00:54 Introduction
02:25 On the nature of progress
05:26 The story so far
06:10 A few quantitative principles: observational principles
07:27 Solving “needle in a haystack” via entropy
14:58 SC populations are Zipf-distributed
22:41 Small numbers prevail in SC decisions
29:44 Patterns are everywhere in SC
36:11 A few quantitative principles: optimization principles
37:20 5 to 10 rounds are needed to fix any SC issue
44:44 Aged SCs are unidirectionally quasi-optimal
49:06 Local SC optimizations only displace problems
52:56 Better problems trump better solutions
01:00:08 Conclusion
01:02:24 Upcoming lecture and audience questions
Описание
Поскольку цепи поставок нельзя характеризовать определёнными количественными законами – в отличие от электромагнетизма – всё же можно наблюдать общие количественные принципы. Под «общими» подразумевается, что они применимы (почти) ко всем цепям поставок. Выявление таких принципов имеет первостепенное значение, так как их можно использовать для упрощения разработки числовых рецептов, предназначенных для предиктивной оптимизации цепей поставок, а также для повышения общей эффективности этих рецептов. Мы рассмотрим два кратких списка принципов: несколько наблюдательных принципов и несколько принципов оптимизации.
Полная расшифровка

Всем привет, и добро пожаловать на эту серию лекций о цепях поставок. Меня зовут Жуаннес Верморель, и сегодня я представлю несколько «Количественных принципов для цепей поставок». Для тех, кто смотрит лекцию в прямом эфире на YouTube, вы можете задавать свои вопросы в любой момент через чат YouTube. Однако я не буду читать ваши вопросы во время лекции. В конце лекции я вернусь к чату и постараюсь ответить хотя бы на большинство вопросов.
Количественные принципы представляют большой интерес, потому что в цепях поставок, как мы видели в первых лекциях, они связаны с управлением опционами. Большинство этих опций имеют количественную природу. Вам приходится решать, сколько купить, сколько произвести, сколько переместить запасов и, возможно, устанавливать цену – повышать её или понижать. Таким образом, количественный принцип, который может способствовать улучшению числовых рецептов для цепей поставок, представляет особый интерес.
Однако, если бы я спросил большинство авторитетов или экспертов в области цепей поставок, каковы их основные количественные принципы для цепей поставок, я подозреваю, что чаще всего получил бы ответ, состоящий из набора методов для улучшения прогнозирования временных рядов или чего-то подобного. Моя личная реакция такова: хотя это интересно и актуально, суть упускается. Я считаю, что в основе недопонимания лежит сама природа прогресса – что такое прогресс и как можно реализовать его в контексте цепей поставок? Позвольте начать с наглядного примера.

Шесть тысяч лет назад было изобретено колесо, а шесть тысяч лет спустя был изобретён чемодан на колесах. Изобретение датируется 1949 годом, что подтверждает данный патент. К тому времени, когда был изобретён чемодан на колесах, мы уже осваивали атомную энергию и даже взорвали первые атомные бомбы.
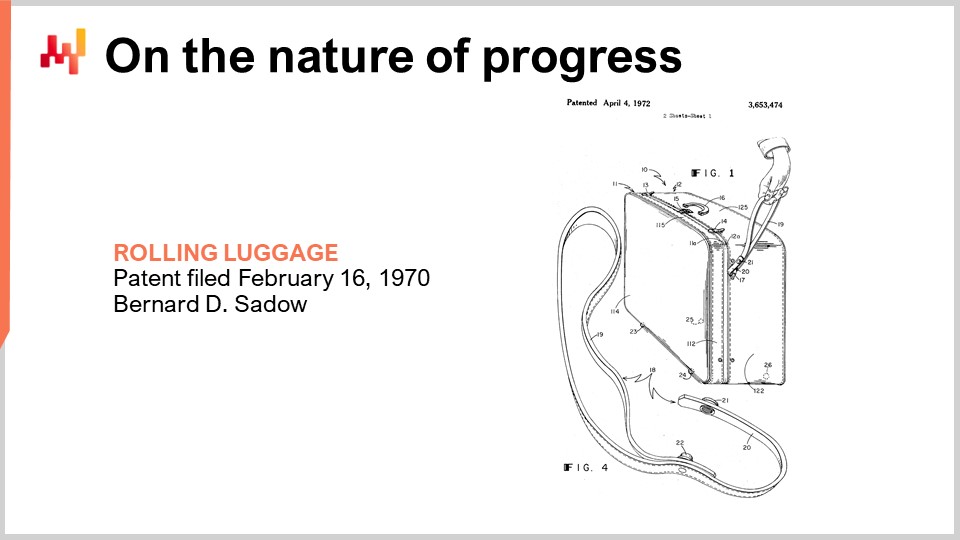
Далее, через 20 лет, в 1969 году человечество отправило первых людей на Луну. В следующем году чемодан на колесах был усовершенствован с помощью немного улучшенной ручки, которая напоминает поводок, как показано в этом патенте. Но все равно это было не очень хорошо.

Затем, через 20 лет, к тому моменту у нас уже был GPS – система глобального позиционирования, служащая гражданским лицам почти десятилетие, и наконец была изобретена правильная ручка для чемодана на колесах.
Здесь можно извлечь как минимум два важных урока. Во-первых, не существует очевидной стрелы времени, когда речь идёт о прогрессе. Прогресс происходит хаотичным, нелинейным образом, и очень сложно оценить, какой прогресс следует ожидать в одной области, исходя из того, что происходит в другой. Это один из аспектов, который нам следует помнить сегодня.
Во-вторых, прогресс не должен отождествляться со сложностью. Можно создать нечто значительно лучшее и одновременно гораздо более простое. Если взять, к примеру, чемодан, то после того, как вы его увидите, его дизайн кажется совершенно очевидным и само собой разумеющимся. Но было ли это легкой задачей для решения? Я бы сказал, что вовсе нет. Простым доказательством того, что управление цепями поставок было сложной задачей, является факт, что передовой индустриальной цивилизации потребовалось чуть более четырех десятилетий, чтобы решить эту проблему. Прогресс обманчив в том смысле, что он не подчиняется правилу сложности. Очень трудно определить, каким был мир до наступления прогресса, потому что прогресс буквально меняет ваше мировоззрение по мере своего развития.

Теперь, вернёмся к обсуждению цепей поставок. Это шестая и последняя лекция в этом прологе. В Интернете на сайте Lokad вы можете ознакомиться с подробным планом всей серии лекций о цепях поставок. Две недели назад я представил тенденции XX века для цепей поставок, рассматривая проблему исключительно с качественной точки зрения. Сегодня я подхожу к этой проблеме с противоположной стороны, используя довольно количественную перспективу.

