Généralisation (Prévision)
La généralisation est la capacité d’un algorithme à générer un modèle - en s’appuyant sur un jeu de données - qui performe bien sur des données jamais vues auparavant. La généralisation revêt une importance cruciale pour la supply chain, car la plupart des décisions reflètent une anticipation du futur. Dans le contexte de la prévision, les données sont invisibles car le modèle prédit des événements futurs, qui sont inobservables. Bien que des progrès substantiels, tant théoriques que pratiques, aient été réalisés sur le front de la généralisation depuis les années 1990, la vraie généralisation demeure insaisissable. La résolution complète du problème de généralisation peut ne pas être très différente de celle du problème de l’intelligence artificielle générale. De plus, la supply chain ajoute son lot de problèmes épineux en plus des défis de généralisation grand public.

Aperçu d’un paradoxe
Créer un modèle qui performe parfaitement sur les données disponibles est simple : il suffit de mémoriser entièrement le jeu de données, puis d’utiliser le jeu de données lui-même pour répondre à toute requête à son sujet. Comme les ordinateurs sont efficaces pour enregistrer de grands jeux de données, concevoir un tel modèle est aisé. Cependant, cela est souvent inutile1, car la raison d’être d’un modèle réside dans sa capacité prédictive au-delà de ce qui a déjà été observé.
Un paradoxe apparemment inéluctable se présente : un bon modèle est celui qui performe bien sur des données actuellement indisponibles mais, par définition, si les données sont indisponibles, l’observateur ne peut effectuer l’évaluation. Le terme « généralisation » se réfère ainsi à l’habile capacité de certains modèles à conserver leur pertinence et leur qualité au-delà des observations disponibles au moment de la construction du modèle.
Bien que la mémorisation des observations puisse être écartée comme une stratégie de modélisation inadéquate, toute stratégie alternative pour créer un modèle est potentiellement soumise au même problème. Peu importe la performance apparente du modèle sur les données actuellement disponibles, il est toujours concevable qu’il s’agisse simplement d’une question de hasard, ou pire, d’un défaut de la stratégie de modélisation. Ce qui peut, au départ, apparaître comme un paradoxe statistique marginal est en réalité un problème d’une envergure considérable.
À titre d’évidence anecdotique, en 1979 la SEC (Securities and Exchange Commission), l’agence américaine chargée de réguler les marchés de capitaux, a introduit sa célèbre Rule 156. Cette règle exige que les gestionnaires de fonds informent les investisseurs que la performance passée n’est pas indicative des résultats futurs. La performance passée est implicitement le « modèle » que la SEC met en garde de ne pas utiliser pour sa puissance de « généralisation » ; c’est-à-dire, sa capacité à prédire quoi que ce soit sur l’avenir.
Même la science elle-même peine à définir ce que signifie extrapoler la « vérité » au-delà d’un ensemble restreint d’observations. Les scandales de la « mauvaise science », qui ont éclaté dans les années 2000 et 2010 autour du p-hacking, indiquent que des domaines entiers de recherche sont défaillants et ne peuvent être de confiance2. S’il existe des cas de fraude flagrante où les données expérimentales ont été manifestement falsifiées, le plus souvent, le cœur du problème réside dans les modèles ; c’est-à-dire, dans le processus intellectuel utilisé pour généraliser ce qui a été observé.
Dans sa forme la plus étendue, le problème de généralisation est indissociable de celui de la science elle-même, et il est donc aussi difficile que de répliquer l’étendue de l’ingéniosité et du potentiel humain. Pourtant, la dimension statistique plus restreinte du problème de généralisation est bien plus abordable, et c’est cette perspective qui sera adoptée dans les sections suivantes.
L’émergence d’une nouvelle science
La généralisation est apparue comme un paradigme statistique au tournant du 20e siècle, principalement sous l’angle de la précision des prévisions3, qui représente un cas particulier étroitement lié aux prévisions de séries temporelles. Au début des années 1900, l’émergence d’une classe moyenne propriétaire d’actions aux États-Unis a suscité un intérêt massif pour des méthodes qui aideraient les gens à sécuriser des rendements financiers sur leurs actifs échangés. Les diseurs de bonne aventure et les prévisionnistes économiques se sont donné la peine d’extrapoler les événements futurs pour un public désireux de payer. Des fortunes ont été faites et perdues, mais ces efforts ont apporté très peu d’éclairage sur la manière « appropriée » d’aborder le problème.
La généralisation est restée, en grande partie, un problème déconcertant pendant la majeure partie du 20e siècle. Il n’était même pas clair si elle appartenait au domaine des sciences naturelles, régi par les observations et les expérimentations, ou au domaine de la philosophie et des mathématiques, régi par la logique et la cohérence interne.
Le temps a filé jusqu’à un moment charnière en 1982, l’année de la première compétition de prévision publique - communément appelée la compétition M4. Le principe était simple : publier un jeu de données composé de 1000 séries temporelles tronquées, laisser les prétendants soumettre leurs prévisions, puis publier le reste du jeu de données (les queues tronquées) accompagné des précisions respectives obtenues par les participants. Grâce à cette compétition, la généralisation, encore perçue à travers le prisme de la précision des prévisions, était entrée dans le domaine des sciences naturelles. Par la suite, les compétitions de prévision sont devenues de plus en plus fréquentes.
Quelques décennies plus tard, Kaggle, fondée en 2010, a ajouté une nouvelle dimension à ces compétitions en créant une plateforme dédiée aux problèmes de prédiction générale (et pas seulement aux séries temporelles). En février 20235, la plateforme a organisé 349 compétitions avec des prix en espèces. Le principe reste le même que celui de la compétition M originale : un jeu de données tronqué est mis à disposition, les prétendants soumettent leurs réponses aux tâches de prédiction données, puis les classements accompagnés de la portion cachée du jeu de données sont révélés. Les compétitions sont toujours considérées comme la référence absolue pour l’évaluation correcte de l’erreur de généralisation des modèles.
