00:00 Введение
02:31 Основные причины неудач в реальных условиях
07:20 Результат: числовой рецепт 1/2
09:31 Результат: числовой рецепт 2/2
13:01 История до настоящего момента
14:57 Выполнение задач сегодня
15:59 Хронология инициативы
21:48 Область применения: ландшафт приложений 1/2
24:24 Область применения: ландшафт приложений 2/2
27:12 Область применения: системные эффекты 1/2
29:21 Область применения: системные эффекты 2/2
32:12 Роли: 1/2
37:31 Роли: 2/2
41:50 Конвейер данных – как
44:13 Слово о транзакционных системах
49:13 Слово об озере данных
52:59 Слово об аналитических системах
57:56 Качество данных: низкий уровень
01:02:23 Качество данных: высокий уровень
01:06:24 Инспекторы данных
01:08:53 Заключение
01:10:32 Предстоящая лекция и вопросы аудитории
Описание
Проведение успешной предиктивной оптимизации цепочки поставок представляет собой сочетание мягких и жёстких проблем. К сожалению, невозможно отделить эти аспекты друг от друга. Мягкие и жёсткие стороны глубоко переплетены. Обычно это переплетение непосредственно противоречит разделению труда, определяемому организационной структурой компании. Мы наблюдаем, что когда инициативы в цепочке поставок терпят неудачу, корневыми причинами неудачи обычно становятся ошибки, допущенные на самых ранних этапах проекта. Более того, первоначальные ошибки, как правило, формируют всю инициативу, делая их практически невозможными для исправления задним числом. Мы представляем наши ключевые выводы, чтобы избежать этих ошибок.
Полная расшифровка

Добро пожаловать в эту серию лекций о цепочках поставок. Я Жоанн Верморель, и сегодня я представлю “Начало работы с инициативой количественной оптимизации цепочки поставок”. Подавляющее большинство инициатив по анализу данных в цепочках поставок терпят неудачу. С 1990 года большинство компаний, управляющих большими цепочками поставок, запускают крупные инициативы предиктивной оптимизации каждые три-пять лет, но с минимальными или отсутствующими результатами. В наши дни большинство команд в цепочках поставок или наука о данных, начиная еще один цикл предиктивной оптимизации — обычно оформленный как проект прогнозирования или оптимизации запасов — даже не осознают, что их компания уже проходила через это, делала это и, возможно, потерпела неудачу уже полдюжины раз.
Выбор еще одного цикла иногда обусловлен верой в то, что на этот раз всё будет иначе, но часто команды даже не осознают, сколько неудачных попыток уже произошло ранее. Анестетические свидетельства этому тому, что Microsoft Excel остаётся инструментом номер один для принятия решений в цепочке поставок, в то время как эти инициативы должны были заменить электронные таблицы лучшими инструментами. Тем не менее, в наши дни очень немногие цепочки поставок могут функционировать без электронных таблиц.
Цель этой лекции — понять, как дать шанс на успех инициативе в цепочке поставок, которая стремится предоставить любой вид предиктивной оптимизации. Мы рассмотрим ряд критически важных компонентов — эти компоненты просты, но часто противоречат интуиции для большинства организаций. Напротив, мы также рассмотрим ряд антипаттернов, которые почти гарантируют провал такой инициативы.
Сегодня я сосредоточен на тактическом исполнении самого начала инициативы в цепочке поставок с установкой «сделать дело». Я не буду обсуждать глобальные стратегические последствия для компании. Стратегия очень важна, но я коснусь этого вопроса в последующих лекциях.

Большинство инициатив в цепочке поставок действительно терпят неудачу, и эту проблему почти никогда не обсуждают публично. Академическое сообщество публикует десятки тысяч статей в год, хвастаясь всевозможными инновациями в области цепочек поставок, включая фреймворки, алгоритмы и модели. Часто в статьях даже утверждается, что инновация уже внедрена в производство где-либо. И всё же, по моим неформальным наблюдениям за миром цепочек поставок, эти инновации нигде не встречаются. Аналогично, поставщики программного обеспечения на протяжении последних трёх десятилетий обещают превосходные замены электронным таблицам, и опять же, мои неформальные наблюдения указывают на то, что электронные таблицы остаются повсеместными.
Мы возвращаемся к вопросу, который уже поднимался во второй главе этой серии лекций о цепочках поставок. Проще говоря, у людей нет стимулов рекламировать неудачи, и поэтому они этого не делают. Более того, поскольку компании, управляющие цепочками поставок, как правило, крупные, проблема усугубляется естественной утратой институциональной памяти, когда сотрудники постоянно сменяют должности. Именно поэтому ни академическое сообщество, ни поставщики не признают эту довольно удручающую ситуацию.
Я предлагаю начать с краткого обзора наиболее частых корневых причин неудач с точки зрения тактического исполнения. Действительно, эти причины обычно обнаруживаются на самых ранних этапах инициативы.
Первая причина неудачи — попытка решить неверные проблемы, то есть проблемы, которые не существуют, не играют роли или отражают неправильное представление о самой цепочке поставок. Оптимизация показателей точности прогнозирования является, пожалуй, архетипом такой неверной проблемы. Снижение процента ошибки прогнозирования не приводит напрямую к дополнительной прибыли в евро или долларах для компании. Та же ситуация возникает, когда компания пытается достигнуть определенных уровней сервиса для своих запасов. Очень редко это приносит заметную прибыль.
Вторая корневая причина неудачи — использование неподходящих программных технологий и архитектуры. Например, поставщики ERP неизменно пытаются использовать транзакционную базу данных для поддержки инициатив по анализу данных, поскольку именно на этой базе построены ERP-системы. Напротив, команды по науке о данных неукоснительно пытаются использовать новейший открытый инструмент машинного обучения, потому что это выглядит круто. К сожалению, неподходящие технологические решения обычно приводят к большим трениям и множеству случайных сложностей.
Третья корневая причина неудачи — неправильное распределение труда и организация. В ошибочной попытке привлечь специалистов на каждом этапе процесса компании склонны раздроблять инициативу между слишком большим количеством людей. Например, подготовку данных очень часто выполняют лица, не ответственные за прогнозирование. В результате возникают ситуации типа «мусор на входе – мусор на выходе». Размывание ответственности за окончательные решения в цепочке поставок почти гарантирует неудачу.
Один пункт, которого я не включил в этот краткий список в качестве корневой причины, — это плохие данные. Данные очень часто обвиняются в неудачах инициатив в цепочке поставок, что слишком удобно, поскольку данные не могут напрямую ответить на эти обвинения. Однако, как правило, данные не являются причиной проблем, по крайней мере, не в смысле работы с некачественными данными. Цепочка поставок крупных компаний оцифровалась десятилетия назад. Каждая позиция, которую покупают, транспортируют, обрабатывают, производят или продают, имеет электронные записи. Эти записи могут быть не идеальными, но, как правило, весьма точны. Если люди не справляются с правильной обработкой данных, виновата не сама транзакция.

