ABC XYZ-Analyse (Bestandsverwaltung)
ABC XYZ-Analyse, ähnlich wie ihr Vorgänger ABC analysis, ist ein Kategorisierungstool, das darauf abzielt, die leistungsstärksten Produkte im Katalog zu identifizieren, um so angemessene Servicegrade und Sicherheitsbestände zu bestimmen. Im Gegensatz zur ABC-Analyse, die sich ausschließlich auf ein einziges Kriterium (typischerweise Verkaufsvolumen oder Umsatz) konzentriert, versucht die ABC XYZ-Analyse, auch eine zweite Dimension (Nachfrageunsicherheit oder Volatilität) zu quantifizieren. Obwohl sie möglicherweise einen etwas hochauflösenderen Leistungsüberblick bietet, bleibt die ABC XYZ-Analyse dennoch eine naive Anwendung der zugrunde liegenden mathematischen Prinzipien und dient lediglich dazu, Bürokratie und Instabilität zu verstärken. Sie übernimmt auch alle Einschränkungen einer klassischen ABC-Analyse, vermittelt jedoch – man könnte sagen – ein noch größeres falsches Sicherheitsgefühl durch mathematischen Hokuspokus.

Durchführung einer ABC XYZ-Analyse
Während eine ABC-Analyse darauf abzielt, eine Reihe von SKUs im finanziellen Hinblick über einen Zeitraum in eine von drei Klassen zu unterteilen und so einem Supply Chain Practitioner eine Aufschlüsselung der SKUs nach finanzieller Bedeutung zu liefern, versucht die ABC XYZ-Analyse, einen Schritt weiterzugehen. Sie versucht, die Nachfrageschwankungen (bzw. Volatilität) für jede SKU im Beobachtungszeitraum zu verstehen und zu quantifizieren und die klassischen A-, B- und C-Klassen mit zusätzlichen X-, Y- und Z-Kategorien zu verbinden. Einfach ausgedrückt misst Nachfrageschwankungen, wie stark sich die Nachfrage im Beobachtungszeitraum verändert hat. Dies könnte unerwartete und/oder isolierte Phasen von extrem hoher (oder niedriger) Nachfrage widerspiegeln oder anhaltende allgemeine Schwierigkeiten bei der Vorhersage, wie viele Einheiten einer SKU tatsächlich benötigt wurden (oder jeden anderen Grund, warum die Nachfrage innerhalb des Zeitraums schwankte). Diese Schwankung soll durch die Bezeichnungen X, Y und Z erfasst werden.
Unter diesem neuen neun-Kategorien-Rahmen sind SKUs der X-Klasse am stabilsten (weisen die geringsten Nachfrageschwankungen auf), die der Y-Klasse etwas stabiler (mittlere Nachfrageschwankungen) und die der Z-Klasse am instabilsten (höchste Nachfrageschwankungen). Aufbauend auf der klassischen ABC-Analyse erhält ein Supply Chain Practitioner eine scheinbar nuanciertere Aufschlüsselung des Katalogs über den Zeitraum, bei der SKUs anhand doppelt so vieler Dimensionen analysiert werden.
Um die neue Klassifikation durchzuführen, folgt ein Supply Chain Practitioner den gleichen anfänglichen Schritten wie bei der klassischen ABC-Analyse. Sobald diese Phase abgeschlossen ist, geht man zum XYZ-Teil der Analyse über, bei dem benötigt wird:
- Die gewünschte Anzahl von Nachfrageschwankungsklassen: in der Regel auf 3 begrenzt, jedoch flexibel.
- Ein Schwellenwert zur Abgrenzung jeder Klasse: ganz nach Ermessen des Supply Chain Practitioners. Ein Beispiel könnte <=10% für die X-Klasse, >10-25% für die Y-Klasse und >25% für die Z-Klasse sein.
- Der Durchschnittswert für jede SKU über den Beobachtungszeitraum: lässt sich problemlos in jeder Tabellenkalkulation berechnen.
- Die Standardabweichung und der Variationskoeffizient für jede SKU: lassen sich ebenfalls problemlos in jeder Tabellenkalkulation berechnen.
