00:00 Introduction
02:49 Demande, prix et profit
09:35 Prix compétitifs
15:23 Envies vs besoins
20:09 L’histoire jusqu’à présent
23:36 Plan pour aujourd’hui
25:17 L’unité de besoin
31:03 Voitures et pièces (récapitulatif)
33:41 Intelligence concurrentielle
36:03 Résolution de l’alignement (1/4)
39:26 Résolution de l’alignement (2/4)
43:07 Résolution de l’alignement (3/4)
46:38 Résolution de l’alignement (4/4)
56:21 Gammes de produits
59:43 Pièces non contraintes
01:02:44 Contrôle de la marge
01:06:54 Classements affichés
01:08:29 Ajustement fin des pondérations
01:12:45 Ajustement fin des compatibilités (1/2)
01:19:14 Ajustement fin des compatibilités (2/2)
01:30:41 Contre-espionnage (1/2)
01:35:25 Contre-espionnage (2/2)
01:40:49 Surstocks et ruptures de stocks
01:45:45 Conditions d’expédition
01:47:58 Conclusion
01:50:33 6.2 Optimisation des prix pour l’aftermarket automobile - Questions?
Description
L’équilibre de l’offre et de la demande dépend en grande partie des prix. Ainsi, l’optimisation des prix appartient au domaine de la supply chain, du moins dans une large mesure. Nous présenterons une série de techniques pour optimiser les prix d’une entreprise fictive de l’aftermarket automobile. À travers cet exemple, nous verrons le danger associé aux raisonnements abstraits qui ne parviennent pas à saisir le contexte réel. Savoir ce qui doit être optimisé est plus important que les détails de l’optimisation elle-même.
Transcription complète

Bienvenue dans cette série de conférences sur la supply chain. Je suis Joannes Vermorel, et aujourd’hui je vais présenter l’optimisation des prix pour l’aftermarket automobile. La tarification est un aspect fondamental de la supply chain. En effet, on ne peut pas se pencher sur l’adéquation d’un certain volume d’offre ou d’un certain volume de stocks sans prendre en compte la question des prix, car les prix influencent significativement la demande. Cependant, la plupart des ouvrages sur la supply chain, et par conséquent, la plupart des supply chain software, négligent complètement la tarification. Même lorsque la tarification est évoquée ou modélisée, cela se fait généralement de manière naïve, interprétant souvent mal la situation.
La tarification est un processus fortement dépendant du domaine. Les prix constituent avant tout un message envoyé par une entreprise vers le marché en général - aux clients, mais aussi aux fournisseurs et aux concurrents. Les subtilités de l’analyse tarifaire dépendent fortement de l’entreprise en question. Aborder la tarification de manière générale, comme le font les microéconomistes, peut être intellectuellement séduisant, mais peut également s’avérer erroné. Ces approches peuvent ne pas être suffisamment précises pour permettre l’élaboration de stratégies de tarification de niveau professionnel.
Cette conférence se concentre sur l’optimisation des prix pour une entreprise fictive de l’aftermarket automobile. Nous reviendrons sur Stuttgart, une entreprise fictive introduite dans le troisième chapitre de cette série de conférences. Nous nous concentrerons exclusivement sur le segment de vente en ligne de Stuttgart qui distribue des pièces automobiles. L’objectif de cette conférence est de comprendre ce qu’implique la tarification une fois que l’on dépasse les banalités et comment aborder la tarification avec une mentalité ancrée dans la réalité. Bien que nous considérions un secteur étroit - les pièces de rechange automobiles pour l’aftermarket - la façon de penser, l’état d’esprit et l’attitude adoptés dans cette conférence lors de la recherche de stratégies tarifaires supérieures seraient essentiellement les mêmes pour des secteurs totalement différents.
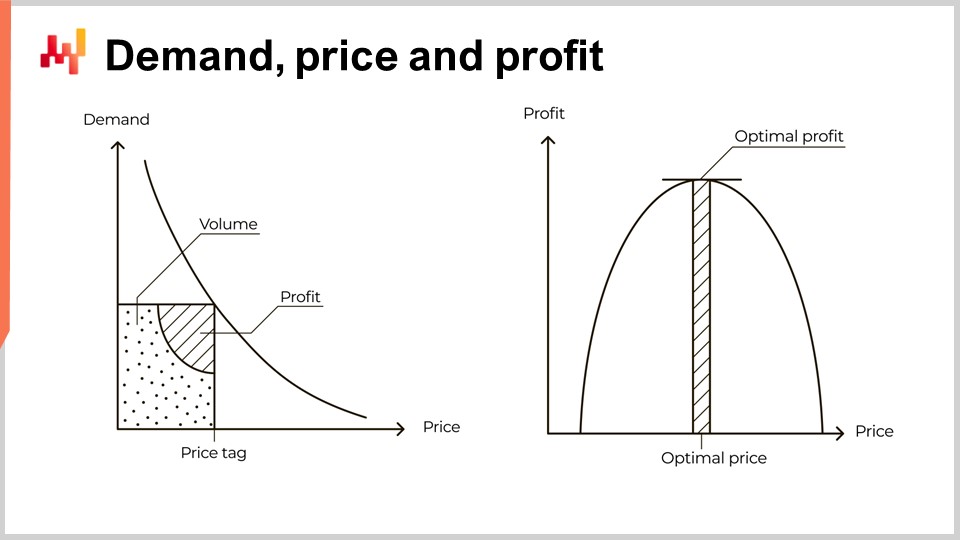
La demande diminue à mesure que le prix augmente. Il s’agit d’un schéma économique universel. L’existence même de produits qui contredisent ce schéma demeure, au mieux, insaisissable. Ces produits sont appelés biens de Veblen. Cependant, en 15 ans chez Lokad, même en traitant avec des marques de luxe, je n’ai jamais eu l’accès à une preuve tangible que de tels produits existent réellement. Ce schéma universel est illustré par la courbe située à gauche de l’écran, généralement appelée courbe de demande. Lorsqu’un marché se fixe un prix, par exemple, le prix d’une pièce de rechange automobile, ce marché génère un certain volume de demande et, espérons-le, un certain volume de profit pour les acteurs qui répondent à cette demande.
En ce qui concerne les pièces de rechange automobiles, celles-ci ne sont définitivement pas des biens de Veblen. La demande diminue bien à mesure que le prix augmente. Toutefois, comme les consommateurs n’ont pas beaucoup de choix lorsqu’ils achètent des pièces automobiles, du moins s’ils veulent continuer à utiliser leur voiture, la demande peut être considérée comme relativement inélastique. Un point de prix plus élevé ou plus bas pour vos plaquettes de frein n’altère pas réellement votre décision d’acheter de nouvelles plaquettes. En effet, la plupart des gens préféreraient acheter de nouvelles plaquettes, même s’ils doivent payer le double du prix habituel, plutôt que de cesser d’utiliser leur véhicule.
Pour Stuttgart, identifier le meilleur prix pour chaque pièce est crucial pour une myriade de raisons. Examinons les deux plus évidentes. Tout d’abord, Stuttgart souhaite maximiser ses profits, ce qui n’est pas trivial car non seulement la demande varie en fonction du prix, mais les coûts varient également avec le volume. Stuttgart doit être en mesure de satisfaire la demande qu’il générera dans le futur, ce qui est encore plus difficile, car les stocks doivent être assurés plusieurs jours, voire semaines à l’avance, en raison des contraintes de délais.
Sur la base de cette exposition limitée, certains manuels, et même certains logiciels d’entreprise, utilisent la courbe illustrée à droite. Cette courbe illustre conceptuellement le volume de profit attendu pour chaque étiquette de prix. Étant donné que la demande diminue à mesure que le prix augmente, et que le coût unitaire diminue lorsque le volume augmente, cette courbe devrait présenter un point de profit optimal maximisant le profit. Une fois ce point optimal identifié, l’ajustement de l’approvisionnement en stocks se présente comme une simple question d’orchestration. En effet, le point optimal fournit non seulement une étiquette de prix, mais aussi un volume de demande.
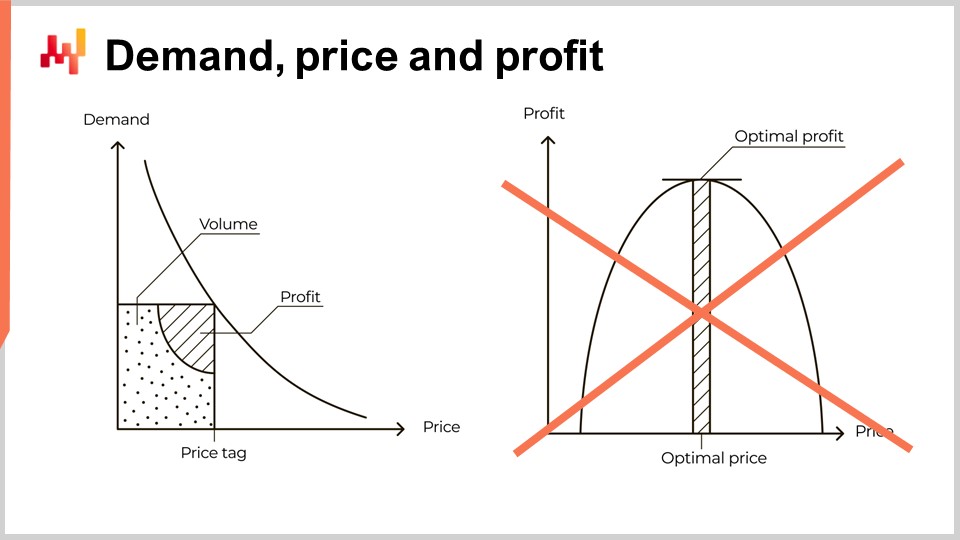
Cependant, cette perspective est profondément erronée. Le problème n’a rien à voir avec la difficulté de quantifier l’élasticité. Ma proposition n’est pas que la courbe de gauche soit incorrecte ; elle est fondamentalement correcte. Mon affirmation est que le saut de la courbe de gauche à celle de droite est erroné. En fait, ce saut est si étonnamment faux qu’il sert en quelque sorte de test probant. Tout fournisseur de logiciels ou manuel de tarification qui présente la tarification de cette manière fait preuve d’un degré dangereux d’illettrisme économique, surtout s’il présente l’évaluation de l’élasticité comme le défi central associé à cette perspective. Ce n’est même pas vaguement le cas. Confier une supply chain réelle à un tel fournisseur ou expert invite à la douleur et à la misère. S’il y a une chose dont votre supply chain n’a pas besoin, c’est d’une interprétation erronée d’une microéconomie mal comprise à grande échelle.
Dans cette série de conférences, il s’agit d’une autre manifestation de rationalisme naïf ou de scientisme, qui s’est avéré à maintes reprises être une menace importante pour les supply chains modernes. Le raisonnement économique abstrait est puissant parce qu’il englobe une multitude de situations. Cependant, le raisonnement abstrait est également susceptible de grossières interprétations erronées. De grandes erreurs intellectuelles qui ne sont pas immédiatement apparentes peuvent survenir lorsqu’on pense de manière très générale.
Pour comprendre pourquoi le saut de la courbe de gauche à celle de droite est incorrect, nous devons examiner de plus près ce qui se passe réellement dans une supply chain. Cette conférence se concentre sur les pièces de rechange automobiles. Nous réexaminerons la tarification du point de vue de Stuttgart, une entreprise fictive de supply chain introduite dans le troisième chapitre de cette série de conférences. Nous ne reviendrons pas sur les détails de cette entreprise. Si vous n’avez pas encore regardé la conférence 3.4, je vous invite à le faire après cette conférence.
Aujourd’hui, nous étudions le segment de vente en ligne de Stuttgart, une division de le e-commerce qui vend des pièces automobiles. Nous explorons les moyens les plus appropriés pour que Stuttgart détermine ses prix et les révise à tout moment. Cette tâche doit être effectuée pour chaque pièce vendue par Stuttgart.

