00:28 イントロダクション
00:43 Robert A. Heinlein
03:03 これまでの経緯
06:52 複数のパラダイムの選択肢
08:20 静的解析
18:26 配列プログラミング
28:08 ハードウェアの混合性
35:38 確率的プログラミング
40:53 微分可能プログラミング
55:12 コードとデータのバージョン管理
01:00:01 セキュアプログラミング
01:05:37 結論:ツールもサプライチェーンでは重要
01:06:40 次回講義と聴衆からの質問
説明
主流の サプライチェーン理論 は企業全体で優位に立つのに苦労しているが、一つのツール、すなわち Microsoft Excel はかなりの運用上の成功を収めている。主流のサプライチェーン理論の 数値的レシピ をスプレッドシートで再実装するのは些細なことだが、理論の認識にもかかわらず、現実にはそうならなかった。我々は、サプライチェーンに成果をもたらす上で卓越した プログラミングパラダイム を採用することで、スプレッドシートが勝利したことを実証する。
完全なトランスクリプト

皆さん、こんにちは。このサプライチェーン講義シリーズへようこそ。私は Joannes Vermorel です。本日は第4回講義「サプライチェーンのためのプログラミングパラダイム」をお届けします。

私が「Vermorelさん、サプライチェーンの知識の中で最も興味深い分野は何だと思いますか?」と尋ねられると、いつも私の最も重要な回答の一つはプログラミングパラダイムです。そして、頻度はそれほど高くはないものの、十分な頻度で、相手から「プログラミングパラダイムですって、Vermorelさん?一体何の話をしているのですか?どうしてそれが現在の課題に関連しているのですか?」という反応が返ってきます。こうした反応は頻繁ではありませんが、起こるたびに、科学小説の大家と称される Robert A. Heinlein の非常に素晴らしい名言を思い出させられます。
ハインラインは有能な人物についての素晴らしい名言を残しており、それは様々な分野での能力の重要性を強調しています。特に、サプライチェーンのように困難な問題が山積する分野では尚更です。これらの問題は、まるで人生そのものと同じくらい困難であり、プログラミングパラダイムを探求する価値は十分にあると私は信じています。それにより、サプライチェーンに大きな価値をもたらす可能性があるのです。
これまでの第1回講義では、サプライチェーンの問題がいかに困難であるかを見てきました。最適解について語る者は本質を見失っており、最適性に近いものは存在しません。第2回講義では、サプライチェーン管理における卓越性を達成するための5つの重要な要件を示す 量的供給チェーンマニフェスト を概説しました。これらの要件は単独では十分ではありませんが、優れた成果を上げるためには欠かせないものです。
第3回講義では、サプライチェーン最適化の文脈におけるソフトウェア製品の提供について議論しました。サプライチェーン最適化は、資本主義的な方法で適切に扱われるべきソフトウェア製品を必要とするという命題を擁護しましたが、そのような製品は既製品として存在しません。多様性が極めて高く、現在の技術では到底対応しきれない課題に直面しているのです。したがって、必然的に完全にオーダーメイドのものとなります。つまり、企業または対象のサプライチェーンのためにオーダーメイドされるソフトウェア製品であるならば、その製品を実際に提供するための適切なツールは何か、という問題が生じます。これが今日のテーマに繋がるのです。適切なツールは、正しいプログラミングパラダイムから始まります。なぜなら、いずれにせよこの製品はプログラムされなければならないからです。

ここまで、最適化側の問題に対処するためのプログラム的能力が必要であることが明らかになりました。管理側とは混同してはいけません。前回の講義でも見たように、Microsoft Excel はこれまでのところ勝者であり、小規模な企業から大企業まであらゆる場所で使われています。数百万ドルを投じた超スマートなシステムを導入している企業においても、Excel は依然として王者です。その理由は、Excel が正しいプログラミング特性を備えているからです。非常に表現力が豊かで、柔軟性があり、アクセスしやすく、保守もしやすいのです。しかし、Excel が最終形態ではありません。私たちはもっと多くのことができると固く信じていますが、そのためには適切なツール、考え方、洞察、そしてプログラミングパラダイムが必要なのです。

プログラミングパラダイムは、聴衆にとって非常に抽象的に感じられるかもしれませんが、実際には過去50年にわたり集中的に研究されてきた学問領域です。この分野では膨大な量の研究が行われ、多くの人々による高品質な成果が蓄積されたライブラリさえ存在します。本日は、Lokad が採用した7つのパラダイムを紹介します。これらのアイデアは我々が新たに発明したものではなく、先人たちが創り出したものを採用したにすぎません。これらすべてのパラダイムは Lokad のソフトウェア製品に実装され、ほぼ10年にわたって本番環境で活用してきた結果、我々の運用上の成功において決定的な役割を果たしてきたと信じています。

このリストを静的解析とともに進めていきましょう。ここでの問題は複雑性です。サプライチェーンにおける複雑性にどのように対処すればよいのでしょうか?数百のテーブルと何十ものフィールドを持つエンタープライズシステムに直面することになるでしょう。例えば、単純な問題として在庫の補充を倉庫で考える場合、考慮すべき点は山積みです。MOQs、価格の切り替え、需要予測、リードタイムの予測、さらには各種返品などが挙げられます。棚スペースの制限、受入能力の上限、そして一部ロットの有効期限切れなども問題となります。結果として、考慮すべき事項が無数に存在するのです。サプライチェーンにおいて「素早く動いて物を壊せ」という考え方は決して適していません。もし不要な在庫1百万ドル相当の商品を誤って注文してしまえば、それは非常に高額なミスとなります。ソフトウェアの一部にサプライチェーンを任せ、日常的な意思決定をさせ、バグが発生すれば数百万の損失につながる状況は避けなければなりません。我々は、設計上極めて高い正確性を持つものを求めています。本番環境でバグを発見するような事態は望むべきではありません。これは、クラッシュが大した問題とならない一般的なソフトウェアとは全く異なります。