Die Standardabweichung, im Kontext eines Jahres an Daten, misst in der Regel, um wie viel die Verkäufe in einem beliebigen Monat vom durchschnittlichen Monatswert des Jahres abwichen. Sobald ein Supply Chain Practitioner diese Information hat, kann er den Variationskoeffizienten (CV) berechnen. Auch bekannt als relative Standardabweichung, ist der CV ein Prozentwert, der angibt, wie weit ein gegebener Datenpunkt vom Mittelwert entfernt ist, was in diesem Fall die Schwankungsbreite der Verkaufszahlen einer SKU über den Beobachtungszeitraum (im Vergleich zum Mittelwert) darstellt. Dieser Prozentwert wird berechnet, indem man die Standardabweichung durch den Durchschnitt dividiert.
Sobald der CV berechnet wurde, sortiert der Supply Chain Practitioner die SKUs gemäß den vorgegebenen Schwellenwerten in die entsprechenden X-, Y- und Z-Klassen. Das Ergebnis ist eine neun-Kategorien-Matrix, in der die SKUs hinsichtlich ihres Umsatzes und ihrer Nachfrageschwankungen sortiert sind.
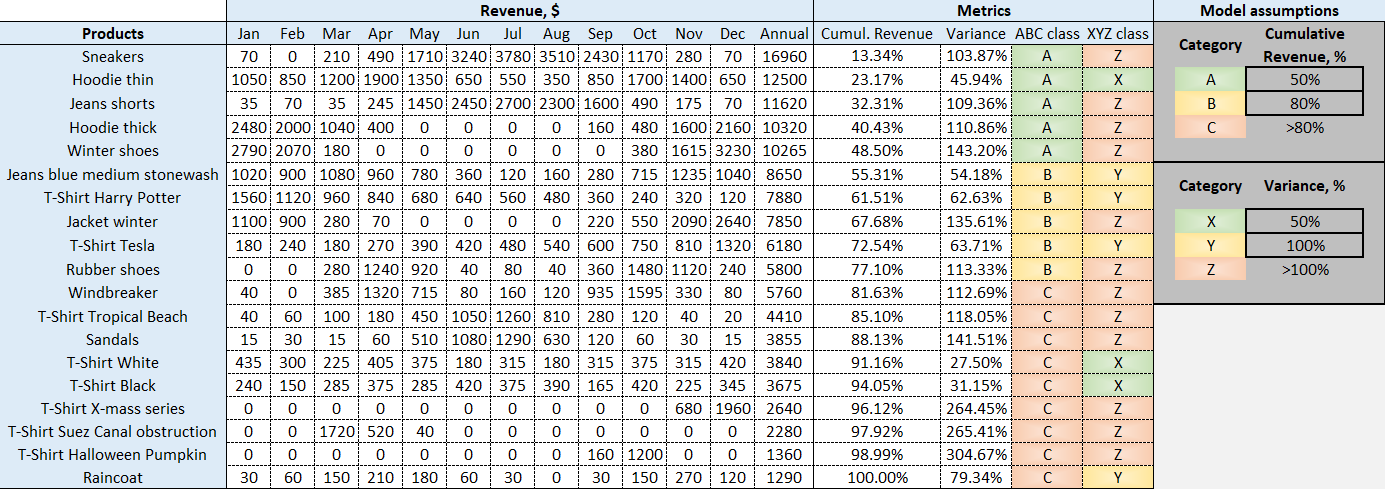
Abb. 1. Eine Modell-ABC XYZ-Analyse, wie sie in der herunterladbaren Excel-Tabelle dargestellt ist. Für genaue Berechnungen konsultieren Sie bitte die Formeln in den entsprechenden Spalten.
