00:17 イントロダクション
03:35 桁の違い
06:55 サプライチェーン最適化の段階
12:17 ハードウェアのSカーブ
15:52 これまでの話
17:34 補助科学
20:25 現代のコンピュータ
20:57 レイテンシ 1/2
27:15 レイテンシ 2/2
30:37 計算、クロックスピード
36:36 計算、パイプライニング、1/3
39:11 計算、パイプライニング、2/3
40:27 計算、パイプライニング、3/3
46:36 計算、スーパー・スカラー 1/2
49:55 計算、スーパー・スカラー 2/2
56:45 メモリ 1/3
01:00:42 メモリ 2/3
01:06:43 メモリ 3/3
01:11:13 データストレージ 1/2
01:14:06 データストレージ 2/2
01:18:36 帯域幅
01:23:20 結論
01:27:33 次回の講義と聴衆からの質問
説明
現代のサプライチェーンは、モーターで動くコンベアベルトが電気を必要とするのと同じように、動作するためにコンピューティングリソースを必要とします。それにもかかわらず、動作が鈍いサプライチェーンシステムは至る所に存在し、1990年以来、コンピュータの処理能力は10,000倍以上に増加しました。現代のコンピューティングリソースの基本的特性に関する理解不足 - ITやデータサイエンスの分野においても - がこの状況を大いに説明しています。numerical recipesの背後にあるソフトウェア設計は、基盤となるコンピューティングハードウェアと対立するべきではありません。
完全な文字起こし

このサプライチェーン講義シリーズへようこそ。私はジョアンネス・ヴェルモレルです。本日は「サプライチェーンのための現代のコンピュータ」をお届けします。西洋のサプライチェーンは既に長い間、場合によっては三十年前からデジタル化されています。コンピュータを利用した意思決定は至る所で行われており、関連する数値レシピはリオーダー・ポイント、min-max在庫、安全在庫など、さまざまな名称で呼ばれ、監督の度合いも異なります。
それでも、現代において巨大なサプライチェーンを運営する大企業を見ると、基本的にコンピュータ駆動の何百万もの意思決定がサプライチェーンのパフォーマンスに大きく影響を及ぼしていることがわかります。従って、サプライチェーン-パフォーマンス-テストの改善は、サプライチェーンを駆動する数値レシピの改善に帰着するのです。そして、より優れた数値レシピ、つまりより良いモデルと正確な予測を求めると、結果的にその優れたレシピは従来よりもはるかに多くのコンピューティングリソースを消費することになります。
コンピューティングリソースは非常に高価であり、サプライチェーンにとって常に課題でした。そして、次のモデルや予測システムの進化の段階では、前のものよりも10倍のコンピューティングリソースを必要とすることがよくあります。確かに、それは追加のサプライチェーンパフォーマンスをもたらす可能性がありますが、その代償としてコンピューティングコストが増加します。過去数十年にわたり、コンピューティングハードウェアは飛躍的に進化してきましたが、本日ご覧いただくように、この進化は現在も進行中であるにもかかわらず、enterprise softwareによってしばしば妨げられています。その結果、より現代的なハードウェアがあってもソフトウェア自体の速度は向上せず、しばしば逆に遅くなることすらあります。
この講義の目的は、聴衆に一定の機械的共感を植え付けることで、卓越したサプライチェーンパフォーマンスを実現するための数値レシピを実装するエンタープライズソフトウェアが、現状そして今後10年後に存在するコンピューティングハードウェアを適切に活用しているのか、あるいは対立していて十分に活用できていないのかを評価できるようにすることにあります。

現代のコンピュータの最も不可解な側面の一つは、関与する桁数の幅です。供給チェーン-管理-定義の視点から見ると、通常、約5桁の違いがあり、それだけで十分な差となります。5桁の違いとは、1単位から100,000単位にまで及ぶことを意味します。前回の講義で触れた小数の法則を思い出してください。大量の単位がある場合、個々に処理するのではなく箱にまとめ、結果的に箱の数ははるかに少なくなります。同様に、多くの箱はパレットにまとめられ、最終的にはパレットの数が大幅に減ります。量的-供給-チェーン-マニフェストは規模の経済を促し、物理的商品の流れを扱うサプライチェーンの視点からは、10%の非効率性すらも十分に大きな意味を持ちます。
コンピュータの領域では状況は全く異なり、15桁の違いを扱っています。1単位から1京単位へと、その数は非常に大きく、実際に視覚化するのは困難です。1バイト(文字や数字を表すためのわずか8ビット)から1ペタバイト(百万ギガバイト)へと変化します。1ペタバイトは、現在Lokadが管理しているデータ量の桁に相当し、巨大なサプライチェーンを運営する大企業もまた、約1ペタバイト規模のデータセットを扱っています。
我々は1 FLOP(1秒あたりの浮動小数点演算)から1ペタFLOP、すなわち百万ギガFLOPSへと移行します。これらの桁数の違いは非常に巨大であり、かつ誤解を招くものです。その結果、サプライチェーンの領域で10%の非効率性と見なされる一方、コンピュータの領域では、通常10%の非効率というよりも、むしろ10倍、場合によっては数桁の非効率となります。つまり、コンピュータのパフォーマンスに関して何か誤りがあれば、そのペナルティは10%ではなく、システムが本来あるべき速度の10倍、100倍、時には1000倍遅くなるのです。これこそが本質であり、エンタープライズソフトウェアと基盤となるコンピューティングハードウェアとの間で真の整合性、すなわち機械的共感が必要とされる理由です。
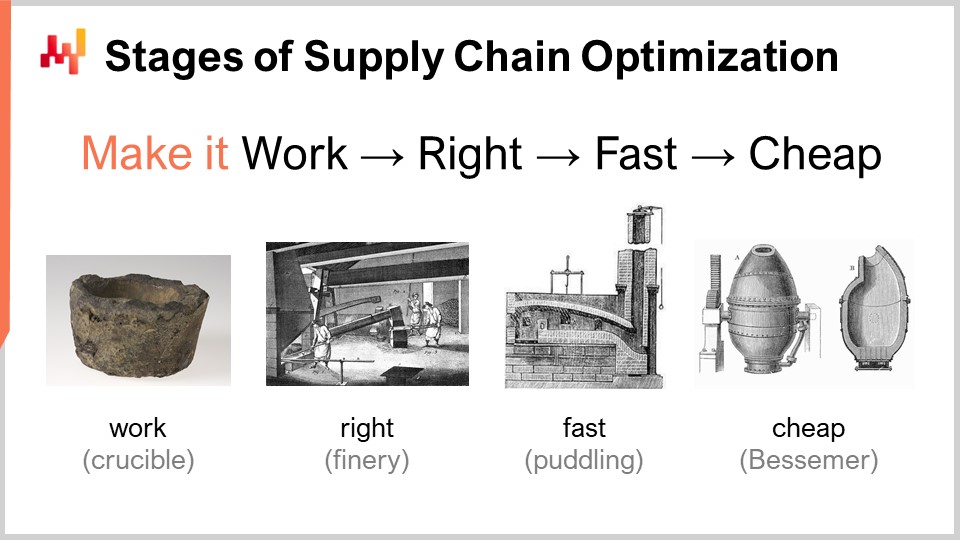
卓越したサプライチェーンパフォーマンスを実現するための数値レシピを考える際、概念的にはいくつかの成熟段階が存在します。もちろん実際の状況は異なるかもしれませんが、これはLokadで特定された典型的な段階です。これらの段階は「動作させる」「正しくする」「速くする」「廉価にする」とまとめることができます。
「動作させる」とは、プロトタイプの数値レシピが、より高いサービス-レベル-定義、死蔵在庫の削減、資産のより良い活用、またはサプライチェーンの観点から価値のあるその他の目標など、本来意図された成果を実際に達成しているかどうかを評価することです。最初の成熟段階では、新たな数値レシピが確実に動作することが求められます。
次に「正しくする」必要があります。サプライチェーンの視点からは、これは本質的にユニークなプロトタイプを生産レベルの品質に変換することを意味します。通常、数値レシピに設計上の正確性を組み込むことが伴います。サプライチェーンは広大かつ複雑、そして何より非常に混沌としています。もし非常に脆弱な数値レシピであれば、たとえ数値手法が優れていたとしても容易に誤りが生じ、結果的に当初意図した利益以上の問題を引き起こしてしまいます。これは成功する方法ではありません。「正しくする」とは、摩擦を最小限に抑え、大規模展開が可能なシステムを確立することです。次に、この数値レシピを速くする必要があります。ここでいう「速く」とは、壁時計時間での迅速さを意味します。計算開始後、結果は数分以内、せいぜい1~2時間以内に出るべきであり、それ以上は許されません。サプライチェーンは混沌としており、企業の歴史の中で、混乱(例:スエズ運河で立ち往生するコンテナ船、パンデミック)や、倉庫の浸水といった事態が必ず訪れます。その際、迅速な対応が求められるのです。次のミリ秒での反応を意味するのではなく、もし計算完了に数日を要する数値レシピであれば、膨大な運用上の摩擦を引き起こしてしまいます。短い人間の時間枠で操作可能なものでなければなりません。