Surapprentissage et sous-apprentissage
Le surapprentissage, comme son antonyme le sous-ajustement, est un problème qui survient fréquemment lors de la création d’un modèle basé sur un jeu de données donné, et qui compromet la capacité de généralisation du modèle. Historiquement6, le surapprentissage est apparu comme le premier obstacle bien compris à la généralisation.
La visualisation du surapprentissage peut être effectuée en utilisant un problème simple de modélisation de séries temporelles. Pour les besoins de cet exemple, supposons que l’objectif est de créer un modèle qui reflète une série d’observations historiques. L’une des options les plus simples pour modéliser ces observations est un modèle linéaire comme illustré ci-dessous (voir Figure 1).
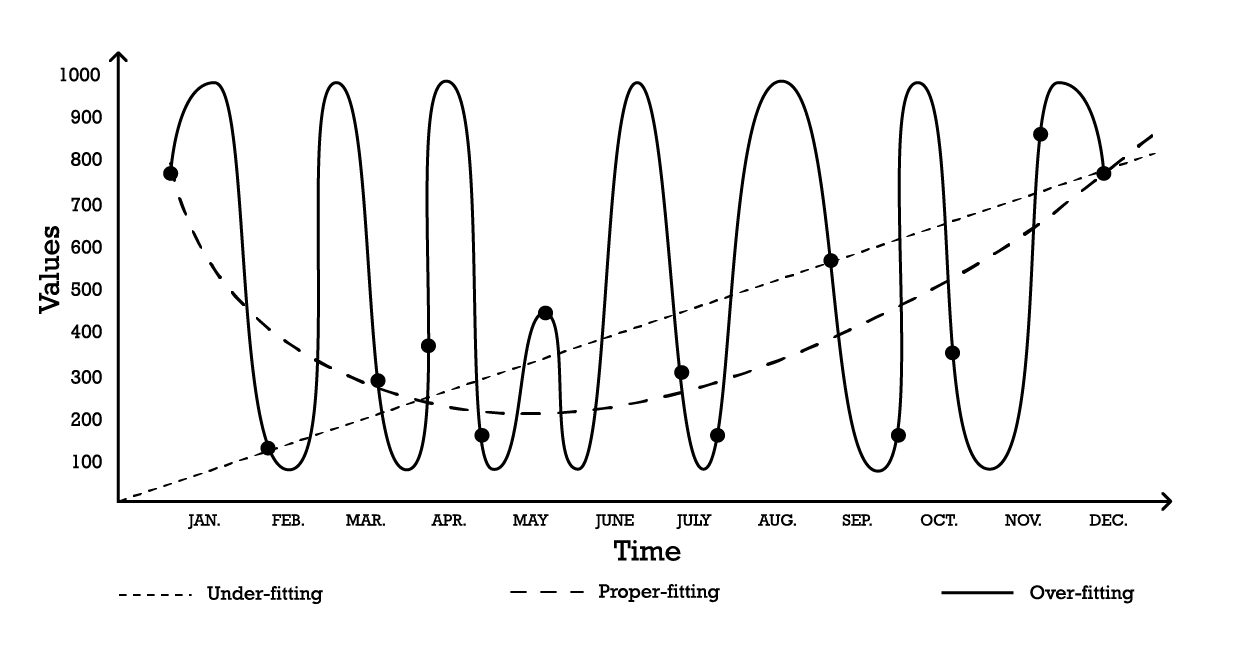
Figure 1: Un graphique composite illustrant trois tentatives différentes d'ajustement d'une série d'observations.
Avec deux paramètres, le modèle de sous-ajustement est robuste, mais, comme son nom l’indique, il sous-ajuste les données, car il échoue clairement à capturer la forme globale de la distribution des observations. Cette approche linéaire présente un biais élevé mais une faible variance. Dans ce contexte, biais doit être compris comme la limitation inhérente de la stratégie de modélisation à saisir les détails fins des observations, tandis que variance doit être comprise comme la sensibilité aux petites fluctuations – possiblement du bruit – des observations.
Un modèle assez complexe pourrait être adopté, selon la courbe de « surapprentissage » (Figure 1). Ce modèle inclut de nombreux paramètres et s’ajuste exactement aux observations. Cette approche présente un biais faible mais une variance manifestement élevée. Alternativement, un modèle d’une complexité intermédiaire pourrait être adopté, comme le montre la courbe de « bon ajustement » (Figure 1). Ce modèle inclut trois paramètres, présente un biais moyen et une variance moyenne. Parmi ces trois options, le modèle de bon ajustement est invariablement celui qui offre les meilleures performances en termes de généralisation.
Ces options de modélisation représentent l’essence du compromis biais-variance.7 8 Le compromis biais-variance est un principe général qui stipule que le biais peut être réduit en augmentant la variance. L’erreur de généralisation est minimisée en trouvant le juste équilibre entre la quantité de biais et de variance.
Historiquement, du début du 20e siècle jusqu’au début des années 2010, un modèle en surapprentissage était défini9 comme étant un modèle contenant plus de paramètres qu’il n’est justifié par les données. En effet, de prime abord, ajouter trop de degrés de liberté à un modèle semble être la recette parfaite pour les problèmes de surapprentissage. Pourtant, l’émergence du deep learning a prouvé que cette intuition, et la définition du surapprentissage, étaient trompeuses. Ce point sera revisité dans la section sur le deep double-descent.