Чтобы количественная инициатива достигла успеха, нам нужно вести правильную борьбу. Что же именно мы пытаемся достичь в первую очередь? Одним из ключевых результатов инициативы в цепочке поставок является основной числовой рецепт, который вычисляет финальные решения в цепочке поставок. Этот аспект уже был обсуждён в Лекции 1.3 в самой первой главе «Доставка, ориентированная на продукт для цепочки поставок». Давайте ещё раз рассмотрим два наиболее критических свойства этого результата.
Во-первых, результат должен быть решением. Например, решение о том, сколько единиц перезаказать сегодня для определённого SKU, является решением. Напротив, прогнозирование того, сколько единиц будет запрошено сегодня для данного SKU, представляет собой числовой артефакт. Чтобы получить решение как конечный результат, необходимо множество промежуточных результатов, то есть множество числовых артефактов. Однако не следует путать средства с целью.
Второе свойство этого результата заключается в том, что выходные данные, являющиеся решением, должны быть полностью автоматизированы в результате чисто автоматизированного программного процесса. Сам числовой рецепт, основной числовой рецепт, не должен включать в себя ручных операций. Естественно, разработка самого числового рецепта, вероятно, будет сильно зависеть от участия высококвалифицированного эксперта в науке. Однако исполнение не должно зависеть от прямого вмешательства человека.
Наличие числового рецепта в качестве результата является основополагающим для превращения инициативы в цепочке поставок в капиталистическое предприятие. Числовой рецепт превращается в производственный актив, приносящий доход. Рецепт необходимо поддерживать, но для этого требуется на порядок или два меньше сотрудников по сравнению с подходами, которые оставляют участие человека на уровне микро-решений.

Тем не менее, многие инициативы в цепочке поставок терпят неудачу, потому что неправильно определяют решения в цепочке поставок как конечный результат инициативы. Вместо этого они сосредотачиваются на предоставлении числовых артефактов. Числовые артефакты предназначены быть компонентами для достижения окончательного решения проблемы, обычно поддерживая сами решения. Наиболее распространёнными артефактами в цепочке поставок являются прогнозы, резервные запасы, EOQ, KPI. Хотя эти числа могут быть интересны, они не являются реальными. Эти числа не имеют немедленного ощутимого физического аналога в цепочке поставок и отражают произвольные моделирующие подходы к цепочке поставок.
Сосредоточение на числовых артефактах приводит к провалу инициативы, поскольку этим числам не хватает одного критического компонента: прямой обратной связи с реальным миром. Когда решение ошибочно, негативные последствия можно отнести непосредственно к решению. Однако в случае с числовыми артефактами ситуация намного более неоднозначна. Действительно, ответственность распределяется повсеместно, так как множество артефактов вносят вклад в каждое отдельное решение. Проблема усугубляется, когда в процесс вмешивается человек.
Отсутствие обратной связи оказывается фатальным для числовых артефактов. Современные цепочки поставок сложны. Возьмите любую формулу для расчёта резервного запаса, экономичного объёма заказа или KPI; почти наверняка эта формула неверна по многим параметрам. Проблема корректности формулы — не математическая задача, а бизнес-задача. Речь идет о том, чтобы ответить на вопрос: «Отражает ли этот расчёт действительно стратегическое намерение моего бизнеса?» Ответ варьируется от компании к компании и даже от года к году по мере развития бизнеса.
Так как числовые артефакты не получают прямой обратной связи из реального мира, им не хватает того механизма, который позволил бы перейти от наивной, упрощенной и, скорее всего, широко ошибочной начальной реализации к примерно корректной версии формулы, которую можно было бы считать пригодной для производства. Тем не менее, числовые артефакты очень заманчивы, поскольку создают иллюзию приближения к решению. Они создают иллюзию рациональности, научности, даже предприимчивости. У нас есть числа, формулы, алгоритмы, модели. Возможно даже проведение тестов и сравнение этих чисел с также вымышленными числами. Улучшение по сравнению с вымышленным эталоном также создает иллюзию прогресса, и это весьма утешительно. Но в конце концов, это остается иллюзией, вопросом моделирующей перспективы.
Компании не получают прибыль, платя людям за просмотр KPI или проведение тестов. Они получают прибыль, принимая одно решение за другим и, надеясь, становясь лучше в принятии следующего решения с каждым разом.
Эта лекция является частью серии лекций о цепочках поставок. Я пытаюсь сделать эти лекции относительно независимыми, но мы достигли точки, в которой имеет смысл смотреть их по порядку. Эта лекция — самая первая лекция седьмой главы, которая посвящена выполнению инициатив в цепочке поставок. Под инициативами в цепочке поставок я подразумеваю количественные инициативы – инициативы, намеренные предоставить что-то в направлении предиктивной оптимизации для компании.
Первая глава была посвящена моему взгляду на цепочку поставок как на область знаний и практики. Во второй главе я представил ряд методологий, существенных для цепочки поставок, поскольку наивные методологии терпят крах из-за враждебной природы многих ситуаций в цепочке поставок. В третьей главе я представил ряд персонажей, сосредоточенных исключительно на проблемах; другими словами, на чем же мы пытаемся сосредоточиться?
В четвёртой главе я представил серию областей, которые, хотя и не являются непосредственно цепочкой поставок, я считаю неотъемлемой частью современной практики управления цепочками поставок. В пятой и шестой главах я представил интеллектуальные элементы численной рецептуры, предназначенной для поддержки решений в цепочке поставок, а именно предсказательную оптимизацию (обобщённое представление прогнозирования) и принятие решений (по сути, математическую оптимизацию, применяемую к задачам цепочки поставок). В седьмой главе мы обсудим, как объединить эти элементы в реальной инициативе по управлению цепочками поставок, которая намерена внедрить эти методы и технологии в производство.

Сегодня мы рассмотрим, что считается правильной практикой для проведения инициативы в области управления цепочками поставок. Это включает формирование инициативы с надлежащим ожидаемым результатом, о котором мы только что говорили, а также соответствующий временной график, масштаб и правильно определённые роли. Эти элементы составляют первую часть сегодняшней лекции.
Вторая часть лекции будет посвящена каналу данных, который является критически важным компонентом для успеха такой инициативы, основанной на данных или зависящей от данных. Хотя тема канала данных достаточно техническая, она требует правильного распределения обязанностей и организации взаимодействия между IT и управлением цепочками поставок. В частности, мы увидим, что контроль качества должен в основном находиться в ведении специалистов по цепочке поставок посредством разработки отчётов о состоянии данных и проведения их проверки.
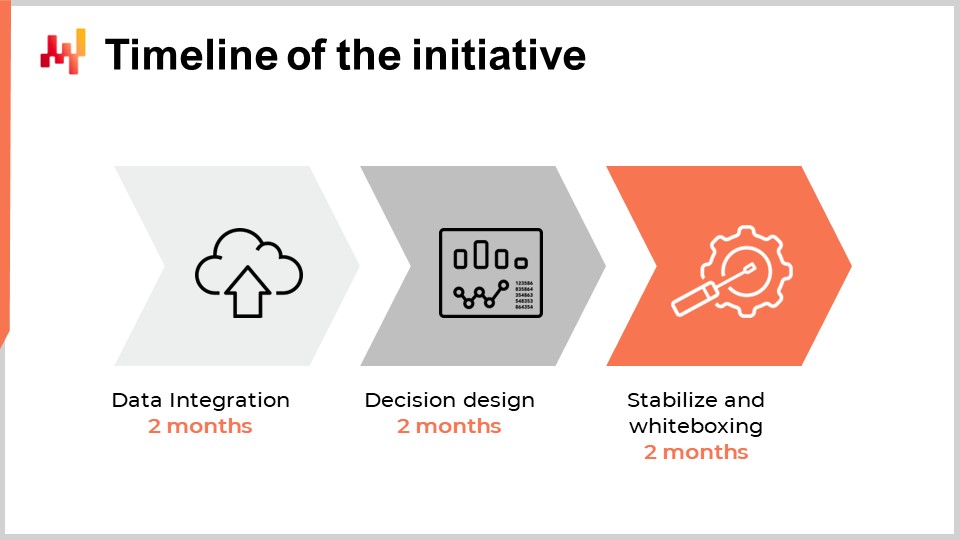
Фаза внедрения является первой стадией инициативы, в ходе которой создаётся базовая численная рецептура, та самая, которая генерирует решение вместе только с поддерживающими элементами. Фаза внедрения завершается постепенным переходом в производство, и в процессе этого перехода первоначальные процессы постепенно автоматизируются самой численной рецептурой.
При определении оптимального временного графика для первой количественной инициативы по управлению цепочками поставок в компании можно подумать, что он зависит от размеров компании, её сложности, типа цепочек поставок и общего контекста. Хотя это отчасти так, опыт, накопленный Lokad за десятилетие и десятки подобных инициатив, показывает, что шесть месяцев почти всегда являются оптимальным сроком. Удивительно, но этот шестимесячный период имеет мало общего с технологией или даже со спецификой цепочек поставок; он гораздо больше зависит от людей и самой организации, а также от того, сколько времени им требуется, чтобы привыкнуть к тому, что обычно воспринимается как совершенно иной способ ведения цепочек поставок.
Первые два месяца посвящены настройке канала данных. Мы вернёмся к этому вопросу через несколько минут, но эта задержка в два месяца обусловлена двумя факторами. Во-первых, нам необходимо сделать канал данных надёжным и устранить редкие проблемы, которые могут проявляться спустя недели. Во-вторых, нам нужно понять семантику данных, то есть разобраться, что означают данные с точки зрения управления цепочками поставок.
В третьем и четвёртом месяцах основное внимание будет уделено быстрым итерациям самой численной рецептуры, которая будет определять решения в цепочке поставок. Эти итерации необходимы, поскольку выработка окончательных решений — обычно единственный способ оценить, есть ли недостатки в базовой рецептуре или в предпосылках, на которых она построена. Эти два месяца также традиционно являются временем, необходимым для того, чтобы специалисты по цепочкам поставок привыкли к очень количественному, финансовому подходу, лежащему в основе этих программных решений.
Наконец, последние два месяца посвящены стабилизации численной рецептуры после, как правило, достаточно интенсивного периода быстрых итераций. Этот период также предоставляет возможность для работы рецептуры в условиях, приближенных к производственным, но ещё не задействующих производство. Эта фаза важна для того, чтобы команды цепочек поставок могли сформировать доверие к этому новому решению.
Наконец, последние два месяца обычно требуются для того, чтобы сезонность проявилась и для формирования доверия к программному обеспечению, принимающему важные решения в цепочке поставок в производственной среде.
В целом, это занимает около шести месяцев, и хотя было бы желательно сократить этот срок, сделать это довольно сложно. Однако шесть месяцев — уже значительный период. Если с первого дня фаза внедрения, когда численная рецептура ещё не управляет решениями в цепочке поставок, затягивается более чем на шесть месяцев, то инициатива уже оказывается под угрозой. Если дополнительная задержка связана с извлечением данных и настройкой канала данных, значит, проблема в IT. Если же задержка вызвана разработкой или конфигурацией решения, возможно, привлечённого сторонним поставщиком, то проблема кроется в самой технологии. И, наконец, если после двух месяцев стабилизации в условиях, приближенных к производственным, переход в производство не происходит, тогда обычно возникает проблема с управлением инициативой.

