00:00 Introduction
03:39 L’automatisation a toujours été l’objectif
06:28 Gestion des exceptions et alertes
10:27 L’histoire jusqu’à présent
14:33 Notre déploiement en production aujourd’hui
15:59 Récapitulatif : livrable, périmètre et rôles
19:01 Dévoiler la forme de la décision
23:00 Réponse dictée par l’héritage
27:20 Itérer jusqu’à zéro pour cent de folie
32:30 Indicateurs ambitieux
36:27 Double exécution : manuel + mécanique
39:19 Paralysie de l’analyse
43:21 Prise de contrôle progressive par l’automatisation
46:08 Sédimentation du processus
48:57 Du planificateur au gestionnaire de réseau
52:46 Le touriste des KPI
54:58 Leadership : du coach au product owner
58:46 Le boss analogique de la supply chain
01:02:25 Conclusion
01:04:44 7.2 Mettre en production des décisions automatisées - Questions ?
Description
Nous recherchons une recette numérique pour piloter toute une classe de décisions routinières, telles que les réapprovisionnements de stocks. L’automatisation est essentielle pour faire de la supply chain une entreprise capitaliste. Cependant, elle comporte des risques substantiels de causer des dommages à grande échelle si la recette numérique est défectueuse. “Fail fast and break things” n’est pas l’état d’esprit approprié pour donner le feu vert à une recette numérique en production. Toutefois, de nombreuses alternatives, telles que le modèle en cascade, sont encore pires puisqu’elles donnent généralement une illusion de rationalité et de contrôle. Un processus hautement itératif est la clé pour concevoir la recette numérique qui s’avère être de niveau production.
Transcription complète

Bienvenue dans cette série de conférences sur la supply chain. Je suis Johannes Vermorel et aujourd’hui je présenterai “Mettre en production des décisions automatisées en supply chain”. Au cours des deux derniers siècles, nos économies ont connu une transformation massive grâce à la mécanisation. Les entreprises qui ont atteint un niveau supérieur de mécanisation par rapport à leurs concurrents ont presque toujours poussé systématiquement ces derniers vers la faillite. La mécanisation nous permet de faire plus, mieux et plus rapidement tout en réduisant les coûts. Cela est vrai pour des tâches physiques comme déplacer des marchandises avec un chariot élévateur au lieu de porter des boîtes à la main, mais il en va de même pour des tâches intellectuelles comme calculer combien d’argent il vous reste à la banque.
Cependant, notre capacité à mécaniser une tâche dépend de la technologie. Il existe encore de nombreuses tâches physiques qui ne peuvent pas encore être mécanisées, par exemple se faire couper les cheveux ou changer les draps. Inversement, il existe encore de nombreuses tâches intellectuelles qui ne peuvent pas encore être mécanisées, comme recruter la bonne personne ou déterminer ce que le client souhaite. Il n’y a aucune raison de penser que ces tâches, qu’elles soient intellectuelles ou mécaniques, ne pourront jamais être mécanisées. Toutefois, la technologie n’est pas encore tout à fait au point.
La plupart des décisions routinières et quotidiennes en supply chain peuvent désormais être automatisées. Il s’agit d’un développement relativement récent. Il y a une décennie, le champ des décisions en supply chain qui pouvaient être automatisées avec succès ne représentait qu’une fraction de l’ensemble des décisions en supply chain. De nos jours, la situation est inversée et, avec la bonne technologie, les décisions répétitives en supply chain qui ne peuvent être automatisées avec succès sont rares. Par automatisation réussie, j’entends un processus dans lequel les décisions automatisées sont supérieures à celles obtenues par un processus manuel, et non la capacité à générer des décisions par un ordinateur, ce qui est trivial tant que l’on ne se soucie pas de la qualité des décisions générées.
Notre objectif aujourd’hui n’est pas la recette numérique - c’est-à-dire le logiciel qui rend possible cette automatisation dès le départ. Dans le contexte des processus de prise de décision en supply chain, les ingrédients nécessaires pour élaborer une telle recette numérique ont été abordés dans les chapitres précédents de cette série de conférences. Notre objectif aujourd’hui porte sur les parties de l’initiative supply chain requises pour mettre en production une telle recette numérique. Le but de cette conférence est de présenter ce qu’il faut pour faire passer une entreprise des décisions supply chain manuelles à des décisions automatisées. À la fin de cette conférence, vous devriez avoir des éclairages sur ce qu’il faut faire et ne pas faire lors de la transition vers l’automatisation. En effet, la pure difficulté technique associée à la recette numérique tend à éclipser les aspects organisationnels qui sont néanmoins tout aussi essentiels pour le succès de l’initiative.

Lorsqu’on présente aux praticiens actuels de la supply chain l’idée de l’automatisation de la prise de décision, leur réaction immédiate tend à être : “C’est une idée tellement futuriste. Nous n’y sommes pas encore du tout.” Cependant, l’automatisation complète des décisions routinières et répétitives en supply chain a littéralement été l’objectif dès le tout début de l’ère numérique des supply chains il y a plus de quatre décennies.
Dès que les ordinateurs sont devenus facilement accessibles aux entreprises, les gens ont réalisé que la plupart des décisions en supply chain étaient des candidats évidents pour une automatisation complète. À l’écran, j’ai sélectionné une liste de publications qui illustrent cette ambition. Dans les années 1970 et 1980, ce domaine n’était même pas encore appelé supply chain. Le terme ne deviendra populaire qu’au cours des années 1990. Cependant, l’intention était déjà claire. Ces systèmes informatiques semblaient immédiatement adaptés pour automatiser les décisions les plus répétitives en supply chain, telles que les réapprovisionnements de stocks.
La chose la plus étonnante pour moi est que cette communauté semble quelque peu inconsciente de ses anciennes ambitions. De nos jours, afin de paraître futuristes, le terme “supply chain autonome” est parfois utilisé par des cabinets de conseil ou des entreprises informatiques pour véhiculer cette perspective de mécanisation des décisions routinières en supply chain. Cependant, le terme “autonomous” me semble inapproprié. Nous n’utilisons pas le terme “logistique autonome” pour désigner un convoyeur équipé d’un système de tri. Le convoyeur est mécanisé, pas autonome. Le convoyeur nécessite encore une supervision technique, mais cette innovation ne représente qu’une infime fraction de la main-d’œuvre qui serait autrement nécessaire à l’entreprise pour transporter les marchandises sans le convoyeur. En ce qui concerne les décisions en supply chain, l’objectif n’est pas de supprimer complètement l’humain de l’organisation, afin d’atteindre une technologie véritablement autonome. L’objectif est simplement de retirer l’humain de la partie la plus chronophage et la plus rudimentaire du processus. C’est exactement la perspective qui a été adoptée dans ces articles publiés il y a quatre décennies et c’est également la perspective que j’adopte dans cette conférence.

Dans les années 1990, il semble que les vendeurs de logiciels, tant les fournisseurs d’ERP que les spécialistes de l’optimisation de stocks, aient largement abandonné l’idée de parvenir à des décisions automatisées en supply chain. Rétrospectivement, les modèles simplistes des années 1970, qui ignoraient en grande partie de nombreux facteurs importants tels que l’incertitude, constituaient la cause racine évidente expliquant pourquoi l’automatisation n’avait pas réussi à l’époque. Cependant, corriger cette cause profonde s’est avéré être au-delà de ce que la technologie pouvait offrir durant cette période. Au lieu de cela, les vendeurs de logiciels se sont rabattus sur des systèmes de gestion des exceptions. Ces systèmes sont censés produire des alertes de stocks basées sur des règles configurées par l’entreprise cliente elle-même. Le raisonnement était le suivant : laissons l’automatisation s’occuper de la majorité des lignes pouvant être traitées automatiquement pour que l’intervention humaine se concentre sur les lignes difficiles, celles qui dépassent la capacité de la machine.
Signalons immédiatement que vendre un système de gestion des exceptions est une très bonne affaire pour le vendeur de logiciels, mais bien moins pour l’entreprise cliente. Tout d’abord, la gestion des exceptions transfère la responsabilité de la performance de la supply chain du vendeur vers le client. Une fois le système de gestion des exceptions en place, si les résultats sont mauvais, c’est la faute du client. Celui-ci aurait dû configurer de meilleures alertes pour empêcher que des situations dommageables ne se produisent dès le départ.
Deuxièmement, créer un système pour gérer les alertes de stocks paramétrées est facile pour le vendeur de logiciels tant qu’il n’a pas à fournir une quelconque valeur de paramètre régissant les alertes sources. En effet, d’un point de vue analytique, être capable de produire une bonne alerte de stocks signifie que vous pouvez concevoir une règle pouvant identifier de manière fiable de mauvaises décisions de stocks. Si vous pouvez concevoir une règle capable d’identifier de manière fiable de mauvaises décisions de stocks, alors par définition, la même règle peut également être utilisée pour produire de manière fiable de bonnes décisions de stocks. En effet, il suffit d’utiliser la règle comme un filtre pour empêcher que de mauvaises décisions ne soient prises.
Troisièmement, la gestion des exceptions est une stratégie assez astucieuse pour le vendeur de logiciels afin d’exploiter la psychologie humaine. En effet, ces alertes exploitent un mécanisme connu sous le nom de “commitment and consistency” par les psychologues expérimentaux. Ce mécanisme crée une forte dépendance, bien que largement accidentelle, au produit logiciel. En bref, une fois que les employés commencent à ajuster les chiffres de stocks, ces nombres ne sont plus arbitraires. Ce sont leurs chiffres, leur travail, et par conséquent, les employés s’attachent émotionnellement au système, que celui-ci offre ou non une performance de supply chain supérieure.
Globalement, la gestion des exceptions est une impasse technologique car, en général, concevoir des exceptions fiables et des alertes fiables est tout aussi difficile que de concevoir une automatisation fiable des décisions. Si vous ne pouvez pas faire confiance à vos alertes et à vos exceptions pour être fiables, alors vous devez tout examiner manuellement de toute façon, ce qui vous ramène au point de départ. Le processus de prise de décision reste strictement manuel.

