Riapprovvigionamento prioritario delle scorte in Excel con previsioni probabilistiche
La presenza di incertezza è un aspetto irriducibile della previsione. Eppure, nel XX secolo, la previsione statistica emerse con la speranza che, dati modelli matematici adeguati, l’incertezza potesse essere eliminata. Di conseguenza, le prime teorie della supply chain hanno minimizzato o addirittura ignorato l’incertezza, poiché si riteneva che tecniche di previsione migliori avrebbero potuto eliminarla o, in alternativa, renderla irrilevante. Benché ben intenzionati, questi approcci risultarono difettosi, in quanto l’incertezza, dopo un secolo di modellazione statistica, rimane risolutamente irriducibile. Nel 2012, Lokad ha inaugurato una prospettiva supply chain, che abbraccia e quantifica l’incertezza. Questo approccio fa uso di previsioni probabilistiche al posto delle classiche previsioni puntuali delle serie temporali. In questa guida, e con il supporto del foglio di calcolo Microsoft Excel, applichiamo le previsioni probabilistiche al problema del riapprovvigionamento dell’inventario. Questo approccio genera una politica di riapprovvigionamento dell’inventario prioritizzata, qui dimostrata tramite Excel. Il nostro intento è duplice: in primis, diffondere questo approccio ad un pubblico che potrebbe non sentirsi a suo agio con strumenti software più avanzati; in secondo luogo, dimostrare che accogliere l’incertezza richiede un determinato cambio di mentalità più che strumenti sofisticati.
Scarica: probabilistic-inventory-replenishment.xlsx
1. Il problema del riapprovvigionamento dell’inventario
Il problema del riapprovvigionamento dell’inventario si concentra sull’identificazione della migliore lista di acquisto – una lista che tenga conto dei vincoli finanziari fondamentali e degli obiettivi dell’azienda. Il metodo per elaborare tale lista dovrebbe funzionare egualmente bene indipendentemente dai limiti di budget, poiché si cerca di massimizzare il ritorno sull’investimento per ogni dollaro speso. Il problema risiede nel fatto che tutti gli SKU competono per gli stessi fondi, per cui il ritorno finanziario derivante dall’immagazzinamento di una determinata unità di SKU deve essere quantificato e classificato nel contesto delle altre unità di ogni SKU.
1.1 La soluzione di riapprovvigionamento prioritario dell’inventario
Il processo di classificazione dell’inventario, come descritto sopra, richiede una prospettiva a livello micro. Per poter confrontare il ritorno derivante dall’aggiunta di una determinata unità di uno SKU a una lista d’acquisto, è necessario considerare diversi fattori. Nello specifico, la probabilità della sua vendita, come indicato da una previsione della domanda probabilistica, e i driver economici — per esempio, il margine di profitto lordo e il prezzo d’acquisto. Ogni quantità considerata, a sua volta, deve essere bilanciata rispetto a vincoli interni ed esterni (quali la capacità limitata del magazzino, i moltiplicatori di lotto e le MOQ/MOV, ecc.). I casi limite, ad esempio quando due (o più) unità hanno la stessa redditività attesa, devono essere integrati in una politica di riapprovvigionamento dell’inventario attraverso la valutazione dell’importanza relativa di ciascun prodotto. Gli SKU non dovrebbero essere considerati isolatamente, bensì insieme. Alcuni SKU, sebbene presentino margini di profitto inferiori se valutati singolarmente (come il latte), sono più importanti perché favoriscono le vendite di prodotti ad alto margine. Pertanto, il beneficio finanziario derivante dal mantenimento dei livelli di servizio di un prodotto a margine inferiore – che facilita altre vendite – rappresenta un ulteriore driver (“stockout cover”)1. Un approccio di riapprovvigionamento prioritario dell’inventario (PIR), che utilizza le previsioni probabilistiche come input, prende in considerazione tutti questi fattori.
In breve, la soluzione PIR può essere riassunta in tre fasi:
1. Costruire una previsione della domanda probabilistica.
2. Elencare tutte le quantità d’acquisto fattibili.
3. Classificare tutte le quantità d’acquisto fattibili in base ai driver economici.
1.2 Riapprovvigionamento prioritario dell’inventario in Excel
Utilizzando dati finanziari per un negozio fittizio, inclusi i driver economici elencati nella sezione precedente, questo foglio di calcolo Excel modella la politica di riapprovvigionamento dell’inventario per tre SKU (penne, tastiere e librerie)2. Le conseguenze finanziarie di ogni unità aggiuntiva di SKU (se ordinata) e la probabilità della sua vendita sono illustrate nel foglio Charts (vedi Figura 1). I diagrammi e i grafici si aggiornano in base agli input e alle ipotesi del modello (ad es., livelli iniziali di stock, prezzi di acquisto e di vendita, ecc.) nel foglio Control Tower (Figura 2). Una lista dettagliata delle opzioni decisionali fattibili viene generata nel foglio Micro purchasing decisions (Figura 3) basandosi sugli input chiave. Questi input sono le previsioni della domanda probabilistica provenienti dal foglio Distribution generators (Figura 4) e gli input del foglio Control Tower. Infine, una tabella delle decisioni di riapprovvigionamento prioritario dell’inventario viene raccolta e classificata in termini di ritorno sull’investimento atteso (vedi il foglio Ranked purchasing decisions in Figura 5).
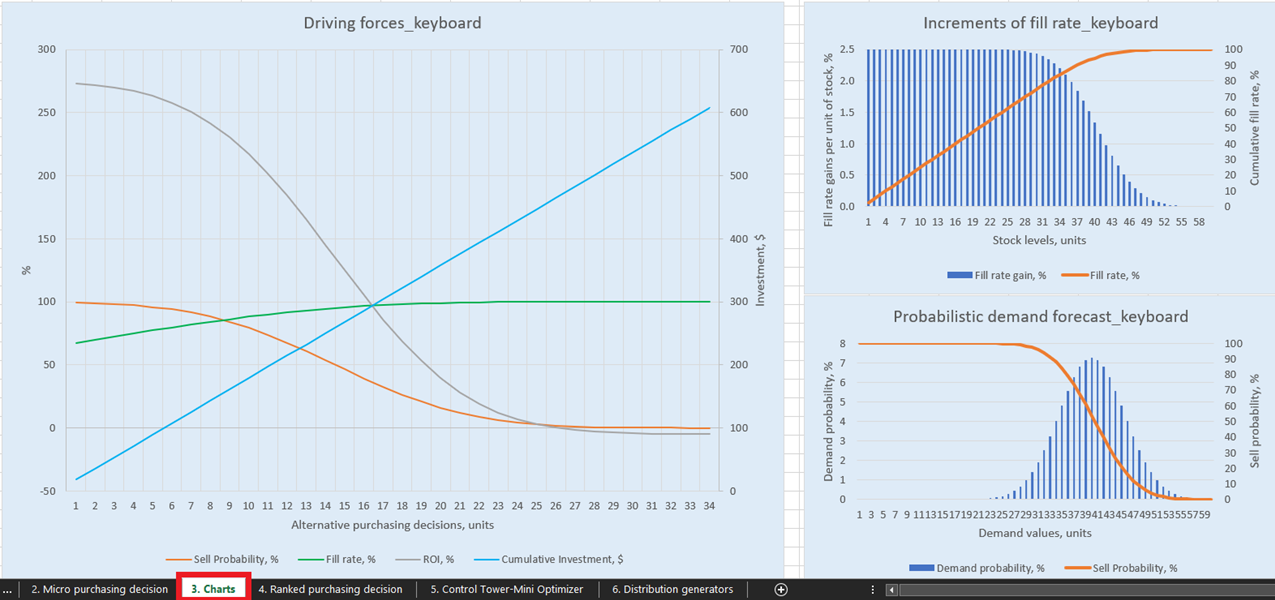
Figura 1. Vista di “Driving forces keyboard” in Charts, posizione evidenziata in rosso.