При попытке внедрить новинку, новый процесс или новую технологию в организацию, распространённая практика предполагает начинать с малого, убеждаясь в её работоспособности, и постепенно расширяться, опираясь на первые успехи. К сожалению, цепочки поставок не склонны следовать общепринятой мудрости, и этот подход имеет свою специфику в определении объёма инициативы. Что касается объёма, существуют две основные движущие силы, которые в значительной степени определяют, что является допустимым объёмом, а что — нет, для инициативы в области цепочек поставок.
Приложенческий ландшафт является первой силой, влияющей на определение объёма. Цепочку поставок в целом нельзя наблюдать напрямую; её можно наблюдать лишь косвенно через призму корпоративного программного обеспечения. Данные будут получаться посредством этих программ. Сложность инициативы во многом зависит от количества и разнообразия этих программ. Каждое приложение является независимым источником данных, и извлечение с последующим анализом данных из любого бизнес-приложения обычно представляет собой значительную задачу. Работа с большим количеством приложений часто означает необходимость иметь дело с различными технологиями баз данных, несовместимой терминологией, разными понятиями, что значительно усложняет ситуацию.
Таким образом, при определении объёма мы должны признать, что допустимые границы обычно задаются самими бизнес-приложениями и их структурой баз данных. В этом контексте «начать с малого» следует понимать как сокращение начального объёма интеграции данных до минимума при сохранении целостности инициативы по управлению цепочками поставок в целом. Лучше углубиться, чем расширять охват в плане интеграции приложений. Как только у вас будет IT-система, способная извлечь записи из таблицы в данном приложении, обычно не составляет труда получить все записи из этой таблицы и из другой таблицы того же приложения.

Одной из распространённых ошибок при определении объёма является использование выборки. Выборка обычно осуществляется путём отбора короткого списка категорий товаров, объектов или поставщиков. Хотя выборка делается с благими намерениями, она не соответствует границам, определённым приложенческим ландшафтом. Для её реализации фильтры применяются уже на этапе извлечения данных, и этот процесс создает ряд проблем, которые могут поставить под угрозу инициативу в области управления цепочками поставок.
Во-первых, фильтрованное извлечение данных из корпоративного программного обеспечения требует больших усилий от IT-команды по сравнению с неотфильтрованным извлечением. Фильтры необходимо сначала разработать, и сам процесс фильтрации склонен к ошибкам. Отладка некорректных фильтров зачастую является утомительным процессом, поскольку требует многочисленных консультаций с IT-специалистами, что замедляет инициативу и, в конечном итоге, ставит её под угрозу.
Во-вторых, если инициатива проводит внедрение на основе выборки данных, это является рецептом для возникновения масштабных проблем с производительностью программного обеспечения по мере расширения инициативы до полного объёма. Плохая масштабируемость, или неспособность обрабатывать большие объемы данных при сохранении контроля над вычислительными затратами, — частый недостаток программного обеспечения. Позволив инициативе работать на выборке, проблемы с масштабируемостью могут быть скрыты, но затем вспыхнуть с новой силой.
Работа с выборкой данных усложняет, а не упрощает, статистический анализ. На самом деле, доступ к большему объёму данных, вероятно, является самым простым способом повышения точности и стабильности почти всех алгоритмов машинного обучения. Выборка данных противоречит этому принципу. Таким образом, при использовании небольшого набора данных инициатива может потерпеть неудачу из-за непредсказуемого числового поведения, наблюдаемого на выборке. Это поведение было бы значительно смягчено, если бы использовался полный набор данных.
Системные эффекты являются второй силой, влияющей на определение объёма. Цепочка поставок — это система, и все её части в той или иной мере взаимодействуют друг с другом. Проблема систем заключается в том, что попытки улучшить одну часть системы часто смещают проблемы, а не устраняют их. Например, рассмотрим проблему распределения запасов для розничной сети с одним распределительным центром и множеством магазинов. Если мы выберем один магазин в качестве первоначального охвата для задачи распределения запасов, то очень просто обеспечить для этого магазина высокий уровень обслуживания от распределительного центра за счёт предварительного резервирования запасов. Таким образом, можно гарантировать, что распределительный центр никогда не столкнется с дефицитом товара при обслуживании этого единственного магазина.
Таким образом, при определении объёма инициативы по управлению цепочками поставок необходимо учитывать системные эффекты. Объём должен быть определён так, чтобы в значительной степени предотвратить локальную оптимизацию за счёт элементов, находящихся вне пределов объёма. Эта задача сложна, поскольку все объёмы в той или иной мере являются проницаемыми. Например, все части цепочки поставок в конечном итоге конкурируют за одну и ту же сумму денежных средств на уровне компании. Каждый доллар, направленный в одну область, — это доллар, который не может быть использован для других целей. Тем не менее, одни объёмы гораздо легче поддаются манипуляциям, чем другие. Важно выбрать такой объём, который будет смягчать системные эффекты, а не усиливать их.

