L'analyse ABC XYZ (stocks)
L’analyse ABC XYZ, tout comme son prédécesseur l’analyse ABC, est un outil de catégorisation destiné à identifier les produits les plus performants dans le catalogue afin de déterminer des niveaux appropriés de taux de service et de stock de sécurité. Contrairement à l’analyse ABC, qui se concentre exclusivement sur un seul critère (typiquement le volume des ventes ou le chiffre d’affaires), l’analyse ABC XYZ tente également de quantifier une seconde dimension (l’incertitude de la demande ou sa volatilité). Bien qu’elle offre peut-être une vision légèrement plus détaillée de la performance, l’analyse ABC XYZ reste une application naïve des principes mathématiques sous-jacents et ne fait qu’amplifier la bureaucratie et l’instabilité. Elle conserve également toutes les limitations d’une analyse ABC classique, tout en procurant, selon certains, une fausse impression de sécurité encore plus grande grâce à un verbiage mathématique.
Réaliser une analyse ABC XYZ
Alors que l’analyse ABC vise à décomposer financièrement un ensemble de SKU en l’une des trois catégories sur une période donnée,1 fournissant ainsi à un praticien de la supply chain une répartition des SKU par importance financière, l’analyse ABC XYZ prétend aller un pas plus loin. Elle tente de comprendre et de quantifier la variance de la demande (ou volatilité) pour chaque SKU sur la période observée, et de fusionner les catégories classiques A, B et C avec des catégories supplémentaires X, Y et Z. En d’autres termes, la variance de la demande est une mesure de l’évolution de la demande au cours de la période observée. Cela peut refléter des périodes inattendues et/ou isolées de demande extrêmement élevée (ou faible), ou une difficulté générale soutenue à prévoir le nombre réel d’unités nécessaires pour un SKU (ou toute autre raison pouvant expliquer des fluctuations de la demande sur la période). C’est cette variance que les désignations X, Y et Z sont censées capturer.
Sous ce nouveau cadre à neuf catégories, les SKU de classe X sont les plus stables (subissent la plus faible variance de la demande), les classes Y sont relativement stables (subissent une variance modérée de la demande), et les classes Z sont les plus instables (subissent la plus grande variance de la demande). En s’appuyant sur l’analyse ABC classique, un praticien de la supply chain se voit proposer une répartition apparemment plus nuancée de son catalogue sur la période, où les SKU sont analysés selon deux fois plus de dimensions.
Pour mettre en œuvre cette nouvelle classification, le praticien de la supply chain suit les mêmes étapes initiales que l’analyse ABC classique. Une fois cette étape terminée, il passe à la partie XYZ de l’analyse, où il faut :
- Le nombre souhaité de classes de variance de la demande : généralement limité à 3, bien que cela reste flexible.
- Un seuil pour séparer chaque catégorie : déterminé entièrement à la discrétion du praticien de la supply chain. Par exemple, <=10% pour la classe X, >10-25% pour la classe Y, et >25% pour la classe Z.
- La moyenne pour chaque SKU sur la période observée : facilement calculable dans n’importe quel tableur.
- L’écart type et le coefficient de variation pour chaque SKU : également calculables facilement dans n’importe quel tableur.
L’écart type, dans le contexte d’une année de données, correspond généralement à l’écart des ventes d’un mois donné par rapport à la moyenne mensuelle annuelle. Une fois ces informations réunies, le praticien de la supply chain peut calculer le coefficient de variation (CV). Également connu sous le nom d’écart type relatif, le CV correspond à une valeur en pourcentage indiquant l’écart d’une donnée par rapport à la moyenne, ce qui, dans ce cas, représente l’ampleur des fluctuations des ventes d’un SKU sur la période observée (par rapport à la moyenne). Cette valeur en pourcentage est obtenue en divisant l’écart type par la moyenne.
Une fois le CV calculé, le praticien de la supply chain répartit les SKU dans leurs classes respectives X, Y et Z selon les seuils prédéterminés. Cela aboutit à une matrice à neuf catégories où les SKU sont classés en fonction de leur chiffre d’affaires et de la variance de leur demande.