ご存知の通り、現代のエンタープライズソフトウェアはクラウド上で動作しており、クラウドコンピューティングプラットフォームでは常に追加のコンピューティングリソースを有料で利用できます。したがって、大量の処理能力をレンタルしているだけで、実際にソフトウェアは速く動作します。ソフトウェア自体がクラウドの提供する全ての処理能力を活用するよう適切に設計されている必要はなく、単に膨大な処理能力を借りることで、速いが非常に非効率な状態となることもあるのです。
次の段階は手法を廉価にすること、つまり過度なクラウドコンピューティングリソースを使用しないようにすることです。この最終段階に到達しなければ、手法の改善は不可能です。もし手法が動作し、正しく、かつ速いとしても、リソースを大量に消費するのであれば、次の数値レシピ段階に進もうとした際、必然的にさらに多くのコンピューティングリソースが必要となり、行き詰ってしまいます。現在の手法を極めてスリムにする必要があり、それにより現状よりも非効率な数値レシピの実験が可能となるのです。
この最終段階こそ、現代のコンピュータで利用可能な基盤ハードウェアを真に活用する必要がある段階です。最初の3段階は多少の妥協が許されるかもしれませんが、最後の段階が鍵となります。「廉価にする」段階に至らなければ、反復改善が不可能となり、結果として行き詰まってしまうのです。だからこそ、たとえ最終段階であっても、これは反復のゲームであり、継続的なイテレーションを行うためには全段階を踏むことが不可欠です。
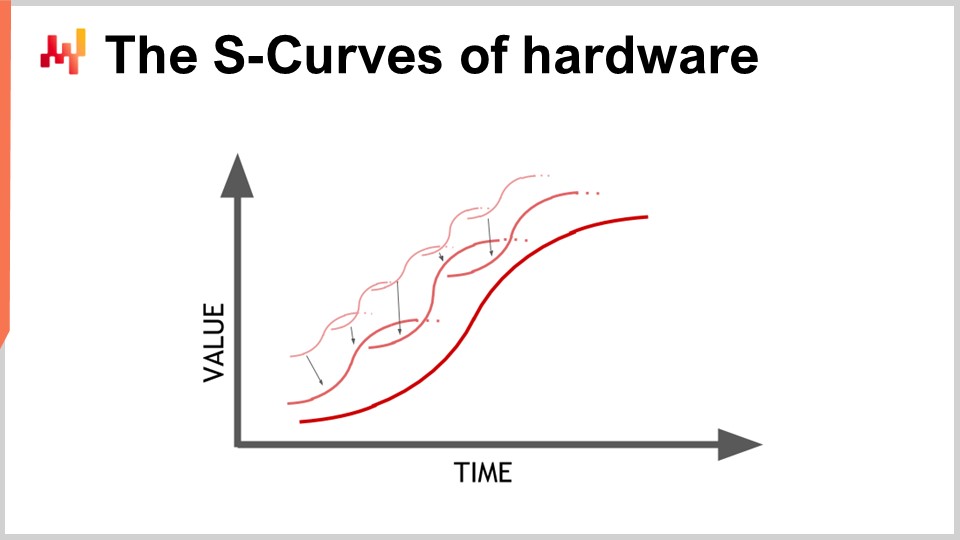
ハードウェアは進化しており、一見指数関数的な成長を遂げているように見えますが、実際のところこの指数関数的な進化は何千ものSカーブから構成されています。Sカーブとは、新しい設計、プロセス、素材、またはアーキテクチャを導入した際、初めは以前のものよりも優れていないものの、革新の効果が発現すると共に急速に上昇し、その後、その効果が使い尽くされると停滞状態に入る曲線です。こうした停滞するSカーブは、何千ものSカーブからなるコンピュータハードウェアの進化の特徴です。素人の目には指数関数的成長に見えますが、専門家は各Sカーブの停滞を確認しており、これが悲観的な見方につながることもあります。専門家でさえ、皆を驚かせる新たなSカーブの出現と、指数関数的成長の継続を常に予測できるわけではありません。
コンピュータハードウェアは依然として進化を続けていますが、その速度は1980年代や1990年代に経験したものとは比べものにならないほど遅く、また予測可能なものとなっています。新たなハードウェア製造工場の建設には巨額の投資が必要とされ、その額はしばしば数億ドルにのぼり、今後5年から10年先の見通しが立つためです。進化のスピードは鈍化しているものの、次の10年間のハードウェア進化については、かなり正確な予測が可能です。
数値レシピを実装するエンタープライズソフトウェアへの教訓は、将来のハードウェアが自動的に全てを改善してくれると受動的に期待してはならないということです。ハードウェアは進化し続けていますが、その進化を享受するためにはソフトウェア側の努力が必要です。今後10年後に存在するハードウェアでより多くのことが可能になるのは、エンタープライズソフトウェアの中核となるアーキテクチャが基盤となるコンピューティングハードウェアを適切に取り入れている場合に限るのです。そうでなければ、実際には今日行っていることよりも状況が悪化する可能性があるのです。これは決して理不尽な話ではありません。
この講義は、サプライチェーン講義シリーズの第4章の最初の講義です。サプライチェーンのペルソナーに関する第3章はまだ完了していません。今後の講義では、補助科学を扱う本章と、サプライチェーンのペルソナーに関する第3章を交互に進める予定です。
序章の最初の章で、サプライチェーンを学問であり実践でもあるとする私見を示しました。サプライチェーンは本質的に手ごわい問題の集合であり、単純な問題ではなく、対立行動や競争のゲームに悩まされることが明らかとなっています。したがって、この分野では素朴な直接的手法は機能せず、方法論に十分な注意を払う必要があるのです。そのため、第2章ではサプライチェーンの研究と、継続的な改善のための実践確立に必要な方法論に焦点を当てました。
第3章「サプライチェーン・ペルソナ」では、サプライチェーン問題そのものの特徴付けに焦点を当て、『解決策ではなく問題に恋せよ』というモットーを掲げました。本日開始する第4章は、サプライチェーンの補助科学に関するものです。

補助科学とは、他の学問分野の研究を支援するための学問分野です。価値判断はなく、一つの分野が他より優れているということではありません。例えば、医学は生物学より優れているわけではなく、生物学は医学の補助科学となります。補助科学の視点は確立されており、医学や歴史など多くの研究分野で普及しています。
医学の分野では、補助科学として生物学、化学、物理学、社会学などが挙げられます。現代の医師が物理学の知識を持たないならば、有能とは見なされません。例えば、X線画像を解釈するためには物理学の基礎を理解している必要があります。歴史についても同様で、長い補助科学の連続性があります。
サプライチェーンに関して言えば、一般的なサプライチェーンの教材、コース、書籍、論文に対する私の最大の批判の一つは、補助科学に踏み込まずにその主題を扱っている点です。それらはサプライチェーンを孤立した、独立した知識の一部であるかのように扱います。しかし、私は現代のサプライチェーン実践は、サプライチェーンに関連する補助科学を十分に活用することによってのみ実現できると考えています。これらの補助科学の一つであり、本日の講義の焦点となるのがコンピューティングハードウェアです。
今回の講義は厳密にはサプライチェーンの講義ではなく、サプライチェーンへの応用を念頭に置いたコンピューティングハードウェアの講義です。1世紀前の方法とは異なり、現代的なサプライチェーン実践にとっては基本的な内容だと考えています。

現代のコンピュータを見てみましょう。この講義では、それらがサプライチェーンにどのような効果をもたらすかを検証し、特にエンタープライズソフトウェアのパフォーマンスに大きな影響を与える側面に焦点を当てます。レイテンシ、コンピュート、メモリ、データストレージ、そして帯域幅について見直します。

光の速さはナノ秒あたり約30センチメートルであり、これは比較的遅い速度です。例えば、5ギガヘルツ(1秒あたり50億回の操作)で動作する現代のCPUにとって重要な距離を考えると、0.2ナノ秒で光が往復できる距離はわずか3センチメートルにすぎません。これは、光速度の制約により、相互作用が3センチメートル以上の距離で発生することができないことを意味しています。これは物理法則によって課せられた厳しい制限であり、これを克服できるかは不明です。
レイテンシは極めて厳しい制約です。サプライチェーンの観点からは、少なくとも2種類の分散型コンピューティングハードウェアが関与しています。ここでいう分散型コンピューティングハードウェアとは、多くのデバイスが同じ物理空間に配置できないものを意味します。当然、それぞれが固有の寸法を持つため、離して配置する必要があります。しかし、分散型コンピューティングが必要な第一の理由は、サプライチェーンそのものが地理的に分散しているという性質にあります。サプライチェーンは設計上、各地に広がっており、それに伴ってコンピューティングハードウェアも各地に配置されることになるのです。光の速さの観点から、たとえデバイス同士が3メートル離れていても、往復に100クロックサイクル必要となるため、すでに非常に遅くなってしまいます。3メートルという距離は、光速と現代CPUのクロックレートの観点からは非常に大きな距離です。