Размышления об определении объёма инициативы по управлению цепочками поставок с точки зрения системных эффектов могут показаться странными для многих специалистов. Когда речь заходит об определении объёма, большинство компаний склонны проецировать свою внутреннюю организационную структуру на этот процесс. Таким образом, выбранные границы объёма зачастую отражают существующее распределение обязанностей внутри компании. Эта закономерность известна как Закон Конвея, предложенный Мелвином Конвеем полвека назад для коммуникационных систем, и с тех пор обнаружено, что он применим гораздо шире, включая критическую сферу управления цепочками поставок.
Границы и силосы в современных цепочках поставок продиктованы разделением обязанностей, которое является следствием довольно ручных процессов, лежащих в основе принятия решений в цепочке поставок. Например, если компания приходит к выводу, что специалист по планированию спроса и предложения не способен управлять более чем 1 000 SKU, а общее число SKU в компании составляет 50 000, то потребуется 50 специалистов для управления ими. Однако распределение оптимизации цепочки поставок между 50 парами рук неизбежно приводит к множеству неэффективностей на уровне всей компании.
Наоборот, инициатива, автоматизирующая эти решения, не обязана придерживаться устаревших границ, отражающих устаревшее или скоро устаревающее распределение обязанностей. Численная рецептура способна оптимизировать 50 000 SKU одновременно и устранить неэффективность, возникающую вследствие разделения на десятки силосов, действующих раздельно друг от друга. Поэтому вполне естественно, что инициатива, направленная на кардинальную автоматизацию этих решений, пересекается с множеством существующих границ в компании. Руководство компании должно противостоять искушению копировать существующие организационные границы, особенно на уровне определения объёма, так как это задаёт тон дальнейшим действиям.

Цепочки поставок сложны с точки зрения аппаратного обеспечения, программного обеспечения и человеческого фактора. Хотя это печально, запуск количественной инициативы по управлению цепочками поставок ещё больше усложняет саму цепочку, по крайней мере, на начальном этапе. В долгосрочной перспективе это может значительно снизить сложность цепочки поставок, но, возможно, мы вернёмся к этому на следующей лекции. Более того, чем больше людей задействовано в инициативе, тем выше её собственная сложность. Если эту дополнительную сложность сразу не взять под контроль, высока вероятность, что инициатива рухнет под её же весом.
Таким образом, при определении ролей в инициативе, то есть кто за что отвечает, нам необходимо определить минимально возможный набор ролей, делающий инициативу жизнеспособной. Минимизируя количество ролей, мы уменьшаем сложность инициативы, что, в свою очередь, значительно повышает её шансы на успех. Этот подход может показаться противоречащим интуитивному подходу крупных компаний, предпочитающих работу с крайне детализированным разделением обязанностей. Крупные компании склонны нанимать узких специалистов, которые занимаются только одним делом. Однако цепочка поставок — это система, и, как и в любой системе, имеет значение комплексный, сквозной подход.
Основываясь на опыте, накопленном в Lokad при проведении подобных инициатив, мы выделили четыре роли, которые обычно представляют минимально необходимое разделение обязанностей для реализации инициативы: руководитель цепочки поставок, специалист по данным, ученый в области цепочек поставок и практик по управлению цепочками поставок.
Роль руководителя цепочки поставок заключается в поддержке инициативы, чтобы она могла вообще состояться. Получение хорошо разработанного числового рецепта для управления решениями в области цепочки поставок в производстве представляет собой огромный прирост как в прибыльности, так и в производительности. Однако это также подразумевает необходимость восприятия множества изменений. Для того чтобы такое изменение произошло в крупной организации, требуется много энергии и поддержки со стороны высшего руководства.
Роль сотрудника по данным заключается в настройке и обслуживании канала данных. Основная масса его вклада ожидается в течение первых двух месяцев инициативы. Если канал данных разработан правильно, последующая работа сотрудника по данным будет требовать очень небольших усилий. Обычно сотрудник по данным не участвует существенно на поздних этапах инициативы.
Роль ученого в области цепочки поставок заключается в создании основного числового рецепта. Эта роль начинается с необработанных транзакционных данных, предоставленных сотрудником по данным. От сотрудника по данным не ожидается подготовка данных, а только их извлечение. Роль ученого в области цепочки поставок заканчивается передачей ответственности за созданное решение по цепочке поставок. Решение принимает не программное обеспечение, а именно ученый в области цепочки поставок. Для каждого созданного решения ученый должен уметь обосновать, почему это решение является адекватным.
Наконец, роль практикующего специалиста по цепочке поставок заключается в том, чтобы оспаривать решения, сформированные числовым рецептом, и предоставлять обратную связь ученому в области цепочки поставок. Практикующему специалисту не суждено принимать решение самостоятельно. Как правило, этот человек до сих пор отвечал за эти решения, по крайней мере в определенном масштабе, и обычно с помощью электронных таблиц и существующих систем. В небольшой компании возможно, чтобы один человек совмещал роли руководителя цепочки поставок и практикующего специалиста по цепочке поставок. Также можно обойтись без сотрудника по данным, если данные доступны напрямую. Это может случаться в компаниях, где инфраструктура данных достигла высокого уровня зрелости. Напротив, если компания очень большая, то в каждой роли может быть назначено всего лишь несколько, но очень немногие люди.
Успешное внедрение основного числового рецепта в производстве оказывает значительное влияние на сферу практикующих специалистов по цепочке поставок. Действительно, в значительной степени суть инициативы заключается в автоматизации прежних функций практикующего специалиста по цепочке поставок. Однако это не означает, что лучшим решением является увольнение этих специалистов после ввода числового рецепта в эксплуатацию. Этот конкретный аспект мы рассмотрим в следующей лекции.

Быть организованным не означает быть эффективным или действенным. Существуют роли, которые, несмотря на благие намерения, создают препятствия для инициатив в области цепочки поставок, зачастую до такой степени, что они приводят к полному провалу этих инициатив. В настоящее время первой ролью, которая вносит наибольший вклад в провал таких инициатив, как правило, является роль дата-сайентиста, и тем более, когда задействована целая команда специалистов по данным. Кстати, компания Lokad узнала об этом на собственном опыте около десятилетия назад.
Несмотря на сходство в названиях, дата-сайентисты и ученые в области цепочки поставок на самом деле выполняют совершенно разные роли. Ученый в области цепочки поставок, прежде всего, заботится о предоставлении реальных, пригодных для производства решений. Если это можно достичь с помощью полусамодостаточного числового рецепта, тем лучше; обслуживание будет легким. Ученый в области цепочки поставок берет на себя полную ответственность за мельчайшие детали цепочки поставок. Надежность и устойчивость к внешнему хаосу важнее, чем сложность.
Наоборот, дата-сайентист сосредоточен на интеллектуальной части числового рецепта — моделях и алгоритмах. В общих чертах, дата-сайентист считает себя экспертом в области машинного обучения и математической оптимизации. Что касается технологий, то дата-сайентист готов изучать новейшие передовые инструменты с открытым исходным кодом, но, как правило, не желает знакомиться с ERP-системой, существующей уже более трех десятилетий, которая управляет компанией. Кроме того, дата-сайентист не является экспертом в области цепочки поставок и обычно не стремится им стать. Дата-сайентист стремится достичь наилучших результатов согласно согласованным метрикам. Ученый не имеет амбиций заниматься самыми обыденными деталями цепочки поставок; за эти элементы отвечают другие люди.
Привлечение дата-сайентистов предрешает провал таких инициатив, потому что, как только они подключаются, внимание сдвигается с цепочки поставок на алгоритмы и модели. Никогда не недооценивайте отвлекающее воздействие, которое новейшая модель или алгоритм может оказать на умного, технологически ориентированного человека.
Вторая роль, которая зачастую создает трение в инициативе по цепочке поставок, — это команда бизнес-аналитики. Когда команда BI участвует в инициативе, она, как правило, становится помехой, пусть и в меньшей степени, чем команда по обработке данных. Проблема с BI в основном носит культурный характер. BI предоставляет отчеты, а не решения. Команда BI обычно готова создавать бесконечные массивы метрик по запросу каждого подразделения компании. Это не та установка, которая подходит для количественной инициативы в сфере цепочки поставок.
Кроме того, бизнес-аналитика как программное обеспечение представляет собой очень специфический класс аналитики данных, ориентированный на кубы или OLAP-кубы, которые позволяют проводить разрез и анализ большинства систем с хранением данных в оперативной памяти в корпоративных системах. Такой подход обычно совершенно не подходит для формирования решений в области цепочки поставок.

