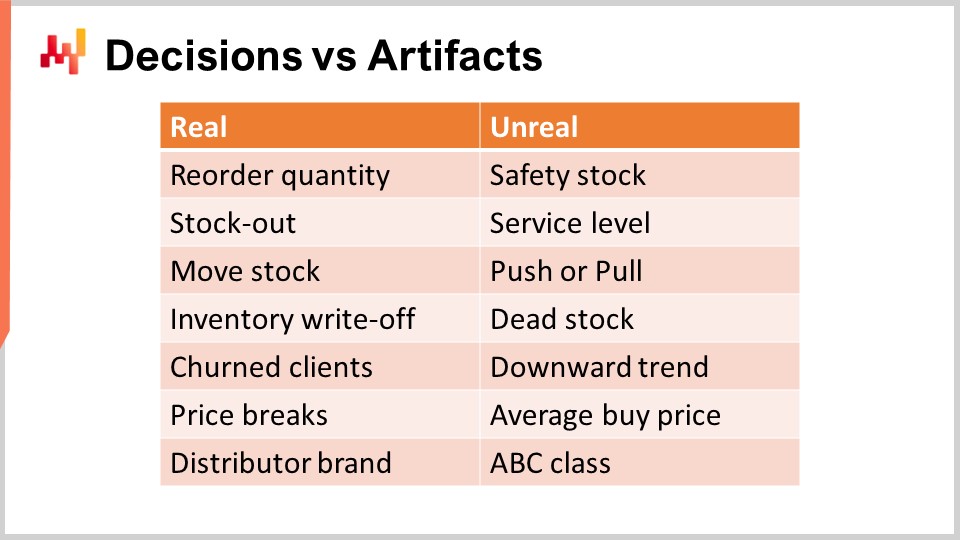
La première étape pour aborder les décisions supply chain consiste à identifier les décisions supply chain réelles. Une décision supply chain a un impact direct, physique et tangible sur la supply chain. Par exemple, déplacer une unité de stock du centre de distribution vers un magasin est tangible ; dès que vous faites cela, il y a une unité supplémentaire sur les étagères du magasin et une unité qui manque désormais au centre de distribution et qui ne peut être réaffectée ailleurs.
En revanche, un artéfact n’a pas d’impact physique tangible direct sur la supply chain. Un artéfact est typiquement soit une étape de calcul intermédiaire qui conduit finalement à une décision supply chain, soit une estimation statistique qui caractérise une propriété d’une partie de votre système supply chain. Malheureusement, je ne peux m’empêcher d’observer une grande confusion dans la littérature sur la supply chain lorsqu’il s’agit de distinguer les décisions des artéfacts.
Attention, les retours sur investissement sont exclusivement obtenus grâce à l’amélioration des décisions. Améliorer les artéfacts est presque toujours sans conséquence, et c’est pour le mieux. Au pire, si une entreprise passe trop de temps à améliorer les artéfacts, cela devient une distraction qui l’empêche d’améliorer ses décisions supply chain réelles. À l’écran se trouve une liste de confusions que j’observe fréquemment dans les cercles supply chain grand public.
Par exemple, commençons par le stock de sécurité. Ce stock n’est pas réel ; vous n’avez pas deux stocks, le stock de sécurité et le stock opérationnel. Il y a un seul stock, et la seule décision qui peut être prise est de savoir si davantage est nécessaire ou non. Le réapprovisionnement d’une quantité est réel, mais le stock de sécurité ne l’est pas. De même, le taux de service n’est pas réel non plus. Le taux de service dépend en grande partie du modèle. En effet, dans la demande de détail, les données de vente sont rares. Ainsi, si vous prenez un SKU donné, vous disposez généralement de trop peu de données pour calculer un taux de service significatif en vous contentant d’examiner le SKU. La manière d’aborder le taux de service passe par des techniques de modélisation et des estimations statistiques, ce qui est acceptable, mais encore une fois, il s’agit d’un artéfact, et non de la réalité. Il s’agit littéralement d’une perspective mathématique que vous avez sur votre supply chain.
De même, push ou pull est également une question de perspective. Une véritable recette numérique qui fonctionne, en tenant compte de l’ensemble du réseau supply chain, ne considérera que la possibilité de déplacer une unité de stock d’une origine vers une destination. Ce qui est réel, c’est le mouvement de stock ; ce qui relève seulement de la perspective, c’est de savoir si vous souhaitez déclencher ce mouvement de stock en fonction des conditions liées à l’origine ou à la destination. Cela définira le push ou le pull, mais c’est, au mieux, une subtilité technique mineure de la recette numérique et cela ne représente pas la réalité fondamentale de votre supply chain.
Le stock mort est essentiellement une estimation du stock à risque de subir une radiation de stocks dans un avenir proche. Du point de vue du client, il n’existe pas de stock mort et de stock vivant. Les deux sont des produits qui peuvent ne pas être également attractifs, mais le stock mort est simplement une évaluation du risque afférent à vos stocks. Cela convient, mais cela ne doit pas être confondu avec les radiations de stocks, qui sont définitives et indiquent qu’une valeur a été perdue.
De même, la tendance à la baisse est également un ingrédient mathématique qui peut exister dans la manière dont vous modélisez la demande observée. Elle sera généralement un facteur dépendant du temps introduit dans le modèle de demande, comme une dépendance linéaire au temps ou peut-être une dépendance exponentielle au temps. Cependant, ce n’est pas la réalité. La réalité pourrait être que votre activité diminue en raison de la perte de clients, le churn étant, entre autres possibilités, la réalité de la supply chain. La tendance à la baisse n’est qu’un artéfact que vous pouvez utiliser pour agréger le modèle.
De même, aucun fournisseur ne vous vendra quoi que ce soit au prix d’achat moyen. La seule réalité est que vous rédigez un bon de commande, sélectionnez des quantités, et selon les quantités que vous avez choisies, vous pourrez bénéficier de remises que vos fournisseurs peuvent offrir. Vous obtiendrez des prix d’achat basés sur ces remises et sur tout ce que vous négociez en sus. Le prix d’achat moyen n’est pas réel, alors faites attention à ne pas commettre d’erreurs en prenant ces artéfacts numériques comme s’ils possédaient un élément de vérité fondamentale.
Enfin, la classification ABC, qui va des meilleures ventes aux produits à rotation lente, n’est qu’une classification triviale, basée sur le volume, des SKU ou des produits que vous possédez. Ces catégories ne sont pas des attributs réels. Typiquement, la moitié des produits passera d’une classe ABC à l’autre d’un trimestre à l’autre, alors qu’il ne se passe réellement rien aux yeux des clients ou du marché pour ces produits. Il ne s’agit que d’un artéfact numérique appliqué au produit et qui ne doit pas être confondu avec des attributs profondément pertinents, tels que l’appartenance d’un produit à une marque de distributeur. C’est un véritable attribut fondamental du produit qui a des conséquences considérables pour votre supply chain. Dans ce chapitre, il devrait devenir de plus en plus évident pourquoi il est impératif de se concentrer sur les décisions supply chain, plutôt que de perdre du temps à traiter des artéfacts numériques.
Lorsque le mot “optimization” est prononcé, la perspective habituelle qui vient à l’esprit pour un public bien informé est celle de l’optimisation mathématique. Étant donné un ensemble de variables et une fonction de perte, l’objectif est d’identifier des valeurs de variables qui minimisent cette fonction de perte. Malheureusement, cette approche marche mal en supply chain car elle suppose que les variables pertinentes sont connues, ce qui n’est généralement pas le cas. Même lorsque c’est le cas, il existe de nombreuses variables, comme les données météorologiques, qui ont un impact sur votre supply chain, mais qui engendrent beaucoup de coûts si vous souhaitez acquérir ces données. Ainsi, il n’est pas évident que l’effort pour acquérir ces données en vue d’optimiser votre supply chain en vaille la peine.
Encore plus problématique, la fonction de perte elle-même est en grande partie inconnue. La fonction de perte peut être estimée d’une manière ou d’une autre, mais seule la confrontation de cette perte avec le retour d’information réel que vous pouvez obtenir de votre supply chain vous fournira des informations valides sur l’adéquation de cette fonction de perte. Il ne s’agit pas d’une question de justesse du point de vue mathématique, mais d’une question d’adéquation. Cette fonction de perte, qui est une construction mathématique, reflète-t-elle de manière adéquate ce que vous cherchez à optimiser pour votre supply chain ? Nous avons abordé cette énigme de l’optimisation alors que nous ne connaissons pas les variables et la fonction de perte dans la Conférence 2.2, intitulée “Optimisation expérimentale.” La perspective de l’optimisation expérimentale affirme que le problème n’est pas donné ; il doit être découvert par le biais d’expériences répétées et itérées. La preuve de la justesse de la fonction de perte et de ses variables émerge non pas en tant que propriété mathématique, mais à travers une série d’observations issues d’expériences bien choisies obtenues directement de la supply chain. L’optimisation expérimentale remet profondément en question notre manière d’aborder l’optimisation, et c’est la perspective que j’adopterai dans ce chapitre. Les outils et techniques que je vais présenter ici sont conçus pour l’optimisation expérimentale.
À tout moment, la recette numérique que nous possédons peut être déclarée obsolète et remplacée par une recette numérique alternative jugée plus en adéquation avec la supply chain dont nous disposons. Ainsi, à tout moment, nous devrions être capables de mettre en production la recette numérique que nous avons et d’exécuter le processus d’optimisation à grande échelle. Par exemple, nous ne pouvons pas dire que nous avons identifié la fonction de perte puis mettre une équipe de data scientists sur le dossier pendant trois mois pour concevoir des techniques d’optimisation logicielle. Au contraire, chaque fois que nous disposons d’une nouvelle recette, nous devrions être capables de la mettre directement en production et de permettre immédiatement aux décisions supply chain de bénéficier de cette nouvelle formulation du problème.
Cette conférence fait partie d’une série de conférences supply chain. J’essaie de rendre ces conférences quelque peu indépendantes, mais nous sommes arrivés à un point où il est plus judicieux de les regarder en séquence. Si vous n’avez pas regardé les conférences précédentes, cela devrait aller, mais cette série aura probablement plus de sens si vous la regardez dans l’ordre de présentation.
Dans le premier chapitre, j’ai présenté mes points de vue sur la supply chain à la fois en tant que domaine d’étude et en tant que pratique. Dans le deuxième chapitre, j’ai présenté une série de méthodologies essentielles pour relever les défis de la supply chain, y compris l’optimisation expérimentale. Ces méthodologies sont nécessaires en raison de la nature adversariale de la plupart des problèmes supply chain. Dans le troisième chapitre, je me suis concentré sur les problèmes eux-mêmes, par opposition aux solutions. Dans le quatrième chapitre, j’ai présenté une série de disciplines qui ne constituent pas exactement la supply chain à proprement parler – les sciences auxiliaires de la supply chain – essentielles à une pratique moderne de la supply chain. Dans le cinquième chapitre, j’ai présenté une série de techniques de modélisation prédictive, notamment les prévisions probabilistes, qui sont indispensables pour faire face à l’incertitude irréductible du futur.
Aujourd’hui, dans cette première conférence du sixième chapitre, nous nous plongeons dans les techniques de prise de décision. La littérature scientifique a livré une abondance de techniques de prise de décision et d’algorithmes au cours des sept dernières décennies, de la programmation dynamique dans les années 1950 à l’apprentissage par renforcement et même au deep learning par renforcement. Le défi, cependant, est d’obtenir des résultats de supply chain de niveau production. En effet, la plupart de ces techniques souffrent de défauts cachés qui les rendent impraticables pour la supply chain pour une raison ou une autre. Aujourd’hui, nous nous concentrons sur l’allocation de stocks de détail comme archétype d’une décision de supply chain. Cette conférence ouvre la voie à des décisions et des situations plus complexes.