もう一つの分散の形態は水平スケーリングです。現代において処理能力を増やす方法は、10倍や100万倍も強力なコンピューティングデバイスを手に入れることではありません。それがエンジニアリングされた方法ではないのです。もしより多くの処理資源が必要ならば、追加のコンピューティングデバイス、より多くのプロセッサ、メモリチップ、ハードドライブを用意する必要があります。ハードウェアを積み重ねることによって、より多くの計算資源を確保するのです。しかし、これらすべてのデバイスは物理的なスペースを必要とするため、センチメートル単位のコンピュータに集中させることができず、結果的にコンピューティングハードウェアは分散されることになります。
プロフェッショナルなインターネット(自宅のWi-Fiではなく、データセンター内で得られるレイテンシ)におけるレイテンシを考えると、すでに光速度の30%以内に収まっています。例えば、フランスのパリ近郊のデータセンターとアメリカのニューヨークとの間のレイテンシは、光速の30%以内にすぎません。これは人類にとって驚くべき成果であり、情報がほぼ光速に近い速度でインターネット上を流れていることを示しています。確かに改善の余地はありますが、既に物理法則が課す厳しい限界に近づいているのです。
その結果、現在ではロンドンと東京を北極点の下を通るケーブルで接続し、金融取引のために数ミリ秒のレイテンシを削減しようとする企業すら現れています。根本的に、レイテンシと光速は非常に現実的な問題であり、物理学における画期的な突破口がなければ、現状のインターネットは本質的にこれ以上向上することはありません。しかし、今後10年間、そのような突破口が現れる兆しはありません。
レイテンシが極めて難しい問題であるため、エンタープライズソフトウェアへの影響は非常に大きいです。情報の往復は致命的であり、エンタープライズソフトウェアのパフォーマンスは、ソフトウェア内に存在する様々なサブシステム間の往復回数に大きく依存します。往復回数は、避けられないレイテンシの大きさを特徴づけます。往復回数を最小限に抑え、レイテンシを改善することは、サプライチェーンの予測的最適化に専念するソフトウェアを含む、ほとんどのエンタープライズソフトウェアにおいて最重要課題です。レイテンシを軽減することは、より優れたパフォーマンスの実現に直結します。

興味深いテクニックとして、全ての聴衆が本番環境で展開するものではないかもしれませんが、レイテンシが引き起こす複雑な問題に対処する方法があります。ナノ秒単位の計算に踏み込むと、時間そのものが捉えにくく、曖昧なものとなります。分散コンピューティングでは正確な時計を得るのが難しく、その欠如が分散型エンタープライズソフトウェアにおいて複雑さを増します。システムの各部分を同期させるためには多数の往復が必要となり、正確な時計がないために、ベクトル時計や複数部分からなるタイムスタンプなどのアルゴリズム的代替手段に頼ることになります。これらはシステム内のデバイス時計の部分的な順序を反映するデータ構造であり、追加の往復がパフォーマンスを低下させる原因となります。
10年以上前にGoogleが採用した巧妙な設計は、チップスケール原子時計を使用することでした。これらの原子時計の分解能は、電子時計やコンピュータに見られる石英ベースの時計よりもはるかに優れています。NISTは、さらに精度の高い日次ドリフトを実現した新たなチップスケール原子時計のセットアップを実証しました。Googleは、グローバルに分散されたSQLデータベース「Google Spanner」の各部分を同期させるために内部原子時計を使用し、往復回数を削減してグローバルなパフォーマンスの向上を実現しました。これは、非常に正確な時間測定によってレイテンシを回避する一つの方法です。
10年先を見据えると、Googleがこの種の巧妙なトリックを使う最後の企業になるとは思えず、チップスケール原子時計も1個あたり約1,500ドルと比較的手頃な価格です。

それでは、コンピュート、すなわちコンピュータによる計算処理について見ていきましょう。80年代と90年代において、クロックスピードは性能向上の魔法の成分でした。実際、コンピュータのクロックスピードを全体的に倍増させることができれば、どのような種類のソフトウェアであっても、コンピュータのパフォーマンスは実質的に倍になるでしょう。すべてのソフトウェアがクロックスピードに比例して線形的に速くなります。クロックスピードを上げることは非常に興味深い課題であり、現在でも向上は続いていますが、その伸びは次第に平坦になっています。約20年前はクロックスピードが約2 GHzでしたが、現在では5 GHzに達しています。
この向上の平坦化の主な理由はパワーウォールにあります。チップのクロックスピードを上げると、エネルギー消費がおおよそ倍増し、そのエネルギーを放散しなければならなくなるからです。問題は熱の放散であり、うまくエネルギーを拡散できなければ、デバイスは熱を蓄積し、最終的には自体が損傷してしまいます。今日では、半導体産業は1秒あたりの動作回数よりも、ワットあたりの動作回数に注目するようになっています。
エネルギー消費が30%増加すると倍になるというこの法則は、両刃の剣です。もしCPUの単位時間あたりの処理能力の一部、例えば4分の1を犠牲にすることに抵抗がなければ、実際にエネルギー消費を半減させることが可能です。これは、エネルギー節約が重要なスマートフォンや、エネルギー自体がコストの主要因であるクラウドコンピューティングにおいて特に興味深い点です。コスト効率の良いクラウドコンピューティングの処理能力を得るには、超高速なCPUを持つことではなく、1 GHz程度の低クロックのCPUを用いて、エネルギー投資に対してより多くの動作回数を実現することが求められます。
パワーウォールは非常に深刻な問題であり、現代のCPUアーキテクチャはこれを緩和するための様々な巧妙な技術を用いています。例えば、現代のCPUはクロックスピードを調整し、一時的にブーストしてから熱を放散するために速度を落とすことができます。また、ダークシリコンと呼ばれる概念も活用されています。これは、CPUがチップ上の高温エリアを交互に使用することで、常に同じエリアが連続して動作する場合と比べてエネルギーの放散が容易になるという考え方です。これは現代設計の非常に重要な要素です。エンタープライズソフトウェアの観点からは、システムを水平に拡張できることが求められます。多数のCPUを用いてより多くの処理を行う必要がありますが、個々のプロセッサはかつてのものよりも弱くなるでしょう。全体としてすべてがより良くなるプロセッサを得るのではなく、ワットあたりの動作回数が多いプロセッサを持つことが重要であり、この傾向は今後も続くはずです。
おそらく10年後には、困難を伴いながらも7または8ギガヘルツに到達するかもしれませんが、果たして実現するのかは定かではありません。2021年時点で、多くのクラウドコンピューティングプロバイダのクロックスピードは通常約2 GHzであるため、これは20年前の水準に戻っており、最もコスト効率の良い解決策といえます。
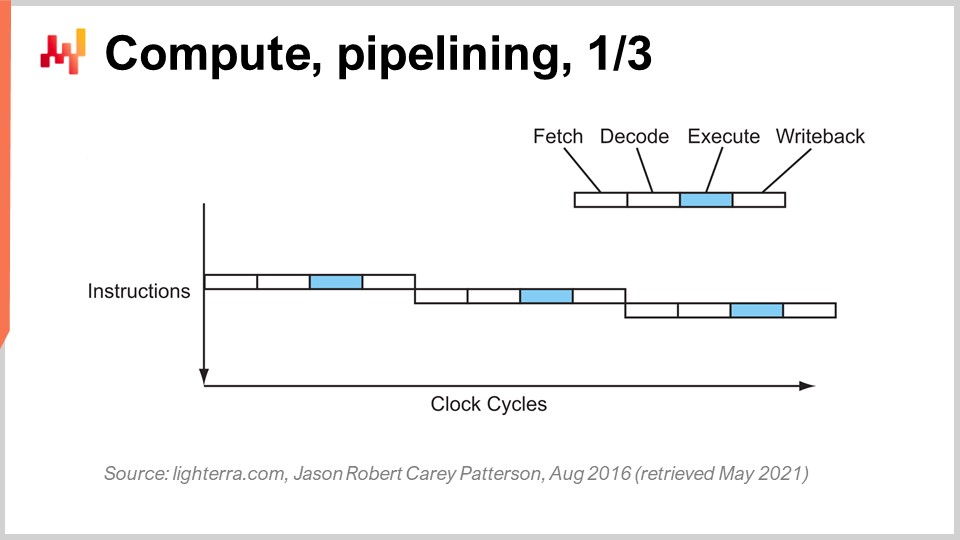
現在のCPU性能に到達するには、一連の重要な革新が必要でした。ここでは、特にエンタープライズソフトウェアの設計に大きな影響を与えたものをいくつか紹介します。この画面に表示されているのは、1980年代初頭までに作られた逐次処理プロセッサの命令フローです。命令がグラフの上から下へと順次実行され、時間の経過を表しています。各命令は、フェッチ、デコード、実行、そして書き戻しという一連の段階を経ます。
フェッチ段階では、命令を取得し、レジスタに登録し、次の命令を取得し、命令カウンタをインクリメントしてCPUの準備を行います。デコード段階では、命令を解読し、内部で実行されるマイクロコードを生成します。実行段階では、レジスタから必要な入力を取得し実際の計算を行い、書き戻し段階では、計算結果を取得してどこかのレジスタに記録します。この逐次処理プロセッサでは、各段階に1クロックサイクルが必要なため、1つの命令を実行するのに4クロックサイクルを要します。ご覧のとおり、複雑な問題が多いため、クロックサイクル自体の周波数を上げることは非常に困難です。
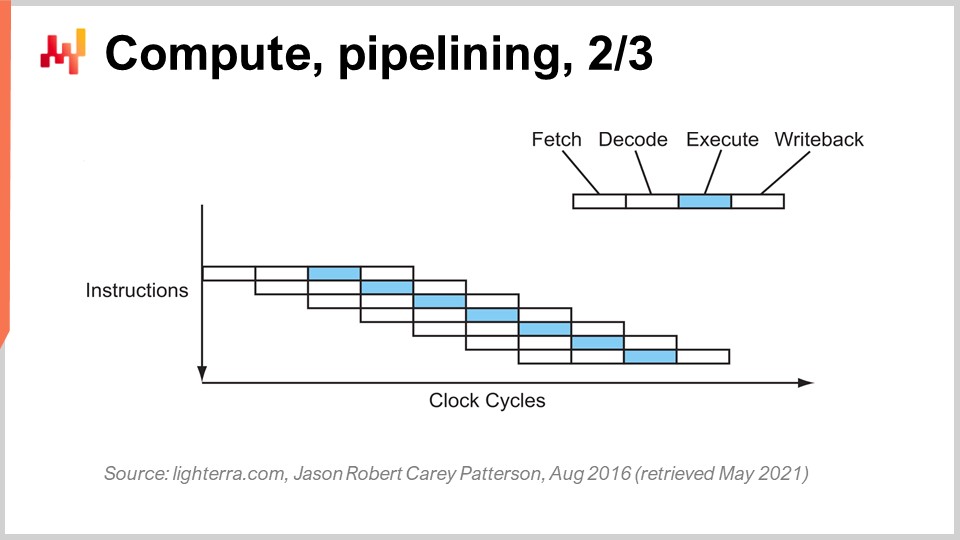
