00:00 はじめに
03:39 自動化は常に目標であった
06:28 例外管理とアラート
10:27 これまでの経緯
14:33 本日の本番展開
15:59 要約:成果物、範囲、および役割
19:01 意思決定の形態を明らかにする
23:00 レガシーに起因する対応
27:20 ゼロパーセントの狂気に向けた反復
32:30 志向的な指標
36:27 二重運用:手動 + 機械的
39:19 分析麻痺
43:21 段階的な自動化への移行
46:08 プロセスの堆積
48:57 プランナーからネットワークマネージャーへ
52:46 KPI観光客
54:58 リーダーシップ:コーチからプロダクトオーナーへ
58:46 アナロジーによるサプライチェーンのボス
01:02:25 結論
01:04:44 7.2 自動化された意思決定を生産に導入する - 質疑応答 ?
説明
私たちは、平凡な意思決定という一連の判断、例えば在庫補充などを駆動する数値的レシピを求めています。自動化はサプライチェーンを資本主義的な事業にするために不可欠ですが、数値レシピに欠陥がある場合、大規模な被害が生じるリスクがあります。「早く失敗して壊す」という考え方は、生産用に数値レシピを承認する適切な心構えではありません。しかし、ウォーターフォールモデルなどの多くの代替案は、たいてい合理性と制御の錯覚を与えるだけで、さらに悪い結果となります。生産グレードであることを証明する数値レシピを設計する鍵は、非常に反復的なプロセスにあります。
全文書起こし

このサプライチェーン講義シリーズへようこそ。私の名前はヨハネス・ヴェルモレルです。本日は「自動化されたサプライチェーンの意思決定を生産に導入する」をお届けします。過去2世紀にわたり、私たちの経済は機械化によって大きな変革を遂げました。競合他社に比べて高度な機械化を達成した企業は、ほぼ必ずその競合他社を体系的に破産に追いやりました。機械化により、フォークリフトで商品を移動させるといった物理的な作業だけでなく、銀行に残っている資金の計算などの知的作業も、より多く、より良く、より速く、かつコスト削減を実現できます。
しかしながら、作業の機械化能力は技術に依存しています。例えば、散髪やシーツ交換といった物理的な作業はまだ機械化できません。一方、適切な人材の採用や顧客のニーズ把握といった知的作業も、依然として十分に機械化できていません。これらの知的または機械的な作業が将来的に機械化できなくなる理由はありませんが、現時点では技術が十分ではありません。
ほとんどの平凡でルーチンなサプライチェーンの意思決定は、現在自動化が可能です。これは比較的新しい発展です。10年前は、自動化が成功するサプライチェーン意思決定の範囲は全体のほんの一部に過ぎませんでした。しかし今日では、適切な技術があれば、自動化が難しい反復的な意思決定は極めて稀です。ここでいう自動化の成功とは、手動プロセスよりも優れた結果を生み出す自動化プロセスのことを指し、単にコンピュータで意思決定を生成できる能力(生成結果の品質を気にしなければ些細な問題)は含みません。
本日の焦点は数値的レシピそのものではなく、そもそもその自動化を可能にするソフトウェアにあります。サプライチェーンの意思決定プロセスにおいて、その数値レシピを構築するための要素は、本講義シリーズの前の章で取り上げられてきました。本日の焦点は、その数値レシピを生産環境に投入するためのサプライチェーンイニシアティブの各部分にあります。この講義の目的は、企業が手動のサプライチェーン意思決定から自動化へ移行するために必要なことを概説することです。講義の終わりまでに、自動化移行時の行うべきことと行うべきでないことについての知見が得られるはずです。実際、数値レシピそのものに伴う高度な技術的難しさが、イニシアティブ成功のために同等に重要な組織的側面をしばしば覆い隠してしまいます。

現代のサプライチェーン実務者に意思決定自動化のアイデアが提示されると、彼らの初動の反応は「これは未来的な考えだ。我々はまだその域に達していない」となりがちです。しかし、平凡で反復的なサプライチェーンの意思決定の完全自動化は、実際に40年以上前のサプライチェーンのデジタル時代の始まりから目指されてきた目標です。
コンピュータが企業に容易に手に入るようになるとすぐに、人々は多くのサプライチェーン意思決定が完全自動化に適していると認識しました。画面には、この野望を示す出版物のリストを厳選して表示しています。1970年代や1980年代には、この分野はまだ「サプライチェーン」とは呼ばれていませんでした。1990年代に入って初めてその用語が普及しましたが、意図は既に明確でした。これらのコンピュータシステムは、在庫補充のような最も反復的な意思決定を自動化するのに即しているように見えました。
最も不思議に思うのは、このコミュニティがかつての野心をほとんど忘れてしまっているように見える点です。今日、未来的に聞こえるように、コンサルティング会社やIT企業が『自律型サプライチェーン』という用語を用いて、平凡な意思決定の機械化を語ることがあります。しかし、「自律型」という表現は私には不適切に感じられます。例えば、仕分けシステムを備えたコンベヤーベルトを「自律的物流」とは呼びません。コンベヤーベルトは機械化されているのであって自律的ではなく、依然として技術的監視が必要です。この革新が、もしコンベヤーベルトがなければ企業が商品運搬に必要とする労働力のごく一部でしかないのと同様に、サプライチェーンの意思決定においても、組織から人間を完全に排除するのが目的ではありません。目標は、単に最も手間がかかり、粗雑なプロセスから人間を取り除くことに過ぎません。これは、40年前に発表された論文で採用された視点と全く同じであり、本講義でも私が採用している視点です。

1990年代、ソフトウェアベンダー、特にERPベンダーや在庫最適化の専門家は、サプライチェーンの意思決定自動化のアイデアをほぼ放棄したようです。振り返ってみると、1970年代の単純なモデル―多くの重要な要素、例えば不確実性をほとんど無視していた―が、自動化が当時成功しなかった明らかな根本原因でした。しかし、この根本原因の解決は、この時期の技術では達成不可能であることが明らかになりました。その代わりに、ソフトウェアベンダーは例外管理システムに依存することとなりました。これらのシステムは、クライアント企業が設定したルールに基づいて在庫アラートを生成することが期待されました。論理はこうでした。自動化で自動処理可能な大部分のラインを任せ、機械の能力を超える難しいラインにのみ人間が介入するようにする。
まず最初に、例外管理システムの販売はソフトウェアベンダーにとって非常に有利ですが、クライアント企業にとってはそうではありません。第一に、例外管理はサプライチェーン-パフォーマンス-テストの負担をベンダーからクライアントへ移してしまいます。例外管理が導入されると、結果が悪い場合、その責任はクライアント側に帰されます。そもそも、損害を防ぐためのより良いアラートを設定すべきだったのです。
第二に、パラメータ化された在庫アラートを管理するシステムの構築は、ソースアラートを規定するパラメータ値を提供する必要がなければ、ソフトウェアベンダーにとって容易な作業です。実際、分析的観点から、優れた在庫アラートを生成できるということは、悪い在庫意思決定を確実に識別できるルールを構築できることを意味します。もし悪い在庫意思決定を確実に識別できるルールが作れるなら、そのルールは当然、良い在庫意思決定をも確実に生み出すために利用できるのです。実際、そのルールは単に悪い決定をフィルタリングするために使われるだけです。
第三に、例外管理は、ソフトウェアベンダーが人間の心理を利用するための、いわば巧妙な戦略でもあります。実際、これらのアラートは、実証心理学者が指摘する「コミットメントと一貫性」として知られるメカニズムを利用しています。このメカニズムは、強力でありながら偶発的な依存をソフトウェア製品に生み出します。要するに、従業員が在庫数値を調整し始めると、その数値はもはや任意の数字ではなくなり、自分たちの数字、自分たちの仕事となるため、システムが実際に優れたサプライチェーンパフォーマンスを発揮するか否かにかかわらず、従業員はそのシステムに感情的に執着するのです。
全体として、例外管理は技術的な行き詰まりです。なぜなら、一般的には、信頼できる例外やアラートを設計することは、意思決定の信頼できる自動化を構築するのと同じくらい困難だからです。もしアラートや例外が信頼できないのなら、結局すべてを手動でレビューする必要があり、元の状態に戻ってしまいます。つまり、意思決定プロセスは依然として完全に手動のままなのです。