Validation croisée et backtesting
La validation croisée est une technique de validation de modèle utilisée pour évaluer dans quelle mesure un modèle se généralisera au-delà de son jeu de données de support. C’est une méthode de sous-échantillonnage qui utilise différentes portions des données pour tester et entraîner un modèle lors de différentes itérations. La validation croisée est l’outil de base des pratiques de prédiction modernes, et presque tous les participants gagnants des compétitions de prédiction font un usage intensif de la validation croisée.
De nombreuses variantes de la validation croisée existent. La variante la plus populaire est la validation k-fold, où l’échantillon original est partitionné aléatoirement en k sous-échantillons. Chaque sous-échantillon est utilisé une fois comme données de validation, tandis que le reste – tous les autres sous-échantillons – est utilisé comme données d’entraînement.
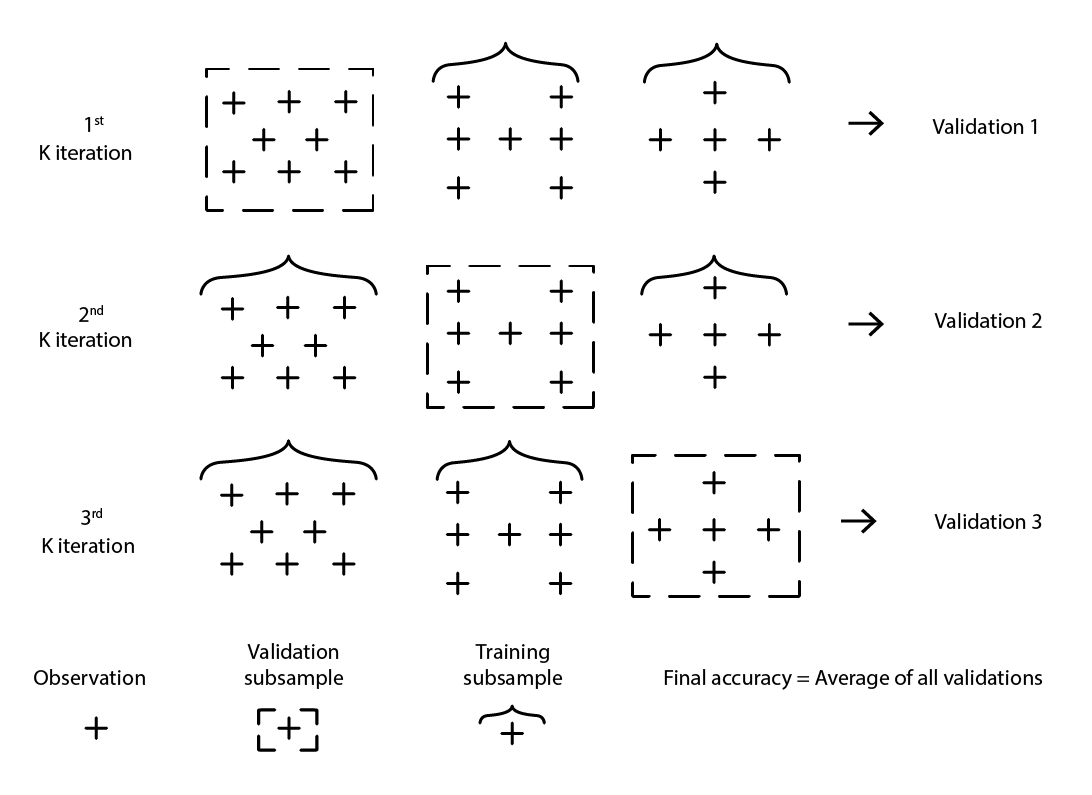
Figure 2: Un exemple de validation K-fold. Les observations ci-dessus proviennent toutes du même jeu de données. La technique construit ainsi des sous-échantillons de données pour des usages de validation et d'entraînement.
Le choix de la valeur k, le nombre de sous-échantillons, est un compromis entre des gains statistiques marginaux et les exigences en termes de ressources informatiques. En effet, avec la validation k-fold, les ressources informatiques augmentent linéairement avec la valeur k, tandis que les bénéfices, en termes de réduction d’erreur, font l’objet de rendements décroissants extrêmes10. En pratique, sélectionner une valeur de 10 ou 20 pour k est généralement « suffisant », car les gains statistiques associés à des valeurs plus élevées ne justifient pas les inconvénients supplémentaires liés à une dépense de ressources informatiques plus importante.
La validation croisée suppose que le jeu de données peut être décomposé en une série d’observations indépendantes. Cependant, dans la supply chain, ce n’est fréquemment pas le cas, car le jeu de données reflète généralement des données historisées où une dépendance temporelle est présente. En présence du temps, le sous-échantillon d’entraînement doit être strictement placé avant celui de validation. En d’autres termes, le « futur », par rapport à la coupure de re-échantillonnage, ne doit pas se retrouver dans le sous-échantillon de validation.