1980年代初頭から使われている鍵となる技術はパイプライニングです。パイプライニングは、プロセッサの計算処理を飛躍的に高速化することができます。その考え方は、各命令が一連の段階を経るという事実に基づき、これらの段階を重ね合わせる(オーバーラップさせる)ことで、CPU自体が命令のパイプラインを持つようにするというものです。この図では、深さ4のパイプラインを持つCPUが示され、常に4つの命令が同時に実行されています。しかし、これらの命令は同じ段階にあるわけではなく、1つがフェッチ段階、1つがデコード段階、1つが実行段階、そして1つが書き戻し段階にあります。このシンプルなトリックにより、パイプライニングだけでプロセッサの実効性能を4倍に引き上げることができました。すべての現代CPUはパイプライニングを活用しています。
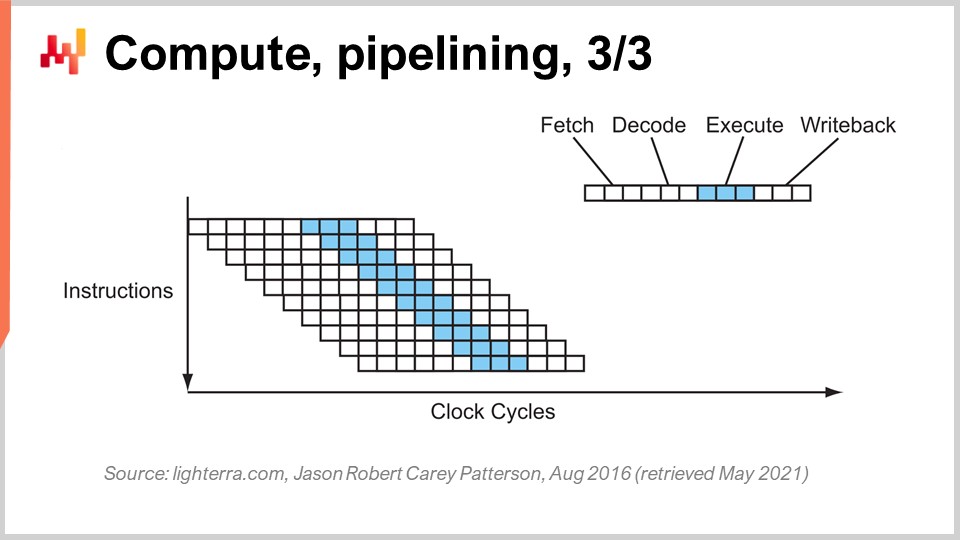
この改善の次の段階は「スーパーパイプライニング」と呼ばれます。現代のCPUは、単純なパイプライニングをはるかに超えた設計となっています。実際、現代のCPUにおける段階数は約30段階に達します。図では例として12段階のCPUが示されていますが、実際には約30段階となるのです。このより深いパイプラインにより、12の操作が同時に実行可能となり、同じクロックサイクルを使用しながらもパフォーマンスが大幅に向上します。
しかし、新たな問題が発生します。次の命令が前の命令の完了前に開始されるため、依存関係のある操作の場合、次の命令の入力計算がまだ終わっておらず、待たなければならなくなります。我々は、利用可能なパイプライン全体を活用して処理能力を最大化したいのです。したがって、現代のCPUは一度に1命令だけでなく、約500命令を一度にフェッチします。これにより、今後実行される命令群を先読みして依存関係を緩和し、実行フローをインターリーブしてパイプラインの深さをフルに活用するのです。
この動作を複雑にする要因は他にも多く、特に分岐が挙げられます。分岐とは、プログラミングにおいて「if」文などの条件記述のことです。その条件の結果が真か偽かにより、プログラムは異なる論理を実行します。このため、依存関係の管理が複雑になり、CPUは今後の分岐がどちらの方向に進むかを推測しなければなりません。現代のCPUは、シンプルなヒューリスティックを用いた高精度なブランチ予測を実施し、99%以上の精度で分岐の方向を予測します。これは、実際のサプライチェーンの文脈において私たちが行う予測よりも優れた精度であり、超深いパイプラインを活用するためにはこの正確性が必要不可欠なのです。
枝予測で使用されるヒューリスティックの一例を挙げると、非常に単純な方法は「前回と同じ方向に枝が進む」と予測するものです。この単純な方法では約90%の精度が得られ、かなり良好です。もしこの方法にひと工夫加え、枝が前回と同じ方向に進むものの、発生元も考慮して「同じ発生元からの同じ枝」と判断すれば、精度は約95%に向上します。現代のCPUは、枝の方向を予測するために、機械学習技法の一つであるかなり複雑なパーセプトロンを実際に使用しています。
適切な条件下では、枝の予測をかなり正確に行え、その結果、最新のプロセッサのパイプラインを最大限に活用することができます。しかし、ソフトウェアエンジニアリングの観点からは、特に枝予測においてプロセッサとうまく協調して動作する必要があります。うまく協調できない場合、枝予測器は間違った予測をしてしまい、その時、CPUは枝の方向を予測し、パイプラインを整え、先行して計算を始めます。そして実際に枝に到達し計算が完了すると、CPUは枝予測が誤っていたことに気付くのです。誤った枝予測は誤った結果をもたらすのではなく、パフォーマンスの低下を引き起こします。CPUはパイプライン全体またはその大部分をフラッシュし、別の計算が行われるまで待機し、その後計算を再開するほかありません。このパフォーマンス低下は非常に大きく、CPUの枝予測ロジックとうまく連携できないエンタープライズ向けソフトウェアのロジックによって、容易に1桁または2桁のパフォーマンス損失を招く可能性があります。
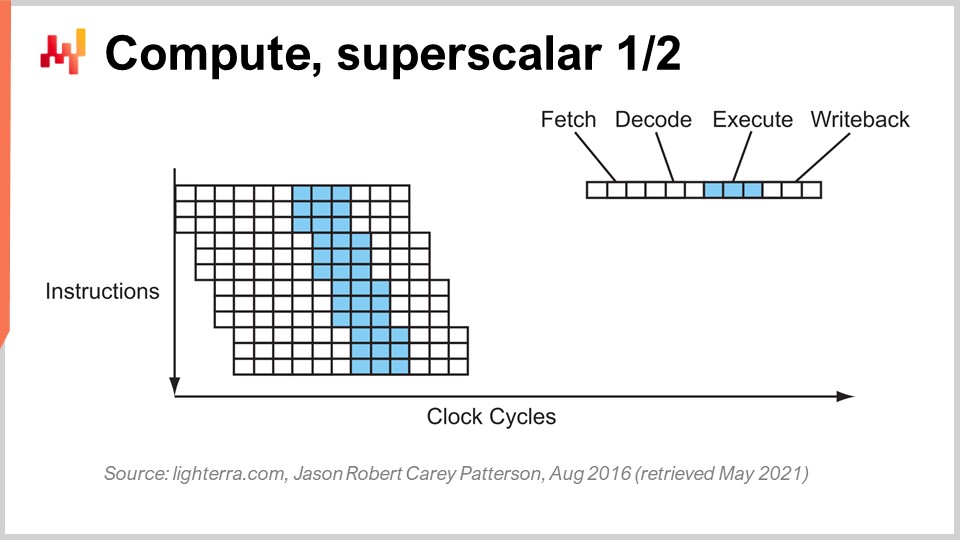
パイプライニングに加え、もう一つ注目すべきテクニックはスーパー・スカラー命令です。CPUは通常、スカラーまたはそのペア、たとえば32ビット浮動小数点精度の2つの数値を一度に処理します。すなわち、一度に1つの数値を処理するスカラー演算を実行します。しかし、過去10年の現代のCPUは、実際にスーパー・スカラー命令を搭載しており、複数の数値ベクトルを直接処理し、ベクトル演算を行えるようになっています。これは、例えば8個の浮動小数点数からなるベクトルと、別の8個の浮動小数点数のベクトルの加算を行い、その結果を示す浮動小数点数のベクトルを得ることができる、という意味です。すべてが1サイクルで実行されます。
例えば、AVX2のような特殊な命令セットは8個の数値のパックを用いて32ビットの精度で演算を行い、AVX512は16個の数値のパックでそれを実現します。これらの命令を活用できれば、1命令、1クロックサイクルで多数の計算を実行できるため、処理速度が桁違いに向上することを意味します。この仕組みはSIMD(Single Instruction, Multiple Data、単一命令・複数データ)として知られ、非常に強力です。過去10年間、計算能力の進歩の大部分を牽引してきた技術であり、現代のプロセッサはますますベクトルベースかつスーパー・スカラーになっています。しかし、エンタープライズソフトウェアの観点からは、これを活用するのは比較的難しい面もあります。パイプライニングでは、ソフトウェアが協調して動く必要があり、たまたま枝予測とうまく連携している場合もあります。しかし、スーパー・スカラー命令に関しては、偶然の産物ではありません。追加の処理能力を活用するためには、ほとんどの場合、ソフトウェアが明示的に何らかの対策を講じる必要があります。これはただで手に入るものではなく、このアプローチを積極的に採用し、通常はデータ自体をデータ並列性が実現できるように整理し、SIMD命令に適した形に配置する必要があるのです。これは決して難解な技術ではありませんが、偶然に実現するものではなく、計算能力に莫大なブーストを与えるものです。

現代のCPUは多くのコアを搭載しており、1つのCPUコアは独立した命令の流れを提供します。非常に多くのコアを搭載した最新のCPUでは、通常最大64コアを持ち、すなわち64の独立した同時実行フローを実現しています。こうした構成により、最新のプロセッサから得られる処理スループットの上限である約1テラフロップに近づけるのです。しかし、それ以上の性能を求める場合は、GPU(グラフィカル・プロセッシング・ユニット)に目を向ける必要があります。思われるかもしれませんが、これらのデバイスはグラフィックスとは全く無関係のタスクにも使用できます。
NVIDIAのようなGPUは、スーパー・スカラー・プロセッサです。ハイエンドCPUのように最大64コアというのではなく、GPUは1万以上のコアを持つことができます。これらのコアは非常に単純で、通常のCPUコアほど強力でも高速でもありませんが、その数は圧倒的に多いため、8個または16個の数値パックだけでなく、文字通り数千の数値を同時に処理するベクトル命令が実現できます。GPUを用いれば、1台のデバイスで30テラフロップ以上の性能を発揮できるため、驚異的な性能となります。市場最高のCPUが1テラフロップを提供するのに対し、最高のGPUは30テラフロップ以上を実現し、これは1桁以上の性能差、すなわち非常に大きな差となります。