Stuttgart n’est pas seul sur ce marché. Dans chaque pays européen où Stuttgart opère, il y a une demi-douzaine de concurrents notables. Cette courte liste d’entreprises, y compris Stuttgart, représente la majorité des parts de marché en ligne pour les pièces de rechange automobiles. Alors que Stuttgart vend exclusivement certaines pièces, pour la plupart des pièces vendues, il y a au moins un concurrent notable qui vend exactement la même pièce. Ce fait a des implications importantes pour l’optimisation des prix de Stuttgart.
Prenons le cas d’une pièce donnée, si Stuttgart décide de fixer le prix de cette pièce à un euro en dessous du prix proposé par un concurrent vendant la même pièce. En théorie, cela rendrait Stuttgart plus compétitif et aiderait à capturer des parts de marché. Mais pas si vite. Le concurrent surveille tous les prix fixés par Stuttgart. En effet, l’aftermarket automobile est un marché très compétitif. Tout le monde dispose d’outils d’intelligence concurrentielle. Stuttgart collecte quotidiennement tous les prix de ses concurrents notables, et les concurrents font de même. Ainsi, si Stuttgart décide de fixer le prix d’une pièce à un euro en dessous du prix proposé par un concurrent, il est raisonnable de supposer qu’en un jour ou deux, le concurrent aura baissé son prix en représailles, annulant le mouvement de prix de Stuttgart.
Bien que Stuttgart puisse être une entreprise fictive, ce comportement concurrentiel décrit ici n’est absolument pas fictif dans l’aftermarket automobile. Les concurrents alignent agressivement leurs prix. Si Stuttgart tente de baisser ses prix de manière répétée, cela conduira à une guerre algorithmique des prix, laissant les deux entreprises avec peu ou pas de marge à la fin de la guerre.
Considérons ce qui se passe si, pour une pièce donnée, Stuttgart décide de fixer le prix de cette pièce à un euro au-dessus du prix proposé par un concurrent. En supposant que tout le reste reste égal à part l’étiquette de prix, Stuttgart n’est tout simplement plus compétitif. Ainsi, même si la clientèle de Stuttgart ne se détourne pas immédiatement au profit du concurrent (car elle pourrait ne pas être au courant de la différence de prix ou rester fidèle à Stuttgart), avec le temps, la part de marché de Stuttgart est vouée à diminuer.
Il existe des sites de comparaison de prix en Europe pour les pièces automobiles. Bien que les clients ne fassent pas une comparaison à chaque fois qu’ils ont besoin d’une nouvelle pièce pour leur voiture, la plupart des clients réévalueront leurs options de temps en temps. Ce n’est pas une solution viable pour Stuttgart d’être systématiquement perçu comme le concessionnaire le plus cher.
Ainsi, nous avons vu que Stuttgart ne peut pas fixer un prix inférieur à celui de la concurrence, car cela déclencherait une guerre des prix. Inversement, Stuttgart ne peut pas fixer un prix supérieur à celui de la concurrence, car cela garantit une érosion de sa part de marché au fil du temps. La seule option restante pour Stuttgart est de chercher un alignement des prix. Ce n’est pas une affirmation théorique : l’alignement des prix est le principal moteur des véritables entreprises de le e-commerce qui vendent des pièces automobiles en Europe.
La courbe de profit intellectuellement séduisante que nous avons présentée précédemment, selon laquelle les entreprises pourraient prétendument choisir le profit optimal, est en grande partie totalement fictive. Stuttgart n’a même pas le choix en matière de tarification. Dans une large mesure, à moins qu’il n’y ait une sorte d’ingrédient secret, l’alignement des prix est la seule option pour Stuttgart.
Les marchés libres sont une bête étrange, comme le disait Engels dans sa correspondance de 1819 : “La volonté individuelle est entravée par celle de tous les autres, et ce qui émerge est quelque chose que personne n’a voulu.” Nous verrons par la suite que Stuttgart conserve encore une marge résiduelle pour fixer ses prix. Cependant, la proposition principale reste : l’optimisation des prix pour Stuttgart est avant tout un problème fortement contraint, qui n’a rien à voir avec une perspective de maximisation naïve entraînée par une courbe de demande.
L’élasticité de la demande par rapport au prix est un concept qui a du sens pour un marché dans son ensemble, mais généralement pas autant pour quelque chose d’aussi localisé qu’un numéro de pièce.

L’idée que la tarification puisse être abordée comme un simple problème de maximisation des profits en s’appuyant sur la courbe de demande est fallacieuse—ou du moins, elle l’est dans le cas de Stuttgart.
En effet, on pourrait soutenir que Stuttgart appartient à un marché des besoins, et la perspective des courbes de profit fonctionnerait encore si nous considérions un marché des envies. En marketing, il est classique de distinguer les marchés des envies des marchés des besoins. Un marché des envies est généralement caractérisé par des offres où les clients peuvent se passer de leur consommation sans subir de conséquences négatives. Dans les marchés des envies, les offres réussies tendent à être fortement liées à la marque du vendeur, et la marque elle-même est le moteur qui génère la demande dès le départ. Par exemple, la mode est l’archétype des marchés des envies. Si vous voulez un sac de Louis Vuitton, alors ce sac ne peut être acheté que chez Louis Vuitton. Bien qu’il y ait des centaines de vendeurs proposant des sacs fonctionnellement équivalents, ils ne seront pas un sac de Louis Vuitton. Si vous renoncez à acheter un sac de Louis Vuitton, alors rien de grave ne vous arrivera.
Un marché de besoin est typiquement caractérisé par des offres où les clients ne peuvent pas renoncer à leur consommation sans en subir de mauvaises conséquences. Dans les marchés de besoins, les marques ne sont pas des moteurs de demande ; elles sont plutôt des moteurs de choix. Les marques guident les clients dans le choix de la source de consommation dès qu’un besoin se présente. Par exemple, l’alimentation et les nécessités de base constituent l’archétype des marchés de besoins. Même si les pièces automobiles ne sont pas strictement indispensables pour survivre, beaucoup de personnes dépendent d’un véhicule pour gagner leur vie, et ainsi, elles ne peuvent pas se permettre de négliger l’entretien de leur véhicule, car le coût de l’absence d’entretien dépasserait de loin celui de l’entretien lui-même.
Bien que le marché secondaire automobile se situe fermement dans le marché de besoins, il existe des nuances. Certains composants, comme les enjoliveurs, relèvent davantage du vouloir que du besoin. De façon plus générale, tous les accessoires sont davantage des désirs que des besoins. Néanmoins, pour Stuttgart, ce sont bien les besoins qui pilotent la grande majorité de la demande.
La critique que je propose ici contre la courbe de profit appliquée à la tarification se généralise à presque toutes les situations dans les marchés de besoins. Stuttgart n’est pas un cas particulier en étant sévèrement limité sur le plan des prix par ses concurrents ; cette situation est pratiquement omniprésente dans les marchés de besoins. Cet argument ne réfute pas la viabilité de la courbe de profit lorsqu’on considère les marchés de désirs.
En effet, on pourrait contre-argumenter que dans un marché de désirs, si le fournisseur détient un monopole sur sa propre marque, alors il devrait être libre de fixer le prix qui maximise son profit, nous ramenant ainsi à la perspective de la courbe de profit pour la tarification. Encore une fois, ce contre-argument illustre les dangers d’un raisonnement économique abstrait en supply chain.
Dans un marché de désirs, la perspective de la courbe de profit est également erronée, mais pour un ensemble de raisons complètement différentes. Les détails de cette démonstration dépassent le cadre de la présente conférence puisqu’ils nécessiteraient une conférence à part entière. Toutefois, à titre d’exercice pour l’audience, je suggère simplement de jeter un œil attentif à la liste des sacs et à leurs prix affichés sur le site le e-commerce de Louis Vuitton. La raison pour laquelle la perspective de la courbe de profit est inappropriée devrait alors apparaître de manière évidente. Sinon, nous réexaminerons sans doute ce cas dans une conférence ultérieure.
Cette série de conférences est conçue, entre autres, comme matériel de formation pour les supply chain scientists chez Lokad. Cependant, j’espère également que ces conférences intéresseront un public beaucoup plus large de praticiens de supply chain. J’essaie de garder ces conférences quelque peu indépendantes, mais j’emploierai quelques concepts techniques qui ont été introduits dans les conférences précédentes. Je ne passerai pas trop de temps à réintroduire ces concepts. Si vous n’avez pas visionné les conférences précédentes, n’hésitez pas à les consulter ultérieurement.
Dans le premier chapitre de cette série, nous avons exploré pourquoi les supply chains doivent devenir programmatiques. Il est fortement souhaitable de mettre en production une recette numérique en raison de la complexité toujours croissante des supply chains. L’automatisation est plus urgente que jamais et il existe une nécessité financière de faire de la pratique supply chain une entreprise capitaliste.
Dans le deuxième chapitre, nous avons consacré du temps aux méthodologies. Les supply chains sont des systèmes compétitifs et cette combinaison défie les méthodologies naïves. Nous avons vu que cette combinaison fait également échouer des modèles qui interprètent ou caractérisent mal la microéconomie.
Le troisième chapitre a passé en revue les problèmes rencontrés dans les supply chains, en mettant de côté les solutions. Nous avons présenté Stuttgart comme l’un des personae de la supply chain. Ce chapitre a tenté de caractériser les types de problèmes décisionnels à résoudre et a montré que des perspectives simplistes, comme choisir la bonne quantité de stocks, ne correspondent pas aux situations réelles. Il existe invariablement une profondeur dans la nature des décisions à prendre.
Le chapitre quatre a passé en revue les éléments nécessaires pour comprendre les pratiques modernes de supply chain, où les éléments logiciels sont omniprésents. Ces éléments sont fondamentaux pour appréhender le contexte plus large dans lequel opère la supply chain digitale.
Les chapitres cinq et six sont consacrés respectivement à la modélisation prédictive et à la prise de décision. Ces chapitres rassemblent des techniques qui fonctionnent bien entre les mains des supply chain scientists d’aujourd’hui. Le sixième chapitre se concentre sur la tarification, un type de décision à prendre parmi tant d’autres.
Enfin, le septième chapitre est consacré à l’exécution d’une initiative de la Supply Chain Quantitative et couvre la perspective organisationnelle.

La conférence d’aujourd’hui sera divisée en deux grands segments. Tout d’abord, nous aborderons la manière d’envisager l’alignement compétitif des prix pour Stuttgart. Aligner les prix sur ceux des concurrents doit être envisagé du point de vue du client, en raison de la structure unique du marché des pièces détachées automobiles. Bien que l’alignement compétitif soit très complexe, il bénéficie d’une solution relativement simple que nous détaillerons.
Deuxièmement, bien que l’alignement compétitif soit la force dominante, ce n’est pas le seul levier d’action. Stuttgart peut avoir besoin, ou souhaiter, de s’écarter sélectivement de cet alignement. Cependant, les bénéfices de ces écarts doivent compenser les risques encourus. La qualité de l’alignement dépend de la qualité des données utilisées pour le construire, aussi nous introduirons une technique de self-supervised learning pour affiner le graphe des compatibilités mécaniques.
Enfin, nous aborderons une courte série de problématiques adjacentes à la tarification. Ces préoccupations ne relèvent pas strictement de la tarification, mais en pratique, elles se traitent le mieux conjointement avec les prix.

Stuttgart doit apposer une étiquette de prix sur chaque pièce qu’elle vend, mais cela n’implique pas que l’analyse des prix doive être effectuée principalement au niveau du numéro de pièce. La tarification est, avant tout, un moyen de communiquer avec les clients.
Prenons un moment pour réfléchir à la manière dont les clients perçoivent les prix proposés par Stuttgart. Comme nous le verrons, la distinction apparemment subtile entre l’étiquette de prix et la perception de cette étiquette n’est en réalité pas subtile du tout.
Lorsqu’un client commence à chercher une nouvelle pièce automobile, généralement une pièce consommable comme les plaquettes de frein, il est peu probable qu’il connaisse le numéro de pièce précis dont il a besoin. Il peut y avoir quelques passionnés d’automobile qui maîtrisent tellement le sujet qu’ils ont un numéro de pièce spécifique en tête, mais ils constituent une petite minorité. La plupart des gens savent simplement qu’ils doivent changer leurs plaquettes de frein, sans connaître le numéro exact de la pièce.
Cette situation conduit à une autre préoccupation sérieuse : la compatibilité mécanique. Il existe des milliers de références de plaquettes de frein sur le marché ; cependant, pour un véhicule donné, il n’y a généralement que quelques dizaines de références compatibles. Ainsi, la compatibilité mécanique ne peut être laissée au hasard.
Stuttgart, comme tous ses concurrents, est pleinement conscient de ce problème. Lorsqu’un visiteur se rend sur le site le e-commerce de Stuttgart, il est invité à spécifier le modèle de sa voiture, puis le site filtre immédiatement les pièces qui ne sont pas mécaniquement compatibles avec le véhicule sélectionné. Les sites des concurrents suivent le même schéma : d’abord choisir le véhicule, puis sélectionner la pièce.
Lorsqu’un client cherche à comparer deux fournisseurs, il compare généralement les offres, et non les numéros de pièce. Un client visiterait le site de Stuttgart, identifierait le coût des plaquettes de frein compatibles, puis répéterait le processus sur le site d’un concurrent. Le client pourrait identifier le numéro de pièce des plaquettes sur le site de Stuttgart, puis rechercher exactement le même numéro sur le site du concurrent, mais en pratique, cela est rare.
Stuttgart et ses concurrents élaborent soigneusement leurs assortiments afin de pouvoir desservir presque tous les véhicules avec une fraction des numéros de pièces automobiles disponibles. En conséquence, ils affichent généralement entre 100 000 et 200 000 numéros de pièces sur leurs sites, et seuls 10 000 à 20 000 numéros de pièces se retrouvent effectivement dans les stocks.
En ce qui concerne notre préoccupation initiale relative à la tarification, il est clair que l’analyse des prix doit être effectuée principalement non pas à travers le prisme des numéros de pièces, mais par l’unité de besoin. Dans le contexte du marché secondaire automobile, une unité de besoin est caractérisée par le type de pièce à remplacer et par le modèle de voiture nécessitant le remplacement.
Cependant, cette vision de l’unité de besoin présente une complication technique immédiate. Stuttgart ne peut pas se fier à une correspondance un à un des prix entre les numéros de pièces pour aligner ses prix sur ceux de ses concurrents. Ainsi, l’alignement des prix n’est pas aussi évident qu’il n’y paraît au premier abord, surtout en tenant compte des contraintes auxquelles Stuttgart doit faire face vis-à-vis de ses concurrents.