Sur l’écran se trouve le résumé de la conférence d’aujourd’hui. Même en considérant le problème de supply chain le plus simple, l’allocation de stocks de détail, nous avons pas mal de terrain à couvrir. Ces éléments représentent des blocs de construction pour des situations plus complexes. Je commencerai par revisiter le manifeste de la Supply Chain Quantitative. Ensuite, j’expliquerai ce que j’entends par le problème d’allocation de stocks de détail. Nous passerons également en revue les forces économiques présentes dans ce problème. Je reviendrai sur la notion de prévision probabiliste et sur la manière dont nous la représentons réellement, ou du moins l’une des options pour la représenter. Nous verrons comment modéliser la décision en affinant la prévision et en affinant les options, qui sont les décisions potentielles candidates.
Nous présenterons ensuite la fonction de récompense de stocks. Cette fonction peut être considérée comme un cadre minimal pour convertir une prévision probabiliste en un score économique qui peut être associé à chaque option d’allocation de stocks, en tenant compte d’une série de facteurs économiques. Une fois que les options ont été notées, nous pouvons procéder à une liste de priorités. Une liste de priorités est d’une simplicité trompeuse mais s’avère incroyablement puissante et pratique dans les supply chain réelles, tant en termes de stabilité numérique que de caractéristiques en boîte blanche.
Avec la liste de priorités, nous pouvons presque sans effort lisser le flux de stocks du centre de distribution vers les magasins, réduisant ainsi le coût opérationnel du centre de distribution. Enfin, nous passerons brièvement en revue la fonction de récompense d’action, qui supplante de nos jours la fonction de récompense de stocks chez Lokad dans pratiquement toutes les dimensions, sauf la simplicité.
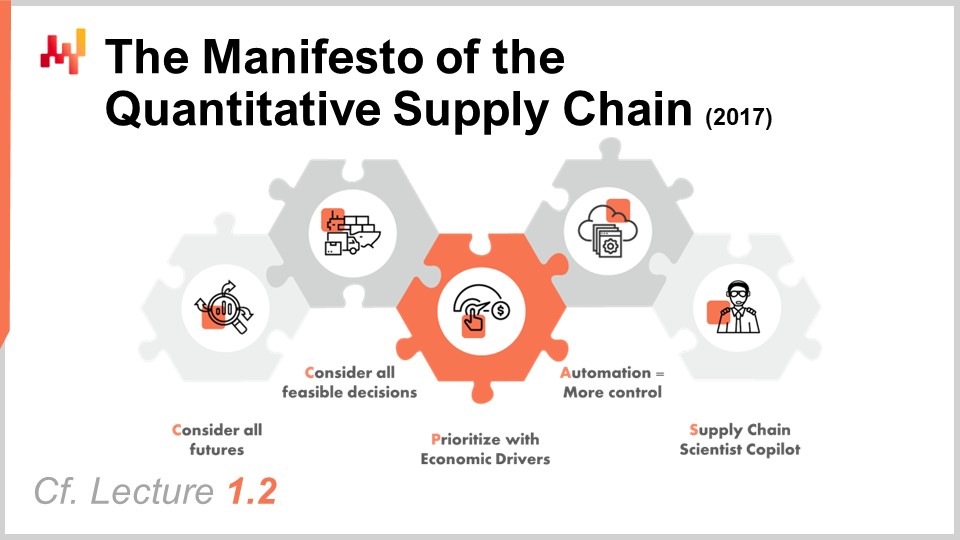
Le manifeste de la Supply Chain Quantitative est un document que j’ai publié à l’origine en 2017. Cette perspective a été largement abordée dans la Conférence 1.2, mais pour plus de clarté, je ferai un bref récapitulatif aujourd’hui. Il y a cinq piliers, mais seuls les trois premiers nous concernent aujourd’hui. Les trois premiers piliers sont :
Considérez tous les futurs possibles, ce qui signifie des prévisions probabilistes ainsi que la prévision de tous les autres éléments comportant un aspect d’incertitude, tels que des lead times variables ou des prix futurs. Considérez toutes les décisions réalisables, en vous concentrant sur les décisions et non sur les artefacts. Priorisez selon les moteurs économiques, qui est le sujet de la conférence d’aujourd’hui.
En particulier, nous verrons comment nous pouvons convertir des prévisions probabilistes en estimations des retours économiques.
Dans le problème d’allocation de stocks de détail. Il s’agit d’une définition que je donne ; elle est quelque peu arbitraire, mais c’est la définition que j’utiliserai aujourd’hui. Nous supposons un réseau à deux niveaux : nous avons un centre de distribution et plusieurs magasins. Le centre de distribution dessert tous les magasins, et s’il existe plusieurs centres de distribution, nous supposons qu’un magasin est desservi par un seul centre de distribution. L’objectif est d’allouer correctement les stocks existants dans le centre de distribution entre les magasins, et tous les magasins se disputent les mêmes stocks présents dans le centre de distribution.
Nous supposons que tous les magasins peuvent être réapprovisionnés quotidiennement avec un planning quotidien depuis le centre de distribution. Ainsi, chaque jour, nous devons décider combien d’unités déplacer pour chaque produit vers chaque magasin. La quantité totale d’unités déplacées ne peut excéder les stocks disponibles dans le centre de distribution, et il est également raisonnable de s’attendre à ce que les magasins aient des limites de capacité de rayonnage. Si le centre de distribution disposait de stocks illimités, le problème se réduirait à une supply chain à un seul niveau, car il n’y aurait jamais besoin de faire un quelconque arbitrage ou compromis entre allouer les stocks à un magasin ou à un autre. La propriété à deux niveaux du réseau n’émerge qu’en raison du fait que les magasins se disputent les mêmes stocks.
Naturellement, nous supposerons une visibilité sur les ventes des magasins et les niveaux de stocks, tant au niveau du centre de distribution que du magasin, c’est-à-dire que nous supposons que les données transactionnelles sont disponibles. Nous supposerons également que les livraisons entrantes à effectuer au centre de distribution sont connues avec des heures d’arrivée estimées (ETAs), qui peuvent comporter un certain degré d’incertitude. Nous supposons également que toutes les informations banales mais critiques sont disponibles, telles que le prix d’achat du produit, le prix de vente du produit, les catégories de produit le cas échéant, etc. Toutes ces informations se trouveraient dans n’importe quel ERP, même vieux de trois décennies, ainsi que dans les WMS et les systèmes de point de vente.
Aujourd’hui, nous n’incluons pas le réapprovisionnement du centre de distribution (DC) dans le problème. En pratique, le réapprovisionnement du centre de distribution et les allocations aux magasins sont étroitement liés, il est donc logique d’aborder ces problèmes ensemble. La raison pour laquelle je ne le fais pas aujourd’hui est pour plus de clarté et de concision dans cette conférence ; nous nous attaquerons d’abord au problème le plus simple. Toutefois, veuillez noter que l’approche que je présente aujourd’hui peut être naturellement étendue pour inclure également le réapprovisionnement du centre de distribution.

Décider de déplacer une unité supplémentaire de stocks dans un magasin pour un produit donné à un jour donné dépend d’une série de forces économiques. Si déplacer l’unité est rentable, nous voulons le faire ; sinon, nous ne le faisons pas. Les principales forces économiques sont listées à l’écran, et en substance, augmenter les stocks dans un magasin entraîne une série d’avantages. Ceux-ci incluent une gross margin plus élevée grâce à l’évitement des ventes perdues, une meilleure qualité de service en réduisant le nombre de stockouts, et une attractivité accrue du magasin.
Malheureusement, augmenter les stocks comporte également des inconvénients, diminuant le retour qui pourrait être attendu d’une augmentation des stocks dans le magasin. Ces inconvénients incluent des coûts de portage supplémentaires, qui peuvent se transformer en radiations de stocks si le stock excède réellement les besoins. Il y a aussi le risque d’une surcharge de réception, qui se produit si le personnel du magasin ne peut pas traiter une livraison trop importante. Cela crée de la confusion et du désordre dans le magasin si la quantité livrée dépasse ce que le personnel peut mettre en rayon. De plus, il y a un coût d’opportunité : chaque fois qu’une unité est placée dans un magasin, elle ne peut être affectée à un autre magasin. Bien qu’elle puisse être renvoyée au centre de distribution et réexpédiée, cela reste généralement très coûteux, c’est donc habituellement une solution de dernier recours. Les détaillants devraient viser une allocation de magasins efficace sans avoir à déplacer les stocks en retour.
Lisser le flux de stocks est également très souhaitable. Un centre de distribution (DC) a une capacité nominale à laquelle il opère avec une efficacité économique maximale. Cette efficacité maximale est dictée par l’aménagement physique du DC ainsi que par le nombre de collaborateurs permanents qui y sont attachés. Idéalement, le DC devrait fonctionner quotidiennement, en restant très proche de sa capacité nominale pour être le plus rentable possible. Cependant, maintenir une efficacité maximale au centre de distribution (DC) nécessite de lisser le flux du DC vers les magasins. La perspective économique diverge de la perspective traditionnelle orientée taux de service que l’on voit souvent dans la littérature classique de la supply chain. Nous recherchons des dollars de retour, pas des points de pourcentage. La seule manière de décider s’il est raisonnable d’ajuster le schéma d’allocation des stocks au niveau du réseau pour réduire les coûts opérationnels, par rapport à une légère dégradation du taux de service en magasin, est d’adopter la perspective économique présentée ici. Si vous adoptez une perspective orientée taux de service, elle ne peut pas fournir ce type de réponses. Notre objectif à ce stade est d’établir des recettes numériques qui estimeront les résultats économiques pour toute décision d’allocation de stocks donnée.
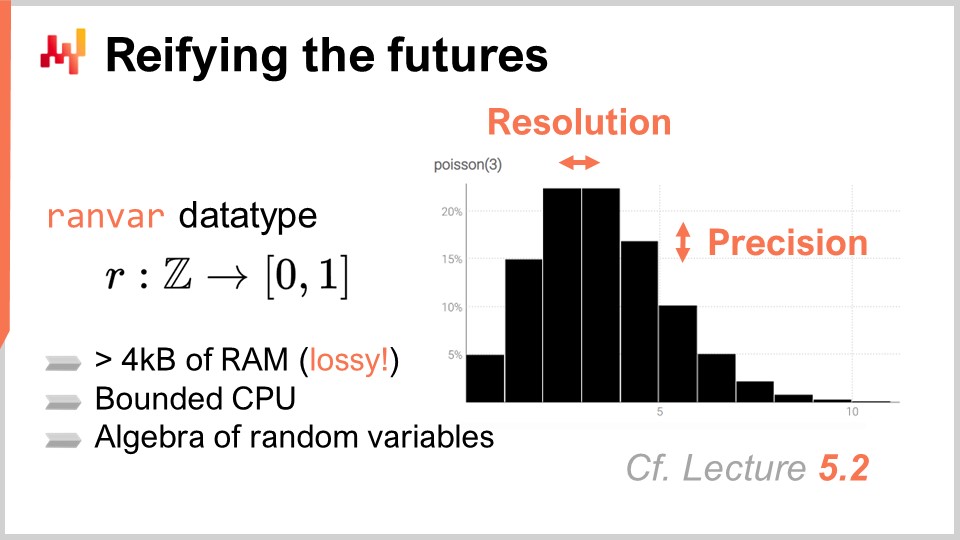
Dans le chapitre précédent, le cinquième chapitre, nous avons discuté de la manière de produire des prévisions probabilistes et introduit un type de données spécialisé, le “ranvar”, qui représente des distributions de probabilités discrètes unidimensionnelles. En bref, un ranvar est un type de données spécialisé utilisé pour représenter une prévision probabiliste unidimensionnelle simple dans Envision.
