00:05 Introduction
02:50 Deux illusions
09:09 Un pipeline de compilateur
14:23 L’histoire jusqu’à présent
18:49 Connaissement
19:40 Conception de langage
23:52 L’avenir
30:35 Le passé
35:57 Choisir les batailles
39:45 Grammaires 1/3
42:41 Grammaires 2/3
49:02 Grammaires 3/3
53:02 Analyse statique 1/2
58:50 Analyse statique 2/2
01:04:55 Système de types
01:11:59 Fonctionnement interne du compilateur
01:27:48 Environnement d’exécution
01:33:57 Conclusion
01:36:33 Prochaine conférence et questions du public
Description
La majorité des supply chains est encore gérée via des tableurs (c.-à-d. Excel), tandis que les systèmes d’entreprise sont en place depuis une, deux, voire parfois trois décennies - supposément pour les remplacer. En effet, les tableurs offrent une expressivité programmatique accessible, alors que ces systèmes ne le font généralement pas. Plus généralement, depuis les années 1960, on observe un co-développement constant de l’industrie du logiciel dans son ensemble et de ses langages de programmation. Des preuves indiquent que la prochaine étape de la performance supply chain sera largement entraînée par le développement et l’adoption de langages de programmation, ou plutôt d’environnements programmables.
Transcription complète

Bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui je présenterai « Langages et Compilateurs pour Supply Chain ». Je ne me souviens pas avoir jamais vu des compilateurs être discutés dans un manuel de supply chain, et pourtant le sujet revêt une importance primordiale. Nous avons vu, dans le tout premier chapitre de cette série, dans la conférence intitulée « Livraison orientée produit », que la programmation est la clé pour capitaliser sur le temps investi par les experts en supply chain. Sans programmation, nous ne pouvons pas capitaliser sur leur temps, et nous traitons les experts en supply chain comme des ressources remplaçables.
De plus, dans ce tout quatrième chapitre, à travers les deux conférences précédentes « Optimisation mathématique pour Supply Chain » et « Machine Learning for Supply Chain », nous avons vu que ces deux domaines - optimisation et apprentissage - ont été entraînés par des paradigmes de programmation au cours de la dernière décennie, au lieu de rester un ensemble d’algorithmes et de modèles comme c’était le cas par le passé. Tous ces éléments soulignent l’importance primordiale des langages de programmation, et posent ainsi la question d’un langage de programmation et d’un compilateur conçus pour répondre aux défis supply chain.
Le but de cette conférence est de démystifier la conception d’un tel langage de programmation destiné aux besoins de la supply chain. Il est fort probable que votre entreprise ne développe jamais un tel langage de programmation en interne. Néanmoins, avoir quelques notions sur le sujet est fondamental afin de pouvoir évaluer l’adéquation des outils dont vous disposez, et d’apprécier l’adéquation des outils que vous envisagez d’acquérir pour relever les défis supply chain auxquels votre entreprise est confrontée. En outre, cette conférence devrait également vous aider à éviter certaines des grandes erreurs que font souvent les personnes n’ayant aucune connaissance dans ce domaine.

Commençons par dissiper deux illusions qui prévalent dans les cercles du logiciel d’entreprise depuis environ trois décennies. La première est l’illusion de la « programmation Lego », où l’on pense que la programmation est quelque chose qui peut être complètement contournée. En effet, la programmation est difficile, et il y a toujours des fournisseurs qui promettent qu’avec leur produit et leur technologie fantastique, la programmation peut être transformée en une expérience visuelle accessible à tous, éliminant entièrement toute la difficulté inhérente à la programmation, de sorte que l’expérience devienne essentiellement comparable à l’assemblage de Lego, une activité que même un enfant peut réaliser.
Cela a été tenté à de nombreuses reprises au cours des deux dernières décennies et a invariablement échoué. Au mieux, des produits destinés à offrir une expérience visuelle se sont transformés en langages de programmation ordinaires, qui ne sont pas particulièrement plus faciles à maîtriser que d’autres langages de programmation. C’est, d’ailleurs, anecdotiquement la raison pour laquelle, par exemple, dans la gamme de produits Microsoft, il y a la série « Visual », comme Visual Basic for Application et Visual Studio. Tous ces produits visuels ont été introduits dans les années 90 dans l’espoir de transformer la programmation en une expérience purement visuelle avec des concepteurs, où il suffirait de faire du glisser-déposer. La réalité est que tous ces outils ont finalement rencontré un succès très significatif, mais ils restent aujourd’hui de simples langages de programmation. Il reste très peu d’éléments visuels provenant des débuts de ces produits.
L’approche Lego a échoué car, fondamentalement, le goulot d’étranglement n’est pas la complexité de la syntaxe de programmation. C’est un obstacle, certes, mais il est minime, surtout comparé à la maîtrise des concepts impliqués dès que vous souhaitez déployer une automatisation sophistiquée. Votre esprit devient le goulot d’étranglement, et votre compréhension des concepts en jeu est bien plus importante que la syntaxe.
La deuxième illusion est celle de la « technologie Star Wars », qui consiste à penser qu’il est si simple de brancher et d’utiliser des technologies fantastiques. Cette illusion séduit aussi bien les fournisseurs que les projets internes. Essentiellement, il devient très tentant de dire qu’il existe cette base de données NoSQL fantastique que l’on peut simplement intégrer, ou cette pile de deep learning fantastique que l’on peut adopter, ou encore cette base de données graphe, ou ce framework distribué actif, etc. Le problème avec cette approche est qu’elle traite la technologie comme dans Star Wars. Lorsqu’on dispose d’une main mécanique, le héros peut simplement l’obtenir, et ça fonctionne. Mais en réalité, ce sont les problèmes d’intégration qui dominent.
Star Wars passe outre le fait qu’il y aurait une série de problèmes : d’abord, il vous faudrait des antibiotiques, puis une longue rééducation de la main pour même pouvoir l’utiliser. Il vous faudrait également un programme de maintenance pour la main, parce qu’elle est mécanique, et qu’en est-il de la source d’alimentation, etc. Tous ces problèmes sont tout simplement ignorés. Vous branchez simplement le morceau de technologie fantastique, et ça fonctionne. Ce n’est pas le cas en réalité. Les problèmes d’intégration dominent, et par exemple, dans les grandes entreprises de logiciels, la plupart des ingénieurs logiciels ne travaillent pas sur des technologies incroyablement cool. La majeure partie du personnel technique de la grande majorité de ces grands fournisseurs de logiciels est dédiée uniquement à l’intégration de toutes les pièces.
Lorsque vous avez des modules, des composants, ou des applications, il vous faut une petite armée d’ingénieurs pour assembler le tout et gérer tous les problèmes qui surgissent lorsque vous essayez de réunir ces éléments. Même une fois tous les obstacles de l’intégration franchis, il vous faut encore beaucoup de personnel technique pour pallier le fait que toute modification d’une partie du système tend à créer des problèmes dans d’autres parties du système. Vous avez donc besoin de ce personnel d’ingénierie pour courir après ces problèmes et les résoudre.
En passant, comme anecdote, un autre problème auquel j’ai été confronté avec des technologies impressionnantes est l’effet Dunning-Kruger qu’elles suscitent chez les ingénieurs. Vous introduisez une technologie cool dans votre stack, et soudain, les ingénieurs, simplement parce qu’ils ont commencé à s’amuser avec une technologie qu’ils comprennent à peine, se croient soudain experts en IA ou quelque chose du genre. C’est un cas typique de l’effet Dunning-Kruger et il est fortement lié au nombre de technologies cool que vous intégrez dans votre solution. En conclusion, avec ces deux illusions, nous voyons que nous ne pouvons vraiment pas contourner le problème de la programmation. Nous devons l’aborder de manière fonctionnelle, y compris les parties difficiles.
Maintenant, cela dit, l’aspect intéressant des langages de programmation est que les fournisseurs de logiciels d’entreprise n’arrêtent pas de réinventer, accidentellement, les langages de programmation, et ce, tout le temps. En effet, dans la supply chain, il existe un besoin féroce de configurabilité. Comme nous l’avons vu dans les conférences précédentes, le monde de la supply chain est diversifié, et les problèmes sont nombreux et variés. Ainsi, lorsque vous avez un produit logiciel pour la supply chain, le besoin de configurabilité est extrêmement intense. Anecdotiquement, c’est pourquoi la configuration d’un logiciel est généralement un projet qui dure plusieurs mois, voire parfois plusieurs années. C’est parce qu’une quantité massive de complexité est impliquée dans cette configuration.
Les paramètres de configuration sont souvent complexes, pas simplement des boutons ou des cases à cocher. Vous pouvez avoir des déclencheurs, des formules, des boucles, et toutes sortes de blocs associés. Cela devient rapidement ingérable, et ce que vous obtenez grâce à ces paramètres de configuration est un langage de programmation émergent. Cependant, étant donné qu’il s’agit d’un langage de programmation émergent, il tend à être de très mauvaise qualité.
La conception d’un véritable langage de programmation est une tâche d’ingénierie bien établie. Il existe des dizaines de livres sur les aspects pratiques de la réalisation d’un compilateur de qualité production. Un compilateur est un programme qui convertit des instructions, généralement des instructions textuelles, en code machine ou en une forme d’instructions de niveau inférieur. Chaque fois qu’il y a un langage de programmation, un compilateur est impliqué. Par exemple, dans un tableur Excel, vous avez des formules, et Excel possède son propre compilateur pour les compiler et les exécuter. Il est fort probable que l’ensemble de l’audience ait utilisé des compilateurs tout au long de sa vie professionnelle sans le savoir.
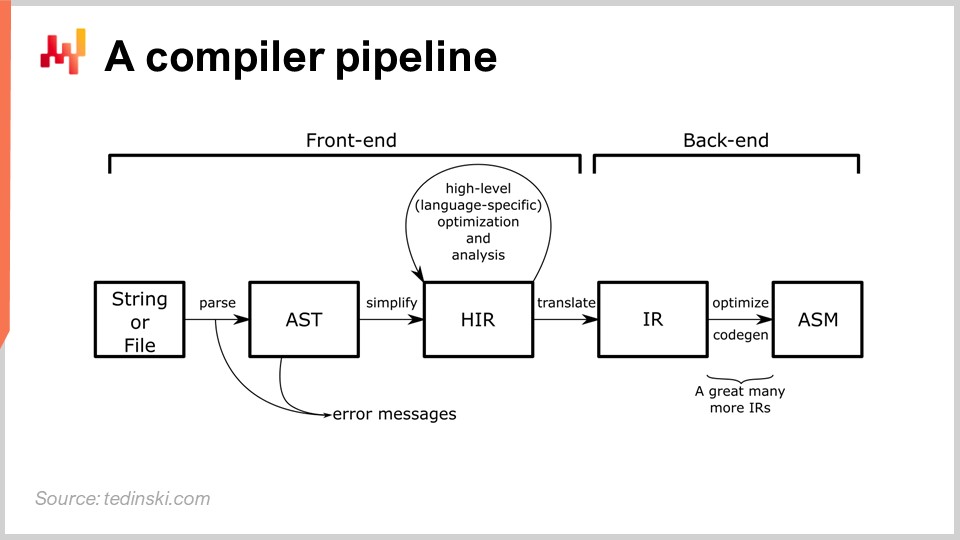
Sur le schéma, vous pouvez voir un pipeline typique, et cet archétype correspond à la plupart des langages de programmation dont vous avez probablement entendu parler, tels que Python, JavaScript, Java et C#. Tous ces langages possèdent un pipeline essentiellement similaire à celui décrit ici. Dans un pipeline de compilateur, il y a une série de transformations, et à chaque étape du processus, vous disposez d’une représentation qui représente l’ensemble du programme. La conception d’un compilateur repose sur une série de transformations bien identifiées, et à chaque étape du processus, vous travaillez sur l’ensemble du programme. Il est simplement représenté différemment.
L’idée est que chaque transformation est responsable d’un ensemble bien défini de problèmes. Vous résolvez ces problèmes, puis passez à la transformation suivante qui traitera un autre aspect du processus. Typiquement, à chaque étape, vous vous rapprochez du code machine. Le compilateur commence par le script, et il débute par des transformations très proches de la syntaxe du langage de programmation concerné. Au cours de ces premières transformations, un compilateur typique détecte les erreurs syntaxiques qui empêchent de transformer un script, qui ne représente même pas un programme valide, en quelque chose d’exécutable. Nous reviendrons plus en détail sur le pipeline du compilateur plus tard dans cette conférence.
Cette conférence est la cinquième du quatrième chapitre de cette série. Dans le premier chapitre, j’ai présenté mes points de vue sur la supply chain, à la fois en tant que domaine d’étude et en tant que pratique. Dans le deuxième chapitre, j’ai passé en revue les méthodologies appropriées pour traiter les situations que l’on rencontre dans la supply chain. Comme nous l’avons vu, la plupart des situations supply chain sont assez adversariales par nature, nous avons donc besoin de stratégies et de méthodologies qui soient résilientes face aux comportements adverses de toutes les parties, tant à l’intérieur qu’à l’extérieur des entreprises.
Le troisième chapitre est consacré au personnel de la supply chain, et il est entièrement dédié à l’étude des problèmes supply chain eux-mêmes. Nous devons prendre soin de ne pas confondre le problème que nous identifions avec la solution que nous pouvons envisager pour y répondre. Ce sont deux préoccupations distinctes : il faut séparer le problème de la solution.
Le quatrième et présent chapitre de cette série de conférences est dédié aux sciences auxiliaires de la supply chain. Ces sciences auxiliaires ne constituent pas la supply chain à proprement parler, mais elles sont très utiles à la pratique de la supply chain moderne. Nous progressons actuellement dans l’échelle des abstractions. Nous avons commencé ce chapitre avec la physique de l’informatique, puis, avec les algorithmes, nous sommes passés dans le domaine du logiciel. Nous avons introduit l’optimisation mathématique, qui présente un grand intérêt pour la supply chain et qui se trouve être également la base du machine learning.
Aujourd’hui, nous abordons les langages et compilateurs, essentiels pour la mise en œuvre de tout type de paradigme de programmation. Bien que le sujet des langages et compilateurs puisse surprendre l’audience, je pense qu’à ce stade, cela ne devrait pas être une trop grande surprise. Nous avons vu que l’optimisation mathématique et le machine learning doivent désormais être abordés via des paradigmes de programmation, ce qui soulève la question de savoir comment implémenter ces paradigmes de programmation. Cela nous conduit à la conception d’un langage de programmation et de son compilateur associé, qui est précisément le sujet d’aujourd’hui.