Comme nous l’avons déjà vu dans la conférence 3.4, le problème de la compatibilité mécanique entre voitures et pièces est traité en Europe, ainsi que dans d’autres grandes régions du monde, grâce à l’existence d’entreprises spécialisées. Ces entreprises commercialisent des jeux de données de compatibilité mécanique, composés de trois listes : une liste de modèles de voitures, une liste de pièces automobiles, et une liste de compatibilités entre voitures et pièces. Cette structure de jeu de données est techniquement connue sous le nom de graphe bipartite.
En Europe, ces jeux de données comportent généralement plus de 100 000 véhicules, plus d’un million de pièces, et plus de 100 millions d’arêtes reliant les voitures aux pièces. Leur maintenance demande un travail considérable, ce qui explique l’existence d’entreprises spécialisées pour les commercialiser. Stuttgart, comme ses concurrents, souscrit à un abonnement auprès de l’une de ces entreprises spécialisées afin d’accéder aux versions actualisées de ces jeux de données. Les abonnements sont nécessaires car, même si l’industrie automobile est mature, de nouvelles voitures et de nouvelles pièces sont continuellement introduites. Pour rester en phase avec le paysage automobile, ces jeux de données doivent être actualisés au minimum trimestriellement.
Stuttgart, ainsi que ses concurrents, utilise ce jeu de données pour alimenter le mécanisme de sélection des véhicules sur leurs sites le e-commerce. Une fois qu’un client a choisi un véhicule, seules sont affichées les pièces qui, d’après le jeu de données de compatibilité, sont démontrablement compatibles avec le véhicule sélectionné. Ce jeu de données est également fondamental pour notre analyse de tarification. Grâce à lui, Stuttgart peut évaluer le point de prix proposé pour chaque unité de besoin.

Le dernier ingrédient significatif manquant pour construire la stratégie d’alignement compétitif de Stuttgart est l’intelligence économique. En Europe, comme dans toutes les grandes régions économiques, il existe des spécialistes de l’intelligence économique — des entreprises qui fournissent des services de scraping de prix. Ces entreprises extraient quotidiennement les prix de Stuttgart et de ses concurrents. Bien qu’une entreprise comme Stuttgart puisse tenter de limiter l’extraction automatisée de ses prix, cette démarche est généralement vaine pour plusieurs raisons :
Premièrement, Stuttgart, comme ses concurrents, souhaite être favorable aux robots. Les bots les plus importants sont les moteurs de recherche, Google détenant, en 2023, une part de marché légèrement supérieure à 90 %. Ce n’est pas le seul moteur de recherche, cependant, et bien qu’il soit possible d’identifier Googlebot, le principal crawler de Google, il est difficile de faire de même pour tous les autres crawlers qui représentent encore environ 10 % du trafic.
Deuxièmement, les spécialistes de l’intelligence économique sont devenus experts au cours de la dernière décennie pour se faire passer pour du trafic internet résidentiel classique. Ces services prétendent avoir accès à des millions d’adresses IP résidentielles, ce qu’ils réalisent en s’associant avec des applications, en profitant des connexions internet des utilisateurs ordinaires, et en collaborant avec des FAI (Fournisseurs d’Accès à Internet) capables de leur prêter des adresses IP.
Ainsi, nous partons du principe que Stuttgart bénéficie d’une liste de prix de haute qualité provenant de ses concurrents notables. Ces prix sont extraits au niveau du numéro de pièce et mis à jour quotidiennement. Cette hypothèse n’est pas spéculative ; c’est l’état actuel du marché européen.

Nous avons désormais rassemblé tous les éléments dont Stuttgart a besoin pour calculer des prix alignés – des prix qui correspondent à ceux de ses concurrents lorsqu’ils sont envisagés du point de vue de l’unité de besoin.
À l’écran, nous présentons le pseudocode relatif au problème de satisfaction de contraintes que nous souhaitons résoudre. Nous énumérons simplement toutes les unités de besoin, c’est-à-dire toutes les combinaisons de types de pièces et de modèles de voitures. Pour chaque unité de besoin, nous énonçons que le prix le plus compétitif proposé par Stuttgart doit être égal à celui proposé par un concurrent.
Examinons rapidement le nombre de variables et de contraintes. Stuttgart peut fixer une étiquette de prix pour chaque numéro de pièce qu’elle propose, ce qui signifie que nous disposons d’environ 100 000 variables. Le nombre de contraintes est un peu plus complexe. Techniquement, nous disposons d’environ 1 000 types de pièces et d’environ 100 000 modèles de voitures, soit approximativement 100 millions de contraintes. Cependant, tous les types de pièces ne se retrouvent pas sur tous les modèles de voitures. Des mesures concrètes indiquent que le nombre de contraintes est plus proche de 10 millions.
Malgré ce nombre réduit de contraintes, nous avons néanmoins 100 fois plus de contraintes que de variables. Nous faisons face à un système fortement surcontraint. Ainsi, nous savons qu’il est peu probable de trouver une solution qui satisfera toutes les contraintes. Le meilleur résultat est une solution de compromis qui en satisfait la majorité.
De plus, les concurrents ne sont pas entièrement cohérents quant à leurs prix. Malgré nos meilleurs efforts, Stuttgart peut se retrouver engagée dans une guerre des prix sur un numéro de pièce, en raison d’une étiquette de prix trop basse. Simultanément, elle peut perdre des parts de marché sur ce même numéro de pièce parce que son étiquette de prix est jugée trop élevée par rapport à celle d’un concurrent. Ce scénario n’est pas théorique ; les données empiriques suggèrent que ces situations se produisent régulièrement, bien que pour un petit pourcentage de numéros de pièces.
Comme nous avons opté pour une résolution approximative de ce système de contraintes, il nous faut préciser le poids à attribuer à chacune d’entre elles. Tous les modèles de voitures ne se valent pas – certains sont associés à d’anciens véhicules qui ont presque entièrement disparu des routes. Nous proposons de pondérer ces contraintes en fonction du volume de demande respectif, exprimé en euros.
Maintenant que nous avons établi le cadre formel de notre logique de tarification, passons au code logiciel proprement dit. Comme nous allons le voir, la résolution de ce système est plus simple que prévu.
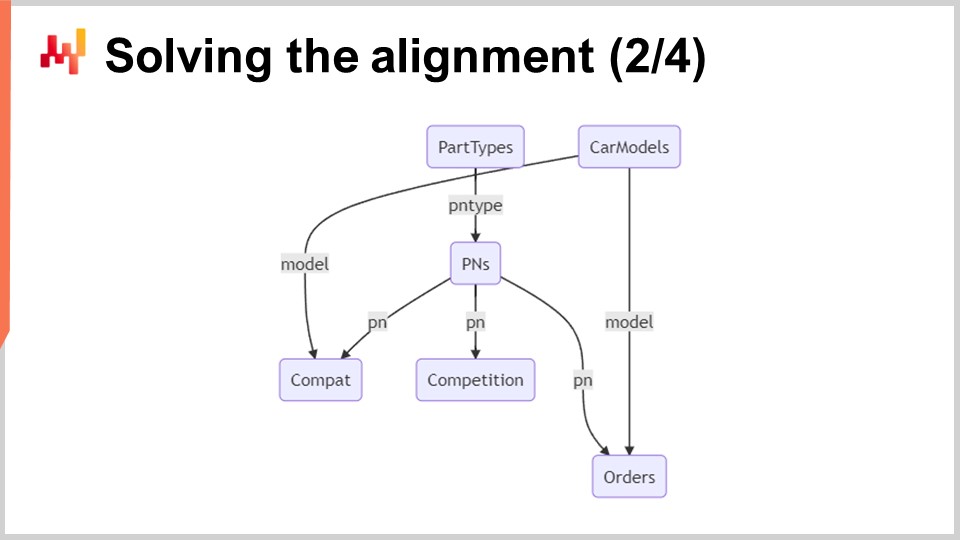
À l’écran, un schéma relationnel minimal illustre les six tables impliquées dans ce système. Les rectangles aux coins arrondis représentent les six tables d’intérêt, et les flèches représentent les relations un-à-plusieurs entre les tables.
Passons en revue brièvement ces tables :
-
Types de pièces : Comme son nom l’indique, cette table répertorie les types de pièces, par exemple, “plaquettes de frein avant”. Ces types servent à identifier quelle pièce peut être utilisée comme remplacement pour une autre. La pièce de remplacement doit non seulement être compatible avec le véhicule mais également être du même type. Il existe environ un millier de types de pièces.
-
Modèles de voitures : Cette table répertorie les modèles de voitures, par exemple, “Peugeot 3008 Phase 2 diesel”. Chaque véhicule possède un modèle, et tous les véhicules d’un même modèle sont supposés avoir le même ensemble de compatibilités mécaniques. Il existe environ une centaine de milliers de modèles de voitures.
-
Numéros de pièces (PNs) : Cette table répertorie les numéros de pièces présents sur le marché de l’après-vente automobile. Chaque numéro de pièce correspond à un et un seul type de pièce. Il y a environ 1 million de numéros de pièces dans cette table.
-
Compatibilité (Compat) : Cette table représente les compatibilités mécaniques et recense toutes les combinaisons valides de numéros de pièces et de modèles de voitures. Avec environ 100 millions de lignes de compatibilités, cette table est de loin la plus grande.
-
Competition : Cette table contient toute l’intelligence concurrentielle du jour. Pour chaque numéro de pièce, une demi-douzaine de concurrents notables affichent le numéro de pièce avec une étiquette de prix. Cela donne environ 10 millions de prix concurrentiels.
-
Orders : Cette table contient les commandes clients passées à Stuttgart sur une période d’environ un an. Chaque ligne de commande inclut un numéro de pièce et un modèle de voiture. Techniquement, il est possible d’acheter une pièce automobile sans spécifier le modèle de la voiture, bien que cela soit rare. Toutes les lignes de commande sans modèle de voiture peuvent être filtrées. En fonction de la taille de Stuttgart, il devrait y avoir environ 10 millions de lignes de commande.
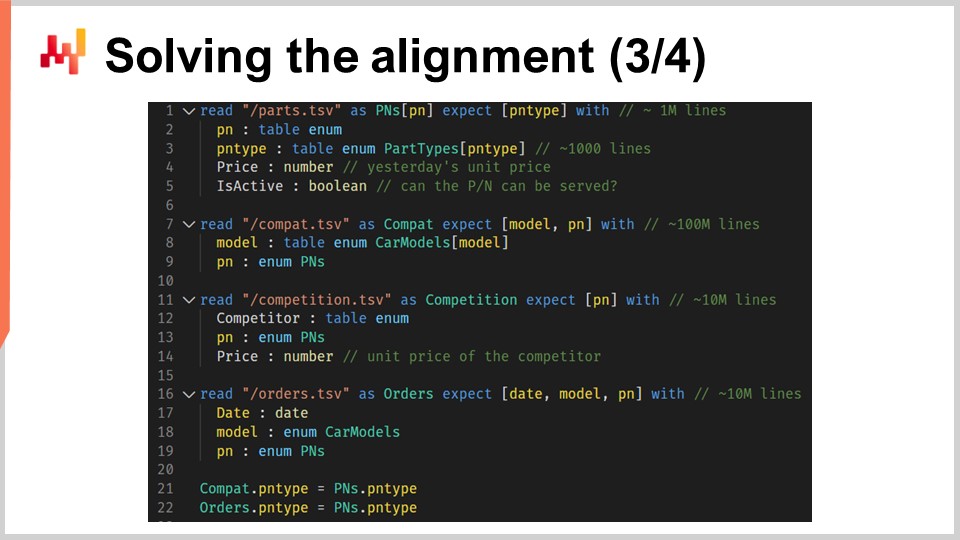
Nous allons maintenant examiner le code qui charge les données relationnelles. Affiché à l’écran, un script charge six tables, écrit en Envision - un langage de programmation spécifique au domaine, conçu par Lokad spécifiquement pour l’optimisation prédictive des supply chains. Bien qu’Envision ait été créé pour augmenter l’efficacité et réduire les erreurs dans les contextes de supply chain, le script peut être réécrit dans d’autres langages tels que Python, bien que cela s’accompagne d’une verbosité accrue et d’un risque d’erreurs plus élevé.
Dans la première partie du script, quatre fichiers texte plats sont chargés. De la ligne 1 à 5, le fichier “path.csv” fournit à la fois les numéros de pièces et les types de pièces, incluant les prix actuels affichés à Stuttgart. Le champ “name is active” indique si un numéro de pièce spécifique est desservi par Stuttgart. Dans cette première table, la variable “PN” se réfère à la dimension principale de la table, tandis que “PN type” est une dimension secondaire introduite par le mot-clé “expect”.
De la ligne 7 à 9, le fichier “compat.tsv” fournit la liste de compatibilité pièce-véhicule ainsi que les modèles de voitures. Il s’agit de la table la plus volumineuse du script. Les lignes 11 à 14 chargent le fichier “competition.tsv”, offrant un instantané de l’intelligence concurrentielle du jour, c’est-à-dire les prix par numéro de pièce et par concurrent. Le fichier “orders.tsv”, chargé des lignes 16 à 19, nous donne la liste des numéros de pièces achetés et les modèles de voitures associés, en supposant que toutes les lignes associées à des modèles de voitures non spécifiés ont été filtrées.
Enfin, aux lignes 21 et 22, la table “types de pièces” est définie comme en amont des deux tables, “compat” et “orders”. Cela signifie que pour chaque ligne dans “compat” ou “orders”, il existe un et un seul type de pièce correspondant. En d’autres termes, “PN type” a été ajouté en tant que dimension secondaire aux tables “compat” et “orders”. Cette première partie du script Envision est simple ; nous chargeons simplement des données à partir de fichiers texte plats et rétablissons la structure de données relationnelle dans le processus.
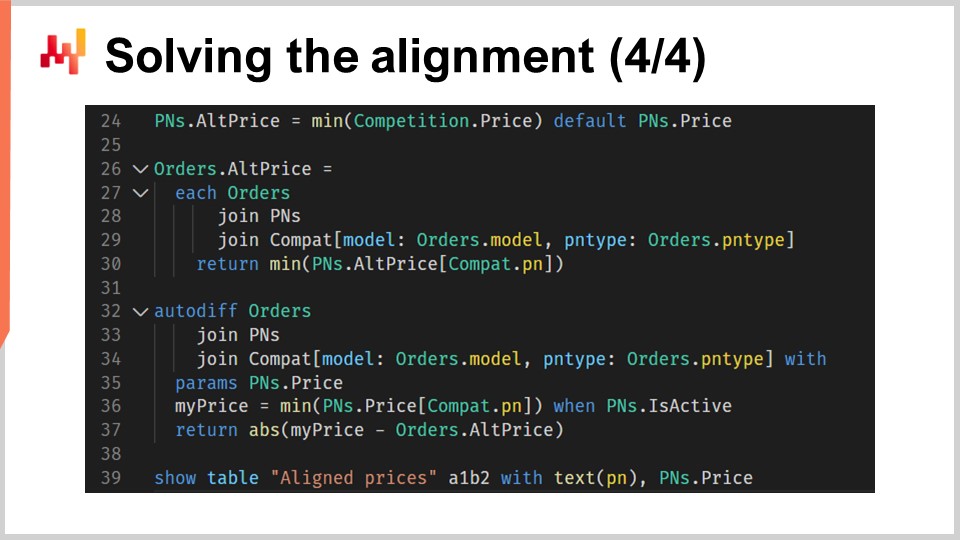
La seconde partie du script, qui est visible à l’écran, est celle où se déroule la logique d’alignement réelle. Cette section constitue une continuité directe de la première partie, et comme vous pouvez le constater, elle ne comporte que 12 lignes de code. Nous utilisons à nouveau la differentiable programming. Pour le public qui ne serait pas familier avec la differentiable programming, il s’agit d’une fusion entre la différentiation automatique et la descente de gradient stochastique. C’est un paradigme de programmation qui s’étend également à l’apprentissage automatique et à l’optimisation. Dans le contexte de la supply chain, la differentiable programming s’avère incroyablement utile dans diverses situations. Tout au long de cette série de conférences, nous avons démontré comment la differentiable programming peut être utilisée pour apprendre des modèles, générer des prévisions probabilistes de demande, et obtenir des prévisions balistiques de lead time. Si la differentiable programming vous est inconnue, je vous recommande de revoir les conférences précédentes de cette série.
Dans la conférence d’aujourd’hui, nous verrons comment la differentiable programming est parfaitement adaptée pour résoudre des problèmes d’optimisation à grande échelle impliquant des centaines de milliers de variables et des millions de contraintes. De manière remarquable, ces problèmes peuvent être résolus en seulement quelques minutes sur un seul CPU avec quelques gigaoctets de RAM. De plus, nous pouvons utiliser les prix précédents comme point de départ, actualisant ainsi nos prix au lieu de recalculer depuis le début.
Veuillez noter un léger bémol. Le mot-clé “join” n’est pas encore supporté par Envision, mais il figure sur notre feuille de route technique pour l’avenir. Des solutions de contournement existent, mais pour plus de clarté, j’utiliserai la syntaxe future d’Envision dans cette conférence.
À la ligne 24, nous calculons le prix le plus bas observé sur le marché pour chaque numéro de pièce. Si un numéro de pièce est vendu exclusivement par Stuttgart et n’a pas de concurrents, nous utilisons le prix propre à Stuttgart par défaut.
De la ligne 26 à 30, pour chaque pièce répertoriée dans l’historique des commandes clients de Stuttgart, l’offre la plus compétitive actuelle est calculée.
À la ligne 27, nous parcourons chaque ligne de commande de la table orders avec “each order”.
À la ligne 28, nous utilisons “join pns” pour inclure la table complète des numéros de pièces pour chaque ligne de commande.
À la ligne 29, nous joignons avec “others”, mais cette jointure est restreinte par deux dimensions secondaires - modèle et type de pièce. Cela signifie que pour chaque ligne dans orders, nous sélectionnons les numéros de pièces qui correspondent à une combinaison de modèle de voiture et de type de pièce, reflétant les pièces compatibles avec l’unité de besoin correspondant à la commande client.
De la ligne 32 à 37, nous résolvons l’alignement en utilisant la differentiable programming, indiquée par le mot-clé “Auto diff”. Le bloc “Auto diff” est déclaré à la ligne 32, tirant parti de la table orders comme table d’observation. Cela signifie que nous pondérons implicitement les contraintes en fonction du volume des ventes propre à Stuttgart. Les lignes 33 et 44 servent le même objectif que les lignes 28 et 29 ; elles parcourent la table orders, fournissant un accès complet à la table des numéros de pièces (“PN”) et un extrait des entrées compatibles.
À la ligne 35, nous déclarons “pns.price” comme les paramètres devant être optimisés par la descente de gradient stochastique. Il n’est pas nécessaire d’initialiser ces paramètres, car nous partons des prix utilisés jusqu’à présent par Stuttgart, rafraîchissant ainsi l’alignement.
À la ligne 36, nous calculons “my price”, qui représente l’offre la plus compétitive de Stuttgart pour l’unité de besoin associée à la ligne de commande. Ce calcul est un mécanisme assez similaire à celui du calcul du prix le plus bas observé, comme réalisé à la ligne 24, en s’appuyant à nouveau sur la liste des compatibilités mécaniques. Les compatibilités sont toutefois restreintes aux numéros de pièces desservis par Stuttgart. Historiquement, les clients ont ou non sélectionné la pièce la plus économiquement avantageuse pour leur véhicule. Quoi qu’il en soit, l’objectif de l’utilisation des commandes clients dans ce contexte est d’attribuer des poids aux unités de besoin.
À la ligne 37, nous utilisons la différence absolue entre le meilleur prix proposé par Stuttgart et le meilleur prix offert par un concurrent pour guider l’alignement. Au sein de ce bloc alternatif, des gradients sont rétroactivement appliqués aux paramètres. La différence que nous trouvons à la fin constitue la fonction de perte. À partir de cette fonction de perte, les gradients se répercutent sur le unique vecteur de paramètres que nous avons ici : “pns.price”. En ajustant progressivement les paramètres (les prix) à chaque itération (une itération correspondant ici à une ligne de commande), le script converge vers une approximation appropriée de l’alignement tarifaire souhaité.
En termes de complexité algorithmique, la ligne 36 prédomine. Cependant, comme le nombre de compatibilités pour un modèle de voiture et un type de pièce donnés est limité (généralement pas plus de quelques dizaines), chaque itération “Auto diff” s’effectue en un temps constant. Ce temps constant n’est pas très faible, comme 10 cycles CPU, mais il n’atteindra pas non plus un million de cycles CPU. Approximativement, un millier de cycles CPU semble raisonnable pour 20 pièces compatibles.
Si nous supposons un seul CPU fonctionnant à deux gigahertz et effectuant 100 époques (une époque correspondant à une descente complète sur l’ensemble de la table d’observation), nous anticiperions un temps d’exécution cible d’environ 10 minutes. Résoudre un problème avec 100 000 variables et 10 millions de contraintes en 10 minutes sur un seul CPU est assez impressionnant. En fait, Lokad obtient des performances globalement conformes à cette attente. Cependant, dans la pratique, pour de tels problèmes, notre goulot d’étranglement est le débit d’E/S plutôt que le CPU.
Une fois de plus, cet exemple met en évidence la puissance d’employer des paradigmes de programmation adaptés aux applications de supply chain. Nous avons commencé avec un problème non trivial, car il n’était pas immédiatement évident de savoir comment exploiter ce jeu de données de compatibilité mécanique d’un point de vue tarifaire. Malgré cela, l’implémentation réelle est simple.
Bien que ce script ne couvre pas tous les aspects qui seraient présents dans une configuration réelle, la logique de base ne nécessite que six lignes de code, laissant ainsi une marge suffisante pour intégrer des complexités supplémentaires que pourraient introduire des scénarios du monde réel.