サプライチェーン最適化においては、これは通常の問題とは異なります。もし誤ってサプライヤーに大規模な誤った注文を出してしまった場合、1週間後に「すみません、間違いでした。注文はなかったことにしてください」と連絡することはできません。そうしたミスは多大な費用を伴います。静的解析と呼ばれるのは、プログラムを実行せずに解析する手法であるという点に由来します。つまり、文やキーワードで記述されたプログラムを、実行することなく解析することで、そのプログラムが本番、特にサプライチェーンの生産に悪影響を及ぼす問題をはらんでいるかどうかを判断できるのです。答えはイエスです。これらの手法は実際に存在し、実装され、非常に価値があります。
例を挙げると、画面に Envision のスクリーンショットが表示されています。Envision は Lokad によってほぼ10年にわたり開発され、サプライチェーンの予測最適化に特化したドメイン固有のプログラミング言語です。これは、オンラインでコードを編集できるウェブアプリである Envision のコードエディターのスクリーンショットです。構文は Python の影響を強く受けています。このたった4行のスクリーンショットで、もし倉庫の在庫補充のための大規模なロジックを記述し、経済変数、例えば価格の切り替えなどをプログラムに組み入れた場合、それらの価格切替が、補充すべき数量という最終的な出力に全く関係を持たないことが分かります。ここには明らかな問題があります。重要な変数である価格切替を導入したにもかかわらず、それがプログラムの出力に何の影響も及ぼしていないのです。つまり、静的解析によって検出可能な問題がここに存在します。もし、コード内に出力に影響を与えない変数が含まれているならば、それは意味をなさない死んだコードであり、複雑性を低減するために排除されるべきです。もしくは、本来計算に組み込むべき重要な経済変数が、注意散漫などにより抜け落ちたという実際のミスである可能性もあります。
静的解析は、設計段階であらゆる程度の正確性を実現するために絶対に必要です。コードを書いている段階、つまりデータに手を付ける前に問題を修正できるからです。もし実行時に問題が発生したとしても、それは夜間に実行されるバッチ処理中、例えば倉庫の在庫補充システムが動作している間に起こる可能性が高いのです。プログラムは、誰も見ていない深夜に実行されることが多いため、その際にクラッシュしてはなりません。クラッシュは、人々が実際にコードを記述しているときに起こるべきです。
静的解析には多くの目的があります。例えば、Lokad では ダッシュボード の WYSIWYG 編集に静的解析を利用しています。WYSIWYG とは “What You See Is What You Get” の略で、見たままが得られるという意味です。折れ線グラフ、棒グラフ、表、色、そして様々なスタイリング効果を用いたレポート用のダッシュボードを構築すると想像してみてください。コードで細かくスタイルを調整するのは非常に手間がかかるため、視覚的に操作できることが理想的です。実装したすべての設定はコード自体に再注入され、これが静的解析によって行われます。
Lokad におけるもう一つの側面は、サプライチェーン全体としてはそれほど重要ではないかもしれませんが、プロジェクト遂行には確かに重要な、我々が開発している Envision というプログラミング言語への対処です。約10年前の初日から、間違いは避けられないと分かっていました。完璧なビジョンを初めから持っているわけではなかったのです。問題は、このプログラミング言語自体の設計上のミスを、いかに便利に修正できるかということでした。ここで、Python は私にとって警告の物語となりました。
新しい言語ではない Python は 1991 年に初めてリリースされ、ほぼ30年前のことです。Python 2 から Python 3 への移行はコミュニティ全体でほぼ10年を要し、関与した企業にとっては悪夢のような非常に苦痛なプロセスでした。私の見解では、Python 自体は十分な構造を持っておらず、プログラミング言語のバージョン間でプログラムを移行できるようには設計されていませんでした。完全に自動化して移行するのは極めて困難であり、それは Python が静的解析を念頭に置いて設計されていなかったからです。サプライチェーン向けのプログラミング言語では、プログラムが長期間運用されることを考慮すると、静的解析において優れた品質を持つものが必要です。サプライチェーンには「3ヶ月待ってください。コードを書き直しているところです。騎兵隊が来るまで待ってください。数ヶ月間は動かさない」という余裕はありません。まるで全速力で走る列車を走行中に修理するようなもので、エンジンを修理している間も列車は動き続けます。これが、本番環境で稼働中のサプライチェーンシステムを修正する様相なのです。システムを一時停止するという贅沢は一切ありません。

第2のパラダイムは配列プログラミングです。サプライチェーンでは複雑性の管理が繰り返し問題となるため、これを制御する必要があります。特定の種類のプログラミングエラーを避けるためのロジックが求められるのです。例えば、プログラマーが明示的に記述するループや分岐があると、非常に困難な問題群に晒されることになります。任意のループを書いて計算時間の保証を試みると、対策が非常に難しくなります。一見ニッチな問題のように思えるかもしれませんが、サプライチェーン最適化においては決してそうではありません。
実際の例を挙げると、あなたが 小売チェーン を運営しているとしましょう。深夜、ネットワーク全体の売上が完全に集約され、そのデータが最適化用のシステムへ渡されます。このシステムには、各店舗ごとに需要予測、在庫最適化、再配分の意思決定を行うために、ちょうど60分のウィンドウが与えられます。処理が完了すると、その結果は倉庫管理システムに渡され、出荷準備が開始されます。トラックは午前5時頃に積み込まれ、午前9時には店舗が開店し、商品が受け取られて棚に陳列されます。
しかし、タイミングが非常に厳格で、もし計算がこの60分のウィンドウを超えてしまうと、サプライチェーン全体の実行が危険にさらされます。実運用でどれほどの時間がかかるかを初めて知るような事態は避けなければなりません。もし、反復回数を自分で決められるループがあると、計算の所要時間の証拠を得るのは非常に困難になります。これはサプライチェーン最適化の話です。すべてをピアレビューして二重にチェックする余裕はありません。パンデミックの影響で、ある国は閉鎖し、他国は通常24時間前の通知で非常に不規則に再開することもあります。迅速に対応する必要があるのです。