このサプライチェーン講義シリーズは24のエピソードを含んでいます。現時点では、これまでに紹介してきたすべての要素が、今日私たちが立っている地点、すなわちこの量的-供給-チェーン-マニフェストイニシアティブを生産に投入する直前に達するために、明確な目的のもと行われてきました。より具体的には、予測に組み込みたい数値レシピそのものであり、この取り組みが本日の講義の焦点となっています。
これらの講義では、「数値レシピ」という用語を、生の履歴データを入力として最終的な意思決定を導く一連の計算を指すために使用しています。この用語は、以前の章で詳細に扱われた多くの異なる概念、方法、技術を反映しているため、あえてあいまいなものにしています。第一章では、なぜサプライチェーンがプログラム的でなければならないのか、またなぜそのような数値レシピを生産に投入することが望ましいのかを見てきました。サプライチェーン自体の複雑性が増すにつれて、自動化の必要性はかつてないほど高まっています。また、供給チェーン-管理-定義を資本主義的な取り組みにするという必然性もあります。
第二章は方法論に捧げられています。実際、サプライチェーンは競争システムであり、この組み合わせは素朴な方法論を打ち砕きます。これまで紹介してきた方法論の中で、サプライチェーンのペルソナーと実験的最適化は、本日のテーマにおいて極めて重要です。サプライチェーンのペルソナーは、適切な形式の意思決定を採用するための鍵となります。この点については、少し後で再度触れます。実験的最適化は、実際に機能するものを提供するために不可欠です。こちらもまた、少し後で再度説明します。
第三章では、供給チェーンのペルソナーを使った解決策を一旦脇に置き、問題点そのものを概観します。この章は、対処すべき意思決定問題の種類を特徴づける試みです。すべてのSKUに対して適切な数量を選ぶという単純な視点は、現実の状況にはあまり適合しないことを示しています。意思決定の形態には、ほぼ必ず深みが存在します。
第四章では、ソフトウェア要素が遍在する現代のサプライチェーン実践を理解するために必要な要素を概観します。これらの要素は、数値レシピやほとんどのサプライチェーンプロセスが動作するより広い文脈を理解するための基礎となります。実際、多くのサプライチェーンの教科書は、その技術や数式がいわゆる真空状態で動作していると暗黙に前提していますが、実際はそうではなく、応用環境が重要なのです。
第5章と第6章は、それぞれ予測モデリングと意思決定に捧げられています。これらの章では、機械学習技術や数学的最適化技術を駆使した数値レシピの核心部分が取り上げられています。最後に、第7章である本章は、数値レシピを生産に投入し、その後も運用を維持することを目的とした量的サプライチェーンイニシアティブの実行に捧げられています。前回の講義では、技術的基盤を整えながらイニシアティブを始動するために必要なことを取り上げました。これは、適切なデータ-抽出-パイプラインの構築を意味します。今日、私たちはゴールを越え、この数値レシピを実際に稼働させるのです。

まず、前回の講義の簡単な要約から始め、続いてイニシアティブの後半段階における3つの重要な側面に進みます。第一の側面は数値レシピの設計に関するものです。しかし、ここで語るのはレシピの数値部分の設計ではなく、その周囲を取り巻くエンジニアリングプロセスの設計についてです。この課題にどのように取り組み、満足のいく解決策が生まれる可能性をイニシアティブに与えるかを見ていきます。
2番目の側面は、数値レシピの適切な展開に関するものです。実際、企業は手動プロセスから始まり、最終的には自動化されたプロセスへと移行すべきです。適切な展開は、この移行、あるいは少なくとも初期段階で欠陥があると判明する数値レシピに伴うリスクを大幅に軽減する可能性があります。
3番目の側面は、自動化が展開された後に企業内で起こるべき変化に関するものです。サプライチェーン部門の人々の役割と任務は、大幅に変化すべきであることが後ほど示されます。
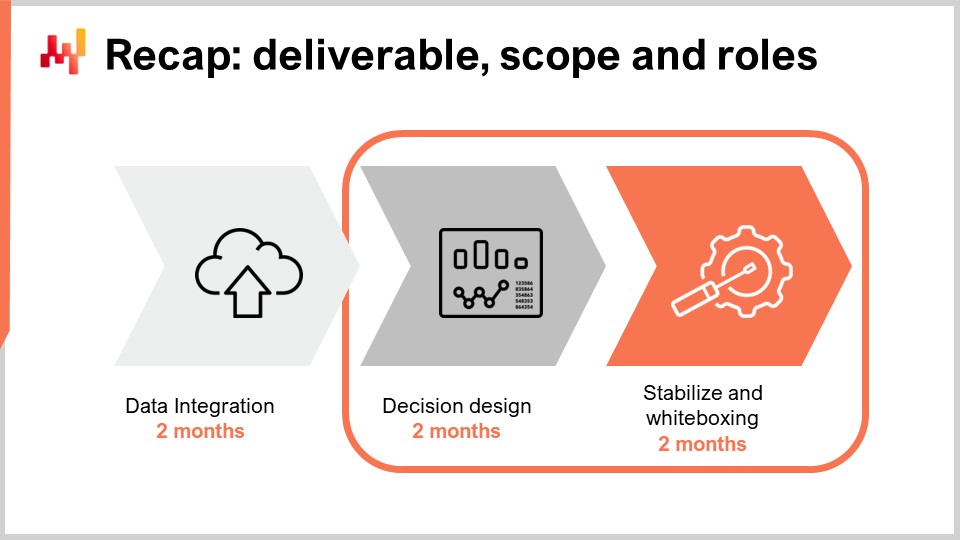
前回の講義では、定量的サプライチェーン施策をいかに始動させるかを見てきました。最も重要な側面を再確認しましょう。成果物は、例えば在庫補充などのサプライチェーンの意思決定を駆動するソフトウェアである、稼働中の数値レシピです。この数値レシピが本番環境に投入されれば、求められている自動化が実現されます。意思決定は、単に中間結果として意思決定計算に寄与するだけの需要予測などの数値的アーティファクトと混同してはなりません。
施策の範囲は、システムとして理解されるサプライチェーンとその基盤となるアプリケーション環境の双方と整合していなければなりません。サプライチェーンのシステム特性に注意を払うことは、問題を解決するどころか、単に場所をずらすだけになるのを防ぐために極めて重要です。例えば、retail chain内のある店舗の在庫最適化が、他の店舗を犠牲にして行われた場合、その最適化は意味を成しません。また、アプリケーション環境に注意を払うことも重要です。初期のデータパイプライン構築の労力を最小限に抑える必要があるからです。ITリソースはほとんどの場合ボトルネックであり、この制限を悪化させないようにしなければなりません。
最後に、この施策には、サプライチェーンエグゼクティブ、データオフィサー、サプライチェーンサイエンティスト、およびサプライチェーンプラクティショナーという4つの役割が特定されました。サプライチェーンエグゼクティブは戦略の所有、変革の推進、およびモデリング選択の仲裁を担います。データオフィサーは、関連する取引データを分析層に提供するためのデータパイプラインの構築を担当します。この講義では、データパイプラインは既に構築済みであると仮定します。サプライチェーンサイエンティストは、スマートなアルゴリズムだけではなく、多くのインストゥルメンテーションを含む数値レシピの実装を担当します。最後に、サプライチェーンプラクティショナーは、従来の手動意思決定プロセスに関わる人物であり、通常は需要と供給のプランナーという役割を担いますが、用語はさまざまです。施策開始時には、彼らが最終的にネットワークマネージャーへと移行することが期待されます。この点は後ほど再考されます。