Envision est un langage de programmation spécifique au domaine, conçu par Lokad dans le seul but d’optimiser prédictivement les supply chains. Bien qu’il n’y ait rien de fondamentalement unique dans Envision dans ces conférences, il est utilisé pour la clarté et la concision de la présentation. Les recettes numériques décrites aujourd’hui peuvent être implémentées dans n’importe quel langage, tel que Python, Julia ou Visual Basic.
L’aspect clé du ranvar est qu’il fournit une algèbre à haute performance des variables aléatoires. La performance est un équilibre entre le coût de calcul, le coût mémoire et le degré d’approximation numérique que vous êtes prêt à tolérer. La performance de calcul est cruciale lorsqu’on traite des réseaux de détail, car il peut y avoir des millions voire des dizaines de millions de SKU, chacun susceptible d’avoir au moins une prévision probabiliste ou ranvar. Par conséquent, vous pouvez vous retrouver avec des millions ou des dizaines de millions d’histogrammes.
La propriété clé du ranvar par rapport à un histogramme est de maintenir à la fois le coût CPU et le coût mémoire bornés et aussi bas que possible. Il est également crucial de s’assurer que l’approximation numérique introduite reste sans incidence du point de vue de la supply chain. Il est important de noter que nous ne traitons pas ici de calcul scientifique, mais de calcul de supply chain. Bien que les calculs numériques doivent être précis, il n’est pas nécessaire d’atteindre une précision extrême. Gardez à l’esprit que nous ne faisons pas ici du calcul scientifique ; nous faisons du calcul de supply chain. Si vous avez une approximation de l’ordre d’une partie par milliard, cela est négligeable du point de vue de la supply chain. Les calculs numériques doivent être précis, mais une précision extrême n’est pas nécessaire.
Dans ce qui suit, nous supposons que la prévision probabiliste sera fournie sous la forme de ranvars, qui sont une série de variables avec un type de données spécifique. En pratique, vous pouvez remplacer les ranvars par des histogrammes et obtenir pratiquement le même résultat, à l’exception des aspects de performance et de commodité.
Maintenant que nous avons nos prévisions probabilistes, considérons comment nous aborderons les décisions. Commençons par examiner les options. Les options sont les décisions potentielles – par exemple, allouer zéro unité d’un produit donné à un magasin donné un jour donné ou allouer une, deux ou trois unités. Si nous décidons d’allouer deux unités, alors cela devient notre décision. Les options sont toutes les possibilités en attente d’être tranchées.
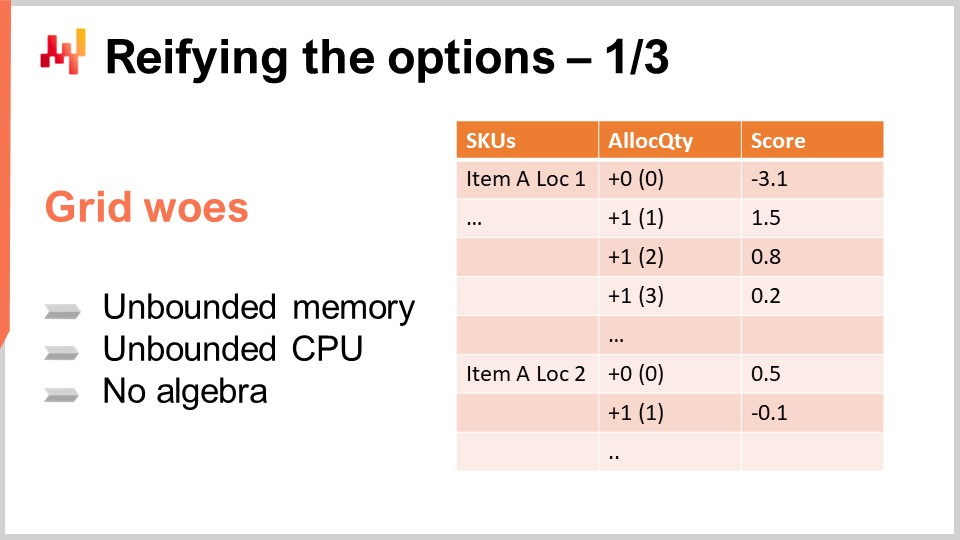
Une manière simple d’organiser ces options est de les placer dans une liste, comme affiché à l’écran. La liste couvre plusieurs SKU, et pour chaque SKU, vous ajoutez une ligne par option. Chaque option représente une quantité à allouer. Vous pouvez allouer zéro, une, deux, trois, et ainsi de suite. En réalité, vous n’avez pas besoin d’aller jusqu’à l’infini ; vous pouvez vous arrêter à la quantité en stock dans le centre de distribution. Plus réalistement, vous avez généralement une limite inférieure, comme la capacité maximale en rayonnage pour le produit dans le magasin.
Ainsi, vous avez une liste qui comprend chaque SKU, et pour chaque SKU, vous avez toutes les quantités pouvant être envisagées comme candidates pour une allocation depuis le centre de distribution. La colonne de score est associée au résultat marginal que vous pourriez attendre de cette allocation. Un score bien conçu garantit qu’en sélectionnant les lignes par ordre décroissant de score, vous optimisez le résultat économique pour le réseau de détail.
Pour les deux SKU affichés à l’écran, le score diminue à mesure que l’allocation augmente, illustrant le phénomène dominant des rendements décroissants observé pour la plupart des SKU. Essentiellement, placer la première unité dans un magasin génère presque toujours un retour supérieur à celui de la seconde. La première unité placée dans un magasin est presque toujours plus rentable que la deuxième. Au départ, vous n’avez rien, vous êtes donc en rupture de stocks. Si vous placez une unité, vous réglez déjà la rupture de stock pour le premier client. Si vous placez une seconde unité, le premier client sera assuré, mais ce n’est que si deux clients se présentent que la deuxième unité sera utile, d’où un retour économique moindre. Cependant, les rendements diminuent généralement à mesure que les stocks augmentent. Il existe quelques exceptions où les retours économiques pourraient ne pas être strictement décroissants d’une ligne à l’autre, mais je reviendrai sur ce cas dans une conférence ultérieure. Pour l’instant, nous nous en tiendrons à la situation simple où les retours diminuent strictement à mesure que les stocks augmentent.
La représentation que nous avons, où nous pouvons voir tous les SKU et options, est généralement appelée une grille. L’intention est de trier cette grille par ROI décroissant (retour sur investissement). Il n’y a rien de répréhensible dans ces grilles en soi, mais elles ne sont pas très efficaces, surtout en termes de calcul ou de mémoire, et elles n’offrent aucun support au-delà d’être un simple grand tableau. Gardez à l’esprit que nous parlons d’un réseau de détail, et cette grille pourrait finir par comporter un milliard de lignes ou plus. Le big data, c’est bien, mais le small data, c’est mieux, car cela crée moins de friction et permet plus d’agilité. Nous souhaitons transformer notre problème de big data en un problème de small data, car le small data simplifie tout en production.

Ainsi, l’une des solutions adoptées par Lokad pour gérer un grand nombre d’options est zedfuncs. Ce type de données, tout comme les ranvars, est l’équivalent du ranvar mais du point de vue de la décision. Les ranvars représentent tous les futurs possibles, tandis que les zedfuncs représentent toutes les décisions possibles. Au lieu de représenter des probabilités comme les ranvars, une zedfunc représente tous les résultats économiques associés à une série discrète unidimensionnelle d’options.
La zedfunc, ou zedfunction, est techniquement une fonction qui associe des entiers, à la fois positifs et négatifs, à des valeurs réelles. C’est la définition technique. Cependant, tout comme pour les ranvars, il n’est pas possible de représenter une fonction arbitraire ou complexe comme les zedfuncs avec une quantité finie de mémoire. Dans ce cas, il faut également faire un compromis entre précision et résolution.
Dans la gestion de la supply chain, les fonctions économiques arbitrairement complexes n’existent pas. Vous pouvez avoir des fonctions de coûts assez complexes, mais elles ne peuvent pas être arbitrairement complexes. En pratique, il est possible de compresser les zedfuncs en dessous de quatre kilo-octets. Ce faisant, vous obtenez un type de données qui représente l’intégralité de votre fonction de coûts et qui la compresse de manière à ce qu’elle reste toujours inférieure à quatre kilo-octets tout en gardant le degré d’approximation numérique sans conséquence du point de vue de la supply chain. Si vous maintenez l’approximation numérique suffisamment faible pour qu’elle ne modifie pas la décision finale que vous êtes sur le point de prendre, qui est discrète, alors on peut dire que l’approximation numérique est complètement sans conséquence puisque, en fin de compte, vous finissez par faire la même chose, même si vous disposiez d’une précision infinie.
La raison de l’utilisation de quatre kilo-octets est liée au matériel informatique. Comme nous l’avons vu dans une conférence précédente sur le matériel informatique moderne pour la gestion de la supply chain, la mémoire à accès aléatoire (RAM) d’un ordinateur moderne, qu’il s’agisse d’une station de travail, d’un ordinateur portable ou d’un ordinateur dans le cloud, ne vous permet pas d’accéder à la mémoire octet par octet. Dès que vous touchez à la RAM, un segment de quatre kilo-octets est récupéré. Par conséquent, il est préférable de maintenir la quantité de données en dessous de quatre kilo-octets car cela correspond à la manière dont le matériel est conçu et opère pour votre supply chain.
L’algorithme de compression utilisé par Lokad pour les zedfuncs diffère de celui utilisé pour les ranvars car nous ne traitons pas les mêmes problèmes numériques. Pour les ranvars, nous nous soucions principalement de préserver la masse des probabilités de nos segments contigus. Pour une zedfunc, l’objectif est différent. Nous voulons généralement préserver la quantité de variation observée d’une position à l’autre car c’est avec cette variation que nous pouvons décider s’il s’agit de la dernière option profitable ou si nous devons nous arrêter. Par conséquent, l’algorithme de compression est également différent.

À l’écran, vous pouvez voir un graphique obtenu pour une zedfunc reflétant certains coûts de portage attendus qui dépendent du nombre d’unités en stock. Les zedfuncs bénéficient du fait d’être un espace vectoriel, ce qui signifie qu’elles peuvent être additionnées et soustraites, tout comme l’espace vectoriel classique associé aux fonctions. En préservant la localité de la mémoire, les opérations peuvent être réalisées un ordre de grandeur plus rapidement comparé à une implémentation naïve par grille où vous disposez d’une très grande table sans structure de données spécifique pour capturer la localité des options interagissant ensemble.
Le graphique que vous avez vu dans la diapositive précédente a été généré par un script. Aux lignes un et deux, nous déclarons deux fonctions linéaires, f et g. La fonction “linear” fait partie de la bibliothèque standard, et “linear of one” est simplement la fonction identité, un polynôme de degré un. La fonction “linear” renvoie une zedfunc, et il est possible d’ajouter une constante à une zedfunc. Nous avons deux polynômes de degré un, f et g. À la ligne trois, nous construisons un polynôme de second degré à travers le produit de f et g. Les lignes 5 à 10 sont des utilitaires, essentiellement du code standard, pour tracer la zedfunc.
À ce stade, nous disposons de notre conteneur de données pour la zedfunc et les résultats économiques. La zedfunc est un conteneur de données, tout comme l’était le ranvar pour la prévision probabiliste. Cependant, nous avons encore besoin de recettes numériques pour calculer ces résultats économiques. Nous avons le conteneur de données, mais je n’ai pas encore décrit comment nous calculons ces résultats économiques et remplissons les zedfuncs.