だから、アレイプログラミングとは、配列に対して直接操作を行うという考え方です。ここにあるコードの断片を見ると、これはEnvisionコード、つまりLokadのDSLです。何が起こっているかを理解するには、「orders.amounts」と書いたときに、実際には変数が現れるということ、そして「orders」がリレーショナルテーブル、つまりデータベースのテーブルとしての意味を持つことを理解しなければなりません。例えば、最初の行では「amounts」がテーブルの1つのカラムとなります。1行目では、ordersテーブルの各行に対して、単に「quantity」というカラムを取り、「price」と掛け合わせ、動的に生成される第3のカラム「amount」を得るという操作を行っているのです。
ちなみに、現代ではアレイプログラミングはデータフレームプログラミングとも呼ばれています。この分野の研究は非常に古く、30年から40年前、あるいは40~50年前にまで遡ります。現在では人々はデータフレームという考え方に馴染んでいますが、以前からはアレイプログラミングとして知られていました。2行目では、SQLのようにフィルタリングを行っています。日付をフィルタリングしており、ordersテーブルには日付があるため、それが対象になります。そして「todayから365日前より大きい日付」、つまり昨年のデータを保持し、その後「products.soldLastYear = SUM(orders.amount)」と記述しています。
さて、興味深いのは、productsとordersの間に「ナチュラルジョイン」と呼ばれる結合が存在する点です。なぜなら、各注文行は1つの商品にのみ関連付けられ、1つの商品は0個または複数の注文行に関連付けられているからです。この構成では、「注文レベルで起こっていることの合計」をそのまま「商品レベル」で計算する、と直接言えるのです。これが9行目で正に行われています。文法は非常にシンプルで、余計な記号や技術的な複雑さがほとんどありません。私は、このコードはデータフレームプログラミングにおいて余計な要素をほとんど含まないと主張したいです。そして、10行目、11行目、12行目では、ダッシュボードにテーブルを表示するという操作を、「LIST(PRODUCTS)」、次に「TO(products)」という非常に便利な方法で行っています。
サプライチェーンにおけるアレイプログラミングには多くの利点があります。まず、特定の種類の問題を完全に排除できるという点です。配列ではオフバイワンのバグが発生しません。また、並列化や計算の分散処理も格段に容易になります。これは非常に興味深いことで、プログラムを1台のローカルマシンでではなく、クラウド上の多数のマシン群で実行できることを意味します。ちなみに、これこそがLokadで実際に行われていることなのです。この自動並列化は非常に大きなメリットをもたらします。
ご覧の通り、サプライチェーン最適化を行う場合、コンピュータハードウェアの使用パターンは非常に断続的です。先ほどの小売ネットワークにおける60分のウィンドウの例に戻ると、計算のためのコンピューティングパワーが必要なのは1時間だけであり、残りの23時間は全く必要ありません。ですから、プログラムを実行する際には、多数のマシンに処理を分散させ、完了後にすべてのマシンを解放して他の計算ができるようにする必要があるのです。そうでなければ、1日中レンタルマシンを支払い続けることになり、しかも使用率が5%程度でしかなく、非常に非効率です。
多くのマシン上に迅速かつ予測可能に処理を分散させ、その後にその計算能力を解放できるというこのアイデアは、マルチテナント構成のクラウドや、Lokadが採用しているその他の数々の技術を必要とします。しかし何よりもまず、これを実現するためにはプログラミング言語自体の協力が不可欠です。一般的なプログラミング言語、例えばPythonのような言語では、このような非常にスマートで的確なアプローチを実現することは不可能なのです。これは単なるトリック以上のもので、ITハードウェアのコストを20分の1に削減し、実行速度を飛躍的に向上させ、サプライチェーンにおける潜在的なバグの多数を排除するものです。まさにゲームチェンジャーと言えるでしょう。
アレイプログラミングは既に、PythonのNumPyやpandasのように、data scientist層の間で非常に人気のある形で存在しています。しかし、もしこれがそれほど重要で有用なものであるならば、なぜこれらが言語自体の第一級市民として扱われていないのでしょうか?もし全てがNumPyを介して行われるのなら、NumPyこそが第一級市民であるべきです。私は、NumPyを超えるアプローチが可能だと考えています。NumPyは1台のマシン上でのアレイプログラミングに過ぎませんが、なぜ複数のマシンによるアレイプログラミングができないのでしょうか?クラウド上のアクセス可能なハードウェア能力を活かせば、はるかに強力かつ適切な実装が可能なのです。
では、サプライチェーン最適化におけるボトルネックは何でしょうか?ゴールドラットの「サプライチェーンにおけるボトルネック以外の改善は幻想に過ぎない」という言葉がありますが、私はこれに大いに同意します。現実的には、サプライチェーン最適化のボトルネックは、残念ながらLokadや私のクライアントにとって木から実るわけではないサプライチェーンサイエンティストであると言えます。
ボトルネックは、企業の戦略や競合他社の対抗戦略をすべて織り込んだ数値レシピを作成し、それを大規模に実行可能な形に変換できるサプライチェーンサイエンティスト、つまり人材そのものです。私が博士課程を始めた頃(ちなみに最終的には修了できなかったのですが)、研究室の皆が皆データサイエンスを実践しているのが目に見えました。大半の人が高度な機械学習モデルのコードを書き、エンターキーを押しては待っていました。もし5~10ギガバイトの大規模なデータセットを扱うなら、リアルタイムではありえません。その結果、研究室全体が数行のコードを書いてエンターキーを押し、そしてコーヒーを飲みながら、またはオンラインで何かを読んでいるという状況になり、生産性は非常に低かったのです。
そのため、私が自分の会社を立ち上げた際には、プログラムを実行して結果が出るまで待つために、一流の超有能な人材に大金を払い続ける事態は避けたいと強く考えていました。理論上は、彼らは複数のプロセスを並列に実行して実験をすることが可能ですが、実際にはそのような事例は見たことがありません。問題解決に没頭する際には、仮説を検証し、その結果を得て次に進む必要があります。高度な技術的作業を同時に複数追うのは、とても困難なのです。