サプライチェーンは、意思決定プロセスの自動化に関して非常に有利です。量的で反復的な単調な意思決定が数多く存在するからです。残念ながら、ほとんどのサプライチェーン教科書で提示されるモデリングの視点は、しばしば過度に単純化されています。教科書の技法自体が単純すぎるというわけではありません。しかし、そこで提示される問題例は往々にして単純であるという点です。例えば、在庫補充の状況を考えると、教科書的視点では最適な在庫ポリシーを求め、再注文すべき単位数を計算します。これは良いアプローチですが、しばしば不完全な回答にとどまります。
例えば、商品の輸送方法として航空便か海上便を選ぶ必要がある場合、これら二つの輸送モードは、リードタイムと輸送コストとの間のトレードオフを示します。また、複数の適格なサプライヤーの中から一社を選定しなければならないこともあります。さらに、数量が十分に多く複数回の出荷が必要な場合、複数の出荷日を持つ正確な出荷計画を決定する必要があります。
このシリーズの第3章、サプライチェーンペルソナに特化した章では、特定のSKUに対して単一の数量を決定する以上に、実際のサプライチェーン状況には多くの微妙な点が存在することが示されました。したがって、サプライチェーンサイエンティストは、サプライチェーンプラクティショナーおよびサプライチェーンエグゼクティブの協力を得ながら、まず意思決定の完全な形態を明らかにする必要があります。意思決定の完全な形態には、実際のサプライチェーン運用の形を作るすべての要素が含まれていなければなりません。これを明らかにすることは容易ではありません。
第一に、大規模なサプライチェーンを運営するほとんどの企業で実施されている労働分担は、通常、意思決定の各側面を複数の従業員、場合によっては複数の部門に分割してしまいます。例えば、ある人物が再注文する数量を決定し、別の人物がどのサプライヤーに発注するかを決める、といった具合です。
第二に、需要急増時にサプライヤーに対して注文の迅速化を依頼するなど、より微妙な意思決定の側面は、施行者がそれらも自動化できる、あるいは自動化すべきであると認識していないため、見落とされがちです。これらの意思決定の完全な形態の記述は、一連のスライドではなく、実際の文章として書き留めることを推奨します。特に、その文章は「なぜ」その意思決定がなされるのかを明確にしなければなりません。つまり、各側面で正確に何が危機に瀕しているのかを明らかにする必要があります。実際、再注文数量のように明白な側面もあれば、見落とされやすい側面も存在します。例えば、サプライヤーが、パッケージが未開封の場合に6ヶ月以内での返品オプションを特定の価格で提供する場合、そのオプションの行使の有無も意思決定の一部であるべきですが、容易に忘れ去られてしまいます。

サプライチェーンの意思決定の完全な形態を特定できなかったり、さらには意思決定自体を誤って特徴付けたりすることは、施策の失敗を確実に招く方法の一つです。特に、大企業で頻繁に見られる誤りの一つが、レガシーに基づく対応です。レガシーに基づく対応の本質は、企業やそのサプライチェーンに実際には適さない意思決定の形式を、既存のトランザクションソフトウェアや組織内の既存プロセスに合わせるために採用してしまう点にあります。
例えば、在庫補充は、再注文すべき実際の数量を直接計算するのではなく、安全在庫水準の計算によって管理されるべきだと判断されることがあります。安全在庫の計算は、ERP内に既に安全在庫が存在するため、容易に感じられるかもしれません。したがって、安全在庫値を再計算すれば、それらの値をERPに容易に注入することができ、DRPで実際に用いられている式を上書きすることになります。
しかしながら、安全在庫には大きな欠点があります。最小注文数量(MOQ)のような基本的な要素でさえ、安全在庫の視点では捉えにくいのです。少なくとも、この実装が支持されるのは、ソフトウェア自体のためではなく、組織内に既に存在するプロセスのためなのです。
例えば、小売ネットワークでは、店舗の補充を担当するチームと、流通センターのスタッフレベルを担当するチームという2つのプランニングチームが存在するかもしれません。しかし、これら2つの問題は本質的には同一です。店舗の再注文数量が決定されると、流通センターに必要なスタッフ数を自由に決定する余地がなくなります。したがって、両チームの任務は本質的に重複しています。この労働分担は、人間が介在している限り機能します。人間は曖昧な要求に対処するのが得意ですが、この曖昧さは、補充またはスタッフ要件の自動化を試みる上で大きな障害となります。
このアンチパターン、すなわちレガシーに基づく対応は、実装すべき変更の量を最小限に抑えるため、非常に魅力的に映ります。しかし、意思決定の自動化は、意思決定へのアプローチそのものを変えるのです。しばしば、レガシーデザインが維持されると、定量的サプライチェーン施策は失敗に終わります。
第一に、既にかなり複雑な数値レシピの設計をさらに複雑化してしまいます。実際、人間の労働分担に適したパターンは、単に機械的に動作するソフトウェアには適していないのです。
第二に、レガシーに基づく対応は自動化がもたらす多くの潜在的なメリットを打ち消してしまいます。実際、サプライチェーンにおいては、企業内部の境界に起因する非効率性が数多く存在します。すべてを一台のコンピューターが処理できるのであれば、かつて労働分担のために設けられた多くの境界は不要になるのです。20~30年前に下された決定が、あなたのサプライチェーンの未来を左右してはなりません。
一度、意思決定の形態が適切に特徴付けられると、サプライチェーンサイエンティストは、過去の取引データを活用して数値レシピそのものの作成に取り掛かります。このシリーズの講義には、学習と最適化に用いられるアルゴリズム技術の細部に特化した2つの章がありますが、ここではそれらの要素には立ち入りません。要するに、サプライチェーンサイエンティストは、自身の知識と経験、そしてサプライチェーンサイエンティストに利用可能なツールを駆使して、初期の数値レシピを作成するために一連の判断を下すのです。
適切なツールと技法があれば、この初期ドラフトは数日、遅くとも数週間のうちに実装されるべきです。実際、ここで議論しているのは、新しい技法を発見しようとする先進的な研究ではなく、対象となるサプライチェーンの特性を取り入れた既知の技法の適用に過ぎません。数値レシピは、意思決定の完全な形態として特定されたすべての要素を厳格に反映しなければなりません。
たとえ非常に有能なサプライチェーンサイエンティストが、最高のツールを駆使したとしても、初回の試行で数値レシピが正確であると期待するのは無意味です。実際、サプライチェーンはあまりにも複雑で不透明であり、特にそのデジタル表現においては、初回で正しい数値レシピを得ることは困難です。メトリクスやベンチマークといった内向きの数値手法では、サプライチェーンサイエンティストがあるデータを誤解していることを検出できません。
企業を運営する取引システムから得られるすべてのテーブルの各列には、通常、複数の解釈方法が存在します。数十もの列を数値レシピに統合することを考えれば、誤りが生じることは確実です。数値レシピの正確さを評価する唯一の方法は、それを実際に試験し、現実のフィードバックを得ることにほかありません。これは、このシリーズの第2章「Experimental Optimization」で議論されました。
したがって、サプライチェーンサイエンティストは、現状の数値レシピがいまだに非常識な結果を出す状況を特定するため、サプライチェーンプラクティショナーと協力しなければなりません。大雑把に言えば、サプライチェーンサイエンティストは、数値レシピが今日下すであろう意思決定を統合するダッシュボードを実装し、サプライチェーンプラクティショナーは非常識に見える行を特定します。
このフィードバックに基づき、サイエンティストは数値レシピにさらなるインストゥルメンテーションを施します。そのインストゥルメンテーションは、インディケーターの形をとり、「なぜこの文脈で一見非常識な意思決定がなされたのか?」という問いに答えようとします。このインストゥルメンテーションにより、例えば経済的ドライバーのモデリングが不適切であるために数値レシピを修正すべきか、あるいは一見非常識な意思決定が、これまでの企業の方法とは異なるだけで実際には正しいのかを判断することが可能となります。
実験的最適化は非常に反復的なプロセスです。一般論として、適切なツールがあれば、専任のサプライチェーンサイエンティストは毎日、新たな数値レシピのバージョンをサプライチェーンプラクティショナーに提示できるはずです。もし数値レシピが適切にインストゥルメント化されていれば、施策が進むにつれて、プラクティショナーが最新の数値レシピに関してフィードバックを提供するのに1日あたり2時間以上は必要とならないでしょう。
反復は、数値レシピがもはや非常識な結果を生み出さなくなり、プラクティショナーが会社に明らかに有害な意思決定を特定できなくなったときに停止します。非常識な意思決定がなくなることは、手動プロセスと比較してより優れた意思決定を生み出すという全体の目標に比べれば低い目標に見えるかもしれません。しかし、初めから数値レシピは、会社の長期的な経済的利益を数学的に最適化するために設計されていることを忘れてはなりません。結果が合理的であれば、最適化は機能していることになり、ましてや最適化基準自体もある程度正しいと証明されるのです。