Laden Sie die Excel-Tabelle herunter: abc-xyz-analysis-tool.xlsx
Die mathematische Perspektive auf ABC und ABC XYZ
Aus rein mathematischer Sicht, sei es implizit oder explizit, versuchen sowohl die ABC-Analyse als auch die ABC XYZ-Analyse, das Konzept der Momente zu nutzen, das eine unendliche Menge quantitativer Maße zur Abbildung einer Funktion darstellt. Im vorliegenden Kontext ist die Funktion eine Verteilung der Verkaufsdaten, und die interessierenden Momente sind die ersten beiden: Mittelwert für die traditionelle ABC-Analyse; Mittelwert und Varianz für die ABC XYZ-Analyse. Im Hinblick auf die ABC-Analyse, da sie sich ausschließlich auf den ersten Moment (Mittelwert) konzentriert, wäre es exakter diesen Ansatz als gleitende Durchschnitts-Segmentierung zu bezeichnen. Grundsätzlich wird nicht versucht, die Unsicherheit der Nachfrage zu identifizieren. Aus diesem Grund versucht die ABC XYZ-Analyse, den zweiten Moment (Varianz) zu nutzen, um diese Unsicherheit zu quantifizieren. Dadurch ähnelt die ABC XYZ-Analyse eher einer Segmentierung mittels gleitendem Durchschnitt und Varianz. Im Gegensatz zum Mittelwert, der allgemein bekannt ist, ist die Varianz weniger umgangssprachlich. Kurz gesagt, gibt sie an, wie weit eine Menge von Werten – hier, die durchschnittlichen monatlichen Verkaufszahlen – vom Durchschnittswert der Menge streut. Die ABC XYZ-Analyse nutzt dieses zusätzliche mathematische Werkzeug, um zu einem angeblich komplexeren Verständnis der Variation eines Datensatzes zu gelangen. Wie effektiv diese Werkzeuge angewendet werden, wird in Grenzen der ABC XYZ noch einmal aufgegriffen.
Wie die ABC XYZ-Analyse die Bestandsverwaltung beeinflusst
Lehrbuchmäßige Anwendungen der ABC XYZ-Analyse, ähnlich wie bei der ABC-Analyse, konzentrieren sich darauf, Servicegrade und Sicherheitsbestand als Ziele festzulegen. Mit Hilfe der neuen ABC XYZ-Matrix kann ein Supply Chain Practitioner theoretisch die interessierenden SKUs besser visualisieren und somit die Bestandsverwaltung so anpassen, dass nicht nur Umsatzaspekte, sondern auch die Kräfte der Nachfrageschwankungen berücksichtigt werden.
Sicherheitsbestand
Eine unmittelbare Anwendung der ABC XYZ-Analyse sind verbesserte Zielwerte für den Sicherheitsbestand. Die A-Klasse-SKUs erhält naturgemäß die höchsten Werte, aber im Gegensatz zur ABC-Analyse wird versucht, zwischen den Mitgliedern der A-Klasse (bzw. C) unter Verwendung der XYZ-Klassen entlang der x-Achse zu differenzieren. Genau hier behaupten die Befürworter der ABC XYZ-Analyse, dass der Ansatz am besten zum Tragen kommt, und vier Extremsituationen von unmittelbarem Interesse werden im Folgenden anhand dieser Perspektive analysiert.
- AX: Diese SKUs erzielen hohe Umsätze und weisen geringe Schwankungen auf. Daher könnte ein Supply Chain Practitioner entscheiden, dass im Vergleich zu den anderen A-Klasse-SKUs ein geringerer Sicherheitsbestand erforderlich ist, um hohe Servicegrad-Ziele zu erreichen.
- AZ: Diese SKUs erzielen möglicherweise ebenso hohe Umsätze wie die von AX und AY, weisen jedoch deutlich höhere Nachfrageschwankungen auf. Folglich könnten höhere Sicherheitsbestände als ratsam erachtet werden.
- CX: Diese SKUs erzielen geringe Gewinne und weisen geringe Schwankungen auf. Ein niedriger Sicherheitsbestand wäre wahrscheinlich die gewählte Vorgehensweise (im Vergleich zu AX, AY, AZ, BX, BY und BZ).
- CZ: Diese SKUs erzielen nicht nur geringe Gewinne, sondern weisen auch erhöhte Nachfrageschwankungen auf. Aus supply chain perspective repräsentieren diese SKUs das Schlimmste aus beiden Welten. Solche SKUs hätten theoretisch einen niedrigen Sicherheitsbestand und wären Hauptkandidaten für eine mögliche Einstellung.
