00:21 はじめに
01:53 予測から学習へ
05:32 機械学習101
09:51 これまでの経緯
11:49 今日の私の予測
13:54 未取得データに対する精度 1/4
16:30 未取得データに対する精度 2/4
20:03 未取得データに対する精度 3/4
25:11 未取得データに対する精度 4/4
31:49 テンプレートマッチャーに栄光あれ
35:36 学習における深淵 1/4
39:11 学習における深淵 2/4
44:27 学習における深淵 3/4
47:29 学習における深淵 4/4
51:59 大きく挑戦するか、諦めるか
56:45 損失を超えて 1/2
01:00:17 損失を超えて 2/2
01:04:22 ラベルを超えて
01:10:24 観察を超えて
01:14:43 結論
01:16:36 今後の講義と聴衆からの質問
説明
サプライチェーンにおいては、すべての意思決定(購買、生産、在庫管理など)が将来の出来事への予測を反映するため、予測は不可逆的なものとなっています。統計学習と機械学習は、理論的にも実践的にも、従来の‘予測’分野にほぼ取って代わりました。ここでは、現代の‘学習’の観点から、データ駆動型の未来予測とは何かを探ります。
全文書き起こし

サプライチェーン講義シリーズへようこそ。私はジョアンネス・ヴェルモレルです。本日は「サプライチェーンのための機械学習」をお届けします。リアルタイムで商品を3Dプリントしたり、配達先にテレポートさせたりすることはできません。実際、ほとんどのサプライチェーンの意思決定は、将来の需要や価格変動を将来の需要として予測するために、前向きに行われなければなりません。つまり、需要側または供給側のいずれか、もしくは両方における予想される市場状況を暗黙的または明示的に反映しているのです。そのため、予測はサプライチェーンにおいて不可欠かつ切り離せない要素となります。私たちは未来を確実に知ることはできず、さまざまな確率で未来を推測するしかありません。本講義の目的は、未来を捉える観点から機械学習が提供するものを理解することにあります。

本講義では、より正確な予測を提供することが、全体としては比較的二次的な関心事であることが分かるでしょう。実際、現代のサプライチェーンにおいて、予測とは時系列予測を意味します。歴史的に、時系列予測は20世紀初頭のアメリカで人気を博しました。実際、アメリカは数百万の中産階級の労働者がおり、彼らは株式を所有する最初の国でした。投資に精通した投資家になりたかったため、自らの投資に関する洞察を求め、時系列と時系列予測はその洞察を直感的かつ効果的に伝える手段であることが判明しました。将来の市場価格、将来の配当、将来の市場シェアについての時系列予測が可能でした。
1980年代および1990年代にサプライチェーンが本質的にデジタル化された際、サプライチェーンのエンタープライズソフトウェアも時系列予測の恩恵を受け始めました。実際、そのようなエンタープライズソフトウェアでは時系列予測が遍在するようになりました。しかし、この画像を見れば、時系列予測が実際には未来を捉える非常に単純かつ単調な方法であることに気づくでしょう。
ご覧の通り、この画像を見ただけで次に何が起こるかを予測することができます。おそらく作業員が現れて、この散乱した状態を片付け、その後フォークリフトの安全確認を行うでしょう。場合によっては簡単な修理まで実施し、高い確信を持って、このフォークリフトが間もなく再稼働されると断言できるでしょう。この画像から、この状況に至るまでの条件も予測できるのです。これらは時系列予測の視点には合致しませんが、それにもかかわらず、非常に重要な予測内容となっています。
これらの予測は、実際の未来に関するものではありません。なぜなら、この画像は少し前に撮影されたものであり、その後に起こった出来事も既に過去のものだからです。しかし、確実な情報がない事象について述べている点で、予測と呼ぶに値します。直接的な測定値は存在しないため、問題となるのは、いかにしてこれらの予測や主張を生み出すことが可能なのか、という点です。
実は、人間である私は生き、様々な出来事を目にし、そこから学んできました。これが、私がこのような主張を展開できる理由です。そして、機械学習とはまさにそのこと、すなわち、機械、特に今日ではコンピューターによる学習能力の再現を目指すものであるということがわかります。この時点で、機械学習が人工知能、認知技術、統計的学習といった他の用語とどのように異なるのか、不思議に思われるかもしれません。ところが、これらの用語は問題そのものよりも、それらを使う人々について多くを物語っているのです。実際、これらの分野間の境界は非常に曖昧です。

さて、ここからは機械学習フレームワークの原型について、いくつかの主要な機械学習の概念を簡単に振り返ってみましょう。機械学習分野で発表されるほとんどの論文やソフトウェアが、かなり大規模にこのフレームワークを活用しています。特徴量とは、予測タスクを実行するために利用可能なデータの一部を指します。つまり、実行したい予測タスクがあり、そのタスクを遂行するために提供されるものとして特徴量(または複数の特徴量)が存在するという考え方です。時系列予測の文脈では、特徴量は時系列の過去のセクションを表し、すべての過去データポイントを表す特徴量のベクトルとなります。
ラベルは、予測タスクの答えを表します。時系列予測の場合、通常は未知の未来の部分、すなわち将来が位置する部分を示します。特徴量とラベルのセットを持っていれば、それは観測値と呼ばれます。典型的な機械学習の設定では、特徴量とラベルの両方を含むデータセット、すなわち訓練データセットが存在することを前提としています。
目的は、特徴量を入力として受け取り、所望の予測ラベルを算出するプログラム、すなわちモデルを構築することにあります。このモデルは、通常、訓練データセット全体を通して学習プロセスを経ることで作られます。機械学習における「学習」とは、実際に予測を行うプログラムを構築する部分を指します。
最後に、損失があります。損失とは、本来のラベルと予測されたラベルとの間の差異を意味します。学習プロセスの目標は、真のラベルにできるだけ近い予測を行うモデルを生成することにあります。つまり、予測されたラベルが真のラベルにできる限り近づくようなモデルを求めるのです。
機械学習は、時系列予測の広範な一般化と見なすことができます。機械学習の観点からは、特徴量は時系列の過去の一部に限らず、あらゆるものであり得ます。また、ラベルも同様に、時系列の未来の一部に限らないあらゆるものであり得ます。モデルも損失も、ほぼ何にでもなり得るのです。つまり、時系列予測よりもはるかに表現力豊かなフレームワークが存在するということです。しかしながら、後に見ていくように、機械学習が学問および実践の分野として達成してきた主要な成果の多くは、私が先ほど簡単に紹介した概念の再検討と挑戦を余儀なくする要素の発見に由来しています。
本講義は、サプライチェーン講義シリーズの第4回目にあたります。補助的な科学は、サプライチェーンそのものではありませんが、サプライチェーンにとって基盤的に重要な要素を表します。第1章では、物理的な研究としても実践としても、サプライチェーンに対する私の見解を提示しました。第2章では、多くの対立する振る舞いを示し、簡単には孤立させることのできないサプライチェーンのような領域に取り組むために必要な一連の手法を検討しました。第3章は、私たちが解決しようとする問題に焦点を当てる一つの方法であるサプライチェーンのペルソナに完全に捧げられています。