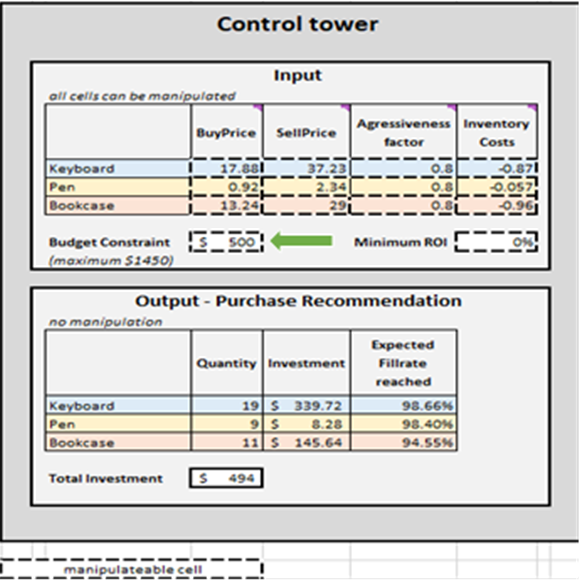
Figura 2. Vista della “Control Tower” situata in Control Tower – Mini Optimizer (foglio 5). È possibile modificare il “Budget Constraint” a qualsiasi valore compreso tra $0 e $1450 (vedi freccia verde).
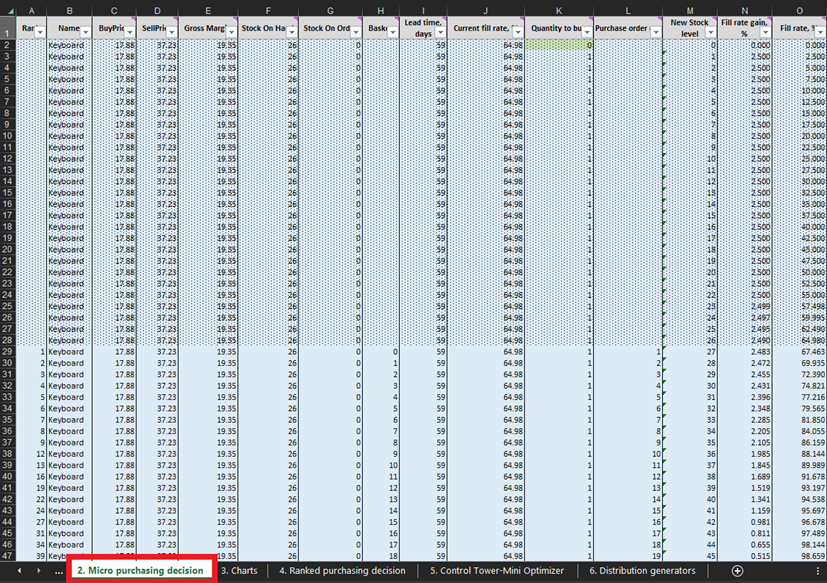
Figura 3. Dove individuare Micro purchasing decisions all'interno di Excel, evidenziato in rosso. Le righe coperte dalla formattazione condizionale a puntini rappresentano dati passati (fino e compresa la riga 28 nell'immagine sopra). Queste informazioni rappresentano le decisioni d'acquisto precedenti. Ci interessa solo tutto ciò che sta al di sotto di questa formattazione condizionale. La medesima formattazione a puntini si applica anche ai dati relativi a penne e librerie.
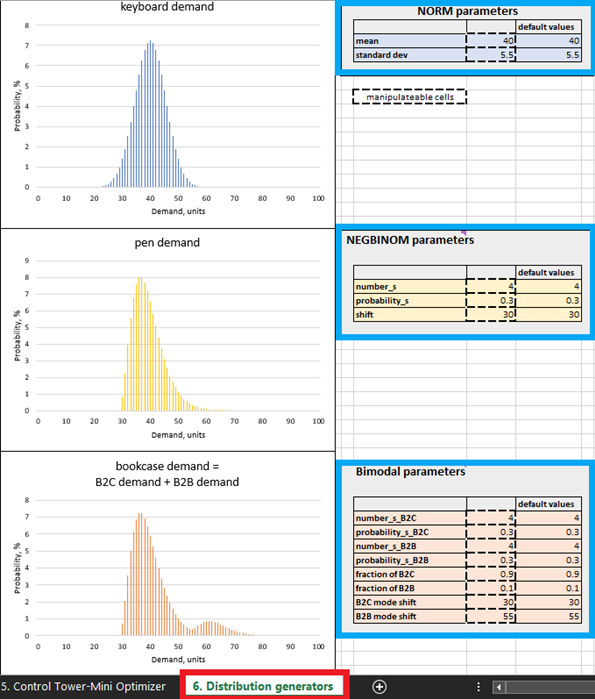
Figura 4. Dove individuare Distribution generators in Excel, evidenziati in rosso. I pannelli di controllo del prodotto sono evidenziati in blu. Le celle con contorni tratteggiati possono essere manipolate.
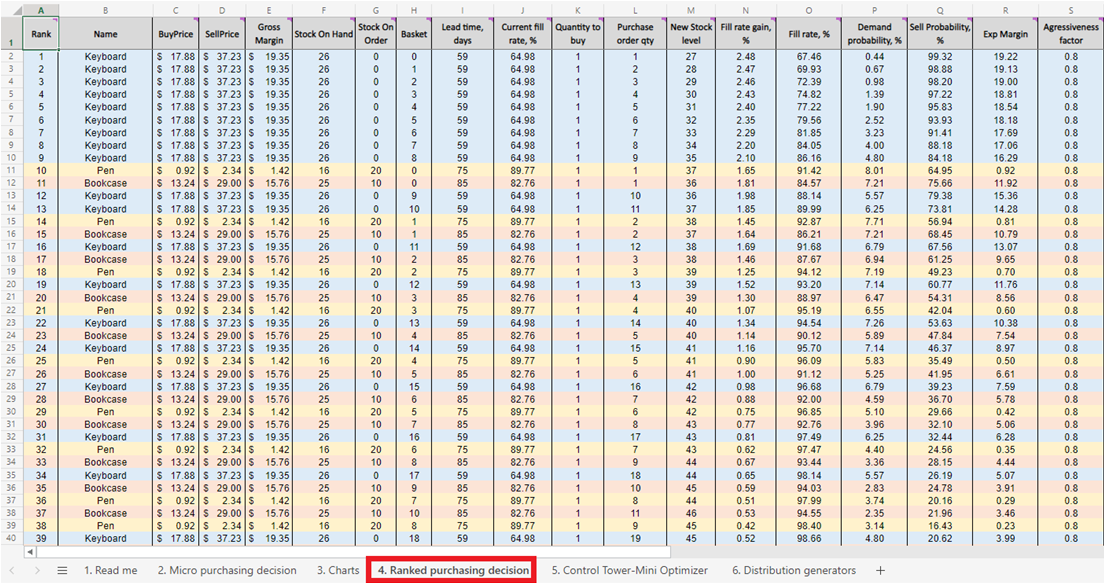
Figura 5. Una lista di riapprovvigionamento prioritario dell'inventario delle micro decisioni d'acquisto, situata nel foglio 4.
2. Previsione della domanda probabilistica
In questo contesto, una previsione probabilistica è l’insieme di tutti i valori di domanda probabili futuri e delle rispettive probabilità. Essa abbraccia l’incertezza intrinseca della domanda futura e può essere elaborata per qualsiasi intervallo di tempo. Come una tradizionale previsione di serie temporali, viene identificato un singolo valore di domanda più probabile (i punti bianchi in Figura 6) e una linea di tendenza (la linea grigia che connette i punti bianchi). Tuttavia, una previsione probabilistica integra l’incertezza mediante l’aggiunta di tutti i possibili valori di domanda (pur non essendo tutti ugualmente probabili). Questo approccio è illustrato in Figura 6, dove differenti intervalli di confidenza rappresentano valori di domanda con probabilità diverse.
