PROGRAMMIERPARADIGMEN FÜR supply chain (VORLESUNG 1.4 ZUSAMMENFASSUNG)
supply chain problems sind wicked und der Versuch, sie ohne geeignete Programmierwerkzeuge – im Kontext eines groß angelegten Unternehmens – anzugehen, erweist sich stets als überaus kostspielige Lernerfahrung. Eine effektive Optimierung der supply chain – ein verstreutes Netzwerk physischer und abstrakter Komplexitäten – erfordert eine Reihe moderner, agiler und innovativer programmierparadigmen. Diese Paradigmen sind integraler Bestandteil der erfolgreichen Identifikation, Betrachtung und Lösung der vielfältigen Probleme, die in einer supply chain inhärent sind.
Vorlesung ansehen

Statische Analyse
Man muss kein Computerprogrammierer sein, um wie einer zu denken, und die ordnungsgemäße Analyse von supply chain-Problemen wird am besten mit einer programmierorientierten Denkweise angegangen, nicht nur mit Programmierwerkzeugen. Traditionelle Softwarelösungen (wie ERPs) sind so konzipiert, dass Probleme zur Laufzeit und nicht zur Kompilierzeit1 angegangen werden.
Dies ist der Unterschied zwischen einer reaktiven Lösung und einer proaktiven. Diese Unterscheidung ist entscheidend, da reaktive Lösungen tendenziell weitaus kostspieliger sind als proaktive, sowohl in finanzieller Hinsicht als auch in Bezug auf die Bandbreite. Diese weitgehend vermeidbaren Kosten sollen genau durch eine programmierorientierte Denkweise vermieden werden, und die statische Analyse ist der Ausdruck dieses Ansatzes.
Statische Analyse beinhaltet die Überprüfung eines Programms (in diesem Fall der Optimierung), ohne es auszuführen, um potenzielle Probleme bevor sie die Produktion beeinträchtigen können zu identifizieren. Lokad nähert sich der statischen Analyse mittels Envision, seiner domänenspezifischen Sprache (DSL). Dies ermöglicht die Erkennung und Korrektur von Fehlern bereits auf der Entwurfsebene (in der Programmiersprache) so schnell und bequem wie möglich.
Stellen Sie sich ein Unternehmen vor, das gerade dabei ist, ein Lagerhaus zu errichten. Man baut nicht zuerst das Lagerhaus und denkt sich dann über dessen Aufteilung Gedanken. Vielmehr wird die strategische Anordnung von Gängen, Regalen und Verladebögen im Vorfeld überlegt, um potenzielle Engpässe vor Baubeginn zu identifizieren. Dies ermöglicht ein optimales Design – und damit einen reibungslosen Ablauf – im zukünftigen Lagerhaus. Diese präzise Planung ist analog zu der Art der statischen Analyse, die Lokad mittels Envision umsetzt.
Die hier beschriebene statische Analyse würde die zugrunde liegende Programmierung der Optimierung modellieren und eventuelle, potenziell nachteilige Verhaltensweisen im Ablauf identifizieren, bevor sie implementiert wird. Solche feindseligen Tendenzen könnten einen Fehler umfassen, der dazu führt, dass versehentlich viel mehr Bestand bestellt wird als benötigt. Als Folge würden derartige Fehler aus dem Code entfernt, bevor sie Schaden anrichten können.
Array-Programmierung
In der supply chain-Optimierung ist eine präzise Zeitsteuerung unerlässlich. Zum Beispiel müssen in einer Einzelhandelskette Daten innerhalb eines 60-Minuten-Fensters konsolidiert, optimiert und an das Lagerverwaltungssystem weitergeleitet werden. Wenn Berechnungen zu lange dauern, kann die Ausführung der gesamten supply chain gefährdet werden. Array-Programmierung behebt dieses Problem, indem sie bestimmte Klassen von Programmierfehlern ausschließt und die Berechnungsdauer garantiert, wodurch supply chain-Praktikern ein vorhersehbarer Zeithorizont für die Datenverarbeitung geboten wird.