この第4章では、コンピューター、アルゴリズム、そして前回の数学的最適化に関する講義といった抽象化の階層を段階的に辿ってきました。これらは現代の機械学習の基礎層と見なすことができます。本日は、日々行われるサプライチェーンのすべての意思決定において不可欠な、未来を捉えるための機械学習の世界に踏み込んでいきます。

さて、本講義の計画は何でしょうか? 機械学習は広大な研究分野であり、本講義は先に紹介した概念やアイデアに関連する一連の短い質問に導かれる形で進められます。これらの質問への回答が、学習そのものやデータへのアプローチの方法を再考させることになるのです。機械学習の最も華々しい成果の一つは、研究者たちが人類の知能を10年以内に再現できると考えていた壮大な初期の野望に比べ、実際にははるかに多くの要素が作用していることに気づかせてくれた点です。
特に、現時点で高度な知能を模倣するための最良の候補であるディープラーニングに注目します。ディープラーニングは極めて実証的な実践として登場しましたが、その進歩と成果は、観測された現象から学ぶという根本的な学習の視点に新たな光を投げかけています。
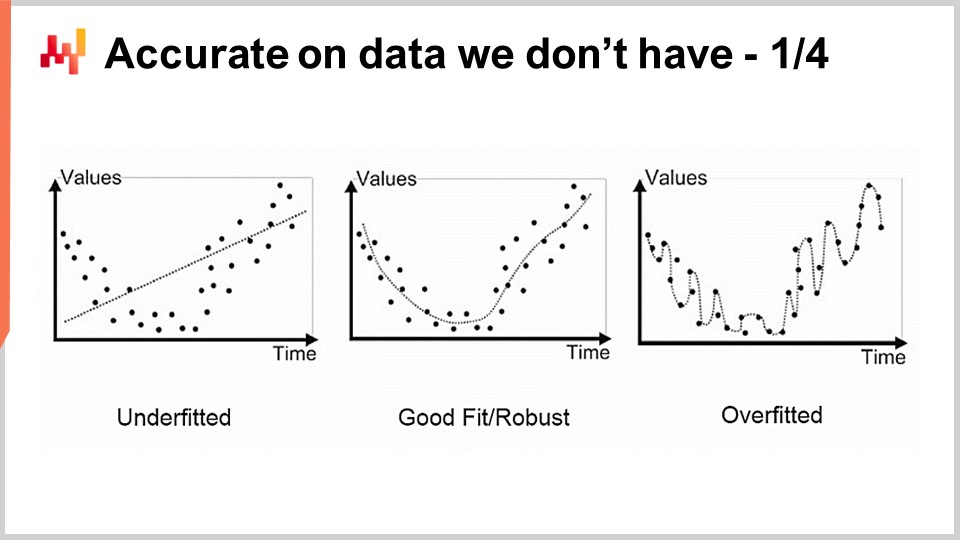
統計的またはその他のモデリングにおける最初の問題は、持っていないデータの精度です。サプライチェーンの視点からすれば、未来を捉えることが我々の関心事であるため、これは非常に重要な点です。定義上、未来はまだ持っていないデータの集合を表します。バックテストや交差検証といった手法によって、持っていないデータの精度について予測すべき内容をある程度経験的に測定することができます。しかしながら、これらの手法がそもそま機能する理由は、非常に興味深く困難な問題でもあります。問題は、既存のデータにフィットするモデルを構築することではなく、十分な次数の多項式を用いればデータにフィットするモデルを簡単に作れるものの、そのモデルが我々の本来捉えたいものを反映していない点にあります。
この問題に対する古典的なアプローチは、バイアス・バリアンス・トレードオフとして知られています。右側にはパラメータが非常に少なく、問題に十分フィットしていないために大きなバイアスを持つモデルがあり、左側にはパラメータが多すぎて過剰適合し、過度のバリアンスを持つモデルがあります。そして中央には、バイアスとバリアンスのバランスが良く取れている、いわゆる良いフィットのモデルがあります。20世紀末まで、この問題にバイアス・バリアンス・トレードオフを超えてどのように取り組むべきかは、かなり不明瞭でした。

持っていないデータの精度に関する最初の真の洞察は、1984年にヴァリアントによって発表された学習可能性の理論に由来します。ヴァリアントはPAC理論 ― おそらくほぼ正確 ― を提唱しました。このPAC理論において、「おそらく」という部分は、一定の確率で十分な答えを返すモデルを意味し、「ほぼ正確」という部分は、その答えが良いまたは有効とされるものから大きく逸脱しないことを意味します。
ヴァリアントは、多くの状況において、何も学習することが不可能である、もしくは、学習するためには極めて膨大なサンプル数が必要となり、実用的ではないことを示しました。これはすでに非常に興味深い結果でした。表示されている数式はPAC理論に由来する不等式であり、おそらくほぼ正確なモデルを構築するためには、観測数nがある一定の値より大きくなければならないことを示しています。この一定の値は、誤差率であるepsilon(ほぼ正確の部分)と、失敗する確率であるeta(1-etaが失敗しない確率)という二つの要因に依存します。
ここで見て分かるのは、失敗の確率やepsilon(十分な範囲)を小さくしたい場合、より多くのサンプルが必要になるということです。この不等式は、仮説空間の濃度にも依存します。つまり、競合する仮説が多いほど、それらを見分けるためにより多くの観測値が必要になるのです。これは非常に興味深い事実で、PAC理論は主に否定的な結果を示すものの、少ないサンプルで証明可能なおそらくほぼ正確なモデルを構築することができない、という点を明確にしているのです。この理論は、実際にどのようにすれば予測タスクをよりうまく解決できるかという方法を具体的に示してはいませんが、交差検証やバックテストといった非常に経験的な測定以上に、持っていないデータの精度という問題にアプローチするための、はるかに堅牢な方法が存在することを明文化した点で画期的でした。
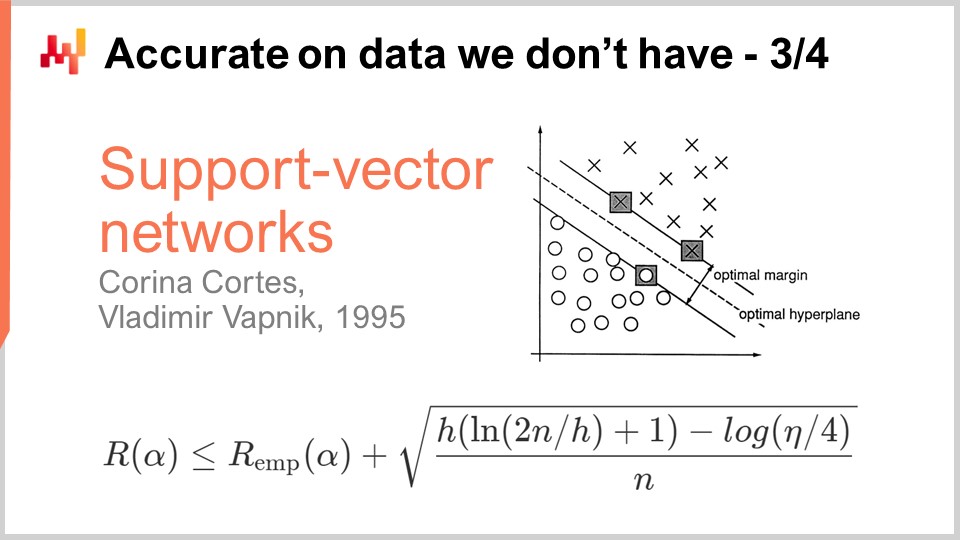
10年後、最初の実用的ブレークスルーは、Vapnikと数名が設立した、現在ではVapnik-Chervonenkis (VC) 理論として知られるものによってもたらされた。この理論は、実際の損失、すなわちリスク(手に入らないデータ上で観測される損失)を捉えることが可能であると示している。数学的に証明できたのは、定義上決して測定できない実際の誤差について、何かを知る能力が存在するという点だ。これは非常に不可解な結果である。
本質的に、このVC理論から得られた公式は、実際のリスクが、手元にあるデータ上で測定可能な経験的リスクと、しばしば構造的リスクと呼ばれる別の項によって上から抑えられることを示している。ここでは、観測数nと、PAC理論と同様に失敗確率であるetaがある。そして、モデルのVC次元を示すhも存在する。VC次元はモデルの学習能力を反映しており、学習能力が高いほどVC次元は大きくなる。
これらの結果から、何でも学習できる能力を持つモデルに対しては、数学的には何も言えないということが分かる。これは非常に不可解だ。もしあなたのモデルが何でも学習できるなら、少なくとも数学的には何も言えない。
1995年のブレークスルーは、CortesとVapnikによる、後にサポートベクターマシン(SVM)として知られるものの実装から生まれた。これらのSVMは文字通りこの数学理論の直接的な実装である。その洞察は、不等式を示す理論を持っているので、手元のデータでの誤差(経験的リスク)とVC次元のバランスをとるモデルを実装できるという点にある。すなわち、これら二つの要素を正確にバランスさせ、等式をできるだけ厳密かつ低く保つ数学的モデルを直接構築できるのだ。これこそがサポートベクターマシン(SVM)の本質である。この結果は非常に衝撃的であったため、非常に良い成果を上げ、機械学習コミュニティに大きな影響を与えた。初めて、手元にないデータでの精度が、方法自体の数学的設計によって直接得られたのである。これは衝撃的かつ強力で、機械学習コミュニティ全体が10年間この道を追い続ける結果となった。たとえ後になって、この道がほとんど行き止まりであることが明らかになっても、その理由は実に驚くべきものであった。
実用的な面では、SVMはほとんど数学理論から生まれたため、計算機ハードウェアとの相性が非常に悪かった。より具体的には、SVMの素朴な実装は観測数に対してメモリ使用量が二次的に増加する。このため非常に膨大なリソースを必要とし、結果としてSVMは非常に遅くなる。その後、オンライン型SVMなどでメモリ要件を大幅に下げる改善がなされたが、それでもSVMは真にスケーラブルな機械学習手法とは見なされなかった。