しかし、救いの手はありました。データサイエンティスト、そして現在のLokadのサプライチェーンサイエンティストは、千行のコードを書いた後に「実行してください」と頼むのではなく、既存の千行にたった2行を追加するだけでスクリプトを実行します。このスクリプトは、ほんの数分前に実行されたのと全く同じデータに対して動作しており、論理もほぼ同一で、追加した2行だけが異なるのです。では、数分ではなく数秒でテラバイト級のデータを処理するにはどうすればいいのでしょうか?答えは、前回のスクリプト実行時にすべての中間計算結果を記録し、非常に安価で高速・便利なSSDなどのストレージに保存しておくことです。
次回プログラムを実行すると、システムはスクリプトがほぼ同一であることに気付き、差分を検出します。そして、計算グラフの観点からほぼ同一と判断し、実際に計算する必要がある部分がごく僅かであるため、結果を数秒で得ることができるのです。これにより、サプライチェーンサイエンティストの生産性は劇的に向上し、エンターキーを押して20分待つ状況から、エンターキーを押して5〜10秒後に結果を得て次に進む状態へと変わります。
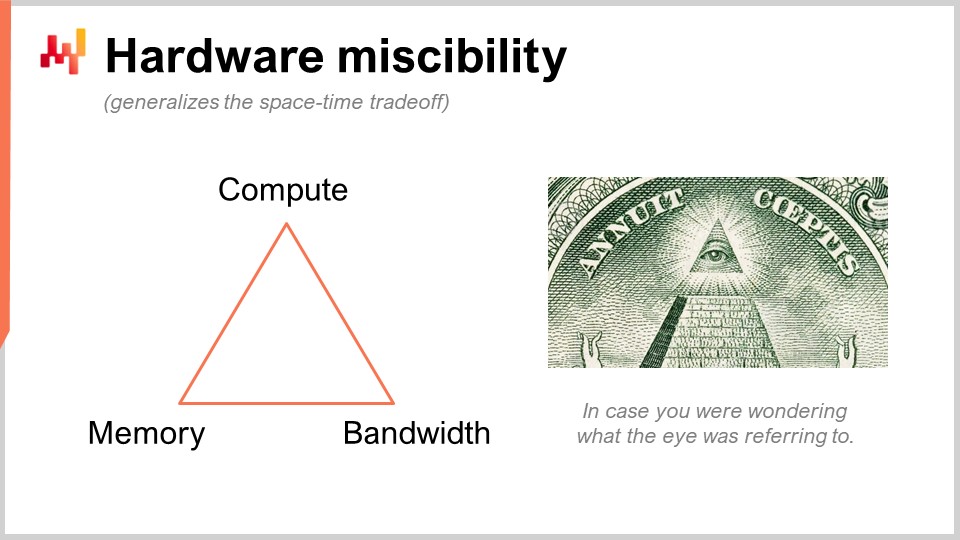
これは一見非常に曖昧に思えるかもしれませんが、実際には生産性に10倍の影響を与えるものです。これは極めて大きな効果です。ここで行っているのは、Lokadが発明したわけではない賢明なトリックを用い、計算という生のリソースをメモリとストレージに置き換えるという考えです。私たちには計算、メモリ(揮発性または永続性)、そして帯域幅という、クラウドコンピューティングプラットフォームでリソースを購入する際の基本的な計算リソースが存在します。実際、あるリソースを他のリソースで補完することが可能で、その目的は最大限のコストパフォーマンスを実現することにあります。
多くの人がインメモリコンピューティングを使うべきだと言いますが、私はそれは無意味だと思います。インメモリコンピューティングというのは、ある特定のリソースにデザインの重点を置くことを意味しますが、実際にはトレードオフが存在します。そして、興味深いのは、こうしたトレードオフや視点を実装しやすくするプログラミング言語と環境が存在するという点です。一般的な汎用プログラミング言語でも可能ですが、手作業で行う必要があるため、その作業をこなせるのはプロのソフトウェアエンジニアのみとなります。サプライチェーンサイエンティストが、プラットフォームの基本的な計算リソースに対して低レベルの操作を自ら行うことはあり得ないのです。これはプログラミング言語自体のレベルで設計されるべきものです。
さて、確率的プログラミングについて話しましょう。定量的サプライチェーンのビジョンを紹介した第2回講義では、最初の要件としてあらゆる可能な未来を考慮する必要があると述べました。この要件に対する技術的な解答が確率的予測です。未来にはあらゆる可能性があるものの、すべてが同じ確率で起こるわけではないのです。不確実性を伴う計算を行うための代数が必要となります。私がExcelに大きな批判をする理由のひとつは、Excelやその他の最新のクラウドベースの表計算ソフトウェアでさえ、不確実性を十分に表現するのが非常に困難であるからです。表計算では、数値だけでは不十分なのです。
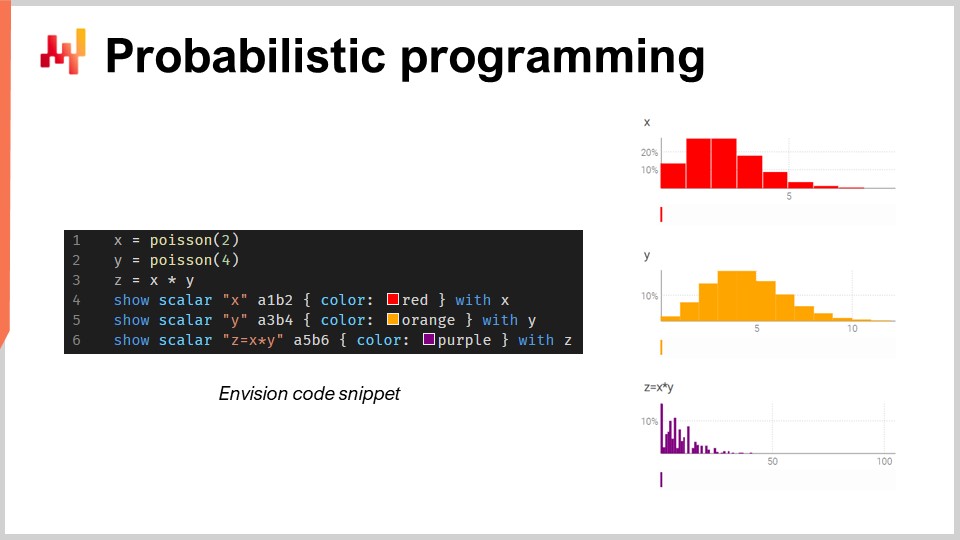
この小さなコード断片では、乱数変数の代数、すなわちEnvisionのネイティブ機能を示しています。1行目では、平均2の離散型ポアソン分布を生成し、それを変数Xに格納しています。次に、同じ手法で別のポアソン分布Yを生成します。そして、ZをXとYの掛け合わせとして計算しています。乱数変数同士のこの掛け算は非常に奇妙に思えるかもしれませんが、サプライチェーンの観点からなぜ必要なのか、例を挙げましょう。
例えば、自動車アフターマーケットでブレーキパッドを販売しているとします。人々はブレーキパッドを1個単位で購入することはなく、2個または4個単位で購入します。したがって、予測を行う際には、顧客が実際にある種類のブレーキパッドを購入しに来る確率を予測する必要があります。これが、ブレーキパッドの需要が0個、1個、2個、3個、4個…と観測される確率を与える最初の乱数変数となります。さらに、顧客が2個か4個のいずれかを購入するかを示す別の確率分布も存在します。もしかすると50:50かもしれませんし、2個購入が10%、4個購入が90%かもしれません。こうした2つの側面があり、実際のブレーキパッドの総消費量を算出するためには、まず顧客がブレーキパッドを求めに来る確率と、次に購入個数の確率分布を掛け合わせる必要があるのです。つまり、不確実な2つの数量を掛け合わせる必要があるということです。
ここでは、2つの乱数変数が独立であると仮定しています。ちなみに、乱数変数同士のこの掛け算は、数学的には離散畳み込みとして知られています。スクリーンショットには、Envisionによって生成されたダッシュボードが表示されています。最初の3行で乱数代数の計算を行い、4行目、5行目、6行目でその結果をウェブページ上のダッシュボードに表示しています。Excelのグリッドのように、例えばA1やB2といった位置にプロットされます。Lokadのダッシュボードは、Excelのグリッドのように、列B、Cなどの位置と、行1、2、3、4、5で構成されています。
ご覧のとおり、離散畳み込みによって得られるZは、非常に奇妙で尖ったパターンを示しており、これはパックや複数購入が可能なサプライチェーンにおいて非常によく見られる特徴です。このような状況では、ロットやパックに関連する乗法的なイベントの要因を分解するほうが通常は適切です。こうした能力を第一級市民として利用できるプログラミング言語が必要なのです。これがまさに確率的プログラミングの本質であり、私たちがEnvisionで実装した方法です。

さて、微分可能プログラミングについて議論しましょう。ここで一言付け加えますが、聴衆の皆さんが内容を完全に理解することは期待していません。皆さんの知性が不足しているのではなく、このトピックは一連の講義に値するほどの内容だからです。実際、今後の講義計画を見ると、微分可能プログラミングに専念する一連の講義が組まれています。今回は非常に高速に進め、内容もかなり暗号的になるため、あらかじめご了承ください。