さらに、線形代数のような特定の計算、ちなみに機械学習やディープラーニングは本質的に行列を利用した線形代数である、といった分野においては、TPU(Tensor Processing Units)のようなプロセッサが存在します。GoogleはTensorFlowに因んで「テンソル」と名付けましたが、実際にはTPUは「行列乗算プロセッシングユニット」と呼ぶべきです。行列乗算の面白い点は、大量のデータ並列性があるだけでなく、操作が非常に反復的であるため、莫大な反復処理が伴うということです。TPUを、計算ユニットが配置された2次元グリッドというシストリック配列として構成することで、ペタフロップの壁を突破し、1台で1000テラフロップ以上を達成することが可能です。ただし、注意点として、Googleは通常の32ビットではなく16ビットの浮動小数点数でこれを実現しています。サプライチェーンの観点から16ビットの精度は決して悪くなく、これは約0.1%の精度を意味し、多くの機械学習や統計処理において、適切に行われれば0.1%の精度で十分であると言えるのです。
計算能力のみを考えると、コンピューティングハードウェアの進化の道筋は、より専門的で硬直したデバイスへ移行していることがわかります。この専門化のおかげで、計算能力に関して莫大な向上が得られるのです。スーパー・スカラー命令では1桁、グラフィックスカードでは1〜2桁、そして純粋に線形代数を活用すれば本質的に2桁の性能向上が実現でき、これは非常に重要なことです。
ちなみに、これらすべてのハードウェア設計は2次元です。現代のチップや処理構造は非常にフラットで、最新のCPUは20層以上にはならず、これらの層は数マイクロンの厚さしかないため、CPU、GPU、TPUは本質的にフラットな構造となっています。「では、第3次元はどうなるのか?」と思うかもしれませんが、実際には、注ぎ込まれたエネルギーを如何に放散するかというパワーウォールの問題があるため、第3次元への進出は実現していないのです。
今後10年間で予測されるのは、これらのデバイスが本質的に2次元のままであるということです。エンタープライズソフトウェアの観点から最大の教訓は、ソフトウェアの中核部分でデータ並列性をしっかりと設計する必要があるということです。これを実現しなければ、生の計算能力の向上を十分に取り込むことはできません。しかし、これは後回しにできるものではなく、システム内のすべてのデータを整理するアーキテクチャの中核で実現されなければなりません。そうでなければ、20年前のプロセッサのような設計から抜け出せなくなってしまいます。
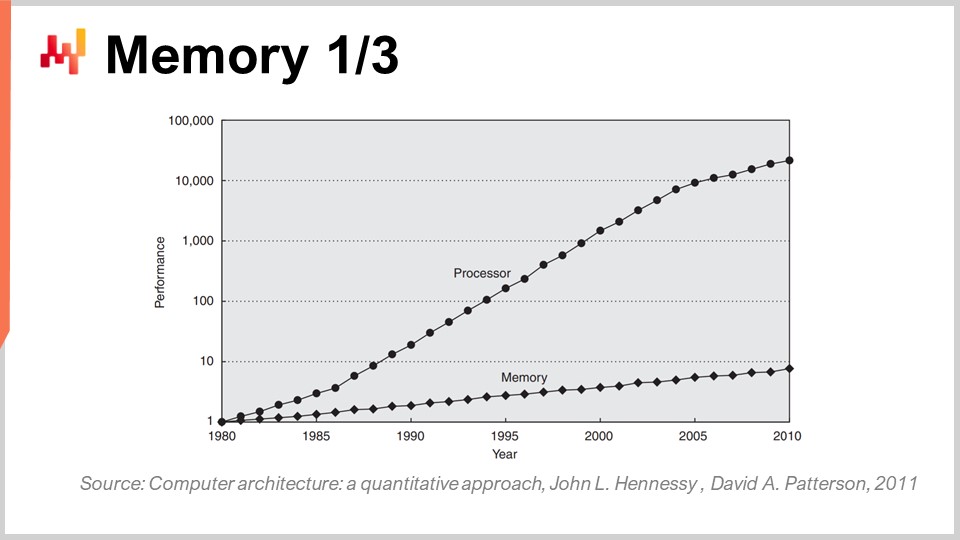
1980年代初頭、メモリはプロセッサと同じ速さで動作しており、1クロックサイクルはメモリでもCPUでも同じでした。しかし、現状はそうではありません。1980年代以降、メモリの速度と、プロセッサのレジスタ内に既に存在するデータへのアクセスレイテンシとの比率は次第に増加しており、最初は比率1でしたが、現在では通常1000を超える比率になっています。この問題はメモリウォール(記憶壁)として知られており、過去40年で着実に拡大してきました。今日もクロックスピードの向上が非常に緩やかなため、わずかに増加は続いていますが、プロセッサのクロックスピードがあまり進歩していないおかげで、メモリウォールそのものの増加は頭打ちとなっています。しかし、現状では、プロセッサ内部に既に存在するデータにアクセスするよりも、メモリへのアクセスは本質的に3桁遅いという極めてアンバランスな状態にあります。
この視点は、今日でも多くの大学で教えられている古典的なアルゴリズム論を完全に覆すものです。古典的なアルゴリズムの考え方は、任意のメモリビットへのアクセス時間が均一である、すなわちすべてのメモリへのアクセスは同じ時間で行われるという前提に基づいています。しかし、現代のシステムではこれは全く当てはまりません。特定のメモリ部分へのアクセスにかかる時間は、実際のデータがコンピュータ内の物理的位置によって大きく左右されるのです。
エンタープライズソフトウェアの観点からは、残念なことに1980年代や1990年代に確立された多くのソフトウェア設計は、この問題が初期の10年ではほとんど問題にならなかったため、完全に無視されていました。しかし、この問題はここ20年で著しく拡大し、その結果、現代のエンタープライズソフトウェアに見られる多くのパターンは、すべてのメモリへのアクセスが一定時間で行われると仮定しており、この設計と完全に対立するものとなっています。
ちなみに、1989年に登場したPythonや1995年のJavaのように、オブジェクト指向プログラミングを採用する言語を考えると、これらは現代コンピュータのメモリ動作の仕組みに大きく逆行しています。オブジェクトが存在する場合、特にPythonのようなレイトバインディングがあると、何かを行うたびにポインタをたどってメモリ内をランダムにジャンプする必要があるのです。もしそのジャンプが、不運にもプロセッサ内に既に存在しない領域へ向かうと、アクセス速度が千倍も低下する可能性があります。これは非常に大きな問題です。

メモリウォールの規模をより正確に把握するために、現代のコンピュータにおける典型的なレイテンシを見てみると興味深い事実が判明します。これらのレイテンシを人間の時間に換算すると、たとえばプロセッサが1秒に1クロックサイクルで動作していると仮定できます。その場合、CPUの典型的なレイテンシは1秒ですが、メモリ上のデータにアクセスするには最長で6分かかることがあります。つまり、1秒に1回の操作が可能でも、メモリ上の何かにアクセスする場合は6分待たなければならず、ディスク上の何かにアクセスする場合は最大で1ヶ月、あるいは1年かかることもあります。これは信じられないほど長い時間であり、講義冒頭で述べた桁違いの性能差がまさにこのことによるものなのです。15桁の性能差を扱う際、非常に欺瞞的であり、情報を適切な場所に配置しなければ、実際に人間の尺度で数ヶ月待たなければならないという莫大なパフォーマンス低下に気付かない可能性があるのです。これは絶対に途方もなく大きな問題です。
ちなみに、エンタープライズソフトウェアエンジニアだけでなく、現代のコンピューティングハードウェアの進化に苦闘しているのは他の分野も同様です。例えば、Intel Optaneシリーズのような超高速SSDカードで得られるレイテンシを見ると、このデバイス上のメモリアクセスのレイテンシの半分は、実際にはカーネル、具体的にはLinuxカーネルのオーバーヘッドによるものであることがわかります。つまり、レイテンシの半分はオペレーティングシステム自体が引き起こしているのです。これはどういう意味かと言うと、Linuxのエンジニアでさえ、現代ハードウェアに追いつくためにはさらなる改良が必要だということであり、いずれも大きな挑戦となっています。
しかし、処理すべきデータが膨大なため、特にサプライチェーンの最適化を考える場合、これはエンタープライズソフトウェアにとって大きな痛手となります。最初から非常に複雑な作業であるのです。エンタープライズソフトウェアの観点からは、キャッシュに格納された、アクセスが速くCPUに近いローカルコピーを活用できるよう、キャッシュと整合性のある設計を取り入れる必要があります。
その仕組みとして、メインメモリ内のバイトにアクセスする場合、現代のソフトウェアではたった1バイトだけにアクセスすることはできません。RAM上の1バイトにアクセスしたい場合でも、ハードウェアは実際に4キロバイト、つまり4キロバイト全体のページをコピーします。根底にある前提は、1バイトを読み始めたら、次に要求するのはその直後のバイトであろうというものです。これが局所性の原理であり、この原理に従って局所性を維持するアクセスを実施すれば、プロセッサとほぼ同じ速さで動作するメモリが実現できるのです。
しかし、これを実現するには、メモリアクセスとデータの局所性との整合性が求められます。特に、Pythonのようにこのような性質をネイティブに提供しないプログラミング言語は多数存在します。逆に、そうした言語は局所性を確保する上で大きな障壁となるのです。これは非常に厳しい課題であり、結局のところ、利用可能なハードウェアと完全に対立する設計パターンに基づいて構築されたプログラミング言語との闘いとなります。この問題は今後10年間で解消されるどころか、ますます悪化する一方です。
