Valeur ajoutée de la prévision
La valeur ajoutée de la prévision1 (FVA) est un outil simple d’évaluation de la performance de chaque étape (et contributeur) du processus de prévision de la demande. Son objectif ultime est d’éliminer le gaspillage dans le processus de prévision en supprimant les points de contact humains (modifications) qui n’augmentent pas la précision des prévisions. Le FVA repose sur la notion que l’obtention d’une plus grande précision des prévisions vaut la peine d’être poursuivie et que l’identification des modifications qui l’augmentent, ainsi que l’élimination de celles qui ne le font pas, est souhaitable. Malgré des intentions positives, le FVA démontre une utilité limitée ponctuelle et, s’il est déployé de manière continue, présente une multitude d’inconvénients, incluant des hypothèses mathématiques défectueuses, des idées reçues sur la valeur intrinsèque d’une précision accrue des prévisions, et l’absence d’une perspective financière robuste.

Aperçu de la valeur ajoutée de la prévision
La valeur ajoutée de la prévision vise à éliminer le gaspillage et à augmenter la précision des prévisions de la demande en encourageant - et en évaluant - les contributions de plusieurs départements (y compris les équipes non spécialisées en planification de la demande, comme Sales, Marketing, Finance, Operations, etc.). En évaluant la valeur de chaque point de contact humain dans le processus de prévision, le FVA fournit aux entreprises des données exploitables sur les modifications qui détériorent la prévision, leur offrant ainsi l’opportunité d’identifier et d’éliminer les efforts et ressources qui ne contribuent pas à une meilleure précision des prévisions.
Michael Gilliland, dont The Business Forecasting Deal a apporté l’attention grand public à cette pratique, soutient2
“Le FVA aide à s’assurer que toutes les ressources investies dans le processus de prévision - du matériel informatique et logiciel au temps et à l’énergie des analystes et de la direction - améliorent la prévision. Si ces ressources n’aident pas à prévoir, elles peuvent être redirigées en toute sécurité vers des activités plus utiles”.
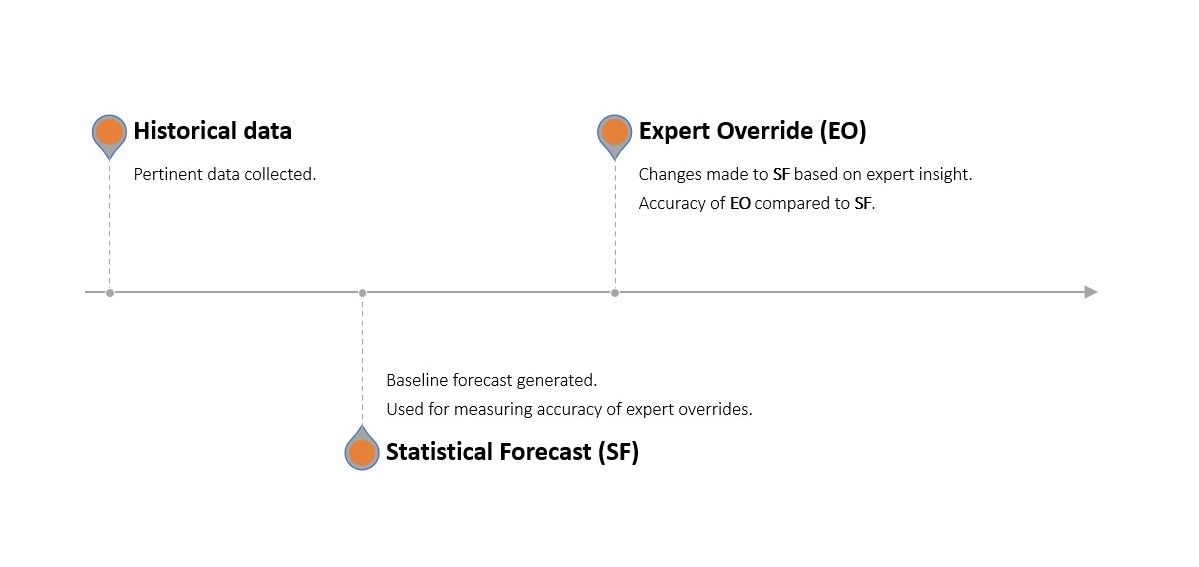
On identifie quelles activités et ressources aident grâce à un processus de prévision en plusieurs étapes où une prévision statistique est générée à l’aide du logiciel de prévision existant de l’entreprise. Cette prévision statistique est ensuite soumise à des modifications manuelles (overrides) par chaque département sélectionné. Cette prévision ajustée est ensuite comparée à une prévision de référence naïve (sans modifications, servant de placebo) et à la demande réelle observée.