Сегодня мы рассмотрим набор принципов. Под принципом я подразумеваю нечто, что можно использовать для улучшения разработки числовых рецептов в целом для всех цепей поставок. Здесь у нас есть стремление к обобщению, и именно поэтому довольно сложно найти что-то, что имело бы первостепенное значение для всех цепей поставок и всех числовых методов их улучшения. Мы рассмотрим два кратких списка принципов: наблюдательные принципы и принципы оптимизации.
Наблюдательные принципы применяются для количественного получения знаний и информации о цепях поставок. Принципы оптимизации связаны с тем, как действовать, когда вы уже приобрели качественные знания о своей цепи поставок, в частности, как использовать эти принципы для улучшения ваших процессов оптимизации.
Давайте начнём с наблюдения за цепью поставок. Меня озадачивает, когда люди говорят о цепях поставок так, как будто могут наблюдать их напрямую своими глазами. Для меня это очень искажённое представление о реальности цепей поставок. Цепи поставок нельзя непосредственно наблюдать человеком, по крайней мере, с количественной точки зрения. Это связано с тем, что цепи поставок по своей природе географически распределены, включают, потенциально, тысячи SKU и десятки тысяч единиц. Глазами человека вы можете наблюдать цепь поставок только такой, какая она есть сегодня, но не такой, какой она была в прошлом. Вы не способны запомнить больше, чем несколько чисел или крошечную часть чисел, связанных с вашей цепью поставок.
Когда вы хотите наблюдать за цепью поставок, вы будете осуществлять такие наблюдения косвенно с помощью корпоративного программного обеспечения. Это очень специфический способ взгляда на цепи поставок. Все количественные наблюдения цепей поставок происходят именно через это конкретное средство: корпоративное программное обеспечение.
Давайте охарактеризуем типичное корпоративное программное обеспечение. Оно будет содержать базу данных, так как подавляющее большинство такого ПО спроектировано именно так. Вероятно, в программном обеспечении будет около 500 таблиц и 10,000 полей (поле по сути является столбцом в таблице). В качестве отправной точки у нас имеется система, способная содержать огромное количество информации. Однако, в большинстве случаев, только малая часть этой программной сложности действительно имеет отношение к интересующей цепи поставок.
Поставщики программного обеспечения разрабатывают корпоративное ПО, учитывая очень разнообразные ситуации в целом. При рассмотрении конкретного клиента, скорее всего, используется только малая часть возможностей программного обеспечения. Это означает, что, хотя в теории может быть 10,000 полей для изучения, в действительности компании используют лишь незначительную их часть.
Задача состоит в том, чтобы отделить релевантную информацию от несуществующих или нерелевантных данных. Мы можем наблюдать цепи поставок только через корпоративное программное обеспечение, и может быть задействовано более одного фрагмента ПО. В некоторых случаях поле никогда не использовалось, и данные остаются постоянными, содержащими только нули или пустые значения. В такой ситуации легко исключить это поле, так как оно не содержит никакой информации. Однако на практике число полей, которые можно исключить с помощью этого метода, составляет всего около 10%, поскольку многие функции в программном обеспечении использовались на протяжении многих лет, даже если случайно.
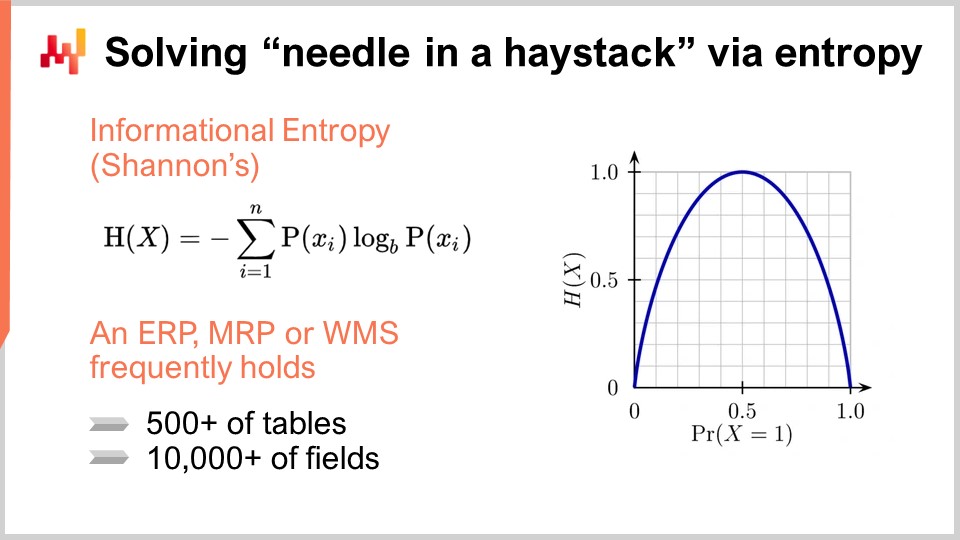
Чтобы выявить поля, которые никогда не использовались по назначению, мы можем обратиться к инструменту, называемому информационной энтропией. Для тех, кто не знаком с теорией информации Шеннона, этот термин может показаться сложным, но на самом деле всё гораздо проще. Информационная энтропия позволяет количественно оценить количество информации в сигнале, где сигнал определяется как последовательность символов. Например, если у нас есть поле, содержащее только два типа значений – true или false, и столбец случайным образом переключается между этими значениями, такой столбец содержит много данных. В отличие от этого, если только одна строка из миллиона имеет значение true, а все остальные строки – false, поле в базе данных содержит практически никакой информации.
Информационная энтропия очень интересна, поскольку позволяет количественно оценить количество информации, представленное в каждом поле вашей базы данных, в битах. Проведя анализ, вы можете ранжировать эти поля от самых информационно насыщенных до наименее насыщенных и исключить те, которые почти не содержат релевантной информации для оптимизации цепей поставок. Информационная энтропия может сначала показаться сложной, но на самом деле её не так трудно понять.