Теперь, когда мы определили рамки инициативы, давайте взглянем на высокоуровневую IT-архитектуру, необходимую для ее реализации.
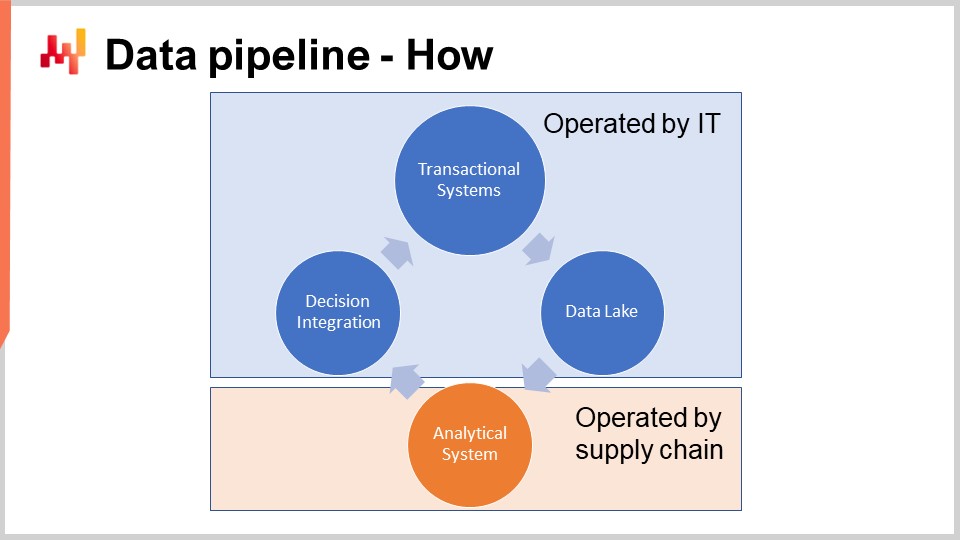
Схема на экране иллюстрирует типичную настройку канала данных для количественной инициативы в области цепочки поставок. В этой лекции я обсуждаю канал данных, не рассчитанный на низкие задержки. Мы хотим, чтобы полный цикл выполнялся примерно за один час, а не за одну секунду. Большинство решений в области цепочки поставок, таких как заказы на закупку, не требуют низкой задержки. Достижение сквозной низкой задержки требует иной архитектуры, что выходит за рамки сегодняшней лекции.