Si les modifications apportées par les départements ont rendu la prévision statistique plus précise (par rapport à la prévision statistique non modifiée), elles ont apporté une valeur positive. Si elles l’ont rendue moins précise, elles ont apporté une valeur négative. De même, si la prévision statistique était plus précise que le placebo, elle ajoutait une valeur positive (et l’inverse si elle était moins précise).
Le FVA est, ainsi, “[une mesure de] la variation d’une métrique de performance en prévision pouvant être attribuée à une étape ou à un participant particulier dans le processus de prévision”2.
Les partisans de la valeur ajoutée de la prévision soutiennent qu’il s’agit d’un outil essentiel dans la gestion de la supply chain. En identifiant quelles parties du processus de prévision sont bénéfiques et lesquelles ne le sont pas, les organisations peuvent optimiser la précision de leurs prévisions. Le raisonnement global est que l’amélioration des prévisions conduit à une meilleure gestion des stocks, à une planification de la production plus fluide et à une allocation des ressources plus efficace.
Cela devrait, par conséquent, réduire les coûts, minimiser les ruptures de stock, et réduire les surstocks, tout en augmentant la satisfaction client et en générant une approche plus inclusive des prévisions et de l’éthique d’entreprise. Le processus s’est avéré remarquablement populaire, le FVA étant appliqué dans plusieurs entreprises notables dans des industries exceptionnellement compétitives, notamment Intel, Yokohama Tire et Nestlé3.
Réaliser une analyse de la valeur ajoutée de la prévision
Réaliser une analyse de la valeur ajoutée de la prévision implique plusieurs étapes intuitives, généralement une version proche de ce qui suit :
-
Définir le processus en identifiant les étapes ou composants individuels, c’est-à-dire la liste des départements qui seront consultés, l’ordre de consultation, et les paramètres spécifiques que chaque contributeur utilisera pour modifier la prévision initiale.
-
Générer une prévision de référence. Cette référence prend généralement la forme d’une prévision naïve. Une prévision statistique est également générée, selon le processus de prévision habituel au sein de l’entreprise, en utilisant le même jeu de données employé pour générer la référence. Cette prévision statistique sert de base à tous les ajustements ultérieurs.
-
Collecter les informations des contributeurs désignés, en respectant exactement les paramètres définis lors de la première étape. Cela peut inclure des informations sur les tendances du marché, des plans promotionnels, des contraintes opérationnelles, etc.
-
Calculer le FVA pour chaque contributeur en comparant la précision de la prévision statistique avant et après l’intervention de ce contributeur. En outre, la précision de la prévision statistique est comparée à celle de la prévision de référence naïve. Les contributions qui améliorent la précision des prévisions obtiennent un FVA positif, tandis que celles qui la diminuent reçoivent un FVA négatif.
-
Optimiser en améliorant ou en éliminant les contributions avec un FVA négatif, tout en préservant ou en renforçant celles avec un FVA positif.
Ces étapes forment un processus continu qui est amélioré de manière itérative dans la quête d’une plus grande précision des prévisions. Le processus de FVA, et sa différence par rapport à un processus de prévision traditionnel, est illustré ci-dessous.
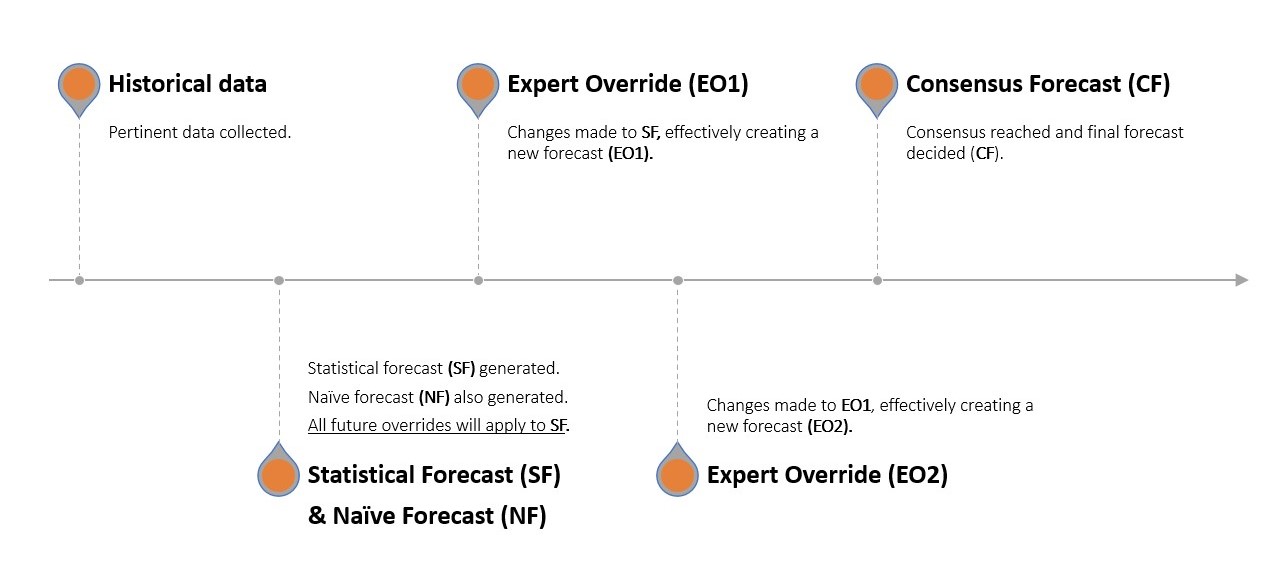