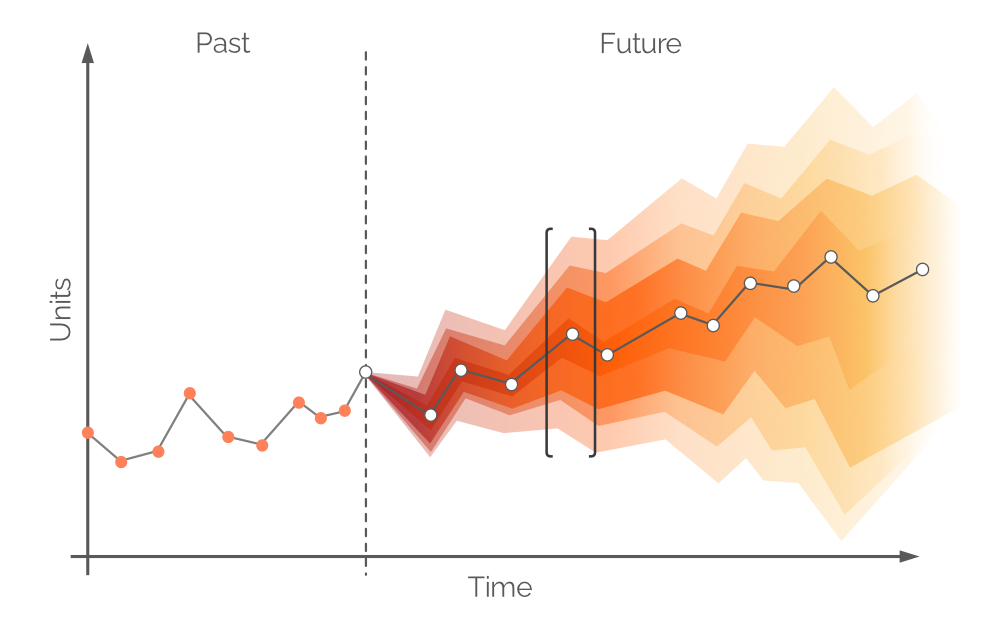
Figura 6. Una previsione probabilistica (domanda sull'asse y; tempo sull'asse x). La linea verticale grigia tratteggiata indica il momento attuale (“adesso”). Il tempo è misurato in giorni, anche se potrebbe essere qualsiasi intervallo desiderato. L'area racchiusa in parentesi nere viene discussa in seguito.
I punti bianchi in Figura 6 rappresentano i valori di domanda più probabili a intervalli futuri fissi. Accompagnano una fascia colorata che corrisponde a un intervallo di valori di domanda alternativi — una distribuzione di probabilità resa a colori. Questo colore sbiadisce lungo l’asse verticale quanto più ci si allontana dal punto bianco, a indicare un’incertezza maggiore e una probabilità inferiore. In generale, le fasce colorate si attenuano con il passare del tempo (lungo l’asse orizzontale), poiché l’incertezza si intensifica con il trascorrere del tempo. Tuttavia, indipendentemente dal grado di incertezza, esiste sempre almeno un valore che è il più probabile, e questo è rappresentato costantemente dai punti bianchi. Un esempio di distribuzione di probabilità per un determinato punto temporale è illustrato in Figura 7.
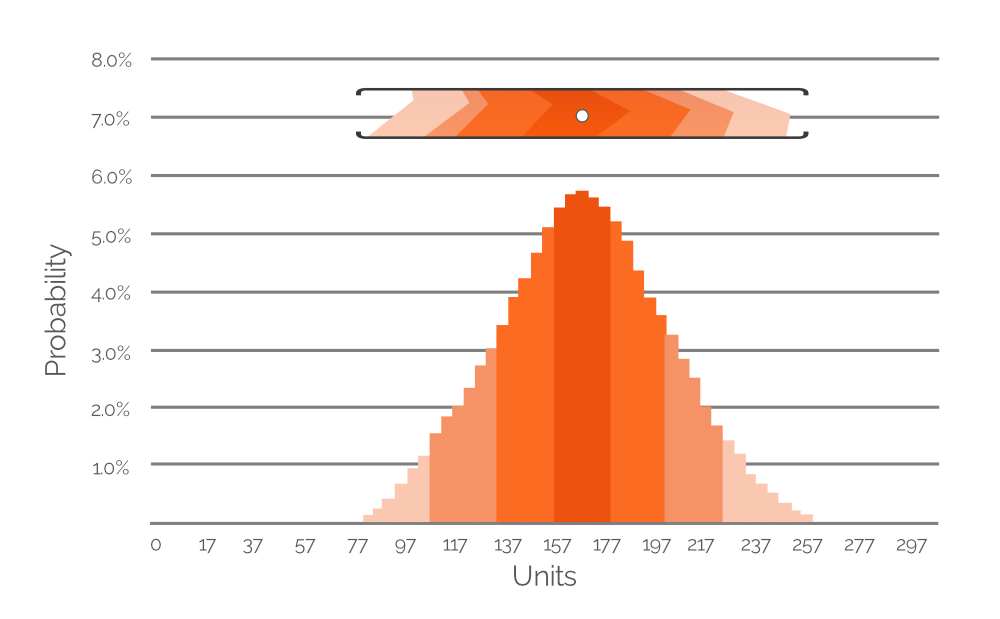
Figura 7. Un istogramma che rappresenta la probabilità di diversi possibili valori di domanda (a intervalli di 20 unità). L'asse y indica il valore di probabilità; l'asse x indica la domanda in unità. L’istogramma è una rappresentazione dell’intervallo di valori evidenziato in Figura 6 (incluso qui a scopo di riferimento).
La Figura 7 esprime i dati evidenziati in Figura 6 sotto forma di istogramma di probabilità, con valori numerici espliciti che indicano la probabilità dei differenti valori di domanda. La codifica a colori è mantenuta per facilitarne la comprensione (ricorda: colori più sfumati indicano una probabilità minore; colori più intensi, una probabilità maggiore). In questo esempio, il valore di domanda più probabile è 167 unità (approssimativamente), motivo per cui il punto bianco nell’intervallo ritagliato di Figura 6 è posizionato direttamente sopra la barra più alta dell’istogramma. Tuttavia, vengono assegnate probabilità anche a valori di domanda estremamente bassi e molto elevati (rispettivamente attorno a 80 e 260 unità, entrambi in una tinta di arancione molto tenue). Ciò dimostra la potenziale ricchezza dei dati di una previsione probabilistica, e istogrammi simili sono inclusi nel foglio Excel – uno per ciascuno dei nostri SKU (vedi Figura 4). Utilizzando questi istogrammi (come in Figura 7 sopra), è possibile identificare e considerare i valori di domanda (in unità) aventi probabilità diversa da zero.
2.1 La costruzione di una previsione probabilistica
Sebbene sia possibile creare una previsione probabilistica reale con dati storici in Excel, questo strumento è probabilmente il meno adatto a tale scopo. In generale, i dettagli per realizzare una previsione probabilistica a livello produttivo sono al di là dell’ambito di questo documento; per semplicità, sono state quindi adottate previsioni probabilistiche sintetiche. I parametri di tali previsioni sintetiche possono essere modificati nei Distribution generators (vedi Figura 4). Tuttavia, si raccomanda di studiare prima le impostazioni predefinite prima di apportare modifiche.
Nelle pratiche tradizionali della supply chain, la domanda è solitamente considerata distribuita normalmente, anche se questo evento è piuttosto raro. Nelle supply chain reali, la maggior parte degli SKU si discosta dai modelli di distribuzione normale. Data questa realtà, abbiamo deliberatamente scelto tre differenti modelli di distribuzione: normale (per le tastiere), binomiale negativa (per le penne) e bimodale (per le librerie – una combinazione di due modelli binomiali negativi). Quanto segue fornisce la giustificazione per tale ipotesi.
Ad esempio, assumiamo che le librerie vengano acquistate sia da privati sia da aziende (ad es. scuole), e per questo utilizziamo una distribuzione bimodale. Nell’impostazione predefinita per le librerie, si registra una domanda frequente da parte dei privati, con uno o due pezzi acquistati per cliente. Questo rappresenta la prima modalità della distribuzione (vedi Figura 4). Le aziende, invece, costituiscono una fonte di domanda meno frequente ma effettuano ordini di dimensioni maggiori (più grandi rispetto a quanto accade per i privati). Quando ciò accade, la loro domanda si somma a quella generata dagli acquisti dei privati, facendo apparire la seconda modalità della distribuzione. Quest’ultima si sposta verso destra (rappresentando valori di domanda elevati) ed è notevolmente più piccola della prima modalità, riflettendo il fatto che si verifica meno frequentemente (Figura 4). Il nostro modello presume inoltre che le penne vengano acquistate da privati con domanda occasionalmente alta (ad esempio, studenti che comprano prima delle date degli esami). Infine, per riflettere il fatto che una distribuzione normale si verifichi occasionalmente, le vendite di tastiere seguono un modello di distribuzione normale.