Als allgemeine Faustregel zeigt die ABC XYZ-Analyse, dass SKUs einen höheren Sicherheitsbestand benötigen, je weiter man sich entlang der x-Achse bewegt, was der gestiegenen Schwierigkeit entspricht, die Nachfrage vorherzusagen (wobei CZ-SKUs eine bemerkenswerte Ausnahme darstellen, wie oben beschrieben).
Servicegrade
Intuitiv ist es von entscheidender Bedeutung, die Servicegrade der A-Klasse-SKUs aufrechtzuerhalten, obwohl man sich dazu entscheiden könnte, niedrigere Werte anzustreben, wenn man sich entlang der x-Achse bewegt. So würden beispielsweise AX-SKUs vermutlich ein höheres Servicegrad-Ziel haben als AZ-SKUs, angesichts der geringeren Nachfrageschwankungen bei erstgenannten im Vergleich zu letztgenannten. Wenn man sich entlang der y-Achse nach unten bewegt, werden die Servicegrad-Ziele im Allgemeinen gesenkt, und wie zu erwarten wäre, würden CZ-SKUs die niedrigsten Servicegrad-Ziele aller neun Kategorien erhalten.
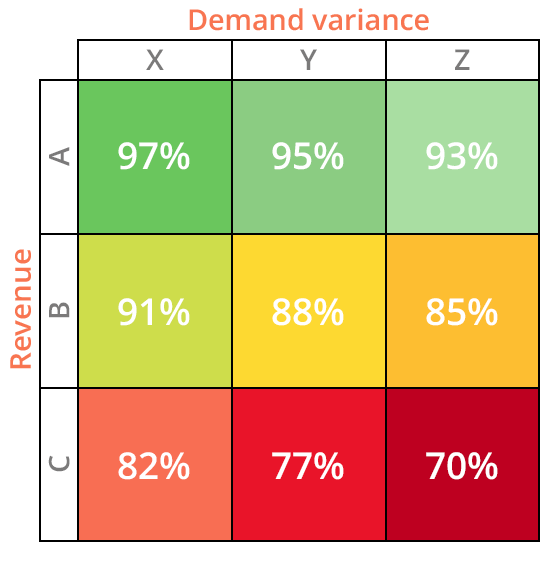
Abb. 2. Eine Modell-ABC XYZ-Matrix mit Umsatz auf der y-Achse und Nachfrageschwankungen auf der X-Achse. Diese Matrix zeigt potenzielle Servicegrad-Ziele für jede Kategorie, wobei die Werte mit sinkendem Umsatz und steigenden Nachfrageschwankungen abnehmen.
Grenzen der ABC XYZ
Obwohl die ABC XYZ-Analyse, wenn auch nur geringfügig, einen besseren Einblick in den Katalog bietet, ist sie ein evolutionärer Versuch, der alle Einschränkungen der ABC-Analyse beibehält und dabei kaum substanziellen Mehrwert liefert. Offensichtlich handelt es sich um eine Innovation ohne Substanz, und es wäre nicht unfair zu behaupten, dass sie sogar zusätzliche Mängelkategorien erfindet, die der ABC-Analyse fehlten.
Praktische Einwände gegen ABC XYZ
- Geringe Auflösung: Genau wie bei der ABC-Analyse erfassen die neun Kategorien einer ABC XYZ-Matrix Nachfragemuster wie steigende versus fallende Trends (siehe Harry Potter- und Tesla-T-Shirts in Abb. 3), begrenzte Angebote (siehe Suez Canal-T-Shirt) und Saisonalität (siehe Winterschuhe) nicht. Folglich bleibt der Einfluss, den diese auf die Bestandsverwaltung haben können, völlig unerforscht. Diese Einschränkung setzt zudem voraus, dass der Supply Chain Practitioner nicht willkürlich noch mehr Klassen entlang jeder Achse gewählt hat, was angesichts der laissez-faire-Natur des Ansatzes durchaus möglich ist.