Voici un résumé du reste de cette conférence. Nous commencerons par des observations de haut niveau concernant l’histoire et le marché des langages de programmation. Nous passerons en revue des industries qui représentent, je le crois, à la fois l’avenir et le passé de la supply chain. Ensuite, nous aborderons progressivement la conception des langages de programmation et des compilateurs, en allant vers des préoccupations de niveau inférieur et les aspects techniques impliqués dans la conception d’un compilateur.

Depuis les années 1950, des milliers de langages de programmation ont été mis en production. Les estimations varient, mais le nombre de langages de programmation utilisés à des fins de production se situe probablement entre mille et dix mille. Beaucoup de ces langages ne sont que des variations ou des cousins les uns des autres, parfois même simplement la base de code d’un compilateur dérivée dans une direction légèrement différente. Il est à noter que plusieurs très grandes entreprises de logiciels d’entreprise se sont considérablement développées grâce à l’introduction de leurs propres langages de programmation. Par exemple, SAP a introduit ABAP en 1983, Salesforce a introduit Apex en 2006, et même Microsoft a commencé avant Windows en développant l’Altair BASIC en 1975.
Historiquement, ceux d’entre vous dans l’audience ayant assez d’âge pour se souvenir des années 90 se rappelleront peut-être qu’à l’époque, les vendeurs commercialisaient des langages de programmation de troisième et quatrième génération. La réalité est qu’il existait une série bien définie de générations – première, deuxième, troisième, quatrième, etc. – menant à la cinquième, où la communauté a essentiellement cessé de compter en termes de générations. Au cours des trois ou quatre premières décennies, tous ces langages de programmation suivaient une progression régulière vers des niveaux d’abstraction plus élevés. Cependant, à la fin des années 90, il existait déjà bien plus de directions possibles, au-delà d’un simple niveau d’abstraction supérieur, en fonction des cas d’utilisation.
Concevoir un nouveau langage de programmation a été réalisé à de nombreuses reprises. C’est un domaine d’ingénierie bien établi, et il existe des livres entiers dédiés au sujet sous un angle très pratique. L’ingénierie d’un nouveau langage de programmation est une pratique bien plus ancrée et prévisible que, disons, réaliser une expérience de data science. Il y a presque la certitude que vous obtiendrez le résultat souhaité si vous appliquez l’ingénierie adéquate, en tenant compte de ce qui est connu aujourd’hui et de ce qui est facilement accessible en termes de connaissances.
Tout cela soulève vraiment la question : qu’en est-il d’un langage de programmation spécifiquement conçu pour les besoins de la supply chain ? En effet, il peut y avoir des avantages significatifs en termes de productivité, de fiabilité et même de performance de la supply chain.