Prenons l’exemple d’un vendeur de pommes. Paul (Demand Planning) informe la direction que l’entreprise a vendu 8 pommes lors de chacun des 3 derniers mois. La prévision naïve indique que l’entreprise vendra à nouveau 8 pommes le mois prochain, mais Paul dispose d’un logiciel statistique avancé qui prédit que 10 pommes seront vendues (prévision statistique). John (Marketing) intervient en déclarant qu’il a l’intention de lancer un nouveau slogan accrocheur ce mois-ci6 et que les ventes seront probablement plus élevées ce mois-ci grâce à son esprit vif. George (Sales) envisage de regrouper des pommes et de baisser légèrement les prix, stimulant ainsi les ventes et augmentant la demande. Richard (Operations) est d’abord déconcerté puis révise la demande prévisionnelle pour refléter une prochaine panne de machines de tri de pommes cruciales qu’il pense avoir un impact négatif sur la capacité de l’entreprise à satisfaire la demande. La prévision statistique a ainsi été ajustée manuellement à trois reprises. Les départements se réunissent ensuite pour parvenir verbalement à une prévision consensuelle.
Un mois plus tard, l’entreprise effectue un backtest pour confirmer l’ampleur du delta7 à chaque étape de ce relais de prévision - c’est-à-dire, l’écart de la contribution de chaque département. Cela n’est pas difficile, car ils disposent désormais des données de ventes réelles du mois précédent et Paul peut isoler, pas à pas, l’erreur introduite par John, George, et Richard, respectivement, ainsi que l’étape de la prévision consensuelle8.
La perspective mathématique sur la valeur ajoutée de la prévision
Derrière les apparences, la valeur ajoutée de la prévision est un processus remarquablement simple et délibérément sans complication. Contrairement aux processus de prévision qui nécessitent une connaissance approfondie des mathématiques et du raisonnement statistique, le FVA « est une approche de bon sens facile à comprendre. Elle exprime les résultats de faire quelque chose par opposition à ne rien faire »3.
Exprimer les résultats d’avoir fait quelque chose par opposition à ne rien faire nécessite toutefois une intervention mathématique, qui prend généralement la forme d’une simple série temporelle - l’épine dorsale des méthodes de prévision. Le but principal de l’analyse de séries temporelles est de représenter de manière pratique et intuitive la demande future sous forme d’une seule valeur exploitable. Dans le contexte du FVA, la série temporelle de base sert de placebo ou de contrôle, contre lequel toutes les modifications apportées par l’analyste (décrites dans la section précédente) sont comparées. Une série temporelle de référence peut être générée par diverses méthodes, incluant généralement diverses formes de prévision naïve. Celles-ci sont couramment évaluées à l’aide de métriques telles que le MAPE, le MAD et le MFE.
Choix d’une prévision de référence
Le choix de la prévision de référence variera en fonction des objectifs ou des contraintes de l’entreprise concernée.
-
Prévision naïve et prévisions naïves saisonnières sont souvent choisies pour leur simplicité. Elles sont faciles à calculer et à comprendre puisqu’elles reposent sur l’hypothèse que les données précédentes se répéteront à l’avenir. Elles fournissent une référence sensée dans de nombreux contextes, en particulier lorsque les données sont relativement stables ou semblent présenter un schéma clair (tendance, saisonnalité, etc.).
-
Random Walk et Random Walk saisonnier sont généralement utilisés lorsque les données manifestent une grande part de hasard ou de variabilité, ou lorsqu’il semble y avoir un fort schéma saisonnier également soumis à des fluctuations aléatoires. Ces modèles ajoutent un élément d’imprévisibilité au concept de prévision naïve, dans le but de refléter l’incertitude inhérente à la prévision de la demande future.