SVMは、過学習しないであろう別の、より優れたクラスのモデルへの道を切り開いた。過学習とは、手元にないデータに対して非常に不正確になることである。最も注目すべき例は、ほぼ直系の後継であるランダムフォレストと勾配ブースティングツリーである。これらの根底には、弱いモデルをより強力に変換するメタアルゴリズムであるブースティングがある。ブースティングは、この講義の前半で触れたKearnsとValiant間で80年代末に提起された疑問から生まれた。
ランダムフォレストの動作を理解するのは比較的単純である。まず訓練データセットを用意し、その中からサンプルを取り出す。次に、そのサンプル上で決定木を構築する。これを繰り返し、初期の訓練データセットから別のサンプルを取り出して別の決定木を構築する。このプロセスを繰り返すことで、多数の決定木が得られる。決定木は、非常に複雑なパターンを捕捉することができないため、機械学習モデルとしては比較的弱い。しかし、これらの木を全て集めて平均化することで得られるのが、初期データのランダムな部分サンプル上で構築されたため「ランダムフォレスト」と呼ばれる、はるかに強力な機械学習モデルである。
勾配ブースティングツリーは、この考え方のわずかな変形である。主な違いは、訓練データセットをサンプリングして独立に決定木を構築するのではなく、まず森を構築し、次に既存の森の残差を見て次の木を構築する点にある。つまり、多数の木からなるモデルを構築し始め、そこから予測と実際の値との差(残差)を求め、その残差のサンプルに対して次の木を訓練するという考えである。実際、ランダムフォレストは若干の過学習を示すものの、特定の条件下では過学習しないという証明も存在する。
興味深いことに、勾配ブースティングツリーは、ここ十数年にわたってほぼすべての機械学習コンペティションで高得点を独占している。Kaggleコンペの約80〜90%を見ると、実質的に勝者となっているのは勾配ブースティングツリーである。しかし、これほどまでに機械学習コンペで支配的な存在であるにもかかわらず、実際のサプライチェーン問題に勾配ブースティングツリーを応用する上では、ほとんど画期的な進展は見られていない。その主な理由は、勾配ブースティングツリーの設計が計算機ハードウェアと非常に相性が悪いからである。
なぜそうなるのかは明らかである。複数の木からなるモデルは、結果として元のデータセットの一部以上の大きさになってしまう。多くの場合、得られるモデルは、初めに用いたデータセットよりもデータ量が多くなってしまう。したがって、元となるデータセットが既に非常に大きい場合、モデルは巨大になり、これが大きな問題となる。
勾配ブースティングツリーの歴史では、2007年にGBM(Gradient Boosted Machines)という実装が登場し、このアプローチがRパッケージで非常に普及した。しかし、初期の段階からスケーラビリティに問題があった。多くの人々はすぐにPGBRT(Parallel Gradient Boosted Regression Trees)を用いて並列処理を試みたが、それでも非常に遅かった。XGBoostは画期的な存在で、スケーラビリティを桁違いに向上させた。XGBoostの鍵となる洞察は、ツリー構築を高速化するために、データを列指向に設計することであった。その後、LightGBMはXGBoostの全ての洞察を取り入れつつ、ツリー構築の戦略を変えた。XGBoostはレベルごとにツリーを成長させたが、LightGBMは葉ごとに成長させることを選択した。その結果、同じ計算機ハードウェア上で、LightGBMはGBMよりも数桁速く動作する。しかし、実際のサプライチェーンの観点からは、勾配ブースティングツリーは通常、実用的には遅すぎるのだ。使用すること自体は不可能ではないが、そのハードルが非常に高いため、通常は採用に値しない。

興味深いことに、勾配ブースティングツリーはほぼすべての機械学習コンペで勝利するにもかかわらず、私の謙虚な意見では、これらのモデルは技術的な行き詰まりである。サポートベクターマシン、ランダムフォレスト、勾配ブースティングツリーはいずれも、単なるテンプレートマッチにすぎないという共通点がある。彼らは非常に優れたテンプレートマッチであるが、それ以上のものではない。特に、入力を直接的に選別またはフィルタリングする以外に、何の表現力も持っていない。
この講義の冒頭で提示したフォークリフトの画像に戻ってみると、たとえ世界中の倉庫から撮影された何百万もの画像をこれらのモデルに与えたとしても、「ああ、この状況でフォークリフトを見た。作業員が来て修理するだろう」といった発言を、どのモデルも下すことは全く期待できない。
実際に見られるのは、これらのモデルが機械学習コンペで勝利しているという事実が、ある状況下では彼らに有利に働く要因によって誤解を招いているということである。第一に、実世界のデータセットは非常に複雑であり、機械学習コンペでは、せいぜい実世界の複雑さのごく一部しか再現していないおもちゃのようなデータセットが用いられる。第二に、勾配ブースティングツリーのようなモデルでコンペに勝つためには、広範な特徴量エンジニアリングが必要となる。これらのモデルは、優れたテンプレートマッチであるがゆえに、適切な特徴量がなければ、その変数の選択だけで優れた結果を出すことはできない。つまり、データ準備に大量の人間の知性を注入する必要がある。これは大きな問題であり、実際のサプライチェーンの問題解決においては、割ける工学時間が限られているため、些細な問題に6か月も費やす余裕はない。
第三の問題は、サプライチェーンにおいてはデータセットが絶えず変化することである。データが変わるだけでなく、問題そのものも徐々に変化していくため、特徴量エンジニアリングに伴う問題がさらに複雑化する。根本的には、私たちは機械学習や予測コンペで勝利するモデルを持っているものの、10年先を考えると、これらのモデルは機械学習の未来ではなく、過去のものとなる。

ディープラーニングは、こうした浅薄なテンプレートマッチへの対抗策として登場した。ディープラーニングはしばしば人工ニューラルネットワークの後継として紹介されるが、実際には、研究者が生物学的比喩を捨て、計算機との相性、すなわち機械的親和性に注目し始めた日から普及し始めたのである。再び申し上げるが、計算機と良好に連携する、いわゆる機械的親和性は極めて重要である。人工ニューラルネットワークとの問題は、生物学を模倣しようとした点にあり、我々が持つコンピュータは、我々の脳を支える生物学的基盤とは全く異なるということである。この状況は、初期の航空宇宙在庫予測の歴史を彷彿とさせ、無数の発明者が鳥を模倣して飛行機を作ろうとした時代を思い出させる。現代では、最速の鳥よりもはるかに速く飛ぶ飛行機が存在するが、その飛行方法は鳥のそれとはほとんど共通点がない。
ディープラーニングに関する最初の洞察は、入力データに対してあらゆる複雑な変換を行える、深く表現力のある何かが必要だということであった。しかし同時に、それは我々が持つ計算機との相性も良好でなければならなかった。つまり、計算機と非常に相性の良い複雑なモデルがあれば、他の方法と比べて、全ての条件が等しい場合に、はるかに桁違いに複雑な関数を学習できる可能性が高いという考えである。
Differentiable programmingは、前回の講義で紹介された、ディープラーニングの基礎層と見なすことができる。ここでは改めて微分可能プログラミングに戻るつもりはないが、まだ視聴していない方は前回の講義をぜひご覧いただきたい。前回の講義を見ていなくても、これからの内容は理解できるはずである。前回の講義は、学習プロセスの細部を明らかにしている。要するに、微分可能プログラミングとは、特定の形のモデルを選択した場合に、そのモデル内に存在するパラメータの最適な値を求める手法にすぎない。