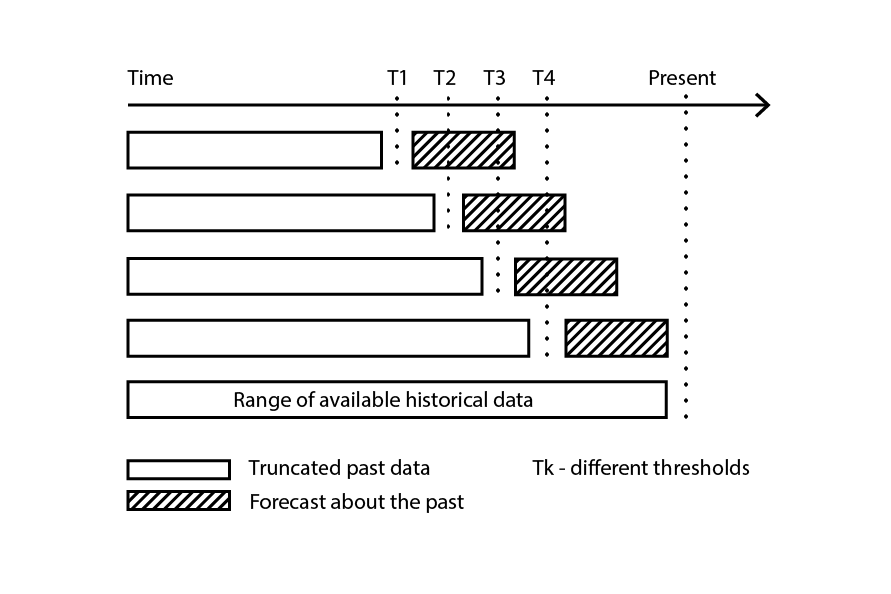
Figure 3: Un exemple de processus de backtesting qui construit des sous-échantillons de données pour des besoins de validation et d'entraînement.
Backtesting représente le type de validation croisée qui adresse directement la dépendance temporelle. Au lieu de considérer des sous-échantillons aléatoires, les données d’entraînement et de validation sont respectivement obtenues via une coupure : les observations antérieures à la coupure appartiennent aux données d’entraînement, tandis que les observations postérieures à la coupure appartiennent aux données de validation. Le processus est itéré en choisissant une série de valeurs de coupure distinctes.
La méthode de re-échantillonnage qui se trouve au cœur de la validation croisée et du backtesting est un mécanisme puissant pour orienter l’effort de modélisation vers une voie de meilleure généralisation. En fait, elle est si efficace qu’il existe une classe entière d’algorithmes d’apprentissage (machine learning) qui intègrent ce mécanisme dans leur fonctionnement. Les plus notables étant les forêts aléatoires et les arbres boostés par gradient.
Briser la barrière dimensionnelle
Naturellement, plus on dispose de données, plus il y a d’informations à en tirer. Par conséquent, toutes choses égales par ailleurs, plus de données devraient mener à de meilleurs modèles, ou du moins à des modèles qui ne sont pas pires que leurs prédécesseurs. Après tout, si davantage de données rend le modèle moins performant, il est toujours possible d’ignorer les données en dernier recours. Pourtant, en raison des problèmes de surapprentissage, éliminer des données est resté la solution du moindre mal jusqu’à la fin des années 1990. C’était le cœur du problème de la « barrière dimensionnelle ». Cette situation était à la fois déconcertante et profondément insatisfaisante. Les percées des années 1990 ont brisé les barrières dimensionnelles avec des éclairages stupéfiants, tant sur le plan théorique que pratique. Dans le processus, ces avancées ont réussi à dérailler – par un pur pouvoir de distraction – l’ensemble du domaine d’étude pendant une décennie, retardant l’avènement de ses successeurs, principalement les méthodes de deep learning, qui seront abordées dans la section suivante.
Pour mieux comprendre ce qui posait problème avec le fait d’avoir plus de données, considérez le scénario suivant : un fabricant fictif souhaite prédire le nombre de réparations non planifiées par an sur de gros équipements industriels. Après une analyse minutieuse du problème, l’équipe d’ingénierie a identifié trois facteurs indépendants qui semblent contribuer aux taux de défaillance. Cependant, la contribution respective de chaque facteur au taux global de défaillance reste incertaine.
Ainsi, un modèle de régression linéaire simple avec 3 variables d’entrée est introduit. Le modèle peut s’écrire sous la forme Y = a1 * X1 + a2 * X2 + a3 * X3, où
- Y est la sortie du modèle linéaire (le taux de défaillance que les ingénieurs souhaitent prédire)
- X1, X2 et X3 sont les trois facteurs (types spécifiques de charges de travail exprimées en heures d’opération) qui peuvent contribuer aux défaillances
- a1, a2 et a3 sont les trois paramètres du modèle qui doivent être identifiés.
La quantité d’observations nécessaire pour obtenir des estimations « assez bonnes » pour les trois paramètres dépend en grande partie du niveau de bruit présent dans l’observation, et de ce qui est considéré comme « assez bon ». Cependant, intuitivement, pour ajuster trois paramètres, au minimum une douzaine d’observations serait requise, même dans les situations les plus favorables. Comme les ingénieurs parviennent à collecter 100 observations, ils régressent avec succès 3 paramètres, et le modèle résultant semble « assez bon » pour être d’un intérêt pratique. Le modèle ne parvient pas à capturer de nombreux aspects des 100 observations, ce qui en fait une approximation très grossière, mais lorsque ce modèle est confronté à d’autres situations à travers des expériences de pensée, l’intuition et l’expérience indiquent aux ingénieurs que le modèle semble se comporter de manière raisonnable.
Fort de leur premier succès, les ingénieurs décident d’approfondir leur investigation. Cette fois, ils tirent parti de l’ensemble complet des capteurs électroniques intégrés dans la machinerie, et grâce aux dossiers électroniques produits par ces capteurs, ils parviennent à augmenter l’ensemble des facteurs d’entrée à 10 000. Initialement, l’ensemble de données se composait de 100 observations, chacune caractérisée par 3 nombres. Maintenant, l’ensemble de données a été élargi ; il s’agit toujours des mêmes 100 observations, mais il y a 10 000 nombres par observation.
