Stock di Sicurezza
Lo stock di sicurezza è un metodo di ottimizzazione dell’inventario che indica quanto inventario deve essere mantenuto oltre la domanda prevista al fine di raggiungere un determinato obiettivo di livello di servizio. Lo stock extra funge da buffer “di sicurezza” - da cui il nome - per proteggere l’azienda dalle fluttuazioni future attese. La formula dello stock di sicurezza dipende sia dalla domanda futura prevista che dal lead time futuro atteso. L’incertezza si assume essere distribuita normalmente per entrambi i fattori. La formula dello stock di sicurezza è onnipresente nella maggior parte dei sistemi di gestione dell’inventario, inclusi i più noti ERPs e MRPs.
Aggiornamento luglio 2020: L’approccio descritto di seguito è il modello “textbook” della supply chain, purtroppo, risulta essere ampiamente disfunzionale. In particolare, né la domanda futura né il lead time futuro sono distribuiti normalmente (cioè non gaussiani). Inoltre, l’intera prospettiva perde di vista il fatto che tutti gli SKU che possono essere ordinati o prodotti dall’azienda competono per le stesse risorse. Consigliamo vivamente di non utilizzare alcun modello di stock di sicurezza quando si tratta di supply chain reali.
Pubblico destinatario: Questo documento è rivolto principalmente ai professionisti della supply chain nel settore retail o manifatturiero. Tuttavia, questo documento è utile anche a sviluppatori di software per contabilità / ERP / eCommerce che desiderano estendere le loro applicazioni con funzionalità di gestione delle scorte.
Abbiamo cercato di mantenere al minimo le conoscenze matematiche richieste, tuttavia non possiamo evitare del tutto l’uso delle formule, dato che lo scopo preciso di questo documento è essere una guida pratica che spiega come calcolare lo stock di sicurezza.
Download: calculate-safety-stocks.xls (Foglio di calcolo Microsoft Excel)
Introduzione
La gestione dell’inventario è un trade-off finanziario tra i costi dell’inventario e i costi da stock-out. Maggiore è la quantità di scorte, maggiore è il capitale di esercizio necessario e maggiore è la svalutazione delle scorte. D’altra parte, se non si dispone di scorte sufficienti, si verificano stock-out, con la perdita di vendite potenziali e la possibilità di interrompere l’intero processo produttivo.
Le scorte d’inventario dipendono essenzialmente da due fattori
- lead demand: la quantità di prodotti che verrà consumata o acquistata.
- lead time: il ritardo tra la decisione di riordino e la rinnovata disponibilità.
Tuttavia, questi due fattori sono soggetti a incertezze
- variazioni della domanda: il comportamento dei clienti può evolversi in modi piuttosto imprevedibili.
- variazioni del lead time: fornitori o trasportatori possono trovarsi ad affrontare difficoltà impreviste.
Decidere il livello di stock di sicurezza equivale implicitamente a fare un compromesso tra tali costi considerando le incertezze.
Il bilanciamento tra i costi dell’inventario e i costi da stock-out dipende molto dal business. Pertanto, anziché considerare direttamente tali costi, introdurremo ora la classica nozione di livello di servizio.
Il livello di servizio esprime la probabilità che un determinato livello di stock di sicurezza non porti a stock-out. Naturalmente, quando gli stock di sicurezza vengono aumentati, aumenta anche il livello di servizio. Quando gli stock di sicurezza diventano molto elevati, il livello di servizio tende al 100% (cioè, la probabilità di incontrare uno stock-out è zero).
La scelta del livello di servizio, ovvero la probabilità accettabile di stock-out, è al di fuori dello scopo di questa guida, ma abbiamo una guida separata su come calcolare i livelli di servizio ottimali.
Modello di riapprovvigionamento dell’inventario
Il punto di riordino è la quantità di scorte che dovrebbe innescare un ordine. Se non ci fossero incertezze (cioè, se la domanda futura fosse perfettamente conosciuta e la fornitura perfettamente affidabile), il punto di riordino sarebbe semplicemente uguale alla domanda totale prevista durante il lead time, chiamata anche domanda del lead time.