Cette série de conférences sur la supply chain comprend deux douzaines d’épisodes. À ce stade, en quelque sorte, tous les éléments que nous avons présentés jusqu’à présent ont été élaborés dans le but explicite d’arriver au point où nous en sommes aujourd’hui : sur le point de mettre en production cette initiative la Supply Chain Quantitative. Plus précisément, c’est la recette numérique que nous souhaitons mettre en prévision, et cette entreprise est au cœur de la conférence d’aujourd’hui.
Dans ces conférences, j’utilise le terme “recette numérique” pour désigner la séquence de calculs qui prend des données historiques brutes en entrée et produit les décisions finales. Cette terminologie est intentionnellement vague car elle reflète une multitude de concepts, méthodes et techniques qui ont été précisément abordés dans les conférences des chapitres précédents. Dans le premier chapitre, nous avons vu pourquoi la supply chain doit devenir programmatique et pourquoi il est fortement souhaitable de pouvoir mettre une telle recette numérique en production. La complexité toujours croissante des supply chains rend l’automatisation plus urgente que jamais. Il y a également un impératif de faire de la pratique supply chain une entreprise capitaliste.
Le deuxième chapitre est consacré aux méthodologies. En effet, les supply chains sont des systèmes compétitifs. Cette combinaison rend les méthodologies naïves obsolètes. Parmi les méthodologies que nous avons présentées, les personae de la supply chain et l’optimisation expérimentale sont d’une importance primordiale pour le sujet d’aujourd’hui. Les personae de la supply chain sont la clé pour adopter la bonne forme de décision. Nous reviendrons sur ce point dans quelques minutes. L’optimisation expérimentale est essentielle pour fournir quelque chose qui fonctionne réellement. Encore une fois, nous reviendrons également sur ce point dans quelques minutes.
Le troisième chapitre dresse un état des lieux du problème, en mettant de côté la solution par le biais des personae de la supply chain. Ce chapitre tente de caractériser les catégories de problèmes de prise de décision qui doivent être abordées. Ce chapitre montre que des perspectives simplistes, comme simplement devoir choisir la bonne quantité pour chaque SKU, ne correspondent pas vraiment aux situations du monde réel. Il existe presque invariablement une profondeur dans la forme des décisions.
Le quatrième chapitre passe en revue les éléments nécessaires pour appréhender une pratique moderne de la supply chain où les éléments logiciels sont omniprésents. Ces éléments sont fondamentaux pour comprendre le contexte plus large dans lequel la recette numérique et en réalité la plupart des processus de la supply chain opèrent. En effet, de nombreux manuels de supply chain supposent implicitement que leurs techniques et formules fonctionnent dans un certain vide. Ce n’est pas le cas. Le paysage applicatif compte.
Les chapitres 5 et 6 sont consacrés respectivement à la modélisation prédictive et à la prise de décision. Ces chapitres couvrent les aspects intelligents de la recette numérique, mettant en avant des techniques de machine learning et des techniques d’optimisation mathématique. Enfin, le septième et présent chapitre est dédié à l’exécution d’une initiative de la Supply Chain Quantitative dont le but est précisément de mettre en production une recette numérique et de la maintenir par la suite. Dans la conférence précédente, nous avons abordé ce qu’il faut pour lancer l’initiative tout en posant les bases techniques appropriées. Cela signifie la mise en place d’un data pipeline. Aujourd’hui, nous voulons franchir la ligne d’arrivée et mettre en action cette recette numérique.

Nous commencerons par un court récapitulatif de la conférence précédente, puis nous aborderons trois aspects importants des dernières étapes de l’initiative. Le premier aspect concerne la conception de la recette numérique. Cependant, je ne parlerai pas de la conception des parties numériques de la recette, mais de la conception du processus d’ingénierie lui-même, qui entoure la recette numérique. Nous verrons comment aborder ce défi afin de donner à l’initiative une chance de faire émerger une solution satisfaisante.
L’aspect deuxième concerne le déploiement correct de la recette numérique. En effet, l’entreprise commence avec un processus manuel et doit finir avec un processus automatisé. Un déploiement adéquat peut largement atténuer le risque associé à cette transition ou plutôt atténuer le risque associé à une recette numérique qui s’avèrerait défectueuse, du moins initialement.
Le troisième aspect concerne le changement qui doit s’opérer dans l’entreprise une fois l’automatisation déployée. Nous verrons que les rôles et les missions des personnes dans la supply chain devraient subir un changement substantiel.
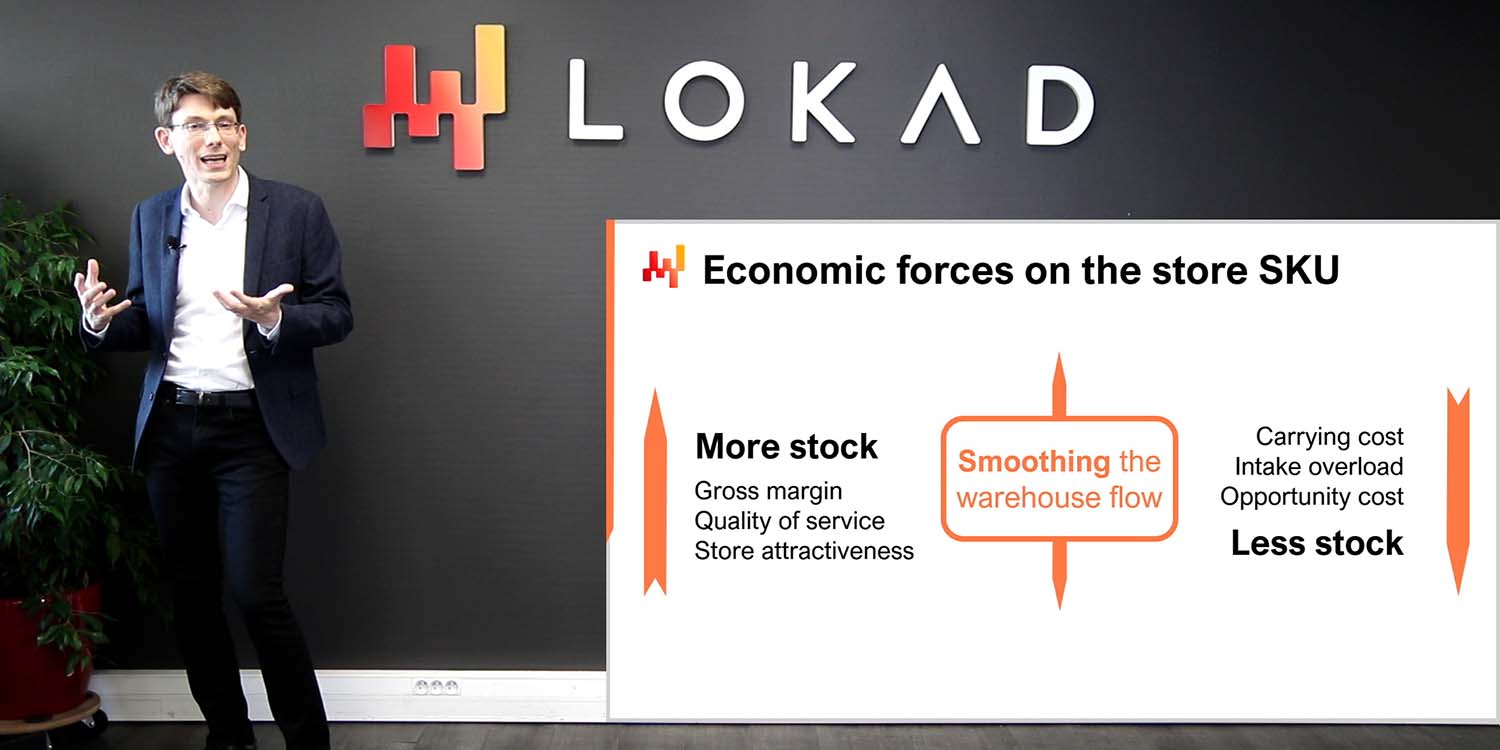
Dans la conférence précédente, nous avons vu comment lancer une initiative de la Supply Chain Quantitative. Revenons sur les aspects les plus importants. Le livrable est une recette numérique opérationnelle, qui est un morceau de logiciel pilotant une catégorie de décisions supply chain, par exemple, le réapprovisionnement des stocks. Cette recette numérique, une fois mise en production, délivrera l’automatisation recherchée. Les décisions ne doivent pas être confondues avec des artefacts numériques comme les prévisions de demande, qui sont seulement des résultats intermédiaires pouvant contribuer au calcul des décisions elles-mêmes.
Le périmètre de l’initiative doit être aligné à la fois avec la supply chain, comprise comme un système, et avec son paysage applicatif sous-jacent. Portant attention aux propriétés systémiques de la supply chain est essentiel afin d’éviter de déplacer des problèmes plutôt que de les résoudre. Par exemple, si l’optimisation de stocks d’un magasin dans une retail chain est effectuée au détriment des autres magasins, alors cette optimisation n’a aucun sens. De plus, prêter attention au paysage applicatif est important car nous devons minimiser les efforts initiaux de mise en place de la plomberie des données. Les ressources informatiques constituent presque toujours un goulot d’étranglement, et nous devons veiller à ne pas exacerber cette limitation.
Enfin, nous avons identifié quatre rôles pour cette initiative, à savoir le cadre supply chain, le data officer, le supply chain scientist, et le praticien supply chain. Le cadre supply chain est responsable de la stratégie, de la conduite du changement et arbitre les choix de modélisation. Le data officer est responsable de la mise en place de la chaîne de données, qui rend les données transactionnelles pertinentes disponibles pour la couche analytique. Dans cette conférence, nous partons du principe que la chaîne de données a déjà été mise en place. Le supply chain scientist est chargé de l’implémentation de la recette numérique, qui inclut beaucoup d’instrumentation, et pas seulement les passages algorithmiques astucieux. Enfin, le praticien supply chain est une personne impliquée dans le processus décisionnel manuel. Cette personne occupe généralement un rôle de planificateur de l’offre et de la demande, bien que la terminologie puisse varier. Au début de l’initiative, on s’attend à ce qu’elle évolue vers le rôle de gestionnaire de réseau d’ici la fin de l’initiative. Nous reviendrons sur ce point plus tard dans la conférence.