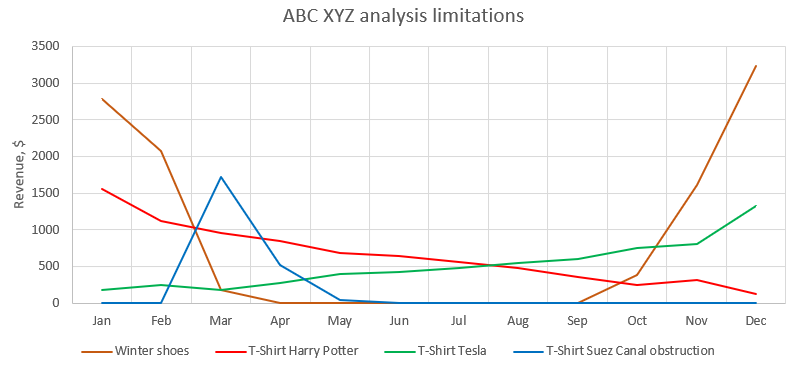
Abb. 3. Das Liniendiagramm zeigt die Grenzfälle, die die ABC XYZ-Analyse im Modell-Datensatz übersehen hat. Beispielsweise endeten sowohl Harry Potter- als auch Tesla-T-Shirts als BY-Klasse-SKUs und würden die gleichen Servicegrad- und Sicherheitsbestand-Ziele erhalten. Dies ignoriert die Tatsache, dass die SKUs nachweislich in völlig entgegengesetzte Richtungen tendieren.
-
Erhöht Instabilität: Die ABC XYZ-Analyse erweitert die willkürliche und instabile Kategorisierung, die durch die ABC-Analyse geschaffen wurde. Der tatsächliche Geldbetrag Unterschied zwischen CZ und CY oder zwischen BZ und sogar BY könnte verschwindend gering sein, wenn nicht fast finanziell unmerklich. Darüber hinaus können, genau wie bei der ABC-Analyse, diese praktisch unmerklichen Unterschiede je nach gewähltem Zeitraum variieren. Beispielsweise könnte eine SKU zwischen AZ und CZ schwanken, indem man den gewählten Zeitraum erweitert oder verkürzt (z. B. monatlich versus vierteljährlich versus jährlich). Ähnlich wie bei der Auswahl der oben beschriebenen neun Kategorien gibt es keinen mehr oder weniger logischen Grund, einen größeren oder kleineren Zeitraum zu wählen.1 Daher ist es zutiefst fehlerhaft, Servicegrad- und Sicherheitsbestand-Ziele basierend auf solch instabilen Eingaben festzulegen.
-
Erhöht Bürokratie: Per Definition erfordern die instabilen Kategorien, die oben beschrieben wurden, dass das Management eingreift und für jede Kategorie eigene Richtlinien festlegt. Dies führt leider zu noch mehr Bürokratie und ungenutzten Kapazitäten. Ebenso wie der Unterschied zwischen einer A- und einer B-SKU möglicherweise nur einen Prozentpunkt (oder einen kleinen Geldbetrag) ausmacht, könnte die Differenz im CV zwischen Y- und Z-Klasse-SKUs kaum wahrnehmbar sein. Diese Parameter sind völlig willkürlich und letztlich von einem Ausschuss festgelegt, weshalb ihre Herkunft fragwürdig ist. Angesichts der Tatsache, dass SKUs während des gesamten Beobachtungszeitraums problemlos zwischen den neun Kategorien wechseln können (unabhängig davon, wo sie am Ende eingeordnet werden), führt die Festlegung willkürlicher Servicegrade allein auf Basis dieser Informationen nicht nur zu unnötiger Verwaltung und Meetings, sondern erhöht auch die Wahrscheinlichkeit kostspieliger Fehlbestandsereignisse. Zudem werden viele, wenn nicht die meisten, der an der Festlegung dieser willkürlichen Parameter beteiligten Entscheider nicht über die erforderliche mathematische Ausbildung verfügen, um den Ansatz zu durchdringen, geschweige denn, um sinnvoll zu den numerischen Rezepten beizutragen. Diese Kritik wird in Theoretische Einwände gegen ABC XYZ weiter ausgeführt. Es sollte auch hervorgehoben werden, dass die ABC XYZ-Analyse – trotz der erweiterten Kategorisierung und Bürokratie – nicht tatsächlich ermittelt, warum bestimmte Produkte schwer vorherzusagen sind, wie zum Beispiel CZ-SKUs. Vielmehr stellt sie lediglich fest, dass sie schwer vorherzusagen sind, und das Management bleibt zurück, um darüber zu streiten, welche Sicherheitsbestand-Formeln willkürlich auf diese zufälligen Kategorisierungen anzuwenden sind.