Évaluation des résultats du FVA
-
MFE (Erreur Moyenne de Prévision) peut être utilisé pour évaluer si une prévision a tendance à surestimer ou sous-estimer les résultats réels. Cela peut être une métrique utile dans une situation où il est plus coûteux de surestimer que de sous-estimer, ou inversement.
-
MAD (Écart Absolu Moyen) et MAPE (Erreur Moyenne Absolue en Pourcentage) fournissent des mesures de la précision des prévisions qui prennent en compte à la fois le sur et le sous-dimensionnement de la demande. Elles pourraient être utilisées comme indicateurs de précision lorsqu’il est important de minimiser la taille globale des erreurs de prévision, indépendamment du fait qu’elles résultent d’une surestimation ou d’une sous-estimation.
Bien que le MAPE soit couramment utilisé dans les sources relatives au FVA, le consensus varie quant à la configuration métrique de prévision à utiliser dans une analyse de FVA2 4 9.
Les limites du FVA
La valeur ajoutée de la prévision, malgré son approche inclusive, ses objectifs nobles et son faible seuil d’entrée, est sans doute soumise à un large éventail de limitations et de faux postulats. Ces insuffisances couvrent de nombreux domaines, notamment les mathématiques, la théorie moderne de la prévision et l’économie.
La prévision n’est pas collaborative
Le FVA repose sur la notion que la prévision collaborative est bénéfique, dans le sens où de multiples interventions humaines (et même consensuelles) peuvent ajouter une valeur positive. Le FVA estime en outre que cette valeur positive de prévision est répartie au sein de l’entreprise, puisque les employés de différents départements peuvent tous posséder des informations précieuses sur la demande future du marché.
Ainsi, le problème tel que le perçoit le FVA est que cette approche collaborative s’accompagne d’inefficacités ennuyeuses, telles que certains points de contact humains apportant une valeur négative. Le FVA cherche donc à trier les collaborateurs de prévision inefficaces afin d’identifier les bons.
Malheureusement, l’idée qu’une prévision soit meilleure lorsqu’elle est réalisée de manière collaborative et inter-départementale va à l’encontre de ce que démontre la prévision statistique moderne - y compris dans le secteur du retail.
Une revue approfondie de la cinquième compétition de prévision Makridakis10 a démontré que « les 50 méthodes les plus performantes étaient basées sur le ML (machine learning). Par conséquent, le M5 est la première compétition M dans laquelle toutes les méthodes les plus performantes étaient à la fois des méthodes ML et meilleures que toutes les autres références statistiques et leurs combinaisons » (Makridakis et al., 2022)11. La compétition d’exactitude M5 était basée sur la prévision des ventes en utilisant des données historiques pour la plus grande entreprise de retail au monde en termes de chiffre d’affaires (Walmart).
En fait, selon Makridakis et al. (2022), “le modèle gagnant [dans le M5] a été développé par un étudiant avec peu de connaissances en prévision et peu d’expérience dans la construction de modèles de prévision des ventes”11, ce qui jette le doute sur l’importance réelle des perspectives de marché des départements disparates dans un contexte de prévision.
Cela ne veut pas dire que des modèles de prévision plus complexes soient intrinsèquement souhaitables. Au contraire, les modèles sophistiqués surpassent souvent les modèles simplistes, et la prévision collaborative de FVA est une approche simpliste face à un problème complexe.
Ignore l’incertitude future
FVA, comme de nombreux outils et techniques liés à la prévision, part du principe que la connaissance du futur (dans ce cas, la demande) peut être représentée sous la forme d’une série temporelle. Il utilise une prévision naïve comme référence (généralement un copier-coller des ventes précédentes) et demande aux collaborateurs d’arrondir manuellement à la hausse ou à la baisse les valeurs d’une prévision statistique. Cela est erroné pour deux raisons.
Tout d’abord, le futur, qu’il s’agisse du futur en général ou en termes de prévision, est fondamentalement incertain. De ce fait, l’exprimer sous la forme d’une valeur unique est une approche intrinsèquement mal avisée (même si complétée par une formule de stock de sécurité). Face à cette incertitude irréductible, l’approche la plus sensée consiste à déterminer une fourchette de valeurs futures probables, évaluée par rapport à leur rendement financier potentiel. Cela l’emporte, d’un point de vue de gestion des risques, sur la tentative d’identifier une valeur unique selon une série temporelle traditionnelle – ce qui ignore totalement le problème de l’incertitude future.
En deuxième lieu, les perspectives (aussi utiles qu’elles puissent paraître) apportées par les collaborateurs sont généralement du type qui ne se traduit guère (voire pas du tout) en une prévision sous forme de série temporelle. Considérez une situation dans laquelle une entreprise sait à l’avance qu’un concurrent est sur le point d’entrer sur le marché. Ou bien, imaginez un monde dans lequel la connaissance concurrentielle indique que votre concurrent le plus féroce prévoit de lancer une nouvelle ligne impressionnante de vêtements d’été. L’idée que ce type de perspectives puisse être intégré de manière collaborative par des non-spécialistes en une valeur unique exprimée dans une série temporelle relève du fantasme.