Cependant, lorsque les ingénieurs tentent d’appliquer la même approche à leur ensemble de données considérablement enrichi, le modèle linéaire ne fonctionne plus. Comme il y a 10 000 dimensions, le modèle linéaire comporte 10 000 paramètres ; et les 100 observations ne sont absolument pas suffisantes pour permettre la régression d’autant de paramètres. Le problème n’est pas qu’il est impossible de trouver des valeurs de paramètres qui conviennent, mais tout le contraire : il est devenu trivial de trouver d’innombrables ensembles de paramètres qui s’ajustent parfaitement aux observations. Pourtant, aucun de ces modèles « ajustés » n’a une utilité pratique. Ces modèles « gros » s’ajustent parfaitement aux 100 observations, mais en dehors de celles-ci, les modèles deviennent insensés.
Les ingénieurs sont confrontés à la barrière dimensionnelle : apparemment, le nombre de paramètres doit rester faible par rapport au nombre d’observations, sinon l’effort de modélisation s’effondre. Ce problème est frustrant car l’ensemble de données « plus grand », avec 10 000 dimensions au lieu de 3, est évidemment plus informatif que le plus petit. Ainsi, un modèle statistique approprié devrait être capable de capturer cette information supplémentaire au lieu de devenir dysfonctionnel lorsqu’il y est confronté.
Au milieu des années 1990, une percée double11, à la fois théorique et expérimentale, a pris d’assaut la communauté. La percée théorique a été la théorie Vapnik–Chervonenkis (VC)12. La théorie VC a prouvé que, pour certains types de modèles, l’erreur réelle pouvait être majorée par ce qui équivalait vaguement à la somme de l’erreur empirique et du risque structurel, une propriété intrinsèque du modèle lui-même. Dans ce contexte, « erreur réelle » désigne l’erreur constatée sur les données que l’on n’a pas, tandis que « erreur empirique » désigne l’erreur constatée sur les données que l’on a. En minimisant la somme de l’erreur empirique et du risque structurel, l’erreur réelle pouvait être minimisée, puisqu’elle était « encadrée ». Cela représentait à la fois un résultat stupéfiant et sans doute le plus grand pas vers la généralisation depuis l’identification du problème de surapprentissage.
Sur le plan expérimental, des modèles plus tard connus sous le nom de Support Vector Machines (SVMs) ont été introduits presque comme une dérivation théorique de ce que la théorie VC avait identifié concernant l’apprentissage. Ces SVMs sont devenus les premiers modèles largement réussis capables d’exploiter de manière satisfaisante des ensembles de données où le nombre de dimensions dépassait le nombre d’observations.
En encadrant l’erreur réelle, un résultat théorique véritablement surprenant, la théorie VC avait brisé la barrière dimensionnelle - quelque chose qui était resté problématique pendant près d’un siècle. Elle a également ouvert la voie à des modèles capables de tirer parti des données de haute dimension. Pourtant, assez rapidement, les SVMs ont eux-mêmes été supplantés par des modèles alternatifs, principalement des méthodes d’ensemble (random forests13 et gradient boosting), qui se sont révélées, au début des années 2000, être des alternatives supérieures14, prévalant tant en termes de généralisation que d’exigences informatiques. Comme les SVMs qu’ils avaient remplacées, les méthodes d’ensemble bénéficient également de garanties théoriques quant à leur capacité à éviter le surapprentissage. Toutes ces méthodes partageaient la propriété d’être des méthodes non paramétriques. La barrière dimensionnelle avait été franchie grâce à l’introduction de modèles qui n’avaient pas besoin d’introduire un ou plusieurs paramètres pour chaque dimension ; contournant ainsi un chemin connu menant aux problèmes de surapprentissage.
Pour revenir au problème des réparations non planifiées mentionné précédemment, contrairement aux modèles statistiques classiques – comme la régression linéaire, qui s’effondre face à la barrière dimensionnelle – les méthodes d’ensemble parviendraient à tirer parti de l’ensemble de données volumineux et de ses 10 000 dimensions, même s’il n’y a que 100 observations. De plus, les méthodes d’ensemble excelleraient plus ou moins directement out of the box. Sur le plan opérationnel, cela a constitué un développement remarquable, car cela supprimait la nécessité de concevoir méticuleusement des modèles en choisissant exactement le bon ensemble de dimensions d’entrée.
L’impact sur la communauté au sens large, tant à l’intérieur qu’à l’extérieur du monde académique, a été massif. La plupart des efforts de recherche au début des années 2000 étaient consacrés à l’exploration de ces approches non paramétriques « soutenues par la théorie ». Pourtant, les succès se sont évaporés assez rapidement avec le temps. En fait, environ vingt ans plus tard, les meilleurs modèles de ce qui est devenu connu sous le nom de perspective de l’apprentissage statistique demeurent les mêmes – ne bénéficiant que d’implémentations plus performantes15.
La double descente profonde
Jusqu’en 2010, la sagesse conventionnelle dictait que, pour éviter les problèmes de surapprentissage, le nombre de paramètres devait rester bien inférieur au nombre d’observations. En effet, comme chaque paramètre représentait implicitement un degré de liberté, avoir autant de paramètres que d’observations était une recette pour assurer le surapprentissage16. Les méthodes d’ensemble contournaient complètement le problème en étant non paramétriques dès le départ. Pourtant, cette observation cruciale s’est avérée fausse, et de façon spectaculaire.
Ce qui est par la suite devenu connu sous le nom d’approche deep learning a surpris presque toute la communauté par le biais de modèles hyperparamétriques. Ce sont des modèles qui ne surapprennent pas pourtant qui contiennent de nombreuses fois plus de paramètres que d’observations.