-
Fehlt die finanzielle Perspektive: Im Kern basiert die ABC XYZ-Analyse auf einem First Order-Ansatz zu economic drivers. Kurz gesagt, betrachtet diese Denkweise SKUs ausschließlich in Bezug auf ihre direkten Margenbeiträge. Obwohl die ABC XYZ-Analyse scheinbar auch Nachfrageschwankungen berücksichtigt, beruht ihr Fundament dennoch darauf, wie viel jede SKU in einem individuellen, direkten Sinn beiträgt (z. B. Umsatz). Dieser Ansatz betrachtet SKUs eher isoliert als in Kombination. Diese Nuance ist das Kennzeichen eines Second Order-Ansatzes, bei dem der Wert einer CX-SKU beispielsweise in Relation zu einer AX-SKU betrachtet wird. Zwar mag die erstgenannte nicht signifikant zum Umsatz beitragen, aber ihre Lagerhaltung könnte den Verkauf der letztgenannten begünstigen, wodurch der indirekte Wert der CX-SKU ihren direkten Wert bei weitem übersteigen kann. Daher ist ein bereits willkürlicher Kategorisierungsprozess, der zu ebenso willkürlichen Bestandsverwaltungspolitiken führt, völlig blind gegenüber diesen feinen wirtschaftlichen Treibern. Dies wird nahezu sicher zu Fällen von Fehlbeständen bei SKUs führen, deren tatsächlicher Wert nicht erkannt wurde.2
Theoretische Einwände gegen ABC XYZ
Auf den ersten Blick mag die ABC XYZ Analyse wie eine überlegene Weiterentwicklung des klassischen ABC-Ansatzes erscheinen, wobei Menschen möglicherweise von der scheinbaren Anwendung halbfortgeschrittener mathematischer Prinzipien beeinflusst werden. Dieser Eindruck ist jedoch ungerechtfertigt, da die Anwendung der Momententheorie durch ABC XYZ naiv ist, angesichts der Tatsache, dass die implizite statistische Analyse, die durchgeführt werden soll, unvollständig ist. Zwar ist es richtig, dass Mittelwert und Varianz gültige Bestandteile einer solchen mathematischen Analyse sind (d.h. das Verständnis der Verteilung einer zufälligen Nachfragevariable), aber es gibt andere ebenso lehrreiche Momente, die völlig außer Acht gelassen werden.
Der dritte Moment, Schiefe, wird in einer ABC XYZ Analyse nicht berücksichtigt, ebenso wenig wie der vierte, Kurtosis. Wie gleichmäßig (oder ungleichmäßig) die Verkäufe um den Mittelwert verteilt sind, wird durch die Schiefe gemessen.3 Die Kurtosis misst hingegen, wie „spitz“ oder „flach“ die Verteilung im Vergleich zu einem normalverteilten Datensatz ist. Beide Momente liefern valide Einblicke in die zugrunde liegenden Daten, weshalb eine robuste statistische Analyse sie als Standardpraxis einbeziehen würde.4
Daher ist die Gültigkeit der statistischen Untersuchung in einer ABC XYZ Analyse bestenfalls unvollständig und im schlimmsten Fall irreführend. Tatsächlich ist die Natur moderner Computertechnik und statistischer Methoden so beschaffen, dass es nicht notwendig ist, den Umfang auf nur vier Momente zu beschränken – selbst eine theoretische zukünftige Iteration von ABC XYZ, die diese Momente einbezieht, wäre im Vergleich dennoch unterlegen.
Lokads Sichtweise
Die ABC XYZ Analyse ist letztlich ein unnötiger und fehlgeleiteter Versuch, die ABC Analyse zu verbessern. Abgesehen von den inherenten Einschränkungen der ABC-Klassifikation liefern die XYZ-Berechnungen keine aussagekräftigen Erkenntnisse, angesichts dessen, wie missverstanden die Forschungsfrage ist und wie unpassend die gewählten Werkzeuge zu ihrer Umsetzung sind.