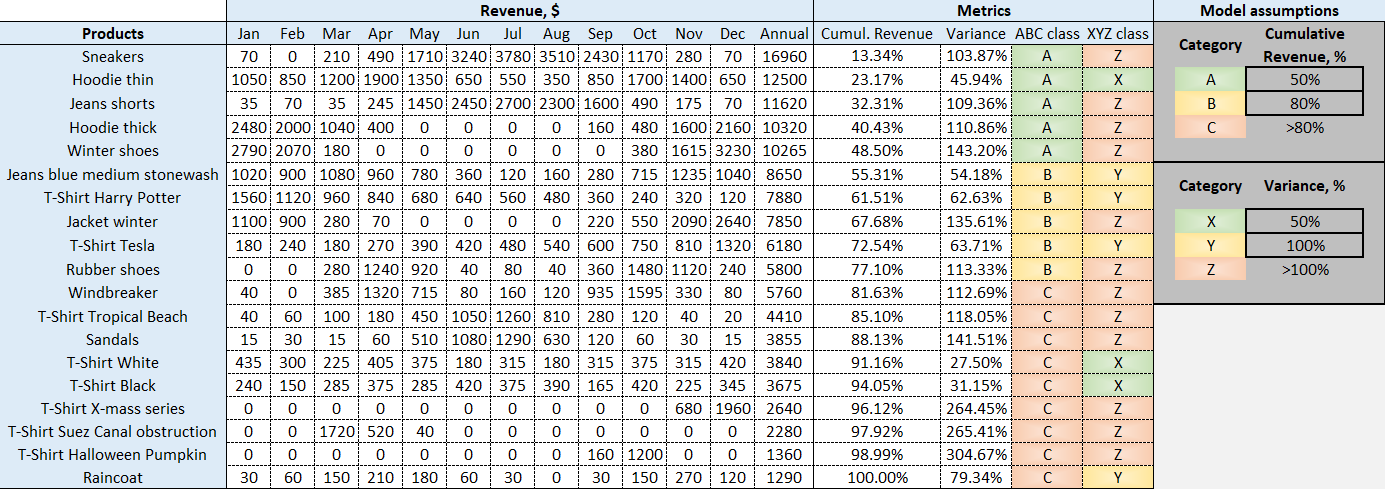
Figure 1. Un modèle d'analyse ABC XYZ, tel que présenté dans le tableur Excel téléchargeable. Pour les calculs explicites, veuillez consulter les formules dans les colonnes concernées.
Téléchargez le tableur Excel : abc-xyz-analysis-tool.xlsx
La perspective mathématique sur l’ABC et l’ABC XYZ
D’un point de vue purement mathématique, que ce soit de manière implicite ou explicite, les analyses ABC et ABC XYZ tentent toutes deux de tirer parti du concept de moments, qui constitue un ensemble infini de mesures quantitatives destinées à cartographier une fonction. Dans le contexte présent, la fonction correspond à une distribution des données de ventes, et les moments d’intérêt sont les deux premiers : la moyenne pour l’analyse ABC traditionnelle ; la moyenne et la variance pour l’analyse ABC XYZ. En ce qui concerne l’analyse ABC, étant donné qu’elle se concentre uniquement sur le premier moment (la moyenne), il serait plus exact de qualifier cette méthode de segmentation par moyenne mobile. Fondamentalement, il n’est pas question d’identifier l’incertitude de la demande. Pour cette raison, l’analyse ABC XYZ cherche à exploiter le second moment (la variance) pour quantifier cette incertitude. Cela rend l’analyse ABC XYZ plus proche d’une méthode de segmentation par moyenne mobile et variance. Contrairement à la moyenne, qui est bien comprise, la variance est un concept un peu moins courant. En résumé, elle représente à quel point un ensemble de valeurs – ici, les données moyennes mensuelles de ventes – est dispersé par rapport à la moyenne de l’ensemble. L’analyse ABC XYZ utilise cet outil mathématique supplémentaire pour aboutir à une compréhension prétendument plus complexe de la variation d’un ensemble de données. L’efficacité avec laquelle ces outils sont appliqués sera réexaminée dans Les limitations de l’ABC XYZ.