数値レシピの高度に反復的なエンジニアリングプロセスは、初期実装に存在する多数の問題を解決できるとしても、最適化における視点自体が誤っている場合、単なる反復だけでは不十分です。このシリーズの講義で既に述べたように、最適化は財務指標、すなわちユーロまたはドルで表現される指標に従って行われるべきです。しかし、この点を明確にしておきたいのです。財務指標を使用しないことは、施策全体を危険にさらすミスなのです。
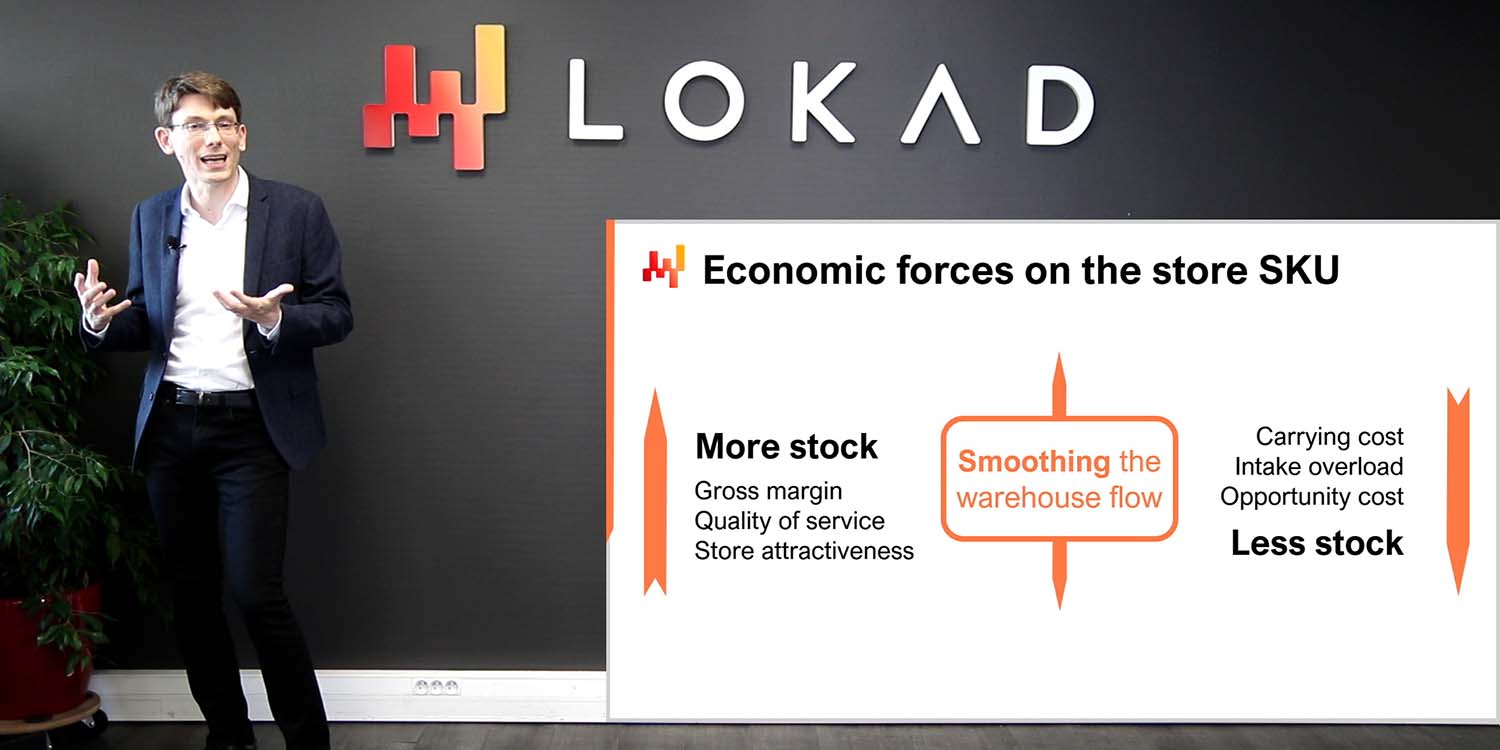
残念ながら、大企業は通常、財務指標を避ける傾向にあります。代わりに、場合によっては0%または100%に到達すれば達成されるとされる、百分率で表されるある種の完璧さを示す志向性の指標を好みます。もちろん、完璧はこの世のものではなく、その極限状態は決して達成されません。サービスレベルは、例えば、志向性指標の原型ともいえるものです。100%サービスレベルは、途方もない量の在庫を必要とするため、達成不可能です。
大企業の一部の管理者は、これらの志向性の指標を愛好します。チームは定例で集まり、これらの指標をさらに改善するために何ができるかを議論します。しかし、これらの指標は必ずしも会社がコントロールできない要因に依存しているため、議論し続けることができます。たとえば、サービスレベルは顧客から示される需要量と、サプライヤーが提供するリードタイムに依存します。需要もリードタイムも、会社の完全な管理下にはありません。
これらの志向性の指標は、人間が意思決定のプロセスに関与している限り、ある程度は企業目標として機能します。なぜなら、人間はそもそもそれらの指標にあまり注意を払わないからです。例えば、たとえ誰もがサービスレベルを向上させるべきだと同意しても、プランナーは多くの文書化されていない例外を維持し続けます。サービスレベルは、在庫リスクが高すぎない、最小発注量が高すぎない、製品が廃止寸前でない、製品に割り当てられた予算が残っている、などの場合を除いて、計画的に引き上げられていくだけです。
残念ながら、これらの志向性の指標は自動化プロセスを展開する際には毒となります。実際、これらの指標は不完全であり、会社にとって本当に望ましい状態を反映していないのです。たとえば、100%サービスレベルの達成は、莫大な過剰在庫を生み出すため、望ましいものではありません。すべての制約や例外を、プランナーの頭の中で起こりうることを模倣するかのように、志向性指標に上乗せして再実装しようとする試みは可能です―無謀ではないが可能です。例えば、「在庫が4か月分以下に保たれる限りサービスレベルを上げる」というルールを定義することが考えられます。しかし、このような数値レシピの設計および実装戦略は非常に脆弱です。直接的な財務最適化は、はるかに安全で優れた道筋です。

供給チェーンの実務者―あるいは、より正確には複数の実務者―と供給チェーン科学者との効果的な協力を実現するためには、初期段階からデュアルラン戦略を採用することをお勧めします。数値レシピは、既存の手動プロセスと並行して毎日実行されるべきです。デュアルランにより、会社は実質的に2つの競合するプロセスを通じて意思決定を二重に生成することになります。しかし摩擦はあるものの、デュアルランは大きなメリットを提供します。まず、供給チェーンの実務者は、現状に即した新鮮な意思決定を得る必要があり、それに基づいて評価を行います。そうでなければ、実務者は自動化された意思決定の意味を把握できず、どの部分が常軌を逸しているのかを特定することすら困難になるのです。実際、実務者の視点からすれば、3週間前の供給チェーンの状況を反映した意思決定は、もはや過去のものです。過去の在庫水準を何時間も見直すことに大した意味はありません。
逆に、自動化された意思決定が新鮮で現状を反映している場合、これらの自動化された決定は、実務者がこれから手動で下す決定と競合することになります。これらの自動化された意思決定は、ひとまず提案として捉えることができます。
第二に、数値レシピを毎日実行することで、全データパイプラインが毎日完全な機能テストを受けることが保証されます。実際、数値レシピは常識的な結果を返すだけでなく、ITインフラの観点からも全く問題なく動作しなければなりません。供給チェーンはすでに十分に混沌としているため、数値レシピが更なる混沌を加えてはなりません。できるだけ早い段階で数値レシピを本番環境に近い条件で運用することで、稀な問題も早期に顕在化し、データ担当者や供給チェーン科学者がそれらを早急に修正する機会が得られるのです。経験則として、数量供給施策開始後3か月目の終わり、すなわち最初の3分の1が経過する頃には、たとえ数値レシピがまだ本番運用の準備ができていなくても、デュアルランは確実に実施されるべきです。
また、デュアルラン開始から1か月以内に、もし科学者が適切に取り組めば、実務者は自動化された意思決定リストの中に、さもなければ見逃してしまうパターンを観察し始めるはずです―たとえ、依然として常軌を逸するような行が残っており、数値レシピの更なる改善が必要であっても。