したがって、エンタープライズソフトウェアの観点からは、データの局所性を確保すると同時に、データの縮小も求められます。大きなデータを小さくできれば、処理速度が向上します。これは直感的ではないかもしれませんが、通常は冗長性を排除することでデータサイズを縮小すれば、キャッシュの効率が良くなり、プログラムの動作が高速化されるのです。画面に示されているように、低レイテンシの下位キャッシュレベルにより多くの重要なデータを格納できます。

最後に、DRAMの場合について具体的に議論しましょう。DRAMは、デスクトップワークステーションやクラウドのサーバーで使用されるRAMを構成する物理的な部品そのもので、DRAMチップから構成されるメインメモリとも呼ばれます。過去10年間、価格の観点ではDRAMの値下がりはほとんど見られず、ギガバイトあたり5ドルから10年後には3ドルになりました。RAMの価格は依然として下がり続けていますが、その低下率はそれほど速くなく、今後数年間は停滞する見込みです。さらに、規模の大きなDRAM製造が可能な主要プレイヤーは3社しか存在しないため、今後10年間で市場に大きな変化が起こる可能性はほとんどありません。
しかし、問題はそこだけに留まりません。ギガバイトあたりの電力消費も問題です。現在のRAMは、10年前に比べてギガバイトあたりわずかに多くの電力を消費していることが分かります。その理由は、現行のRAMがより高速であり、パワーウォールの法則が適用されるため、クロック周波数を上げると電力消費が大幅に増加するからです。ちなみに、DRAMは本質的にアクティブな部品であるため、電気漏れを防ぐために常にリフレッシュする必要があり、電源を切るとすべてのデータが失われます。セルを常にリフレッシュし続けなければならないのです。
したがって、エンタープライズソフトウェアの結論としては、DRAMは進化が止まっている唯一のコンポーネントであると言えます。処理能力のように急速に進歩している要素は他にも数多く存在しますが、DRAMについては非常に停滞しています。クラウドコンピューティングのコストの大部分を占める電力消費も考慮すると、RAMの進歩はほとんど見られません。したがって、メインメモリを過度に重視する設計、すなわち「インメモリ設計」を謳うベンダーの提案には注意が必要です。これらのキーワードを心に留めておきましょう。
ベンダーがインメモリ設計を主張するたびに、彼らが伝えたいのは—それ自体はあまり魅力的な提案ではありませんが—その設計が将来のDRAMの進化、すなわちコストが下がらないという既知の事実に完全に依存しているということです。10年後、サプライチェーン内でのデータ収集能力が向上し、企業がより多くのデータを収集・共有するようになるため、処理すべきデータ量が現在の約10倍になることを考慮すれば、10年後には大企業のサプライチェーンが現在の10倍のデータを収集しているのは不合理ではありません。しかし、RAMのギガバイトあたりの価格はそのままです。計算すれば、ほぼ同じことをするために、クラウドコンピューティングやITコストが事実上桁違いに高くなる可能性があります。重要なのは、あらゆるインメモリ設計を避けるべきだという点です。これらの設計は非常に時代遅れであり、以下でどのような代替策があるのかを検討していきます。

次に、永続的なデータ保存、すなわちデータストレージについて見ていきましょう。基本的に、広く使われているデータストレージには2種類あります。1つはハードディスクドライブ(HDD)や回転ディスク、もう1つはソリッドステートドライブ(SSD)です。興味深いのは、回転ディスクのレイテンシがひどいことで、この画像を見るとその理由が容易に理解できます。これらのディスクは実際に回転しており、ディスク上の任意のデータポイントにアクセスするためには、平均してディスクが半回転するのを待たなければなりません。最上位のディスクが1分間に約10,000回転していることを考えると、圧縮不可能な約3ミリ秒のレイテンシが内蔵されていることになります。これはディスクが回転して目的のデータ位置に到達するための機械的な時間であり、これ以上改善することはありません。
HDDはレイテンシの点で非常に劣るだけでなく、電力消費という別の問題も抱えています。一般的に、HDDとSSDはどちらも1台あたり1時間に約3ワットを消費します。これは現在の標準的な状況です。しかし、ハードディスクが動作している限り、たとえデータの読み込みをしていなくても、ディスクを回し続けるために3ワットの電力を消費し続けます。1分間に10,000回転に達するには多くの時間が必要なため、たとえ使用頻度が低くとも、ディスクは常に回し続けなければならないのです。
一方、ソリッドステートドライブは、アクセス時に3ワットを消費しますが、データにアクセスしていない際にはほとんど電力を消費しません。ごく微量の残留電力はありますが、ミリワット単位で非常に小さいです。これは非常に興味深い点で、大量のSSDを設置しても、使用していなければ電力コストはかかりません。ここ10年間で業界全体がHDDからSSDへの移行を進めています。
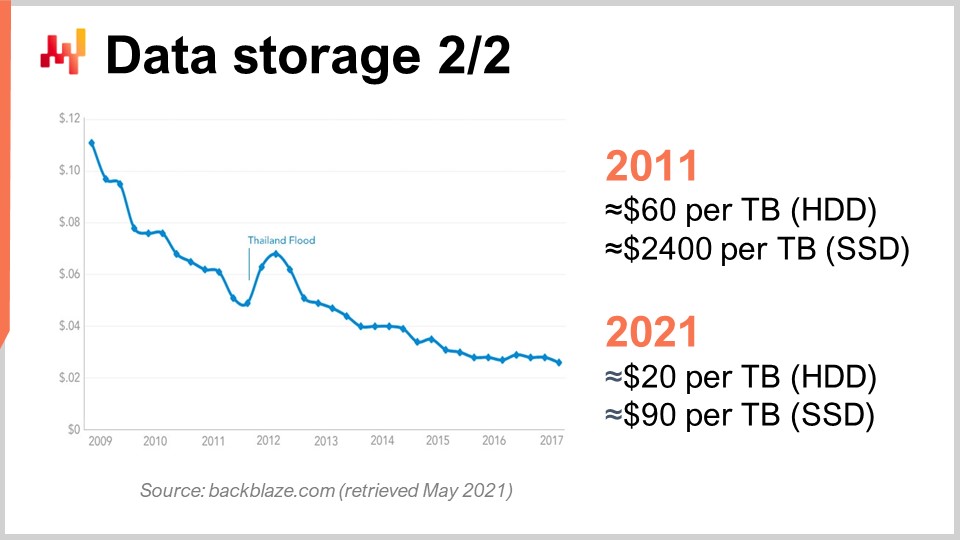
これを理解するために、このグラフを見てみましょう。ここ数年、HDDとSSDのギガバイトあたりの価格は低下しています。しかし、現在その価格は横ばい状態になっています。データ自体は若干古いものですが、ここ数年で大きな変動はありません。過去10年間を見ると、10年前にはSSDがテラバイトあたり2,400ドルという極めて高価なものであったのに対し、ハードドライブはテラバイトあたり60ドル程度でした。しかし、現時点ではハードドライブの価格は約3分の1、つまりテラバイトあたり約20ドルにまで下がり、SSDの価格は25分の1以上に低下しています。SSD価格の低下傾向は止まることなく、SSDは今、そして今後10年間も最も進化するコンポーネントとなっており、非常に興味深い状況です。
ちなみに、現代のコンピュートデバイス(CPU、GPU、TPU)の設計は基本的に2次元で、最大でも20層程度でした。しかし、SSDに関しては設計がますます3次元化しており、最新のSSDでは約176層を持っています。オーダーとしては200層に近づいています。これらの層が非常に薄いことから、将来的には数千層を持ち、桁違いの記憶容量を実現するデバイスが登場するのも不合理ではありません。もちろん、暗黒シリコンや電力散逸の問題により、これら全てのデータに常時アクセスできるわけではありません。
実際、適切に運用すれば、多くのデータは非常に低頻度でしかアクセスされません。SSDは、ビットをオンにすることはできてもオフにすることができない、という多くの特性を伴う非常に特異なハードウェア設計になっています。つまり、最初はすべて0であると仮定すると、0を1に変えることは可能ですが、1をローカルで0に戻すことはできません。それを行うには、最大8メガバイトにも及ぶブロック全体をリセットする必要があり、これにより書き込み時にはビットを0から1に変更できるものの、1から0にすることはできなくなります。1から0に変更するためには、ブロック全体をフラッシュして再書き込みする必要があり、これが「書き込み増幅」と呼ばれる様々な問題を引き起こします。
過去10年間、SSDには内部的にこれらの問題を緩和するためのフラッシュトランスレーションレイヤーと呼ばれる層が実装されるようになりました。これらのレイヤーは時とともに改善されています。しかし、さらなる改善の余地は大きく、エンタープライズソフトウェアの観点からは、SSDの利点を最大限に活かすために設計を最適化する必要があります。SSDはデータ保存に関してすでにDRAMよりもはるかに有利であり、賢く運用すれば、ハードウェア産業の進歩により、今後10年で桁違いの性能向上が期待できるのです。DRAMについてはそのような見通しはありません。