Les supply chains sont particulièrement favorables à l’automatisation des processus décisionnels. Il existe de nombreuses décisions banales et hautement répétitives qui sont de nature quantitative. Malheureusement, la perspective de modélisation proposée dans la plupart des manuels supply chain est généralement excessivement simpliste. Je ne dis pas que les techniques de manuel sont trop simples ou simplistes. Cependant, je dis simplement que le genre de problèmes présenté dans ces manuels tend à être simpliste. Prenons, par exemple, une situation de réapprovisionnement des stocks. La perspective du manuel recherche la politique de stocks optimale pour calculer combien d’unités doivent être re-commandées. Cela va, mais c’est souvent une réponse plutôt incomplète.
Par exemple, nous pourrions devoir décider si les marchandises vont être expédiées par avion ou par mer, les deux modes de transport représentant un compromis entre lead time et le coût de transport. Nous pourrions devoir choisir un fournisseur parmi plusieurs fournisseurs éligibles. Nous pourrions devoir déterminer le plan d’expédition exact avec plusieurs dates d’expédition si la quantité est suffisamment grande pour justifier plusieurs envois.
Le troisième chapitre de cette série, un chapitre dédié aux personae supply chain, a présenté des vues détaillées de situations réelles de supply chain dans lesquelles nous constatons qu’il y a presque toujours des subtilités au-delà du simple choix d’une quantité pour un SKU donné. Ainsi, le supply chain scientist, avec l’aide du praticien supply chain et du cadre supply chain, doit commencer par dévoiler la forme complète de la décision. La forme complète de la décision doit inclure tous les éléments qui contribuent à façonner le fonctionnement réel de la supply chain. Découvrir la forme complète de la décision est difficile.
Premièrement, la division du travail telle qu’implémentée dans la plupart des entreprises exploitant une grande supply chain fragmente généralement les différents aspects de la décision entre plusieurs employés et parfois entre plusieurs départements. Par exemple, une personne détermine la quantité à re-commander tandis qu’une autre décide quel fournisseur recevra le bon de commande.
Deuxièmement, les aspects plus subtils de la décision, tels que demander au fournisseur d’accélérer la commande lorsqu’il y a eu un pic de demande, tendent à être négligés car les praticiens ne se rendent pas compte que ces aspects peuvent et doivent également être automatisés. Je suggère que la description de cette forme complète de décision soit rédigée, non pas sous forme de série de diapositives mais sous forme de véritable texte. En particulier, le texte doit clarifier le “pourquoi”. Qu’est-ce qui est exactement en jeu pour chaque aspect de la décision ? En effet, si certains aspects de la décision peuvent paraître relativement évidents, comme la quantité lors d’une commande de réapprovisionnement, d’autres aspects peuvent être négligés ou oubliés. Par exemple, un fournisseur pourrait offrir, moyennant un certain prix, l’option de retourner les marchandises dans les six mois si les colis restent intacts. Exercer ou non cette option devrait faire partie de la décision, mais cela peut facilement être oublié.

Ne pas identifier la forme complète de la décision supply chain, ou pire, mal caractériser la décision dans son ensemble, est l’une des manières les plus sûres d’échouer l’initiative. En particulier, la réponse dictée par l’héritage est l’une des erreurs les plus fréquentes dans les grandes entreprises. L’essence de cette réponse héritée est d’adopter une forme de décision qui n’a pas réellement de sens pour l’entreprise et sa supply chain, mais qui est adoptée néanmoins parce que cette forme correspond à un logiciel transactionnel existant ou à un processus préexistant au sein de l’organisation.
Par exemple, il peut être décidé que le réapprovisionnement des stocks doit être contrôlé par le calcul des niveaux de safety stock au lieu de calculer directement les quantités réelles à re-commander. Le calcul des safety stocks peut sembler plus facile puisque ces safety stocks existent déjà dans l’ERP. Ainsi, si les valeurs de safety stock devaient être recalculées, ces valeurs pourraient être facilement injectées dans l’ERP, remplaçant ainsi la formule réellement utilisée dans le DRP.
Cependant, les safety stocks présentent des limites substantielles. Même quelque chose d’aussi élémentaire qu’une quantité minimale de commande (MOQ) ne s’inscrit pas dans une perspective de safety stock. Au minimum, cette implémentation est privilégiée non pas en raison d’un logiciel particulier, mais en raison de processus préexistants dans l’organisation.
Par exemple, un réseau de distribution peut avoir deux équipes de planification : une équipe dédiée au réapprovisionnement des magasins et une équipe dédiée aux niveaux de personnel des centres de distribution. Cependant, ces deux problèmes sont fondamentalement les mêmes. Une fois que les quantités de réapprovisionnement pour les magasins ont été déterminées, il n’y a plus de marge pour décider de la quantité de personnel nécessaire pour les centres de distribution. Ainsi, les deux équipes ont des missions fondamentalement qui se chevauchent. Cette division du travail fonctionne tant que des humains interviennent. Les humains excellent à gérer des exigences ambiguës. Toutefois, cette ambiguïté constitue un obstacle majeur à toute tentative d’automatiser le réapprovisionnement ou les besoins en personnel.
Ce contre-modèle, la réponse dictée par l’héritage, est très tentant car il minimise la quantité de changements à mettre en œuvre. Cependant, l’automatisation de la décision modifie même l’approche à adopter pour la prendre. Fréquemment, si le design hérité est maintenu, alors l’initiative de la Supply Chain Quantitative est vouée à l’échec.
Premièrement, cela complique encore davantage la conception de la recette numérique qui est déjà une entreprise assez complexe. En effet, les schémas qui étaient appropriés pour une division du travail entre employés humains ne sont pas ceux qui conviennent à un logiciel fonctionnant de manière purement mécanique.
Deuxièmement, la réponse héritée annule également bon nombre des avantages potentiels associés à l’automatisation. En effet, dans la supply chain, de nombreuses inefficacités se trouvent aux frontières existant au sein de l’entreprise. L’automatisation élimine la nécessité de la plupart de ces frontières, celles qui ont été introduites simplement en raison d’une manière particulière d’organiser la division du travail, ce qui n’a pas de sens lorsqu’un ordinateur s’occupe de l’ensemble du processus. Ne laissez pas des décisions prises il y a deux ou trois décennies dicter l’avenir de votre supply chain.
Une fois que la forme de la décision a été correctement caractérisée, le supply chain scientist commence à élaborer la recette numérique elle-même, en tirant parti des données transactionnelles historiques. Dans cette série de conférences, deux chapitres sont dédiés aux subtilités des techniques algorithmiques pouvant être utilisées pour apprendre et optimiser. Je ne reviendrai pas sur ces éléments aujourd’hui. Disons simplement que le supply chain scientist prend une série de décisions de jugement afin d’élaborer une première version de la recette numérique basée sur ses connaissances, son expérience ainsi que sur les outils disponibles pour les supply chain scientists.
Avec les bons outils et techniques, ce premier brouillon peut et doit être implémenté en quelques jours, quelques semaines au maximum. En effet, nous ne parlons pas de recherches avancées visant à découvrir une technique novatrice, mais simplement d’élaborer une adaptation de techniques connues qui tiennent compte des spécificités de la supply chain concernée. En effet, la recette numérique doit très strictement respecter toutes les subtilités de la décision telles qu’elles ont été identifiées dans leur forme complète.
Même en considérant un supply chain scientist très compétent s’appuyant sur les meilleurs outils que l’argent peut acheter, il est vain d’espérer que la recette numérique soit correcte dès la première tentative. En effet, les supply chains sont trop complexes et obscures, notamment dans leurs représentations digitales, pour qu’une recette numérique soit parfaite dès la première fois. Les méthodes numériques introspectives, comme l’utilisation de métriques et de benchmarks, ne peuvent détecter une mauvaise interprétation d’une donnée par le supply chain scientist.
Pour chaque colonne de chaque table issue du système transactionnel qui fait fonctionner l’entreprise, il existe généralement plusieurs manières d’interpréter ces données. Étant donné qu’il s’agit de dizaines de colonnes à intégrer dans la recette numérique, des erreurs sont garanties. La seule façon d’évaluer la justesse de la recette numérique est de la tester et d’obtenir des retours concrets du terrain. Cela a été abordé dans le deuxième chapitre de cette série dans la conférence intitulée “Optimisation Expérimentale”.
Ainsi, le supply chain scientist doit collaborer avec le praticien supply chain afin d’identifier les situations où la recette numérique, dans sa forme actuelle, renvoie encore des résultats insensés. De manière générale, le supply chain scientist implémente un dashboard qui consolide la décision telle qu’elle serait prise aujourd’hui par la recette numérique, et le praticien supply chain tente d’identifier des lignes qui semblent insensées.
À partir de ces retours, les scientifiques instrumentent davantage la recette numérique. L’instrumentation prend la forme d’indicateurs qui tentent de répondre à la question : pourquoi cette décision apparemment insensée a-t-elle été prise dans ce contexte ? Grâce à cette instrumentation, il devient possible de décider si la recette numérique doit être corrigée, par exemple parce qu’un levier économique est mal modélisé, ou si la décision apparemment insensée est en réalité correcte, simplement différente de la manière dont les choses étaient faites jusqu’à présent dans l’entreprise.
L’optimisation expérimentale est un processus hautement itératif. En règle générale, avec les bons outils, un supply chain scientist à plein temps doit être capable de présenter une nouvelle itération de la recette numérique chaque jour au praticien supply chain. Si la recette numérique est correctement instrumentée, au fur et à mesure de l’avancement de l’initiative, le praticien ne devrait pas avoir besoin de plus de deux heures par jour pour fournir des retours sur la dernière itération de la recette numérique.
L’itération s’arrête lorsque la recette numérique ne génère plus de résultats insensés, c’est-à-dire lorsque le praticien ne peut plus identifier de décisions manifestement nuisibles à l’entreprise. L’absence de décisions insensées peut sembler être un seuil bas comparé à notre objectif global de générer des décisions supérieures à celles du processus manuel. Cependant, rappelons que la recette numérique a été conçue dès le départ pour réaliser explicitement une optimisation mathématique de l’intérêt économique à long terme de l’entreprise. Si les résultats sont sensés, alors l’optimisation fonctionne et, plus important encore, cela prouve que le critère d’optimisation lui-même est en quelque sorte correct.