Comment l’analyse ABC XYZ informe la politique des stocks
Les applications théoriques de l’analyse ABC XYZ, tout comme l’analyse ABC, reposent sur l’attribution de cibles de taux de service et de stock de sécurité. Grâce à la nouvelle matrice ABC XYZ, un praticien de la supply chain peut, en théorie, mieux visualiser les SKU concernés et, ainsi, ajuster les politiques de stocks pour tenir compte non seulement des préoccupations liées au chiffre d’affaires, mais aussi des forces de la variance de la demande.
Stock de sécurité
Une application immédiate de l’analyse ABC XYZ est l’amélioration des cibles de stock de sécurité. Les SKU de la classe A reçoivent naturellement les niveaux les plus élevés, mais, contrairement à l’analyse ABC, il est tenté d’opérer une différenciation entre les membres de la classe A (ou de la classe C) en utilisant les classes XYZ le long de l’axe des x. C’est ici que les défenseurs de l’analyse ABC XYZ soutiennent que l’approche atteint son apogée, et quatre cas extrêmes d’intérêt immédiat seront analysés ci-dessous sous cet angle.
- AX : Ces SKU génèrent un chiffre d’affaires élevé et subissent une faible variance. Ainsi, un praticien de la supply chain pourrait décider que des niveaux de stock de sécurité plus faibles sont nécessaires par rapport aux autres SKU de la classe A, afin d’atteindre des cibles élevées de taux de service.
- AZ : Ces SKU peuvent générer un chiffre d’affaires tout aussi élevé que ceux des classes AX et AY, mais subissent une variance de demande sensiblement plus importante. En conséquence, des niveaux de stock de sécurité plus élevés pourraient être jugés prudents.
- CX : Ces SKU génèrent peu de profit et subissent une faible variance. Des niveaux bas de stock de sécurité seraient probablement adoptés (par rapport à AX, AY, AZ, BX, BY et BZ).
- CZ : Ces SKU non seulement génèrent peu de profit, mais subissent également des niveaux élevés de variance de demande. Du point de vue de la gestion de la supply chain, ces SKU représentent le pire des deux mondes. Théoriquement, ces SKU auraient de faibles niveaux de stock de sécurité et seraient de bons candidats pour une éventuelle suppression.
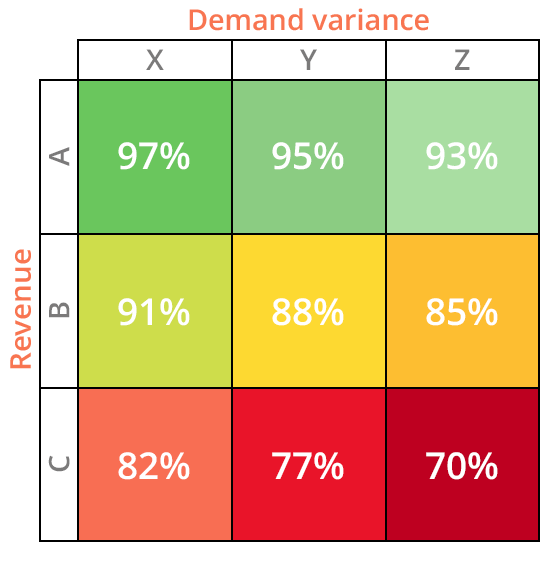
En règle générale, l’analyse ABC XYZ indique que les SKU requièrent plus de stock de sécurité à mesure que l’on se déplace le long de l’axe des x, en raison de la difficulté accrue à prévoir la demande (les SKU de la classe CZ constituant une exception notable, comme décrit ci-dessus).
Taux de service
Intuitivement, maintenir des taux de service élevés pour les SKU de la classe A est d’une importance primordiale, bien que l’on puisse opter pour des niveaux plus bas à mesure que l’on se déplace le long de l’axe des x. Par exemple, les SKU AX auraient probablement une cible de taux de service plus élevée que les SKU AZ, étant donné la variance de demande réduite associée aux premiers par rapport aux seconds. À mesure que l’on descend le long de l’axe des y, les cibles de taux de service sont généralement réduites, et, comme on peut s’y attendre, une politique sensée verrait les SKU de la classe CZ recevoir les cibles de taux de service les plus basses de l’ensemble des neuf catégories.