最後に、帯域幅について話しましょう。帯域幅は技術的には最も解決された問題の一つかもしれません。しかし、帯域幅が確保できたとしても、現在では途方もないレベルの帯域幅を実現できます。商業面では通信業界は非常に複雑で多くの問題を抱えており、そのためエンドユーザーは光通信の進歩によるすべての恩恵を実感できていません。
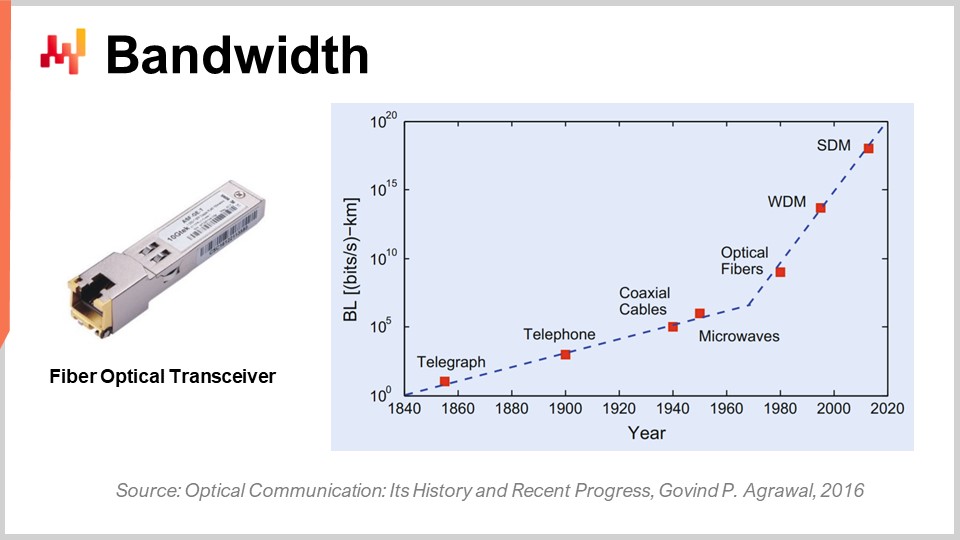
光ファイバーのトランシーバーを用いた光通信においては、その進歩は本当に驚異的です。おそらく、1980年代や1990年代のCPUの進化に匹敵するものです。例として、波長分割多重(WDM)や空間分割多重(SDM)を用いると、1本の光ファイバーケーブルで秒間0.1テラバイトものデータ転送が実現可能になっています。これは非常に巨大な数字です。1本のケーブルで、実質的にデータセンター全体を賄えるほどのデータを運ぶことができます。さらに印象的なのは、通信業界が古いケーブルを利用しながら、全く新しいトランシーバーを開発し、驚異的な性能を引き出している点です。新たにファイバーを敷設する必要はなく、10年前に敷設されたファイバーに新しいトランシーバーを取り付けるだけで、同じケーブルで何桁も多い帯域幅を実現できるのです。
興味深いのは、光通信には一般的な法則が存在するということです。すなわち、10年ごとに、電気通信を光通信に置き換えるのが有利になる距離が短くなっているのです。数十年前、例えば20年前には、光通信が電気通信を上回るには約100メートルの距離が必要でした。つまり、100メートル未満であれば銅線、100メートル以上であれば光ファイバーが選ばれていました。しかし、最新の技術では、わずか3メートル程度の距離でも光通信が有利です。さらに10年先を見据えると、半メートルという極めて短い距離でも光通信が優位になる状況が現れても驚かないでしょう。これは、いずれコンピュータ自体が内部に光伝送路を備えるようになる可能性を示唆しており、電気伝送路よりも性能が優れているためです。
エンタープライズソフトウェアの観点からも、これは非常に興味深い点です。将来的に帯域幅のコストが大幅に低下することを意味しており、これはNetflixのような莫大な帯域幅を消費する企業によって大いに補助されています。つまり、レイテンシを回避するために、ユーザーに対してあらかじめ大量のデータを転送し、実際に必要なデータをより低いレイテンシで利用できるようにする、といった手法が可能になるのです。不要なデータを転送しても問題なのは帯域幅ではなく、レイテンシだからです。「どのデータが必要になるか不確実であれば、本当に必要な量の千倍のデータを事前に送り、エンドユーザーに近づけ、ユーザーまたはプログラムに操作させてラウンドトリップを最小限にすれば、性能向上が期待できる」という考え方が有益です。これは、今日のアーキテクチャ上の意思決定に大きな影響を与え、今後10年後にこの種のハードウェアの進化で性能向上が得られるかどうかを左右することになるのです。

結論として、レイテンシはソフトウェア工学における我々の時代の最大の課題です。これは、現在および将来のあらゆる性能に大きな影響を与えます。性能は絶対に重要であり、ITコストだけでなく、サプライチェーンで働く人々の生産性にも影響するからです。最終的には、サプライチェーンそのもののパフォーマンスにも直結し、十分な性能がなければ、高度な最適化や予測最適化といった賢明な数値戦略すら実現できません。しかし、全般的に見て、より良い性能を求めるこの戦いは、少なくともエンタープライズソフトウェアの領域では勝利していません。新しいシステムは、しばしば古いシステムよりも遅くなることがあり、これは深刻な問題です。性能の低いソフトウェアは、企業に途方もないコストをもたらします。
一例を挙げると、より良いコンピューティングハードウェアが必ずしも優れた性能を提供するとは限らないということが分かります。インターネット上のある人々は、キーを押してから対応する文字が画面に表示されるまでの時間、すなわち入力レイテンシ(入力ラグ)を測定しました。1983年のApple II(1MHzプロセッサ搭載)では、その時間は30ミリ秒でした。しかし、2016年のLenovo X1(2.6GHzプロセッサ搭載の優れたノートブック)では、レイテンシが110ミリ秒と測定されました。つまり、何千倍も優れたハードウェアを使用しているにもかかわらず、レイテンシはほぼ4倍も遅い結果となったのです。これは、機械的な相性を考慮せず、現在のハードウェアに注意を払わなかった場合に起こる典型的な現象です。ハードウェアと協調せずに運用すれば、その報いとして性能が低下するのです。
問題は非常に現実的です。私の提案は、たとえオープンソースであろうとなかろうと、あなたの会社のエンタープライズソフトウェアを検討し始める際に、今日学んだ機械的共感の要素を思い出すことです。ソフトウェアを見て、それがコンピューティングハードウェアの根本的な動向を取り入れているのか、あるいは全く無視しているのかを慎重に考えてください。もし無視しているなら、性能が時間の経過とともに向上するどころか、むしろ悪化する可能性が高いということです。現代ではほとんどの改善が、クロックスピードではなく専門化によって達成されています。この高速道路を見逃すと、時間とともにどんどん遅くなる道を進むことになってしまいます。これらのソリューションは通常、取り消すことのできない初期の重要な設計上の判断から生じるため、避けるべきです。一度採用してしまうと永遠にその影響を受け、年々悪化していくばかりです。こうした視点で判断する際は、10年先を見据えるべきです。

では、質問を見ていきましょう。今回の講義はかなり長かったですが、挑戦的なテーマでした。
質問: 量子コンピュータと、それが複雑なサプライチェーン最適化問題にどのように役立つかについて、あなたはどう考えますか?
非常に興味深い質問です。18か月前、IBMの量子コンピュータのベータ版に登録したとき、クラウド上で量子コンピュータへのアクセスが開始されました。専門家たちはSカーブが平坦化するのを確認しつつも、新たなカーブがどこからともなく現れることはないと見ています。量子コンピューティングもその一例です。しかし、量子コンピュータはサプライチェーンに関して非常に厳しい課題を提示すると考えています。まず、先ほど述べたように、エンタープライズソフトウェアの世界での現代の闘いはレイテンシであり、量子コンピュータはその問題には何の効果もありません。量子コンピュータは、極めて厳密な計算問題に対して最大10桁の速度向上を実現できる可能性があります。つまり、量子コンピュータはTPUの次の段階であり、非常に厳密な演算を驚異的な速さでこなすのです。
これは非常に興味深いのですが、正直なところ、現時点で私の知る限り、エンタープライズソフトウェア内でスーパースカラー命令を活用できている企業はごくわずかです。つまり、市場全体でスーパースカラーGPUが提供する10倍から28倍の速度向上を十分に活かしきれていないということです。サプライチェーン分野でこれを実践しているのはほとんどなく、Lokadでさえも例外かもしれません。TPUに関しては、実際のところ使用している企業はほぼ存在しないと思います。Googleは大規模に活用していますが、サプライチェーンに関連してTPUを利用した例は私の知る限りありません。量子プロセッサはTPUの次のステージになるでしょう。
私は量子コンピュータで何が起こっているかに非常に注目していますが、これが我々の直面するボトルネックではないと考えています。約70年前に確立されたフォン・ノイマン方式を再検討するのは刺激的ですが、これが今後10年間、我々またはサプライチェーンが直面する主要な問題ではありません。それ以降のことは、私にも予測がつきません。はい、全てを変える可能性も、そうでない可能性もあります。
質問: クラウドおよびSaaSの提供は、組織が固定費を活用して変換するのを可能にしています。こうしたサービスを提供する企業は、固定費やそれに伴うリスクの軽減にも取り組んでいるのでしょうか?