Например, представляя предметно-ориентированный язык программирования, мы реализовали информационную энтропию в виде агрегатора. Взяв таблицу, например, данные из плоского файла data.csv с тремя столбцами, мы можем построить сводку того, сколько энтропии содержится в каждом столбце. Этот процесс позволяет легко определить, какие поля содержат наименьшее количество информации, и исключить их. Используя энтропию в качестве ориентира, вы можете быстро начать проект, вместо того чтобы тратить на это годы.
Переходя к следующему этапу, мы делаем первые наблюдения за цепями поставок и рассматриваем, что следует ожидать. В естественных науках по умолчанию ожидаются нормальные распределения, также известные как колоколообразные кривые или гауссовы распределения. Например, рост 20-летнего мужчины или его вес будут иметь нормальное распределение. В мире живых организмов многие измерения следуют этой закономерности. Однако в случае цепей поставок это не так. Практически ничего интересного в цепях поставок не имеет нормального распределения.
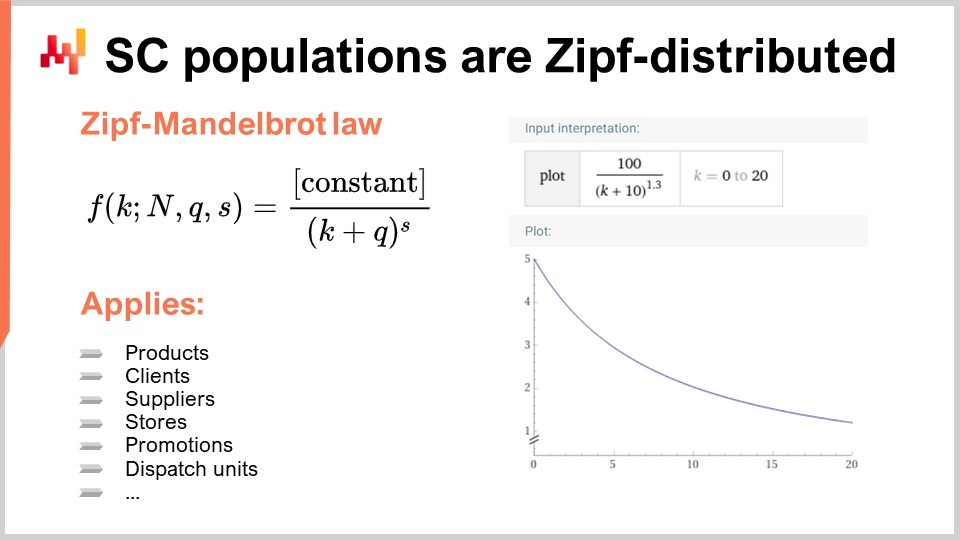
Вместо этого практически все распределения, представляющие интерес в цепях поставок, следуют закону Зипфа. Распределение Зипфа проиллюстрировано в данной формуле. Чтобы понять эту концепцию, представьте популяцию продуктов, где измеряемым показателем является объём продаж каждого продукта. Вы ранжируете продукты от самого высокого до самого низкого объёма продаж за определённый период, например, за год. Вопрос заключается в том, существует ли модель, которая предсказывает форму кривой, и если задан ранг, то предоставит ожидаемый объём продаж. Именно об этом и говорит распределение Зипфа. Здесь f представляет форму закона Зипфа-Мандельброта, а k обозначает k-ый по величине элемент. Существует два параметра, q и s, которые по сути определяются, как и mu (среднее) и sigma (дисперсия) для нормального распределения. Эти параметры можно использовать для подгонки распределения к интересующей популяции. Закон Зипфа-Мандельброта включает в себя эти параметры.
Важно отметить, что практически каждая популяция, представляющая интерес в цепях поставок, подчиняется распределению Зипфа. Это относится к продуктам, клиентам, поставщикам, промоакциям и даже единицам отгрузки. Распределение Зипфа по сути является потомком принципа Парето, но оно более управляемо и, на мой взгляд, более интересно, поскольку предоставляет явную модель того, чего ожидать от любой популяции в цепочке поставок. Если вы сталкиваетесь с популяцией, которая не следует распределению Зипфа, скорее всего, проблема кроется в данных, а не в истинном отклонении от принципа.

Чтобы использовать концепцию распределения Ципфа в реальном мире, можно воспользоваться Envision. Если мы посмотрим на этот фрагмент кода, то увидим, что для применения этой модели к реальному набору данных требуется всего несколько строк кода. Здесь я предполагаю, что существует совокупность интересующих нас данных в плоском файле с названием “data.csv”, содержащем один столбец, представляющий количество. Обычно у вас был бы идентификатор продукта и количество. На строке 4 я вычисляю ранги с помощью агрегатора рангов и сортирую по количеству. Затем, между строками 6 и 11, я вхожу в блок дифференцируемого программирования, явно обозначенный Autodev, где я объявляю три скалярных параметра: c, q и s, как в формуле слева на экране. Затем я вычисляю предсказания модели Ципфа и использую среднеквадратичную ошибку между наблюдаемым количеством и предсказанием модели. Вы буквально можете провести регрессию распределения Ципфа, используя всего несколько строк кода. Даже если это звучит сложно, с помощью подходящих инструментов это довольно просто.