In pratica, a causa delle incertezze, abbiamo
punto di riordino = domanda del lead time + stock di sicurezza
Se assumiamo che le previsioni non siano distorte (in termini statistici), avere zero stock di sicurezza porterebbe a un livello di servizio del 50%. Infatti, previsioni non distorte significano che c’è la stessa probabilità che la domanda futura sia maggiore o minore della domanda del lead time (ricorda che la domanda del lead time è solo un valore previsto).
Attenzione: le previsioni possono essere non distorte senza essere esatte. Il bias indica un errore sistematico del modello di previsione (es: sovrastimare sempre la domanda del 20%).
Distribuzione normale dell’errore
A questo punto, abbiamo bisogno di un modo per rappresentare l’incertezza nella domanda del lead time. Ne seguente, assumeremo che l’errore sia distribuito normalmente, vedi l’immagine qui sotto.
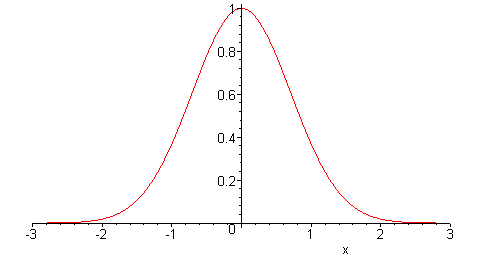
Note statistiche: questa ipotesi di distribuzione normale non è del tutto arbitraria. In certe situazioni, gli stimatori statistici convergono a una distribuzione normale come indicato dal teorema del limite centrale. Tuttavia, queste considerazioni sono al di fuori dello scopo di questa guida.
Una distribuzione normale è definita solo da due parametri: la sua media e la sua varianza. Poiché assumiamo che le previsioni non siano distorte, assumiamo che la media della distribuzione dell’errore sia zero, il che non significa che stiamo assumendo un errore nullo.
Determinare la varianza dell’errore di previsione è un compito più delicato. Lokad, come la maggior parte dei toolkit di previsione, fornisce delle stime MAPE (Mean Absolute Percentage Error) associate alle sue previsioni. Per completezza, spiegheremo come semplici euristiche possano essere utilizzate per superare questo problema.
In particolare, la varianza all’interno dei dati storici può essere usata come una buona euristica per stimare la varianza dell’errore di previsione. David Piasecki suggerisce anche di utilizzare la domanda prevista invece della domanda media nell’espressione della varianza, cioè
dove $$E$$ è l’operatore di media, $$y_t$$ è la domanda storica per il periodo $$t$$ (tipicamente la quantità di vendite) e $$y’$$ la domanda prevista.
L’idea chiave dietro questa ipotesi è che l’errore di previsione è molto spesso correlato alla quantità di variazione attesa: maggiori sono le variazioni imminenti, maggiore è l’errore nelle previsioni.
In realtà, il calcolo di questa varianza dell’errore coinvolge alcune sottigliezze che saranno trattate in dettaglio di seguito.
Espressione dello stock di sicurezza
A questo punto, abbiamo determinato sia la media che la varianza, quindi la distribuzione dell’errore è nota. Ora dobbiamo calcolare il livello di errore accettabile all’interno di questa distribuzione. In precedenza, abbiamo introdotto la nozione di livello di servizio (una percentuale) per fare ciò.
Note: Assumiamo un lead time statico. Tuttavia, un approccio molto simile può essere usato per un lead time variabile. Vedi
Per convertire il livello di servizio in un livello di errore chiamato anche fattore di servizio, dobbiamo usare la distribuzione normale cumulativa inversa (a volte chiamata anche distribuzione normale inversa) (vedi NORMSINV per la funzione corrispondente in Excel). Per quanto possa sembrare complicato, non lo è; consigliamo di dare un’occhiata al normal distribution applet per avere una visione più chiara. Come puoi vedere, la funzione cumulativa trasforma la percentuale in un area sotto la curva, la soglia dell’asse X corrispondente al valore del fattore di servizio.
Intuitivamente, calcoliamo
stock di sicurezza = deviazione standard dell'errore * fattore di servizio
Più formalmente, sia $$S$$ lo stock di sicurezza, abbiamo
dove $$\sigma$$ è la deviazione standard (cioè la radice quadrata di $$\sigma^2$$, la varianza definita sopra), $$cdf$$ è la distribuzione normale cumulativa normalizzata (media zero e varianza uguale a uno) e $$P$$ il livello di servizio.