All’interno dei Distribution generators (Figura 4), è possibile modificare le distribuzioni della domanda cambiando i parametri nelle celle modificabili. Ad esempio, aumentando la media per le tastiere (vedi “NORM parameters” in Figura 4) da 40 a 50, la distribuzione si sposterà di 10 unità a destra. Di conseguenza, l’ROI atteso per tutte le unità di tastiera aumenterà. Analogamente, è possibile apportare modifiche ai parametri delle distribuzioni binomiale negativa (per le penne) e bimodale (per le librerie).
Poiché Excel non esprime in modo adeguato questo tipo di calcolo, questa dimostrazione limita le modifiche a 100 unità per prodotto. Ad esempio, impostare la media delle tastiere a 99 porterà quasi il 50% delle unità di domanda a non essere calcolate nel foglio Micro purchasing decisions.
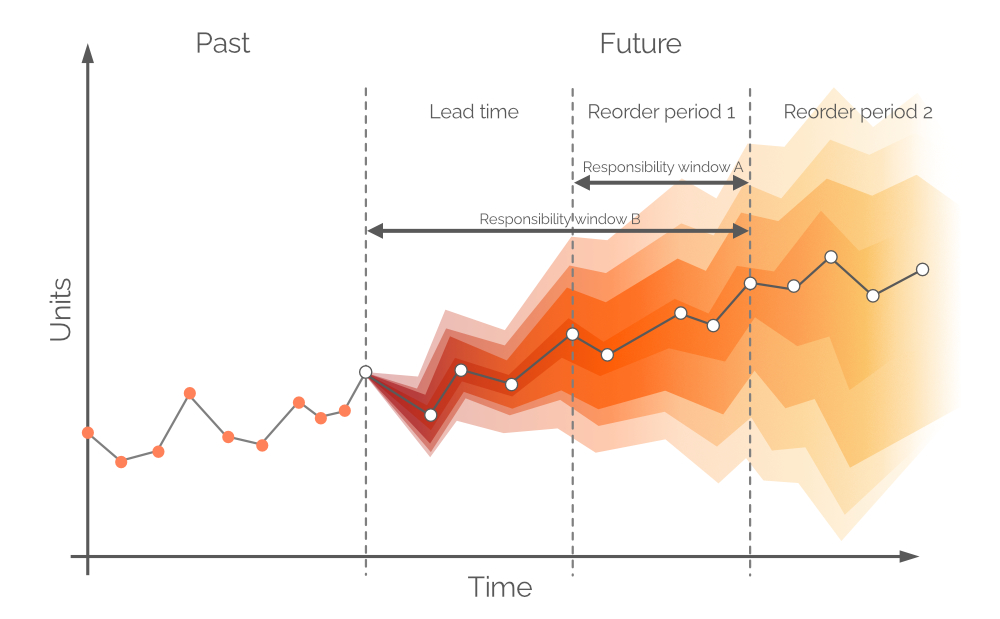
2.2 Selezione di un orizzonte per una previsione della domanda probabilistica
In genere, le previsioni sono suddivise in intervalli giornalieri/settimanali/mensili, anche se questi periodi discreti hanno un’utilità e un valore limitati dal punto di vista del rifornimento. La domanda nei prossimi lead time non può essere coperta dalle decisioni di acquisto prese oggi a meno che non siano ammessi backorders, perché eventuali unità acquistate arriveranno dopo un periodo pari al lead time. Pertanto, la domanda dovrebbe essere coperta dallo stock in mano e dallo stock in ordine del negozio (vedi Figura 8), supponendo che le unità in ordine arrivino prima della domanda. Quindi, la previsione probabilistica si occupa della domanda tra i punti di riordino o, in altre parole, della domanda durante il Periodo di riordino 1 (vedi Figura 9). La domanda futura più remota sarà coperta dagli ordini futuri (vedi il Periodo di riordino 2, in Figura 9).

Figura 8. Stock on Hand (colonna F) e Stock on Order (colonna G), evidenziati in rosso, sono situati in Micro purchasing decisions. Lead time, colonna I, è evidenziato in blu.
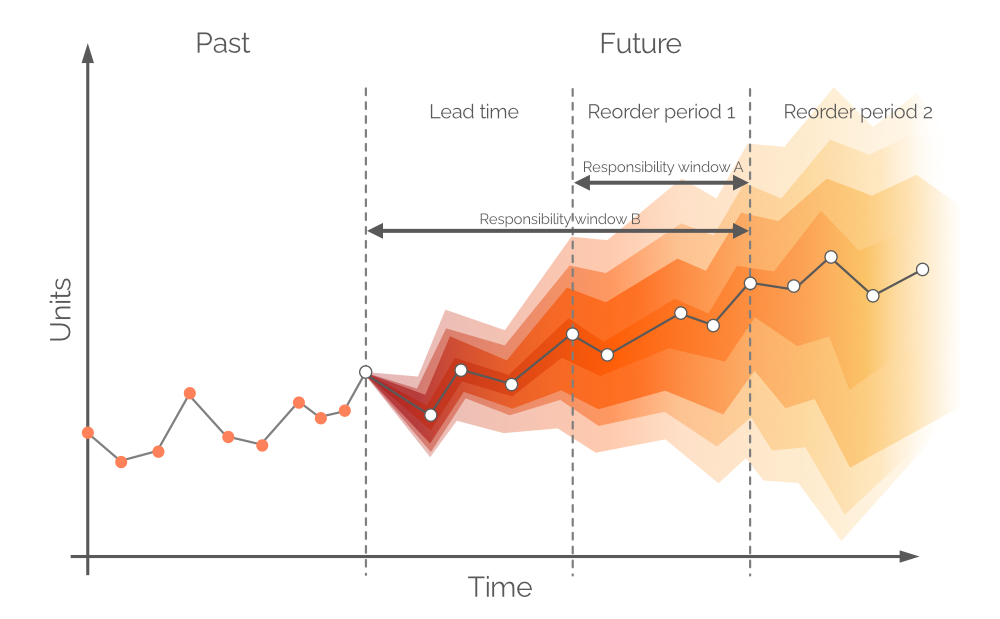
Figura 9. Una rappresentazione visiva di finestre di responsabilità alternative. La domanda è sull’asse y, il tempo sull’asse x, con la linea verticale grigia tratteggiata a sinistra che indica il momento attuale (“adesso”, come da Figura 6). La previsione probabilistica in questo documento si occupa della domanda nell’orizzonte pari a Responsibility window B.
In teoria, la previsione della domanda probabilistica dovrebbe essere costruita sul periodo di tempo pari al Periodo di riordino 1 – questa finestra temporale viene definita come Responsibility window A (vedi Figura 9). Per fare ciò, dovremmo effettuare proiezioni future per lo stock in mano e lo stock in ordine al termine del lead time. Tuttavia, la domanda nel lead time – per la quale abbiamo già preso decisioni durante il periodo d’ordine precedente – è anch’essa probabilistica, e questo comporterebbe livelli di stock che sono a loro volta distribuzioni di probabilità3. Consentendo i backorders (una pratica comune in alcuni settori) una previsione probabilistica può essere costruita su un periodo congiunto (Lead time più Periodo di riordino 1, come da Figura 9, alias Responsibility window B).
Si può presumere che i livelli attuali di stock in mano e stock in ordine serviranno la domanda durante il periodo del lead time. Se si verifica un evento di stockout, ogni domanda successiva sarà coperta dai backorders. Tali backorders saranno soddisfatti dalle decisioni di micro purchasing prese a partire da oggi. Ciò ci consente di trattare lo stock in mano e lo stock in ordine come valori discreti (invece che casuali)4.