デュアルランが定着すると、供給チェーンの実務者は毎日1〜2時間、自動化された数値レシピが生成した意思決定をチェックし、依然として常軌を逸している部分を特定しようとすることが期待されます。しかし時には、状況が単に不明瞭な場合もあります。意思決定が驚きを与える―数値レシピが遅いのか、そうでないのか―実務者は不確実さを感じ、その際には科学者に対してさらなる計測機能を追加し、事例を明らかにするよう依頼すべきです。このプロセスこそが、本講義シリーズで「数値レシピのホワイトボックス化」と呼ばれているものです。ホワイトボックス化とは、数値レシピを関係者に対して可能な限り透明にするプロセスであり、数値レシピへの信頼を構築する上で極めて重要なものです。
自動化された意思決定がダッシュボード上の表にまとめられていると仮定すると、最も典型的な計測方法は、意思決定の列の横に追加の列を設けることになります。例えば、再注文数量を考える場合、現有庫数、予想平均リードタイム、1日あたりの予測平均需要など、明らかな計測用の列が考えられます。この計測は、実務者が自動化された意思決定の健全性を迅速に評価するために非常に重要です。しかし、数値レシピに積み重ねられる計測項目の量には注意が必要です。ホワイトボックス化プロセスの一環として自動化された意思決定を装飾するために導入される各指標は、意思決定そのものの見やすさを少しずつ乱雑にしてしまいます。良いものも過剰になれば悪いものとなり得るのです。もし、2か月間の実行後も実務者がルーチン的にさらなる計測機能を要求し、データパイプラインがすでに安定しているのであれば、問題が生じている可能性があります。
問題の根本原因は、数値レシピの高度な部分に起因している可能性があります。本講義の第5章と第6章では、解釈可能性の観点で、すべての技術やモデルが同等に生まれるわけではないことを示しました。多くのモデルは、その設計上、データ科学者でさえも理解しづらいほど不透明です。本日は、解釈可能性に適合するモデルの種類については改めて触れません。この議論のため、数値レシピに組み込まれているモデルは供給チェーンの観点から十分に解釈可能であると仮定します。この文脈において、もし施策がさらなる計測機能の無限の要求により停滞しているようであれば、その最も可能性の高い原因は「分析麻痺(analysis paralysis)」です。供給チェーンの実務者が、数値レシピに関する評価を過度に慎重に行いすぎているのです。これは、手動プロセスに対して行われる以上の厳格な検証を数値レシピに対して求めることに他なりません。施策が分析麻痺に陥らないようにするのは、供給チェーンエグゼクティブの役割です。そして、もしそれが起こった場合―そして起こり得る―供給チェーンエグゼクティブは、人間が下す意思決定もまた不完全であることを、優しくチームに思い出させる責任があるのです。我々が求めているのは、手動プロセスに対する改善であって、完璧さではありません。

数値レシピがもはや常軌を逸した意思決定を生成せず、意思決定自体が適切な計測機能を備えるようになったならば、自動化プロセスが手動プロセスに置き換わるための段階的な引継ぎを始める時期です。経験則として、この段階にはデュアルラン開始から2~4か月以内に到達するべきです。デュアルランの初日から、数値レシピは施策全体の範囲で稼働しているはずです。理論上は、手動の意思決定から自動化されたものへの移行は、実質的に一夜にして起こり得るのです。
しかし、実際には理論と異なることがよくあります。大企業の場合、すべての意思決定を一夜にしてあるプロセスから別のプロセスへと移行することは重要です。供給チェーンは非常に複雑であり、予期せぬ事態が発生することを想定すべきです。したがって、最初は単一の製品カテゴリのような小さな運用範囲から始め、そこから拡大していく方が賢明です。引継ぎの初期段階では、各イテレーションに1週間あるいは2週間程度を要するのが適切です。供給チェーン実務者と供給チェーン科学者の双方が、自動化された意思決定がどのように展開されるかを慎重に検証する必要があります。そして、もしこの小さな運用範囲内で何も予期せぬ事態が発生せず、たとえ数値レシピがこの時点で更なる常軌を逸す決定を生成しなくなったとしても、自動化された意思決定が取引システムに統合される方法に問題がある可能性は依然として存在します。数値レシピが数週間本番運用を担った後、スコープが比較的小さくても、イテレーションを加速させるのが適切です。
引継ぎは各イテレーションごとに著しい進展を遂げ、イテレーション自体の期間も短縮され得ます。最終的には週に2回のイテレーションとなる可能性もあります。実際、自動化プロセスへの移行全体の期間は、十分に短く保たれるべきです。そうでなければ、引継ぎの遅延自体が別の種類のリスクをもたらすからです。供給チェーンは常に変化し、その適用環境も流動的であるため、引継ぎは企業の規模と複雑さに応じて2~4か月を超えてはなりません。

供給チェーンが手動プロセスから自動化プロセスに移行する際、組織内でも一連の変化が必要となります。大企業は変革が非常に困難なことで知られていますが、変化には2つの方向性があります。組織はプロセスを追加するか、もしくはプロセスを削除するかのどちらかです。
プロセスを削除することは、プロセスを追加するよりもはるかに困難です。プロセスを追加するということは、人員を増やすことであり、その反対は企業の最上層からの予算項目という形でのみ反対が起こるのに対し、プロセスを削除するということは、人員の解雇、または少なくともその職務の廃止を伴いながら従業員を維持し再教育することを意味します。プロセスを削除する場合、現場全体からの反対が予想され、ただし経営層からの反対はほとんどありません。
数値レシピを本番運用に持ち込む最も簡単な方法は、既存の手動プロセスを維持しながらデュアルランを無期限に続けることです。手動プロセスはそのまま残り、自動化された意思決定は単なる提案として活用されます。このアプローチは安全に感じられ、手動プロセスに伴う最悪のミスのいくつかを実務者が特定するのに僅かな利点をもたらすかもしれません。しかし、デュアルランを無期限に継続すると、組織が何かを削除できなくなり、プロセスの「堆積化」を招くのです。
供給チェーンの実践を資本主義的な取り組み―すなわち生産的な資産―に変えるためには、組織は手動プロセスを放棄しなければなりません。手動プロセスは行き詰まりであり、時間が経っても改善されることはありません。組織は、手動プロセスに費やしていたすべての時間とエネルギーを、自動化プロセスの継続的改善へと転換しなければなりません。手動プロセスを維持することは、自動化とその提供するものを最大限に活用する能力を妨げるだけです。特に、手動による上書きが続く限り、介入によって何も真に再現可能ではなく、再現性が最適化には必要不可欠であるため、最適化は不可能となります。

たとえ平凡で反復的な意思決定であっても、意思決定の自動化は供給チェーン管理の方法においてパラダイムシフトをもたらします。その変革は非常に大きいため、全く無視されがちです。しかし、変化は必ず訪れます。2世紀にわたる経済の漸進的な機械化は、ひとたび自動化可能なものは必ず自動化されるということを明らかにしてきました。しばらくすると、以前の状態に戻ることは不可能なのです。Lokadは、非常に自動化された環境下で約100の供給チェーンを運営しており、供給チェーン自動化が既に実現していることの生きた証拠を提供しています―ただし、まだ広く普及していないだけです。
我々のクライアントにおいて実施される最大の変革の一つは、需要および供給プランナーの役割に関するものです。業界内では在庫管理者、カテゴリー・マネージャー、または供給マネージャーなど様々な呼称で呼ばれるこれらの役割は、50から5,000 SKUに及ぶショートリストを担当する従業員によって担われます。プランナーは、そのショートリスト内のSKUの継続的な供給を確保する責任があり、在庫補充や生産バッチの開始、あるいはその両方をトリガーします。作業の分担は明確であり、SKUの数が増加すれば、プランナーの数も増加するのです。
プランナーの焦点は内部に向けられています。この人物は、スプレッドシートに集約された数字や、ダッシュボードに表示される数字を眺めることに多くの時間を費やします。プランナーは、企業向けソフトウェアツールを活用している場合もありますが、ほとんどの場合、最終的な意思決定は自ら管理するスプレッドシート上で行われます。スプレッドシートの目的は、プランナーが下す意思決定を支援するための、アクセスしやすく完全にカスタマイズ可能な数値の文脈を提供することにあります。プランナーの日常業務は、毎週、場合によっては毎日、ショートリストに含まれるSKU全体を見直すことです。
しかし、一度数値レシピが生産段階に入ると、プランナーがSKUの候補リストを手動でレビューするスケジュールを維持する意味はなくなります。プランナーはネットワークマネージャーの役割へと移行すべきです。データ関連のルーチンから大幅に解放されたネットワークマネージャーは、サプライヤーとの上流、クライアントとの下流といったネットワークとのコミュニケーションに時間を費やし、数値レシピの設計を支える前提条件を再検討することができます。数値レシピを脅かす最大の危険は、その予測精度を失うことではなく、関連性を失うことにあります。ネットワークマネージャーは、少なくともまだデータのレンズを通しては見えない要素を特定しようと努めます。それは、数値レシピを細部まで管理したり、意思決定自体に数値的な調整を加えたりすることではなく、数値レシピによって無視または誤解され続けている要因を特定することにあるのです.
ネットワークマネージャーは、サプライチェーンのサイエンティストと実行役の双方向けの洞察を統合します。これらの洞察に基づいて、サイエンティストは状況に対する新たな理解を反映すべく、数値レシピを調整または再構築することができます.