Pour aborder cette question, nous devons jeter un coup d’œil vers l’avenir. Heureusement pour nous, la manière la plus simple de regarder vers le futur est d’examiner une industrie qui a systématiquement eu une décennie d’avance sur tout le monde depuis environ trois décennies, à savoir l’industrie du jeu vidéo. Il s’agit aujourd’hui d’une industrie très importante, et pour vous donner une idée de son ampleur, l’industrie du jeu vidéo représente actuellement les deux tiers de la taille comparative de l’industrie aérospatiale mondiale, et elle connaît une croissance bien plus rapide que l’aérospatiale. Dans dix ans, les jeux vidéo pourraient même être plus importants que l’aérospatiale.
Ce qui est intéressant dans l’industrie du jeu vidéo, c’est qu’elle possède une structure très bien établie. Tout d’abord, nous avons les moteurs de jeu, dont les deux leaders sont Unity et Unreal. Ces moteurs de jeu disposent des composants de bas niveau nécessaires pour des graphismes 3D super intensifs et raffinés, et ils définissent le cadre de l’infrastructure de votre code. Il existe quelques entreprises qui conçoivent des produits très complexes appelés moteurs de jeu, et ces moteurs sont utilisés par l’ensemble de l’industrie.
Ensuite, nous avons les studios de jeu, qui développent le code de chaque jeu. Le code de jeu sera une base de code généralement spécifique au jeu en développement. Le moteur de jeu nécessite des ingénieurs logiciels extrêmement compétents sur le plan technique, même s’ils ne connaissent pas forcément très bien l’univers du jeu. Le développement du code de jeu n’exige pas autant de compétences techniques brutes. Cependant, les ingénieurs qui développent ce code doivent comprendre le jeu sur lequel ils travaillent. Le code de jeu établit la plateforme pour les mécanismes de jeu, mais il n’indique pas les subtilités.
Cette tâche est généralement gérée par les game designers, qui ne sont pas des ingénieurs logiciels, mais qui écrivent du code dans les langages de script mis à leur disposition par l’équipe d’ingénierie responsable du code de jeu. Nous avons ces trois étapes : les moteurs de jeu, impliquant des ingénieurs logiciels ultra techniques créant des blocs de construction fondamentaux ; les studios, qui disposent d’équipes d’ingénierie, généralement une par jeu, développant le jeu en tant que plateforme pour les mécanismes de jeu ; et enfin, les game designers, qui ne sont pas des ingénieurs logiciels mais des spécialistes du jeu, implémentant le comportement qui rendra les joueurs, c’est-à-dire les clients en fin de chaîne, heureux.
De nos jours, le code de jeu est fréquemment accessible à la communauté de fans, ce qui signifie que les game designers peuvent écrire des règles et potentiellement modifier le jeu, mais que les fans, de simples consommateurs, peuvent le faire aussi. Il existe quelques anecdotes intéressantes dans l’industrie. Par exemple, le jeu Dota 2, qui connaît un succès incroyable, a débuté comme une modification d’un jeu existant. La première version, simplement nommée Dota, était une modification purement réalisée par des fans du jeu Warcraft 3. Vous pouvez constater que ce degré de configurabilité et de programmabilité au niveau des règles de jeu est très étendu, car il était possible, à partir d’un jeu commercial existant, Warcraft 3, de créer un jeu entièrement nouveau, qui est ensuite devenu un immense succès commercial avec sa deuxième version. Cela est intéressant, et nous pouvons commencer à nous demander, en observant l’industrie du jeu, ce que cela signifie pour l’industrie de la supply chain.
Eh bien, nous pourrions envisager quel type de parallèle établir. Nous pourrions imaginer un moteur de supply chain qui se charge des parties algorithmiques très complexes, de l’infrastructure de bas niveau et des blocs technologiques fondamentaux, tels que l’optimisation mathématique et le machine learning. L’idée est que, pour chaque supply chain, il faudrait une équipe d’ingénierie pour rassembler toutes les données pertinentes et intégrer l’ensemble du paysage applicatif.
Dans un premier temps, nous aurions besoin de l’équivalent des game designers, qui seraient des spécialistes de la supply chain. Ces spécialistes ne sont pas des ingénieurs logiciels, mais ce sont eux qui écriront, au moyen d’un code simplifié, toutes les règles et mécanismes nécessaires pour mettre en œuvre l’optimisation prédictive d’intérêt pour la supply chain. L’industrie du jeu offre un exemple concret de ce qui est susceptible de se produire dans le domaine de la supply chain au cours de la prochaine décennie.

Jusqu’à présent, l’approche de l’industrie du jeu en supply chain reste de la science-fiction, à l’exception de quelques entreprises. Je crois que la plupart de ces entreprises sont clientes de Lokad. Pour revenir au sujet d’aujourd’hui, nous avons vu dans des conférences précédentes qu’Excel reste le numéro un des langages de programmation dans cette industrie. D’ailleurs, en termes de langage de programmation, Excel est un langage fonctionnel réactif, si bien qu’il constitue même sa propre catégorie.
Vous entendez peut-être aujourd’hui des fournisseurs proposant de moderniser les supply chains en utilisant une configuration de data science. Cependant, mon observation informelle au cours de la dernière décennie est que la grande majorité de ces initiatives ont échoué. Cela appartient déjà au passé, et pour comprendre pourquoi, nous devons examiner la liste des langages de programmation impliqués. Si l’on regarde Excel, on constate qu’il implique essentiellement deux langages de programmation : les formules Excel et VBA. VBA n’est même pas une exigence ; on peut aller loin avec seulement des VLOOKUP dans Excel. En général, il s’agit d’un seul langage de programmation, et il est accessible aux non-ingénieurs logiciels.
D’un autre côté, la liste des langages de programmation nécessaires pour reproduire les capacités d’Excel avec une configuration de data science est assez étendue. Nous aurons besoin de SQL, et potentiellement de plusieurs dialectes de SQL, pour accéder aux données. Nous aurons besoin de Python pour implémenter la logique de base. Cependant, Python seul tend à être lent, donc il se pourrait que vous ayez besoin d’un sous-langage, comme NumPy. À ce stade, vous ne réalisez toujours rien en termes de machine learning ou d’optimisation mathématique, ainsi, pour une véritable analyse numérique hardcore, il vous faudra autre chose, un autre langage de programmation en soi, comme PyTorch, par exemple. Maintenant que vous disposez de tous ces éléments, vous avez déjà un sacré nombre de pièces en mouvement, si bien que la configuration même de l’application sera assez complexe. Vous aurez besoin d’une configuration, et cette configuration sera écrite avec encore un autre langage de programmation, comme JSON ou XML. On peut dire que ces langages ne sont pas des langages super complexes, mais cela vient s’ajouter à l’ensemble.
Ce qui se passe lorsque vous avez autant de pièces mobiles, c’est qu’il vous faut généralement un système de build, quelque chose qui peut exécuter tous les compilateurs et les recettes banales nécessaires à la production du logiciel. Les systèmes de build possèdent leurs propres langages. L’approche traditionnelle repose sur un langage appelé Make, mais il en existe bien d’autres. De plus, puisque Excel est capable d’afficher des résultats, il vous faut un moyen d’afficher les informations à l’utilisateur et de visualiser les éléments. Cela sera réalisé avec un mélange de JavaScript, HTML et CSS, ajoutant ainsi d’autres langages à la liste.
À ce stade, nous avons une longue liste de langages de programmation, et une configuration de production réelle pourrait être encore plus complexe. Cela explique pourquoi la plupart des entreprises qui ont tenté d’adopter cette chaîne de data science au cours de la dernière décennie ont massivement échoué et sont restées avec Excel en pratique. La raison en est qu’il faut maîtriser près d’une douzaine de langages de programmation au lieu d’un seul, comme c’est le cas avec Excel. Nous n’avons même pas encore abordé les véritables problèmes de la supply chain ; nous nous sommes contentés d’examiner les aspects techniques liés à la mise en œuvre.

Commençons maintenant à réfléchir à ce à quoi ressemblerait un langage de programmation pour la supply chain. Tout d’abord, nous devons décider de ce qui fait partie intégrante du langage en tant que citoyen de première classe et de ce qui doit être délégué aux bibliothèques. En effet, avec les langages de programmation, il est toujours possible de confier certaines capacités à des bibliothèques. Par exemple, considérons le langage de programmation C. Il est considéré comme un langage de bas niveau, et le C ne possède pas de ramasse-miettes. Cependant, il est possible d’utiliser un ramasse-miettes tiers sous forme de bibliothèque dans un programme en C. Du fait que la collecte des ordures n’est pas un citoyen de première classe dans le langage C, la syntaxe tend à être relativement verbeuse et fastidieuse.
Pour les besoins de la supply chain, des problématiques comme l’optimisation mathématique et le machine learning sont habituellement traitées sous forme de bibliothèques. Ainsi, nous avons un langage de programmation, et toutes ces préoccupations sont essentiellement déléguées à des bibliothèques tierces. Cependant, si nous devions concevoir un langage de programmation pour la supply chain, il serait vraiment pertinent d’intégrer ces problématiques en tant que citoyens de première classe dans le langage lui-même. De plus, il serait logique d’avoir les données relationnelles comme une composante de première classe du langage. Dans la supply chain, le paysage applicatif, qui comprend de nombreux logiciels d’entreprise, possède des données relationnelles sous forme de bases de données relationnelles, comme les bases SQL, à profusion. Pratiquement tous les produits logiciels d’entreprise actuels ont, au cœur, une base de données relationnelle, ce qui signifie que dès que nous voulons toucher aux données pour la supply chain, nous interagissons forcément avec des données de nature relationnelle. Ces données se présentent sous forme d’une liste de tables extraites de l’ensemble de ces bases alimentant diverses applications, et chaque table comporte une liste de colonnes ou de champs.
Il est vraiment judicieux d’intégrer les données relationnelles dans le langage. De plus, qu’en est-il de l’interface utilisateur (UI) et de l’expérience utilisateur (UX) ? L’un des points forts d’Excel est que tout cela est entièrement intégré dans le langage, de sorte que vous n’avez pas un langage de programmation suivi de toutes sortes de bibliothèques tierces pour gérer la présentation, le rendu et l’interaction avec l’utilisateur. Tout cela fait partie du langage. Intégrer ces aspects en tant que citoyens de première classe serait également d’un intérêt très pertinent pour la supply chain, au moins si nous voulons être aussi performants qu’Excel peut l’être pour la supply chain.