微分可能プログラミングが最適なパラメータの特定に焦点を当てる一方で、機械学習はデータから学習するための最も有能なモデルの形態を見つけることに焦点を当てる。

では、入力データに対して任意の複雑な変換を反映できる、任意に複雑な関数のテンプレートをどのように作成するか?まず、浮動小数点数で構成された回路から始めよう。なぜ浮動小数点数か?それは、前回の講義でも見たように、勾配降下法を適用できるスケーラブルな性質を持っているからである。つまり、入力も出力も浮動小数点数となる一連の数値を用いるということになる。
では、中間部分はどうするか?線形代数学、より具体的には行列の乗算を行おう。なぜ行列乗算なのか?その答えは、この第4章の最初の講義で示された。これは、現代のコンピュータがどのように設計されているかに関係しており、線形代数に徹するだけで処理速度を劇的に向上させることが可能になるからだ。では、入力に線形変換、つまり後で学習したいパラメータを含むWという名前の行列との行列乗算を適用した場合、どのようにしてより複雑にできるだろうか?第二の行列乗算を加えることができる。しかし、線形代数の講義を思い出せば、線形関数と別の線形関数を掛け合わせると得られるのは、結局線形関数に過ぎない。したがって、行列乗算を単に組み合わせても、最終的には行列乗算のままであり、完全に線形である。
我々が行うのは、線形演算の間に非線形性を交互に挟み込むことです。これはまさにこの画面で行ったことと同じです。ディープラーニングの文献で一般的にRectified Linear Unit(ReLU)として知られる関数を交互に挟み込みました。この名前は、その働きに比べると非常に複雑に聞こえますが、実際は単純な関数であり、ある数値を取り、その数値が正ならばそのまま返し(すなわち恒等関数)、負の場合は0を返すだけです。あるいは、値とゼロのうち大きい方を返す、とも書けます。これは非常に単純な非線形性です。
もっと洗練された非線形関数を使うことも可能です。歴史的に、ニューラルネットワークに取り組んでいた人々は、我々のニューロンが実際に機能している方法を模倣するために、洗練されたシグモイド関数を使いたがっていました。しかし実際には、無関係なものを計算するために処理能力を浪費する理由はあるでしょうか?重要な洞察は、何か非線形なものを導入する必要があるということであり、どの非線形関数を使うかはそれほど重要ではありません。唯一重要なのは、それを非常に高速に動作させることです。全体をできるだけ高速に保ちたいのです。
ここで構築しているのは、ディープラーニングにおける全結合層(dense layers)と呼ばれるものです。全結合層は、本質的には非線形性(Rectified Linear Unit)を伴う行列積です。これらは積み重ねることができます。画面上には通常マルチレイヤパーセプトロンと呼ばれるネットワークが示されており、今回は3層になっています。これを積み重ね続ければ、20層や2000層にもできるでしょう;いずれにしても大した違いはありません。実際、どんなに単純に見えても、たった数層のネットワークを微分可能なプログラミングフレームワークに組み込めば、そこでパラメータを得ることができ、最初はランダムに選ばれたパラメータを訓練できるのです。初期化したい場合は、すべてのパラメータをランダムに初期化すればよいだけです。非常に多様な問題に対して、かなり良い結果が得られるでしょう。
これは非常に興味深いことで、現時点でディープラーニングの基本的な要素はほぼすべて揃っているということです。ですから、聴衆の皆さん、おめでとうございます!これで「ディープラーニングのスペシャリスト」を履歴書に書き始めてもよいかもしれません。まあ、実際はそれだけではありませんが、良い出発点と言えるでしょう。

実際のところ、ディープラーニングはテンソル代数、すなわちコンピュータ化された線形代数以外の理論をほとんど必要としません。しかし、ディープラーニングには無数のテクニックが絡んでいます。例えば、入力の正規化や勾配の安定化を行わなければなりません。そのような操作を多数積み重ねると、ネットワークを逆伝播する際に勾配が指数関数的に増大し、ある時点でその数値を表現する能力を超えてしまいます。現実のコンピュータは、どんなに大きな数でも表現できるわけではありません。やがて、32ビットや16ビットの浮動小数点数で数値を表現する能力の限界に達してしまうのです。勾配の安定化には無数のテクニックが存在します。例えば、一般的にはバッチ正規化が用いられますが、他にもさまざまな方法があります。
もし入力に幾何学的な構造がある場合、たとえば時系列のような一次元(サプライチェーンで見られる過去の売上など)、二次元(画像を思い浮かべてください)、三次元(映画のようなもの)、四次元など、入力に幾何学的な構造があれば、その構造を捉えるための特殊な層が存在します。最も有名なものは、おそらく畳み込み層と呼ばれるものです。
さらに、カテゴリカルな入力に対処するための技法やテクニックも存在します。ディープラーニングでは、すべての入力が浮動小数点値であるため、カテゴリカル変数をどのように扱うのでしょうか?その答えは、埋め込み(embeddings)です。また、代理損失と呼ばれる、急峻な勾配を示し収束プロセスを促進する代替の損失関数が存在し、最終的にデータから学べる情報を増幅します。無数のテクニックがあり、これらすべてのテクニックは、微分可能なプログラミングという基盤の上に構築されるプログラムに簡単に組み込むことができます。
ディープラーニングとは、微分可能なプログラミングが提供する訓練プロセスを経た後、極めて高い学習能力を持つプログラムをどのように構築するかに尽きます。画面上に示したほとんどの項目はプログラム的な性質を持っており、これらすべてを支えるプログラミングパラダイムである微分可能なプログラミングが存在することは非常に便利です。
ここまでで、なぜディープラーニングが従来の機械学習と異なるのかがより明確になるはずです。ディープラーニングはモデルそのものを重視するのではありません。実際、多くのオープンソースのディープラーニングライブラリには、そもそもモデルすら含まれていません。ディープラーニングで真に重要なのは、特定の状況に合わせて大幅にカスタマイズする必要があるテンプレートとも言えるモデルアーキテクチャです。しかし、適切なアーキテクチャを採用すれば、カスタマイズを行ったとしてもモデル本来の学習能力の本質は保持されると期待できます。ディープラーニングでは、あまり興味深くない最終モデルから、真の研究対象であるアーキテクチャへと焦点が移るのです。
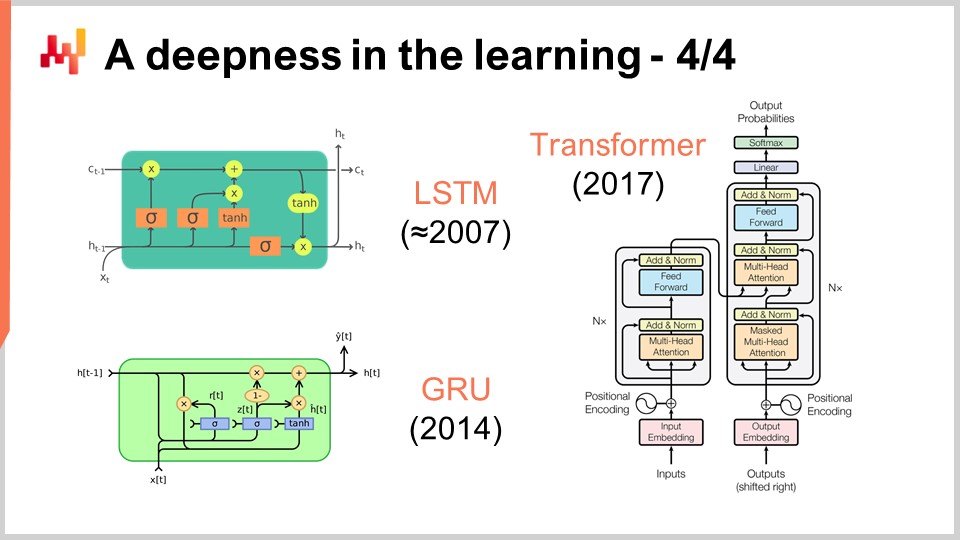
画面上には、一連の注目すべきアーキテクチャの例が示されています。まず、LSTM(Long Short-Term Memoryの略)は2007年頃から稼働し始めました。LSTMの出版履歴はやや複雑ですが、基本的には2007年にディープラーニングスタイルで動作し始めたのです。その後、LSTMと本質的には同じものの、より単純で洗練されたGated Recurrent Units(GRU)に取って代わられました。実際、LSTMの複雑さの多くは、生物学的なメタファーに起因しています。生物学的メタファーを捨てると、ほぼ同じ働きをするよりシンプルなものが得られることが判明しました。これがGated Recurrent Units(GRU)です。その後、Transformerが登場し、基本的にLSTMとGRUの両方を陳腐化させました。Transformerは、必要とする計算資源がはるかに少なく、高速で、なおかつ学習能力がさらに高いという点でブレークスルーとなりました。