3. Identificare le opzioni di decisione di rifornimento fattibili
In uno scenario reale di rifornimento dell’inventario, bisognerebbe delineare tutte le opzioni decisionali fattibili, poiché non esiste un modo semplice per passare da una previsione probabilistica alla singola decisione migliore (quantità d’acquisto, in questo caso) per ogni prodotto. Invece di una scelta unica e perfetta, un approccio probabilistico presenta una gamma di possibili decisioni che devono essere valutate in termini di fattibilità.
Fattibilità qui ha il significato comune che una decisione è immediatamente attuabile; può essere eseguita “così com’è” senza ulteriori calcoli o controlli. Ad esempio, una decisione è “fattibile” se è redditizia e soddisfa tutti i nostri vincoli (ad es., MOQs, EOQs, taglie di lotto, spedizioni complete in container shipments, e qualsiasi altro vincolo che può esistere nella nostra supply chain)5.
Ad ogni riga del foglio delle Micro purchasing decisions (Figure 3 e 10), dobbiamo considerare l’aggiunta di un’unità in più di stock al nostro ordine d’acquisto per un determinato prodotto6. Il nostro “presente” (o Giorno 1 di questo esperimento) inizia alla riga 29, che mostra il livello attuale di stock. Questo viene calcolato come somma di Stock On Hand e Stock On Order. Se decidiamo di aggiungere un’unità all’ordine d’acquisto, la quantità complessiva verrà calcolata nella colonna L come la somma di tutte le unità considerate finora per l’acquisto (vedi note in Figura 10).
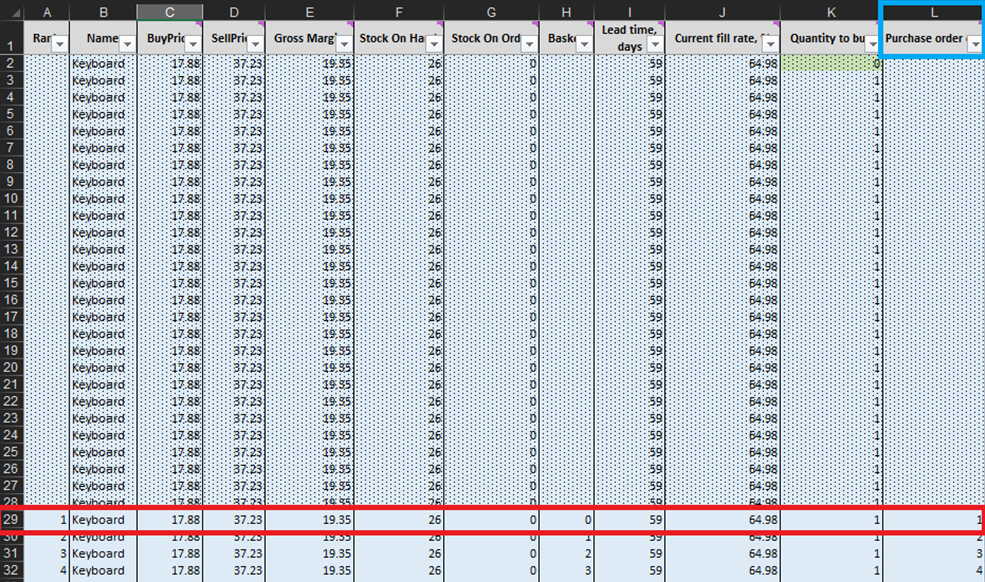
Figura 10. Visione dall’interno del foglio delle Micro purchasing decisions. La riga 29, evidenziata in rosso, è il punto d’inizio del nostro esperimento (per le tastiere). La colonna dell’ordine d’acquisto è evidenziata in blu. Lo stesso principio si applica alle righe 140 (per gli ordini di penne) e 240 (per gli ordini di librerie).
Una volta identificate queste decisioni d’inventario fattibili, calcoleremo e classificheremo il rendimento economico di ogni acquisto possibile. Nota che non valutiamo il rendimento dell’acquisto per le unità che attualmente sono o stock in mano o stock in ordine (colonne F e G nella Figura 10). Dato che queste unità sono già state acquistate, il rendimento economico teorico è stato determinato (e classificato) in una data precedente. Ad esempio, se osserviamo i dati relativi alle tastiere nella Figura 10, attualmente ci sono 26 unità in stock. Pertanto, i calcoli inizieranno dalla riga 29 e si valuterà se ordinare la prima unità di stock aggiuntivo (che aumenterebbe il livello di stock da 26 a 27 unità).
3.1 Valutare le decisioni d’acquisto fattibili
Per scegliere la migliore quantità d’acquisto per ogni prodotto, è necessario calcolare il rendimento monetario atteso a livello unitario per ogni quantità fattibile (per ogni prodotto), considerando l’incertezza futura rappresentata dalla previsione probabilistica. Questo è un concetto di valore atteso adattato al livello più granulare del decision-making.
In realtà, ogni tipo di fattore economico andrebbe considerato quando si cerca di calcolare il rendimento atteso per ogni decisione fattibile7. Ai fini di questa dimostrazione, ecco i fattori che prenderemo in considerazione:
- Sell price: Quanto addebitiamo ai clienti per il prodotto.
- Carrying/Storage cost: Quanto ci costa mantenere il prodotto in magazzino.
- Buy price: Quanto ci costa acquistare il prodotto dal nostro fornitore/ingrosso.
- Stockout cover: Descritto di seguito in dettaglio, essendo un fattore meno noto ma comunque importante8.
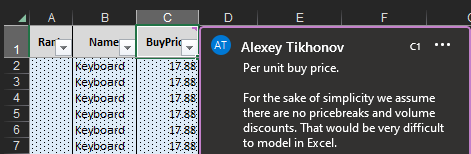
Figura 11. Nota esplicativa per Buy Price, visualizzabile passando il mouse sul titolo della colonna. Esiste una definizione per ogni colonna in ciascun foglio del documento Excel.
Stockout cover rappresenta un incentivo finanziario per mantenere un’unità di prodotto in stock, ma non con l’obiettivo esplicito di venderlo. Questo fattore economico viene usato per modellare la relativa importanza di un prodotto rispetto agli altri. Incentiva ad evitare un evento di stockout per quei prodotti che potrebbero essere considerati meno importanti a causa del loro contributo di margine diretto, poiché tali prodotti possono contribuire in modo significativo ai margini di profitto in maniera indiretta. In questo senso, esso si configura più come un reward driver9. Pur essendo un fattore poco preciso, è cruciale identificare tutti i prodotti critici (anche quelli che non sono motori diretti del margine).
3.2 Calcolo del punteggio di ciascuna decisione fattibile
La conseguenza economica totale (o purchase reward) di una decisione di rifornimento dell’inventario è la somma di tutti i fattori economici, inclusi margine atteso, costo di gestione dell’inventario, e stockout cover (definiti in dettaglio di seguito). Il costo di storage è incluso in questi calcoli come fattore negativo, agendo da controforza per bilanciare le nostre decisioni di rifornimento dell’inventario.
Di seguito viene presentata un’analisi delle implicazioni economiche delle formule in ogni colonna, utilizzando la riga 29 del foglio delle Micro purchasing decisions come esempio (vedi Figura 12).

Figura 12. Una ripartizione dei fattori per le colonne chiave, utilizzando la riga 29 delle Micro purchasing decisions (foglio Excel 2). Alcune colonne sono state nascoste per comodità della figura.
Per calcolare il rendimento atteso per ciascuna decisione sono necessari i seguenti fattori:
Margine lordo (colonna E) = Sell price – Buy Price.
Probabilità di vendita (colonna Q) = vedi formula nel foglio10.
Probabilità di non vendita (nessuna colonna) = 100% - Probabilità di vendita
Margine atteso (colonna R) = Margine lordo * Probabilità di vendita/100.
Fattore di aggressività (colonna S) = Varia da 0 a 1. 0,8 è stato selezionato per questo strumento.
Stockout cover (colonna T) = Sell price * Fattore di aggressività * Probabilità di vendita
Costo di storage (colonna U)
Costo atteso dell’inventario (colonna V) = Costo di storage * Probabilità di non vendita11.
Utilizzando i dati sopra, il purchase reward per ogni decisione d’inventario a livello micro (cioè per ogni unità di ogni prodotto) viene calcolato come segue:
Purchase reward (colonna W) = Margine atteso + Stockout Cover + Costo atteso dell’inventario.