Транзакционные системы являются основным источником данных и отправной точкой канала данных. Эти системы включают ERP, WMS и EDI. Они управляют потоком товаров, таким как закупки, транспортировка, производство и продажа. Эти системы содержат почти все данные, необходимые для основного числового рецепта. Практически в любой крупной компании эти системы или их предшественники используются уже не менее двух десятилетий.
Поскольку эти системы содержат почти все необходимые данные, может возникнуть соблазн реализовать числовой рецепт непосредственно в них. Действительно, почему бы и не сделать это? Внедрив числовой рецепт прямо в ERP, мы избавляемся от необходимости создавать весь канал данных. К сожалению, это не работает из-за самого дизайна этих транзакционных систем.
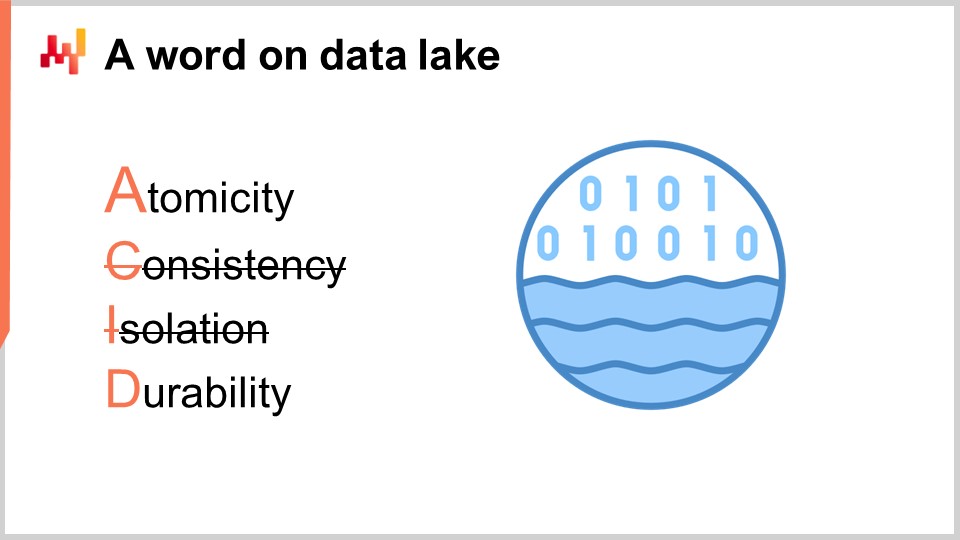
Эти транзакционные системы неизменно построены на транзакционной базе данных. Такой подход к разработке корпоративного программного обеспечения оставался чрезвычайно стабильным на протяжении последних четырех десятилетий. Выберите любую компанию, и, скорее всего, каждое бизнес-приложение в эксплуатации было реализовано на основе транзакционной базы данных. Транзакционные базы данных предоставляют четыре ключевых свойства, известных под акронимом ACID, что означает атомарность, согласованность, изоляцию и надежность. Я не буду вдаваться в подробности этих свойств, достаточно сказать, что они делают базу данных чрезвычайно подходящей для безопасного и параллельного выполнения множества мелких операций чтения и записи. Количество операций чтения и записи при этом обычно находится в относительном равновесии.
Однако цена за столь полезные ACID-свойства на микроуровне заключается в том, что транзакционная база данных оказывается крайне неэффективной при обслуживании крупных операций чтения. Если операция чтения охватывает значительную часть всей базы данных, то, как правило, при использовании базы данных, ориентированной на детальное обеспечение этих ACID-свойств, можно ожидать, что стоимость вычислительных ресурсов вырастет примерно в 100 раз по сравнению с архитектурами, которые не уделяют столь пристального внимания ACID-свойствам. ACID хорош, но обходится очень дорого.
Более того, когда кто-либо пытается прочитать значительную часть базы данных, сама база данных может стать неотзывчивой на некоторое время, так как значительная часть ее ресурсов будет задействована для обслуживания этого одного большого запроса. Многие компании жалуются, что их бизнес-системы работают медленно, и что эти системы часто зависают на одну секунду или дольше. Обычно низкое качество обслуживания связывают с тяжёлыми SQL-запросами, пытающимися прочитать слишком много строк одновременно.
Следовательно, основной числовой рецепт не может работать в той же среде, что и транзакционные системы, поддерживающие производство. Действительно, числовым рецептам необходимо получать доступ к большинству данных при каждом запуске. Таким образом, числовой рецепт должен быть строго изолирован в собственной подсистеме, хотя бы для того, чтобы не ухудшать производительность транзакционных систем.
Кстати, хотя уже несколько десятилетий известно, что размещать ресурсоемкий процесс в транзакционной системе — ужасная затея, это не мешает большинству поставщиков транзакционных систем (ERP, MRP, WMS) продавать интегрированные аналитические модули, например, модули оптимизации запасов. Интеграция таких модулей неизбежно приводит к проблемам с качеством обслуживания, предоставляя при этом скромные возможности. Все эти проблемы можно свести к одной конструктивной ошибке: транзакционная система и аналитическая система должны находиться в строгой изоляции.
Озеро данных просто. Оно является зеркалом транзакционных данных, предназначенным для очень крупных операций чтения. Действительно, мы видели, что транзакционные системы оптимизированы для множества мелких операций чтения, а не для очень крупных. Таким образом, чтобы сохранить качество обслуживания транзакционной системы, правильным решением является тщательное дублирование транзакционных данных в другую систему, а именно в озеро данных. Это дублирование должно осуществляться с особой осторожностью, чтобы сохранить качество обслуживания транзакционной системы, что обычно означает постепенное считывание данных и избегание резких пиков нагрузки на транзакционную систему.
Как только соответствующие транзакционные данные скопированы в озеро данных, само озеро обслуживает все запросы к данным. Дополнительным преимуществом озера данных является его способность обслуживать несколько аналитических систем. Пока мы обсуждаем цепочку поставок, если маркетинговый отдел захочет свою аналитику, им понадобятся те же транзакционные данные, и то же можно сказать о финансах, продажах и т.д. Таким образом, вместо того чтобы каждое подразделение компании реализовывало собственный механизм извлечения данных, имеет смысл консолидировать все эти извлечения в одном озере данных, в одной системе.
На техническом уровне озеро данных может быть реализовано с использованием реляционной базы данных, как правило, настроенной на извлечение больших объемов данных с использованием колонкового хранения. Озера данных также могут быть реализованы как репозиторий плоских файлов, обслуживаемых через распределенную файловую систему. По сравнению с транзакционной системой, озеро данных отказывается от детализированных транзакционных свойств. Цель заключается в том, чтобы предоставлять большой объем данных как можно дешевле и надежнее — ни больше, ни меньше.
Озеро данных должно являться зеркалом исходных транзакционных данных, то есть копировать их без каких-либо изменений. Важно не обрабатывать данные в озере. К сожалению, IT-команда, ответственная за создание озера данных, может быть соблазнена упростить работу для других команд и немного подготовить данные. Однако изменение данных неизменно приводит к осложнениям, которые подрывают аналитические возможности на последующих этапах. Кроме того, строгое соблюдение принципа зеркалирования значительно сокращает усилия, необходимые IT-команде для создания и последующего обслуживания озера данных.
В компаниях, где уже имеется команда BI, может возникнуть соблазн использовать BI-системы в качестве озера данных. Однако я настоятельно рекомендую не делать этого и никогда не использовать конфигурацию BI в качестве озера данных. Действительно, данные в BI-системах (системах бизнес-аналитики) уже неизменно претерпевают значительные преобразования. Использование данных BI для формирования автоматизированных решений в цепочке поставок приводит к проблемам типа «мусор на входе, мусор на выходе». Озеро данных должно питаться только из первоисточников, таких как ERP, а не из вторичных источников, таких как BI-система.
Аналитическая система — это та система, которая содержит основной числовой рецепт. Это также система, предоставляющая все отчеты, необходимые для реализации самих решений. На техническом уровне аналитическая система включает «умные части», такие как алгоритмы машинного обучения и алгоритмы математической оптимизации. Хотя на практике эти «умные части» не доминируют в исходном коде аналитической системы. Обычно подготовка данных и их инструментирование занимают как минимум в десять раз больше строк кода, чем части, связанные с обучением и оптимизацией.
Аналитическая система должна быть отделена от озера данных, поскольку эти две системы принципиально различаются с технологической точки зрения. Как программное обеспечение, озеро данных должно быть очень простым, стабильным и чрезвычайно надежным. Напротив, аналитическая система должна быть сложной, постоянно эволюционирующей и чрезвычайно эффективной с точки зрения эффективности цепочки поставок. В отличие от озера данных, которое должно обеспечивать почти идеальное время безотказной работы, аналитическая система даже не обязана работать постоянно. Например, если речь идет о ежедневных решениях по пополнению запасов, то аналитическая система должна запускаться и работать только один раз в день.
Как правило, лучше, чтобы аналитическая система не генерировала решения, чем принимала неверные решения и пускала их в производство. Задержка решений в цепочке поставок на несколько часов, например, заказов на закупку, обычно менее критична, чем принятие неправильных решений. Поскольку конструкция аналитической системы, как правило, сильно зависит от ее интеллектуальных компонентов, не существует универсальных указаний относительно ее дизайна. Однако есть по крайней мере одно ключевое свойство, которое должно быть строго соблюдено в экосистеме: эта система должна быть без состояния.
Аналитическая система должна максимально избегать наличия внутреннего состояния. Иными словами, вся экосистема должна начинаться с данных, представленных данным озером, и заканчиваться генерированными запланированными решениями в цепочке поставок вместе с сопроводительными отчетами. Часто случается так, что когда какой-либо компонент аналитической системы работает слишком медленно, например алгоритм машинного обучения, возникает соблазн ввести состояние, то есть сохранить некоторую информацию с предыдущего выполнения для ускорения следующего. Однако такой подход, когда полагаются на ранее вычисленные результаты вместо того, чтобы каждый раз пересчитывать всё с нуля, опасен.
Действительно, наличие состояния внутри аналитической системы подвергает решения риску. Хотя проблемы с данными неизбежно возникают и исправляются на уровне озера данных, аналитическая система может всё равно выдавать решения, отражающие уже устраненную проблему. Например, если модель прогнозирования спроса обучается на поврежденном наборе данных о продажах, то модель останется ошибочной, пока не будет переобучена на свежем, исправленном наборе данных. Единственный способ избежать того, чтобы аналитическая система страдала от эха проблем с данными, уже исправленных в озере данных, — это обновлять все данные каждый раз. В этом и заключается суть безсостояния.
Как правило, если какая-либо часть аналитической системы оказывается слишком медленной для ежедневной замены, эту часть следует считать имеющей проблему с производительностью. Цепочки поставок хаотичны, и наступит день, когда что-то случится — пожар, локдаун, кибератака — что потребует немедленного вмешательства. Компания должна иметь возможность обновить все свои решения по цепочке поставок в течение одного часа. Компания не должна ждать и застрять на 10 часов, пока проходит медленный этап обучения машинного обучения.