La fonction de récompense des stocks est un petit cadre destiné à calculer les rendements économiques pour chaque niveau de stock d’une SKU unique, en tenant compte d’une prévision probabiliste et d’une courte série de facteurs économiques. La fonction de récompense des stocks a été historiquement introduite chez Lokad pour unifier nos pratiques. Dès 2015, Lokad travaillait déjà depuis quelques années avec des prévisions probabilistes, et par tâtonnements, nous avions déjà découvert une série de recettes numériques qui fonctionnaient bien. Cependant, elles n’étaient pas vraiment unifiées ; c’était un peu le bazar. La fonction de récompense des stocks a consolidé, à l’époque, toutes ces idées en un cadre propre, ordonné et minimaliste. Depuis 2015, de meilleures méthodes ont été développées, mais elles sont également plus complexes. Par souci de clarté, il vaut toujours mieux commencer par la fonction de récompense des stocks et présenter cette fonction en premier.
La fonction de récompense des stocks consiste réellement à trouver une recette numérique qui nous donnera un calcul des résultats économiques attachés à ces prévisions probabilistes. La fonction de récompense des stocks obéit à l’équation que vous pouvez voir à l’écran, et elle définit les rendements économiques à l’instant t que vous pouvez obtenir pour le stock disponible, k. La variable R représente le rendement économique, qui est exprimé en unités telles que des dollars ou des euros. La fonction a deux variables : le temps (t) et le stock disponible (k). Nous voulons calculer ce rendement pour tous les niveaux de stock possibles.
Il y a quatre variables économiques à prendre en compte :
M est la marge brute par unité vendue. C’est la marge que vous gagnerez en servant avec succès une unité. S est la pénalité de rupture de stock, une sorte de coût virtuel que vous engagez chaque fois que vous ne parvenez pas à servir une unité à un client. Même si vous n’avez pas à payer de pénalité à votre client, il y a un coût associé au fait de ne pas fournir un service adéquat, et ce coût doit être modélisé. L’une des manières les plus simples de modéliser ce coût est d’attribuer une pénalité pour chaque unité que vous ne parvenez pas à servir. C est le coût de portage, le coût par unité et par période de temps. Si vous avez une unité en stock pendant trois périodes, cela représente trois fois C ; si vous avez deux unités en stock pendant trois périodes, cela représente six fois C. Alpha est utilisé pour actualiser les rendements futurs. L’idée est que ce qui se passe dans un futur lointain compte moins que ce qui est sur le point de se produire dans un avenir proche. La fonction de récompense des stocks est aussi simple qu’elle peut l’être sans être excessivement simpliste. L’équation indique que si la demande dépasse le stock disponible, le rendement inclut la marge pour tout le stock que nous possédons.
C’est ce que dit la première ligne : nous avons k marges, donc nous vendons toutes les unités que nous possédons, puis nous subissons une pénalité qui sera Y(t) - k pour toutes les unités que nous n’avons pas pu servir.
Sinon, si le stock disponible dépasse la demande, nous pouvons bénéficier de Y(t) multiplié par M, ce qui représente la marge de ce que nous avons vendu aujourd’hui. Ensuite, nous devons payer les coûts de portage. Les coûts de portage pour aujourd’hui seront ce qui reste en fin de journée, c’est-à-dire k - Y(t) multiplié par C, plus alpha multiplié par la fonction de récompense des stocks R* pour le lendemain.
Il y a une subtilité avec R*. Elle est presque identique à la fonction de récompense des stocks R, sauf que nous fixons simplement la pénalité de rupture de stock à zéro. La raison est simple : nous supposons, du point de vue des stocks, que nous aurons ultérieurement des opportunités de réapprovisionner le stock. Si nous observons une rupture de stock aujourd’hui, il est trop tard, donc nous subissons la pénalité de rupture de stock. Cependant, une pénalité de rupture de stock censée survenir demain est considérée comme évitable.
Cependant, pour une pénalité de rupture de stock censée survenir dans le futur, lors d’une période ultérieure, nous supposons qu’un réapprovisionnement peut se produire à chaque période. Ainsi, pour la rupture de stock qui surviendrait à une période ultérieure, lorsque nous disposons encore du temps pour effectuer une nouvelle commande tardive, la rupture de stock n’est pas encore effective. Nous avons encore la possibilité de la résoudre, et c’est pourquoi nous fixons la pénalité de rupture de stock à zéro, car nous anticipons qu’il y aura, espérons-le, une autre commande qui empêchera la rupture de stock de se produire.
L’actualisation temporelle alpha est très utile car elle élimine essentiellement la nécessité de spécifier un horizon temporel précis. La fonction de récompense des stocks ne fonctionne pas avec un horizon temporel fini ; on va jusqu’à l’infini. Grâce à alpha, qui est une valeur strictement inférieure à un, les résultats économiques liés à des événements dans un futur très lointain deviennent insignifiants, ils deviennent sans conséquence. Nous n’avons aucun type de coupure, qui est toujours arbitraire, comme réduire l’horizon de votre supply chain à 60 jours, 90 jours, un an ou deux ans.

Dans Envision, la fonction de récompense des stocks prend un ranvar en entrée et renvoie une zedfunc. La fonction de récompense des stocks est un petit module qui transforme une prévision probabiliste (un ranvar) en une zedfunc, qui est un conteneur pour les rendements économiques estimés sur une série d’options. Comme son nom l’indique, la fonction de récompense des stocks est le rendement économique associé à chaque position de stocks : ce qui se passe si je n’ai aucune unité en stock, une unité en stock, deux unités, trois unités, etc. La zedfunc reflétera les résultats économiques pour chaque niveau de stock, en encodant le rendement économique associé au niveau de stock correspondant.
Le processus de calcul de ces zedfuncs est illustré à l’écran. À la ligne 1, nous introduisons une demande simulée pour une journée, qui n’est qu’une distribution de Poisson aléatoire. Aux lignes 2 à 7, nous introduisons les variables économiques, et d’ailleurs, nous avons deux alphas. Il y a une autre subtilité : nous avons un effet de cliquet sur les stocks. Une fois que le stock a été envoyé vers le magasin, il est généralement très coûteux de le ramener. Cela reflète le fait que toute allocation faite à un magasin est pratiquement définitive. En termes de coûts de portage, l’alpha ne devrait pas être trop faible, car nous engagerons réellement ces coûts de portage en cas de surstock. Nous ne pouvons pas annuler cette décision. Cependant, en ce qui concerne l’alpha lié à la marge, la réalité est que, tout comme nous aurons d’autres opportunités pour aborder d’éventuelles ruptures de stock, nous aurons d’autres occasions d’apporter plus de stock et d’obtenir la même marge avec un stock envoyé à une date ultérieure. Ainsi, nous devons actualiser de manière beaucoup plus agressive ce qui se passe du côté de la marge par rapport à ce qui se passe du côté des coûts de portage.
Aux lignes 9 à 11, nous introduisons la fonction de récompense des stocks elle-même. Cette fonction, la fonction de récompense des stocks que j’ai présentée dans la diapositive précédente, peut être décomposée linéairement en ses trois composants, traitant respectivement la marge, le coût de portage et la pénalité de rupture de stock séparément. En effet, nous avons une séparation linéaire, et dans Envision, ces trois composants sont calculés séparément. Nous pouvons multiplier la zedfunc par le facteur M, qui représenterait la marge brute.
Aux lignes 13 à 15, la récompense finale est recomposée en additionnant les trois composants économiques. Dans ce script, nous tirons parti du fait que nous avons un espace vectoriel de zedfuncs. Ces zedfuncs ne sont pas des nombres ; ce sont des fonctions. Mais nous pouvons les additionner, et le résultat de l’addition est une autre fonction, qui est également une zedfunc. La variable reward est le résultat de l’addition de ces trois composants. En coulisses, le calcul de la fonction de récompense des stocks est effectué à travers une analyse par point fixe, qui peut être réalisée en temps constant pour chaque composant. Ce calcul en temps constant peut sembler être une subtilité technique mineure, mais lorsqu’on gère un grand réseau de distribution, cela fait la différence entre un prototype sophistiqué et une solution de grade production véritable.

À ce stade, nous avons consolidé tous les ingrédients nécessaires pour résoudre le problème d’allocation des stocks. Nous avons des prévisions probabilistes exprimées sous forme de ranvars, une technique pour transformer ces ranvars en une fonction donnant les rendements économiques pour toute valeur de stock disponible, et ces résultats économiques peuvent être représentés de manière pratique sous forme de zedfuncs. Pour finalement résoudre le problème d’allocation des stocks, nous devons répondre à la question clé : si nous ne pouvons déplacer qu’une seule unité de stock, laquelle devons-nous déplacer et pourquoi ? Tous les magasins du réseau se disputent le même stock dans le centre de distribution, et la qualité de la décision de déplacer une unité de stock du centre de distribution vers un magasin spécifique dépend de l’état global du réseau. Vous ne pouvez pas évaluer si cette décision est bonne en regardant simplement un magasin.
Par exemple, supposons que nous ayons un magasin disposant déjà de deux unités en stock, et si nous ajoutons une troisième unité, nous augmentons le taux de service attendu de 80 % à 90 %. C’est bien, et peut-être que davantage de personnes au sein du réseau seraient d’accord avec l’idée d’apporter une unité supplémentaire pour que le taux de service passe de 80 à 90. Cela semble très raisonnable, donc ils diraient que c’est une bonne initiative. Cependant, que se passe-t-il si cette unité que nous sommes sur le point de déplacer, cette troisième unité, est en réalité la dernière disponible dans le centre de distribution ? Nous avons un autre magasin dans le réseau qui subit déjà une rupture de stock, et si nous déplaçons cette unité vers le magasin où elle devient la troisième unité, nous prolongeons la rupture de stock pour le magasin déjà en rupture pour le même produit. Dans cette situation, il est presque certain que déplacer l’unité vers le magasin déjà en rupture constitue une meilleure décision et devrait être prioritaire.
C’est pourquoi il n’est pas logique d’évaluer économiquement les niveaux de stocks au niveau de la SKU. Le problème des optimisations locales, c’est qu’elles ne fonctionnent pas lorsqu’on opère dans des systèmes plus vastes. Dans les supply chains, si vous traitez les choses localement, vous ne faites que déplacer les problèmes ; vous ne résolvez rien. L’adéquation d’un niveau de stocks pour une SKU dépend de l’état du réseau. Cet exemple simple clarifie pourquoi les calculs de stocks de sécurité ou les calculs de point de réapprovisionnement sont en grande partie absurdes, du moins pour des situations réelles, comparativement aux exemples simplifiés présents dans les manuels de supply chain.
Ici, nous voulons vraiment prioriser toutes les allocations de stocks les unes par rapport aux autres, et l’option qui ressort au sommet est la réponse à notre question : ce sera l’unique unité qui devrait être déplacée si nous ne pouvons déplacer qu’une seule unité.