Это подводит меня к еще одному наблюдательному аспекту цепей поставок: цифры, которые вы ожидаете на любом уровне цепи поставок, малы, обычно менее 20. У вас будет не только немного наблюдений, но и сами наблюдаемые числа будут малы. Конечно, этот принцип зависит от используемых единиц измерения, но когда я говорю “цифры”, я имею в виду те, которые имеют канонический смысл с точки зрения цепи поставок, и которые вы пытаетесь наблюдать и оптимизировать.
Причина, по которой у нас есть только малые числа, связана с эффектами масштаба. Возьмем, к примеру, футболки в магазине. Магазин может иметь тысячи футболок на складе, что кажется большим числом, но на самом деле у них сотни различных типов футболок с вариациями по размеру, цвету и дизайну. Если вы начнете рассматривать футболки с точки зрения релевантной для цепи поставок (на уровне SKU), магазин не будет иметь тысячи экземпляров футболок для данного SKU; вместо этого их будет всего несколько.
Если у вас есть больше футболок, вы не будете иметь тысячи футболок, лежащих без дела, так как это было бы кошмаром с точки зрения их обработки и перемещения. Вместо этого вы упакуете эти футболки в удобные коробки, что и происходит на практике. Если у вас есть распределительный центр, который занимается большим количеством футболок, поскольку вы отправляете их в магазины, то, скорее всего, эти футболки действительно будут находиться в коробках. Возможно, даже имеется коробка, содержащая полный ассортимент футболок с различными размерами и цветами, что облегчает их обработку по цепочке. Если у вас много коробок, у вас не будет тысячи таких коробок. Вместо этого, если у вас есть десятки коробок, вы аккуратно организуете их на поддонах. Один поддон может вместить несколько десятков коробок. Если у вас много поддонов, они не будут организованы как отдельные единицы; скорее всего, они будут организованы в контейнеры. А если у вас много контейнеров, вы будете использовать грузовое судно или что-то подобное.
Моя точка зрения заключается в том, что когда речь идет о числах в цепи поставок, действительно значимое число всегда остается маленьким. Эту ситуацию нельзя обойти, просто переходя на более высокий уровень агрегации, потому что по мере перехода на более высокий уровень агрегации начинают действовать эффекты масштаба, и вы стремитесь ввести механизм пакетирования для снижения эксплуатационных затрат. Это происходит многократно, поэтому независимо от того, на каком масштабе вы смотрите – будь то конечный продукт, продаваемый поштучно в магазине, или массово производимый товар – все сводится к игре малых чисел.
Даже если у вас есть фабрика, производящая миллионы футболок, скорее всего, у вас будут огромные партии, и число, представляющее для вас интерес, — это не количество футболок, а количество партий, которое будет значительно меньше.
К чему я веду этот принцип? Прежде всего, взгляните на то, как выглядят большинство методов в научных вычислениях или статистике. Оказывается, что в большинстве других областей, не связанных с цепями поставок, принята обратная картина: большое количество наблюдений и большие числа, где точность имеет значение. В цепях поставок же числа малы и дискретны.
Мое предложение заключается в том, что нам нужны инструменты, основанные на этом принципе, которые глубоко учитывают и принимают тот факт, что у нас будут маленькие числа, а не большие. Если у вас есть инструменты, разработанные исключительно с учетом закона больших чисел — либо из-за большого количества наблюдений, либо из-за самих больших чисел — то вы столкнетесь с полной несоответственностью, когда дело касается цепей поставок.
Кстати, это имеет существенные программные последствия. Если у вас маленькие числа, существует множество способов, которыми программные слои могут воспользоваться этим наблюдением. Например, если вы посмотрите на набор данных по строкам транзакций для гипермаркета, то, исходя из моего опыта и наблюдений, 80% строк имеют количество, равное единице, которое продается конечному покупателю в гипермаркете. Значит, нужны ли вам 64 бита информации для представления этой информации? Нет, это полная трата пространства и времени на обработку. Принятие этой концепции может привести к операционному выигрышу в один или два порядка. Это не просто мечтательное размышление; существуют реальные операционные выгоды. Вы можете подумать, что современные компьютеры очень мощные, и они таковы, но если у вас есть больше вычислительной мощности, вы можете использовать более продвинутые алгоритмы, которые делают все еще лучше для вашей цепи поставок. Нет смысла тратить эту вычислительную мощность только потому, что у вас парадигма, ожидающая больших чисел, когда преобладают маленькие.
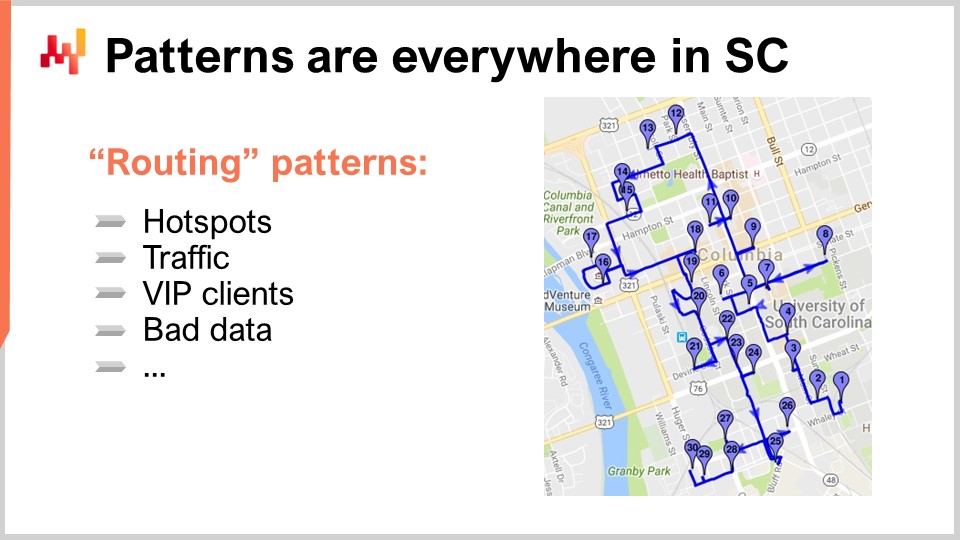
Это подводит меня к последнему наблюдательному принципу на сегодня: шаблоны присутствуют повсюду в цепях поставок. Чтобы понять это, давайте рассмотрим классическую задачу цепи поставок, в которой обычно считают, что шаблоны отсутствуют: оптимизацию маршрута. Классическая задача оптимизации маршрута включает список доставок, которые необходимо выполнить. Вы можете разместить доставки на карте, и вам нужно найти маршрут, который минимизирует время транспортировки. Вы хотите установить такой маршрут, который проходит через каждую точку доставки, минимизируя общее время перевозки. На первый взгляд кажется, что эта задача является полностью геометрической и не предполагает использования шаблонов в решении.
Однако я утверждаю, что такая точка зрения совершенно неверна. Подходя к задаче с такого ракурса, вы рассматриваете математическую задачу, а не проблему цепи поставок. Цепи поставок — это итерационные игры, в которых одни и те же проблемы возникают вновь и вновь. Если вы занимаетесь организацией доставок, то, скорее всего, вы осуществляете их каждый день. Это не один маршрут; это буквально один маршрут в день, по крайней мере.
Более того, если вы занимаетесь доставками, у вас, вероятно, есть целый автопарк и водители. Проблема заключается не только в оптимизации одного маршрута; необходимо оптимизировать целый автопарк, и эта игра повторяется ежедневно. Именно здесь проявляются все шаблоны.
Во-первых, точки на карте распределены не случайным образом. Есть горячие точки — географические территории с высокой плотностью доставок. Могут существовать адреса, куда осуществляется доставка почти ежедневно, например, штаб-квартира крупной компании в большом городе. Если вы крупная компания электронной коммерции, вероятно, вы доставляете посылки по этому адресу каждый рабочий день. Эти горячие точки не являются неизменными; у них есть сезонность. Некоторые районы могут быть очень спокойными летом или зимой. Существуют шаблоны, и если вы хотите быть действительно успешным в оптимизации маршрутов, вы должны учитывать не только места возникновения горячих точек, но и то, как они изменяются в течение года. Кроме того, необходимо учитывать трафик. Вы не должны думать только о геометрическом расстоянии, потому что трафик зависит от времени суток. Если водитель начинает движение в определенный момент дня, то по мере продвижения по маршруту трафик будет изменяться. Чтобы хорошо справляться с этой задачей, необходимо учитывать шаблоны трафика, которые изменяются и могут быть надежно предсказаны заранее. Например, в Париже в 9:00 утра и в 18:00 весь город оказывается в полной пробке, и даже необязательно быть экспертом в прогнозировании, чтобы это понимать.
Также происходят спонтанные события, такие как аварии, которые нарушают обычные схемы трафика. Если рассматривать доставки с математической точки зрения, предполагается, что все точки доставки одинаковы, но это не так. Могут быть VIP-клиенты или конкретные адреса, куда необходимо доставить половину вашего груза. Эти ключевые точки на маршруте нужно учитывать для эффективной оптимизации.
Также необходимо учитывать контекст, и часто данные о мире бывают неполными. Например, если мост закрыт, а программа об этом не знает, проблема заключается не в том, что при первом запуске не узнали о закрытии моста, а в том, что программа так и не обучается на этой проблеме и всегда предлагает маршрут, который должен быть оптимальным, но оказывается бессмысленным. Люди начинают возражать против системы, что не является хорошим практическим решением оптимизации маршрута с точки зрения цепей поставок.
Суть в том, что когда мы рассматриваем ситуации в цепях поставок, шаблоны встречаются повсюду. Мы должны быть осторожны, чтобы не увлечься элегантными математическими структурами и помнить, что те же соображения применимы к прогнозированию временных рядов. Я привел задачу оптимизации маршрута в качестве примера, потому что в этом случае она проявляется наиболее явно.
В заключение, мы должны наблюдать цепь поставок со всех доступных измерений, а не только тех, которые очевидны или где решение представляется элегантным.