Bien que le processus d’ingénierie hautement itératif de la recette numérique puisse corriger de nombreux problèmes présents dans l’implémentation initiale, les itérations à elles seules ne suffisent pas si la perspective adoptée pour l’optimisation est erronée. Dans cette série de conférences, j’ai déjà affirmé que l’optimisation devait être effectuée selon une métrique financière, c’est-à-dire une métrique exprimée en euros ou en dollars. Cependant, permettez-moi de clarifier cette affirmation : ne pas utiliser une métrique financière est une erreur qui met en péril l’ensemble de l’initiative.
Malheureusement, les grandes organisations évitent généralement les métriques financières. À la place, elles préfèrent les métriques aspirantes, qui se présentent sous forme de pourcentage et représentent une sorte de perfection qui serait atteinte si l’on arrivait à 0 % ou à 100 %, selon le cas. Naturellement, la perfection n’appartient pas à ce monde, et cette situation limite ne sera jamais atteinte. taux de service sont, par exemple, l’archétype de la métrique aspirante. Le 100% taux de service est impossible à atteindre, car cela impliquerait une quantité déraisonnable de stocks.
Certains managers dans les grandes entreprises adorent ces métriques aspirantes. Les équipes se réunissent régulièrement pour discuter de ce qui peut être fait pour améliorer davantage ces métriques. Comme ces métriques dépendent invariablement de facteurs qui échappent au contrôle de l’entreprise, elles peuvent être réexaminées sans fin. Par exemple, les taux de service dépendent du volume de la demande exprimée par les clients et des délais de livraison offerts par les fournisseurs. Ni la demande ni les délais de livraison ne sont entièrement sous le contrôle de l’entreprise.
Ces métriques aspirantes fonctionnent en quelque sorte comme des objectifs d’entreprise lorsque les humains restent dans la boucle décisionnelle, car ils n’accordent pas trop d’attention à ces indicateurs dès le départ. Par exemple, même si tout le monde convient que le taux de service devrait être augmenté, les planificateurs maintiendront encore de nombreuses exceptions non documentées. Le taux de service sera systématiquement augmenté, sauf si le risque de stocks est trop élevé, si la quantité minimale de commande est trop importante, si le produit est sur le point d’être supprimé, ou s’il ne reste plus de budget pour le produit, etc.
Malheureusement, ces métriques aspirantes se transforment en poison lors du déploiement d’un processus automatisé. En effet, ces métriques sont incomplètes et ne reflètent pas ce qui est réellement souhaitable pour l’entreprise. Par exemple, atteindre un taux de service de 100 % n’est pas souhaitable, car cela créerait d’énormes surstocks pour l’entreprise. Il est possible – non pas imprudent mais possible – d’essayer de réimplémenter toutes ces contraintes, toutes ces exceptions en sus des métriques aspirantes. Je veux dire, constituer une recette numérique visant les métriques aspirantes avec de nombreuses contraintes mimant ce qui pourrait se passer dans l’esprit d’un planificateur. Par exemple, nous pourrions définir la règle selon laquelle le taux de service doit être augmenté tant que nous maintenons les stocks inférieurs à l’équivalent de quatre mois d’approvisionnement. Cependant, cette stratégie de conception et de mise en œuvre effective de la recette numérique est excessivement fragile. L’optimisation financière directe constitue une voie bien plus sûre et supérieure.

Afin d’atteindre une collaboration efficace entre le Supply Chain practitioner – ou, plus vraisemblablement, des practitioners – et le Supply Chain Scientist, je recommande d’adopter dès le départ une stratégie de dual-run. La recette numérique devrait être exécutée quotidiennement parallèlement au processus manuel préexistant. Avec le dual-run, l’entreprise génère effectivement la décision deux fois, à travers deux processus concurrents. Cependant, malgré la friction, le dual-run offre des avantages substantiels. Premièrement, le Supply Chain practitioner a besoin de décisions fraîchement générées qui correspondent à la situation actuelle pour pouvoir réaliser son évaluation. Sinon, le practitioner ne pourra même pas donner de sens à la décision automatisée, ni identifier les éléments aberrants. En effet, du point de vue du practitioner, les décisions reflétant la situation de la supply chain d’il y a trois semaines relèvent de l’histoire ancienne. Il y a peu à gagner à passer des heures à revisiter les niveaux de stocks passés.
Au contraire, si les décisions automatisées sont fraîches et reflètent la situation actuelle, alors ces décisions entrent en concurrence avec celles que le practitioner s’apprête à prendre manuellement. Ces décisions automatisées peuvent, pour le moment, être considérées comme de simples suggestions.
Deuxièmement, l’exécution quotidienne de la recette numérique garantit que l’ensemble du pipeline de données subit un test fonctionnel complet chaque jour. En effet, la recette numérique ne doit pas seulement renvoyer des résultats sensés ; elle doit également fonctionner de manière impeccable du point de vue de l’infrastructure informatique. Les supply chains sont déjà assez chaotiques et la recette numérique ne doit pas ajouter sa propre couche de chaos par-dessus. Mettre la recette dans des conditions proches de la production le plus tôt possible permet aux problèmes rares de se manifester rapidement, offrant ainsi au data officer et aux Supply Chain Scientists la possibilité de les corriger rapidement. À titre indicatif, d’ici la fin du premier tiers – c’est-à-dire à la fin du troisième mois après le lancement d’une initiative de Supply Chain Quantitative – le dual-run devrait être en place, même si la recette numérique n’est pas encore prête à être mise en production.
De plus, à la fin du premier mois de dual-run, si le scientist accomplit correctement son travail, le practitioner devrait commencer à observer des tendances dans la liste des décisions automatisées qui auraient été autrement manquées, même s’il subsiste encore quelques lignes aberrantes nécessitant une amélioration supplémentaire de la recette numérique.