それは場合によります。もし私がクラウドコンピューティングプラットフォームで、処理能力を提供している立場なら、あなたのエンタープライズソフトウェアをできるだけ効率的にすることが本当に自分の利益になるでしょうか?いいえ。私は仮想マシン、ギガバイト単位の帯域幅、ストレージを提供しているので、実際にはその逆です。私の利益は、あなたに極力非効率なソフトウェアを利用させ、多大なリソースを消費させ、従量課金制にさせることにあります。
内部的には、Microsoft、Amazon、Googleなどの大手テック企業は、自社のコンピューティング資源の最適化に非常に積極的です。しかし、顧客に仮想マシンをレンタルして請求する最前線では、同様に積極的です。もし顧客が、使用しているエンタープライズソフトウェアが極めて非効率なために、実際に必要なサイズの10倍の仮想マシンをレンタルしている場合、顧客の過誤を修正することは彼らの利益にはならないのです。それで問題なく、むしろ良いビジネスとなります。システムインテグレーターとクラウドコンピューティングプラットフォームがパートナーとして連携する傾向を考えれば、これらの企業が必ずしもあなたの最善の利益を第一に考えているわけではないと理解できるでしょう。SaaSに関しては状況が少し異なります。実際、ユーザーごとにSaaSプロバイダーへ支払う場合、それは企業の利益に沿うものであり、例えばLokadの場合もそうです。我々は使用するコンピューティング資源ごとに課金するのではなく、通常は固定の月額料金で顧客に請求しているからです。したがって、SaaSプロバイダーは自社のコンピューティング資源の消費において非常に積極的です。
しかし、注意すべきは、SaaS企業であれば、顧客にとっては非常に魅力的な改善でも、自社にとってはハードウェア面で非常にコストがかかる行動をためらう傾向があるという点です。すべてが順風満帆というわけではなく、サプライチェーン分野で活動する全てのSaaSプロバイダーには、利益相反の問題が存在するのです。例えば、レイテンシ改善やウェブページをより高速にするために全システムの再設計に投資することも可能ですが、そうするとコストがかかり、顧客が自然に追加料金を支払うとは限りません。
この問題はエンタープライズソフトウェアになるとさらに拡大します。なぜなら、ソフトウェアを購入する人と実際に使用する人が通常異なるからです。そのため、多くのエンタープライズシステムが非常に遅いのです。ソフトウェア購入者は、毎日超低速なシステムに対処しなければならない需要計画者や在庫管理者ほど苦しむことがありません。エンタープライズソフトウェア固有の問題として、すべてのインセンティブを十分に検討する必要があり、しばしば対立するインセンティブが存在するのです。
質問: ハードウェアの進歩を踏まえると、Lokadはどれくらい自社のアプローチを見直す必要があったのでしょうか?実際の問題解決の文脈で、例を挙げることは可能でしょうか?
Lokadは、テクノロジースタックを約6回ほど大幅に再構築したと考えています。しかし、Lokadは2008年に設立され、その後も全体アーキテクチャの大規模な書き直しを約6回行いました。ソフトウェア自体が劇的に進化したからではなく、進化はしていたものの、再構築の主な理由はハードウェアの進化そのものではなく、むしろハードウェアについての理解を深めたことにありました。今日私が提示したすべての内容は、実は10年前にすでに注意を払っていた人々には既知のものでした。つまり、ハードウェアは進化しているものの、その進化は非常に緩やかで、多くのトレンドは10年先でも予測可能であるのです。これは長期にわたる戦いと言えます。
Lokadは大規模な書き直しを繰り返してきましたが、それはハードウェアがタスクを変えたというよりも、私たちが徐々に無能さから脱却し、能力を高め、ハードウェアをどのように活用すべきかをより理解するようになったことの表れでした。しかし、例外もあり、実際に画期的な変化をもたらした要素も存在しました。その最も顕著な例がSSDです。HDDからSSDへの移行は、パフォーマンスにおいて完全なゲームチェンジャーとなり、アーキテクチャにも大きな影響を与えました。具体例として、Lokadが提供するドメイン特化型プログラミング言語Envisionの全設計は、ハードウェアレベルで得た知見に基づいています。それは単一の成果ではなく、考えられるあらゆることをより速く実行するための取り組みなのです。
10億行×100列のテーブルを、同じコンピューティング資源で100倍速く処理したい場合、可能でしょうか?はい、可能です。非常に大きなテーブル同士の結合を、最小限のコンピューティング資源で行いたい場合も、同様に可能です。また、エンドユーザーに対して100ものテーブルを500ミリ秒未満で表示するような超複雑なdashboardsを実現できるでしょうか?はい、我々はそれを成し遂げました。これらは一見平凡な成果に見えますが、そのおかげで、かなり洗練された予測最適化のレシピを実運用に乗せることができたのです。そこに至るすべてのステップを、非常に高い生産性で実行する必要がありました。
サプライチェーン向けの数値レシピで非常に洗練された処理を実現しようとする際の最大の課題は、「動作させる」段階ではなく、「正しくする」、「速くする」、「安くする」という成熟の段階をどう乗り越えるかにあります。大学生に頼んで、数週間でサプライチェーンのパフォーマンス向上をもたらす一連のプロトタイプを作成することは可能です。たったPythonや、その日適当なオープンソースの機械学習ライブラリを使えば、賢く意欲的な学生たちが数週間で動作するプロトタイプを生み出すでしょう。しかし、それを大規模な実運用環境に持ち込むことは決してできません。そこが問題であり、「正しくする」、「速くする」、「安くする」というすべての成熟段階をどう乗り越えるかが重要なのです。そこにハードウェアとの親和性と反復改善の能力が真価を発揮します。
単一の成果というものは存在しません。しかし、例えば我々がprobabilistic forecastingを導入しているという場合、その処理自体にはそれほど大きなコンピューティングパワーは必要ありません。真に大量の計算能力を必要とするのは、極めて広範な確率分布を活用し、ありとあらゆる可能な未来を見極め、それらの未来とあらゆる選択肢を組み合わせる処理です。そうすることで、財務的な最適化とともに最良の選択肢を選ぶことができますが、これは非常にコストがかかります。もし十分に最適化されていなければ、行き詰まってしまうのです。Lokadが実運用環境でprobabilistic forecastingを利用できているという事実は、全てのお客様向けパイプラインにおいてハードウェアレベルの最適化を徹底してきた証です。現在、我々は約100社にサービスを提供しています。
質問: レイテンシを回避するため、クラウドサービスを利用するのではなく、エンタープライズソフトウェア(ERP、WMS)のために自社サーバーを保有する方が良いと思いますか?
現代では、ほとんどのレイテンシはシステム内に発生しているため、どちらでも大差はありません。これは、ユーザーとERP間のレイテンシの問題ではありません。確かに、非常に低いレイテンシの場合、約50ミリ秒の遅延が加わるかもしれません。例えば、パリで業務を行っているのに、ERPがメルボルンに置かれている状況は望ましくありません。データセンターは業務の拠点に近い場所であるべきです。しかし、現代のクラウドコンピューティングプラットフォームは世界中に数十のデータセンターを持っているため、自社内ホスティングとクラウドサービスとの間には大きなレイテンシの差は生じません。
通常、自社内ホスティングとは、ERPを工場や倉庫の中に直接配置することではなく、コンピューティングハードウェアをレンタルしているデータセンターに設置することを意味します。現代のクラウドコンピューティングプラットフォームの観点からは、自社内ホスティングとクラウドサービスとの間に実質的な違いはないと考えています。
本当に違いを生むのは、内部で往復通信を最小限に抑えるERPを持っているかどうかです。例えば、ERPのパフォーマンスを著しく低下させるのは、ビジネスロジックとリレーショナルデータベース間のやり取りです。もしウェブページを表示するために何百回もの往復通信が必要なら、そのERPは非常に遅くなります。したがって、往復通信が大量に発生しないエンタープライズソフトウェアの設計を考慮する必要があります。これはソフトウェア自体の内部的な性質であり、設置場所にはあまり依存しません。
質問: ハードウェアアーキテクチャの機能を余すところなく活用する新たなハードウェア設計を取り入れる、全く新しいプログラミング言語は必要だと思いますか?
はい、そう思います。ただし率直に申し上げると、ここには私自身の利益相反も関わっています。これはまさにLokadがEnvisionで実現したことです。Envisionは、現代のコンピュータが持つ全ての処理能力を活用するのが困難であるという観察から生まれましたが、プログラミング言語自体をパフォーマンスを念頭に設計すれば、その限界を超えることができるのです。言い換えれば、超常的な性能を実現できるのです。そのため、サプライチェーン向けのプログラミングパラダイムに関する講義1.4で、例えば配列プログラミングやデータフレームプログラミングといった適切なパラダイムを選び、それらの概念を取り入れたプログラミング言語を構築すれば、ほぼ無料で性能が得られると述べたのです。
あなたが支払う代償は、PythonやC++のような言語ほど表現力が高くなくなるという点ですが、サプライチェーンに関連するすべてのユースケースをカバーし、表現力の低下を受け入れるのであれば、莫大な性能向上を達成できると信じています。それが私の信念であり、例えばサプライチェーン最適化の観点からは、オブジェクト指向プログラミングが何の利益ももたらさないと述べた理由でもあります。
逆に、これは基盤となるコンピューティングハードウェアに対してのみ逆効果をもたらすパラダイムです。オブジェクト指向プログラミングが全く悪いというわけではありませんが、サプライチェーンの予測最適化という観点からは意味を持たないのです。ですから、本当に新しいプログラミング言語が必要だと強く思います。
繰り返しになりますが、Pythonは本質的に1980年代後半に設計されたもので、現代のコンピュータで見られる全ての要素を把握できていません。設計上、マルチスレッドを活用できず、グローバルロックが存在するため複数のコアを利用できません。局所性も活かせず、レイトバインディングがメモリアクセスを複雑にし、非常に多様な変数のために大量のメモリを消費し、結果としてキャッシュへの負荷が高くなるのです。
これらは、Pythonを使用することで今後数十年にわたって困難に直面し、状況がますます悪化していく問題です。決して改善されることはありません。
次回の講義は、今から3週間後、同じ曜日・同じ時間に行われます。パリ時間の午後3時、6月9日に開始されます。サプライチェーン向けの現代的なアルゴリズム、すなわちサプライチェーンのための現代的なコンピュータの対となるものについて議論する予定です。それでは、また次回お会いしましょう。