Это подводит меня ко второй серии принципов, связанных с тем, как мы должны смотреть на нашу цепь поставок. До сих пор мы рассмотрели четыре принципа: косвенное наблюдение, корпоративное программное обеспечение, разбор хаоса для определения того, что является релевантным, и энтропия. Мы наблюдали, что распределения часто следуют закону Ципфа, и даже при наличии маленьких чисел можно увидеть, как возникают шаблоны. Возникает вопрос: как действовать? С математической точки зрения, когда мы хотим определить наилучший путь действий, мы применяем некоторую оптимизацию, что является количественной перспективой.

Первое, что стоит отметить, заключается в том, что как только в производстве появляется логика оптимизации для цепей поставок, возникают проблемы, такие как ошибки. Корпоративное программное обеспечение — очень сложное создание, часто полное ошибок. По мере разработки собственной логики оптимизации для вашей цепи поставок возникает множество проблем. Однако если логика достаточно хороша, чтобы быть запущенной в производство, любые возникающие проблемы, скорее всего, являются исключениями. Если бы это не было исключением и программа или логика давала сбой каждый раз, она никогда бы не попала в производство.
Суть этого принципа заключается в том, что на устранение любой проблемы требуется от пяти до десяти итераций. Под “пятью-десятью итерациями” я имею в виду, что вы столкнетесь с проблемой, проанализируете её, выясните коренную причину, а затем попытаетесь применить исправление. Но чаще всего исправление не решает проблему. Вы обнаружите, что внутри проблемы была скрыта другая проблема, или проблема, которую вы думали, что решили, на самом деле не являлась настоящей причиной, или ситуация выявила более широкий класс проблем. Возможно, вы устранили небольшой случай более широкой проблемы, но будут возникать и другие, являющиеся вариациями той, которую, как вам казалось, вы решили.
Цепи поставок — сложные, постоянно меняющиеся системы, действующие в реальном мире, что затрудняет создание идеального решения, корректного для всех ситуаций. В большинстве случаев вы делаете максимально возможную попытку устранить проблему, а затем испытываете обновленную логику в реальных условиях, чтобы увидеть, работает она или нет. Вам придется повторять итерации, чтобы окончательно устранить проблему. Принцип о том, что для исправления проблемы требуется от пяти до десяти итераций, имеет серьезные последствия для скорости адаптации и частоты обновления или перерасчета логики оптимизации цепей поставок. Например, если у вас есть логика, которая генерирует квартальный прогноз на следующие два года и запускается только раз в квартал, исправление любых проблем может занять от одного до двух лет — невероятно долго.
Даже если у вас есть логика, которая запускается каждый месяц, как в случае процесса S&OP, исправление проблемы может занять до года. Именно поэтому важно увеличивать частоту запуска логики оптимизации цепей поставок. Например, в Lokad каждый элемент логики запускается ежедневно, даже для прогнозов на пять лет вперед. Эти прогнозы обновляются ежедневно, даже если они почти не меняются с дня на день. Цель заключается не в повышении статистической точности прогнозирования, а в том, чтобы логика выполнялась достаточно часто для быстрого выявления и устранения любых проблем или ошибок.
Это наблюдение не является уникальным для управления цепями поставок. Умные инженеры в таких компаниях, как Netflix, популяризировали идею хаос-инжиниринга. Они поняли, что исключения встречаются редко, и что единственный способ устранить их — это повторять эксперимент чаще. В результате они создали программное обеспечение под названием Chaos Monkey, которое вносит хаос в их программную инфраструктуру, создавая сетевые сбои и случайные аварии. Цель Chaos Monkey — ускорить проявление исключений, чтобы инженерная команда могла быстрее их устранить.
Хотя может показаться контрпродуктивным вводить дополнительный уровень хаоса в ваши операции, этот подход оказался эффективным для Netflix, известного своей высокой надежностью. Они понимают, что при возникновении проблем, вызванных программным обеспечением, требуется множество итераций для их решения, и единственный способ добраться до сути проблемы — это быстрая итерация. Chaos Monkey — лишь один из способов повышения скорости итераций.
С точки зрения цепочки поставок, концепция Chaos Monkey может быть не напрямую применима, но идея повышения частоты запуска алгоритмов оптимизации цепочки поставок по-прежнему крайне актуальна. Каким бы алгоритмом вы ни пользовались для оптимизации своей цепочки поставок, он должен работать с высокой скоростью и частотой; в противном случае вы так и не исправите существующие проблемы.