En réalité, toute similarité avec de véritables ventes futures (valeur ajoutée positive) sera entièrement fortuite, dans la mesure où les interventions humaines (qu’il s’agisse d’arrondir la demande à la hausse ou à la baisse) représentent des expressions équivalentes du même apport défectueux. Ainsi, une personne qui apporte une valeur négative n’est pas, d’un point de vue logique, plus « à droite » ou « à tort » que celle qui apporte une valeur positive.
Fondamentalement, FVA tente d’imposer des propriétés tridimensionnelles (les perspectives humaines) sur une surface bidimensionnelle (une série temporelle). Cela peut sembler correct selon un certain angle, mais cela ne signifie pas que ça le soit. Cela confère à FVA une apparence de rigueur statistique assez trompeuse.
Même si l’entreprise utilise un processus de prévision traditionnel avec un minimum de points de contact humains (comme le montre la Figure 1), si la prévision statistique sous-jacente analysée par FVA est une série temporelle, l’analyse elle-même relève d’un exercice de gaspillage.
Ironiquement Gaspilleur
En tant que démonstration ponctuelle de surconfiance et de prise de décision biaisée basée sur des décisions, FVA a son utilité. Des prix Nobel ont été décernés pour la profondeur, l’étendue et la persistance des biais cognitifs dans la prise de décision humaine12 13, et il est tout à fait concevable que certaines équipes n’acceptent pas à quel point l’intervention humaine défaillante est généralement erronée jusqu’à ce qu’on le leur démontre de manière catégorique.
Cependant, en tant qu’outil de gestion continu, FVA est intrinsèquement défectueux et sans doute contradictoire. Si vos prévisions statistiques sont surpassées par une prévision naïve et des ajustements collaboratifs, il convient vraiment de se poser la question suivante :
Pourquoi les modèles statistiques échouent-ils?
Malheureusement, FVA n’apporte aucune réponse à cela, car il n’est fondamentalement pas conçu pour le faire. Il ne fournit pas d’indications sur pourquoi les modèles statistiques pourraient sous-performer, seulement sur le fait qu’ils sous-performent. FVA n’est donc pas tant un outil de diagnostic qu’une loupe.
Bien qu’une loupe puisse être utile, elle ne fournit pas d’informations exploitables sur les problèmes sous-jacents du logiciel de prévision statistique. Comprendre pourquoi vos prévisions statistiques sous-performent a une valeur directe et indirecte bien supérieure, et c’est quelque chose que FVA ne clarifie pas davantage.
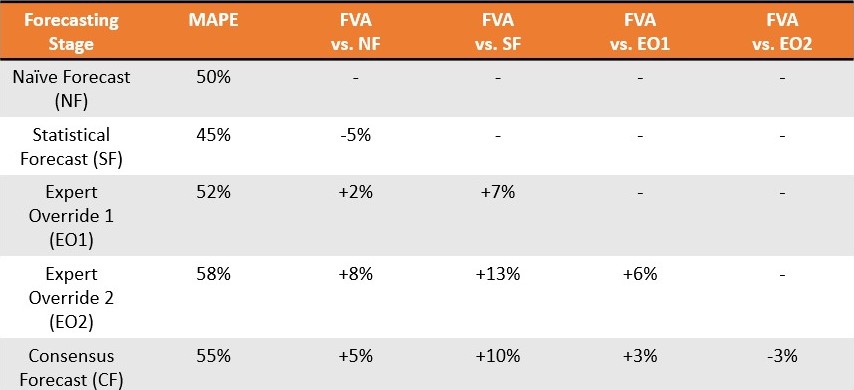
Non seulement le logiciel FVA ne fournit pas cet aperçu essentiel, mais il formalise aussi le gaspillage de différentes manières. Gilliland (2010) présente une situation théorique dans laquelle une prévision consensuelle est surpassée pendant 11 semaines sur 13 (taux d’échec de 85 %), avec une erreur moyenne de 13,8 points de pourcentage. Plutôt que de justifier un arrêt immédiat, le conseil est de
“présenter ces résultats à votre direction et essayer de comprendre pourquoi le processus consensuel a cet effet. Vous pouvez commencer à analyser la dynamique de la réunion de consensus et les agendas politiques des participants. En fin de compte, la direction doit décider si le processus consensuel peut être corrigé pour améliorer la précision de la prévision, ou s’il doit être éliminé."2
Dans ce scénario, non seulement le logiciel FVA ne diagnostique pas le problème sous-jacent de la performance de la prévision statistique, mais la couche d’instrumentation FVA ne fait qu’accroître la bureaucratie et l’allocation des ressources en disséquant des activités qui, de toute évidence, n’apportent aucune valeur.