Auch bekannt als data frame programming, ermöglicht dieser Ansatz, Operationen direkt an Datenarrays durchzuführen, anstatt an isolierten Datensätzen. Lokad realisiert dies durch den Einsatz von Envision, seiner DSL. Array-Programmierung kann die Datenmanipulation und -analyse vereinfachen, etwa indem Operationen auf ganzen Datenkolonnen statt auf einzelnen Einträgen in jeder Tabelle ausgeführt werden. Dies erhöht die Effizienz der Analyse erheblich und reduziert in der Folge die Wahrscheinlichkeit von Fehlern in der Programmierung.
Stellen Sie sich einen Lagerverwalter vor, der zwei Listen hat: Liste A zeigt die aktuellen Bestandsniveaus, und Liste B enthält die eingehenden Lieferungen für die Produkte in Liste A. Anstatt jedes Produkt einzeln durchzugehen und die eingehenden Lieferungen (Liste B) manuell zu den aktuellen Bestandsniveaus (Liste A) hinzuzufügen, wäre eine effizientere Methode, beide Listen gleichzeitig zu verarbeiten, sodass die Bestandszahlen aller Produkte in einem Zug aktualisiert werden können. Dies würde sowohl Zeit als auch Aufwand sparen und entspricht im Wesentlichen dem, was Array-Programmierung bezweckt2.
In der Realität erleichtert Array-Programmierung die Parallelisierung und Verteilung der Berechnung der enormen Datenmengen, die in der supply chain-Optimierung anfallen. Durch die Verteilung der Berechnungen auf mehrere Maschinen können Kosten reduziert und Ausführungszeiten verkürzt werden.
Hardware-Mischbarkeit
Einer der Hauptengpässe in der supply chain-Optimierung ist die begrenzte Anzahl an supply chain scientists. Diese Wissenschaftler sind dafür verantwortlich, numerische Rezepte zu erstellen, die die Strategien der Kunden sowie die feindseligen Machenschaften der Wettbewerber berücksichtigen, um umsetzbare Erkenntnisse zu liefern.
Diese Experten sind nicht nur schwer zu finden, sondern müssen, sobald sie verfügbar sind, oft mehrere hardwarebezogene Hürden überwinden, die sie von der schnellen Ausführung ihrer Aufgaben trennen. Hardware-Mischbarkeit – die Fähigkeit, mit der verschiedene Komponenten innerhalb eines Systems harmonieren und zusammenarbeiten – ist entscheidend, um diese Hindernisse zu beseitigen. Hierbei werden drei grundlegende Computerressourcen betrachtet:
- Compute: Die Rechenleistung eines Computers, bereitgestellt entweder durch die CPU oder GPU.
- Memory: Die Datenspeicherkapazität eines Computers, realisiert über RAM oder ROM.
- Bandwidth: Die maximale Rate, mit der Informationen (Daten) zwischen verschiedenen Teilen eines Computers oder über ein Computernetzwerk übertragen werden können.
Die Verarbeitung großer Datensätze ist in der Regel ein zeitaufwändiger Prozess, der zu einer geringeren Produktivität führt, während Ingenieure auf die Ausführung von Aufgaben warten. In einer supply chain-Optimierung könnte man Codeschnipsel (die routinemäßige Zwischenrechnungsschritte darstellen) auf Solid-State-Drives (SSDs) speichern. Dieser einfache Schritt ermöglicht es supply chain scientists, ähnliche scripts mit nur geringfügigen Anpassungen viel schneller auszuführen, wodurch die Produktivität erheblich gesteigert wird.
Im obigen Beispiel wurde ein günstiger Memory-Hack genutzt, um den Rechenaufwand zu senken: Das System stellt fest, dass das verarbeitete Script nahezu identisch zu früheren ist, sodass die Berechnung in Sekunden anstatt in mehreren zehn Minuten erfolgen kann.
Diese Art der Hardware-Mischbarkeit ermöglicht es Unternehmen, den größtmöglichen Wert aus ihren Investitionsdollars zu schöpfen.