Dans la conception d’un langage, la grammaire représente la forme formelle des règles qui définissent un programme valide selon le nouveau langage de programmation que vous introduisez. Essentiellement, vous commencez par un morceau de texte, puis vous appliquez d’abord un analyseur lexical (lexer), qui est une catégorie spécifique d’algorithmes ou un petit programme. Le lexer décompose votre texte, le programme que vous venez d’écrire, en une séquence de tokens. Il isole toutes les variables et symboles en jeu dans votre langage de programmation. La grammaire permet de convertir cette séquence de tokens en la sémantique réelle du programme, définissant ce que signifie le programme et l’ensemble exact, sans ambiguïté, des opérations à effectuer pour l’exécuter.
La grammaire elle-même est généralement abordée comme un compromis entre les préoccupations que vous souhaitez internaliser dans votre langage et les concepts que vous souhaitez externaliser. Par exemple, si nous traitons les données relationnelles comme une préoccupation externe, le programmeur devrait introduire de nombreuses structures de données spécialisées telles que des dictionnaires, des tables de correspondance et des tables de hachage pour effectuer manuellement, dans le langage, toutes ces opérations. Si la grammaire souhaite internaliser l’algèbre relationnelle, cela signifie que le programmeur peut généralement écrire toute la logique relationnelle directement sous sa forme relationnelle. Cependant, cela implique que toutes ces contraintes relationnelles et cette algèbre relationnelle deviennent une charge que la grammaire doit supporter.
Du point de vue de la supply chain, étant donné que les données relationnelles sont extrêmement répandues dans les logiciels d’entreprise, il est fort logique d’avoir une grammaire qui prenne en charge directement, au niveau du langage, toutes les problématiques liées au relationnel.

Les grammaires en informatique sont un sujet énormément étudié. Elles existent depuis des décennies, et pourtant, c’est probablement le seul domaine dans lequel les fournisseurs de logiciels d’entreprise échouent le plus lamentablement. En effet, ils finissent invariablement par inventer des langages de programmation accidentels qui émergent naturellement dès qu’interviennent des réglages de configuration complexes. Lorsque vous avez des conditions, des déclencheurs, des boucles et des réponses, il vous faut généralement prendre en charge ce langage au lieu de le laisser simplement émerger de lui-même.

Ce qui se passe, c’est que lorsque vous n’avez pas de grammaire, chaque fois que vous apportez des modifications à l’application, vous finissez par obtenir des conséquences hasardeuses sur le comportement réel du système. D’ailleurs, cela explique aussi pourquoi la mise à niveau d’une version d’un logiciel d’entreprise à une autre est généralement très complexe. La configuration est censée rester la même, mais lorsque vous essayez réellement d’exécuter la même configuration dans la version suivante du logiciel, vous obtenez des résultats complètement différents. La cause fondamentale de ces problèmes est le manque de grammaire et de sémantiques formalisées établies pour ce que la configuration est censée signifier.
La manière typique de représenter une grammaire est de manière formelle en utilisant la forme de Backus-Naur (BNF), qui est une notation spéciale. À l’écran, ce que vous pouvez voir est un mini langage de programmation qui représente les adresses postales des États-Unis. Chaque ligne comportant un signe égal représente une règle de production. Ce que vous avez à gauche est un symbole non terminal, et à droite du signe égal se trouve une séquence de symboles terminaux et non terminaux. Les symboles terminaux sont en rouge et représentent des symboles qui ne peuvent pas être dérivés davantage. Les symboles non terminaux sont entre crochets et peuvent être dérivés davantage. Cette grammaire ici n’est pas complète ; il faudrait ajouter de nombreuses règles de production pour obtenir une grammaire complète. Je voulais simplement garder cette diapositive raisonnablement concise.
Une grammaire est quelque chose de très simple à définir en termes de syntaxe pour votre langage de programmation, et elle garantit également qu’elle sera non ambiguë. Cependant, ce n’est pas parce qu’elle est écrite en utilisant la forme de Backus-Naur qu’elle sera une grammaire valide ou même une bonne grammaire. Pour obtenir une bonne grammaire, nous devons faire un peu plus que cela. La manière mathématique de caractériser une bonne grammaire est d’avoir une grammaire sans contexte. On dit qu’une grammaire est sans contexte si les règles de production peuvent être appliquées à n’importe quel non terminal, quelle que soit la nature des symboles que l’on trouve à droite ou à gauche. L’idée est qu’une grammaire sans contexte est une grammaire dans laquelle vous pouvez appliquer les règles de production dans n’importe quel ordre, et dès que vous identifiez une correspondance ou une dérivation, vous l’appliquez.
Ce que vous obtenez avec une grammaire sans contexte, c’est une grammaire qui, si vous y apportez une modification et que celle-ci crée une ambiguïté, le compilateur ne sera pas capable de compiler le programme où l’ambiguïté se produit. Cela est d’un intérêt primordial lorsque vous avez l’intention de maintenir une configuration sur une longue période. Dans le supply chain, la plupart des logiciels d’entreprise sont très pérennes. Il n’est pas rare de voir des logiciels d’entreprise fonctionner pendant deux ou trois décennies. Chez Lokad, nous servons plus de 100 entreprises, et il est assez courant d’extraire des données de systèmes en place depuis plus de trois décennies, notamment avec de grandes entreprises.
Avec une grammaire sans contexte, vous bénéficiez de la garantie que s’il y a un changement à apporter à ce langage (et rappelez-vous, quand je dis “langage”, je peux vouloir dire quelque chose d’aussi basique que des paramètres de configuration), vous serez en mesure d’identifier les ambiguïtés qui surgissent lorsque vous appliquez ce changement. Cela évite que ces ambiguïtés ne se produisent sans que vous vous rendiez compte que vous avez un problème, ce qui peut entraîner des difficultés lors de la mise à niveau d’un système à un autre.
Ce qui se passe lorsque les gens ne connaissent rien aux grammaires, c’est qu’ils écrivent manuellement un analyseur. Si vous n’avez jamais entendu parler d’une grammaire, un ingénieur logiciel écrira un analyseur, c’est-à-dire un programme qui crée de manière aléatoire une sorte d’arbre représentant la version analysée de votre programme. Le problème, c’est que vous obtenez une sémantique pour votre programme qui est incroyablement spécifique à la version du programme que vous possédez. Ainsi, si vous modifiez ce programme, vous modifiez la sémantique et vous obtiendrez des résultats différents, ce qui signifie que vous pouvez avoir la même configuration mais un comportement différent pour votre supply chain.
Heureusement, en 2004, Brian Ford a introduit une petite percée avec un article intitulé “Parsing Expression Grammars: A Recognition-Based Syntactic Foundation.” Grâce à ce travail, Ford a fourni à la communauté un moyen de formaliser ce genre d’analyseur ad hoc accidentel que l’on trouve sur le terrain. Par exemple, ces grammaires sont appelées Parsing Expression Grammars (PEGs) et, avec les PEGs, vous pouvez transformer ces analyseurs empiriques semi-accidentels en de véritables grammaires formelles d’une certaine nature.
Python, par exemple, n’a pas exactement une grammaire sans contexte mais possède un PEG. Les PEGs sont plutôt corrects si vous disposez d’un ensemble étendu de tests automatisés, car, dans ce cas, vous pouvez maintenir la sémantique au fil du temps. En effet, avec les PEGs, vous avez une formalisation de votre grammaire, ce qui vous place dans une meilleure situation par rapport au fait de ne pas avoir de grammaire et de ne disposer que d’un analyseur. Cependant, en termes d’évolution de la sémantique, avec un PEG, vous ne détecterez pas automatiquement un changement de sémantique si vous modifiez la grammaire elle-même. Ainsi, vous devez disposer d’une suite étendue de tests automatisés au-dessus de votre PEG, ce qui, d’ailleurs, est exactement ce que fait la communauté Python. Ils disposent d’un ensemble de tests automatisés très robuste et étendu. Maintenant, d’un point de vue supply chain, je pense que les grammaires non seulement vous font prendre conscience de leur importance, mais constituent également un test décisif. Vous pouvez réellement tester les fournisseurs de logiciels d’entreprise lorsque vous discutez d’un logiciel présentant une complexité significative. Vous devriez demander au fournisseur quelle grammaire il utilise pour la configuration complexe. Si le fournisseur répond “c’est quoi une grammaire ?”, alors vous savez que vous êtes en difficulté et que la maintenance sera probablement lente et coûteuse.

La programmation est très difficile, et les gens feront de nombreuses erreurs. Si c’était facile, nous n’aurions même pas besoin de programmer. Un bon langage de programmation minimise le temps nécessaire pour identifier une erreur et la corriger. C’est l’un des aspects les plus critiques d’un langage de programmation, garantissant une productivité décente pour quiconque écrit du code.
Considérons la situation suivante : lorsque vous écrivez du code, si l’erreur peut être détectée au fur et à mesure, comme une faute de frappe avec un soulignement rouge dans Microsoft Word, alors le cycle de rétroaction pour corriger l’erreur peut être aussi court que 10 secondes, ce qui est idéal. Si l’erreur ne peut être détectée qu’au démarrage du programme, le cycle de rétroaction durera au moins 10 minutes. Dans le supply chain, nous avons souvent de grands ensembles de données à traiter, et nous ne pouvons pas nous attendre à ce que le programme commence à analyser toutes les données en quelques secondes. En conséquence, si le problème ne se produit qu’à l’exécution, le cycle de rétroaction sera de 10 minutes ou plus.
Si l’erreur ne peut être détectée qu’après l’exécution complète du script, c’est-à-dire que le programme comporte une erreur sans planter, le cycle de rétroaction prendra environ 10 heures ou plus. Nous sommes passés de 10 secondes de rétroaction en temps réel à 10 minutes si nous devons exécuter le programme, puis à 10 heures si nous devons inspecter les résultats numériques et les KPI produits par le programme.
Il existe un scénario encore pire : si la plateforme sur laquelle vous opérez n’est pas strictement déterministe, c’est-à-dire qu’avec les mêmes entrées et données, elle peut vous fournir des résultats différents. Cela n’est pas aussi étrange que cela puisse paraître, car dans le supply chain, nous pouvons avoir des choses comme des simulations Monte Carlo en cours. S’il y a une part d’aléatoire dans les résultats, il se peut qu’un échec survienne de temps à autre et, dans ce cas, le cycle de rétroaction est généralement supérieur à 10 jours. Nous sommes donc passés de 10 secondes à 10 jours, et les enjeux en termes de réduction de ce cycle de rétroaction sont immenses. L’analyse statique regroupe un ensemble de techniques qui peuvent être appliquées pour détecter des problèmes, des erreurs ou des défaillances sans même exécuter le programme. Avec l’analyse statique, l’idée est que vous n’exécutez même pas le programme, ce qui signifie que vous pouvez signaler l’erreur en temps réel pendant que quelqu’un tape, tout comme un soulignement rouge pour une faute de frappe dans Microsoft Word. Plus généralement, il est très intéressant de transformer chaque problème de manière à ce qu’il remonte dans la chaîne vers une rétroaction plus rapide, convertissant ainsi des problèmes qui prendraient des jours à être identifiés en minutes, ou des minutes en secondes, et ainsi de suite.
D’un point de vue supply chain, nous avons vu dans une des conférences précédentes que les supply chains peuvent s’attendre à beaucoup de chaos. Nous ne pouvons pas avoir des cycles de publication classiques où vous attendez la prochaine version de votre logiciel. Parfois, il se produit des événements extraordinaires, comme une modification tarifaire, un porte-conteneurs bloqué dans un canal ou une pandémie. Ces situations d’urgence nécessitent des corrections en urgence, et la quantité d’analyse statique que vous pouvez appliquer à votre langage de programmation détermine en grande partie le chaos que vous allez rencontrer en production à cause d’erreurs non détectées en temps réel lors de la saisie du code. Les événements extraordinaires peuvent sembler rares, mais en pratique, les surprises dans le supply chain sont assez courantes.