残念ながら、数値レシピの展開に反対することは、プランナーが現状を維持する唯一の方法ではありません。もう一つの戦略は、同じ業務ルーチンを継続することにあります。すなわち、SKUの候補リストの見直しを続けるが、意思決定を上書きする代わりに、何か発見があった場合はそれをサプライチェーンサイエンティストに報告するだけにするのです。人々は自分の習慣を好み、大企業の従業員はなおさらです.
このアプローチの問題点は、一度自動化が導入されると、サプライチェーンサイエンティストは自動化プロセスの良い結果も悪い結果も直接観察できるようになることです。プランナーとサイエンティストは同じデータにアクセスできますが、定義上、サイエンティストはプランナーよりも強力な分析ツールにアクセスできるのです。したがって、自動化が進むと、数値レシピの継続的な改善において、プランナーのフィードバックの付加価値は急速に低下します.
プランナーは解析に費やす時間が増えるため、サイエンティストにより多くの指標やダッシュボードの作成を求めるようになるでしょう。これが「KPIツーリズム」につながり、指標の数が増加し、ただそれらを確認するだけでフルタイムの仕事になってしまいます。この作業負荷はサイエンティストにとっても気を散らす要因となります。展開後のこの段階では、数値レシピの改善には、実際の実装における弱点を十分に把握することが必要です。サイエンティストはこの作業に理想的な立場にあるのに対し、プランナーはそれにあまり適していません。支援するために、プランナーはネットワークマネージャーとなり、前述のように外部に目を向け始めるべきです。そうでなければ、プランナーの役割はKPIツーリズムに陥るだけです.

サプライチェーンエグゼクティブの仕事は、主に組織とそのプロセスによって定義されます。日常的な意思決定が手動プロセスの結果である限り、各プランナーが自分自身のSKU候補リストを操作するという労働分担を採用せざるを得ません。したがって、サプライチェーンエグゼクティブは何よりもまずプランナーのチームのマネージャーなのです。もし、企業が中間管理職の層を必要とするほど大規模であれば、エグゼクティブはプランナーを間接的に管理するに留まるかもしれません。しかし、サプライチェーンの部門は依然として変わらず、プランナーが下部に位置するピラミッド構造です。必然的に、優れたサプライチェーンエグゼクティブであるということは、それらプランナーの優れたコーチであることを意味します。エグゼクティブ自身がサプライチェーンの意思決定を行っているのではなく、意思決定を行っているのはプランナーなのです。意思決定の改善は、主にプランナーがより良い仕事をすることにかかっています.
サプライチェーンソフトウェアのベンダーは、自社のツールが違いを生み出すと主張します。しかし、既に指摘したように、企業内にどれだけのツールが揃っていても、これらの意思決定はほとんどの場合、スプレッドシートによって行われています。したがって、最終的にはプランナーが自分のスプレッドシートで何をしているかに帰着するのです.
一度サプライチェーンの意思決定の一分類が自動化されると、サプライチェーンエグゼクティブの仕事は大きく変わります。その仕事は、同じ業務の変種をこなす多くのプランナーをコーチングすることではなくなります。今やエグゼクティブの任務は、会社がサプライチェーン自動化を最大限に活用できるよう、必要なあらゆる措置を講じることにあるのです。エグゼクティブは、サプライチェーンの意思決定を実質的に推進するソフトウェア製品のオーナーとならなければなりません.
実際、サプライチェーンサイエンティストの焦点と貢献は内向きであり、かつてのプランナーの貢献と同様です。サイエンティストは数値レシピを内部からしか改善できません。彼らにアプリケーション全体や企業全体のプロセスを再構築することは期待できません。これを実現するのはサプライチェーンエグゼクティブの仕事です。特に、エグゼクティブは自動化の継続的な改善のためのロードマップの策定に責任を持ちます.
プランナーが意思決定を行っていた限り、ロードマップはほぼ自明のものでした。プランナーは従来通りの業務を続け、次の四半期のミッションも前四半期とほぼ同じでした。しかし、一度自動化が導入されると、数値レシピの改善にはほぼ常にこれまでに行われたことのない新たな試みが必要になります。ソフトウェアを作成する際、正しい方法で行われていれば、同じことを繰り返さず、前進していくものです。一つの洞察が得られたら、次は新たな種類の洞察を追求しなければなりません。ソフトウェア製品オーナーの下で働く人々のミッションは、設計上、常に変化し続けるのです.
新たな方向性と目標は、突然空から降ってくるものではありません。サプライチェーンエグゼクティブが、サプライチェーンソフトウェア製品の開発を有利な方向へ導く責任を担っているのです.

サプライチェーンが日常的に直面する問題の大部分はソフトウェアの問題です。これは、先進国の企業において、すべての意思決定がスプレッドシートから手動で導かれている場合でさえ、10年以上にわたり続いている状況です。この状況は、サプライチェーンがERP、CRM、WMS、OMS、PIM、そして企業ソフトウェアベンダーが好む数十の三文字の頭字語など、多くのシステムの交差点に位置しているために直接的に生じているのです。サプライチェーンは、ビジネスのエンドツーエンドの視点を求めるため、結果的に企業のほとんどのアプリケーション領域を結びつけることになります。しかし、ほとんどの企業は、ソフトウェアについてほとんど知識のないサプライチェーンリーダーを選び続けているようです。さらに悪いことに、そのようなリーダーの中には、ソフトウェアについて何も学ぶ気がない者もいるのです。この状況は「アナリティクス・サプライチェーン・バス」のアンチパターンと呼ばれます。ここでいうソフトウェアとは、私がこの講義シリーズの第4章で扱った、コンピュータハードウェアからソフトウェアエンジニアリングに至るまでのテーマを含む分野を指します.
近年、サプライチェーンのトップマネジメントにおけるソフトウェアリテラシーの欠如は、企業にとって大きな問題を引き起こしています。経営陣がソフトウェアの専門知識なしで十分にやっていけると信じるか、外部のソフトウェア専門知識があれば十分だと信じるか、いずれにしても結果は良くありません.
もし経営陣がソフトウェアの専門知識なしで十分にやっていけると信じるなら、企業は販売面・購買面のすべての電子チャネルで競争力を失っていくでしょう。しかし、多くの従業員が電子チャネルの重要性を認識しているため、経営陣の好みは別として、シャドーITが横行することになります。さらに、企業内の次の大規模なソフトウェア移行においては、この移行が大幅に管理不行き届きとなり、初めから回避すべきソフトウェア関連の問題により、長期間低品質なサービスが提供されることは間違いありません.
もし経営陣が外部のソフトウェア専門知識で十分に対応できると信じるなら、前述の場合よりはわずかに状況は改善するかもしれませんが、大して違いはありません。たとえば、採用プロセスがある規制に準拠しているかどうかという、狭く自己完結した問題であれば、外部の専門家に頼るのは問題ありません。しかし、サプライチェーンの課題は自己完結したものではなく、企業全体、さらには企業外にも広がっています。専門知識を外部に委託できると考える際の最も一般的な落とし穴は、大手ソフトウェアベンダーに不合理な額の資金を投入し、彼らが問題を解決してくれることを期待してしまうことです。驚くことに、彼らは解決してくれません。これらの問題の唯一の解決策は、トップマネジメントによる最低限のソフトウェアリテラシーなのです.
本日、私たちは自動化されたサプライチェーンの意思決定を生産に導く方法について概説しました。このプロセスは、設計、エンジニアリング、そして変革の実施が混在したものです。数多くの一見容易または安心できる道が、イニシアチブの失敗へと直結するという難しい旅路です。成功するためには、サプライチェーンのトップマネジメントと従業員の双方の役割と使命の大幅な進化が必要です.
手動プロセスに深く依存している企業にとって、このようなイニシアチブの実行は途方もなく見えるかもしれません。そのため、現状維持が唯一の選択肢のように思われるでしょう。しかし、私はこの結論に対して二つの観点から反論します。第一に、旅路は困難であるものの、ほとんどのビジネス投資と比べればコストが低いのです。需要プランナー5人分の年間コストを再投資することで、50人分の需要プランナーの業務負荷を自動化できます。もちろん、大手企業向けソフトウェアベンダーは、開始するだけで何千万円もかかると主張するでしょうが、はるかにコストのかからない代替策も存在します。第二に、旅路は困難であっても、実際には選択肢ではありません。日常的で反復的なサプライチェーンの意思決定のために大量の事務職員を抱える企業は、自社の内部プロセスによる長いリードタイムにも苦しんでいます。そのような企業は、ルーチンの意思決定プロセスを自動化している企業に対抗できなくなるのです。自動化によって得られる競争優位性は、初めは常に控えめですが、手動プロセスでは改善ができない一方で、自動化は時間と共に改善可能なため、競争優位性は指数関数的に強まっていきます。現時点では、自動化されたサプライチェーンの意思決定は未来的と捉えられるかもしれませんが、今から二十年後にはその逆になるでしょう。手動プロセスは、過去の時代の時代遅れな遺物とみなされるのです.