La genèse du deep learning est complexe et peut être retracée jusqu’aux premières tentatives de modéliser les processus du cerveau, à savoir les réseaux de neurones. Détailler cette genèse est au-delà du cadre de la présente discussion, toutefois il convient de noter que la révolution du deep learning du début des années 2010 a commencé juste au moment où le domaine abandonnait la métaphore du réseau de neurones au profit de la mechanical sympathy. Les implémentations de deep learning ont remplacé les modèles précédents par des variantes bien plus simples. Ces nouveaux modèles ont tiré parti d’alternatives computing hardware, notamment les GPUs (graphics processing units), qui se sont avérés, quelque peu par hasard, parfaitement adaptés aux opérations d’algèbre linéaire qui caractérisent les modèles de deep learning17.
Il a fallu près de cinq années de plus pour que le deep learning soit largement reconnu comme une percée. Une part considérable de la réticence provenait du camp de l’apprentissage statistique – par coïncidence, la section de la communauté qui avait réussi à briser la barrière dimensionnelle deux décennies plus tôt. Bien que les explications de cette réticence varient, la contradiction apparente entre la sagesse conventionnelle en matière de surapprentissage et les revendications du deep learning a certainement contribué à un niveau appréciable de scepticisme initial concernant cette nouvelle classe de modèles.
La contradiction est demeurée en grande partie non résolue jusqu’en 2019, lorsque la double descente profonde a été identifiée18, un phénomène caractérisant le comportement de certaines classes de modèles. Pour ces modèles, augmenter le nombre de paramètres dégrade d’abord l’erreur de test (par surapprentissage), jusqu’à ce que le nombre de paramètres devienne suffisamment important pour inverser la tendance et améliorer à nouveau l’erreur de test. La « seconde descente » (de l’erreur de test) n’était pas un comportement prédit par la perspective du compromis biais-variance.
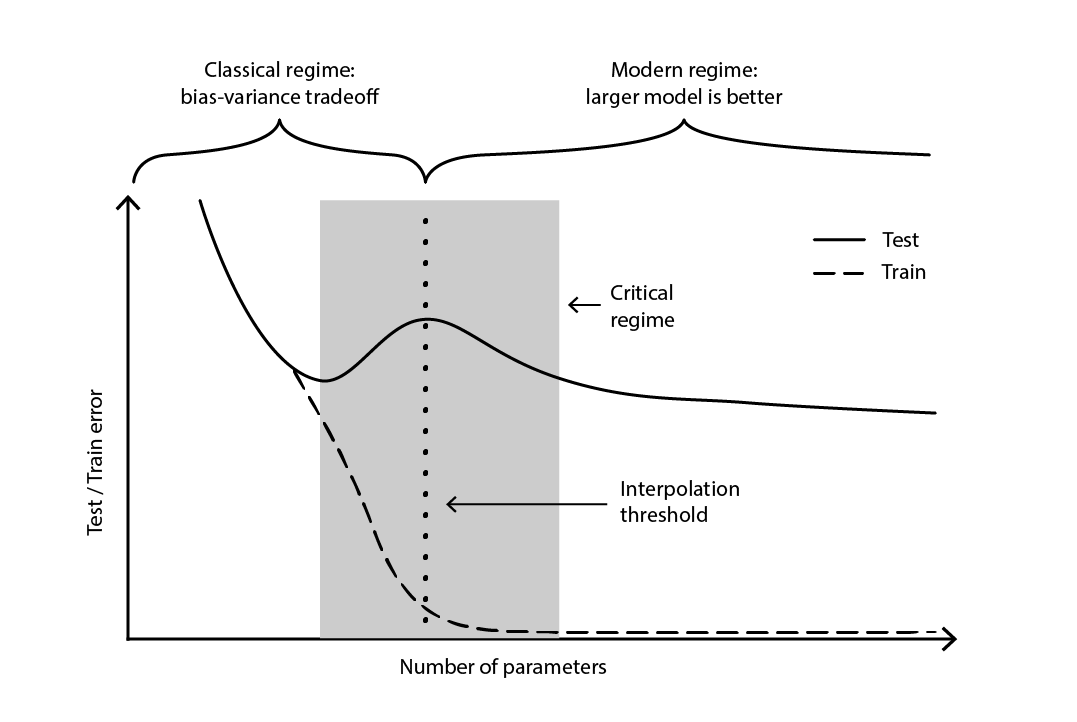
Figure 4. Une double descente profonde.
La Figure 4 illustre les deux régimes successifs décrits ci-dessus. Le premier régime est le compromis classique biais-variance qui semble venir avec un nombre « optimal » de paramètres. Pourtant, ce minimum s’avère être un minimum local. Il existe un second régime, observable si l’on continue d’augmenter le nombre de paramètres, qui présente une convergence asymptotique vers une véritable erreur de test optimale pour le modèle.
La double descente profonde a non seulement réconcilié les perspectives statistique et deep learning, mais a également démontré que la généralisation reste relativement mal comprise. Elle a prouvé que les théories largement répandues – courantes jusqu’à la fin des années 2010 – présentaient une vision déformée de la généralisation. Cependant, la double descente profonde ne fournit pas encore de cadre – ni quelque chose d’équivalent – qui prédirait la puissance de généralisation (ou son absence) des modèles en fonction de leur structure. À ce jour, l’approche reste résolument empirique.
Les épines de la supply chain
Comme cela a été abordé en profondeur, la généralisation est extrêmement difficile, et les supply chains parviennent à ajouter leur lot de bizarreries, intensifiant encore la situation. D’abord, les données recherchées par les praticiens de la supply chain peuvent rester à jamais inaccessibles ; non pas partiellement invisibles, mais totalement inobservables. Ensuite, le simple acte de prédiction peut modifier le futur, ainsi que la validité de la prédiction, puisque les décisions sont basées sur ces mêmes prédictions. Ainsi, lorsqu’on aborde la généralisation dans un contexte de supply chain, une approche à deux volets doit être utilisée ; l’un étant la solidité statistique du modèle et l’autre le raisonnement de haut niveau qui le soutient.