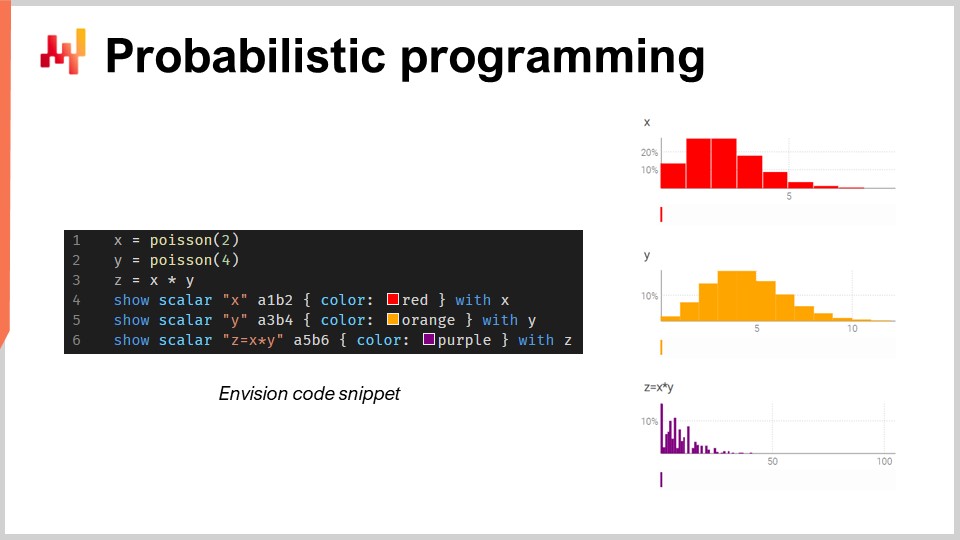
Probabilistisches Programmieren
Es gibt eine unendliche Anzahl möglicher zukünftiger Ergebnisse, doch sind sie nicht alle gleich wahrscheinlich. Angesichts dieser irreduziblen Unsicherheit müssen die genutzten Programmierwerkzeuge ein probabilistisches Vorhersagemodell übernehmen. Obwohl Excel historisch gesehen das Fundament vieler supply chains war, lässt es sich im großen Maßstab mit probabilistischen Vorhersagen nicht einsetzen, da diese Art der Prognose die Fähigkeit erfordert, die Algebra der Zufallsvariablen zu verarbeiten3.
Kurz gesagt ist Excel in erster Linie für deterministische Daten (d.h. feste Werte, wie statische ganze Zahlen) ausgelegt. Zwar lässt es sich modifizieren, um einige Wahrscheinlichkeitsfunktionen auszuführen, doch fehlen ihm die fortschrittliche Funktionalität sowie die Gesamtheit an Flexibilität und Ausdrucksstärke, die erforderlich sind, um mit der komplexen Manipulation von Zufallsvariablen in der probabilistischen Nachfrageprognose umzugehen. Stattdessen ist eine probabilistische Programmiersprache – wie Envision – besser dafür geeignet, die Unsicherheiten, die in der supply chain auftreten, darzustellen und zu verarbeiten.
Betrachten Sie einen Autozubehörhandel, der Bremsbeläge verkauft. In diesem hypothetischen Szenario müssen Kunden Bremsbeläge entweder in Chargen von 2 oder 4 gleichzeitig kaufen, und das Geschäft muss diese Unsicherheit bei der Nachfrageprognose berücksichtigen.
Falls das Geschäft Zugang zu einer probabilistischen Programmiersprache hat (im Gegensatz zu einer endlosen Anzahl von Tabellenkalkulationen), kann es den Gesamtverbrauch mithilfe der Algebra der Zufallsvariablen – die in allgemeinen Programmiersprachen typischerweise fehlt – viel genauer schätzen.
Differenzierbares Programmieren
Im Kontext der supply chain-Optimierung ermöglicht differenzierbares Programmieren dem numerischen Rezept, auf Basis der bereitgestellten Daten zu lernen und sich anzupassen. Differenzierbares Programmieren, kombiniert mit einem stochastischen Gradientenabstieg, erlaubt es einem supply chain scientist, komplexe Muster und Zusammenhänge innerhalb der supply chain zu entdecken. Mit jeder neuen Programmieriteration werden Parameter erlernt, und dieser Prozess wird tausende Male wiederholt. Dies geschieht, um die Diskrepanz zwischen dem aktuellen Prognosemodell und den vergangenen Daten zu minimieren4.