Ainsi, l’installation d’une couche de logiciel FVA garantit que l’on continue de recevoir des images de basse résolution d’un problème en cours et dirige des ressources précieuses vers la compréhension d’apports défectueux qui auraient pu être ignorés dès le départ.
Cela n’est, sans doute, pas la répartition la plus judicieuse des ressources de l’entreprise, qui pourraient être utilisées à d’autres fins.
Surestime la Valeur de la Précision
Fondamentalement, FVA part du principe que l’augmentation de la précision des prévisions mérite d’être poursuivie isolément, et procède selon ce postulat comme s’il s’agissait d’une évidence. L’idée qu’une précision accrue des prévisions soit souhaitable est indéniablement attrayante, mais cela – d’un point de vue commercial – part du principe qu’une plus grande précision se traduit par une rentabilité supérieure. Ce n’est manifestement pas le cas.
Cela ne veut pas dire qu’une prévision précise ne vaut pas la peine d’être obtenue. Au contraire, une prévision précise devrait être étroitement liée à une perspective purement financière. Une prévision pourrait être 40 % plus précise, mais le coût associé signifierait que l’entreprise réalise 75 % de profits en moins dans l’ensemble. La prévision, bien qu’appréciablement plus précise (valeur ajoutée positive), n’a pas réduit les dollars d’erreur. Cela viole le principe fondamental des affaires : gagner plus d’argent, ou du moins ne pas le gaspiller.
En ce qui concerne FVA, il est tout à fait concevable que la valeur ajoutée positive générée par un département soit une perte nette pour l’entreprise, alors que la valeur ajoutée négative en provenance d’un autre soit imperceptible. Bien que Gilliland reconnaisse que certaines activités pourraient augmenter la précision sans ajouter de valeur financière, cet aspect n’est pas poursuivi jusqu’à son aboutissement logique : une perspective purement financière. Gilliland utilise l’exemple d’un analyste augmentant la précision de la prévision d’un seul point de pourcentage :
“Le simple fait qu’une activité de processus présente une FVA positive ne signifie pas nécessairement qu’elle doit être conservée dans le processus. Nous devons comparer les bénéfices globaux de l’amélioration au coût de cette activité. La précision supplémentaire augmente-t-elle les revenus, réduit-elle les coûts ou rend-elle les clients plus satisfaits ? Dans cet exemple, l’intervention de l’analyste a réduit l’erreur d’un point de pourcentage. Mais devoir engager un analyste pour examiner chaque prévision peut être coûteux, et si l’amélioration ne représente qu’un point de pourcentage, cela en vaut-il vraiment la peine ?”2
En d’autres termes, une augmentation de 1 % pourrait ne pas valoir la peine d’être poursuivie, mais une augmentation plus importante de la précision des prévisions pourrait l’être. Cela part du principe que la valeur financière est liée à une plus grande précision des prévisions, ce qui n’est pas nécessairement vrai.
Ainsi, il existe une dimension financière inéluctable dans la prévision qui est, au mieux, sous-estimée dans FVA (et, au pire, à peine remarquée). Cette perspective purement financière devrait réellement constituer la base sur laquelle se construit un outil destiné à réduire le gaspillage.
Vulnérable à la Manipulation
FVA présente également une opportunité évidente de truquage et de manipulation des prévisions, surtout si la précision des prévisions est utilisée comme mesure de la performance des départements. C’est l’esprit de la loi de Goodhart, qui stipule qu’une fois qu’un indicateur devient la principale mesure de succès (par accident ou délibérément), cet indicateur cesse alors d’être utile. Ce phénomène peut souvent ouvrir la voie à des interprétations erronées et/ou à la manipulation.
Supposons que l’équipe commerciale soit chargée d’apporter des ajustements à court terme à la prévision de la demande en fonction de ses interactions avec les clients. Le département commercial pourrait considérer cela comme une opportunité de signaler sa valeur et de commencer à modifier la prévision même lorsque cela n’est pas nécessaire, dans le but de démontrer une FVA positive. Il pourrait surestimer la demande, donnant l’impression qu’il génère de la valeur, ou recalculer la demande à la baisse, laissant penser qu’il corrige une projection trop optimiste d’un département précédent. Dans tous les cas, le département commercial pourrait apparaître comme plus précieux pour l’entreprise. Par conséquent, le département marketing pourrait alors se sentir sous pression pour apparaître lui aussi comme générant de la valeur, et l’équipe commencerait à apporter des ajustements arbitraires similaires à la prévision (et ainsi de suite).