Classement des options d’allocation de stocks est relativement simple avec les bons outils. Passons en revue ce script Envision. À la ligne 1, nous créons trois SKUs nommés A, B et C. À la ligne 2, nous générons des prix d’achat aléatoires allant de 1 à 10 comme données simulées. À la ligne 3, nous générons des zedfuncs simulées censées représenter la récompense que nous avons pour chacun de ces SKUs. En pratique, un zedfunc devrait être calculée avec la fonction de récompense des stocks, mais juste pour garder le code concis, nous utilisons des données simulées ici. La récompense est une fonction linéaire décroissante qui atteindra zéro au niveau de stock 6. À la ligne 4, nous créons une table G, une abréviation pour la grille qui représente nos niveaux de stocks en main. Nous supposons que les niveaux de stocks supérieurs à 10 ne valent pas la peine d’être évalués. Cette hypothèse est raisonnable, compte tenu du fait qu’en termes de données simulées, nous avons une fonction de récompense qui devient négative au-delà d’un niveau de stocks en main de 6. À la ligne 6, nous extrayons la récompense marginale pour chaque unité en stock afin d’obtenir cette table de grille. Nous utilisons le zedfunc, une fonction qui représente les récompenses, pour extraire la valeur pour la position de stock G.N. Il est à noter qu’à partir de la ligne 6, peu importe comment les données ont été générées initialement. De la ligne 1 à 4, il s’agit simplement de données simulées qui ne seraient pas utilisées en production, mais à partir de la ligne 6, ce serait essentiellement la même chose si vous étiez en production.
À la ligne 7, nous définissons le score comme un ratio entre les dollars de rendement (qui est indiqué par le zedfunc) et le dollar investi, qui est le prix d’achat. Nous calculons un ratio entre le montant en dollars que vous récupérerez divisé par le montant en dollars que vous devez payer pour une unité. Essentiellement, le score le plus élevé est obtenu pour l’allocation de stocks qui génère le taux de retour sur investissement le plus élevé par dollar alloué à ce magasin.
Enfin, aux lignes 9 à 15, nous affichons une table triée par scores décroissants. Il est important de souligner qu’il n’y a aucune logique sophistiquée dans le script. Les quatre premières lignes ne font que générer des données simulées, et les six dernières lignes se contentent d’afficher une allocation priorisée. Une fois que les zedfuncs sont présentes et que nous disposons d’une fonction représentant les retours économiques par niveau de stocks, transformer ces zedfuncs en une prioritized list est tout à fait simple.

Sur l’écran, la table obtenue en exécutant le script Envision précédent montre que le SKU nommé C est classé en première position. Tous les SKUs ont les mêmes rendements économiques pour leur première unité, à savoir 5 $ de rendement. Cependant, C affiche le prix d’achat le plus bas à 3,99 $, et ainsi, lorsque nous divisons la récompense de 5 $ par 3,99 $, nous obtenons un score d’environ 1,25, ce qui se trouve être le score le plus élevé sur la grille. La deuxième unité de C affiche un score d’environ 1, ce qui est le deuxième score le plus élevé.
Pour la troisième position dans la grille, nous avons un autre SKU nommé B. B présente un prix d’achat plus élevé, et ainsi son score pour la première unité n’est que de 0,96. Cependant, en raison des rendements décroissants que nous obtenons en allouant les deux premières unités à C, la première unité de B affiche un score supérieur à la troisième unité de C, et est donc classée au-dessus de cette dernière. Essentiellement, cette liste de priorités va très en profondeur, mais elle est conçue pour être tronquée par un seuil. Par exemple, nous pouvons décider qu’il existe un retour sur investissement minimal, et seules les unités au-dessus de ce retour sont allouées. Une fois le seuil défini, nous pouvons prendre toutes les lignes qui se situent au-dessus de ce seuil et compter le nombre de lignes par SKU. Cela nous donne le nombre total d’unités à allouer pour chaque SKU. Nous reviendrons sur ce problème de seuil dans un instant, mais l’idée est qu’une fois que vous avez défini un seuil, vous agrégerez les comptes par SKU, ce qui vous donnera la quantité totale à allouer pour chaque SKU. C’est exactement ce à quoi s’attendrait votre WMS ou ERP existant dans le centre de distribution pour organiser l’expédition du lendemain vers les magasins.
La liste de priorités n’est qu’une vue conceptuelle destinée à décider de ce qui prime réellement. Cependant, vous appliquez un seuil, agrégerez, et ensuite vous revenez aux quantités d’allocation par SKU pour chaque SKU de votre réseau de magasins.
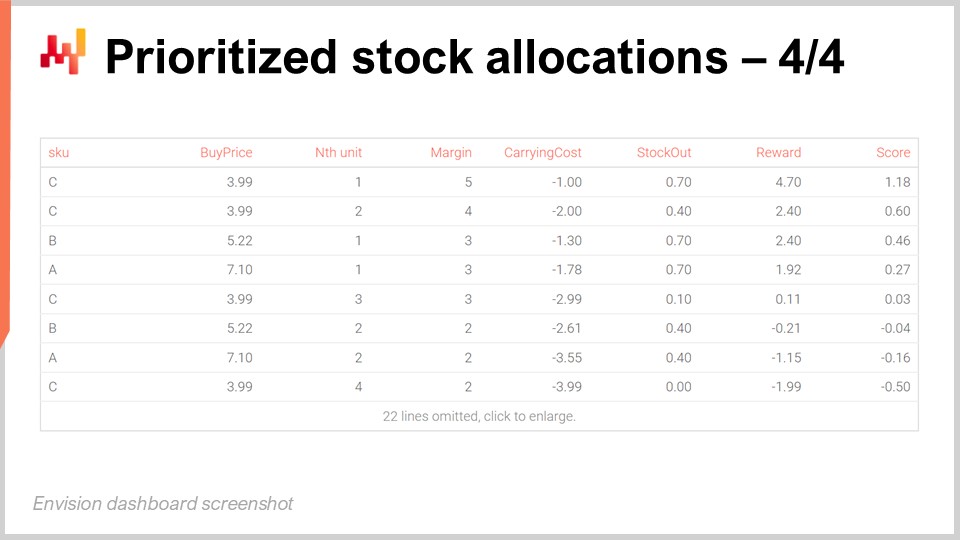
La vue d’affichage de l’allocation priorisée de stocks est à la fois trompeusement simple et puissante. Au fil des lignes, nous voyons la compétition s’organiser entre nos options d’allocation. Les meilleurs SKUs sont alloués en premier, mais dès que nous atteignons des niveaux de stocks plus élevés, ces SKUs deviennent moins compétitifs par rapport à d’autres SKUs qui ne disposent pas d’autant de stocks. La liste de priorités passe d’un SKU à l’autre, maximisant les retours économiques attendus sur le capital alloué aux magasins.
Sur cet écran, nous avons une variante de la table précédente, obtenue avec un autre script Envision qui est une version minimale de celui présenté deux diapositives plus tôt. Essentiellement, je décompose les facteurs économiques qui contribuent à la récompense. Ici, nous avons trois colonnes supplémentaires : marge, coût de détention et rupture de stock. La marge est la marge brute moyenne attendue pour cette unité allouée. Le coût de détention représente le coût moyen attendu pour mettre cette unité en stocks dans le magasin. La rupture de stock correspond à la pénalité attendue qui sera évitée, c’est pourquoi la pénalité de rupture de stock est une valeur positive ici. La récompense finale est simplement la somme de ces trois composantes, et toutes ces valeurs sont exprimées en montants monétaires, tels que des dollars. La colonne indiquant les dollars de marge, les dollars de coût de détention, les dollars de rupture de stock, et la récompense correspond au montant total en dollars que vous pouvez attendre en mettant cette unité dans le magasin.
Cela rend la compréhension et le débogage de cette recette numérique, exprimée en dollars, nettement plus faciles par rapport aux pourcentages. En effet, toute recette numérique non triviale est conçue pour être assez opaque. Vous n’avez pas besoin de deep learning pour obtenir une opacité profonde ; même une régression linéaire modeste sera largement opaque dès que plusieurs facteurs sont impliqués dans cette régression. Cette opacité, inhérente à toute recette numérique non triviale, met une supply chain du monde réel en danger car les praticiens de la supply chain peuvent se perdre, être confus et distraits par les complexités de modélisation.
La liste d’allocation priorisée, qui décompose les moteurs économiques, est un outil d’audit puissant. Elle permet aux praticiens de la supply chain de remettre directement en question les fondamentaux plutôt que de se perdre dans les subtilités techniques. Vous pouvez poser directement des questions telles que : Avons-nous des coûts de détention qui sont cohérents avec la situation ? Ces coûts sont-ils alignés avec le type de risques que nous prenons ? Vous pouvez ignorer la prévision, la saisonnalité, et la façon dont vous modélisez la saisonnalité, la manière dont vous intégrez la tendance décroissante, etc. Vous pouvez contester directement le résultat final, qui correspond à des dollars de retours pour ces coûts de détention. Sont-ils réels ? Ont-ils du sens ? Très souvent, vous pouvez repérer des chiffres aberrants et les corriger directement.
Évidemment, vous souhaitez éviter ces situations, mais n’agissez pas en partant du principe que, dans la supply chain, tous les problèmes relèvent de questions de prévision incroyablement subtiles. La plupart du temps, les problèmes sont brutaux. Il peut se produire une situation, par exemple des données mal traitées, et alors vous obtenez des chiffres complètement aberrants, tels que des marges négatives ou des coûts de détention négatifs qui provoquent des ravages dans votre supply chain.
Si votre instrumentation de supply chain se concentre exclusivement sur la précision des prévisions, vous êtes aveugle à 90 % (voire plus) des problèmes réels. Dans une supply chain à grande échelle, cette estimation serait probablement de l’ordre de 99 %. L’instrumentation de supply chain est absolument fondamentale pour mettre en lumière les facteurs clés qui influencent les décisions, et ces facteurs doivent être de nature économique si vous voulez espérer vous concentrer sur ce qui rend votre entreprise rentable. Sinon, si vous opérez en pourcentages, vous ne pouvez pas prioriser vos propres actions, et vous traiterez les dysfonctionnements de manière indiscriminée. Nous parlons d’une supply chain à grande échelle, donc il y a toujours une multitude de dysfonctionnements numériques. Si vous traitez tous ces dysfonctionnements de manière indifférenciée, cela signifie que vous travaillez toujours sur des éléments largement sans conséquences. C’est pourquoi il vous faut des dollars de retours et des dollars de coûts. C’est ainsi que vous pouvez réellement prioriser votre travail et vos efforts de développement pour vos recettes numériques. Parfois, vous n’avez même pas besoin de décider si un bug vaut la peine d’être corrigé ; s’il s’agit de quelques dollars de friction par an, ce n’est même pas un bug qui mérite d’être corrigé en pratique.
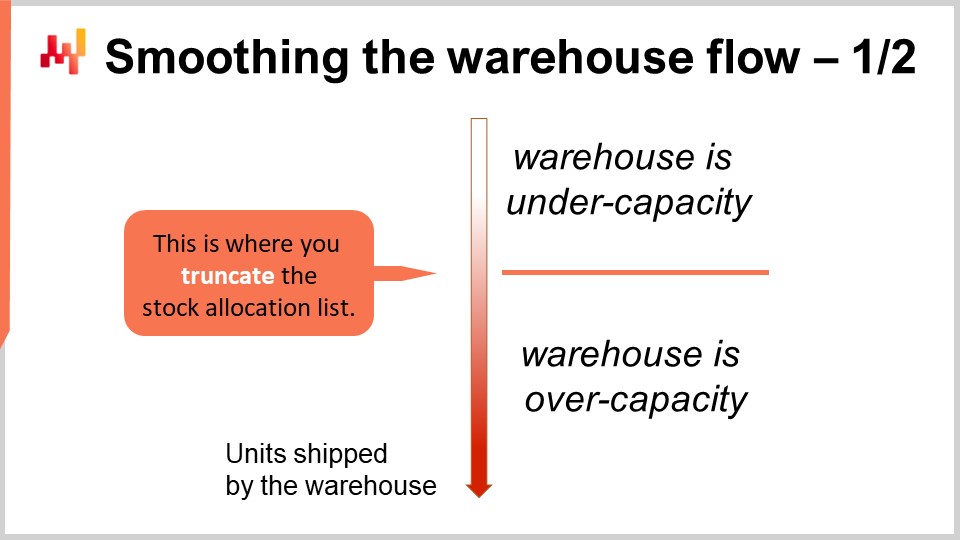
Maintenant, revenons à la question de choisir le bon seuil pour la liste d’allocation. Nous avons constaté que nous observons des rendements décroissants lorsque nous allouons davantage de stocks aux magasins. Cependant, nous devons considérer l’ensemble de la supply chain, et pas seulement le warehouse ou centre de distribution. J’utilise ces deux termes de manière interchangeable ici. Le warehouse ou centre de distribution est dominé par des coûts fixes. En effet, il est possible d’augmenter le personnel avec des intérimaires, mais cela tend à coûter plus cher et engendre d’autres problèmes, comme le fait que la main-d’œuvre temporaire est généralement moins qualifiée que la main-d’œuvre permanente.