Il existe des preuves mathématiques qu’il n’est pas possible de détecter toutes les erreurs avec un langage de programmation général dans une situation générale. Par exemple, il n’est même pas possible de prouver que le programme se terminera, ce qui signifie qu’il n’est pas possible de garantir que ce que vous avez écrit ne continuera pas à s’exécuter indéfiniment.
Avec l’analyse statique, on obtient généralement trois catégories : certaines parties du code sont probablement bonnes, certaines sont probablement mauvaises, et pour de nombreux éléments intermédiaires, on ne sait tout simplement pas. L’idée est que plus vous déplacez du “je ne sais pas” vers “code mauvais”, plus vous devrez investir d’efforts en termes de conception du langage pour convaincre le compilateur que votre programme est valide. Il faut donc trouver un équilibre entre l’investissement que vous souhaitez réaliser pour convaincre le langage de programmation que votre code est correct et le nombre de garanties que vous voulez obtenir sur le programme à la compilation, même avant son exécution. Cela relève de la productivité.
Voici maintenant une liste rapide des erreurs typiques détectées par l’analyse statique, incluant des erreurs de syntaxe, telles qu’une virgule ou une parenthèse oubliée. Certains langages de programmation ne peuvent même pas détecter les erreurs de syntaxe avant l’exécution, comme Bash, le langage de shell sur Linux. L’analyse statique peut également détecter des erreurs de type, qui se produisent lorsque vous avez un type incorrect ou un nombre incorrect d’arguments pour une fonction que vous appelez.
Le code inaccessible peut également être détecté, ce qui signifie que le code est correct, mais qu’il ne s’exécutera jamais car le programme entier peut s’exécuter sans jamais atteindre cette portion de code. C’est comme du code mort ou une connexion logique oubliée. Le code inconsequential est un autre problème qui peut être identifié, où le code s’exécute mais n’a aucun impact sur le résultat final. C’est une variante du code inaccessible.
Le code sur-dépensé peut également être détecté, ce qui fait référence à du code qui s’exécuterait, sauf que la quantité de ressources informatiques nécessaires dépasse largement ce que vous pouvez vous permettre pour votre programme. Un programme consomme des ressources telles que la mémoire, le stockage et le CPU. Grâce à l’analyse statique, vous pouvez démontrer qu’un bloc de code consomme bien plus de ressources que ce que vous pouvez vous permettre, en tenant compte de contraintes telles que la nécessité de terminer le calcul dans un délai spécifique. Vous préféreriez que cela échoue à la compilation plutôt que d’exécuter votre programme pendant une heure pour ensuite échouer en raison d’un dépassement de délai, ce qui entraînerait une productivité très faible.
Cependant, il y a une subtilité avec l’analyse statique. En tapant, vous manipulez constamment un programme invalide. Au fur et à mesure que vous tapez, vous transformez un programme valide en un programme invalide. Une solution de niveau industriel pour cette situation s’appelle le Language Server Protocol. Cet outil accompagne un langage de programmation et représente ce qui se fait de mieux en termes de retour d’erreur en temps réel pour les programmes que vous écrivez.
Grâce au Language Server Protocol, vous pouvez accéder à des fonctionnalités telles que “aller à la définition” lorsque vous cliquez sur une variable. Le Language Server Protocol est fondamentalement avec état, mémorisant la dernière version correcte de votre programme ainsi que les annotations et la sémantique disponibles. Il préserve ces annotations et ces petits détails même lorsque votre programme est en panne simplement parce que vous avez appuyé sur une touche en trop, et qu’il n’est plus valide. C’est une révolution en termes de productivité, et dès qu’une certaine urgence se fait sentir, cela fait une énorme différence pour le supply chain.