Dans ce scénario, la mesure FVA, initialement destinée à améliorer la précision des prévisions, devient simplement un mécanisme politique permettant aux départements de signaler leur valeur plutôt que d’apporter une véritable valeur, une critique même reconnue par les partisans de FVA9. Ces exemples démontrent les dangers potentiels de la loi de Goodhart en ce qui concerne FVA14.
Les partisans de FVA pourraient soutenir que ces critiques psychologiques constituent tout l’enjeu de FVA, à savoir l’identification des apports précieux versus les apports inutiles. Cependant, étant donné que les biais associés aux interventions humaines en prévision sont désormais si bien compris, les ressources consacrées à disséquer ces apports chargés de biais seraient mieux employées dans un processus qui évite (autant que possible) ces apports dès le départ.
Solution Locale à un Problème Systémique
Implicitement, la tentative d’optimiser la prévision de la demande de manière isolée présuppose que le problème de la prévision de la demande est distinct des autres problèmes de la supply chain. En réalité, la prévision de la demande est complexe en raison de l’interaction d’une large gamme de causes systémiques de la supply chain, incluant l’influence des lead times variables des fournisseurs, des disruptions imprévues dans la supply chain, des choix d’allocation des stocks, des stratégies de tarification, etc.
Tenter d’optimiser la prévision de la demande de manière isolée (alias, local optimization) est une approche erronée, étant donné que les problèmes au niveau du système – les véritables causes profondes – ne sont pas correctement compris ni traités.
Les problèmes de supply chain – dont la prévision de la demande est assurément l’un – sont comme des personnes debout sur un trampoline : déplacer une personne crée un déséquilibre pour tout le monde15. Pour cette raison, une optimisation holistique de bout en bout est préférable à la tentative de traiter les symptômes de manière isolée.
L’avis de Lokad
Le Forecast Value Added prend une mauvaise idée (la prévision collaborative) et la sophistique, habillant cette mauvaise idée de couches de logiciels inutiles tout en dilapidant des ressources qui auraient de meilleures utilisations alternatives.
Une stratégie plus sophistiquée consisterait à regarder au-delà du seul concept de précision des prévisions et à opter plutôt pour une politique de gestion des risques qui réduit les dollars d’erreur. Conjuguée à une approche de prévision probabiliste, cette mentalité s’éloigne des KPI arbitraires – tels qu’augmenter la précision des prévisions – et intègre la totalité de vos facteurs économiques, contraintes et chocs potentiels de la supply chain dans votre processus décisionnel concernant les stocks. Ces types de vecteurs de risque (et de gaspillage) ne peuvent être quantifiés (et éliminés) efficacement par un outil qui exploite une perspective collaborative de séries temporelles, telle que celle retrouvée dans le Forecast Value Added.
De plus, en séparant la prévision de la demande de l’optimisation globale de la supply chain, FVA (peut-être involontairement) augmente la complexité accidentelle du processus de prévision de la demande. La complexité accidentelle est synthétique et résulte de l’accumulation progressive de bruit inutile – généralement d’origine humaine – dans un processus. Ajouter des étapes et des logiciels redondants au processus de prévision, comme le fait FVA, est un exemple typique de complexité accidentelle et peut rendre le problème considérablement plus complexe.
La prévision de la demande est un problème intentionnellement complexe, c’est-à-dire qu’il s’agit d’une tâche intrinsèquement déroutante et gourmande en ressources. Cette complexité est une caractéristique immuable du problème et représente une catégorie de défis bien plus préoccupante que les questions de complexité accidentelle. Pour cette raison, il est préférable d’éviter les tentatives de solutions qui simplifient à l’excès et déforment fondamentalement le problème16. Pour reprendre la rhétorique médicale de la littérature FVA, c’est la différence entre guérir une maladie sous-jacente et traiter constamment les symptômes au fur et à mesure qu’ils apparaissent17.
En bref, FVA existe dans l’espace entre la théorie de pointe de la supply chain et la prise de conscience du public à son sujet. Une meilleure formation sur les causes sous-jacentes de l’incertitude de la demande – et ses racines dans la discipline supply chain en évolution – est recommandée.