Une fois le dual-run en place, il est attendu que le Supply Chain practitioner consacre un certain temps – une ou deux heures par jour – à examiner les décisions générées par la recette numérique et qu’il tente d’identifier les éléments qui ne sont pas encore tout à fait sensés. Cependant, parfois, la situation restera tout simplement obscure. Une décision est surprenante – peut-être que la recette numérique est lente, peut-être ne l’est-elle pas. Le practitioner se sent incertain et, dans ce cas, il devrait demander au scientist d’ajouter davantage d’instrumentation pour clarifier la situation. Ce processus correspond exactement à ce que l’on désigne dans cette série de conférences par le white-boxing de la recette numérique. Le white-boxing est un processus dans lequel la recette numérique est rendue aussi transparente que possible pour les actionnaires. Le white-boxing est une bonne chose – essentielle même – pour instaurer la confiance dans la recette numérique.
En supposant que les décisions automatisées soient rassemblées dans un tableau du dashboard, la forme d’instrumentation la plus typique consistera en des colonnes supplémentaires placées à côté des colonnes de décision. Par exemple, si l’on envisage les quantités de réapprovisionnement, il existe des colonnes d’instrumentation évidentes, telles que la quantité en stock, le délai moyen prévu, la demande moyenne quotidienne attendue, etc. Cette instrumentation est essentielle pour que le practitioner puisse évaluer rapidement la pertinence des décisions automatisées. Cependant, nous devons rester attentifs à la quantité d’instrumentation qui vient s’ajouter à la recette numérique. Chaque indicateur supplémentaire introduit pour agrémenter la décision automatisée dans le cadre du white-boxing encombre un peu plus la vue que l’on peut avoir des décisions elles-mêmes. Trop de bien peut devenir du mal. Si, après deux mois d’exécution, le practitioner continue de demander systématiquement plus d’instrumentation alors que le pipeline de données est déjà stabilisé, alors nous pourrions avoir un problème.
La cause profonde du problème peut être liée aux aspects complexes de la recette numérique. Dans les chapitres 5 et 6 de cette série, nous avons vu que toutes les techniques et tous les modèles ne se valent pas en termes d’interprétabilité. De nombreux modèles sont très opaques par conception, même pour les data scientists qui les utilisent. Je ne vais pas revenir aujourd’hui sur les classes de modèles répondant aux critères d’interprétabilité. Pour les besoins de cette discussion, je vais simplement supposer que les modèles intégrés dans la recette numérique sont correctement interprétables du point de vue de la supply chain. Dans ce contexte, lorsque l’initiative semble stagner en raison d’un flux incessant de demandes d’instrumentation supplémentaire, la cause principale la plus probable est la paralysie par l’analyse. Le Supply Chain practitioner réfléchit trop à son évaluation de la recette numérique. C’est là l’essence même de la paralysie par l’analyse. Le practitioner soumet la recette numérique à un niveau d’examen qui dépasse ce qui est appliqué au processus manuel. Il incombe au responsable supply chain de s’assurer que l’initiative ne tombe pas dans la paralysie par l’analyse. Et si cela se produit, ce qui peut arriver, il revient également au responsable supply chain de rappeler doucement à l’équipe que les décisions humaines sont également imparfaites. Nous recherchons une amélioration par rapport au processus manuel et non la perfection.

Une fois que la recette numérique ne génère plus de décisions aberrantes et que les décisions elles-mêmes bénéficient d’un niveau d’instrumentation jugé approprié, il est temps d’envisager une transition progressive du processus automatisé pour remplacer le processus manuel. En règle générale, ce stade devrait être atteint dans un délai de deux à quatre mois après le lancement du dual-run. Dès le premier jour du dual-run, la recette numérique devrait fonctionner sur l’ensemble du périmètre de l’initiative. Ainsi, en théorie, la transition des décisions manuelles vers des décisions automatisées pourrait se faire pratiquement du jour au lendemain.
Cependant, la pratique contredit souvent la théorie. Dans le cas d’une entreprise de taille importante, il est essentiel de transférer toutes les décisions du processus manuel vers le processus automatisé du jour au lendemain. Les supply chains sont très complexes et il faut s’attendre à l’inattendu. Il est donc plus judicieux de commencer par un périmètre opérationnel restreint, comme une seule catégorie de produits, puis d’élargir par la suite. Pour les premières étapes de la transition, il convient de prévoir une itération d’une ou peut-être deux semaines. Tant le Supply Chain practitioner que les Supply Chain Scientists doivent examiner attentivement la manière dont se matérialisent les décisions automatisées. Et si rien d’inattendu ne survient sur ce périmètre restreint, et même si la recette numérique ne génère plus de décisions apparemment aberrantes à ce stade, il peut subsister des problèmes dans l’intégration des décisions automatisées aux systèmes transactionnels. Une fois que la recette numérique aura conduit la production pendant quelques semaines, même si le périmètre était relativement réduit, il sera approprié d’accélérer les itérations.
La prise de contrôle peut connaître des augmentations plus substantielles à chaque itération et la durée des itérations peut également être compressée, avec éventuellement jusqu’à deux itérations par semaine. En effet, la durée totale de la transition vers le processus automatisé doit rester raisonnablement courte. Sinon, le retard dans la prise de contrôle introduit d’autres types de risques. La supply chain évolue sans cesse, tout comme son environnement applicatif. En règle générale, la transition ne devrait pas excéder deux à quatre mois, selon l’échelle et la complexité de l’entreprise.

À mesure que la supply chain passe d’un processus manuel à un processus automatisé, une série de changements au sein de l’organisation doit également se produire. Les grandes organisations sont notoirement difficiles à changer, mais il existe deux directions distinctes pour le changement. L’organisation peut ajouter un processus ou en supprimer un.
Supprimer un processus est bien plus difficile que d’en ajouter un. Ajouter un processus signifie recruter du personnel, et la seule opposition à cela viendra de la haute direction, car cela représente une dépense budgétaire supplémentaire. Supprimer un processus signifie licencier des personnes ou, du moins, supprimer leurs postes tout en conservant et en requalifiant les employés. Lorsqu’un processus est supprimé, la situation s’inverse. On peut s’attendre à une opposition généralisée au sein de l’organisation, à l’exception de la haute direction.
La façon la plus simple de mettre une recette numérique en production consiste à maintenir un dual-run indéfiniment. Le processus manuel existant est conservé et exploite désormais les décisions automatisées en tant que simples suggestions. Cette approche paraît sécuritaire et peut même offrir des gains marginaux, les suggestions automatiques aidant les practitioners à identifier certaines des pires erreurs associées au processus manuel. Cependant, maintenir le dual-run indéfiniment conduit à une sédimentation des processus, où l’organisation échoue à supprimer un élément.
Pour que les pratiques de supply chain deviennent une initiative capitaliste – un atout productif – l’organisation doit se départir du processus manuel. Ce dernier est une impasse, il n’évoluera plus avec le temps. L’organisation doit rediriger tout le temps et l’énergie consacrés au processus manuel vers l’amélioration continue du processus automatisé. Conserver le processus manuel ne fait qu’entraver la capacité à tirer pleinement parti de l’automatisation et de ce qu’elle peut offrir. En particulier, tant que les interventions manuelles continueront d’avoir lieu, rien ne sera véritablement reproductible en raison de ces interventions, et par conséquent, rien ne pourra être réellement optimisé, puisqu’optimiser nécessite la reproductibilité.

L’automatisation des décisions, même lorsqu’il s’agit de décisions banales et répétitives, représente un changement de paradigme dans la gestion des supply chains. Le changement est si important qu’il est tentant de le rejeter dans son ensemble. Cependant, le changement arrive. Deux siècles de mécanisation progressive de notre économie ont clairement démontré que, dès qu’une opération peut être automatisée, elle le sera. Après un certain temps, il n’est plus possible de revenir à l’état antérieur. Lokad gère environ 100 supply chains dans des configurations hautement automatisées, fournissant la preuve vivante que l’automatisation de la supply chain est déjà là ; elle n’est simplement pas encore répandue.
L’un des plus grands changements à mettre en œuvre par nos clients concerne le rôle du planificateur de l’offre et de la demande. La forme la plus courante de ces rôles, qui porte divers noms dans l’industrie – tels que inventory managers, category managers ou supply managers – implique qu’un employé prenne en charge une liste restreinte de SKU, pouvant varier de 50 à 5 000 SKU selon le volume de flux. Le planificateur est responsable de la disponibilité continue des SKU de cette liste, soit en déclenchant le réapprovisionnement des stocks, soit en lançant des lots de production, ou les deux. La division du travail est simple : à mesure que le nombre de SKU augmente, le nombre de planificateurs augmente également.
L’attention du planner est tournée vers l’intérieur. Cette personne passe beaucoup de temps à examiner des chiffres, soit consolidés dans un tableur, soit affichés sur des tableaux de bord. Les planners peuvent exploiter des outils logiciels d’entreprise, mais ils finalisent presque toujours leurs décisions dans des tableurs qu’ils gèrent personnellement. Le but du tableur est de fournir un contexte numérique accessible et entièrement personnalisable pour soutenir les décisions prises par le planner. La routine du planner consiste à revisiter toute la liste restreinte des SKU chaque semaine, voire chaque jour.
Cependant, une fois la recette numérique mise en production, il n’est plus nécessaire de maintenir ce calendrier de révision manuelle de la liste restreinte des SKU par le planner. Le planner devrait évoluer vers le rôle de responsable de réseau. Largement affranchi des tâches liées aux données, le responsable de réseau peut consacrer son temps à communiquer avec le réseau, tant en amont avec les fournisseurs qu’en aval avec les clients, et à revoir les hypothèses qui soutiennent la conception de la recette numérique. Le danger principal qui menace la recette numérique n’est pas de perdre sa précision (voir accuracy), mais de perdre sa pertinence. Le responsable de réseau cherche à identifier ce qui ne peut être vu à travers le prisme des données, du moins pas encore. Il ne s’agit pas de microgérer la recette numérique ou d’apporter des ajustements numériques aux décisions elles-mêmes, mais d’identifier les facteurs qui restent ignorés ou mal compris par la recette numérique.
Le responsable de réseau consolide les enseignements destinés à la fois aux Supply Chain Scientist et aux dirigeants supply chain. Sur la base de ces enseignements, les scientifiques peuvent ajuster ou refondre la recette numérique afin de refléter une compréhension renouvelée de la situation.