Figure 2. Un modèle de matrice ABC XYZ avec le chiffre d'affaires sur l'axe des y et la variance de la demande sur l'axe des X. Cette matrice affiche des cibles potentielles de taux de service pour chaque désignation, avec des niveaux qui diminuent à mesure que le chiffre d'affaires baisse et que la variance de la demande augmente.
Limites de l’ABC XYZ
Bien qu’elle offre, semble-t-il, une vision (légèrement) plus approfondie du catalogue, l’analyse ABC XYZ est une tentative d’évolution qui conserve toutes les limitations de l’analyse ABC tout en apportant très peu de substance. Franchement, il s’agit d’une innovation sans envergure, et il n’est pas exagéré de suggérer qu’elle invente même des catégories supplémentaires de défauts dont l’analyse ABC était dépourvue.
Objections pratiques à l’ABC XYZ
- Faible résolution : Comme dans l’analyse ABC, les neuf catégories d’une matrice ABC XYZ passent à côté de schémas de demande tels que les tendances à la hausse ou à la baisse (voir les t-shirts Harry Potter et Tesla dans la Figure 3), les offres limitées (voir le t-shirt Suez Canal) et la saisonnalité (voir les chaussures d’hiver). Par conséquent, l’impact que ces éléments peuvent avoir sur les politiques de stocks reste totalement inexploré. Cette limitation suppose également que le praticien de la supply chain n’a pas arbitrairement opté pour encore plus de catégories le long de chaque axe, ce qui est tout à fait possible compte tenu de la nature laissez-faire de l’approche.
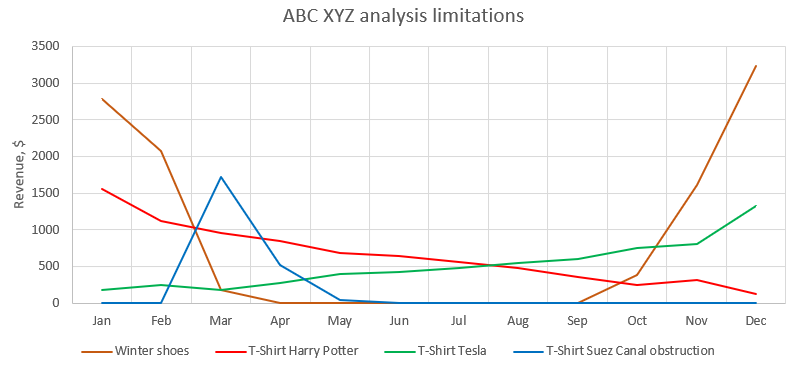
Figure 3. Le graphique linéaire démontre les cas limites que l'analyse ABC XYZ a manqués dans l'ensemble de données du modèle. Par exemple, les t-shirts Harry Potter et Tesla se sont terminés en tant que SKU de classe BY et auraient reçu les mêmes cibles de taux de service et de stock de sécurité. Cela occulte le fait que les SKU affichent des tendances clairement opposées.
-
Accroît l’instabilité : L’analyse ABC XYZ prolonge la catégorisation arbitraire et instable créée par l’analyse ABC. La véritable différence en dollars et centimes entre CZ et CY, ou BZ et même BY, pourrait être négligeable, voire presque financièrement imperceptible. De plus, tout comme dans une analyse ABC, ces différences pratiquement imperceptibles peuvent varier en fonction des horizons temporels sélectionnés. Par exemple, un SKU pourrait osciller entre AZ et CZ simplement en élargissant ou en réduisant la période choisie (par exemple, des horizons mensuels versus trimestriels ou annuels). À l’instar du choix des neuf catégories décrit ci-dessus, il n’y a ni plus ni moins de pertinence à opter pour une période temporelle plus longue ou plus courte.2 En conséquence, fixer des cibles de taux de service et de stock de sécurité basées sur des entrées aussi instables est profondément erroné.