これらのアーキテクチャの多くは、何らかのメタファーを伴っています。LSTMは「長短期記憶」という認知的メタファーを持ち、Transformerは情報検索のメタファーを持っています。しかし、これらのメタファーは予測力がほとんどなく、実際にはこれらのアーキテクチャが機能する本質から注意を逸らす混乱や分散の原因となる可能性すらあります。
Transformerは、その多用途性からサプライチェーン分野でも非常に注目されています。今日では、自動運転から自動翻訳、その他多くの難解な問題に至るまで、ほぼあらゆる分野で利用されています。これは、適切なアーキテクチャを選択することの威力を示しており、それにより多様な問題に対応できるのです。サプライチェーンにおいて、機械学習で何かを成し遂げる上での主な難点の一つは、対処すべき問題の多様性があまりにも驚異的であるということです。直面するあらゆるサブ問題に対して、研究に5年も費やすチームを持つ余裕はありません。次の問題を解決するたびに機械学習の半分を再発明する必要がない、迅速に動かせる何かが求められています。
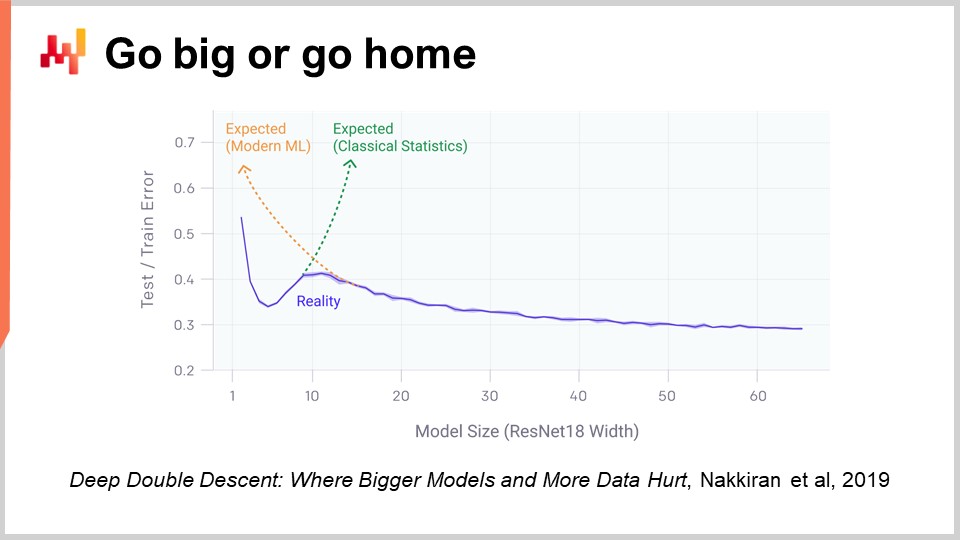
ディープラーニングの非常に驚くべき側面の一つは、パラメータの膨大な数です。数分前に紹介したマルチレイヤパーセプトロンでは、全結合層(行列積を伴う)によって、これらの行列に非常に多くのパラメータが存在する可能性があります。実際、訓練データセット内のデータポイントや観測値と同じくらいのパラメータ数を持つことはそれほど困難ではありません。講義の冒頭で見たように、これほど多くのパラメータを有するモデルは、過学習に劇的に陥るはずなのです。
しかし、ディープラーニングの現実はさらに不可解です。観測数に比べてはるかに多くのパラメータを持つ状況が多々あるのに、劇的な過学習の問題は発生しません。さらに不可解なことに、ディープラーニングモデルは訓練データセットに完全に適合する傾向があり、その結果、訓練データに対してはほぼゼロの誤差を示しながらも、未知のデータに対しても予測力を保持するのです。
2年前、OpenAIが発表したDeep Double Descentの論文は、この状況に非常に興味深い光を当てました。研究チームは、機械学習の領域において本質的に「不気味の谷」が存在することを示しました。つまり、パラメータがわずかなモデルではバイアスが大きく、未知のデータに対する結果の質があまり良くないということです。これは、従来の機械学習や統計学の見解と一致します。パラメータ数を増やせばモデルの質は向上しますが、ある時点で過学習が始まるのは確かです。これは、先に述べたアンダーフィッティングとオーバーフィッティングの議論で見たものと全く同じであり、バランスを見出す必要があります。
しかし、彼らが示したのは、パラメータ数を増し続けると、非常に奇妙な現象が起こるということです。すなわち、過学習が次第に減少していくのです。これは、従来の統計学習理論が予測するものとは正反対です。この挙動は偶然の産物ではなく、非常に頑健で広範に見られる現象であることが示されました。多くの状況で常に発生しており、その理由はまだ十分に解明されていませんが、現時点で明らかなのは、ディープダブルディセントが非常に現実的で広く存在するということです。
これはまた、なぜディープラーニングが機械学習の世界に参入するのが比較的遅かったのかを理解する助けにもなります。ディープラーニングが成功するためには、まず数万、あるいは数十万のパラメータを処理できるモデルを構築し、この不気味の谷を乗り越えなければなりませんでした。1980年代や1990年代には、ハードウェアの計算リソースがこの不気味の谷を飛び越えることができなかったため、ディープラーニングのブレークスルーはあり得なかったのです。
幸いにも、現代の計算ハードウェアを用いれば、数百万、あるいは数十億のパラメータを持つモデルを容易に訓練することが可能です。先の講義でも指摘したように、現在ではFacebookのような企業が1兆を超えるパラメータを有するモデルの訓練に取り組んでいます。つまり、我々は非常に大きな前進が可能なのです。

これまで、損失関数が既知であると仮定してきました。しかし、なぜそれが当然である必要があるのでしょうか?実際、サプライチェーンの観点からファッションストアの状況を考えてみましょう。ファッションストアは全てのSKUに対して在庫レベルを持っており、将来の需要を予測したいと考えています。この店舗における将来の需要の、信頼できる1つのシナリオを予測したいのです。あるSKUの在庫が切れると、カニバリゼーションや代替が観察されるはずです。特定のSKUがストックアウトに達すると、通常その需要の一部は類似商品の方に戻るはずです。
しかし、このようなアプローチを、平均絶対パーセント誤差(MAPE)、平均絶対誤差(MAE)、平均二乗誤差(MSE)など、SKU単位や日単位、週単位で機能する古典的な予測指標で試みても、これらの挙動を捉えることはできません。本当に求めているのは、カニバリゼーションや代替効果をどれだけ正確に捉えられているかを示す指標です。しかし、その損失関数はどのような形をしているべきなのでしょうか?それは非常に不明瞭で、かなり洗練された振る舞いが要求されるようです。ディープラーニングの大きなブレークスルーのひとつは、損失関数は学習されるべきだという洞察を得たことにあります。まさに、画面上の画像が生成されたのはそのためです。これは完全に機械生成された画像であり、写っている人々は実在しません。画像は生成されたものであり、その問題は、画像が優れたフォトリアリスティックな人間の肖像であるかどうかを判定する損失関数または指標をどのように構築するか、というものでした。
実際、平均絶対パーセント誤差(MAPE)方式の観点で考えると、ピクセル単位で動作する指標になってしまいます。問題は、ピクセル単位で評価する指標では、画像全体が人間の顔に見えるかどうかについて何も語ってくれない点です。ファッションストアにおけるSKUや需要予測の場合も同様です。SKU単位の指標を用いるのは容易ですが、それでは店舗全体の大局像について何も示せません。にもかかわらず、サプライチェーンの観点からは、SKU単位での正確さではなく、店舗全体での正確さが重要なのです。つまり、各SKUごとに良いかどうかではなく、店舗全体として在庫レベルが適切かどうかを知りたいのです。では、ディープラーニングコミュニティはこの問題にどのように対処したのでしょうか?
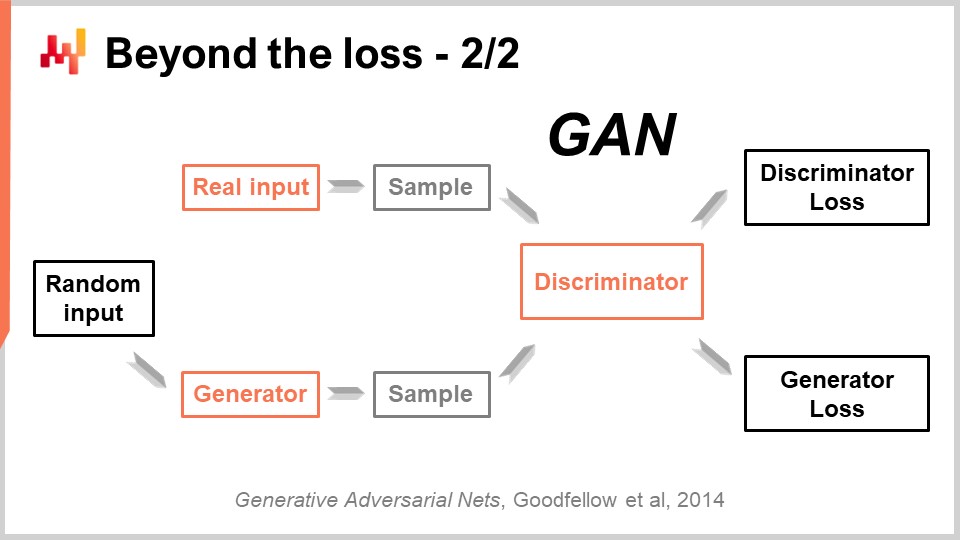
この非常に印象的な成果は、Generative Adversarial Networks(GANs)と呼ばれる、見事にシンプルな手法によって達成されました。報道では、これらの技術がディープフェイク(deepfakes)として知られているのを耳にしたかもしれません。ディープフェイクとは、このGAN手法を用いて生成された画像のことです。では、どのように機能するのでしょうか?