Malheureusement, s’opposer au déploiement de la recette numérique n’est pas la seule façon pour le planner de maintenir le statu quo. Une autre stratégie consiste à poursuivre la même routine de travail : continuer à examiner la liste restreinte des SKU mais, au lieu de passer outre les décisions, se contenter de transmettre les constats, le cas échéant, au Supply Chain Scientist. Les gens aiment leurs habitudes, et les employés des grandes entreprises encore plus.
Le problème avec cette approche est qu’une fois l’automatisation en place, les Supply Chain Scientist peuvent observer directement les résultats du processus automatisé, tant les bons que les mauvais. Le planner et les scientifiques ont accès aux mêmes données ; cependant, le scientifique, par définition, dispose d’outils d’analyse plus puissants que le planner. Ainsi, une fois l’automatisation déployée, la valeur ajoutée des retours du planner diminue rapidement lorsqu’il s’agit de l’amélioration continue de la recette numérique.
Comme le planner dispose désormais de plus de temps pour analyser, il est probable qu’il demande au scientifique de concevoir davantage d’indicateurs et de tableaux de bord. Cela conduit au “KPI tourism” : augmenter le nombre d’indicateurs à examiner jusqu’à ce que leur simple consultation devienne un travail à temps plein. Cette charge de travail devient également une distraction pour les scientifiques. À ce stade, après déploiement, améliorer la recette numérique requiert une bonne compréhension des faiblesses de l’implémentation actuelle. Le scientifique est idéalement placé pour effectuer ce travail, tandis que le planner y est beaucoup moins adapté. Pour être utile, le planner devrait devenir un responsable de réseau et, comme indiqué précédemment, commencer à se tourner vers l’extérieur. Sinon, le rôle du planner se réduit au KPI tourism.

Le rôle du supply chain executive est largement défini par l’organisation et ses processus. Tant que les décisions banales demeurent le fruit d’un processus manuel, l’organisation n’a d’autre choix que d’adopter une division du travail où chaque planner gère sa propre liste restreinte des SKU. Ainsi, le supply chain executive est avant tout le manager d’une équipe de planners. Si l’entreprise est suffisamment grande pour justifier un niveau de middle management, l’executive peut alors ne gérer les planners que de manière indirecte. Néanmoins, la division supply chain reste la même : une pyramide avec des planners à la base. Par nécessité, être un bon supply chain executive signifie être un bon coach pour ces planners. L’executive ne conduit pas les décisions supply chain ; ce sont les planners qui les prennent. Améliorer ces décisions relève principalement d’un meilleur travail effectué par les planners.
Les éditeurs de logiciels supply chain soutiennent que leurs outils peuvent faire la différence. Cependant, comme nous l’avons déjà souligné, les tableurs sont presque toujours utilisés pour prendre ces décisions, peu importe le nombre d’outils déployés dans l’entreprise. En fin de compte, tout se résume à ce que font les planners avec leurs propres tableurs.
Une fois qu’une catégorie de décisions supply chain a été automatisée, le rôle du supply chain executive change considérablement. Le travail ne consiste plus à coacher une grande équipe de planners qui effectuent tous des variantes du même travail. Le rôle consiste désormais pour le supply chain executive à faire tout ce qui est nécessaire pour que l’entreprise tire le meilleur parti de son automatisation supply chain. L’executive doit devenir le propriétaire du produit logiciel qui conduit effectivement les décisions supply chain.
En effet, le focus et la contribution des Supply Chain Scientist sont tournés vers l’intérieur, tout comme les anciennes contributions des planners. Les scientifiques ne peuvent améliorer la recette numérique que de l’intérieur. On ne peut pas leur demander de refondre le paysage applicatif ou les processus plus larges de l’entreprise. C’est le rôle du supply chain executive de faire en sorte que cela se produise. En particulier, l’executive devient responsable de l’établissement d’une feuille de route pour l’amélioration continue de l’automatisation.
Tant que les décisions étaient prises par les planners, la feuille de route était en grande partie évidente. Les planners continuaient à faire ce qu’ils font, et la mission du trimestre suivant était en grande partie similaire à celle du trimestre précédent. Cependant, une fois l’automatisation mise en place, améliorer la recette numérique implique presque toujours de faire quelque chose qui n’a jamais été fait auparavant. Lors de la conception d’un logiciel, si vous le faites correctement, vous ne vous répétez pas – vous passez à autre chose. Une fois un aperçu acquis, un nouveau type d’aperçu doit être recherché. La mission des personnes travaillant sous un software product owner change continuellement par conception.
Les nouvelles orientations et objectifs ne tombent pas du ciel. Il incombe au supply chain executive de piloter le développement du produit logiciel supply chain dans des directions favorables.

La majorité des problèmes quotidiens auxquels sont confrontées les supply chains sont des problèmes logiciels. Cela fait déjà plus d’une décennie que c’est le cas dans les pays développés, même dans les entreprises où toutes les décisions sont tirées manuellement à partir de tableurs. Cette situation est la conséquence directe du fait que les supply chains se trouvent à la croisée de nombreux systèmes : l’ERP, le CRM, le WMS, l’OMS, le PIM, et des dizaines d’acronymes de trois lettres chéris par les éditeurs de logiciels d’entreprise décrivant les différentes composantes logicielles qui regroupent toutes les données d’intérêt pour la supply chain. Les supply chains nécessitent une perspective de bout en bout de l’entreprise et, par conséquent, elles finissent par connecter la majeure partie du paysage applicatif de celle-ci. Cependant, la plupart des entreprises semblent encore choisir des leaders supply chain qui connaissent très peu le logiciel. Pire encore, certains de ces leaders n’ont aucune intention d’apprendre quoi que ce soit sur le logiciel. Cette situation est l’anti-pattern du “analytics supply chain bus”. Quand je dis logiciel, il faut comprendre le type de sujet que j’ai abordé dans le quatrième chapitre de cette série de conférences, avec des thèmes allant du matériel informatique à l’ingénierie logicielle.
De nos jours, l’illettrisme en logiciel au sein de la direction supply chain annonce de sérieux problèmes pour l’entreprise. Soit la direction pense qu’elle peut très bien s’en sortir sans expertise en logiciel, soit elle estime pouvoir s’en sortir avec une expertise logicielle externe. Dans tous les cas, les conséquences ne sont pas bonnes.
Si la direction estime pouvoir s’en sortir sans expertise en logiciel, l’entreprise va perdre du terrain sur tous les canaux électroniques, tant du côté de la vente que de l’achat. Pourtant, comme de nombreux employés réalisent que ces canaux électroniques sont importants, que la direction supply chain l’accepte ou non, le shadow IT sera omniprésent. De plus, soyez assurés que pour la prochaine grande transition logicielle au sein de l’entreprise, cette transition sera largement mal gérée, entraînant de longues périodes de qualité de service médiocre en raison de problèmes liés au logiciel qui auraient dû être évités dès le départ.
Si la direction pense pouvoir s’en sortir avec une expertise logicielle tiers, c’est légèrement mieux que dans le cas précédent, mais pas de beaucoup. S’appuyer sur des experts externes est acceptable si l’on fait face à un problème étroit et autonome, comme s’assurer que votre processus de recrutement est conforme à une réglementation. Cependant, les défis supply chain ne sont pas autonomes ; ils s’étendent à l’ensemble de l’entreprise et très souvent même au-delà. Le piège le plus fréquent associé à l’idée que l’expertise peut être externalisée consiste à injecter des sommes d’argent déraisonnables à de grands éditeurs de logiciels, en espérant qu’ils résoudront les problèmes pour vous. Surprise — ils ne le feront pas. Le seul remède à ces problèmes est un minimum d’alphabétisation logicielle au niveau de la direction.
Aujourd’hui, nous avons exposé comment mettre en production des décisions supply chain automatisées. Le processus est un mélange de conception, d’ingénierie et de conduite du changement. C’est un parcours difficile, jalonné de nombreux chemins apparemment simples ou rassurants qui mènent directement à l’échec de l’initiative. Pour réussir, l’initiative requiert une évolution substantielle des rôles et des missions tant de la direction supply chain que de ses employés.
Pour les entreprises profondément enracinées dans leurs processus manuels, mener une telle initiative peut sembler insurmontable, et maintenir le statu quo peut paraître comme la seule option. Cependant, je ne partage pas cette conclusion pour deux raisons. Premièrement, bien que le parcours soit ardu, il est peu coûteux, du moins comparé à la plupart des investissements d’entreprise. En réinvestissant le coût annuel de cinq demand planners, l’entreprise peut automatiser la charge de travail de 50 demand planners. Naturellement, les grands éditeurs de logiciels d’entreprise peuvent affirmer qu’il faut des dizaines de millions de dollars pour même commencer, mais il existe des alternatives beaucoup plus allégées. Deuxièmement, le parcours peut être ardu, mais il n’est pas vraiment optionnel. Les entreprises qui emploient des armées de commis pour prendre leurs décisions supply chain banales et répétitives souffrent également de longs délais internes auto-imposés. Ces entreprises ne resteront pas compétitives face à celles qui ont automatisé leurs processus décisionnels routiniers. L’avantage compétitif tiré de l’automatisation est toujours modeste au début ; cependant, comme l’automatisation peut être améliorée avec le temps alors qu’un processus manuel ne le peut pas, l’avantage compétitif devient exponentiellement plus fort avec le temps. À l’heure actuelle, les décisions supply chain automatisées peuvent encore être perçues comme futuristes, mais dans deux décennies, ce sera le contraire. Les processus manuels seront considérés comme des vestiges archaïques d’une époque révolue.