Una volta ottenuta la stima del purchase reward, è possibile calcolare il punteggio finale che successivamente utilizzeremo per classificare tutte le decisioni considerate.
Score (colonna Y) = Purchase reward / Investment (colonna X)12.
Dato che il stockout cover è un fattore poco preciso che incorpora sia rendimenti diretti che indiretti, il purchase reward non riflette in modo rigoroso il rendimento atteso di una decisione d’inventario in isolamento. Se si desiderasse calcolare questo tipo di rendimento, andrebbe escluso lo stockout cover da tale formula13.
4. Classificazione delle decisioni di rifornimento dell’inventario fattibili
Una volta ottenuto il punteggio per ogni decisione d’acquisto fattibile (per ogni prodotto), viene generata una lista che viene ordinata in ordine decrescente (dal più alto al più basso) nelle Ranked purchasing decisions (vedi Figura 13). Ogni decisione d’inventario fattibile viene ordinata in base a un ROI positivo %. Inoltre, a ciascuna decisione viene assegnato un ranking ordinale (1°, 2°, 3°, ecc.) (vedi colonna A nella stessa figura).
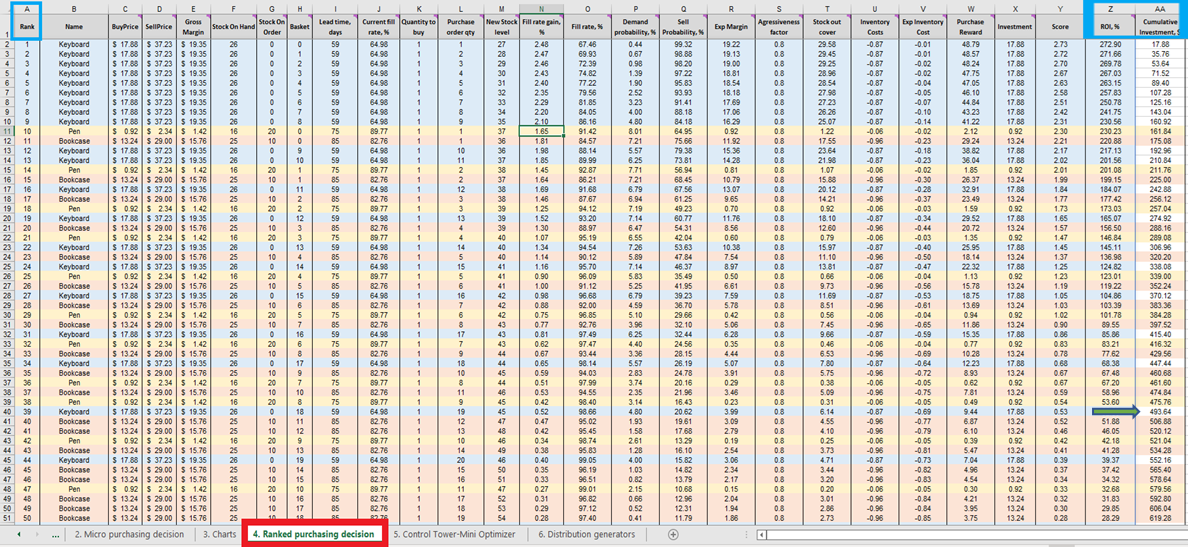
Figura 13. Posizione delle *Ranked purchasing decisions* evidenziata in rosso. Le colonne A, Z e AA sono evidenziate in blu. La cella 40 (il punto di cut-off per un budget di $500 – il valore predefinito del foglio di calcolo) è indicata dalla freccia verde.
Ranked purchasing decisions presenta righe a colori per ciascun prodotto (tastiere, penne e librerie), utilizzate qui per dimostrare come la scelta di aggiungere una singola unità extra di qualsiasi dato prodotto interagisca con ogni altra unità extra di ogni altro prodotto. Ciascuna di queste decisioni d’inventario influenza collettivamente il ROI. Infine, viene calcolato un valore di investimento cumulativo (colonna AA, Figura 13). Questo valore può essere utilizzato per indicare il punto in cui interrompere le decisioni d’acquisto in base ai vincoli di budget – anche se questo è solo uno dei possibili indicatori di interruzione14.
5. Determinare i criteri di terminazione
In termini di selezione di un punto di terminazione (sia nelle Ranked purchasing decisions che nella realtà), i criteri variano in funzione di numerose variabili. Ad esempio, si potrebbe disporre di un budget modesto, rendendo difficile massimizzare il ROI a causa di margini particolarmente stretti. In alternativa, potrebbe esserci un target complessivo per il livello di servizio, che deve essere bilanciato con l’esigenza di massimizzare i margini di profitto.
Per analisi ancora più dettagliate, i criteri di terminazione potrebbero comprendere la ricerca di un ROI massimizzato con obiettivi di livello di servizio variabili per ogni prodotto o categoria. I criteri di terminazione sono dunque una scelta strategica che va presa dopo una riflessione approfondita sugli obiettivi aziendali complessivi. Il prioritized inventory replenishment (PIR) è estremamente flessibile in questo senso; i criteri di terminazione per ogni ciclo d’acquisto possono essere regolati utilizzando la medesima procedura di ordinamento.
Per visualizzazioni esplicite delle nostre possibili decisioni di rifornimento dell’inventario, sono disponibili tre grafici per ogni prodotto nel dashboard Charts (foglio 3, vedi Figura 14). Di particolare interesse è “Driving forces_product name” (l’esempio della Keyboard è utilizzato in Figura 14), che mostra l’evoluzione del ROI a fronte di diverse quantità d’acquisto a livello unitario.
Come evidente dal grafico, esiste un punto oltre il quale un aumento della quantità d’acquisto risulterà in un ROI negativo. Ciò accade perché, a un certo punto, non ha più senso acquistare ulteriori unità, poiché i margini attesi verranno ridotti in modo critico dall’aumento dei costi attesi dell’inventario.
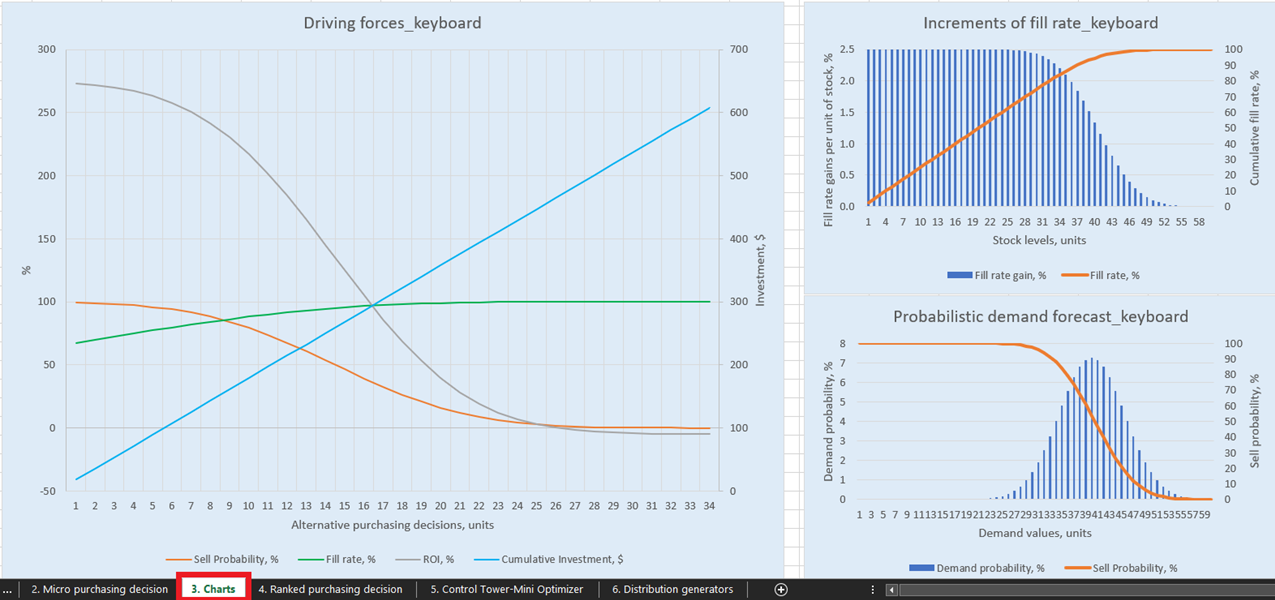
Figura 14. Visione di “Driving forces_keyboard” in Charts, posizione evidenziata in rosso.