De plus, les données disponibles ne sont pas toujours les données désirées. Prenons l’exemple d’un fabricant qui souhaite prévoir la demande afin de décider des quantités à produire. Il n’existe pas de données historiques de « demande ». Au lieu de cela, les données historiques de ventes représentent le meilleur substitut disponible pour le fabricant afin de refléter la demande historique. Cependant, les ventes historiques sont faussées par les ruptures de stock. Des ventes nulles, causées par des ruptures de stock, ne doivent pas être confondues avec une demande nulle. Bien qu’un modèle puisse être conçu pour rectifier cet historique de ventes en une sorte d’historique de la demande, l’erreur de généralisation de ce modèle est par conception insaisissable, car ni le passé ni le futur ne détient ces données. En bref, la « demande » est une construction nécessaire mais intangible.
Dans le jargon du machine learning, modéliser la demande est un problème d’apprentissage non supervisé où la sortie du modèle n’est jamais observée directement. Cet aspect non supervisé défie la plupart des algorithmes d’apprentissage, ainsi que la plupart des techniques de validation de modèles – du moins, dans leur version « naïve ». De plus, il contredit même l’idée d’un concours de prédiction, signifiant ici un processus simple en deux étapes où un ensemble de données original est divisé en une sous-partie publique (d’apprentissage) et une sous-partie privée (de validation). La validation elle-même devient par nécessité un exercice de modélisation.
En d’autres termes, la prédiction effectuée par le fabricant façonnera, d’une manière ou d’une autre, le futur auquel il sera confronté. Une forte demande prévisionnelle signifie que le fabricant va intensifier sa production. Si l’entreprise est bien gérée, des économies d’échelle devraient être réalisées dans le processus de fabrication, réduisant ainsi les coûts de production. En retour, le fabricant est susceptible de tirer parti de ces économies nouvellement découvertes afin de baisser les prix, gagnant ainsi un avantage concurrentiel sur ses rivaux. Le marché, à la recherche de l’option la moins chère, pourrait rapidement adopter ce fabricant comme son option la plus compétitive, déclenchant ainsi une augmentation de la demande bien au-delà de la projection initiale.
Ce phénomène est connu sous le nom de prophétie auto-réalisatrice, une prédiction qui tend à se réaliser en vertu de la croyance influente que les participants accordent à cette prédiction. Une perspective peu orthodoxe, mais non entièrement déraisonnable, caractériserait les supply chains comme de gigantesques machines de Rube Goldberg auto-réalisatrices. Au niveau méthodologique, cet enchevêtrement de l’observateur et de l’observation complique encore la situation, car la généralisation devient associée à la capture de l’intention stratégique qui sous-tend les évolutions de la supply chain.
À ce stade, le défi de la généralisation, tel qu’il se présente dans la supply chain, pourrait sembler insurmontable. Les tableurs, qui restent omniprésents dans les supply chains, suggèrent certainement que telle est la position par défaut, quoique implicite, de la plupart des entreprises. Un tableur est, en effet, avant tout un outil permettant de reporter la résolution du problème à un jugement humain ad hoc, plutôt qu’à l’application d’une méthode systématique.
Bien que se fier au jugement humain soit invariablement la réponse incorrecte (en soi), ce n’est pas non plus une réponse satisfaisante au problème. La présence de ruptures de stock ne signifie pas que tout est permis en matière de demande. Certes, si le fabricant a maintenu des taux de service moyens supérieurs à 90 % au cours des trois dernières années, il serait hautement improbable que la demande (observée) ait pu être 10 fois supérieure aux ventes. Ainsi, il est raisonnable de s’attendre à ce qu’une méthode systématique puisse être conçue pour faire face à de telles distorsions. De même, la prophétie auto-réalisatrice peut également être modélisée, notamment par la notion de politique telle que comprise par la théorie du contrôle.
Ainsi, lorsqu’on considère une supply chain réelle, la généralisation nécessite une approche à deux volets. D’abord, le modèle doit être statistiquement solide, autant que le permettent les vastes sciences de l’apprentissage. Cela englobe non seulement des perspectives théoriques telles que la statistique classique et l’apprentissage statistique, mais aussi des efforts empiriques comme le machine learning et les concours de prédiction. Revenir aux statistiques du XIXe siècle n’est pas une proposition raisonnable pour une pratique supply chain du XXIe siècle.
Deuxièmement, le modèle doit être soutenu par un raisonnement de haut niveau. Autrement dit, pour chaque composant du modèle et chaque étape du processus de modélisation, il devrait y avoir une justification qui a du sens du point de vue de la supply chain. Sans cet ingrédient, le chaos opérationnel19 est presque garanti, généralement déclenché par une certaine évolution de la supply chain elle-même, de son écosystème opérationnel ou de son paysage applicatif sous-jacent. En effet, tout l’enjeu du raisonnement de haut niveau n’est pas de faire fonctionner un modèle une fois, mais de le faire fonctionner de manière durable sur plusieurs années dans un environnement en perpétuelle évolution. Ce raisonnement est l’ingrédient pas si secret qui permet de décider qu’il est temps de réviser le modèle lorsque sa conception, quelle qu’elle soit, n’est plus en adéquation avec la réalité et/ou les objectifs commerciaux.
