Дифференцируемое программирование для оптимизации работы с крупномасштабными реляционными данными
В сложном мире управления цепями поставок реляционные данные являются основой. Системы ERP, WMS, PMS и другие программные инструменты, повсеместно используемые в цепочках поставок, работают на реляционных базах данных, отслеживая всё — от уровней запасов до взаимоотношений с поставщиками. Реляционные данные состоят из серии взаимосвязанных таблиц, каждая из которых богата многочисленными столбцами с информацией. Однако, когда дело доходит до машинного обучения и математической оптимизации, реляционные данные часто оказываются в тени более простых форм, таких как векторы, последовательности и графы.
Реляционные данные — благодаря своей богатой сложности — предоставляют более глубокое и нюансированное представление об операциях, чем их более простые аналоги (упомянутые выше векторы, последовательности и графы). Тем не менее, большинство корпоративного программного обеспечения испытывает трудности с эффективным использованием данных в их реляционной форме. Итог? Принудительное втиснение квадратных колышков в круглые отверстия, отчаянные попытки сжать реляционные данные в инструменты, разработанные для более простых моделей. Это несоответствие ставит компании в невыгодное положение, словно использование хоккейной клюшки для игры в гольф — теоретически возможно, но далеко не оптимальное сочетание инструмента и задачи.
Решив исследовать этот незамеченный аспект, несколько лет назад Paul Peseux начал кандидатскую диссертацию в Lokad с целью сделать реляционные данные полноценными элементами как в обучении, так и в оптимизации. Его исследовательские усилия привели к серии замечательных улучшений поддержки дифференцируемого программирования в рамках Envision — DSL Lokad (домен-специфичный язык программирования), предназначенного для оптимизации цепочек поставок. Впечатляющие результаты исследования Пола теперь используются в производстве, как правило, скрытые в возможностях autodiff.
Автор: Paul Peseux
Дата: Сентябрь 2023
Аннотация:
Данная кандидатская диссертация представляет три вклада в область дифференцируемого программирования с акцентом на реляционные данные. Реляционные данные широко распространены в таких отраслях, как здравоохранение и цепочки поставок, где информация часто организована в виде структурированных таблиц или баз данных. Традиционные методы машинного обучения испытывают трудности при работе с реляционными данными, тогда как модели машинного обучения с белым ящиком более подходят, но их разработка представляет собой сложную задачу.