Una volta determinati i criteri di terminazione, le decisioni di rifornimento dell’inventario prioritizzate vengono aggregate per SKU, aggiornando contestualmente la Quantità, l’Investimento e il Fillrate attesi raggiunti in Output-Purchase Recommendation per ciascun SKU (vedi Figura 15). È possibile modificare i vincoli di budget ($0 a $1450), il che aggiornerà di conseguenza l’elenco degli acquisti raccomandati. Per comodità, la control tower presenta due ulteriori blocchi: Base Case – hard copy e Changes to base scenario. Il primo è statico e mostra le impostazioni predefinite per la dimostrazione così come progettate da Lokad; il secondo evidenzia le differenze tra qualsiasi modifica apportata e l’impostazione predefinita di Lokad.
La lista di raccomandazione degli acquisti nella Control tower rappresenta l’obiettivo di questa dimostrazione (vedi Figura 15).
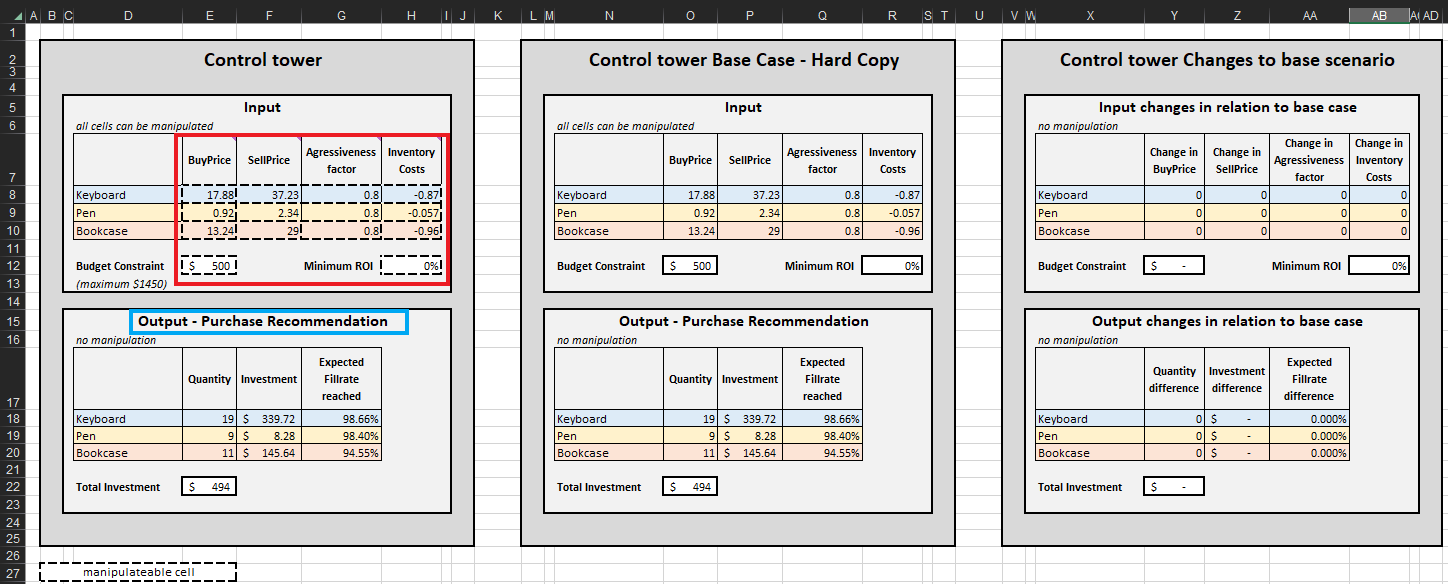
Figura 15. Visione del Control Tower-Mini Optimizer (foglio 5). Le celle modificabili sono evidenziate in rosso. “Purchase recommendation” è evidenziato in blu e rappresenta l’obiettivo di un approccio di rifornimento dell’inventario prioritizzato.
6. Conclusione
Le previsioni tradizionali delle serie temporali sono semplicemente incapaci di catturare il livello di granularità necessario per prendere decisioni di reintegro dell’inventario che riflettano l’incertezza futura e la piena portata dei vincoli e dei fattori trainanti. Questo accade perché esse mancano di una dimensione esplicita dell’incertezza, rappresentata dai valori di probabilità per gli esiti futuri attesi. Poiché una serie temporale tradizionale è sostanzialmente cieca a questo tipo di dati, un metodo classico come il safety stock equivale a una mera ipotesi: insufficiente e si perdono vendite redditizie con ROI atteso positivo; eccessivo e si riduce il ROI accumulando unità che (come dimostrato nel foglio di calcolo) hanno ROI atteso negativo.
Il reintegro dell’inventario prioritizzato, utilizzando previsioni probabilistiche, è la nostra soluzione a questo problema. Tale approccio considera le scelte di reintegro dell’inventario in combinazione, piuttosto che isolatamente. In questo modo, il guadagno finanziario atteso delle nostre scelte di reintegro può essere pienamente quantificato e rivelato. La base di tale approccio risiede nell’abbracciare l’incertezza e nel sfruttare gli input delle previsioni probabilistiche. Di conseguenza, si può ottenere una maggiore comprensione di quali livelli di servizio (per SKU) generino ricompense finanziarie significative, anziché fissare obiettivi arbitrari.
L’approccio PIR dimostrato in questo documento è stato costruito utilizzando dati sintetici e parametri ristretti. Queste scelte sono state fatte per adattare un comune strumento (Excel) a uno scopo non convenzionale (PIR). Tra le altre necessarie concessioni, il numero di SKU e di unità è stato limitato (rispettivamente a 3 e 100) per ridurre i tempi di elaborazione, poiché l’analisi dei dati di un intero catalogo (per non parlare dei dati di più negozi) sarebbe troppo laboriosa. Inoltre, non sono stati applicati vincoli di supply chain. Crucialmente, Excel non è progettato per elaborare variabili casuali – un passaggio chiave nella generazione di previsioni probabilistiche e nella definizione della politica PIR. Queste limitazioni non si applicano a una soluzione PIR di livello produttivo.
I professionisti della supply chain i cui business hanno superato Excel sono invitati a inviare un’email a contact@lokad.com per organizzare una dimostrazione di una soluzione PIR di livello produttivo.
7. Panoramica del Foglio di Calcolo
7.1 Leggimi
Questo foglio funge da pagina iniziale per l’utente. È presente un link a un tutorial online (quello che stai leggendo adesso).
7.2 Decisioni di Acquisto Micro
Questo è il secondo foglio ed è dedicato a un’analisi finanziaria finemente granulare di tutte le opzioni fattibilmente eseguibili per il reintegro. Si noti che nessuna manipolazione manuale dei dati viene effettuata qui. Questo foglio visualizza soltanto i risultati dei calcoli basati sugli input dei fogli Control Tower e Distribution generators.
Caratteristiche principali:
- Le righe con formattazione condizionale rappresentano le “decisioni passate” e non possono essere modificate. Si consiglia di utilizzare l’app desktop, poiché quella basata su browser di Excel a volte risulta inaffidabile sotto il profilo della formattazione.
- Posizionando il cursore su ciascuna intestazione di colonna verrà visualizzata una definizione/nota utile.
7.3 Grafici
Questo è il terzo foglio ed è dedicato alla visualizzazione dei principali fattori trainanti nelle decisioni di reintegro dell’inventario. Si noti che nessuna manipolazione manuale dei dati viene effettuata qui. Questo foglio è progettato per aiutare il professionista a visualizzare (e quindi a comprendere meglio) il funzionamento interno del processo PIR.
Caratteristiche principali:
- Tre grafici per SKU (tastiera, penna e scaffale).