Чтобы работать надежно, аналитическая система должна быть правильно инструментирована. Именно для этого существуют отчеты о состоянии данных и инспекторы данных. Кстати, все эти элементы находятся в ведении цепочки поставок; они не ответственны за это IT. Мониторинг состояния данных представляет собой самую первую фазу обработки данных, даже до самой подготовки данных, и осуществляется внутри аналитической системы. Состояние данных является частью инструментов числового рецепта. Отчет о состоянии данных указывает, приемлем ли вообще запуск числового рецепта. Этот отчет также указывает источник проблемы с данными, если таковая имеется, чтобы ускорить ее устранение.
Мониторинг состояния данных – это практика в Lokad. За последнее десятилетие эта практика оказалась бесценной для предотвращения ситуации «мусор на входе – мусор на выходе», которая, по-видимому, повсеместна в мире корпоративного программного обеспечения. Действительно, когда инициатива по обработке данных терпит неудачу, часто винят плохие данные. Однако важно отметить, что обычно практически не прилагается никаких инженерных усилий для обеспечения качества данных с самого начала. Качество данных не падает с неба; оно требует инженерных усилий.
Конвейер данных, представленный до сих пор, довольно минималистичен. Отражение данных реализовано настолько просто, насколько это возможно, что хорошо с точки зрения качества программного обеспечения. Однако, несмотря на этот минимализм, здесь присутствует множество движущихся частей: много таблиц, множество систем, много людей. В результате ошибки встречаются повсюду. Это корпоративное программное обеспечение, и обратное было бы довольно удивительно. Мониторинг состояния данных внедрен, чтобы помочь аналитической системе выжить в окружающем хаосе.
Состояние данных не следует путать с очисткой данных. Состояние данных заключается лишь в том, чтобы гарантировать, что данные, предоставленные аналитической системе, являются точным отражением транзакционных данных, существующих в транзакционных системах. Здесь нет попыток исправить данные; данные анализируются такими, какие они есть.
В Lokad мы обычно различаем состояние данных низкого уровня и высокого уровня. Состояние данных низкого уровня — это панель мониторинга, которая объединяет все структурные и объемные аномалии данных, такие как очевидные проблемы — например, записи с нерациональными датами или числами или “осиротевшие” идентификаторы, у которых отсутствуют ожидаемые соответствия. Все эти проблемы видны и, фактически, являются простыми. Сложная проблема начинается с тех вопросов, которые невозможно увидеть, потому что данные вообще отсутствуют. Например, если при извлечении данных поступают сведения о продажах за вчерашний день, содержащие только половину ожидаемых строк, это может реально угрожать производству. Неполные данные особенно коварны, потому что обычно они не мешают числовому рецепту генерировать решения, за исключением того, что эти решения окажутся мусором, поскольку исходные данные неполные.
Технически, в Lokad мы стараемся объединить мониторинг состояния данных на одной панели, и эта панель, как правило, предназначена для IT-команды, поскольку большинство проблем, выявленных мониторингом состояния данных низкого уровня, связано с самим конвейером данных. В идеале IT-команда должна мгновенно понимать, все ли в порядке или требуется дальнейшее вмешательство.

Мониторинг состояния данных высокого уровня рассматривает все бизнес-аномалии — элементы, которые выглядят некорректно с точки зрения бизнеса. Состояние данных высокого уровня охватывает такие элементы, как отрицательные уровни запасов или аномально большие минимальные объемы заказа. Оно также включает такие вещи, как цены, которые не имеют смысла, поскольку компания будет работать в убыток или с нелепо высокими маржами. Мониторинг состояния данных высокого уровня пытается охватить все элементы, по которым специалист по цепочке поставок, взглянув на данные, может сказать: “Это не может быть правильно; у нас проблема.”
В отличие от отчета о состоянии данных низкого уровня, отчет о состоянии данных высокого уровня предназначен в первую очередь для команды цепочки поставок. Действительно, проблемы вроде аномальных минимальных объемов заказа будут восприниматься как проблемы только тем специалистом, который достаточно знаком с бизнес-средой. Цель этого отчета — предоставить возможность мгновенно определить, что все в порядке и что дальнейшее вмешательство не требуется.
Ранее я говорил, что аналитическая система должна быть без состояния. Однако оказывается, что состояние данных является исключением, подтверждающим правило. Действительно, многие проблемы можно выявить, сравнивая сегодняшние индикаторы с теми же индикаторами, собранными за предыдущие дни. Таким образом, мониторинг состояния данных обычно сохраняет некоторое состояние, которое, по сути, представляет собой ключевые индикаторы за предыдущие дни, чтобы иметь возможность выявить выбросы в текущем состоянии данных. Однако, поскольку мониторинг состояния данных — это чисто вопрос наблюдения, худшее, что может случиться, если проблема на уровне озера данных устранена, а затем в состоянии данных остаются эхо прошлых проблем, — это серия ложных срабатываний этих отчетов. Логика, генерирующая решения в цепочке поставок, остается полностью без состояния; состояние касается лишь небольшой части инструментов.
Мониторинг состояния данных, как на низком, так и на высоком уровнях, представляет собой компромисс между риском принятия неверных решений и риском несвоевременной доставки решений. При рассмотрении больших цепочек поставок неразумно ожидать, что 100 процентов данных будут корректными — ошибочные транзакционные записи происходят, пусть и редко. Таким образом, объем проблем должен быть признан достаточно низким, чтобы числовой рецепт мог функционировать. Компромисс между этими двумя рисками — чрезмерная чувствительность к сбоям данных или чрезмерная терпимость к проблемам с данными — в значительной степени зависит от экономического состава цепочки поставок.
В Lokad мы разрабатываем и настраиваем эти отчеты для каждого клиента отдельно. Вместо того чтобы преследовать каждый возможный случай повреждения данных, специалист по цепочкам поставок, отвечающий за реализацию мониторинга состояния данных низкого и высокого уровня, а также инспекторов данных, о которых я расскажу через минуту, старается настроить мониторинг так, чтобы он был чувствителен к тем проблемам, которые действительно наносят ущерб и происходят в интересующей цепочке поставок.
В терминологии Lokad инспектор данных, или просто инспектор, — это отчет, который объединяет все соответствующие данные, касающиеся конкретного объекта интереса. Ожидается, что объект интереса будет одним из ключевых элементов с точки зрения цепочки поставок — продуктом, поставщиком, клиентом или складом. Например, если речь идет об инспекторе данных для продуктов, тогда для любого конкретного продукта, продаваемого компанией, мы должны иметь возможность увидеть на одном экране все данные, связанные с этим продуктом. В инспекторе данных для продуктов представлений, по сути, столько, сколько продуктов, поскольку когда я говорю, что мы видим все данные, я имею в виду все данные, привязанные к одному штрихкоду или артикулу, а не ко всем продуктам в целом.
В отличие от отчетов о состоянии данных низкого и высокого уровня, которые представляют собой панели, позволяющие быстро оценить ситуацию, инспекторы реализуются для того, чтобы решать вопросы и устранять проблемы, которые неизбежно возникают при проектировании и последующей эксплуатации основного числового рецепта. Действительно, для принятия решения в цепочке поставок нередко требуется объединить данные из десятка таблиц, возможно, из нескольких транзакционных систем. Поскольку данные разбросаны повсюду, когда решение кажется подозрительным, обычно сложно определить источник проблемы. Может возникнуть разрыв между данными, видимыми аналитической системой, и данными, существующими в транзакционной системе. Может быть неисправный алгоритм, который не способен уловить статистическую закономерность в данных. Может быть неверное восприятие, и решение, которое кажется подозрительным, на самом деле может быть правильным. В любом случае, назначение инспектора — предоставить возможность детально изучить интересующий объект.
Чтобы инспекторы были полезными, они должны отражать специфику как цепочки поставок, так и прикладного ландшафта. В результате создание инспекторов почти всегда является индивидуальной задачей. Тем не менее, как только работа выполнена, инспектор становится одним из столпов инструментирования самой аналитической системы.
В заключение, хотя большинство количественных инициатив в сфере цепочек поставок обречены на провал еще до своего старта, это не обязательно должно быть так. Тщательный выбор результатов, сроков, объема и правил необходим для предотвращения проблем, которые неизбежно приводят к провалу этих инициатив. К сожалению, эти решения часто оказываются несколько противоинтуитивными, как Lokad убедился за 14 лет своей работы.
На самых ранних этапах инициатива должна быть полностью посвящена настройке конвейера данных. Ненадежный конвейер данных — один из самых верных способов обеспечить провал любой инициативы, основанной на данных. Большинство компаний, даже большинство IT-отделов, недооценивают важность высоконадежного конвейера данных, который не требует постоянного тушения пожаров. Хотя основная часть настройки конвейера данных ложится на IT-отдел, сама цепочка поставок должна отвечать за инструментирование той аналитической системы, которую она эксплуатирует. Не рассчитывайте, что IT сделает это за вас; это задача команды цепочки поставок. Мы наблюдали два различных типа инструментирования: отчеты о состоянии данных, охватывающие всю компанию, и инспекторы данных, поддерживающие глубокую диагностику.