これにて本日の講義は終了です。まもなく質問に移ります。次回の講義は例年通り、11月の第一週の水曜日、パリ時間の午後3時に行われます。第三章に戻り、サプライチェーンのペルソナについて検討します。それは、シュトゥットガルトという架空の自動車アフターマーケット企業に関するものです。自動車業界は、あらゆる産業の中でも突出した業界であり、再びサプライチェーンの教科書には十分に反映されていない、かなり具体的な一連の課題を呈しています.
それでは、質問を見ていきましょう.
Question: 定量的なサプライチェーンは、独自の理想的な労働分担を必要とするのでしょうか?
はい、段階的な移行は可能ですが、手動プロセスにおける労働分担は、プランナーが管理できるSKUの数に制限があるという事実によって定義されていました。SKUが増えればプランナーも増えます。これは非常に単純な労働分担のあり方です。大企業で自動化プロセスを導入したい場合、専門性を持つ人材が必要になります。例えば、ネットワークマネージャーは、クライアントが認識するサービス品質の専門家になるかもしれません。認識は重要であり、抽象的なサービス品質、例えばサービスレベルそのものではなく、クライアント自身の視点が関係するのです。そのため、ある人はその分野に特化するでしょう。別のネットワークマネージャーは、例えば一部のサプライヤーとのより緊密な連携と統合によりリードタイムを短縮し、新たな選択肢を提供できるという特定の側面に特化するかもしれません。すると、労働分担は、分析の観点から検証し、再検討し、再分析すべき多くの角度に焦点が当たるようになります。これには複数の人が取り組むことができます。しかし、再度言いますが、これは単にSKUのリストのように明確なものを持つという話ではありません。それは、物事を改善する本質でもあるのです。ひょっとすると、より良いアイデアを出し合い、整理するために、単に複数の人が必要になるかもしれません。一度定量的なサプライチェーンの取り組みの道を歩み始めれば、その労働分担は、特定の分野において深い知識を持つ専門家が協力して、より優れた製品を生み出す継続的なエンジニアリングプロセスに非常に近いものとなるのです.
Question: 財務指標の代わりにパーセンテージを使用することは、旧来のプロセスの非効率性を隠すのに役立ちます。その場合、イニシアチブが成功する可能性はどの程度高いのでしょうか?
これは非常に含みのある質問です。大企業やその中の多くのマネージャーが、そのような理想的な指標を好む理由のひとつは、非難の対象とならないからです。一度、指標がパーセンテージで表されると、それが直近の四半期だけで特定の人物が率いる特定の部門で犯されたミスにより失われた何百万ドル分を意味していることに誰も気づかなくなるのです。これらのパーセンテージは非常に不透明であり、実際、ドルやユーロなどの金額に置き換えれば、非効率性の実態が明らかになり、その規模が絶大であることが判明するため、これらのイニシアチブを成功させることは非常に困難な課題となります.
Lokadの経験では、在庫の価値を認定する200人以上の監査人が存在し、すべての数字が公開市場に開示されている上場企業において、在庫価値が企業に有利な方向へ20%ずれていることが判明しました。これは、帳簿上に100万ユーロ以上の在庫を抱える企業の話です。驚くべきことに、その在庫は実際に数十年にわたって200人以上によって監査され、すべてがデジタル化されていたのです.
こうした事実を暴くとき、難しいことではありますが、問題には厳しく、人には柔軟であるべきだと私は考えています。企業は、問題を無視して人を解雇するのではなく、人には柔軟に、問題には本当に厳しく対処する方法を学ばなければなりません。
質問: 大企業は必要以上に多くのKPIを使用しています。イニシアチブを展開する際、どのようにしてすべてのKPIに挑戦するのですか?
非常に良い質問です。これらのKPIは、プランナーが手作業で行う作業を支援する上で大きな気晴らしに過ぎません。一度数値的なレシピがあれば、なぜそれほど多くのKPIに気を遣う必要があるのでしょうか?最適化するすべてのものは、財務基準に組み込まれるべきです。各潜在的な意思決定において、どれだけのお金がかかるか、結果に応じてどれだけの利益または損失が出るかを示す指標を持つべきです。無限に指標を積み上げる代わりに、財務指標を洗練させたいのであれば、要素を追加すればいいのです。しかし、それはレポートに余分な列を加えるのではなく、特定の意思決定に割り当てた値に対して、数ユーロまたは数ドルを加算または減算する追加要因を与えて少し調整するという意味に過ぎません。
基本的に、これらの財務目標以外のすべては数値的レシピによって無視されます。数値的レシピは、財務目標を厳密に最適化する数学的最適化プロセスを実行しているのです。これが全てです。他のすべての指標は無視されます。自動化されたセットアップは、これらの指標が無意味であることをより明確に示します。これらはレシピに組み込まれず、数値的レシピに考慮されず、意思決定プロセスの一部にもなっていません。また、サービスレベルのような目標指標が逆効果であることも明確にします。サービスの質を無理に100%に高めることは企業にとって望ましい結果ではないのです。適切に行えば、自動化は実際に必要な指標を明確にし、実際にはそれほど多くの指標が求められていないことに気づかせてくれます。また、プロセスに関わる人が少なければ、指標を追加し続けるプレッシャーも低くなります。プランナーの大規模なチームでは、各自が自分のお気に入りの1つまたは2つの指標を持ちがちです。もし200人いて、全員が個人的な都合のために追加の指標を望むなら、結果として200の指標が出来上がり、明らかに多すぎます。しかし、スタッフがその十分の一であれば、指標を積み上げるプレッシャーははるかに低くなるのです。
質問: 需要計画ソフトウェアのベンダーは、クライアントへの展開前にカスタマイズを行う際、セーフティストックの要件など見込み客のエコシステムをどのように理解するのでしょうか?つまり、展開が完了すれば、予測誤差に関して落とし穴は存在しなくなるということでしょうか?
1970年代にサプライチェーンの意思決定へ自動化をもたらすことに失敗したと私が考える古典的な視点は、パッケージ化されたソフトウェアソリューションが企業の問題を解決できるという前提に基づいていました。しかし、これは事実ではないと私は固く信じています。パッケージ化されたソフトウェアは、些細でないサプライチェーンには適合しません。実際に起こるのは、在庫最適化や予測モジュールを搭載したエンタープライズソフトウェアベンダーが製品を企業に販売しようとし、不足している機能があればそれを次々と追加していくということです。10年以上の年月を経て、結果として何百もの画面や数千のパラメータ値を持つ巨大で膨れ上がったソフトウェア製品になってしまうのです。
問題は、ソフトウェア製品が複雑になるほど、データや企業が持つべきものに対しての期待がより具体的になり、その結果、既に多くのシステムが導入され、非常に複雑なサプライチェーン最適化製品を有するクライアント企業に組み込むのが一層困難になることです。あちこちにギャップや不一致が生じるのです。
実際、私が話を聞いたほとんどの大企業は、先進国で20~30年にわたりデジタルサプライチェーンを運用しており、この20~30年の間に既に6種類程度の需要計画、在庫最適化、サプライチェーン設計ソフトウェアソリューションを導入しています。つまり、彼らは既に何度もそれを経験しているのです。通常、従業員は会社に在籍する期間が短いため、これらのプロセスが過去20~30年に繰り返し行われてきたことに気づいていません。それでもなお、プロセスは完全に手作業で行われ、しばしばExcelのようなツールに依存しています。問題は予測誤差ではなく、どのシステムを使っても完璧な予測ができるという考え自体が滑稽である点にあります。完璧な予測を生成することは不可能であり、サプライチェーンを手作業で運営する人間も完璧な情報にアクセスできるわけではありません。需要計画担当者だからといって、完璧に需要を予測できる訳ではないのです。