ここで注目するサプライチェーンの問題、すなわちカニバリゼーションと代替について進めましょう。これらの問題は非常に興味深く、おそらく遍在する時系列予測が最も容赦なく失敗する場面です。なぜなら、しばしば顧客や見込み客から、例えば「バックパックのような特定の商品の13週間先の予測が可能か」と問い合わせがあるからです。答えは可能ですが、明らかに、あるバックパックの需要を予測する際、その製品以外のバックパックに対する取り扱い次第で大きく左右されます。もしバックパックが1種類だけなら、その商品の需要が集中するかもしれませんが、10種類のバリエーションを導入すれば、当然多くのカニバリゼーションが発生します。参照の数を10倍にしたからといって、売上総額が10倍になるわけではありません。従って、カニバリゼーションと代替は必然的に起こる現象であり、これらはサプライチェーン全体に蔓延しています。
カニバリゼーションや代替をどのように分析するのでしょうか? Lokadで私たちが行っている方法は、唯一の方法とは言いませんが、確実に有効なアプローチであり、通常、顧客と製品を結ぶグラフを観察することで実施しています。なぜなら、カニバリゼーションは、同一の顧客をめぐって製品同士が競合する時に生じるからです。カニバリゼーションとは、顧客が何らかのニーズを持っているにもかかわらず、好みがあり、その親和性に合う製品群の中からたった1つだけを選ぶという現象の反映に他なりません。これがカニバリゼーションの本質です。
これを分析するには、まず売上の時系列ではなく、顧客と製品間の歴史的取引を結ぶグラフを分析する必要があります。実際、ほとんどのビジネスにおいて、このデータは容易に入手できます。eコマースの場合はもちろん、販売した各ユニットについて顧客情報があるからです。B2Bでも同様です。さらに、小売のB2Cにおいても、現代の小売チェーンの多くは、カードを提示した顧客の二桁パーセンテージを把握するロイヤリティプログラムを持っているため、誰が何を購入しているのかを知ることができます。全トラフィックの100%ではありませんが、10%以上の取引で顧客と製品のペアが分かれば、この種の分析には十分な情報と言えるのです。
この比較的小さなスニペットでは、顧客と製品間の親和性分析について詳述します。これは、あらゆるカニバリゼーション分析を行うための基礎ステップそのものです。それでは、このコードで何が起きているのか見ていきましょう。
1行目から5行目は非常に単純です。取引履歴を含むフラットファイル、具体的には日付、製品、顧客、数量の4列からなるCSVファイルを読み込んでいるだけです。これはごく基本的なもので、例を具体的にするために一部の列しか使用していないに過ぎません。取引履歴では、すべての取引において顧客が識別されていると仮定しています。つまり、単にテーブルからデータを読み込んでいるだけなのです。
次に、7行目と8行目では、製品用テーブルと顧客用テーブルを作成しています。本番環境では通常、これらのテーブルを自ら作成するのではなく、他のフラットファイルから読み込みます。例を極めてシンプルに保つため、取引履歴で観測された製品から製品テーブルを抽出し、同様に顧客テーブルも作成しているだけです。ご覧の通り、これはシンプルにするためのトリックです。
さて、10行目、11行目、12行目ではラテン空間に関する処理が行われ、ここから少し複雑になります。まず、10行目では64行のテーブルを作成しています。このテーブルは何も保持しておらず、ただ64行あるという事実によって定義されているだけです。つまり、これはプレースホルダーのようなもので、多くの行があるにもかかわらず列を持たない単純なテーブルです。それだけではあまり実用的ではありません。次に、「P」とは、本質的に直積(デカルト積)という数学的操作であり、すべての組み合わせを生成するテーブルです。これは、製品テーブルの各行とテーブル「L」の各行の組み合わせごとに1行ずつ存在するテーブルです。したがって、このテーブル「P」は製品テーブルよりも64行多くなり、顧客に対しても同様の操作を行っています。つまり、この追加の次元であるテーブル「L」を用いて、各テーブルを膨張させているのです。
これが、私のラテン空間の基盤となります。つまり、各製品については64個の値からなるラテン空間を学び、各顧客についても同様に64個の値からなるラテン空間を学びます。顧客と製品間の親和性を知るためには、単に両者のドット積(内積)を計算すればよいのです。ドット積は、二つのベクトルの各要素ごとの積を計算し、その合計を求める操作です。技術的に聞こえるかもしれませんが、要するに各要素の積を計算して合算する、ということなのです。
これらのラテン空間というのは、いわば作り話のようなパラメーターを持つ空間を構築するための洒落た専門用語に過ぎません。微分可能プログラミングのすべての魔法は、14行目から18行目までのわずか5行で行われます。ここではキーワード「autodiff」と「transactions」が使われ、これは対象のテーブル、つまり観測データのテーブルであることを示しています。このテーブルを行ごとに処理して学習プロセスを進めます。このブロック内で、学習したいパラメーター、すなわちまだ値が分かっていない数値を宣言しているのです。これらはランダムな数値で初期化されます。
ここで「X」、「X*」、および「Y」を導入しています。「X*」が具体的に何をしているのかについては、詳細には踏み込みません(後の質問で触れるかもしれません)。損失関数となる表現、つまりその合計を返しています。協調フィルタリングや行列分解のアイデアは、二部グラフ上のすべてのエッジに適合するラテン空間を学習するというものです。技術的には少し複雑ですが、サプライチェーンの観点から見ると、実際に行っていることは非常に単純で、製品と顧客間の親和性を学習しているのです。
非常に難解に思えるかもしれませんが、どうかお付き合いください。今後、より考察深い入門講義も用意しています。全体が5行で完結しているのは実に驚異的なことです。ここで「5行」と言っても、実際は巨大な複雑性を持つサードパーティライブラリを呼び出して知性を隠しているわけではありません。いいえ、ここでは「autodiff」と「params」という2つのキーワード以外に機械学習の魔法は一切働いていません。「autodiff」は微分可能プログラミングが行われるブロックを定義するために使われ、ちなみにこのブロックでは何でもプログラム可能であり、プログラムを注入することすらできます。そして「params」により問題を宣言するだけで、これですべて完結するのです。つまり、背後で百万行にも及ぶライブラリが全ての作業を担っているわけではなく、不透明な魔法は一切ありません。必要な情報はすべてこの画面上にあり、これがプログラミングパラダイムとライブラリの違いを示しています。プログラミングパラダイムは、複雑さを包み隠す巨大なサードパーティライブラリに頼ることなく、わずか数行のコードでカニバリゼーション分析のような、信じられないほど洗練された機能にアクセスすることを可能にします。これにより、非常に複雑に見える問題も短いコードで解決できるのです。