L’algorithme d’alignement, tel que présenté précédemment, privilégie la simplicité et la clarté plutôt qu’une approche exhaustive. Dans une configuration réelle, des facteurs supplémentaires seraient à prévoir. Je passerai en revue ces facteurs prochainement, mais commençons par reconnaître que ces facteurs peuvent être pris en compte en étendant cet algorithme d’alignement.
Vendre à perte n’est pas seulement imprudent, c’est aussi illégal dans de nombreux pays, comme la France, bien qu’il existe des exceptions dans des circonstances particulières. Pour empêcher la vente à perte, une contrainte peut être ajoutée à l’algorithme d’alignement qui impose que le prix de vente dépasse le prix d’achat. Cependant, il est également utile d’exécuter l’algorithme sans cette contrainte “no loss” afin d’identifier d’éventuels problèmes d’approvisionnement. En effet, si un concurrent peut se permettre de vendre une pièce en dessous du prix d’achat de Stuttgart, ce dernier doit s’attaquer au problème sous-jacent. Très probablement, il s’agit d’un problème d’approvisionnement ou d’achat.
Regrouper simplement tous les numéros de pièces est naïf. Les clients n’ont pas la même disposition à payer pour tous les fabricants d’équipements d’origine (OEM). Par exemple, les clients sont plus enclins à accorder de l’importance à une marque bien connue comme Bosch par rapport à un OEM chinois moins connu en Europe. Pour répondre à cette préoccupation, Stuttgart, comme ses pairs, classe les OEM dans une liste restreinte de gammes de produits, allant de la plus coûteuse à la moins coûteuse. Nous pouvons avoir, par exemple, la gamme motorsport, la gamme grand public, la gamme de marques distributeurs, et la gamme économique.
L’alignement est ensuite construit pour garantir que chaque numéro de pièce soit aligné au sein de sa propre gamme de produits. De plus, l’algorithme d’alignement devrait imposer que les prix soient strictement décroissants lors du passage de la gamme motorsport à la gamme économique, car toute inversion serait source de confusion pour les clients. En théorie, si les concurrents fixaient correctement les prix de leurs propres offres, de telles inversions n’auraient pas lieu. Toutefois, en pratique, les clients se trompent parfois dans la tarification de leurs propres pièces, et il leur arrive occasionnellement de fixer des prix différents.
Il n’y a que quelques centaines d’OEM, et les classer dans leurs gammes de produits respectives peut se faire manuellement, et éventuellement avec l’aide d’enquêtes clients en cas d’ambiguïtés qui ne pourraient pas être directement résolues par les experts du marché de Stuttgart.

Malgré l’adoption de gammes de produits, de nombreux prix de numéros de pièces ne sont pas activement influencés par la logique d’alignement. En effet, seuls les numéros de pièces qui contribuent activement à offrir le meilleur prix au sein d’une unité de besoin sont effectivement ajustés par la descente de gradient pour créer l’alignement approximatif que nous recherchons au sein de la même gamme de produits.
Sur deux numéros de pièces ayant des compatibilités mécaniques identiques, un seul verra son prix ajusté par le solveur d’alignement. L’autre numéro de pièce recevra toujours des gradients nuls, et son prix d’origine restera inchangé. Ainsi, en résumé, bien que le système comporte un ensemble complet de contraintes, de nombreuses variables ne sont pas du tout contraintes. Selon la granularité des gammes de produits et l’étendue de l’intelligence concurrentielle, ces numéros de pièces non contraints peuvent représenter une fraction considérable du catalogue, possiblement la moitié des numéros de pièces. Bien que la fraction, une fois exprimée en volume de ventes, soit bien inférieure.
Pour ces numéros de pièces, Stuttgart requiert une stratégie de tarification alternative. Bien que je ne dispose pas d’un processus algorithmique strict à suggérer pour ces pièces non contraintes, je proposerais deux principes directeurs.
Premièrement, il devrait y avoir un écart de prix non négligeable, disons de 10 %, entre la pièce la plus compétitive de la gamme de produits et la pièce suivante. Avec un peu de chance, certains concurrents ne seront pas aussi habiles que Stuttgart pour reconstruire les unités de besoin. Ainsi, ces concurrents pourraient passer à côté de l’étiquette de prix qui influence réellement l’alignement, les amenant à réviser leur prix à la hausse, ce qui est souhaitable pour Stuttgart.
Deuxièmement, il pourrait y avoir certaines pièces avec une étiquette de prix beaucoup plus élevée, disons 30 % plus chère, tant que ces pièces ne se retrouvent pas en chevauchement avec d’autres gammes de produits. Ces pièces servent de leurres pour leurs homologues à meilleur prix, une stratégie techniquement connue sous le nom de decoy pricing. Le leurre est délibérément conçu pour être une option moins attractive que l’option cible, rendant cette dernière plus précieuse et incitant le client à la choisir plus souvent. Ces deux principes suffisent à étaler en douceur les prix non contraints au-delà de leurs seuils concurrentiels.