Examinons maintenant le système de types. À titre d’approximation grossière, un système de types est un ensemble de règles qui s’appuie sur la catégorisation des objets dans votre programme, ou sur la catégorisation des éléments que vous manipulez, pour préciser si certaines interactions sont autorisées ou interdites. Par exemple, les types typiques incluent les chaînes de caractères, les entiers et les nombres à virgule flottante, qui sont tous des types très basiques. Il définira qu’ajouter deux entiers est valide, mais qu’ajouter une chaîne de caractères et un entier ne l’est pas, sauf en JavaScript où la sémantique est différente.
Les systèmes de types, en général, constituent un problème de recherche ouvert et peuvent devenir incroyablement abstraits. Pour y voir plus clair, il faut préciser qu’il existe deux sortes de types, souvent confondues. D’abord, il y a les types des valeurs, qui n’existent qu’à l’exécution, lorsque le programme tourne réellement. Par exemple, en Python, si l’on considère une fonction qui renvoie le premier élément d’un tableau d’entiers, alors le type de la valeur renvoyée par cette fonction sera un entier. Dans cette perspective, tous les langages de programmation ont des types – ils sont tous typés.
Ensuite, il y a les types de variables, qui n’existent qu’à la compilation, pendant que le programme est compilé et non encore exécuté. Le défi concernant les types de variables consiste à extraire autant d’informations que possible sur ces variables lors de la compilation. Si nous revenons à l’exemple précédent, en Python, il peut être possible ou non d’identifier le type de la valeur renvoyée par la fonction, car Python n’est pas entièrement fortement typé à la compilation.
D’un point de vue supply chain, nous recherchons un système de types qui supporte ce que nous avons l’intention de faire pour le bénéfice de la supply chain. Nous voulons être aussi restrictifs que possible pour détecter les problèmes et bugs dès le début, mais également aussi flexibles que possible pour permettre toutes les opérations susceptibles de présenter un intérêt. Par exemple, considérez l’addition d’une date et d’un entier. Dans un langage de programmation classique, vous diriez probablement que ce n’est pas légitime, mais d’un point de vue supply chain, si nous avons une date et souhaitons ajouter sept jours, il serait logique d’écrire “date + 7”. Il existe de nombreuses opérations en planification supply chain qui impliquent de déplacer des dates d’un certain nombre de jours, il serait donc utile de disposer d’une algèbre où il est permis d’effectuer une addition entre une date et un nombre.
En termes de types, souhaitons-nous autoriser l’addition d’une date à une autre ? Probablement pas. Cependant, souhaitons-nous autoriser la soustraction entre deux dates ? Pourquoi pas ? Si nous soustrayons une date d’une autre qui la précède, nous obtenons le delta, qui pourrait être exprimé en jours. Cela a beaucoup de sens pour les calculs impliqués dans la planification.
En poursuivant sur le sujet des dates, il existe également des caractéristiques susceptibles d’intéresser lorsqu’on réfléchit à ce qu’un système de types devrait faire pour nous en matière de préoccupations supply chain. Par exemple, qu’en est-il de restreindre l’intervalle de temps acceptable ? Nous pourrions dire que les dates en dehors d’une plage de 20 ans dans le passé et de 20 ans dans le futur ne sont tout simplement pas valides. Il y a de fortes chances que, lors d’une opération de planification, et à un moment donné du programme, si nous manipulons une date située à plus de 20 ans dans le futur, il soit presque certain que ce n’est pas un scénario de planification valide pour la plupart des industries. Dans la plupart des cas, vous ne planifiez pas des opérations quotidiennes plus de 20 ans à l’avance. Ainsi, nous pouvons non seulement reprendre les types usuels, mais les redéfinir de manière plus restrictive et plus appropriée aux besoins supply chain.
De plus, il y a tout l’aspect de l’incertitude. En gestion de la supply chain, nous regardons toujours vers l’avenir, mais malheureusement, l’avenir est toujours incertain. La manière mathématique d’embrasser l’incertitude est par le biais des variables aléatoires. Il serait logique d’incorporer des variables aléatoires dans le langage pour représenter la demande future incertaine, les délais d’approvisionnement, et les retours clients, entre autres.
Chez Lokad, nous avons conçu Envision, un langage de programmation dédié à l’optimisation prédictive des supply chains. Envision est un mélange de SQL, Python, d’optimisation mathématique, de deep learning et de capacités big data, le tout intégré en tant que citoyens de première classe dans le langage lui-même. Ce langage est accompagné d’un environnement de développement intégré (IDE) basé sur le web, ce qui signifie que vous pouvez écrire un script à partir du web et bénéficier de toutes les fonctionnalités modernes d’édition de code. Ces scripts opèrent sur un système de fichiers distribué intégré qui fait partie de l’environnement Lokad, de sorte que la couche de données est entièrement intégrée au langage de programmation.
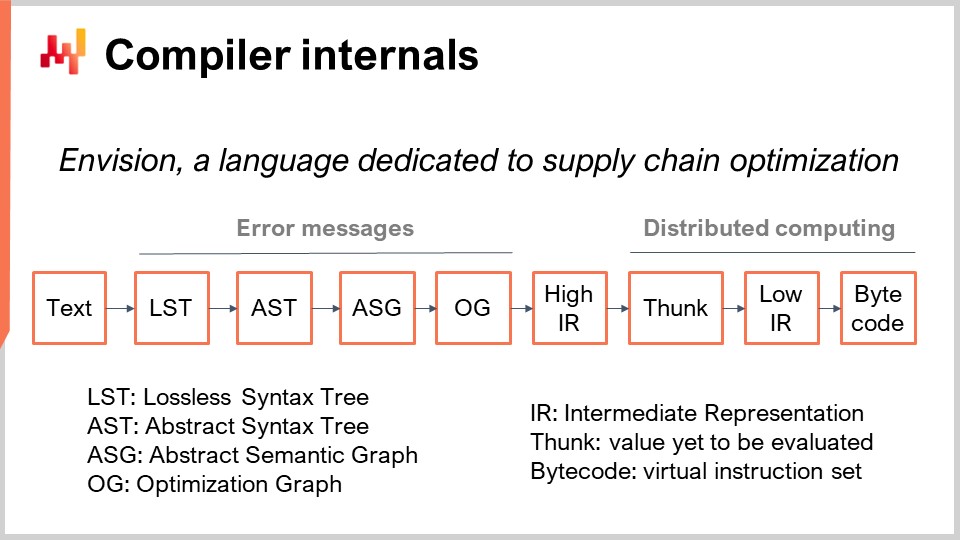
Les scripts Envision s’exécutent sur une flotte de machines, conçues pour tirer parti de l’ensemble du cloud computing. Lorsque le script est lancé, il se répartira sur de nombreuses machines afin de s’exécuter plus rapidement. À l’écran, vous pouvez voir le pipeline du compilateur utilisé par Envision. Aujourd’hui, nous n’allons pas discuter de ce langage de programmation ; nous allons simplement discuter de son pipeline de compilation, car c’est le sujet d’intérêt de la conférence d’aujourd’hui.
Tout d’abord, nous partons d’un morceau de texte qui contient le script Envision. Il représente un programme écrit par un expert supply chain, et non par un ingénieur logiciel, pour répondre à un défi spécifique supply chain. Ce défi pourrait consister à décider quoi produire, quoi réapprovisionner, quoi déplacer, ou s’il faut ajuster un prix à la hausse ou à la baisse. Ces cas d’utilisation impliquent des décisions sur ce qu’il faut produire, réapprovisionner, déplacer, ou si les prix doivent être ajustés à la hausse ou à la baisse. Le texte du script contient les instructions, et l’idée est de traiter ce script et d’obtenir l’Arbre Syntaxique Sans Perte (LST). Le LST est intéressant car il représente une représentation très spécifique qui ne supprime aucun caractère. Même les espaces blancs non significatifs sont préservés. La raison en est de garantir que toute réécriture automatisée du programme ne modifie pas le code existant. Cette approche évite des situations où des outils réorganisent le code, déplacent les indentations ou provoquent d’autres perturbations qui rendent le code difficile à reconnaître.
Une opération de refactoring de base, par exemple, pourrait impliquer le renommage d’une variable et de toutes ses occurrences dans le programme sans toucher à rien d’autre. À partir du LST, nous passons à l’Arbre Syntaxique Abstrait (AST), où nous simplifions l’arbre. Les parenthèses ne sont pas nécessaires à cette étape car la structure arborescente définit les priorités de toutes les opérations. De plus, nous effectuons une série d’opérations de desugaring pour supprimer toute syntaxe fournie pour le bénéfice du programmeur final.
Passant de l’AST au Graphe Syntaxique Abstrait (ASG), nous aplatissons l’arbre. Ce processus consiste à décomposer des instructions complexes comportant des expressions fortement imbriquées en une séquence d’instructions élémentaires. Par exemple, une instruction telle que “a = b + c + d” serait scindée en deux instructions, chacune comportant une seule addition. C’est précisément ce qui se produit lors de la transition de l’AST à l’ASG.
À partir de l’ASG, nous passons au Graphique d’Optimisation (OG), où nous effectuons le façonnage des types et la diffusion, en particulier en relation avec l’algèbre relationnelle. Comme mentionné précédemment, Envision intègre une algèbre relationnelle dans le langage. Comme cela a été suggéré à de nombreuses reprises, Envision intègre une algèbre relationnelle, comme dans les bases de données relationnelles ou SQL, en tant que citoyen de première classe. Il existe de nombreuses opérations relationnelles, et nous vérifions que ces opérations relationnelles sont valides selon le schéma des tables avec lesquelles nous opérons lors de la transition de l’ASG à l’OG. Le Graphique d’Optimisation (OG) représente la dernière étape de notre front-end du compilateur et se compose d’opérations relationnelles pures et élémentaires appliquées au programme, représentant de minuscules portions de logique. Comme en SQL, ces éléments sont de nature relationnelle.
Le graphique d’optimisation est appelé “optimization” parce qu’il existe de nombreuses transformations qui se produisent de OG à OG. Ces transformations interviennent car, lorsqu’il s’agit d’algèbre relationnelle, organiser les opérations d’une certaine manière peut accélérer considérablement l’exécution du programme. Par exemple, en SQL, si vous avez un filtre suivi d’une opération, ou une opération suivie d’un filtre, il est bien meilleur de filtrer d’abord les données, puis d’appliquer l’opération. Cela garantit que les opérations ne sont appliquées qu’aux données nécessaires, améliorant ainsi l’efficacité.
Chez Lokad, la dernière étape du compilateur front-end est la Représentation Intermédiaire Haute (HIR). Le HIR constitue une frontière propre, stable et documentée entre le front-end et le back-end du pipeline de compilation. Contrairement au Graphique d’Optimisation (OG), qui change constamment en raison des heuristiques, le HIR est stable et fournit une entrée cohérente pour le back-end du compilateur. De plus, le HIR est sérialisable, ce qui signifie qu’il peut facilement être transformé en un paquet d’octets à transférer d’une machine à une autre. Cette propriété est essentielle pour distribuer les calculs sur plusieurs machines.
À partir de la Représentation Intermédiaire Haute, nous passons aux “funcs”. Les funcs sont des valeurs qui n’ont pas encore été évaluées et représentent les blocs atomiques de calcul dans une exécution distribuée. Par exemple, lors de l’addition de deux vecteurs gigantesques provenant d’une table contenant des milliards de lignes, il y aura une série de funcs représentant diverses portions de ces vecteurs. Chaque func est responsable d’additionner une portion des deux vecteurs et est exécutée sur une machine. Les gros calculs sont divisés en plusieurs funcs afin de répartir la charge de travail sur plusieurs CPU et plusieurs machines si le calcul est suffisamment important pour justifier ce degré de distribution. Les funcs sont qualifiées de “lazy” parce qu’elles ne sont pas évaluées d’emblée ; elles le sont lorsqu’elles sont nécessaires. De nombreux calculs peuvent être effectués avant que certaines funcs ne soient réellement calculées, et une fois qu’une func est calculée, celle-ci est remplacée par son résultat.
À l’intérieur de la func, vous trouverez la représentation intermédiaire basse, qui représente la logique impérative de bas niveau qui s’exécute au sein de la func. Elle peut, par exemple, inclure des boucles et des accès aux dictionnaires. Enfin, cette représentation intermédiaire de bas niveau est compilée en bytecode, qui représente l’objectif final de notre pipeline de compilation. Chez Lokad, nous ciblons le bytecode .NET, techniquement connu sous le nom de MSIL.
D’un point de vue supply chain, ce qui est vraiment intéressant, c’est qu’à travers ce pipeline de compilation sans doute complexe, nous reproduisons le niveau d’intégration que l’on trouve dans Microsoft Excel. Le langage est intégré à la couche de données et à la couche UI/UX, permettant aux utilisateurs de voir et d’interagir avec les résultats du programme, tout comme ils le feraient avec un tableur Excel. Cependant, contrairement à Excel, nous abordons des domaines bien plus intéressants pour la gestion supply chain en intégrant les concepts relationnels en tant que citoyens de première classe, ainsi que l’optimisation mathématique et le deep learning.
À la fois l’optimisation mathématique et le deep learning dans ce pipeline traversent l’ensemble du pipeline, au lieu de se contenter d’appeler une librairie qui se trouve quelque part. Avoir le deep learning en tant que citoyen de première classe dans le pipeline permet d’obtenir des messages d’erreur plus intelligibles, ce qui fait une grande différence en termes de productivité pour les experts supply chain.