-
Accroît la bureaucratie : Par définition, les catégories instables décrites ci-dessus nécessitent l’intervention de la direction pour établir des politiques distinctes pour chacune d’elles. Cela se traduit malheureusement par la création d’encore plus de bureaucratie et par une perte de capacité opérationnelle. Tout comme la différence entre un SKU de classe A et un SKU de classe B pourrait être d’un seul point de pourcentage (ou d’une poignée de dollars), l’écart de CV entre les SKU des classes Y et Z pourrait être à peine perceptible. Ces paramètres sont complètement arbitraires et finalement déterminés par comité, ce qui les rend de provenance discutable. En gardant à l’esprit que les SKU peuvent facilement passer d’une catégorie à une autre tout au long de la période observée (quel que soit leur classement final), fixer des taux de service arbitraires sur la base de ces informations non seulement crée une administration et des réunions inutiles, mais augmente également la probabilité d’événements coûteux de rupture de stock. De plus, bon nombre, voire la plupart, des responsables impliqués dans la définition de ces paramètres arbitraires manqueront de la formation mathématique requise pour analyser l’approche, sans parler de contribuer de manière significative aux recettes numériques. Cette critique est développée dans Les objections théoriques à l’ABC XYZ. Il convient également de souligner que, malgré la catégorisation et la bureaucratie accrues, l’analyse ABC XYZ n’identifie pas réellement pourquoi certains produits sont difficiles à prévoir – comme les SKU de classe CZ. Elle se contente de déterminer qu’ils sont difficiles à prévoir, laissant la direction se chamailler sur les formules de stock de sécurité à appliquer arbitrairement à ces catégorisations hasardeuses.
-
Manque de perspective financière : Fondamentalement, l’analyse ABC XYZ repose sur une approche de premier ordre des moteurs économiques. En bref, cet état d’esprit considère les SKU uniquement en termes de leurs contributions directes à la marge. Bien que l’ABC XYZ semble également prendre en compte la variance de la demande, sa fondation reste basée sur la contribution individuelle et directe de chaque SKU (par exemple, le chiffre d’affaires). Cette approche examine les SKU de manière isolée plutôt qu’en combinaison. Cette nuance est la marque d’une approche de second ordre, où la valeur d’un SKU de classe CX, par exemple, est envisagée en relation avec un SKU de classe AX. Bien que le premier ne contribue pas de manière significative au chiffre d’affaires, le conserver en stock peut faciliter la vente du second, ainsi la valeur indirecte du CX peut largement l’emporter sur sa valeur directe. Par conséquent, un processus de catégorisation déjà arbitraire, qui aboutit à des politiques de stocks tout aussi arbitraires, est complètement aveugle à ces subtils moteurs économiques. Cela se traduira presque certainement par des cas de ruptures de stock pour des SKU dont la véritable valeur n’a pas été reconnue.3
Objections théoriques à ABC XYZ
À première vue, l’analyse ABC XYZ peut sembler être une itération supérieure de l’approche classique ABC, avec des personnes peut-être influencées par l’application apparente de principes mathématiques semi-avancés. Cette impression est toutefois imméritée, car l’adoption par ABC XYZ de la théorie des moments est naïve, étant donné que l’analyse statistique implicite qu’elle cherche à effectuer est incomplète. Bien qu’il soit juste de dire que la moyenne et la variance sont des éléments valides d’une analyse mathématique de ce type (c’est-à-dire, la compréhension de la distribution d’une variable de demande aléatoire), il existe d’autres moments aussi instructifs qui sont complètement négligés.
Le troisième moment, l’asymétrie, n’est pas présent dans une analyse ABC XYZ, ni le quatrième, la kurtose. La manière dont les ventes se répartissent de manière égale (ou non) autour de la moyenne est mesurée par l’asymétrie.4 La kurtose, par ailleurs, mesure combien la distribution est « pointue » ou « aplatie » en comparaison avec un ensemble de données normalement distribué. Ces deux moments fournissent des informations valides sur les données sous-jacentes, c’est précisément pourquoi une analyse statistique robuste les intégrerait par défaut.5
En conséquence, la validité de l’analyse statistique dans une analyse ABC XYZ est, au mieux, inachevée et, au pire, trompeuse. En fait, la nature de l’informatique moderne et des techniques statistiques est telle qu’il n’est pas nécessaire de limiter le champ d’application à seulement quatre moments, ainsi même une itération théorique future d’ABC XYZ qui intègrerait ces moments serait néanmoins insuffisante en comparaison.