L’alignement concurrentiel, associé à une dose de decoy pricing, suffit à attribuer une étiquette de prix à chaque numéro de pièce exposé à Stuttgart. Cependant, le taux de gross margin qui en résulte est susceptible d’être trop faible pour Stuttgart. En effet, aligner Stuttgart avec tous ses concurrents notables exerce une pression énorme sur sa marge.
D’une part, aligner les prix est une nécessité ; sinon, Stuttgart sera totalement écarté du marché avec le temps. D’autre part, Stuttgart ne peut pas se ruiner en préservant sa part de marché. Il est crucial de se rappeler que la future gross margin associée à une stratégie tarifaire donnée ne peut être qu’estimée ou prévisionnée. Il n’existe aucune méthode exacte pour déduire le taux de croissance futur d’un ensemble de prix, puisque tant les clients que les concurrents s’adaptent.
En supposant que nous ayons une estimation raisonnablement précise du taux de gross margin que Stuttgart devrait attendre la semaine prochaine, il est important de souligner que la partie « précision » de cette hypothèse n’est pas aussi déraisonnable qu’elle en a l’air. Stuttgart, comme ses concurrents, opère sous de sévères contraintes. À moins que la stratégie tarifaire de Stuttgart ne soit fondamentalement modifiée, la gross margin à l’échelle de l’entreprise ne variera pas beaucoup d’une semaine à l’autre. Nous pouvons même considérer le taux de gross margin observé la semaine dernière comme un proxy raisonnable de ce que Stuttgart devrait attendre la semaine prochaine, en supposant naturellement que la stratégie tarifaire reste inchangée.
Supposons que le taux de gross margin de Stuttgart soit prévu à 13 %, mais que Stuttgart ait besoin d’un taux de 15 % pour se soutenir. Que devrait faire Stuttgart face à une telle situation ? Une réponse consiste à sélectionner aléatoirement des « unités de besoins » et à augmenter leurs prix d’environ 20 %. Les types de pièces privilégiés par les clients pour leur premier achat, comme les essuie-glaces, devraient être exclus de cette sélection. Obtenir ces premiers clients est coûteux et difficile, et Stuttgart ne devrait pas risquer ces achats initiaux. De même, pour des types de pièces très coûteux, comme les injecteurs, les clients sont susceptibles de comparer beaucoup plus. Ainsi, Stuttgart ne devrait probablement pas risquer de paraître non concurrentiel sur ces achats importants.
Cependant, en dehors de ces deux situations, je soutiendrais que sélectionner aléatoirement des « unités de besoins » et les rendre non concurrentielles par des prix plus élevés est une option raisonnable. En effet, Stuttgart doit augmenter certains de ses prix, conséquence inévitable de la recherche d’un taux de croissance de marge supérieur. Si Stuttgart adopte un schéma détectable en le faisant, alors les avis en ligne risquent de le signaler. Par exemple, si Stuttgart décide de renoncer à être concurrentiel sur des pièces de Bosch ou sur des pièces compatibles avec les véhicules Peugeot, il y a un réel danger que Stuttgart soit connu comme le concessionnaire qui n’offre pas de bonnes affaires pour les véhicules Bosch ou Peugeot. L’aléatoire rend Stuttgart quelque peu insondable, ce qui est précisément l’effet recherché.
Les rangs d’affichage sont un autre facteur crucial dans le catalogue en ligne de Stuttgart. Plus précisément, pour chaque « unité de besoin », Stuttgart doit classer toutes les pièces éligibles. Déterminer la meilleure façon de classer ces pièces est un problème adjacent à la tarification qui mérite une conférence à part entière. Dans la perspective présentée dans cette conférence, on s’attendrait à ce que les rangs d’affichage soient calculés après la résolution du problème d’alignement. Cependant, il serait également concevable d’optimiser simultanément les étiquettes de prix et les rangs d’affichage. Ce problème présenterait environ 10 millions de variables au lieu des 100 000 variables dont nous avons traité jusqu’à présent. Néanmoins, cela ne modifie pas fondamentalement l’ampleur du problème d’optimisation, puisque nous avons de toute façon 10 millions de contraintes à gérer. Je n’aborderai pas aujourd’hui quel type de critère pourrait être utilisé pour orienter cette optimisation des rangs d’affichage, ni comment exploiter la descente de gradient pour l’optimisation discrète. Cette dernière problématique est assez intéressante mais sera abordée dans une conférence ultérieure.

L’importance relative de l’« unité de besoin » est presque entièrement définie par les flottes de véhicules existantes. Stuttgart ne peut pas s’attendre à vendre 1 million de plaquettes de frein pour un modèle de voiture qui ne compte que 1 000 véhicules en Europe. On pourrait même soutenir que les véritables consommateurs de pièces sont les véhicules eux-mêmes plutôt que leurs propriétaires. Bien que les véhicules ne paient pas pour leurs pièces (ce sont les propriétaires qui le font), cette analogie permet de souligner l’importance de la flotte.
Cependant, il est raisonnable de s’attendre à d’importantes distorsions concernant l’achat de pièces en ligne par les particuliers. Après tout, acheter des pièces est principalement un moyen d’économiser de l’argent par rapport à un achat indirect via un garage. Par conséquent, l’âge moyen des véhicules tel qu’observé par Stuttgart devrait être supérieur à ce que les statistiques générales du marché automobile suggèrent. De même, les personnes conduisant des voitures onéreuses sont moins susceptibles d’essayer d’économiser de l’argent en effectuant elles-mêmes des réparations. Ainsi, la taille et la catégorie moyennes des véhicules observées par Stuttgart devraient être inférieures à ce que la statistique générale du marché laisserait penser.
Ces spéculations ne sont pas vaines. Ces distorsions sont en effet observées chez tous les grands détaillants de pièces automobiles en ligne en Europe. Pourtant, l’algorithme d’alignement, tel que présenté précédemment, exploite l’historique des ventes de Stuttgart en tant que proxy de la demande. Il est concevable que ces biais puissent compromettre le résultat de l’algorithme d’alignement des prix. Que ces biais aient un impact négatif sur Stuttgart relève fondamentalement d’un problème empirique, puisque l’ampleur du problème, s’il en existe un, dépend fortement des données. L’expérience de Lokad indique que l’algorithme d’alignement et ses variantes sont assez robustes face à ce type de biais, même en surestimant ou en sous-estimant le poids d’une « unité de besoin » par un facteur de deux ou trois. La contribution principale de ces pondérations, en termes de tarification, semble aider l’algorithme d’alignement à résoudre les conflits lorsque le même numéro de pièce appartient à deux « unités de besoin » qui ne peuvent être traitées conjointement. Dans la majorité de ces situations, une « unité de besoin » surpasse largement l’autre en volume. Ainsi, même une estimation erronée de ces volumes a peu de conséquences sur les prix.
Identifier les plus grands écarts entre ce que la demande aurait dû être pour une « unité de besoin » et ce que Stuttgart observe comme ventes réalisées peut s’avérer très utile. Un volume de ventes étonnamment faible pour une « unité de besoin » donnée tend à indiquer des problèmes banals avec la plateforme de e-commerce. Certaines pièces pourraient être mal étiquetées, d’autres pourraient avoir des images incorrectes ou de faible qualité, etc. En pratique, ces biais peuvent être identifiés en comparant les ratios de ventes pour un modèle de voiture donné en fonction des différents types de pièces. Par exemple, si Stuttgart ne vend aucune plaquette de frein pour un modèle de voiture donné, alors que les volumes de ventes pour d’autres types de pièces sont conformes à ce qui est généralement observé, il est peu probable que ce modèle ait une consommation exceptionnellement faible de plaquettes de frein. La cause profonde se trouve presque certainement ailleurs.
Une liste supérieure de compatibilités mécaniques constitue un avantage concurrentiel. Connaître des compatibilités inconnues de vos concurrents vous permet de potentiellement les sous-tarifer sans déclencher une guerre des prix, gagnant ainsi un avantage pour accroître votre part de marché. Inversement, identifier des compatibilités incorrectes est essentiel pour éviter des retours coûteux de la part des clients.
En effet, le coût de commander une pièce incompatible est modeste pour un garage, car il existe probablement un processus établi pour renvoyer la pièce non utilisée au centre de distribution. Toutefois, le processus est beaucoup plus fastidieux pour les clients particuliers qui peuvent même ne pas réussir à reconditionner correctement la pièce pour son retour.
Il y a peu d’incitations à partager cette connaissance avec les entreprises spécialisées qui maintiennent ces ensembles de données en premier lieu, car cette connaissance profiterait principalement à la concurrence. Il est difficile d’évaluer le taux d’erreur dans ces ensembles de données, mais chez Lokad, nous estimons qu’il oscille autour d’un faible pourcentage en un chiffre pour les deux cas. Il y a quelques pour cent de faux positifs, lorsque qu’une compatibilité est déclarée alors qu’elle n’existe pas, et quelques pour cent de faux négatifs, lorsqu’une compatibilité existe mais n’est pas déclarée. En considérant que la liste des compatibilités mécaniques comprend plus de 100 millions de lignes, il y aurait très probablement environ sept millions d’erreurs selon des estimations prudentes.
Par conséquent, il est dans l’intérêt de Stuttgart d’améliorer cet ensemble de données. Les retours clients signalés comme étant causés par une compatibilité mécanique faussement positive peuvent certainement être exploités à cette fin. Cependant, ce processus est lent et coûteux. De plus, comme les clients ne sont pas des techniciens automobiles professionnels, ils pourraient signaler une pièce comme incompatible alors qu’ils ont simplement échoué à la monter. Stuttgart peut retarder la décision de déclarer une pièce incompatible jusqu’à ce que plusieurs plaintes aient été formulées, mais cela rend le processus encore plus coûteux et plus long.
Ainsi, une recette numérique pour améliorer cet ensemble de données de compatibilité serait hautement désirable. Il n’est pas évident qu’il soit même possible d’améliorer cet ensemble de données sans recourir à des informations supplémentaires. Cependant, de manière quelque peu surprenante, il s’est avéré que cet ensemble de données peut être amélioré sans aucune information additionnelle. Cet ensemble de données peut être utilisé pour se rebooter lui-même en une version supérieure.
J’ai personnellement découvert cette réalisation au premier trimestre 2017 alors que je menais une série d’expériences de deep learning pour Lokad. J’ai utilisé une factorisation matricielle, une technique bien connue pour le filtrage collaboratif. Le filtrage collaboratif est le problème central dans la construction d’un système de recommandation, qui consiste à identifier le produit susceptible de plaire à un utilisateur en fonction des préférences connues de cet utilisateur pour une courte liste de produits. Adapter le filtrage collaboratif aux compatibilités mécaniques est simple : remplacer les utilisateurs par des modèles de voiture et remplacer les produits par des pièces automobiles. Voilà, le problème est adapté.
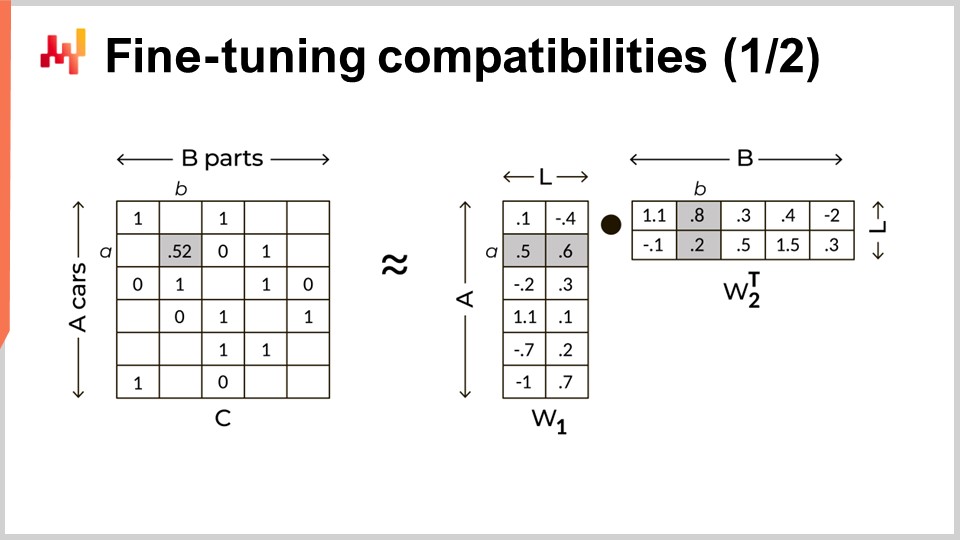
De manière plus générale, la factorisation matricielle est applicable à toute situation impliquant un graphe bipartite. Elle est également utile au-delà de l’analyse de graphes. Par exemple, l’adaptation à faible rang des large language models (LLMs), une technique devenue extrêmement populaire pour affiner les LLMs, repose également sur l’astuce de la factorisation matricielle. Celle-ci est illustrée à l’écran. À gauche, nous avons la matrice de compatibilité avec des uns pour indiquer une compatibilité entre une voiture et une pièce, et des zéros pour indiquer l’incompatibilité entre un modèle de voiture et un numéro de pièce. Nous voulons remplacer cette grande et très creuse matrice par le produit de deux matrices denses plus petites. Ces deux matrices sont visibles à droite. Elles servent à factoriser la grande matrice. Effectivement, nous plaçons chaque modèle de voiture et chaque numéro de pièce dans un espace latent. La dimension de cet espace latent est notée par un L majuscule à l’écran. Cet espace latent est conçu pour capturer les compatibilités mécaniques mais avec bien moins de dimensions que la matrice originale. En limitant la dimension de cet espace latent, nous cherchons à apprendre les règles cachées qui gouvernent ces compatibilités mécaniques.