Notes
-
Forecast Value Added et Forecast Value Add sont utilisés pour désigner le même outil d’analyse de prévision. Bien que les deux termes soient largement employés, une préférence négligeable existe en Amérique du Nord pour le second (selon Google Trends). Cependant, Michael Gilliland l’a explicitement appelé Forecast Value Added tout au long de The Business Forecasting Deal – le livre (et l’auteur) le plus souvent cité dans les discussions sur le FVA. ↩︎
-
Gilliland, M. (2010). The Business Forecasting Deal, Wiley. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Gilliland, M. (2015). Forecast Value Added Analysis: Step by Step, SAS. ↩︎ ↩︎ ↩︎
-
Chybalski, F. (2017). Forecast value added (FVA) analysis as a means to improve the efficiency of a forecasting process, Operations Research and Decisions. ↩︎ ↩︎
-
La table de modèles a été adaptée de Schubert, S., & Rickard, R. (2011). Using forecast value added analysis for data-driven forecasting improvement. IBF Best Practices Conference. Le rapport en escalier apparaît également dans The Business Deal de Gilliland. ↩︎
-
John a opté pour “All you need is apples” plutôt que pour le légèrement plus verbeux “We can work it out…with apples”. ↩︎
-
Dans le contexte présent, delta est une mesure de l’erreur introduite dans la prévision par chaque membre du processus de prévision. Cette utilisation du terme diffère légèrement du delta dans le trading d’options, qui mesure le taux de variation du prix d’une option par rapport au prix d’un actif sous-jacent. Les deux sont des expressions globales de la volatilité, mais le diable se cache dans les détails. ↩︎
-
Le lecteur est invité à remplacer la prévision de la demande de pommes par la prévision de la demande pour un vaste réseau mondial de magasins, à la fois en ligne et hors ligne, qui possèdent tous un catalogue de 50 000 SKUs. La difficulté, sans surprise, augmente de façon exponentielle. ↩︎
-
Les compétitions de prévision Spyros Makridakis, connues familièrement sous le nom de M-competitions, se déroulent depuis 1982 et sont considérées comme l’autorité principale en matière de méthodologies de prévision de pointe (et parfois révolutionnaires). ↩︎
-
Makridakis, S., Spiliotis, E., & Assimakopolos, V., (2022). M5 Accuracy Competition: Results, Findings, and Conclusions. Il est à noter que toutes les 50 méthodes les plus performantes n’étaient pas basées sur le ML. Il y avait une exception notable… Lokad. ↩︎ ↩︎
-
Le travail (à la fois individuel et collectif) de Daniel Kahneman, Amos Tversky et Paul Slovic représente un exemple rare de recherche scientifique de référence ayant rencontré un succès grand public. Thinking, Fast and Slow de Kahneman, publié en 2011 – qui détaille une grande partie de sa recherche primée par le Nobel en 2002 – est un texte de référence en vulgarisation scientifique et traite des biais en prise de décision à un degré dépassant le cadre de cet article. ↩︎
-
Karelse, J. (2022), Histories of the Future, Forbes Books. Karelse consacre un chapitre entier à la discussion des biais cognitifs dans un contexte de prévision. ↩︎
-
Il s’agit d’un point non trivial. Les départements ont généralement des KPI à atteindre, et la tentation de truquer les prévisions pour servir leurs propres intérêts est à la fois compréhensible et prévisible (jeu de mots voulu). Pour contextualiser, Vandeput (2021, cité précédemment) observe que la haute direction – le dernier maillon du carrousel FVA – peut consciemment fausser la prévision pour satisfaire les actionnaires et/ou les membres du conseil. ↩︎
-
Cette analogie est tirée de la psychologue Carol Gilligan. Gilligan l’avait à l’origine utilisée dans le contexte du développement moral des enfants et de l’interrelation des actions humaines. ↩︎
-
Il est bon de planter un drapeau ici. Solution(s) est un terme quelque peu inapproprié dans le contexte de la complexité intentionnelle. Tradeoff(s) – proposés en versions meilleure ou pire – refléteraient mieux l’équilibre délicat requis pour aborder des problèmes intentionnellement complexes. On ne peut pas vraiment résoudre un problème où deux ou plusieurs valeurs s’opposent totalement. Un exemple en est la lutte entre la réduction des coûts et l’obtention de taux de service plus élevés. Étant donné que l’avenir est irréductiblement incertain, il n’existe aucun moyen de prévoir la demande avec une précision de 100 %. On peut cependant atteindre un taux de service de 100 % – si tel est l’enjeu commercial principal – simplement en stockant bien plus de stocks que l’on ne pourrait jamais vendre. Cela entraînerait d’énormes pertes, ainsi les entreprises, implicitement ou autrement, acceptent qu’il existe un tradeoff inévitable entre les ressources et le taux de service. En conséquence, le terme “solution” encadre de manière inappropriée le problème comme s’il était susceptible d’être résolu plutôt que atténué. Voir Basic Economics de Thomas Sowell pour une analyse approfondie de la lutte entre compromis rivaux. ↩︎
-
Dans The Business Forecasting Deal, Gilliland compare la FVA à un essai clinique, les prévisions naïves jouant le rôle d’un placebo. ↩︎