Дифференцируемое программирование предлагает потенциальное решение, рассматривая запросы к реляционным базам данных как дифференцируемые программы, что позволяет разрабатывать модели машинного обучения с белым ящиком, способные непосредственно анализировать реляционные данные. Основная цель данного исследования — изучить применение методов машинного обучения к реляционным данным с использованием техник дифференцируемого программирования.
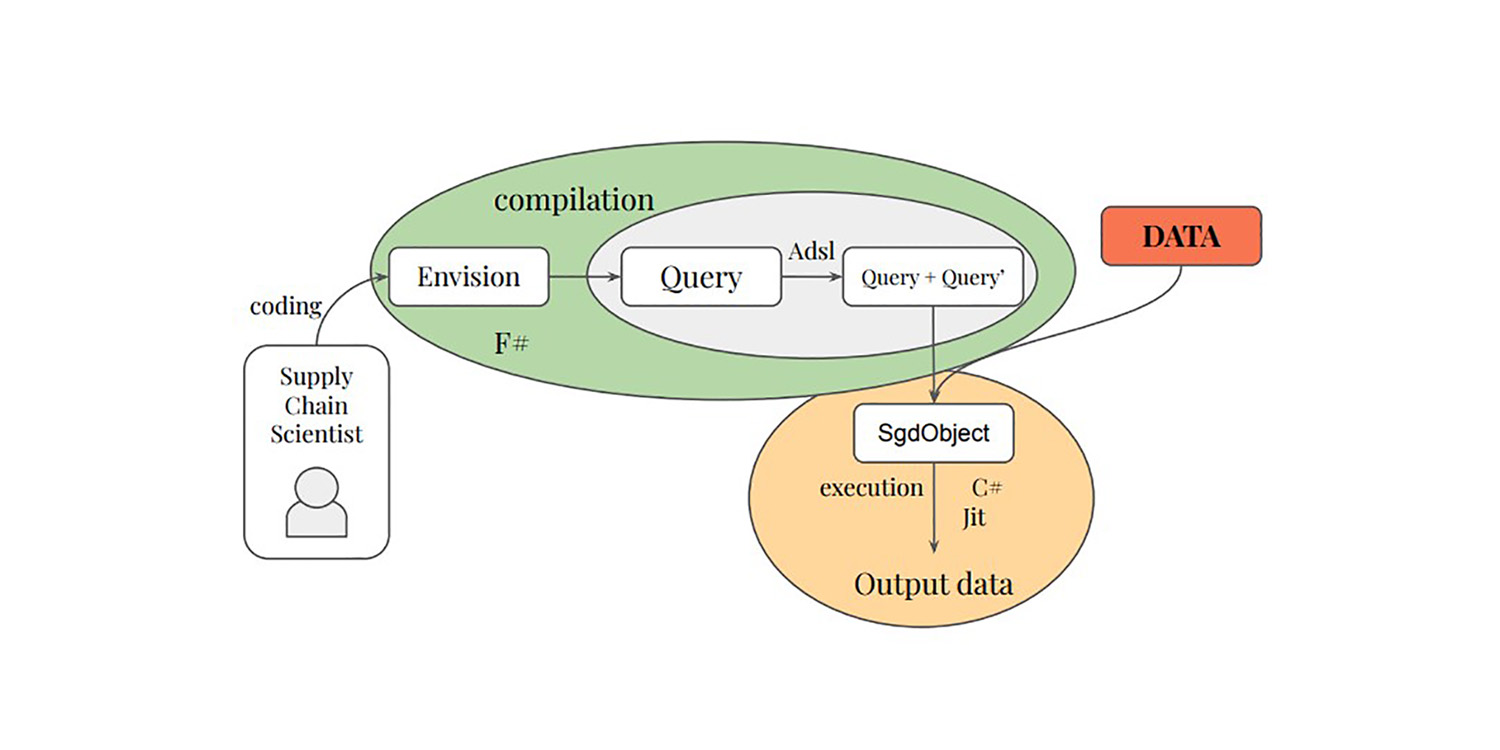
Первый вклад диссертации заключается во введении дифференцируемого слоя в реляционные языки программирования как с теоретической, так и с практической стороны. Язык программирования Adsl был создан для выполнения дифференцирования и транскрипции реляционных операций запроса. Домен-специфичный язык Envision был дополнен возможностями дифференцируемого программирования, что позволяет разрабатывать модели, использующие реляционные данные в нативной среде реляционного программирования.
Второй вклад заключается в разработке нового оценщика градиента под названием GCE, предназначенного для категориальных признаков, представленных в реляционных данных. Практическая польза GCE была продемонстрирована на различных категориальных наборах данных и моделях, и он был реализован для моделей глубокого обучения. GCE также интегрирован как нативный оценщик градиента в дифференцируемый программный слой Envision, чему способствовал первый вклад данной диссертации.
Третий вклад заключается в разработке обобщённого оценщика градиента под названием Стохастическое Путевое Автоматическое Дифференцирование (SPAD), который получает свою стохастичность из декомпозиции кода. SPAD вводит идею обратного распространения лишь части градиента для сокращения использования памяти при обновлении параметров. Реализация данного подхода к оценке градиента стала возможной благодаря принятым решениям при дифференцировании Adsl.
Данное исследование имеет значительные последствия для отраслей, зависящих от реляционных данных, открывая новые возможности и улучшая принятие решений посредством применения моделей машинного обучения с белым ящиком к реляционным данным с использованием техник дифференцируемого программирования.
Жюри:
Защита состоялась перед жюри, состоящим из:
- Thierry Paquet, профессор университета (Университет Руэн Нормандия), руководитель диссертации.
- Maxime Berar, доцент (Университет Руэн Нормандия), со-руководитель диссертации.
- Romain Raveaux, доцент (Университет Тур), референт.
- Thierry Artières, профессор университета (ECM / LIS – AMU – CNRS), референт.
- Cécilia Zanni-Merk, профессор университета (INSA Rouen Normandie), экзаменатор.
- Laurent Wendling, профессор университета (Paris Cité University), экзаменатор.
- Victor Nicolet, CTO Lokad, советник.