この仕組みは、まずジェネレーター(生成器)から始まります。ジェネレーターはランダムな値であるノイズを入力として受け取り、本ケースでは画像を生成します。もしサプライチェーンのケースに置き換えると、例えば、このファッションストアにおいて、次の3ヶ月間に観測される全SKUの需要の軌跡を生成することになるでしょう。このジェネレーター自体がディープラーニングネットワークなのです。
次にディスクリミネーター(識別器)を用意します。ディスクリミネーターもまたディープラーニングネットワークであり、その目的は、生成されたものが本物か合成かを判断する方法を学習することにあります。ディスクリミネーターは、単に本物か偽物かを判定する二値分類器です。もしディスクリミネーターがサンプルを偽物、すなわち合成物と正しく予測できた場合、その勾配をジェネレーターに逆伝播させ、ジェネレーターに学習させるのです。
この設定によって起こるのは、ジェネレーターが識別器を実際に騙し混乱させるサンプルを生成する方法を学び始めることです。同時に、識別器は実際のサンプルと合成サンプルをより正確に見分ける方法を学んでいきます。このプロセスをたどると、最終的には信じられないほどリアルなサンプルを生成する非常に高品質なジェネレーターと、本物かどうかを判別できる優れた識別器の両方が得られる状態に収束するはずです。これが、GANを用いてフォトリアルな画像を生成する際にまさに行われていることです。サプライチェーンに話を戻すと、特定の状況において最適な指標はMAPE、加重MAPE、あるいはそれ以外であると主張するサプライチェーンの専門家が存在します。彼らは特定の状況下でこの指標やあの指標を使用すべきだとレシピを提示します。しかし、実際にはディープラーニングが示すところによれば、予測指標という考え方自体が時代遅れなのです。もし、単なるポイントごとの精度ではなく高次元の精度を実現したいのであれば、指標自体を学習する必要があります。現時点では、これらの技術を活用しているサプライチェーンはほぼ存在しないと思われますが、いずれ将来的にはそうなるでしょう。生成型敵対ネットワークまたはその派生技術を用いて予測指標を学習することが標準になり、単なるポイントごとの正確性にとどまらず、本当に重要な微妙な高次元の挙動を捉える方法となるのです。

これまで、すべての観測はラベル付きであり、そのラベルは我々が予測したい出力でした。しかし、入力と出力という問題として定式化できない状況も存在します。つまり、ラベルが利用できない場合です。サプライチェーンの例で言えば、それはハイパーマーケットのケースです。ハイパーマーケットでは、在庫数が完全に正確であるとは限りません。商品は破損、盗難、賞味期限切れになることもあり、システム内の電子記録が実際に顧客が目にする棚の状況を正確に反映していない理由は数多く存在します。棚卸は非常に高価であるため、正確な在庫のリアルタイムデータソースとはなり得ません。棚卸は実施可能ですが、毎日ハイパーマーケット全体をチェックすることはできません。その結果、多少不正確な大量の在庫データが存在することになります。量は豊富ですが、どれが正確でどれが不正確かを識別することは困難です。
これは、本質的に教師なし学習が非常に意味を持つ状況です。何かを学習したいけれど、データはあるものの正解となるラベルが存在しない場合です。我々が持っているのは膨大なデータのみであり、教師なし学習は何十年にもわたり機械学習コミュニティの聖杯とされてきました。長い間、それは未来の話であり、遠い未来のことと思われていました。しかし、最近、この分野で驚くべきブレークスルーが起こりました。その一例が、Facebookチームによる「Unsupervised Machine Translation Using Monolingual Corpora Only」という論文で達成された成果です。
この論文でFacebookチームが行ったのは、英語のテキストコーパスとフランス語のテキストコーパスのみを使用して翻訳システムを構築することでした。この二つのコーパスは共通点が全くなく、同じテキストさえも含まれていません。ただ、英語とフランス語のテキストが存在するだけです。そして、実際の翻訳ペアをシステムに提供することなく、英語からフランス語への翻訳システムを学習させたのです。これは非常に驚くべき成果です。ちなみに、この成果は先ほど紹介した生成型敵対ネットワークを彷彿とさせる手法を用いることで達成されています。同様に、Googleのチームは2年前にBERT (Bidirectional Encoder Representations from Transformers) を発表しました。BERTは大部分が教師なしで学習されるモデルです。再びテキストの話ですが、BERTでは膨大なテキストデータベースからランダムに単語をマスクし、その単語を予測するようにモデルを訓練し、これをコーパス全体で繰り返すという方法が取られています。この手法を自己教師あり学習と呼ぶ人もいますが、BERTの非常に興味深い点は、サプライチェーンにおいてもデータの一部を隠しながら、機械がデータを完全に再構成できる仕組みを作り出せるという点にあります。
これがサプライチェーンにとって極めて重要な理由は、自然言語処理の文脈でBERTが行っていることを他の多くの領域に応用できるからです。これは究極の「もしも」に答えるマシンです。例えば、「もし私がもう一店舗持っていたら?」という問いに対して、データを修正して店舗を追加し、学習済みの機械学習モデルに問い合わせるだけで答えが得られます。もし製品が一つ増えたら?もしクライアントが一人増えたら?もしこの製品の価格が変わったら?といった具合です。教師なし学習は、データをペアのリストとしてではなく全体として扱うことを可能にし、データ内にあるあらゆる側面に対して予測を行える非常に汎用的な仕組みを提供します。これは非常に強力なアプローチです。
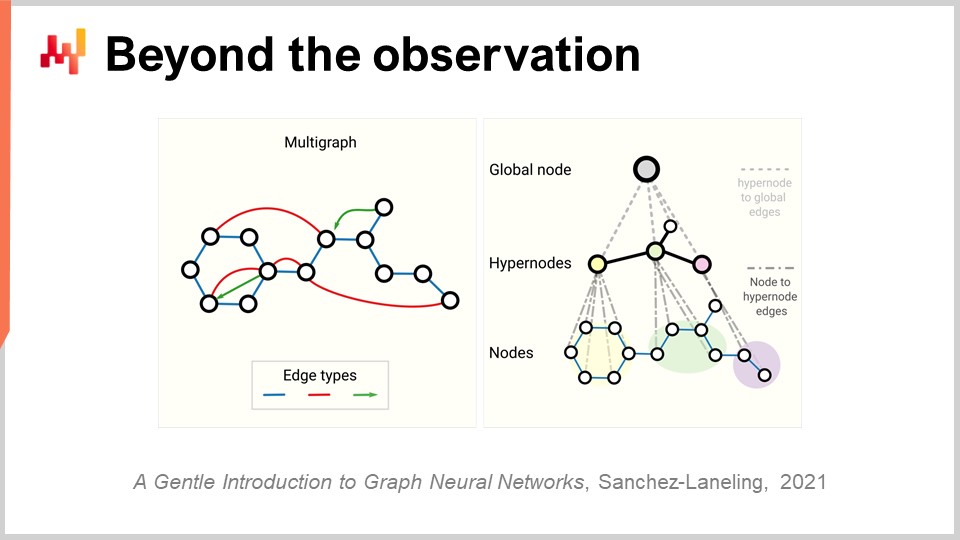
さて、最後に、観測という概念全体を再検討する必要があります。当初、観測とは特徴とラベルのペアであると言いました。ラベルを除外する方法は見出しましたが、特徴自体や観測そのものはどうでしょうか。サプライチェーンの問題は、実際には観測そのものが存在しないという点にあります。サプライチェーンを独立または均質な観測の集合に分解できるかどうかも明確ではありません。前の講義で議論したように、サプライチェーンを観測するためには、サプライチェーン自体を直接科学的に観測するのではなく、企業用ソフトウェアの各部分に記録されたデータを通じて間接的に観測する必要があります。これにはERP、WMS、POSなどが含まれます。結局のところ、我々が持っているのは、トランザクションデータベース上に実装されたこれらのシステムから収集された取引記録だけなのです。したがって、観測は独立しておらず、これらの記録は実際にリレーショナルデータベース内で互いに関連付けられているのです。例えば、ロイヤルティカードを持つ顧客は、そのカードを通じて購入したすべての製品と関連しています。すべての製品は、それを取り扱うすべての店舗と関連付けられ、各店舗は、その店舗にサービスを提供できるすべての倉庫と関連しています。つまり、観測は独立しておらず、膨大なリレーショナル構造が重なり合っているのです。
このような相互に連結されたデータに対処するためのディープラーニングにおけるブレークスルーは、グラフ学習として知られています。グラフ学習は、ファッション業界における代替品や共食いといった挙動に対処するために必要なものです。共食いを最も理解する方法は、すべての製品が同じ顧客を巡って競争していると考えることです。そして、顧客と製品を結びつけるデータを分析することで、その共食いの状況を解析できます。なお、グラフ学習は、全く別物であるグラフデータベースとは関係がないことに注意してください。グラフデータベースは、単にグラフをクエリするためのデータベースであり、学習プロセスは伴いません。グラフ学習は、グラフ自体の追加的な特性や、観測しきれない、もしくは完全に観測できない関係性を学習し、行動に移せる知識としてその関係性を装飾することにあります。
私の見解では、サプライチェーンは設計上、すべての部品が相互に連結しているシステムであるため ― これがサプライチェーンの呪いであり、局所的な最適化が他の問題を引き起こす唯一の原因 ― グラフ学習はサプライチェーンおよび機械学習の問題に対処するためのアプローチとして、ますます普及していくだろうと思います。本質的に、グラフニューラルネットワークは、グラフを扱うために設計されたディープラーニング技術なのです。