De loin, cette proposition pourrait sembler vulnérable à la critique antérieure adressée aux tableurs – celle contre le report du travail difficile à un jugement humain insaisissable. Bien que cette proposition reporte encore l’évaluation du modèle au jugement humain, l’exécution du modèle est envisagée comme entièrement automatisée. Ainsi, les opérations quotidiennes sont destinées à être entièrement automatisées, même si les efforts d’ingénierie en cours pour améliorer davantage les numerical recipes ne le sont pas.
Notes
-
Il existe une technique algorithmique importante appelée “memoization” qui remplace précisément un résultat qui pourrait être recalculé par son résultat pré-calculé, échangeant ainsi plus de mémoire contre moins de calcul. Cependant, cette technique n’est pas pertinente pour la présente discussion. ↩︎
-
Pourquoi la plupart des résultats de recherche publiés sont faux, John P. A. Ioannidis, août 2005 ↩︎
-
Du point de vue de la prévision des séries temporelles, la notion de généralisation est abordée via le concept de “précision”. La précision peut être considérée comme un cas particulier de la “généralisation” lorsqu’il s’agit des séries temporelles. ↩︎
-
Makridakis, S.; Andersen, A.; Carbone, R.; Fildes, R.; Hibon, M.; Lewandowski, R.; Newton, J.; Parzen, E.; Winkler, R. (avril 1982). “La précision des méthodes d’extrapolation (séries temporelles) : Résultats d’une compétition de prévision”. Journal of Forecasting. 1 (2): 111–153. doi:10.1002/for.3980010202. ↩︎
-
Kaggle in Numbers, Carl McBride Ellis, consulté le 8 février 2023, ↩︎
-
L’extrait de 1935 “Peut-être sommes-nous démodés, mais pour nous, une analyse à six variables basée sur treize observations ressemble plutôt à du surapprentissage”, extrait de “The Quarterly Review of Biology” (Sep, 1935 Volume 10, Number 3, pp. 341 – 377), semble indiquer que le concept statistique de surapprentissage était déjà établi à cette époque. ↩︎
-
Grenander, Ulf. Sur l’analyse spectrale empirique des processus stochastiques. Ark. Mat., 1(6):503–531, 08 1952. ↩︎
-
Whittle, P. Tests of Fit in Time Series, Vol. 39, No. 3/4 (déc., 1952), pp. 309-318 (10 pages), Oxford University Press ↩︎
-
Everitt B.S., Skrondal A. (2010), Cambridge Dictionary of Statistics, Cambridge University Press. ↩︎
-
Les avantages asymptotiques de l’utilisation de valeurs de k plus élevées pour la validation croisée k-fold peuvent être déduits du théorème central limite. Cette observation suggère qu’en augmentant k, nous pouvons nous rapprocher d’environ 1 / sqrt(k) de l’épuisement complet du potentiel d’amélioration apporté par la validation croisée k-fold en premier lieu. ↩︎
-
Réseaux à vecteurs de support, Corinna Cortes, Vladimir Vapnik, Machine Learning volume 20, pages 273–297 (1995) ↩︎
-
La théorie Vapnik-Chervonenkis (VC) n’était pas le seul candidat pour formaliser ce que signifie « l’apprentissage ». Le cadre PAC (probably approximately correct) de Valiant, en 1984, a ouvert la voie aux approches formelles d’apprentissage. Cependant, le cadre PAC manquait de l’immense traction et des succès opérationnels dont jouissait la théorie VC à l’approche du millénaire. ↩︎
-
Random Forests, Leo Breiman, Machine Learning volume 45, pages 5–32 (2001) ↩︎
-
Une des conséquences malheureuses du fait que les Support Vector Machines (SVMs), fortement inspirées par une théorie mathématique, aient peu de sympathie mécanique pour le matériel informatique moderne. L’inadéquation relative des SVMs à traiter de grands ensembles de données – incluant des millions d’observations ou plus – par rapport aux alternatives a scellé le sort de ces méthodes. ↩︎
-
XGBoost et LightGBM sont deux implémentations open-source des méthodes d’ensemble qui restent très populaires dans les cercles du machine learning. ↩︎
-
Par souci de concision, il y a ici une légère simplification. Il existe tout un domaine de recherche dédié à la “régularisation” des modèles statistiques. En présence de contraintes de régularisation, le nombre de paramètres, même pour un modèle classique comme une régression linéaire, peut sans danger dépasser le nombre d’observations. En présence de régularisation, aucune valeur de paramètre ne représente pleinement un degré de liberté, mais plutôt une fraction de celui-ci. Il serait donc plus approprié de se référer au nombre de degrés de liberté, au lieu de se référer au nombre de paramètres. Comme ces considérations tangentielles n’altèrent pas fondamentalement les points de vue présentés ici, la version simplifiée suffit. ↩︎
-
En fait, la causalité est inverse. Les pionniers du deep learning ont réussi à reconfigurer leurs modèles originaux - les réseaux neuronaux - en modèles plus simples qui reposaient presque exclusivement sur l’algèbre linéaire. L’objectif de cette reconception était précisément de permettre l’exécution de ces nouveaux modèles sur du matériel informatique qui échangeait polyvalence contre puissance brute, notamment les GPU. ↩︎
-
Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, décembre 2019 ↩︎
-
La grande majorité des initiatives data science en supply chain échouent. Mes observations informelles indiquent que l’ignorance, de la part du data scientist, de ce qui fait fonctionner la supply chain est la cause principale de la plupart de ces échecs. Bien qu’il soit incroyablement tentant – pour un data scientist récemment formé – d’exploiter le package de machine learning open-source le plus récent et le plus étincelant, toutes les techniques de modélisation ne sont pas également adaptées pour soutenir un raisonnement de haut niveau. En fait, la plupart des techniques “mainstream” sont tout simplement terribles lorsqu’il s’agit du processus de whiteboxing. ↩︎