Cela conclut la conférence d’aujourd’hui. Nous passerons dans une minute aux questions. La prochaine conférence aura lieu la première semaine de novembre, le mercredi, à 15 h, heure de Paris, comme d’habitude. Nous reviendrons sur le troisième chapitre avec une persona supply chain. Il s’agira d’une entreprise fictive nommée Stuttgart, qui est une société de l’après-vente automobile. Nous verrons que l’automobile est l’industrie des industries, et qu’elle présente une série de défis assez spécifiques qui, une fois de plus, ne sont pas correctement reflétés dans les manuels supply chain.
Examinons les questions.
Question: La Supply Chain Quantitative requiert-elle sa propre manière idéale de division du travail ?
Oui, cela peut se faire par une transition progressive, mais l’idée est que la division du travail que vous aviez avec un processus manuel était déterminée par le fait qu’un planner ne peut gérer qu’un nombre limité de SKU. Plus de SKU, plus de planners. Il s’agit d’une division du travail très simpliste. Lorsque vous avez une grande entreprise et que vous souhaitez mettre en place un processus automatisé, l’idée est de disposer de personnes spécialisées. Par exemple, un responsable de réseau peut devenir un spécialiste de la qualité de service telle que perçue par le client. La perception compte ; il ne s’agit pas de la qualité de service abstraite, comme les taux de service. Peut-être que les clients ont leur propre vision à ce sujet, de sorte que quelqu’un peut s’y spécialiser. Un autre responsable de réseau peut se spécialiser dans un angle précis où une coordination et une intégration plus étroites avec certains fournisseurs pourraient, par exemple, raccourcir les délais de livraison et offrir de nouvelles options. Soudainement, la division du travail se focalise davantage sur les nombreux angles qu’il faut étudier, revisiter et réanalyser d’un point de vue analytique. Plusieurs personnes peuvent être affectées à cette tâche. Mais encore une fois, il ne s’agit pas d’avoir quelque chose d’aussi tranché qu’une liste de SKU. C’est aussi l’essence de l’amélioration. Il se peut simplement qu’il faille plusieurs personnes pour faire du brainstorming ensemble, essayer d’identifier les meilleures idées et les trier.
Question: L’utilisation de pourcentages au lieu de métriques financières aide-t-elle à masquer les inefficacités du processus hérité ? Dans ce cas, quelle est la probabilité que l’initiative réussisse ?
C’est une question très lourde. L’une des raisons pour lesquelles les grandes entreprises, et autant de managers parmi elles, aiment ces indicateurs aspirants, c’est qu’ils ne sont assortis d’aucune responsabilité. Une fois que vous disposez d’un indicateur exprimé en pourcentage, personne ne se rend compte qu’il représente des millions de dollars perdus en raison d’une erreur spécifique commise par une division particulière dirigée par une certaine personne rien que pour le dernier trimestre. Ces pourcentages sont incroyablement opaques, et il est très difficile de faire réussir ces initiatives car, très souvent, une fois que vous exprimez les choses en dollars ou en euros, vous découvrez l’ampleur réelle des inefficacités, qui peut être absolument massive.
Dans l’expérience Lokad, pour des entreprises cotées divulguant tous les chiffres aux marchés publics avec plus de 200 auditeurs certifiant la valeur des stocks, nous avons constaté que les valeurs des stocks étaient surestimées de 20 % en faveur de l’entreprise. Nous parlons d’une entreprise disposant de plus d’un million d’euros de stocks dans ses livres. Ce qui est dingue, c’est que les stocks avaient été audités par plus de 200 personnes pendant littéralement des décennies, et que tout avait été digitalisé pendant des décennies également.
Quand vous découvrez ce genre de choses, c’est difficile, mais je crois que la manière d’aborder cela est d’être rigoureux sur les problèmes et indulgent sur les personnes. Les entreprises doivent apprendre à être indulgentes envers les personnes et vraiment strictes avec les problèmes, au lieu d’ignorer le problème et de renvoyer les personnes.
Question: Les grandes entreprises utilisent beaucoup plus de KPI qu’il n’en faut. Lorsque vous déployez l’initiative, comment remettez-vous en cause tous ces KPI ?
Très bonne question. Tous ces KPI représentent une grande distraction et viennent soutenir le travail effectué manuellement par les planificateurs. Une fois que vous disposez d’une recette numérique, pourquoi vous soucieriez-vous même de tous ces KPI ? Tout ce que vous optimisez devrait être intégré dans vos critères financiers. Vous devriez disposer d’une métrique qui vous indique, pour chaque décision potentielle, combien d’argent est en jeu, combien vous gagnerez ou perdrez selon l’issue de la décision. Plutôt que d’accumuler une série interminable d’indicateurs, si vous souhaitez affiner votre métrique financière, vous pouvez ajouter un facteur. Mais cela ne signifie pas que vous ajoutez une colonne supplémentaire dans le rapport ; cela signifie simplement que vous ajustez un peu en attribuant un facteur additionnel qui ajoute ou soustrait de quelques euros ou dollars aux valeurs que vous assignez à une décision donnée.
Fondamentalement, tout ce qui se trouve en dehors de ces objectifs financiers est ignoré par la recette numérique. La recette numérique exécute un processus d’optimisation mathématique qui optimise strictement un objectif financier. Voilà tout. Tous les autres indicateurs sont ignorés. Une configuration automatisée rend beaucoup plus évident que ces indicateurs sont inutiles. Ils ne sont pas pris en compte dans la recette, ils ne sont pas considérés par la recette numérique, et ils ne font même pas partie du processus de prise de décision. Cela clarifie également que les indicateurs aspirants, comme les taux de service, sont contre-productifs. Vous ne pouvez pas simplement porter votre qualité de service à un taux de service de 100 % parce que ce n’est pas un résultat souhaitable pour l’entreprise. Lorsqu’elle est réalisée correctement, l’automatisation clarifie ce qui est réellement nécessaire en termes d’indicateurs, et vous vous rendez compte qu’il n’en faut pas tant. De plus, parce que moins de personnes sont impliquées dans le processus, la pression pour ajouter toujours plus d’indicateurs est moindre. Un autre aspect d’avoir de grandes équipes de planificateurs est que chaque personne tend à avoir un ou deux indicateurs favoris. Si vous avez 200 personnes et que chacune veut qu’un indicateur soit ajouté pour sa commodité personnelle, vous vous retrouvez avec 200 indicateurs, ce qui est bien trop. Mais si vous n’avez qu’un dixième de ce personnel, la pression pour accumuler les indicateurs est bien moindre.
Question: Comment les éditeurs de logiciels de demand planning comprennent-ils les écosystèmes de leurs clients potentiels, tels que les exigences de stock de sécurité, tout en procédant à une personnalisation avant le déploiement chez le client ? Je veux dire, une fois le déploiement effectué, il n’y a aucun piège en termes d’erreur de prévision.
La perspective classique, qui selon moi a échoué à apporter l’automatisation aux décisions supply chain dans les années 1970, était basée sur l’hypothèse qu’une solution logicielle packagée pouvait résoudre les problèmes des entreprises. Je suis fermement convaincu que ce n’est pas le cas. Un logiciel packagé ne peut s’adapter à aucune supply chain non triviale. Ce qui se passe, c’est qu’un éditeur de logiciels d’entreprise proposant une sorte de module d’optimisation de stocks et de prévision tente de vendre le produit à une entreprise et, comme des fonctionnalités manquent, il continue de les ajouter. Au bout de dix ans ou plus, ils se retrouvent avec un produit logiciel monstrueux et surchargé, comprenant des centaines d’écrans et des milliers de valeurs de paramètres.
Le problème, c’est que plus le produit logiciel est complexe, plus vos attentes en termes de données et de ce que l’entreprise devrait posséder sont spécifiques. Plus le produit logiciel est complexe, plus il devient difficile de l’intégrer dans l’entreprise cliente, car vous disposez d’une supply chain complexe avec de nombreux systèmes déjà en place et d’un produit d’optimisation de la supply chain super complexe. Il existe des lacunes et des décalages partout.
La réalité, c’est que la plupart des grandes entreprises auxquelles j’ai parlé exploitent des supply chains digitales dans les pays développés depuis deux à trois décennies, et elles ont déjà déployé une demi-douzaine de solutions logicielles de demand planning, d’optimisation de stocks et de conception de supply chain au cours des deux ou trois dernières décennies. Elles ont donc déjà fait l’expérience, pas une seule fois, mais une demi-douzaine de fois. Habituellement, les gens n’ont pas été dans l’entreprise suffisamment longtemps pour se rendre compte que ces processus se répètent depuis deux ou trois décennies. Et pourtant, les processus restent complètement manuels et reposent souvent sur des outils comme Excel. Le problème n’est pas l’erreur de prévision ; je crois qu’il s’agit d’un mauvais diagnostic du problème, car l’idée que vous pourriez obtenir une prévision parfaite avec un système ou un autre est ridicule. Il n’est pas possible de générer une prévision parfaite, et les humains qui gèrent une supply chain manuellement n’ont pas non plus accès à une information parfaite. Ce n’est pas parce que vous êtes un planificateur de demande humain que vous pouvez prévoir la demande parfaitement.