次に、微分可能プログラミングの仕組みについて少し説明します。ここには2つの重要なポイントがあります。一つは自動微分です。工学系の訓練を受けた方なら、微分を計算する方法が2通りあることをご存知でしょう。一つはシンボリック微分です。例えば、xの二乗の場合、xに関して微分すると2xになる、というものです。これがシンボリック微分です。もう一方は数値微分で、関数f(x)を微分する場合、f’(x) ≈ (f(x + ε) - f(x)) / εという形になります。これが数値微分です。しかし、どちらの方法も、ここで求めていることには適していません。シンボリック微分は、その微分結果が元のプログラムよりもはるかに複雑になるという問題があり、数値微分は数値的に不安定で、多くの数値安定性の問題を引き起こします。
自動微分は、70年代に考案され、ここ10年で世界に再発見された素晴らしいアイデアです。これは、任意のコンピュータプログラムの導関数を計算できるという考えであり、非常に驚くべきものです。さらに驚異的なのは、その導関数となるプログラムが元のプログラムと同じ計算複雑度を持つという点で、これは驚嘆に値します。微分可能なプログラミングとは、自動微分と学習したいパラメータの組み合わせに過ぎません。
では、どのようにして学習するのでしょうか? 微分を得ることができれば、勾配を逆伝播させることができ、確率的勾配降下法を用いてパラメータの値に微調整を加えることができます。これらのパラメータを調整することによって、複数回の確率的勾配降下の繰り返しで、納得のいくパラメータに徐々に収束し、学習または最適化したい対象を達成することができるのです。
微分可能なプログラミングは、たとえば私が説明しているような、クライアントと製品の親和性を学習したいといった学習問題に利用できます。また、制約下での最適化など、数値最適化問題にも応用可能であり、このパラダイムは非常にスケーラブルです。ご覧の通り、この側面はEnvisionにおいて一級市民として扱われています。ちなみに、Envisionの構文に関してはまだ改善中の部分がいくつかあるため、現時点でそれらの機能が完全実装されているとは言えません。しかし、その本質は既に備わっています。まだ進化の途中にあるいくつかの微細な点については、ここで詳しく述べるつもりはありません。

さて、次にあなたのシステムの生産準備に関連する別の問題について見ていきましょう。通常、サプライチェーン最適化においては、ハイゼンバグに直面することがあります。ハイゼンバグとは一体何でしょうか? それは、最適化が行われたにもかかわらず、ごみのような結果を生み出す苛立たしいバグの一種です。例えば、在庫補充のためのバッチ計算を夜間に行ったところ、翌朝にはその結果の一部が意味不明で、重大なミスを引き起こしていたとしましょう。この問題を再び起こしたくないためにプロセスを再実行すると、問題は消えてしまうのです。つまり、問題が再現されず、ハイゼンバグ自体も現れなくなるのです。
奇妙な極端な例のように聞こえるかもしれませんが、Lokadの初期数年では、これらの問題が繰り返し発生していました。特にデータサイエンス系のサプライチェーンの取り組みが、未解決のハイゼンバグによって失敗していくのを何度も見てきました。生産環境で発生したバグをローカルで再現しようとしても再現できず、問題は解決されないままでした。そして数ヶ月にわたるパニックの末、通常はプロジェクト全体がひっそりと終了し、人々はExcelのスプレッドシートに戻ることになったのです。
もしロジックの完全な再現性を実現したいのであれば、コードとデータの両方をバージョン管理する必要があります。聴衆のソフトウェアエンジニアやデータサイエンティストの多くは、コードのバージョン管理という概念に馴染みがあるでしょう。しかし、プログラムが実行される際に、どのバージョンのコードとデータが使用されているかを正確に把握できるように、すべてのデータもバージョン管理する必要があります。新たなトランザクションやその他の要因によってデータが変化しているため、翌日には問題が再現できなくなり、初めにバグを引き起こした条件がすでに存在しなくなってしまうのです。
あなたのプログラミング環境が、生産環境での特定の時点でのロジックとデータを正確に再現できることを保証する必要があります。これは、すべての要素を完全にバージョン管理することを意味します。改めて言えば、これを実現するためには、プログラミング言語とプログラミングスタックが協力しなければなりません。プログラミングパラダイムがスタック内で一級市民として扱われなくても実現は可能ですが、その場合、サプライチェーンサイエンティストは自らの行動やプログラミングの方法に非常に慎重でなければなりません。さもなければ、結果を再現することができなくなってしまいます。これは、すでにサプライチェーン自体から大きなプレッシャーを受けているサプライチェーンサイエンティストに、さらに莫大な負担をかけることになるのです。彼らが、自分自身の結果を再現できないという偶発的な複雑さに直面することは望ましくありません。Lokadでは、これを「タイムマシン」と呼んでおり、過去の任意の時点の全てを再現することが可能です。
注意すべきは、再現が昨晩に行われたことだけに留まらない点です。場合によっては、事後または長い時間が経過してからミスが発見されることもあります。例えば、リードタイムが3か月の仕入先に対して発注を行った場合、その発注が全く意味を成していなかったことを3か月後に発見するかもしれません。その問題が何であったのかを突き止めるためには、その偽の発注を作成した3か月前の時点にまで遡る必要があります。これは、直近数時間分だけのバージョン管理ではなく、文字通り過去1年間の実行履歴を完全に保持することを意味します。

もう一つの懸念は、ランサムウェアやサイバー攻撃がサプライチェーンに与える影響の増大です。これらの攻撃は極めて破壊的であり、非常に高額な損害を引き起こす可能性があります。ソフトウェア主導のソリューションを実装する際には、自社およびサプライチェーンをサイバー攻撃やその他のリスクに対してより脆弱にしていないかを慎重に検討する必要があります。この観点から、ExcelやPythonは理想的な選択とは言えません。これらのコンポーネントはプログラム可能であるため、多数のセキュリティ脆弱性を抱えている可能性があるのです。