Ainsi, tout warehouse ou centre de distribution possède une capacité cible à partir de laquelle il opère avec une efficacité économique maximale. La capacité cible peut être augmentée ou diminuée, mais généralement, cela implique d’ajuster la taille du personnel permanent, ce qui est un processus relativement lent. Vous pouvez vous attendre à ce qu’un warehouse ajuste sa capacité cible d’un trimestre à l’autre, mais vous ne pouvez pas vous attendre à ce que le warehouse ajuste sa capacité nominale, celle à laquelle il atteint son efficacité maximale, d’un jour à l’autre. Ce n’est pas aussi dynamique.
Nous souhaitons que le warehouse fonctionne à une efficacité maximale, ou le plus près possible de celle-ci, en permanence, à moins que nous n’ayons une incitation économique suffisamment forte pour agir autrement. La perspective de l’allocation priorisée de stocks ouvre la voie pour réaliser exactement cela. Nous pouvons tronquer la liste en la rallongeant ou en la raccourcissant légèrement et en ajustant le seuil pour qu’il soit aligné avec la capacité cible du warehouse. En pratique, cela présente trois avantages majeurs.
Premièrement, lisser le flux du warehouse. Ce faisant, vous maintenez le warehouse au maximum de sa capacité la majeure partie du temps, économisant ainsi beaucoup de coûts d’exploitation. Deuxièmement, votre processus d’allocation de stocks devient beaucoup plus résilient face à tous les petits incidents qui surviennent dans une supply chain réelle. Un camion peut être impliqué dans un léger accident de circulation, certains employés peuvent ne pas se présenter parce qu’ils sont malades – il y a des tonnes de petites raisons qui viendront perturber vos plans. Cela n’empêchera pas le warehouse de fonctionner, mais il se peut qu’il n’opère pas exactement à la capacité que vous aviez prévue. Avec cette liste de priorités, vous pouvez optimiser la capacité utilisée par votre warehouse, même si ce n’est pas exactement celle que vous aviez planifiée initialement.
Le troisième avantage est que, grâce à cette approche d’une liste de priorités pour l’allocation des stocks, votre équipe supply chain n’a plus besoin de micromanager les niveaux de personnel du warehouse. Il vous suffit d’ajuster la capacité cible de votre warehouse pour qu’elle corresponde approximativement à la vélocité de vente de votre réseau de magasins. Micromanager la capacité quotidiennement devient alors largement sans conséquence.
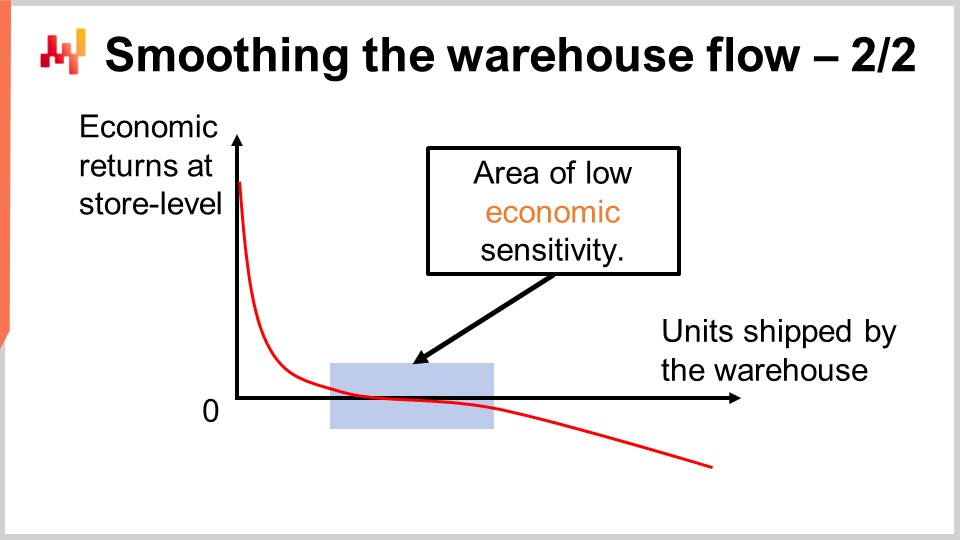
L’expérience de Lokad indique que lisser le flux du warehouse à l’aide d’un seuil de capacité fixe fonctionne bien dans la plupart des situations de vente au détail. Sur l’écran, vous pouvez observer la courbe typique de rendement économique que l’on verrait en considérant tous les seuils possibles. Sur l’axe des X, nous avons le nombre d’unités expédiées depuis le warehouse. Nous partons du principe que les unités sont expédiées une par une afin de pouvoir observer la contribution marginale de chaque unité. Naturellement, en production, les unités sont expédiées en lots et non une par une, mais c’est simplement pour que nous puissions tracer la courbe. Sur l’axe des Y, nous avons les résultats économiques marginaux au niveau du magasin, c’est-à-dire pour la nième unité expédiée à un magasin quelconque du réseau. Les toutes premières unités allouées génèrent l’essentiel des retours. En pratique, le haut de la liste consiste invariablement en des situations de rupture de stock nécessitant une résolution immédiate. C’est pourquoi les premières unités traitent les ruptures de stock, et c’est pourquoi les rendements économiques sont très élevés. Par la suite, les rendements diminuent et nous entrons dans une portion plate de la courbe.
Cette zone est ce que j’appelle la zone de faible sensibilité économique. Essentiellement, nous rapprochons progressivement le taux de service de 100 %, sans toutefois créer beaucoup de stocks morts. Lorsque vous effectuez ce type d’allocation priorisée, si nous allouons des stocks allant au-delà de la résolution des problèmes de rupture de stock, nous finissons par accumuler des stocks sur les produits à forte rotation. Nous créons des stocks dans des emplacements qui ne sont pas strictement nécessaires à l’instant présent. Nous aurons des opportunités ultérieures de reconstituer les stocks sans être confrontés à une rupture entre-temps, mais l’impact reste minimal puisque les stocks seront vendus relativement rapidement. Essentiellement, il s’agit simplement du coût d’opportunité lié au déplacement des stocks du centre de distribution vers un magasin. Nous perdons progressivement des options futures à mesure que nous allouons davantage de stocks.
Cette zone est relativement plate et commencera à devenir assez négative lorsque nous allouerons tant de stocks que nous commencerons à générer des situations entraînant des radiations de stocks avec une probabilité non triviale. Si vous continuez à allouer davantage, vous engendrez des situations de surstock graves, et ainsi, vous verrez la courbe devenir très négative. Si vous poussez trop loin, vous générez des tonnes de radiations de stocks à l’avenir. Tant que le seuil se situe dans ce segment à faible sensibilité, tout va bien, et le seuil n’est pas ultra sensible à l’endroit où vous le fixez. C’est pourquoi la capacité du warehouse ne doit pas nécessairement reproduire exactement le volume des ventes quotidiennes.
En effet, dans la plupart des réseaux de vente au détail, vous observez un cycle hebdomadaire très marqué dans vos ventes, où certains jours, par exemple le samedi, sont ceux où vous vendez le plus. Cependant, l’entrepôt n’a pas besoin de reproduire exactement ce cycle hebdomadaire. Vous pouvez maintenir une moyenne très stable, et l’idée est que votre capacité cible devrait approximativement correspondre à votre volume de ventes global pour votre réseau de magasins. Si votre capacité cible est toujours un peu inférieure à votre volume de ventes global dans le réseau, ce qui se passera, c’est que vous épuiserez progressivement tous vos magasins, puis vous ferez face à un gros problème. Inversement, si vous poussez chaque jour un peu plus que ce que vous vendez réellement, alors, très rapidement, vous saturerez complètement vos magasins.
Tant que vous restez relativement équilibré, vous n’avez pas besoin de microgérer le cycle hebdomadaire ; cela fonctionnera bien. La raison pour laquelle il n’est pas nécessaire de microgérer ce cycle, c’est que les toutes premières unités fournissent la majeure partie des retours, et le système, d’un point de vue économique, n’est pas si sensible tant que le seuil reste approximativement dans ce segment plat.

Maintenant, j’ai présenté la fonction de récompense des stocks pour plus de clarté et de concision, car nous avions déjà beaucoup de choses à couvrir dans ce cours. Cependant, la fonction de récompense des stocks n’est pas l’apogée de la science supply chain. Elle est quelque peu naïve lorsqu’il s’agit des subtilités des prévisions probabilistes.
En 2021, l’un d’entre nous chez Lokad a publié la fonction de récompense d’action. La fonction de récompense d’action est le descendant spirituel, si vous voulez, de la fonction de récompense des stocks, mais cette fonction propose une perspective bien plus détaillée sur les prévisions probabilistes elles-mêmes. En effet, toutes les prévisions probabilistes ne se valent pas. La saisonnalité, les délais d’approvisionnement variables et les heures d’arrivée prévues pour les centres de distribution sont tous pris en compte dans la fonction de récompense d’action, alors qu’ils ne l’étaient pas dans la fonction de récompense des stocks.
D’ailleurs, ces capacités nécessitent également une prévision plus granulaire, donc vous avez besoin d’une technologie de prévision supérieure capable de générer toutes ces prévisions probabilistes pour tirer parti de la fonction de récompense des stocks. À cet égard, la fonction de récompense des stocks est moins exigeante. Sur le plan conceptuel, la fonction de récompense d’action permet également un découplage net entre la fréquence de commande (la fréquence à laquelle vous commandez) et le délai d’approvisionnement (le temps nécessaire pour reconstituer le stock une fois la décision prise). Ces deux éléments étaient amalgamés dans la fonction de récompense des stocks. Avec la récompense d’action, ils sont clairement séparés.
Enfin, la fonction de récompense d’action intègre également une perspective de responsabilité décisionnelle, qui est une astuce simple mais assez ingénieuse pour récolter la majeure partie des avantages qu’offrirait une véritable politique sans avoir à en introduire une. Nous aborderons plus tard dans les cours ce que signifient réellement les politiques du point de vue technique, mais en résumé, dès que vous commencez à introduire des politiques, cela devient plus compliqué. C’est intéressant, mais c’est définitivement plus complexe. Ici, la récompense d’action dispose d’une astuce ingénieuse qui vous permet littéralement de contourner le besoin de recourir à une politique tout en récoltant la plupart des bénéfices économiques qui y seraient associés.

La fonction de récompense des stocks ainsi que son alternative supérieure, la fonction de récompense d’action, sont utilisées en production depuis des années chez Lokad. Ces fonctions simplifient essentiellement des catégories entières de problèmes qui affligent autrement les réseaux de vente au détail. Par exemple, l’analyse des stocks morts devient triviale en se contentant de regarder les retours économiques associés à chaque unité de stock présente dans un magasin. Pourtant, il existe de nombreux aspects que je n’ai pas abordés aujourd’hui. Je traiterai de ces points dans de futurs cours.