Kannibalisierung und Substitution – innerhalb eines einzigen Katalogs – sind zwei Modellprobleme, die in diesem Zusammenhang näher beleuchtet werden sollten. In beiden Szenarien konkurrieren mehrere Produkte um dieselben Kunden, was eine komplexe Ebene der Prognosekomplexität darstellt. Die nachgelagerten Effekte dieser Kräfte werden in der Regel nicht durch traditionelle Zeitreihenprognosen erfasst, die hauptsächlich den Trend, die Saisonalität und das Rauschen bei einem einzelnen Produkt berücksichtigen, ohne die Möglichkeit von Wechselwirkungen mit einzubeziehen.
Differenzierbares Programmieren und stochastischer Gradientenabstieg können genutzt werden, um diese Probleme anzugehen, beispielsweise durch die Analyse historischer Transaktionsdaten, die Kunden und Produkte verbinden. Envision ist in der Lage, eine derartige Untersuchung – genannt Affinitätsanalyse – zwischen Kunden und Käufen durchzuführen, indem es einfache Flachdateien mit ausreichender historischer Tiefe einliest: nämlich Transaktionen, Daten, Produkte, Kunden und Abnahmemengen5.
Mit nur einem handvoll einzigartigen Codes kann Envision die Affinität zwischen einem Kunden und einem Produkt bestimmen, wodurch es dem supply chain scientist ermöglicht wird, das numerische Rezept, das die entsprechende Empfehlung liefert, weiter zu optimieren6.
Versionierung von Code & Daten
Ein oft übersehener Aspekt der langfristigen Optimierungsfähigkeit ist die Sicherstellung, dass das numerische Rezept – einschließlich jedes enthaltenen Code-Schnipsels und Datenstücks – bezogen, nachverfolgt und reproduziert werden kann7. Ohne diese Versionskontrolle wird die Fähigkeit, das Rezept im Falle unvorhergesehener Ausnahmen (heisenbugs in der Computerwelt) rückzuentwickeln, erheblich eingeschränkt.
Heisenbugs sind lästige Ausnahmen, die Probleme in Optimierungsberechnungen verursachen, aber verschwinden, wenn der Prozess erneut ausgeführt wird. Dies kann ihre Behebung überaus schwierig machen, was dazu führt, dass einige Initiativen scheitern und die supply chain wieder auf Excel-Tabellen zurückgreift. Um Heisenbugs zu vermeiden, ist eine vollständige Replizierbarkeit der Logik und Daten der Optimierung notwendig. Dies erfordert eine Versionskontrolle aller im Prozess verwendeten Codes und Daten, um sicherzustellen, dass die Umgebung exakt zu den Bedingungen eines beliebigen früheren Zeitpunkts reproduziert werden kann.
Sichere Programmierung
Neben schiefgelaufenen Heisenbugs bringt die zunehmende Digitalisierung der supply chain eine entsprechende Anfälligkeit für digitale Bedrohungen mit sich, wie etwa Cyberangriffe und Ransomware. In dieser Hinsicht gibt es zwei Haupt- und üblicherweise unbewusste Ursachen für Chaos: das programmierbare System, das man einsetzt, und die Personen, denen man den Zugang dazu erlaubt. Letzteres ist schwer vorherzusehen, was versehentliche Inkompetenz betrifft (ganz zu schweigen von Fällen absichtlicher Boshaftigkeit); beim Ersteren sind die gezielten Entscheidungen auf Design-Ebene von größter Bedeutung, um diese Minenfelder zu umgehen.
Anstatt wertvolle Ressourcen in den Ausbau des Cyber-Sicherheitsteams zu investieren (in Erwartung reaktiven Handelns, wie etwa dem Löschen von Bränden), können kluge Entscheidungen in der Designphase des Programmiersystems ganze Kategorien nachgelagerter Probleme eliminieren. Durch das Entfernen redundanter Funktionen – wie im Fall von Lokad der SQL-Datenbank – lassen sich vorhersehbare Katastrophen, beispielsweise ein SQL-Injection-Angriff, vermeiden. Ebenso bedeutet die Wahl von Append-Only-Persistenzschichten (wie sie von Lokad verwendet werden), dass das Löschen von Daten (sei es durch Freund oder Feind) viel schwieriger wird8.