Теперь устоявшиеся цепочки поставок являются квазиидеальными, и когда я говорю «устоявшиеся», я имею в виду цепочки, которые функционируют уже два десятилетия или более. Другими словами, ваши предшественники по цепочке поставок не были полностью некомпетентны. Когда вы рассматриваете инициативы по оптимизации цепочки поставок, слишком часто встречаются амбициозные цели, такие как сокращение запасов вдвое, повышение уровня сервиса с 95% до 99%, устранение дефицита товара, или сокращение сроков поставки вдвое. Это масштабные, односторонние шаги, когда вы сосредотачиваетесь на одном ключевом показателе и пытаетесь кардинально его улучшить. Однако я заметил, что эти инициативы почти всегда проваливаются по простой причине: когда вы берете цепочку поставок, которая функционирует десятилетиями, обычно в методах работы кроется определённая скрытая мудрость.
Например, если уровень сервиса составляет 95%, то попытка повысить его до 99% вполне может привести к резкому увеличению запасов и образованию значительного количества нераспроданного товара. Аналогично, если у вас есть определённый объём запасов, и вы запускаете масштабную инициативу по их сокращению вдвое, это, вероятно, создаст значительные проблемы с качеством обслуживания, которые не могут быть поддержаны.
Я заметил, что многие специалисты по цепочкам поставок, которые не понимают принципа, что устоявшиеся цепочки поставок являются односторонне квазиидеальными, склонны к колебаниям вокруг локального оптимума. Имейте в виду, что я не утверждаю, что устоявшиеся цепочки являются оптимальными, но они односторонне квазиидеальны. Если посмотреть на аналогию с Гранд-Каньоном, то река вырезает оптимальный путь благодаря неотвратимой силе гравитации. Даже если приложить силу, в десять раз большую, река всё равно будет извиваться.
Суть в том, что в устоявшихся цепочках поставок, если вы хотите добиться значительных улучшений, вам необходимо одновременно корректировать множество переменных. Сосредоточение на одной переменной не даст желаемого результата, особенно если ваша компания работает по старым принципам в течение десятилетий. Ваши предшественники, вероятно, сделали несколько вещей правильно в своё время, так что вероятность столкнуться с абсолютно дисфункциональной цепочкой поставок, которой никто не уделял внимания, минимальна. Цепочки поставок — это сложные проблемы, и хотя создание полностью дисфункциональных ситуаций в больших масштабах возможно, такое случается крайне редко.

Другой аспект, который следует учитывать, заключается в том, что локальная оптимизация лишь смещает проблемы, а не решает их. Чтобы это понять, необходимо осознать, что цепочки поставок являются системами, и когда речь идёт об эффективности цепей поставок, нас интересует только общая производительность системы. Локальная эффективность важна, но она является лишь частью общей картины.
Распространённое мышление состоит в том, что можно применить стратегию «разделяй и властвуй» для решения проблем в целом, а не только проблем цепочки поставок. Например, в розничной сети с множеством магазинов вы можете захотеть оптимизировать уровни запасов в каждом магазине. Однако проблема в том, что если у вас есть сеть магазинов и распределительных центров, каждый из которых обслуживает множество магазинов, то микроконтроль одного магазина для достижения отличного уровня обслуживания в нём за счёт остальных оказывается тривиальным.
Правильный подход заключается в том, чтобы, имея одну единицу товара в распределительном центре, задаться вопросом: «Где эта единица наиболее востребована?» Какое действие будет для меня наиболее прибыльным? Проблема оптимизации распределения запасов, или задача управления запасами, имеет смысл только на уровне системы, а не на уровне отдельного магазина. Если вы оптимизируете работу одного магазина, то, скорее всего, создадите проблемы в другом.
Когда я говорю «локально», этот принцип не должен пониматься только в географическом смысле; он может быть и чисто логическим внутри цепочки поставок. Например, если вы — компания электронной коммерции с множеством категорий товаров, вы можете захотеть распределить различные бюджеты для разных категорий. Это ещё один тип стратегии «разделяй и властвуй». Однако если вы разбиваете бюджет и выделяете фиксированную сумму в начале года для каждой категории, то что произойдёт, если спрос на товары в одной категории удвоится, а в другой сократится вдвое? В этом случае возникает проблема неправильного распределения средств между этими двумя категориями. Сложность в том, что нельзя применить какую-либо логику «разделяй и властвуй». Если вы используете методы локальной оптимизации, то можете создать проблемы, пытаясь создать, казалось бы, оптимизированное решение.

Это подводит меня к последнему принципу, который, пожалуй, является самым сложным из всех, что я сегодня представил: лучшие проблемы важнее лучших решений. Это может вызывать существенные недоразумения, особенно в некоторых академических кругах. В классическом образовании обычно преподносят так: вам представляют чётко сформулированную проблему, и затем вы начинаете искать для неё решения. Например, в математической задаче один студент может предложить более краткое, элегантное решение, и оно считается лучшим.
Однако в реальности дело обстоит иначе в управлении цепочками поставок. Чтобы проиллюстрировать это, вернёмся на 60 лет назад и взглянем на проблему приготовления пищи — крайне трудоёмкого процесса. Раньше люди предполагали, что в будущем роботы смогут выполнять кулинарные задачи, тем самым значительно повышая производительность повара. Такой образ мышления был распространён в 1950‑х и 1960‑х годах.
Перемотаем время до сегодняшнего дня, и становится очевидно, что так не развивается ситуация. Чтобы минимизировать усилия на приготовление пищи, люди теперь покупают готовые блюда. Это ещё один пример смещения проблемы. Обеспечение супермаркетов готовыми блюдами является более сложной задачей с точки зрения цепочки поставок, чем поставка сырья, из-за увеличенного ассортимента и более коротких сроков годности. Проблема была решена посредством улучшенного решения для цепочки поставок, а не за счёт более совершенного метода готовки. Проблема приготовления пищи была полностью устранена и переопределена как предоставление достаточно приличного блюда при минимальных усилиях.
Что касается цепочек поставок, академическая точка зрения зачастую сосредоточена на поиске более совершенных решений для существующих проблем. Хорошим примером могут служить конкурсы на Kaggle, где у вас есть набор данных, проблема и потенциально сотни или тысячи команд, соревнующихся за лучшее предсказание на этих данных. Проблема чётко определена, и тысячи решений конкурируют друг с другом. Проблема такого подхода заключается в том, что создаётся впечатление, что для улучшения вашей цепочки поставок необходимо просто найти лучшее решение.
Суть этого принципа заключается в том, что лучшее решение может помочь лишь незначительно, но только незначительно. Обычно настоящую помощь оказывает переосмысление самой проблемы, что оказывается удивительно сложным. Это касается и количественных задач. Вам необходимо пересмотреть свою стратегию цепочки поставок и основную проблему, которую следует оптимизировать.
Во многих кругах проблемы воспринимаются как нечто статичное и неизменное, и все стремятся найти для них лучшее решение. Я не отрицаю, что более совершённый алгоритм прогнозирования временных рядов может быть полезен, но прогнозирование временных рядов относится к области статистического прогнозирования, а не к мастерству управления цепочками поставок. Если вернуться к моему первоначальному примеру с дорожным чемоданом, то ключевым улучшением у чемодана на колёсах было не в самих колёсах, а в ручке. На первый взгляд это не имело ничего общего с колёсами, и именно поэтому понадобилось 40 лет, чтобы найти решение – нужно мыслить нестандартно, чтобы выявить более существенную проблему.
Этот количественный принцип заключается в том, чтобы бросить вызов проблемам, с которыми вы сталкиваетесь. Возможно, вы недостаточно глубоко анализируете проблему, и существует склонность влюбляться в решение, хотя нужно сосредоточиться на самой проблеме и тех аспектах, которые остаются непонятными. Как только проблема становится чётко сформулированной, наличие хорошего решения обычно сводится к обыденной задаче исполнения, что не так уж сложно.