需要計画担当者は、完璧ではない予測でも十分に仕事をこなすことができます。彼らは魔法使いや超先進的な科学者ではありません。予測が苦手というわけでもありませんが、世界中で何十万人も雇用されているこの業界の需要計画担当者全員が、超才能を有し、信じられないほど正確な需要予測を達成できるという期待をする理由はありません。このシステムが機能するのは、彼らが自分たちの経験則や、予測が不十分であっても乗り切るための手動によるサプライチェーン管理方法を持っているからです。
自動化されたセットアップにおける目標は、そもそも予測がそれほど優れていなくても問題なく機能するシステムを構築することです。これが確率的予測アプローチの本質であり、精度を高めることよりも、予測がそれほど良くないという事実を認め、受け入れることにあります。先ほどのベンダーに話を戻すと、ここ40年間で業界全体が満足のいく自動化を実現できなかったと私は考えており、その根本的な問題は、企業が単にモジュールを接続するだけで済むというパッケージ化された視点にあったのです。これはうまく機能しません。サプライチェーンはあまりにも多様で柔軟、かつ常に変化しているため、そのような機械的なアプローチでは成功し得ないのです。
質問: 今回提示された視点を踏まえて、売上や在庫など会社内の異なる予測をどのように調和させる問題に取り組むのですか?
私の疑問は、そもそもなぜ予測を行うのかということです。予測は単なる数値的な人工物に過ぎず、重要ではありません。より良い予測が存在するからといって、企業がより利益を上げるわけにはなりません。予測は、この講義シリーズの前章で私が言った通り、数値的な人工物です。これは、特定の意思決定を導く上で有用であるかどうかは別として、抽象概念にすぎません。実際、考慮する意思決定に応じて、必要な予測の種類は大きく変わるのです。
上位に予測があり、その予測に基づいてサプライチェーン全体を調整できるという考えに挑戦します。私自身の経験からも、このアプローチはうまくいかないと強く反対しています。私は、シニアプランニングプロセスが売上側で予測を作成する、多大なサンドバッグ運動のような企業を数多く見てきました。営業担当者は、もしその数字を上回れば後で容易に期待を超えることができるため、しばしば大幅に控えめな予測を提示します。工場や 倉庫 の人々は、これらの数字が自分たちに向かってくるのを見て、それが絶対に正しいはずがないと考え、数字を破棄して全く別の判断を下します。私の意見では、大多数の企業が行う予測作業は、単なる無意味な官僚的努力に過ぎません。それ自体に付加価値はありません。
数量的なサプライチェーンの視点からは、単なる技術的な予測ではなく、重要な意思決定に焦点を当てることが不可欠です。ある種の意思決定は、そもそも予測を必要としないか、あるいは必要であったとしても、企業が現在想定しているものとは全く異なるタイプの予測が求められるかもしれません。一般に予測というと、ほとんどの人は 時系列 予測を意味します。しかし、この講義シリーズの第三章―サプライチェーンのペルソナと実際の状況に焦点を当てた章―に戻ると、時系列予測がしばしば答えではないことがわかります。予測の形式自体が、ビジネスで識別したいパターンを捉えるには不十分なのです。
結論として、これらの予測を調整しようとする試みすら行わないことを提案します。むしろ、予測を無視し、意思決定そのものに集中するのです。優れた意思決定を生み出すレシピを工夫するために何が必要かを見極めれば、すべての予測は完全に無視できる可能性が高いのです。
財務指標とパーセンテージで表されるKPI結果を比較するというコメントに対しては、サービスレベルや フィルレート を財務指標と相関させて比較することは可能です。しかし、これが実際に企業に投資収益率をもたらすのでしょうか?より良い在庫判断は企業に価値を生み出しますが、KPIの相関に時間を費やすことはそれに寄与しません。多くの企業はパーセンテージで表されるこれらのKPIに依存していますが、それらはしばしば意味のない官僚的な気晴らしに過ぎないのです。
エンタープライズソフトウェアのベンダーは、これらの指標をクライアント企業に販売できるため、より多くの指標を求める傾向にあります。実際、サプライチェーンのある種の意思決定において、毎日注目すべき数値が10個あれば十分な場合が多いのです。人間が毎日注目すべき10個の数値を特定するのは通常困難で、しばしばそれ以下で十分なのです。それで全く問題ありません。サプライチェーン上の問題は、対象となる企業やサプライチェーンに非常に特有なものになる傾向がありますが、不可能なほど複雑ではありません。私は、サプライチェーンの状況に何千もの経済的ドライバーが必要だというわけではなく、サプライチェーンは大きく異なり、対象となるサプライチェーンの微妙な部分に適合する正しい問題を解決する必要があると言っているのです。ひとつのサプライチェーンでは、在庫コスト、粗利益、その他の基本的なドライバーが3~4個存在し、さらに特定のビジネスに特有の4~5個の(再び)財務指標があるかもしれません。合計しても、依然として10個未満なのです。
財務KPIとサプライチェーンKPIのトレードオフのバランスに関する質問に対しては、「はい」とも「いいえ」とも言えます。もし、財務KPIが最適化すべきものではないと考えるなら、それはそもそもの財務KPIの定義に問題があることを意味します。この講義シリーズの第一章で述べたように、財務指標を確立する際には通常、考慮すべき2つのドライバー群があります。第一のグループは、粗利益、在庫価値、購買費用など、財務が簿記上で直接読み取れる要素を含み、第二のグループは、顧客の信頼や、サービス品質が低い場合の暗黙のペナルティなどのドライバーを含みます。これらすべてを統合する必要があるのです。
財務的視点は、トレードオフがあるKPIを持つことではありません。むしろ、すべてを統合して、パフォーマンスおよび意思決定のための1つのドルまたはユーロ単位のスコアにすることなのです。サプライチェーンKPIと財務KPIを調整することではなく、在庫の実際のコスト、ストックアウトの実際のコスト、そして再発注が最適な選択であるかどうかについて、関係者が合意できるガバナンス体制を企業内に確立することにあるのです。
サプライチェーンを駆動するソフトウェア製品を所有するというこの新しい視点から見ると、サプライチェーン幹部の仕事は、社内で合意形成を促進することにあります。人々が毎月数字を見直し、無意味な売上数字に合意するという、無思慮な S&OP プロセスを推進するのではなく、サプライチェーンディレクターが主導するS&OP 2.0を実施するのです。S&OPベンダーが言うのとは逆に、CEOがS&OPプロセスを所有する必要はなく、それはむしろCEOにとって気を散らす要因となるかもしれません。CEOをすべての戦いに巻き込む必要はありません。
サプライチェーンディレクターの使命は、財務責任者、マーケティング責任者、営業責任者と協力して、サービス品質などの要因が財務に与える影響をどのように測定するかについて合意に達することです。これが彼らの仕事なのです。各種指標の調整は不要です。なぜなら、それらはすでにサプライチェーン責任者またはサプライチェーンディレクター(企業内での役職に応じて)の指導の下での作業によって、あらかじめ統合されているからです。
これで本日の講義は終了です。次回は11月の第一週にお会いしましょう。