Bien que la factorisation matricielle puisse sembler être un grand concept technique, ce n’en est pas un. C’est une astuce élémentaire de l’algèbre linéaire. Le seul aspect trompeur est qu’elle fonctionne si bien malgré sa simplicité. À l’écran se trouve une implémentation complète de cette technique en moins de 30 lignes de code.
De la première à la troisième ligne, nous lisons le fichier plat qui répertorie les compatibilités mécaniques. Ce fichier est chargé dans une table nommée M par souci de concision, signifiant matrice. Cette liste est en réalité une représentation creuse de la matrice de compatibilité. Lors du chargement, nous créons également deux autres tables nommées car_models et pns. Ces éléments nous donnent trois tables : M, car_models et pns.
Les lignes cinq et six consistent à mélanger aléatoirement la colonne contenant les modèles de voiture. Le but de ce mélange est de créer des zéros aléatoires, ou des incompatibilités aléatoires. En effet, la matrice de compatibilité est très creuse. Lorsqu’on choisit une voiture et une pièce au hasard, il est presque certain que cette paire soit incompatible. La confiance que nous avons dans le fait que cette association aléatoire soit nulle est en réalité plus forte que celle que nous avons dans la liste initiale des compatibilités. Ces zéros aléatoires sont exacts à 99,9 % par conception en raison de la rareté de la matrice, tandis que les compatibilités connues le sont peut-être à 97 %.
La ligne huit consiste à créer l’espace latent avec 24 dimensions. Bien que 24 dimensions puissent paraître nombreuses pour des embeddings, c’est très peu comparé aux large language models, qui ont des embeddings de plus d’un millier de dimensions. Les lignes neuf et dix consistent à créer les deux petites matrices, nommées pnl et car_L, que nous utiliserons pour factoriser la grande matrice. Ces deux matrices représentent environ 24 millions de paramètres pour pnl et 2,4 millions de paramètres pour car_L. Cela est considéré comme faible comparé à la grande matrice, qui contient environ 100 milliards de valeurs.
Il convient de souligner que la grande matrice n’est jamais matérialisée dans ce script. Elle n’est jamais explicitement convertie en un tableau ; elle est toujours maintenue sous forme d’une liste de 100 millions de compatibilités. La convertir en tableau serait extrêmement inefficace en termes de ressources informatiques.
Les lignes 12 à 15 introduisent deux fonctions d’assistance nommées sigmoid et log_loss. La fonction sigmoid est utilisée pour convertir le produit brut de la matrice en probabilités, des nombres compris entre 0 et 1. La fonction log_loss représente la perte logistique. La perte logistique applique la vraisemblance logarithmique, une métrique utilisée pour évaluer la justesse d’une prédiction probabiliste. Ici, elle sert à évaluer une prédiction probabiliste pour un problème de classification binaire. Nous avons déjà rencontré la vraisemblance logarithmique lors du cours 5.3, consacré à la prévision probabiliste des délais. Il s’agit d’une variation plus simple de la même idée. Ces deux fonctions sont marquées avec le mot-clé autograd, indiquant qu’elles peuvent être différenciées automatiquement. La petite valeur de un sur un million est un epsilon introduit pour la stabilité numérique. Elle n’a aucune incidence sur la logique autrement. De la ligne 17 à 29, nous avons la factorisation de matrices elle-même. Une fois de plus, nous utilisons la programmation différentiable. Il y a quelques minutes, nous utilisions la programmation différentiable pour résoudre approximativement un problème de satisfaction de contraintes. Ici, nous l’utilisons pour aborder un problème d’apprentissage auto-supervisé.
Aux lignes 18 et 19, nous déclarons les paramètres à apprendre. Ces paramètres sont associés aux deux petites matrices, pnl et car_L. Le mot-clé “auto” indique que ces paramètres sont initialisés aléatoirement en tant que déviations aléatoires issues d’une distribution gaussienne centrée sur zéro, avec un écart-type de 0,1.
Les lignes 20 et 21 introduisent deux paramètres spéciaux qui accélèrent la convergence. Il ne s’agit que de 48 nombres au total, une goutte d’eau dans l’océan comparé à nos petites matrices qui contiennent encore des millions de nombres. Et pourtant, j’ai constaté que l’introduction de ces paramètres accélère considérablement la convergence. Il est important de souligner que ces paramètres n’introduisent aucun degré de liberté pour le modèle existant. Ils n’ajoutent qu’un tout petit nombre de degrés de liberté supplémentaires dans le processus d’apprentissage. L’effet net est qu’ils réduisent de plus de la moitié le nombre d’époques nécessaires.
Aux lignes 22 à 24, nous chargeons les embeddings. À la ligne 22, nous avons l’embedding pour une seule pièce nommée px. À la ligne 23, nous avons l’embedding pour un seul modèle de voiture nommé mx. La paire px et mx sera notre arête positive, une compatibilité jugée comme vraie. À la ligne 24, nous avons l’embedding pour un autre modèle de voiture nommé mx2. La paire px et mx2 sera notre arête négative, une compatibilité jugée comme fausse. En effet, mx2 a été choisi aléatoirement grâce au mélange effectué à la ligne six. Les trois embeddings px, mx et mx2 possèdent exactement 24 dimensions, puisqu’ils appartiennent à l’espace latent, représenté par la table L dans ce script.
À la ligne 26, nous exprimons la probabilité, telle que définie par notre modèle, via un produit scalaire indiquant que cette arête est positive. Nous savons que cette arête est positive, du moins c’est ce que nous indique le jeu de données de compatibilité. Mais ici, nous évaluons ce que notre modèle probabiliste dit à son propos. À la ligne 27, nous exprimons la probabilité, également définie par notre modèle probabiliste, via le produit scalaire indiquant que cette arête est négative. Nous supposons que cette arête est négative car il s’agit d’une arête aléatoire. Encore une fois, nous évaluons cette probabilité pour voir ce que notre modèle en dit. À la ligne 29, nous renvoyons l’opposé de la vraisemblance logarithmique associée à cette arête. La valeur de retour est utilisée comme une perte à minimiser par la descente de gradient stochastique. Ici, cela signifie que nous maximisons la vraisemblance logarithmique, ou le critère de classification binaire probabiliste, entre paires compatibles et incompatibles.
Par la suite, au-delà de ce qui est montré dans ce script, la grande matrice peut être comparée au produit scalaire de deux petites matrices. Les divergences entre les deux représentations révèlent à la fois les faux positifs et les faux négatifs des jeux de données d’origine. Le plus étonnant est que la représentation factorisée de cette grande matrice s’avère être plus précise que la matrice d’origine.
Malheureusement, je ne peux pas présenter les résultats empiriques associés à ces techniques, car les jeux de données de compatibilité pertinents sont tous propriétaires. Cependant, mes conclusions, validées par quelques acteurs de ce marché, indiquent que ces techniques de factorisation de matrices peuvent être utilisées pour réduire le nombre de faux positifs et de faux négatifs jusqu’à un ordre de grandeur. En termes de performance, je suis passé d’environ deux semaines de calcul pour obtenir une convergence satisfaisante avec le deep learning toolkit que j’utilisais, CNTK – le deep learning toolkit de Microsoft en 2017 – à environ une heure avec le runtime actuel offert par Envision. Les premiers deep learning toolkits offraient une forme de programmation différentiable ; cependant, ces solutions étaient fortement optimisées pour les grands produits matriciels et les grandes convolutions. Les toolkits plus récents, comme Jax de Google, me laissent penser qu’ils offriraient des performances comparables à celles d’Envision.
Cela soulève la question : pourquoi les entreprises spécialisées qui gèrent les jeux de données de compatibilité n’utilisent-elles pas déjà la factorisation de matrices pour nettoyer leurs jeux de données ? Si tel était le cas, la factorisation de matrices n’apporterait rien de nouveau. Cette technique d’apprentissage automatique existe depuis presque 20 ans. Elle a été popularisée dès 2006 par Simon Funk. Ce n’est plus exactement à la pointe de la technologie. Ma réponse à cette question initiale est : je ne sais pas. Peut-être que ces entreprises spécialisées commenceront à utiliser la factorisation de matrices après avoir regardé ce cours, ou peut-être pas.
Quoi qu’il en soit, cela démontre que la programmation différentiable et la modélisation probabiliste sont des paradigmes très polyvalents. De loin, la prévision des délais n’a rien à voir avec l’évaluation des compatibilités mécaniques, et pourtant les deux peuvent être abordés avec le même instrument, à savoir la programmation différentiable et la modélisation probabiliste.

Le jeu de données des compatibilités mécaniques n’est pas le seul jeu de données susceptible de s’avérer inexact. Parfois, les outils d’intelligence compétitive rapportent également des données erronées. Même si le processus de web scripting est assez fiable lorsqu’il s’agit d’extraire des millions de prix à partir de pages web semi-structurées, des erreurs peuvent survenir. Identifier et corriger ces prix erronés est un défi en soi. Cependant, cela mériterait également un cours spécifique, car les problèmes tendent à être à la fois spécifiques au site ciblé et à la technologie utilisée pour le web scripting.
Bien que les préoccupations liées au web scraping soient importantes, ces problèmes surviennent avant l’exécution de l’algorithme d’alignement et doivent donc être en grande partie découplés de l’alignement lui-même. Les erreurs de scraping n’ont pas à être laissées au hasard. Il y a deux manières de jouer le jeu de l’intelligence compétitive : soit vous améliorez vos chiffres, les rendant meilleurs et plus précis, soit vous dégradez ceux de vos concurrents, les rendant moins précis. C’est là tout l’enjeu du contre-espionnage.
Comme discuté précédemment, bloquer les robots en se basant sur leur adresse IP ne va pas fonctionner. Cependant, il existe des alternatives. La couche de transport réseau n’est même pas la plus intéressante sur laquelle jouer si nous avons l’intention de semer une confusion bien ciblée. Il y a environ dix ans, Lokad a mené une série d’expériences de contre-espionnage pour vérifier si un grand site e-commerce, comme SugAr, pouvait se défendre contre des concurrents. Le résultat ? Oui, c’est possible.
À un moment donné, j’ai même pu confirmer l’efficacité de ces techniques de contre-espionnage par une inspection directe des données fournies par le spécialiste du web scraping, habituellement sans méfiance. Le nom de code de cette initiative était Bot Defender. Ce projet a été interrompu, mais vous pouvez encore voir quelques traces de Bot Defender dans notre archive publique de blog.
Plutôt que d’essayer de refuser l’accès aux pages HTML, ce qui serait une proposition vouée à l’échec, nous avons décidé d’interférer de manière sélective avec les web scrapers eux-mêmes. L’équipe de Lokad ne connaissait pas tous les détails de la conception de ces web scrapers. En considérant la structure DHTML d’un site e-commerce donné, il n’est pas trop difficile d’émettre une hypothèse éclairée sur la manière dont une entreprise exploitant ces web scrapers procèderait. Par exemple, si chaque page HTML du site StuttArt possède une classe CSS particulièrement pratique nommée “unit price” qui isole le prix du produit au centre de la page, il est raisonnable de supposer que pratiquement tous les robots utiliseront cette classe CSS très pratique pour isoler le prix dans le code HTML. En effet, à moins que le site StuttArt n’offre un moyen encore plus commode d’obtenir les prix, comme une API ouverte pouvant être interrogée librement, cette classe CSS représente la voie évidente pour extraire les prix.
Cependant, puisque la logique du web scraping est évidente, il est également clair de savoir comment interférer de manière sélective avec cette logique. Par exemple, StuttArt peut décider de sélectionner quelques produits bien ciblés et de “poisonner” le HTML. Dans l’exemple à l’écran, visuellement, les deux pages HTML s’afficheront pour les humains comme une étiquette de prix de 65 euros et 50 centimes. Cependant, la deuxième version de la page HTML sera interprétée par les robots comme affichant 95 euros au lieu de 65. Le chiffre “9” est tourné par CSS pour apparaître comme un “6”. Le robot de scraping typique, qui se fie au balisage HTML, ne va pas détecter cela.
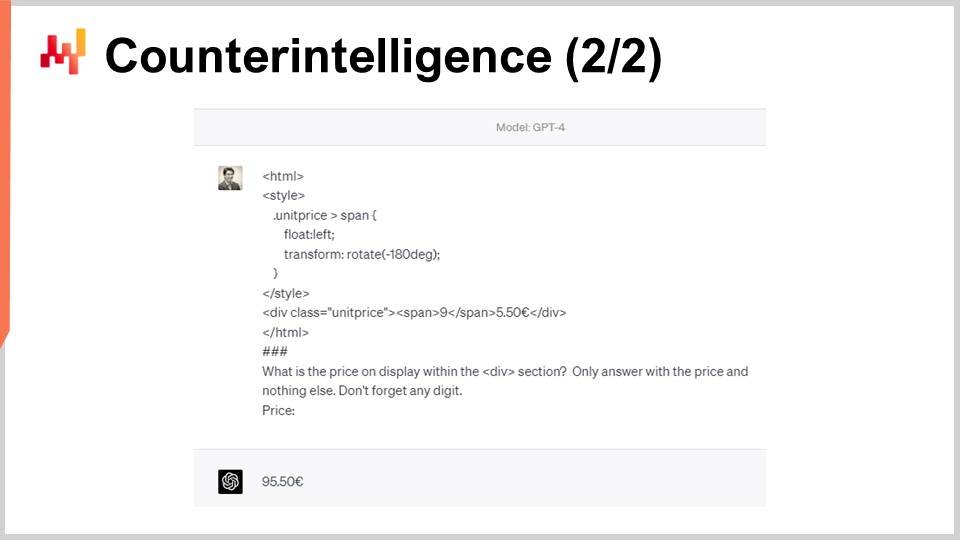
Dix ans plus tard, même un modèle de langage de grande envergure sophistiqué comme GPT-4, qui n’existait pas à l’époque, est encore trompé par ce simple tour de passe-passe en CSS. À l’écran, on voit que GPT-4 n’extrait pas un prix de 65 euros comme il se devait, mais répond plutôt 95 euros. Il existe, de manière marginale, des dizaines de façons de concevoir un code HTML qui offre une étiquette de prix évidente pour un robot, divergent de celle qu’un être humain lirait sur le site. Faire pivoter un “9” pour qu’il ressemble à un “6” n’est qu’un des tours les plus simples parmi une vaste gamme de techniques similaires.
Une contre-mesure à cette technique consisterait à rendre la page, créer le bitmap complet, puis appliquer la Reconnaissance Optique de Caractères (OCR) à ce bitmap. Cependant, cela est assez coûteux. Les entreprises d’intelligence compétitive doivent revérifier des dizaines de millions de pages web quotidiennement. En règle générale, exécuter un processus de rendu de page web suivi d’une OCR augmente le coût de traitement d’au moins un facteur de 100, et plus probablement d’un facteur de 1000.
À titre de référence, en mai 2023, Microsoft Azure facture un dollar pour mille opérations OCR. Étant donné qu’il y a plus de 10 millions de pages à surveiller quotidiennement par les spécialistes de l’intelligence compétitive en Europe, cela représente un budget de 10 000 dollars par jour pour l’OCR uniquement. Et Microsoft Azure, soit dit en passant, est assez compétitif sur ce front.
En tenant compte d’autres coûts comme la bande passante pour ces précieuses adresses IP résidentielles, il est fort probable que nous parlions ici d’un budget annuel en ressources de calcul de l’ordre de 5 millions d’euros si nous empruntons cette voie. Un budget annuel de plusieurs millions est envisageable, mais les marges des entreprises de web scraping sont faibles et elles ne suivront pas cette voie. Si, par des moyens beaucoup moins coûteux, elles peuvent obtenir une intelligence compétitive avec une précision de 99 %, cela suffit à satisfaire leurs clients.
Pour revenir à StuttArt, il serait imprudent d’utiliser cette technique de contre-espionnage pour empoisonner tous les prix, car cela entraînerait une escalade de la course aux armements avec les web scrapers. Au lieu de cela, StuttArt devrait judicieusement choisir le un pour cent de références qui auront un impact maximal en termes d’intelligence compétitive. Très probablement, les web scrapers ne remarqueront même pas le problème. Même si les web scrapers remarquent ces contre-mesures, tant que cela est perçu comme un problème de faible intensité, ils n’interviendront pas. En effet, le web scraping s’accompagne de toute une série de problèmes mineurs : le site que vous voulez analyser peut être extrêmement lent, il peut être hors service, ou la page d’intérêt peut présenter des dysfonctionnements. Une promotion conditionnelle pourrait être en vigueur, rendant le prix peu clair pour la pièce concernée.
Du point de vue de StuttArt, il reste à choisir le un pour cent de numéros de pièces qui présentent un intérêt maximal en termes d’intelligence compétitive. Ces pièces seraient typiquement celles que StuttArt souhaiterait réduire le plus en prix, mais sans déclencher une guerre des prix. Il existe plusieurs approches pour y parvenir. Un type de pièces à fort intérêt est constitué des consommables bon marché, comme les essuie-glaces. Un client qui souhaite essayer StuttArt pour son premier achat a peu de chances de commencer par un injecteur à 600 euros. Un premier client est beaucoup plus susceptible de débuter avec un essuie-glace à 20 euros en guise d’essai. Plus généralement, les nouveaux clients se comportent très différemment des clients réguliers. Ainsi, le un pour cent de pièces que StuttArt devrait probablement vouloir rendre particulièrement attractives, sans déclencher une guerre des prix, sont celles qui sont le plus susceptibles d’être achetées par ces nouveaux clients.