サプライチェーンの問題に取り組むデータサイエンティストやサプライチェーンサイエンティストのチームがある場合、ソフトウェア業界で一般的な綿密かつ反復的なピアレビューのプロセスに十分な時間を割くことはできません。もし、関税が一夜にして変更されたり、倉庫が浸水したりした場合、迅速な対応が求められます。コードの仕様書やレビューに数週間も費やす余裕はありません。問題は、デフォルトで会社に誤って被害を与える可能性を秘めた人々に対して、プログラミングの能力を与えている点にあります。意図的な不正従業員が存在すればさらに悪化するかもしれませんが、それはさておき、誰かが誤ってITシステムの内部情報を露呈してしまうというリスクもあります。サプライチェーン最適化システムは、その定義上、全社にわたる大量のデータにアクセスできるため、このデータは単なる資産ではなく、同時に重大な負債にもなり得るのです。
あなたが求めているのは、安全なプログラミングを促進するプログラミングパラダイムです。あなたは、ある種の操作を決して行えないプログラミング言語が欲しいのです。たとえば、なぜサプライチェーン最適化のためにシステムコールを行えるプログラミング言語が必要なのでしょうか?Pythonでもシステムコールは可能ですし、Excelでも同様です。しかし、そもそもそのような機能を備えたプログラマブルなシステムが必要な理由は何でしょうか?それは、まるで自分の足を撃つために銃を購入するようなものです。
サプライチェーン最適化に必要のない機能やクラスが存在しないものが欲しいのです。もしこれらの機能が存在すれば、それは大きな負債となります。設計上、安全なプログラミングを強制するツールなしにプログラム可能な機能を導入してしまうと、サイバー攻撃やランサムウェアのリスクが高まり、事態は悪化します。
もちろん、サイバーセキュリティチームの規模を倍にすれば補うことは可能ですが、それは非常にコストがかかり、緊急のサプライチェーンの状況に対処する際には理想的ではありません。通常のプロセス、レビュー、承認にかける時間がない中で、迅速かつ安全に行動する必要があります。また、ヌル参照例外、メモリエラー、オフバイワンループ、副作用といった些細な問題を排除する安全なプログラミングが求められるのです。

結論として、ツール選びは重要です。昔の格言に「刀を持って銃撃戦に挑むな」というものがあります。必要なのは、大学で学んだものだけでなく、適切なツールとプログラミングパラダイムです。あなたのサプライチェーンのニーズを満たすためには、プロフェッショナルで生産向けのものが求められます。劣ったツールでいくらかの結果は得られるかもしれませんが、それは決して素晴らしいものではありません。すばらしい音楽家がスプーンだけで音楽を奏でることはできても、適切な楽器を用いればはるかに良い音楽を生み出せるのです。

さて、質問に進みましょう。約20秒の遅延があることにご注意ください。つまり、あなたが見ているビデオと私があなたの質問を読むタイミングには若干のラグがあります。
質問: オペレーションズ・リサーチの観点から見た動的計画法はどうですか?
動的計画法は、その名前にもかかわらずプログラミングパラダイムではありません。むしろ、アルゴリズムの技法です。つまり、あるアルゴリズム的なタスクを実行したり、特定の問題を解決する際に、同じ部分的な操作を非常に頻繁に繰り返すという考え方です。動的計画法は、前述した時間と空間のトレードオフの一例で、計算時間を節約するために少し多めのメモリを投資するというものです。これは1960年代、70年代にさかのぼる初期のアルゴリズム技法の一つです。良い技法ですが、その名前はやや不運です。なぜなら、実際には「動的」な要素はなく、本質的にプログラミングというよりもアルゴリズムの考案に関するものだからです。従って、私にはそれはプログラミングパラダイムとはみなせず、単なる特定のアルゴリズム技法に過ぎないと考えています。
質問: ヨハネスさん、優れたサプライチェーンエンジニアが持つべき参考書をいくつかご紹介いただけますか?残念ながら、私はこの分野には不慣れで、現在はデータサイエンスとシステムエンジニアリングに注力しています。
現存の文献については非常に複雑な感想を持っています。最初の講義で、サプライチェーンに関する学術研究の頂点だと信じる2冊の本を紹介しました。もし2冊読んでみたいのであれば、それらを読むとよいでしょう。しかし、これまで読んできた本には常に問題を感じています。基本的に、理想化されたサプライチェーンのためのおもちゃのような数値レシピのコレクションを提示する人々がいますが、これらの本はサプライチェーンに正しい角度からアプローチしておらず、サプライチェーンが極めて手強い問題であるという本質を完全に見落としていると考えています。方程式、アルゴリズム、定理、証明といった非常に技術的な文献も豊富にありますが、私はそれらも本質を捉えきれていないと思います。
そして、もう一つのタイプのサプライチェーン管理の本、すなわちコンサルタント風の書籍があります。これらの本は、2ページごとにスポーツの比喩を用いるため、一目でそれだとわかります。また、SWOT(強み、弱み、機会、脅威)の2x2バージョンのような単純な図が多用されており、これらは低品質な思考方法だと考えています。これらの本の長所は、サプライチェーンが非常に手強い取り組みであること、そしてそれが人々によって繰り広げられるゲームであり、ありとあらゆる奇妙な事態が起こりうるという点をよく理解していることです。それは評価に値します。しかし、通常コンサルタントや経営学部の教授によって書かれるこれらの本は、実行可能な方法論を示していません。最終的なメッセージは「より良いリーダーになれ」「もっと賢くあれ」「より多くのエネルギーを持て」といったものであり、私にとってはそれは実行可能なものではありません。ソフトウェアのように、極めて価値ある何かに変換できる要素が与えられていないのです。
ということで、私は最初の講義に立ち返ります。もし読みたいのであればその2冊を読んでも構いませんが、時間の無駄になるかどうかはわかりません。人々が何を書いたのかを知ることは大切です。文献の中でコンサルタント風な側面に目を向けるなら、私のお気に入りはカタナの著作です。これは最初の講義では挙げませんでした。すべてが悪いわけではなく、たとえコンサルタント風であっても、才能を持っている人もいます。カタナの著作、特に動的サプライチェーンに関する本をぜひチェックしてみてください。その本は参考文献に掲載する予定です。
質問: カニバリゼーションや品揃えの決定といった、並列化が容易でない問題に対して、どのように並列化を活用するのですか?