ABC XYZ zielt darauf ab, Praktikern zu helfen, geeignete Bestandsverwaltungsrichtlinien für schwer vorhersagbare SKUs (z.B. AZ oder CZ) zu identifizieren, ohne dabei zu ergründen, warum diese SKUs schwer zu prognostizieren sein könnten. Darüber hinaus liefert die Analyse keine detaillierte Perspektive darauf, wie SKUs miteinander interagieren (ihr indirekter Wert), was eine entscheidende Rolle bei der Festlegung differenzierter Servicegrad- und entsprechender Lagerbestandsziele spielt. Indem diese Aspekte ignoriert werden, tastet die Analyse im Dunkeln.
Hinsichtlich der zugrunde liegenden Werkzeuge verdoppelt der Ansatz die willkürlichen Parameter seines Vorgängers und verdreifacht die Anzahl der Klassen, während er ein teilweise fundiertes Verständnis der Statistik integriert. Dieser Fehltritt kann nicht ignoriert werden, so wohlmeinend die Befürworter von ABC XYZ auch sein mögen. Die potenzielle Gefahr liegt in der Fassade der Strenge, die die XYZ-Berechnungen den Lesern präsentieren. Im Gegensatz zur ABC-Analyse, die nahezu jedem mit einem funktionierenden Computer und einem funktionierenden Gehirn zugänglich ist, soll ABC XYZ einige statistische Prinzipien nutzen, die für Ungeübte recht fortgeschritten und beeindruckend erscheinen können. Dies ist jedoch eine Schlagwort-Krücke, die ihr eigenes Gewicht nicht trägt. Eine sachgerechte statistische Analyse von Verkaufsdaten ist zwar mithilfe von Momenten möglich, erfordert jedoch ein weitaus anspruchsvolleres Verständnis von Momenten, als man in der ABC XYZ Analyse findet.
Schlussendlich opfert die ABC XYZ Analyse statistische Robustheit, um für den allgemeinen supply chain Praktiker zugänglich zu bleiben. Dieser Kompromiss führt zu einem Prozess, der Instabilität verstärkt und die Anwender von den zugrunde liegenden zentralen Fragestellungen ablenkt. Praktiker, deren Unternehmen über solche Praktiken hinausgewachsen sind, können gerne eine E-Mail an contact@lokad.com senden, um eine Demonstration einer produktionsreifen PIR Lösung zu vereinbaren – Lokads Antwort auf die Probleme, die ABC XYZ zu lösen versucht.
Anmerkungen
-
Zugegeben, es gibt eine untere Grenze des Nutzens; die Auswahl von nur einer Woche an Daten hätte fast keinen beweisenden Wert. Sobald jedoch ein Datensatz von ausreichender historischer Tiefe (sagen wir, 3 Monate Verkaufsdaten) ermittelt wurde, gibt es fast keinen logischen Einwand gegen den Vorschlag, ihn um einen weiteren Monat zu erweitern. Das Ergebnis würde, wie oben erwähnt, fast mit Sicherheit einige SKUs in der ABC XYZ Matrix verschieben. Dies unterstreicht ein weiteres Problem des ABC XYZ Prozesses: Sobald eine ausreichende Datenmasse erreicht ist, ist der Prozess sofort anfällig für weiteres Herumbasteln. Dies steht im Widerspruch zu dem, wofür eine Kategorisierung gedacht ist: robuste und aussagekräftige Abgrenzungen zwischen den Einträgen zu schaffen. ↩︎
-
Dies ist eine sehr kurze Zusammenfassung von Lokads Perspektive und deutet darauf hin, dass die Absicherung bei Lagerengpässen als entscheidender wirtschaftlicher Treiber zu betrachten ist. Beide Konzepte werden in unserem priorisierten Bestandsauffüllung in Excel mit Wahrscheinlichkeitsvorhersagen Tutorial ausführlicher behandelt. ↩︎
-
Oder „SKU-ness“, wenn Sie möchten. ↩︎
-
So wie pi unendlich viele Ziffern enthält, besitzt eine Wahrscheinlichkeitsdichtefunktion unendlich viele Momente unterschiedlicher Ordnung. In der Praxis werden jedoch in der Regel nur die ersten vier verwendet. ↩︎