Pour aborder un dernier sujet, les compilateurs ciblent de nos jours presque toujours une machine virtuelle, mais ces machines virtuelles, à leur tour, sont compilées vers une autre machine virtuelle. À l’écran, les couches VM typiques que l’on trouve dans une configuration serveur sont très similaires à ce que nous avons avec un script Envision. Je viens de présenter le pipeline de compilation, mais fondamentalement, ce serait pratiquement la même pile si nous pensions à un script Python ou à un tableur Excel exploité depuis un serveur. Lors de la conception d’un compilateur, vous choisissez essentiellement la couche dans laquelle vous allez injecter le code. Plus la couche est profonde, plus vous devez aborder de subtilités techniques. Pour choisir la couche, il y a une série de préoccupations qui doivent être prises en compte.
Premièrement, il y a la sécurité. Comment protéger votre mémoire et qu’est-ce que le programme devrait ou ne devrait pas accéder ? Si vous disposez d’un langage de programmation générique, vos options sont limitées. Il se peut que vous deviez opérer au niveau du système d’exploitation invité, bien que même cela puisse ne pas être très sécurisé. Il existe des méthodes pour sandboxer, mais c’est très délicat, vous pourriez donc même devoir descendre plus bas que cela.
Deuxièmement, il y a la question des fonctionnalités de bas niveau qui vous intéressent. Par exemple, cela peut être important si vous souhaitez obtenir une exécution plus performante, réduisant la quantité de ressources de calcul nécessaires pour terminer votre programme. Vous pouvez décider de descendre suffisamment bas afin de gérer la mémoire et les threads. Cependant, ce pouvoir s’accompagne de la responsabilité de gérer effectivement la mémoire et les threads.
Troisièmement, il y a des fonctionnalités de commodité comme la garbage collection, la stack trace, le debugger et le profiler. En général, toute l’instrumentation autour du compilateur est plus complexe que le compilateur lui-même. Le nombre de fonctionnalités de commodité dont vous bénéficiez ne doit pas être sous-estimé.
Quatrièmement, il y a des préoccupations concernant l’allocation des ressources. Si vous utilisez un tableur Excel sur votre bureau, Excel peut consommer toutes les ressources informatiques de votre poste de travail. Cependant, avec Envision ou SQL, vous avez plusieurs utilisateurs à servir, et vous devez décider comment allouer les ressources. De plus, avec Envision, il ne s’agit pas seulement de servir plusieurs utilisateurs, mais plusieurs entreprises, car Lokad est multi-tenant. Cela a du sens en supply chain car le besoin en ressources informatiques est très intermittent pour la plupart des supply chains.
Typiquement, vous n’avez besoin d’un pic de calcul intense que pendant environ une demi-heure ou peut-être une heure, puis rien pendant les 23 heures suivantes. Ensuite, le cycle se répète quotidiennement. Si vous deviez allouer des ressources matérielles de calcul à une seule entreprise, ces ressources resteraient inutilisées 90 % du temps, voire plus. Ainsi, vous souhaitez pouvoir répartir la charge de travail sur plusieurs machines et sur de nombreuses entreprises, potentiellement des entreprises opérant dans différents fuseaux horaires.
Enfin, il y a la question de l’écosystème. L’idée est que lorsque vous décidez d’une couche spécifique et d’une machine virtuelle spécifique à cibler pour votre compilateur, il sera assez commode d’intégrer et d’interfacer votre compilateur avec ce qui cible également exactement les mêmes machines virtuelles. Cela soulève la question de l’écosystème : que peut-on trouver au même niveau que ce que vous ciblez, afin de ne pas réinventer la roue pour chaque petit détail impliqué dans toute votre pile ? C’est la dernière préoccupation importante.

En conclusion, félicitations aux heureux élus qui sont arrivés si loin dans cette série de conférences supply chain. C’est probablement l’une des conférences les plus techniques à ce jour. Les compilateurs sont, sans doute, un élément très technique ; cependant, la réalité des supply chains modernes est que tout est médiatisé par un langage de programmation. Il n’existe plus de supply chain brute, directement observable. La seule façon d’observer une supply chain est à travers la médiation des enregistrements électroniques produits par toutes les pièces de logiciels d’entreprise constituant le paysage applicatif. Ainsi, un langage de programmation est nécessaire, et par défaut, ce langage de programmation se trouve être Excel.
Cependant, si nous voulons faire mieux qu’Excel, nous devons réfléchir sérieusement à ce que signifie réellement “mieux” d’un point de vue supply chain et ce que cela implique en termes de langages de programmation. Si une entreprise n’a pas la bonne stratégie ou la bonne culture, aucune technologie ne pourra la sauver. Cependant, si la stratégie et la culture sont solides, alors les outils comptent vraiment. Les outils, y compris les langages de programmation, définiront votre capacité à exécuter, la productivité que vous pouvez attendre de vos experts supply chain, et la performance que vous obtiendrez de votre supply chain en transformant la macro-stratégie en des milliers de décisions quotidiennes banales que votre supply chain doit prendre. Être capable d’évaluer l’adéquation des outils, y compris les langages de programmation que vous envisagez d’utiliser pour répondre aux défis supply chain, est d’une importance primordiale. Si vous n’êtes pas en mesure d’évaluer, alors ce n’est qu’un simple cargo cult.