なぜ並列化が容易でないのでしょうか?確率的勾配降下法は比較的簡単に並列化できます。確率的な勾配ステップはランダムな順序で実行でき、同時に複数のステップを進めることが可能です。したがって、確率的勾配降下法に基づく処理は、どれも容易に並列化できると考えています。
カニバリゼーションに対処する場合により難しいのは、別の種類の並列化、すなわち「何を先にするか」を扱うことです。もしある製品を最初に投入して予測を立て、その後別の製品を投入すると、状況が変わってしまいます。解決策は、全体の状況を一括して扱える方法を持つことです。「まずこの製品を投入して予測し、次に別の製品を投入して最初の予測を修正する」という手順を踏むべきではありません。すべてを同時に、一括して行うのです。そのためには、より多くのプログラミングパラダイムが必要になります。今日紹介したプログラミングパラダイムは、そのために大いに役立つでしょう。
品揃えの決定に関しては、こうした問題は並列化に大きな困難を伴いません。同じことは、世界規模の小売ネットワークを持ち、すべての店舗の品揃えを最適化しようとする場合にも当てはまります。各店舗について並列に計算を行うことができます。1店舗ずつ順番に品揃えを最適化していくのは望ましくありません。それは誤った方法だからです。むしろ、ネットワーク全体を並列に最適化し、すべての情報を伝播させ、それから繰り返すのです。さまざまな手法があり、適切なツールがあれば、その実現はずっと容易になります。
質問: グラフデータベースのアプローチを使用していますか?
いいえ、技術的かつ正統な意味でのグラフデータベースは使用していません。市場には非常に興味深いグラフデータベースが多数存在しますが、私たちLokadが内部で使用しているのは、統一されたモノリシックなコンパイラスタックによる完全な垂直統合で、従来のクラシックスタックに見られる要素をすべて完全に排除する方法です。これにより、計算性能において非常に優れたパフォーマンス、つまりハードウェアに近いレベルの性能を達成しています。これは、私たちが極めて優れたプログラマーであるからではなく、従来存在していたほぼすべての層を取り除いたからです。Lokadでは、文字通り一切のデータベースを使用していません。持続性のためのデータ構造の整理に至るまで、すべてを担当するコンパイラが存在します。これは少々奇妙ですが、その方法の方がはるかに効率的で、クラウド上の多数のマシンに向けてスクリプトをコンパイルするという考え方とも非常に相性が良いのです。ハードウェアの観点から見たとき、ターゲットプラットフォームは1台のマシンではなく、多数のマシンの集まりなのです。
質問: Pythonコードや勾配降下法、貪欲法などの関連アルゴリズムも実行するPower BIについて、あなたの意見をお聞かせいただけますか?
ビジネスインテリジェンスに関連するもの、特にPower BIに対して私が抱く問題は、そのパラダイムがサプライチェーンにとって不適切だという点です。すべての問題を、ただ次元ごとに切り分けるハイパーキューブとして捉えてしまいます。根本的には、表現力の問題があり、それが非常に制約的なのです。中間にPythonを組み合わせて使用することになれば、ハイパーキューブに起因する表現力の乏しさを補うためにPythonが必要になるのです。しかし、前の質問で述べたように現代のエンタープライズソフトウェアは層が多すぎるという呪いがあります。追加する層ごとに非効率やバグが発生するのです。Power BIにPythonを組み合わせて使えば、層があまりにも多くなってしまいます。つまり、Power BI自体が他のシステムの上に乗っており、すでにPower BI以前に複数のシステムが存在しています。その上にPower BIがあり、さらにその上にPythonがあります。しかし、Pythonが単独で機能しているのでしょうか?いいえ、おそらくPandasやNumPyといったPythonライブラリも使うことになるでしょう。こうしてPython内にも層が積み重なり、最終的には何十もの層が出来上がります。どの層にもバグが潜む可能性があるため、状況は非常に悪夢のようになるでしょう。
私は、ただ単に膨大な数のスタックを抱えるという解決策を支持していません。C++では「間接の層をもう一つ追加すれば、どんな問題も解決できる」という冗談がありますが、これは多少無意味な発言です。しかし、私は、核心設計が不十分な製品に対し、問題に正面から取り組むのではなく、揺るがない土台の上に次々と追加していくというアプローチには断固反対です。そのような方法では、生産性が低下し、解決できないバグとの闘いが続き、さらにはメンテナンス性の面でも悪夢に近い状況になるだけです。
質問: 協調フィルタリング分析の結果を、たとえばバックパックのような各製品の需要予測アルゴリズムにどのように組み込むことができますか?
申し訳ありませんが、このトピックは次回の講義で取り上げます。簡潔に言えば、既存の予測アルゴリズムにこれを組み込むべきではありません。よりネイティブに統合された何かを用意するべきです。従来の予測手法に戻るのではなく、従来の方法を捨て、全く根本的に異なる方式でこれを活用するのです。しかし、この件は後の講義で詳しく議論します。今日はこれで十分です。
これで本講義は終了です。ご参加いただいた皆さん、誠にありがとうございました。次回の講義は1月6日水曜日、同じ時間、同じ曜日に行います。私自身はクリスマス休暇を取る予定ですので、皆さんにメリークリスマスとハッピーニューイヤーをお祈りします。来年も講義シリーズを続けていきます。ありがとうございました。