- Il grafico delle “forze trainanti” visualizza i principali fattori trainanti per ogni decisione a livello unitario (per ogni SKU). Per questo motivo, l’asse x contiene solo le unità di un SKU che non sono ancora state ordinate.
- Altri due grafici (“incrementi del tasso di riempimento” e “previsione probabilistica della domanda”) contengono tutte le unità di stock – lo stock disponibile e le unità che possono essere ordinate.
7.4 Decisioni di Acquisto Classificate
Questo è il quarto foglio ed è dedicato all’elenco di tutte le decisioni di reintegro fattibilmente eseguibili, ordinate in ordine decrescente in base al ROI/punteggio. Questa lista è ordinata automaticamente a partire dai dati del foglio 2 (Decisioni di Acquisto Micro). Le decisioni fattibili sono visualizzate in relazione l’una con l’altra (vedi “Caratteristiche principali” sotto). Si noti che nessuna manipolazione manuale dei dati viene effettuata qui. A seconda delle modifiche apportate agli input nei fogli 5 e 6, questa lista cambierà.
Caratteristiche principali:
- Le decisioni fattibili di reintegro dell’inventario sono classificate in ordine decrescente (dal massimo al minimo) in base al ROI/punteggio.
- L’investimento cumulativo viene calcolato per le decisioni ordinate (vedi colonna AA del foglio 4).
- Posizionando il cursore su ciascuna intestazione di colonna verrà visualizzata una definizione/nota utile.
7.5 Control Tower - mini ottimizzatore
Questo è il quinto foglio e riassume le assunzioni del modello (input) e le decisioni raccomandate (output). I dati nelle celle modificabili possono essere cambiati per variare le assunzioni del modello e, di conseguenza, l’output del modello.
Caratteristiche principali:
- Tre blocchi per assistere nella dimostrazione: “Control tower” per la manipolazione manuale degli input; “Base Case – Hard copy” per visualizzare le impostazioni predefinite; e “Changes to base scenario” per mostrare la differenza tra le impostazioni aggiornate e quelle predefinite (vedi foglio 5).
- Un quarto blocco (“Model Assumptions”), situato sotto “Control tower”, è dedicato alla manipolazione delle assunzioni iniziali di stock (vedi foglio 5).
- Solo i dati nelle celle modificabili possono essere cambiati.
7.6 Distribution generators
Questo è il sesto foglio ed è dedicato alla generazione di previsioni probabilistiche della domanda. I parametri nelle celle modificabili possono essere cambiati, il che comporterà l’aggiornamento delle distribuzioni e la visualizzazione di nuovi valori di domanda probabilistica.
Caratteristiche principali:
- Un grafico di distribuzione per SKU.
- Ogni SKU ha un diverso pattern di distribuzione (la motivazione è spiegata nella sezione 2.1).
- A sinistra della serie di grafici di distribuzione c’è una tabella dedicata alla manipolazione dei parametri delle distribuzioni.
- Solo i parametri nelle celle modificabili possono essere cambiati.
- Posizionando il cursore sulle intestazioni di colonna rilevanti (nella tabella) verrà mostrata una definizione/nota utile.
Note
-
Considera latte e cioccolato. Il primo è un prodotto a basso margine, tuttavia è considerato un bene di prima necessità, mentre il secondo è discrezionale con margini di profitto più elevati. Le persone tendono ad acquistare insieme beni di prima necessità e prodotti discrezionali, ma la penalità per la mancanza di latte è diversa rispetto al cioccolato. Un cliente potrebbe sostituire un prodotto discrezionale (biscotti) con un altro (cioccolato) in caso di esaurimento, ma se non riesce ad acquistare un bene di prima necessità (latte), potrebbe abbandonare completamente il negozio. Per questo motivo, la copertura dello stockout risulterebbe maggiore per il latte rispetto al cioccolato, indipendentemente dal margine di profitto lordo. Dal nostro punto di vista, la copertura dello stockout è una ricompensa piuttosto che una penalità, in quanto è intesa a consentire vendite maggiori. ↩︎
-
Tre prodotti sono sufficienti per illustrare il concetto e al contempo mantenere il documento conciso e digeribile. ↩︎
-
I livelli di stock diventano probabilistici in quanto sottraiamo la domanda probabilistica dai valori discreti di stock (un valore discreto meno una distribuzione di probabilità dà luogo ad un’altra distribuzione di probabilità). Tutto ciò renderebbe troppo complicato spiegare le cose tramite Excel, in quanto non è adatto a eseguire calcoli con variabili casuali (pensate alle ‘distribuzioni di probabilità della domanda’). ↩︎
-
Queste concessioni sono necessarie per dimostrare il principio generale di un approccio probabilistico. In realtà, i backorder non sono sempre utilizzati e i tempi di consegna sono probabilistici e soggetti a variazioni. ↩︎
-
Per semplicità, non abbiamo applicato alcun vincolo di supply chain. ↩︎
-
Come accennato in precedenza, non è necessario modificare alcun dato in Decisioni di Acquisto Micro. Tutta la manipolazione dei dati viene effettuata tramite i fogli 5 e 6. ↩︎
-
In questo foglio Excel, i driver economici sono espressi in dollari, sebbene la valuta sia irrilevante. ↩︎
-
L’elenco dei driver economici sopra indicati non è esaustivo e gli scenari reali di reintegro dell’inventario (e di supply chain) presenteranno quasi certamente altri fattori. Ciò è particolarmente vero quando si tratta della produzione di beni e dei vincoli legati alla deperibilità. ↩︎
-
Questo driver è meno definito in un contesto B2C rispetto a uno B2B. Per quest’ultimo, spesso esistono penalità esplicite associate agli eventi di stockout, come penali contrattuali; per il primo, è difficile quantificare finanziariamente l’impatto negativo di un evento di stockout. In generale, il suo valore sarà elevato per i prodotti che infliggono un impatto sproporzionatamente negativo sull’attrattività di un’azienda (indipendentemente dal contributo diretto al margine dell’SKU). Il latte, come discusso in precedenza, non è un generatore di margine per i supermercati, ma il suo posizionamento strategico (solitamente nella parte posteriore del supermercato) spinge i clienti a percorrere corsie dopo corsie di altri prodotti (quasi tutti con margini maggiori). Se un supermercato subisce un evento di stockout con questo prodotto fondamentale (che le persone tendono ad acquistare molto regolarmente e in quantità), ciò potrebbe indurli ad abbandonare il supermercato, fare acquisti altrove e possibilmente non tornare (se tali eventi di stockout sono frequenti). ↩︎
-
La probabilità di vendita deriva dalle distribuzioni di probabilità generate nel foglio Distribution generators (foglio 6). ↩︎
-
Il costo continuo derivante dal non riuscire a vendere e quindi dall’obbligo di immagazzinare un’unità invenduta di un SKU. ↩︎
-
L’investimento è, in questo scenario, lo stesso del prezzo di acquisto, ma solo perché le nostre decisioni d’acquisto non sono vincolate da MOQ o moltiplicatori di lotto. ↩︎
-
Il modo più semplice per farlo è impostare il fattore di aggressività (colonna S della Figura 12) a zero, cosa che un’azienda potrebbe fare se decidesse che un evento di stockout non ha impatti negativi. Un piccolo consiglio: sicuramente li ha. ↩︎
-
Ad esempio, il nostro budget predefinito è di $500, per cui interromperemmo le decisioni d’acquisto alla cella 40 (vedi Figura 13), poiché la cella 41 ha un valore di $506.88 ed è al di fuori del nostro budget. Aggregheremmo quindi i numeri per prodotto, che costituirebbero la nostra lista di acquisto (vedi Output – Purchase recommendation in Control Tower, secondo la Figura 2). Come già accennato, è possibile modificare il budget preimpostato di $500 (vedi Figura 2 per le istruzioni) a qualsiasi valore compreso tra $0 e $1450. Questo dimostrerà come la lista di acquisto cambi con differenti vincoli di budget. Indipendentemente dalle limitazioni finanziarie, le Decisioni di Acquisto Classificate identificheranno la migliore possibile combinazione di decisioni d’inventario, dal punto di vista del ROI, per tutte le righe comprese tra il rango 1 e il punto di terminazione. ↩︎