結論として、機械学習はより正確な予測を提供するものだと考えるのは、控えめに言っても非常に単純な見方です。これは、自動車の主な目的がより速い馬に乗ることであると主張するようなものです。確かに、機械学習を通じてより正確な予測が達成できる可能性はありますが、それは全体像のごく一部に過ぎません。そして、その全体像は、機械学習コミュニティにおけるブレークスルーに伴ってますます大きくなっています。我々は、特徴、ラベル、観測、モデル、損失という一連の概念を含む機械学習の基本的なフレームワークから始まりました。この小さな基本フレームワークは、時系列予測の視点よりもはるかに一般的なものでした。しかし、最近の機械学習の進展により、これらの概念自体が徐々にその重要性を失いつつあることが明らかになっています。なぜなら、我々はこれらの概念を超える方法を発見しているからです。サプライチェーンにとって、このパラダイムシフトは極めて重要であり、予測に関しても同様のシフトを適用しなければならないことを意味しています。機械学習は、データへのアプローチ方法とその活用法を根本的に再考させ、これまで閉ざされていた扉を今や大きく開くカギとなっているのです。

では、いくつかの質問を見てみましょう。
Question: ランダムフォレストはバギングを使用していないのですか?
私の主張は、そう、ランダムフォレストはバギングの拡張形であり、単なるバギング以上の要素を含んでいるということです。バギング自体は興味深い手法ですが、機械学習の手法を見るときには常に「この手法は、共食いや代替といった非常に難しい問題の学習に向けて進展させ得るのか? そして、この手法は自分の持つ計算機ハードウェアとうまく連携するのか?」と自問する必要があります。これが、この講義から得るべき重要なポイントの一つです。
Question: 企業がすべてをロボットによる自動化に向けて推進する中で、物流倉庫作業員の未来はどうなるのでしょうか? 近い将来、彼らはロボットに取って代わられるのでしょうか?
この質問は機械学習と直接関係しているわけではありませんが、非常に良い質問です。工場は大規模なロボット化に向けて劇的な変革を遂げており、その方法がロボットであってもそうでなくても、生産性は大幅に向上しています。中国の工場の多くが既に高度に自動化されているのもその証拠です。一方で、倉庫はその波に乗るのがやや遅れました。しかし、近年、倉庫がますます機械化・自動化される方向に進んでいるのが見受けられます。必ずしもロボットだけというわけではなく、より高度な自動化を実現するためのさまざまな競合技術が存在するのです。結局のところ、その傾向は明らかです。倉庫や物流センターは、既に製造現場で目の当たりにしているような大規模な生産性向上を遂げることになるでしょう。
ご質問にお答えすると、人間がロボットに取って代わられるわけではなく、自動化に取って代わられるのです。自動化は時にはロボットの形を取ることもありますが、直感的にロボットと結びつけられる技術を使わずに、生産性を大幅に向上させる巧妙な仕組みであったりもします。しかし、私はサプライチェーンの物流部門全体が縮小していくと考えています。現在、成長している唯一の理由は、電子商取引の台頭によりラストマイルの対応が必要となっているからです。労働力の大部分がラストマイルに関わっており、この部分も近い将来自動化されるでしょう。自律走行車は目前に迫っており、約束されたこの10年のうちに、多少の遅れはあるものの実現しつつあります。
Question: サプライチェーンで働くために、機械学習を学ぶ時間を投資する価値があると思いますか?
絶対に価値があります。私の考えでは、機械学習はサプライチェーンの補助科学のようなものです。現代の医師に化学の専門家であることは求められていませんが、もし自分が化学について全く知らないと患者に告げたら、現代医師としての力量に疑問を抱かれるでしょう。機械学習は、医療関係者が化学に取り組むのと同じように、手段として学ぶべきものであり、それ自体が目的ではありません。サプライチェーンで真剣に仕事をするのであれば、機械学習のしっかりとした基礎知識が必要です。
Question: 機械学習を適用した具体例を挙げてもらえますか? そのツールは実運用されましたか?
私自身、起業家でありLokadのCEOであるJoannes Vermorelの立場から申し上げると、現在、100社を超える企業が生産環境で機械学習を多岐にわたるタスクに利用しています。これらのタスクには、リードタイムの予測、需要の確率的予測、返品の予測、品質問題の予測、予期せぬ修理の平均間隔の再評価、そして競合価格の正誤判定などが含まれます。さらには、自動車アフターマーケットにおける車と部品の互換性マトリックスの再評価など、多数の応用例があります。機械学習を利用することで、データベースのエラーの大部分を自動的に修正できるのです。Lokadでは、これらの100社以上がすでに実運用されており、ほぼ10年にわたってこの状況が続いています。未来は既に到来しているのです。ただし、その普及は均一ではありません。
Question: 自分の時間を使って機械学習を学ぶ最良の方法は何ですか? Udemy、Courseraなどのサイトをおすすめしますか?
私の提案は、Wikipediaと論文の読解を組み合わせることです。ご覧の通り、この講義では基本を理解し、分野の最新動向を把握することが重要だと示されています。これらの講義で実際の研究論文を引用しているのもそのためです。二次情報を鵜呑みにせず、発表された原典に直接当たってください。これらすべての資料はオンラインで直接入手可能です。機械学習に関する論文には、書き方が不十分で読みにくいものもありますが、見事に書かれ、現在起こっていることを明確に示している論文も存在します。私の提案は、まずは分野の概要を把握するためにWikipediaに当たり、全体像を掴んだ後で論文を読み始めることです。最初は不明瞭に感じるかもしれませんが、しばらくすれば慣れてきます。UdemyやCourseraに頼ることも可能ですが、個人的にはそうしませんでした。私がこの講義で目指すのは、皆さんに大局観を掴むための直感的なヒントを提供することです。細かい点に踏み込むのであれば、何年も、あるいは何十年も前に発表された実際の論文に直接飛び込むべきです。一次情報に当たって、自分の知性を信じてください。
深層学習は非常に経験に基づく研究分野です。多くの作業は数学的には極めて複雑ではなく、通常は高校卒業後に学ぶレベルを超えることはないので、かなりアクセスしやすい分野です。
質問: OpenAIのCodeXやCo-Pilotのようなノーコードツールの台頭により、将来的にサプライチェーンの実務者が平易な英語でモデルを書くようになるとお考えですか?
短く言えば、いいえ、全くそうはならないと思います。コーディングを回避できるという考えは長い間存在していました。例えば、MicrosoftのVisual Basicは、もはやプログラミングする必要がなく、レゴのように視覚的に部品を組み合わせるだけで済むという視覚的ツールとして意図されていました。しかし現代では、このアプローチは効果がないと証明され、次のトレンドは物事を言語で表現する手法へと向かっています。
しかし、これらの講義で数学的な数式を使用する理由は、多くの場合、あなたが伝えようとしていることを明確に示す唯一の方法が数式でしか表現できないからです。英語などの自然言語は、多くの場合不正確で解釈の余地がありやすいという問題があります。一方、数学的な数式は非常に正確で明瞭です。平易な言葉は非常に曖昧で、その用途はあるものの、数式を用いる理由は、言いたいことに対して明確な意味を与えるためなのです。私は数式の使用をできるだけ控えていますが、使うときは、口頭で伝える以上に明確にアイデアを伝えるための唯一の方法だと感じたときです。
ローコードプラットフォームについては非常に懐疑的です。このアプローチは過去に何度も試みられてきましたが、大きな成功を収めた例はほとんどありません。私個人の見解では、コーディングがなぜ難しいのかを特定し、偶発的な複雑さを取り除くことで、サプライチェーン管理に適したコーディングを実現するべきだと思います。残るのは、サプライチェーン向けに正しく行われるコーディングであり、それこそがLokadの目指すところです。
質問: 機械学習は、季節性や通常の販売履歴データの需要予測をより正確にするのでしょうか?