Éviter une guerre des prix et l’érosion de parts de marché sont deux issues extrêmement négatives pour StuttArt, il faut donc des circonstances particulières pour dévier du principe d’alignement. Nous avons déjà vu l’une de ces circonstances, à savoir la nécessité de contrôler la marge brute. Cependant, ce n’est pas la seule. Les surstocks et les ruptures de stock sont deux autres candidats de premier plan à envisager pour ajuster les prix. Les surstocks sont mieux gérés de manière proactive. Il vaudrait mieux pour StuttArt d’éviter complètement les surstocks, mais des erreurs surviennent ainsi que des fluctuations de marché, et malgré des politiques minutieuses de réapprovisionnement de stocks, StuttArt sera régulièrement confronté à des surstocks localisés. La tarification est un mécanisme précieux pour atténuer ces problèmes. StuttArt est toujours mieux de vendre les pièces en surstock avec une remise substantielle plutôt que de ne pas les vendre du tout, ainsi les surstocks doivent être intégrés dans la stratégie de tarification.
Limitons le champ des surstocks aux seules pièces qui sont très susceptibles de se transformer en dépréciation de stocks. Dans ce contexte, les surstocks peuvent être abordés par un ajustement de l’alignement des coûts qui abaisse l’étiquette de prix à une marge brute proche de zéro, voire légèrement en dessous, en fonction des réglementations et de l’ampleur du surstock.
À l’inverse, les ruptures de stock, ou plutôt les quasi-ruptures, devraient voir leur étiquette de prix révisée à la hausse. Par exemple, si StuttArt n’a plus que cinq unités en stock pour une pièce qui se vend habituellement à raison d’une unité par jour, et que le prochain réapprovisionnement n’arrivera pas avant dans 15 jours, alors cette pièce va très certainement connaître une rupture de stock. Il n’est donc pas utile de se précipiter pour provoquer la rupture de stock. StuttArt pourrait augmenter le prix de cette pièce. Tant que la baisse de la demande est suffisamment faible pour que StuttArt évite une rupture de stock, cela n’aura pas d’importance.
Les outils d’intelligence concurrentielle sont de plus en plus capables de surveiller non seulement les prix, mais également les délais de livraison annoncés pour les pièces présentées sur le site web d’un concurrent. Cela offre à StuttArt la possibilité de surveiller non seulement ses propres ruptures de stock, mais aussi celles qui se produisent chez ses concurrents. Une cause fréquente d’une rupture de stock chez un détaillant est une rupture de stock chez un fournisseur. Si le constructeur (OEM) lui-même est en rupture de stock, alors StuttArt, ainsi que tous ses concurrents, risque fort de se retrouver en rupture de stock. Dans le cadre de l’algorithme d’alignement des prix, il est raisonnable de retirer de cet alignement les pièces qui sont soit en rupture de stock chez les fournisseurs, soit en rupture de stock sur le site web du concurrent. Les situations de rupture de stock des concurrents peuvent être surveillées via les délais de livraison lorsque ces derniers reflètent des conditions inhabituelles. De plus, si un constructeur d’équipements d’origine (OEM) commence à annoncer des délais inhabituels pour les pièces, il pourrait être temps d’augmenter les tarifs de ces pièces. Cela s’explique par le fait que cela indique que tout le monde sur le marché aura vraisemblablement du mal à se procurer davantage de pièces automobiles auprès de cet OEM particulier.
À ce stade, il devrait être assez évident que l’optimisation des prix et l’optimisation de stocks sont des problèmes étroitement couplés, et ainsi, ces deux problèmes doivent être résolus conjointement en pratique. En effet, au sein d’une même unité de besoin, la pièce qui bénéficie à la fois du prix le plus bas et du rang d’affichage le plus élevé dans sa gamme de produits va absorber l’essentiel des ventes. La tarification oriente la demande à travers de nombreuses alternatives dans l’offre de StuttArt. Il n’est pas logique d’avoir une équipe chargée des stocks tentant de prévoir les prix tels que générés par l’équipe de tarification. Au lieu de cela, il devrait y avoir une fonction supply chain unifiée qui aborde conjointement ces deux préoccupations.

Les conditions de livraison sont une partie intégrante du service. En ce qui concerne les pièces automobiles, non seulement les clients ont de grandes attentes quant au fait que StuttArt respectera ses promesses, mais ils pourraient même être prêts à payer un supplément si le processus est accéléré. Plusieurs grandes entreprises de e-commerce vendant des pièces automobiles en Europe proposent déjà des prix distincts selon le délai de livraison. Ces prix distincts ne reflètent pas seulement des options d’expédition différentes, mais éventuellement aussi des options d’approvisionnement distinctes. Si le client est prêt à attendre une ou deux semaines, alors StuttArt bénéficie d’options d’approvisionnement supplémentaires, et StuttArt peut répercuter une partie des économies directement sur les clients. Par exemple, une pièce peut n’être acquise par StuttArt qu’après avoir été commandée par le client, éliminant ainsi complètement le coût de détention et le risque de stocks.
Les conditions de livraison compliquent l’intelligence concurrentielle. Premièrement, les outils d’intelligence concurrentielle doivent récupérer des informations sur les délais, et pas seulement sur les prix. De nombreux spécialistes de l’intelligence concurrentielle font déjà cela, et StuttArt doit faire de même. Deuxièmement, StuttArt doit ajuster son algorithme d’alignement des prix afin de refléter les différentes conditions de livraison. La programmation différentiable peut être utilisée pour fournir une estimation de la valeur, exprimée en euros, apportée par l’économie d’une journée. On s’attend à ce que cette valeur dépende du modèle de voiture, du type de pièce et du nombre de jours de livraison. Par exemple, passer d’un délai de livraison de trois jours à un délai de deux jours est beaucoup plus avantageux pour le client que de passer d’un délai de 21 jours à 20 jours.

En conclusion, une stratégie de tarification vaste a été proposée aujourd’hui pour StuttArt, un persona supply chain dédié au marché en ligne de l’après-vente automobile. Nous avons vu que la tarification n’est pas sujette à une quelconque stratégie d’optimisation locale. Le problème de la tarification est en effet non local en raison de la compatibilité mécanique qui propage l’impact d’une étiquette de prix pour une pièce donnée sur de nombreuses unités de besoin. Cela nous a conduits à adopter une approche de la tarification comme un alignement au niveau de l’unité de besoin. Deux sous-problèmes ont été abordés grâce à la programmation différentiable. Premièrement, nous avons résolu un problème de satisfaction de contraintes approximatif pour l’alignement concurrentiel lui-même. Deuxièmement, nous avons abordé le problème de l’auto-amélioration des ensembles de données de compatibilité mécanique afin d’améliorer la qualité de l’alignement, mais aussi celle de l’expérience client. Nous pouvons ajouter ces deux problèmes à notre liste croissante des problèmes de supply chain qui bénéficient d’une solution simple lorsqu’ils sont abordés par la programmation différentiable.
Plus généralement, s’il y a un enseignement à tirer de cette conférence, ce n’est pas que l’après-vente automobile soit une exception en matière de stratégies de tarification. Au contraire, l’enseignement est que nous devons toujours nous attendre à faire face à de nombreuses spécificités, quel que soit le secteur d’activité. Il y aurait eu tout autant de spécificités si nous avions examiné un autre persona supply chain au lieu de nous concentrer sur StuttArt, comme nous l’avons fait aujourd’hui. Ainsi, il est inutile de chercher une réponse définitive. Toute solution en formule fermée est vouée à ne pas pouvoir traiter l’afflux infini de variations qui surviendront au fil du temps dans une supply chain réelle. Au lieu de cela, nous avons besoin de concepts, de méthodes et d’instruments qui non seulement nous permettent de traiter l’état actuel de la supply chain, mais qui sont également susceptibles d’être modifiés de manière programmatique. La programmabilité est essentielle pour pérenniser les recettes numériques de tarification.