La prochaine conférence portera sur l’ingénierie logicielle. Aujourd’hui, nous avons discuté des outils ; cependant, la prochaine fois, nous aborderons les personnes qui utilisent ces outils et le type de travail d’équipe nécessaire pour bien faire le travail. La conférence se tiendra le même jour de la semaine, le mercredi, à 15h, heure de Paris.
Maintenant, je vais jeter un œil aux questions.
Question : Lors de la sélection de logiciels pour des supply chains, comment les entreprises qui ne sont pas férues de technologie peuvent-elles évaluer si le compilateur et la programmation conviennent à leurs besoins ?
Eh bien, je suis presque sûr qu’une entreprise typique qui exploite une supply chain typique n’a pas les qualifications pour concevoir un véhicule, pourtant elle parvient à acheter des camions qui sont adaptés aux exigences de sa supply chain et de son transport. Ce n’est pas parce que vous n’êtes pas un expert et que vous n’êtes pas capable de reconstruire et de re-concevoir un camion que vous ne pouvez pas avoir une opinion très solide sur le fait de savoir si c’est un bon camion pour vos besoins de transport. Ainsi, je ne dis pas que les entreprises qui ne sont pas férues de technologie devraient faire un bond en avant incroyable et devenir soudainement des expertes en conception de compilateurs. Cependant, je crois qu’en seulement une heure et demie, nous avons couvert pas mal de terrain. Avec dix heures supplémentaires d’une introduction plus détaillée et à un rythme plus lent, vous apprendriez tout ce dont vous aurez jamais besoin en termes de conception de langages pour les besoins de la supply chain.
Il y a une différence entre être un expert et être d’une ignorance telle que l’on peut se faire vendre un scooter en prétendant que c’est un camion. Si nous devions transposer ce type d’ignorance que j’ai observée en matière de conception de logiciels d’entreprise à l’industrie automobile, des gens prétendraient qu’un scooter est un semi et vice versa, et s’en tireraient.
Cette série de conférences porte sur des sciences auxiliaires, il n’est donc pas prévu que les personnes souhaitant devenir praticiens de la supply chain deviennent des experts dans ces domaines. Néanmoins, en acquérant quelques connaissances de base, vous pouvez aller très loin dans l’évaluation. La plupart du temps, il vous suffit d’avoir juste assez de connaissances pour poser des questions pointues. Si le fournisseur vous donne une réponse insensée, cela ne fait pas bonne impression. Si vous ne savez même pas quelles questions techniques poser, vous pouvez vous faire berner.
Ma suggestion est que vous n’avez pas besoin de devenir incroyablement férus de technologie ; il vous suffit d’être suffisamment averti pour être un amateur débutant capable de trouver des failles et d’évaluer si l’ensemble s’écroule ou s’il existe une véritable substance derrière. Il en va de même pour l’optimisation mathématique, le machine learning, les CPU, etc. L’idée est d’en savoir assez pour faire la distinction entre quelque chose de frauduleux et quelque chose de légitime.
Question : Avez-vous directement abordé le problème des langages de programmation existants qui ne sont pas conçus pour la supply chain ?
C’est une très bonne question. Concevoir un tout nouveau langage de programmation peut sembler complètement fou. Pourquoi ne pas opter pour quelque chose de déjà bien établi, comme Python, et y apporter les petites modifications dont nous avons besoin ? Cela aurait pu être une option. Le problème est que la principale question n’est pas vraiment ce que nous devons ajouter à ces langages, mais ce que nous devons en retirer.
Ma principale préoccupation concernant Python n’est pas qu’il ne dispose pas d’une algèbre probabiliste ou d’une algèbre relationnelle intégrée. Ma critique numéro un est qu’il s’agit d’un langage de programmation générique et entièrement capable, et qu’il expose donc la personne qui va écrire du code à toutes sortes de concepts, comme la programmation orientée objet en Python, qui sont complètement sans importance du point de vue de la supply chain. Le problème n’était pas tant de prendre un langage et d’y ajouter quelque chose, mais de prendre un langage et d’essayer d’en retirer une multitude d’éléments. Cependant, le problème est que dès que l’on retire des choses à un langage de programmation existant, tout se casse.
Par exemple, la première version de Python est sortie en 1990, c’est donc un langage de programmation âgé de 30 ans. La quantité de code dans une stack populaire comme Python est absolument gigantesque, et pour une bonne raison. Je ne le critique pas ; c’est une stack très solide, mais également énorme. En fin de compte, nous avons évalué diverses options : prendre un langage de programmation, en retirer une multitude d’éléments jusqu’à ce que nous soyons satisfaits de ce que nous avons, ou considérer que tous ces langages de programmation ont eux-mêmes de nombreux héritages.
Nous avons évalué l’effort nécessaire pour créer un tout nouveau langage, et au final, c’était clairement en faveur de la création d’un nouveau langage. Concevoir un nouveau langage de programmation est un domaine bien établi, donc bien que cela puisse paraître incroyable, ce ne l’est pas. Il existe des centaines de livres qui vous fournissent des recettes, et c’est désormais même accessible aux étudiants en informatique. Il y a même des professeurs dans les départements d’informatique qui donnent à leurs étudiants un devoir, sur un semestre, de créer un compilateur pour un nouveau langage de programmation.
En fin de compte, nous avons décidé que les supply chains étaient suffisamment vastes pour justifier un effort dédié. Oui, vous pouvez toujours recycler des éléments qui n’ont pas été conçus pour les supply chains, mais les supply chains constituent une industrie et un ensemble de problèmes mondiaux et majeurs. Nous avons donc pensé qu’à l’échelle à laquelle nous nous situons, il est logique de faire les choses correctement et de créer quelque chose directement pour la supply chain plutôt que de recourir à un recyclage accidentel.
Question : Pour l’optimization de la supply chain, Envision est approprié car il comprend SQL, Python, etc. Cependant, pour le WMS, ERP, où le flux de processus est essentiel plutôt que l’optimisation mathématique, comment pouvez-vous évaluer son compilateur et son langage de programmation ?
C’est une très bonne question. J’ai personnellement envisagé l’idée qu’il existe dans cette industrie des acteurs qui ont réellement conçu leurs propres langages de programmation, uniquement pour bénéficier de la mise en œuvre de quelque chose de complètement transactionnel par nature, orienté vers le workflow. La supply chain, telle que je la conçois, est essentiellement axée sur l’optimisation prédictive. Cependant, M. Nannani a parfaitement raison ; qu’en est-il de toute la partie gestion, comme l’ERP, le WMS, etc. ?
Il s’avère qu’il y a de nombreuses entreprises dans ce domaine qui ont conçu leur propre langage de programmation. J’ai mentionné SAP, qui possède ABAP, conçu juste pour cela. Malheureusement, ABAP n’a pas bien vieilli, à mon avis. Il y a plein d’éléments dans ABAP qui n’ont vraiment pas de sens au XXIe siècle. On voit vraiment que ce truc a été conçu en ‘83, et cela se remarque. Par exemple, dans Microsoft Dynamics, l’ERP a son propre langage de programmation. Dynamics AX a son propre langage de programmation, et il existe de nombreux projets ERP qui, dans une large mesure, apportent leur propre langage de programmation. Donc, il existe bel et bien.
Maintenant, est-ce que ces langages sont vraiment le summum de ce que nous pouvons faire en termes de langages de programmation modernes et à la pointe de la technologie en 2021 ? Je ne le pense pas, et c’est là aussi le problème que j’évoquais : les fournisseurs de logiciels d’entreprise continuent de réinventer les langages de programmation, mais en général, ils font un travail très médiocre. C’est simplement un design d’ingénierie hasardeux. Ils ne prennent même pas le temps de lire les nombreux livres disponibles sur le marché, et ensuite, ce sont de pauvres ingénieurs qui se retrouvent avec un sacré foutoir.
Pour revenir à votre question, j’ai envisagé l’idée que Lokad se lance dans ce domaine et crée un langage conçu non pas pour l’optimisation, mais pour soutenir le workflow. Cependant, à ce stade, la croissance de Lokad est telle que nous ne pouvons pas nous diversifier et nous occuper des workflows. Je suis absolument certain que c’est tout à fait exact, et qu’il y aura de nouveaux acteurs qui émergeront et accompliront un excellent travail pour la partie gestion du problème. Lokad ne s’attaque qu’à la partie optimisation des supply chains ; il y a également la partie gestion.
Question : Python est actuellement considéré comme un langage de programmation standard. Y a-t-il des évolutions en cours sur le marché ?
C’est une très bonne question. Vous voyez, quand on me parle de “standards”, j’ai assez d’expérience pour voir les standards aller et venir. Je ne suis pas très vieux, mais quand j’étais au lycée, le standard était le C++. Dans les années 90, le C++ était le standard. Pourquoi feriez-vous autrement ? Puis vint Java, autour de l’année 2000, et la combinaison de Java et XML était le standard.
Les gens disaient même que les universités de l’époque s’étaient transformées en “écoles de Java”. C’était littéralement le terme du jour autour de l’année 2000 ; on disait : “Ce n’est plus une université d’informatique ; c’est juste une école de Java.” Quelques années plus tard, lorsque j’ai fondé Lokad, le langage de programmation pour tout ce qui était pertinent en matière de statistiques était encore R. Python était encore très marginal, et R dominait absolument le domaine en termes d’analyse statistique.
Au fur et à mesure que nous progressons en termes de langages de programmation, le C++ s’est estompé. Microsoft a introduit le C# en 2002 et la plateforme .NET, qui a cannibalisé une partie significative de l’écosystème C++. Une grande partie des développeurs C++ dans le monde étaient chez Microsoft, une entreprise très massive. L’essentiel du message est qu’il y a eu une évolution continue, et chaque année, les gens considèrent cela comme s’il existait un standard, mais ce standard change constamment.
JavaScript existe depuis 20 ans, mais il n’était pas particulièrement remarquable. Puis, un livre publié autour de 2009 ou 2012, intitulé “JavaScript: The Good Parts”, a révélé que JavaScript n’était pas complètement insensé. Vous pouviez utiliser JavaScript pour un projet réel sans perdre la tête ; il fallait simplement s’en tenir aux bonnes parties. Soudainement, JavaScript est devenu incontournable, et les gens ont commencé à l’utiliser côté serveur avec un système appelé Node.js.
Python n’a gagné en notoriété qu’il y a quelques années, après que la communauté Python ait subi une mise à niveau pénible de la version 2.7 à la version 3.x. À l’issue de cette mise à niveau, l’intérêt pour Python a été renouvelé. Cependant, de nombreux dangers guettent Python. Ce n’est pas un très bon langage selon les critères du XXIe siècle. C’est un langage âgé de 30 ans, et son âge se voit. Si vous voulez quelque chose de meilleur dans tous les domaines, sauf en termes de maturité, vous pourriez vous tourner vers Julia. Julia est supérieur à Python dans presque tous les aspects pour la data science, sauf en maturité, où Julia accuse encore des années de retard.
Il y a une multitude d’évolutions en cours, et il est facile de confondre l’état de l’industrie avec quelque chose qui est censé être un standard pérenne. Par exemple, dans l’écosystème Apple, il y avait Objective-C, puis Apple a décidé de produire Swift en remplacement, qui est maintenant en train de remplacer Objective-C. Le paysage des langages de programmation évolue encore beaucoup, et bien que cela prenne du temps, si nous regardons l’écosystème dans dix ans, il y aura probablement une évolution significative. Python ne sortira peut-être pas comme le langage de programmation dominant, car il existe de nombreuses options rivales qui apportent de meilleures réponses.
Question : Les entreprises alimentaires et les startups du le e-commerce pensent souvent pouvoir gagner la bataille avec des équipes de data science et des langages à usage général. Quel serait votre principal argument de vente pour les amener à affiner cette approche et à leur faire réaliser qu’ils ont besoin de quelque chose de plus spécifique au problème ?
Comme je l’ai dit, c’est le problème de l’effet Dunning-Kruger. Vous donnez à un ingénieur logiciel un système de programmation linéaire en nombres entiers mixtes pour faire de la programmation en nombres entiers, et une semaine plus tard, cette personne pensera qu’elle est soudainement devenue une experte en optimisation discrète. Alors, comment gagnez-vous la bataille ? Pour être honnête, généralement, nous ne les gagnons pas. Ce que je fais, c’est décrire comment les catastrophes vont se dérouler.
C’est simple lorsque vous utilisez des blocs technologiques génériques pour créer des prototypes fantastiques. Ces prototypes fonctionnent brillamment grâce à l’illusion Star Wars – vous avez simplement votre morceau de technologie isolé. Lorsque ces entreprises commenceront à essayer de mettre ces choses en production, elles auront des difficultés, la plupart du temps à cause de problèmes très banals. Elles feront face à des problèmes d’intégration constants, contrairement à Google, Microsoft ou Amazon, qui peuvent se permettre d’avoir mille ingénieurs pour s’occuper de toute la plomberie.
TensorFlow, par exemple, est difficile à intégrer. Google dispose des 1000 ingénieurs nécessaires pour assembler TensorFlow dans tous ses pipelines d’extraction de données et applications pour ses besoins. Mais la question est de savoir si les startups ou les entreprises du le e-commerce peuvent se permettre d’avoir autant de personnes pour s’occuper de toute la plomberie ? Généralement, la réponse est non. Les gens imaginent qu’en choisissant simplement ces outils, ils pourront sélectionner les éléments et les assembler, et que cela fonctionnera magiquement. Mais ce n’est pas le cas. Cela nécessite une énorme quantité d’ingénierie.
Au fait, certains fournisseurs de logiciels d’entreprise souffrent du même problème. Ils ont beaucoup trop de composants dans leur solution, ce qui explique pourquoi le déploiement d’une solution, sans aucune personnalisation, prend déjà des mois parce qu’il y a tant de parties instables dans le système qui ne sont que faiblement intégrées. Cela devient très difficile.
Je suppose que c’était la dernière question. À la prochaine fois.