本プレゼンテーションで述べたように、機械学習は正確性という概念を不要なものにしています。直近の大規模時系列予測コンペティション、M5コンペティションを見ると、上位10のモデルはすべて何らかの形で機械学習モデルでした。つまり、機械学習は予測の精度を上げるのでしょうか?実際のところ、コンペティションの結果に基づけばそうですが、他の手法と比べると僅かに精度が向上するに留まり、劇的な精度向上というわけではありません。
さらに、予測を一面的な視点で捉えてはいけません。季節性について正確性を問うと、製品一品ずつに焦点を当てることになりますが、それは正しいアプローチではありません。本当の正確性とは、新製品の投入が他のすべての製品に与える影響、すなわち一定のカニバリゼーションをどのように引き起こすのかを評価することにあります。鍵は、このカニバリゼーションをモデル内でどのように反映させるかが正確かどうかを評価することです。すると、これは突然多次元の問題となります。講義で生成ネットワークを用いて示したように、正確性の本来の意味するところのメトリックは学習されるべきであり、与えられるものではありません。平均絶対誤差、平均絶対百分率誤差、二乗平均誤差などの数学的な式は、単なる数学的基準に過ぎません。それらは実際に求められるメトリックではなく、非常に単純な指標にすぎないのです。
質問: 予測者の日常業務は自動モードでの予測に置き換えられるのでしょうか?
私の見解では、未来は既に到来していますが、その普及は均等ではありません。Lokadではすでに毎日何千万ものSKUを予測しており、給与台帳上に予測の調整を行う人を見当たりません。つまり、はい、すでに実現されていますが、それは全体のごく一部に過ぎません。もし人が予測の調整やモデルのチューニングを必要とするのであれば、そのプロセス自体に問題があることを示しており、その部分を自動化することで解決すべきです。
再び、Lokadの経験から言うと、これらの作業はすでに完全に排除されています。なぜなら、私たちは既にそれを実施しているからです。この方法は私たちだけのものではなく、私たちにとってはほぼ10年前の古い話と言っても過言ではありません。
質問: 機械学習はサプライチェーンの意思決定にどの程度積極的に活用されているのでしょうか?
それは企業によります。Lokadではあらゆる現場で活用されており、私が「Lokadでは」と言うときは、Lokadがサービスを提供している企業におけることを意味します。しかし、市場の大多数は未だに基本的にExcelを使用しており、機械学習は全く採用されていません。Lokadは何十億ユーロまたはドル相当の在庫を実際に管理しているため、これはすでに現実の問題となっています。しかし、Lokad自体は市場全体の0.1%にも満たないため、我々は依然として例外的な存在です。私たちは急成長しており、競合他社も多く存在します。私の推測では、サプライチェーン全体の市場においてはまだ周辺的な取り組みですが、二桁の成長を見せています。長期間にわたる指数関数的成長の力を過小評価してはいけません。最終的には非常に大きな市場となるでしょうし、望むならばLokadもその一員となるでしょうが、それはまた別の話です。
質問: サプライチェーンに多くの未知数が存在する中で、モデルの入力に仮定を設けるための戦略は何でしょうか?
要点は、確かに未知数は山ほどありますが、モデルの入力として利用できるものは実際のところ選べる余地がほとんどないということです。要するに、ERPなどの企業システムに既に存在するデータに依存するということです。もしあなたのERPに過去の在庫レベルの履歴があれば、それを機械学習モデルの一部として利用できます。逆に、現在の在庫レベルのみを記録しているならそのデータは利用できません。追加の入力として在庫レベルのスナップショットを取ることは可能ですが、肝心なのは、入力として使用できるものは文字通りシステムに存在するものである、という点です。
私の典型的なアプローチは、新たなデータソースを構築しなければならない場合、それは非常に鈍く、苦痛な作業になるということです。そしてそれはサプライチェーンにおける機械学習導入の出発点とはならないでしょう。大企業は何十年も前からデジタル化されているため、ERPやWMSといったトランザクションシステムに既にあるデータは、素晴らしい出発点となっています。もし後になって、競合情勢の情報、正確な在庫レベル、またはサプライヤーから示されるETAなど、より多くの情報が必要だと気づいた場合、それらはモデルの入力として価値ある追加情報となるでしょう。通常、入力として使うものは、そもそも予測しようとするものと相関関係があるという直感に基づいており、その程度の高い直感で十分な場合が多いです。定義が難しい常識さえあれば、それで十分です。これはエンジニアリング上のボトルネックではありません。
質問: 価格決定が将来の需要予測(確率的な観点を含む)に与える影響は何で、機械学習的にはどのように対処すればよいのでしょうか?
これは非常に良い質問です。LokadTVのエピソードの一つで、この問題に取り組んだことがあります。学んだことは、通常、ポリシー、すなわち様々な事象への反応方法を制御するオブジェクトとして知られるものへと変換されるという考え方です。予測というのは、モンテカルロ法のような風景を生成することであり、固定されたデータポイントではなく、各段階で観察可能な需要を生成し、その時に下す判断を生成し、直後の市場の反応を再生成するという、はるかに生成的なプロセスなのです。
これにより、あなたの需要反応生成プロセスの正確性を評価するのは非常に複雑になり、実際には予測メトリックを学習する必要が出てきます。それは非常に骨の折れる作業ですが、そのために正確性メトリックを一面的な問題として捉えてはいけないのです。要するに、需要予測は生成器となり、根本的に動的であって静的ではありません。それは生成的なものです。この生成器は、エージェント、すなわちポリシーとして実装されるものに反応します。生成器とポリシー決定システムの両方を学習しなければならず、さらに損失関数も学習する必要があります。学ぶべきことは多いですが、幸いなことに、深層学習は非常にモジュール化され、プログラム的なアプローチであり、これらすべての技術の組み合わせに非常に適しています。
質問: 特に中小企業において、データの収集は困難でしょうか?
はい、非常に困難です。その理由は、売上高が1,000万ドル未満の企業の場合、IT部門というものが存在しないからです。小規模なERPが導入されている可能性はありますが、たとえツールが優れていても、まともなITチームが存在しないのです。データを依頼しても、クライアント企業内でSQLクエリを実行してデータを抽出できる能力を持った人物がいないのです。
ご質問の意図を正しく理解しているか分かりませんが、問題はデータの収集そのものではありません。データの収集は、既存の会計ソフトやERPを通じて自然に行われており、今日ではかなり小規模な企業でも利用可能なERPがあります。問題は、そうした企業向けソフトウェアからデータを抽出することにあります。売上高が2,000万ドル未満で、かつeコマース企業でない企業では、IT部門が存在しない可能性が高いのです。仮に小規模なIT部門があったとしても、通常は全員分の機器やWindowsデスクトップのセットアップを担当する1人だけであり、データベースやより高度なIT管理業務に精通した人物ではない場合が多いのです。
さて、これで終わりです。次回のセッションは、数週間後の10月13日(水)に行われます。それでは、またお会いしましょう!
参考文献
- 学習可能性の理論, L. G. Valiant, 1984年11月
- サポートベクターネットワーク, Corinna Cortes, Vladimir Vapnik, 1995年9月
- ランダムフォレスト, Leo Breiman, 2001年10月
- LightGBM: 非常に効率的な勾配ブースティング決定木, Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu, 2017
- Attention Is All You Need, Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, 最終改訂 2017年12月
- Deep Double Descent: より大きなモデルとより多くのデータが害を及ぼす場合, Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever, 2019年12月
- StyleGANの画像品質の解析と改善, Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila, 最終改訂 2020年3月
- Generative Adversarial Networks, Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, 2014年6月
- 単言語コーパスだけを用いた教師なし機械翻訳, Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, 最終改訂 2018年4月
- BERT: 言語理解のための深層双方向Transformerの事前学習, Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, 最終改訂 2019年5月
- グラフニューラルネットワークへの優しい入門, Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko, 2021年9月