Certains de ces aspects peuvent en réalité être traités avec des variations relativement mineures de ce que j’ai présenté aujourd’hui. C’est le cas, par exemple, des multiplicateurs de lots et du rééquilibrage des stocks. Vous devez apporter très peu de modifications aux scripts que je viens de montrer aujourd’hui pour pouvoir aborder ces problèmes. Lorsque je parle de rééquilibrage des stocks, je fais référence au rééquilibrage des stocks entre les magasins du réseau, soit en renvoyant les stocks vers le DC, soit en déplaçant directement les stocks entre les magasins, en tenant compte des coûts de transport spécifiques.
Ensuite, il y a certains aspects qui demandent plus de travail tout en restant relativement simples. Par exemple, prendre en compte les coûts d’opportunité, des coûts de transport fixes et la surcharge d’entrée en magasin, qui se produit lorsque le personnel d’un magasin n’est pas capable de traiter toutes les unités qu’il a reçues. Ils n’ont pas le temps, un jour donné, de les mettre en rayon, ce qui crée ainsi un grand désordre dans le magasin. Ces aspects sont envisageables, mais ils nécessiteront sans aucun doute un travail considérable en plus de ce que j’ai présenté aujourd’hui.
Il existe d’autres aspects, comme le merchandising ou l’amélioration de l’attractivité globale du magasin, qui devraient faire partie de la priorisation. Ceux-ci requièrent une approche technologique supérieure, car de simples variations mineures de ce que j’ai présenté aujourd’hui ne suffisent pas. Comme d’habitude, je recommande une bonne dose de scepticisme chaque fois qu’un expert affirme disposer d’une méthode optimale. En supply chain, il n’existe pas de méthodes optimales ; nous disposons d’outils, certains se révèlent meilleurs, mais aucun ne s’approche même vaguement de ce qui pourrait être qualifié d’optimal.
En conclusion, les pourcentages d’erreur sont sans importance ; ce qui compte, ce sont les dollars d’erreur. Ces dollars sont déterminés par ce que fait votre supply chain au niveau physique. La plupart des KPIs sont, au mieux, insignifiants ; ils font partie du processus supply chain visant à améliorer continuellement les recettes numériques qui pilotent les décisions supply chain. Cependant, même en tenant compte des KPIs essentiels pour améliorer ces recettes numériques, nous parlons de résultats assez indirects comparés à une amélioration directe de la recette numérique qui guide la décision et génère immédiatement de meilleurs résultats pour votre supply chain.
Les feuilles Excel sont omniprésentes dans la supply chain, et je pense que c’est parce que la théorie dominante de la supply chain n’a pas réussi à promouvoir les décisions en tant que citoyens de première classe. En conséquence, les entreprises gaspillent du temps, de l’argent et se concentrent sur des citoyens de seconde classe, à savoir des artefacts. Mais, au bout du compte, des décisions doivent être prises : les stocks doivent être alloués, et il faut choisir le prix, votre argument de vente et le prix d’attaque. Faute de support adéquat, les praticiens de la supply chain retombent sur le seul outil qui leur permet de traiter les décisions comme des citoyens de première classe, et cet outil se trouve être Excel.
Cependant, les décisions supply chain peuvent être traitées comme des citoyens de première classe, et c’est exactement ce que nous avons fait aujourd’hui. Les outils ne sont même pas si complexes, du moins en considérant la complexité ambiante du paysage applicatif typique d’une supply chain moderne. De plus, des outils adéquats permettent de débloquer des capacités telles que le lissage du flux de stocks depuis les centres de distribution jusqu’au magasin avec un effort minimal. Ces capacités sont simples à obtenir avec les bons outils, mais elles illustrent également le type de réalisations que l’on ne peut jamais espérer d’une feuille Excel, du moins pas avec une configuration de niveau production.

Je suppose que c’est tout pour aujourd’hui. Le prochain cours aura lieu mercredi, le 6 juillet, à la même heure, soit 15 h, heure de Paris. Je passerai au septième chapitre pour discuter de l’exécution tactique d’une initiative supply quantitative. D’ailleurs, je reviendrai sur le chapitre 5, concernant les prévisions probabilistes, et le chapitre 6, concernant les techniques de prise de décision, dans de futurs cours. Mon objectif est d’avoir une perspective complète et accessible sur tous les éléments avant de me plonger en profondeur dans un sujet spécifique.
À ce stade, je vais en fait jeter un œil aux questions.
Question: La zedfunc pourrait avoir des possibilités infinies. Est-ce que toutes les solutions ne seraient pas à court terme dans ce cas ?
La zedfunction est littéralement un conteneur de données pour une séquence d’options, de sorte que l’horizon applicable est intégré dans la valeur alpha, les valeurs d’actualisation temporelle que j’ai utilisées dans mes scripts. Fondamentalement, l’horizon cible que vous avez intégré dans le résultat économique d’une zedfunction ne se trouve pas vraiment dans les zedfunctions elles-mêmes ; il se trouve davantage dans les calculs économiques qui les complètent. N’oubliez pas que les zedfunctions ne sont que des conteneurs de données. C’est ce qui les rend, à court ou à long terme, et, évidemment, vous souhaitez ajuster vos recettes numériques afin qu’elles reflètent vos priorités. Par exemple, si votre entreprise est sous une énorme pression à cause de problèmes de trésorerie, vous aurez probablement une perspective beaucoup plus à court terme en ce qui concerne l’apport de liquidités, c’est-à-dire essentiellement liquider vos stocks. Si vous disposez de beaucoup de liquidités, peut-être préférez-vous retarder les ventes à une période ultérieure, en vendant à un meilleur prix et en assurant une meilleure marge brute. Encore une fois, toutes ces choses sont possibles avec les zedfunctions. Les zedfunctions ne sont que des conteneurs ; elles ne présupposent pas nécessairement une quelconque recette numérique pour les résultats économiques que vous souhaitez y intégrer.
Question: Je pense que la plupart des hypothèses doivent être basées sur des valeurs réelles existantes des fonctions objectives, n’est-ce pas ?
Qu’est-ce qui est réel ? C’est l’essence du problème que j’ai abordé dans le cours sur l’optimisation expérimentale. Le problème, c’est que chaque fois que vous dites que vous disposez de valeurs ou de mesures ou d’autres données, ce que vous avez, ce sont des constructions mathématiques, des constructions numériques. Ce n’est pas parce que c’est numérique que c’est correct. La manière dont j’aborde une supply chain est celle d’une science expérimentale ; il faut se connecter au monde réel. C’est ainsi que vous décidez si quelque chose est réel ou non. La question est, et je suis tout à fait d’accord, que les hypothèses ne doivent pas être basées sur des valeurs réelles préexistantes, car il n’existe pas de telles valeurs. Elles doivent être vérifiées ; ces hypothèses doivent être testées et confrontées aux observations concrètes que vous pouvez réaliser sur votre supply chain. La justesse de vos hypothèses ne peut être évaluée qu’en établissant un contact avec la réalité de votre supply chain.
C’est là que réside la difficulté de cette perspective d’optimisation expérimentale, car la perspective d’optimisation mathématique suppose simplement que toutes les variables sont connues, que toutes les variables sont réelles, que toutes peuvent être observées, et que la fonction de perte peut être correcte. Mais ce que je veux dire, c’est qu’une supply chain est un système super complexe. Ce n’est pas le cas. La plupart du temps, ce que vous avez, ce sont des mesures assez indirectes. Quand je parle de niveau de stocks, je ne vais pas réellement en magasin pour vérifier si le niveau de stocks est correct. Ce que j’obtiens, c’est une mesure très indirecte, un enregistrement électronique provenant d’un système enterprise software qui avait été mis en place typiquement il y a deux décennies pour des raisons qui n’avaient rien à voir avec la data science dès le départ. C’est ce que je dis : le problème avec la réalité, c’est qu’une supply chain est toujours distribuée géographiquement, donc tout ce que vous mesurez, tout ce que vous observez en termes de valeurs, sont des mesures indirectes. D’une certaine manière, la réalité de ces mesures est toujours sujette à caution. Il n’existe pas d’observation directe. Vous pouvez effectuer une observation directe juste pour faire un contrôle ou une vérification, mais cela ne peut représenter qu’un infime pourcentage de toutes les valeurs que vous devez manipuler pour votre supply chain.
Question: Dans les fonctions de récompense des stocks, en plus des paramètres simples comme la marge, nous traitons également des pénalités de rupture de stock. Comment apprend-on au mieux à optimiser ces paramètres complexes ?
C’est une très bonne question. En effet, les pénalités de rupture de stock sont réelles ; sinon, personne ne se donnerait la peine d’obtenir des taux de service élevés. La raison pour laquelle vous souhaitez avoir des taux de service élevés, c’est que, d’un point de vue économique, chaque détaillant que je connais est convaincu de la réalité des pénalités de rupture de stock. Les clients n’apprécient pas de ne pas bénéficier d’un service de qualité. Mais je ne dirais pas qu’elles sont complexes ; elles sont compliquées. Elles sont intrinsèquement difficiles, et une partie de leur complexité réside dans le fait qu’il s’agit littéralement de la stratégie à long terme du réseau de vente au détail qui est en jeu. Avec la plupart de mes clients, par exemple, la pénalité de rupture de stock est un sujet dont je discute directement avec le PDG de l’entreprise. Cela remonte tout en haut ; c’est la stratégie ultra-long terme du réseau de vente au détail qui est en jeu.
Donc, ce n’est pas que c’est complexe, mais c’est définitivement compliqué car il s’agit d’une discussion à enjeux très élevés. Que voulons-nous réellement faire ? Comment voulons-nous traiter les clients ? Souhaitons-nous dire que nous avons les meilleurs prix et, désolé, si la qualité du service n’est pas la meilleure possible, mais que vous proposez quelque chose d’unique à des prix très bas ? Ou bien préférez-vous l’innovation ? Si vous optez pour l’innovation, cela signifie que de nouveaux produits arrivent en permanence, et si de nouveaux produits affluent constamment, cela implique que les anciens produits disparaissent progressivement, et qu’il faut donc tolérer des ruptures de stock, car c’est ainsi que l’on continue d’introduire de la nouveauté.
La pénalité de rupture de stock est difficile à évaluer car elle engage directement des enjeux élevés dans la stratégie à long terme de l’entreprise. En pratique, la meilleure façon de l’évaluer est de mener des expériences. Vous choisissez une valeur, faites une estimation approximative de la valeur de la pénalité de rupture de stock, du facteur de pénalité de stock, puis vous examinez le type de stocks que vous obtenez dans vos magasins. Ensuite, vous laissez les personnes, avec leur ressenti, juger si cela correspond au niveau de stocks qui refléterait leur magasin idéal. Est-ce bien ce qu’elles veulent réellement pour leurs clients ? Est-ce ce qu’elles souhaitent vraiment obtenir avec leur réseau de vente au détail ?
Vous voyez, il y a cette discussion avec aller-retour. Typiquement, le Supply Chain Scientist va tester une série de valeurs, présenter les types de résultats économiques, et aussi expliquer les coûts macro qui sont associés à un levier. Ils pourraient dire, “D’accord, nous pouvons appliquer une pénalité de rupture de stock très élevée, mais attention, si nous faisons cela, cela signifie que notre logique d’allocation de stocks poussera toujours énormément de stocks vers les magasins.” Parce que si le message est que les ruptures de stock sont fatales, alors cela signifie que nous devons vraiment faire tout ce que nous pouvons pour éviter qu’elles se produisent. Essentiellement, nous devons avoir cette discussion avec de nombreuses itérations afin que la direction puisse faire une vérification de réalité : “Ma stratégie à long terme est-elle économiquement viable par rapport à ce que mon réseau de vente au détail peut réellement faire ?” C’est ainsi que vous convergez progressivement. Au fait, ce n’est pas quelque chose de gravé dans la pierre. Les entreprises changent et ajustent leur stratégie au fil du temps, donc ce n’est pas parce que vous appliquez un facteur de pénalité de rupture de stock en 2010 qu’en 2022 il doit être la même valeur.