Obwohl Excel und Python ihre Vorteile haben, fehlt es ihnen an der erforderlichen Programmier-Sicherheit, um all den Code und die Daten zu schützen, die für die in diesen Vorlesungen diskutierte skalierbare supply chain-Optimierung notwendig sind.
Anmerkungen
-
Kompilierzeit bezeichnet den Zeitpunkt, zu dem der Code eines Programms in ein maschinenlesbares Format umgewandelt wird, bevor es ausgeführt wird. Laufzeit bezeichnet den Zeitpunkt, zu dem das Programm tatsächlich vom Computer ausgeführt wird. ↩︎
-
Dies ist eine sehr grobe Annäherung an den Prozess. In Wirklichkeit ist er viel komplexer, aber das liegt im Zuständigkeitsbereich von Computerexperten. Vorrangig geht es darum, dass Array-Programmierung zu einem wesentlich schlankeren (und kosteneffizienteren) Berechnungsprozess führt, dessen Vorteile im Kontext der supply chain zahlreich sind. ↩︎
-
Einfach ausgedrückt bezieht sich dies auf die Manipulation und Kombination von Zufallswerten, wie das Berechnen des Ergebnisses eines Würfelwurfs (oder von mehreren hunderttausend Würfen im Kontext eines großen supply chain-Netzwerks). Es umfasst alles von grundlegender Addition, Subtraktion und Multiplikation bis hin zu weitaus komplexeren Funktionen wie der Bestimmung von Varianzen, Kovarianzen und Erwartungswerten. ↩︎
-
Versuchen Sie, ein tatsächliches Rezept zu perfektionieren. Es mag ein grundlegendes Schema geben, auf das Sie zurückgreifen, aber das perfekte Gleichgewicht der Zutaten – und der Zubereitung – zu erreichen, erweist sich als schwer fassbar. Tatsächlich gibt es bei einem Rezept nicht nur geschmackliche Überlegungen, sondern auch solche bezüglich Textur und Aussehen. Um die perfekte Variante des Rezepts zu finden, nimmt man feine Anpassungen vor und notiert die Ergebnisse. Statt mit jeder denkbaren Würze und jedem Kochutensil zu experimentieren, nimmt man fundierte Änderungen basierend auf dem Feedback vor, das bei jeder Iteration beobachtet wird (z. B. etwas mehr oder weniger Salz hinzufügen). Mit jeder Iteration lernt man mehr über die optimalen Proportionen, und das Rezept entwickelt sich weiter. Im Kern ist dies, was differentiable programming und stochastic gradient descent mit dem numerischen Rezept in a supply chain optimization bewirken. Bitte sehen Sie sich die Vorlesung für die mathematischen Details an. ↩︎
-
Wenn zwischen zwei Produkten, die bereits im eigenen Katalog sind, eine starke Affinität festgestellt wird, kann das darauf hindeuten, dass sie sich ergänzen, das heißt, sie werden häufig zusammen gekauft. Wenn festgestellt wird, dass Kunden mit hoher Ähnlichkeit zwischen zwei Produkten wechseln, könnte dies auf Substitution hindeuten. Allerdings, wenn ein neues Produkt eine starke Affinität zu einem bestehenden Produkt aufweist und zu einem Rückgang der Verkäufe des bestehenden Produkts führt, kann dies auf Kannibalisierung hindeuten. ↩︎
-
Es versteht sich von selbst, dass dies vereinfachte Beschreibungen der zugrunde liegenden mathematischen Operationen sind. Dennoch sind die mathematischen Operationen, wie in der Vorlesung erklärt, nicht allzu verwirrend. ↩︎
-
Zu den populären Versionskontrollsystemen gehören Git und SVN. Sie ermöglichen es mehreren Personen, gleichzeitig am gleichen Code (oder jeglichem Inhalt) zu arbeiten und Änderungen zusammenzuführen (oder abzulehnen). ↩︎
-
Mit Append-only-Persistenzschicht ist eine Strategie zur Datenspeicherung gemeint, bei der neue Informationen der Datenbank hinzugefügt werden, ohne bestehende Daten zu modifizieren oder zu löschen. Lokad’s Append-only-Sicherheitsdesign wird in der umfangreichen Sicherheits-FAQ behandelt. ↩︎