Les planificateurs de demande sont capables d’exercer leur métier avec des prévisions imparfaites. Ces personnes ne sont ni des magiciens ni des scientifiques ultra-avancés. Ils ne sont peut-être pas mauvais en matière de prévision, mais il n’y a aucune raison de s’attendre à ce que, en moyenne, les planificateurs de demande dans cette industrie, qui emploie des centaines de milliers de personnes à travers le monde, soient tous super talentueux et capables de prévisions de demande incroyablement précises. Ce qui fait fonctionner le système, c’est que ces personnes ont leurs propres heuristiques et méthodes pour gérer manuellement la supply chain qui subsistent malgré la médiocrité des prévisions dont ils disposent.
L’objectif dans votre configuration automatisée est d’avoir un système qui fonctionne parfaitement même si les prévisions ne sont pas d’excellente qualité dès le départ. C’est l’essence même de l’approche de prévision probabiliste ; il ne s’agit pas d’affiner l’exactitude, mais de reconnaître et d’accepter le fait que la prévision n’est pas si bonne. Si nous revenons à ces éditeurs, je crois que l’industrie a collectivement échoué à apporter un degré satisfaisant d’automatisation pendant les quatre dernières décennies, et le cœur du problème résidait dans la perspective packagée, où l’on s’attendait à ce que les entreprises branchent simplement un module et en aient fini. Cela ne fonctionne pas. Les supply chains sont bien trop diverses, polyvalentes et en constante évolution pour qu’une approche mécanique puisse réussir.
Question: Avec la perspective présentée, comment abordez-vous le problème de réconcilier les différentes prévisions de l’entreprise, telles que celles des ventes, des stocks, et d’autres ?
Ma question est la suivante : pourquoi faites-vous même des prévisions en premier lieu ? Les prévisions ne sont que des artefacts numériques ; elles n’ont pas d’importance. Votre entreprise ne sera pas plus rentable parce qu’il y a une meilleure prévision. Les prévisions sont exactement ce que j’ai appelé, dans les chapitres précédents de cette série de conférences, un artefact numérique. C’est une abstraction qui peut ou non s’avérer utile pour tirer certaines classes de décisions. Il s’avère que, selon la décision envisagée, le type de prévision dont vous avez besoin peut être très différent.
Je conteste l’idée selon laquelle vous pourriez disposer d’une prévision de haut niveau pour ensuite orchestrer l’ensemble de la supply chain sur la base de ces prévisions. Je suis fermement en désaccord avec cette approche, car ce n’est pas mon expérience, et je crois que cela ne fonctionne pas si bien. J’ai vu de nombreuses entreprises où un processus de planification de haut niveau produit des prévisions du côté des ventes, ce qui est un exercice massif de sous-estimation délibérée. Les commerciaux sous-estiment souvent largement leurs prévisions, car ainsi, s’ils les dépassent, ils peuvent plus facilement dépasser les attentes par la suite. Les personnes dans les usines ou les entrepôts voient ces chiffres arriver et peuvent penser qu’ils ne peuvent pas éventuellement être corrects, alors ils rejettent le chiffre et font quelque chose de complètement différent. À mon avis, les exercices de prévision menés par la grande majorité des entreprises ne sont que des efforts bureaucratiques inutiles. Il n’y a aucune valeur ajoutée là-dedans.
Du point de vue d’une Supply Chain Quantitative, il est essentiel de se concentrer sur les décisions qui comptent, plutôt que sur les prévisions, qui ne seraient que des détails techniques. Certaines classes de décisions n’ont même pas besoin qu’une prévision soit faite ou, si c’est le cas, elles pourraient nécessiter un type de prévision très différent de celui que les entreprises envisagent actuellement. Quand on parle de prévision, la plupart des gens entendent par là des prévisions par séries temporelles. Cependant, si vous revenez au troisième chapitre de cette série de conférences, qui est dédié aux personas de supply chain et aux situations réelles, vous constaterez que les prévisions par séries temporelles ne sont souvent pas la réponse. La forme même de la prévision est inadéquate pour capturer les schémas que nous souhaitons identifier dans l’entreprise.
Pour conclure, je suggérerais de ne même pas essayer de réconcilier ces prévisions. Au lieu de cela, ignorez-les et concentrez-vous sur les décisions elles-mêmes. Voyez ce qu’il faut pour concevoir des recettes qui génèrent de bonnes décisions, et il est fort probable que toutes ces prévisions puissent être entièrement ignorées.
En réponse au commentaire concernant la comparaison des résultats financiers avec les KPI exprimés en pourcentage, il est vrai que vous pouvez établir des corrélations en essayant de mettre en relation les taux de service ou les fill rates avec vos indicateurs financiers. Cependant, cela crée-t-il réellement un retour sur investissement pour l’entreprise ? Prendre de meilleures décisions de stocks peut créer de la valeur pour l’entreprise, mais passer du temps à corréler les KPI ne le fait pas. De nombreuses entreprises sont accro à ces KPI exprimés en pourcentage, mais ils ne sont souvent que des distractions bureaucratiques dénuées de sens.
Les éditeurs de logiciels d’entreprise adorent ces indicateurs car ils peuvent les vendre aux entreprises clientes, ce qui conduit de nombreux éditeurs à en réclamer davantage. En réalité, pour une catégorie de décisions supply chain, disposer de dix chiffres pertinents à consulter chaque jour est déjà pas mal. Il est généralement difficile d’identifier même dix chiffres qui mériteraient d’être consultés quotidiennement par un humain. Souvent, il y en a encore moins, et cela va très bien. Les catégories de problèmes dans les supply chains tendent à être très spécifiques à l’entreprise et à la supply chain concernée, mais elles ne sont pas d’une complexité insurmontable. Je ne dis pas que les situations supply chain nécessitent des milliers de leviers économiques. Je dis plutôt que les supply chains varient énormément, et vous devez vous assurer de résoudre le bon problème qui correspond aux subtilités de la supply chain concernée. Pour une supply chain donnée, vous pourriez avoir trois ou quatre leviers de base comme le coût du stock, la marge brute et d’autres facteurs que l’on retrouve quasiment partout. Ensuite, vous pourriez avoir quatre ou cinq indicateurs, de nouveau des métriques financières, très spécifiques à une activité particulière. Au total, nous sommes encore en dessous de dix chiffres.
En réponse à la question sur l’équilibre entre les KPI financiers et les KPI supply chain, je dirais oui et non. Si vous pensez que les KPI financiers ne sont pas ceux que vous devriez optimiser, alors il y a un problème dans la définition même de vos KPI financiers. Dans le premier chapitre de cette série de conférences, j’ai mentionné qu’il y avait généralement deux cercles de leviers à considérer lors de l’établissement d’une métrique financière. Le premier cercle comprend des facteurs que la finance peut directement lire dans les comptes, tels que la marge brute, la valeur des stocks et les coûts d’achat. Le second cercle inclut des leviers tels que la fidélité des clients et la pénalité implicite en cas de faible qualité de service. Tout cela doit être intégré.
La perspective financière ne consiste pas à avoir des KPI où il y a un compromis. Au contraire, il s’agit de consolider le tout en un seul score en dollars ou en euros pour votre performance et votre prise de décision. Il ne s’agit pas de réconcilier les KPI supply chain avec les KPI financiers. Il s’agit plutôt de mettre en place une gouvernance dans l’entreprise de sorte que les gens puissent se mettre d’accord sur le coût réel du stock, le coût réel des ruptures de stock, et sur la pertinence d’une décision de réapprovisionnement ou non.
Dans cette nouvelle perspective de maîtriser le produit logiciel qui pilote la supply chain, le rôle du cadre de la supply chain est de faciliter le consensus au sein de l’entreprise. Plutôt que d’animer un processus S&OP dénué de sens où les gens tentent de revoir les chiffres chaque mois et de se mettre d’accord sur des chiffres de vente insignifiants, il s’agit de mettre en œuvre un S&OP 2.0 dirigé par le directeur de la supply chain. Contrairement à ce que disent les éditeurs de S&OP, le PDG n’a pas à maîtriser le processus S&OP, car cela pourrait davantage le distraire. Il n’est pas nécessaire d’impliquer le PDG dans chaque bataille.
La mission du directeur de la supply chain est de travailler avec le responsable financier, le responsable marketing et le responsable commercial pour se mettre d’accord sur la manière de mesurer l’impact financier de facteurs tels que la qualité de service. C’est leur travail. Il n’est pas nécessaire de réconcilier diverses métriques, car elles sont déjà pré-unifiées grâce au travail mené sous la direction du responsable de la supply chain ou du directeur de la supply chain, selon le titre en vigueur dans l’entreprise.
Cela conclut la conférence d’aujourd’hui. Nous vous retrouvons la prochaine fois durant la première semaine de novembre.