Avant de passer aux questions, j’aimerais annoncer que la prochaine conférence aura lieu la première semaine de juillet. Ce sera un mercredi comme d’habitude, à la même heure de la journée - 15h, heure de Paris. Je revisiterai le chapitre un en examinant de plus près ce que l’économie, l’histoire et la théorie des systèmes nous apprennent sur la supply chain et la planification de la supply chain.
Passons maintenant aux questions.
Question: Entendez-vous donner une conférence sur la visualisation du total cost of ownership pour une supply chain ? En d’autres termes, une analyse TCO de l’ensemble de la supply chain en utilisant l’analytique des données et l’optimisation globale des coûts ?
Oui, cela fait partie du parcours de cette série de conférences. Des éléments de cela ont déjà été discutés dans plusieurs conférences. Mais l’essentiel, c’est que ce n’est pas vraiment un problème de visualisation. L’enjeu du total cost of ownership n’est pas un problème de visualisation des données ; c’est un problème de mentalité. La plupart des pratiques supply chain sont extrêmement dédaigneuses de la perspective financière. Ils visent des taux de service d’erreur, et non des dollars ou des euros d’erreur. La plupart, malheureusement, poursuivent ces pourcentages. Ainsi, il est nécessaire d’opérer un changement de mentalité.
La deuxième chose est qu’il y a des éléments abordés dans la conférence qui faisait partie du premier chapitre - l’approche orientée produit, comme dans la livraison orientée produit logiciel pour la supply chain. Nous devons penser non seulement au premier cercle des moteurs économiques, mais aussi à ce que j’appelle le deuxième cercle des moteurs économiques. Ce sont des forces insaisissables, par exemple, si vous réduisez le prix d’un produit d’un euro en créant une promotion, une analyse naïve pourrait laisser penser que cela m’a coûté un euro de marge simplement parce que j’ai accordé ce rabais d’un euro. Mais la réalité est qu’en faisant cela, vous créez une attente parmi votre clientèle pour qu’elle s’attende à ce rabais d’un euro à l’avenir. Et ainsi, cela entraîne un coût. C’est un coût de second ordre, mais il est bien réel. Tous ces moteurs économiques du deuxième cercle sont des facteurs importants qui n’apparaissent pas dans votre grand livre ou vos comptes. Oui, je vais aborder davantage d’éléments qui décrivent ces coûts. Cependant, ce n’est pour la plupart pas un problème analytique en termes de visualisation ou de création de graphiques ; c’est une question de mentalité. Nous devons accepter que ces éléments doivent être quantifiés, même s’ils sont incroyablement difficiles à quantifier.
Lorsque nous commençons à discuter du total cost of ownership, nous devons également aborder le nombre de personnes nécessaires pour faire fonctionner cette solution supply chain. C’est l’une des raisons pour lesquelles, dans cette série de conférences, je dis que nous avons besoin de solutions programmatiques. Nous ne pouvons pas avoir une armée de commis ajustant des spreadsheets ou des tableaux et faisant des choses incroyablement inefficaces en termes de coûts, comme gérer les alertes d’exceptions dans les logiciels de supply chain. Les alertes et exceptions consistent à traiter l’ensemble de vos effectifs dans l’entreprise comme des co-processeurs humains pour le système. Cela est extrêmement coûteux.
L’analyse du total cost of ownership est avant tout une question de mentalité, d’avoir la bonne perspective. Dans la prochaine conférence, j’aborderai également d’autres angles, en particulier ce que l’économie nous dit sur la supply chain. C’est très intéressant car nous devons réfléchir à ce que signifie réellement le total cost of ownership pour une solution supply chain, surtout si nous commençons à penser à la valeur qu’elle apporte à l’entreprise.
Question: Pour des références techniquement compatibles à une unité de besoin, il existe des différences perçues en termes de qualité, d’activité, argent, or, etc. Comment prenez-vous cela en compte dans l’égalisation des prix des concurrents ?
C’est tout à fait correct. C’est pourquoi il est nécessaire d’introduire des gammes de produits. Ce niveau d’attractivité peut généralement être encadré en environ une demi-douzaine de classes qui représentent des standards de qualité pour les pièces. Par exemple, il y a la gamme motorsport, qui comprend les pièces les plus luxueuses avec une compatibilité mécanique excellente. Ces pièces sont également esthétiques, et leur emballage est de grande qualité.
Mon expérience dans ce marché est que, bien qu’il existe une infinité de variations permettant d’améliorer légèrement la qualité d’une pièce, le marché est pratiquement convergé vers environ une demi-douzaine de gammes de produits allant du très cher au moins cher. Lorsque nous regroupons les pièces de StuttArt, nous devons les classer par gammes de produits. Il en va de même pour les pièces des concurrents, ce qui signifie que nous devons connaître la gamme de qualité d’une pièce, même si celle-ci n’est pas vendue par StuttArt.
StuttArt doit avoir une connaissance approfondie de toutes les pièces du marché. Cela n’est pas aussi difficile qu’il n’y paraît car la plupart des fabricants fournissent des informations sur la qualité attendue de leurs pièces. Ces éléments sont assez codifiés par les constructeurs d’équipements d’origine (OEM) eux-mêmes. Nous bénéficions du fait que le marché automobile est un marché incroyablement établi et mûr, existant depuis plus d’un siècle. Les entreprises qui vendent ces ensembles de données de compatibilité, notamment pour les voitures et les compatibilités de pièces, fournissent également une multitude d’attributs pour les pièces et les modèles de voitures. Nous parlons de centaines d’attributs. Ces ensembles de données sont vastes et riches. À l’origine, ces ensembles de données étaient utilisés par les professionnels des centres de réparation pour savoir comment effectuer les réparations. Ils sont même accompagnés de pièces jointes au format PDF et de documentation technique. C’est très riche ; vous disposez de dizaines de gigaoctets de données, y compris des images et des photos. Je ne faisais qu’effleurer la surface en termes de valeur marchande de ces ensembles de données.
Question: Comment les réglementations variables selon les régions impactent-elles l’optimisation des prix pour les entreprises automobiles ? Par exemple, vous avez mentionné Peugeot, une entreprise française. En quoi votre approche pour Peugeot différerait-elle de celle d’une entreprise similaire en Scandinavie ou en Asie ?
La Scandinavie possède pour l’essentiel le même marché automobile. Ils ont quelques marques différentes, mais il est trop petit pour soutenir sa propre industrie automobile. En ce qui concerne l’industrie automobile, la Scandinavie est comme le reste des 350 millions d’Européens. En revanche, l’Asie est vraiment différente. L’Inde et la Chine sont des marchés à part entière.
En ce qui concerne l’optimisation des prix, les réglementations n’ont pas tant empêché que retardé l’apparition de distributeurs de pièces automobiles en ligne. Par exemple, en Europe, il y a 20 ans, il y a eu une bataille juridique. Des pionniers comme StuttArt, qui furent les premières entreprises à vendre des pièces automobiles en ligne, ont dû faire face à des contentieux juridiques. Ils vendaient des pièces automobiles et affirmaient sur leur site web qu’elles étaient identiques à celles vendues par les constructeurs automobiles d’origine.
Des entreprises comme StuttArt disaient : “Je ne vous vends pas n’importe quelle pièce automobile, je vous vends exactement la même pièce que celle que le constructeur automobile utiliserait.” Ils pouvaient faire cette affirmation parce qu’ils achetaient la même pièce exacte dans la même usine. Si une pièce provient, disons, de Valeo et est montée sur une voiture Peugeot, il existe une association connue. Ce qui a été décidé il y a une vingtaine d’années, c’est que plusieurs tribunaux en Europe ont statué qu’il était légal pour un site web d’affirmer vendre exactement la même pièce que celles qui sont qualifiées de pièces d’origine d’une voiture. Cette incertitude réglementaire a retardé l’essor des pièces automobiles d’occasion vendues en ligne, probablement d’environ cinq ans. Les pionniers se battaient dans les tribunaux contre les constructeurs automobiles pour avoir le droit de vendre des pièces automobiles en ligne tout en affirmant qu’il s’agissait de pièces d’origine pour la voiture. Une fois clarifié, ils pouvaient le faire tant qu’ils étaient honnêtes et qu’ils achetaient véritablement la même pièce automobile chez Valeo ou Bosch, exactement comme la pièce qui est montée sur la voiture.
Cependant, il existe encore des limitations. Par exemple, il y a encore des pièces qui caractérisent l’apparence visuelle de la voiture, et seul le constructeur automobile peut les vendre en tant que pièces d’origine. Par exemple, le capot de la voiture. Ces réglementations ont un impact en ce sens qu’elles restreignent la gamme de pièces pouvant être vendues librement en ligne tout en prétendant que la pièce est exactement la même que celle du constructeur d’origine. Nous parlons de pièces ayant des implications non seulement en termes de compatibilité mécanique, mais aussi de sécurité. Certaines de ces pièces sont critiques pour la sécurité.
En Asie, un problème que je n’ai pas abordé ici concerne les contrefaçons. Gérer les contrefaçons est très différent en Europe comparé à l’Asie. Des contrefaçons existent en Europe, mais le marché est mature et catalysé. Les OEMs et les fabricants automobiles se connaissent très bien. Bien que des contrefaçons existent, le problème demeure très minime. Dans des marchés comme l’Asie, en particulier en Inde et en Chine, il existe encore pas mal de problèmes liés aux contrefaçons. Ce n’est pas vraiment un problème de régulation, puisque les contrefaçons sont tout aussi illégales en Chine qu’en Europe. Le problème réside dans l’application de la loi, dont le niveau est bien inférieur en Asie qu’en Europe.
Question: Essayons-nous d’optimiser un prix globalement ou par rapport aux concurrents ?
La fonction d’optimisation s’applique conceptuellement à chaque unité de besoin – une unité de besoin correspondant à un modèle de voiture et à un type de pièce. Pour chaque unité de besoin, vous obtenez une différence de prix en euros entre le point de prix de StuttArt, qui est la meilleure offre de StuttArt, et le point de prix du concurrent. Vous prenez la différence absolue entre ces deux prix et les additionnez ; voilà votre fonction. Nous n’allons pas utiliser naïvement cette somme de différences de prix ; nous allons y ajouter un coefficient qui reflète le volume de ventes annuel de chaque unité de besoin.
Par conséquent, la fonction d’optimisation pour votre problème de satisfaction de contraintes est la somme des différences absolues entre le meilleur prix offert par StuttArt pour l’unité de besoin et le meilleur prix offert par la concurrence. Vous ajoutez un facteur de pondération qui reflète l’importance annuelle, également exprimée en euros, de cette unité de besoin. Vous faites de votre mieux pour refléter l’état du marché européen.
La raison pour laquelle vous souhaitez pondérer en fonction de l’importance de l’unité de besoin plutôt que de l’unité de besoin de StuttArt est que, si StuttArt est si peu compétitif qu’il ne vend rien de cette unité, vous pouvez vous retrouver avec un problème de compétitivité. Par conséquent, cette unité est écartée en termes d’alignement, ce qui conduit à des ventes nulles. Ensuite, vous vous retrouvez dans un cercle vicieux où, n’étant pas compétitif, il ne se vend rien, et donc l’unité de besoin elle-même est considérée comme négligeable.
Question: Voyez-vous des conséquences inattendues survenir si une approche de machine learning par modélisation différentiable devenait la norme dans l’industrie, avec le risque que des modèles très similaires se fassent concurrence ?
Cette question est difficile car, par définition, si c’est une conséquence inattendue, personne ne l’avait anticipée, pas même moi. Il est très difficile de prévoir quel type de conséquences pourrait être jugé inattendu.
Cependant, de manière plus sérieuse, cette industrie est pilotée par des techniques algorithmiques depuis une décennie. Il s’agit d’un raffinement en termes de précision d’intention. Vous désirez une méthode numérique qui soit plus étroitement alignée avec vos objectifs. Mais fondamentalement, ce n’est pas comme si nous partions de zéro ; aujourd’hui, c’est fait manuellement et dans dix ans, ce sera réalisé automatiquement à l’aide de recettes numériques. Cela se fait déjà grâce à des recettes numériques. Lorsque vous avez 100 000 prix à maintenir et actualiser chaque jour, une forme d’automatisation s’impose.
Peut-être que votre automatisation consiste en un gigantesque tableur Excel dans lequel vous opérez toutes sortes de magie noire, mais cela reste un processus algorithmique. Les gens n’ajustent pas les prix manuellement, sauf pour quelques pièces lors d’occasions rares. En grande partie, c’est déjà un processus algorithmique, et nous faisons déjà face à de nombreuses conséquences imprévues. Par exemple, pendant les confinements en Europe, les gens passaient plus de temps chez eux et faisaient des achats en ligne. Cela peut sembler contre-intuitif, mais ils utilisaient toujours beaucoup leurs voitures, et donc, faisaient davantage d’achats. Cependant, de nombreuses entreprises vendant des pièces automobiles en ligne sont devenues moins actives sur le plan des promotions, car leur organisation était devenue plus compliquée du fait que tout le monde travaillait de chez soi.
Par conséquent, pendant quelques mois durant les confinements de 2020, il y eut bien moins de bruit algorithmique généré par les promotions. Les réponses algorithmiques étaient bien plus simples de la part de chacun. Il y avait des jours où l’on pouvait voir de manière bien plus nette le type de réponses algorithmiques déclenchées lors de l’actualisation quotidienne.
C’est un modèle assez mature dans une industrie bien établie, puisque tout se fait désormais via le trading électronique. Quant aux conséquences imprévues ou inattendues, il est plus difficile de les prévoir.
Permettez-moi d’offrir une réflexion finale sur un domaine potentiellement surprenant. Beaucoup s’attendent à ce que les véhicules électriques simplifient tout parce qu’ils comportent moins de pièces comparés aux moteurs à combustion interne. Cependant, du point de vue d’une entreprise comme StuttArt, pour les 10 prochaines années, les véhicules électriques signifieront beaucoup plus de pièces sur le marché.
Jusqu’à ce que, et si, les véhicules électriques deviennent dominants, nous aurons toujours tous les anciens véhicules équipés de moteurs à combustion. Ces véhicules dureront environ 20 ans. N’oubliez pas que StuttArt, en tant qu’entreprise, traite des véhicules qui ne sont pas exactement neufs. Beaucoup de ces véhicules sont de bonne qualité et seront toujours présents dans environ 20 ans. Mais en attendant, nous verrons de nombreux véhicules électriques supplémentaires arriver sur le marché avec une multitude de pièces différentes. Cela pourrait faire augmenter progressivement le nombre de pièces variées, créant encore plus de défis et de complications.
Je crois que cela nous amène à la fin de la conférence d’aujourd’hui. S’il n’y a plus de questions, j’ai hâte de vous retrouver pour la prochaine conférence qui aura lieu lors de la première semaine de juillet, le mercredi à 15h, heure de Paris, comme d’habitude. Merci beaucoup, et à bientôt.