В заключение, изучение цепочек поставок предлагает множество впечатляющих и авторитетных взглядов. Эти подходы могут быть весьма сложными, но вопрос, который я хотел бы задать аудитории: не может ли всё это оказаться абсолютно ошибочным? Действительно ли мы уверены, что такие элементы, как прогнозирование временных рядов и исследование операций, являются правильными перспективами для решения проблемы? Независимо от уровня сложности и десятилетий инженерных наработок и усилий, направленных в этих направлениях, действительно ли мы на правильном пути?
Сегодня я представляю ряд принципов, которые, по моему мнению, имеют первостепенное значение для управления цепочками поставок. Однако они могут показаться странными большинству из вас. У нас существуют два мира — проверенный и странный, — и вопрос в том, что произойдёт через несколько десятилетий.

Прогресс, как правило, развивается хаотично и нелинейно. Смысл этих принципов в том, чтобы помочь вам принять мир, полный хаоса, где всегда возможно неожиданное. Эти принципы могут помочь вам разрабатывать более быстрые, надёжные и эффективные решения, способные улучшить ваши цепочки поставок с количественной точки зрения.

Теперь перейдём к вопросам.
Вопрос: Как распределения Ципфа соотносятся с законом Парето?
Закон Парето — это эмпирическое правило 80-20, но с количественной точки зрения распределение Ципфа представляет собой явную прогностическую модель. У него имеются прогностические возможности, которые можно проверять на наборах данных весьма прямолинейно.
Вопрос: Разве распределение Ципфа-Мандельброта не стоит рассматривать как логарифмическую кривую для наблюдения колебаний в цепочке поставок, как это делают эпидемиологи при отчёте о случаях и смертях?
Безусловно. На философском уровне вопрос заключается в том, живёте ли вы в стране посредственности или в стране экстримов. Цепочки поставок и большинство человеческих дел существуют в мире крайностей. Логарифмические кривые действительно полезны, если вы хотите визуализировать амплитуду акций. Например, если вы хотите увидеть амплитуды всех прошлых промо-акций для крупных розничных сетей за последние 10 лет, использование обычной шкалы может сделать всё остальное невидимым, просто потому что самая крупная акция была настолько больше остальных. Поэтому использование логарифмической шкалы может помочь вам лучше увидеть вариации. При использовании распределения Ципфа-Мандельброта я даю вам модель, которую можно буквально развернуть в несколько строк кода, что является чем-то большим, чем просто логарифмическое представление данных. Однако я согласен, что основная интуиция остаётся той же. Для получения философской перспективы высокого уровня я рекомендую прочитать работы Насима Талеба о Mediocristan против Extremistan в его книге «Антихрупкость».
Вопрос: Что касается локальной оптимизации цепочек поставок, имеете ли вы в виду базовые данные, которые поддерживают сотрудничество в сети поставок и SNLP?
Моя проблема с локальной оптимизацией заключается в том, что крупные компании, управляющие основными цепочками поставок, обычно имеют матричную организационную структуру. Эта структура, с её мышлением «разделяй и властвуй», влечёт за собой локальную оптимизацию по своей сути. Например, рассмотрим две разные команды — одну, ответственную за прогнозирование спроса, и другую, принимающую решения по закупкам. Эти две задачи — прогнозирование спроса и оптимизация закупок — полностью взаимосвязаны. Вы не можете проводить локальную оптимизацию, сосредоточившись только на проценте ошибки в прогнозировании спроса и затем отдельно оптимизировав закупки на основе эффективности обработки. Существуют системные эффекты, и их нужно учитывать вместе.
Самая большая проблема для большинства крупных, устоявшихся компаний, управляющих значительными цепочками поставок, заключается в том, что для количественной оптимизации необходимо мыслить на уровне всей системы и всей компании. Это противоречит десяткам лет работы в матричной организации, где люди стали сосредоточиваться исключительно на своих четко определённых границах, забывая о более широкой картине.
Другой пример данной проблемы — это товарные запасы в магазинах. Запасы выполняют две функции: с одной стороны, они удовлетворяют спрос клиентов, а с другой — представляют собой товарное предложение. Чтобы обеспечить правильное количество запасов, необходимо учитывать проблему качества обслуживания и проблему привлекательности магазина. Привлекательность магазина заключается в том, чтобы он выглядел привлекательно и интересно для клиентов, что является больше маркетинговой задачей. В компании существуют маркетинговый отдел и отдел цепочек поставок, и они не всегда взаимодействуют естественным образом при оптимизации цепочек поставок. Моя мысль такова: если не объединить все эти аспекты, оптимизация не сработает.
Что касается вашего вопроса по SNLP, проблема в том, что люди собираются лишь для того, чтобы проводить собрания, что неэффективно. Несколько месяцев назад мы опубликовали эпизод Lokad TV, посвящённый SNLP, так что вы можете обратиться к нему, если хотите обсудить SNLP более детально.
Вопрос: Как следует распределять время и энергию между стратегией цепочки поставок и количественным исполнением?
Это отличный вопрос. Ответ, как я упоминал во второй лекции, заключается в том, что необходима полная автоматизация рутинных задач. Это позволит вам посвятить всё своё время и энергию непрерывному стратегическому усовершенствованию ваших числовых алгоритмов. Если вы тратите более 10% времени на решение повседневных задач по выполнению цепочки поставок, у вас проблема в методологии. Эксперты по цепям поставок слишком ценны, чтобы тратить своё время и силы на рутинные задачи, которые, в первую очередь, следует автоматизировать.
Вам необходимо следовать методологии, которая позволяет посвящать почти всю энергию стратегическому мышлению, которое затем немедленно воплощается в виде превосходных числовых алгоритмов, управляющих ежедневными операциями в цепочке поставок. Это относится к моей третьей лекции о поставке, ориентированной на продукт, то есть о поставке программного продукта.
Вопрос: Можно ли гипотетически предположить своего рода анализ потолка, то есть лучшее возможное улучшение для проблем цепочки поставок с учетом их системной формулировки?