Сегодня мы обсудили, как начать инициативу, но в следующий раз мы увидим, как ее завершить или, точнее, как, надеюсь, довести до реализации. На следующей лекции, которая состоится в среду, 14 сентября, мы продолжим наше путешествие и увидим, какие шаги требуются для создания основного числового рецепта, а затем для постепенного внедрения генерируемых им решений в производство. Мы также более подробно рассмотрим, что этот новый подход к цепочкам поставок означает для повседневной работы специалистов по цепочкам поставок.
Теперь давайте рассмотрим вопросы.
Вопрос: Почему именно шесть месяцев является сроком, после которого реализация проводится некорректно?
Я бы сказал, что проблема не в самом сроке в шесть месяцев. Проблема в том, что, как правило, инициативы изначально настроены на провал. Вот в чем дело. Если ваша инициатива по предиктивной оптимизации начинается с расчета, что результаты будут получены через два года, это почти гарантирует, что инициатива в какой-то момент распадется и не принесет ничего в производство. Если бы была возможность, я бы предпочел, чтобы инициатива достигла успеха за три месяца. Однако, по моему опыту, шесть месяцев — это минимальный срок для того, чтобы довести такую инициативу до производства. Любая дополнительная задержка увеличивает риск провала инициативы. Очень трудно еще сильнее сжать этот срок, потому что, как только вы решаете все технические проблемы, оставшиеся задержки отражают время, необходимое людям для вовлечения в инициативу.
Вопрос: Специалисты по цепочкам поставок могут расстроиться из-за инициативы, которая заменяет большую часть их объема работы, например, работу отдела закупок, в связи с автоматизацией решений. Как вы посоветуете с этим справляться?
Это очень важный вопрос, который, надеюсь, будет рассмотрен на следующей лекции. На сегодня, что я могу сказать, так это то, что я считаю: большинство того, что делают специалисты по цепочкам поставок в современных условиях, не приносит большого удовлетворения. В большинстве компаний людям выдают набор SKU или номеров деталей, и затем они бесконечно просматривают его, принимая все необходимые решения. По сути, их работа сводится к тому, чтобы раз в неделю или, возможно, раз в день просматривать электронную таблицу. Это не приносит удовлетворения.
Краткий ответ заключается в том, что подход Lokad решает проблему, автоматизируя все рутинные аспекты работы, чтобы специалисты с реальной экспертизой в цепочке поставок могли начать пересматривать основы этой цепочки. Это позволяет им больше общаться с клиентами и поставщиками для повышения эффективности. Речь идет о сборе инсайтов, чтобы мы могли усовершенствовать числовой рецепт. Выполнение числового рецепта требует значительных усилий, и очень немногие будут скучать по тем временам, когда им приходилось каждый день просматривать электронные таблицы.
Question: Ожидается ли от специалистов по цепочке поставок работа с отчетами о состоянии данных для того, чтобы ставить под сомнение решения, генерируемые учеными по цепочке поставок?
От специалистов по цепочке поставок ожидается работа с инспекторами данных, а не с отчетами о состоянии данных. Отчеты о состоянии данных представляют собой всекорпоративную оценку, отвечающую на вопрос, достаточно ли качественны данные на входе аналитической системы для того, чтобы числовой рецепт мог эффективно функционировать с этим набором данных. Вывод отчета о состоянии данных представляет собой бинарное решение: дать зеленый свет на выполнение числового рецепта или отказаться от него, заявив, что существует проблема, которую необходимо исправить. Инспекторы данных, о которых будет рассказано подробнее на следующей лекции, являются точкой входа для специалистов по цепочке поставок при получении инсайтов относительно предлагаемого решения в цепочке поставок.
Question: Возможно ли ежедневно обновлять аналитическую модель, например, устанавливая инвентарную политику, ведь система цепочки поставок не будет реагировать на ежедневные изменения политики, а просто будет подавать шум в систему?
Чтобы ответить на первую часть вопроса, ежедневное обновление аналитической модели, безусловно, возможно. Например, когда Lokad работала в 2020 году во время локдаунов в Европе, страны закрывались и открывались с уведомлением всего за 24 часа. Это создавало чрезвычайно хаотичную ситуацию, требующую постоянных и немедленных корректировок каждый день. Lokad функционировала в этих экстремальных условиях, управляя локдаунами, которые начинались или заканчивались ежедневно по всей Европе почти 14 месяцев.
Таким образом, ежедневное обновление аналитической модели возможно, но не обязательно желательно. Верно, что системы цепочки поставок обладают большой инерцией, и первое, что должен учитывать корректный числовой рецепт, — это эффект трещотки большинства решений. Как только вы даете команду на производство и сырье расходуется, отменить производство невозможно. Многие решения уже приняты, и это следует учитывать при принятии новых. Однако, когда вы понимаете, что вашей цепочке поставок необходима кардинальная смена курса, нет смысла откладывать это исправление лишь ради отсрочки принятия решения. Лучшее время для внесения изменений — это сейчас. Что касается аспекта шума в вопросе, всё сводится к правильному проектированию числовых рецептов. Существует множество неправильных разработок, которые являются нестабильными, где небольшие изменения в данных вызывают существенные колебания в решениях, являющихся итогом работы числового рецепта. Числовой рецепт не должен давать скачков при незначительных колебаниях в цепочке поставок. Именно поэтому Lokad приняла вероятностный подход к прогнозированию. Используя вероятностный подход, можно сконструировать модели, которые будут гораздо стабильнее, по сравнению с моделями, пытающимися предсказать среднее значение и реагирующими на выбросы в цепочке поставок. Question: Одна из проблем, с которыми мы сталкиваемся в цепочке поставок в очень крупных компаниях, — это их зависимость от различных исходных систем. Разве не крайне сложно объединить все данные из этих источников в единую систему?
Я полностью согласен с тем, что получение всех данных представляет собой значительную проблему для многих компаний. Однако следует задаться вопросом, почему это вообще является проблемой. Как я уже упоминал ранее, 99% бизнес-приложений, используемых крупными компаниями в наши дни, основаны на современных, хорошо сконструированных транзакционных базах данных. Возможно, еще встречаются несколько суперстарых реализаций на COBOL с использованием архаичного бинарного хранения, но это редкость. Подавляющее большинство бизнес-приложений, даже развернутых в 1990-х годах, работают с чистой промышленной транзакционной базой данных на заднем плане.
Когда у вас уже есть транзакционный бэкенд, почему тогда должно быть сложно скопировать эти данные в data lake? Чаще всего проблема в том, что компании не просто пытаются скопировать данные — они стремятся сделать гораздо больше. Они пытаются подготовить и преобразовать данные, зачастую чрезмерно усложняя процесс. Большинство современных настроек баз данных обладают встроенными возможностями зеркалирования данных, что позволяет реплицировать все изменения из транзакционной базы данных во вторичную. Это стандартная функция, присущая, вероятно, 20 наиболее часто используемым транзакционным системам на рынке.
Компании часто испытывают трудности с консолидацией данных, потому что они пытаются сделать слишком многое, и их инициативы рушатся под собственной сложностью. Как только данные консолидированы, компании часто ошибочно полагают, что объединение данных должно осуществляться ИТ-, BI- или data science-командами. Суть моего утверждения в том, что за собственными числовыми рецептами должна стоять сама цепочка поставок, так же как за маркетингом, продажами и финансами. Это не должно быть поперечное подразделение поддержки, которое пытается сделать это за компанию. Объединение данных из разных систем обычно требует множества бизнес-инсайтов. Крупные компании часто терпят неудачу, поручая эту работу эксперту из ИТ-, BI- или data science-команды, когда её следует выполнять внутри соответствующего подразделения.
Спасибо большое за ваше время сегодня, ваш интерес и ваши вопросы. До встречи в следующий раз после лета, в сентябре.