Surtout, par exemple, avec l’essor du le e-commerce. Il existe de nombreux réseaux de vente au détail qui se contentent de dire, “Eh bien, je suis devenu beaucoup plus tolérant aux ruptures de stocks dans mes magasins, surtout pour les magasins spécialisés.” Parce qu’essentiellement, lorsqu’un produit manque, notamment une variante en termes de taille, les gens vont simplement le commander en ligne sur le le e-commerce. Le magasin devient comme un showroom. Ainsi, la qualité de service d’un showroom devient très différente de ce qui était attendu lorsque le magasin était littéralement le seul moyen de vendre les produits.
Question: Pouvons-nous avoir une fonction de récompense de stocks composée pour comprendre correctement la tendance au cours d’une période donnée ?
Comprendre la tendance de quoi exactement ? S’il s’agit d’une tendance de la demande, la fonction de récompense de stocks est une fonction qui consomme une prévision probabiliste. Ainsi, quelle que soit la tendance que vous observez dans la demande, cela reflète généralement la manière dont vous modélisez cette demande. En ce qui concerne la fonction de récompense de stocks, la prévision probabiliste intègre déjà tout cela, qu’il y ait une tendance ou non.
Maintenant, si vous avez une autre question concernant la perspective stationnaire de la récompense de stocks, vous avez tout à fait raison. La fonction de récompense de stocks adopte une perspective complètement stationnaire. Elle suppose que la demande se répète de manière probabiliste à chaque période exactement de la même façon, de sorte qu’il n’y a ni tendance ni saisonnalité. C’est une perspective purement stationnaire. Dans cette situation, la réponse est non, la fonction de récompense de stocks n’est pas capable de traiter une demande non stationnaire. Cependant, la fonction de récompense d’action est capable d’y répondre. Cela a également été l’une des motivations pour passer à la fonction de récompense d’action, car elle peut gérer une demande probabiliste non stationnaire.
Question: Nous partons du principe que la capacité de l’entrepôt est fixe, mais elle dépend des efforts de picking, packing et shipping. Ne devrait-on pas définir les points de coupure par l’optimisation des opérations de l’entrepôt ?
Oui, absolument. C’est ce que j’ai dit quand vous vous trouvez dans cette zone de faible sensibilité économique. Votre liste de priorités, représentant l’allocation priorisée de stocks, n’est pas très sensible quant au moment de la coupure, tant que celle-ci se situe dans ce segment. En moyenne, vous devriez être vraiment équilibré en termes de quantité poussée et vendue, ce qui a du sens. Si vous souhaitez ajuster légèrement différemment le seuil après avoir exécuté la logique d’optimisation de l’entrepôt, en tenant compte de tous les efforts et variations de picking, packing et shipping, cela ne pose pas de problème. Vous pouvez avoir des variations de dernière minute. La beauté de cette liste d’allocation priorisée de stocks est que vous pouvez littéralement finaliser l’étendue exacte des unités expédiées à la dernière minute. La seule opération dont vous avez besoin est une agrégation, qui peut être effectuée très rapidement, vous offrant ainsi davantage d’options. C’est exactement ce que j’ai dit lorsque j’ai mentionné que cette approche ouvre de nouvelles classes d’optimisation supply chain. Elle vous permet de décider juste à temps pour réorganiser vos efforts de picking, packing et shipping, au lieu d’être rigidement attaché à une enveloppe d’expédition préétablie qui ne correspond pas vraiment aux ressources exactes dont vous disposez et à l’effort nécessaire pour l’exécuter.
Question: Le lissage des flux de l’entrepôt exige-t-il un lissage du flux de production ? Ce modèle de décision prend-il cela en compte ?
Je dirais qu’il ne nécessite pas naturellement un flux de production lissé. Pour de nombreux réseaux de vente au détail, comme les magasins de produits généraux, les commandes se font auprès de grandes entreprises FMCG qui produisent de très gros lots de leur côté. Il n’est pas nécessaire de lisser le flux de production pour générer des avantages en termes de coûts d’exploitation du centre de distribution. Même si la production n’est pas lissée, vous bénéficiez déjà du simple fait de déplacer les expéditions du centre de distribution vers les magasins.
Cependant, vous avez tout à fait raison. Si vous représentez une marque verticalement intégrée qui a internalisé ses installations de production, ses centres de distribution et ses magasins, alors il existe un vif intérêt à réaliser une optimisation à l’échelle du supply chain et à lisser l’ensemble du flux. Cette approche d’optimisation à l’échelle du réseau est parfaitement alignée avec l’esprit de ce que j’ai présenté aujourd’hui. Toutefois, si vous souhaitez vraiment optimiser un véritable réseau supply chain multi-échelons, il vous faudra une technique différente de celle que j’ai exposée aujourd’hui. Il existe de nombreux éléments constitutifs qui vous permettront de le faire, mais vous ne pouvez pas simplement ajuster les scripts que j’ai présentés aujourd’hui pour y parvenir. Ce sera le type de technologie pour lequel nous aborderons la configuration multi-échelons dans de prochaines conférences. C’est plus compliqué.
Question: L’approche de récompense de stocks et l’erreur attendue me rappellent le concept de valeur attendue en finance. De votre point de vue, pourquoi cette approche n’est-elle pas encore courante dans les cercles supply chain ?
Vous avez tout à fait raison. Ce genre de pratiques, comme une véritable analyse économique des résultats, est réalisé depuis des lustres dans les cercles financiers. Je pense que la plupart des banques effectuent ces calculs depuis les années 80, et probablement que certaines personnes les réalisaient même avant, à l’aide d’un stylo et de papier. Donc oui, c’est quelque chose qui existe depuis des lustres dans d’autres secteurs.
Je pense que le problème avec les supply chains était qu’avant l’avènement d’internet, elles étaient distribuées géographiquement par nature, avec des magasins, des centres de distribution, et d’autres points répartis. Avant 1995, il était possible, mais très compliqué, de transférer des données via internet pour les entreprises. C’était faisable, mais le faire de manière fiable, à moindre coût, tout en disposant de systèmes d’entreprise permettant de consolider toutes ces données, était rare. Essentiellement, les supply chains se sont numérisées très tôt, dans les années 80, mais elles n’étaient pas fortement interconnectées. L’ingrédient du réseautage et toute l’infrastructure sont arrivés relativement tard, je dirais après l’an 2000 pour la plupart des entreprises.
Le problème était le suivant : imaginez que vous opériez dans un centre de distribution mais que vous soyez assez isolé du reste du réseau, de sorte que le gestionnaire d’entrepôt ne disposait pas des ressources nécessaires pour réaliser des calculs numériques sophistiqués. Le gestionnaire d’entrepôt avait un entrepôt à gérer et n’était généralement pas un analyste. Ainsi, ces pratiques qui existaient avant l’ère d’internet, où toutes les informations étaient accessibles via le réseau, ont perduré. Ce serait la raison, et d’ailleurs, les supply chains sont généralement de très grandes bêtes compliquées et complexes, elles évoluent donc lentement.
Avec le partage des données à travers le réseau grâce à de très beaux data lakes – disons que c’était en 2010, bien que cela remonte à 10 ans – ce que j’observe, c’est que certaines entreprises se déplacent maintenant, d’autres l’ont déjà fait, mais une décennie n’est pas si longue compte tenu de la taille et de la complexité des supply chains. C’est pourquoi ce type d’analyses a été la norme en finance pendant environ quatre décennies, et qu’il n’émerge que maintenant dans la supply chain, du moins c’est mon humble avis.
Question: Qu’en est-il du coût de rupture de stock, principalement calculé sur le coût de mauvaise affectation ?
Vous pouvez le faire. Encore une fois, le coût de rupture de stock est littéralement une décision que vous prenez. C’est votre perspective stratégique sur le type de service que vous souhaitez que votre réseau de vente au détail offre à vos clients. Il n’existe pas de réalité de base ; c’est littéralement ce que vous voulez. La question du coût de mauvaise affectation est la suivante : la réalité est que la plupart des réseaux de vente au détail ne survivent que grâce à une clientèle fidèle. Les gens reviennent aux magasins, que ce soit un magasin de produits généraux qu’ils visitent chaque semaine, un magasin de mode qu’ils fréquentent chaque trimestre, ou un magasin de meubles auquel ils retournent tous les deux ans. La qualité de service est essentielle pour maintenir la loyauté client à long terme et garantir une expérience positive dans votre magasin. En règle générale, le coût de la perte de cette loyauté pour la plupart des magasins surpasse de loin les coûts de mauvaise affectation. Une exception qui me vient à l’esprit concerne les magasins de vente au détail dont la stratégie de marque est axée sur le fait d’être les moins chers. Dans ce cas, ils pourraient sacrifier l’assortiment et la qualité de service, en privilégiant les bas prix avant tout.
Question: Quel est l’objectif de constituer des stocks dans votre entrepôt ? Est-ce de maintenir les produits à bas prix ou de fournir aux magasins des produits à des prix plus élevés ?
C’est une excellente question. Pourquoi conserver des stocks dans le centre de distribution ? Pourquoi ne pas cross-dock tout directement en envoyant tout aux magasins ?
Il existe des réseaux de vente au détail qui pratiquent le cross-docking pour tout, mais même avec cette approche, il y a un délai entre le moment où vous passez commande auprès de vos fournisseurs et celui où vous expédiez effectivement les stocks vers les magasins. Vous pouvez commander des quantités spécifiques en ayant en tête un certain schéma d’allocation, mais vous avez la flexibilité de changer d’avis lorsque les stocks sont livrés au centre de distribution. Vous n’avez pas à rester rigoureusement lié au schéma d’allocation que vous aviez envisagé il y a deux jours.
Vous pouvez décider de ne pas conserver de stocks dans le centre de distribution et de simplement pratiquer le cross-docking, mais à cause du délai, vous pouvez changer d’avis et effectuer un dispatch légèrement différent. Cela peut être utile, par exemple, lorsque vous rencontrez une rupture de stock due à une hausse inattendue de la demande. Bien qu’il soit préférable d’éviter une rupture de stock, cela indique un excès de demande par rapport à ce qui était prévu, ce qui n’est pas entièrement négatif.
Dans d’autres situations, conserver des stocks dans l’entrepôt est nécessaire en raison des contraintes de commande avec les fournisseurs. Par exemple, les entreprises FMCG pourraient ne vous permettre de passer commande qu’une fois par semaine, et elles souhaitent généralement livrer un camion complet à votre centre de distribution. Vos commandes seront volumineuses et groupées, et votre centre de distribution sert de tampon pour ces livraisons. Ce centre vous offre également l’option de changer d’avis quant à l’allocation des stocks.
Tant que les stocks se trouvent dans le centre de distribution, vous pouvez changer d’avis. Cependant, une fois qu’ils sont alloués à un magasin spécifique, le coût de transport pour les ramener à l’entrepôt est souvent prohibitivement élevé et il vaut mieux l’éviter.
Merci beaucoup, et j’espère vous revoir la prochaine fois. Nous discuterons de la façon d’exécuter des stratégies tactiques et de lancer une véritable initiative de la Supply Chain Quantitative dans une entreprise réelle. À la prochaine !