Я бы сказал — нет, абсолютно нет. Полагать, что существует некий оптимум или потолок, эквивалентно утверждению, что у человеческой изобретательности есть предел. Хотя у меня нет доказательств того, что у человеческой изобретательности нет предела, это одно из моих основных убеждений. Цепочки поставок — это сложные проблемы. Вы можете трансформировать проблему и даже превратить то, что кажется большой проблемой, в отличное решение и источник потенциала для роста компании. Например, взгляните на Amazon. Джефф Безос в начале 2000-х понял, что для того чтобы быть успешным ритейлером, ему понадобится масштабная, надежная программная инфраструктура. Но эта масштабная, промышленного уровня инфраструктура, необходимая для работы электронной коммерции Amazon, была невероятно дорогостоящей, обойдясь компании в миллиарды. Поэтому команды Amazon решили превратить эту облачную вычислительную инфраструктуру, представлявшую собой огромные инвестиции, в коммерческий продукт. Сегодня эта инфраструктура массовых вычислений является одним из основных источников прибыли Amazon.
Когда вы начинаете размышлять о сложных проблемах, вы всегда можете переопределить задачу более эффективным способом. Вот почему я считаю ошибочным полагать, что существует некое оптимальное решение. Если мыслить в терминах анализа потолка, вы рассматриваете фиксированную проблему, и с этой фиксированной точки зрения решение может оказаться, вероятно, квазиоптимальным. Например, если посмотреть на колеса современных чемоданов, они, вероятно, являются квазиоптимальными. Но не существует ли чего-то совершенно очевидного, что мы упускаем? Возможно, есть способ сделать колеса намного лучше — изобретение, которое еще не создано. Как только мы его увидим, оно покажется совершенно самоочевидным.
Вот почему мы должны считать, что для этих проблем не существует потолка, потому что сами проблемы произвольны. Вы можете переопределить проблему и решить, что игра должна вестись по совершенно другим правилам. Это сбивает с толку, потому что люди любят думать, что у них есть чётко сформулированная проблема, и они могут найти её решение. Современная западная система образования акцентирует внимание на поиске решения, когда вам дают проблему и оценивают качество вашего решения. Однако куда интереснее вопрос: каково качество самой проблемы.
Вопрос: Лучшие решения действительно решают проблемы, но иногда поиск лучшего решения может стоить и времени, и денег. Существуют ли обходные пути для этого?
Абсолютно. Опять же, если у вас есть решение, которое теоретически верно, но его реализация занимает целую вечность, это не является хорошим решением. Такой подход часто встречается в некоторых академических кругах, где сосредоточены на поиске идеального решения по узким математическим критериям, не имеющим ничего общего с реальным миром. Именно об этом я и говорил, когда упоминал правильную задачу оптимизации.
Примерно каждый квартал ко мне подходит профессор с просьбой проверить его онлайн-алгоритм для решения задачи оптимизации маршрута. Большинство статей, которые я сейчас рецензирую, посвящены онлайн-форматам. Мой ответ всегда один и тот же: вы не решаете правильную задачу. Мне безразлично ваше решение, потому что вы даже не думаете правильно о самой проблеме.
Прогресс не следует путать с утонченностью. Существует ошибочное представление, что прогресс движется от чего-то простого к чему-то утонченному. На самом деле, прогресс часто достигается, если начать с чего-то невероятно запутанного и, благодаря превосходному мышлению и технологиям, достичь простоты. Например, если вы посмотрите на мою последнюю лекцию о тенденциях в цепочках поставок XXI века, вы увидите Механизм Марли, который доставлял воду во дворец Версаля. Это была безумно сложная система, в то время как современные электрические насосы намного проще и эффективнее.
Прогресс не обязательно заключается в повышенной утонченности. Иногда она требуется, но это не является основным ингредиентом прогресса.
Вопрос: Крупные розничные сети управляют уровнем своих запасов, но должны выполнять заказы почти мгновенно. Иногда они решают самостоятельно запускать промо-акции, которые не инициированы поставщиком. Каков подход к прогнозированию и подготовке на уровне поставщика?
Во-первых, нужно взглянуть на проблему с другой стороны. Вы рассматриваете её с точки зрения прогнозирования, когда ваш клиент, крупный ритейлер, внезапно проводит масштабную акцию. Итак, так ли это плохо? Если они продвигают ваши продукты, не уведомляя вас, это просто факт жизни. Если изучить историю, они обычно делают это регулярно, и даже можно заметить определенные закономерности.
Если вернуться к моим принципам, закономерности встречаются повсюду. Прежде всего, вам нужно принять точку зрения, что будущее невозможно точно предсказать; вместо этого требуются вероятностные прогнозы. Даже если вы не можете в совершенстве предвидеть колебания, они могут оказаться не полностью неожиданными. Возможно, вам следует изменить правила игры, вместо того чтобы позволять поставщику полностью вас удивлять. Возможно, необходимо договориться об обязательствах, связывающих ритейлера, розничную сеть и поставщика. Если розничная сеть начнет проводить масштабное продвижение, не предупредив поставщика, поставщика реалистично нельзя будет привлечь к ответственности за несоблюдение качества обслуживания.
Возможно, решение заключается в более совместном подходе. Может быть, поставщику следует усовершенствовать оценку рисков. Если материалы, продаваемые поставщиком, не являются скоропортящимися, возможно, выгоднее иметь пару месяцев запасов. Часто люди думают о нулевой задержке, нулевых запасах и нуле во всем, но действительно ли это то, чего ожидают от вас клиенты? Возможно, ваши клиенты ожидают дополнительную ценность в виде обильных запасов. Опять же, ответ зависит от различных факторов.
Вам нужно рассмотреть проблему с разных углов, и не существует простого решения. Необходимо действительно тщательно обдумать проблему и рассмотреть все доступные варианты. Возможно, вопрос не в увеличении запасов, а в расширении производственных мощностей. Если спрос резко возрастает, и масштабный скачок не является чрезмерно дорогостоящим, а поставщики поставщиков могут достаточно быстро предоставить материалы, возможно, всё, что вам нужно, — это более универсальные производственные мощности. Это позволит перенаправить мощности на то, что в данный момент резко востребовано.
Кстати, такое действительно существует в некоторых отраслях. Например, в упаковочной промышленности имеются огромные мощности. Большинство машин в этой отрасли — промышленные принтеры, которые относительно недороги. Люди, работающие в упаковочном бизнесе, обычно имеют много принтеров, которые большую часть времени не используются. Однако, когда происходит крупное событие или крупный бренд решает провести масштабное продвижение, у них есть возможность напечатать тонны новых упаковок, соответствующих новому маркетинговому курсу бренда.
Таким образом, многое зависит от различных факторов, и я извиняюсь за отсутствие однозначного ответа. Но я могу с уверенностью сказать, что вам нужно действительно тщательно обдумать проблему, с которой вы сталкиваетесь.
На этом заканчивается сегодняшняя лекция, шестая и последняя пролога. Через две недели, в тот же день и в то же время, я проведу лекцию о личностях в цепочке поставок. До встречи.