L’avis de Lokad
L’analyse ABC XYZ est, en fin de compte, une tentative inutile et mal orientée d’améliorer l’analyse ABC. En mettant de côté les limitations inhérentes de la classification ABC, les calculs XYZ échouent à fournir des insights significatifs étant donné à quel point sa question de recherche est mal comprise et combien les outils choisis sont inappropriés pour l’exécuter.
ABC XYZ vise à aider les praticiens à identifier des politiques de stocks appropriées pour les SKUs difficiles à prévoir (par ex., AZ ou CZ) sans déterminer pourquoi ces SKUs pourraient être difficiles à anticiper. De plus, elle ne fournit aucune perspective détaillée sur la manière dont les SKUs interagissent (leur valeur indirecte), ce qui joue un rôle crucial dans la détermination de taux de service nuancés et d’objectifs de niveau de stock respectifs. En ignorant ces préoccupations, l’analyse tâtonne essentiellement dans l’obscurité.
En termes d’outils sous-jacents, l’approche double les paramètres arbitraires de son prédécesseur et triple le nombre de classes, tout en incorporant une compréhension partielle des statistiques. Cette transgression ne peut être ignorée, si bien intentionnés soient les partisans d’ABC XYZ. Le danger potentiel réside dans la patine de rigueur que les calculs XYZ présentent aux lecteurs. Contrairement à l’analyse ABC, accessible à presque toute personne disposant d’un ordinateur fonctionnel et d’un cerveau actif, ABC XYZ prétend exploiter quelques principes statistiques qui, pour les non-initiés, peuvent sembler assez avancés et impressionnants. Cependant, ceci est une béquille de mots à la mode qui ne se soutient pas par elle-même. Une analyse statistique appropriée des données de ventes est possible en utilisant des moments, mais elle requiert une compréhension beaucoup plus sophistiquée des moments que celle que l’on trouve dans l’analyse ABC XYZ.
En fin de compte, l’analyse ABC XYZ sacrifie la robustesse statistique pour rester accessible au praticien général de supply chain. Ce compromis se traduit par un processus qui amplifie l’instabilité et détourne l’attention des utilisateurs des problèmes sous-jacents d’intérêt. Les praticiens dont les entreprises ont dépassé de telles pratiques sont invités à envoyer un email à contact@lokad.com pour organiser une démonstration d’une solution PIR de qualité production – la réponse de Lokad aux problèmes que tente de résoudre ABC XYZ.
Notes
-
Typiquement, les SKUs de classes A, B et C, où A représente les plus rentables, C les moins, et B se situe quelque part entre les deux. La période correspond généralement à une année civile, mais cela peut varier. ↩︎
-
Certes, il existe une limite inférieure à l’utilité ; sélectionner les données d’une seule semaine aurait une valeur probante presque nulle. Cependant, une fois qu’un ensemble de données d’une profondeur historique suffisante (disons, 3 mois de ventes) a été constitué, il n’y a presque aucune objection logique à l’idée qu’il pourrait être augmenté d’un mois supplémentaire. Le résultat en serait, comme mentionné ci-dessus, de fait modifier presque certainement le placement de certains SKUs dans la matrice ABC XYZ. Cela souligne un autre problème avec le processus ABC XYZ : une fois qu’une masse probante de données est atteinte, le processus devient immédiatement vulnérable à de nouveaux tâtonnements. Cela va à l’encontre de ce qu’une catégorisation est censée accomplir : fournir des limites robustes et significatives entre les entrées. ↩︎
-
Il s’agit d’un résumé très bref de la perspective de Lokad et cela préfigure la couverture de rupture de stock comme un moteur économique crucial. Ces deux concepts sont développés dans notre tutoriel sur le réapprovisionnement priorisé des stocks. ↩︎
-
Ou “SKU-ness” si vous préférez. ↩︎
-
Tout comme pi contient un nombre infini de chiffres, une fonction de densité de probabilité possède un nombre infini de moments d’ordre différent. Cependant, en pratique, généralement seuls les quatre premiers sont utilisés. ↩︎