Ricordando che
punto di riordino = domanda del lead time + stock di sicurezza
Sia $$R$$ il punto di riordino, abbiamo
Corrispondenza tra lead time e periodo di previsione
Finora, abbiamo semplicemente assunto che per un dato lead time fossimo in grado di produrre direttamente la corrispondente previsione della domanda futura. In pratica, non funziona esattamente così. L’analisi dei dati storici di solito inizia aggregando i dati in periodi di tempo (tipicamente settimane o mesi).
Tuttavia, il periodo scelto potrebbe non corrispondere esattamente al lead time; pertanto, sono necessari ulteriori calcoli per esprimere la domanda del lead time e la sua varianza associata (considerando che stiamo ancora assumendo una distribuzione normale per l’errore di previsione, come descritto nella sezione precedente).
Intuitivamente, la domanda del lead time può essere calcolata come la somma dei valori previsti per i periodi futuri che si intersecano con il segmento del lead time. Bisogna fare attenzione ad adeguare correttamente l’ultimo periodo previsto.
Formalmente, sia $$T$$ il periodo e $$L$$ il lead time. Scriviamo
dove $$k$$ è un intero e $$0 ≤ α < 1$$. Sia $$D$$ la domanda del lead time. Allora, abbiamo l’espressione finale per la domanda del lead time
dove $$y’_n$$ è la domanda prevista per il $$n^{th}$$ periodo futuro.
Considerando le stesse ipotesi di distribuzione normale, possiamo calcolare la varianza dell’errore di previsione come
dove $$y’$$ è la previsione media per periodo
Ancora, $$\sigma^2$$ è calcolata qui come una varianza per periodo mentre avremmo bisogno di una varianza che corrisponda al lead time. Sia $$\sigma_{L}^2$$ la varianza per lead time aggiustata, abbiamo
Infine, possiamo esprimere nuovamente il punto di riordino come
Utilizzare Excel per calcolare il punto di riordino
Questa sezione descrive come calcolare il punto di riordino con Microsoft Excel. Si consiglia di dare un’occhiata al foglio di calcolo Excel di esempio fornito.
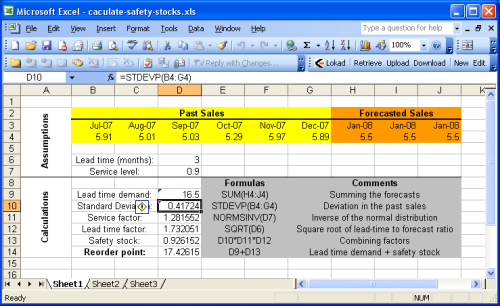
Il foglio di calcolo di esempio è fondamentalmente diviso in due sezioni: le ipotesi in alto e i calcoli in basso. Le previsioni sono considerate parte delle ipotesi perché la previsione delle vendite (o della domanda) è al di fuori dello scopo di questa guida. Puoi fare riferimento al nostro tutorial per le previsioni di vendita con Microsoft Excel per maggiori dettagli.
La maggior parte delle formule introdotte nella sezione precedente sono operazioni molto semplici (addizioni, moltiplicazioni) che sono facili da eseguire con Microsoft Excel. Tuttavia, due funzioni sono degne di nota
- NORMSINV (Microsoft KB): stima la distribuzione normale cumulativa, indicata come cdf sopra.
- STDEV (Microsoft KB): stima la deviazione standard, indicata come $$\sigma$$ sopra. Ricordiamo che la deviazione standard $$\sigma$$ è la radice quadrata della varianza $${\sigma^2}$$.
Per semplicità, il primo foglio non implementa l’euristica $${\sigma^2 = E[ (y_t - y’)^2 ]}$$ nel calcolo del fattore di servizio. Questo approccio è implementato nel Foglio2 (il secondo foglio del documento Excel). Poiché nell’esempio abbiamo assunto previsioni stazionarie, il punto di riordino rimane identico con o senza questa euristica.
Risorse
Inventory Management and Production Planning and Scheduling, Edward A. Silver, David F. Pyke, Rein Peterson, Wiley; 3ª edizione, 1998